
Machine learning can expand our life, capabilities and capacities.
—Harkrishan Panesar
Machine learning is a rapidly evolving and exciting discipline within computer science, blending a range of skills including exploration and discovery, engineering, and analysis. Machine learning uses large amounts of factual, historical data to help us better understand behaviors.
While it can seem intimidating at first, a step-by-step approach to machine learning and its prerequisites can be used to conduct a successful project without the need to be an expert statistician or programmer. Although a knowledge of mathematics and programming is certainly advantageous, many machine learning algorithms are available out of the box and use preexisting libraries, and so there is seldom a requirement to develop novel algorithms from scratch.
The approach to a machine learning project is as unique as the problem it is trying to solve. However, the workflows involved in the lifecycle of a machine learning or data science project are detailed for use as a methodology.
Conducting a Machine Learning Project
An appreciation of the workflows involved in conducting a machine learning project highlights the skills that will be required within a project team and helps to communicate these with others.
The objective of a machine learning project is to develop algorithms that learn from the signals within the data they are trained upon.
- 1.
Framing: Specifying the problem at hand as a learning task (and identifying whether it is a machine learning problem before proceeding)
- 2.
Data preparation: Involving data exploration, analysis, insight, and cleaning
- 3.
Training model(s): Choosing learning methods, applying them to create a model, and attempting to optimize the models created
- 4.
Evaluation: An objective assessment of the method and results
- 5.
Dissemination: Reporting the results of evaluation to stakeholders and ensuring explainability
- 6.
Deployment: Releasing the trained machine learning model, monitoring ongoing usage and accuracy
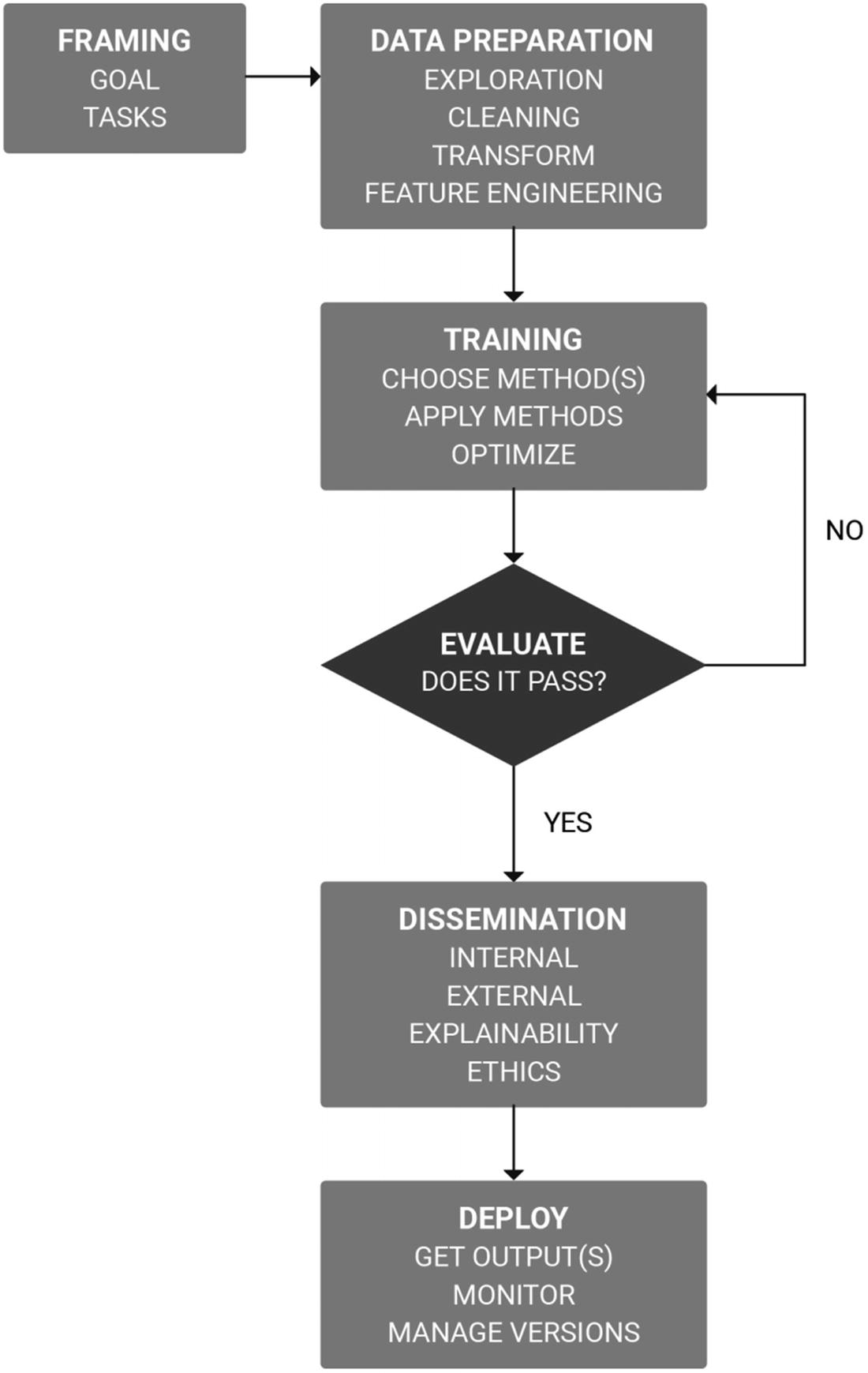
Workflows involved in performing a machine learning project
Framing: Specifying the Problem
Why is it important?
What do you hope to achieve? What are your best hopes?
What are the inputs and outputs for the task at hand?
Is this data available?
How will the results be beneficial?
Is this exploratory?
What are the KPIs (key performance indicators); how is performance measured?
What does success look like?
Do we have the talent on hand to attempt the task?
What are the limitations to the task at hand? This could include time, finance, skillsets, experience, domain knowledge, data availability, and so forth.
To solve the problem, data available to you will include examples and background information.
Collecting Examples
Categorization is a skill that can be learned through examples. It can be used for predictive tasks such as disease risk or resource demand prediction.
Certain problems present themselves in traditional healthcare settings, such as data from medical appointments and certain diagnoses having complementary handwritten notes. Bad examples can help to introduce error. For classification, examples are typically provided in the form of positives and negatives.
Background Information
This refers to the knowledge and axioms associated with a machine learning problem. This may include metadata, attributes, or relationships between concepts.
For example, in a hypertension prediction tool, the diagnosis of type 2 diabetes would be related to the likelihood of hypertension based on medical evidence and data. This is information that is utilized in the concepts learned to achieve categorizations.
Errors in the Data
Be mindful of the fact that errors from the real world can creep in, for example, from human error, incorrect classifications, missing data, incorrect background information, and repeated data.
Errors could creep in, for example, from the digitalization of paper documents and the machine reading of written text. It is important to remember the model is only as good as the data it is provided. It is worth spending time verifying the data to ensure that human errors are minimized.
Data Preparation
Machine learning algorithms learn from the data they are trained on. It is mission critical to provide the model with valid and robust data to learn.
Data must be prepared in a usable format. In a real-world scenario, this would involve understanding the data that would be used to model the problem and exporting the data. The data must then be processed to ensure correct formatting, removal of erroneous data, and the fixing of any missing data. The dataset size may be more than required, and so dataset sampling may also be required.
Every machine learning candidate will acquire skills in data preparation. Data preprocessing is essential to have tidy, valid data. Tidy, valid data is key to having robust, veracious outcomes. In order to develop a machine learning model that is highly domain applicable, technical experts who efficiently implement algorithms must work with domain experts who can understand data, classify it, and figure out trends and patterns.
Data preparation is by far the most vital aspect of machine learning.
How Much Data Do I Need?
Sadly, there is no definitive answer to this question—it depends. This is something that you explore through training your model and deploying it in the real world.
Several factors can affect the “learning curve.” These include the complexity of the problem and the complexity of the algorithm. This, in turn, affects the amount of data required. Whether the model can make outputs that have veracity in the real world will depend on the sophistication of the algorithm and quality of data provided.
Assess the availability and usefulness of more data. In a healthcare setting, randomized controlled trials on medications rarely assess more than 1,000 patients in any given setting. In a surgery setting, access to bigger data is likely but may not be required for training a model.
Nonlinear, nonparametric algorithms require more data to become better as to their accuracy. These are typically the more powerful machine learning methods. However, due to the validity of the data affecting both bias and variance, it’s key to train and validate the model robustly on as much data as efficiently possible.
Training the Machine Learning Model
The standard question any newcomer to machine learning has is “Which algorithm should I use?” The algorithm of choice depends on several factors including the size, quality, and nature of data; the task deadline; and available resources and motivation for using the data. The learning technique is also referred to as the “representation of the solution,” as each machine learning approach represents data differently. Algorithms themselves are available off the shelf and do not need coding from scratch.
Classification: Logistic regression, support vector machines, random forest, naive Bayes
Regression: Linear regression
Feature reduction: PCA, LDA
Clustering: k-Means, LDA
Collaborative filtering: Alternating least squares
It is almost impossible to predict which approach will best perform on the data. And even if the model does perform well during training and validation, that is no guarantee that it will perform well in the real world.
The “No Free Lunch” theorem in machine learning states that there is no one algorithm that works best for every problem. This is particularly relevant for supervised learning, as there are many factors that affect the performance of an algorithm.
What Programming Language Should I Use?
R is typically used for statistical analysis. It allows you to understand and explore data using statistical methods and graphs and contains an extensive range of machine learning algorithms.
Python is a language well suited to machine learning. Extensions such as numpy and SciPy are particularly useful for machine learning and data analysis.
Matlab is the language many university students begin with. It is useful for fast prototyping, as it contains a large machine learning repository.
SQL is a language used for managing data held in a traditional database management system (DBMS).
Should I Code My Machine Learning Algorithm from Scratch?
Several decisions need to be made from a resource and value perspective that affect the approach. A proof of concept project may be short of time, whereas a highly specific and complex task will contain a blend of approaches.
It is entirely possible to run a machine learning algorithm through implementing the ready-made algorithms provided by learning libraries such as scikit-learn, SciPy, pandas, Matplotlib, TensorFlow, Keras, and so forth.
This has been the traditional approach to machine learning: establishing a data science team that includes members experienced in languages such as Python and R. Members with experience in machine learning will typically be more impactful than those who are beginners to machine learning concepts.
Engineers develop an understanding of the appropriate machine learning techniques to employ given certain problems through experience. This experience can prove vital in avoiding wasted time, resources, and exploration.
Engineers with fundamentals in computer science will typically be familiar with many of the concepts present in machine learning. Choosing a programming language can influence the APIs and standard libraries you can use in your implementation. Enthusiasts may want to avoid using ready-made algorithms and code the implementations themselves to gain greater knowledge of the mathematics, statistics, and logic involved.
In many instances where time is constrained, time for engineering enthusiasm is limited. Cloud-based services such as Google AI, Microsoft Azure, IBM Watson, and a host of other providers allow the provider to take care of the algorithm; and many provide visual interfaces that enable the user to attempt particular machine learning techniques on the data uploaded.
Cloud-based vendors offering data mining and machine learning applications are growing and available at a low cost. One of the benefits of using such vendors is the ability to try more than one type of model for an experiment and compare the results, allowing you to find the best solution for your problem task.
For those with more traditional programming experience, almost all offer API or web service creation facilities, allowing you to create an interface to engage with the hosted model. All that is required to integrate with APIs is an efficient traditional programmer or web developer.
As the world adopts open source, consider browsing for implementations that already exist through GitHub, Reddit, and other machine learning forums.
API stands for application programming interface. APIs enable communication between software components and, in particular, can be used to interface between cloud-based machine learning providers and in-house development teams. There are many public APIs that can be used to assist in your machine learning tasks.
Embedding machine learning APIs should be approached with diligence and discretion. In an increasingly open source environment, as well as good documentation and functionality, ensure there are visible displays of popularity and robustness such as GitHub status, search engine popularity, and conversations.
Training and Test Data
A test set and training set are selected from the prepared data. The algorithm is trained on the training dataset and evaluated against the test dataset.
Signal: The true underlying pattern in a dataset
Noise: Random or irrelevant patterns in a dataset
Some machine learning techniques may return one solution, whereas others may produce several. It is often a case of gathering their outputs (also referred to as hypotheses, or learned models) and evaluating their outputs.
The assessment of hypotheses is conducted through evaluating the predictive accuracy, comprehensibility, or utility. In most cases, Occam’s razor is used, where the simplest solution is chosen if all else is equal. After the assessment is complete, a candidate hypothesis is chosen.
There are various ways to partition data into training and test datasets to train the machine learning model.
Predictive accuracy
Predictive accuracy refers to the accuracy at which the agent performs the task of classification.
Comprehensibility
Comprehensibility refers to how well we as humans can understand the output. In the real world, this could translate into many different settings.
Two Facebook bots recently began talking to each other in a language of their own which was incomprehensible to humans [93].
Utility
Utility refers to the problem-specific measure of worth. For example, in drug synthesis, a combination of compounds that are unsafe for human consumption may be the best combination. This would not have the greatest utility. Equally, this may override accuracy and comprehensibility.
Hold-Back Method
The hold-back method is a simple training method that can be employed that involves holding a proportion of the data to test on, leaving the remaining data for training, and validating the model.
Testing will typically give an indicator of the model’s effectiveness or accuracy.
n-Fold Cross-Validation
The n-fold cross-validation involves splitting the dataset into equally sized groups of instances (or folds). The model is then trained on all but one fold and tested on the final, left-out fold. This process is repeated, and each fold is left out for one iteration.
The number of folds can vary based on the size of the dataset. Common folds include three, five, seven, and ten folds. The aim is to balance between the size and representation of data in the training and test datasets. It enables the model to be tested n times on different datasets. This enables us to make the most out of the data, training n times on it.
Some machine learning texts may refer to cross-validation as the cross-validation stage of the machine learning process. This is because machine learning engineers often use this approach to reduce the likelihood of overfitting.
Monte Carlo Cross-Validation
Monte Carlo cross-validation is similar to n-fold cross-validation. It involves randomly splitting the dataset into training and test data. The model is tuned to the training data, and predictive accuracy is evaluated using the test data. Results are then averaged over the splits.
Which Algorithms Should I Use?
The algorithm to use is not often identifiable from the outset. Try a number of techniques that are relevant to your problem. This allows you to compare and choose the solution judged on accuracy, comprehensibility, and utility. Even the most experienced data engineer would be unable to tell which algorithm will perform the best before trying the various algorithms.
All machine learning software support multiple algorithms. Find the best algorithm for the job by trying as many as feasible.
Evaluation and Optimization of the Method and Results
The performance of machine learning tasks varies on the representation of data given. For example, a patient record analyzed by an AI system does not examine the patient directly. Instead, data is fed into a system, with each piece of information relating to the representation of the patient known as a feature. It is not necessary to require complete feature sets as part of representations to have highly confident outputs.
The goal of a machine learning algorithm is to generalize well, neither underfitting nor overfitting. Generalization refers to the model performing with maximum accuracy on instances not seen during training.
Evaluation methodologies for machine learning projects are discussed in greater detail in Chapter 7.
Algorithm Accuracy Evaluation
A false positive is received if the output from a binary classification agent that is given new data should have been categorized as negative but was classified as positive.
A false negative is when an agent categorizes new data as negative but is incorrect.
In many medical settings, a false positive is not as bad as having a false negative. For example, false positives in this instance could include the diagnosis of illness for a patient based on a set of particular symptoms. It is evidently better to be told that you have a condition and not have it in reality, rather than being told you do not have a condition, only to be told that in fact you do. A false negative would mean that someone was not diagnosed, which is perhaps more concerning.
A simple way of measuring predictive accuracy of a particular hypothesis over a test dataset is to calculate the number of correctly identified outcomes (both positive and negative).
(133 + 98)/250 = 92.4%
This would be a 92 out of 100 chance of correctly categorizing an unseen example.
Generalization is measured by accuracy. Both under- and overfitting cause poor model performance and are detrimental to accuracy. If a model was classifying with 92% accuracy in testing but only 30% on unseen data, we would say that the model doesn’t generalize well from training to unseen data.
This is overfitting. Overfitting is when a model fits the training data too well. It memorizes answers rather than learning concepts from them. In this case, the model cannot distinguish signal from noise and learns the noise present in the data. As such, the model does not understand the actual patterns, or signals, in the data. The model does not apply to new data which is detrimental to the model’s ability to generalize, and the model is not useful. Decision trees are examples of algorithms that can overfit training data. This can be improved through pruning. In many cases, it’s a case of keeping things surprisingly simple.
If a model performs better on training datasets than on unseen test sets, then the model is likely to be overfitting. Cross-validation is a technique to employ to measure against overfitting. Further still, training with more data may help algorithms infer hypotheses better.
The concept of “more data gives better results” is misguiding. In many cases, more data may help. However, more data does not imply good data. If data with noise were to be added, it wouldn’t help reduce overfitting. Hence, this is why it’s paramount to ensure data is clean and appropriate.
Data leakage occurs when data you are using to train your machine learning model has the information you are trying to predict in it. This leads to poor generalization and contributes to overfitting. Data leakage can occur from test data leaking into training data or additional features. A trivial example of data leakage would be a model that uses the response variable itself as a predictor, thus concluding, for example, that “a patient with conjunctivitis has conjunctivitis.”
If the performance of your machine learning algorithm is too good to be true, data leakage may be the reason it is. An n-fold cross-validation can help to reduce data leakage.
Underfitting is simple to detect, as it will have poor performance. It refers to a model that cannot model the training data or generalize to new data. Typically, this would be represented by simple models that have too few features. Results would tend to show bias over variance (i.e., wrong outcomes).
Bias and Variance
Supervised machine learning aims to understand the signal from the dataset while ignoring the noise.
There is a machine learning dilemma of minimizing the two sources of prediction error that prevent supervised learning algorithms from generalizing beyond their training set. There is a trade-off between a model’s ability to minimize bias and variance (also known as the bias–variance trade-off).
Bias
Low bias: Better understanding of true signal from a dataset
High bias: Worse understanding of true signal from a dataset
High bias can often indicate that a better machine learning technique is available.
Variance
Low-variance algorithms output similar models based on the dataset.
High-variance algorithms output sufficiently different models based on the dataset.
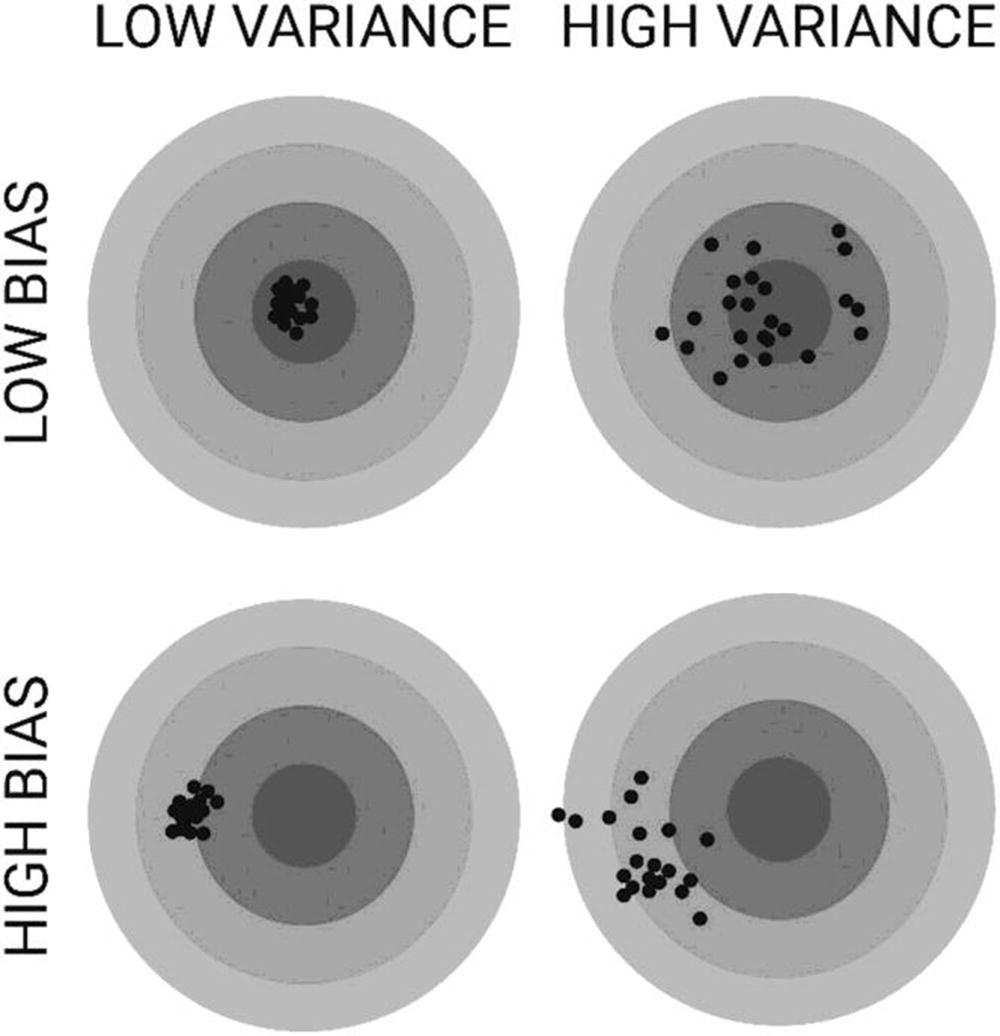
Bias and variance illustrated
As you move further away from the bull’s-eye, the predictions become worse. If each new model was represented by a new dart, each throw would represent a realization of the model given the variability in the training data. With a good distribution of data for training, models can predict well.
Data with anomalies and redundancies will result in poor predictions. This can be visualized on a dartboard.
The trade-off engineers must make with machine learning algorithms is that an algorithm with low bias must be flexible to enable it to fit the data well. However, if there is too much flexibility, each dataset will be interpreted differently and have high variance. There are several ways to reduce algorithm complexity, which are discussed in Chapter 4.
Many supervised learning toolkits provide methods to control the bias–variance trade-off either automatically or by providing a parameter that can be adjusted.
Low-variance algorithms tend to have reduced complexity when compared to low-bias algorithms. Low-variance algorithms have a simple or rigid structure that results in models that are consistent but inaccurate on average. This includes algorithms like regression, naïve Bayes, and so forth.
Low-bias algorithms tend to be more complex with a more flexible structure. As a result, they are accurate on average; however, they can be inconsistent. This includes nonparametric algorithms such as decision trees and k-nearest neighbor.
Total error = Bias^2 + Variance + Irreducible error

Finding optimal algorithm balance
The irreducible error refers to error regardless of the model or dataset that is used. This is the noise that comes from the training data. It is a constant, as real-world data always has some degree of noise.
Performance Measures
Examples of methods for evaluating algorithms include accuracy, prediction and recall, squared error, likelihood, posterior probability, cost, and entropy K–L divergence.
Optimization
Just because a model performs well doesn’t mean it is the best and only model. The key is to get the maximum veracity from your results. Techniques such as cross-validation are useful to determine confidence in model results. However, we can optimize machine learning algorithms further.
Besides, we may want to improve the performance regarding time to output.
Algorithms can be optimized through the following.
Algorithm Tuning
Tuning can be understood as the process of optimizing the parameters that impact the model to enable the algorithm to perform the “best,” based on what “best” is specified as.
Training and Validation Data
Approaching a machine learning problem with an n-fold cross-validation technique allows you to validate your results, whereas a hold-back methodology has a waterfall approach to learning.
Evaluating a Range of Methods
Trialing a variety of machine learning methods is useful to determine which can achieve the most accurate results.
Improving Results with Better Data
There are some ways to improve performance with data, including the following.
Getting More Data
If you can get more data, this may help the model to improve its performance.
Getting Better-Quality Data
Rather than more data, it’s often better, where possible, to get better-quality data. Typically, this would improve the signal within the data and reduce the noise. You can also enhance the quality of data through cleaning the data.
Resample Data
Partitioning the sample data into different sizes or distributions may represent the concept better or help improve performance by reducing attributes (features).
Data Representation
Data can be represented in different ways through the varying machine learning methods. Changing the type of machine learning method applied and reevaluating the problem may optimize your model.
Feature Selection
Addressing features that are and are not important can present new inferences for your model to learn. Increasing the number of features may not always be beneficial. However, in unsupervised learning instances, it may be beneficial to include all features to ensure nothing goes unexplored.
Feature Engineering
The key to success is the representation of data. Feature engineering involves exposing the data in other ways through decomposition and aggregation.
One of the most famous quotes behind the power of data is that of Google’s research director and machine learning pioneer Peter Norvig, claiming “We don’t have better algorithms. We just have more data.”
Should I Choose a Supervised or Unsupervised Algorithm?
When developing models, it’s rarely a case of supervised or unsupervised learning. In fact, they can often be used together. Unsupervised learning is a useful technique for dimensionality reduction and feature engineering, which can be used in supervised learning problems.
Ensembles
Ensembles are created when several classifiers specialize in various aspects of the problem. Ensembles turn a model into a feature. There are three types of ensemble algorithms known as bagging, boosting, and stacking, covered in Chapter 4.
Ensembles are for advanced practitioners of machine learning.
Problem Distribution
Another optimization method is distributing the processing used for a machine learning task. Tools from Microsoft, such as Azure, and from Google, such as AI.io, are examples of warehouses that can distribute problems at scale. In reality, most problems can be contained on a multicore implementation.
Implementation Problems
The user interface or UI is the key component in a machine learning application that has human interaction. This is not only where results will be displayed but where the most intelligence can be gathered. Rethinking the user interface and user experience is worth considering when engaging with people.
Disseminating the Results
In many settings, this is the most crucial aspect to ensure internal stakeholders support machine learning projects. Whether the machine learning project was successful or not is immaterial; if people do not understand the reasons behind events, support to adopt innovative technologies can be lost. Typically, a PowerPoint presentation and white paper will be good enough to present within an organization.
There are many ways to report the results, and to varying degrees of evaluation. An internal white paper, for instance, may have been reviewed internally by organization stakeholders, whereas the publishing of an article evaluating the innovation within a peer-reviewed journal may be more favorable. As healthcare rapidly embraces big data and machine learning, robust evidence to demonstrate the benefits and impact of AI is essential to ensure that only evidence-based, clinically proven frameworks and technologies are used and built upon.
Just like you would not want to take a counterfeit medication, you would not want to engage with technology that affects your health which is without evaluation or publicly available, scrutinizable data.
Why: Define the context of the problem and the motivation behind solving the problem.
Problem: Describe the issue as a question.
Solution: Explain the answer to the questions proposed.
Findings: Describe the discoveries made in the data and inferences made by the models.
Conclusions: Evaluate what was learned from the project, addressing the limitations, ethical concerns, privacy, and data sensitives (particularly with data regulations such as CCPA and GDPR).
Monitoring: If the plan is to deploy the model, how are predictions monitored and evaluated through usage?
Once you’ve reported your findings, it’s up to your stakeholders to determine the value of the project before deployment, if even deployed at all.
Topics for discussion include how to handle the reporting of false negatives and false positives and the accuracy of predictive claims. The implications of predictions are a crucial consideration. Some concerns may be first-time problems. For instance, what are the legalities of using the data involved? When is a machine learning model truly predictive, or is it merely coincidence? What are the implications of being able to diagnose someone’s cancer risk precisely?
Novel sources of information such as wearable devices, trackers, and EHRs place machine learning in the space of innovation and ethical wonderment. The implications for broader healthcare and insurance are massive and should be taken into consideration with machine learning research projects.
Understanding the task at hand
Calibration has relevance in clinical practice and refers to the relationship between the predictions made by the model and the observed outcomes.
As an example, if the prediction model “predicts 70% risk of mortality in the next one year for a patient with lung cancer, then the model is well calibrated if in our dataset, approximately 70% of patients with lung cancer die within the next one year.”
Do I Need to Disseminate Project Results Before Deploying?
Ultimately, deploying a machine learning model before disseminating the results of the project to wider stakeholders is an organizational decision. There are a number of inherent risks with this approach, including lack of governance and understanding by others within a team or organization. Resources will be required to manage and monitor deployments, and these are best anticipated for rather than reacted against.
Several forms of independent evaluation should take place before deploying a public project. As well as prediction evaluation, cyber-security must be addressed, with penetration testing and cyber-incident response assessments. Machine learning models can cause unintended consequences—and these can shake a team who is neither aware of nor involved in the ramifications.
Deployment
Deploying a machine learning model is the process of moving the model from a testing or staging environment to a production environment. The model can then be accessed by others and provide output to other agents whether human or computer.
Machine learning models only provide value if they are made available, making deployment the final, crucial phase of the machine learning project lifecycle.
Deployment will also contain a mechanism of recording all observations and predictions and a process whereby this growing log is monitored and periodically assessed to ensure relevance and lack of harm. Most deployed projects will be hosted in cloud-based servers making auditing a relatively simple exercise. An added benefit is found in that cloud-based servers support scalability.
A process to monitor and manage the deployed model’s usage and triage concerning data should be implemented.
Conclusion
Machine learning starts with asking the right question. More often than not, question framing this is the most difficult part of the process. And by far, the most resource-intensive part is data preparation.
Framing the right question provides a clearly defined objective function which enables stakeholders to identify the data that is required, approaches to solving the problem, potential impact, and resources required. The first question proposed may not be the right question, but iteratively revising the question enables progress toward a clearer, more defined goal. Without the right question being posted, data science teams can lose endless hours collecting data and training models that are no good for their intended purpose.
Be prepared for the possibility that the hypothesis or question you pose may not be answerable by the signal within your data—and explore the consequences of this possibility.
As organizations leverage machine learning, not fully understanding the true cause of perceived failures could diminish the perceived value of AI and lead to less support in the future.
Look for simplicity. Wherever possible, it is better to keep it simple than over-engineer and build complex and expensive machine learning models which are difficult to explain and disseminate.