
This chapter aims to explain a common pattern for enhancing local data with external content found at URLs or over APIs. Examples of this are when URLs are received from GDELT or Twitter. We offer readers a tutorial using the GDELT news index service as a source of news URLs, demonstrating how to build a web scale news scanner that scrapes global breaking news of interest from the Internet. We explain how to build this specialist web scraping component in a way that overcomes the challenges of scale. In many use cases, accessing the raw HTML content is not sufficient enough to provide deeper insights into emerging global events. An expert data scientist must be able to extract entities out of that raw text content to help build the context needed track broader trends.
In this chapter, we will cover the following topics:
- Create a scalable web content fetcher using the Goose library
- Leverage the Spark framework for Natural Language Processing (NLP)
- De-duplicate names using the double metaphone algorithm
- Make use of GeoNames dataset for geographic coordinates lookup
What makes data science different from statistics is the emphasis on scalable processing to overcome complex issues surrounding the quality and variety of the collected data. While statisticians work on samples of clean datasets, perhaps coming from a relational database, data scientists in contrast, work at scale with unstructured data coming from a variety of sources. While the former focuses on building models having high degrees of precision and accuracy, the latter often focuses on constructing rich integrated datasets that offer the discovery of less strictly defined insights. The data science journey usually involves torturing the initial sources of data, joining datasets that were theoretically not meant to be joined, enriching content with publicly available information, experimenting, exploring, discovering, trying, failing, and trying again. No matter the technical or mathematical skills, the main difference between an average and an expert data scientist is the level of curiosity and creativity employed in extracting the value latent in the data. For instance, you could build a simple model and provide business teams with the minimum they asked for, or you could notice and leverage all these URLs mentioned in your data, then scrape that content, and use these extended results to discover new insights that exceed the original questions business teams asked.
Unless you have been working really hard in early 2016, you will have heard about the death of the singer David Bowie, aged 69, on January 10, 2016. This news has been widely covered by all media publishers, relayed on social networks, and followed by lots of tributes paid from the greatest artists around the world. This sadly is a perfect use case for the content of this book, and a good illustration for this chapter. We will use the following article from the BBC as a reference in this section:
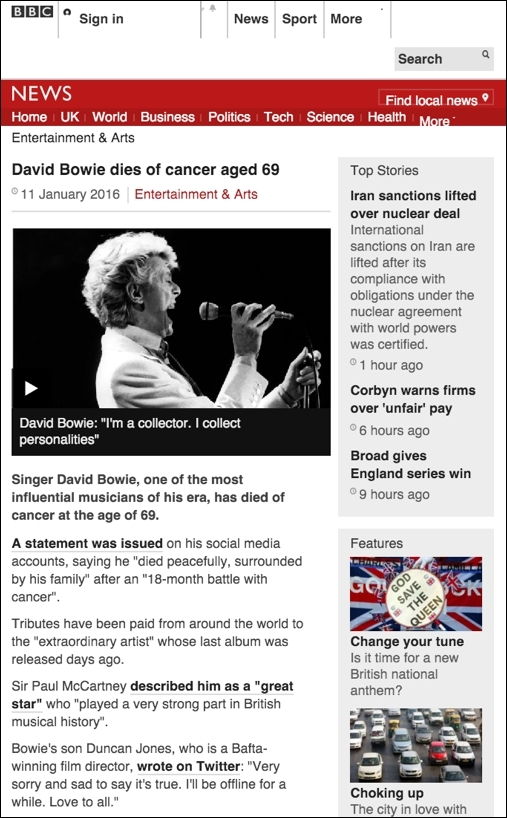
Looking at the HTML source code behind this article, the first thing to notice is that most of the content does not contain any valuable information. This includes the header, footer, navigation panels, sidebar, and all the hidden JavaScript code. While we are only interested in the title, some references (such as the publishing date), and at most, really only a dozens lines for the article itself, analyzing the page will require parsing more than 1500 lines of HTML code. Although we can find plenty of libraries designed for parsing HTML file content, creating a parser generic enough that can work with unknown HTML structures from random articles might become a real challenge on its own.
We delegate this logic to the excellent Scala library Goose (https://github.com/GravityLabs/goose). This library opens a URL connection, downloads the HTML content, cleanses it from all its junk, scores the different paragraphs using some clustering of English stop words, and finally returns the pure text content stripped of any of the underlying HTML code. With a proper installation of imagemagick, this library can even detect the most representative picture of a given website (out of the scope here). The goose dependency is available on Maven central:
<dependency> <groupId>com.gravity</groupId> <artifactId>goose</artifactId> <version>2.1.23</version> </dependency>
Interacting with the Goose API is as pleasant as the library itself. We create a new Goose configuration, disable the image fetching, modify some optional settings such as the user agent and time out options, and create a new Goose object:
def getGooseScraper(): Goose = {
val conf: Configuration = new Configuration
conf.setEnableImageFetching(false)
conf.setBrowserUserAgent(userAgent)
conf.setConnectionTimeout(connectionTimeout)
conf.setSocketTimeout(socketTimeout)
new Goose(conf)
}
val url = "http://www.bbc.co.uk/news/entertainment-arts-35278872"
val goose: Goose = getGooseScraper()
val article: Article = goose.extractContent(url)Calling the extractContent method returns an Article class with the following values:
val cleanedBody: String = article.cleanedArticleText val title: String = article.title val description: String = article.metaDescription val keywords: String = article.metaKeywords val domain: String = article.domain val date: Date = article.publishDate val tags: Set[String] = article.tags /* Body: Singer David Bowie, one of the most influential musicians... Title: David Bowie dies of cancer aged 69 Description: Tributes are paid to David Bowie... Domain: www.bbc.co.uk */
Using such a library, opening a connection and parsing the HTML content did not take us more than a dozen lines of code, and the technique can be applied to a random list of articles' URLs regardless of their source or HTML structure. The final output is a cleanly parsed dataset that is consistent, and highly useable in downstream analysis.
The next logical step is to integrate such a library and make its API available within a scalable Spark application. Once integrated, we will explain how to efficiently retrieve the remote content from a large collection of URLs and how to make use of non-serializable classes inside of a Spark transformation, and in a way that is performant.
The Goose library on Maven has been compiled for Scala 2.9, and therefore is not compatible with Spark distribution (requires Scala 2.11 for version 2.0+ of Spark). To use it, we had to recompile the Goose distribution for Scala 2.11 and, for your convenience, we made it available on our main GitHub repository. This can be quickly installed using the commands below:
$ git clone [email protected]:gzet_io/goose.git $ cd goose && mvn clean install
Note, you will have to modify your project pom.xml file using this new dependency.
<dependency> <groupId>com.gravity</groupId> <artifactId>goose_2.11</artifactId> <version>2.1.30</version> </dependency>
Any Spark developer working with third-party dependencies should have experienced a NotSerializableException at least once. Although it might be challenging to find the exact root cause on a large project with lots of transformations, the reason is quite simple. Spark tries to serialize all its transformations before sending them to the appropriate executors. Since the Goose class is not serializable, and since we built an instance outside of a closure, this code is a perfect example of a NotSerializableException being thrown.
val goose = getGooseScraper()
def fetchArticles(urlRdd: RDD[String]): RDD[Article] = {
urlRdd.map(goose.extractContent)
}We simply overcome this constraint by creating an instance of a Goose class inside of a map transformation. By doing so, we avoid passing any reference to a non-serializable object we may have created. Spark will be able to send the code as-is to each of its executors without having to serialize any referenced object.
def fechArticles(urlRdd: RDD[String]): RDD[Article] = {
urlRdd map { url =>
val goose = getGooseScraper()
goose.extractContent(url)
}
}Improving performance of a simple application that runs on a single server is sometimes not easy; but doing so on a distributed application running on several nodes that processes a large amount of data in parallel is often vastly more difficult, as there are so many additional factors to consider that affect performance. We show next, the principles we used to tune the content fetching library, so it can be confidently run on clusters at any scale without issues.
It is worth mentioning that in the previous example, a new Goose instance was created for each URL, making our code particularly inefficient when running at scale. As a naive example to illustrate this point, it may take around 30 ms to create a new instance of a Goose class. Doing so on each of our millions of records would require 1 hour on a 10 node clusters, not to mention the garbage collection performance that would be significantly impacted. This process can be significantly improved using a mapPartitions transformation. This closure will be sent to the Spark executors (just like a map transformation would be) but this pattern allows us to create a single Goose instance per executor and call its extractContent method for each of the executor's records.
def fetchArticles(urlRdd: RDD[String]): RDD[Article] = {
urlRdd mapPartitions { urls =>
val goose = getGooseScraper()
urls map goose.extractContent
}
}Exception handling is a cornerstone of proper software engineering. This is especially true in distributed computing, where we are potentially interacting with a large number of external resources and services that are out of our direct control. If we were not handling exceptions properly, for instance, any error occurring while fetching external website content would make Spark reschedule the entire task on other nodes several times before throwing a final exception and aborting the job. In a production-grade, lights-out web scraping operation, this type of issue could compromise the whole service. We certainly do not want to abort our whole web scraping content handling process because of a simple 404 error.
To harden our code against these potential issues, any exceptions should be properly caught, and we should ensure that all returned objects should consistently be made optional, being undefined for all the failed URLs. In this respect, the only bad thing that could be said about the Goose library is the inconsistency of its returned values: null can be returned for titles and dates, while an empty string is returned for missing descriptions and bodies. Returning null is a really bad practice in Java/Scala as it usually leads to NullPointerException – despite the fact most developers usually write a This should not happen comment next to it. In Scala, it is advised to return an option instead of null. In our example code, any field we harvest from the remote content should be returned optionally, as it may not exist on the original source page. Additionally, we should address other areas of consistency too when we harvest data, for example we can convert dates into strings as it might lead to serialization issues when calling an action (such as collect). For all these reasons, we should redesign our mapPartitions transformation as follows.
- We test for the existence of each object and return optional results
- We wrap the article content into a serializable case class
Content - We catch any exception and return a default object with undefined values
The revised code is shown as follows:
case class Content(
url: String,
title: Option[String],
description: Option[String],
body: Option[String],
publishDate: Option[String]
)
def fetchArticles(urlRdd: RDD[String]): RDD[Content] = {
urlRdd mapPartitions { urls =>
val sdf = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ssZ")
val goose = getGooseScraper()
urls map { url =>
try {
val article = goose.extractContent(url)
var body = None: Option[String]
var title = None: Option[String]
var description = None: Option[String]
var publishDate = None: Option[String]
if (StringUtils.isNotEmpty(article.cleanedArticleText))
body = Some(article.cleanedArticleText)
if (StringUtils.isNotEmpty(article.title))
title = Some(article.title)
if (StringUtils.isNotEmpty(article.metaDescription))
description = Some(article.metaDescription)
if (article.publishDate != null)
publishDate = Some(sdf.format(article.publishDate))
Content(url, title, description, body, publishDate)
} catch {
case e: Throwable => Content(url, None, None, None, None)
}
}
}
}Although most of the time, the performance of a Spark application can greatly be improved from changes to the code itself (we have seen the concept of using mapPartitions instead of a map function for that exact same purpose), you may also have to find the right balance between the total number of executors, the number of cores per executor, and the memory allocated to each of your containers.
When doing this second kind of application tuning, the first question to ask yourself is whether your application is I/O bound (lots of read/write access), network bound (lots of transfer between nodes), memory, or CPU bound (your tasks usually take too much time to complete).
It is easy to spot the main bottleneck in our web scraper application. It takes around 30 ms to create a Goose instance, and fetching the HTML of a given URL takes around 3 seconds to complete. We basically spend 99% of our time waiting for a chunk of content to be retrieved, mainly because of the Internet connectivity and website availability. The only way to overcome this issue is to drastically increase the number of executors used in our Spark job. Note that since executors usually sit on different nodes (assuming a correct Hadoop setup), a higher degree of parallelism will not hit the network limit in terms of bandwidth (as it would certainly do on a single node with multiple threads).
Furthermore, it is key to note that no reduce operation (no shuffle) is involved at any stage of this process as this application is a map-only job, making it linearly scalable by nature. Logically speaking, two times more executors would make our scraper two times more performant. To reflect these settings on our application, we need to make sure our data set is partitioned evenly with at least as many partitions as the number of executors we have defined. If our dataset were to fit on a single partition only, only one of our many executors would be used, making our new Spark setup both inadequate and highly inefficient. Repartitioning our collection is a one-off operation (albeit an expensive one) assuming we properly cache and materialize our RDD. We use parallelism of 200 here:
val urlRdd = getDistinctUrls(gdeltRdd).repartition(200) urlRdd.cache() urlRdd.count() val contentRdd: RDD[Content] = fetchArticles(urlRdd) contentRdd.persist(StorageLevel.DISK_ONLY) contentRdd.count()
The last thing to remember is to thoroughly cache the returned RDD, as this eliminates the risk that all its lazily defined transformations (including the HTML content fetching) might be re-evaluated on any further action we might call. To stay on the safe side, and because we absolutely do not want to fetch HTML content over the internet twice, we force this caching to take place explicitly by persisting the returned dataset to DISK_ONLY.