
Consolidating information into a directory is the primary reason for implementing LDAP. Administrative controls that allow a directory administrator to more easily manage that LDAP directory are therefore relevant to the business value LDAP provides. This type of operational functionality differs from the client-server operations I examined in Chapter 3.
This chapter addresses directory management topics. Of these topics, most are not included in the LDAP standard yet. Some of the topics are addressed by RFC documents but are not formally associated with the standard. The first half of the chapter explains advanced LDAP namespace concepts, including replication, referrals, and aliases. This discussion leads to the management issues surrounding multiple LDAP servers. Special attention is given to a distributed directory service and the effort required to integrate independent directories to centralize management. Directory security concepts and recommendations are next, followed by some of the common server parameters and maintenance tools that you can use with LDAP.
Centralizing information into an LDAP directory raises the need for fault tolerance
Mycompany's decision to implement an LDAP directory may be stressful. Mycompany will centralize critical information into a single repository and integrate key business processes with this directory. The implications of the central directory being unavailable are greater than when the information was in several nonintegrated directories. How can Mycompany have any peace of mind that its directory will be available if a directory server fails?
Directory replication can provide fault tolerance, but it isn't part of the LDAP standard yet
Replication is the simplest solution. With replication, you deploy more than a single directory server. The information in the directory is then replicated between multiple directory servers, and the replicated information can be accessed from several points of distribution. However, LDAP has no specifications on how replication should be accomplished. Implementation of this feature is left to vendors. Almost every vendor does implement this feature, though. Fortunately, there is ongoing IETF discussion about what type of replication model should be used to distribute directory information from one LDAP server to another. An LDAP replication standard should emerge in the future. Mycompany will need to closely compare how each vendor implements directory replication before choosing a product.
A partition is the portion of the directory that is replicated to other servers
A partition is the portion of the directory that is replicated to other servers. The partition is a naming context (or directory suffix) that forms the element of replication. Some vendors allow flexibility with respect to the portion of the directory that can be a partition. The directory partition is replicated (by some means chosen by the vendor) to other directory servers. Usually (but not always), the administrator has some choice of how often replication occurs and can designate which partition is replicated to which server. The term “partition” designates a unit of the directory that is being replicated. This unit is usually the same as a naming context, but it might be a smaller or larger portion of the directory.
A replica is a replicated copy of directory information
A replica is a copy of a directory partition. The term “replica” refers to the subservient copies of the master partition. The difference between a partition and a replica is subtle. A replica is the replicated unit of the directory.
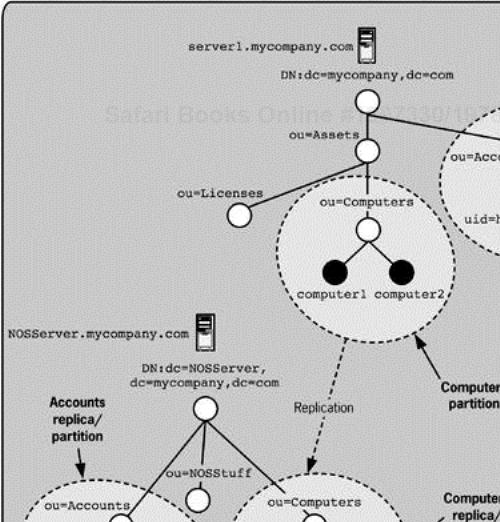
Figure 5-1 shows examples of replication used by Mycompany. In the figure, we see part of the Mycompany directory as well as a separate directory for Mycompany's network operating system directory. The two directories have different base DNs and even different directory structures. The Accounts and Computers naming contexts of the Mycompany directory are being replicated to the NOS directory because the Mycompany directory is the primary source of information to make authoritative changes. The Accounts and Computers naming contexts (of either directory) can be referred to as partitions because they are the units of replication. You might simply call the Accounts naming context the Accounts partition and not designate which directory or server it is on, because replication makes the content identical. Each of the Accounts partitions can also be referred to as replicas because both directories are the destination of replication. The Computers partition of the NOS directory is also a replica. However, the Computers partition of the Mycompany directory is not a replica, because it is not the destination of replication, but only a source.
In single-master models, directory information must flow from one server; in multimaster models, there are multiple directions of flow
Some replication models suggest a single-master model, in which one directory server holds the authoritative (writable) version of any particular partition, and the other servers have this version replicated to them. In the single-master model, all modifications of data must be made on the single authoritative server and the other servers are read-only replicas. In Figure 5-1, the Computers partition is being replicated in a single-master model from the Mycompany directory to the NOS directory. In a multimaster model, all the servers hold an equally authoritative version that can each be modified. Sometimes a ring topology is used to limit the replication connections, but not always. In Figure 5-1, the Accounts partition is being replicated in a multimaster model between both servers, so that changes can be made on either server and propagated to the other. The multimaster model makes the replica and partition terminology much harder to distinguish, because replication is being done in multiple directions. Therefore, it shouldn't be surprising that the terms “partition” and “replica” can frequently be used interchangeably in contexts in which they can't be distinguished.
The NOSServer.mycompany.com server has the Computers container replicated to it. The network operating system can then make use of the authoritative ownership and location information that the Assets department must own. Server1.mycompany.com is the authoritative server for computer entries.
Server1 is authoritative because new computers are first known about by the Assets department at Mycompany, and because Mycompany considers the Assets department primarily responsible for computers. The people in the Assets department create a computer entry for a computer and enter any asset tag numbers, ownership information, physical location, and any other information they need to track the computer as an asset. The Assets department has given NOS administrators access to the NOS-specific attributes on the computer entries in the central directory so they can do their work. Note that administrators of the NOSServer shouldn't make any changes to the Computers replica because they would be overwritten by replication.
Generally speaking, most vendors support only a single-master replication model. A read-only server (in other words, a server that contains only replicas) will usually generate a referral to the master server when a modification is attempted. This eliminates client confusion and simplifies management.
LDAP v3 implements referrals to provide cross-reference to other LDAP directories
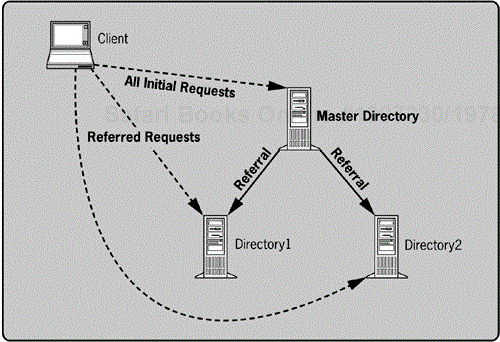
LDAP v2 had problems garnering widespread support because a centralized directory was limited to a single server. This single server could become a bottleneck or a single point of failure. LDAP v3 provides considerably more structural flexibility with referrals. A referral is a response returned to the LDAP client that instructs the client to contact another LDAP server to perform the operation the client requested. The client then automatically contacts the other LDAP server. Typically, referrals are encountered during search operations, but modify, delete, and all the other operations can follow referrals as well. The process of contacting a second LDAP server to follow a referral is called chasing the referral. All LDAP client software should support this functionality to be in compliance with the LDAP standard. Referrals will cause a greater latency in response time because the client must do additional work by contacting the second server after receiving the referral response from the first server. This additional complexity for the client was initially given great weight in designing the standard, and it was one of the reasons LDAP v2 didn't have much support for referrals. But this gain of functionality at what is a small cost of client complexity has become one of the most significant features of LDAP v3.
Referrals allow greater flexibility in directory architecture
By using referrals, you can create a cohesive structure of LDAP servers with different namespaces, as demonstrated in Figure 5-2. Each individual LDAP server may contain referrals to the other servers at the appropriate place within the internal directory structure. This allows Mycompany to break up a namespace into contiguous pieces on several servers or connect two independent directory servers. Referrals can help overcome scaling problems, in which a single server's response is poor, but multiple servers could handle the capacity for millions of entries.
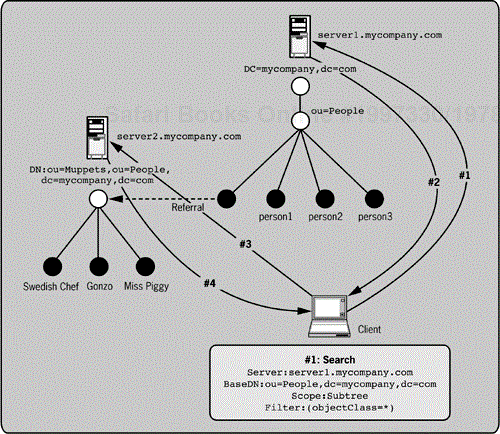
The client must resolve referrals
The client must replace any host, port, and base DN components of the original LDAP operation with components supplied by the referral. If the referral contains a different base DN, the base DN of the referral is used, and the original base DN is discarded for the purpose of chasing the referral. Similarly, if a search filter is designated in the referral, it is used. But if a component isn't designated in the referral, the component from the original request is used. The client forms a new composite request from the merging of the original request and the referral, and then acts on this request.
Figure 5-2 demonstrates the client-server interaction when referrals are involved. The client requests the search operation noted in message #1. The server replies with message #2, which includes the entries for person1, person2, person3, and a referral to the server2.mycompany.com servers, with a specific DN, in the URL format covered earlier. The client then automatically chases this referral with a new request in message #3. This request simply replaces the BaseDN parameter of the original request. The second server replies with message #4, which includes Gonzo, Miss Piggy, and the Swedish Chef. Finally, the client reports all six entries as the results of the original request. In some cases, the results are reported in real time as they return.
You can turn off referral chasing
Incidentally, some LDAP client implementations can be configured to not chase referrals. In some cases, this ability extends to designating which kinds of referrals should or shouldn't be chased. For example, you might want to stop the client from chasing external referrals or from chasing subordinate referrals. The ability to designate this choice can either be a persistent setting for all subsequent searches or a parameter for single searches.
A variety of referral types provide a means of directory integration and organization
Referrals that point to DN locations that are contiguous with the server's directory namespace are called subordinate or superior referrals depending on whether they point up or down in the namespace. You can even use a referral to point to any place on the same directory server. More importantly, you can also connect directory servers with disparate namespaces. Referrals that point to DN locations outside the server's directory namespace are called external referrals. You can also specify default referrals, which are returned on all requests for entries that aren't located within the directory's local namespace and for which the directory has no other name resolution information. The variety of referral types supports an incredible amount of flexibility in directory design, interoperation, and integration. Later in the chapter, we will examine the usefulness of referrals in the context of directory integration solutions.
If an LDAP directory contacted by a client doesn't know about an attribute used in the DN and the entry holds a subordinate referral, the referral will fail. In this case, the attribute's OID can be substituted for the attribute type, and the referral will be successfully generated. This rare situation might happen if all the LDAP servers involved didn't have the same schema definitions.
Referrals are represented with the LDAP URL syntax
LDAP referrals follow the syntax of the LDAP URL format. Each referral must have at least a single URL, and it can have more than one. But if there is more than one URL, each must be equally capable of completing the operation. In other words, if multiple URLs are listed in a referral, each of the destinations must return the same results. By following the LDAP URL format, the hostname, port, base DN, and search filter are easily communicated to the LDAP client. An interesting side note is that a referral doesn't need to designate the LDAP protocol, and it might designate another protocol operation. But the LDAP client would need to support such an operation.
Using a variety of referrals can produce a distributed directory with greater functionality
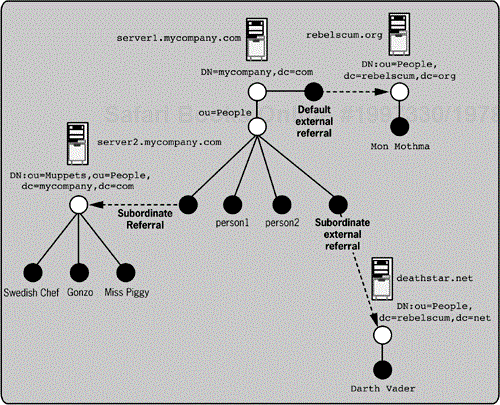
Figure 5-3 shows examples of subordinate, external, and default referrals. In the example, mycompany.com has a subordinate referral in the People container to the Muppets container on the server2.mycompany.com server. The namespace on server2.mycompany.com extends the namespace on server1.mycompany.com, with an additional container (ou=Muppets) that isn't present on the server1.mycompany.com server. The example also shows an external referral to the deathstar.net server. Again, the People container in the mycompany.com directory holds the referral, but this time it is a referral external to the directory namespace. Note how the namespace on deathstar.net is not contiguous with the namespace on mycompany.com. Finally, the example shows a default referral in the root of the mycompany.com directory to the People container in the rebelscum.org directory. The default referral is external to the directory namespace.
An LDAP client might have the following searches:
1. | Server: | server1.mycompany.com |
Base DN: |
| |
Scope: |
| |
Search Filter: |
| |
2. | Server: | server1.mycompany.com |
Base DN: |
| |
Scope: |
| |
Search Filter: |
|
Example of default referral in URL form
In the first search, server1.mycompany.com would find that the base DN was outside the namespace contained on the server. The server would then check all referrals within the scope to locate the appropriate namespace. In this case, it happens to have a default referral to the namespace in question, and it will pass this referral back to the client. The referral will take the following form:
ldap://rebelscum.org/ou=People,dc=rebelscum,dc=org??
one?objectclass=person
Note that the referral is passed in URL form. This format allows both the hostname and other pertinent LDAP information to be communicated. Note that the same scope is carried forward on the referral. The client will use this referral to search rebelscum.org. The Mon Mothma person entry should be returned as a result of this process. Had the original base DN been cn=Fred Flintstone,dc=Bedrock,dc=gov, the default referral to the rebelscum.org server still would have been passed to the client. The client would fail to find Fred's entry, but the referral would still be passed. The default referral is the last resort, so to speak, and is passed when the directory doesn't have any valid reference to the namespace desired.
Example of multiple referrals on a search
In the second search, the client has contacted server1.mycompany.com and would like all person entries below the People container in the mycompany.com namespace. The server responds with a list of the two person entries contained on the server (person1 and person2), as well as two separate referrals:
ldap://deathstar.net/ou=People,dc=deathstar,dc=net??
sub?objectclass=person
ldap://server2.mycompany.com/ou=People,dc=mycompany,
dc=domain,dc=com??sub?objectclass=person
The LDAP client then chases these referrals. The server2.mycompany.com server reports three person entries (Miss Piggy, Gonzo, and Swedish Chef), while the deathstar.net server reports one entry (Darth Vader). The LDAP client reports the results (six entries) from all three servers in a response and indicates successful completion after all the referrals have been chased, and there are no outstanding server responses.
With chaining, the server chases the referrals
Chaining can also provide a way to connect LDAP servers together. Chaining is similar to referrals, except that the server initially contacted by the client chases the referrals for the client and provides a complete response to the client, instead of making the client chase referrals and compose this complete response. This approach results in a more efficient response time for the client, but it places additional burden on the server. Chaining is not part of the LDAP standard, and it is not widely implemented by vendors. The chaining concept comes from the X.500 directory standard, and you may find that LDAP directory implementations that are also X.500 compliant may support chaining. Some LDAP vendors implemented chaining support during the LDAP v2 timeframe, and this support was called server-side referral handling.
An alias provides a means to refer to a single entry
Aliases are another concept inherited from the X.500 standards. An alias is a special type of entry that provides a redirection mechanism to an entry in the same directory. The alias is a “dummy” record that simply points to a “real” record, which is called the target of the alias. An alias differs from a referral conceptually in three ways. First, an alias can point at only another entry within the same directory. A referral can do this as well, but it can also point to other directories (or any valid URL destination). Second, an alias can point at only a single entry. In contrast, a referral can point at a single entry, an entire directory, or something between. A referral can be very complex when a filter is used. Third, the server resolves the alias, while a client must chase referrals. There are a few other differences between a referral and alias that I'll cover later, but these are the primary ones. So an alias is simple in contrast, but still useful.
Aliases allow an entry to be in two places at once
An alias provides a useful means of placing an entry in two or more locations in the directory. The LDAP namespace prohibits a Web-like structure; but by using an alias, you can circumvent this restriction for a single entry. This functionality can help to eliminate problems that a structure introduces. For example, Luke Skywalker's person entry might belong in both the Sales and Marketing OUs because he fills two functional roles for Mycompany. But these functional roles are not under the same branch in the directory, so this isn't possible. The alias solves this problem; an alias could be placed in one of the OUs and the real entry placed in the other OU. Aliases are not specifically documented in the LDAP RFC standards. The LDAP RFC standards refer to the possibility of their use but do not require that an LDAP server implementation support them. The LDAP standards also reference the X.500 documentation regarding aliases. Mycompany will keep alias support on its list of items to check when examining LDAP vendor implementations.
The alias name is different from the target name
An alias entry can have a different RDN than the target entry. This provides a layer of abstraction for protecting names that require privacy. The alias with an abstracted name can be located in a container with public access, while the entry with a private name resides in another hidden container. The user never knows about the real entry's private name and assumes the alias's public name is the real thing.
Aliases are good only for searches
Aliases redirect the client only on the LDAP search operation. Modify and delete operations are performed on the alias entry itself to allow you to make changes to it. The add operation also does not redirect aliases. This setup may sound like nonsense, but an example will illustrate the point. If an add operation created an entry beneath an alias that targeted a container, the operation would place the new entry not in the targeted container, but instead beneath the alias.
Alias behavior is influenced by client search parameters
The LDAP server resolves aliases differently depending on the client configuration. The client must also specify whether the server should dereference the alias. One of the LDAP search parameters designates the behavior the server should use in handling aliases. These parameters are covered in Chapter 3. You should be aware of the default setting of this parameter for the client implementation deployed, so the desired behavior is taken without the need to manually designate the parameter on each search operation.
A distributed directory can improve service
A distributed directory service employs more than a single server to provide service to clients. These multiple directory servers can contain identical information, or only part of the whole directory. The reasons to distribute an LDAP directory across multiple servers are many and varied. This design allows regional specific directory entries to be placed on a server local to the region and supports physically separate servers for management by different political departments within the same organization. You can achieve a distributed directory with referrals or with replication.
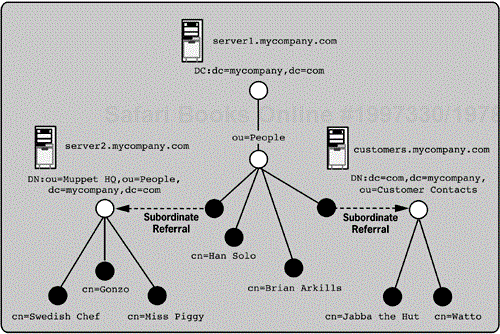
Figure 5-4 shows a distributed directory with people entries based in distinct regions as well as political departments divided across different servers. Recall that Mycompany had a reorganization that placed the Customer Contact information managed by the Sales department under the People information managed by the Human Resources department. After this reorganization, the Sales department received a separate directory server (customers.mycompany.com) for the customer contact information. The directory implementation with this new server is shown in Figure 5-4. Additionally, the people at Muppet headquarters are all on the server2.mycompany.com server, to consolidate the administration duties at Muppet headquarters to a single server.
A distributed directory increases service reliability
Distribution across multiple servers can improve the client's perception of availability and reliability by distributing the operational load. Distribution of the directory can also decrease the risk of service outage or data loss by replicating the entire directory partition to multiple servers. For example, the people located at Muppet headquarters might see improved directory performance because their directory data is kept on a server local to their site.
Replication achieves distribution with a minimum of administrative overhead
In most cases, distributing an LDAP directory across multiple servers is preferable because of the associated management benefits. Centralization of resources increases the impact of service outages, but distributing the service across multiple servers can decrease this overall risk. In particular, replication of the directory is valuable because it distributes the points of failure while keeping management of the directory simple.
Figures 5-5 and 5-6 show distributed directories with single-master and multimaster replication, respectively.
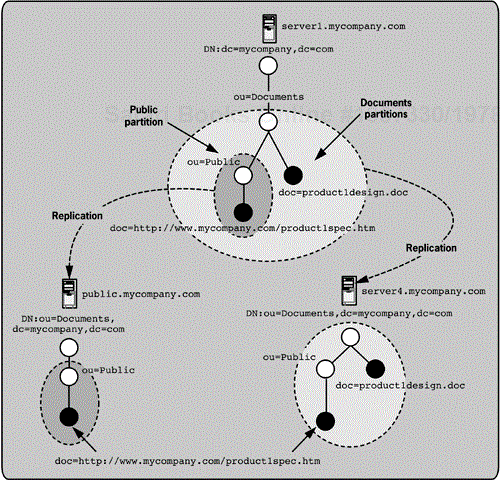
Replication makes distribution easy
You can more easily accomplish server and directory maintenance if the directory is distributed via replication. Distribution across multiple servers can also happen because of organizational circumstances such as the merger of two companies. The issues associated with integrating two initially disparate LDAP directories with one another are addressed later in the chapter.
The directory namespace flexibility plus replication can combine into creative solutions
The flexibility of the directory namespace means that replication can be creatively used to distribute information. In Figure 5-5, the Documents naming context on server1.mycompany.com is used as a partition in a single-master replication model to two different directory servers. The two replica servers serve different purposes and have slightly different partitions replicated. The entire Documents partition is replicated to server4.mycompany.com to provide load balancing for company employees who use the directory heavily to work with documents. The Public partition is replicated to the public.mycompany.com server. This server allows anonymous access to public clients, and all public information, such as the public documents, can be replicated to it. Other public information, such as public calendar events, might also be replicated to it even though this isn't shown in Figure 5-5. If public calendar events were replicated to this server, the best approach would be to have a second top-level naming context for these entries. Although all the examples so far have only a single top-level naming context, more than one top-level naming context can exist. For example, the directory products discussed in the last three chapters (Part II) all have multiple top-level naming contexts. Also note that the top-level naming context on the public server is not identical to the other server namespaces. There is no requirement that all distributed directory servers have an identical top-level namespace.
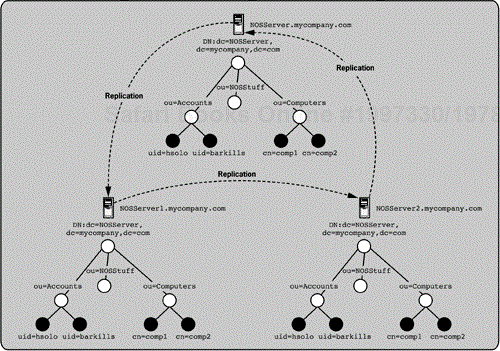
In Figure 5-6, the Mycompany's NOS directory (see Figure 5-1) is shown in more detail. There are three directory servers in a ring replication topology in the NOS directory, which means that changes made at any of the servers will be propagated to the others. This arrangement provides load balancing for the NOS directory that is heavily used daily to support computer services, authentication, and other infrastructure at Mycompany. There is a brief lag before a change is propagated across all the servers, and a vendor-specific change-tracking system ensures that the last change made to any particular entry is the one that wins. You may recall that portions of the NOS directory have replication relationships with the Mycompany central directory. As a refresher, the Computers naming context in the NOS directory is a replica of the Computers partition in the central directory, whereas the Accounts naming context shares a multimaster replication relationship with the central directory. These replication relationships help to ensure that the relevant information in the NOS directory is integrated with other business systems at Mycompany. What is noteworthy about the replication between the NOS directory and the central Mycompany directory is that replication can occur across directories with different topologies and partitions employed.
Sometimes replication creates greater maintenance requirements
In some instances, replicating a directory across multiple servers is not a good thing. These instances typically are related to protecting the access and integrity of directory data. For example, if your directory data includes security information such as account passwords or private certificate keys, you may want to limit the number of servers this critical information is stored on, especially if the physical security of the directory servers can't be guaranteed. The security of distributed directory servers should not be ignored. Another example of when replication wouldn't be a good idea is when connectivity between directory servers is poor or bandwidth is low. The value of the directory depends on the quality and timeliness of the data it holds. When replication cannot complete in a timely manner, users will complain.
Maintenance on a distributed directory may have additional costs
A directory that is distributed in a nonreplicated manner may have additional maintenance costs. A good example of such a situation is a directory with distributed naming contexts based on the geographical location. This directory may require data maintenance tasks that affect all these regional directory servers. For example, a schema modification that affects the entire directory might require a modification on each directory server. Coordination and implementation of these tasks would be more challenging.
Vendors create management problems when they implement standalone LDAP directories
LDAP provides a directory standard that cuts across platform divisions and seems to provide an interoperable panacea for your enterprise. But in actual implementation, this is messier than it seems. Frequently, vendors implement a product that makes use of LDAP, but in a very narrow way. For example, a vendor product might run only in a proprietary directory or with a specific nonstandard schema. There are network operating system directories based on LDAP that are designed to support only a single operating system or with key functionality that works only if the directory is on a specific platform, as well as application products with a standalone application directory that is designed for that application's use. The examples are numerous and annoy the practical nature in all of us.
Disparate directories pose a problem of management
Because we want our directories to be centralized so data is consistent and up-to-date, managing these disparate directories poses a problem. This is the problem that the metadirectory products try to solve; and regardless of whether you use metadirectories, you need good approaches to solving this integration problem.
The following section on integration addresses practical implementation concerns instead of analyzing how the technology works, as the rest of the book does. Here I focus on the abstract approach and concepts behind directory integration instead of trying to cover every possible permutation of integration scenarios. This section looks at the roles involved in directory integration, forms a set of questions about directory data usage that will be invaluable to you as you design a real-world architecture, looks briefly at metadirectories as a possible instant solution, and finally examines the common approaches used to integrate disparate directories. Appendix C includes the real-world example of Stanford University's existing directory integration, which illustrates most, if not all, of the concepts introduced here.
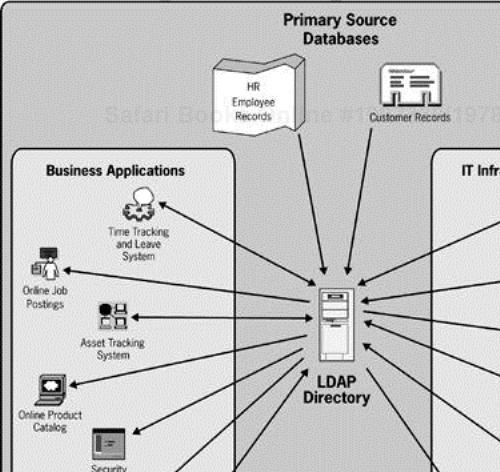
You can employ many different products to meet the business needs of your organization. Weaving these products together into a distributed directory service so the data each product uses is shared and consistent is the ultimate goal of integration. Distinguishing sets of data, the source of each set, uses of each set, and any special concerns is critical to finding successful solutions. This process of creating a data architecture for a distributed directory may involve more than finding just technical solutions, because the data sets may have political or legal issues that govern their use. Business policies about the use of some data may be needed, as well as development or purchase of software solutions to help manage data consistency. Figure 5-7 shows a directory at the center of an enterprise data architecture at Mycompany. The following sections refer to this diagram.
Where does the data come from?
Consider carefully the source of the data to be managed. The data may come from several different sources. Some data may come from a Human Resources system. Other data may come from a certificate authority. Mycompany may have multiple suborganizations that are sources of data for the directory. The source of data is critical to the design of an integrated solution.
Who “owns” the data?
A person or division within Mycompany may be given the responsibility of handling a set of data. Noting ownership of sets of data is critical to an integrated design, because the owner may want to restrict where that data is replicated, and how it can be accessed. The owner may also have special privacy concerns about access to the data. In cases of overlapping data sources, the owner is the arbiter of what information is authoritative.
What is the data?
Sometimes the nature of the data determines whether it can be distributed across multiple servers. For example, distributing shared secret key information or passwords has many implications regarding the level of security needed on each of the distributed servers. Some data related to people is considered private. For example, users would complain if salary information were distributed across directory servers needlessly.
Who/what needs the data?
Consumers of data can be services, users, or business systems that provide a critical administrative task. The consumer needs access to data and performs actions based on that data. For example, an HR application at Mycompany might query the directory for all the person entries and print a physical phone book. In contrast, a subscriber is another directory service or application that other consumers use to access the data that is passed to the subscriber. For example, an e-mail service at Mycompany might offer an organization-wide address book. This address book service might periodically pull person entry information from the directory to republish this information to e-mail clients. But the difference between consumers and subscribers is slight.
Evaluating the needs of consumers includes examining
How consumers use the data
What access controls consumers use on any subsequent products or data
How to manage authoritative data modification
An example of this evaluation process illustrates the interdependencies that are involved. The basic questions that an administrator at Mycompany might ask are noted in italics.
What products or systems need to have access to which data sets? Let's say an e-mail system needs access to portions of the human resource data, including the person's name, contact information, and particularly e-mail address.
How will a consumer service or product use the data that it has access to? Specifically, how does the e-mail system use this data? It might publish an e-mail address book, and by doing so expose users to undesirable spam or violate privacy policies. Clearly this use needs to be accounted for, and you need to ask the following:
Will a consumer service apply a consistent level of access control to the data? Some access controls might limit who can view this address book, or whether someone is put into the address book at all.
Will the consumer service want to make changes to the data? Specifically, what if users of the e-mail system want to update their e-mail address data via the e-mail system? Changes to the local copy of data need to be reconciled with the authoritative source.
How does the consumer service manage data modification? Does the service redirect the user's changes directly to the source, or are local changes reconciled somehow with the directory service? If the e-mail service uses LDAP, we might be able to use a referral to redirect client modifications to the source; but otherwise, we may need to disallow direct modifications within the address book or design our own process to push changes back to the source directory. Clearly, the consumers of data are also critical to the design of an integrated solution.
The privacy of data in a directory can be a legal issue
Many organizations have privacy statements about personal information, legal regulations on certain information, or critical business reasons that necessitate protecting data in their directory. Governments, hospitals, and educational institutions all have federal restrictions (some with jail time for offenses) for publishing sensitive data that might be stored in a directory. The Family Educational Rights and Privacy Act of 1974 (FERPA) and Health Insurance Portability and Accountability Act of 1996 (HIPAA) are two examples of legislation that mandates privacy protections on some personal data. These types of restrictions typically allow sensitive data to be used to support business functions, but not beyond these functions.
Some vendors disregard privacy legal issues
A vendor implementation might make the establishment of privacy protection more difficult. Some vendors design the default schema in a way that undermines modifications that would support privacy. Others assume that some information is public that your organization (or the federal government via legislation) considers private. Imagine that the RDN for a person entry is forced to be the person's name and this attribute is assumed to be public in order for the product to work successfully. In other words, the directory doesn't allow access controls that restrict naming attributes. This design is clearly unacceptable, and Mycompany will avoid products with such privacy issues.
Metadirectories promise to seamlessly integrate these standalone directories, but they may not stand the test of time
Metadirectories promise to solve the issue of managing many disparate directories by seamlessly integrating the data among them. Products take diverse approaches to this task. This area is still in the early stages of maturity, despite several years of product launches. The challenge of integrating standalone directories involves complex issues that are not simple to solve.
Learning a metadirectory product is not simple and in most cases requires special training. Most metadirectories require additional custom extension via scripts to deal with the business rules needed. Because of all these factors, metadirectory products may fail completely, and the basic approaches employed by metadirectories may instead become the common solution deployed by organizations. In other words, some organizations may choose to develop their own custom metadirectory that uses many of the same approaches.
Metadirectories aren't standardized, but the discussion here should help you understand the products
Many of the companies that offered these products a few years ago are now out of business, and more may follow. Therefore, this discussion focuses on the basic concepts and architectures used by metadirectories rather than on specific products. You can use these concepts when your organization looks at metadirectory products to solve your directory integration problems. You should realize that no standard currently addresses this area, and there is very little public information available. The alternative to buying a metadirectory product is to develop and maintain a custom solution to meet your needs.
Referrals and chaining can glue standalone directories together into a master directory
This approach involves taking each existing directory service and integrating it as a part of a master directory service. The master directory might be one of the existing directories, based on some choice by your organization, perhaps the one that is most used or with the best integration functionality. Or the master directory might be a new directory with no data of its own. The end result is that all the directory services can be accessed from the master directory, and from the user standpoint the directories are merged into one. A master directory that supports both X.500 and LDAP will accommodate the widest range of technology. Existing standalone directories are integrated with LDAP referrals and chaining. The master directory server returns LDAP referrals to the client, directing the client to the correct directory server for the question being asked. Figure 5-8 shows how this configuration works conceptually. Alternatively, with chaining the master directory server connects to the LDAP server on behalf of the client.
Index directories only hold referrals and become a single entry point for many directories
Some organizations and indeed some countries go a step further and implement what are called directory index servers. These index servers hold referrals to many independent directories rather than data. Clients can use these index servers to find information across all the linked directories. In other words, each entry in an independent directory has a corresponding referral entry in the index server, in an identical hierarchy to that of the independent directory. The index server then becomes a one-stop destination for many directories. Index servers represent the same idea as a master directory, but they may implement additional functionality, such as a gateway for the Web so search engines can access the data in all the indexed directories.
Implementing a master directory is not trivial
Creating a master directory or index directory can require quite a bit of work. The independent directories must support some common authentication method so clients are not required to authenticate multiple times. Additionally, the authorization model employed on each directory should be similar, so a user doesn't have widely different experiences while being redirected.
There are resources available to help implement an index server
Earlier in this chapter I referred to the Dante DESIRE project that provided resources to implement an index server with these types of functionality. Additionally, some vendors are beginning to implement this type of functionality. Microsoft, for example, implements a simple version of an index server (which they call a global catalog) with Active Directory.
Synchronization can glue standalone directories together into a master directory
This approach allows the multiple directories to exist but works to share the information between them via directory synchronization. In other words, the directory entries or the data in those entries is copied from one directory to another. You can employ different techniques to share data between directory services, but generally there is duplication of data. It doesn't matter that there are multiple directories because the data in each is centrally available. The end result of this approach is that the multiple directory services share common data. The user perception is that each of the directories contains the same information. Figure 5-9 demonstrates how this approach is configured. When the business needs that mandate the different directory servers (or vendors) evaporate, eliminating the unnecessary server is simple with this approach because the data has been duplicated already.
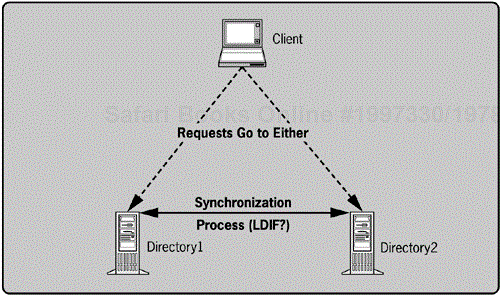
Creating a directory synchronization mechanism can be simple if a common schema is shared. Both directories should also share a common method of synchronization. For example, replication, LDIF, or DSML can be used as a method of synchronization. If both directories support a common way to move directory data between them, some automation can be introduced, which makes management much easier. The topic of moving data across directories is discussed later in this chapter.
Clever user interfaces can make users unaware of multiple directories
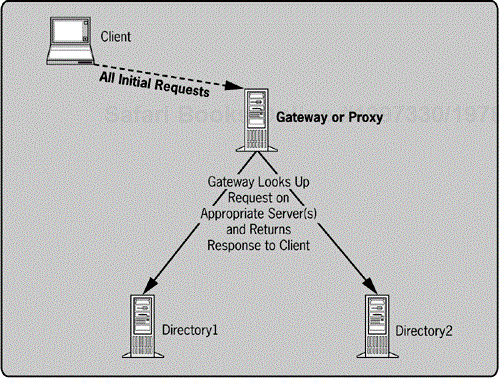
A loose directory interconnection approach leaves multiple directories with different information in place and provides the user with a convenient mechanism to access each of these independent services via a single interface (see Figure 5-10). The LDAP-enabled Web interface discussed in Chapter 3 is a good example of such an approach. Loose directory interconnection focuses on providing a common user interface to multiple directories. This approach is sometimes called a gateway or proxy. Many problems are left by this approach if it is used alone, as it doesn't unify the data in the separate directories into a consistent version. Providing only a common client interface to the independent data sets may be useful, though. Elimination of the work involved in integrating the disparate directories is usually at the cost of integration with client applications and services. However, the cost of educating users on multiple directories is reduced.
The data harvester approach is often used in conjunction with the prior approaches to build the specific architecture desired. The idea is to have LDAP-enabled software that harvests data from one directory to another. By harvest, I mean both a pull and push of data—a pull from one source directory and a push to a subscriber directory. This approach is also called data brokering, with the software agent called a broker.
A harvester moves a specified set of data from one directory to another, but this is not replication
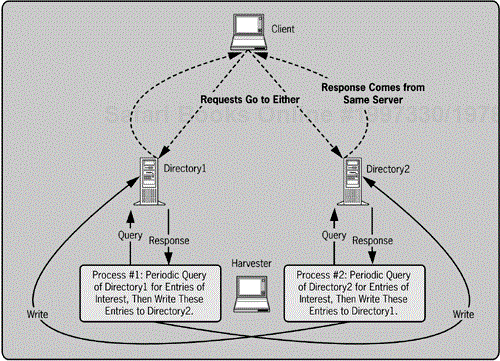
I call this software a harvester because its primary function is to harvest data. Harvesters have only a slightly different effect than replication. Replication pushes an entire partition of data within a directory, whereas a harvester copies only a very specific subset of data. For example, a harvester might copy (or harvest) all entries with objectclass=user or entries in a specific container. Replication also differs from harvesting in that replication is initiated by one of the directory servers and is a server-to-server operation. Whereas harvesting is intrinsically a client-server model, the harvester is a client of both directories. The software usually resides on a computer separate from the two LDAP directory servers it connects, which means an additional point of failure. Another implication is the need to encrypt the sessions between the harvester and both directories. Figure 5-11 shows how this approach might be configured.
Metadirectory products have harvesters called connectors, but you can build your own harvester
Almost all metadirectory products use a similar approach and call the software connectors. The term “connector” implies more functionality than the harvester, and in fact metadirectory products usually do implement more functionality—therefore the slight difference in terminology. A typical metadirectory connector provides the additional ability to map attributes with different names between the two directories. Mycompany can build its own custom software to provide all this functionality, and creating a simple version isn't difficult. More complex functionality provided by a metadirectory might modify the attribute values to make them conform to a specific limitation between the two directories. The advantage of using a harvester or connector is that it is more configurable than replication, but it has the same disadvantage as replication in that it is time dependent and collisions are possible.
Harvesters use the LDAP APIs and are more flexible than replication
A harvester uses the LDAP operations to search for data in one directory and push it to another directory. This reliance on existing functions eases the creation of a custom harvester. This is also why a harvester is considerably more flexible than replication. The harvester can specify distinct sets of data by using complex search filters and base DNs that aren't the same as a partition. However, if either the source or subscriber is not an LDAP directory, building a harvester is obviously more complex.
The harvester must solve the problem of getting notified of changes
A harvester has one critical problem. It is time dependent. A harvester can copy data between directories, but it needs either some intelligent way to determine when to harvest or notification that the data it is interested in has changed. There are several solutions to this problem, depending on the sophistication needed.
Three solutions lend themselves to this problem
One solution is to simply harvest on a periodic basis. Mycompany must live with the possibility that data could be inconsistent and unreliable between these periodic updates. This approach is the same as the most basic replication technologies. Another solution is to use an LDAP control. Chapter 3 describes three LDAP controls—PSEARCH, TSEARCH, and DIRSYNC—that can be used to notify the harvester of directory changes. Some of these controls have the added benefit of being able to distinguish important information about directory changes. Some products support one of these controls. In the future, the IETF LCUP effort should produce a standard that helps address this issue. Another solution involves implementing an event database to track changes. This solution is applicable only in an environment in which all changes to the master directory are tracked. For more detail on this kind of solution, see Appendix C, which describes the directory architecture and harvesters at Stanford University.
Aside from using a connector or harvester to move data between directories, you can take advantage of two file format standards that enable bulk importation and exportation of directory data or bulk modifications of existing directory data. Almost all LDAP directories provide support for LDIF, and an overwhelming majority of vendors have committed to supporting DSML. Both these standards define file formats for representing the directory data in an easily transmittable format. Neither of these standards addresses how an LDAP directory should provide support for operations that import or export these formats. For these formats to be truly valuable in automating directory integration across vendors, some standardization of the operational aspect of these formats is needed.
LDIF is a file format for LDAP directory entries
LDIF stands for the LDAP Data Interchange Format. LDIF is used to represent the entries of an LDAP directory or a set of changes to an LDAP directory in a text-based file format. You can use LDIF for a variety of management functions, including directory backup, replication, schema modifications, and bulk import or modifications of directory information.
LDIF allows complex manipulations on large sets of entries
Manipulation of directory information while it is in the LDIF format is much easier than in an LDAP directory. Text manipulation programming languages such as perl can be used to do more complex operations and perform bulk modifications on many directory entries while they are in a text-based file format. The LDIF format lends itself to simplifying changes to data sets that would be more difficult without it. For example, imagine that Mycompany has moved to a new city. As the administrator, you need to modify the postalCode attribute of employees to 87345, which is the postal code at the new site. Without LDIF, you could find all the entries with the postalCode set by using a presence filter (postalCode=*), but modifying all the entries would require painstaking work. With LDIF, you could dump all the entries to a file. Using perl or even a text editor like Microsoft Word, you could search and replace using the postalCode string as a match phrase.
The LDIF format can be used to request LDAP operations
The LDIF file format is specified in RFC 2849, and it is used to define an operation on an entry and the data elements needed for such operations. Each LDIF file can describe either LDAP directory entries or a set of changes to LDAP directory entries, but not both. If the LDIF file describes directory changes, each entry is preceded by a changerecord statement that indicates the LDAP operation associated with the entry that follows. Entries are separated by a line separator, and comment lines are permitted. Controls can be specified in LDIF.
The easiest way to become familiar with LDIF is to view a few examples. As a point of reference, most of the example entries used in this book are represented in the LDIF format without the changerecord statement. For your convenience, some explanatory comments are interspersed in Examples 5-1 and 5-2.
Example 5-1. LDIF entry with folding and encoding in both base64 and UTF-8
version: 1
dn: cn=Han Solo, ou=People, dc=myserver, dc=domain, dc=com
objectclass: top
objectclass: person
objectclass: organizationalPerson
cn: Han Solo
sn: Solo
uid: hsolo
telephonenumber: +1 650 555 1212
# Comment lines are marked with a pound character
# Note that the postalAddress value is base64 encoded.
# This is noted by the double colon between type and value.
postalAddress:: NzIyLTM0MyBOZXJmaGVyZGVyIERpc3RyaWN0LCBDb3J1c2NhbnQ=
# Note the folding of a line that is too long, with a space to
# denote a continuation of the previous line.
description:Mister Solo is a retired smuggler, who loves to take
unnecessary risks.
# Note the language code use, as well as the UTF8 encoding of the
# value. Spanish largely uses the ascii character set, but the ñ
# character in Señor is notably translated.
description;lang-es:: Señor el Solo es un contrabandista jubilado,
que ama de tomar los riesgos innecesarios.
Example 5-2. LDIF file containing a series of change records including use of a control
version: 1 # Add an entry dn: cn=Mara Skywalker, ou=People, dc=myserver, dc=domain, dc=com changetype: add objectclass: top objectclass: person objectclass: organizationalPerson cn: Mara Skywalker sn: Skywalker sn: Jade uid: mara jpegphoto:[left] file:///bin/photos/mara.jpg # Note that URLs are supported # Delete an entry dn: cn=Chewbacca, ou=People, dc=myserver, dc=domain, dc=com changetype: delete # Modify a relative distinguished name dn: cn=Part2, ou=Xwing Parts, ou=Parts, dc=myserver, dc=domain, dc=com changetype: modrdn newrdn: cn=Hyperdrive spanner deleteoldrdn: 1 # Rename an entry and move all of its children to a new location dn: ou=Droid Parts, ou=Xwing Parts, ou=Parts, dc=myserver, dc=domain, dc=com changetype: modrdn newrdn: ou=Droids deleteoldrdn: 0 newsuperior: ou=People, dc=myserver, dc=domain, dc=com # Modify an entry: add an additional value to the postaladdress # attribute, completely delete the description attribute, and # delete a specific value from the organization attribute dn: cn=Luke Skywalker, ou=People, dc=myserver, dc=domain, dc=com changetype: modify add: postaladdress postaladdress: 1 Jedi Academy $ Old Temple $ Yavin 4 - delete: description - replace: title title: Jedi Knight title: Jedi Master - delete: o o: Rebel Alliance # Delete a container and all subordinate entries with the # Tree Delete control. The criticality field is "true" so the # operation will fail if the control isn't supported. dn: ou=Xwing Parts ou=Parts, dc=myserver, dc=domain, dc=com control: 1.2.840.113556.1.4.805 true changetype: delete
DSML represents directory data in an XML language intended for browsers
Directory Services Markup Language (DSML) is the proposed XML open standard for directories. XML is a metalanguage used to represent data in a text-based format. The format is very similar to HTML, because they both use tags, but it is not HTML. XML is not meant for human consumption; rather, it is code. XML is generally more readable than typical code, but its power lies in its flexibility. DSML is simply a specific set of recommendations that translate an XML document into something meaningful to a directory. And a directory might create an XML document as output to a client or in a batch dump like LDIF.
DSML has widespread vendor support
DSML is supported by significant software companies like IBM, Microsoft, Novell, Oracle, and Netscape, which also happen to be the leading LDAP directory vendors. DSML seeks to represent not only directory data in terms of XML but also LDAP directory operations. DSML v1 defines the directory data structures that can be employed, and DSML v2 defines the LDAP operations.
Directory operations can also be represented in DSML
Representing directory operations in a textual format is not unique, as the LDIF standard also represents directory operations in this format. In fact, the approach taken is strikingly similar to LDIF, except DSML has a clear operational model whereas LDIF does not. DSML uses the HTTP protocol for operation, whereas LDIF has nothing. DSML v2 lets you send one or more operations in a single request document, and a single response document returns the results of these operations. Two bindings (or transport mechanisms) have been defined for DSML v2 so far: Simple Object Access Protocol (SOAP) and files. SOAP uses an XML encoding of a request and response to deliver a message over a protocol such as HTTP.
DSML enables organizations to easily build Web-based applications that leverage the directory
DSML allows Web-based applications to easily integrate with a directory. As a result, Web developers don't have to find a way to represent or format directory data. Using the XML language, they can take advantage of the DSML components to represent directory data within their Web-based applications. Users see a consistent data format, and they don't have to wait for a more lengthy development process. DSML should open another way for disparate directories to easily communicate and represent data in each other. Novell's eDirectory already has an XML interface that allows XML-based LDAP operations, and several other vendors have incorporated support in their SDKs or via gateway products that act as a middle-tier interface. It will be only a matter of time before all the directories adopt DSML functionality.
DSML requires programming to be used
Note that DSML is only a language, and as such it is only a tool that can be used with one of the approaches just described. But clearly, DSML should eventually make the job of a metadirectory, whether it be a product or a custom solution, much easier. You can find out more about DSML at http://www.dsml.org and http://www.oasis-open.org/committees/dsml/. Keep your eye on this technology and on how it affects directory functionality. Clearly the potential to make a directory interoperate better with other technology is significant.
The LDAP v3 standard was marred by lack of security
Securing an LDAP directory is a significant concern. It was such a significant concern for the IETF that the existing LDAP v3 standards were “marred” with a warning note indicating that the standard did not address security. Fortunately, several LDAP v3 standard documents have emerged since then to address this oversight. RFC 3377 removed the warning by revising the standard to include these later documents that address security.
Authentication, authorization, and encryption are common ways to provide security
Computer security is concerned with several primary concepts. One is the idea of proving who you are. This is called authentication, and usually there are two parties involved with a third party of mutual trust. Another is the idea of assigning certain access rights or privileges to someone, and requiring certain rights to access resources or perform actions on resources. This is called authorization, and it usually involves something called the ACL, or access control list, which holds the authorization information. Another is the idea of transmitting or storing data securely so it is kept private. This is called encryption, and it usually involves a public-private key technology.
RFCs 2829 and 2830 standardize security recommendations for LDAP
These basic security concepts are addressed in two RFCs: RFC 2829 and RFC 2830. RFC 2830 addresses the specifics of data encryption issues via the Transport Layer Security (TLS) standard, while RFC 2829 standardizes a minimum set of requirements for authentication, authorization, and encryption depending on the intended use of an LDAP directory. Because RFC 2829 comes late in the development of the LDAP standard, it is understandably more abstract as it seeks to maintain interoperability between existing implementations, while establishing a minimum set of security standards. The RFC does an excellent job of addressing these issues, and it is successful in providing some specific recommendations.
Authentication establishes identity
Authentication is the process of asserting and proving that you are who you say you are. In other words, it establishes the identity of a client. This identity in general terms is known as the authentication identity, but in practice it is usually a username, user identity (uid), ticket, or certificate. Authentication is a fairly complex process, because it involves multiple parties and those parties generally must trust a third party as the authority for establishing (in other words, verifying) identity. The verification stage usually involves a password, but different authentication schemes use the password in different ways.
Password-based authentication methods are generally less secure
The less secure authentication methods communicate the password in some form to the party that is verifying identity. The basic authentication method (known as cleartext) does this, as do several other methods that use an encryption algorithm to make the password harder for malicious listeners to decode. These types of methods are less secure because a malicious listener can capture the password even if it is encrypted and eventually decode it for personal use.
Some password-based authentications are more secure by design
Some methods of shared secret authentication methods don't transmit the password on the wire. These authentication methods are considered secure, because it is much harder to steal someone else's identity. Kerberos is one example of this type of authentication method, as is DIGEST-MD5. Generally speaking, the party that verifies identity and the user share a secret (a password). The user enters the password, but the process on his computer doesn't send this password. Instead, it uses the password to encrypt and decrypt a challenge and response from the party that verifies identity. This party has assurance that only someone who knows the shared secret can pass the challenge.
Public key authentication methods are more secure
Public-private key authentication methods are considered more secure, because they do not subject a password to transport. These methods protect the password by using an encryption algorithm that uses the password as the private key to encode and decode nonsensitive information that is communicated. In this way, the password is never exposed because the server-authority doesn't know it (it knows the public key) and the local client never communicates the password.
Both SASL and TLS are recommended by RFC 2829
RFC 2829 proposes specific authentication requirements for specific circumstances. Public directories that allow only read operations can use anonymous authentication. Anonymous authentication occurs when a client has not successfully completed an LDAP bind operation or has completed one using empty credentials. Nonpublic directories that support the range of LDAP client operations should support both TLS data encryption as well as SASL authentication.
You should use a strong authentication method
However, supporting these technologies does not mean that access requires their use, or that trivial encryption is what is employed. For example, there is an anonymous SASL mechanism that provides no better protection than no authentication at all. To address this, RFC 2829 imposes the following authentication requirements. Directories that support password-based authentication must support the DIGEST-MD5-SASL mechanism described in RFC 2831, and are encouraged to require this mechanism or a stronger one for access. This guideline helps to ensure that malicious intermediaries must spend a substantial amount of effort to compromise a password.
Authorization determines access to a resource
Authorization is the process of establishing whether a client is authorized to access resources. Authorization can be determined by a combination of access control factors like authentication identity, source IP address, encryption strength, authentication method, operation requested, and resource requested.
Access control factors help determine the access control policy
An access control policy defines the restrictions on a resource. The access control policy is expressed in terms of the access control factors and the resources that are restricted. The common access rights available can vary from implementation to implementation, but Table 5-1 lists the typical rights employed. The rights listed apply to an entry, but most directories support setting access rights at the attribute or container level as well.
Inheritance makes access control management easier
It is also common for access control to be inherited by subordinate resources. In the context of a directory, access control inheritance would mean that access controls applied to a container would apply to all the entries under that container, including other containers and their subordinate entries. Applying access control to the logical root of a directory with inheritance would affect all the directory entries.
LDAP operations are easily linked to access control rights
One can see how applying the typical access rights listed in Table 5-1 to entries would affect how client operation requests were handled. An authorization identity (in other words, client user) might be permitted to read entries, and therefore successfully complete an LDAP search operation; but that identity might not be permitted to modify entries and might fail to complete an LDAP modify operation. The typical access rights map fairly directly to LDAP operations.
Table 5-1. Typical directory access rights
Access Right | Description |
|---|---|
No Access | No access is allowed to this entry. |
List | Enumerate name(s) of entry. |
Read | Read attribute value of entry. |
Add | Add a new entry or add new attributes to existing entry. |
Modify | Modify the existing attributes of an entry. |
Rename | Rename entry. |
Delete | Delete entry. |
Admin | Change the ACL of the entry. |
Access control lists link specific identities to specific access rights to a resource
A common implementation of the access control policy is the ACL. An ACL is associated with a resource to provide an access control policy. An ACL usually consists of a list of access control entries (ACEs). Each ACE designates an authorization identity and access rights. An access control list is associated with a specific resource, and therefore the ACEs within that access control list designate what level of access any authorization identity has to that resource.
The authentication identity is usually the authorization identity
Generally, an authorization identity is mapped to the authentication identity. This makes the most sense—if you are going to go to the trouble of authenticating a user, you might as well use that authentication identity. Usually the authentication identity is mapped to the DN of an entry that represents the person. RFC 2829 requires that an LDAP directory support DN mapping if a password or credentials are stored in the directory. However, the implementation doesn't have to actually do this mapping; it just must support it. The mapping is usually a one-to-one relationship: one authentication identity to one DN. But it can be a many-to-one relationship, with many authentication identities mapping to a single DN.
The authorization identity can be many other access control factors
However, the authorization identity doesn't have to correspond to the authentication identity at all. Other access factors, like source IP, authentication method, encryption level, or membership in a group, can be used as the authorization identity. Source IP as an authorization factor uses the IP of the client to allow or deny the operation requested. This is less sophisticated than using an authentication identity, because client IP addresses are easily spoofed, and IP addresses are not authenticated. Authentication method as an authorization factor uses the method requested by the client to help determine whether to allow an operation. For example, if a client uses cleartext authentication, the client might not be allowed to access any entries because of the poor security employed by the client. This approach would help prevent malicious users impersonating the client from accessing sensitive directory entries. Encryption level is used as an authorization factor in a similar manner, if you want some resources or operations to be more highly protected via encryption. When group membership is used as an authorization identity, the DN that maps to the authentication identity must be listed in the membership attribute of the group entry. These methods are less commonly employed, but are valuable factors in helping to secure resources. Sometimes they are used in combination to provide a much more robust authorization control.
RFC 2829 recommends a few authorization requirements
RFC 2829 recommends very few authorization requirements. RFC 2829 requires that the root DSE be available to anonymous clients. Additionally, the RFC recommends that idle connections should be timed out, and expensive requests from unauthenticated clients should fail. The scarcity of authorization requirements in the standard should not be considered poor, because almost no authorization factors are required by the standard, and more abstract recommendations allow different implementations to address authorization in the manner deemed most appropriate to the vendor. The standard does require that the authorization identity be supported by all implementations via the SASL authentication mechanism, and this provides for a clear point of interoperability between implementations.
Encryption provides privacy
Encryption is the process of making the information passed between two parties private by use of a transformation of the information. This encryption protects all the data passed between these parties from snooping, and it provides a level of privacy. The value of this privacy is directly proportional to the strength of the encryption technology employed, and the algorithm used. The basics of encryption are presented here.
Encryption strength is based on the algorithm used and the length of the key employed
Any encryption is based on two elements, namely an algorithm and a key. The algorithm is a special mathematical function that transforms the data into an unintelligible form. There are many common algorithms that are publicly known and used. The fact that these algorithms are known does not affect the strength of the encryption, because the key forms the basis of the encryption strength.
The key length is the basis of encryption strength
The key is a special string that is used by the algorithm in the transformation process. The key can usually be used to transform the data both ways, but this isn't always true. The length of the key determines how many possible keys can be used with the encryption. For example, encryption with a key of 4-bit length would have only 16 possible keys. The length of the key determines the strength of the encryption. An encryption with a 4-bit key length would be considered so trivial that not even a calculator would be needed to break it. The recommended key length for a minimum strength is dependent on the processing power available. Several years ago a key length of 40 bits was considered strong enough, but no longer. You should choose the longest key length supported, taking the extra processing time to support encryption with a longer key into account. 128 bits is a common choice.
The encryption technologies described here relate to LDAP in two primary ways. First, LDAP client-server sessions transmit data across public wires. To ensure privacy of directory data, SSL or TLS must be employed. This implies that certificates for the LDAP directory must be supported and maintained on an ongoing basis. Optimally, you would also require that clients have their own certificates as well. In some instances, depending on the vendor product, this requirement may require implementing a certificate authority to provide the LDAP directory certificate. Second, certificate authorities need a place to store and publish certificates and certificate revocation lists. The LDAP directory fits this need very well. Encryption underlies any authentication that the directory requires for access. A good grasp of encryption will help guide implementation decisions that ensure the integrity of the directory data is reasonably protected.
For these reasons, LDAP directory administrators usually are familiar with the organization's encryption policies and PKI (public key infrastructure) architecture. Additionally, the directory administrator is likely to be in charge of managing certificates. In any event, a familiarity with encryption is worthwhile so the administrator has a sense of the strength of the privacy and access control LDAP can provide.
Both parties share the same key in secret key encryption
Encryption in which the key can be used to both encrypt data and decrypt it is called shared secret key encryption. The key in this instance is known as a shared secret key. Shared secret key encryption generally requires very little processing time, which makes it attractive for encrypting large amounts of data. We were talking about shared secret encryption when we discussed Kerberos and DIGEST-MD5 in the previous section, Authorization.
Secret keys must be communicated safely and stored safely
However, secret key encryption has a problem. How do the two parties decide on and communicate the shared secret key to each other? Without some prior encryption protecting their communication, it is difficult to share a secret key. This problem gets worse as one imagines all the parties one might wish to communicate with, and the number of different secret keys needed to support encrypted communication between all these parties. Usually scalability isn't a problem because a single authority holds all the shared secret keys, and everyone agrees to trust that single authority. However, that single authority and the party still must somehow communicate the secret they share. Public key encryption handles this issue.
A pair of specially linked keys is used with public key encryption
Public key encryption uses a pair of keys with an algorithm that has a special feature. The pair of keys consists of a public key and a private key. The public key is published for anyone to know, whereas the private key is kept secret from everyone but the user. Only the private key can decrypt data that is encrypted with the algorithm and the public key. Similarly, only the public key can decrypt data that is encrypted with the private key. Attempts to decrypt an encrypted message without the opposite paired key will fail. This technique solves the problem of distributing and choosing a key for the two parties, because the two parties don't share the same key. It doesn't matter who knows your public key, because the public key can't be used to impersonate you. Figure 5-12 shows the relationship of the pair of keys to the encryption process. All the arrows in Figure 5-12 going in a clockwise direction could just as easily go in a counterclockwise direction.
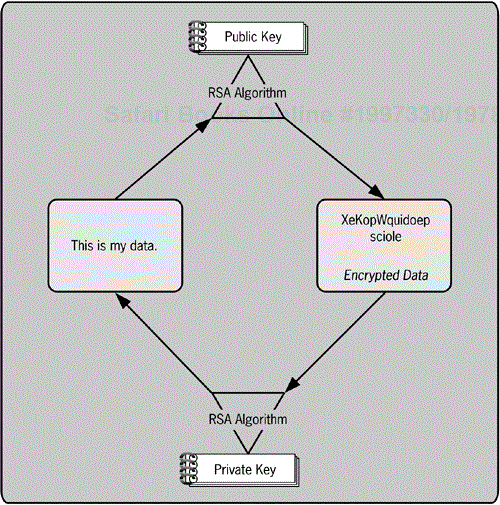
Let's say I want to send a shared secret to you. I would encrypt the shared secret using my private key. This would indicate that the shared secret came from me. Then I'd encrypt the results of that with your public key. This would guarantee that only you could decrypt the shared secret.
Public key encryption is slower and requires an outside authority to verify identity
Public key encryption, however, has a few problems. It requires more significant processing time, so it is not ideal for encrypting large amounts of data. There is also an issue of authentication that is somewhat outside the scope of the problem it is designed to solve. Say I get an encrypted message from Bill Gates along with a public key. I decrypt it with the public key, and this proves that the person who sent it has the private key that corresponds to the public key. But it doesn't prove that the message was sent by Bill Gates. This problem is solved by certificates, which I discuss after looking at one particular use of public key encryption.
Digital signatures provide authentication and data integrity to data messages
A digital signature for me connotes a picture of my signature scanned in a computer. Because my signature is illegible, I'm glad this isn't what digital signatures really are. A digital signature is a specific application of public key encryption. The idea is to encrypt a representation of the message and append it to the message to provide a measure of authentication, as well as proof that the message wasn't altered in transit.
The encrypted message digest is the digital signature
A special algorithm called a hash function takes the message and computes a brief string that is based on the message body. This string of characters is called a message digest or checksum. For example, one commonly used hash using SHA-1 results in a 20-byte message digest. The message digest is then encrypted with the private key and the result is appended to the end of the message. The recipient can use your public key to decrypt the appended message digest, compute a personal message digest of the body of the message, and compare the two results. Assuming they match, the recipient knows that you sent the message and that no one has tampered with the message in transit.
A digital signature does not provide privacy, nor does it prove identity without an outside authority source
Note that a digital signature does not encrypt the message. It does not provide privacy, but it is a way to provide message authentication and data integrity. However, there are several problems with digital signatures. For example, let's say the CEO of Mycompany sends an e-mail to Han Solo that says, “You're fired!” The CEO attaches his digital signature to verify that he sent it. Luke Skywalker just happens to intercept this e-mail. He saves the e-mail and later sends it to several other employees to trick them into thinking they have been fired. Unless the checksum protects the message header that includes the recipient and time, this scenario could happen. Also note that if the public key is sent along with the message, there still is no real verification of the identity of the sender. This is what certificates are about. A digital signature is designed to provide authentication, but one still needs a trusted authority to reliably associate the key pair with a specific person.
Certificates map a public key to an identity. A CA is the authority other parties can trust
Certificates associate a public key with an identity. To learn more about certificates, review RFC 2459. As described in the previous section, you need a trusted authority to manage these certificates and assert that the certificate is valid, in other words, that the public key is really associated with the identity. This authority is called a certificate authority or CA.
The CA issues certificates and places its signature on each as a mark of authenticity
Figure 5-13 shows a simplified representation of a CA and a certificate. The CA issues certificates. The CA is in turn referenced as the source of authority in all certificates that the CA has issued. A user can know that a CA really issued a certificate because the CA puts its digital signature on each certificate it issues. You verify that a certificate is valid by checking this digital signature, which requires getting the public key (and certificate) of the CA. A certificate usually has a time period for which it is valid.
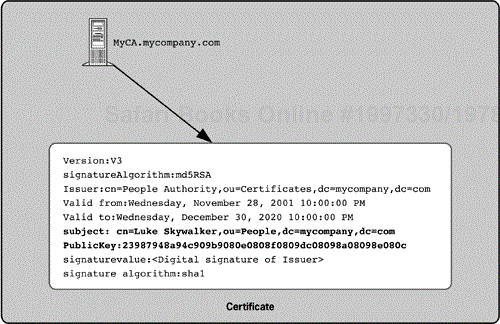
CAs have a hierarchy of authority, but ultimately the user decides whether to trust each CA
A CA's certificate in turn references other CAs as the source of authority. This hierarchy of authority helps the user and applications check how authentic the certificate might be. Additionally, each CA provides a list of certificates that have been revoked. You are probably now wondering how you know whether to trust the identity of a CA. After all, anyone might bring up a CA and have it create a certificate with Bill Gates's name on it. This doesn't mean that messages that use this certificate really are from Bill Gates, because the CA isn't necessarily trustworthy. There are several public CAs, such as VeriSign, that are fairly well trusted by organizations. But ultimately, you must decide to trust the chain of CAs listed for any given certificate, just as you must decide to trust authorities in other systems of authentication. This element of trusting a third party (and that party's security of their CAs and policies verifying identity before issuing a certificate) is one of the reasons certificates haven't completely replaced other technologies yet. Other reasons include solving how to easily deploy the certificate to users, and how the certificate can physically follow the user. It is important to note that solutions to these issues are sometimes included with the software or operating system deployed. For example, it is fairly common for operating systems to trust a list of well-known public CAs by default.
SSL combines public and secret key encryption
Secure Sockets Layer (SSL) is the most commonly used implementation of public key encryption. SSL is used to encrypt the session traffic between two hosts. SSL uses public key encryption to pass a shared secret key. This shared secret key is then used by both systems to implement secret key encryption on all subsequent session traffic between the two hosts. This elegant combination of both public and secret key encryption avoids the slow processing that comes with public key encryption, while solving the problem of safely distributing a secret key.
SSL can be used to encrypt a service session between any two parties
SSL is typically used to encrypt traffic to Web sites such as a commercial Web site. Browsers are passed certificates and understand how to deal with the encryption with a minimum of user intervention, while the details below the surface are fascinating and complex. However, other services make use of SSL. In fact, any service that passes data between two parties that needs to be kept private should consider using SSL.
TLS is the successor to SSL, and it is an Internet standard
SSL is not a formal standard in the sense that many other technologies are. Netscape owns the SSL standard. Transport Layer Security (TLS) is a similar technology that is a formal standard. RFC 2246 describes the TLS standard in detail and briefly outlines the relationship between SSL and TLS. Basically, TLS is a successor to SSL, and it will likely subsume SSL. TLS implementations can downgrade to act like SSL.
Server-based parameters help control directory operations
Most LDAP vendors implement server-side configuration parameters that allow the directory administrator to control some of the behavior of the server. In almost every case, the LDAP client options noted in Chapter 3 are also implemented on the server as a global control. Recall that client options apply only to the client's session. In this case, these server parameters would affect all client sessions and override client options when there is disagreement. Some vendors include additional parameters that provide help to control directory behavior and maintenance. The following section discusses the more common parameters, but again these parameters are not necessarily in all implementations and are certainly not required by the LDAP standard.
Server-based parameters also indirectly affect directory security
The session timeout parameter controls the maximum period of time the server will process an operation for a client. The search query limit controls the maximum number of entries to return on any operation. These two limits can help in limiting the effectiveness of a denial-of-service attack based on resource consumption. Anonymous user controls can be used to limit what operations a server will perform for a client that hasn't completed a bind operation successfully. Allowed authentication methods denote which authentication methods clients can use with the bind operation. Administrators should follow the security recommendations noted in this chapter and, in particular, pay close attention to the lowest strength authentication method allowed. IP restrictions can be used as an access control factor in denying or allowing a client access to the directory server. A referral chaining parameter controls whether the directory server should chase referrals for the client. This parameter has implications on server resources when referrals are used widely.
There are a multitude of other management tasks associated with a directory. Although it is not useful to address the specifics of all those tasks here, mentioning the common ones is worthwhile so you are familiar with some of the tasks directory administrators and technical managers should be prepared to support. Use this list as a useful starting point for further research and implementation planning.
Certificate authority management—. Management of certificates, revocation lists, and the certificates used to establish trust between CAs is a critical function.
User account management—. People have to log in, and LDAP directories often store the organization's user accounts. Providing account management is a common task.
Directory server storage management—. The directory must have space to grow.
DNS records—. The records that provide access to the directory are a critical dependency. There is no maintenance needed; but should the records break, you will want to know how to fix them quickly.
Schema maintenance—. The initial implementation will require an in-depth examination of your needs and will translate these needs into the specific schema elements that support your goals. The need to store new types of data in the directory will be an ongoing process, and having a clear methodology on how to propose and evaluate schema changes will be useful. Failure to deal with the schema usually results in the need for a lengthy data cleanup effort later.
Replication troubleshooting—. If there are collisions or failures in the replication process, you will need to intervene.
Bulk modifications—. The directory administrator may be called on to make bulk modifications to the directory data.
Performance monitoring—. Perception is everything. Performance monitoring will help you provide a reliable directory that doesn't seem slow to users. It will help you gauge when to upgrade or add additional servers, and maybe help detect a problem before users do.
Backups—. Loss of data is still far too common an occurrence. Have a backup system in place before bringing up a directory.
Documentation—. People have to use what is designed. You need up-to-date user documentation, in-depth developer documentation, internal directory administrator documentation that addresses architecture, maintenance, and management, and probably one high-level overview for managers explaining how the directory can be used to enable other technical projects.
Distribution and integration of LDAP directories relies on several critical functionalities
Distributing LDAP directories across multiple servers increases reliability and makes maintenance more manageable. Replication, referrals, chaining, aliases, and LDIF are all critical functionality for providing distribution. These same functionalities also provide the means for integrating both distributed and disparate directories. But the problem of integration can be very difficult, and it may require extensive development or an expensive metadirectory product. Fortunately, DSML may provide some critical relief in the near future.
Directory security differs between products and will require investigation
Directory security is an area in which products differ widely. Access control factors, authentication methods, and encryption strength provide some key areas to investigate when you are comparing products. LDAP directories can also provide a convenient distribution and storage mechanism for PKI.