
What High Availability Options Are There?
Understanding your high availability requirements is only the first step in implementing a successful high availability application. Knowing what available technical options exist is equally as important. Then, by following a few basic design guidelines, it will be possible to match your requirements to the “correct” high availability technical solution. This chapter will introduce you to a variety of fundamental HA options such as RAID disk arrays and MSCS clustering, as well as other more high-level options such as SQL clustering and data replication that should lead you to a solid high availability foundation.
Fundamental Areas to Start With
If you remember the hardware/software stack presented in Chapter 1, “Essential Elements of High Availability,” it outlined each major component and how if one component fails, the others may also be affected. With this in mind, the best approach for moving into supporting high availability is to work on shoring up the basic foundation components first (as suggested in the one-two punch approach already). Figure 2.1 depicts the initial foundation components to target.
Figure 2.1. Initial foundation components.
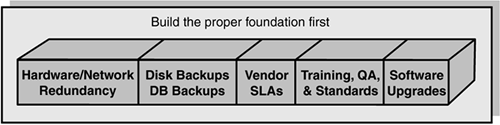
By addressing these first, you add a significant amount of stability and high availability capability across your hardware/system stack. In other words, you are moving up to a level where you should be starting from, before you completely jump into a particular high availability solution. If you do nothing further from this point, you will have already achieved a portion of your high availability goals.
Hardware— To get to this foundation level, start by addressing your basic hardware issues for high availability and fault tolerance. This would include redundant power supplies, UPS systems, redundant network connections, and ECC Memory (Error Correcting). Also available are “hot-swappable” components such as disks, CPUs, and memory. And, most servers are now using multiple CPUs, fault tolerant disk systems like RAID disk arrays, mirrored disks, Storage Area Network (SAN), Network Attached Storage (NAS), redundant fans, and so on. Cost may drive the full extent of what you choose to build out. However, start with the following
Redundant power supplies (and UPS)
Redundant fan systems
Fault tolerant disks—RAID disk arrays (1 through 10), preferably “hot swappable”
ECC memory
Redundant Ethernet connections
Backup— Next look at the basic techniques and frequency of your disk backups and database backups. Often this is way behind in what it needs to be to guarantee recoverability and even the basic level of high availability. I've lost track of the number of times I've walked into a customer site and found out that the database backups were not being run, were corrupted, or weren't even considered necessary. You would be shocked by the list of fortune 1000 companies where this occurs.
Operating System— Not only do you make sure that all upgrades to your OS are applied, but that the configuration of all options are correct. This would include making sure you have antivirus software installed (if applicable) along with the appropriate firewalls for external facing systems.
Vendor Agreements— Come in the form of software licenses, software support agreements, hardware service agreements, and both hardware and software service level agreements. Essentially, you are trying to make sure you can get all software upgrades and patches for your OS and for your application software at any time, as well as get software support, hardware support agreements, and both software and hardware service level agreements (SLAs) in place that will guarantee a level of service within a defined period of time
Training— This is multifaceted, in that training can be for software developers to guarantee the code they write is optimal, for system administrators who need to administer your applications, and even for the end-users themselves to make sure they use the system correctly. All play into the ultimate goals of achieving high availability.
Quality Assurance— Testing as much as possible and doing it in a very formal way is a great way to guarantee a system's availability. I've seen dozens of studies over the years that clearly show that the more thoroughly you test (and more formal your QA procedures are), the fewer software problems you will have. To this day I'm not sure why people skimp on testing. It has such a huge impact in system reliability and availability.
Standards/Procedures— This is interlaced heavily with training and QA. Coding standards, code walkthroughs, naming standards, formal system development life cycles, protecting tables from being dropped, use of governors, and so on all contribute to more stable and potentially more highly available systems.
Server Instance Isolation— By design, you may want to isolate applications (SQL Server's applications and their databases, and so on) away from each other in order to mitigate the risk of one of these applications causing the other to fail. Plain and simple, never put other applications in each other's way if you don't have to. The only things that might force you to load up a single server with all of your applications would be expensive licensing costs for each server's software, and perhaps hardware scarcity (strict limitations to the number of servers available for all applications). We will explore more details of this in a bit.
Fault Tolerant Disk: RAID and Mirroring
When it comes to creating a fault tolerant disk subsystem, you can do basic “vanilla” mirroring of a disk or varying RAID disk array configurations. These are tried and true methods, but which one to use is the tricky part. The problem is that there are often significant implementation aspects such as the performance impact, complexity of administration, and cost that must be understood thoroughly. So, let's look at disk mirroring first.
Basically, disk mirroring is a technique that writes data to two duplicate disks simultaneously (or three if doing triple-mirroring) as part of a single logical disk write operation. In other words, when you write a piece of data to a disk that has been mirrored, it is automatically written to the primary disk AND to the mirrored (duplicate) disk at the same time. Both disks in the mirror are usually the same size and have the same technical specification. If the primary disk fails, for any reason, the mirrored (duplicate) disk is automatically used as the primary. The application that was using the disk never knows that a failure has occurred, thus enhancing your application's availability greatly. At some point, you can swap in a new disk and re-mirror it, and off you go again without missing a beat. Figure 2.2 illustrates the basic disk-mirroring concept of data being written simultaneously.
Figure 2.2. Mirrored disk—simultaneous writes.

Of course, the downside of disk mirroring is that the mirrored disk drive(s) are not directly usable, and you are effectively burning up double the amount of disk drives. This can be costly as well, as many servers don't have the sheer space within their physical rack footprint to house numerous mirrored disks. Very often, separate external disk drive rack systems (with separate power supplies) solve this problem.
What should be mirrored? In many high availability systems, the first disk drive that is targeted for mirroring is the one that contains the OS. This one mirroring choice instantly increases the availability of the system by some factor and is considered a fundamental cornerstone for high availability. For non-RAID systems, you can selectively choose critical pieces of your application and its underlying databases as high candidates for mirrored disk. Figure 2.3 illustrates an MS SQL Server 2000–based ERP system that has been laid out within a mirrored disk configuration.
Figure 2.3. ERP System (MS SQL Server 2000 based)—mirrored disk.

The use of disk mirroring has also been integrated into various RAID level configurations. These will be explained in the next section.
Redundant Array of Independent Disks (RAID)
Perhaps the most popular method of increasing system availability is by implementing various RAID disk configurations. This will, by definition, make the underlying disk subsystem much more stable and available with less susceptibility to disk failures. Using certain RAID configurations is another strong tool that you can use as part of your foundation for high availability. Let's look at what RAID really is.
RAID stands for Redundant Array of Independent Disks and has several “levels” of configurations that yield different capabilities. The primary goal of RAID is to decrease disk subsystem failures. Some configurations are highly redundant and incorporate disk mirroring. Some use sophisticated algorithms for spreading data out over several disks so that if any one disk fails, the others can continue processing. In addition, the data that was on the failed disk can be recovered from what is stored on the other disks (RAID 5). This is almost like magic. But, where there is magic there is cost (both in performance and in hardware). Figure 2.4 summarizes the common RAID level configurations.
Figure 2.4. RAID levels summary.

Disk controller manufacturers and disk drive manufacturers sell various types of disk controllers for these RAID arrays that may also have different amounts of cache (memory) built in. These product offerings give you a great deal of flexibility in regard to defining different RAID level configurations that best suit your needs. Since many of the defined RAID levels are not commercially viable (or available), we will describe only the ones that are best suited for a company's high availability solution (from a cost, management, and fault tolerance point of view). These are RAID levels 0, 1, 5, and 1+0 (10).
RAID 0: Striping (without Parity)— RAID 0 (zero) is simply a disk array that consists of one or more physical disks that have no parity checking (error checking of disk writes/reads) at all. This is really just a series of disk drives sitting on the operating system without any redundancy or error checking whatsoever—no fault tolerance. The disk striping comes from the ability to spread segments (data blocks) across more than one physical disk for performance. Figure 2.5 shows this basic RAID level configuration and how data blocks can be striped across multiple disks. A piece of data (A) is broken down into data block A1 (on Disk W) and data block A2 (on Disk X). The payoff comes when you need to retrieve the data. On average, because of the striping, the data is stored more shallowly and is readily retrieved (as compared to normal non-striped data storage retrieval). In other words, you don't have to seek as deep into an individual disk to retrieve a piece of data; it is, on average, located higher up on multiple disks and assembled more quickly. This translates directly into faster retrieval times. For the best performance, you can have one disk drive per controller, or at the very least one disk drive per channel (as seen in Figure 2.5).
Figure 2.5. RAID level 0.
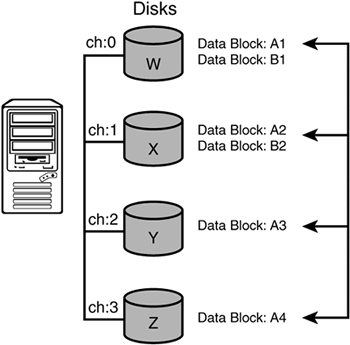
RAID 0 is often configured to support file access that doesn't need to be protected from failure but does need to be fast (no additional overhead in any way).
You would be surprised at the number of things that meet this type of requirement. RAID 0 is also used in combination with both RAID 1+0 (10) and RAID 0+1 (01) to produce much more robust availability. These will be described shortly.
RAID 1: Mirroring (with duplexing)— RAID 1 is the first RAID level that handles disk failures and therefore is truly fault tolerant. RAID 1 is mirroring for one or more disks at a time. In other words, if you configure five disks with RAID 1 (mirroring), you will need five additional redundant disks for their mirror. Think of this as “mirrored pairs.” As has already been described, when writes occur to this RAID 1 configuration, they are simultaneously written to the redundant (mirrored) disks. If a failure of any primary disk should ever occur, the mirrored disk is instantly activated. Most mirrored configurations may well read from either the mirrored or primary disk for data (it doesn't matter since the disks are identical and this read traffic is managed by the disk controller). However, for every logical disk write, there will be two separate physical disk writes (primary and the mirror). Duplexing is achieved by adding a redundant disk controller card for additional fault tolerance. Figure 2.6 illustrates a RAID 1 configuration.
Figure 2.6. RAID level 1.
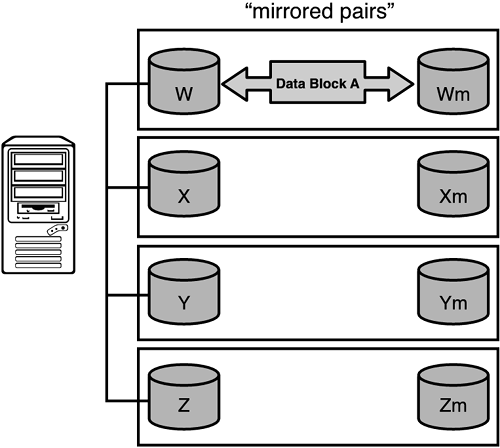
This RAID configuration offers good results for folks who need a certain level of write fault tolerance but can withstand the slight performance impact of the additional physical writes. To reestablish a mirrored pair (after a disk failure has occurred), you just pop in a replacement disk, re-copy the good disk's data to the new disk, and off you go.
RAID 5: Block-level striping with distributed parity— The notion of parity is first introduced with RAID 3. Parity means that there will be a data parity value generated (and stored) for a piece of data (or block of data) when it is written, and this parity is checked when it is read (and corrected if necessary). RAID 5 distributes the parity storage across all the disks in the array in such a way that any piece of data can be recovered from the parity information found on all of the other disks. Figure 2.7 shows this striped, distributed parity technique.
Figure 2.7. RAID level 5.
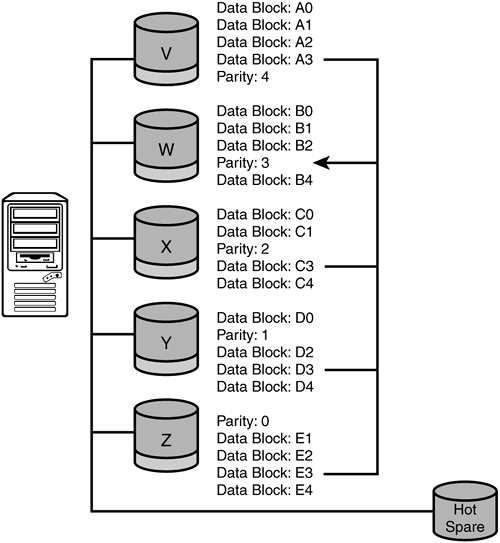
To put this another way, if the disk containing data blocks A is lost, the data can be recovered from the parity values that are stored on all of the other disks. Notice that a data block never stores its own parity values. This makes RAID 5 a good fault-tolerant option for those applications that need this type of availability.
In most RAID 5 implementations, a hot spare is kept online that can be used automatically when a failure has occurred. This hot spare gets rebuilt with data blocks (and parity) dynamically from all of the surviving disks. You usually notice this via RAID failure alarms, and there is a huge disk subsystem slowdown during this rebuild. Once completed, you are back in a fault tolerant state. However, RAID 5 configurations cannot sustain two disk failures at one time because this would not allow the complete parity values that are needed to rebuild a single disk's data blocks to be accessed. RAID 5 requires that there be up to four (or more) physical disk writes for every logical write that is done (one write to each parity storage). This translates to poor performance for write and update intensive applications, but ample performance for read intensive applications.
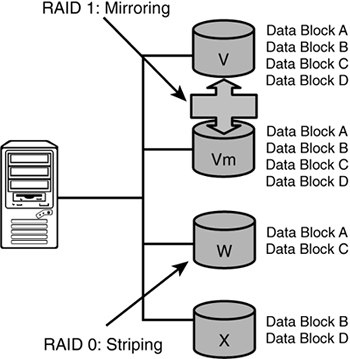
RAID 0+1, 01, 0/1: Mirrored stripes— RAID 0+1 is implemented as a mirrored array (RAID 1) whose segments are RAID 0 arrays. This is not the same as RAID 1+0 (10), as you will see in a bit. RAID 0+1 has the same fault tolerance as RAID level 5. It also has the same overhead for fault tolerance as mirroring alone. Fairly high read/write rates can be sustained due to the multiple stripe segments of the RAID 0 portion.
The downside of RAID 0+1 is when a single drive fails, the whole array deteriorates to a RAID level 0 array because of the approach used of mixing striping with mirroring this way. Figure 2.8 shows how this mirrored stripe configuration is achieved.
Figure 2.8. RAID Level 0+1 (0/1).
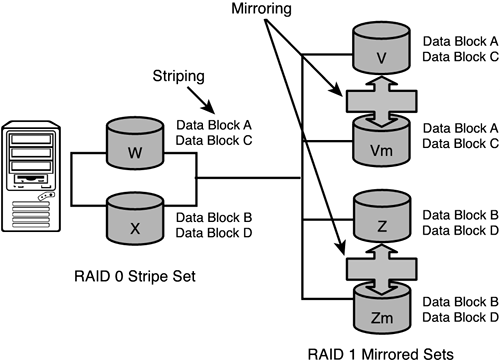
RAID 1+0,10,1/0: Stripe of Mirrors— RAID 1+0 is implemented as a striped array (RAID 0) whose segments are mirrored arrays (RAID 1). This is more favorable in regard to failures. Basically, RAID 1+0 has the same fault tolerance as RAID level 1 (mirroring). The failure of a single disk will not put any other mirrored segments in jeopardy. This is considered to be better than RAID 0+1 in this regard. And, to the delight of many a system designer, RAID 1+0 can sustain very high read/write rates because of the striping (the RAID 0). Figure 2.9 shows the subtleties of this RAID 1+0 configuration.
Figure 2.9. RAID Level 1+0 (10).
Mitigate Risk by Spreading Out Server Instances
Server instance isolation was briefly touched on in a prior section of this chapter, but needs to be expanded on because it is so critical and because application isolation should become a part of your fundamental design principles. As was mentioned, by design, you should try to isolate applications (SQL Server's applications and their associated databases, and so on) away from each other in order to mitigate the risk of one of these applications causing the other to fail. A classic example of this is when a company loads up a single SQL Server instance with between two and eight applications and their associated databases. The only problem is that the applications are sharing memory, CPUs, and internal work areas such as TempDB. Figure 2.10 shows a loaded up SQL Server instance that is being asked to service four major applications (Appl 1 DB thru Appl 4 DB).
Figure 2.10. Applications sharing a single SQL Server 2000 instance.
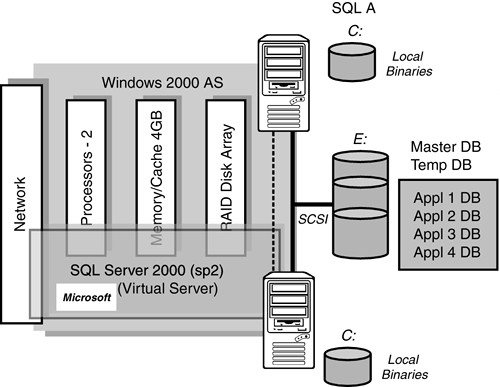
This single SQL Server instance is sharing memory (cache) and critical internal working areas such as TempDB with all four major applications. Everything runs along fine until one of these applications submits a runaway query and all other applications being serviced by that SQL Server instance come to a grinding halt. Most of this built-in risk could have been avoided by simply putting each application (or perhaps two applications) onto their own SQL Server instance, as shown in Figure 2.11. This fundamental design approach reduces greatly the risk of one application affecting another.
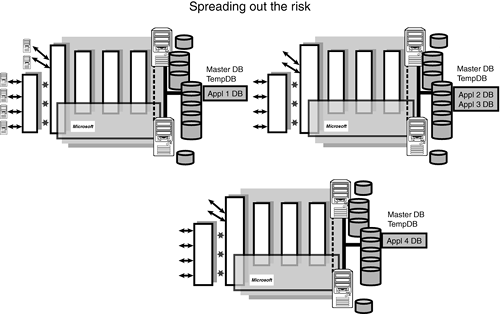
I've lost count of the number of companies that have made this very fundamental error. The trouble is they keep adding new applications to their existing server instance without a full understanding of the “shared” resources that underpin the environment. It is very often too late when they finally realize that they are hurting themselves “by design.” The readers of this book have now been given proper warning of the risks. If other factors such as cost or hardware availability dictate otherwise, then at least it is a calculated risk that is entered into knowingly (and is properly documented as well).