
The UNIX operating system built its reputation on a small number of concepts, all of which are simple yet powerful. We’ve seen most of them by now: standard input/output, pipes, text-filtering utilities, the tree-structured file system, and so on. UNIX also gained notoriety as the first small-computer operating system to give each user control over more than one process. We call this capability user-controlled multitasking.
You may not think that multitasking is a big deal. You’re probably used to the idea of running a process in the background by putting an ampersand (&) at the end of the command line. You have also seen the idea of a subshell in Chapter 4, when we showed how shell scripts run.
In this chapter, we will cover most of bash’s features that relate to multitasking and process handling in general. We say “most” because some of these features are, like the file descriptors we saw in the previous chapter, of interest only to low-level systems programmers.
We’ll start out by looking at certain important primitives for identifying processes and for controlling them during login sessions and within shell scripts. Then we will move out to a higher-level perspective, looking at ways to get processes to communicate with each other. We’ll look in more detail at concepts we’ve already seen, like pipes and subshells.
Don’t worry about getting bogged down in low-level technical details about UNIX. We will provide only the technical information that is necessary to explain higher-level features, plus a few other tidbits designed to pique your curiosity. If you are interested in finding out more about these areas, refer to your UNIX Programmer’s Manual or a book on UNIX internals that pertains to your version of UNIX. You might also find UNIX Power Tools of value.
We strongly recommend that you try out the examples in this chapter. The behavior of code that involves multiple processes is not as easy to understand on paper as most of the other examples in this book.
UNIX gives all processes numbers, called process IDs, when they are created. You will notice that when you run a command in the background by appending & to it, the shell responds with a line that looks like this:
$ alice &[1] 93In this example, 93 is the process ID for the alice process. The [1] is a job number assigned by the shell (not the operating system). What’s the difference? Job numbers refer to background processes that are currently running under your shell, while process IDs refer to all processes currently running on the entire system, for all users. The term job basically refers to a command line that was invoked from your shell.
If you start up additional background jobs while the first one is still running, the shell will number them 2, 3, etc. For example:
$duchess &[2] 102 $hatter &[3] 104
Clearly, 1, 2, and 3 are easier to remember than 93, 102, and 104!
The shell includes job numbers in messages it prints when a background job completes:[1]
[1]+ Done alice
We’ll explain what the plus sign means soon. If the job exits with non-zero status (see Chapter 5), the shell will indicate the exit status:[2]
[1]+ Exit 1 alice
The shell prints other types of messages when certain abnormal things happen to background jobs; we’ll see these later in this chapter.
Why should you care about process IDs or job numbers? Actually, you could probably get along fine through your UNIX life without ever referring to process IDs (unless you use a windowing workstation—as we’ll see soon). Job numbers are more important, however: you can use them with the shell commands for job control.[3]
You already know the most obvious way of controlling a job: create one in the background with &. Once a job is running in the background, you can let it run to completion, bring it into the foreground, or send it a message called a signal.
The built-in command fg brings a background job into the foreground. Normally this means that the job will have control of your terminal or window and therefore will be able to accept your input. In other words, the job will begin to act as if you typed its command without the &.
If you have only one background job running, you can use fg without arguments, and the shell will bring that job into the foreground. But if you have several jobs running in the background, the shell will pick the one that you put into the background most recently. If you want some other job put into the foreground, you need to use the job’s command name, preceded by a percent sign (%), or you can use its job number, also preceded by %, or its process ID without a percent sign. If you don’t remember which jobs are running, you can use the command jobs to list them.
A few examples should make this clearer. Let’s say you created three background jobs as above. Then if you type jobs, you will see this:
[1] Running alice & [2]- Running duchess & [3]+ Running hatter &
jobs has a few interesting options. jobs -l also lists process IDs:
[1] 93 Running alice & [2]- 102 Running duchess & [3]+ 104 Running hatter &
The -p option tells jobs to list only process IDs:
93 102 104
(This could be useful with command substitution; see Task 8-1.) The -n option lists only those jobs whose status has changed since the shell last reported it—whether with a jobs command or otherwise. -r restricts the list to jobs that are running, while -s restricts the list to those jobs which are stopped, e.g., waiting for input from the keyboard.[4] Finally, you can use the -x option to execute a command. Any job number provided to the command will be substituted with the process ID of the job. For example, if alice is running in the background, then executing jobs -x echo %1 will print the process ID of alice.
If you type fg without an argument, the shell will put hatter in the foreground, because it was put in the background most recently. But if you type fg %duchess (or fg %2), duchess will go in the foreground.
You can also refer to the job most recently put in the background by %+. Similarly, %- refers to the next-most-recently backgrounded job (duchess in this case). That explains the plus and minus signs in the above: the plus sign shows the most recent job whose status has changed; the minus sign shows the next-most-recently invoked job.[5]
If more than one background job has the same command, then % command will distinguish between them by choosing the most recently invoked job (as you’d expect). If this isn’t what you want, you need to use the job number instead of the command name. However, if the commands have different arguments, you can use %? string instead of % command. %? string refers to the job whose command contains the string. For example, assume you started these background jobs:
$hatter mad &[1] 189 $hatter teatime &[2] 190 $
Then you can use %?mad and %?teatime to refer to each of them, although actually %?ma and %?tea are sufficient to uniquely identify them.
Table 8-1 lists all of the ways to refer to background jobs. Given how infrequently people use job control commands, job numbers or command names are sufficient, and the other ways are superfluous.
Just as you can put background jobs into the foreground with fg, you can also put a foreground job into the background. This involves suspending a job, so that the shell regains control of your terminal.
To suspend a job, type CTRL-Z while it is running.[6] This is analogous to typing CTRL-C (or whatever your interrupt key is), except that you can resume the job after you have stopped it. When you type CTRL-Z, the shell responds with a message like this:
[1]+ Stopped commandThen it gives you your prompt back. To resume a suspended job so that it continues to run in the foreground, just type fg. If, for some reason, you put other jobs in the background after you typed CTRL-Z, use fg with a job name or number.
For example:
alice is running...CTRL-Z[1]+ Stopped alice $hatter &[2] 145$ fg %alicealice resumes in the foreground...
The ability to suspend jobs and resume them in the foreground comes in very handy when you have a conventional terminal (as opposed to a windowing workstation) and you are using a text editor like vi on a file that needs to be processed. For example, if you are editing a file for the troff text processor, you can do the following:
$vi myfileedit the file...CTRL-ZStopped [1] vi$ troff myfiletroff reports an error$ fgvi comes back up in the same place in your file
Programmers often use the same technique when debugging source code.
You will probably also find it useful to suspend a job and resume it in the background instead of the foreground. You may start a command in the foreground (i.e., normally) and find that it takes much longer than you expected—for example, a grep, sort, or database query. You need the command to finish, but you would also like control of your terminal back so that you can do other work. If you type CTRL-Z followed by bg, you will move the job to the background.[7]
You can also suspend a job with CTRL-Y. This is slightly different from CTRL-Z in that the process is only stopped when it attempts to read input from the terminal.
We mentioned earlier that typing CTRL-Z to suspend a job is similar to typing CTRL-C to stop a job, except that you can resume the job later. They are actually similar in a deeper way: both are particular cases of the act of sending a signal to a process.
A signal is a message that one process sends to another when some abnormal event takes place or when it wants the other process to do something. Most of the time, a process sends a signal to a subprocess it created. You’re undoubtedly already comfortable with the idea that one process can communicate with another through an I/O pipeline; think of a signal as another way for processes to communicate with each other. (In fact, any textbook on operating systems will tell you that both are examples of the general concept of interprocess communication, or IPC.[8])
Depending on the version of UNIX, there are two or three dozen types of signals, including a few that can be used for whatever purpose a programmer wishes. Signals have numbers (from 1 to the number of signals the system supports) and names; we’ll use the latter. You can get a list of all the signals on your system, by name and number, by typing kill -l. Bear in mind, when you write shell code involving signals, that signal names are more portable to other versions of UNIX than signal numbers.
When you type CTRL-C, you tell the shell to send the INT (for “interrupt”) signal to the current job; CTRL-Z sends TSTP (on most systems, for “terminal stop”). You can also send the current job a QUIT signal by typing CTRL- (control-backslash); this is sort of like a “stronger” version of CTRL-C.[9] You would normally use CTRL- when (and only when) CTRL-C doesn’t work.
As we’ll see soon, there is also a “panic” signal called KILL that you can send to a process when even CTRL- doesn’t work. But it isn’t attached to any control key, which means that you can’t use it to stop the currently running process. INT, TSTP, and QUIT are the only signals you can use with control keys.[10]
You can customize the control keys used to send signals with options of the stty command. These vary from system to system—consult your manpage for the command—but the usual syntax is stty signame char. signame is a name for the signal that, unfortunately, is often not the same as the names we use here. Table 1-7 in Chapter 1 lists stty names for signals found on all versions of UNIX. char is the control character, which you can give using the convention that ^(circumflex) represents “control.” For example, to set your INT key to CTRL-X on most systems, use:
stty intr ^X
Now that we’ve told you how to do this, we should add that we don’t recommend it. Changing your signal keys could lead to trouble if someone else has to stop a runaway process on your machine.
Most of the other signals are used by the operating system to advise processes of error conditions, like a bad machine code instruction, bad memory address, or division by zero, or “interesting” events such as a timer (“alarm”) going off. The remaining signals are used for esoteric error conditions of interest only to low-level systems programmers; newer versions of UNIX have even more signal types.
You can use the built-in shell command kill to send a signal to any process you created—not just the currently running job. kill takes as an argument the process ID, job number, or command name of the process to which you want to send the signal. By default, kill sends the TERM (“terminate”) signal, which usually has the same effect as the INT signal you send with CTRL-C. But you can specify a different signal by using the signal name (or number) as an option, preceded by a dash.
kill is so named because of the nature of the default TERM signal, but there is another reason, which has to do with the way UNIX handles signals in general. The full details are too complex to go into here, but the following explanation should suffice.
Most signals cause a process that receives them to die; therefore, if you send any one of these signals, you “kill” the process that receives it. However, programs can be set up to Section 8.4 specific signals and take some other action. For example, a text editor would do well to save the file being edited before terminating when it receives a signal such as INT, TERM, or QUIT. Determining what to do when various signals come in is part of the fun of UNIX systems programming.
Here is an example of kill. Say you have an alice process in the background, with process ID 150 and job number 1, which needs to be stopped. You would start with this command:
$ kill %1If you were successful, you would see a message like this:
[1]+ Terminated alice
If you don’t see this, then the TERM signal failed to terminate the job. The next step would be to try QUIT:
$ kill -QUIT %1If that worked, you would see this message:
[1]+ Exit 131 alice
The 131 is the exit status returned by alice.[11] But if even QUIT doesn’t work, the “last-ditch” method would be to use KILL:
$ kill -KILL %1This produces the message:
[1]+ Killed alice
It is impossible for a process to Section 8.4 a KILL signal—the operating system should terminate the process immediately and unconditionally. If it doesn’t, then either your process is in one of the “funny states” we’ll see later in this chapter, or (far less likely) there’s a bug in your version of UNIX.
Here’s another example.
The solution to this task is simple, relying on jobs -p:
kill "$@" $(jobs -p)
You may be tempted to use the KILL signal immediately, instead of trying TERM (the default) and QUIT first. Don’t do this. TERM and QUIT are designed to give a process the chance to “clean up” before exiting, whereas KILL will stop the process, wherever it may be in its computation. Use KILL only as a last resort!
You can use the kill command with any process you create, not just jobs in the background of your current shell. For example, if you use a windowing system, then you may have several terminal windows, each of which runs its own shell. If one shell is running a process that you want to stop, you can kill it from another window—but you can’t refer to it with a job number because it’s running under a different shell. You must instead use its process ID.
This is probably the only situation in which a casual user would need to know the ID of a process. The command ps gives you this information; however, it can give you lots of extra information as well.
ps is a complex command. It takes several options, some of which differ from one version of UNIX to another. To add to the confusion, you may need different options on different UNIX versions to get the same information! We will use options available on the two major types of UNIX systems, those derived from System V (such as many of the versions for Intel Pentium PCs, as well as IBM’s AIX and Hewlett-Packard’s HP/UX) and BSD (Mac OS X, SunOS, BSD/OS). If you aren’t sure which kind of UNIX version you have, try the System V options first.
You can invoke ps in its simplest form without any options. In this case, it will print a line of information about the current login shell and any processes running under it (i.e., background jobs). For example, if you were to invoke three background jobs, as we saw earlier in the chapter, the ps command on System V-derived versions of UNIX would produce output that looks something like this:
PID TTY TIME COMD 146 pts/10 0:03 -bash 2349 pts/10 0:03 alice 2367 pts/10 0:17 hatter 2389 pts/10 0:09 duchess 2390 pts/10 0:00 ps
The output on BSD-derived systems looks like this:
PID TT STAT TIME COMMAND 146 10 S 0:03 /bin/bash 2349 10 R 0:03 alice 2367 10 D 0:17 hatter teatime 2389 10 R 0:09 duchess 2390 10 R 0:00 ps
(You can ignore the STAT column.) This is a bit like the jobs command. PID is the process ID; TTY (or TT) is the terminal (or pseudo-terminal, if you are using a windowing system) the process was invoked from; TIME is the amount of processor time (not real or “wall clock” time) the process has used so far; COMD (or COMMAND) is the command. Notice that the BSD version includes the command’s arguments, if any; also notice that the first line reports on the parent shell process, and in the last line, ps reports on itself.
ps without arguments lists all processes started from the current terminal or pseudo-terminal. But since ps is not a shell command, it doesn’t correlate process IDs with the shell’s job numbers. It also doesn’t help you find the ID of the runaway process in another shell window.
To get this information, use ps -a (for “all”); this lists information on a different set of processes, depending on your UNIX version.
Instead of listing all processes that were started under a specific terminal, ps -a on System V-derived systems lists all processes associated with any terminal that aren’t group leaders. For our purposes, a “group leader” is the parent shell of a terminal or window. Therefore, if you are using a windowing system, ps -a lists all jobs started in all windows (by all users), but not their parent shells.
Assume that, in the previous example, you have only one terminal or window. Then ps -a will print the same output as plain ps except for the first line, since that’s the parent shell. This doesn’t seem to be very useful.
But consider what happens when you have multiple windows open. Let’s say you have three windows, all running terminal emulators like xterm for the X Window System. You start background jobs alice, duchess, and hatter in windows with pseudo-terminal numbers 1, 2, and 3, respectively. This situation is shown in Figure 8-1.
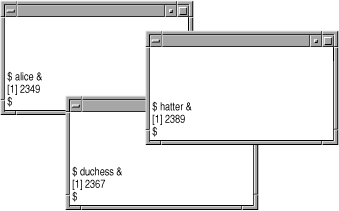
Assume you are in the uppermost window. If you type ps, you will see something like this:
PID TTY TIME COMD 146 pts/1 0:03 bash 2349 pts/1 0:03 alice 2390 pts/1 0:00 ps
But if you type ps -a, you will see this:
PID TTY TIME COMD 146 pts/1 0:03 bash 2349 pts/1 0:03 alice 2367 pts/2 0:17 duchess 2389 pts/3 0:09 hatter 2390 pts/1 0:00 ps
Now you should see how ps -a can help you track down a runaway process. If it’s hatter, you can type kill 2389. If that doesn’t work, try kill -QUIT 2389, or in the worst case, kill -KILL 2389.
On BSD-derived systems, ps -a lists all jobs that were started on any terminal; in other words, it’s a bit like concatenating the results of plain ps for every user on the system. Given the above scenario, ps -a will show you all processes that the System V version shows, plus the group leaders (parent shells).
Unfortunately, ps -a (on any version of UNIX) will not report processes that are in certain conditions where they “forget” things like what shell invoked them and what terminal they belong to. Such processes are known as “zombies” or “orphans.” If you have a serious runaway process problem, it’s possible that the process has entered one of these states.
Let’s not worry about why or how a process gets this way. All you need to understand is that the process doesn’t show up when you type ps -a. You need another option to ps to see it: on System V, it’s ps -e (“everything”), whereas on BSD, it’s ps -ax.
These options tell ps to list processes that either weren’t started from terminals or “forgot” what terminal they were started from. The former category includes lots of processes that you probably didn’t even know existed: these include basic processes that run the system and so-called daemons (pronounced “demons”) that handle system services like mail, printing, network filesystems, etc.
In fact, the output of ps -e or ps -ax is an excellent source of education about UNIX system internals, if you’re curious about them. Run the command on your system and, for each line of the listing that looks interesting, invoke man on the process name or look it up in the UNIX Programmer’s Manual for your system.
User shells and processes are listed at the very bottom of ps -e or ps -ax output; this is where you should look for runaway processes. Notice that many processes in the listing have ? instead of a terminal. Either these aren’t supposed to have one (such as the basic daemons) or they’re runaways. Therefore it’s likely that if ps -a doesn’t find a process you’re trying to kill, ps -e (or ps -ax) will list it with ? in the TTY (or TT) column. You can determine which process you want by looking at the COMD (or COMMAND) column.
We’ve been discussing how signals affect the casual user; now let’s talk a bit about how shell programmers can use them. We won’t go into too much depth about this, because it’s really the domain of systems programmers.
We mentioned above that programs in general can be set up to Section 8.4 specific signals and process them in their own way. The trap built-in command lets you do this from within a shell script. trap is most important for “bullet-proofing” large shell programs so that they react appropriately to abnormal events—just as programs in any language should guard against invalid input. It’s also important for certain systems programming tasks, as we’ll see in the next chapter.
The syntax of trap is:
trap cmd sig1 sig2 ...That is, when any of sig1, sig2, etc., are received, run cmd, then resume execution. After cmd finishes, the script resumes execution just after the command that was interrupted.[12]
Of course, cmd can be a script or function. The sigs can be specified by name or by number. You can also invoke trap without arguments, in which case the shell will print a list of any traps that have been set, using symbolic names for the signals.
Here’s a simple example that shows how trap works. Suppose we have a shell script called loop with this code:
while true; do
sleep 60
doneThis will just pause for 60 seconds (the sleep command) and repeat indefinitely. true is a “do-nothing” command whose exit status is always 0.[13] Try typing in this script. Invoke it, let it run for a little while, then type CTRL-C (assuming that is your interrupt key). It should stop, and you should get your shell prompt back.
Now insert this line at the beginning of the script:
trap "echo 'You hit control-C!'" INT
Invoke the script again. Now hit CTRL-C. The odds are overwhelming that you are interrupting the sleep command (as opposed to true). You should see the message “You hit control-C!”, and the script will not stop running; instead, the sleep command will abort, and it will loop around and start another sleep. Hit CTRL-Z to get it to stop and then type kill %1.
Next, run the script in the background by typing loop &. Type kill %loop (i.e., send it the TERM signal); the script will terminate. Add TERM to the trap command, so that it looks like this:
trap "echo 'You hit control-C!'" INT TERM
Now repeat the process: run it in the background and type kill %loop. As before, you will see the message and the process will keep on running. Type kill -KILL %loop to stop it.
Notice that the message isn’t really appropriate when you use kill. We’ll change the script so it prints a better message in the kill case:
trap "echo 'You hit control-C!'" INT
trap "echo 'You tried to kill me!'" TERM
while true; do
sleep 60
doneNow try it both ways: in the foreground with CTRL-C and in the background with kill. You’ll see different messages.
The relationship between traps and shell functions is straightforward, but it has certain nuances that are worth discussing. The most important thing to understand is that functions are considered part of the shell that invokes them. This means that traps defined in the invoking shell will be recognized inside the function, and more importantly, any traps defined in the function will be recognized by the invoking shell once the function has been called. Consider this code:
settrap ( ) {
trap "echo 'You hit control-C!'" INT
}
settrap
while true; do
sleep 60
doneIf you invoke this script and hit your interrupt key, it will print “You hit control-C!” In this case the trap defined in settrap still exists when the function exits.
Now consider:
loop ( ) {
trap "echo 'How dare you!'" INT
while true; do
sleep 60
done
}
trap "echo 'You hit control-C!'" INT
loopWhen you run this script and hit your interrupt key, it will print “How dare you!” In this case the trap is defined in the calling script, but when the function is called the trap is redefined. The first definition is lost. A similar thing happens with:
loop ( ) {
trap "echo 'How dare you!'" INT
}
trap "echo 'You hit control-C!'" INT
loop
while true; do
sleep 60
doneOnce again, the trap is redefined in the function; this is the definition used once the loop is entered.
We’ll now show a more practical example of traps.
The basic idea is to use cat to create the message in a temporary file and then hand the file’s name off to a program that actually sends the message to its destination. The code to create the file is very simple:
msgfile=/tmp/msg$$ cat > $msgfile
Since cat without an argument reads from the standard input, this will just wait for the user to type a message and end it with the end-of-text character CTRL-D.
The only thing new about this script is $$ in the filename expression. This is a special shell variable whose value is the process ID of the current shell.
To see how $$ works, type ps and note the process ID of your shell process (bash). Then type echo "$$“; the shell will respond with that same number. Now type bash to start a subshell, and when you get a prompt, repeat the process. You should see a different number, probably slightly higher than the last one.
A related built-in shell variable is ! (i.e., its value is $!), which contains the process ID of the most recently invoked background job. To see how this works, invoke any job in the background and note the process ID printed by the shell next to [1]. Then type echo "$!“; you should see the same number.
To return to our mail example: since all processes on the system must have unique process IDs, $$ is excellent for constructing names of temporary files.
The directory /tmp is conventionally used for temporary files. Many systems also have another directory, /var/tmp, for the same purpose.
Nevertheless, a program should clean up such files before it exits, to avoid taking up unnecessary disk space. We could do this in our code very easily by adding the line rm $msgfile after the code that actually sends the message. But what if the program receives a signal during execution? For example, what if a user changes her mind about sending the message and hits CTRL-C to stop the process? We would need to clean up before exiting. We’ll emulate the actual UNIX mail system by saving the message being written in a file called dead.letter in the current directory. We can do this by using trap with a command string that includes an exit command:
trap 'mv $msgfile dead.letter; exit' INT TERM msgfile=/tmp/msg$$ cat > $msgfile # send the contents of $msgfile to the specified mail address... rm $msgfile
When the script receives an INT or TERM signal, it will remove the temp file and then exit. Note that the command string isn’t evaluated until it needs to be run, so $msgfile will contain the correct value; that’s why we surround the string in single quotes.
But what if the script receives a signal before msgfile is created—unlikely though that may be? Then mv will try to rename a file that doesn’t exist. To fix this, we need to test for the existence of the file $msgfile before trying to delete it. The code for this is a bit unwieldy to put in a single command string, so we’ll use a function instead:
function cleanup {
if [ -e $msgfile ]; then
mv $msgfile dead.letter
fi
exit
}
trap cleanup INT TERM
msgfile=/tmp/msg$$
cat > $msgfile
# send the contents of $msgfile to the specified mail address...
rm $msgfileSometimes a signal comes in that you don’t want to do anything about. If you give the null string (“” or `') as the command argument to trap, then the shell will effectively ignore that signal. The classic example of a signal you may want to ignore is HUP (hangup). This can occur on some UNIX systems when a hangup (disconnection while using a modem—literally “hanging up”) or some other network outage takes place.
HUP has the usual default behavior: it will kill the process that receives it. But there are bound to be times when you don’t want a background job to terminate when it receives a hangup signal.
To do this, you could write a simple function that looks like this:
function ignorehup {
trap "" HUP
eval "$@"
}We write this as a function instead of a script for reasons that will become clearer when we look in detail at subshells at the end of this chapter.
Actually, there is a UNIX command called nohup that does precisely this. The start script from the last chapter could include nohup:
eval nohup "$@" > logfile 2>&1 &
This prevents HUP from terminating your command and saves its standard and error output in a file. Actually, the following is just as good:
nohup "$@" > logfile 2>&1 &
If you understand why eval is essentially redundant when you use nohup in this case, then you have a firm grasp on the material in the previous chapter. Note that if you don’t specify a redirection for any output from the command, nohup places it in a file called nohup.out.
Another way to ignore the HUP signal is with the disown built-in.[14] disown takes as an argument a job specification, such as the process ID or job ID, and removes the process from the list of jobs. The process is effectively “disowned” by the shell from that point on, i.e., you can only refer to it by its process ID since it is no longer in the job table.
disown’s -h option performs the same function as nohup; it specifies that the shell should stop the hangup signal from reaching the process under certain circumstances. Unlike nohup, it is up to you to specify where the output from the process is to go.
disown also provides two options which can be of use. -a with no other arguments applies the operation to all jobs owned by the shell. The -r option with does the same but only for currently running jobs.
Another “special case” of the trap command occurs when you give a dash (-) as the command argument. This resets the action taken when the signal is received to the default, which usually is termination of the process.
As an example of this, let’s return to Task 8-2, our mail program. After the user has finished sending the message, the temporary file is erased. At that point, since there is no longer any need to clean up, we can reset the signal trap to its default state. The code for this, apart from function definitions, is:
trap abortmsg INT
trap cleanup TERM
msgfile=/tmp/msg$$
cat > $msgfile
# send the contents of $msgfile to the specified mail address...
rm $msgfile
trap - INT TERMThe last line of this code resets the handlers for the INT and TERM signals.
At this point you may be thinking that you could get seriously carried away with signal handling in a shell script. It is true that “industrial strength” programs devote considerable amounts of code to dealing with signals. But these programs are almost always large enough so that the signal-handling code is a tiny fraction of the whole thing. For example, you can bet that the real UNIX mail system is pretty darn bullet-proof.
However, you will probably never write a shell script that is complex enough, and that needs to be robust enough, to merit lots of signal handling. You may write a prototype for a program as large as mail in shell code, but prototypes by definition do not need to be bullet-proofed.
Therefore, you shouldn’t worry about putting signal-handling code in every 20-line shell script you write. Our advice is to determine if there are any situations in which a signal could cause your program to do something seriously bad and add code to deal with those contingencies. What is “seriously bad”? Well, with respect to the above examples, we’d say that the case where HUP causes your job to terminate is seriously bad, while the temporary file situation in our mail program is not.
We’ve spent the last several pages on almost microscopic details of process behavior. Rather than continue our descent into the murky depths, we’ll revert to a higher-level view of processes.
Earlier in this chapter, we covered ways of controlling multiple simultaneous jobs within an interactive login session; now we’ll consider multiple process control within shell programs. When two (or more) processes are explicitly programmed to run simultaneously and possibly communicate with each other, we call them coroutines.
This is actually nothing new: a pipeline is an example of coroutines. The shell’s pipeline construct encapsulates a fairly sophisticated set of rules about how processes interact with each other. If we take a closer look at these rules, we’ll be better able to understand other ways of handling coroutines—most of which turn out to be simpler than pipelines.
When you invoke a simple pipeline—say, ls | more—the shell invokes a series of UNIX primitive operations, or system calls. In effect, the shell tells UNIX to do the following things; in case you’re interested, we include in parentheses the actual system call used at each step:
Create two subprocesses, which we’ll call P1 and P2 (the fork system call).
Set up I/O between the processes so that P1’s standard output feeds into P2’s standard input (pipe).
Start /bin/ls in process P1 (exec).
Start /bin/more in process P2 (exec).
Wait for both processes to finish (wait).
You can probably imagine how the above steps change when the pipeline involves more than two processes.
Now let’s make things simpler. We’ll see how to get multiple processes to run at the same time if the processes do not need to communicate. For example, we want the processes alice and hatter to run as coroutines, without communication, in a shell script. Our initial solution would be this:
alice & hatter
Assume for the moment that hatter is the last command in the script. The above will work—but only if alice finishes first. If alice is still running when the script finishes, then it becomes an orphan, i.e., it enters one of the “funny states” we mentioned earlier in this chapter. Never mind the details of orphanhood; just believe that you don’t want this to happen, and if it does, you may need to use the “runaway process” method of stopping it, discussed earlier in this chapter.
There is a way of making sure the script doesn’t finish before alice does: the built-in command wait. Without arguments, wait simply waits until all background jobs have finished. So to make sure the above code behaves properly, we would add wait, like this:
alice & hatter wait
Here, if hatter finishes first, the parent shell will wait for alice to finish before finishing itself.
If your script has more than one background job and you need to wait for specific ones to finish, you can give wait the process ID of the job.
However, you will probably find that wait without arguments suffices for all coroutines you will ever program. Situations in which you would need to wait for specific background jobs are quite complex and beyond the scope of this book.
In fact, you may be wondering why you would ever need to program coroutines that don’t communicate with each other. For example, why not just run hatter after alice in the usual way? What advantage is there in running the two jobs simultaneously?
Even if you are running on a computer with only one processor (CPU), then there may be a performance advantage.
Roughly speaking, you can characterize a process in terms of how it uses system resources in three ways: whether it is CPU-intensive (e.g., does lots of number crunching), I/O-intensive (does a lot of reading or writing to the disk), or interactive (requires user intervention).
We already know from Chapter 1 that it makes no sense to run an interactive job in the background. But apart from that, the more two or more processes differ with respect to these three criteria, the more advantage there is in running them simultaneously. For example, a number-crunching statistical calculation would do well when running at the same time as a long, I/O-intensive database query.
On the other hand, if two processes use resources in similar ways, it may even be less efficient to run them at the same time as it would be to run them sequentially. Why? Basically, because under such circumstances, the operating system often has to “time-slice” the resource(s) in contention.
For example, if both processes are “disk hogs,” the operating system may enter a mode where it constantly switches control of the disk back and forth between the two competing processes; the system ends up spending at least as much time doing the switching as it does on the processes themselves. This phenomenon is known as thrashing; at its most severe, it can cause a system to come to a virtual standstill. Thrashing is a common problem; system administrators and operating system designers both spend lots of time trying to minimize it.
If you have a computer with multiple CPUs you should be less concerned about thrashing. Furthermore, coroutines can provide dramatic increases in speed on this type of machine, which is often called a parallel computer; analogously, breaking up a process into coroutines is sometimes called parallelizing the job.
Normally, when you start a background job on a multiple-CPU machine, the computer will assign it to the next available processor. This means that the two jobs are actually—not just metaphorically—running at the same time.
In this case, the running time of the coroutines is essentially equal to that of the longest-running job plus a bit of overhead, instead of the sum of the runtimes of all processes (although if the CPUs all share a common disk drive, the possibility of I/O-related thrashing still exists). In the best case—all jobs having the same runtime and no I/O contention—you get a speedup factor equal to the number of CPUs.
Parallelizing a program is often not easy; there are several subtle issues involved and there’s plenty of room for error. Nevertheless, it’s worthwhile to know how to parallelize a shell script whether or not you have a parallel machine, especially since such machines are becoming more and more common.
We’ll show how to do this—and give you an idea of some problems involved—by means of a simple task whose solution is amenable to parallelization.
We’ll call this script mcp. The command mcp filename dest1 dest2 ... should copy filename to all of the destinations given. The code for this should be fairly obvious:
file=$1
shift
for dest in "$@"; do
cp $file $dest
doneNow let’s say we have a parallel computer and we want this command to run as fast as possible. To parallelize this script, it’s a simple matter of firing off the cp commands in the background and adding a wait at the end:
file=$1
shift
for dest in "$@"; do
cp $file $dest &
done
waitSimple, right? Well, there is one little problem: what happens if the user specifies duplicate destinations? If you’re lucky, the file just gets copied to the same place twice. Otherwise, the identical cp commands will interfere with each other, possibly resulting in a file that contains two interspersed copies of the original file. In contrast, if you give the regular cp command two arguments that point to the same file, it will print an error message and do nothing.
To fix this problem, we would have to write code that checks the argument list for duplicates. Although this isn’t too hard to do (see the exercises at the end of this chapter), the time it takes that code to run might offset any gain in speed from parallelization; furthermore, the code that does the checking detracts from the simple elegance of the script.
As you can see, even a seemingly trivial parallelization task has problems resulting from multiple processes that have concurrent access to a given system resource (a file in this case). Such problems, known as concurrency control issues, become much more difficult as the complexity of the application increases. Complex concurrent programs often have much more code for handling the special cases than for the actual job the program is supposed to do!
Therefore, it shouldn’t surprise you that much research has been and is being done on parallelization, the ultimate goal being to devise a tool that parallelizes code automatically. (Such tools do exist; they usually work in the confines of some narrow subset of the problem.) Even if you don’t have access to a multiple-CPU machine, parallelizing a shell script is an interesting exercise that should acquaint you with some of the issues that surround coroutines.
To conclude this chapter, we will look at a simple type of interprocess relationship: that of a subshell with its parent shell. We saw in Chapter 3 that whenever you run a shell script, you actually invoke another copy of the shell that is a subprocess of the main, or parent, shell process. Now let’s look at subshells in more detail.
The most important things you need to know about subshells are what characteristics they get, or inherit, from their parents. These are as follows:
The current directory
Environment variables
Standard input, output, and error, plus any other open file descriptors
Signals that are ignored
Just as important are the things that a subshell does not inherit from its parent:
Shell variables, except environment variables and those defined in the environment file (usually .bashrc)
Handling of signals that are not ignored
We covered some of this in Chapter 3, but these points are common sources of confusion, so they bear repeating.
Subshells need not be in separate scripts; you can also start a subshell within the same script (or function) as the parent. You do this in a manner very similar to the command blocks we saw in the last chapter. Just surround some shell code with parentheses (instead of curly brackets), and that code will run in a subshell. We’ll call this a nested subshell.
For example, here is the calculator program from the last chapter, with a subshell instead of a command block:
( while read line; do
echo "$(alg2rpn $line)"
done
) | dcThe code inside the parentheses will run as a separate process. This is usually less efficient than a command block. The differences in functionality between subshells and command blocks are very few; they primarily pertain to issues of scope, i.e., the domains in which definitions of things like shell variables and signal traps are known. First, code inside a nested subshell obeys the above rules of subshell inheritance, except that it knows about variables defined in the surrounding shell; in contrast, think of blocks as code units that inherit everything from the outer shell. Second, variables and traps defined inside a command block are known to the shell code after the block, whereas those defined in a subshell are not.
For example, consider this code:
{
hatter=mad
trap "echo 'You hit CTRL-C!'" INT
}
while true; do
echo "$hatter is $hatter"
sleep 60
doneIf you run this code, you will see the message $hatter is mad every 60 seconds, and if you hit CTRL-C, you will see the message, You hit CTRL-C!. You will need to hit CTRL-Z to stop it (don’t forget to kill it with kill %+). Now let’s change it to a nested subshell:
(
hatter=mad
trap "echo 'You hit CTRL-C!'" INT
)
while true; do
echo "$hatter is $hatter"
sleep 60
doneIf you run this, you will see the message $hatter is; the outer shell doesn’t know about the subshell’s definition of hatter and therefore thinks it’s null. Furthermore, the outer shell doesn’t know about the subshell’s trap of the INT signal, so if you hit CTRL-C, the script will terminate.
If a language supports code nesting, then it’s considered desirable that definitions inside a nested unit have a scope limited to that nested unit. In other words, nested subshells give you better control than command blocks over the scope of variables and signal traps. Therefore, we feel that you should use subshells instead of command blocks if they are to contain variable definitions or signal traps—unless efficiency is a concern.
A unique but rarely used feature of bash is process substitution. Let’s say that you had two versions of a program that produced large quantities of output. You want to see the differences between the output from each version. You could run the two programs, redirecting their output to files, and then use the cmp utility to see what the differences were.
Another way would be to use process substitution. There are two forms of this substitution. One is for input to a process: >(list); the other is for output from a process: <(list). list is a process that has its input or output connected to something via a named pipe. A named pipe is simply a temporary file that acts like a pipe with a name.
In our case, we could connect the outputs of the two programs to the input of cmp via named pipes:
cmp <(prog1) <(prog2)
prog1 and prog2 are run concurrently and connect their outputs to named pipes. cmp reads from each of the pipes and compares the information, printing any differences as it does so.
This chapter has covered a lot of territory. Here are some exercises that should help you make sure you have a firm grasp on the material. Don’t worry if you have trouble with the last one; it’s especially difficult.
Write a shell script called pinfo that combines the jobs and ps commands by printing a list of jobs with their job numbers, corresponding process IDs, running times, and full commands.
Take a non-trivial shell script and “bullet-proof” it with signal traps.
Take a non-trivial shell script and parallelize it as much as possible.
Write the code that checks for duplicate arguments to the mcp script. Bear in mind that different pathnames can point to the same file. (Hint: if $i is “1”, then eval `echo ${$i}' prints the first command-line argument. Make sure you understand why.)
[1] The messages are, by default, printed before the next prompt is displayed so as not to interrupt any output on the display. You can make the notification messages display immediately by using set -b.
[2] In POSIX mode, the message is slightly different: "[1]+ Done(1) alice“. The number in parentheses is the exit status of the job. POSIX mode can be selected via the set command or by starting bash in POSIX mode. For further information, see Table 2-1 and Table 2-5
[3] If you have an older version of UNIX, it is possible that your system does not support job control. This is particularly true for many systems derived from Xenix, System III, or early versions of System V. On such systems, bash does not have the fg and bg commands, job number arguments to kill and wait, typing CTRL-Z to suspend a job, or the TSTP signal.
[4] Options -r and -s are not available in bash prior to version 2.0.
[5] This is analogous to ~+ and ~- as references to the current and previous directory; see the footnote in Chapter 7. Also: %% is a synonym for %+.
[6] This assumes that the CTRL-Z key is set up as your suspend key; just as with CTRL-C and interrupts, this is conventional but by no means required.
[7] Be warned, however, that not all commands are “well-behaved” when you do this. Be especially careful with commands that run over a network on a remote machine; you may end up confusing the remote program.
[8] Pipes and signals were the only IPC mechanisms in early versions of UNIX. More modern versions like System V and BSD have additional mechanisms, such as sockets, named pipes, and shared memory. Named pipes are accessible to shell programmers through the mknod(1) command, which is beyond the scope of this book.
[9] CTRL- can also cause the shell to leave a file called core in your current directory. This file contains an image of the process to which you sent the signal; a programmer could use it to help debug the program that was running. The file’s name is a (very) old-fashioned term for a computer’s memory. Other signals leave these “core dumps” as well; unless you require them, or someone else does, just delete them.
[10] Some BSD-derived systems have additional control-key signals.
[11] When a shell script is sent a signal, it exits with status 128+N, where N is the number of the signal it received. In this case, alice is a shell script, and QUIT happens to be signal number 3.
[12] This is what usually happens. Sometimes the command currently running will abort (sleep acts like this, as we’ll see soon); at other times it will finish running. Further details are beyond the scope of this book.
[13] This command is the same as the built-in shell no-op command “:”.
[14] disown is not available in versions of bash prior to 2.0.