
Shell provides different ways to sort the input text using the sort command. It's also possible to remove repeated lines from sorted/unsorted input text using the uniq command. The input text to sort and uniq commands can be given from a file, or redirected from another command.
The lines in the input text are sorted in the following order:
- Numbers from 0 to 9
- Uppercase letters from A to Z
- Lowercase letters from a to z
The syntax will be as follows:
sort [OPTION] [FILE …]
Single or multiple input files can be provided to sort for sorting.
The sort command takes multiple options to provide flexibility in sorting. The popular and important OPTION to sort have been discussed in the following table:
Now, we will see with the help of examples, how different sorting can be done on the input text data.
In our example, we will consider the sort1.txt file for sorting. The content of this file is as follows:
$ cat sort1.txt Japan Singapore Germany Italy France Sri Lanka
To sort the content alphabetically, we can use the sort command without any option:
$ sort sort1.txt France Germany Italy Japan Singapore Sri Lanka
To sort the content in reverse order, we can use the –r option:
$ sort -r sort1.txt Sri Lanka Singapore Japan Italy Germany France
Sorting multiple files: We can also sort multiple files collectively, and the sorted output can be used for further queries.
For example, consider sort1.txt and sort2.txt files. We will reuse the content of the sort1.txt file from the previous example. The content of sort2.txt is as follows:
$ cat sort2.txt India USA Canada China Australia
We can sort both the files together alphabetically as follows:
$ sort sort1.txt sort2.txt Australia Canada China France Germany India Italy Japan Singapore Sri Lanka USA
We can also use the -o option to save the sorted output of files in a file instead of displaying it on stdout:
$ sort sort1.txt sort2.txt -o sorted.txt $ cat sorted.txt Australia Canada China France Germany India Italy Japan Singapore Sri Lanka USA
We can sort an output redirected from another command. The following example shows the sorting of the df -h command output:
$ df -h # Disk space usage in human readable format
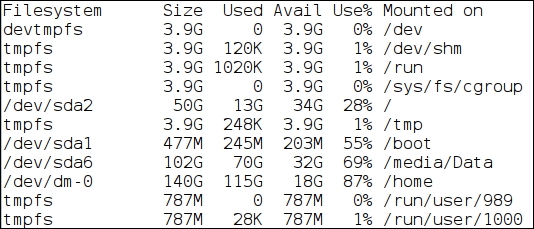
The following command sorts output of df by its 2nd column content:
$ df -h | sort -hb -k2 #. Sorts by 2nd column according to size available:

We can sort the ls -l output according to the last modification day and month:
$ ls -l /var/cache/ # Long listing content of /var/cache

To sort the ls -l output, first sort according to the month that is the 6th field using the -M option, and if the month for two or more row is the same, then sort according to the day that is the 7th field using -n for numerical sort:
$ ls -l /var/cache/ | sort -bk 6M -nk7

In many use-case, we need to remove duplicate items and keep only one occurrence of items. It is very useful when the output of a command or input file is too big, and it contains lot of duplicate lines. To get unique lines from a file or redirected output, the shell command uniq is used. One important point to note is that, in order to get the uniq output, input should be sorted, or first run the sort command to make it sorted. The syntax will be as follows:
sort [OPTION] [INPUT [OUTPUT]]
An input to uniq can be given from a file or another command's output.
If an input file is provided, then an optional output file can also be specified on a command line. If no output file is specified, the output will be printed on stdout.
The options that uniq supports are discussed in the following table:
|
Option |
Description |
|---|---|
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
|
Consider the unique.txt file as an example on which we will run the
uniq command with its options. The content of unique.txt is as follows:
$ cat unique.txt Welcome to Linux shell scripting 1 Welcome to LINUX shell sCripting 2 Welcome To Linux Shell Scripting 4 2 4 Welcome to Linux shell scripting 2 3 Welcome to Linux shell scripting 2 Welcome to Linux shell scripting Welcome to LINUX shell sCripting
To remove duplicate lines from the unique.txt file, we can do the following:
- Firstly, sort the file and then redirect the sorted text to the
uniqcommand:$ sort unique.txt | uniq - Use the
-uoption with thesortcommand:$ sort -u unique.txt
The output from running either of the commands will be the same, as follows:

We can use the -c option to print the number of occurrences of each line in the input file:
$ sort unique.txt | uniq -c

Using the options -c and -i will print the uniq lines along with the occurrence count. A comparison for unique line will be done case-insensitive:
$ sort unique.txt | uniq -ci

To get only those lines in file that have appeared only once, the -u option is used:
$ sort unique.txt | uniq -u 1 3 Welcome To Linux Shell Scripting
Similarly, to get the lines that have been appeared more than once in a file, -d is used:
$ sort unique.txt | uniq -d 2 4 Welcome to Linux shell scripting Welcome to LINUX shell sCripting
We can also tell the uniq command to find unique lines based on comparing only the first N character of the line:
$ sort unique.txt | uniq -w 10 1 2 3 4 Welcome to Linux shell scripting Welcome To Linux Shell Scripting