
Chapter 1 introduced the schema and its importance. The schema defines the rules that govern much of what the LDAP directory can do. When you change the rules of a game, the game can change significantly. The nice thing about the schema is that users interacting with the directory usually don't need to be aware of it, and certainly they don't need to understand how it works.
The schema holds a central importance, which is hidden from users
The schema determines the type of data a directory holds
But the schema defines more than just the rules of interaction; it defines what kinds of entries can be created in the directory. It defines what information the directory can store. So modifying the schema can greatly increase the value of the LDAP directory and its flexibility.
Modifying the schema can extend the functionality of a directory
You modify the schema to allow new types of objects or to create a new attribute type. The impact of creating a new type of entry can add greatly to the functionality of a directory. You can also add to the attribute-matching rules and, by doing so, change how the LDAP directory resolves search operations. I discuss some interesting examples of schema modifications at the end of this chapter.
The schema components are highly interdependent
The schema consists of several components. Figure 4-1 represents how each of these schema elements relates in the context of the schema. You can use it to visualize each of these elements as it is explained. There is quite a bit of interdependency between each of the elements; in fact, each schema element might depend on several other schema elements. Complex elements such as object classes and attributes are built from simpler elements such as syntaxes and matching rules. Figure 4-1 shows this dependency among elements.
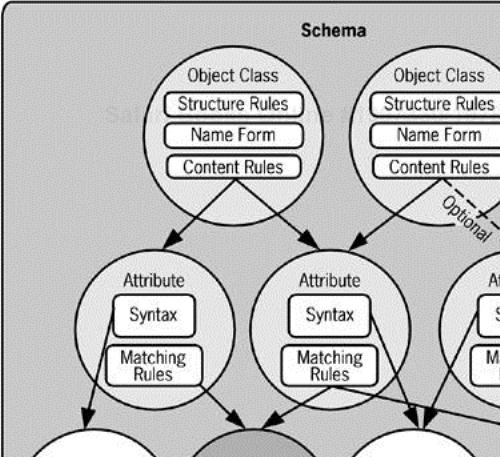
Object classes and attributes are the top level of the schema
An object class defines the kind of entry allowed in the directory. An object class definition consists of content rules, structure rules, the name form, and additional operational information. Content rules within the object class definition detail the attributes that an object class contains. Structure rules define how each object class participates in the namespace, in other words, where entries of the object class can reside. The name form defines what attribute(s) can be used to name entries of the object class. An attribute defines the kind of information associated with each of these object classes, and therefore in the entries. The attribute type is the definition of the attribute. An attribute type is defined by syntax, matching rules, and other operational information about the attribute. The syntax determines how data values are represented. Matching rules determine how to compare these data values in an LDAP operation.
Syntax is the building block of matching rules and attribute types
Syntax defines the kind and form of the data allowed in the attribute value. An example of syntax is a Boolean value. For a value to fit the Boolean syntax, it must be either FALSE or TRUE. Other syntaxes allow for data to be represented in the directory in a variety of forms. Matching rules also use syntax and are included in the attribute type definition.
Schema checking maintains the integrity of the directory
Chapter 1 introduced the concept of schema checking. On every add, modify, or modifyRDN operation, the attribute values must be checked to see whether they meet the schema requirements for the object class and attribute type. If these checks fail, the operation fails. The schema-checking process is concerned primarily with ensuring that the data structure of a directory is consistent. This process is analogous to the work of a referee or official, who makes sure the game is played according to the rule book.
Several documents define the recommended LDAP schema
The default schema that an LDAP directory begins with is defined by several documents. RFC 2252 describes the framework for the LDAP schema, in other words, the portion of the schema that supports the internal directory functions and allows you to define specific components in the schema. This framework includes a set of syntaxes, matching rules, and attribute types.
RFC 2252 also describes the encoding rules that should be used to represent the data in attribute values during LDAP operations. Including a description of the encoding method ensures that LDAP will interoperate across implementations. RFC 2256 describes the user schema, in other words, the portion of the schema with which clients regularly interact. There are only two requirements in this RFC that every LDAP server must implement. But the RFC contains many recommendations on object classes and attributes, and nearly all vendors implement these recommendations.
X.500 schema definitions are valid for LDAP
The LDAP schema uses the same schema definitions developed for X.500 directories because X.500 was LDAP's predecessor. For example, the RFCs noted previously draw heavily on definitions established in standards for X.501, X.520, and X.521, as documented by the ITU, which is an international standards organization. This close tie to X.500 directories provides a convenient pool of historically tested definitions to build upon, while also allowing vendors to implement a directory that supports both LDAP and X.500.
The LDAP schema is flexible
The lack of a required default schema means that Mycompany has a great deal of flexibility when implementing its directory. Vendors can also take advantage of this flexibility to create functionality for their purposes, and individual organizations can pick and choose schema modifications as they design their directories. Extensions to the schema can be made after implementation to extend the functionality of a directory.
LDAP v3 publicizes its schema to clients
LDAP v3 requires that the schema be published in a subschema entry that can be found by querying the value of the subschemaSubentry attribute of any directory entry. The value of this entry is the DN of the subschema entry that holds the published schema. By publishing the schema, the client can be made aware of functionality that the server supports. This also can simplify schema maintenance both by making the schema easier to modify, and by leveraging any other maintenance the directory supports, such as replication.
An object class defines the types of entries in a directory
Object classes define what entries are possible in an LDAP directory. Every entry in an LDAP directory has an attribute named objectclass, and the objectclass attribute value(s) corresponds to an object class definition in the schema. Object classes define what attributes are required and which are optionally available for use with a directory entry. They also provide a convenient way for a user to query for all the entries with a particular objectclass attribute. For example, I might want to find all the entries with objectclass=user so I can identify all the user accounts in a Microsoft Active Directory.
Three categories of object classes create a template for building object classes
There are three categories of object classes: abstract classes, auxiliary classes, and structural classes. Every entry in the directory has at least one structural class and one abstract class, and it may have auxiliary classes. Some vendor implementations of LDAP do not distinguish between these categories of object classes, but this doesn't mean that these categories aren't used by the underlying schema. Any particular object class may build on another object class definition or pick the attractive parts of another object class definition; object class categories are what enable this functionality, even if they aren't formally acknowledged by the vendor. Object classes can either include or inherit existing definitions, thereby forming relationships between object classes. These relationships mean that one object class has a whole set of object classes depending on it, so a hierarchy is formed. The purpose of each of the categories of object classes, and how each helps you build new object classes, is discussed shortly.
The object class definition contains several key fields that help to define an entry of the object class and what rules that entry follows. The following fields are part of the object class definition:
OID—. The unique object identifier for this object class.
Name—. The name used to refer to the object class.
Description—. Brief description of what the object class represents.
Inactive status—. Indicated by
OBSOLETE, which means the object class is inactive.Superior class—. Lists the object class(es) on which this object class is based. Some schema formats label this field
SUPwhile others call itSUBCLASS OF.Category of object class—. Specified with the presence of
abstract,auxiliary, orstructural. By default,structuralis assumed. The categories indicate to the schema-checking process how to create an entry of that object class, and what attributes are required or allowed.Mandatory attributes—. Usually noted by a
MUSTfield, which lists all the attributes that must have values for an entry of this object class to exist.Optional attributes—. Usually noted by a
MAYfield, which lists all the attributes that are allowed on an entry of this object class.
Although the following object class fields are not defined in RFC 2252, many LDAP directories also support them:
Naming attribute—. Designates which attribute or attributes are used for naming (RDN) of entries of this object class. You can designate more than one attribute to form multivalued RDNs.
Superior rules—. Designate which object classes can contain entries of this object class.
To illustrate, here is an example of the subschema object class definition:
subschema OBJECT-CLASS ::= {
SUBCLASS OF { top }
KIND auxiliary
MAY CONTAIN { dITStructureRules | nameForms |
ditContentRules | objectClasses |
attributeTypes | matchingRules |matchingRuleUse }
ID 2.5.20.1}
Most products store the schema in a text file
Most directory products use a text file to store the schema definitions. This text file can be modified to include new definitions or change existing ones. Many products require that the LDAP server be restarted for changes to be recognized. The subschema object class definition uses the ASN.1 schema format. Definitions follow a special format that is dependent on the vendor. Appendix B examines the common schema formats.
Some products allow schema modifications via LDAP operations
Some directories represent the schema object classes and attributes as directory entries, allowing LDAP clients to search and modify the schema definitions via LDAP operations. For example, the person object class might exist as an entry at cn=person,ou=Schema,dc=mycompany,dc=com. In this fictitious example, the mandatory attributes are listed in a special attribute called must, and the optional attributes in a special attribute called may. An LDAP client with the proper access control can modify the definitions. Although it doesn't follow the details of this fictitious example, Microsoft's Active Directory product is an example of a product that allows users to add or modify the schema via LDAP operations.
Creating the entry you want may require using multiple object classes
Object class definitions let you create entries that have the attributes, content rules, and name form you want. Let's say you want to create an entry with a particular profile in Mycompany's directory. But among the existing object classes, there is no single class that fits the profile you want. You have two choices. Either you pick and choose from among the existing object classes, and create an entry that has several object classes. Or you design a new object class.
You may have to build a new object class to get the entry you want
Let's further suppose that there isn't any combination of existing object classes that fits the profile you want, because an attribute is missing or the combination of content rules from multiple classes is too restrictive. But an existing object class does have some of the elements you need. You must create a new object class, and it would be easier if you could build on that existing object class. The following two sections explore your options.
Object class inheritance allows content and structure rules to be shared
Your new object class can inherit name form, content rules, and structure rules from another object class. When a new object class builds on an existing object class, the new object class is said to be a subclass of the original, and it inherits the traits of the existing object class. We'll look at what inheritance means shortly. The original class is called the superior class or superclass of the new object class. This relationship is included in the definition of the new object class in the superior field.
A hierarchical relationship of object classes is created when you use inheritance
This relationship between object classes is similar to the relationships that scientists observe in biological classifications. There is a hierarchy among life form classes, just as there is a hierarchy among object classes. If a life form is classified as human, it is also classified as an animal, a mammal, and a primate. A human shares some characteristics with all other animals, mammals, and primates, but it also has other unique characteristics. Figure 4-2 shows a concrete example of the hierarchical relationship between object classes. The ASN.1 schema format is used to represent the object class definitions.

Inheritance allows entries of one object class to take the traits of another object class
If I call you human, I don't also need to call you a mammal; everyone assumes that you are a mammal. In a similar fashion, if you create an entry with an object class that is the subclass of another, you do not need to indicate all the superior classes. The directory assumes those other classes and automatically includes them in the entry. When you create an entry of the new subclass, the objectclass attribute value of the new entry will have both the new object class name and the names of any object classes noted in the SUP field. The new entry is required to follow the rules and requirements defined in the schema for all these object classes.
Inheritance results in simpler schema definitions
Note that the new subclass does not explicitly include the schema definitions for any of its superclasses. It doesn't need to. The requirements, rules, and definitions are all inherited when you create the entry. The directory takes care of these details. Building inheritance into entry creation results in elegant and efficient object class definitions, as well as a simplified process for creating an entry. Figure 4-3 shows how the elements of object classes are used to create an entry of a subclass. On the entry, the italicized attributes are optional, the bolded attributes must be supplied by the client request, and the single attribute shown in regular font is automatically supplied by the directory itself.
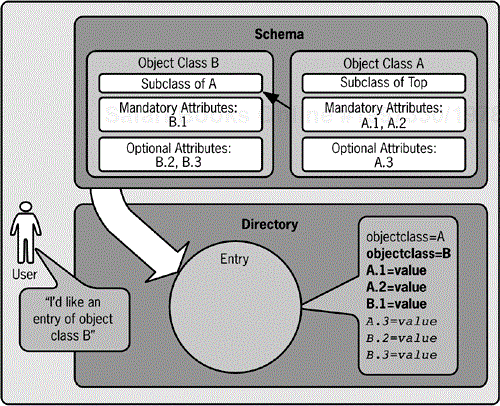
An example of creating an entry using an inherited object class
An example of how inheritance works will illustrate this concept. Using the definitions shown in Figure 4-2, I send an add operation to Mycompany's directory with the following parameters:
DN: |
|
Attributes: |
cn=Boba Fett;sn=Fett;objectclass=inetOrgPerson; |
An entry with the following information is created:
DN: |
cn=Boba Fett,ou=People,dc=mycompany,dc=com cn=Boba Fett sn=Fett objectclass=inetOrgPerson objectclass=OrganizationalPerson objectclass=person objectclass=top |
Note that three additional objectclass values were automatically added. Had I left off the sn attribute in the add operation parameters, the operation would have failed. Even though I'm creating an entry of inetOrgPerson, I must meet all the requirements of every superclass of inetOrgPerson, and sn is a requirement of the object class person. I might have added any of the optional attributes in any of the four object class definitions shown in Figure 4-2. So inetOrgPerson gives me four object classes even though I have to specify only one.
You use abstract classes to build other object classes
Abstract classes form the building blocks of other object classes. You use an abstract class as a template via inheritance to build other object classes. There is a special abstract class called top that is the ultimate superclass of all object classes. To build an object class that doesn't inherit anything, you build an object class that is a direct subclass of top. The abstract class is the least frequently used, and it is typically used to support internal LDAP operations as opposed to building a data structure for an entry.
Structural classes are used in every directory entry
Each directory entry must contain one structural class. A structural class always uses inheritance, and it must be a subclass of another object class. Conversely, only structural classes can use inheritance; abstract classes and auxiliary classes cannot use inheritance. A structural class can be a superclass of another object class.
Instead of using inheritance to create the entry you need in Mycompany's directory, you might use an auxiliary class. The combination of an existing object class that has some of the elements you require plus a newly defined auxiliary class would result in the entry you need. To create your entry, you'd need to explicitly add both the existing object class and the auxiliary class.
You use auxiliary classes to mix and match
An auxiliary class augments the other object classes of an entry without the costs tied to inheritance. The auxiliary class is never involved in inheritance because an auxiliary class is never the superclass for a structural or abstract class. Instead, auxiliary classes are explicitly included in an entry rather than included implicitly via inheritance. You use auxiliary classes to add specific functionality to a standard object class without modifying the original object class definition. The same auxiliary class may be added to entries with different object classes. This is the most significant advantage of the auxiliary class. In other words, the auxiliary class is not part of a chain of inheritance, and you can use it with entries of differing classes. Figure 4-4 shows how the elements of auxiliary classes are combined with other classes in the creation of an entry. The attributes shown in italics are optional, and the attributes shown in bold must be supplied by the client request.
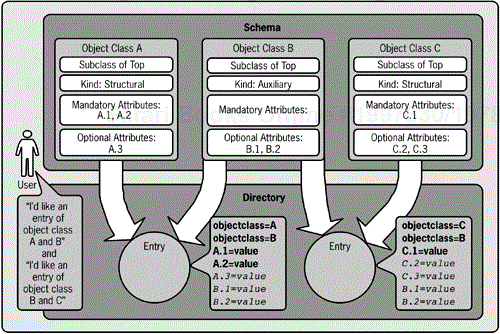
Auxiliary classes are outside of class inheritance chains
Many LDAP directories allow an object class to inherit from only a single class, so only one superclass is allowed for any particular object class. This constraint leads to a dependent chain of object classes that inherit the characteristics of all the superclasses in the chain. You might want some of the characteristics (usually attributes), but not others. This chain of dependencies is why the auxiliary class is important; the auxiliary class doesn't participate in an inheritance chain. The auxiliary classes that maximize this benefit have no mandatory attributes and include only optional attributes, thus truly allowing the class to extend functionality. You use the features of the auxiliary class to augment object classes that don't (and shouldn't) have a hierarchical relationship to one another.
For example, Mycompany may want to attach a globally unique identifier (guid) to each group (objectclass=groupOfUnique Names) and user (objectclass=inetOrgPerson) entry in the directory. The guid is defined as an attribute. An auxiliary object class guidClass is defined with the guid attribute as an optional attribute. Then the guidClass object class can be added to each of the group and user entries. We would do this via a modify request that added objectclass=guidClass. Finally, guid values can be added to all the entries. These values could be added via the same modify request that added the auxiliary class.
Consider the alternative, assuming a directory that supports only single inheritance. The alternative using class inheritance would require that you define two distinct object classes that are subclasses of groupOfUniqueNames and inetOrgPerson, respectively. Call each of these subclasses guidgroupOfUniqueNames and guidinetOrgPerson. Each of these would effectively have the same purpose—to add the same single optional attribute—but you would have to provide both definitions to circumvent the single inheritance issue.
An attribute type is described in what is called the AttributeType-Description in RFC 2252, and the AttributeType in RFC 2251.
An attribute is defined by an attribute type, which is composed primarily of syntax and matching rules
An attribute type contains several key fields. These fields help to define the attribute as well as what rules that attribute follows. The critical fields define the syntax and matching rules for the attribute. The syntax defines the kind and form of the data allowed in the attribute value. The matching rules define how the directory can determine whether an asserted value matches an attribute value during an LDAP operation. As noted earlier, matching rules also use syntax. The attribute type also specifies whether multiple attribute values are acceptable. By default, an attribute is multivalued, meaning that an attribute can have multiple values on each entry.
The following fields are part of the AttributeTypeDescription:
OID—. Unique object identifier for this attribute type.
Name—. Usually specified with the
NAMElabel, which is the name used to refer to the attribute type.Description—. Usually indicated with the
DESClabel, which is a brief description of what the attribute type represents.Inactive status—. Usually specified with the presence of the
OBSOLETElabel, which means the attribute type is inactive.Superior class—. Lists the attribute type on which this attribute type is based.
Equality matching rule—. Matching rule used to determine whether an asserted value matches an attribute value.
Order matching rule—. Matching rule used to determine whether an asserted value is ordered before or after an attribute value.
Substring matching rule—. Matching rule used to determine whether an asserted string value with a wildcard character matches an attribute value.
Syntax—. The kind and form of the data allowed in the attribute value.
Number of allowed values—. Whether only a single value or multiple values are allowed. By default, multiple values are assumed. The presence of
SINGLE-VALUEindicates only a single value is allowed.Collective—. By default, not collective is assumed.
Modifiable—. Whether the attribute value can be modified by user-initiated LDAP operations. By default, the attribute value is user modifiable.
Usage—. Type of operations for which the attribute is used. By default,
userApplicationsis assumed.userApplications,directoryOperation,distributedOperation, anddSAOperationare all valid values; however, many vendor implementations throw out these values and replace them with only two values:userorapplicationandoperational. Attributes that are not markeduserApplicationsare not returned by default on a search operation, because they are considered information that only the internal directory needs to support internal operations.
To illustrate, here is an example of the createTimestamp attribute definition:
( 2.5.18.1 NAME 'createTimestamp' EQUALITY
generalizedTimeMatch
ORDERING generalizedTimeOrderingMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.24
SINGLE-VALUE NO-USER-MODIFICATION USAGE
directoryOperation )
This definition is given in the BNF schema format, which is different from the format used for the example object class earlier in this chapter. For more details on schema formats, see Appendix B.
Attributes can have more than one name
Any particular attribute type can have more than a single name. These names are synonyms for each other. For example, the attribute facsimiletelephonenumber might have fax as a synonymous name. Or cn might have commonName as a synonym. The synonymous names are included in the NAME field of an attribute type definition. The first name in the NAME field of an attribute type definition is called the canonical attribute name. Within a directory that shares a common schema, a user can generally employ these synonyms interchangeably, but this doesn't necessarily hold true between directories with different schemas.
How synonymous names are handled is not standardized, which is problematic
Usually LDAP directories prefer to return attribute names in the canonical form, replacing any synonymous name used in a request. For example, I might ask for fax, but get back facsimiletelephonenumber. Attribute name synonyms are not governed by the LDAP standards, and how any particular vendor or organization implements them is unregulated. When Mycompany needs to integrate multiple LDAP directories, the attribute name that one directory allows or prefers may be different from that of another directory. This difference can cause serious integration problems. Hopefully this oversight in the standard will be addressed in the future.
Subtyping is not defined in the LDAP standard, yet it is mentioned as a feature
The existing standards (in RFC 2256, Section 5.50) mention the possibility of subtyping but don't explain it. Subtypes are common in X.500; and because LDAP was originally thought to be an extension of X.500, the definition was implied. Now that LDAP directories are being implemented without X.500 support, this omission in the standard presents a problem.
An attribute subtype builds on an existing attribute definition
As you might expect, the concept of subtypes is similar to that of subclasses. Subtypes are for attributes what subclasses are for object classes. You can extend an existing attribute type into a subtype. The attribute subtype inherits the syntax and matching rules of its supertype. For example, the cn attribute type is derived from the name attribute type. cn is therefore a subtype of name. And name would be a supertype of cn. The cn attribute description doesn't include any syntax or matching rules because it inherits these elements from the name attribute definition. Figure 4-5 shows this relationship.
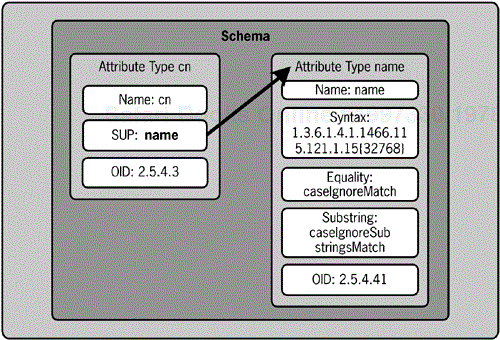
Subtypes change how the search operation operates
Subtypes extend the functionality of the directory. Searches that ask for the name attribute will return name values as well as values from all subtypes of name. For example, a search for all the entries with any value present in the name attribute (in other words, (name=*)) will return all the entries with values in name or cn (and the many other subtypes of name).
Subtypes are usually seen only in LDAP products with X.500 support
As noted already, subtypes are only a possibility in LDAP, not a requirement. Few LDAP implementations include this functionality, and these implementations usually include X.500 functionality as well. Subtypes can be a powerful addition, but they change many of the basic assumptions, so Mycompany will be cautious when using them.
An Attribute-Description associates special attribute options with an attribute type
The AttributeDescription is defined in RFC 2251 as a superset of the attribute type definition. This is not the attribute type, but a slightly larger definition. The AttributeDescription encapsulates the attribute type definition, allowing special attribute options to be specified. These attribute options are largely undefined in terms of their purpose. Historically they have been used to change the format of the attribute value that is communicated to the client.
Figure 4-6 shows how the AttributeDescription and attribute options relate to an entry in a directory and a client that might use that attribute option. In the figure, the client would like attribute A of entry Y to be returned with the munge option. Attribute A's schema definition includes the munge option, so this request is allowed. The directory looks up the value of attribute A and then reformats that value based on the syntax defined for the munge option. The directory reports to the client the attribute value seen through this munge reformatting.
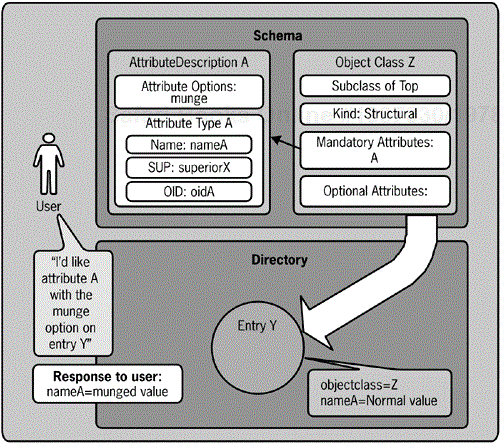
The
binaryoption changes the format of the attribute value communicated to the client
For example, RFC 2251 gives an example of the binary option in which you can force the server to change the syntax format of the attribute value that is communicated to the client to a binary format instead of the typical string-based syntax. This does not necessarily mean the server must store the attribute value in the binary format, just that it must communicate the value in a binary format to the client.
Options do not have to change the format
You can also use attribute options to indicate the language in the attribute value. This approach doesn't change the format of the value, but rather indicates that the value is stored in a specific language. For details on language support via attribute options, see the following section, Language Support.
Clients specify attribute options by appending them to the attribute type
Users specify the attribute option(s) they want by appending a semicolon and the name of the option to the end of the attribute type in the relevant search or compare operation parameter. For example, the binary option with the cn attribute would be specified cn;binary. You could use this approach in a compare operation in which you want to compare a data value in binary form but the attribute value has a string syntax. You can specify multiple options at once. Servers that don't recognize a requested option should treat the request as an unrecognized attribute type and the operation will fail. The only common use of the binary option is with digital certificates, for example, userCertificate:binary. Here it is used to correct an invalid assumption made in the early days of LDAP about how digital certificates are represented. You should never search for digital certificates without the binary option.
LDAP supports multiple languages in data format, but further support is needed
LDAP supports the possibility of international language support, based on Unicode. LDAP v3 specifically uses Unicode Transformation Format-8 (UTF-8), which is a character set that can be used to represent virtually all written languages. Because LDAP uses Unicode, you don't need to specially denote what language an attribute value takes. Using multivalued attributes, several languages could be supported at once. However, special syntaxes and matching rules that support a specific language might be required in a multiple-language directory, so a user of a particular language could search and receive results using the rules of that language.
Attribute-based language code suffixes are used to extend support
The approach to this issue has been standardized somewhat in RFC 2596. For this purpose, the RFC proposes to specially designate language codes that are associated with an attribute type definition via the attribute option portion of the Attribute-Description. The attribute option functionality noted in RFC 2251 was intended as a way to allow extensions to the framework of the LDAP directory.
The language code desired is added to the option field of the attribute type in the schema
In terms of the schema, each attribute type definition can be extended with the desired language codes. RFC 1766 specifies the language code suffix to be used. So for example, Mycompany might choose to extend the description attribute type with the Spanish language. Mycompany would modify the description AttributeDescription in the schema, adding lang-es to the option portion of the definition. Then users could specify this option during a search request. In this example, description; lang-es would be specified as the full attribute type designation, meaning the description attribute type using the Spanish language.
Entries with the extended attribute option can have a value both for the option format and for the default format
The entries in the directory that have an attribute with a language option defined can have values for both the language option and the base attribute type. For example, if the description attribute type were extended with the Spanish language as noted already, the following entry would be valid:
objectClass=person cn=Brian Arkills sn=Arkills description=He is very crazy. description;lang-es=Está muy loco.
Each language option desired would have to be individually set because the server does not automatically translate the value from the default format to the language option format.
Multiple language options can be set
Directory administrators can modify the AttributeDescription to support many language options; then users can set an attribute value for each of the language options for that attribute type. The syntax of each attribute doesn't need to change, because UTF-8 supports multiple character sets. Also the data that is communicated to the user is not transformed in any way, as it is with the binary option.
Searches on attribute options work like they do for attribute subtypes
In terms of search behavior, you can consider each language option a subtype of the attribute type. Just as you can expect that a search on the attribute supertype will return a match for all the attribute subtypes, so a search on an attribute type will return a match on that type and all the language options for that type. With attribute subtypes, the reverse is not true; a search for a specific language option of an attribute type does not return values of the attribute type without a language option. You can find specific examples that illustrate this behavior in the RFC. Despite this search behavior, the language option extensions are not subtypes defining a new attribute type; they are options.
Matching rules that support language and cultural rules are needed
RFC 2596 does not supply a complete solution in every case. As mentioned earlier, matching rules that support the cultural rules specific to a language are needed for full functionality. Matching rules are needed to define many issues of syntax that are often taken for granted. Examples include:
The order of characters in the language's alphabet
Issues of language type, such as what is a number and what is an alphabetic character
The cultural formats for common data types like time, money, and date
We'll look at matching rules shortly. Mycompany will want to carefully review language support in a potential product if this is a critical requirement.
Operational attributes support internal directory operations
Operational attributes are used by the directory to support internal directory operations, and they are the attributes not marked with a usage of userApplications. Several of these operational attributes are required by LDAP v3 in the rootDSE entry and the subschema entry. Other operational attributes can be of value to the client because they contain information that can reveal what an LDAP server supports, what rules might be used, and even information of critical importance, such as the last modified time for an entry.
Operational attributes are noteworthy enough to list
The only way to get a handle on the operational attributes is to peruse the standards and your vendor documentation. In Tables 4-1 and 4-2, the operational attributes from the standard are listed by the type distinction noted in RFC 2252. The OID, syntax, matching rules, and other information are not listed, so you can focus on the description and intended function. You can easily obtain this information in RFC 2252, Sections 5.1 through 5.4.3. More detail is outside the scope of this book and may be dependent on the specific vendor implementation.
The subschema publishes the schema to clients
The subschema object class is a required element of the LDAP v3 standard; it is one of only two required object classes. The subschema is used to advertise the supported schema in an LDAP directory. The subschema entry (there can be more than one in each directory) is used by clients to determine what rules they can expect when interacting with that specific LDAP directory.
Table 4-1. directoryOperation attributes
Attribute Name | Description |
|---|---|
createTimestamp | Keeps track of when an entry was created. |
modifyTimestamp | Keeps track of when an entry was last modified. |
creatorsName | Keeps track of who created an entry. |
modifiersName | Keeps track of who last modified an entry. |
subschemaSubentry | Contains the DN of a |
attributeTypes | Contains a list of the supported attribute types; is located in the |
objectClasses | Contains a list of the supported object classes; is located in the |
matchingRules | Contains a list of the supported matching rules; is located in the |
matchingRuleUse | Contains a list of the supported matching rules that are available via the extended match filter described in Chapter 3. This attribute is located in the |
dITStructureRules | Contains the structure rules that this server supports. |
nameForms | Contains the name forms that this server supports. |
| ditContentRules | Contains the content rules that this server supports. |
Table 4-2. dSAOperation Attributes
Attribute Name | Description |
|---|---|
namingContexts | Identifies the naming contexts that this server supports directly or indirectly. An empty string value indicates that this server should contain the entire directory namespace. The client can use this attribute to find a suitable namespace to search. |
altServer | Refers to another LDAP server that is equally capable of providing a response. The value is in an LDAP URL format. LDAP clients can cache this information so if the server becomes unavailable, the client can continue operation with the other server(s). |
supportedExtension | Contains OIDs for the extended operations that the server supports. |
supportedControl | Contains OIDs for the controls that the server supports. |
supportedSASLMechanisms | Contains OIDs for the supported SASL mechanisms that the server supports. |
supportedLDAPVersion | Contains the version of the LDAP protocol that the server supports. |
The subschema entry has at least four mandatory attributes and many optional attributes. The mandatory attributes include cn, objectClass, objectClasses, and attributeTypes. object-Classes contains a list of all the supported object classes in the directory. attributeTypes contains a list of all the supported attributes in the directory. The optional, operational attributes of the subschema entry are known as the directoryOperation attributes. See Table 4-1 for these attributes and a short description. You find the subschema entry by asking for the value of the operational attribute subschemaSubentry, which is on the rootDSE entry as well as every entry in the directory. The value is the DN of the subschema entry.
The rootDSE entry provides basic information about a directory server. The rootDSE entry has no defined object class in the standard. It must, however, exist and allow the dSAOperation operational attributes listed in Table 4-2. Additional attributes may be located in the rootDSE entry to support vendor-specific functionality. The dSAOperation operational attributes can also be included in other object class definitions.
ASN.1 is commonly used to build syntax
A syntax defines the data format used by an attribute type or matching rule. A special system called Abstract Syntax Notation One (ASN.1) is used to convey the definition of a syntax. ASN.1 is defined by X.209 and is similar to the BNF notation (defined in RFC 822). ASN.1 is a flexible system that can be used to define a variety of data types, from integers and strings to complex sets and sequences of a variety of data types. It is used to build type definitions from what you might call a predefined toolbox. This toolbox consists of a small set of simple types like integer, IA5string (ASCII), or bit string (binary), along with special operators to denote ways to combine these simple types, using sequences, sets, and multiple choice. Complex type definitions can be built by referencing less complex definitions via substitution.
ASN.1 helps to provide cross-platform interoperability
ASN.1 has several advantages. One is that ASN.1 has special encoding rules called BER and DER that define how content represented in ASN.1 can be put in messages fit for transmission. LDAP uses BER encoding, specifically a simplified subset of BER. ASN.1 messages are placed in a format it calls octet strings. Octet strings are arbitrarily long strings of 8-byte data. So an octet string's length should always have a factor of 8. Incidentally, ASN.1 is used by many standards, including X.509 certificates used by SSL and Kerberos version 5, which make those technologies easier to integrate with LDAP.
There are no default syntaxes in the standard, only commonly used ones
RFC 2252 lists 58 default syntaxes for LDAP servers, but only defines 33 of those listed. Vendor implementations are under no obligation to implement any of these syntaxes, and they may implement new ones. This is an area of possible extensibility, but it could be at the cost of breaking interoperability with other clients or servers. For the most common of these syntaxes, see Appendix B.
The syntaxes that an LDAP server supports may be published in the subschema entry in an attribute called ldapSyntaxes. Unfortunately, including this attribute and the information it contains is not required by the standard.
Matching rules are used to compare data values
Matching rules are used by the LDAP server to compare an attribute value with an assertion value supplied by the LDAP client search or compare operations. The server also uses matching rules to transform the client assertion value to an attribute value in add or modify operations. Finally, the server uses matching rules to compare asserted DN names with the DNs of entries in the directory. Pretty much every LDAP operation uses a matching rule, and many times a single operation will use matching rules more than once. Matching rules have a simple definition that link a name and OID with a syntax. Attributes then include the matching rules in their definitions so at least equality matches are supported for each attribute type.
Extended operations employ matching rule use definitions for the attributes specified in the definition
Matching rule use definitions are slightly different from matching rule definitions. A matching rule use definition links a matching rule definition with specific attribute types for use in extended search filters. You employ this type of definition to associate a matching rule with an attribute type outside the attribute type definition. Values of the matchingRuleUse attribute, listed earlier in the chapter, denote the matching rules used by the directory. Each value denotes a matching rule use definition that tells the directory which matching rules to use with specific attribute types in extended search filter operations.
Syntaxes are used to build matching rules
Both matching rule definitions and matching rule use definitions are dependent on syntax definitions. The syntaxes Matching Rule Description and Matching Rule Use Description are used to build the matching rules. Syntaxes are also defined for matching rules whose assertion value syntax is different from the attribute value syntax. The basic matching rules noted in RFC 2252 are listed in Table B-1 in Appendix B.
An OID is a string of numbers that guarantees the uniqueness of an object
An OID is a special number designed to uniquely identify some object, regardless of the technology. Object classes, attribute types, syntaxes, matching rules, and controls use them. In fact, an OID is required for every object definition. OIDs are used outside directory technology in areas in which guaranteeing uniqueness is important. For example, Management Information Base modules (MIBs) use them. A MIB is commonly used by management software to understand the status of each entity. One common use of MIBs is monitoring and managing networked computers. An OID is an arbitrarily long string of integers separated by periods. For example, 1.4.23.98740 is a valid OID. An OID can be used in place of the object's name.
OIDs are centrally governed, with delegated authority
The Internet Assigned Numbers Authority (IANA) governs the OID space and gives out OIDs by request. Once an organization has an OID, it owns all extensions of that OID space. If Mycompany were granted the OID 1.4.23.98740, it would also own 1.4.23.98740.1 and 1.4.23.98740.2 and so on. Extending an OID is called creating an arc. Common convention is to organize each type of object into a separate arc. Mycompany might put its object classes under 1.4.23.98740.1, attributes under 1.4.23.98740.2, syntaxes under 1.4.23.98740.3, matching rules under 1.4.23.98740.4, controls under 1.4.23.98740.5, and so on. But there are no rules about this. Mycompany can delegate an arc to you, for example 1.4.23.98740.6, but Mycompany better not also use that arc, or you and Mycompany may run into problems with the objects in that space have any interoperation. The Web site http://www.alvestrand.no/objectid/top.html is the only public listing of OIDs. It is an informal attempt to provide a mapping between the OID space and definitions.
OIDs aren't special, but they are required
In summary, OIDs don't enable any special functionality, but they do uniquely identify the definition of objects. Fortunately, users never have to know about OIDs; only administrators and those who design schema definitions need to work with them.
Schema checking ensures that an operation doesn't violate the schema definitions
The schema holds definitions, but the directory must ensure that all requested operations follow those definitions. To do so, it uses a process called schema checking. Schema checking, which isn't mentioned in the LDAP standard, is another of the concepts borrowed from X.500. Vendors therefore choose how (and whether) to implement schema checking. In general, a schema-checking process will ensure that
All attribute values conform to the syntax noted in the schema definitions.
All mandatory attributes for an entry's defined object classes are present.
DN syntax is used properly.
For example, the DN syntax is verified by checking the attribute(s) designated in the name form to see whether the values meet the DN syntax rules. The DN is not usually an attribute of the entry so it must be checked independently.
Schema violations cause the entire operation to fail
If the schema-checking process finds a violation of the schema definitions, it will return an error to the client that requested the operation. The entire operation will fail to ensure that partially completed operations do not result in a state that is undesirable to the user.
The following interesting definitions are not mentioned in the LDAP standard. As noted earlier, the schema is one of the primary places where the directory can be extended and the directory functionality increased. This makes new schema definitions valuable. Because incongruities in the schema between LDAP directories can create integration issues, standardization of new schema definitions is even more important. The following definitions are all noted in standards documents or in documents that are in the process of becoming standardized.
DNS namespace mapping is supported via RFC 2247
RFC 2247 describes the dc attribute as well as the dcObject and domain object classes. These schema elements are used to allow the use of DNS names within the DN syntax. The dc attribute makes it clear which part of the DN maps to a DNS name. The dc attribute maps directly to a DNS name, either the name of a zone or a hostname. It is the naming attribute for entries of both the dcObject and domain object classes. Values of the dc attribute are not case sensitive, which matches the DNS standard. Nearly every LDAP vendor implements this RFC.
The
dcObjectis used to attach a DNS name to an existing container object class
The dcObject object class is an auxiliary object class, and it can be used to extend the definition of existing entries that are being used as containers, like organizational units, to support a clear mapping to the DNS namespace. The dc attribute is a mandatory attribute of the dcObject object class.
You use the domain to create objects with DNS names
The domain object class is a structural object class. You use it to represent new entries that do not need to be based on an existing object class definition. The dc attribute is a mandatory attribute, and there are several useful optional attributes.
The
extensibleObjectincludes every attribute type as an optional attribute
The extensibleObject object class is very interesting indeed. Entries of the extensibleObject object class allow you to use any attribute type. You might use this flexibility to represent objects that do not conform to a tidy classification or to give an entry maximum functionality without the hassle of carefully designing an object class. You can see one such use in Chapter 8.
You can use
extensibleObjectto extend an existing object class
The extensibleObject object class is auxiliary, and you can add it to another object class definition to extend its functionality. Mandatory attributes of the other object class are still required. The definition of the extensibleObject object class does not literally include the hundreds of available attributes in the list of optional attributes; instead, it implicitly includes them. You can use this object class to avoid turning off the schema-checking process, because it allows all the optional attributes within the rules of the schema.
Use the
dynamicObjectfor transient data
RFC 2589 describes the dynamicObject object class and the extended operations needed to support it. You use the dynamicObject object class to represent a dynamic entry that expires if the entry is not updated periodically. This object class is appropriate for representing data that is time dependent. Meetings and temporary employees are two common examples of short-lived data suited to this object class. The directory administrator can use this object class to automatically maintain data whose accuracy is guaranteed only for a certain period of time.
A time-to-live attribute establishes when the object will be deleted, unless a client operation intervenes
The dynamic functionality is accomplished via a time-to-live attribute that automatically decrements, unless a client operation intervenes to reset the attribute value. The dynamicObject object class is auxiliary. An entry that is dynamic can't become static, and vice versa. There are structural rules imposed on entries of the object class, to prevent the loss of static entries below a dynamic entry, should the dynamic entry expire.
Java object schema allows Java code to be stored in LDAP
One exciting development is the opportunity to store Java objects in an LDAP directory. Combined with the Java LDAP API, which is in the process of being standardized, this enables Java applications at your organization to access common sets of code as well as other directory information. RFC 2713 specifies a standardized way to store a Java object. It includes schema definitions for object classes and attribute types to represent this data.
inetOrgPersonis a contemporary definition for a person entry
The common user object classes listed in RFC 2256 don't fully address the type of information associated with a person. The inetOrgPerson object class defined in RFC 2798 is an attempt to provide a closer definition. It includes definitions for the following new attribute types: vehicle license number, department number, display name, employee number, employee type, JPEG photograph, preferred language, MIME certificate, and PKCS certificate. This object class is implemented in almost all contemporary vendor implementations, and you may want to find out more about it by reading RFC 2798.
Significant extensions to LDAP are constantly being developed. A wise LDAP administrator pays attention to the public efforts to standardize extensions by participating in IETF proceedings. Table 4-3 lists significant examples of efforts under development at the time of this book's publication that will probably result in a published standard.
Table 4-3. Interesting LDAP schema Internet drafts
Internet-Draft Title | Description |
|---|---|
LDAP Schema for DHCP | Defines a schema for DHCP configuration. Entries can represent DHCP configurations for an entire network. This in turn enables centralized management of DHCP services. |
Kerberos KDC LDAP Schema | Includes definitions for attributes defining a realm, a realm policy, principals, and principal policies. This enables central management of Kerberos services, as well as allowing for the possibility of interoperability between different Kerberos implementations. |
Definition of an object class to hold LDAP change records | Used to efficiently support replication. |
The schema determines directory functionality
In summary, the schema employed by an LDAP product is one of the biggest factors contributing to the functionality of that product. Although the LDAP standard specifies very little of the schema or even the model employed by a vendor, vendors have followed the X.500 schema model with few deviations.
The object classes, attributes, syntaxes, and matching rules control the behavior of the directory and diversity of information it can hold. A directory that doesn't support a specific syntax or allow Mycompany to create its own will prevent Mycompany from creating some special attribute that will either give it an advantage over its competitors or provide a way to integrate an application or standalone directory.
Understanding the details of the schema is not required, but it can further the usefulness of a directory
Understanding of what the schema does and how to extend it is important for directory administrators, but most users do not need to know anything about these topics. Users that create many entries may need to have some understanding of object classes, inheritance, and interesting attributes. Some directory administrators may not need to know much detail about the schema, if the vendor supplies a comprehensive schema. But ultimately understanding of the schema will lead to further use of Mycompany's directory and extend the value it provides.
For tables of common syntaxes and matching rules, see Appendix B. An overview of the syntax for the different schema formats, together with examples, is also included.