
As a data scientist, one of the most important tasks is to load data into your data science platform. Rather than having uncontrolled, ad hoc processes, this chapter explains how a general data ingestion pipeline in Spark can be constructed that serves as a reusable component across many feeds of input data. We walk through a configuration and demonstrate how it delivers vital feed management information under a variety of running conditions.
Readers will learn how to construct a content register and use it to track all input loaded to the system and to deliver metrics on ingestion pipelines, so that these flows can be reliably run as an automated, lights-out process.
In this chapter, we will cover the following topics:
- Introduce the Global Database of Events, Language, and Tone (GDELT) dataset
- Data pipelines
- Universal ingestion framework
- Real-time monitoring for new data
- Receiving streaming data via Kafka
- Registering new content and vaulting for tracking purposes
- Visualization of content metrics in Kibana to monitor ingestion processes and data health
Even with the most basic of analytics, we always require some data. In fact, finding the right data is probably among the hardest problems to solve in data science (but that's a whole topic for another book!). We have already seen in the last chapter that the way in which we obtain our data can be as simple or complicated as is needed. In practice, we can break this decision down into two distinct areas: ad hoc and scheduled.
- Ad hoc data acquisition: is the most common method during prototyping and small scale analytics as it usually doesn't require any additional software to implement. The user acquires some data and simply downloads it from source as and when required. This method is often a matter of clicking on a web link and storing the data somewhere convenient, although the data may still need to be versioned and secure.
- Scheduled data acquisition: is used in more controlled environments for large scale and production analytics; there is also an excellent case for ingesting a dataset into a data lake for possible future use. With the Internet of Things (IoT) on the increase, huge volumes of data are being produced in many cases, if the data is not ingested immediately it is lost forever. Much of this data may not have an apparent use today, but could have in the future; so the mindset is to gather all of the data in case it is needed and delete it later when we are sure it is not.
It's clear we need a flexible approach to data acquisition that supports a variety of procurement options.
There are many ways to approach data acquisition, ranging from home-grown bash scripts through to high-end commercial tools. The aim of this section is to introduce a highly-flexible framework that we can use for small-scale data ingest, and then grow as our requirements change all the way through to a full, corporately-managed workflow if needed. That framework will be built using Apache NiFi. NiFi enables us to build large-scale, integrated data pipelines that move data around the planet. In addition, it's also incredibly flexible and easy to build simple pipelines usually quicker even than using bash or any other traditional scripting method.
We have chosen to use Apache NiFi as it offers a solution that provides the ability to create many pipelines of varying complexity that can be scaled to truly big data and IoT levels, and it also provides a great drag and drop interface (using what's known as flow-based programming https://en.wikipedia.org/wiki/Flow-based_programming ). With patterns, templates, and modules for workflow production, it automatically takes care of many of the complex features that traditionally plague developers such as multithreading, connection management, and scalable processing. For our purposes, it will enable us to quickly build simple pipelines for prototyping, and scale these to full production where required.
It's pretty well documented and easy to get running by following the information on https://nifi.apache.org/download.html. It runs in a browser and looks like this:

We leave the installation of NiFi as an exercise for the reader, which we would encourage you to do as we will be using it in the following section.
Hopefully, we have NiFi up and running now and can start to ingest some data. So, let's start with some global news media data from GDELT. Here's our brief, taken from the GDELT website, http://blog.gdeltproject.org/gdelt-2-0-our-global-world-in-realtime/:
"Within 15 minutes of GDELT monitoring a news report breaking anywhere the world, it has translated it, processed it to identify all events, counts, quotes, people, organizations, locations, themes, emotions, relevant imagery, video, and embedded social media posts, placed it into global context, and made all of this available via a live open metadata firehose enabling open research on the planet itself.
[As] the single largest deployment in the world of sentiment analysis, we hope that by bringing together so many emotional and thematic dimensions crossing so many languages and disciplines, and applying all of it in realtime to breaking news from across the planet, that this will spur an entirely new era in how we think about emotion and the ways in which it can help us better understand how we contextualize, interpret, respond to, and understand global events."
Quite a challenging remit I think you'd agree! Therefore, rather than delay, pausing to specify the details here, let's get going straight away. We'll introduce the aspects of GDELT as we use them throughout the coming chapters.
In order to start consuming this open data, we'll need to hook into that metadata firehose and ingest the news streams onto our platform. How do we do this? Let's start by finding out what data is available.
GDELT publishes a list of the latest files on their website. This list is updated every 15 minutes. In NiFi, we can set up a dataflow that will poll the GDELT website, source a file from this list, and save it to HDFS so we can use it later.
Inside the NiFi dataflow designer, create a HTTP connector by dragging a processor onto the canvas and selecting GetHTTP function.

To configure this processor, you'll need to enter the URL of the file list as:
http://data.gdeltproject.org/gdeltv2/lastupdate.txt
Also, provide a temporary filename for the file list you will download. In the example below, we've used NiFi's expression language to generate a universally unique key so that files are not overwritten (UUID()).
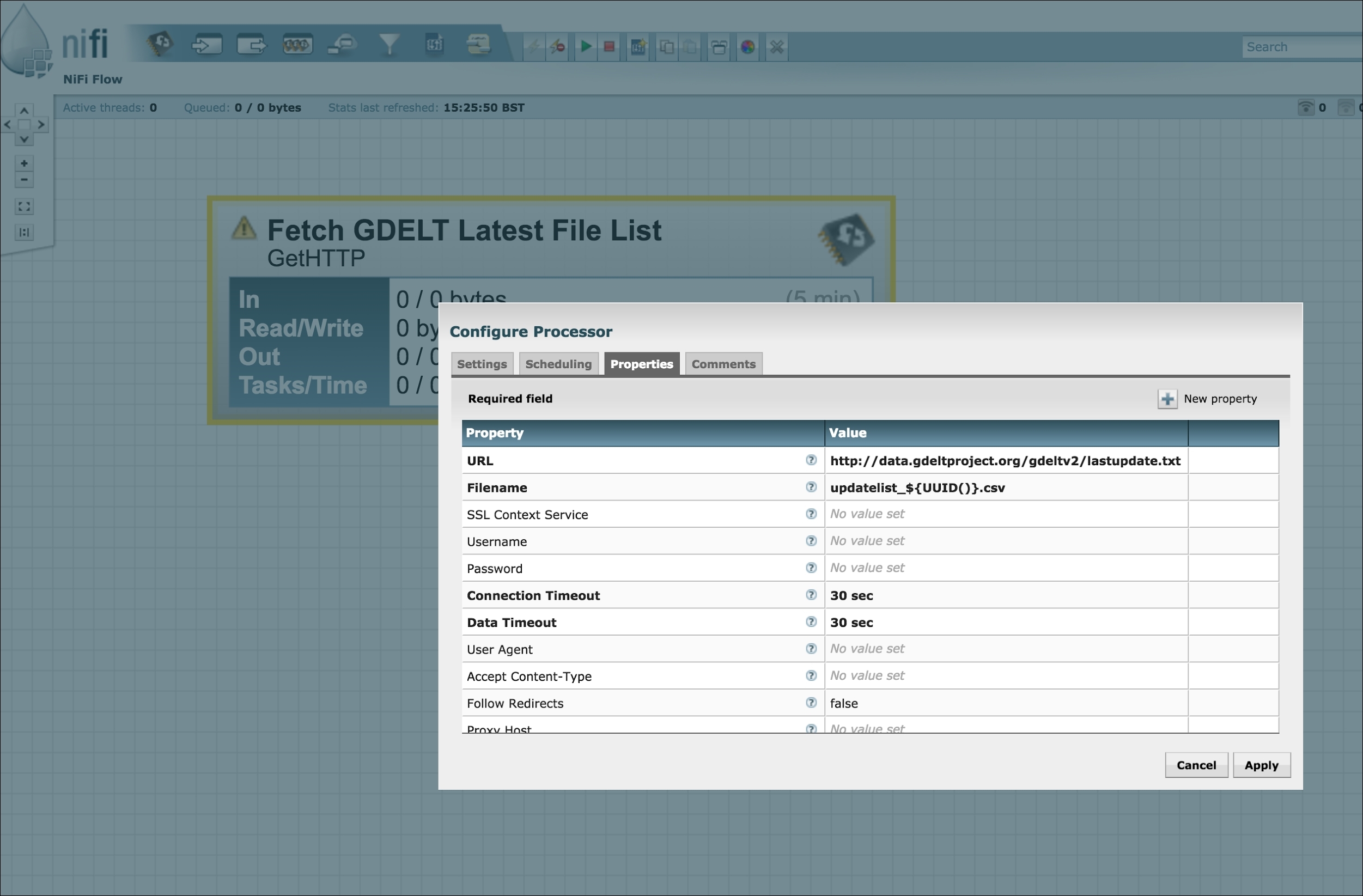
It's worth noting that with this type of processor (GetHTTP method), NiFi supports a number of scheduling and timing options for the polling and retrieval. For now, we're just going to use the default options and let NiFi manage the polling intervals for us.
An example of the latest file list from GDELT is shown as follows:

Next, we will parse the URL of the GKG news stream so that we can fetch it in a moment. Create a regular expression parser by dragging a processor onto the canvas and selecting ExtractText. Now, position the new processor underneath the existing one and drag a line from the top processor to the bottom one. Finish by selecting the success relationship in the connection dialog that pops up.
This is shown in the following example:

Next, let's configure the ExtractText processor to use a regular expression that matches only the relevant text of the file list, for example:
([^ ]*gkg.csv.*)
From this regular expression, NiFi will create a new property (in this case, called url) associated with the flow design, which will take on a new value as each particular instance goes through the flow. It can even be configured to support multiple threads.
Again, this is example is shown as follows:

It's worth noting here, that while this is a fairly specific example, the technique is deliberately general purpose and can be used in many situations.
Now that we have the URL of the GKG feed, we fetch it by configuring an InvokeHTTP processor to use the url property we previously created as it's remote endpoint, and dragging the line as before.

All that remains is to decompress the zipped content with an UnpackContent processor (using the basic .zip format) and save to HDFS using a PutHDFS processor, like so:

So far, this flow looks very point-to-point, meaning that if we were to introduce a new consumer of data, for example, a Spark-streaming job, the flow must be changed. For example, the flow design might have to change to look like this:

If we add yet another, the flow must change again. In fact, each time we add a new consumer, the flow gets a little more complicated, particularly when all the error handling is added. This is clearly not always desirable, as introducing or removing consumers (or producers) of data, might be something we want to do often, even frequently. Plus, it's also a good idea to try to keep your flows as simple and reusable as possible.
Therefore, for a more flexible pattern, instead of writing directly to HDFS, we can publish to Apache Kafka. This gives us the ability to add and remove consumers at any time without changing the data ingestion pipeline. We can also still write to HDFS from Kafka if needed, possibly even by designing a separate NiFi flow, or connect directly to Kafka using the Spark-streaming.
To do this, we create a Kafka writer by dragging a processor onto the canvas and selecting PutKafka.

We now have a simple flow that continuously polls for an available file list, routinely retrieving the latest copy of a new stream over the web as it becomes available, decompressing the content, and streaming it record-by-record into Kafka, a durable, fault-tolerant, distributed message queue, for processing by the Spark-streaming or storage in HDFS. And what's more, without writing a single line of bash!