
Chapter 8
Coping with Malicious Software
This chapter is likely to seem quite out of place in this book. Nevertheless, after dedicating so many chapters of this book towards malicious software attacks we felt obliged to present some results on how to defend against these attacks. This chapter is not a how-to manual to recover from a viral infection. Rather, a number of proactive and reactive security measures are given to combat the spread of self-replicating malware. Antiviral heuristics are presented along with their counter-heuristics, their counter-counter-heuristics, and so forth, to illuminate the challenges facing viral containment. The chapter also includes heuristics for identifying cryptoviruses and cryptotrojans wherever they may reside. These heuristics are based on the fact that cryptoviruses and cryptotrojans must contain a public key which has certain mathematical properties.
8.1 Undecidability of Virus Detection
A number of real-world problems that would be nice to be able to solve are in fact not solvable. For instance, it would be useful to be able to determine algorithmically if on input1 M and w, where M is an arbitrary given Turing machine and w is an arbitrary given input string, whether or not M accepts2 w. This is known as the halting problem. It is a decision problem since the answer comes in the form of yes or no. To solve this problem it would be necessary for the Turing machine to answer correctly for all possible input machines and all possible inputs to those machines. Such a program would be an invaluable tool for assessing the correctness of programs, since a program is correct if and only if it always outputs the correct answer and halts on all inputs. However, using a Cantor diagonalization argument Alan Turing proved that no such Turing machine exists [306]. This is not a complexity issue; it is a computability issue since the problem as stated is not solvable at all.
It is an unfortunate consequence in the theory of secure computing that the same applies to testing whether or not an arbitrary program is infected with an arbitrary virus. Adleman proved that if an algorithm exists that can detect the presence of viruses in the general case, then an algorithm exists that solves the halting problem. Since the halting problem is Turing undecidable, this proves that the problem of detecting viruses is Turing undecidable [3].
Regardless of this fundamental limitation to virus detection, methods are needed to identify viruses since hackers continue to write and release computer viruses. As a result heuristics have been developed and deployed to identify both known viruses and viruses that are yet to be written. By virtue of being heuristic in nature they each fail in specific cases, but they nonetheless raise the bar in terms of what is necessary to spread viruses successfully.
To deal with these heuristics, virus writers have reacted by developing their own suite of heuristics to bypass antiviral heuristics. These heuristics constitute counter-heuristics and some of them are surprisingly general in nature. However, these in turn have led to the development of counter-counter-heuristics in antiviral software, and so on. The end result has been an ongoing tug-of-war between detection and evasion methods.
8.2 Virus Identification and Obfuscation
There are several challenges surrounding the design of robust computer viruses and worms and designing algorithms to detect viruses and worms wherever present. The first part of this section covers the issue of string matching. String matching is often used by antivirus programs to positively identify viral strains. But, it is also a method that is used by viruses to identify themselves. Viral self-identification is necessary to prevent overpopulation and to prevent a host from being infected multiple times. The development of string matching antiviral programs lead to the development of polymorphic viruses, which are viruses that are specifically designed to foil string matching antiviral programs. The notion of a polymorphic virus is covered at the end of this section.
8.2.1 Virus String Matching
By definition, a virus spreads by copying a possibly altered version of itself to other programs, which in turn continue the viral replication. An unavoidable problem in designing such viruses is the possibility of multiple infection. How does a virus know if it already infected a given program? If the virus has no way of knowing this, then it may end up infecting the same program so many times that the user notices a suspicious loss in disk space.
Some viruses were programmed not to care about multiple infections. For example, the Israeli virus will infect a host multiple times [289]. This implies that viruses need an algorithm for identifying whether or not a given executable is already infected. This decision problem is exactly the same decision problem that antiviral software faces when analyzing the same executable. The virus writer can include within the virus an efficient algorithm for solving the decision problem and use it to prevent multiple infections. But the drawback to this is that if the virus is ever discovered it solves the problem of identifying the virus in the wild for the antiviral analyst. A viral detection algorithm is therefore a mixed blessing for both parties:
- virus writer: prevents the virus from infecting programs multiple times and thereby minimizes the chances that the virus will be discovered due to loss of disk space. But, at the same time it gives a detection algorithm to antiviral analysts when the virus is found.
- antiviral analyst: lowers the chance that a user will find the virus due to unexplained loss of disk space. But once found it has the benefit of solving the problem of identifying the virus in the wild (assuming it is well written).
Viruses that are indiscriminate about the executables they infect are very dangerous since they have the potential to bring down host systems by their replication alone. The fallout due to the famous Internet Worm is a case in point [287, 288].
It is possible to slow the rate of infection to prevent a virus from being discovered right away, without including a self-detection mechanism. This can be accomplished by limiting the timeframe in which the virus replicates on a given machine [302]. To limit the timeframe the virus stores a circularly linked list internally to keep track of the most recently infected machines. Each list element contains a timestamp and a machine name.3 The virus is designed to replicate for a specified time interval ![]() on any given machine (e.g.,
on any given machine (e.g., ![]() = 2 days). When it is executed it obtains the name of the machine that it is currently on. If the name is not contained in the linked list then it overwrites the oldest element in the list with the current machine name and the current time, and then infects another program on the machine. If the name is contained in the linked list then the timestamp
= 2 days). When it is executed it obtains the name of the machine that it is currently on. If the name is not contained in the linked list then it overwrites the oldest element in the list with the current machine name and the current time, and then infects another program on the machine. If the name is contained in the linked list then the timestamp ![]() for that element is retrieved. If the current time exceeds
for that element is retrieved. If the current time exceeds ![]() plus
plus ![]() then the virus does not infect anything and sends control to the host. Otherwise, the virus infects another program. This method minimizes the excess infections that occur due to backtracking, but does prevent a given program from being infected more than once.
then the virus does not infect anything and sends control to the host. Otherwise, the virus infects another program. This method minimizes the excess infections that occur due to backtracking, but does prevent a given program from being infected more than once.
Designing a self-detection algorithm involves some subtle issues. For example, it is tempting to include an ID string in a virus at a known offset from the end of the virus. When the virus appends itself to the end of a host, the ID string is at a known offset from the end of the program. However, it is naive to assume that a program is infected if and only if the ID appears at the given offset since the program could have become infected by another virus.
The simplest viruses copy themselves to host applications without significantly altering themselves. When this occurs there is an easy way for viruses and antiviral programs to determine if a given executable is infected. The basic method for doing so is called pattern matching [69]. The idea is to take a string of bytes from the virus that does not change from generation to generation and use it to find other instances of the virus. By checking an executable for the presence of this substring it can be determined whether or not the executable is infected. Antiviral programs called scanners perform this scanning process. If the string is sufficiently long and the pattern it contains is unique this method will detect the presence of the virus in infected programs.
The approach is not flawless since the string may appear naturally in certain programs. For instance, this can occur in programs that perform complicated copy-protection operations that contain a large amount of binary data, and so on. As a result this method sometimes produces false positives. However, this method can never produce a false negative when used to identify known viruses.4 String matching is performed correctly every time and the string will never be missed.5 As a result a string matcher that claims to detect all known viruses will never indicate that a program is free of infection when in fact the program is infected.
A countermeasure to scanners is to design the virus so that it does not contain any of the strings contained in the database. This is incredibly easy for a virus writer to do: the virus writer infects a program with the virus and then subjects the program to all available antivirus tools to see if the virus is found. A scanner is capable of detecting a deployed virus only after the needed search string is included in the list of search strings. It is often the case that a new virus is detected only after it mounts a successful attack on a host. Consequently, scanners are not very proactive in identifying viruses. The measure is occasionally proactive since a new virus sometimes reuses the code of other viruses or contains trivial modifications and as a result succumbs to an existing search string.
To perform comprehensive viral scanning it is necessary to perform the lowest level read operations that are possible, since a surprising number of hiding places exist for viral code. For example, most file systems break a disk down into clusters that are fixed in size (e.g., 1024 bytes). An executable seldom occupies an integral number of clusters exactly and as a result there are often unused bytes at the end of executables. The number of unused bytes is dictated by the difference between the physical end-of-file marker and the logical end-of-file marker. The 1963 virus, among others, takes the liberty of storing data in this area [283].
Also, hard disks are typically designed to support multiple operating systems by allowing the disk to be divided into multiple partitions. Computers are often sold with only one preinstalled operating system and one low-level partition for the operating system. In some cases there is still space left over for another tiny partition. Assuming a virus is not too large it could turn this free space into a partition for itself without encroaching on the resident operating system at all. In the case of a multipartite virus this implies that the boot sector phase of the virus would appear to occupy no space at all from the perspective of the operating system. Such viruses gain control from the ROM code of the computer before the boot sector of the operating system is even executed.
On MS-DOS systems this physical boot sector is called the master boot record (MBR) and is exploited by the Monkey virus [283]. In general, boot sector viruses are very dangerous since they gain control of the computer before anything else [289]. This illustrates that malware can sometimes be overlooked by scanners that obtain their data through operating system read calls.
Antivirus scanners have proven to be an effective reactive security measure against viruses and are widely used to check executables, boot sectors, RAM, and so on. Many are even sophisticated enough to first decompress and then scan files compressed using popular compression programs. Antiviral products that scan for viruses often include software that is capable of disinfecting programs. Since the viruses they search for have already been carefully analyzed, in many cases it is possible to algorithmically remove them from the host program. However, whenever possible, infected programs should be deleted and backups should be reinstalled.
8.2.2 Polymorphic Viruses
A straightforward countermeasure to viral scanning is designing a virus to modify its own coding sequence. In laboratory experiments, Fred Cohen produced viruses that had no common sequences of over three bytes between each subsequent generation by using encryption [67, 69]. Such viruses are called polymorphic viruses, otherwise known as evolutionary viruses.
Numerous polymorphic viruses have appeared in the wild. For example, the Tremor virus is a polymorphic virus that has almost 6,000,000,000 forms [283]. A polymorphic virus typically consists of two parts: a header and a body. When dormant, the body remains in encrypted form. When activated, the header is the first section of code to receive control from the operating system. The header decrypts the body in memory. Once the body is decrypted the header transfers control to the body. The body then performs the normal viral operations. When the body is finished it sends control to the host program (see Figure 8.1).
The header stores the symmetric key needed to decrypt the body. This key can be chosen uniformly at random in each generation of the virus and the plaintext of the body can be encrypted using the new key. The new key is stored in the decryption header to ensure that decryption will proceed correctly. By making certain assumptions about the randomness of the resulting ciphertexts, it may be argued that detecting the virus using search strings requires that the search string be taken from the header.
Virus writers have a variety of methods for making the decryption header change as well. Some approaches for this are more effective than others. One obvious method is to employ several different ciphers and randomly select among them. This is a good approach but may in some cases lead to unacceptably large viruses.
Another common approach is to weave dummy instructions between the instructions that constitute the decryption algorithm. Most processors support a NOP instruction that literally does nothing. It is shorthand for no-operation and has many uses. On RISC machines these instructions cause the program to wait until all pending bus activity is completed. This allows synchronization of the pipeline and prevents instruction overlap. It is not uncommon on CISC machines to see NOP instructions woven within the sections of a switch statement to improve the performance of the instruction cache by aligning each section on a new cache line.
There are also a number of arithmetic dummy instructions. For instance, the additive identity element 0 can be used in an ADD instruction. The assembly language instruction ADD aℓ, 0 adds the value 0 to the machine register aℓ and clearly does not change aℓ. The instruction MUL aℓ, 1 multiplies the value in aℓ by 1 and also preserves the value in aℓ. There are dummy instructions for logical operations as well. For example, OR aℓ, 0 performs a bitwise logical OR operation and does not change the value in aℓ.
Another type of dummy instruction is any instruction that operates on registers that are not used in the underlying algorithm. For example, many algorithms do not require the use of all of the data registers at once on the target microprocessor. In this case the addition, multiplication, and so on, of any number in that register has a null effect. All of these dummy instructions have the potential to foil string-matching scanners.
There exist a number of tools that antiviral analysts use that specifically search for such dummy instructions. These tools typically have false positive rates that are very high and as a result make them unsuitable for use by the average user. They nonetheless greatly minimize the time needed for skilled analysts to find polymorphic code.
A better way to obfuscate the decryption header is to replace instructions with other instructions that perform the same operation and to exploit the fact that many instructions can be reordered without affecting the overall correctness of the algorithm [282]. For example, on Intel processors there are many ways to set register aℓ to zero, including:

Figure 8.1 Typical polymorphic virus
- MOV aℓ,0
- SUB aℓ, aℓ
- XOR aℓ, aℓ
- AND aℓ, 0
In the case that code can be reordered, the virus can choose an ordering randomly when creating a modified decryption header. For example, the value x + y + z can be derived by computing t1 = x + y and then by computing t2 = t1 + z. Alternatively, it can be derived by computing t1 = y + z and then t2 = t1 + x. This works since integers are commutative under addition.
When four instructions are completely interchangeable there are 4! ways to order them. Implementing this correctly is subtler than it seems since to be truly correct, one of the 4! permutations must be chosen uniformly at random. A typical random number generator will output a random byte or byte sequence. Such a generator can therefore be used to implement a random bit generator. To choose one of the 4! = 4 * 3 * 2 * 1 = 24 permutations uniformly at random the following Las Vegas algorithm can be performed. Five random bits are taken from the random bit generator. These 5 bits constitute a number chosen uniformly at random between 0 and 31 inclusive. If the number is less than 24 then it is used to select the permutation. Otherwise another 5 bits are generated and the process is repeated.
Once this number is found it is necessary to translate it into the appropriate permutation over the four instructions, for example, (0, 2, 1, 3). There are well-known methods in algorithmic combinatorics to efficiently translate such numbers into the combinatorial objects they represent. These are referred to as unranking algorithms. When working with permutations the Trotter-Johnson algorithm is an efficient way to perform ranking and unranking [142, 163, 301].
Register usage is another aspect that is easily randomized. On the Motorola 68000 Microprocessor there are eight general-purpose data registers. A given decryption algorithm may only require the use of four data registers. There are ![]() ways of selecting four distinct registers from the set of eight registers. Kreher and Stinson give a comprehensive overview of ranking and unranking algorithms for k-element subsets (that is, binomial coefficients) [163].
ways of selecting four distinct registers from the set of eight registers. Kreher and Stinson give a comprehensive overview of ranking and unranking algorithms for k-element subsets (that is, binomial coefficients) [163].
Choosing the set of registers to use uniformly at random may seem like a good heuristic, but with a bit more effort a better approach may be as follows. To make the code less conspicuous, the set of registers should be chosen according to the way the host uses them. This may be accomplished by analyzing the host, calculating the probability distribution over the registers, and then selecting the set of registers to use based on that probability distribution. If for whatever reason a given compiler never uses a particular register, then the decryption header will never employ that register either, thereby making heuristic detection via inhomogeneous code less likely.
Another approach to heuristically obfuscating a decryption header is to interleave another algorithm within the header. For example, by weaving within the header an arbitrary algorithm such as Mergesort and having it sort legitimate data, it may be considerably more difficult to determine that the header performs decryption. In the end all of these heuristics succumb to reverse engineering by an analyst or a carefully crafted program that specifically looks for this type of obfuscation.6 However, a virus writer's goal is often to simply bypass all existing antiviral programs and not worry about what will be developed further down the road.
It has been observed that since many viruses execute before the host, it is often possible to positively identify polymorphic viruses by letting them decrypt themselves [197]. The general idea is to emulate the operation of the host program for the first few thousand or so instructions and then scan the resulting executable for the presence of known polymorphic viruses. The method is called generic decryption and involves three components: a CPU emulator, an emulation control module, and a scanner. The CPU emulator is designed to emulate a particular CPU such as a Pentium IV processor. The emulation control module determines such things as how many instructions will be emulated7 and is also responsible for making sure that no damage is done to the underlying machine as a result of the presence of malware. For example, writes to the disk may be prevented or otherwise contained. The scanner is applied to the code at regular intervals during the emulation to attempt to detect malicious software. Generic decryption can be performed on the fly along with traditional scanning methods to help identify polymorphic viruses wherever present.
A countermeasure to generic decryption is to make the virus decrypt its body with some fixed probability. The virus could generate a random number and with some probability not decrypt its main body at all. For example, when the virus gains control in a given invocation of the host program, it could roll a six-sided die. If the result is “1” then the virus could decrypt itself and then try to replicate. If the result is not “1” then it could simply send control back to the host.
Another countermeasure to generic decryption is to make the virus gain control at a randomly determined offset within the host program. Implementing this countermeasure is more complicated than it seems since simply overwriting portions of the host will likely lead to crashes. As usual, the bulk of the virus could be stored at the end of the executable. The problem then remains to modify the host to send control to the virus. One approach to accomplishing this is to choose an offset within the host randomly and overwrite the code at that location with a jump instruction. The original code would need to be stored within the virus, and the overlaid jump instruction would send control to the virus unconditionally. When the virus finishes executing it repairs the host by overwriting the jump instruction with the original host code and then sends control back to where it normally would have been. This has been demonstrated experimentally (see Appendix A.4).
This approach is not without its risks, however. The jump instruction and the viral code that follows it should preserve the state of the program. Register values should be pushed onto the stack, and so on, and popped when the virus completes. Also, if the jump instruction is too long it might overwrite code that forms an entry point for another jump instruction within the host. This could cause the host program to crash as a result of the inserted jump instruction. The virus would have to heuristically analyze the host to make certain that this cannot occur. If the host were naturally polymorphic, this analysis would be just as hard as the problem faced by antiviral programs. Finally, race conditions could cause faulty behavior within the host. If the jump instruction were written over an atomic action that operates on a semaphore and if the viral operation exacerbates the race-condition, then the infected host could crash or produce erroneous results.8
Another general heuristic for detecting polymorphic viruses is to look for changes in memory where the code for the currently running executable resides [218]. Symantec developed a tool that interprets the program one instruction at a time and that takes note of every byte in the program's code space that changes. This method is a solid countermeasure, but has certain weaknesses. For example, it is possible to make the virus create multiple encryption layers with decryption headers in the host. These small headers can decipher the rest of the binary executable and therefore almost every byte of the program in memory can be changed. Another issue to deal with is programs that spawn child programs.9
An unavoidable aspect of making a virus difficult to detect is that by doing so it becomes harder for the virus to detect itself. This makes it difficult for the virus writer to prevent multiple infections. The more a virus writer strives to make the virus undetectable, the more difficult it becomes for the virus to detect itself. This leads to the aforementioned trade-off wherein the virus writer has to decide whether or not to include a virus detection algorithm within the virus. Assuming that multiple infections are not tolerable, the true threat model that a virus writer faces is that of preventing the virus from being discovered in the first place.
8.3 Heuristic Virus Detection
Viruses perform actions that are not typical of normal programs. As a result there are several heuristics that can be used to detect them whenever they are present. For example, a virus replicates by definition. Word processors, web browers, and e-mail programs do not replicate. So, any program that contains code that adds code to another program could in fact be infected with a virus. However, there are certain obvious exceptions to this rule. For example, software companies often release fixes to their software in the form of patches. These patches are programs that add or overwrite code to a program on the machine. Software patches allow portions of large programs to be repaired without reinstalling the entire program.
In this section several virus detection heuristics are described. These include the detection of code abnormalities such as unusual program entry points and unusual program behavior such as self-replicating code. The section concludes with ways of detecting cryptographic functions in binary progams. These latter heuristics are designed to help detect cryptoviruses and cryptotrojans.
8.3.1 Detecting Code Abnormalities
Scanners are excellent protection mechanisms for viruses that have already been discovered. However, virus writers often subject viruses to antiviral scanners before releasing them, thus guaranteeing that they do not contain any of the known search strings. More often than not such viruses are only discovered as a result of the activation of their payloads. It is therefore desirable to be able to detect new viruses before they have a chance to sabotage computer systems. This motivates the need for proactive antiviral mechanisms that heuristically detect computer viruses.
One approach to proactively detecting viruses relies on the fact that many viruses append themselves to the end of executables and change the entry point to point to themselves. In bulky programs this initial jump may be abnormally large and thereby indicate the presence of a virus. Some viruses change the entry points to very unusual locations and this forms another heuristic for viral detection.
Weber, Schmid, Geyer, and Shatz at Cigital Labs devised a handful of clever methods for detecting malware [314]. Their methods were implemented in a toolkit called the Portable Executable Analysis Toolkit, or PEAT for short. PEAT is designed to detect malware that has been added to programs after they have been compiled, and is based on the premise that hand-crafted malware introduces statistical discrepancies when it appears within an otherwise homogenous binary executable.
When a compiler creates a program it often creates jump tables for functions and has internal jumps and subroutine calls throughout. However, when malware is appended there will typically be only one jump into the added malware and one jump out to send control back to the host. In this case there may be a noticeable lack of flow control instructions between the malware and its host. PEAT looks for flow control anomalies such as this to help identify malware. Also, most programs are written in high-level languages, whereas malware is typically written in assembly language and as a result tends to be more compact and efficient. When malware is attached to a homogenous executable there is often a statistical difference in the instruction frequencies between the two regions. PEAT searches for these variations and reports them to the user. The PEAT toolkit has a false positive rate that is too high for most end-users but is ideal for reducing the time needed for skilled analysts to identify malicious code.10
8.3.2 Detecting Abnormal Program Behavior
By definition viruses copy possibly altered versions of themselves into host programs. Many antiviral programs exploit this intrinsic property of computer viruses to identify new strains. By looking specifically for executable code that modifies other executable code there is a chance that new strains will be identified before they have a chance to execute their payloads. At the heart of every operating system is an operating system services layer that provides exactly this functionality.
Modern operating systems provide a set of service routines to applications that enable the applications to make full use of the computer and its peripherals. For example, there are well-defined operating system routines to read keystrokes from the keyboard, read and write data to disk drives, and so forth. By providing developers with a standard interface to common peripherals, the specifics of particular peripheral devices may be ignored without hindering their usability. This standard interface therefore provides a level of abstraction for software developers and eases the overall software development process. Device drivers help bridge the gap between operating system calls and the underlying peripheral machinery. The operating system expects to be supplied with a device driver whenever a new device is attached to the system. This provides operating system developers with their own level of abstraction. The amount of code needed to interface directly with device drivers is often substantial and so the operating system service routines help to minimize the amount of code used in individual applications.
Application programs typically access operating system routines using software interrupts. To invoke an operating system routine such as reading in a keystroke from the keyboard, the program typically places various parameters in CPU registers and then executes a software interrupt instruction (e.g., INT 21h). The CPU then temporarily suspends the operation of the program and looks up the address of the operating system routine for that interrupt in the interrupt vector table (see Figure 8.2). Control is then sent to the address and the operation is carried out. When the operating system routine is finished it returns control back to the calling program by executing an interrupt return instruction (e.g., IRET). The values that are returned are typically left for the calling program in CPU registers. For instance, the values may indicate whether or not a key was pressed and which key was pressed, if any.
Many viruses propagate by first opening the target executable file with write permissions followed by a call to write to the file. It would therefore make sense to scan executables for a software interrupt that opens executables for writing followed by a software interrupt that attempts to write to the file. However, in the case of polymorphic viruses this will not always work since the interrupt instructions could be encrypted.
A heuristic solution to this problem is to monitor at run-time all attempts to open files with write permissions and all attempts to write data to the disk. An effective way to carry out this form of monitoring is to modify the operating system service routines to be more suspicious of the applications that call them. Interrupt patching is a standard systems programming technique that can be utilized to add such functionality to otherwise trusting operating system service routines.
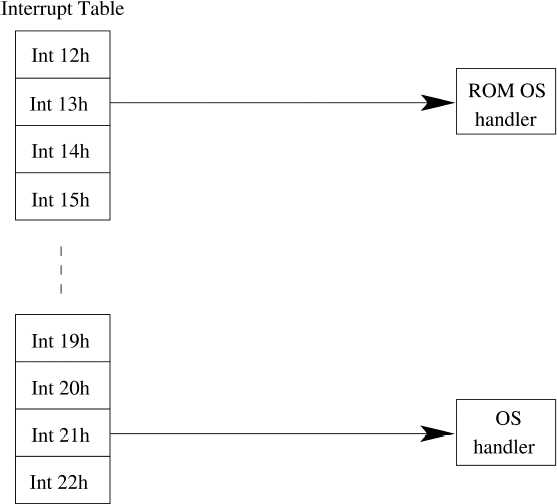
Figure 8.2 Operating system software interrupt handling
To patch an interrupt, an interrupt handler is loaded into memory in a persistent and non-relocatable block. The entry in the interrupt table corresponding to the operating system routine being patched is overwritten with the starting address of the new interrupt handler. When the handler finishes executing it sends control to the address that was originally contained in the interrupt table. Many operating systems have service routines for manipulating the interrupt vector table. Common functions include returning the interrupt handler address for a particular interrupt and setting the interrupt handler address for a particular interrupt.
On occasion a bug is found in a native operating system routine and the routine needs to be replaced. This presents a problem when the routine is located in ROM since it cannot be modified without replacing the chip on the motherboard.11 One solution is to distribute a software update that patches the buggy interrupt. Such a patch can replace the original handler entirely by executing an interrupt return instruction when it completes instead of sending control to the buggy handler.
The ability to patch operating system routines provides a good approach to heuristically detecting attempts to modify executable code. An interrupt activity monitor works by loading antiviral interrupt handlers soon after the computer is booted. These handlers are collectively managed and typically span several different operating system routines (see Figure 8.3). When they gain control they analyze the circumstances surrounding the call and often maintain state information across calls. They take note of such things as opening executable files for writing followed by attempts to write to the file. In general, monitors look for attempts to write to any sector containing executable code such as device drivers, boot sectors, and so on [185, 289]. They also typically look for attempts to reformat floppy disks and other potentially malicious acts.
When a suspicious sequence of events occurs an activity monitor will normally display a message to the user that implicates the calling program. The monitor may also request permission from the user to pass control to the operating system service routine. If the user agrees to let the operation continue, control is then sent to the original address that was listed in the interrupt table (see Figure 8.4). This way, users have a chance to stop a virus before it writes itself to another program.
One of the dangers in using activity monitors is that if the alerts occur too frequently, the user may then become desensitized to them. Alerts may arise when a software patch is applied, when a new program is compiled, when a program utilizes a copy protection scheme that causes the program to write to itself (e.g., WordPerfect [185]), and so on. This form of “cry wolf” makes it more likely that users will allow a virus to spread in spite of warnings from an activity monitor. Unlike scanners, activity monitors are designed to identify both existing and future viruses, and as a result activity monitors are prone to yield false negative results. False negatives are guaranteed due to the undecidability of viral detection.
How do viruses deal with this heuristic countermeasure? There are a variety of ways that viruses bypass activity monitors. A boot sector virus can gain access to the interrupt table before activity monitors and as a result learn the starting addresses of the operating system routines that it needs to call. Once learned, the virus can call them directly when needed or temporarily modify the interrupt table to contain the original addresses. However, it is not uncommon for activity monitors to patch operating system routines that manipulate the interrupt table. In this case the boot sector virus could manipulate the interrupt table directly.
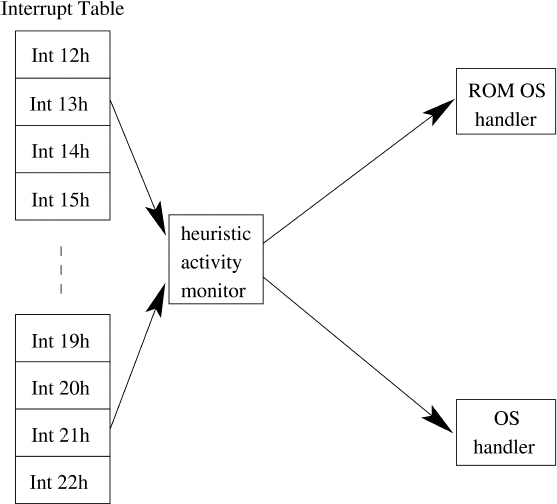
Figure 8.3 Heuristic interrupt monitor
Another viral defense against activity monitors that boot sector viruses can take is to create a viral patch that encompasses all of the interrupts that the virus will need to invoke (see Figure 8.5). In this situation the virus does not need to utilize the interrupt table at all. It therefore makes all the difference in the world which program gains access to the interrupt table first: the virus or the activity monitor. As a result the interrupt table has traditionally formed a battleground in older PC operating systems.
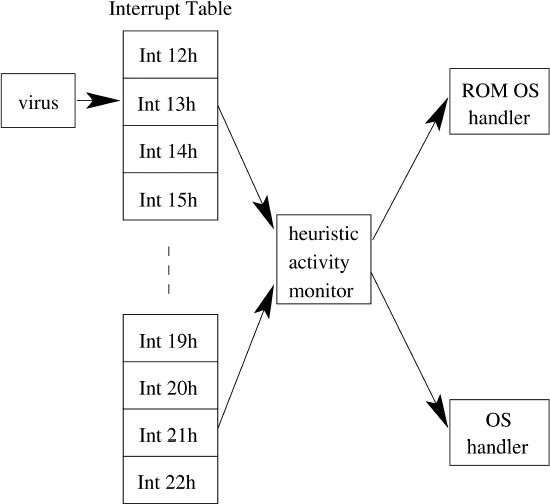
Figure 8.4 Virus detected by activity monitor
A challenge for viruses is to be able to call operating system routines on a machine that is already running an activity monitor. Such a situation arises when an infected program is run for the first time on a machine that is judiciously guarded by an activity monitor. The reason that this is a non-trivial undertaking is that when the operating system routine is patched with an activity monitor, the starting address of the operating system routine is overwritten in the interrupt table with the starting address of the activity monitor. The starting address for the operating system routine is typically stored somewhere within the activity monitor to allow control to be transferred to the operating system routine. Tunneling is a method in which a virus tries to recover the starting address of the original operating system routine by heuristically analyzing the activity monitor code [239, 283]. If all of the needed addresses are successfully recovered, the virus can call the original operating system routines directly and circumvent the activity monitor completely.

Figure 8.5 Virus bypassing an activity monitor
A cumbersome and oftentimes risky way to avoid this type of activity monitor is to implement all of the needed operating system functionality directly within the virus [185]. This way there is no need to utilize the operating system services. However, this is very difficult to do while keeping the size of the virus at a minimum.
Viruses that patch operating system interrupts are invoked frequently since they gain control whenever an application makes a service request. The fact that they gain control frequently makes it easy for them to infect programs since they can infect the currently running program as opposed to performing a directory search. Many of the early viruses replicate by infecting interrupt handlers [289]. Some cleverly written memory-resident viruses only write themselves to other executables during normal write operations. On disk drives that have lights, this implies that the light goes on only when the light would normally go on and as a result makes such viruses difficult to detect.
Viruses that patch interrupts have the added benefit of being able to utilize stealth methods [283]. A stealth virus patches one or more operating system read calls and when an attempt is made to read a sector containing the virus (e.g., the boot sector), the virus returns the uninfected version of the image. The Pakistani Brain virus camouflaged its presence by patching the BIOS read interrupt on IBM PC machines [289]. Consequently, when an integrity check is computed on a machine that is infected with a stealth virus, the integrity check will pass and thereby fail to detect the presence of the virus. This threat implies that it is important to boot from a clean operating system in order to check for viruses.
In carefully designed operating systems it is quite difficult for viruses to gain access to the interrupt table. Many of the early viruses had free reign over the interrupt table since the early personal computers were not designed with the threat of computer viruses in mind. One of the primary reasons why these early viruses were so successful is that older PC operating systems were based on a very weak trust model. This model assumed that each machine was used by a single trustworthy user [289]. The model did not take into account large exchanges of software and as a result these early viruses flourished.
The danger of viral replication is minimized in operating systems that run in protected kernel mode, such as UNIX. Security kernels were originally designed to provide provable security. They evolved from the notion of a reference monitor12 that was described in the Anderson Report [6]. A reference monitor is an abstraction of the access checking function of object monitors [121]. The main idea behind a security kernel is to have a small nucleus of operating system software that is tasked with administering the security policy of the entire system. Provided that the kernel is small, the verification effort is much less than what would be required to verify a complete operating system [85].
A security kernel operates in a separate address space that is not accessible to user programs. Privileged operations such as starting I/O and halting the CPU are available exclusively to the kernel. User programs request services from the kernel via system calls. System calls are used to cause the kernel to read from the keyboard, read/write to disk drives, and so on. System calls are usually implemented as hardware traps that change execution mode of the CPU and the current address space mapping. The kernel validates the parameters supplied by user programs before they are used in order to guarantee the correctness of the system. All parameters that are passed are copied into the kernel address space [169]. Open research on security kernels began in the early 1970s and a number of prototypes were implemented soon thereafter [256, 290, 312].
In the UNIX operating system, programs inherit the access privileges of the user that is currently logged in. As long as the user avoids logging in as root whenever possible, it is very difficult for a virus to gain total control of the machine. Usually when a virus succeeds at becoming root it succeeds due to the exploitation of a bug that exists in the underlying operating system.
8.3.3 Detecting Cryptographic Code
Cryptographic malware is a subset of all malicious software. Examples of malicious software that do not employ cryptography include the cookie-monster virus. Its name derives from the cookie monster on the television show Sesame Street. It would flash up the message “I want a cookie” on the monitor. The word “cookie” had to be fed to the virus to keep it quiet [185]. A cookie monster Trojan that ran on PDP machines was also reported [129]. The relationship between cryptography and malware may be depicted by way of a Venn diagram (see Figure 8.6). Polymorphic viruses that employ trivially breakable symmetric encryption still fall within the intersection, yet due to their simplistic nature they should probably be plotted more towards the malware set as opposed to the cryptographic code set.
It follows that one way to heuristically detect cryptoviruses is to heuristically detect the presence of cryptographic code. The absence of cryptographic code implies that absence of cryptoviruses, cryptotrojans, and so on. In considering this problem, a number of heuristics immediately come to mind. For example, many cryptographic libraries test primality by first performing trial division using small primes. It is not uncommon for a primality-testing program to store an array constant consisting of all prime numbers that fit within 16 bits. These are ordered from smallest to largest (e.g., 2, 3, 5, 7, 11, 13, 17, ...). It is possible to detect such implementations using a form of string matching. Basically, this sequence of primes is searched for taking into account little endian and big-endian machine architectures. However, the majority of cryptovirus attacks that have been presented do not involve primality testing (the exception is the RSA SETUP attack). So this cryptographic code detection heuristic is likely to be of little use in those cases.

Figure 8.6 Malware and cryptographic code
In a similar vein it is straightforward to detect many symmetric ciphers as well. These algorithms have fixed constants in the form of substitution boxes and permutation boxes. When in plaintext form, they are relatively easy to detect using string-matching techniques. The ability to detect decryption algorithms is crucial in detecting advanced polymorphs. The heuristic detection of Feistel transformations can also indicate the presence of cryptographic hash functions. This helps to infer semantics about the program in question since it reveals some of the underlying cryptographic functions that are used.
A general heuristic13 to detect public key cryptography implementations is to look for the presence of the Karatsuba multiplication algorithm [150]. The Karatsuba algorithm is an efficient algorithm for multiplying two large numbers together. It follows the divide-and-conquer paradigm and has a complexity of O(nlog23) where n is the size in bits of the numbers being multiplied.14 The classic multiplication algorithm that is taught in grade school has a running time of O(n2).
Karatsuba is used in many cryptographic libraries since it speeds up RSA, ElGamal, DSA, and a wealth of other algorithms. The algorithm is given below. For simplicity it is assumed that |x| = |y| = 2α for some integer α > 0. The notation |x| denotes the bit length of x.
Karatsuba(x, y):
1. if |x| ≤ 16 then return (x * y)
2. m = |x|/2
3. compute a and b such that x = a2m + b
4. compute c and d such that y = c2m + d
5. t = Karatsuba(a, c)
6. u = Karatsuba(a + b, c + d)
7. v = Karatsuba(b, d)
8. output (tv22m + (u − t − v)2m + v) and halt
The reason that Karatsuba is faster than the classical approach is that it divides a problem into three problems of half the size.
The recursive structure of Karatsuba lends itself to a simple detection heuristic. The heuristic requires that the call graph of the program in question be constructed from the binary code. There is ongoing research in the area of reconstructing call graphs from binary programs [62, 63, 64, 65]. A call graph is a directed graph where each vertex is a function and each directed edge is a pointer to a function that the vertex calls. There are a number of algorithms and packages available that can be used to construct the call graph for a given program. If such a graph contains a cycle, then it contains a recursive function call. In a straightforward implementation, Karatsuba will have the calling structure depicted in Figure 8.7.
Since Karatsuba calls itself exactly three times, one would expect it to contain a single function that sends control to the Karatsuba entry point exactly three times. An algorithm like Mergesort that divides a problem into two problems of half the size would contain a function that called Mergesort exactly twice, and so on. This implies that Karatsuba can be singled out to a degree. Detecting whether or not a directed graph contains a cycle is an elementary problem. It can be accomplished by performing a breadth-first search of the graph, while maintaining a list of vertices that have been visited. When a back-edge is found that leads to a vertex that has already been visited, a cycle has been found. By storing the parent of each vertex in a parent array, the cycle can be traversed backwards and written down.
It is worth noting that a generalization of Karatsuba exists. Also, large integer multiplication can be performed using Strassen multiplication. This method is based on the Fast Fourier Transform and is a good candidate for parallel implementation. Thus, other recursive structures can be heuristically searched for as well.

Figure 8.7 Recursive structure of karatsuba
Another potential approach to detecting cryptoviruses and cryptotrojans is to search for the public keys they contain. Shamir and Someren investigated approaches for algorithmically searching for RSA public and private keys in bulk data [268]. This was within the context of lunch time attacks where an attacker gets brief access to a machine and wants to search for cryptographic keys quickly. This notion is useful for detecting malware that uses such keys as well. In this section heuristics are given for detecting various types of public keys. Consider discrete log trapdoor. A discrete logarithm based key pair typically comes in 3 forms:
- ((y, g, p), x) where y = gx mod p, ordp(g) = p − 1, p − 1 has large prime divisor
- ((y, g, p), x) where y = gx mod p, ordp(g) = (p − 1)/2 = q where q is prime
- ((y, g, p, q), x) where y = gx mod p, ordp(g) = q, where q is prime
In all three pairs, the first tuple is the public key and x is the private key. In form (2) p is a safe prime. Here ordp(g) denotes the order of g modulo p. In form (1), g generates ![]() . In forms (2) and (3), g has order q and generates a prime order subgroup of
. In forms (2) and (3), g has order q and generates a prime order subgroup of ![]() .
.
Multiprecision integers are typically stored in one's complement format in cryptographic libraries. Typically, p is 768 or 1024 bits in length. The value y is almost always the same length as p. The value g is sometimes chosen randomly, but a common heuristic in choosing a generator g is to try g = 2, 3, 4, 5, 6,... until one is found. It is believed that the factorization of p − 1 must be known to test if a value is a generator. This heuristic is likely to work when g is chosen uniformly at random. The idea is to heuristically identify these parameters in embedded code based on the fact that they are typically high-entropy strings of specific lengths. Certain assertions exist based on the mathematical relations. These assertions are listed below for each form:
- The value p is prime: This is a somewhat weak assertion, but it is worth noting that this form is old-fashioned. ElGamal encryptions that use such keys are not semantically secure against plaintext attacks.
- The value p is prime, (p − 1)/2 is prime, g(p−1)/2 = 1 mod p.
- The value p is prime, q is prime, q divides p − 1 evenly, gq = 1 mod p, q is typically 160 bits in this setting (e.g., DSA).
Checking for such assertions has the potential of minimizing false positives. For example, if form (3) is satisfied, there is a good chance that a public key has been found.
It is worth articulating the failure probability for form (3) above, since this is the one with the lowest false positive rate. A random value in ![]() will have order q with probability about q/p. This is found by dividing the number of elements in G by the number of elements in
will have order q with probability about q/p. This is found by dividing the number of elements in G by the number of elements in ![]() . Here G is the prime order subgroup of
. Here G is the prime order subgroup of ![]() generated by g. Typically, q is 160 bits and p is say, 768 bits. So, this probability is about 2160/2768 = 2−608. Note that the public key y will also have order q modulo p. Hence, the heuristic need only find y or g. This probability is so astronomically small that if this assertion holds, a public key will most certainly have been found in the software.
generated by g. Typically, q is 160 bits and p is say, 768 bits. So, this probability is about 2160/2768 = 2−608. Note that the public key y will also have order q modulo p. Hence, the heuristic need only find y or g. This probability is so astronomically small that if this assertion holds, a public key will most certainly have been found in the software.
In DSA, the prime p varies from 512 to 1024 bits in multiples of 64 bits. One would expect 768 or 1024 to be used the most. The following heuristic can be used to search for DSA public keys of the form (y, g, q, p) in binaries. It runs in time polynomial in the length of the binary code that is analyzed. However, it is somewhat computationally intensive and so is most practically applied when a binary has been found that is believed to contain a Trojan, virus, worm, and so on, and the malware is not identified by other means, for example, commercial antiviral software.
This heuristic searches for (y, q, p) from (y, g, p, q) where yq = 1 mod p. The reason that we do not search for g is that g can be very small (10 bits or less, and so on). But, for a randomly chosen private key x, y will almost certainly be as long as p in bits.
The heuristic assumes that big numbers are stored on byte boundaries. It can be coded to handle big endian and little endian architectures. For simplicity assume that the bytes are ordered from most significant to least significant. The heuristic can handle one's complement and two's complement big integers, since the numbers are the same when they are positive. All public key parameters are positive.
In this example we will assume that p is 1024 bits and q is 160 bits. Hence, p is 128 bytes and q is 20 bytes. The following is the heuristic to find prime order subgroup trapdoors in binaries:
- Scan the binary for 1024-bit primes p. This is done by checking the first 128 bytes, then shifting one byte, testing primality, shifting one byte, testing primality, and so on. The end result is a list Lp of 1024 bit primes. For a random byte stream, the Prime Number Theorem implies that 1 in 1024 values will be prime naturally. Remove all values from Lp that have low entropy.
- Scan the binary for 160-bit primes q. This is the same as in step 1, except that it is for a different size prime. Let the resulting list be Lq. Remove all values from Lq that have low entropy.
- Scan the binary for 1024 bit values y that have high entropy. Let the resulting list be Ly. This list may be quite large.
- For each possible 3-tuple (y, q, p) where y
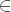 Ly, q Lq, and p Lp, compute yq mod p. If this quantity equals 1 then output (y, q, p) for this tuple. Note that multiple 3-tuples might be output in this step.
Ly, q Lq, and p Lp, compute yq mod p. If this quantity equals 1 then output (y, q, p) for this tuple. Note that multiple 3-tuples might be output in this step.
In general, if a single 3-tuple is output, a prime order subgroup public key has been found in the binary.
8.4 Change Detection
Computer viruses must invariably change their hosts in some way in order to infect them. As a result one way to detect infections is to look for changes in executables. It may be tempting to simply consider the size in bytes of executables in order to detect changes since by adding code to a program one would think that the resulting program would be larger than the original. But this is not necessarily the case. If the binary code in the host executable is redundant then it can be compressed to make the added viral code less noticeable.
For example, a virus could be written that performs Huffman compression and decompression [134] and that has space reserved internally for a Huffman tree. When an executable is considered for infection, the Huffman tree for the executable is computed and the compression ratio is calculated. If the size of the compressed executable plus the size of the virus is less than or equal to the size of the original executable, then the virus decides to infect the executable. The virus then compresses the executable and pads it as necessary so that the resulting data when combined with the virus is the same length in bytes as the original executable. It is necessary that such a virus gain control before the host program to prevent the infected executable from crashing. When the virus gains control it performs its normal viral operations, decompresses the host, and then sends control to the host.
8.4.1 Integrity Self-Checks
File sizes alone are therefore not sufficient for identifying changes to executables. A better approach is to utilize cryptographic integrity checks [68, 70]. A program can perform cryptographic integrity checks at runtime to help ascertain whether or not the program has been changed in any way. A simple approach is to compute a cryptographic hash of the executable after the program is compiled and include the hash value inside a routine that is appended to the program, much like a Trojan horse program. This program will recompute the hash on the body of the executable at run-time and compare the result with the internally stored value. The routine sends control to the body of the executable if and only if the hash values are equal. The design of self-checking software is a well-studied area [70, 327].
A drawback to cryptographic integrity checks is that they notify the user of changes only after they occur. This line of defense therefore falls into the category of being reactive in nature. Also, it is critical that the initial cryptographic hash values are computed on executables that are known to be virus-free. To prevent false alarms it is necessary to update the hash values whenever software updates are applied. In environments in which programs are frequently added and updated this solution may prove cumbersome.
There exists a subtler problem with integrity self-checks. Consider a virus that replicates as follows. Once control is sent to the host the virus immediately gains control and searches the file system for two programs to infect. Once found, the virus infects both of them and then disinfects itself from its host in memory.15 The virus then sends control to its host. If the host performs an integrity check on itself in memory then it will pass since it is in the same pristine form that it would be if it were never infected. It passes since the host is no longer infected. Like other viruses, this virus will also benefit from an exponential infection rate since it performs two infections each time it disinfects itself. The virus therefore demonstrates a fundamental weakness in viral self-checking. The self-disinfection defense constitutes a mixed blessing, both from the perspective of the virus writer and from the perspective of antiviral analysts:
- virus writer: Has the benefit of preventing the virus from being discovered by hosts that perform integrity self-checks. However, it assists antiviral analysts in devising a cure for the virus.
- antiviral analyst: Has the drawback of preventing executables that perform integrity self-checks from finding the virus. But once found, it reveals the steps necessary to safely remove the virus.
8.4.2 Program Inoculation
Activity monitors form a solid proactive measure to prevent viruses from spreading in the first place. However, the numbing alerts that they present to the user can negatively impact the success of the measure. Another proactive measure is to inoculate programs against specific viruses [289]. Inoculation is a procedure that protects a given program from being infected in the first place. It only works against viruses that actively prevent multiple infections in a given host. In this procedure an executable is modified in such a way that it appears to the virus as if it is already infected. More often than not this involves appending data to the end of the application that contains data at a particular offset that leads the virus to believe that a copy is already in the host. The appended data is benign and serves only to fool the virus into thinking that the application is already infected.
The main problem with this solution is that there may be far too many viruses to protect against. Also, if this method is applied to an executable that checks its own integrity then it may fail to run in response to the modification. The addition of the benign data to the code will with overwhelming probability cause cryptographic integrity checks to fail.
8.4.3 Kernel Based Signature Verification
To be most effective the integrity checking should be conducted externally on the program rather than internally. External integrity checking programs exist that take snapshots of vulnerable programs and sectors when they are first installed. Some time later these programs take new snapshots and compare them with the old ones. If a new snapshot does not match the corresponding old snapshot then the user is notified. Such snapshots duplicate the executable code exactly and therefore identify changes perfectly. This form of external checking is most effective when it is applied from within a secure kernel. For reasons of efficiency a cryptographic hash can be used in lieu of raw images. Before running an application, the kernel computes the cryptographic hash of the file and compares the result with the internally stored value in the kernel space. The program is executed if and only if they match.
Although this method is a clear improvement, it does not prevent programs from being altered after leaving the manufacturer and before installation on the user's machine. A powerful end-to-end solution to this problem combines the notion of a secure kernel with digital signatures [85, 87]. In this method the kernel stores the root and CA digital certificates of the PKI used to certify the application that is to be run. The manufacturer digitally signs the application and releases it along with the digital signature and certificate that are needed to verify the signature. When the user runs the application, the certificate and signature are given to the kernel. The kernel verifies the authenticity of the certificate using the internally stored CA certificate and also checks a Certificate Revocation List if necessary. Once the certificate is deemed valid it is used to verify the signature on the application. The application is run if and only if the certificate and signature are valid. When a signature is valid the user can be overwhelmingly certain that the program has not been tampered with.
This form of integrity checking will never produce false positive results. If the digital signature is invalid, then the application has been changed without a doubt. However, there is a negligible chance that a false negative will result. A malicious user or program can change an application and still have the signature verify correctly with an exponentially small probability.
In retrospect it is safe to say that the early viruses spread rampantly only because of the initial short-sightedness of PC manufacturers. With the Internet revolution and the proliferation of secure kernels in desktop PCs, virus writers today face hurdles that they really should have been facing two decades ago. It is a classic case of existing yet neglected technology. Public key cryptography promises to close this gap even further and provide more secure and more reliable computing environments in the years to come.
1To be precise, the input is a Gödelization of M and of w.
2Turing machine M accepts w if M(w) terminates in a final state.
3A machine name can be a hard drive label, IP address, and so on.
4Stealth viruses (explained later) are an exception to this rule since they have the potential to alter the scanner's perception of the true binary data in the program.
5Polymorphic viruses are a different case. The question here is whether or not a program contains a particular substring.
6This further motivates the study of the cryptocomputing problem.
7Due to the halting problem there is no general way to determine if a program will halt or not.
8There are a myriad of other problems that could arise as well. For example, the inserted jump could alter a checksum, cause a digital signature verification to fail, and so on.
9For example, processes often fork and exec in UNIX thereby creating more heap zones that need to be analyzed.
10A number of other companies provide antiviral software that perform viral scanning, heuristic detection, and disinfection. Such products include Symantec Antivirus and McAfee VirusScan. These products typically have lower false positive rates than PEAT against known viruses but higher false negative rates against new viruses.
11The contents of EEPROM chips can actually be changed by users, but this often requires explicit user intervention. It is a very security-intensive operation since malware can be burned into the chip.
12The notion of a reference monitor was suggested by Roger Schell.
13This heuristic was developed by Adam at Cigital Labs.
14This may be proven by setting up the recurrence relation and solving it.
15And from the disk image, if possible.