
Chapter 1: Introduction to Kubernetes Infrastructure and Production-Readiness
With more and more organizations adopting Kubernetes for their infrastructure management, it is becoming the industry de facto standard for orchestrating and managing distributed applications both in the cloud and on premises.
Whether you are an individual contributor who is migrating their company's applications to the cloud or you are a decision-maker leading a cloud transformation initiative, you should plan the journey to Kubernetes and understand its challenges.
If this book has a core purpose, it is guiding you through the journey of building a production-ready Kubernetes infrastructure while avoiding the common pitfalls. This is our reason for writing about this topic, as we have witnessed failures and successes through the years of building and operating Kubernetes clusters on different scales. We are sure that you can avoid a lot of these failures, saving time and money, increasing reliability, and fulfilling your business goals.
In this chapter, you will learn about how to deploy Kubernetes production clusters with best practices. We will explain the roadmap that we will follow for the rest of the book, and explain foundational concepts that are commonly used to design and implement Kubernetes clusters. Understanding these concepts and the related principles are the key to building and operating production infrastructure. Besides, we will set your expectations about the book's scope.
We will go through the core problems that this book will solve and briefly cover topics such as Kubernetes production challenges, a production-readiness characteristics, the cloud-native landscape, and infrastructure design and management principles.
We will cover the following topics in this chapter:
- The basics of Kubernetes infrastructure
- Why Kubernetes is challenging in production
- Kubernetes production-readiness
- Kubernetes infrastructure best practices
- Cloud-native approach
The basics of Kubernetes infrastructure
If you are reading this book, you already made your decision to take your Kubernetes infrastructure to an advanced level, which means you are beyond the stage of evaluating the technology. To build production infrastructure, the investment remains a burden and it still needs a solid justification to the business and the leadership within your organization. We will try to be very specific in this section about why we need a reliable Kubernetes infrastructure, and to clarify the challenges you should expect in production.
Kubernetes adoption is exploding across organizations all over the world, and we expect this growth to continue to increase, as the International Data Corporation (IDC) predicts that around 95 percent of new microservices will be deployed in containers by 2021. Most companies find that containers and Kubernetes help to optimize costs, simplify deployment and operations, and decrease time to market, as well as play a pivotal role in the hybrid cloud strategies. Similarly, Gartner predicts that more than 70 percent of organizations will run two or more containerized applications in production by 2021 compared to less than 20 percent in 2019.
Kubernetes components
As we are concerned about building a reliable Kubernetes cluster, we will cover an overview of the Kubernetes cluster architecture and its components, and then you will learn about production challenges.
Kubernetes has a distributed systems architecture – specifically, a client-server one. There are one or more master nodes, and this is where Kubernetes runs its control plane components.
There are worker nodes where Kubernetes deploys the pods and the workloads. A single cluster can manage up to 5,000 nodes. The Kubernetes cluster architecture is shown in the following diagram:

Figure 1.1 – Kubernetes cluster architecture
The preceding diagram represents a typical highly available Kubernetes cluster architecture with the core components. It shows how the Kubernetes parts communicate with each other. Although you have a basic understanding of the Kubernetes cluster architecture, we will need to refresh this knowledge over the next section because we will interact with most of these components in deeper detail when creating and tuning the cluster configuration.
Control plane components
Control plane components are the core software pieces that construct the Kubernetes master nodes. All of them together belong to the Kubernetes project, except etcd, which is a separate project on its own. These components follow a distributed systems architecture and can easily scale horizontally to increase cluster capacity and provide high availability:
- kube-apiserver: The API server is the manager of the cluster components and it is the interface responsible for handling and serving the management APIs and middling the communication between cluster components.
- etcd: This is a distributed, highly available key-value data store that acts as the backbone of the cluster and stores all of its data.
- kube-controller-manager: This manages the controller processes that control the cluster – for example, the node controller that controls the nodes, the replication controller that controls the deployments, and the endpoint controller that controls services endpoints exposed in the cluster.
- kube-scheduler: This component is responsible for scheduling the pods across the nodes. It decides which pod goes to which node according to the scheduling algorithm, available resources, and the placement configuration.
Node components
Node components are a set of software agents that run on every worker node to maintain the running pods and provide network proxy services and the base runtime environment for the containers:
- kubelet: An agent service that runs on each node in the cluster, this periodically takes a set of pod specs (a manifest file in YAML format that describes a pod specification) and ensures that the pods described through these specs are running properly. Also, it is responsible for reporting to the master on the health of the node where it is running.
- kube-proxy: This is an agent service that runs on each node in the cluster to create, update, and delete network roles on the nodes, usually using Linux iptables. These network rules allow inter-pod and intra-pod communication inside and outside of the Kubernetes cluster.
- Container runtime: This is a software component that runs on each node in the cluster, and it is responsible for running the containers. Docker is the most famous container runtime; however, Kubernetes supports other runtimes, such as Container Runtime Interface (CRI-O) and containerd to run containers, and kubevirt and virtlet to run virtual machines.
Why Kubernetes is challenging in production
Kubernetes could be easy to install, but it is complex to operate and maintain. Kubernetes in production brings challenges and difficulties along the way, from scaling, uptime, and security, to resilience, observability, resources utilization, and cost management. Kubernetes has succeeded in solving container management and orchestration, and it created a standard layer above the compute services. However, Kubernetes still lacks proper or complete support for some essential services, such as Identity and Access Management (IAM), storage, and image registries.
Usually, a Kubernetes cluster belongs to a bigger company's production infrastructure, which includes databases, IAM, Lightweight Directory Access Protocol (LDAP), messaging, streaming, and others. Bringing a Kubernetes cluster to production requires connecting it to these external infrastructure parts.
Even during cloud transformation projects, we expect Kubernetes to manage and integrate with the on-premises infrastructure and services, and this takes production complexity to a next level.
Another challenge occurs when teams start adopting Kubernetes with the assumption that it will solve the scaling and uptime problems that their apps have, but they usually do not plan for day-2 issues. This ends up with catastrophic consequences regarding security, scaling, uptime, resource utilization, cluster migrations, upgrades, and performance tuning.
Besides the technical challenges, there are management challenges, especially when we use Kubernetes across large organizations that have multiple teams, and if the organization is not well prepared to have the right team structure to operate and manage its Kubernetes infrastructure. This could lead to teams struggling to align around standard tools, best practices, and delivery workflows.
Kubernetes production-readiness
Production-readiness is the goal we need to achieve throughout this book, and we may not have a definitive definition for this buzzword. It could mean a cluster capable to serve production workloads and real traffic in a reliable and secure fashion. We can further extend this definition, but what many experts agree on is that there is a minimum set of requirements that you need to fulfill before you mark your cluster as production-ready.
We have gathered and categorized these readiness requirements according to the typical Kubernetes production layers (illustrated in the following diagram). We understand that there are still different production use cases for each organization, and product growth and business objectives are deeply affecting these use cases and hence the production readiness requirements. However, we can fairly consider the following production-ready checklist as an essential list for most mainstream use:
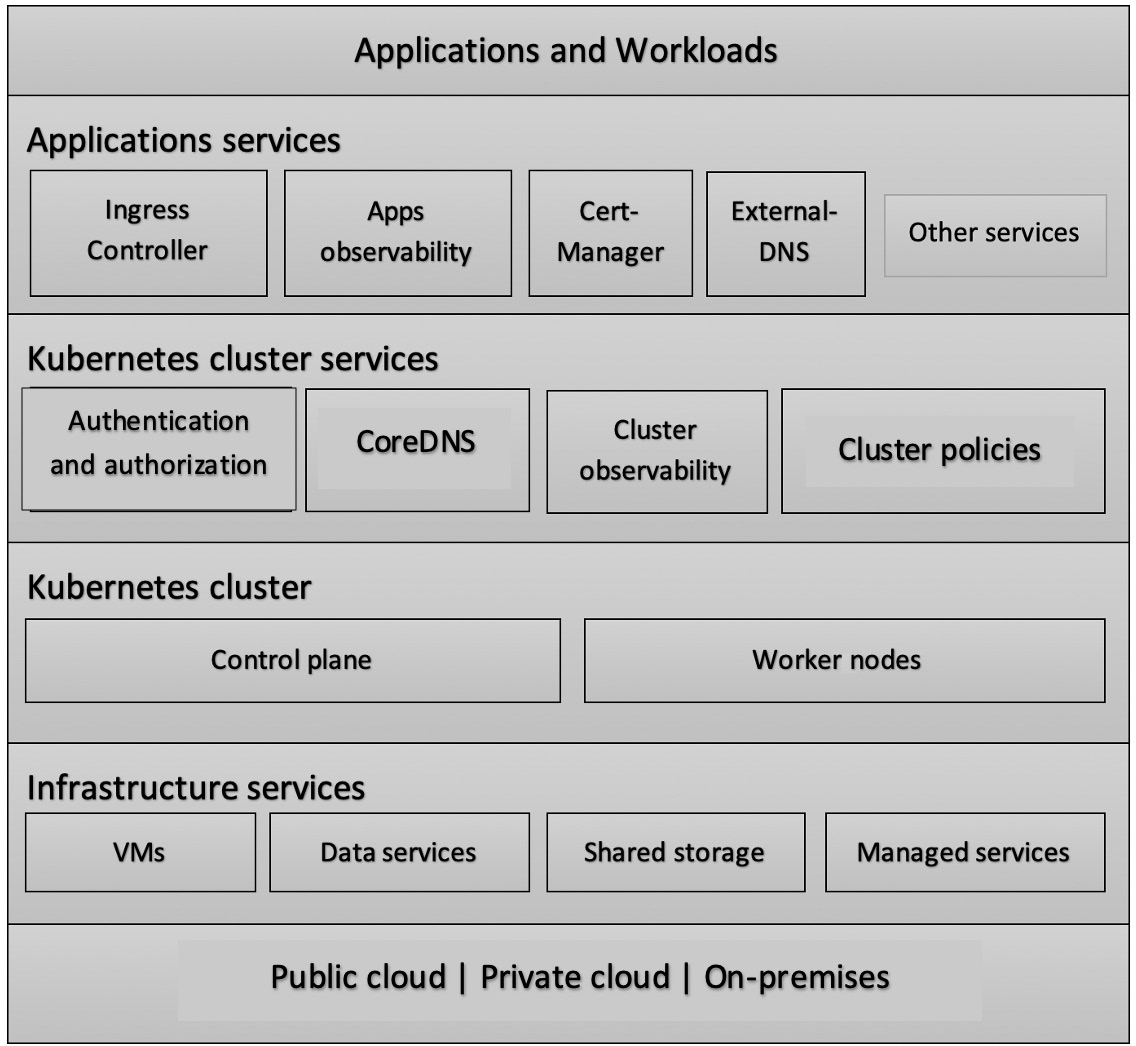
Figure 1.2 – Kubernetes infrastructure layers
This diagram describes the typical layers of Kubernetes infrastructure. There are six layers, which include physical, on-premises, or cloud infrastructure; the infrastructure services layer; the cluster layer; the cluster services layer; the applications supporting services layer; and finally, the applications layer. You will learn about these layers in depth while navigating this book and see how to design a Kubernetes production architecture that brings these layers seamlessly together.
The production-readiness checklist
We have categorized the production-readiness checklist items and mapped them to the corresponding infrastructure layers. Each checklist item represents a design and implementation concern that you need to fulfill to consider your cluster a production-ready. Throughout this book, we will cover the checklist items and their design and implementation details.
Cluster infrastructure
The following checklist items cover the production-readiness requirements on the cluster level:
- Run a highly available control plane: You can achieve this by running the control plane components on three or more nodes. Another recommended best practice is to deploy the Kubernetes master components and etcd on two separate node groups. This is generally to ease etcd operations, such as upgrades and backups, and to decrease the radius of control plane failures.
Also, for large Kubernetes clusters, this allows etcd to get proper resource allocation by running it on certain node types that fulfill its extensive I/O needs.
Finally, avoid deploying pods to the control plane nodes.
- Run a highly available workers group: You can achieve this by running a group or more of worker nodes with three or more instances. If you are running these workers groups using one of the public cloud providers, you should deploy them within an auto-scaling group and in different availability zones.
Another essential requirement to achieve worker high availability is to deploy the Kubernetes cluster auto scaler, which enables worker nodes to horizontally upscale and downscale based on the cluster utilization.
- Use a shared storage management solution: You should consider using a shared storage management solution to persist and manage stateful apps' data. There are plenty of choices, either open source or commercial, such as AWS Elastic Block Store (EBS), Elastic File System (EFS), Google Persistent Disk, Azure Disk Storage, ROOK, Ceph, and Portworx. There is no right or wrong choice among them, but it all depends on your application use case and requirements.
- Deploy infrastructure observability stack: Collecting logs and metrics on the infrastructure level for nodes, network, storage, and other infrastructure components is essential for monitoring a cluster's infrastructure, and also to get useful insights about the cluster's performance, utilization, and troubleshooting outages.
You should deploy a monitoring and alerting stack, such as Node Exporter, Prometheus, and Grafana, and deploy a central logging stack, such as ELK (Elasticsearch, Logstash, and Kibana). Alternatively, you can consider a complete commercial solution, such as Datadog, New Relic, AppDynamics, and so on.
Fulfilling the previous requirements will ensure the production-readiness of the cluster infrastructure. Later in this book, we will show you in more detail how to achieve each of these requirements through infrastructure design, Kubernetes configuration tuning, and third-party tools usage.
Cluster services
The following checklist items cover the production-readiness requirements on the cluster services level:
- Control cluster access: Kubernetes introduces authentication and authorization choices and lets the cluster's admin configure them according to their needs. As a best practice, you should ensure authentication and authorization configuration is tuned and in place. Integrate with an external authentication provider to authenticate cluster's users, such as LDAP, OpenID Connect (OIDC), and AWS IAM.
For authorization, you need to configure the cluster to enable Role-Based Access Control (RBAC), Attribute-Based Access Control (ABAC), and webhooks.
- Hardening the default pod security policy: Pod security policy (PSP) is a Kubernetes resource that is used to ensure a pod has to meet specific requirements before getting created.
As a best practice, we recommend that you limit any privileged pods within the kube-system namespace. For all other namespaces that host your apps pods, we recommend assigning a restrictive default PSP.
- Enforce custom policies and rules: Rules and policy enforcement are essential for every Kubernetes cluster. This is true for both a small single-tenant cluster and a large multi-tenant one. Kubernetes introduces native objects to achieve this purpose, such as pod security policies, network policies, resource limits, and quotas.
For custom rules enforcement, you may deploy an open policy agent, such as OPA Gatekeeper. This will enable you to enforce rules such as pods must have resource limits in place, namespaces must have specific labels, images must be from known repositories, and many others.
- Deploy and fine-tune the cluster DNS: Running a DNS for Kubernetes clusters is essential for name resolution and service connectivity. Managed Kubernetes comes with cluster DNS pre-deployed, such as CoreDNS. For self-managed clusters, you should consider deploying CoreDNS too. As a best practice, you should fine-tune CoreDNS to minimize errors and failure rates, optimize performance, and adjust caching, and resolution time.
- Deploy and restrict network policies: Kubernetes allows all traffic between the pods inside a single cluster. This behavior is insecure in a multi-tenant cluster. As a best practice, you need to enable network policies in your cluster, and create a deny-all default policy to block all traffic among the pods, then you create network policies with less restrictive ingress/egress rules to allow the traffic whenever it is needed for between specific pods.
- Enforce security checks and conformance testing: Securing a Kubernetes cluster is not questionable. There are a lot of security configurations to enable and tune for a cluster. This could get tricky for cluster admins, but luckily, there are different tools to scan cluster configuration to assess and ensure that it is secure and meets the minimum security requirements. You have to automate running security scanning tools, such as kube-scan for security configuration scanning, kube-bench for security benchmarking, and Sonobuoy to run Kubernetes standard conformance tests against the cluster.
- Deploy a backup and restore solution: As with any system, Kubernetes could fail, so you should have a proper backup and restore process in place. You should consider tools to back up data, snapshot the cluster control plane, or back up the etcd database.
- Deploy an observability stack for the cluster components: Monitoring and central logging is essential for Kubernetes components such as control-plane, kubelet, container runtime, and more. You should deploy a monitoring and alerting stack such as Node Exporter, Prometheus, and Grafana, and deploy a central logging stack, such as EFK (Elasticsearch, Fluentd, and Kibana).
Fulfilling the previous requirements will ensure the production-readiness of the cluster services. Later in this book, we will show you in more detail how to achieve each of these requirements through Kubernetes configuration tuning and third-party tools usage.
Apps and deployments
The following checklist items cover the production-readiness requirements on the apps and deployments level:
- Automate images quality and vulnerability scanning: An app image that runs a low-quality app or that is written with poor-quality specs can harm the cluster reliability and other apps running on it. The same goes for images with security vulnerabilities. For that, you should run a pipeline to scan images deployed to the cluster for security vulnerabilities and deviations from quality standards.
- Deploy Ingress Controller: By default, you can expose Kubernetes services outside the cluster using load balancers and node ports. However, the majority of the apps have advanced routing requirements, and deploying an Ingress Controller such as Nginx's Ingress Controller is a de facto solution that you should include in your cluster.
- Manage certificates and secrets: Secrets and TLS certificates are commonly used by modern apps. Kubernetes comes with a built-in Secrets object that eases the creation and management of secrets and certificates inside the cluster. In addition to that, you can extend secrets object by deploying other third-party services, such as Sealed Secrets for encrypted secrets, and Cert-Manager to automate certificates from certificate providers such as Let's Encrypt or Vault.
- Deploy apps observability stack: You should make use of Kubernetes' built-in monitoring capabilities, such as defining readiness and liveness probes for the pods. Besides that, you should deploy a central logging stack for the applications' pods. Deploy a blackbox monitoring solution or use a managed service to monitor your apps' endpoints. Finally, consider using application performance monitoring solutions, such as New Relic APM, Datadog APM, AppDynamics APM, and more.
Fulfilling the previous requirements will ensure the production-readiness of the apps and deployments. Later in this book, we will show you in more detail how to achieve each of these requirements through Kubernetes configuration tuning and third-party tool usage.
Kubernetes infrastructure best practices
We have learned about the basics of Kubernetes infrastructure and have got a high-level understanding of the production readiness characteristics of the Kubernetes clusters. Now, you are ready to go through the infrastructure best practices and design principles that will lead you through the way building and operating your production clusters.
The 12 principles of infrastructure design and management
Building a resilient and reliable Kubernetes infrastructure requires more than just getting your cluster up and running with a provisioning tool. Solid infrastructure design is a sequence of architecture decisions and their implementation. Luckily, many organizations and experts put these principles and architectural decisions into real tests.
The following list summarizes the core principles that may lead the decision-maker through the Kubernetes infrastructure design process, and throughout this book, you will learn about these principles in detail, and apply them along the way:
- Go managed: Although managed services could looks pricier than self-hosted ones, it is still preferred over them. In almost every scenario, a managed service is more efficient and reliable than its self-hosted counterpart. We apply this principle to Kubernetes managed services such as Google Kubernetes Engine (GKE), Azure Kubernetes Service (AKS), and Elastic Kubernetes Service (EKS). This goes beyond Kubernetes to every infrastructure service, such as databases, object stores, cache, and many others. Sometimes, the managed service could be less customizable or more expensive than a self-hosted one, but in every other situation, you should always consider first the managed service.
- Simplify: Kubernetes is not a simple platform, either to set up or operate. It solves the complexity of managing internet scale workloads in a world where applications could scale up to serve millions of users, where cloud-native and microservices architectures are the chosen approach for most modern apps.
For infrastructure creation and operation, we do not need to add another layer of complexity as the infrastructure itself is meant to be a seamless and transparent to the products. Organization's primary concern and focus should remain the product not the infrastructure.
Here comes the simplification principle; it does not mean applying trivial solutions but simplifying the complex ones. This leads us to decisions such as choosing fewer Kubernetes clusters to operate, or avoiding multi-cloud; as long as we do not have a solid use case to justify it.
The simplification principle applies to the infrastructure features and services we deploy to the cluster, as it could be very attractive to add every single service as we think it will make a powerful and feature-rich cluster. On the contrary, this will end up complicating the operations and decreasing platform reliability. Besides, we can apply the same principle to the technology stack and tools we choose, as unifying the tools and technology stack across the teams is proven to be more efficient than having a set of inhomogeneous tools that end up hard to manage, and even if one of these tools is best for a specific use case, simplicity always pays back.
- Everything as Code (XaC): This is the default practice for modern infrastructure and DevOps teams. It is a recommended approach to use declarative infrastructure as code (IaC) and configuration as code (CaC) tools and technologies over their imperative counterparts.
- Immutable infrastructure: Immutability is an infrastructure provisioning concept and principle where we replace system components for each deployment instead of updating them in place. We always create immutable components from images or a declarative code, where we can build, test, and validate these immutable systems and get the same predictable results every time. Docker images and AWS EC2 AMI are examples of this concept.
This important principle leads us to achieve one of the desired characteristics of Kubernetes clusters, which is treating clusters as cattle instead of pets.
- Automation: We live in the era of software automation, as we tend to automate everything; it is more efficient and easier to manage and scale, but we need to take automation with Kubernetes to a further level. Kubernetes comes to automate the containers' life cycle, and it also comes with advanced automation concepts, such as operators and GitOps, which are efficient and can literally automate the automations.
- Standardization: Having a set of standards helps to reduce teams' struggle with aligning and working together, eases the scaling of the processes, improves the overall quality, and increases productivity. This becomes essential for companies and teams planning to use Kubernetes in production, as this involves integrating with different infrastructure parts, migrating services from on-premises to the cloud, and way more complexities.
Defining your set of standards covers processes for operations runbooks and playbooks, as well as technology standardization as using Docker, Kubernetes, and standard tools across teams. These tools should have specific characteristics: open source but battle-tested in production, support the other principles, such as Infrastructure as code, immutability, being cloud-agnostic, and being simple to use, and deploy with minimum infrastructure.
- Source of truth: Having a single source of truth is a cornerstone and an enabler to modern infrastructure management and configuration. Source code control systems such as Git are the standard choice to store and version infrastructure code, where having a single and dedicated source code repository for infrastructure is a recommended practice.
- Design for availability: Kubernetes is a key enabler for the high availability of both the infrastructure and the application layers. Having high availability as a design pillar since day 1 is critical for getting the full power of Kubernetes, so at every design level, you should consider high availability, starting from the cloud and Infrastructure as a Service (IaaS) level by choosing multi-zone or region architecture, then going through the Kubernetes layer by designing a multi-master cluster, and finally, the application layer by deploying multiple replicas of each service.
- Cloud-agnostic: Being cloud-agnostic means that you can run your workloads on any cloud with a minimal vendor-lock, but take care of getting obsessed with the idea, and make it as a goal on its own. Docker and Kubernetes are the community's answer to creating and managing cloud-agnostic platforms. This principle also goes further to include other technologies and tool selection (think Terraform versus CloudFormation).
- Business continuity: Public cloud with its elasticity solved one problem that always hindered the business continuity for the online services, especially when it made scaling infrastructure almost instant, which enabled small businesses to have the same infrastructure luxury that was previously only for the giant tech companies.
However, coping with the increased scaling needs and making it real-time remains a challenge, and with introducing containers to deploy and run workload apps become easy to deploy and scale in seconds. This put the pressure back on Kubernetes and the underlying infrastructure layers to support such massive real-time scaling capabilities of the containers. You need to make a scaling decision for the future to support business expansion and continuity. Questions such as whether to use a single large cluster versus smaller multiple clusters, how to manage the infrastructure cost, what the nodes' right sizes are, and what the efficient resource utilization strategy is…all of these questions require specific answers and important decisions to be taken!
- Plan for failures: A lot of distributed systems characteristics apply to Kubernetes containerized apps; specifically, fault tolerance, where we expect failures, and we plan for system components failures. When designing a Kubernetes cluster, you have to design it to survive outages and failures by using high-availability principles. But you also have to intentionally plan for failures. You can achieve this through applying chaos engineering ideas, disaster recovery solutions, infrastructure testing, and infrastructure CI/CD.
- Operational efficiency: Companies usually underestimate the effort required to operate containers in production – what to expect on day 2 and beyond, and how to get prepared for outages, cluster upgrades, backups, performance tuning, resource utilization, and cost control. At this phase, companies need to figure out how to deliver changes continuously to an increasing number of production and non-production environments, and without the proper operations practices, this could create bottlenecks and slow down the business growth, and moreover, lead to unreliable systems that cannot fulfill customers' expectations. We witnessed successful Kubernetes production rollouts, but eventually, things fell apart because of operations teams and the weak practices.
These 12 principles are proven to be a common pattern for successful large scale cloud infrastructure rollouts. We will apply these principles through most of this book's chapters, and we will try to highlight each principle when we make a relevant technical decision based on it.
Applications definition and deployment
Probably, a successful and efficient Kubernetes cluster will not save an application's poor design and implementation. Usually, when an application does not follow containerization best practices and a highly available design, it will end up losing the cloud-native benefits provided by the underlying Kubernetes:
- Containerization: This is the de facto standard delivery and deployment form of cloud workloads. For production reliability, containerization best practices play a vital role. You will learn about this principle in detail over the upcoming chapters. Bad practices could lead to production instability and catastrophic outages, such as ignoring containers' graceful shutdown and processes termination signals, and improper application retries to connect to dependent services.
- Applications' high availability: This is by deploying two or more app replicas and making use of Kubernetes' advanced placement techniques (node selectors, taints, Affinity, and labeling) to deploy the replicas into different nodes and availability zones, as well as defining pod disruption policies.
- Application monitoring: This is done by defining readiness and liveness probes with different checks, deploying Application Performance Monitoring (APM), and using the famous monitoring approaches, such as RED (Rate, Errors, and Duration), and USE (Utilization, Saturation, and Errors).
- Deployment strategy: Kubernetes and cloud-native make deployments easier than ever. These frequent deployments bring benefits to the businesses, such as reducing time to market, faster customer feedback on new features, and increasing product quality overall. However, there are downsides to these as well, as frequent deployments could affect product reliability and uptime if you do not plan and manage properly. This is when defining a deployment and rollback strategy (rolling update, recreate, canary, blue/green, and deployment) comes in place as one of the best practices for application deployments.
The consideration of these four areas will ensure smooth application deployment and operations into the Kubernetes cluster, though further detailed technical decisions should be taken under each of these areas, based on your organization's preferences and Kubernetes use case.
Processes, team, and culture
Cloud transformation came with shocking changes to organizations' culture and processes, and the way they manage and operate infrastructure and applications. DevOps is a reflection of this deep impact of adopting the cloud mentality to organizations' culture, as it affected how companies do dev and ops and how their internal teams are organized.
Day after another, the line between dev and ops is getting thinner, and by introducing Kubernetes and the cloud-native approaches DevOps teams are reshaping into a Site Reliability Engineering (SRE) model and also hiring dedicated platform teams, as both approaches consider recommended practices for structuring teams to manage and operate Kubernetes.
Cloud-native approach
The Cloud Native Computing Foundation (CNCF) defines cloud-native as scalable applications running in modern dynamic environments that use technologies such as containers, microservices, and declarative APIs. Kubernetes is the first CNCF project, and it is the world's most popular container orchestration platform.
Cloud-native computing uses an open source and modern commercial third-party software stack to build, package, and deploy applications as microservices. Containers and container orchestrators such as Kubernetes are key elements in the cloud-native approach, and both are enabling achieving a cloud-native state and satisfying the 12-factor app methodology requirements. These techniques enable resource utilization, distributed system reliability, scaling, and observability, among others.
The 12-factor app methodology
The 12-factor app methodology defines the characteristics and design aspects for developers and DevOps engineers building and operating software-as-a-service. It is tightly coupled with cloud-native architecture and methods. Find out more about it here: https://12factor.net/.
The Cloud Native Computing Foundation
In 2014, Google open sourced Kubernetes, which works much like their internal orchestrator, Borg. Google has been using Borg in their data centers to orchestrate containers and workloads for many years. Later, Google partnered with the Linux Foundation to create CNCF, and Borg implementation was rewritten in Go, renamed to Kubernetes. After that, a lot of technology companies joined CNCF, including Google's cloud rivals: Microsoft and Amazon.
CNCF's purpose is building and managing platforms and solutions for modern application development. It supervises and coordinates the open source technologies and projects that support cloud-native software development, but there are also key projects by commercial providers.
Why we should care about cloud-native
CNCF states the following:
CNCF cloud-native recommendations and software stack are a cornerstone to high-quality up-to-date Kubernetes infrastructure, and this is a critical part of the production-grade infrastructure that we intend to deliver and operate. Following CNCF and keeping track of their solutions landscape is one of the best practices that Kubernetes platform creators and users should keep at the top of their checklists.
Cloud-native landscape and ecosystem
The cloud-native landscape is a combination of open source and commercial software projects supervised and supported by CNCF and its members. CNCF classified these projects according to the cloud-native functionalities and the infrastructure layers. Basically, the landscape has four layers:
- Provisioning: This layer has projects for infrastructure automation and configuration management, such as Ansible and Terraform, and container registry, such as Quay and Harbor, then security and appliance, such as Falco, TUF, and Aqua, and finally, key management, such as Vault.
- Runtime: This layer has projects for container runtime, such as containerd and CRI-O, cloud-native storage, such as Rook and Ceph, and finally, cloud-native networking plugins, such as CNI, Calico, and Cilium.
- Orchestration and management: This is where Kubernetes belongs as a schedular and orchestrator, as well as other key projects, such as CoreDNS, Istio, Envoy, gRPC, and KrakenD.
- App definition and development: This layer is mainly about applications and their life cycle, where it covers CI/CD tools, such as Jenkins and Spinnaker, builds and app definition, such as Helm and Packer, and finally, distributed databases, streaming, and messaging.
The CNCF ecosystem provides recommendations that cover every aspect of the cloud-native and Kubernetes needs. Whenever applicable, we will make use of these CNCF projects to fulfill cluster requirements.
Cloud-native trail map
The cloud native trail map is CNCF's recommended path through the cloud-native landscape. While this roadmap is meant for cloud-native transformations, it still intersects with our Kubernetes path to production, as deploying Kubernetes as the orchestration manager is a major milestone during this trail map.
We have to admit that most Kubernetes users are starting their cloud transformation journeys or are in the middle of it, so understanding this trail map is a cornerstone for planning and implementing a successful Kubernetes rollout.
CNCF recommends the following stages for any cloud-native transformation that is also supported by different projects through the cloud-native landscape:
- Containerization: Containers are the packaging standard for cloud-native applications, and this is the first stage that you should undergo to cloud-migrate your applications. Docker containers prove to be efficient, lightweight, and portable.
- Continuous Integration and Continuous Delivery/Deployment (CI/CD): CI/CD is the second natural step after containerizing your applications, where you automate building the containers images whenever there are code changes, which eases testing and application delivery to different environments, including development, test, stage, and even further to production.
- Orchestration and application definition: Once you deploy your applications' containers and automate this process, you will face container life cycle management challenges, and you will end up creating a lot of automation scripts to handle containers' restart, scaling, log management, health checks, and scheduling. This is where orchestrators come onto the scene; they provide these management services out of the box, and with orchestrators such as Kubernetes, you get far more container life cycle management, but also an infrastructure layer to manage cloud underlayers and a base for your cloud-native and microservices above it.
- Observability and analysis: Monitoring and logging are integral parts of cloud-native applications; this information and metrics allow you to operate your systems efficiently, gain feasibility, and maintain healthy applications and service-level objectives (SLOs).
- Service proxy, discovery, and mesh: In this stage, your cloud-native apps and services are getting complex and you will look for providing discovery services, DNS, advanced load balancing and routing, A/B testing, canary testing and deployments, rate limiting, and access control.
- Networking and policy: Kubernetes and distributed containers networking models bring complexity to your infrastructure, and this creates an essential need for having a standard yet flexible networking standard, such as CNCF CNI. Therefore, you need to deploy compliant plugins such as Calico, Cilium, or Weave to support network policies, data filtering, and other networking requirements.
- Distributed database and storage: The cloud-native app model is about scalability, and conventional databases could not match the speed of the cloud-native scaling requirements. This is where CNCF distributed databases fill the gap.
- Streaming and messaging: CNCF proposes using gRPC or NATS, which provide higher performance than JSON-REST. gRPC is a high-performance open source RPC framework. NATS is a simple and secure messaging system that can run anywhere, from large servers and cloud instances to Edge gateways and IoT devices.
- Container registry and runtime: A container registry is a centralized place to store and manage the container images. Choosing the right registry with features that include performance, vulnerability analysis, and access control is an essential stage within the cloud-native journey. Runtime is the software layer that is responsible for running your containers. Usually, when you start the containerization stage you will use a Docker runtime, but eventually, you may consider CNCF-supported runtimes, such as CRI-O or containerd.
- Software distribution: The Update Framework (TUF) and its Notary implementation are both projects that are sponsored by CNCF, and they provide modern and cloud-native software distribution.
It is wise to treat the preceding cloud-native transformation stages as a recommended path. It is unlikely that companies will follow this roadmap rigidly; however, it is a great basis to kick off your cloud transformation journey.
Summary
Building a production-grade and reliable Kubernetes infrastructure and clusters is more than just provisioning a cluster and deploying applications to it. It is a continuous journey that combines infrastructure and services planning, design, implementation, CI/CD, operations, and maintenance.
Every aspect comes with its own set of technical decisions to make, best practices to follow, and challenges to overcome.
By now, you have a brief understanding of Kubernetes infrastructure basics, production challenges, and readiness features. Finally, we looked at the industry best practices for building and managing successful Kubernetes productions and learned about the cloud-native approach.
In the next chapter, we will learn the practical details of how to design and architect a successful Kubernetes cluster and the related infrastructure, while exploring the technical and architectural decisions, choices, and alternatives that you need to handle when rolling out your production clusters.
Further reading
You can refer to the following book if you are unfamiliar with basic Kubernetes concepts:
Getting Started with Kubernetes – Third Edition: https://www.packtpub.com/virtualization-and-cloud/getting-started-kubernetes-third-edition