
In this chapter we will look at some of the most common attacks that are being carried out against web applications and servers today. Knowing the anatomy of these attacks is the first step in understanding how they can be blocked, so we will first seek to understand the details of the attacks, and then see how they can be blocked using ModSecurity.
Web applications can be attacked from a number of different angles, which is what makes defending against them so difficult. Here are just a few examples of where things can go wrong to allow a vulnerability to be exploited:
The web server process serving requests can be vulnerable to exploits. Even servers such as Apache, that have a good security track record, can still suffer from security problems—it's just a part of the game that has to be accepted.
The web application itself is of course a major source of problems. Originally, HTML documents were meant to be just that—documents. Over time, and especially in the last few years, they have evolved to also include code, such as client-side JavaScript. This can lead to security problems. A parallel can be drawn to Microsoft Office, which in earlier versions was plagued by security problems in its macro programming language. This, too, was caused by documents and executable code being combined in the same file.
Supporting modules, such as
mod_phpwhich is used to run PHP scripts, can be subject to their own security vulnerabilities.Backend database servers, and the way that the web application interacts with them, can be a source of problems ranging from disclosure of confidential information to loss of data.
Only amateur attackers blindly try different exploits against a server without having any idea beforehand whether they will work or not. More sophisticated adversaries will map out your network and system to find out as much information as possible about the architecture of your network and what software is running on your machines. An attacker looking to break in via a web server will try to find one he knows he can exploit, and this is where a method known as HTTP fingerprinting comes into play.
We are all familiar with fingerprinting in everyday life—the practice of taking a print of the unique pattern of a person's finger to be able to identify him or her—for purposes such as identifying a criminal or opening the access door to a biosafety laboratory. HTTP fingerprinting works in a similar manner by examining the unique characteristics of how a web server responds when probed and constructing a fingerprint from the gathered information. This fingerprint is then compared to a database of fingerprints for known web servers to determine what server name and version is running on the target system.
More specifically, HTTP fingerprinting works by identifying subtle differences in the way web servers handle requests—a differently formatted error page here, a slightly unusual response header there—to build a unique profile of a server that allows its name and version number to be identified. Depending on which viewpoint you take, this can be useful to a network administrator to identify which web servers are running on a network (and which might be vulnerable to attack and need to be upgraded), or it can be useful to an attacker since it will allow him to pinpoint vulnerable servers.
We will be focusing on two fingerprinting tools:
httprintOne of the original tools — the current version is 0.321 from 2005, so it hasn't been updated with new signatures in a while. Runs on Linux, Windows, Mac OS X, and FreeBSD
httpreconThis is a newer tool which was first released in 2007. It is still in active development. Runs on Windows.
Let's first run httprecon against a standard Apache 2.2 server:
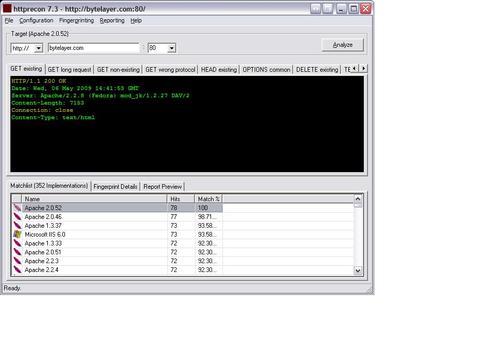
And now let's run httprint against the same server and see what happens:
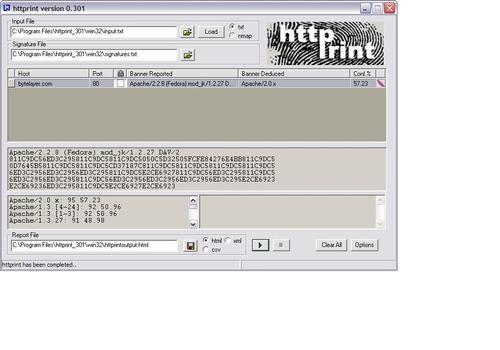
As we can see, both tools correctly guess that the server is running Apache. They get the minor version number wrong, but both tell us that the major version is Apache 2.x.
Try it against your own server! You can download httprint at http://www.net-square.com/httprint/ and httprecon at http://www.computec.ch/projekte/httprecon/.
Note
Tip
If you get the error message Fingerprinting Error: Host/URL not found when running httprint, then try specifying the IP address of the server instead of the hostname.
The fact that both tools are able to identify the server should come as no surprise as this was a standard Apache server with no attempts made to disguise it. In the following sections, we will be looking at how fingerprinting tools distinguish different web servers and see if we are able to fool them into thinking the server is running a different brand of web server software.
There are many ways a fingerprinting tool can deduce which type and version of web server is running on a system. Let's take a look at some of the most common ones.
The server banner is the string returned by the server in the Server response header (for example: Apache/1.3.3 (Unix) (Red Hat/Linux)). We already saw in Chapter 1 how this banner can be changed by using the ModSecurity directive SecServerSignature. Here is a recap of what to do to change the banner:
# Change the server banner to MyServer 1.0 ServerTokens Full SecServerSignature "MyServer 1.0"
The HTTP response header contains a number of fields that are shared by most web servers, such as Server, Date, Accept-Ranges, Content-Length, and Content-Type. The order in which these fields appear can give a clue as to which web server type and version is serving the response. There can also be other subtle differences—the Netscape Enterprise Server, for example, prints its headers as Last-modified and Accept-ranges, with a lowercase letter in the second word, whereas Apache and Internet Information Server print the same headers as Last-Modified and Accept-Ranges.
Another way to gain information on a web server is to issue a non-standard or unusual HTTP request and observe the response that is sent back by the server.
The HTTP DELETE command is meant to be used to delete a document from a server. Of course, all servers require that a user is authenticated before this happens, so a DELETE command from an unauthorized user will result in an error message—the question is just which error message exactly, and what HTTP error number will the server be using for the response page?
Here is a DELETE request issued to our Apache server:
$ nc bytelayer.com 80 DELETE / HTTP/1.0 HTTP/1.1 405 Method Not Allowed Date: Mon, 27 Apr 2009 09:10:49 GMT Server: Apache/2.2.8 (Fedora) mod_jk/1.2.27 DAV/2 Allow: GET,HEAD,POST,OPTIONS,TRACE Content-Length: 303 Connection: close Content-Type: text/html; charset=iso-8859-1 <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>405 Method Not Allowed</title> </head><body> <h1>Method Not Allowed</h1> <p>The requested method DELETE is not allowed for the URL /index.html.</p> <hr> <address>Apache/2.2.8 (Fedora) mod_jk/1.2.27 DAV/2 Server at www.bytelayer.com Port 80</address> </body></html>
As we can see, the server returned a 405—Method Not Allowed error. The error message accompanying this response in the response body is given as The requested method DELETE is not allowed for the URL /index.html. Now compare this with the following response, obtained by issuing the same request to a server at www.iis.net:
$ nc www.iis.net 80
DELETE / HTTP/1.0
HTTP/1.1 405 Method Not Allowed
Allow: GET, HEAD, OPTIONS, TRACE
Content-Type: text/html
Server: Microsoft-IIS/7.0
Set-Cookie: CSAnonymous=LmrCfhzHyQEkAAAANWY0NWY1NzgtMjE2NC00NDJjLWJlYzYtNTc4ODg0OWY5OGQz0; domain=iis.net; expires=Mon, 27-Apr-2009 09:42:35 GMT; path=/; HttpOnly
X-Powered-By: ASP.NET
Date: Mon, 27 Apr 2009 09:22:34 GMT
Connection: close
Content-Length: 1293
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1"/>
<title>405 - HTTP verb used to access this page is not allowed.</title>
<style type="text/css">
<!--
body{margin:0;font-size:.7em;font-family:Verdana, Arial, Helvetica, sans-serif;background:#EEEEEE;}
fieldset{padding:0 15px 10px 15px;}
h1{font-size:2.4em;margin:0;color:#FFF;}
h2{font-size:1.7em;margin:0;color:#CC0000;}
h3{font-size:1.2em;margin:10px 0 0 0;color:#000000;}
#header{width:96%;margin:0 0 0 0;padding:6px 2% 6px 2%;font-family:"trebuchet MS", Verdana, sans-serif;color:#FFF;
background-color:#555555;}
#content{margin:0 0 0 2%;position:relative;}
.content-container{background:#FFF;width:96%;margin-top:8px;padding:10px;position:relative;}
-->
</style>
</head>
protocol responses, HTTP fingerprintingDELETE command, issuing<body>
<div id="header"><h1>Server Error</h1></div>
<div id="content">
<div class="content-container"><fieldset>
<h2>405 - HTTP verb used to access this page is not allowed.</h2>
<h3>The page you are looking for cannot be displayed because an invalid method (HTTP verb) was used to attempt access.</h3>
</fieldset></div>
</div>
</body>
</html>
The site www.iis.net is Microsoft's official site for its web server platform Internet Information Services, and the Server response header indicates that it is indeed running IIS-7.0. (We have of course already seen that it is a trivial operation in most cases to fake this header, but given the fact that it's Microsoft's official IIS site we can be pretty sure that they are indeed running their own web server software.)
The response generated from IIS carries the same HTTP error code, 405; however there are many subtle differences in the way the response is generated. Here are just a few:
IIS uses spaces in between method names in the comma separated list for the Allow field, whereas Apache does not
The response header field order differs—for example, Apache has the Date field first, whereas IIS starts out with the Allow field
IIS uses the error message The page you are looking for cannot be displayed because an invalid method (HTTP verb) was used to attempt access in the response body
A similar experiment can be performed by specifying a non-existent HTTP protocol version number in a request. Here is what happens on the Apache server when the request GET / HTTP/5.0 is issued:
$ nc bytelayer.com 80 GET / HTTP/5.0 HTTP/1.1 400 Bad Request Date: Mon, 27 Apr 2009 09:36:10 GMT Server: Apache/2.2.8 (Fedora) mod_jk/1.2.27 DAV/2 Content-Length: 295 Connection: close Content-Type: text/html; charset=iso-8859-1 <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>400 Bad Request</title> </head><body> <h1>Bad Request</h1> <p>Your browser sent a request that this server could not understand.<br /> </p> <hr> <address>Apache/2.2.8 (Fedora) mod_jk/1.2.27 DAV/2 Server at www.bytelayer.com Port 80</address> </body></html>
There is no HTTP version 5.0, and there probably won't be for a long time, as the latest revision of the protocol carries version number 1.1. The Apache server responds with a 400—Bad Request Error, and the accompanying error message in the response body is Your browser sent a request that this server could not understand. Now let's see what IIS does:
$ nc www.iis.net 80 GET / HTTP/5.0 HTTP/1.1 400 Bad Request Content-Type: text/html; charset=us-ascii Server: Microsoft-HTTPAPI/2.0 Date: Mon, 27 Apr 2009 09:38:37 GMT Connection: close Content-Length: 334 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN""http://www.w3.org/TR/html4/strict.dtd"> <HTML><HEAD><TITLE>Bad Request</TITLE> <META HTTP-EQUIV="Content-Type" Content="text/html; charset=us-ascii"></HEAD> <BODY><h2>Bad Request - Invalid Hostname</h2> <hr><p>HTTP Error 400. The request hostname is invalid.</p> </BODY></HTML>
We get the same error number, but the error message in the response body differs—this time it's HTTP Error 400. The request hostname is invalid. As HTTP 1.1 requires a Host header to be sent with requests, it is obvious that IIS assumes that any later protocol would also require this header to be sent, and the error message reflects this fact.
Another tweak is to use a non-existent protocol name such as FAKE when issuing the request. This is Apache's response to such a request:
$ nc bytelayer.com 80 GET / FAKE/1.0 HTTP/1.1 200 OK Date: Mon, 27 Apr 2009 09:50:37 GMT Server: Apache/2.2.8 (Fedora) mod_jk/1.2.27 DAV/2 Last-Modified: Thu, 12 Mar 2009 01:10:41 GMT ETag: "6391bf-4d-464e1a71da640" Accept-Ranges: bytes Content-Length: 77 Connection: close Content-Type: text/html Welcome to our web page.
Apache actually delivers the web page with a 200—OK response code, as if this had been a properly formed GET request. In contrast, this is the response of Internet Information Services:
$ nc www.iis.net 80 GET / FAKE/1.0 HTTP/1.1 400 Bad Request Content-Type: text/html; charset=us-ascii Server: Microsoft-HTTPAPI/2.0 Date: Mon, 27 Apr 2009 09:51:56 GMT Connection: close Content-Length: 311 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN""http://www.w3.org/TR/html4/strict.dtd"> <HTML><HEAD><TITLE>Bad Request</TITLE> <META HTTP-EQUIV="Content-Type" Content="text/html; charset=us-ascii"></HEAD> <BODY><h2>Bad Request</h2> <hr><p>HTTP Error 400. The request is badly formed.</p> </BODY></HTML>
IIS responds with a 400 error, citing error message The request is badly formed. Interesting is also that IIS immediately returns the response after I pressed Enter a single time at the end of typing GET / FAKE/1.0—normally, HTTP requires that two newlines follow the request line, something that can be seen in Apache's response to the same request, where there is a blank line between the request line and the start of the response.
You may be familiar with the Last-Modified HTTP header. This is used to allow web browsers to cache downloaded content, such as image files, and avoids them having to re-download content that hasn't changed since it was last accessed. The ETag header (short for "Entity Tag") works in a similar way, but uses additional information about a file such as its size and inode number (which is a number associated with each file in the Linux file system) to construct a tag that will change only if one of these properties change.
ETag headers can be used by fingerprinting tools as one property to profile the server. In addition, using ETags can actually degrade performance—for example, if you are running several web servers to balance the load for a site and rely on the default Apache ETag configuration (as set by the FileETag directive) then each server will return a different ETag for the same file, even when the file hasn't changed. This is because the inode number will be different for the file on each server. The changing ETag values will cause browsers to re-download files even though they haven't changed.
Disabling ETags can therefore be beneficial both for website performance and to make it more difficult to fingerprint the web server. In Apache, you can use the Header directive to remove the ETag header:
Header unset ETag
One note of caution is that if you run WebDAV with mod_dav_fs, you shouldn't disable the ETag since mod_dav_fs uses it to determine if files have changed.
Since we don't want to be more helpful than necessary to potential attackers, we will now attempt to use ModSecurity rules together with some other configuration tweaks to make automated HTTP fingerprinting tools think that we are running a Microsoft IIS/6.0 server.
We will be using the information we now have available on how fingerprinting tools work to create a set of rules to defeat them. Here is a list of what we need to implement:
Allow only the request methods GET, HEAD, and POST
Block all HTTP protocol versions except 1.0 and 1.1
Block requests without a
HostheaderBlock requests without an
AcceptheaderSet the server signature to Microsoft-IIS/6.0
Add an X-Powered-By: ASP.NET 2.0 header
Remove the
ETagheader
Here are the rules used to implement this:
# # Defeat HTTP fingerprinting # # Change server signature SecServerSignature "Microsoft-IIS/6.0" # Deny requests without a host header SecRule &REQUEST_HEADERS:Host "@eq 0" "phase:1,deny" # Deny requests without an accept header SecRule &REQUEST_HEADERS:Accept "@eq 0" "phase:1,deny" # Deny request that don't use GET, HEAD or POST SecRule REQUEST_METHOD !^(get|head|post)$ "phase:1,t:lowerCase,deny" # Only allow HTTP version 1.0 and 1.1 SecRule REQUEST_PROTOCOL !^http/1.(0|1)$ "phase:1,t:lowercase,deny" # Add X-Powered-By header to mimic IIS Header set X-Powered-By "ASP.NET 2.0" # Remove the ETag header Header unset ETag
Now let's run httprint and httprecon against our server again and see what happens. This is the result when running httprint:
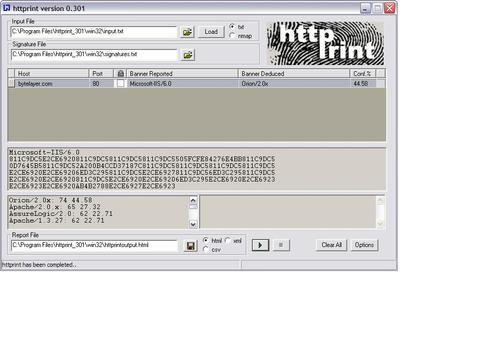
And this is what happens when running httprecon:
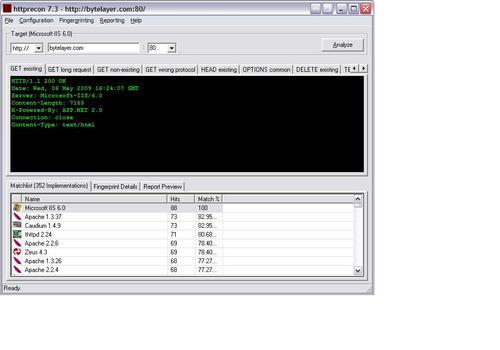
Success! Both fingerprinting tools are now no longer identifying the server as Apache. Httprint thinks we are running Orion/2.0.x, while httprecon has been successfully fooled into identifying the server as Microsoft IIS 6.0.
Requests routed via proxy servers can be problematic for some sites. If you run any type of discussion forum, users can hide behind the perceived anonymity of a proxy server and launch anything from profanity-laden tirades in forum posts to outright denial of service attacks. You may therefore want to block proxied requests if you find that they cause problems on your site.
One way to do this is to check for the presence of the X-Forwarded-For header in the HTTP request. If this header exists, it means that the request was made by a proxy server on behalf of the real user.
This rule detects and blocks requests by proxy servers that use the X-Forwarded-For header:
SecRule &REQUEST_HEADERS:X-Forwarded-For "@gt 0" deny
The rule uses the& operator to return the number of request headers present with the name X-Forwarded-For. If this number is greater than zero, that means such a header is present, and the request is blocked.
Another similar header used by some proxy servers is the Via header, which you may also want to detect to catch a greater number of proxy servers. Keep in mind, though, that there are many legitimate uses for proxy servers, so before blocking every detectable proxy server out there, consider what legitimate traffic you will be blocking.
Cross-site scripting attacks occur when user input is not properly sanitized and ends up in pages sent back to users. This makes it possible for an attacker to include malicious scripts in a page by providing them as input to the page. The scripts will be no different than scripts included in pages by the website creators, and will thus have all the privileges of an ordinary script within the page—such as the ability to read cookie data and session IDs. We already saw an example of cross-site scripting in the previous chapter on virtual patching, and in this chapter we will look in more detail on how to prevent such attacks.
The name "cross-site scripting" is actually rather poorly chosen—the name stems from the first such vulnerability that was discovered, which involved a malicious website using HTML framesets to load an external site inside a frame. The malicious site could then manipulate the loaded external site in various ways—for example, read form data, modify the site, and basically perform any scripting action that a script within the site itself could perform. Thus cross-site scripting, or XSS, was the name given to this kind of attack.
The attacks described as XSS attacks have since shifted from malicious frame injection (a problem that was quickly patched by web browser developers) to the class of attacks that we see today involving unsanitized user input. The actual vulnerability referred to today might be better described as a "malicious script injection attack", though that doesn't give it quite as flashy an acronym as XSS. (And in case you're curious why the acronym is XSS and not CSS, the simple explanation is that although CSS was used as short for cross-site scripting in the beginning, it was changed to XSS because so many people were confusing it with the acronym used for Cascading Style Sheets, which is also CSS.)
Cross-site scripting attacks can lead not only to cookie and session data being stolen, but also to malware being downloaded and executed and injection of arbitrary content into web pages.
Cross-site scripting attacks can generally be divided into two categories:
Reflected attacks
This kind of attack exploits cases where the web application takes data provided by the user and includes it without sanitization in output pages. The attack is called "reflected" because an attacker causes a user to provide a malicious script to a server in a request that is then reflected back to the user in returned pages, causing the script to execute.
Stored attacks
In this type of XSS attack, the attacker is able to include his malicious payload into data that is permanently stored on the server and will be included without any HTML entity encoding to subsequent visitors to a page. Examples include storing malicious scripts in forum posts or user presentation pages. This type of XSS attack has the potential to be moredamaging since it can affect every user who views a certain page.
The most important measure you can take to prevent XSS attacks is to make sure that all user-supplied data that is output in your web pages is properly sanitized. This means replacing potentially unsafe characters, such as angled brackets (< and>) with their corresponding HTML-entity encoded versions—in this case< and>.
Here is a list of characters that you should encode when present in user-supplied data that will later be included in web pages:
|
Character |
HTML-encoded version |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
In PHP, you can use the htmlentities() function to achieve this. When encoded, the string<script> will be converted into<script>. This latter version will be displayed as<script> in the web browser, without being interpreted as the start of a script by the browser.
In general, users should not be allowed to input any HTML markup tags if it can be avoided. If you do allow markup such as<a href="..."> to be input by users in blog comments, forum posts, and similar places then you should be aware that simply filtering out the<script> tag is not enough, as this simple example shows:
<a href="http://www.google.com" onMouseOver="javascript:alert('XSS Exploit!')">Innocent link</a>
This link will execute the JavaScript code contained within the onMouseOver attribute whenever the user hovers his mouse pointer over the link. You can see why even if the web application replaced<script> tags with their HTML-encoded version, an XSS exploit would still be possible by simply using onMouseOver or any of the other related events available, such as onClick or onMouseDown.
I want to stress that properly sanitizing user input as just described is the most important step you can take to prevent XSS exploits from occurring. That said, if you want to add an additional line of defense by creating ModSecurity rules, here are some common XSS script fragments and regular expressions for blocking them:
|
Script fragment |
Regular expression |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
You may have seen the ModSecurity directive SecPdfProtect mentioned, and wondered what it does. This directive exists to protect users from a particular class of cross-site scripting attack that affects users running a vulnerable version of the Adobe Acrobat PDF reader.
A little background is required in order to understand what SecPdfProtect does and why it is necessary. In 2007, Stefano Di Paola and Giorgio Fedon discovered a vulnerability in Adobe Acrobat that allows attackers to insert JavaScript into requests, which is then executed by Acrobat in the context of the site hosting the PDF file. Sound confusing? Hang on, it will become clearer in a moment.
The vulnerability was quickly fixed by Adobe in version 7.0.9 of Acrobat. However, there are still many users out there running old versions of the reader, which is why preventing this sort of attack is still an ongoing concern.
The basic attack works like this: An attacker entices the victim to click a link to a PDF file hosted on www.example.com. Nothing unusual so far, except for the fact that the link looks like this:
http://www.example.com/document.pdf#x=javascript:alert('XSS'),
Surprisingly, vulnerable versions of Adobe Acrobat will execute the JavaScript in the above link. It doesn't even matter what you place before the equal sign, gibberish= will work just as well as x= in triggering the exploit.
Since the PDF file is hosted on the domain www.example.com, the JavaScript will run as if it was a legitimate piece of script within a page on that domain. This can lead to all of the standard cross-site scripting attacks that we have seen examples of before.
This diagram shows the chain of events that allows this exploit to function:

The vulnerability does not exist if a user downloads the PDF file and then opens it from his local hard drive.
ModSecurity solves the problem of this vulnerability by issuing a redirect for all PDF files. The aim is to convert any URLs like the following:
http://www.example.com/document.pdf#x=javascript:alert('XSS'),
into a redirected URL that has its own hash character:
http://www.example.com/document.pdf#protection
This will block any attacks attempting to exploit this vulnerability. The only problem with this approach is that it will generate an endless loop of redirects, as ModSecurity has no way of knowing what is the first request for the PDF file, and what is a request that has already been redirected. ModSecurity therefore uses a one-time token to keep track of redirect requests. All redirected requests get a token included in the new request string. The redirect link now looks like this:
http://www.example.com/document.pdf?PDFTOKEN=XXXXX#protection
ModSecurity keeps track of these tokens so that it knows which links are valid and should lead to the PDF file being served. Even if a token is not valid, the PDF file will still be available to the user, he will just have to download it to the hard drive.
These are the directives used to configure PDF XSS protection in ModSecurity:
SecPdfProtect On SecPdfProtectMethod TokenRedirection SecPdfProtectSecret "SecretString" SecPdfProtectTimeout 10 SecPdfProtectTokenName "token"
The above configures PDF XSS protection, and uses the secret string SecretString to generate the one-time tokens. The last directive, SecPdfProtectTokenName, can be used to change the name of the token argument (the default is PDFTOKEN). This can be useful if you want to hide the fact that you are running ModSecurity, but unless you are really paranoid it won't be necessary to change this.
The SecPdfProtectMethod can also be set to ForcedDownload, which will force users to download the PDF files instead of viewing them in the browser. This can be an inconvenience to users, so you would probably not want to enable this unless circumstances warrant (for example, if a new PDF vulnerability of the same class is discovered in the future).
One mechanism to mitigate the impact of XSS vulnerabilities is the HttpOnly flag for cookies. This extension to the cookie protocol was proposed by Microsoft (see http://msdn.microsoft.com/en-us/library/ms533046.aspx for a description), and is currently supported by the following browsers:
Internet Explorer (IE6 SP1 and later)
Firefox (2.0.0.5 and later)
Google Chrome (all versions)
Safari (3.0 and later)
Opera (version 9.50 and later)
HttpOnly cookies work by adding the HttpOnly flag to cookies that are returned by the server, which instructs the web browser that the cookie should only be used when sending HTTP requests to the server and should not be made available to client-side scripts via for example the document.cookie property. While this doesn't completely solve the problem of XSS attacks, it does mitigate those attacks where the aim is to steal valuable information from the user's cookies, such as for example session IDs.
A cookie header with the HttpOnly flag set looks like this:
Set-Cookie: SESSID=d31cd4f599c4b0fa4158c6fb; HttpOnly
HttpOnly cookies need to be supported on the server-side for the clients to be able to take advantage of the extra protection afforded by them. Some web development platforms currently support HttpOnly cookies through the use of the appropriate configuration option. For example, PHP 5.2.0 and later allow HttpOnly cookies to be enabled for a page by using the following ini_set() call:
<?php
PDF XSS, cross-site scriptingHttpOnly cookies, usingini_set("session.cookie_httponly", 1);
?>
Tomcat (a Java Servlet and JSP server) version 6.0.19 and later supports HttpOnly cookies, and they can be enabled by modifying a context's configuration so that it includes the useHttpOnly option, like so:
<Context> <Manager useHttpOnly="true" /> </Context>
In case you are using a web platform that doesn't support HttpOnly cookies, it is actually possible to use ModSecurity to add the flag to outgoing cookies. We will see how to do this now.
Assuming we want to add the HttpOnly flag to session identifier cookies, we need to know which cookies are associated with session identifiers. The following table lists the name of the session identifier cookie for some of the most common languages:
|
Language |
Session identifier cookie name |
|---|---|
|
PHP |
|
|
JSP |
|
|
ASP |
|
|
ASP.NET |
|
The table shows us that a good regular expression to identify session IDs would be (sessionid|sessid), which can be shortened to sess(ion)?id. The web programming language you are using might use another name for the session cookie. In that case, you can always find out what it is by looking at the headers returned by the server:
echo -e "GET / HTTP/1.1 Host:yourserver.com "|nc yourserver.com 80|head
Look for a line similar to:
Set-Cookie: JSESSIONID=4EFA463BFB5508FFA0A3790303DE0EA5; Path=/
This is the session cookie—in this case the name of it is JESSIONID, since the server is running Tomcat and the JSP web application language.
The following rules are used to add the HttpOnly flag to session cookies:
#
# Add HttpOnly flag to session cookies
#
SecRule RESPONSE_HEADERS:Set-Cookie "!(?i:HttpOnly)" "phase:3,chain,pass"
SecRule MATCHED_VAR "(?i:sess(ion)?id)" "setenv:session_cookie=%{MATCHED_VAR}"
Header set Set-Cookie "%{SESSION_COOKIE}e; HttpOnly" env=session_cookie
We are putting the rule chain in phase 3—RESPONSE_HEADERS, since we want to inspect the response headers for the presence of a Set-Cookie header. We are looking for those Set-Cookie headers that do not contain an HttpOnly flag. The (?i: ) parentheses are a regular expression construct known as a mode-modified span. This tells the regular expression engine to ignore the case of the HttpOnly string when attempting to match. Using the t:lowercase transform would have been more complicated, as we will be using the matched variable in the next rule, and we don't want the case of the variable modified when we set the environment variable.
If a cookie header without the HttpOnly flag is found, the second rule looks to see if it is a session identifier cookie. If it is, the setenv action is used to set the environment variable %{SESSION_COOKIE}. ModSecurity cannot be used to modify the cookie header directly (ModSecurity content injection can only prepend data to the beginning of the response or append it to the end of the response), so we are using a plain Apache directive—the Header directive—to modify the cookie header:
Header set Set-Cookie "%{session_cookie}e; HttpOnly" env=session_cookie
Header directives can use the env= syntax, which means that they will only be invoked if the named environment variable is set. In this case, the Header directive will only be invoked if the %{SESSION_COOKIE} environment variable was set by the ModSecurity rule chain. When invoked, the header directive sets the Set-Cookie header to its previous value (%{SESSION_COOKIE}e is what does this—the e at the end is used to identify this as an environment variable). The string ; HttpOnly is then appended to the end of the previous header.
If we now look at the HTTP headers returned by the server, the session ID cookie will have the HttpOnly flag set:
$ echo -e "GET / HTTP/1.0 " | nc localhost 80 | head ... Set-Cookie: JSESSIONID=4EFA463BFB5508FFA0A3790303DE0EA5; Path=/; HttpOnly
Note
Cleaning XSS Code from Databases
Scrubbr is the name of a tool for cleaning databases of stored XSS attacks that is made available at no charge by the Open Web Application Security Project (OWASP). Scrubbr works by examining database tables for stored malicious scripts.
The developers have this to say about how the tool works:
If you can tell Scrubbr how to access your database, it will search through every field capable of holding strings in the database for malicious code. If you want it to, it will search through every table, every row, and every column.
Scrubbr can be downloaded at http://code.google.com/p/owaspscrubbr/, and more information on the tool is available on the OWASP homepage at http://www.owasp.org/index.php/Category:OWASP_Scrubbr.
Cross-site request forgeries (CSRF) are attacks that trick the victim's browser into submitting a request to another site where the user is logged in, causing that site to believe the user has initiated an action, and that action is then executed as if the user had initiated it. In other words, cross-site request forgeries execute some action on a site that the user never intended.
One example would be if while you are logged into your bank's online banking site someone got you to visit a page that contained the following<img> tag:
<img src="http://www.bank.com/transfer.php?amount=10000&from=8982773722&to=898271972">
As we already know that an<img> tag can be used to execute GET requests, this would cause money to be transferred from one account to another assuming the banking site can do this via GET requests. This is the essence of CSRF attacks—to embed code into a page that causes an action to be executed without the user's knowledge. The aim can be to transfer money, get the user to buy things at auction sites, make him send messages to other users on a site, or any number of things to make it look like the logged-in user on a site has performed some action which was in reality initiated by the CSRF code.
To get a clearer picture, imagine this scenario:
You do your online banking with Acme Bank
Acme Bank's website is vulnerable to CSRF attacks
You also regularly visit the gardening forum at gardening.com
Now suppose your long-time enemy Ned is aware of your browsing habits. Since he's got an axe to grind he hatches a scheme to transfer $10,000 from your personal savings account to his own account. Since Ned knows that you use Acme bank and are also a regular visitor at gardening.com, he starts a topic at the gardening forum with the title "Wild fuchsias for sale", knowing you are a fan of fuchsias and have been looking for quality specimens for some time.
If you take the bait and click on the topic in the forum, Ned's evil HTML tag will get downloaded by your browser:
<img src="http://bank.acme.com/transfer.php?amount=10000&from=8982773722&to=898271972">
If you are logged into your banking site at the time your browser attempts to render the forum topic, your well-meaning browser will attempt to fetch the image located at bank.acme.com/transfer.php, passing the entire query string along with it. Unbeknownst to you, you have just transferred enough money to buy a small car to Ned.
Protecting against CSRF attacks can be challenging. Superficially, it might look like only GET requests are vulnerable, since that is what the browser uses in our examples with the malicious<img> tags. However, that is not true as with the right script code it is possible for a client-side script to perform POST requests. The following code uses Ajax technology to do just that:
<script>
var post_data = 'name=value';
var xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
xmlhttp.open("POST", 'http://url/path/file.ext', true);
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4) {
alert(xmlhttp.responseText);
}
};
xmlhttp.send(post_data);
</script>
The core of the problem is that the requests come from the user's own browser and look like legitimate requests. The mainstream solutions today revolve around giving the user's browser some piece of information that it must then transmit back when performing an action. Examples include:
Generating a token that is sent together with forms to the user. Any action taken must then include this token or it will be rejected.
Randomizing page names. This gives a user unique URLs to perform actions, and should preferably be changed for each new user session. This makes it difficult for the attacker to know where to submit the requests.
Requiring authentication to perform important actions. Usually this is done by requesting the username and password to be entered, but for high-security sites such as banking sites this can also involve the user using a small hardware device to generate an authorization code that is submitted to the server.
As we have already seen, accepting unfiltered input from users can be dangerous. A particular class of exploit occurs when data submitted by users is used to cause the execution or display of a file which the user normally wouldn't have privileges to.
Attackers often combine multiple vulnerabilities to achieve maximum effect. Shell command execution is one exploit scenario which usually doesn't happen on its own—after all, very few web applications take user input and perform the exec() system call on them. However, consider the following chain of events:

In this chain of event, we can see how two vulnerabilities were combined to deadly effect:
This shows that trying to prevent shell command execution is worthwhile (and once again reaffirms the principle of Defense in Depth). I say "trying" since there will always be ways to write system commands that circumvent any detection patterns, however some protection is better than none.
The following are some common Linux system commands, program names, and paths that you may wish to block:
The following rule will block the above when present in arguments:
SecRule ARGS "(rm|ls|kill|(send)?mail|cat|echo|/bin/|/etc/|/tmp/)" "deny"
Null byte attacks exploit the fact that the C programming language (and related languages) use a null byte (0x00) to signify the end of a string. The string dog, for example, is stored in memory in the following way when the C programming language is used:
|
|
|
|
|
In other programming languages, such as Java, strings are stored as arrays, and the total length of the string is stored in a separate location, which means that a Java string is perfectly capable of containing a null byte in the middle of the string.
This difference in how strings and null bytes are handled by different programming languages enable some attacks to take place that exploit the null byte to fool one part of a system by making it think a string has ended at a null byte, while another part will happily process the full input string.
Consider a simple JSP page that displays a text file to a visitor by using the filename parameter supplied to the page:
<%
String filename = request.getParameter("file");
if (filename.endsWith(".txt")) {
// Include text file in output page
}
%>
The page attempts to ensure that only files with the extension .txt can be displayed to the visitor. However, if an attacker supplies a filename argument of /etc/passwd%00.txt, then a null byte attack is possible. Since Java strings can contain null bytes, the filename will pass the check filename.endsWith(".txt"). When the filename string is passed to an underlying operating system function to open the file, a problem will arise if that system function treats the string as null-terminated since anything after the null byte will be ignored. The operating system will end up opening the file /etc/passwd instead, and this file will then be displayed to the attacker.
ModSecurity contains two transformation functions to deal with null bytes in input: replaceNulls and removeNulls. The first function replaces null bytes with whitespace, while the second one removes null bytes completely. Since null bytes are very rarely needed for valid input, it is a good idea to include one of these transformation functions in the SecDefaultAction list:
SecDefaultAction "phase:2,deny,log,status:403,t:removeNulls"
Should a null byte ever be required in input, then the transformation function can be overridden using the t:-removeNulls syntax:
SecRule ARGS:data "pass,t:-removeNulls"
Null byte attacks are a perfect example of how fragile web applications can be since they are glued together using many different programming languages, and how subtle the attacks can be—who would have expected that the differences in string handling between Java and the operating system could lead to problems like this? It is something that could be easily missed even during a code review.
Normally, requesting a file with a .php extension will cause mod_php to execute the PHP code contained within the file and then return the resulting web page to the user. If the web server is misconfigured (for example if mod_php is not loaded) then the .php file will be sent by the server without interpretation, and this can be a security problem. If the source code contains credentials used to connect to an SQL database then that opens up an avenue for attack, and of course the source code being available will allow a potential attacker to scrutinize the code for vulnerabilities.
Preventing source code revelation is easy. With response body access on in ModSecurity, simply add a rule to detect the opening PHP tag:
# Prevent PHP source code from being disclosed SecRule RESPONSE_BODY "<?" "deny,msg:'PHP source code disclosure blocked'"
Preventing Perl and JSP source code from being disclosed works in a similar manner:
# Prevent Perl source code from being disclosed SecRule RESPONSE_BODY "#!/usr/bin/perl" "deny,msg:'Perl source code disclosure blocked'" # Prevent JSP source code from being disclosed SecRule RESPONSE_BODY "<%" "deny,msg:'JSP source code disclosure blocked'"
Normally, all web servers should be configured to reject attempts to access any document that is not under the web server's root directory. For example, if your web server root is /home/www, then attempting to retrieve /home/joan/.bashrc should not be possible since this file is not located under the /home/www web server root. The obvious attempt to access the /home/joan directory is, of course, easy for the web server to block, however there is a more subtle way to access this directory which still allows the path to start with /home/www, and that is to make use of the .. symbolic directory link which links to the parent directory in any given directory.
Even though most web servers are hardened against this sort of attack, web applications that accept input from users may still not be checking it properly, potentially allowing users to get access to files they shouldn't be able to view via simple directory traversal attacks. This alone is reason to implement protection against this sort of attack using ModSecurity rules. Furthermore, keeping with the principle of Defense in Depth, having multiple protections against this vulnerability can be beneficial in case the web server should contain a flaw that allows this kind of attack in certain circumstances.
There is more than one way to validly represent the .. link to the parent directory. URL encoding of .. yields %2e%2e, and adding the final slash at the end we end up with %2e%2e%2f.
Here, then is a list of what needs to be blocked:
../..%2f.%2e/%2e%2e%2f%2e%2e/%2e./
Fortunately, we can use the ModSecurity transformation t:urlDecode. This function does all the URL decoding for us, and will allow us to ignore the percent-encoded values, and thus only one rule is needed to block these attacks:
SecRule REQUEST_URI "../" "t:urlDecode,deny"
The rise of weblogs, or blogs, as a new way to present information, share thoughts, and keep an online journal has made way for a new phenomenon: blog comments designed to advertise a product or drive traffic to a website.
Blog spam isn't a security problem per se, but it can be annoying and cost a lot of time when you have to manually remove spam comments (or delete them from the approval queue, if comments have to be approved before being posted on the blog).
Blog spam can be mitigated by collecting a list of the most common spam phrases, and using the ability of ModSecurity to scan POST data. Any attempted blog comment that contains one of the offending phrases can then be blocked.
From both a performance and maintainability perspective, using the @pmFromFile operator is the best choice when dealing with large word lists such as spam phrases. To create the list of phrases to be blocked, simply insert them into a text file, for example, /usr/local/spamlist.txt:
viagra v1agra auto insurance rx medications cheap medications ...
Then create ModSecurity rules to block those phrases when they are used in locations such as the page that creates new blog comments:
# # Prevent blog spam by checking comment against known spam # phrases in file /usr/local/spamlist.txt # <Location /blog/comment.php> SecRule ARGS "@pmFromFile /usr/local/spamlist.txt" "t:lowercase,deny,msg:'Blog spam blocked'" </Location>
Keep in mind that the spam list file can contain whole sentences—not just single words—so be sure to take advantage of that fact when creating the list of known spam phrases.
SQL injection attacks can occur if an attacker is able to supply data to a web application that is then used in unsanitized form in an SQL query. This can cause the SQL query to do completely different things than intended by the developers of the web application. We already saw an example of SQL injection in Chapter 5, where a tainted username was used to bypass the check that a username and password were valid login credentials. To recap, the offending SQL query looked like this:
SELECT * FROM user WHERE username = '%s' AND password = '%s';
The flaw here is that if someone can provide a password that looks like' OR '1'='1, then the query, with username and password inserted, will become:
SELECT * FROM user WHERE username = 'anyuser' AND password = '' OR '1'='1';
This query will return all users in the results table, since the OR '1'='1' part at the end of the statement will make the entire statement true no matter what username and password is provided.
Let's take a look at some of the most common ways SQL injection attacks are performed.
An SQL UNION statement can be used to retrieve data from two separate tables. If there is one table named cooking_recipes and another table named user_credentials, then the following SQL statement will retrieve data from both tables:
SELECT dish_name FROM recipe UNION SELECT username, password FROM user_credentials;
It's easy to see how the UNION statement can allow an attacker to retrieve data from other tables in the database if he manages to sneak it into a query. A similar SQL statement is UNION ALL, which works almost the same way as UNION—the only difference is that UNION ALL will not eliminate any duplicate rows returned in the result.
If the SQL engine allows multiple statements in a single SQL query then seemingly harmless statements such as the following can present a problem:
SELECT * FROM products WHERE id = %d;
If an attacker is able to provide an ID parameter of 1; DROP TABLE products;, then the statement suddenly becomes:
SELECT * FROM products WHERE id = 1; DROP TABLE products;
When the SQL engine executes this, it will first perform the expected SELECT query, and then the DROP TABLE products statement, which will cause the products table to be deleted.
MySQL can be used to read data from arbitrary files on the system. This is done by using the LOAD_FILE() function:
SELECT LOAD_FILE("/etc/passwd");
This command returns the contents of the file /etc/passwd. This works for any file to which the MySQL process has read access.
MySQL also supports the command INTO OUTFILE which can be used to write data into files. This attack illustrates how dangerous it can be to include user-supplied data in SQL commands, since with the proper syntax, an SQL command can not only affect the database, but also the underlying file system.
This simple example shows how to use MySQL to write the string some data into the file test.txt:
mysql> SELECT "some data" INTO OUTFILE "test.txt";
There are three important steps you need to take to prevent SQL injection attacks:
Use SQL prepared statements.
Sanitize user data.
Use ModSecurity to block SQL injection code supplied to web applications.
These are in order of importance, so the most important consideration should always be to make sure that any code querying SQL databases that relies on user input should use prepared statements. As we learned in the previous chapter, a prepared statement looks as follows:
SELECT * FROM books WHERE isbn = ? AND num_copies < ?;
This allows the SQL engine to replace the question marks with the actual data. Since the SQL engine knows exactly what is data and what SQL syntax, this prevents SQL injection from taking place.
The advantages of using prepared statements are twofold:
They effectively prevent SQL injection.
They speed up execution time, since the SQL engine can compile the statement once, and use the pre-compiled statement on all subsequent query invocations.
So not only will using prepared statements make your code more secure—it will also make it quicker.
The second step is to make sure that any user data used in SQL queries is sanitized. Any unsafe characters such as single quotes should be escaped. If you are using PHP, the function mysql_real_escape_string() will do this for you.
Finally, let's take a look at strings that ModSecurity can help block to prevent SQL injection attacks.
The following table lists common SQL commands that you should consider blocking, together with a suggested regular expression for blocking. The regular expressions are in lowercase and therefore assume that the t:lowercase transformation function is used.
|
SQL code |
Regular expression |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
For example, a rule to detect attempts to write data into files using INTO OUTFILE looks as follows:
SecRule ARGS "intos+outfile" "t:lowercase,deny,msg:'SQL Injection'"
The s+ regular expression syntax allows for detection of an arbitrary number of whitespace characters. This will detect evasion attempts such as INTO%20%20OUTFILE where multiple spaces are used between the SQL command words.
We've all seen the news stories: "Large Company X was yesterday hacked and their homepage was replaced with an obscene message". This sort of thing is an everyday occurrence on the Internet.
After the company SCO initiated a lawsuit against Linux vendors citing copyright violations in the Linux source code, the SCO corporate website was hacked and an image was altered to read WE OWN ALL YOUR CODE—pay us all your money. The hack was subtle enough that the casual visitor to the SCO site would likely not be able to tell that this was not the official version of the homepage:
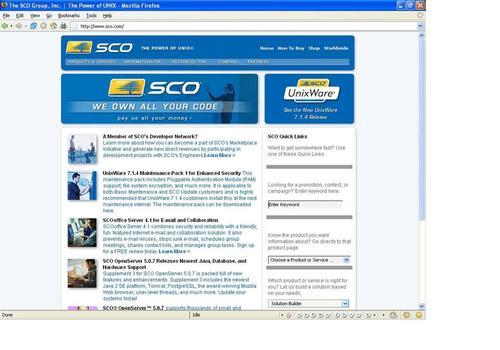
The above image shows what the SCO homepage looked like after being defaced—quite subtle, don't you think?
Preventing website defacement is important for a business for several reasons:
Potential customers will turn away when they see the hacked site
There will be an obvious loss of revenue if the site is used for any sort of e-commerce sales
Bad publicity will tarnish the company's reputation
Defacement of a site will of course depend on a vulnerability being successfully exploited. The measures we will look at here are aimed to detect that a defacement has taken place, so that the real site can be restored as quickly as possible.
Detection of website defacement is usually done by looking for a specific token in the outgoing web pages. This token has been placed within the pages in advance specifically so that it may be used to detect defacement—if the token isn't there then the site has likely been defaced. This can be sufficient, but it can also allow the attacker to insert the same token into his defaced page, defeating the detection mechanism. Therefore, we will go one better and create a defacement detection technology that will be difficult for the hacker to get around.
To create a dynamic token, we will be using the visitor's IP address. The reason we use the IP address instead of the hostname is that a reverse lookup may not always be possible, whereas the IP address will always be available.
The following example code in JSP illustrates how the token is calculated and inserted into the page.
<%@ page import="java.security.*" %>
<%
String tokenPlaintext = request.getRemoteAddr();
String tokenHashed = "";
String hexByte = "";
// Hash the IP address
MessageDigest md5 = MessageDigest.getInstance("MD5");
md5.update(tokenPlaintext.getBytes());
byte[] digest = md5.digest();
for (int i = 0; i < digest.length; i++) {
hexByte = Integer.toHexString(0xFF & digest[i]);
if (hexByte.length() < 2) {
hexByte = "0" + hexByte;
}
tokenHashed += hexByte;
}
// Write MD5 sum token to HTML document
out.println(String.format("<span style='color: white'>%s</span>", tokenHashed));
%>
Assuming the background of the page is white, the<span style="color: white"> markup will ensure it is not visible to website viewers.
Now for the ModSecurity rules to handle the defacement detection. We need to look at outgoing pages and make sure that they include the appropriate token. Since the token will be different for different users, we need to calculate the same MD5 sum token in our ModSecurity rule and make sure that this token is included in the output. If not, we block the page from being sent and sound the alert by sending an email message to the website administrator.
#
# Detect and block outgoing pages not containing our token
#
SecRule REMOTE_ADDR ".*" "phase:4,deny,chain,t:md5,t:hexEncode, exec:/usr/bin/emailadmin.sh"
SecRule RESPONSE_BODY "!@contains %{MATCHED_VAR}"
We are placing the rule in phase 4 since this is required when we want to inspect the response body. The exec action is used to send an email to the website administrator to let him know of the website defacement. For an example of such a script, see the Sending alert emails section in Chapter 2.
Brute force attacks involve an attacker repeatedly trying to gain access to a resource by guessing usernames, passwords, email addresses, and similar credentials. They can be incredibly effective if no protection is in place, since most users choose passwords that are short and easy to remember. Furthermore, most users will use nearly identical passwords on all websites for which a login is required, and so compromise of one password can lead to the user having his account compromised at a whole range of other sites.
A good way to defend against brute force attacks is to allow a certain number of login attempts, say three, and after that start delaying or blocking further attempts. Let's see how we can use ModSecurity to accomplish this.
If your login verification page is situated at yoursite.com/login, then the following rules will keep track of the number of login attempts by users:
#
# Block further login attempts after 3 failed attempts
#
<LocationMatch ^/login>
# Initalize IP collection with user's IP address
SecAction "initcol:ip=%{REMOTE_ADDR},pass,nolog"
# Detect failed login attempts
SecRule RESPONSE_BODY "Username does not exist" "phase:4,pass,setvar:ip.failed_logins=+1,expirevar:ip.failed_logins=60"
# Block subsequent login attempts
SecRule IP:FAILED_LOGINS "@gt 3" deny
</Location>
The rules initialize the ip collection and increase the field ip.failed_logins after each failed login attempt. Once more than three failed logins are detected, further attempts are blocked. The expirevar action is used to reset the number of failed login attempts to zero after 60 seconds, so the block will be in effect for a maximum of 60 seconds.
Another approach is to start delaying requests once the threshold number of login attempts has been reached. This has the advantage of not denying access in case a legitimate user has actually forgotten his password and needs more attempts to remember it. Here are the rules to do that:
#
# Throttle login attempts after 3 failed attempts
#
<LocationMatch ^/login>
SecAction "initcol:ip=%{REMOTE_ADDR},pass,nolog"
SecRule RESPONSE_BODY "Username does not exist" "phase:4,pass,setvar:ip.failed_logins=+1,expirevar:ip.failed_logins=10"
SecRule IP:FAILED_LOGINS "@gt 3" "phase:4,allow,pause:3000"
</Location>
The pause action is what delays the request, and the time specified is in milliseconds, so the above will delay the response for three seconds once the limit of three failed login attempts has been exceeded.
When a user requests an URL like http://www.example.com/, with no filename specification, Apache will look for the file specified by the DirectoryIndex setting (for example index.html). If this file is found, it is served to the user. If it doesn't exist, what happens next is determined by whether the Apache option called Indexes is enabled or not.
The Indexes option can be enabled for a directory in the following way:
<Directory /home/www/example> Options +Indexes </Directory>
If the Indexes option is active then Apache will generate a directory listing and display it to the user if the default DirectoryIndex file is not found. This listing contains the names of all files and sub-directories in the requested directory, and this can be a problem for several reasons:
Files that were never meant to be publicly disclosed can be requested by the user, even if they are not linked from anywhere
Names of subdirectories are displayed, and again this may lead to the user wandering into directories that were never meant for public disclosure
In a perfect world, you would never have files under the web server root that users should not be able to download, and all directories or files requiring authorization should be protected by the appropriate HTTP authentication settings. However, in the real world, files and directories do sometimes end up under the web server root even when they are not meant to be accessible by all users. Therefore it makes sense to turn off directory indexing so that this listing is never generated:
<Directory /home/www> Options -Indexes </Directory>
Even with this in place, sometimes directory indexing can get turned back on—configuration files get edited or replaced with defaults. One option would be to comment out the line for the mod_autoindex module in the Apache configuration file:
# # Disable directory indexing # # LoadModule autoindex_module modules/mod_autoindex.so
However, even this can fail should the configuration file be returned to its default at some point, or if a web server vulnerability causes the directory index to be returned even though Options -Indexes is set. Consider for example the vulnerability discovered in 2001 that affected Apache version 1.3.20 and earlier, described as follows in the changelog for Apache when the corrected version 1.3.22 was released:
A vulnerability was found when Multiviews are used to negotiate the directory index. In some configurations, requesting a URI with a QUERY_STRING of M=D could return a directory listing rather than the expected index page.
This shows that unexpected circumstances can cause directory indexes to be returned even when the web server administrator does everything correctly. Therefore, in keeping with the Defense in Depth principle, adding a precautionary set of rules to ModSecurity to block any directory index from escaping the web server can be a good idea.
These rules will block the Apache directory index from being returned:
# # Prevent directory listings from accidentally being returned # SecRule REQUEST_URI "/$" "phase:4,deny,chain,log, msg:'Directory index returned'" SecRule RESPONSE_BODY "<h1>Index of /"
The above rule chain is placed in phase 4, since we need to examine the response body for the telltale signature<h1>Index of /, which is what Apache returns in directory index pages. This string could potentially be contained within regular HTML documents, so we do an additional check in the first rule—the request URI has to end with a forward slash, which it does when the user requests a directory. Even if the user were to request /example, without a trailing slash, the Apache module mod_dir will issue a 301—Moved permanently redirect to /example/ before the directory listing is returned (or not returned, as will be the case with the rule chain above active).
If you're under attack by a sophisticated adversary, he will most likely be hiding behind an anonymizing proxy—sometimes he will even be using multiple chained proxies to avoid detection. The illustration below shows how this works when two proxy servers are involved. The web server will only see the IP address of the last proxy server, and even if the proxy server administrator co-operated to help find an attacker, the logs would only show the IP address of the proxy server before it in the chain.
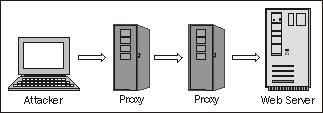
Wouldn't it be great to be able to get the real IP address of an attacker and have it logged if a severe enough attack is taking place? The real IP address can be what makes or breaks an investigation if an attack ever has to be reported to the police.
The first step in implementing real IP address detection is to realize that ModSecurity's redirect action can be used to redirect to a different page when an attack is detected. We will just be redirecting to a standard 404—Not Found error page.
Now the remaining problem is: What do we put on this modified error page to detect the attacker's IP address? One possible avenue of approach would be to include some JavaScript code in the error page to try to find out his IP address. Unfortunately, it's not possible to detect the IP address of a computer using JavaScript—using the function java.net.InetAddress.getLocalHost() returns localhost on all systems.
However, what if the attacker has Java enabled in his browser? In that case, it is actually possible to use Java to detect the IP address of the attacking computer. We will basically be turning the attacker's own web browser against him by loading a Java applet that will detect his IP address and transmit it to our server. The following diagram illustrates how this works:
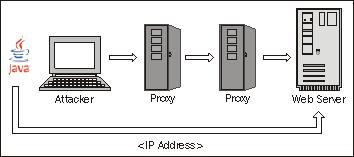
Lars Kindermann has a ready-made Java applet to detect IP addresses called "MyAddress" which is available at http://www.reglos.de/myaddress/MyAddress.html. Simply download this to your web server by saving the MyAddress.class file that is linked to on the page.
To get the attacker's IP address we will be using a technique familiar from the section on cross-site scripting attacks—the use of an<img> tag to transmit data back to our server. In this case, the data we will be transmitting is the attacker's IP address. Once we have the attacker's IP address—say 1.2.3.4—we will include the following<img> tag on the error page to capture his IP address:
<img src='http://www.ourserver.com/log_ip.php?ip=1.2.3.4'>
This will cause the attacker's web browser to perform a GET request to the page at www.ourserver.com/log_ip.php, handily providing the IP address in the query string. It is then a simple matter for the script log_ip.php to record the IP address in a database table or a text file.
This is the code that needs to be included on our modified error page in order to retrieve the IP address by invoking the Java applet and then printing out the<img> tag:
<applet code="MyAddress.class" mayscript width="0" height"=0"></applet>
<script>
function MyAddress(IP) {
document.write("<img src='http://www.ourserver.com/log_ip.php?ip=" + IP + "'>");
}
</script>
This first line uses an<applet> tag to load the Java applet called MyAddress.class. The subsequent lines execute JavaScript code that does two things:
Retrieves the IP address of the attacker's computer.
Writes an
<img>tag to the web page that references our own server to send the IP address back to us.
You can see that the second step is what makes this similar to cross-site scripting.
This suffers from a small problem—the<img> tag doesn't actually reference a valid image, which will cause the attacker to see a page with a "broken image" icon. Luckily, this is easily resolved by setting the width and height attributes of the image to zero:
<applet code="MyAddress.class" mayscript width="0" height="0"></applet>
<script>
function MyAddress(IP) {
document.write("<img src='http://www.ourserver.com/log_ip.php?ip=" + IP + "' width='0' height='0'>");
}
</script>
Now, the final piece of the puzzle is just to redirect detected attacks to the log_ip.php page. The following ModSecurity rule illustrates how to do this:
SecRule ARGS "/etc/passwd" "pass,redirect:/log_ip.php"
Though real IP-detection may not be preferable for "everyday" attacks, it can be a handy tool in those cases where finding out the IP of the attacker is essential to prevent further crimes from taking place or assisting the police in an investigation.
In this chapter, we looked at different methods of attack currently used against web applications and servers. We learned the anatomy behind attacks such as cross-site scripting, cross-site request forgeries, and SQL injection. We saw how ModSecurity can be used to mitigate or block these attacks, and how ModSecurity can be a vital part of applying the Defense in Depth strategy. In the last sections of the chapter we learned how to defeat HTTP fingerprinting and how to detect the real IP address of an attacker if he is surfing via a proxy server but has Java enabled in his browser.