
Building Your HA Solution with One or More of These Options
Once we have the proper foundation in place, we can build a tailored software-driven high availability solution much more easily and “match” one or more high availability options to YOUR requirements. Remember, different high availability solutions will yield different results. The focus of this book will be on the Microsoft offerings since they are potentially already available in your company's software stack. Figure 2.12 identifies the current Microsoft options that can be drawn upon together or individually.
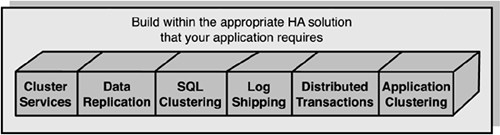
With the exception of application clustering (which is available as part of a particular application's capabilities—like with some application server technologies), all are readily available “out-of-the-box” from Microsoft from the Windows Server family of products and from Microsoft SQL Server 2000.
It is important to understand that one or more of these options can be used together, but not all go together. As an example, you would be using Microsoft Cluster Services (MSCS) along with Microsoft SQL Server 2000's SQL Clustering to implement the SQL clustering database configuration. We will get into much more detailed explanations on these in the next few chapters. But, first let's describe a brief overview of each of these options.
Microsoft Cluster Services (MSCS)
Cluster Services could actually be considered a part of the basic foundation components that we described earlier, except that it's possible to build a high availability system without it (one that uses numerous redundant hardware components and disk mirroring or RAID for its disk subsystem, for example). Microsoft has made MSCS the cornerstone of their clustering capabilities, and MSCS is utilized by applications that are “cluster-enabled.” The prime example of a cluster-enabled technology is MS SQL Server 2000.
So, what is MSCS anyway?
MSCS is the additional Windows OS configuration information that will define and manage from between two to four servers as “nodes” in a cluster. These nodes are aware of each other and can be set up to take over cluster-aware applications from any node that fails (a failed server). This cluster will also share and control one or more disk subsystems as part of its high availability capability. MSCS is only available within the Microsoft Windows Advanced Server and Data Center operating system (OS) products. It is NOT available with standard Windows servers (Win2k Professional, and so on). Don't be alarmed though. If you are looking at a high availability system to begin with, there is a high probability that your applications are already running with these enterprise-level OS versions. Figure 2.13 illustrates a basic two-node MSCS configuration.
Figure 2.13. MSCS cluster services basic configuration.
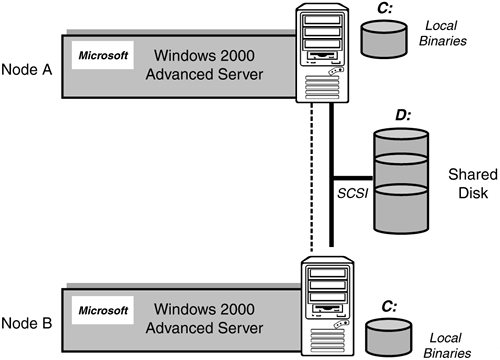
In Chapter 4, “Microsoft Cluster Services,” we will completely build up a clustered configuration and detail the minimal hardware components that must be present for MSCS. MSCS can be set up in an active/passive or active/active model. Essentially, in an active/passive mode, one server sits idle (is passive) while the other is doing the work (is active). If the active server fails, the passive one takes over the shared disk and the cluster-aware applications instantaneously. I believe some people think this is “magic.” We will see exactly how this is done in Chapter 4. And, it's not magic.
SQL Clustering
If you want a SQL Server instance to be clustered for high availability, you are essentially asking that this SQL Server instance (and the database) be completely resilient to a server failure and completely available to the application without the end-user ever even noticing that there was a failure. Microsoft provides this capability through the SQL clustering option within SQL Server 2000. SQL clustering builds on top of cluster services (MSCS) for its underlying detection of a failed server and for its availability of the databases on the shared disk (which is controlled by MSCS). SQL Server is a “cluster aware/enabled” technology. This is done by creating a “virtual” SQL Server that is known to the application (the constant in the equation), and then two physical SQL Servers that share one set of databases. Only one SQL Server is active at a time and just goes along and does its work. If that server fails (and with it the physical SQL Server instance), the passive server (and the physical SQL Server instance on that server) simply takes over instantaneously. This is possible because cluster services also controls the shared disk where the databases are. The end-user (and application) pretty much never know which physical SQL Server instance they are on, or if one failed or not. Figure 2.14 illustrates a typical SQL clustering configuration that is built on top of MSCS.
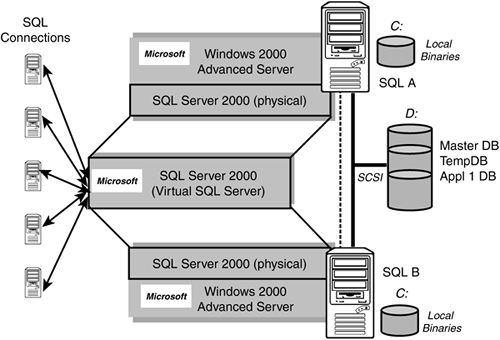
Setup and management of this type of configuration is much easier than you realize. More and more, SQL clustering is the method chosen for most high availability solutions. Later on, you will see that other methods may also be viable for achieving high availability (based on the application's HA requirements). We will fully outline SQL clustering in its own chapter shortly. Extending the clustering model to include network load balancing (NLB) pushes this particular solution even further into higher availability. Figure 2.15 shows a four-host network load balanced (NLB) cluster architecture acting as a virtual server to handle the network traffic.
Figure 2.15. An NLB host cluster with a two-node server cluster.
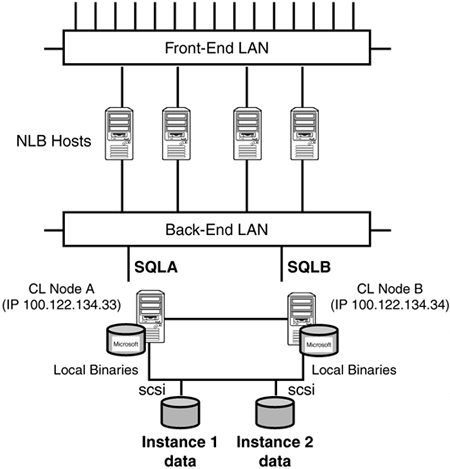
Each NLB host works together among the four hosts distributing the work efficiently. NLB automatically detects the failure of a server and repartitions client traffic among the remaining servers.
Data Replication
The next technology option that can be utilized to achieve high availability is data replication. Originally data replication was created to off-load processing from a very busy server (such as an OLTP application that must also support a big reporting workload) or to distribute data for different, very distinct user bases (such as worldwide geographic specific applications). As data replication (transactional replication) became more stable and reliable, it started to be used to create “warm,” almost “hot” standby SQL Servers that could also be used to fulfill basic reporting needs. If the primary server ever failed, the reporting users would still be able to work (hence a higher degree of availability achieved for them) and the replicated reporting database could be utilized as a substitute for the primary server if needed (hence a warm standby SQL Server). When doing transactional replication in the “instantaneous replication” mode, all data changes are replicated to the replicate servers extremely quickly. This may fit some companies' availability requirements and also fulfill their distributed reporting requirements as well. Figure 2.16 shows a typical SQL data replication configuration that serves as a basis for high availability and also fulfills a reporting server requirement at the same time.
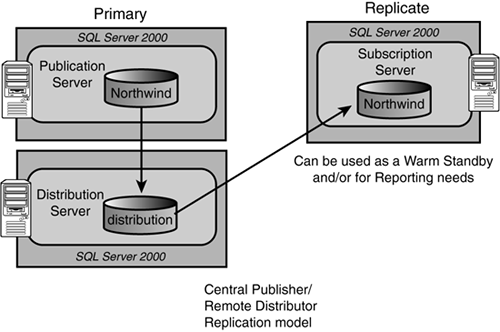
The downside comes into play if ever the replicate is needed to become the primary server (take over the work from the original server). It takes a bit of administration that is NOT transparent to the end-user. Connection strings have to be changed, ODBC data sources need to be updated, and so on. But, this may be something that would take minutes as opposed to hours of database recovery time, and may well be tolerable to the end-users. In addition, a risk of not having all of the transactions from the primary server also exists. But, often, a company is willing to live with this small risk in favor of availability. Remember, this replicated database is a mirror image of the primary database (up to the point of the last update), which makes it very attractive as a warm standby. For databases that are primarily read-only, this is a great way to distribute the load and mitigate risk of any one server failing. More on this in Chapter 7, “Microsoft SQL Server Data Replication.”
Log Shipping
Another, more direct method of creating a completely redundant database image is log shipping. Microsoft certifies log shipping as a method of creating an “almost hot” spare. Some folks even use log shipping as an alternative to data replication (it has been referred to as “the poor man's data replication”). Keep in mind that log shipping does three primary things:
Makes an exact image copy of a database on one server from a database dump
Creates a copy of that database on one or more other servers from that dump
Continuously applies transaction log dumps from the original database to the copy
In other words, log shipping effectively replicates the data of one server to one or more other servers via transaction log dumps. Figure 2.17 shows a source/destination SQL Server pair that has been configured for log shipping.
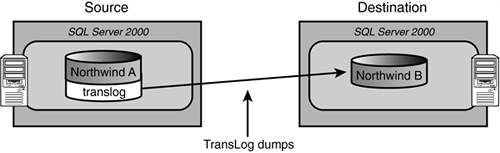
This is a great solution when you have to create one or more fail-over servers. It turns out that, to some degree, log shipping fits the requirement of creating a read-only subscriber as well. The gating factors for using log shipping as the method of creating and maintaining a redundant database image are
Data latency—The time that exists between the frequency of the transaction log dumps on the source database and when these dumps get applied to the destination DBs.
Sources and destinations must be the same SQL Server version.
Data is read-only on the destination SQL Server until the log shipping pairing is broken (as it should be to guarantee that the translogs can be applied to the destination SQL Server).
The data latency restrictions might quickly disqualify log shipping as a full-proof high availability solution. However, log shipping might be adequate for certain situations. If a failure ever occurs on the primary SQL Server, a destination SQL Server that was created and maintained via Log Shipping can be swapped into use at a moment's notice. It would contain exactly what was on the source SQL Server (right down to every user id, table, index, and file allocation map, except for any changes to the source database that occurred after the last log dump that was applied). This directly achieves a level of high availability. It is still not quite completely transparent though, since the SQL Server instance names are different and the end-user may be required to log in again to the new server instance.
Distributed Transactions
A slightly more complex approach to high availability might be to create a distributed application that is “programmed” to be aware of a failed server (data source). In other words, when data is needed (read only) by an application, it tries its primary data location first, and if that is not available, it tries a secondary data location, and so on. When updates (inserts/deletes/updates) occur at any one of the data locations, a single distributed transaction needs to be used to guarantee the integrity of all data locations (often referred to as two-phase commit). Building applications that span two or more data locations will be utilizing the distributed transaction coordinator (MS DTC).
Each Microsoft SQL Server will have an associated distributed transaction coordinator (MS DTC) on the same machine with it. For that matter, MS DTC is present on your Windows Server regardless of whether you have SQL Server installed or not.
The MS DTC allows applications to extend transactions across two or more instances of MS SQL Server (or other data sources) and participate in transactions managed by transaction managers that comply with the X/Open DTP XA standard. The MS DTC will act as the primary coordinator for these distributed transactions. MS DTC ensures that all updates are made permanent in all data locations (committed), or makes sure that all of the work is undone (rolled back) if it needs to be. Figure 2.18 shows how an application could be developed to do a primary data read request against one location, and if that access fails (because the location has failed), it would try a secondary location that had the same data. Updates to data by the application must be made in both locations at once so that data integrity would be guaranteed.
Figure 2.18. A distributed transaction approach.
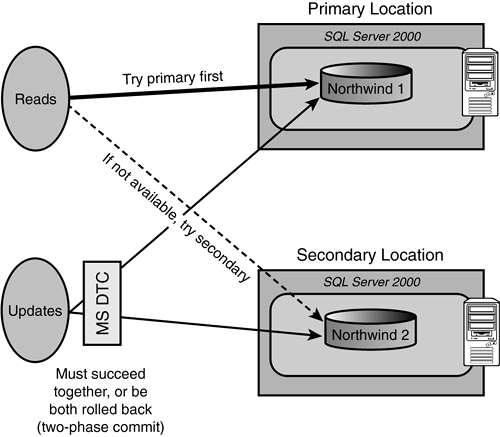
As you can also see in this figure, MS DTC will provide the update transaction stability to all locations. The application takes on more of the burden of high availability in this case, but provides a reasonably good high availability result. The update capability of the application is lost for a period of time, but the read capability is never lost.