
Any fool can know. The point is to understand.
—Albert Einstein
The first Checkers program from machine learning pioneer Arthur Samuel debuted in 1956, demonstrating artificial “intelligence” capabilities [68].
Since then, not only has the application of AI grown; there is now a velocity, volume, and variety of data that has never been seen before. Samuel’s software ran on the IBM 701, a computer the size of a double bed. Data was typically discrete.

Components of AI
We see and engage with “artificial” intelligence, whether developed by machine learning or otherwise, in our everyday lives: in ordering an Uber, ordering food on a digital menu, looking for an Airbnb, searching on eBay, asking Alexa a question, scrolling through Facebook, and engaging in digital therapeutics.
A case study on the use of AI-powered digital therapeutics is detailed further in Chapter 10.
Pondering on the AI humans are able to develop is limited only by the human imagination. New and innovative devices are increasingly connected to the cloud and increasing the wealth of opportunities in healthcare.
With a wealth of data at its helm as an industry, AI is shifting its focus onto the power of machine learning and deep learning, where machines can learn for themselves—and this is accelerating current generation breakthroughs in the AI space.
If Samuel’s Checkers program demonstrated simple AI, machine learning is best demonstrated through AlphaGo Zero, which learned to play checkers simply by playing games against itself, surpassed human level of play, and defeated the previous version of AlphaGo by 100 games to 0 [69].
Machine learning systems are not uncommon in healthcare. Researchers at Houston Methodist Research Institute in Texas have developed an agent that is enabling review and translation of mammograms 30 times faster than a human doctor and with 99% accuracy [70].
According to the American Cancer Society, 50% of the 12.1 million mammograms performed annually yield false results, meaning that healthy women get told they have cancer [70]. The software, which can be understood as an autonomous entity, learned from millions of mammogram records, reducing the risk of false positives.
There are many books and resources on the field of AI and machine learning. Although a comprehensive and mathematically grounded discipline, this book aims to cover the topic for the discerned reader, without delving too deep into the semantics of linear algebra, probability, and statistics.
This chapter will cover many of the topics within machine learning, beginning with an introduction to the basics of AI and terminologies and then moving on to the various forms of learning and data mining.
Algorithms are covered in the next chapter.
Basics
Before delving into the depths of AI and machine learning, it is useful to understand several key definitions. A brief guide to useful terminology is included in the following, with a more in-depth glossary at the end of this book.
Agent
An agent is anything that can be seen as perceiving its environment through sensors and acting on them through effectors. This takes Russell and Norvig’s approach to agents. As a result, this includes robots, humans, and software programs.
There are many different types of agents, which can be classified into categories based on their characteristics. Artificial Intelligence: A Modern Approach (AIMA) is a comprehensive textbook on artificial intelligence written by AI experts Stuart J. Russell and Peter Norvig [71].
How should the agent behave? Rational agents are agents that do the right thing. This can be represented by a mathematical measure, or evaluation of the agent’s performance, which the agent can seek to maximize.
An agent can be understood as a mapping between percept sequences and actions. For example, a medical diagnosis system may treat a patient in a hospital as its environment: perceiving symptoms, findings, and patient’s answers. It may then act on these through questions, tests, and treatments with the goal of having a healthy patient.
The definition of an agent applies to a software program or algorithm.
Autonomy
In AI, autonomy refers to the extent to which the agent’s behaviors are determined by its own experience.
If there is no autonomy, all decisions are made from a static dataset or knowledge base. In a completely autonomous situation, an agent would make decisions at random. Agents have the explicit ability to become more autonomous over time.
Software, just like humans, can learn from experiences over time. Systems can learn from experiences in their environment (at its most basic, “learning” from some new data) to become more autonomous in it.
Interface
An interface agent is one that provides an interface to a complex system.
Performance
Performance is the measure used to evaluate the behavior of the agent in the environment. It answers the question, “Does the agent do what it’s supposed to do in the environment?”
Goals
Goals refer to what the agent is trying to achieve. In the field of machine learning, the goal is not to be able to get the agent to “learn.” Instead, this refers to the overall goal or objective.
Goals can be broken down into smaller tasks. For example, to accomplish the goal of a Caesarean section, the tasks could be considered cutting open the abdomen, bringing the baby out, checking the baby is healthy, and stitching the abdomen back up again.
Utility
Utility refers to the agent’s own, internal performance assessment—that is, the agent’s own measure of performance at any given state. This may differ from the performance of the agent. It is noteworthy that the utility function is not necessarily the same as the performance measure, although it can be.
An agent may have no explicit utility function, whereas there is always some performance measure. A utility function is used to map a state to a real number, which describes the associated degree of happiness or progress toward a goal or objective.
This allows rational decisions in cases where there are several paths to the same goal, allowing an agent to distinguish the paths better than others.
Knowledge
Knowledge is acquired by an agent through its sensors or knowledge about the environment.
Knowledge can be used to decide how to act; if it is stored, it can be used to store previous knowledge states (or, in other words, a history); and it can be used to determine how actions may affect the environment.
Machine learning is data driven. Thus, the dawn of ubiquitous data and pervasive computing is fantastic for developing systems with real-world application.
Environment
The environment is the state of the world for an agent. An environment has several characteristics, following Russell and Norvig’s lead.
Accessibility
This refers to how much of the environment the agent has access to. In cases of missing information, agents may need to make informed guesses to act rationally.
Determinism
Environments can be deterministic or nondeterministic. Deterministic environments are environments where the exact state of the world can be understood. In this instance, utility functions can understand their performance. In nondeterministic environments, the exact state of the world cannot be determined, which makes utility functions rely on making best-guess decisions .
Episodes
Episodic environments are those where the agent's current action choice does not rely on its past actions. Non-episodic environments require agents to plan for the effects of their current actions.
Type of Environment
Static environments are where the environment doesn’t change while an agent is making a decision. Dynamic environments can change during processing, so agents may need to feed back into the environment or anticipate changes between the time of input and output.
Flow of Data to Environment
One critical aspect of agent design is how the data is received. In a chess game, for example, there are only a finite number of moves that the agent can select. This would be a discrete environment, as there are only so many moves that can be performed. On the other hand, on the operating table, for example, things can change at the last millisecond. Continuous data environments are environments in which data seems infinite or without end.
An intelligent agent is fundamentally one that can display characteristics such as learning, independence, adaptability, inference, and to a degree, ingenuity.
For this to occur, an agent must be able to determine sequences of actions autonomously through searching, planning, and adapting to changes in its environment and from feedback through its past experiences. Within machine learning, there are further terminologies.
Training Data
Training data is the data that will be used by the learning algorithm to learn possible hypotheses. An example is a sample of x including its output from the target function.
Target Function
This is the mapping function f from x to f(x).
Hypothesis
This is an approximation of f. Within data science, a machine learning model approximates a target function for mapping input x to outputs (y).
Learner
The learner is the learning algorithm or process that creates the classifier.
Validation
Validation includes methods used within machine learning development that provide a method of evaluation of model performance.
Dataset
A dataset is a collection of examples.
Feature
A feature is a data attribute and its value. As an example, skin color is brown is a feature where skin color is the attribute and brown is the value.
Feature Selection
This is the process of choosing the features required to explain the outputs of a statistical model while excluding irrelevant features.
What Is Machine Learning?
Machine learning is a subset of AI where computer models are trained to learn from their actions and environment over time with the intention of performing better.
In 1959, Checkers’ creator Arthur Samuel defined machine learning as a “field of study that gives computers the ability to learn without being explicitly programmed” [72].
Machine learning was born from pattern recognition and the theory that computers can learn without being programmed to perform specific tasks—that is, systems that learn without being explicitly programmed. As a result, learning is driven by data—with intelligence acquired through the ability to make effective decisions based on the nature of the learning signal or feedback. The utility of these decisions is evaluated against the goal.
Machine learning focuses on the development of algorithms that adapt to the presentation of new data and discovery. Machine learning exemplifies principles of data mining but is also able to infer correlations and learn from them to apply to new algorithms. The goal is to mimic the ability to learn in a human, through experience, and achieving the assigned task without, or with minimal, external (human) assistance.
Just as with learning in humans, machine learning is composed of many approaches. At its most basic, first, things are memorized. Second, we learn from extracting information (through reading, listening, learning new things). And third, we learn from example.
For example, if we were being taught square numbers and if students were shown a set of numbers Y = {1, 4, 9, 16, …} and taught that Y = n*n, they would typically understand the notion of square numbers without being explicitly taught every square number.
How Is Machine Learning Different from Traditional Software Engineering?
Traditional software engineering and machine learning share a common objective of solving a problem or set of problems. The approach to problem-solving is what distinguishes the two paradigms.
Traditional software engineering or programming refers to the task of computerizing or automating a task such that a function or program, given an input, provides an output. In other words, writing a function f, such that given input x, output y = f(x).
This is done with logic, typically if–else statements, while loops, and Boolean operators.
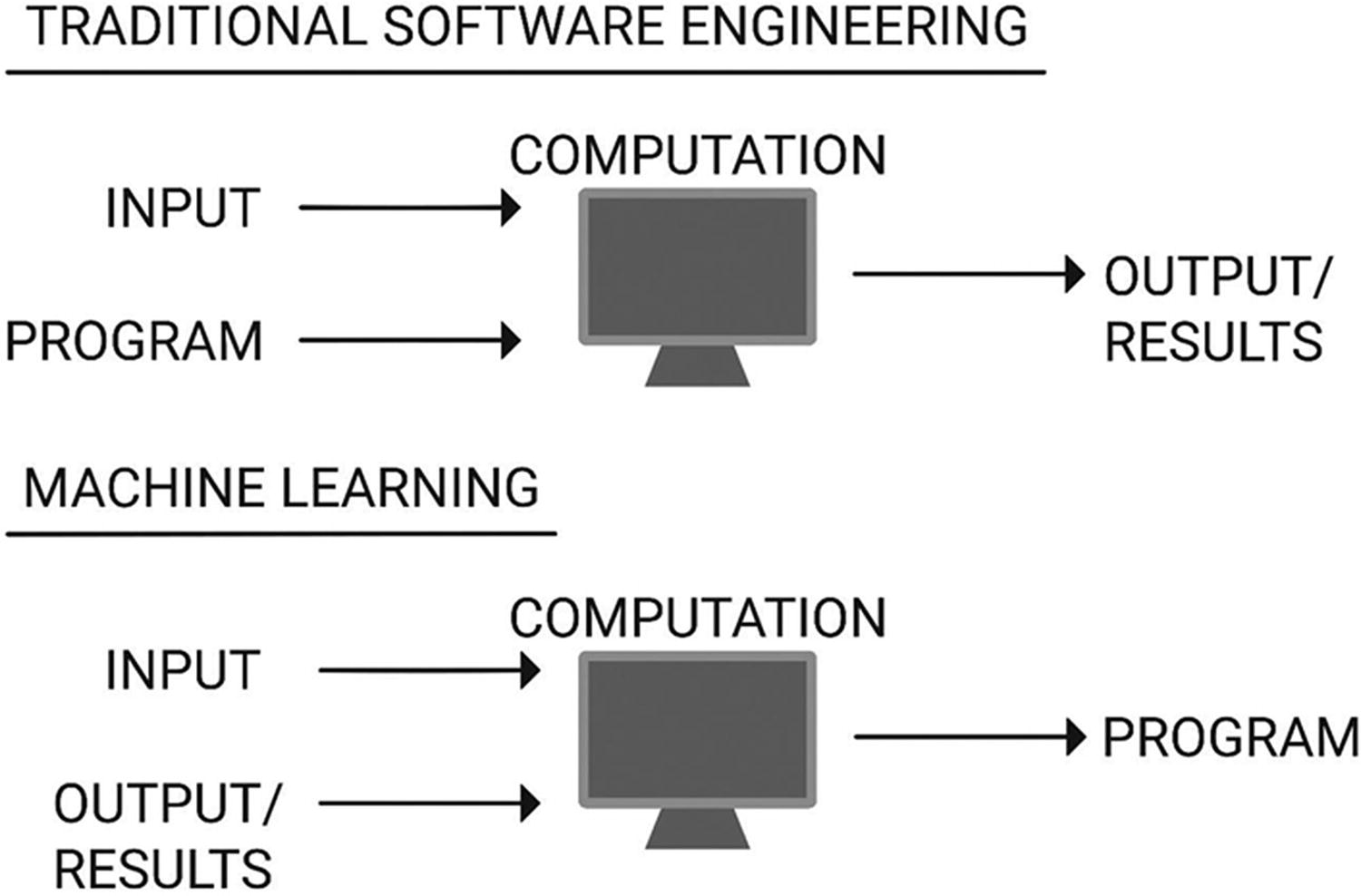
How machine learning works
Whereas traditional programs have been written by humans to solve a problem, machine learning programs learn through reasoning to solve a problem from examples, rules, and information. Many classifiers in machine learning assist with prediction.
Machine learning programs can also learn to generalize and help with issues of uncertainty due to the use of statistics and probability-driven techniques. Models can learn from previous computations or experience to produce reliable, repeatable decisions and results.
The availability of data, information on the Internet, and leaps in the amount of digital data being produced, stored, and made accessible for analysis are enabling engineers to realize machines that can learn what we prefer and personalize to our requirements.
Machine learning can be seen everywhere if you look hard enough—in web search rankings, drug design, personalization of preferences and social network feeds, music recommendations, logistics, web page design, self-driving cars, fridges, washing machines, TVs, and virtual assistants.
Machine Learning Basics
Supervised learning (also known as inductive learning)
Unsupervised learning
Semi-supervised learning
Reinforcement learning
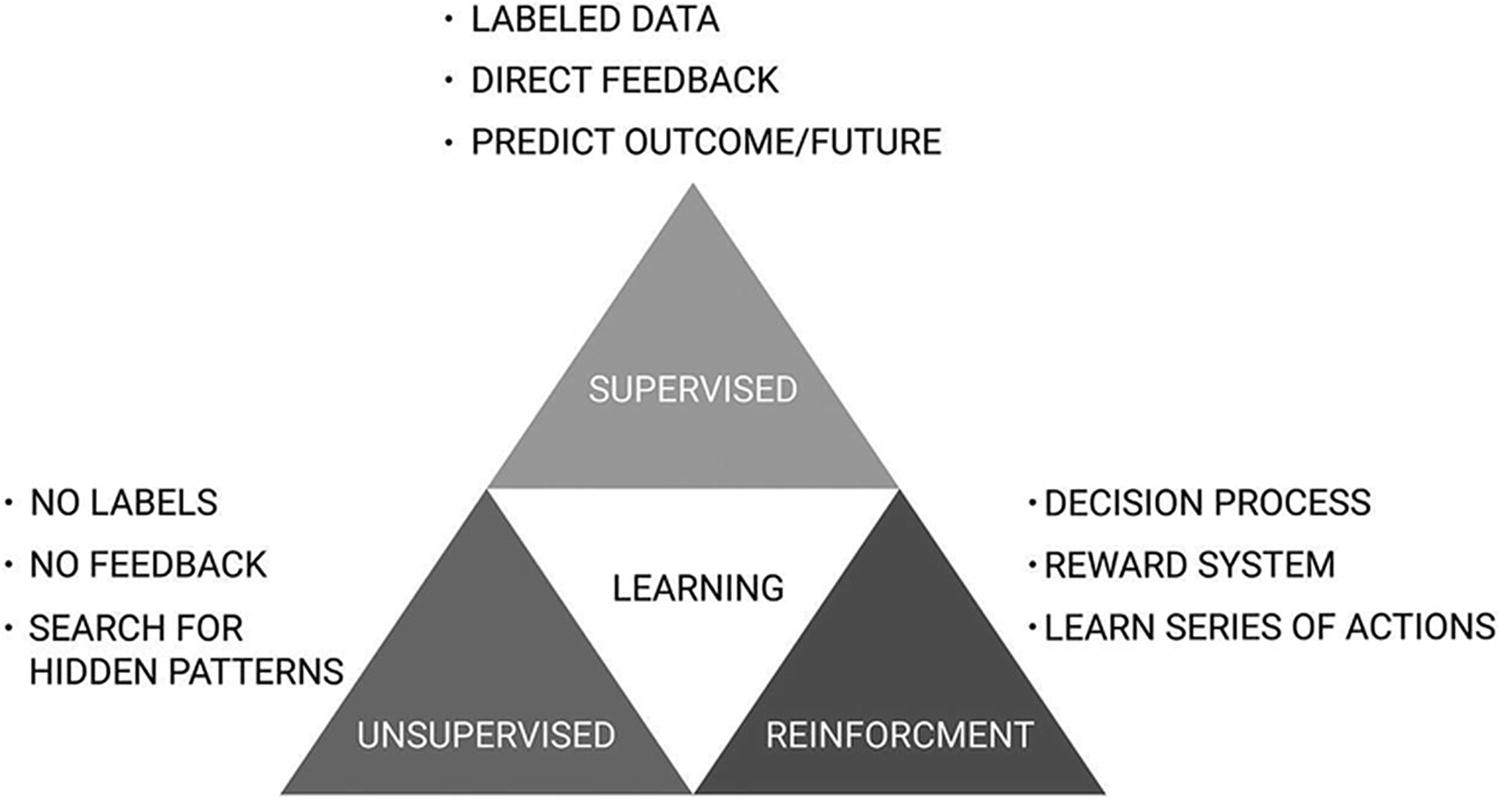
Methods of learning
Supervised Learning
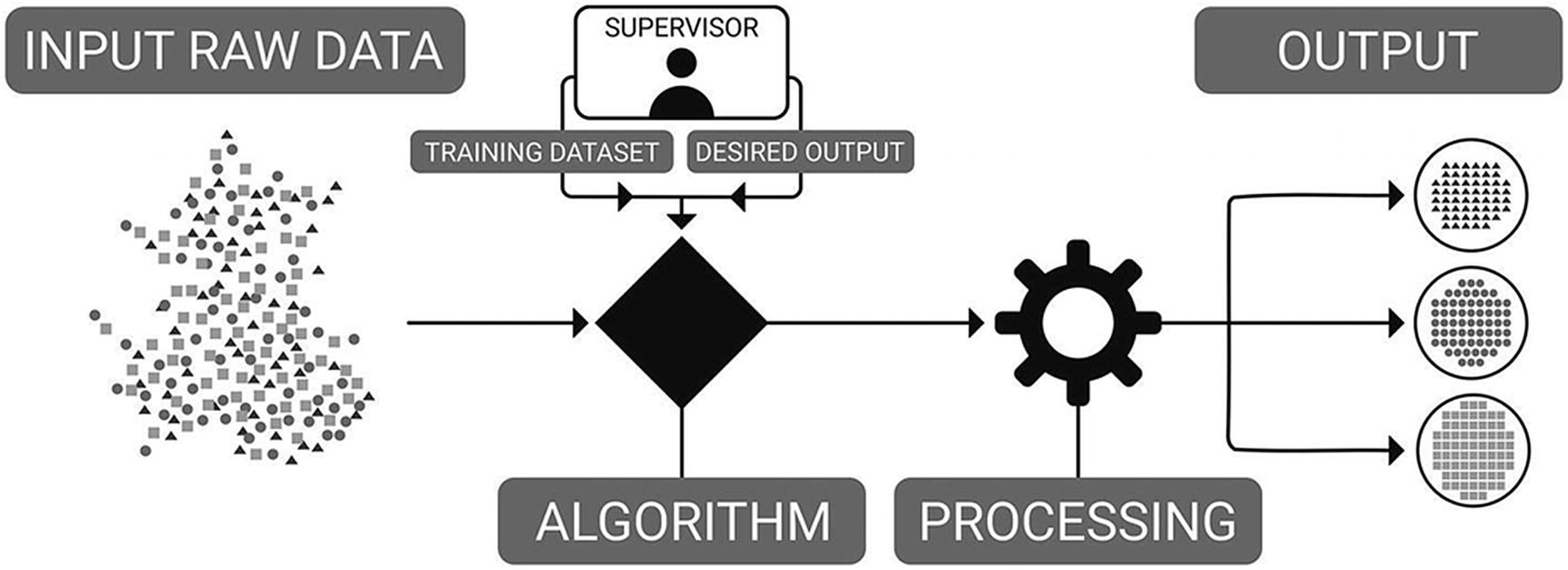
Supervised learning: how it works
The training data guides the development of the algorithm. A model is created through a training process in which the model makes predictions and is corrected when predictions are incorrect.
Training continues until the model achieves the desired level of accuracy on the training data. Supervised algorithms include logistic regression. Supervised machine learning algorithms can apply what has been learned in the past to new data using labeled data examples to predict future events.
The learning algorithm can also compare the output with the correct output to find any errors and modify the model accordingly.
Supervised learning problems can be employed in the following forms.
Classification
This is to predict the outcome based on a training dataset where the output variable is in the form of distinct categories. Models are built through inputting training data in the form of prelabeled data.
Support vector machines
Naïve Bayes
Gaussian Bayes
k-Nearest neighbors (kNNs)
Logistic regression
An example of classification is the label (or, in real-world application, diagnosis) of someone as sick or unhealthy based on a set of symptoms.
Regression
Regression is very similar to classification. The only difference between classification and regression is that regression is the outcome of a given sample where the output variable is in the form of real values (i.e., the temperature as a value, rather than a classification of hot or cold).
Examples include height, body temperature, and weight. Linear regression, polynomial regression, support vector machine (SVM), ensembles, decision trees, and neural networks are examples of regression models.
Forecasting
This is the method of making predictions based on past and present data. This is also known as time series forecasting. An ensemble is a type of supervised learning that combines multiple, different, machine learning models to predict an outcome on a new sample. In an ensemble, models become features.
Unsupervised Learning
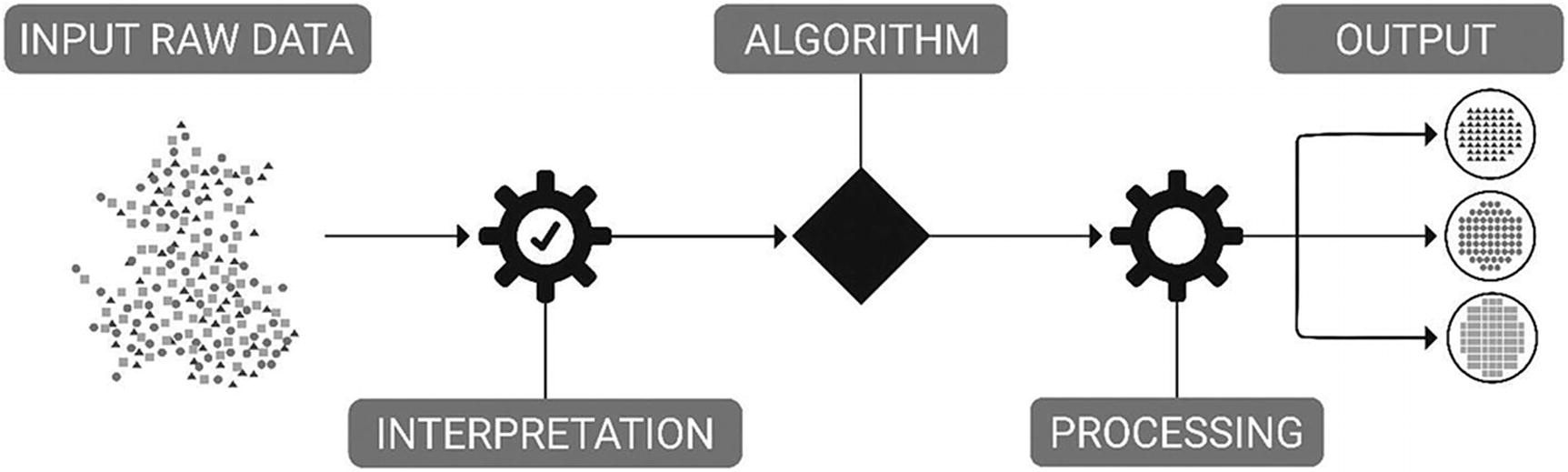
Unsupervised learning: how it works
As data is unlabeled, there is no evaluation of the accuracy of the structure that is output by the algorithm.
Data may be missing both classifications and labels. Thus, the model is developed through interpretation: through finding hidden structures and inferences in the input data. This may be through the extraction of rules, reducing data redundancy, or as the result of organizing data.
This includes clustering, dimensionality reduction, and association rule learning. The algorithm may never find the right output but instead models the underlying structure of the data.
There are three types of unsupervised learning problems as defined in the following.
Association
Association is the discovery of the probability of the co-occurrence of items in a collection. This is used extensively in marketing as well as healthcare to inform decisions.
For instance, this would be the percentage likelihood of developing any form of cancer if diagnosed with obesity. Association is similar to classification; however, any attribute can be predicted in association, whereas classification is binary.
Clustering
Clustering refers to grouping items such that items within the same cluster are more like each other than to items from another cluster.
Dimensionality Reduction
Dimensionality reduction can be achieved through feature selection and feature extraction. Dimensionality reduction may mathematically re-represent or transform data.
Feature Extraction
Feature extraction performs data transformation from a high-dimensional to a low-dimensional space. This can involve reducing the variables of a dataset while maintaining data integrity and ensuring that the most important information is represented.
Feature extraction methods can be used for dimensionality reduction. Typically, a new set of features would be created from the original feature set. An example would be combining all of a patient’s clinical test results into a health risk scoring from the results that are demonstrated to affect mortality.
Apriori algorithm
FP growth (also known as frequent pattern growth)
Hidden Markov Model
Principal component analysis (PCA)
Singular value decomposition (SVD)
k-Means
Neural networks
Deep learning
Deep learning utilizes deep neural network architectures, which are types of machine learning algorithms.
Semi-supervised
Semi-supervised learning is a hybrid where there is a mixture of labeled and unlabeled data in the input. Although there may be a desired outcome, the model also learns structures to organize data and make predictions. Example problems are classification and regression.
Reinforcement Learning
This is where systems interact with a dynamic environment in which an agent must perform a specific goal. Reinforcement learning acts as an intersection between machine learning, behavioral psychology, ethics, and information theory.
The algorithm is provided feedback concerning rewards and punishments as it navigates the problem. Reinforcement learning allows the agent to decide the next best action based on its current state and by learning behaviors that will maximize the reward. Optimal actions (or an optimal policy) are typically learned through trial and error and feedback. This allows the algorithm to determine ideal behaviors within context.
Reinforcement learning is typically used in robotics, for instance, a robotic hoover that learns to avoid collisions by receiving negative feedback through bumping into tables, chairs, and so forth—although today, this also involves computer vision techniques.
Reinforcement learning differs from standard supervised learning in that correct examples are never presented nor are suboptimal decisions explicitly corrected. The focus is on performance in the real world.

Reinforcement learning: how it works
DeepMind, for example, exposed their AlphaGo agent to master the ancient Chinese game of Go through showing “AlphaGo a large number of strong amateur games to help it develop its own understanding of what reasonable human play looks like. Then we had it play against different versions of itself thousands of times, each time learning from its mistakes and incrementally improving until it became immensely strong” [73].
Reinforcement learning is used in autonomous vehicles. In the real world, the agent requires consideration of aspects of the environment including current speed, road obstacles, surrounding traffic, road information, and operator controls.
An agent learns to act in a way (or develop a policy) that is appropriate for the specific state of the environment. This leads to new ethical dilemmas posed by AI and machine learning for agents with reward-driven programming.
Data Mining
Pattern predictions based on trends and behaviors
Prediction based on probable outcomes
Analysis of large datasets (particularly unstructured)
Clustering through identification of facts previously unknown
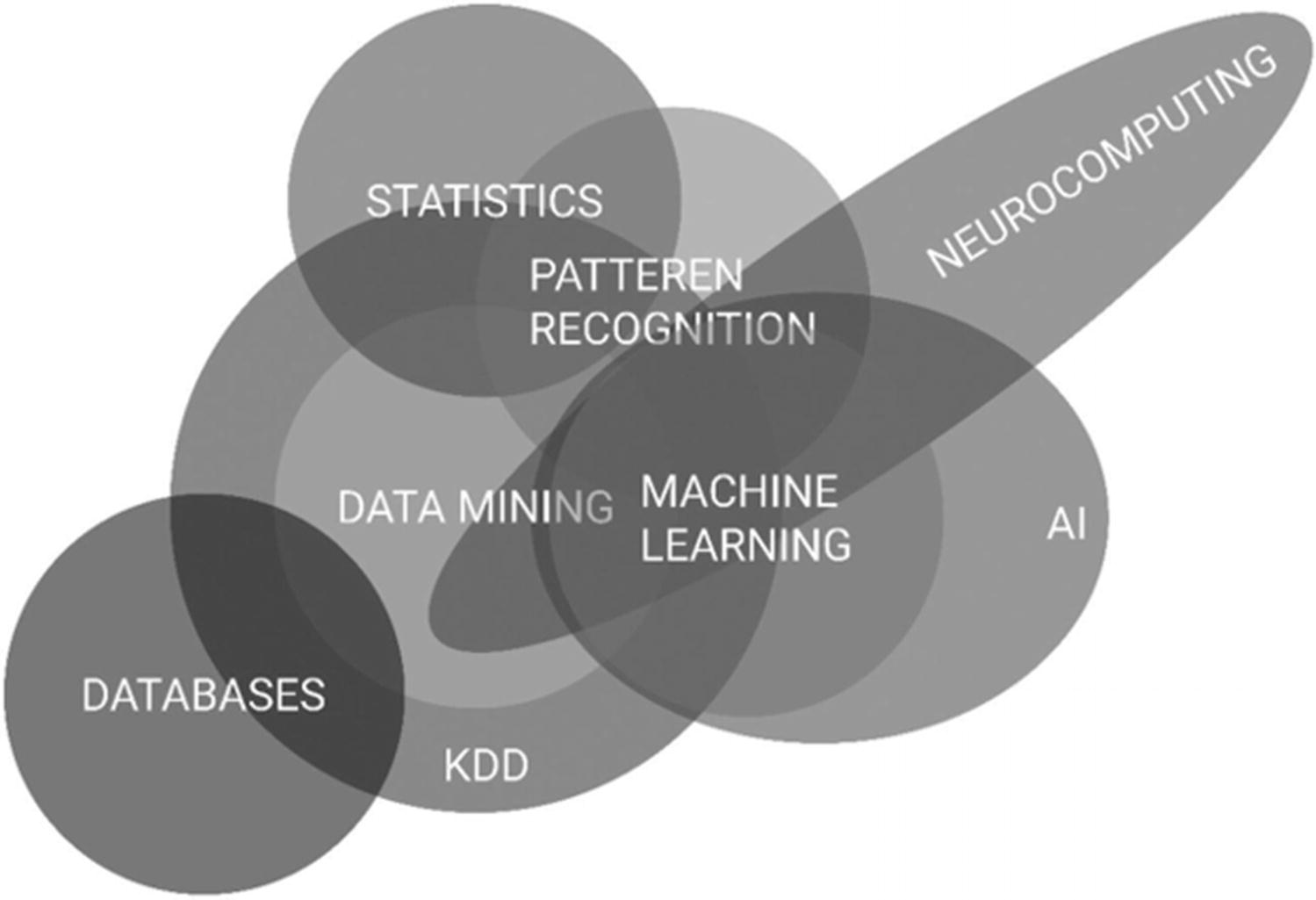
Data mining and its wider synergies
Data mining is most often seen in day-to-day sentiment analysis of user, customer, or patient feedback.
Data mining also allows forecasting, through identifying relationships within the data. This can help insurance companies detect risky customer behavior patterns.
Machine learning can be used for data mining. Data mining will inform decisions such as the kind of learning models best suited for solving the problem at hand. However, data mining also encompasses techniques besides those encapsulated within machine learning. In data mining, the task is of unknown knowledge discovery, whereas machine learning performance is evaluated with respect to reproducing known knowledge.
For instance, if you have a dataset of a patient’s blood pressures, you can perform anomaly detection, which is considered a data mining task to identify previously unknown outliers. The task may make use of machine learning techniques, perhaps a k-means algorithm for cluster analysis, to identify the anomalous data and assist the algorithm’s learning.
C4.5
k-Means
Support vector machines
Apriori
EM (expectation–maximization)
PageRank
AdaBoost
kNN
Naive Bayes
CART (Classification and Regression Trees)
Parametric and Nonparametric Algorithms
Algorithms may be parametric or nonparametric in form. Algorithms that can be simplified to a known, finite form are labeled parametric, whereas nonparametric algorithms learn functional form from the training data.
In other words, with nonparametric algorithms, the complexity of the model grows with the amount of training data. With parametric models, there is a fixed structure or set of parameters making parametric models faster than nonparametric models.
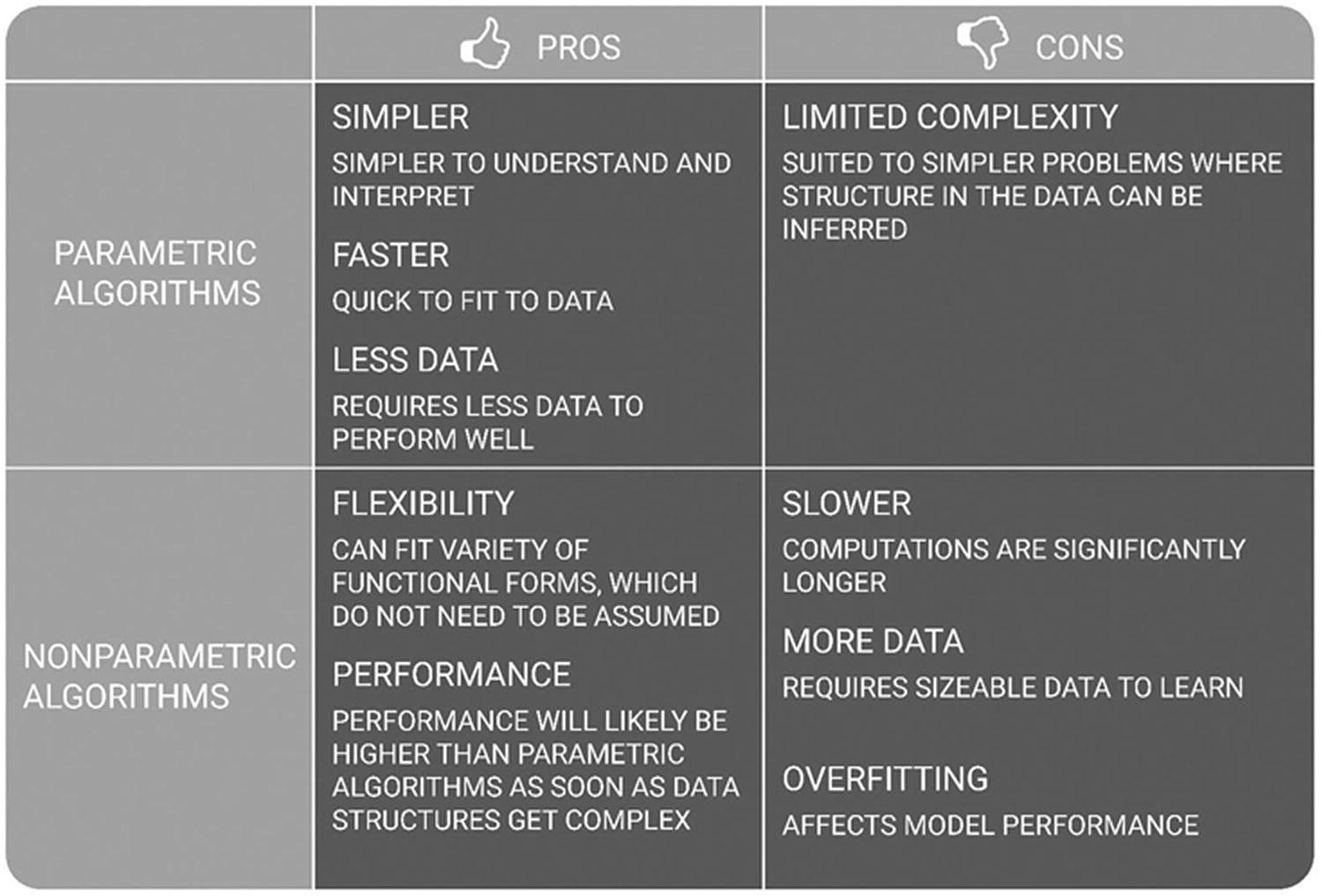
Parametric vs. nonparametric algorithms
When to Use Parametric and Nonparametric Algorithms
Parametric algorithms simplify a function to a known form and learn function coefficients from trained data. As such, strong assumptions are made about the data. Parametric algorithms are useful in that they are quick to learn from data and do not require much of it and can be used in scenarios that require easy to explain results.
Nonparametric algorithms use a varying number of parameters. k-Nearest neighbors, neural networks, and decision trees are nonparametric and suited to scenarios where there is more data and requirement for higher performance.
How Machine Learning Algorithms Work
Y = f(x),
Output = function(Input).
Inputs and outputs can be referred to as variables and are typically vector in format: f refers to the function, which you are trying to infer from the Input.
Take the example of a patient who is to be prescribed a particular treatment. In real life, the process may include the patient looking at research describing qualities about the medication or treatment they are recommended.
For example, if they were to see that the research mostly consists of words like “good,” “great,” “safe,” and so forth, then we would conclude from the sentiment that the treatment is a good treatment, and we can feel confident in accepting it. Whereas if words like “bad,” “not good quality,” and “unsafe” were to appear regularly, then we would conclude that it is probably better to look for another treatment. The research helps us perform an action based on the pattern of words that exist in the treatment research.
Machine learning attempts to understand this human decision-making process through algorithms. It focuses on the development of algorithms (or programs) that can access data and use it to learn for themselves. Machine learning is very good for classification and prediction tasks.
Machine learning is most commonly used for predictive analytics—learning the mapping of Y = f(X) to make predictions of Y for new X.
Fraud detection x is the property of the transaction f(x) is whether a transaction is fraudulent.
Disease diagnosis x are the properties of the patient f(x) is whether a patient has disease.
Speech recognition x are the properties of a speech input f(x) is the response given to the instruction contained within the speech input.
The process of machine learning begins with input data provided as examples, direct experience, or instructions—to identify patterns within the data and make better decisions in the future based on the data that was provided.
The aim is to enable the program to learn automatically without human intervention or assistance and adjust rational actions accordingly.
Conclusion
Readers should have an understanding of machine learning and data mining, approaches to performing learning tasks and key considerations when using these techniques. Most importantly, it has covered how machine learning algorithms work.
The next chapter will use this foundation knowledge to focus on algorithm choice and design, model considerations, and best practice.