
Have you ever wondered whether there are limits to what computer programs can solve? Nowadays, computers appear to do a lot more than unravel mathematical equations. In the past half-century, programming has become the ultimate tool for automating tasks and saving time. But how much can we automate, and how do we go about doing so?
Can a computer observe a photograph and say, “Aha—I see a lovely couple walking over a bridge under an umbrella in the rain”? Can software make medical decisions as accurately as trained professionals can? Can software make better predictions about stock market performance than humans could? The achievements of the past decade hint that the answer to all these questions is a resounding yes and that the implementations appear to have a common strategy.
Recent theoretical advances coupled with newly available technologies have enabled anyone with access to a computer to attempt their own approach to solving these incredibly hard problems. (Okay, not just anyone, but that’s why you’re reading this book, right?)
A programmer no longer needs to know the intricate details of a problem to solve it. Consider converting speech to text. A traditional approach may involve understanding the biological structure of human vocal cords to decipher utterances by using many hand-designed, domain-specific, ungeneralizable pieces of code. Nowadays, it’s possible to write code that looks at many examples and figures out how to solve the problem, given enough time and examples.
Take another example: identifying the sentiment of text in a book or a tweet as positive or negative. Or you may want to identify the text even more granularly, such as text that implies the writer’s likes or loves, things that they hate or is angry or sad about. Past approaches to performing this task were limited to scanning the text in question, looking for harsh words such as ugly, stupid, and miserable to indicate anger or sadness, or punctuation such as exclamation marks, which could mean happy or angry but not exactly in-between.
Algorithms learn from data, similar to the way that humans learn from experience. Humans learn by reading books, observing situations, studying in school, exchanging conversations, and browsing websites, among other means. How can a machine possibly develop a brain capable of learning? There’s no definitive answer, but world-class researchers have developed intelligent programs from different angles. Among the implementations, scholars have noticed recurring patterns in solving these kinds of problems that led to a standardized field that we today label machine learning (ML).
As the study of ML has matured, the tools for performing machine learning have become more standardized, robust, high-performing, and scalable. This is where TensorFlow comes in. This software library has an intuitive interface that lets programmers dive into using complex ML ideas.
Chapter 2 presents the ins and outs of this library, and every chapter thereafter explains how to use TensorFlow for the various ML applications.
1.1 Machine-learning fundamentals
Have you ever tried to explain to someone how to swim? Describing the rhythmic joint movements and fluid patterns is overwhelming in its complexity. Similarly, some software problems are too complicated for us to easily wrap our minds around. For this task, machine learning may be the tool to use.
Handcrafting carefully tuned algorithms to get the job done was once the only way of building software. From a simplistic point of view, traditional programming assumes a deterministic output for each input. Machine learning, on the other hand, can solve a class of problems for which the input-output correspondences aren’t well understood.
Machine learning is characterized by software that learns from previous experiences. Such a computer program improves performance as more and more examples are available. The hope is that if you throw enough data at this machinery, it’ll learn patterns and produce intelligent results for newly-fed input.
Another name for machine learning is inductive learning, because the code is trying to infer structure from data alone. The process is like going on vacation in a foreign country and reading a local fashion magazine to figure out how to dress. You can develop an idea of the culture from images of people wearing local articles of clothing. You’re learning inductively.
You may never have used such an approach when programming, because inductive learning isn’t always necessary. Consider the task of determining whether the sum of two arbitrary numbers is even or odd. Sure, you can imagine training a machine-learning algorithm with millions of training examples (outlined in figure 1.1), but you certainly know that this approach would be overkill. A more direct approach can easily do the trick.

Figure 1.1 Each pair of integers, when summed, results in an even or odd number. The input and output correspondences listed are called the ground-truth dataset.
The sum of two odd numbers is always an even number. Convince yourself: take any two odd numbers, add them, and check whether the sum is an even number. Here’s how you can prove that fact directly:
-
For any integer n, the formula 2n + 1 produces an odd number. Moreover, any odd number can be written as 2n + 1 for some value n. The number 3 can be written as 2(1) + 1. And the number 5 can be written as 2(2) + 1.
-
Suppose that we have two odd numbers, 2n + 1 and 2m + 1, where n and m are integers. Adding two odd numbers yields (2n + 1) + (2m + 1) = 2n + 2m + 2 = 2(n + m + 1). This number is even because 2 times anything is even.
Likewise, we see that the sum of two even numbers is an even number: 2m + 2n = 2(m + n). Last, we also deduce that the sum of an even with an odd is an odd number: 2m + (2n + 1) = 2(m + n) + 1. Figure 1.2 presents this logic more clearly.
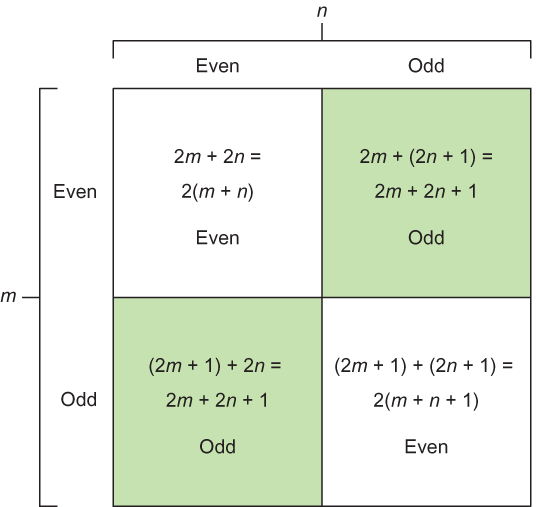
Figure 1.2 The inner logic behind how the output response corresponds to the input pairs
That’s it! With absolutely no use of machine learning, you can solve this task on any pair of integers someone throws at you. Directly applying mathematical rules can solve this problem. But in ML algorithms, we can treat the inner logic as a black box, meaning that the logic happening inside may not be obvious to interpret, as depicted in figure 1.3.
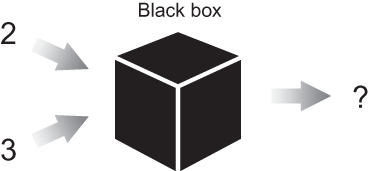
Figure 1.3 An ML approach to solving problems can be thought of as tuning the parameters of a black box until it produces satisfactory results.
1.1.1 Parameters
Sometimes, the best way to devise an algorithm that transforms an input to its corresponding output is too complicated. If the input is a series of numbers representing a grayscale image, for example, you can imagine the difficulty of writing an algorithm to label every object in the image. Machine learning comes in handy when the inner workings aren’t well understood. It provides us a toolkit for writing software without defining every detail of the algorithm. The programmer can leave some values undecided and let the machine-learning system figure out the best values by itself.
The undecided values are called parameters, and the description is referred to as the model. Your job is to write an algorithm that observes existing examples to figure out how to best tune parameters to achieve the best model. Wow, that’s a mouthful! But don’t worry; this concept will be a recurring motif.
1.1.2 Learning and inference
Suppose that you’re trying to bake desserts in an oven. If you’re new to the kitchen, it can take days to come up with both the right combination and perfect ratio of ingredients to make something that tastes great. By recording a recipe, you can remember how to repeat a dessert.
Machine learning shares the idea of recipes. Typically, we examine an algorithm in two stages: learning and inference. The objective of the learning stage is to describe the data, which is called the feature vector, and summarize it in a model. The model is our recipe. In effect, the model is a program with a couple of open interpretations, and the data helps disambiguate it.
Note A feature vector is a practical simplification of data. You can think of it as a sufficient summary of real-world objects in a list of attributes. The learning and inference steps rely on the feature vector instead of the data directly.
Similar to the way that recipes can be shared and used by other people, the learned model is reused by other software. The learning stage is the most time-consuming. Running an algorithm may take hours, if not days or weeks, to converge into a useful model, as you will see when you begin to build your own in chapter 3. Figure 1.4 outlines the learning pipeline.

Figure 1.4 The learning approach generally follows a structured recipe. First, the dataset needs to be transformed into a representation—most often, a list of features—that the learning algorithm can use. Then the learning algorithm chooses a model and efficiently searches for the model’s parameters.
The inference stage uses the model to make intelligent remarks about never-before-seen data. This stage is like using a recipe you found online. The process of inference typically takes orders of magnitude less time than learning; inference can be fast enough to work on real-time data. Inference is all about testing the model on new data and observing performance in the process, as shown in figure 1.5.

Figure 1.5 The inference approach generally uses a model that has already been learned or given. After converting data into a usable representation, such as a feature vector, this approach uses the model to produce intended output.
1.2 Data representation and features
Data is a first-class citizen of machine learning. Computers are nothing more than sophisticated calculators, so the data we feed our machine-learning systems must be mathematical objects such as scalars, vectors, matrices, and graphs.
The basic theme in all forms of representation is features, which are observable properties of an object:
-
Vectors have a flat and simple structure, and are the typical embodiments of data in most real-world machine-learning applications. A scalar is a single element in the vector. Vectors have two attributes: a natural number representing the dimension of the vector, and a type (such as real numbers, integers, and so on). Examples of 2D vectors of integers are (1, 2) and (-6, 0); similarly, a scalar could be 1 or the character a. Examples of 3D vectors of real numbers are (1.1, 2.0, 3.9) and (∏, ∏/2, ∏/3). You get the idea: a collection of numbers of the same type. In a program that uses machine learning, a vector measures a property of the data, such as color, density, loudness, or proximity—anything you can describe with a series of numbers, one for each thing being measured.
-
Moreover, a vector of vectors is a matrix. If each feature vector describes the features of one object in your dataset, the matrix describes all the objects; each item in the outer vector is a node that’s a list of features of one object.
-
Graphs, on the other hand, are more expressive. A graph is a collection of objects (nodes) that can be linked with edges to represent a network. A graphical structure enables representing relationships between objects, such as in a friendship network or a navigation route of a subway system. Consequently, they’re tremendously harder to manage in machine-learning applications. In this book, our input data will rarely involve a graphical structure.
Feature vectors are practical simplifications of real-world data, which can be too complicated to deal with. Instead of attending to every little detail of a data item, using a feature vector is a practical simplification. A car in the real world, for example, is much more than the text used to describe it. A car salesman is trying to sell you the car, not the intangible words spoken or written. Those words are abstract concepts, similar to the way that feature vectors are summaries of the data.
The following scenario explains this concept further. When you’re in the market for a new car, keeping tabs on every minor detail of different makes and models is essential. After all, if you’re about to spend thousands of dollars, you may as well do so diligently. You’d likely record a list of the features of each car and compare these features. This ordered list of features is the feature vector.
When shopping for cars, you might find comparing mileage to be more lucrative than comparing something less relevant to your interest, such as weight. The number of features to track also must be right—not too few, or you’ll lose information you care about, and not too many, or they’ll be unwieldy and time consuming to keep track of. This tremendous effort to select both the number of measurements and which measurements to compare is called feature engineering or feature selection. Depending on which features you examine, the performance of your system can fluctuate dramatically. Selecting the right features to track can make up for a weak learning algorithm.
When training a model to detect cars in an image, for example, you’ll gain an enormous performance and speed improvement if you first convert the image to grayscale. By providing some of your own bias when preprocessing the data, you end up helping the algorithm, because it won’t need to learn that colors don’t matter when detecting cars. The algorithm can instead focus on identifying shapes and textures, which will lead to much faster learning than trying to process colors as well.
The general rule of thumb in ML is that more data produces better results. But the same isn’t always true of having more features. Perhaps counterintuitively, if the number of features you’re tracking is too high, performance may suffer. Populating the space of all data with representative samples requires exponentially more data as the dimension of the feature vector increases. As a result, feature engineering, as depicted in figure 1.6, is one of the most significant problems in ML.
You may not appreciate this fact right away, but something consequential happens when you decide which features are worth observing. For centuries, philosophers have pondered the meaning of identity; you may not immediately realize that you’ve come up with a definition of identity through your choice of specific features.

Figure 1.6 Feature engineering is the process of selecting relevant features for the task.
Imagine writing a machine-learning system to detect faces in an image. Suppose that one of the necessary features for something to be a face is the presence of two eyes. Implicitly, a face is now defined as something with eyes. Do you realize the kind of trouble that this definition can get you into? If a photo of a person shows them blinking, your detector won’t find a face, because it can’t find two eyes. The algorithm would fail to detect a face when a person is blinking. The definition of a face was inaccurate to begin with, and it’s apparent from the poor detection results.
Nowadays, especially with the tremendous speed at which capabilities like smart vehicles and autonomous drones are evolving, identity bias, or simply bias, in ML is becoming a big concern, because these capabilities can cause loss of human life if they screw up. Consider a smart vehicle that has never seen a person in a wheelchair because the training data never included those examples, so the smart car does not stop when the wheelchair enters the crosswalk. What if the training data for a company’s drone delivering your package never saw a female wearing a hat before, and all other training instances with things that look like hats were places to land? The hat—and, more important, the person—may be in grave danger!
The identity of an object is decomposed into the features from which it’s composed. If the features you’re tracking for one car match the corresponding features of another car, they may as well be indistinguishable from your perspective. You’d need to add another feature to the system to tell the cars apart; otherwise, you’ll think they’re the same item (like the drone landing on the poor lady’s hat). When handcrafting features, you must take great care not to fall into this philosophical predicament of identity.

A robot is trying to fold a shirt. What are good features of the shirt to track?

Here are images of three objects: a lamp, a pair of pants, and a dog. What are some good features that you should record to compare and differentiate objects?
Feature engineering is a refreshingly philosophical pursuit. For those who enjoy thought-provoking escapades into the meaning of self, I invite you to meditate on feature selection, because it’s still an open problem. Fortunately for the rest of you, to alleviate extensive debates, recent advances have made it possible to automatically determine which features to track. You’ll be able to try this process yourself in chapter 7.
Now consider the problem of a doctor looking at a set of N 244 × 244 (width × height) squamous-cell images like the ones shown in figure 1.7 and trying to determine whether they indicate the presence of cancer. Some images definitely indicate cancer; others do not. The doctor may have a set of historical patient images that he could examine and learn from over time, so that when he sees new images, he develops his own representation model of what cancer looks like.
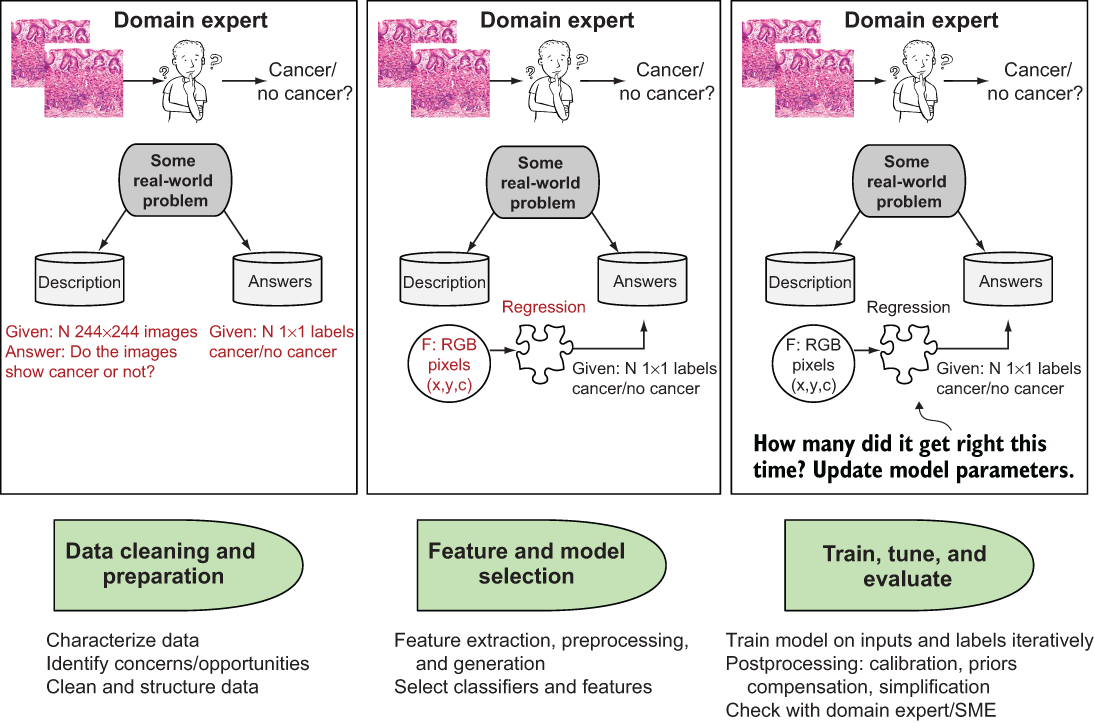
Figure 1.7 The machine-learning process. From left to right, doctors try to determine whether images representing biopsies of cells indicate cancer in their patients.

Feature vectors are representations of real-world data used by both the learning and inference components of machine learning. The input to the algorithm isn’t the real-world image directly, but its feature vector.
In machine learning, we are trying to emulate this model building process. First, we take N input squamous cancer cell 244 × 244 images from the historical patient data and prepare the problem by lining up the images with their associated labels (cancer or no cancer). We call this stage the data cleaning and preparation stage of machine learning. What follows is the process of identifying important features. Features include the image pixel intensities, or early value for each x, y, and c, or (244, 244, 3), for the image’s height, width, and three-channel red/green/blue (RGB) color. The model creates the mapping between those feature values and the desired label output: cancer or no cancer.
1.3 Distance metrics
If you have feature vectors of cars you may want to buy, you can figure out which two cars are most similar by defining a distance function on the feature vectors. Comparing similarities between objects is an essential component of machine learning. Feature vectors allow us to represent objects so that we may compare them in a variety of ways. A standard approach is to use the Euclidian distance, which is the geometric interpretation you may find most intuitive when thinking about points in space.
Suppose that we have two feature vectors, x = (x1, x2, ..., xn) and y = (y1, y2, ..., yn). The Euclidian distance ||x - y || is calculated with the following equation, which scholars call the L2 norm:

The Euclidian distance between (0, 1) and (1, 0) is
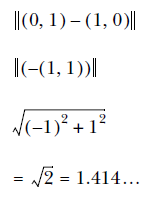
That function is only one of many possible distance functions, however. The L0, L1, and L-infinity norms also exist. All these norms are valid ways to measure distance. Here they are in more detail:
-
The L0 norm counts the total nonzero elements of a vector. The distance between the origin (0, 0) and vector (0, 5) is 1, for example, because there’s only one nonzero element. The L0 distance between (1, 1) and (2, 2) is 2, because neither dimension matches up. Imagine that the first and second dimensions represent username and password, respectively. If the L0 distance between a login attempt and the true credentials is 0, the login is successful. If the distance is 1, either the username or password is incorrect, but not both. Finally, if the distance is 2, neither username nor password is found in the database.
-
The L1 norm, shown in figure 1.8, is defined as Σxn. The distance between two vectors under the L1 norm is also referred to as the Manhattan distance. Imagine living in a downtown area like Manhattan, where the streets form a grid. The shortest distance from one intersection to another is along the blocks. Similarly, the L1 distance between two vectors is along the orthogonal directions. The distance between (0, 1) and (1, 0) under the L1 norm is 2. Computing the L1 distance between two vectors is the sum of absolute differences at each dimension, which is a useful measure of similarity.

Figure 1.8 The L1 distance is called the Manhattan distance (also the taxicab metric) because it resembles the route of a car in a gridlike neighborhood such as Manhattan. If a car is traveling from point (0, 1) to point (1, 0), the shortest route requires a length of 2 units.
-
The L2 norm, shown in figure 1.9, is the Euclidian length of a vector, (Σ(xn)2)1/2 It’s the most direct route you can possibly take on a geometric plane to get from one point to another. For the mathematically inclined, this norm implements the least-squares estimation as predicted by the Gauss-Markov theorem. For the rest of you, it’s the shortest distance between two points in space.
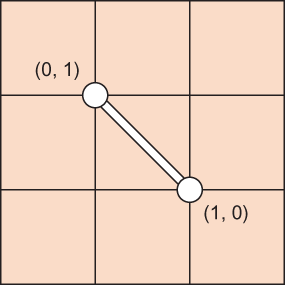
Figure 1.9 The L2 norm between points (0, 1) and (1, 0) is the length of a single straight-line segment between both points.
-
The L-N norm generalizes this pattern, resulting in (Σ(|xn|)N)1/N. We rarely use finite norms above L2, but it’s here for completeness.
-
The L-infinity norm is (Σ(|xn|)∞)1/∞. More naturally, it’s the largest magnitude among each element. If the vector is (-1, -2, -3), the L-infinity norm is 3. If a feature vector represents costs of various items, minimizing the L-infinity norm of the vector is an attempt to reduce the cost of the most expensive item.
1.4 Types of learning
Now that you can compare feature vectors, you have the tools necessary to use data for practical algorithms. Machine learning is often split into three perspectives: supervised learning, unsupervised learning, and reinforcement learning. An emerging new area is meta-learning, sometimes called AutoML. The following sections examine all four types.
1.4.1 Supervised learning
By definition, a supervisor is someone higher up in the chain of command. When we’re in doubt, our supervisor dictates what to do. Likewise, supervised learning is all about learning from examples laid out by a supervisor (such as a teacher).
A supervised machine-learning system needs labeled data to develop a useful understanding, which we call its model. Given many photographs of people and their recorded corresponding ethnicities, for example, we can train a model to classify the ethnicity of a never-before-seen person in an arbitrary photograph. Simply put, a model is a function that assigns a label to data by using a collection of previous examples, called a training dataset, as reference.
A convenient way to talk about models is through mathematical notation. Let x be an instance of data, such as a feature vector. The label associated with x is f (x), often referred to as the ground truth of x. Usually, we use the variable y = f (x) because it’s quicker to write. In the example of classifying the ethnicity of a person through a photograph, x can be a 100-dimensional vector of various relevant features, and y is one of a couple of values to represent the various ethnicities. Because y is discrete with few values, the model is called a classifier. If y can result in many values, and the values have a natural ordering, the model is called a regressor.
Let’s denote a model’s prediction of x as g (x). Sometimes, you can tweak a model to change its performance dramatically. Models have parameters that can be tuned by a human or automatically. We use the vector to represent the parameters. Putting it all together, g (x|) more completely represents the model, read “g of x given.”
NOTE Models may also have hyperparameters, which are extra ad-hoc properties of a model. The term hyper in hyperparameter may seem a bit strange at first. A better name could be metaparameter, because the parameter is akin to metadata about the model.
The success of a model’s prediction g(x|) depends on how well it agrees with the ground truth y. We need a way to measure the distance between these two vectors. The L2 norm may be used to measure how close two vectors lie, for example. The distance between the ground truth and the prediction is called the cost.
The essence of a supervised machine-learning algorithm is to figure out the parameters of a model that result in the least cost. Mathematically put, we’re looking for a θ* (pronounced theta star) that minimizes the cost among all data points x ∈ X. One way of formalizing this optimization problem is the following equation:
θ* = argminθCost(θ|X)
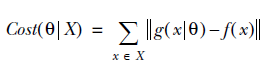
Clearly, brute-forcing every possible combination of x (also known as a parameter space) will eventually find the optimal solution, but at an unacceptable run time. A major area of research in machine learning is about writing algorithms that efficiently search this parameter space. Some of the early algorithms include gradient descent, simulated annealing, and genetic algorithms. TensorFlow automatically takes care of the low-level implementation details of these algorithms, so I won’t get into them in too much detail.
After the parameters are learned one way or another, you can finally evaluate the model to figure out how well the system captured patterns from the data. A rule of thumb is to not evaluate your model on the same data you used to train it, because you already know it works for the training data; you need to tell whether the model works for data that wasn’t part of the training set, to make sure your model is general-purpose and not biased to the data used to train it. Use the majority of the data for training and the remainder for testing. If you have 100 labeled data points, for example, randomly select 70 of them to train a model and reserve the other 30 to test it, creating a 70-30 split.
1.4.2 Unsupervised learning
Unsupervised learning is about modeling data that comes without corresponding labels or responses. The fact that we can make any conclusions at all on raw data feels like magic. With enough data, it may be possible to find patterns and structure. Two of the most powerful tools that machine-learning practitioners use to learn from data alone are clustering and dimensionality reduction.
Clustering is the process of splitting the data into individual buckets of similar items. In a sense, clustering is like classifying data without knowing any corresponding labels. When organizing your books on three shelves, for example, you likely place similar genres together, or maybe you group them by the authors’ last names. You might have a Stephen King section, another for textbooks, and a third for anything else. You don’t care that all the books are separated by the same feature, only that each book has something unique that allows you to organize it into one of several roughly equal, easily identifiable groups. One of the most popular clustering algorithms is k-means, which is a specific instance of a more powerful technique called the E-M algorithm.
Dimensionality reduction is about manipulating the data to view it from a much simpler perspective—the ML equivalent of the phrase “Keep it simple, stupid.” By getting rid of redundant features, for example, we can explain the same data in a lower-dimensional space and see which features matter. This simplification also helps in data visualization or preprocessing for performance efficiency. One of the earliest algorithms is principle component analysis (PCA), and a newer one is autoencoders, which are covered in chapter 7.
1.4.3 Reinforcement learning
Supervised and unsupervised learning seem to suggest that the existence of a teacher is all or nothing. But in one well-studied branch of machine learning, the environment acts as a teacher, providing hints as opposed to definite answers. The learning system receives feedback on its actions, with no concrete promise that it’s progressing in the right direction, which might be to solve a maze or accomplish an explicit goal.
Unlike supervised learning, in which training data is conveniently labeled by a “teacher,” reinforcement learning trains on information gathered by observing how the environment reacts to actions. Reinforcement learning is a type of machine learning that interacts with the environment to learn which combination of actions yields the most favorable results. Because we’re already anthropomorphizing algorithms by using the words environment and action, scholars typically refer to the system as an autonomous agent. Therefore, this type of machine learning naturally manifests itself in the domain of robotics.
To reason about agents in the environment, we introduce two new concepts: states and actions. The status of the world frozen at a particular time is called a state. An agent may perform one of many actions to change the current state. To drive an agent to perform actions, each state yields a corresponding reward. An agent eventually discovers the expected total reward of each state, called the value of a state.
Like any other machine-learning system, performance improves with more data. In this case, the data is a history of experiences. In reinforcement learning, we don’t know the final cost or reward of a series of actions until that series is executed. These situations render traditional supervised learning ineffective, because we don’t know exactly which action in the history of action sequences is to blame for ending up in a low-value state. The only information an agent knows for certain is the cost of a series of actions that it has already taken, which is incomplete. The agent’s goal is to find a sequence of actions that maximizes rewards. If you’re more interested in this subject, you may want to check out another topical book in the Manning Publications family: Grokking Deep Reinforcement Learning, by Miguel Morales (Manning, 2020; https://www .manning.com/books/grokking-deep-reinforcement-learning).
1.4.4 Meta-learning
Relatively recently, a new area of machine learning called meta-learning has emerged. The idea is simple. Data scientists and ML experts spend a tremendous amount of time executing the steps of ML, as shown in figure 1.7. What if those steps—defining and representing the problem, choosing a model, testing the model, and evaluating the model—could themselves be automated? Instead of being limited to exploring only one or a small group of models, why not have the program itself try all the models?
Many businesses separate the roles of the domain expert (refer to the doctor in figure 1.7), the data scientist (the person modeling the data and potentially extracting or choosing features that are important, such as the image RGB pixels), and the ML engineer (responsible for tuning, testing, and deploying the model), as shown in figure 1.10a. As you’ll remember from earlier in the chapter, these roles interact in three basic areas: data cleaning and prep, which both the domain expert and data scientist may help with; feature and model selection, mainly a data-scientist job with a little help from the ML engineer; and then train, test, and evaluate, mostly the job of the ML engineer with a little help from the data scientist. We’ve added a new wrinkle: taking our model and deploying it, which is what happens in the real world and is something that brings its own set of challenges. This scenario is one reason why you are reading the second edition of this book; it’s covered in chapter 2, where I discuss deploying and using TensorFlow.
What if instead of having data scientists and ML engineers pick models, train, evaluate, and tune them, we could have the system automatically search over the space of possible models, and try them all? This approach overcomes limiting your overall ML experience to a small number of possible solutions wherein you’ll likely choose the first one that performs reasonably. But what if the system could figure out which models are best and how to tune the models automatically? That’s precisely what you see in figure 1.10b: the process of meta-learning, or AutoML.

Figure 1.10 Traditional ML and its evolution to meta-learning, in which the system does its own model selection, training, tuning, and evaluation to pick the best ML model among many candidates
1.5 TensorFlow
Google open-sourced its machine-learning framework, TensorFlow, in late 2015 under the Apache 2.0 license. Before that, it was used proprietarily by Google in speech recognition, Search, Photos, and Gmail, among other applications.
The library is implemented in C++ and has a convenient Python API, as well as a less-appreciated C++ API. Because of the simpler dependencies, TensorFlow can be quickly deployed to various architectures.
Similar to Theano—a popular numerical computation library for Python that you may be familiar with (http://deeplearning.net/software/theano)—computations are described as flowcharts, separating design from implementation. With little to no hassle, this dichotomy allows the same design to be implemented on mobile devices as well as large-scale training systems with thousands of processors. The single system spans a broad range of platforms. TensorFlow also plays nicely with a variety of newer, similarly-developed ML libraries, including Keras (TensorFlow 2.0 is fully integrated with Keras), along with libraries such as PyTorch (https://pytorch.org), originally developed by Facebook, and richer application programming interfaces for ML such as Fast.Ai. You can use many toolkits to do ML, but you’re reading a book about TensorFlow, right? Let’s focus on it!
One of the fanciest properties of TensorFlow is its automatic differentiation capabilities. You can experiment with new networks without having to redefine many key calculations.
note Automatic differentiation makes it much easier to implement backpropagation, which is a computationally-heavy calculation used in a branch of machine learning called neural networks. TensorFlow hides the nitty-gritty details of backpropagation so you can focus on the bigger picture. Chapter 11 covers an introduction to neural networks with TensorFlow.
All the mathematics is abstracted away and unfolded under the hood. Using TensorFlow is like using WolframAlpha for a calculus problem set.
Another feature of this library is its interactive visualization environment, called TensorBoard. This tool shows a flowchart of the way data transforms, displays summary logs over time, and traces performance. Figure 1.11 shows what TensorBoard looks like; chapter 2 covers using it.

Figure 1.11 Example of TensorBoard in action
Prototyping in TensorFlow is much faster than in Theano (code initiates in a matter of seconds as opposed to minutes) because many of the operations come precompiled. It becomes easy to debug code due to subgraph execution; an entire segment of computation can be reused without recalculation.
Because TensorFlow isn’t only about neural networks, it also has out-of-the-box matrix computation and manipulation tools. Most libraries, such as PyTorch, Fast.Ai, and Caffe, are designed solely for deep neural networks, but TensorFlow is more flexible as well as scalable.
The library is well-documented and officially supported by Google. Machine learning is a sophisticated topic, so having an exceptionally reputable company behind TensorFlow is comforting.
1.6 Overview of future chapters
Chapter 2 demonstrates how to use various components of TensorFlow (see figure 1.12). Chapters 3-10 show how to implement classic machine-learning algorithms in TensorFlow, and chapters 11-19 cover algorithms based on neural networks. The algorithms solve a wide variety of problems, such as prediction, classification, clustering, dimensionality reduction, and planning.

Figure 1.12 This chapter introduces fundamental machine-learning concepts, and chapter 2 begins your journey in TensorFlow. Other tools can apply machine-learning algorithms (such as Caffe, Theano, and Torch), but you’ll see in chapter 2 why TensorFlow is the way to go.
Many algorithms can solve the same real-world problem, and many real-world problems can be solved by the same algorithm. Table 1.1 covers the ones laid out in this book.
Table 1.1 Many real-world problems can be solved by using the corresponding algorithm found in its respective chapter.
TIP If you’re interested in the intricate architecture details of TensorFlow, the best available source is the official documentation at https://www.tensorflow.org/ tutorials/customization/basics. This book sprints ahead and uses TensorFlow without slowing down for the breadth of low-level performance tuning. If you’re interested in cloud services, you may want to consider Google’s solution for professional-grade scale and speed (https://cloud.google.com/products/ai).
Summary
-
TensorFlow has become the tool of choice among professionals and researchers for implementing machine-learning solutions.
-
Machine learning uses examples to develop an expert system that can make useful statements about new inputs.
-
A key property of ML is that performance tends to improve with more training data.
-
Over the years, scholars have crafted three major archetypes that most problems fit: supervised learning, unsupervised learning, and reinforcement learning. Meta-learning is a new area of ML that focuses on exploring the entire space of models, solutions, and tuning tricks automatically.
-
After a real-world problem is formulated in a machine-learning perspective, several algorithms become available. Of the many software libraries and frameworks that can accomplish an implementation, we chose TensorFlow as our silver bullet. Developed by Google and supported by its flourishing community, TensorFlow gives us a way to implement industry-standard code easily.