
CHAPTER 2
Developing the Micro-ISV Way
You were probably tempted to skip this chapter. The first chapter was helpful for finding what to write, and the following chapters on the business and marketing stuff look useful—but you already know how to program, you've done it for a living, and you've found what works for classes, for clients, or in your IT shop, right?
If only that were so!
Writing software from scratch to solve a problem you've picked, especially software you're going to turn around and actually sell to some (you hope!) measurable part of the human race, is incredibly different from what you're most likely used to doing in a class or a job. That's why this chapter is a must read: you need to understand the realities of micro-ISV design and development.
When you're working for a company, a good grade, or a client, someone else defines at least initially what you're developing. In other words, when you get a requirements document, meet with the users, get a class syllabus, or sit down with someone who is going to pay you, someone else defines the problem you need to solve.
When you're a micro-ISV, there is no someone else. It's all up to you, whether the you at your micro-ISV means one programmer or a set of partners.
In this chapter, you'll move from vision to beta product. Along the way, you'll see some of the tools and methods that work for micro-ISV development and look at some of the features of the code base about which you need to be concerned.
In this chapter, however, you won't find a whole lot about software development methodologies you may have used or at least read about: no Extreme Programming (XP) or Agile Software Development (ASD) and no Scrum, Rational Unified Process (RUP), Common Object Request Broker Architecture (CORBA), or Structured Systems Analysis and Design Methodology (SSADM). All these methodologies focus on how groups of programmers can work together—which isn't much help when your programming team consists of just you.
While I'm still wearing my flame-proof shorts, let me throw a bit more lighter fluid around: I won't cover how embracing open source will make your micro-ISV a success, because I don't think it will. Now, please, before every open source zealot flames me and my copy of Firefox stops working, hear me out. Open source may just be the greatest way to create anything, but it's a lousy way to start a small profit-making business, which is the focus of this book.
Instead, I'll first cover a few techniques that have worked in my micro-ISV and have worked for other micro-ISVs for getting to beta—that wonderful point when you actually have something to show for all your hard work and something that may, just may, replace that regular paycheck you gave up. Then, again from a profit-making perspective, you'll learn some of the "production values" that will make your micro-ISV ready for the big time.
Designing Your Application
Before you can start coding your micro-ISV application or manufacturing your micro-product, you need to design it. At the start of the process (see Chapter 1), you identified a problem a bunch of people have that you want to solve in a better or different way from the existing solutions.
By the end of the design phase, you want a coherent and realistic definition of what your product looks like, acts like, and feels like for the people who are going to buy it. Once you have the design, although plenty of technical challenges are still ahead, you've accomplished the first goal and can see where you have to go from there.
Now, one fine day some bright young thing is going to build something that is half-crystal ball and half-neural net that will read your innermost design thoughts, pass them through the collective unconsciousness, and spit out a 300-page specification detailing every function, screen, dialog box, and button your application will need. In the meantime, there's use cases and paper prototyping.
Creating Use Cases
Way back when, in 1986, Ivar Jacobson formalized the idea of writing down how users interact with a software application, instead of leaving that to the tech writers who would write the documentation a few weeks before the app shipped. At the time, it was a fairly heretical idea that a programmer would actually leave the MIS department (the old buzzword for IT), sit down with a bunch of users, and actually work out what those users would see an application doing.
The funny thing about heretical ideas is that given enough time, more than a few of them become conventional wisdom: whether you do XP, ASD, RUP, or some flavor of Unified Modeling Language (UML), use cases have become the accepted way of defining the interaction between people and software for design purposes.
Use cases are the natural bridge between the overall concept of your micro-ISV application and the stuff on the screen that performs actions when clicked; working through how your customers will use your software is a surefire technique for getting the scope of your application down on paper.
Generally, a use case will have the following sections:
A name: For example, Print Reports, Subscribe to New Service, or Add Task to Task Catalog.
A date stamp, version number, and IDs of related use cases: Use cases are meant to be iterative; keeping track of what version you're looking at is a must.
A summary: For example, "The user has decided to add an existing task to the Task Catalog. They select the task, click Add, and immediately see a copy of the task listed in the Task Catalog."
Precondition(s): This is where you cover what has to already be true before this use case will work. For example, "A task exists."
Trigger(s): This is how the use case starts. For example, a trigger could be "The user selects a task displayed in the section grid."
Main path: This is the play-by-play description of what the user does, how the system responds, and the back-and-forth through the main path of what the user case is about. Usually this is the successful path, and it doesn't describe at all what the application is doing internally.
Alternatives: This is a polite way of saying what happens when either the user or the application (or both) does something wrong in the main path. This can also cover alternative ways of performing actions.
Postconditions: Postconditions describe the effects of the use case and cover what has been accomplished.
Business rules: Here's where you make sure you capture whatever rules and restrictions your program needs to correctly mirror what people expect. For example, a business rule could be that "A checking account contains debits and credits."
Note: Sometimes this is the best part of a use case; this is where you stick protoclass structure ideas, features to check, and open issues.
One of the nice parts of starting a micro-ISV (besides burning most of your ties) is that you get to decide how much or how little of any given structure or formalism you want to use. For me, as I work through a major chunk of a program, I first write a bunch of use case headlines, as shown in Figure 2-1. Then, once I have good coverage of everything, I flesh out the preconditions, triggers, main path, and postconditions.
When I started working on my micro-ISV's first commercial product, a task and project management application called MasterList Professional, I defined what problems MasterList Professional would solve by creating use cases. By doing this, I could start thinking about how best to solve those problems.

Figure 2-1. Jotting down use case headlines for MasterList Professional
Use cases are the logical, deterministic, word-processed half of the design story. They don't really describe the application—just the interaction between your potential customers and your application. As helpful as use cases are for identifying what your application will do, they are by no means the only tool you need to develop a design you can start architecting.
Creating Paper Prototypes
Most programmers, once they've gotten their use cases together, will either jump right in and start defining classes and objects or, worse, fire up their Integrated Development Environment (IDE) and start creating code—anything to avoid that messy, gooey human interface stuff.
Big mistake.
Pick any category of software you want at http://www.download.com. Take a quick look at any eight of the apps from what sound like small companies. Write down your gut reaction to the screen shot for each app, ranking it from a low of 1 ("Yuck!") to a high of 5 ("Ooh, shiny!").
Now look at their number of downloads. Notice the correlation?
The bottom-line reality of selling software is, Ugly doesn't cut it. As indifferent as you might be to how a program or a Web service looks because you have an educated idea about how a given function works, the other 99.9 percent of people will pick pretty over ugly every time.
This has some pretty serious implications for micro-ISV development: it's not enough for your application, Web service, or product to work right; it needs to make it past the customer's ugly filter if you're going to have the chance to sell it. Instead of slapping a Windows Explorer-like tree view on top of your application, you need to take a user interface–centric approach to both design and development.
The specifics of good user interface design are beyond the scope of this book, but you'll find a slew of books and Web sites listed in this book's appendix to get you started. I also can summarize the general principles of good user interface design, particularly for micro-ISV applications, in three bullet points:
- Do what people expect. (And if you're not sure what that is, ask.)
- Be nice to your users.
- Create prototypes on paper until your application makes sense to someone who has never seen it.
Paper prototyping is the tool of choice for defining the user interface for your micro-ISV's software, Web service, or product for several reasons:
Paper prototypes are fast: No matter how many years you've programmed, you can still draw a screen faster on paper than programming one in Flash, Delphi, or Visual Basic 6.
Paper prototypes let you focus on one aspect of the interface: Say, for example, you're trying to decide the layout of a dialog box for your app. You can start with how the user makes their initial selections and "squiggle" out the rest.
Paper prototypes keep you focused on the interface: If you use, say, Visual Basic 6 to work out the design of your app's interface, you'll have to constantly fight the temptation to think about the programming that will be needed, not the interface that defines what's needed.
Paper prototypes keep expectations low: No one expects a paper prototype to work, and for every drawing you save, you'll toss four.
While paper prototyping MasterList Professional, and about 50 custom applications for corporate customers, I've found that not all paper is created equal. When it comes time to start defining a new part of an application's interface, I take three or four 5×8-inch legal pads, a large cup of strong coffee, and a cat and then go sit away from all computers and start sketching the user interface.
Now, these sketches are terrible—they're just little squiggly lines in something like a box, as shown in Figure 2-2.
Figure 2-2. Creating MasterList Professional's small paper prototype
The nice feature of paper prototypes is that I can whip out five or six in the time it takes for the cat to get fidgety and decide he has better things to do. With the rough cuts and the relevant use cases, I can sit down, finish my coffee, and draw a full paper version of the screen I'm working on (as shown in Figure 2-3) and then move on to the next thing.

Figure 2-3. Creating an early paper prototype for MasterList Professional's Home tab
Paper prototypes aren't just about static screens. Another technique I've found that works is storyboarding. A storyboard is nothing more than a successive set of drawings or sketches showing how features progress; creative types in film, television, and advertising have been using storyboards for decades, as shown in Figure 2-4.
The reason I'm showing you some of the 70,000 or so images of storyboards Google has indexed is to drive home two points about storyboarding: there's no one right way to create storyboards, and storyboards can be extremely flexible to suit your needs.
Now, I'll be the first to admit that if I had to make my living drawing, I'd be living under an overpass in short order. Your drawing ability isn't the point. All you want to do when you initially create paper prototypes is create something that's a useful approximation of what your customers will ultimately see.
Figure 2-4. Viewing storyboards in Google Images
If you want to dig further into paper prototyping, I strongly recommend Paper Prototyping: The Fast and Easy Way to Design and Refine User Interfaces by Carolyn Snyder (Morgan Kaufmann, 2003). In the meantime, Table 2-1 describes some of the finer points to keep in mind when paper prototyping your micro-ISV application.
Table 2-1. Dos and Don'ts for Paper Prototyping
| Do | Don't |
| Do draw first, critique later. | Don't get hung up on making features exactly to scale. |
| Do use big pads, little pads, and paper stolen from your printer. | Don't redo entire drawings because one part is wrong. (Instead, draw it on another sheet, cut it out, and paste over it.) |
| Do try to find a methodology for paper prototyping that yields the same level of detail each time. | Don't ignore times when you find too many interface elements on one paper "screen shot." This is a warning you're expecting too much from your customer! |
| Do write as many notes as you need on the same sheet as the drawing. | Don't forget to process these notes into your decisions document (see the next section) and your schedule (see the "Developing the Schedule" section). |
| Do refer to your use cases to make sure your interface delivers. | Don't try to draw every possible variation of a process. |
Decisions, Decisions
One of the less frequently mentioned parts of designing is that it isn't just about what you put into an application, Web service, or product; it's about what you decide to omit. As you develop your micro-ISV flagship product, keep a log or project notebook of the decisions you make as you go along in a decisions document, as shown in Figure 2-5.

Figure 2-5. Creating a decisions document for MasterList Professional
Few tasks are more frustrating than working through how one part of your program should work and then revisiting the design weeks or months later and wondering why you decided on that design.
A good decisions document helps you set the scope of your product, records the fruits of your research efforts, and identifies potential enhancements. Whether you create the document in a word processor, a spreadsheet, a database, as Web pages, or a wiki is up to you. Just keep in mind that like a lot of design issues, you want to keep it simple enough so you never need to worry about how to record your decisions.
Instead, you can worry about something everybody just loves: the schedule.
Developing the Schedule
A man is known by the company he organizes.
—Ambrose Bierce (1842–1914), American author, editor, journalist1
Ambrose didn't have to deal with milestones, deadlines, or the dreaded schedule; otherwise, his dictionary would have been about three times longer. But you do, even if the only resource you have to level is you, and every critical path runs from your fingers to your keyboard.
When you're a team of one programmer (or even two or three people), you can narrow the process of creating, revising, updating, and completing the dreaded schedule to the core essentials:
- What has to be done?
- How long do you think it will take to do each task?
- How long did it take in reality?
Reread that last bullet—it's a killer. Estimating software tasks is somewhere between a best guess and throwing darts blindfolded in a high wind. Results are going to vary widely. That may be OK if you're working for someone else (even if you're working 18-hour days, your paycheck is hitting your account as scheduled); it's Definitely Not OK if you're in a race between getting your micro-ISV up and running and making money before the last of yours runs out.
Make no mistake: if you're going to make it to the Promised Land of milk, honey, and revenue, you'll have to find some way to keep and maintain your development schedule.
In the following sections, I'll cover the two methods that I know work: a method based on Joe Spolsky's Painless Software Schedules and MasterList Professional.
Using Painless Software Schedules
If you search for the term software schedule on Google, the first entry you're likely to find is the "Painless Software Schedules" article Joel Spolsky wrote on his Web site in 2000.2 Now, Joel is a genuinely Smart Guy, and this article lays out a simple way to use Microsoft Excel to create software schedules worth the paper they're printed on.
Here's the gist of Joel's approach:
__________
1. The Devil's Dictionary (Bloomsbury, 2004)
- Use Microsoft Excel.
- Keep it simple. Seven columns will do, as shown in Figure 2-6.
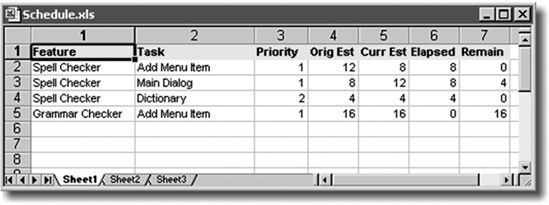
Figure 2-6. Doing Painless Software Schedules the Joel way
- Divide features into tasks.
- Only the programmer who is going to write the code can schedule it.
- Define tasks as hours so you describe real blocks of programming effort, not wishful thinking.
- Keep your schedule working by keeping track of both the original estimate and current estimate for each task. The difference between the two is important and useful.
- Update your elapsed time daily.
- Include debugging, integration, and other tasks such as updating your documentation and performing unit test cases.
- The schedule works if it's telling you the truth. You may not like the truth, you may have to decide to cut features, but that's not the schedule's fault.
The beauty of Joel's method is that as long as you stick to it, the method will tell you the truth about your development schedule; I know of several micro-ISVs that have used Joel's method to develop their software. And, in 2002 and 2003, I used Joel's method to plan and execute my first foray into noncustom software, MasterList-XL.
MasterList-XL (http://www.safarisoftware.com/mlxlDownload.htm) took Joel's ideas and ran. Specifically, I tracked my tasks in Microsoft Excel, made them real tasks and not wishes, and added two points I thought were missing from Joel's original equation: some tasks have to be done by a certain date, and the more time you spend on less important tasks, the less time you can spend on more important tasks.
Something like 40,000 people have downloaded MasterList-XL since I first made it available, and I've heard from enough people over the years who still use it to manage all sorts of projects, including micro-ISV projects, to know it works.
But although I still give MasterList-XL away for free, I've developed what I think is a better tool for managing projects: MasterList Professional.
Using MasterList Professional
I'll keep this section of this book ultrashort for a couple of reasons. First, the software itself, my company's Web site, and my blog do a good job of making the case for using MasterList Professional to manage not just the design and development of a micro-ISV's product but all the other projects you need to complete. You can read about it, watch movies of it, and try it for free for 45 days at http://www.safarisoftware.com.
The second reason is to demonstrate 1 little applied earnestness of intent here: the main message I hope you take away from this section of the book is that whatever has been your business experience with scheduling projects, scheduling your micro-ISV product's development is both doable and necessary.
Examining Your Development Infrastructure
Source Control Management (SCM) is one of those "infrastructure" things you usually get to take for granted when you get paid on a regular schedule to program and get a steady supply of electricity, phones that work, and office supplies. Entire chunks of IT departments spend their time worrying about repository backups and the like; aren't you glad you don't have to do this?
That was then, this is now, and now the IT department is just you. Just as there's a programmer's heaven where you can buy fun, interesting things, there's a programmer's hell where you go if you don't build a safety net for your development efforts. You don't want to go there—it's a painful place, with lots of unhappy people, and it takes a long time to leave.
Been there, done that.
Let me tell you a quick story of why SCM for a micro-ISV isn't like shoes for fish: In the first half of 2005 when I was still doing contract development, the latest version of an application I wrote for a good client of mine who provides specialized management consulting to certain portions of the U.S. government developed a wee problem. The app stopped working.
Build 79 worked fine on my dev machine, my test boxes, and the client's test boxes, and it locked up tight when installed using a special installer that had worked fine for the past 78 builds.
Now, the usual solution would be to rebuild the install script or, if necessary, change installers. No can-do: we had to use the existing installer, because it manages to let you install a Windows app through some parallel dimension that never touches the actual operating system, letting people install the app and run it from a CD—something my client's client, those certain portions of the federal government, is quite fond of nowadays.
Did I mention the installer stopped running the new build five days before a key presentation to one of my client's clients? Did I mention that some features in the new build absolutely had to be demonstrated? Did I mention that the makers of this installer had decided to take a collective trip to some small Pacific island and weren't answering their phones or emails? Did I mention that the man whom this presentation was going to be made to was at the top of a chain of command with more firepower than all the bombs dropped during World War II?
Now, I wish I could say that with a quick flip of the SCM's diffing software I was able to move the key features back into a build that this transdimensional installer liked, but I can't.
You see, about five years ago when the SCM system that came with a certain IDE I used for most of my work died for no apparent reason, I did what a lot of small developers do and swore off SCM as something just not worth the bother. Oops!
Well, after spending 36 hours straight programming the new features back into a build that could be installed, the presentation went off without a hitch. And after the install vendor's staff came back from wherever they were and revved their installer, the mysterious problem disappeared. And after I had ended up with two differing code bases because some of my client's clients control weapons of mass destruction and others don't, I was able to easily merge the two code bases into one using one of the two SCMs I'll cover next.
What's more, by some fluke in the free market system, both these SCM tools offer a free license to solo developers.
Using SourceGear Vault
Remember Eric Sink from Chapter 1, the guy who coined the term micro-ISV? Eric's company, SourceGear, makes one of the best ways micro-ISVs can protect their code: Vault.
Vault (http://www.sourcegear.com, $199 USD per license without support) is a source control client-server application for Windows environments built as a seamless replacement for Microsoft's moribund Visual SourceSafe. Figure 2-7 shows Vault at work.
Figure 2-7. A tale of two code bases: Vault at work
SourceGear's main market is all those development shops and IT departments that are fed up with Microsoft Visual SourceSafe's limitations and arthritis and are comfortable adding another SQL Server-driven application to their production mix.
Although SourceGear's main market is enterprise, Sink makes the following points about why SCM should be part of every programmer's development infrastructure in his blog:
When I use a source control tool all by myself, here are the benefits that I find still apply:
It's an undo mechanism. Whenever I get to a good stopping point in my code, I check in my changes to the repository. From that point on, I can be less careful. I can try coding some crazy new idea, and when it doesn't work, I just revert my working folder to my last check-in point.
It's a historical archive. Sometimes I want to undo much further back. My repository history contains a full copy of every version I have ever checked in. If I ever need to go back and find something I once had, it's there.
It's a reference point for diff. A source control tool can easily show a diff of all the changes I've made since my last check-in.
It's a backup. When I regularly check in my work, I always know that there are two copies of it. If my *&^%#@! laptop hard drive dies again, my code is still safe in the repository.
It's a journal of my progress. When I do my regular check-ins, I write a comment explaining what I was doing. These comments serve as a log or a journal, explaining the motivation behind every change I have ever made.
It's a server. Sometimes I'm coding on different computers. The repository becomes my central server. I can go anywhere I want, and I can still get to my code.
When I interviewed Sink for this book, I asked him if he had any other points to add:
People who don't think source control is helpful for one person are usually the same people who think they can live without it for a team of two or three. So they try to "just get by," storing their files on a public file server. Anyone who has experienced the pain of this situation has realized that source control is always worth the trouble for any plurality of developers and has vowed never to repeat the mistake.
Those who have not experienced this pain would be wise to learn from those who have.
Another interesting aspect of Vault is that it's free for a single developer. Why? "The main reason is that it allows Vault to be used by a whole bunch of solo consultants, many of whom go on to recommend Vault to their clients," Sink explains.
Using Perforce Software
With more than 160,000 developers at 3,500+ organizations worldwide, Perforce is based in Alameda, California, and is a major player in the SCM world. The Perforce SCM system (http://www.perforce.com/perforce/products.html, $800 USD per single annual license) has clients for Windows, Mac OS X, Linux, Solaris, and FreeBSD. Figure 2-8 shows Perforce's Windows client, and Figure 2-9 shows Perforce's WinMerge program.
Figure 2-8. Perforce's Windows client
Figure 2-9. Perforce's WinMerge program
Perforce may look like massive overkill for a micro-ISV. This isn't so, says Nigel Chanter, Perforce's chief operating officer (COO):
Programming teams of any size need Source Control. Without it, releases go out the door with uncertain contents. Bug fixes get lost, and engineers see their development efforts wasted in a blundered process.
What could be more frustrating than debugging a block of code only to discover that someone else debugged that same block of code the day before? Imagine hunting for the most recent revision of a software module, completed three weeks ago by a team that has since been reassigned…. Finally, picture the amount of time wasted if you had to re-create a specific version of a piece of software shipped to a customer six months ago, and the customer is now calling you because there are bugs that need fixing.
All of these problems could be avoided by employing Source Control.
Source Control tools are the means by which the evolution of a software product can be tracked and managed. As a subject, Source Control has often been accused of lacking excitement. That is, in fact, the point of SCM: some excitement can be done without. All these examples apply to teams of two or two thousand, and some apply to that lone developer.
Also, interestingly enough, Perforce is free for up to two developers: "Perforce does indeed offer a free two-user version (five client workspaces); however, we offer technical support only to paying customers or prospects evaluating the product for purchase," Chanter adds.
When the Going Gets Tough, the Tough Get Virtual
One of the hardest parts of being a micro-ISV is dealing with the god-awful configuration mess. Regardless of whether you're developing a desktop, server-based, or hybrid application, the endless permutations of operating systems, browsers, and core components can drive you crazy. Then, just for fun, add the need to support at least a modicum of international audiences, and you have a major risk factor to becoming a successful micro-ISV.
For example, MasterList Professional is a relatively simple Visual Basic 6 application storing its data in a single Microsoft Access (.mdb) file, incorporating ten third-party controls (.ocx files). Or at least I thought it was simple until I found myself dealing with about ten flavors of ActiveX Data Objects (ADO), screen resolutions that ran from 640×800 to dual 1600×1200 monitors, and the joys of Hungarian date formats.
If you want your application to succeed (make money and not drive you crazy), you want to manage this risk from the start of your development process. And unless you happen to own a couple dozen computers, you need to think about how to create and manage virtual test environments.
In the following sections, I'll cover three strategies that use different toolsets and give you a way to define your own. These strategies are by no means equal, but they're all better than not having any strategy at all.
Strategy 1: Back Up Images
Until a few years ago, creating hard disk images was the best available way of "provisioning" your testing environment. You can still use a product such as Symantec Norton Ghost 10.0 (http://www.symantec.com, $69.95 USD) to create images of a working base machine and then restore your test machine as needed by overwriting it with an image when you need to do so.
Although creating a test machine from an image works, it's at best only a partial solution. It's slow, taking anywhere from 10 to 20 minutes to reapply an image stored on the testing computer's hard drive and longer—much longer—if you have to go across the network.
Many a developer cried out for a better tool, and unsurprisingly, the call was answered.
Strategy 2: Use Microsoft Virtual PC (Connectix)
In the last decade, Connectix started selling a nifty application that could somehow create a Windows PC running inside a Windows PC. This Virtual PC for Windows solution could do just about everything a real PC could do: install and test software, run Microsoft Office, talk to the network, and talk to the Internet. If you crashed the virtual machine, no big deal: just restart the app, and try again.
This development didn't go unnoticed in Redmond, Washington. In August 2003, Microsoft acquired Connectix for a large, undisclosed sum, promising to continue to develop and support these virtualization products.
As of this writing, not much has happened with Microsoft Virtual PC. It still lets you run as a guest operating system every operating system Microsoft has released back to MS-DOS 6.22; the software comes free as part of the MSDN Universal Subscription via the Empower Program, which is very good. Or, you can buy it as a stand-alone product (https://partner.microsoft.com/global/40010429, $129 USD).
Strategy 3: Use VMware and VMTN
Then there's VMware. Where Virtual PC ends, VMware Workstation 5 (http://www.vmware.com/, $189 USD per developer), Physical to Virtual (P2V) Assistant, and virtualization servers take off.
Take, for instance, the Snapshot Manager, as shown in Figure 2-10. With snapshots, you can incrementally save your virtual machine like you would a document or spreadsheet. With the Snapshot Manager, you get a clear, simple interface for managing those snapshots that shows how each virtual machine you created relates to its predecessor and successors.
VMware performs all the features Microsoft Virtual PC does but does them so much better that you end up with another level of functionality. Figure 2-11 and Figure 2-12 show running Windows XP in a virtual PC in VMware on a Windows XP notebook, complete with antispyware and antivirus programs running. Figure 2-13 and Figure 2-14 show MasterList Professional being downloaded and installed, and Figure 2-15 shows it running.
Figure 2-10. I'm in love: the Snapshot Manager.
Figure 2-11. Running Windows XP in VMware
Figure 2-12. Viewing a too real virtual machine
Figure 2-13. Downloading MasterList Professional
Figure 2-14. Installing MasterList Professional
Figure 2-15. Running MasterList Professional in its own VM
Although aimed squarely at enterprise-sized companies that want to save on development and deployment costs, a VMware solution means micro-ISVs can create and manage entire virtual testing centers for a pittance.
"I would argue that VMware is one of those critical pieces of software for a start-up, precisely because it allows you to use the resources of a much larger company without actually deploying those physical resources," says Kevin Epstein, VMware's vice president for marketing. He adds the following:
If I'm a single guy in a garage with two solid server machines, and I'm trying to develop a multitier app and test it against ten clients, I don't have the physical resources to do that. But if I choose to deploy all those resources within a set of virtual machines, I could create that infrastructure within the confines of a single physical machine and still have leftover workspace—instead of developing something, testing something, and finding it doesn't work and having to wipe the entire system and start over [on a test PC]. Even if I backed it up, it's still several hours' time. With VMware, I just hit reset, and I'm back to a clean state.
Like Virtual PC, VMware lets you create a virtual PC, install your operating system and app, and then test. But it's the "deeper-thinking" features of VMware that make it a compelling micro-ISV tool:
- You can quickly take snapshots while deep in your application and then quickly reset to exactly where you were (no more virtual reboots).
- The built-in movie recorder lets you capture the steps leading to a bug's appearance.
- You can set how much random access memory (RAM), disk space, and bandwidth your virtual PC will have. Besides meaning you no longer need to keep old PCs around for testing, you can test other features such as how your Web site looks to a visitor accessing the Internet via dial-up access.
- Multiple virtual PCs and servers can run at the same time, talking with each other and, if desired, other real resources such as the Internet. You can box sets of virtual PCs, controlling them as a set. You can easily modify these teams of virtual PCs, adding or dropping virtual PCs as needed.
- It offers extremely good optimization. A virtual PC typically runs faster than a real PC, you can clone a virtual PC as a linked clone that saves only the difference between states, and memory is managed and shared between virtual PCs running at the same time, meaning you don't need about a third more memory for each virtual PC.
- You can run VMware on a PC running either Windows or Linux and create virtual machines running Windows, Linux, or a variety of other x86-based operating systems.
- It offers a scriptable application programming interface (API) for VMware's virtualization servers; for example, you could launch a series of virtual PCs that each launches your application or a test harness application and then takes snapshots of the results while you sleep after a hard day's work.
- It gives you the ability to import a Microsoft Virtual PC or a Norton Ghost image file into a VMware virtual machine file.
So, what does your testing or development PC need to run VMware well? From my experience, a virtual Windows XP PC runs as fast or faster than a physical computer on a notebook computer with an Intel Pentium M processor 750 and 1GB of PC2700 DDR RAM. The key factor is memory; you need "good, high-speed RAM and lots of it," according to Epstein. "With a lot of RAM, you can build things that will work faster and better in virtual space than in physical space. He adds the following:
It's the same thing as if you had a room full of physical machines, with someone walking around, turning one on, starting tests, waiting for results to compile, and stopping tests. But instead of physically turning them on, the API is doing all the work for you.
In June 2005, VMware went one large step further and started offering its entire set of applications and servers on a subscription basis for $299 USD per developer per year for development and testing.
Addressing the Quality Issue
Although it may seem strange to talk about quality here, ensuring that your development process delivers a product with as few bugs as possible is an infrastructure issue. You can't add quality to a code base; you need to have a process that makes quality code.
The quality issue is especially important for micro-ISVs. Customers tend to take bugs more personally when they're in an application from a small company than from, say, Microsoft. Also, the more bugs in your product, the more of your limited time will have to go to tech support and be stolen from marketing; remember, you get only 1,440 minutes a day.
A robust beta program with at least the second phase of it public will reveal bugs (see the next section), but you want to give some serious thought about how to make quality improvements part of your development infrastructure. And that means testing.
By and by, programmers hate to test their code. For some, this is because they came up the ranks from testing. For others, this is because that's what testers do. For most, this is because after spending two or six or sixteen hours coding, all the little gray cells are limp. However, as bad as testing is, not testing is worse. At the very least, you need to reread the code you write.
Let me tell you a little story about what not reading your code can cost you: In the early 1980s, I got one of my first contract programming jobs at AT&T when the big, nasty monopoly was being subdivided into a bunch of mini-monopolies, and somebody had to do the programming to tally for the first time whether a customer was going to defect from Ma Bell. Since AT&T's MIS division said it would take five years to develop a polling system, but the federal judge said it would take one year, each region got to work out—somehow—how to process this data.
I got to be, along with a few others, a junior part of the somehow.
The processing had to be done using a statistics package called SAS and JCL—that's Statistical Analysis System and Job Control Language—because that was all we could run on AT&T's mainframes. Think of the scene in Mel Brooks' Young Frankenstein when the creature is brought to life, and you have the right idea.
Anyway, one day when I got to work I found the rest of the team huddled around a desk looking fairly nauseous, pouring over the job results of the run I'd coded and submitted the day before. Roy, my boss, looked up, and asked me the following:
"Bob, did you remember to check your JCL code before submitting it last night?"
"Yeah, I think I did...uhh...why?"
"Well, if you'd checked line 144, you would have found the statement where you incremented by zero."
"Incremented by zero?"
"Right. And that means this entire data run is junk. Expensive junk. Very, very expensive junk."
"Uhh...how expensive, Roy?"
"Oh, about a quarter million dollars. But don't worry, we won't take it out of your pay this time."
Needless to say, the lesson stuck in my mind.
The following are three methods you can use to avoid the mistakes that might cost your micro-ISV a great deal of potential revenue. These are by no means the only ways of ensuring quality code, but they should get you started.
Method 1: Use a Code Checklist
Using a code checklist is the easiest method of the lot. Go into Microsoft Word, write the half-dozen coding mistakes you've last made, print the document, and look at the list as you review the code you wrote today. See any familiar faces? Write down other ways you miss the mark as they crop up, and revise your code's checklist.doc periodically.
What you'll notice over time is coding is just like spelling. You make certain coding mistakes repeatedly, but if you focus on them, you'll make them less often.
Just the process of checking my code against my private coding checklist identifies about half of the coding mistakes I make, especially those nasty increment-by-zero blunders and other simple errors. Give it a try!
Strategy 2: Use Unit Testing and Test Driven Development
Depending on what you're using to code your micro-ISV's application, you may be able to sufficiently modularize your code to test each unit independently from the rest of your code base. Visual Basic 6, ASP Classic, and JavaScript don't lend themselves to class-by-class or unit-by-unit testing; Visual Basic .NET, C#, .NET, ASP.NET, Java, and other modern languages do.
The concept of unit testing is simple: build a test harness that exercises each unit of code for correctness and can be repeated as often as that code changes. One of the shining success stories of the open source movement has been a family of tools by different teams, starting with Erick Gamma and Kent Beck, for automating creating and running unit tests for Java.
In the Windows development community, NUnit (http://www.nunit.org) is by far the most popular tool and has spawned a constellation of alternative interfaces and add-ons. With Microsoft Visual Studio 2005, NUnit has been "embraced and expanded" as a standard best practice for enterprise programming. Figure 2-16 shows you NUnit in action.

Figure 2-16. Running NUnit 2.2 tests
How to use NUnit as part of your testing and development infrastructure is beyond the scope of this book; you'll find a set of resources to get you started in the appendix. The point I'm making here is one of the emerging core best practices of professional programmers (bugs = less money): you should strongly consider incorporating at least some unit testing in your micro-ISV development process.
In fact, a growing school (swarm? flock?) of developers say not only should developers create and manage their own unit tests but they should create the unit tests before they code.
Pioneered by XP proponents, Test Driven Development (TDD) is unit testing squared and cubed:
- Quickly add a test.
- Run all tests to see the new one fail (there's no code there yet!).
- Code just enough so the new test might work.
- Run all the tests, and see them all work, including the new test.
- Refactor your code.
By iteratively writing your tests first, several good things happen: you're forced to think about what each module or class is supposed to do, your code has far fewer bugs, and your refactored code tends to be of a higher quality.
TDD has its disadvantages too: much of your time is going to go to writing tests, not production code. And, although TDD works great on the internal aspects of an application, it isn't well suited to testing the user interface. Although you'll find a list of TDD resources in the appendix, here are two thoughts to consider before dismissing TDD as too "out there" for practical use:
- Would you rather spend x amount of time writing tests or at least 2x debugging code downstream?
- Software tools exist that are explicitly designed for testing applications from the user interface in; in fact, one of them is the third method for building quality into your development infrastructure.
Strategy 3: Use AutomatedQA's Test Complete
As thoroughly as you check your code against your list and unit test your classes, there's still the little matter of something going wrong as your customers actually use your application. Actually, it's not a little matter; nothing will kill a potential sale as fast as when a potential customer clicks a button in your application only to have it crash.
In the past, most companies' IT shops had dedicated testers who spent their days (and nights sometimes) clicking through test scripts and black-box testing your apps. Or, if an IT department was well funded (or has been recently embarrassed), the testers would work within an expensive automated testing suite such as IBM Rational Functional Tester or Mercury TestDirector.
Like your company ID card, those resources have gone away. So, what's a micro-ISV to do? In short, get AutomatedQA's TestComplete (http://www.automatedqa.com/products/testcomplete/; $349.99 USD for the standard version, $799.99 USD for the web application testing enterprise version, 30-day trial version available). TestComplete is a remarkable product for various forms of testing but shines for its ability to test on Windows platform desktop applications.
Learning, let alone mastering, TestComplete isn't something you can do over a lunch break, so let me run quickly through how this tool works so you can see whether it will work for your micro-ISV.
Let's say you're planning to make a million bucks with your micro-ISV's first Windows desktop application, Orders.3 After you download, install, and start TestComplete, you start your application and click the Record Script button in TestComplete. You'll then see TestComplete's Recording toolbar, as shown in Figure 2-17.
Next, you exercise a function, such as creating a new order while TestComplete is recording your mouse and keyboard's events. (You can opt for recording at an even lower level, but most times that just gets in the way, since TestComplete can find most controls in most programming environments.) Along the way, you can save what your app or the screen looks like and the internal state of most variables in your application for later automated comparison.
So, you've created your order, stopped recording, and returned to TestComplete. TestComplete has written the test for you, as shown in Figure 2-18.
__________
3. Yes, some micro-ISVs have made more than $1 million over the course of a few years; no, they didn't do so with this example application.
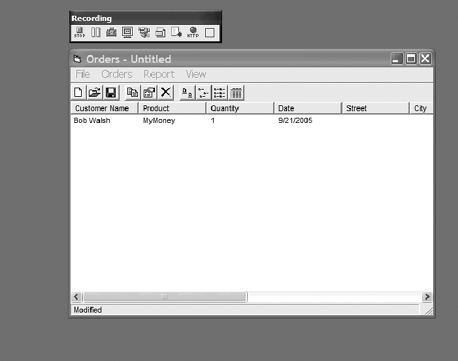
Figure 2-17. Recording your application with TestComplete
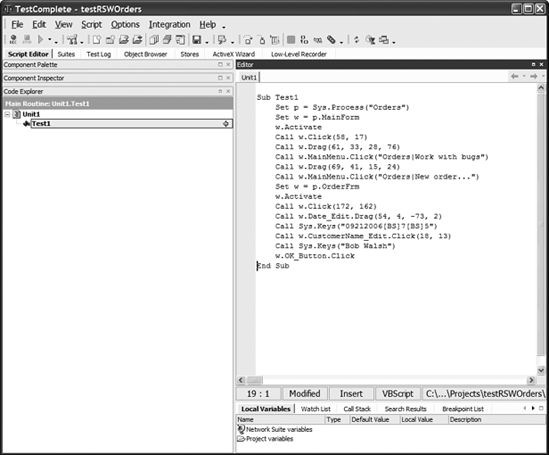
Figure 2-18. Viewing the recorded script
Now, TestComplete could have written this test in any of five programming languages (VBScript, JScript, Delphi, C++, and C#). Also, this could have been an app written in any .NET language, Visual Basic 6, Visual C++, MFC, ATL, Java, or Borland VCL, or it could have been a Web-based application (PHP or Ruby on Rails). In any of these cases, TestComplete could have handled it with aplomb.
By the way, if this looks more like an IDE than a simple editor, it is. TestComplete supports breakpoints, call stacks, watchpoints, and the ever-popular autocompletion feature when you're editing or writing tests, as shown in Figure 2-19.
Figure 2-19. Using TestComplete autocompletion
Now that you have a test, you can run it. TestComplete saves detailed information on each test run inside itself or externally as Extensible Markup Language (XML), XML Style Language (XSL), and Hypertext Markup Language (HTML) that you can peruse in a browser, and you can build a whole set of structured and conditional tests as part of your test project, as shown in Figure 2-20.
TestComplete has been around since 1999 and has won numerous industry awards. The bottom line is the time, effort, and money it will cost you to implement TestComplete are all paid back when you release, and it pays back even more with each subsequent release.
Figure 2-20. Viewing the results of this test
Getting the Beta Advantage
Up to now I've been talking about your micro-ISV as if it were a one-person show and its success were up to you (and your partners, if you have them). But you should be working with a whole other crew of people during the design and development phase: your beta testers.
At some point between when the last major feature is working and before you expect to actually make money, it's time to find as many people as you can who, in exchange for your undying gratitude and a free license, will put your software or Web service through various kinds of tests, tortures, and tribulations.
I say various because beta testers will range from a bunch of people who say they will try your software to a precious few who will stay up nights coming up with suggestions to improve your product.
Over the years, more and more micro-ISVs have come to realize the power, value, and necessity of getting lots of beta testers to try their product, so you actually have two problems as a start-up: how do you get enough beta testers to give your product a thorough whacking, and how do get good enough beta testers who will like your product so much that they start that all-important word of mouth?
Quantity Has a Quality All Its Own
How hard it will be to solve the first problem—getting enough active beta testers—will depend on two considerations primarily: the type of product you're developing and the size of your market. A nearly infinite number of people seem to exist who are willing to play...er...test game software, and exactly zero exist who are willing to work the bugs out of your electrical power grid optimization software.
Although no one solution exists for every micro-ISV, here are five strategies you can try:
- Ask everyone for whom you have an email address.
- Announce it on your Web site, if you have one.
- Post short announcements at any forum you regularly contribute to and that allows such notices.
- Post short announcements at forums concerned with the problem you're going to solve, if that forum, mailing list, or discussion group allows such postings.
- Blog about your micro-ISV, and let people find you.
- Email bloggers who are writing about the problem, and invite them to try your application, Web service, or product before it goes public.
This last tactic is a definite win-win: bloggers get more grist for their mills, an opportunity to "discover" something neat, and at the least a new take on something they care about. You get a beta tester who, if they like your product, can pull in a whole bunch more beta testers and perhaps get a buzz about your product going.
The tactics that work for your micro-ISV and how hard you have to work to attract beta testers will give you a changeable prediction of how your product is likely to fare once you release it: if no one is interested in beta testing it, the outlook isn't good.
Organizing Your Beta Program
However you find beta testers, you'll want at least three features in place before you launch your beta test:
- A mailing list program or service that will let you easily communicate with just your beta testers. I've used both Infacta's GroupMail (
http://www.infacta.com/asp/common/groupmail.asp, starting at $99 USD) and MailerMailer (http://www.mailermailer.com/; see also Chapter 5) and recommend both. They make it easy to send semipersonalized emails to the people who raised their hand when you asked for volunteers. - Some form of a beta tester agreement each person agrees to before they get access. At a minimum, the agreement should spell out what you want (frequent bug reports), what they get (something valuable for free), that they don't get what they want unless you get what you want, and that they shouldn't attempt to share, sell, or otherwise distribute access to your product without your prior consent.
- A way for beta testers to be able to talk to other testers without giving up their privacy—in short, some form of discussion forum. Forums are a great way to let your beta testers know you know what they know.
Once you have your initial batch of beta testers (you'll need more later when half your beta testers find better uses of their time, believe me), how do you get the quality of information out of them you want? First, your software or Web service needs to report beta problems to you automatically. Second, talk to them—not just about bugs that surface but about what they like or dislike about your app.
The more you talk to them and listen to what they have to say, the more likely they are to help you by pointing out missing features, suggesting improvements, and asking questions you haven't thought of asking.