
17
Network Software – The User Experience
Back to earth again, the next five chapters address various aspects of network software. Chapter 18 of 3G Handset and Network Design looked at traffic-shaping protocols in some detail. This chapter provides a short reprise of traffic shaping and tracks the changes that have taken place over the past eight years.
In 2002 the discussion revolved around the scale of the efficiency gain potential of IP networks and specifically IP networks with a radio network attached. At the time, Nortel were claiming that the 3 G air interface combined with an IP network would reduce delivered cost per bit by a factor of twenty. This was absurd. Nortel is no longer in business, a salutary warning to companies that allow marketing to become disconnected from engineering reality.
The issue was that while it is very possible to achieve performance gain there is normally an associated performance cost in some other area that is often not factored into the marketing message. In this case, the performance cost of the theoretical efficiency gain was a loss of network determinism. In January 2003 after the book was published we wrote a technology topic on IP network processor performance limitations. The summary of this is as follows.
17.1 Definition of a Real-Time Network
The IEEE defines a real-time operating system as ‘A system that responds to external asynchronous events in a predictable amount of time’. Handset hardware and software engineers, for example, need to make sure that application layer and physical layer functions are executed within known and predictable time scales in response to known and predictable external events and requests – this is often described as a deterministic process.
We can apply a similar definition to a real-time network as ‘A network that can provide throughput to asynchronous traffic in a predictable amount of time’. Network hardware and software engineers need to make sure that router processors can process offered traffic within known and predictable time scales. This in turn requires an understanding of the offered traffic mix and offered traffic properties, particularly any time interdependencies present between different channel streams.
17.2 Switching or Routing
The general assumption was, and is, that there will be more routing and less switching over time and less use of hardware, greater use of software to reduce cost and improve flexibility. However, software-based routing introduces delay and delay variability – the time taken to capture a packet, the time taken to check the header and routing table, the time packets spend in buffers waiting for the router to deal with other packets and the time packets spend in buffers waiting for egress bandwidth to become available (queuing delay).
Traffic-shaping protocols such as Diffserv and MPLS can help manage queuing delay (i.e. reduce delay for some packets by increasing delay for other packets) but queuing delay can still be 20 or 30 milliseconds and varies depending on traffic load. Transmission retries (using TCP/IP) introduce additional variable delay.
17.3 IP Switching as an Option
Rather than treating packets individually, a sequence of packets can be processed as a complete entity – the first packet header contains the properties and bandwidth requirements of the whole packet stream – this is described as flow switching or IP switching – ‘a sequence of packets treated identically by a possibly complex routing function’. This would seem like a good idea, particularly as session persistency increases over time. However, session properties and session characteristics tend to change as a session progresses, so more flexibility is needed. It is difficult to deliver flexibility and deterministic routing or switch performance.
17.4 Significance of the IPv6 Transition
An additional challenge for an IPv4 router is that it never quite knows what type of packet it will have to deal with next. IPv6 tries to simplify things by using a fixed-length rather than variable-length header and by reducing the 14 fields used in IPv4 to 8 fields – the protocol version number, traffic class (similar to type of service in IPv4), a flow label to manage special priority requests, payload length, next header, hop limit, source address and destination address. This is one of the reasons Japanese vendors are keen on mandatory IPv6 in routers – it makes deterministic performance easier to achieve.
17.5 Router Hardware/Software Partitioning
Performance can also be made more predictable by adding in a hardware coprocessor (or parallel coprocessors) to the router. Figure 17.1 shows the packet-flow sequence in a packet processor.
Figure 17.1 Router packet processing.1
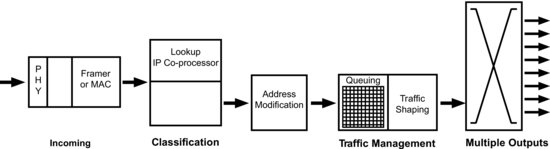
To minimise delay, the router divides packet processing into a number of tasks.
The data comes in from the physical layer and is demultiplexed in accordance with the MAC (medium access control) layer rule set, packets within frames within multiframes. The packet is then sent for classification. At this point a hardware coprocessor may be used to improve look-up performance. Performance is defined by the number of searches per second, the number of entries in the table, and whether or not multiprotocol tables are used. Multiprotocol tables are needed if differentiated classes of service are supported. A software-based standard processor-based solution can take several hundred instruction cycles to classify a packet with QoS and/or security attributes. A coprocessor can perform the task in a single clock cycle but lacks flexibility. It can only be used when the decisions to be taken are largely predefined and repetitive. This is hardware-based switching rather than software-based routing.
17.6 The Impact of Increasing Policy Complexity
This looks like a good solution but there's a drawback. Session complexity increases over time. For example, we might need to support an increasing number of multiuser to multiuser multimedia exchanges. In these exchanges, policy management can become complex. Policy rights might be ascribed to the user such as a priority right of access to delivery or storage bandwidth. The user, the user's device or the user's application may be (likely will be) authenticated and the user's traffic may have end-to-end encryption added for additional security. In a multiuser session, the security context may change/will change as users join, leave or rejoin the session. This implies substantial flexibility in the way in which packets are handled, hard to realise in a hardware coprocessor.
In an ideal world we would like to combine consistent deterministic throughput and flexibility. In practice this is hard to achieve. One (simple) way to achieve consistent performance and flexibility is to overdimension transmission bandwidth in the IP network but this has a cost implication. Consistent network performance therefore comes with a price tag attached. Having to handle highly asynchronous traffic increases that price tag. Bursty bandwidth is expensive bandwidth.
The theoretical understanding of this can be traced back to 1909 when A K Erlang published his ‘Theory of Probabilities and Telephone Conversations’ – we still use the Erlang as a unit of measurement to dimension Node B, RNC and core network capacity and (rather dangerously) use Erlang traffic-arrival formula to design network processor components.
The good thing about voice traffic is that it is reasonably predictable. Multimedia traffic is also quite predictable though we have less experience and knowledge of ‘mixed’ media/‘rich’ media traffic-arrival patterns (and less experience of how we should treat the traffic). This means that networks don't always behave as expected – their behaviour is not consistent with traditional queuing theory. The anecdotal experience is that as we move from voice to a mix of voice, data and multimedia, networks become progressively more badly behaved.
One reason for this bad behaviour is the increasing burstiness of the offered traffic that effectively puts network components (network processing and network router buffers) into compression. This results in packet loss and (if using TCP) transmission retries.
These ‘bandwidth effects’ can be due to transmission bandwidth constraints, buffer bandwidth constraints and/or signalling bandwidth constraints. Traffic-shaping protocols (TCP, RSVP, MPLS, etc.) may help to modulate these effects or may make matters worse! It is thus quite difficult sometimes to know whether we are measuring cause or effect when we try and match traffic-arrival and traffic-throughput patterns.
Benoit Mandelbrot (1982),2 and subsequently Kihong Park, Willinger3 and others have characterised network traffic in terms of a series of multiplicative processes and cascades – the end result is a turbulent network.
Whether using TCP or UDP, the network effectively behaves as a filter, including bulk delay and group delay effects and creates backpressure when presented with too much traffic or bursty traffic (which puts the network into compression). The effect is similar to the reflection coefficient in matching networks (VSWR).
The problem of turbulent networks is that it is difficult to predict the onset of turbulence – the point of instability, the point at which a ‘fluid’ flow becomes laminar. The reason that it is difficult to predict the onset of turbulence is that turbulence is turbulent. Lewis Fry Richardson (the uncle of Sir Ralph Richardson) produced some seminal work on turbulence just prior to the First World War when there was a particular interest in knowing how well aeroplanes could fly. Richardson was so inspired by the mathematical complexity (and apparent unpredictability) of turbulence that he wrote a poem about ‘little eddy’ behaviour – the behaviour of the little eddies or whorls that you notice in dust storms or snow storms.
Big whorls have little whorls which feed on their velocity And little whorls have lesser whorls and so on to viscosity. Figure 17.2 illustrates this concept of the network as a filter, attempting to smooth out offered traffic turbulence.
Figure 17.2 The network as a filter (the turbulent network).
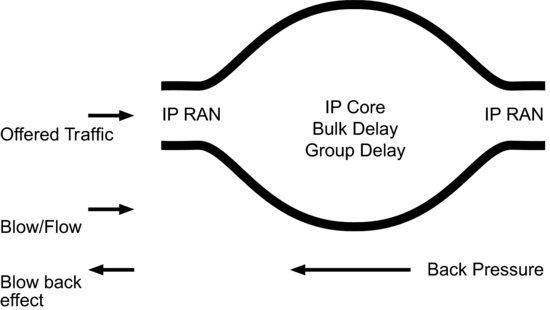
17.7 So What Do Whorls Have to Do with Telecom Networks?
Well, in order to understand network instability, we need to understand the geometry of turbulence. At what point does the flow of a liquid or gas or packet stream go from smooth to laminar (an unsmooth flow) and what are the cumulative causes.
In a wireless wide-area network, the root cause is the increasingly wide dynamic range of the traffic being fired into the network from cellular handsets. Release 99 3GPP1 specified that data rates could vary on the uplink between 15 and 960 kbps from frame to frame (from one 10 millisecond frame to the next 10 millisecond frame). Ten Releases later the bandwidth excursion has increased significantly and is mapped to two millisecond and in the longer term one-millisecond and half-millisecond frame lengths. This is bursty bandwidth coming from multiple similar sources. Unfortunately, merging these traffic streams together does not necessarily result in traffic smoothing – bursty data streams aggregated together may produce even burstier traffic streams. This burstiness exercises (effectively compresses) RF and DSP components in the radio layer and router and switch components in the network. RF and DSP components in compression go nonlinear and create intermodulation and distortion. Router and switch components in compression produce packet loss and packet delay (first-order effects) and loss and delay variability (second-order effects). These effects can be particularly damaging for nonelastic/inelastic traffic.
Kihong Park adds to the anxiety by suggesting that this offered traffic (in particular the burstiness of the offered traffic) can become strongly ‘self-similar’. Self-similar traffic is traffic that shows noticeable (and when scaled, remarkably similar) burst patterns at a wide range of time scales – typically four or five orders of magnitude, milliseconds, seconds, tens of seconds, hundreds of seconds, thousands of seconds.
It's rather like qualifying the effect of using multiple OVSF codes at the radio layer, we can predict the dynamic range of the burstiness but not when the burstiness will occur, through we can predict how often it will occur.
Kihong Park's work is based on multiple-source variable bit rate video. The traffic coming from mobile broadband devices is not dissimilar, therefore we need to consider the impact of this traffic on network resource provisioning.
Self-similar traffic has long-range dependence – this means that it has a cumulative ‘fill effect’ on the buffer, in other words we need more buffer bandwidth than traditional telecom traffic theory would suggest. However, if we add additional buffer bandwidth we not only increase end-to-end delay (first-order effect) but end-to-end delay variability (second-order effect). Given that as we shift towards a richer media multiplex with an increasing percentage of conversational traffic exchanges our traffic by definition will become less elastic, this will be problematic.
17.7.1 So What's the Answer?
Philippe Jacquet, one of the contributors to Kihong Park's book paints a gloomy picture ‘Actual router capacitors are dangerously underestimated with regard to traffic conditions’. While this is almost certainly true it is also reasonable to say that provided transmission bandwidth is adequately provisioned then next-generation networks will work quite well but will cost rather more than expected.
It also implies a significant shift away from present network processor design trends and a shift in the functional partitioning between software switching (flexible but slow) or hardware switching (fast but inflexible).
You can of course have flexible and fast but end up with overcomplex and expensive parallel processing engines heavily dependent on overcomplex and expensive memory (S-RAM and CAM).
Decisions on software/hardware partitioning self-evidently have to be based on the requirements and characteristics of the traffic being processed. As traffic becomes increasingly asynchronous it becomes progressively harder to control buffer delay and buffer-delay variability. However, it's not just ‘burstiness’ that needs to be considered when deciding on network processor performance.
17.7.2 Longer Sessions
First, let's consider the impact of longer sessions. Sessions are getting longer partly because file sizes are getting bigger but also because sessions are becoming more complex. Multimedia sessions tend to last longer than voice calls, multiuser sessions tend to last longer than one-to-one conversations and conversational exchanges last longer than best-effort exchanges.
As session lengths increase it becomes more economic to switch in hardware or, put another way, you don't need lots of software instructions to switch a long session – it's a relatively simple and deterministic transaction.
17.7.3 Shorter Packets with a Fixed Rather than Variable Length
Packet size is reducing over time. This is because multimedia components are source coded using periodic sampling – typically 20 milliseconds for voice (the syllabic rate). Video sampling rates depend on the frame rate and source coding used but generally you will end up with a MAC layer that produces a stream of fixed-length packets of typically 40 bytes. The decision to use fixed rather than variable-length packets is driven by the need to get multiplexing efficiency even when the data rates coming from multiple sources can be widely different (video encoding is moving increasingly towards variable rate).
It is obviously absurd to take a 40-byte payload and add a 40-byte IPv6 header to each packet, so the idea of treating each packet as an individual entity in a multimedia network is no longer valid. As we move towards short, fixed-length packets it makes sense to hardware switch. Figure 17.3 illustrates this shift.
Figure 17.3 Hardware switching increases as packet length reduces.
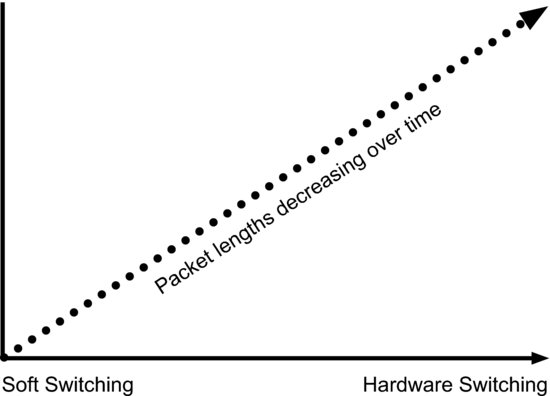
17.7.4 Fixed Routing
As session length increases, we move progressively towards providing less rather than more routing flexibility.
Traditionally in an IP network, routing flexibility has been promoted due to its ability to improve transmission bandwidth utilisation and increase network resilience. However, the cost is delay (first-order effect) and delay variability (second-order effect). As traffic becomes more inelastic over time we become less tolerant to any change in routing trajectory. Routing flexibility is antithetical to network determinism.
Conversely, if we have fixed routing we don't need to have routing tables, thus saving on CAM memory. If we don't need packet-by-packet classification we don't need classifiers (saving on S-RAM). If we also decide we don't need or cannot tolerate buffering because delay and delay variability compromises our inelastic traffic then we can also get rid of all or at least some of that expensive S-DRAM and DDR DRAM.
Also, as we reduce the buffering used in network components we reduce the need to manage memory – the software processes implicit in memory management introduce delay and delay variability in the end-to-end communications channel. So it may be that the need for flexibility and the benefits of flexibility in next-generation networks are overstated. What is really needed is predictable and stable end-to-end performance that can be mapped to clearly defined quality of experience metrics. The easiest and lowest-cost way to achieve this may be to overdimension network delivery bandwidth.
So the thesis is that as session lengths increase and as we move towards fixed-length packets and fixed routing trajectories it makes more sense to hardware switch and less sense to software switch.
This goes against the present trend in which a number of vendors are promoting general-purpose network processors for IP RAN and IP core network applications (including Node B and RNC routers). The selling point of these network processors is that they offer flexibility (which we are saying will not be needed). We also have to consider that this flexibility has a cost in terms of additional processor, memory and bus bandwidth overhead.
Apart from cost implications, these overheads imply higher power consumption and some performance cost in terms of additional end-to-end delay and delay variability.
One option is to introduce hardware coprocessors to speed up time-sensitive tasks but this can result in quite complex (and difficult to manage) hardware/software configuration. Somehow, we need to work out what would be an optimum trade off point.
17.8 Packet Arrival Rates
First, we need to decide how much time we have to process a packet. A 40-byte packet has an arrival rate of 160 nanoseconds at OC48 (2.5 Gbps), 35 nanoseconds at OC192 (10 Gbps) and 8 nanoseconds at OC768 (40 Gbps). When you consider that memory access even in high-performance S-RAM is around 6 nanoseconds then you can see that you don't have much chance for multiple memory searches at higher throughput rates.
Consider also that classification software can take several hundred clock cycles and a router update can typically take well over 100 cycles. If you want line-rate or near-line-rate processing you would end up with some interesting clock speeds.
17.9 Multilayer Classification
We also need to consider the level of classification used on the packet. If this includes deep packet classification then a data payload search is needed. The data may be several hundred bits long and may be located at random within the payload.
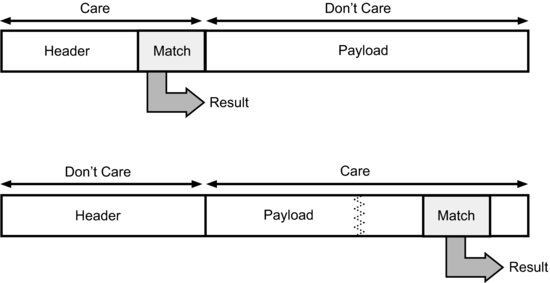
As we move down the protocol stack we find we may have to ‘parse’ out MPLS headers (4 bytes) or RSVP/Diffserv in addition to the 20-byte IPv4 or 40-byte IPv6 header. This is shown in Figure 17.4.
Figure 17.5 shows that reading a header is relatively straightforward and deterministic but becomes much harder if we need to look into the payload. We introduce delay and delay variability into the classification process.
Figure 17.4 Multilayer classification.
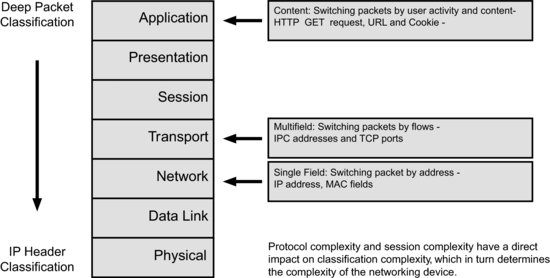
Figure 17.5 Header versus data payload searches.
The whole process of classification means we have to put the packet somewhere while we examine it. As we move down the protocol stack we need better and better performance from our memory and we can find we end up spending large sums of money, particularly when provisioning S-RAM and CAM (content-addressable memory). Note that these memory overheads are in addition to the buffer memory needed for queue management (prior to accessing egress bandwidth from the router). Figure 17.6 illustrates these classification memory overheads.
Figure 17.6 Classification memory overheads.
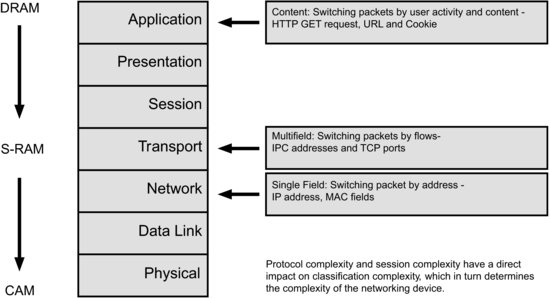
Note also that both classification and queue memory need to be substantially overprovisioned to deal with asynchronous and (at times) highly asymmetric traffic.
The end result is that router hardware and router software will cost more than expected and perform less well than expected.
17.9.1 Summary – Telecom Cost Complexity
Telecom costing has always been a complex process involving amortisation of fixed facilities with a life span of 50 years or more (think telegraph poles and traditional telephone exchanges). Universal service obligations and access guarantees have always implied a substantial overprovisioning of access and network bandwidth.
17.9.2 Popular Myths – Packet is Cheaper
The transition from circuit-switched to packet-routed networks has been promoted as a mechanism for improving network and transmission bandwidth multiplexing efficiency that in turn is supposed to deliver a decrease in the cost of delivery measured in euroherz or dollarherz or eurobytes or dollarbytes of network transmission bandwidth.
Multiplexing efficiency is dependent on buffering. Buffering has two cost components – the cost of the memory and processor bandwidth needed to store, manage and prioritise buffered packet streams and the (largely hidden) cost of supporting differentiated classes of service.
This cost is dependent on the offered traffic mix – conversational traffic costs more to deliver than best effort because it cannot be buffered. This is of course only true if the multiplexing efficiency of buffering exceeds the cost of overprovisioning transmission bandwidth beyond the point at which buffering would no longer be required. If a significant percentage of offered traffic is real time/conversational, the assumption of a multiplexing gain from buffering is invalid.
Additional network efficiency is supposedly achievable by deploying flexible end-to-end routing. Again, any efficiency gain achievable is directly dependent on the offered traffic mix. If a significant percentage of offered traffic is real time/conversational, the assumption of a multiplexing gain from routing flexibility is invalid. The amount of bandwidth used increases as the number of hops increase and/or the routing trajectory becomes progressively more indirect.
17.9.3 IP Protocol and Signalling Overheads
At protocol level, the overheads of SS7 have been, or are being, replaced by the ‘lighter signalling load’ of the TCP/IP or UDP protocol stack working with traffic shaping and IP prioritisation protocols (MPLS, Diffserv, RSVP, etc.). Any efficiency gain achievable is directly dependent on the offered traffic mix. If a significant percentage of offered traffic is real time/conversational, the assumption of an efficiency gain from IP signalling and traffic shaping is invalid.
If average packet lengths are 1500 bytes or so, IPV4 or IPV6 address overheads are relatively trivial. However, if a significant percentage of traffic is multimedia and time-sensitive or time-interdependent, IP packet traffic (IP voice, IP audio, IP video) will be mapped on to fixed and short (typically 92 bytes or less) fixed-length packets and IP address overhead will be substantial. In radio systems, this can be equivalent to taking between 4 and 5 dB of link budget out of the radio system. Given that one dB of link budget (rather approximately) equates to a 10% increase in network density then it is clear that IP addressing and signalling overhead adds directly to the dollardensity costs of deploying a wireless network. Similarly, a multimedia multiplex will require fixed length packets in order to preserve the time-domain properties of the multiplex. The flexibility of variable-length packets (one of the claimed advantages of IP when compared to ATM) therefore no longer applies.
17.9.4 Connectionless is Better than Connection Orientated?
The always-on connectivity implicit in a packet network delivers efficiency benefits when handling small bursts of data. In a GSM network, the 1 to 2 seconds of setup delay in a circuit switched call (or 3 to 4 seconds in a Release 99 network) represents a major overhead when handling short bursts of data. However, these packet efficiency benefits are only valid with a short session duration. Most present evidence suggests that in a multimedia network, sessions are substantially longer than traditional telecom voice calls and are increasing over time. This suggests that any supposed efficiency benefits achievable from having a connectionless end-to-end channel are becoming increasingly invalid.
This also affects the overall efficiency of call-setup protocols such as SIP. A SIP message generates about 8 kilobytes of signalling load. A change in session property (a new user or additional content stream) requires a new SIP message exchange. As sessions become more complex over time, SIP becomes progressively less efficient and requires substantially higher signalling bandwidth than existing SS7 signalling.
17.9.5 The Hidden Costs of IP MMS
An IP MMS (IP multimedia subsystem) enabled multiservice network is rather like a postal or courier service but instead of two classes of service (first class or second class for postal services, priority or standard for couriers) there are 4 levels of service. Note that the postal service in the UK loses money on second-class mail and makes money on first-class mail. This is partly because first-class mail has a higher value but also because second-class mail costs more to deliver. The additional costs are incurred because the storage costs (and related storage administration) now exceed the benefits of holding back mail to fully fill increasingly inexpensive trucks (rather bizarrely the real costs of running a large delivery van up and down the motorway are going down rather than up over time). With international carriers, the same tipping points apply and as aviation costs have reduced (larger, cheaper more efficient aeroplanes) it becomes cheaper not to store and forward but just to forward. The same principle applies to indirect routing. Although the cost of indirect routing may decrease over time, the process still consumes additional bandwidth. This is also true of wireless mesh networks, which can be remarkably spectrally inefficient due to routing inconsistencies and associated user signalling overheads.
17.9.6 So is the Internet an Efficient Transport System?
Not really. It's robust because that's what it's designed for. It was, however, never designed to handle multimedia traffic and if you expect it to deliver the same end-to-end channel performance in terms of latency and jitter as an ATM or circuit-switched network, then any supposed efficiency benefits will rapidly disappear. All Internet protocols are inherently inefficient and either waste bandwidth through transmission retries (TCP/IP) or lost packets (UDP) or a mixture of both.
17.9.7 So Why is the Internet so Cheap and Why does it Work so Well?
Because it is presently grossly overprovisioned and has been financed by the pension funds that lost investors money in the dot com dot bust cycle.
17.9.8 So if IP Networks are Neither More Efficient nor Lower Cost than Circuit-Switched or ATM Networks, Why are Telecoms Operators Deploying Them?
Well that's a good question and one of the answers is that to an extent hardware costs are reducing as hardware (and to a lesser extent software) in the network becomes a commodity, but this is in reality a modest incremental process. Complex ATM hardware is being replaced with complex soft switch platforms with high clock speed processors, extravagantly provisioned high-performance buffer memory cards and unstable traffic-shaping protocols. Not really a big leap forward.
As the Internet becomes more aggressively loaded over time, the real costs of delivery will start to reappear and will need to be factored in to end-to-end delivery cost calculations. If the route to reduced cost compromises the user experience then this is a self-defeating process.
1 Reproduced from 3G Handset and Network, Design Varrall and Belcher, Page 406, Figure 17.1, John Wiley, ISBN 0 471 22936-9.
2 The Fractal Geometry of Nature, Benoit B Mandelbrot, 1983 Edition, ISBN 0-7167-1186-9.
3 Self-similar Network Traffic and Performance Evaluation, Edited by Kihong Park and Walter Willinger, Wiley, New York, 2000 Edition, ISBN 0-471-31974-0.