
Applications often input data for processing and output processing results. Data is input from a file or some other source and is output to a file or some other destination. Java supports I/O via the classic I/O APIs located in the java.io package and the new I/O (NIO) APIs located in java.nio and related subpackages (and java.util.regex). This chapter introduces you to the classic I/O APIs.
We don’t describe each and every class of that API though, and we refrain from method listings which do not supersede copying from the official API documentation. For any details, please see the JSE documentation.
Working with the File API
Applications often interact with a filesystem , which is usually expressed as a hierarchy of files and directories starting from a root directory .
Android and other platforms on which a virtual machine runs typically support at least one filesystem. For example, a Unix/Linux (and Linux-based Android) platform combines all mounted (attached and prepared) disks into one virtual filesystem. In contrast, Windows associates a separate filesystem with each active disk drive.
Java offers access to the underlying platform’s available filesystem(s) via its concrete java.io.File class . File declares the File[] listRoots() class method to return the root directories (roots) of available filesystems as an array of File objects.
The set of available filesystem roots is affected by platform-level operations, such as inserting or ejecting removable media, and disconnecting or unmounting physical or virtual disk drives.
Dumping Available Filesystem Roots to Standard Output
If you happened to run DumpRoots on a Unix or Linux platform, you would receive one line of output that consists of the virtual filesystem root (/).
Constructing File Instances
The first statement assumes a Unix/Linux platform, starts the pathname with root directory symbol /, and continues with directory name x, separator character /, and file or directory name y. (It also works on Windows, which assumes this path begins at the root directory on the current drive.)
A path is a hierarchy of directories that must be traversed to locate a file or a directory. A pathname is a string representation of a path; a platform-dependent separator character (such as the Windows backslash [] character) appears between consecutive names.
The second statement assumes a Windows platform, starts the pathname with drive specifier C:, and continues with root directory symbol , directory name temp, separator character (escaped by a second backslash), and file name x.dat (although x.dat might refer to a directory). (We could also use forward slashes on Windows.)
Each statement’s pathname is an absolute pathname, which is a pathname that starts with the root directory symbol; no other information is required to locate the file/directory that it denotes. In contrast, a relative pathname doesn’t start with the root directory symbol; it’s interpreted via information taken from some other pathname.
The java.io package’s classes default to resolving relative pathnames against the current user (also known as working) directory, which is identified by system property user.dir and which is typically the directory in which the virtual machine was launched. (Chapter 7 showed you how to read system properties via java.lang.System’s getProperty() method.)
File instances contain abstract representations of file and directory pathnames (these files or directories may or may not exist in their filesystems) by storing abstract pathnames, which offer platform-independent views of hierarchical pathnames. In contrast, user interfaces and operating systems use platform-dependent pathname strings to name files and directories.
An abstract pathname consists of an optional platform-dependent prefix string, such as a disk drive specifier—which is / for the Unix/Linux root directory or \ for a Windows Universal Naming Convention (UNC) pathname—and a sequence of zero or more string names. The first name in an abstract pathname may be a directory name or, in the case of Windows UNC pathnames, a hostname. Each subsequent name denotes a directory; the last name may denote a directory or a file. The empty abstract pathname has no prefix and an empty name sequence.
The conversion of a pathname string to or from an abstract pathname is inherently platform dependent. When a pathname string is converted into an abstract pathname, the names within this string may be separated by the default name-separator character or by any other name-separator character that is supported by the underlying platform. When an abstract pathname is converted into a pathname string, each name is separated from the next by a single copy of the default name-separator character.
The default name-separator character is defined by the system property file.separator and is made available in File’s public static separator and separatorChar fields; the first field stores the character in a java.lang.String instance and the second field stores it as a char value.
File offers additional constructors for instantiating this class. See the API documentation for details.
Learning About Stored Abstract Pathnames
After obtaining a File object, you can interrogate it to learn about its stored abstract pathname and other properties by calling various methods that are described in the API documentation.
Obtaining Abstract Pathname Information
You can try the same code with a dot (.) as pathname and “” for the empty string, or of course any other pathname pointing to a file.
Learning About a Pathname’s File or Directory
Obtaining File/Directory Information
Obtaining Disk Space Information
A partition is a platform-specific portion of storage for a filesystem, for example, C:. Obtaining the amount of partition free space is important to installers and other applications. Until Java 6 arrived, the only portable way to accomplish this task was to guess by creating files of different sizes.
long getFreeSpace() returns the number of unallocated bytes in the partition identified by this File object’s abstract pathname; it returns zero when the abstract pathname doesn’t name a partition.
long getTotalSpace() returns the size (in bytes) of the partition identified by this File object’s abstract pathname; it returns zero when the abstract pathname doesn’t name a partition.
long getUsableSpace() returns the number of bytes available to the current virtual machine on the partition identified by this File object’s abstract pathname; it returns zero when the abstract pathname doesn’t name a partition.
Although getFreeSpace() and getUsableSpace() appear to be equivalent, they differ in the following respect: unlike getFreeSpace(), getUsableSpace() checks for write permissions and other platform restrictions, resulting in a more accurate estimate.
The getFreeSpace() and getUsableSpace() methods return a hint (not a guarantee) that a Java application can use all (or most) of the unallocated or available bytes. These values are a hint because a program running outside the virtual machine can allocate partition space, resulting in actual unallocated and available values being lower than the values returned by these methods.
Listing Directories
File also declares methods that return the names of files and directories located in the directory identified by a File object’s abstract pathname. The method names are list() and listFiles() (with varying parameters). See the API documentation for more details.
Listing Specific Names
The overloaded listFiles() methods return arrays of Files. For the most part, they’re symmetrical with their list() counterparts.
Creating and Manipulating Files and Directories
File also declares several methods for creating new files and directories and manipulating existing files and directories. You can create and initialize files with createNewFile(), create temporary files via createTempFile(), delete files via delete(), make directories via mkdir() or mkdirs(), rename files via renameTo(), and change the modification date and time via setLastModified(). The API documentation tells you more.
Suppose you’re designing a text-editor application that a user will use to open a text file and make changes to its content. Until the user explicitly saves these changes to the file, you want the text file to remain unchanged.
Because the user doesn’t want to lose these changes when the application crashes or the computer loses power, you design the application to save these changes to a temporary file every few minutes. This way, the user has a backup of the changes.
You can use the overloaded createTempFile() methods to create the temporary file. If you don’t specify a directory in which to store this file, it’s created in the directory identified by the java.io.tmpdir system property.
You probably want to remove the temporary file after the user tells the application to save or discard the changes. The deleteOnExit() method lets you register a temporary file for deletion; it’s deleted when the virtual machine ends without a crash/power loss.
Experimenting with Temporary Files
After outputting the location where temporary files are stored, TempFileDemo creates a temporary file whose name begins with text and ends with the .txt extension. TempFileDemo next outputs the temporary file’s name and registers the temporary file for deletion upon the successful termination of the application.
Setting and Getting Permissions
boolean setExecutable(boolean executable, boolean ownerOnly) enables (pass true to executable) or disables (pass false to executable) this abstract pathname’s execute permission for its owner (pass true to ownerOnly) or everyone (pass false to ownerOnly). When the filesystem doesn’t differentiate between the owner and everyone, this permission always applies to everyone. It returns true when the operation succeeds. It returns false when the user doesn’t have permission to change this abstract pathname’s access permissions or when executable is false and the filesystem doesn’t implement an execute permission.
boolean setExecutable(boolean executable) is a convenience method that invokes the previous method to set the execute permission for the owner.
boolean setReadable(boolean readable, boolean ownerOnly) enables (pass true to readable) or disables (pass false to readable) this abstract pathname’s read permission for its owner (pass true to ownerOnly) or everyone (pass false to ownerOnly). When the filesystem doesn’t differentiate between the owner and everyone, this permission always applies to everyone. It returns true when the operation succeeds. It returns false when the user doesn’t have permission to change this abstract pathname’s access permissions or when readable is false and the filesystem doesn’t implement a read permission.
boolean setReadable(boolean readable) is a convenience method that invokes the previous method to set the read permission for the owner.
boolean setWritable(boolean writable, boolean ownerOnly) enables (pass true to writable) or disables (pass false to writable) this abstract pathname’s write permission for its owner (pass true to ownerOnly) or everyone (pass false to ownerOnly). When the filesystem doesn’t differentiate between the owner and everyone, this permission always applies to everyone. It returns true when the operation succeeds. It returns false when the user doesn’t have permission to change this abstract pathname’s access permissions.
boolean setWritable(boolean writable) is a convenience method that invokes the previous method to set the write permission for the owner.
Along with these methods, Java 6 retrofitted File’s boolean canRead() and boolean canWrite() methods and introduced a boolean canExecute() method to return an abstract pathname’s access permissions. These methods return true when the file or directory object identified by the abstract pathname exists and when the appropriate permission is in effect. For example, canWrite() returns true when the abstract pathname exists and when the application has permission to write to the file.
Checking a File’s or Directory’s Permissions
Working with the RandomAccessFile API
Files can be created and/or opened for random access in which a mixture of write and read operations can occur until the file is closed. Java supports this random access via its concrete java.io.RandomAccessFile class.
RandomAccessFile has its place in Android app development. For example, you can use this class to read an app’s raw resource file. To learn how, check out “RandomAccessFile in Android raw resource file” (http://stackoverflow.com/questions/9335379/randomaccessfile-in-android-raw-resource-file).
The details about how to work with random access files can be looked up in the API documentation. For Android development it is usually recommended to work with databases instead of random access files.
Working with Streams

Conceptualizing output and input streams as flows of bytes
Java’s use of the word stream is analogous to stream of water, stream of electrons, and so on.
Java recognizes various stream destinations, such as byte arrays, files, screens, sockets (network endpoints), and thread pipes. Java also recognizes various stream sources. Examples include byte arrays, files, keyboards, sockets, and thread pipes. (We will discuss sockets in Chapter 13.)
Stream Classes Overview

All output stream classes except for PrintStream are denoted by their OutputStream suffixes
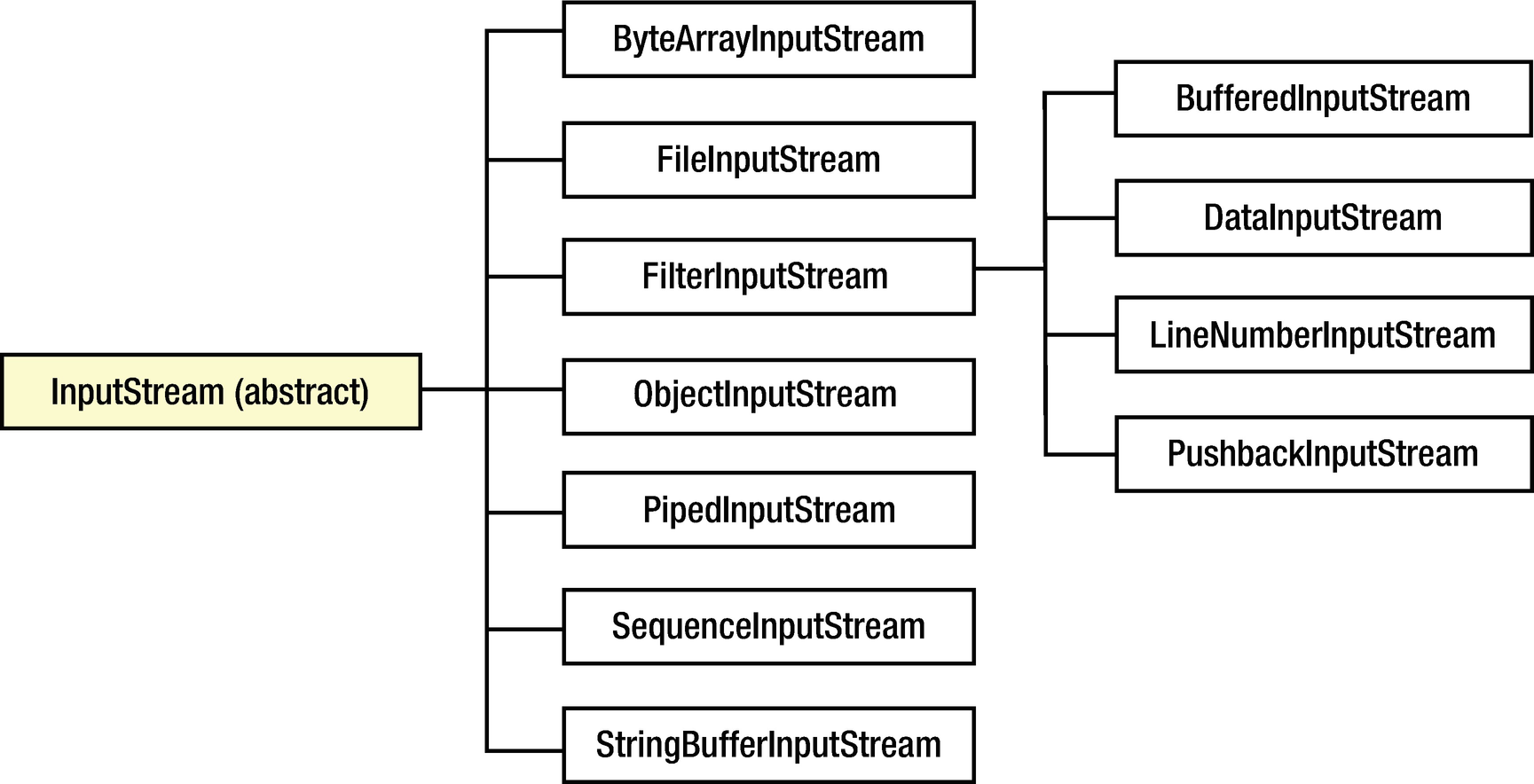
Note that LineNumberInputStream and StringBufferInputStream are deprecated
LineNumberInputStream and StringBufferInputStream have been deprecated because they don’t support different character encodings, a topic we discuss later in this chapter. LineNumberReader and StringReader are their replacements. (We discuss readers later in this chapter.)
PrintStream is another class that should be deprecated because it doesn’t support different character encodings; PrintWriter is its replacement. However, it’s doubtful that Oracle (and Google) will deprecate this class because PrintStream is the type of the System class’s out and err class fields, and too much legacy code depends upon this fact.
In the next several sections, we take you on a tour of most of java.io’s output stream and input stream classes.
ByteArrayOutputStream and ByteArrayInputStream
Byte arrays are often useful as stream destinations and sources. The ByteArrayOutputStream class lets you write a stream of bytes to a byte array; the ByteArrayInputStream class lets you read a stream of bytes from a byte array.
ByteArrayOutputStream and ByteArrayInputStream are useful in a scenario where you need to convert an image to an array of bytes, process these bytes in some manner, and convert the bytes back to the image.
This example obtains an image file’s pathname and then calls the concrete android.graphics.BitmapFactory class’s Bitmap decodeFile(String pathname) class method. This method decodes the image file identified by pathname into a bitmap and returns a Bitmap instance that represents this bitmap.
format identifies the format of the compressed image. We’ve chosen to use the popular Portable Network Graphics (PNG) format.
quality hints to the compressor as to how much compression is required. This value ranges from 0 through 100, where 0 means maximum compression at the expense of quality and 100 means maximum quality at the expense of compression. Formats such as PNG ignore quality because they employ lossless compression.
stream identifies the stream on which to write the compressed image data.
When compress() returns true, which means that it successfully compressed the image onto the byte array output stream in the PNG format, the ByteArrayOutputStream object’s toByteArray() method is called to create and return a byte array with the image’s bytes.
Continuing, the array is processed, a ByteArrayInputStream object is created with the processed bytes serving as the source of this stream, and BitmapFactory’s BitMap decodeStream(InputStream is) class method is called to convert the byte array input stream’s source of bytes to a BitMap instance
FileOutputStream and FileInputStream
Files are common stream destinations and sources. The concrete FileOutputStream class lets you write a stream of bytes to a file; the concrete FileInputStream class lets you read a stream of bytes from a file.
FileOutputStream(String name) overwrites an existing file. To append data instead of overwriting existing content, call a FileOutputStream constructor that includes a boolean append parameter and pass true to this parameter.
Copying a Source File to a Destination File
Listing 12-7’s main() method first verifies that two command-line arguments, identifying the names of source and destination files, are specified. It then proceeds to instantiate FileInputStream and FileOutputStream and enter a while loop that repeatedly reads bytes from the file input stream and writes them to the file output stream.
Of course something might go wrong. Perhaps the source file doesn’t exist, or perhaps the destination file cannot be created (e.g., a same-named read-only file might exist). In either scenario, FileNotFoundException is thrown and must be handled. Another possibility is that an I/O error occurred during the copy operation. Such an error results in IOException.
Regardless of an exception being thrown or not, the input and output streams are closed via the finally block. In a simple application like this, we could ignore the close() method calls and let the application terminate. Although Java automatically closes open files at this point, it’s good form to explicitly close files upon exit.
Because close() is capable of throwing an instance of the checked IOException class, a call to this method is wrapped in a try block with an appropriate catch block that catches this exception. Notice the if statement that precedes each try block. This statement is necessary to avoid a thrown NullPointerException instance should either fis or fos contain the null reference
PipedOutputStream and PipedInputStream
Threads must often communicate. One approach involves using shared variables. Another approach involves using piped streams via the PipedOutputStream and PipedInputStream classes. The PipedOutputStream class lets a sending thread write a stream of bytes to an instance of the PipedInputStream class, which a receiving thread uses to subsequently read those bytes.
Attempting to use a PipedOutputStream object and a PipedInputStream object from a single thread is not recommended because it might deadlock the thread.
PipedOutputStream declares a void connect(PipedInputStream dest) method that connects this piped output stream to dest. This method throws IOException when this piped output stream is already connected to another piped input stream.
PipedInputStream declares a void connect(PipedOutputStream src) method that connects this piped input stream to src. This method throws IOException when this piped input stream is already connected to another piped output stream.
Piping Randomly Generated Bytes from a Sender Thread to a Receiver Thread
Listing 12-8’s main() method creates piped output and piped input streams that will be used by the senderTask thread to communicate a sequence of randomly generated byte integers and by the receiverTask thread to receive this sequence.
The sender task’s run() method explicitly closes its pipe stream when it finishes sending the data. If it didn’t do this, an IOException instance with a “write end dead” message would be thrown when the receiver thread invoked read() for the final time (which would otherwise return -1 to indicate end of stream). For more information on this message, check out Daniel Ferbers’s “Whats this? IOException: Write end dead” blog post (http://techtavern.wordpress.com/2008/07/16/whats-this-ioexception-write-end-dead/).
FilterOutputStream and FilterInputStream
Byte array, file, and piped streams pass bytes unchanged to their destinations. Java also supports filter streams that buffer, compress/uncompress, encrypt/decrypt, or otherwise manipulate a stream’s byte sequence (i.e., input to the filter) before it reaches its destination.
A filter output stream takes the data passed to its write() methods (the input stream), filters it, and writes the filtered data to an underlying output stream, which might be another filter output stream or a destination output stream such as a file output stream.
Filter output streams are created from subclasses of the concrete FilterOutputStream class , an OutputStream subclass. FilterOutputStream declares a single FilterOutputStream(OutputStream out) constructor that creates a filter output stream built on top of out, the underlying output stream.
Scrambling a Stream of Bytes
out identifies the output stream on which to write the scrambled bytes.
map identifies an array of 256 byte integer values to which input stream bytes map.
The constructor first passes its out argument to the FilterOutputStream parent via a super(out); call. It then verifies its map argument’s integrity (map must be nonnull and have a length of 256: a byte stream offers exactly 256 bytes to map) before saving map.
The write(int) method is trivial: it calls the underlying output stream’s write(int) method with the byte to which argument b maps. FilterOutputStream declares out to be protected (for performance), which is why we can directly access this field.
It’s only essential to override write(int) because FilterOutputStream’s other two write() methods are implemented via this method.
A filter input stream takes the data obtained from its underlying input stream—which might be another filter input stream or a source input stream such as a file input stream—filters it, and makes this data available via its read() methods (the output stream).
Filter input streams are created from subclasses of the concrete FilterInputStream class, an InputStream subclass. FilterInputStream declares a single FilterInputStream(InputStream in) constructor that creates a filter input stream built on top of in, the underlying input stream.
It is easy to subclass FilterInputStream. At minimum, declare a constructor that passes its InputStream argument to FilterInputStream’s constructor and override FilterInputStream’s read() and read(byte[], int, int) methods.
When a stream instance is passed to another stream class’s constructor, the two streams are chained together. For example, the scrambled input stream is chained to the file input stream.
For an example of a filter output stream and its complementary filter input stream, check out the “Extending Java Streams to Support Bit Streams” article (www.drdobbs.com/184410423) on the Dr. Dobb’s website. This article introduces BitStreamOutputStream and BitStreamInputStream classes that are useful for outputting and inputting bit streams. The article then demonstrates these classes in a Java implementation of the Lempel-Ziv-Welch (LZW) data compression and decompression algorithm.
BufferedOutputStream and BufferedInputStream
FileOutputStream and FileInputStream have a performance problem . Each file output stream write() method call and file input stream read() method call results in a call to one of the underlying platform’s native methods, and these native calls slow down I/O.
A native method is an underlying platform API function that Java connects to an application via the Java Native Interface (JNI) . Java supplies reserved word native to identify a native method. For example, the RandomAccessFile class declares a private native void open(String name, int mode) method. When a RandomAccessFile constructor calls this method, Java asks the underlying platform (via the JNI) to open the specified file in the specified mode on Java’s behalf.
When a write buffer is full, write() calls the underlying output stream write() method to empty the buffer. Subsequent calls to BufferedOutputStream’s write() methods store bytes in this buffer until it’s once again full.
When the read buffer is empty, read() calls the underlying input stream read() method to fill the buffer. Subsequent calls to BufferedInputStream’s read() methods return bytes from this buffer until it’s once again empty.
DataOutputStream and DataInputStream
FileOutputStream and FileInputStream are useful for writing and reading bytes and arrays of bytes. However, they provide no support for writing and reading primitive-type values (such as integers) and strings.
Integer values are written and read in big-endian format (the most significant byte comes first). Check out Wikipedia’s “Endianness” entry (http://en.wikipedia.org/wiki/Endianness) to learn about the concept of endianness.
Floating-point and double-precision floating-point values are written and read according to the IEEE 754 standard, which specifies 4 bytes per floating-point value and 8 bytes per double-precision floating-point value.
Strings are written and read according to a modified version of UTF-8, a variable-length encoding standard for efficiently storing 2-byte Unicode characters. Check out Wikipedia’s “UTF-8” entry (http://en.wikipedia.org/wiki/Utf-8) to learn more about UTF-8.
DataOutputStream declares a single DataOutputStream(OutputStream out) constructor. Because this class implements the DataOutput interface, DataOutputStream also provides access to the same-named write methods as provided by RandomAccessFile.
DataInputStream declares a single DataInputStream(InputStream in) constructor. Because this class implements the DataInput interface, DataInputStream also provides access to the same-named read methods as provided by RandomAccessFile.
Outputting and Then Inputting a Stream of Multibyte Values
Object Serialization and Deserialization
Java provides the DataOutputStream and DataInputStream classes to stream primitive-type values and String objects. However, you cannot use these classes to stream non-String objects. Instead, you must use object serialization and deserialization to stream objects of arbitrary types.
Object serialization is a virtual machine mechanism for serializing object state into a stream of bytes. Its deserialization counterpart is a virtual machine mechanism for deserializing this state from a byte stream.
An object’s state consists of instance fields that store primitive-type values and/or references to other objects. When an object is serialized, the objects that are part of this state are also serialized (unless you prevent them from being serialized). Furthermore, the objects that are part of those objects’ states are serialized (unless you prevent this), and so on.
Java supports default serialization and deserialization, custom serialization and deserialization, and externalization.
Default Serialization and Deserialization
Default serialization and deserialization is the easiest form to use but offers little control over how objects are serialized and deserialized. Although Java handles most of the work on your behalf, there are a couple of tasks that you must perform.
Your first task is to have the class of the object that’s to be serialized implement the java.io.Serializable interface, either directly or indirectly via the class’s superclass. The rationale for implementing Serializable is to avoid unlimited serialization.
Serializable is an empty marker interface (there are no methods to implement) that a class implements to tell the virtual machine that it’s okay to serialize the class’s objects. When the serialization mechanism encounters an object whose class doesn’t implement Serializable, it throws an instance of the java.io.NotSerializableException class (an indirect subclass of IOException).
Security: If Java automatically serialized an object containing sensitive information (such as a password or a credit card number), it would be easy for a hacker to discover this information and wreak havoc. It’s better to give the developer a choice to prevent this from happening.
Performance: Serialization leverages the Reflection API (discussed in Chapter 8), which tends to slow down application performance. Unlimited serialization could really hurt an application’s performance.
Objects not amenable to serialization: Some objects exist only in the context of a running application and it’s meaningless to serialize them. For example, a file stream object that’s deserialized no longer represents a connection to a file.
Implementing Serializable
Because Employee implements Serializable, the serialization mechanism will not throw a NotSerializableException instance when serializing an Employee object. Not only does Employee implement Serializable, the String class also implements this interface.
Your second task is to work with the ObjectOutputStream class and its writeObject() method to serialize an object and the OutputInputStream class and its readObject() method to deserialize the object.
Although ObjectOutputStream extends OutputStream instead of FilterOutputStream, and although ObjectInputStream extends InputStream instead of FilterInputStream, these classes behave as filter streams.
Java provides the concrete ObjectOutputStream class to initiate the serialization of an object’s state to an object output stream. This class declares an ObjectOutputStream(OutputStream out) constructor that chains the object output stream to the output stream specified by out.
When you pass an output stream reference to out, this constructor attempts to write a serialization header to that output stream. It throws NullPointerException when out is null and IOException when an I/O error prevents it from writing this header.
ObjectOutputStream serializes an object via its void writeObject(Object obj) method. This method attempts to write information about obj’s class followed by the values of obj’s instance fields to the underlying output stream.
This declaration specifies transient to avoid serializing a password for some hacker to encounter. The virtual machine’s serialization mechanism ignores any instance field that’s marked transient.
Check out the “Transience” blog post (www.javaworld.com/community/node/13451) to learn more about transient.
writeObject() throws IOException or an instance of an IOException subclass when something goes wrong. For example, this method throws NotSerializableException when it encounters an object whose class doesn’t implement Serializable.
Because ObjectOutputStream implements DataOutput, it also declares methods for writing primitive-type values and strings to an object output stream.
Java provides the concrete ObjectInputStream class to initiate the deserialization of an object’s state from an object input stream. This class declares an ObjectInputStream(InputStream in) constructor that chains the object input stream to the input stream specified by in.
When you pass an input stream reference to in, this constructor attempts to read a serialization header from that input stream. It throws NullPointerException when in is null, IOException when an I/O error prevents it from reading this header, and java.io.StreamCorruptedException (an indirect subclass of IOException) when the stream header is incorrect.
ObjectInputStream deserializes an object via its Object readObject() method. This method attempts to read information about obj’s class followed by the values of obj’s instance fields from the underlying input stream.
readObject() throws java.lang.ClassNotFoundException, IOException, or an instance of an IOException subclass when something goes wrong. For example, this method throws java.io.OptionalDataException when it encounters primitive-type values instead of objects.
Because ObjectInputStream implements DataInput, it also declares methods for reading primitive-type values and strings from an object input stream.
Serializing and Deserializing an Employee Object
There’s no guarantee that the same class will exist when a serialized object is deserialized (perhaps an instance field has been deleted). During deserialization, this mechanism causes readObject() to throw java.io.InvalidClassException—an indirect subclass of the IOException class—when it detects a difference between the deserialized object and its class.
Every serialized object has an identifier. The deserialization mechanism compares the identifier of the object being deserialized with the serialized identifier of its class (all serializable classes are automatically given unique identifiers unless they explicitly specify their own identifiers) and causes InvalidClassException to be thrown when it detects a mismatch.
Perhaps you’ve added an instance field to a class, and you want the deserialization mechanism to set the instance field to a default value rather than have readObject() throw an InvalidClassException instance. (The next time you serialize the object, the new field’s value will be written out.)
You can avoid the thrown InvalidClassException instance by adding a static final long serialVersionUID = long integer value; declaration to the class. The long integer value must be unique and is known as a stream unique identifier (SUID).
During deserialization, the virtual machine will compare the deserialized object’s SUID to its class’s SUID. If they match, readObject() will not throw InvalidClassException when it encounters a compatible class change (such as adding an instance field). However, it will still throw this exception when it encounters an incompatible class change (such as changing an instance field’s name or type).
Whenever you change a class in some fashion, you must calculate a new SUID and assign it to serialVersionUID.
Externalization
Along with default serialization/deserialization and custom serialization/deserialization, Java supports externalization. Unlike default/custom serialization/deserialization, externalization offers complete control over the serialization and deserialization tasks.
Externalization helps you improve the performance of the reflection-based serialization and deserialization mechanisms by giving you complete control over what fields are serialized and deserialized.
For details, please see the API documentation of the Externalizable interface.
PrintStream
Of all the stream classes, PrintStream is an oddball: it should have been named PrintOutputStream for consistency with the naming convention. This filter output stream class writes string representations of input data items to the underlying output stream.
PrintStream uses the default character encoding to convert a string’s characters to bytes. (We’ll discuss character encodings when we introduce you to writers and readers in the next section.) Because PrintStream doesn’t support different character encodings, you should use the equivalent PrintWriter class instead of PrintStream. However, you need to know about PrintStream because of standard I/O (see Chapter 1 for an introduction to this topic).
PrintStream instances are print streams whose various print() and println() methods print string representations of integers, floating-point values, and other data items to the underlying output stream. Unlike the print() methods, println() methods append a line terminator (as defined by the operating system) to their output.
The println() methods call their corresponding print() methods followed by the equivalent of the void println() method , which eventually results in line.separator’s value being output. For example, void println(int x) outputs x’s string representation and calls this method to output the line separator.
PrintStream offers three other features that you’ll find useful:
Unlike other output streams, a print stream never rethrows an IOException instance thrown from the underlying output stream. Instead, exceptional situations set an internal flag that can be tested by calling PrintStream’s boolean checkError() method, which returns true to indicate a problem.
PrintStream objects can be created to automatically flush their output to the underlying output stream. In other words, the flush() method is automatically called after a byte array is written, one of the println() methods is called, or a newline is written.
PrintStream declares a PrintStream format(String format, Object... args) method for achieving formatted output. Behind the scene, this method works with the Formatter class that we introduce in Chapter 14. PrintStream also declares a printf(String format, Object... args) convenience method that delegates to the format() method. For example, invoking printf() via out.printf(format, args) is identical to invoking out.format(format, args).
Standard I/O Revisited
In previous chapters we already frequently used standard I/O functionalities to write data to the console or some pipe. Namely, System.err and System.out can readily be used to write data to the standard error and output stream. And also, although we didn’t stress it, we can use System.in.read() to input data from the standard input stream.
public static final InputStream in
public static final PrintStream out
public static final PrintStream err
These fields contain references to InputStream and PrintStream objects that represent the standard input, standard output, and standard error streams.
When you invoke System.in.read(), the input is originating from the source identified by the InputStream instance assigned to in. Similarly, when you invoke System.out.print() or System.err.println(), the output is being sent to the destination identified by the PrintStream instance assigned to out or err, respectively.
On an Android device, you can view content sent to standard output and standard error by looking at the Android Studio’s logcat output.
void setIn(InputStream in)
void setOut(PrintStream out)
void setErr(PrintStream err)
Programmatically Specifying the Standard Input Source and Standard Output/Error Destinations
Listing 12-13 presents a RedirectIO application that lets you specify (via command-line arguments) the name of a file from which System.in.read() obtains its content as well as the names of files to which System.out.print() and System.err.println() send their content. It then proceeds to copy standard input to standard output and then demonstrates outputting content to standard error.
Next, new FileInputStream(args[0]) provides access to the input sequence of bytes that is stored in the file identified by args[0]. Similarly, new PrintStream(args[1]) provides access to the file identified by args[1], which will store the output sequence of bytes, and new PrintStream(args[2]) provides access to the file identified by args[2], which will store the error sequence of bytes.
This command line produces no visual output on the screen. Instead, it copies the contents of RedirectIO.java to out.txt. It also stores Redirected error output in err.txt.
Working with Writers and Readers
Java’s stream classes are good for streaming sequences of bytes, but they’re not good for streaming sequences of characters because bytes and characters are two different things: a byte represents an 8-bit data item and a character represents a 16-bit data item. Also, Java’s char and String types naturally handle characters instead of bytes.
More importantly, byte streams have no knowledge of character sets (sets of mappings between integer values, known as code points, and symbols, such as Unicode) and their character encodings (mappings between the members of a character set and sequences of bytes that encode these characters for efficiency, such as UTF-8).
If you need to stream characters, you should take advantage of Java’s writer and reader classes, which were designed to support character I/O (they work with char instead of byte). Furthermore, the writer and reader classes take character encodings into account.
Early computers and programming languages were created mainly by English-speaking programmers in countries where English was the native language. They developed a standard mapping between code points 0 through 127, and the 128 commonly used characters in the English language (such as A–Z). The resulting character set/encoding was named American Standard Code for Information Interchange (ASCII) .
The problem with ASCII is that it’s inadequate for most non-English languages. For example, ASCII doesn’t support diacritical marks such as the cedilla used in French. Because a byte can represent a maximum of 256 different characters, developers around the world started creating different character sets/encodings that encoded the 128 ASCII characters, but also encoded extra characters to meet the needs of languages such as French, Greek, or Russian. Over the years, many legacy (and still important) data files have been created whose bytes represent characters defined by specific character sets/encodings.
The International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC) have worked to standardize these 8-bit character sets/encodings under a joint umbrella standard called ISO/IEC 8859. The result is a series of substandards named ISO/IEC 8859-1, ISO/IEC 8859-2, and so on. For example, ISO/IEC 8859-1 (also known as Latin-1) defines a character set/encoding that consists of ASCII plus the characters covering most Western European countries. Also, ISO/IEC 8859-2 (also known as Latin-2) defines a similar character set/encoding covering Central and Eastern European countries.
Despite ISO’s/IEC’s best efforts, a plethora of character sets/encodings is still inadequate. For example, most character sets/encodings only allow you to create documents in a combination of English and one other language (or a small number of other languages). You cannot, for example, use an ISO/IEC character set/encoding to create a document using a combination of English, French, Turkish, Russian, and Greek characters.
This and other problems are being addressed by an international effort that has created and is continuing to develop Unicode, a single universal character set. Because Unicode characters are bigger than ISO/IEC characters, Unicode uses one of several variable-length encoding schemes known as Unicode Transformation Format (UTF) to encode Unicode characters for efficiency. For example, UTF-8 encodes every character in the Unicode character set in 1 to 4 bytes (and is backward compatible with ASCII).
The terms character set and character encoding are often used interchangeably. They mean the same thing in the context of ISO/IEC character sets in which a code point is the encoding. However, these terms are different in the context of Unicode in which Unicode is the character set and UTF-8 is one of several possible character encodings for Unicode characters.
Writer and Reader Classes Overview

Unlike FilterOutputStream, FilterWriter is abstract

Unlike FilterInputStream, FilterReader is abstract
For brevity, we focus only on the Writer, Reader, OutputStreamWriter, OutputStreamReader, FileWriter, and FileReader classes in this chapter
Writer and Reader
Writer declares several append() methods for appending characters to this writer. These methods exist because Writer implements the java.lang.Appendable interface, which is used in partnership with the Formatter class (discussed in Chapter 14) to output formatted strings.
Writer declares additional write() methods, including a convenient void write(String str) method for writing a String object’s characters to this writer.
Reader declares read(char[]) and read(char[], int, int) methods instead of read(byte[]) and read(byte[], int, int) methods.
Reader doesn’t declare an available() method.
Reader declares a boolean ready() method that returns true when the next read() call is guaranteed not to block for input.
Reader declares an int read(CharBuffer target) method for reading characters from a character buffer. (I discuss CharBuffer in Chapter 14.)
OutputStreamWriter and InputStreamReader
The concrete OutputStreamWriter class (a Writer subclass) is a bridge between an incoming sequence of characters and an outgoing stream of bytes. Characters written to this writer are encoded into bytes according to the default or specified character encoding.
The default character encoding is accessible via the file.encoding system property.
Each call to one of OutputStreamWriter’s write() methods causes an encoder to be called on the given character(s). The resulting bytes are accumulated in a buffer before being written to the underlying output stream. The characters passed to the write() methods are not buffered.
The concrete InputStreamReader class (a Reader subclass) is a bridge between an incoming stream of bytes and an outgoing sequence of characters. Characters read from this reader are decoded from bytes according to the default or specified character encoding.
Each call to one of InputStreamReader’s read() methods may cause one or more bytes to be read from the underlying input stream. To enable the efficient conversion of bytes to characters, more bytes may be read ahead from the underlying stream than are necessary to satisfy the current read operation.
OutputStreamWriter and InputStreamReader declare a String getEncoding() method that returns the name of the character encoding in use. If the encoding has a historical name, that name is returned; otherwise, the encoding’s canonical name is returned.
FileWriter and FileReader
Logging Messages to an Actual File
connect() attempts to instantiate FileWriter, whose instance is saved in fw on success; otherwise, fw continues to store its default null reference.
disconnect() attempts to close the file by calling FileWriter’s close() method, but only when fw doesn’t contain its default null reference.
log() attempts to write its String argument to the file by calling FileWriter’s void write(String str) method, but only when fw doesn’t contain its default null reference.
connect()’s catch block specifies IOException instead of FileNotFoundException because FileWriter’s constructors throw IOException when they cannot connect to existing normal files; FileOutputStream’s constructors throw FileNotFoundException.
log()’s write(String) method appends the line.separator value (which we assigned to a constant for convenience) to the string being output instead of appending , which would violate portability.
- 1.
What is the purpose of the File class?
- 2.
What do instances of the File class contain?
- 3.
What does File’s listRoots() method accomplish?
- 4.
What is a path and what is a pathname?
- 5.
What is the difference between an absolute pathname and a relative pathname?
- 6.
How do you obtain the current user (also known as working) directory?
- 7.
Define parent pathname.
- 8.
File’s constructors normalize their pathname arguments. What does normalize mean?
- 9.
How do you obtain the default name-separator character?
- 10.
What is a canonical pathname?
- 11.
What is the difference between File’s getParent() and getName() methods?
- 12.
True or false: File’s exists() method only determines whether or not a file exists.
- 13.
What is a normal file?
- 14.
What does File’s lastModified() method return?
- 15.
True or false: File’s list() method returns an array of Strings where each entry is a file name rather than a complete path.
- 16.
What is the difference between the FilenameFilter and FileFilter interfaces?
- 17.
True or false: File’s createNewFile() method doesn’t check for file existence and create the file when it doesn’t exist in a single operation that’s atomic with respect to all other filesystem activities that might affect the file.
- 18.
File’s createTempFile(String, String) method creates a temporary file in the default temporary directory. How can you locate this directory?
- 19.
Temporary files should be removed when no longer needed after an application exits (to avoid cluttering the filesystem). How do you ensure that a temporary file is removed when the virtual machine ends normally (it doesn’t crash and the power isn’t lost)?
- 20.
How would you accurately compare two File objects?
- 21.
What is the purpose of the RandomAccessFile class?
- 22.
What is the purpose of the "rwd" and "rws" mode arguments?
- 23.
What is a file pointer?
- 24.
True or false: When you call RandomAccessFile’s seek(long) method to set the file pointer’s value, and when this value is greater than the length of the file, the file’s length changes.
- 25.
What is a stream?
- 26.
What is the purpose of OutputStream’s flush() method?
- 27.
True or false: OutputStream’s close() method automatically flushes the output stream.
- 28.
What is the purpose of InputStream’s mark(int) and reset() methods?
- 29.
How would you access a copy of a ByteArrayOutputStream instance’s internal byte array?
- 30.
True or false: FileOutputStream and FileInputStream provide internal buffers to improve the performance of write and read operations.
- 31.
Why would you use PipedOutputStream and PipedInputStream?
- 32.
Define filter stream.
- 33.
What does it mean for two streams to be chained together?
- 34.
How do you improve the performance of a file output stream or a file input stream?
- 35.
How do DataOutputStream and DataInputStream support FileOutputStream and FileInputStream?
- 36.
What is object serialization and deserialization?
- 37.
What is the purpose of the Serializable interface?
- 38.
What does the serialization mechanism do when it encounters an object whose class doesn’t implement Serializable?
- 39.
Identify the three stated reasons for Java not supporting unlimited serialization.
- 40.
How do you initiate serialization? How do you initiate deserialization?
- 41.
True or false: Class fields are automatically serialized.
- 42.
What is the purpose of the transient reserved word?
- 43.
What does the deserialization mechanism do when it attempts to deserialize an object whose class has changed?
- 44.
How does the deserialization mechanism detect that a serialized object’s class has changed?
- 45.
How can you add an instance field to a class and avoid trouble when deserializing an object that was serialized before the instance field was added?
- 46.
How do you customize the default serialization and deserialization mechanisms without using externalization?
- 47.
How do you tell the serialization and deserialization mechanisms to serialize or deserialize the object’s normal state before serializing or deserializing additional data items?
- 48.
What is the difference between PrintStream’s print() and println() methods?
- 49.
What does PrintStream’s noargument void println() method accomplish?
- 50.
Why are Java’s stream classes not good at streaming characters?
- 51.
What does Java provide as the preferred alternative to stream classes when it comes to character I/O?
- 52.
What is the purpose of the OutputStreamWriter class? What is the purpose of the InputStreamReader class?
- 53.
How do you identify the default character encoding?
- 54.
What is the purpose of the FileWriter class? What is the purpose of the FileReader class?
- 55.
Create a Java application named Touch for setting a file’s or directory’s timestamp to the current time. This application has the following usage syntax: java Touch pathname.
- 56.
Improve Listing 12-7’s Copy application (performance wise) by using BufferedInputStream and BufferedOutputStream. Copy should read the bytes to be copied from the buffered input stream and write these bytes to the buffered output stream.
- 57.
Create a Java application named Split for splitting a large file into a number of smaller partx files (where x starts at 0 and increments, for example, part0, part1, part2, and so on). Each partx file (except possibly the last partx file, which holds the remaining bytes) will have the same size. This application has the following usage syntax: java Split pathname. Furthermore, your implementation must use the BufferedInputStream, BufferedOutputStream, File, FileInputStream, and FileOutputStream classes.
Summary
Applications often input data for processing and output processing results. Data is input from a file or some other source and is output to a file or some other destination. Java supports I/O via the classic I/O APIs located in the java.io package.
File I/O activities often interact with a filesystem. Java offers access to the underlying platform’s available filesystem(s) via its concrete File class. File instances contain the pathnames of files and directories that may or may not exist in their filesystems.
Files can be opened for random access in which a mixture of write and read operations can occur until the file is closed. Java supports this random access by providing the concrete RandomAccessFile class.
Java uses streams to perform I/O operations. A stream is an ordered sequence of bytes of arbitrary length. Bytes flow over an output stream from an application to a destination and flow over an input stream from a source to an application.
The java.io package provides several output stream and input stream classes that are descendants of the abstract OutputStream and InputStream classes. BufferedOutputStream and FileInputStream are examples.
Java’s stream classes are good for streaming sequences of bytes but are not good for streaming sequences of characters because bytes and characters are two different things, and because byte streams have no knowledge of character sets and encodings.
If you need to stream characters, you should take advantage of Java’s writer and reader classes, which were designed to support character I/O (they work with char instead of byte). Furthermore, the writer and reader classes take character encodings into account.
The java.io package provides several writer and reader classes that are descendants of the abstract Writer and Reader classes. FileWriter and FileReader are examples. These convenience classes are based on file output/input streams and OutputStreamWriter/InputStreamReader.
This chapter focused on I/O in the context of a filesystem. However, you can also perform I/O in the context of a network. Chapter 13 introduces you to several of Java’s network-oriented APIs.