
Chapter 2: Your Machine Learning Project
The approach of this book is to iterate through a practical business project – namely, stock market prediction – and, with this use case, explore through the different chapters the different features of MLflow. We will use a structured approach to frame a machine learning problem and project. A sample pipeline will be created and used to iterate and evolve the project in the remainder of the book.
Using a structured framework to describe a machine learning problem helps the practitioner to reason more efficiently about the different requirements of the machine learning pipeline. We will present a practical pipeline using the requirements elicited during framing.
Specifically, we will cover the following sections in this chapter:
- Exploring the machine learning process
- Framing the machine learning problem
- Introducing the stock market prediction problem
- Developing your machine learning baseline pipeline
Technical requirements
For this chapter, you will need the following prerequisites:
- The latest version of Docker installed on your machine. If you don't already have it installed, please follow the instructions at https://docs.docker.com/get-docker/.
- Access to a Bash terminal (Linux or Windows).
- Access to a browser.
- Python 3.5+ installed.
- MLflow installed locally as described in Chapter 1, Introducing MLflow.
Exploring the machine learning process
In this chapter, we will begin by describing the problem that we will solve throughout the book. We aim to focus on machine learning in the context of stock trading.
Machine learning can be defined as the process of training a software artifact – in this case, a model to make relevant predictions in a problem. Predictions are used to drive business decisions, for instance, which stock should be bought or sold or whether a picture contains a cat or not.
Having a standard approach to a machine learning project is critical for a successful project. The typical iteration of a machine learning life cycle is depicted in Figure 2.1:

Figure 2.1 – Excerpt of the acquired data with the prediction column
Let's examine each stage in detail:
- Ideation: This phase involves identifying a business opportunity to use machine learning and formulating the problem.
- Prototyping: This involves verifying the feasibility and suitability of existing datasets to implement the planned idea.
- Pilot: This involves evaluating and iterating over a machine learning algorithm in order to make the decision of whether to progress or not to the subsequent phase.
- Production deployment: Upon successful piloting, we should be able to run the machine learning project in production and allow it to start receiving production traffic.
These high-level phases defined in Figure 2.1 are definitely not static and are generally iterative, with dynamic movement between the phases to refine and improve.
It should be noted that machine learning is not the solution to every problem. Before deciding on machine learning, a deep evaluation needs to be made of the problem or project at hand to decide whether or not to apply machine learning.
There are simple scenarios where a machine learning solution is a good candidate, for instance, in the following cases:
- When simple rules and heuristics are not enough to solve the problem at hand.
- It's very expensive to solve the problem with the current state-of-the-art solutions.
- When the rules and code to solve a problem are very intricate and hard to maintain.
The advent of machine learning brought changes to various areas; one of these areas is the finance field. Before computers, finance was based on trading papers in small offices with a reduced number of transactions. With computers, the situation changed; there are now millions of transactions done per day. Millions of people trade with each other without having to meet in person or have any other sort of physical contact.
In finance and the stock trading space, machine learning can be used in the following contexts:
- Data mining: To identify patterns in your dataset using advanced predictive analytics. It's very common for advanced data analysts to use machine learning models as part of their analysis process and to drive business decisions.
- Pair trading: A technique of using two pairs of stocks that are in opposite directions of the market. Basically, this works by selling or buying when each of the stocks is out of phase with its normal behavior as the markets are known to converge after some time.
- Stock forecasting: Simple prediction, based on the current time series of what a particular stock will be traded for at a point in the future.
- Anomaly detection: Detecting abnormal situations in the market reveals itself to be very important to prevent auto-trading systems from operating on days when the market is anomalous.
- Sentiment analysis: The stock market is known to be driven mostly by sentiments of participants around companies and businesses. This technique uses, for instance, messages on social media or other mediums, using natural language processing techniques to gauge sentiment (for example, positive, negative, or neutral).
Next, we'll look at framing the problem for machine learning.
Framing the machine learning problem
Machine learning problem framing, as defined in this section, is a technique and methodology to help specify and contextualize a machine learning problem in such a way that an engineering solution can be implemented. Without a solid approach to tackling machine learning problems, it can become very hard to extract the real value of the undertaking.
We will draw inspiration from the approaches of companies such as Amazon and Google, which have been successfully applying the technique of machine learning problem framing.
The machine learning development process is highly based on the scientific method. We undergo different stages of stating a goal, data collection, hypothesis testing, and conclusion. It's expected that we will cycle through the different stages of the workflow until either a good model is identified or it becomes apparent that it's impossible to develop one.
The following subsections depict the framework that we will use in the rest of the book to elicit a machine learning problem-solving framework.
Problem statement
Understanding the problem that we are solving is very important before we attempt anything else. Defining a problem statement for the problem at hand is a clear way to define your problem. The following are reasonable examples of a machine learning problem statement:
- Predict whether the stock market for a specific ticker will go up tomorrow.
- Predict whether we have a cat in a picture.
In this part of the process, we specify the specific type of machine learning problem that we are aiming to solve. The following are common types of problems:
- Classification: This type of problem requires you to predict a label or class as the output of your model, for example, classifying whether an email text is spam or not spam. It can be a binary classification or a multiclass classification. A good example of a multiclass variant is classifying the digits given the handwriting.
- Regression: This is if you need, for instance, to have a model predict a numeric value from a training dataset. Good examples are predicting temperature based on atmospheric features and predicting the exact value in dollars of a given stock.
- Clustering: Consists of discovering natural groupings of data when you don't have labels to train models. It groups similar data points into the same groups using a distance metric. Clustering can be used to identify fraudulent transactions as they won't belong to an existing grouping.
- Generative model: This is a novel type of machine learning where new data is generated based on the existing data and is statistically similar to the input data. It's widely used in modern language models such as GPT-3 from OpenAI.
- Reinforcement learning: A type of machine learning where the agent/model interacts with the environment to learn optimal behavior to maximize the reward. One famous application is the AlphaGo agent from Google DeepMind, which was able to outperform the best human player at the board game Go. A very important application is to train an automated trading stock agent using profitability as the reward.
Important note
There are multiple taxonomies for machine learning problems; the listing in this section is by no means exhaustive. This list is relevant to the examples in the book.
Success and failure definition
Getting the success definition from a business is very important to put your problem in perspective. For instance, for the stock market case, the following can be outlined as a desirable outcome: "Using the model of this project, we would like to improve the profitability up to 56% of our daily trading operations as they are currently profitable in 50% of the daily trades."
So, if we have successful trades only 30% of the time, the model is clearly a failure. It will generally be dependent on business criteria.
Having a business metric as a success definition, instead of a technical metric such as accuracy, precision, or recall, helps keep the solution aligned to tangible goals to an organization.
Model output
The model output in the context of machine learning problem framing is dependent on the type of problem that you are solving. For instance, a regression model output will be a specific number (for example, 10.5 as a stock prediction) and a classification will return a label (for example, true when a cat is detected) and a probabilistic threshold.
Your model output should definitely be related to your outcome definition.
Output usage
Stating how your prediction will be used helps unveil the reasoning for the model development, helping the developers to get context and ownership of the problem, for instance, deciding whether you will use your prediction directly in a UI or use it to feed an upstream system.
Heuristics
Problems solved with machine learning can be approximated by rules and heuristics. Having a heuristic as a starting point for a machine learning pipeline is generally a recommended approach to starting a project.
For instance, a valid heuristic for the stock trading prediction problem would be using the last day's prediction as the first baseline production heuristic. The goal of the model developer is then to beat the baseline with a better model.
Data layer definition
Defining precisely the input and output in the context of your model helps clarify and guide the development of your machine learning problem.
Data sources
This section on framing the problem comprises identifying raw data sources and documenting them during the problem framing process. Examples of raw data sources are public or proprietary datasets and their definitions and data dictionaries.
It's important to identify whether the data is labeled or not at this stage, and the effort that will be needed to label the data.
Model input/output
Model development involves defining the precise inputs to be used in the model. Given all the data sources available, specifying the model input or feature sets becomes essential in order to execute your pipeline. Alongside your input, the desired target should be defined.
The model input/output is better framed as a table, as in Figure 2.2, in order to facilitate reasoning and model implementation. One row of example data is added for clarity:
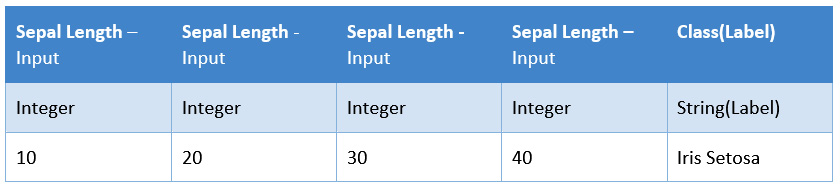
Figure 2.2 – Example of documenting the inputs/outputs of a model
Next, we'll look at using the machine learning problem framing technique on the stock trading scenario that we will work on throughout the book.
Introducing the stock market prediction problem
The scenario that we will cover in the remaining chapters of the book is of the hypothetical company PsyStock LLC, which provides a platform for amateur traders, providing APIs and UIs to solve different predictions in the context of stock prediction.
As machine learning practitioners and developers, we should be able to build a platform that will allow a team of data scientists to quickly develop, test, and bring into production machine learning projects.
We will apply and frame the problems initially so we can build our platform upon the basis of the definitions of the problems. It should be noted that the problem framing will evolve as we learn more about the problem: the initial framing will give us guidance on the problem spaces that we will be tackling.
The following are the core projects that we will use as references in the rest of the book for machine learning development in MLflow.
Stock movement predictor
This is the project for the first API that the company PsyStock LLC will provide to its customers. This API will return true if a given stock ticker will go up in the stock market and false if not.
Problem statement
The problem statement is to predict through a machine learning classifier whether the market will go up or not in a single day.
Success and failure definition
Success, in this case, is defined by the percentage of days in a month where the system predicted the correct direction of the market. Success is basically whether the system is accurate, from a market direction perspective, more than 60% of the time – basically, the expected value of being better than the random baseline.
Model output
The model output is 1 for an increase in value of a stock ticker and 0 for non-increase.
Output usage
The output of the model will be used to provide the Rest API with a true or false value based on a defined threshold of accuracy on the classification.
The expected latency for this problem is under 1,000 milliseconds.
Heuristics
The simplest heuristic to solve this problem is using a random predictor for each input, with an equal probability of the market going up or down.
Data layer definition
Let's define each part of our data layer.
Data sources
Historical stock market datasets as provided by the Yahoo Finance public API.
Model input/output
Let's look at the input and output, next:
- Input: Historical end-of-the-day price of a given ticker for the last 10 days.
- Output: 1 for increasing and 0 for not increasing in the next period.
The following table shows the input/output data of a model:

Figure 2.3 – Example of documenting the input/outputs of a model
Sentiment analysis of market influencers
The sentiment machine learning pipeline will predict whether the sentiment over a stock ticker is positive or negative on social media and provide it as an API to the users of the machine learning platform that we are developing in this book.
Problem statement
To predict whether a given stock ticker has positive sentiment for the current day of relevant market influencers on Twitter selected by PsyStock LLC.
Success and failure definition
Success, in this case, is a bit harder to define, as the fact of a sentiment being positive can't exactly be tracked to a market metric. The definition of success on this particular prediction problem should be a proxy for how many times a user is a repeat user of the API.
Model output
The model output is basically a number matching the polarity of the tweet – positive, negative, or neutral sentiment – of a ticker.
Output usage
The output of this system will be used in a Rest API that will be provided on request, with the number of positive, neutral, and negative polarities for a given ticker.
Heuristics
A very simple heuristic to implement as a baseline for this problem is to count the number of times that the words up and down are used. Whichever word is more frequent for a ticker, its value will be used for polarity. If the percentage of frequency between the two words is less than 10%, we will assume that the ticker sentiment was neutral.
Data layer definition
The most readily available raw data for this problem is social media. Twitter provides an easy-to-consume and search API where we can search by ticker and influencer handle.
Data sources
The source data will be acquired through the Twitter API to search for tickers given an updatable list of market influencers.
Model input/output
The system that will serve the model will receive a tweet and return the classified sentiment (positive, negative, or neutral):
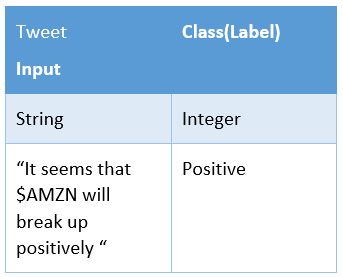
Figure 2.4 – Example of documenting the input/outputs of a model
In this section, we just defined the initial problems that we will tackle, end to end, throughout the book. We will be refining the definition of the problem frame and improving it when necessary and updating the problem frame as required.
In the next section, we'll look at using the definition of the heuristics during problem framing to create the first base pipeline that we will work on improving.
Developing your machine learning baseline pipeline
For our machine learning platform, we will start with a very simple, heuristic-based pipeline, in order to get the infrastructure of your end-to-end system working correctly and an environment where the machine learning models can iterate on it.
Important note
It is critical that the technical requirements are correctly installed in your local machine to follow along. The assumption on this section is that you have MLflow and Docker installed as per the Technical requirements section.
By the end of this section, you will be able to create our baseline pipeline. The baseline pipeline value is to enable rapid iteration to the model developers. So, basically, an end-to-end infrastructure with placeholders for training and model serving will be made available to the development team. Since it's all implemented in MLflow, it becomes easy to have specialization and focus of the different types of teams involved in a machine learning project. The engineering teams will focus on improving the pipeline while the data science-oriented teams will have a way to rapidly test and evaluate their models:
- Implement the heuristic model in MLflow.
In the following block of code, we create the RandomPredictor class, a bespoke predictor that descends from the mlflow.pyfunc.PythonModel class. The main predict method returns a random number between 0 and 1:
import mlflow
class RandomPredictor(mlflow.pyfunc.PythonModel):
def __init__(self):
pass
def predict(self, context, model_input):
return model_input.apply(lambda column: random.randint(0,1))
We use a specific functionality of creating a custom model in MLflow; more details about custom models can be found at https://mlflow.org/docs/latest/python_api/mlflow.pyfunc.html#pyfunc-create-custom.
- Save the model in MLflow.
The following block of code saves the model with the name random_model in a way that can be retrieved later on. It registers within the MLflow registry in the local filesystem:
model_path = "random_model"
baseline_model = RandomPredictor()
mlflow.pyfunc.save_model(path=model_path, python_model=random_model)
At this stage, we basically instantiate the model and store it on the model registry as configured by the local environment.
- Run your mlflow job:
mlflow run .
- Start the serving API:
mlflow models serve -m ./mlruns/0/b9ee36e80a934cef9cac3a0513db515c/artifacts/random_model/
- Test the API of your model.
You have access to a very simple Flask server that can run your model. You can test the execution by running a curl command in your server:
curl http://127.0.0.1:5000/invocations -H 'Content-Type: application/json' -d '{"data":[[1,1,1,1,0,1,1,1,0,1,1,1,0,0]]}' [1]%
At this stage, we have a baseline dummy model that the goal of the model developers team is now to improve upon. This same pipeline will be used in the next chapter to build a data science development environment with the initial algorithms of the platform being built in this book.
Summary
In this chapter, we introduced the machine learning problem framing approach, and explored some of the motivation behind adopting this framework.
We introduced the stock market prediction machine learning platform and our initial set of prediction problems using the ML problem framing methodology.
We briefly introduced in this chapter the use case of a stock market prediction basic pipeline that will be used in the rest of the book.
In the next chapter, we will focus on creating a data science development environment with MLflow using the definitions of the problem made in this chapter.
Further reading
In order to further your knowledge, you can consult the documentation at the following links:
- Reference information on the Google machine learning problem framing framework: https://developers.google.com/machine-learning/problem-framing
- Reference information on the Amazon machine learning framing framework: https://docs.aws.amazon.com/wellarchitected/latest/machine-learning-lens/ml-problem-framing.html