
Appendix A. Types of web APIs and protocols
In this appendix, we study the API protocols we can use to implement application interfaces. Each of these protocols evolved to address specific problems in the integration between API consumers and producers. We discuss the benefits and the limitations of each protocol so that we can make the best choice when designing and building our own APIs. We will discuss the following protocols:
Choosing the right type of API is fundamental for the performance and integration strategy of our microservices. The factors that will condition our choice of API protocol include these:
-
Type of API consumer: small devices, mobile applications, browsers, or other microservices
-
The capabilities and resources we wish to expose; for example, whether it is a hierarchical data model that can be organized around endpoints or a highly interconnected net of resources with cross-references among them
We take these factors into consideration when discussing the benefits and constraints of each protocol in the following sections to assess their suitability for different scenarios.
A.1 The dawn of APIs: RPC, XML-RPC, and JSON-RPC
Let’s begin by explaining a remote procedure call and its two most common implementations, namely, XML-RPC and JSON-RPC. As you can see in figure A.1, a remote procedure call (RPC) is a protocol that allows a client to invoke a procedure or subroutine in a different machine. The origins of this form of communication go back to the 1980s, with the emergence of distributed computing systems, and over time it has evolved into standard implementations.1 Two popular implementations are XML-RPC and JSON-RPC.

XML-RPC is an RPC protocol that uses Extensible Markup Language (XML) over HTTP to exchange data between a client and a server. It was created by Dave Winer in 1998, and it eventually grew into what later came to be known as SOAP (see section A.2).
With the increasing popularity of JavaScript Object Notation (JSON) as a data serialization format, an alternative implementation of RPC came in the form of JSON-RPC. It was introduced in 2005 and offers a simplified way for exchanging data between an API client and the server. As you can see in figure A.2, JSON-RPC payloads usually include three properties:
-
method—The method or function that the client wishes to invoke in the remote server -
params—The parameters that must be passed to the method or function on invocation

Figure A.2 Using JSON-RPC, an API client sends a request to an API server invoking the calculate_price() function to get the price of a medium cup of cappuccino. The server responds with the result of the invocation: $10.70.
In turn, JSON-RPC response payloads include the following parameters:
RPC is a lightweight protocol that allows you to drive API integrations without having to implement complex interfaces. An RPC client only needs to know the name of the function it needs to invoke in the remote server, with its signature. It doesn’t need to look for different endpoints and comply with their schemas as in REST. However, the lack of a proper interface layer between the API consumer and the producer inevitably tends to create tight coupling between the client and the implementation details of the server. As a consequence, a small change in implementation details risks breaking the integration. For this reason, RPC is recommended mostly for internal API integrations, where you’re in full control of both the client and the server.
A.2 SOAP and the emergence of API standards
This section discusses the Simple Object Access Protocol (SOAP). SOAP enables communication with web services through the exchange of XML payloads. It was introduced in 1998 by Dave Winer, Don Box, Bob Atkisnon, and Mohsen Al-Ghosein for Microsoft, and after a number of iterations, it became a standard protocol for web applications in 2003. SOAP was conceived as a messaging protocol, and it runs on top of a data transport layer, such as HTTP.
SOAP was designed to meet three major goals:
-
Extensibility—SOAP can be extended with capabilities found in other messaging systems.
-
Neutrality—It can operate over any data transfer protocol of choice, including HTTP, or directly over TCP or UDP, among others.
-
Independence—It enables communication between web applications regardless of their programming models.
The payloads exchanged with a SOAP endpoint are represented in XML, and as illustrated in figure A.3, they include the following properties:
-
Envelope(required)—Identifies the XML document as a SOAP payload -
Header(optional)—Includes additional information about the data contained in the message, for example, the type of encoding -
Body(required)—Contains the payload (actual message being exchanged) of the request/response -
Fault(optional)—Contains errors that occurred while processing the request

Figure A.3 At the top of a SOAP message, we find a section called Envelope that tells us that this is a SOAP payload. An optional Header section includes metadata about the message, such as the type of encoding. The Body section includes the actual payload of the message: the data being exchanged between the client and the server. Finally, a section called Fault includes details of any errors raised while processing the payload.
SOAP was a major contribution to the field of APIs. The availability of a standard protocol for communication across web applications led to the emergence of vendor APIs. Suddenly, it was possible to sell digital services by simply exposing an API that everybody could understand and consume.
In recent years, SOAP has been superseded by newer protocols and architectures. The factors that contributed to the decline of SOAP include these:
-
The payloads exchanged through SOAP contain large XML documents, which consume a large amount of bandwidth.
-
XML is difficult to read and maintain, and it requires careful parsing, which makes exchanging messages structured in XML less convenient.
-
SOAP does not provide a clear framework for organizing the data and capabilities that we want to expose through an API. It provides a way of exchanging messages, and it is up to the agents involved on both sides of the API to decide how to make sense of such messages.
A.3 RPC strikes again: Fast exchanges over gRPC
This section discusses a specific implementation of the RPC protocol called gRPC,2 which was developed by Google in 2015. This protocol uses HTTP/2 as a transport layer and exchanges payloads encoded with Protocol Buffers (Protobuf)—a method for serializing structured data. As we explained in chapter 2, serialization is the process of translating data into a format that can be stored or transferred over a network. Another process must be able to pick up the saved data and restore it to its original format. The process of restoring serialized data is also known as unmarshalling.
Some serialization methods are language specific, such as pickle for Python. Some others, like the popular JavaScript Object Notation (JSON) format, are language agnostic and can be translated into the native data structures of other languages.
An obvious shortcoming of JSON is that it only allows for the serialization of simple data representations consisting of strings, Booleans, arrays, associative arrays, and null values. Because JSON is language agnostic and must be strictly transferable across languages and environments, it cannot allow for the serialization of language-specific features, like NaN (not a number) in JavaScript, tuples or sets in Python, or classes in object-oriented languages.
Python’s pickle format allows you to serialize any type of data structure running in your Python programs, including custom objects. The shortcoming, though, is that the serialized data is highly specific to the version of Python that you were running at the time of dumping the data. Due to slight changes in the internal implementation of Python between different releases, you cannot expect a different process to be able to reliably parse a pickled file.
Protobuf comes somewhere in between: it allows you to define more complex data structures than JSON, including enumerations, and it is able to generate native classes from the serialized data, which you can extend to add custom functionality. As you can see in figure A.4, in gRPC you must first define the schema for the data structures that you want to exchange over the API using the Protobuf specification format, and then use the Protubuf CLI to automatically generate code for both the client and the API server.

Figure A.4 gRPC uses Protobuf to encode the data exchanged through the API. Using the protoc CLI, we can generate code (stubs) for both the client and the server from a Protobuf specification.
The data structures generated from the Protobuf specifications are called stubs. The stubs are implemented in code native to the language we use to build the API client and the server. As you can see in figure A.5, the stubs take care of parsing and validating the data exchanged between client and server.

Figure A.5 The stubs generated with Protobuf take care of parsing the payloads exchanged between the API client and the API server and translating them into native code.
gRPC offers a more reliable approach for API integrations than plain RPC. The use of Protobuf serves as an enforcement mechanism that ensures the data exchanged between the client and the server comes in the expected format. It also helps to make sure that communication over the API is highly optimized, since the data is exchanged directly in binary format. For this reason, gRPC is an ideal candidate for the implementation of internal API integrations where performance is a relevant factor.3
A.4 HTTP-native APIs with REST
This section explains Representational State Transfer (REST) and its main features. REST is an architectural style for the design of web services and their interfaces. As we saw in chapter 4, REST APIs are structured around resources. We distinguish two types of resources, collections and singletons, and we use different URL paths to represent them. For example, in figure A.6, /orders represents a collection of orders, while /orders/{order_id} represents the URI of a single order. We use /orders to retrieve a list of orders and to place new orders, and we use /orders/{order_id} to perform actions on a single order.

Figure A.6 REST APIs are structured around endpoints. We distinguish between singleton endpoints, such as GET /orders/8, and collection endpoints, such as GET /orders. Leveraging the semantics of HTTP methods, REST API responses include HTTP status codes that signal the result of processing the request.
Good REST API design leverages features from the HTTP protocol to deliver highly expressive APIs. For example, as you can see in figure A.7, we use HTTP methods to define API endpoints and express their intent (POST to create resources and GET to retrieve resources); we use HTTP status codes to signal the result of processing a request; and we use HTTP payloads to carry exchange data between the client and the server.
We document REST APIs using the OpenAPI standard, which was originally created in 2010 by Tony Tam under the name Swagger API. The project gained in popularity, and in 2015 the OpenAPI Initiative was launched to maintain the specification. In 2016, the specification was officially released under the name OpenAPI Specification (OAS).
The data exchanged through a REST API goes in the body of an HTTP request/response. This data can be encoded in any type of format the producer of the API wishes to enforce, but it is common practice to use JSON.
Thanks to the possibility of creating API documentation with a high level of detail in a standard specification format, REST is an ideal candidate for enterprise API integrations and for building public APIs with a large and diverse range of consumers.
A.5 Granular queries with GraphQL
This section explains GraphQL and how it compares to REST. GraphQL is a query language based on graphs and nodes. As of the time of this writing, it is one of the most popular choices for the implementation of web APIs.4 It was developed by Facebook in 2012 and publicly released in 2015.
GraphQL is designed to address some of the limitations of REST APIs, such as the difficulty of representing certain operations through HTTP endpoints. For example, let’s say you ordered a cup of coffee through the CoffeeMesh website, and later you change your mind and decide to cancel the order. Which HTTP method is most appropriate to represent this action? You can argue that cancelling an order is akin to deleting it, so you could use the DELETE method. But, is cancelling really the same as deleting? Are you going to delete the order from your records after cancellation? Probably not. You could argue that it should be a PUT or a PATCH request since you are changing the state of the order to cancelled. Or you could say it should be a POST request since the user is triggering an operation that involves more than simply updating a record. However you look at it, HTTP does present some limitations when it comes to modeling user actions, and GraphQL gets around this problem by not constraining itself to using elements of the HTTP protocol exclusively.
Another limitation of REST is the inability for clients to make granular requests of data, technically known as overfetching. For example, imagine that an API exposes /products and /ingredients resources. As you can see in figure A.7, with /products we can get a list of products, including the IDs of their ingredients. However, if we want to get the name of each ingredient, we must request the details of each ingredient to the /ingredients API. The result is the API client needs to send various requests to the API to obtain a simple representation of a product. The API client also receives more information than it needs: in each request against the /ingredients API, the client receives a full description of each ingredient, when it only needs the name. Overfetching is a challenge for small devices such as mobile phones, which may not be able to handle and store large amounts of data and may have more limited network access.
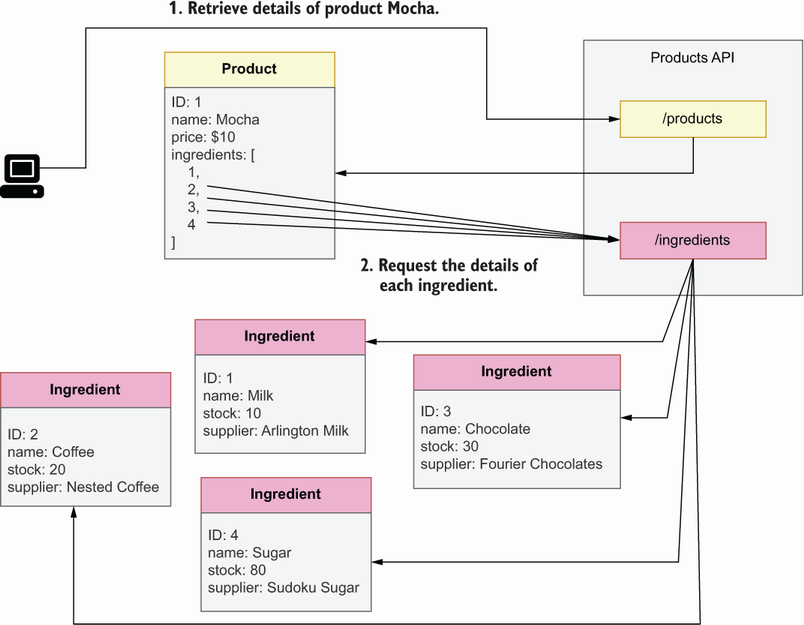
Figure A.7 A limitation of REST APIs is the inability of API clients to make granular requests of data, otherwise known as overfetching. In the figure, the /products endpoint returns a list of products with the IDs of their ingredients. To obtain the ingredients’ names, the client must request the details of each ingredient from the /ingredients endpoint. As a result, the API client ends up making too many requests to the server and receiving more data than it needs.
GraphQL avoids these problems by allowing clients to make granular queries on the server. With GraphQL, we can create relationships between different data models, allowing API clients to fetch data from related entities. For example, in figure A.8, an API client can request a list of products and the names of their ingredients in a single request. By allowing clients to retrieve the data they need from the server in a single request, GraphQL is an ideal candidate for APIs, which are consumed by clients with limited network access or limited storage capabilities, such as mobile devices. GraphQL is also a good choice for APIs with highly interconnected resources, in which users are likely to fetch data from related entities, such as products and ingredients in figure A.8.
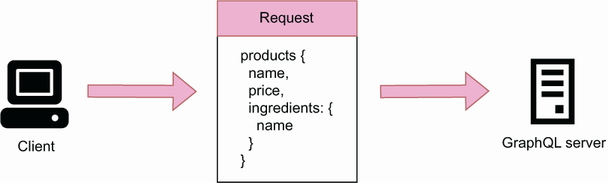
Figure A.8 Using a GraphQL API, we can query data from related entities, such as products and ingredients. In this figure, an API client requests a list of products with the names of their ingredients.
Despite its benefits, GraphQL also comes with constraints. A major limitation of GraphQL is that it doesn’t provide great support for custom scalar types. GraphQL ships with a basic set of built-in scalars, such as integer (Int) and string (String). GraphQL allows you to declare your own custom scalars, but you can’t document their shape or how they’re validated using the SDL. In the words of GraphQL’s official documentation, “It’s up to our implementation to define how that type should be serialized, deserialized, and validated” (https://graphql.org/learn/schema/). Since one of the cornerstones of robust API integrations is great documentation, GraphQL is a challenging choice for public APIs that must be reliably consumed by external clients.
Another limitation of GraphQL is that all the queries are typically done with POST requests, which makes it more difficult to cache the responses. In my experience, most developers also find it more difficult to interact with a GraphQL API. In fact, Postman’s 2022 State of the API Report found that only 28% of the surveyed developers use GraphQL, and up to 14% of them hadn’t heard of it. While interacting with a REST API may be as simple as hitting a GET endpoint, with GraphQL you must know how to build query documents and how to send them to the server. Since developers are less familiar with GraphQL, choosing this technology may make your APIs less likely to be consumed.
1 Bruce Jay Nelson is credited with the introduction of the term remote procedure call in his doctoral dissertation (Technical Report CSL-81-9, Xero Palo Alto Research Center, Palo Alto CA, 1981). For a more formal description of the implementation requirements of RPC, see Andrew B. Birrell and Bruce Jay Nelson, “Implementing Remote Procedure Calls,” ACM Transactions on Computer Systems, vol. 2, no. 1, 1984, pp. 39–59.
2 You’re surely wondering what the “g” in gRPC stands for. According to the official documentation, it stands for a different word in every release. For example, in version 1.1 it stands for “good,” while in version 1.2 it stands for “green,” and so on (https://grpc.github.io/grpc/core/md_doc_g_stands_for.html). Some people believe that the “g” stands for Google, as this protocol was invented by Google (see “Is gRPC the Future of Client-Server Communication?” by Bleeding Edge Press, Medium, July 19, 2018, https://medium.com/@EdgePress/is-grpc-the-future-of-client-server-communication-b112acf9f365).
3 According to Postman’s 2022 State of the API Report, 11% of the surveyed developers use gRPC (https://www.postman.com/state-of-api/api-technologies/#api-technologies).
4 According to Postman’s 2022 State of the API Report, 28% of the surveyed developers use GraphQL (https://www.postman.com/state-of-api/api-technologies/#api-technologies).