

And Then There Are the Lawyers: An Illustrative Legal Matter
Most information technology projects are governed by contracts that assign responsibilities to each party and provide specific legal remedies for delayed implementation or project failure. Because data is typically involved in all information technology projects, the potential impact of such constraints is huge. Distinct incentives: Data management saves legal costs
In formal court proceedings, court costs can be assessed and assigned but, in many cases, outsourced information technology project contracts now require the parties to submit to private, binding arbitration to resolve disputes. Arbitration agreements, however, heavily favor contractors because of additional costs to the client associated with arbitration—not to mention outright legal costs. As a result, far too many consultants get away with poor performance because the client doesn’t have the stomach to fund the cost of the legal action required to hold the contractors to their advertised service levels.
We have been employed over the years in various capacities to provide expert witness support related to legal disputes. In our opinion, far too often, excessive costs force a client to settle for far less than that to which they are truly entitled. However, in legal disputes, the court system can impose standards, such as those propagated by the IEEE (pronounced, I triple E; the Institute of Electrical and Electronics Engineers), on the performance of such contracts. So, for starters, organizations should seriously rethink acceptance of standard arbitration clauses common in today’s information technology contracts.
Let us describe a situation related to conversion from a legacy system to a state-of-the-market enterprise resource planning (ERP) tool. Much of the material comes from an article we wrote for IEEE Computer wherein an important development was described regarding the use of standards by which information technology contracts and contractor performance were being evaluated (Aiken, Billings et al. 2010). The article relates how the court system imposed standards, such as those propagated by the IEEE, on information technology projects in arbitration—and this is really important—where none of the parties are affiliated with the IEEE. All names are fictitious for obvious reasons.
Company X received a directive from its parent corporation mandating replacement of its legacy payroll and personnel systems with a specific ERP software package designed to standardize payroll and personnel processing enterprise-wide. Upon the vendor’s recommendation of a “specialist” integrator, Company X contracted with the recommended specialist to implement the new system and convert its legacy data for $1 million.
The contracted timeline was six months, beginning in July and wrapping up with a “big bang” conversion at the end of December. The year-end conversion failed, allegedly due to the system integrator’s poor data migration practices. It became necessary for Company X to run both the old and new systems in parallel—a complex and expensive situation which could have been avoided, and one that Company Y had assured would not occur. When conversion was pushed into April of the following year, Company X slowed and then ceased paying invoices from the system integrator. In July, the system integrator pulled its implementation team, and Company X initiated arbitration. The messy sequencing toward arbitration is shown in Figure 23.
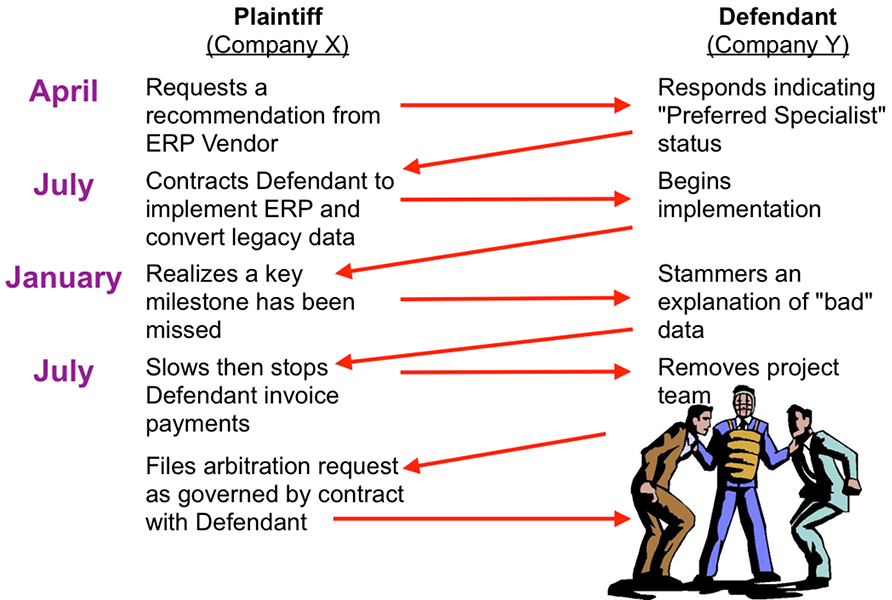
Figure 23 Messy sequencing towards arbitration
Note: every contract we have seen has a clause similar, if not identical, to the one in this instance:
[Company Y] warrants that the services it provides hereunder will be performed in a professional and workmanlike manner in accordance with industry standards.
Precisely defining these standards (such as “professional and workmanlike manner”) would quickly become a key issue. While providing expert witness testimony in the arbitration proceedings, we were asked to address six specific items of contention, each with its origins in data management, although only issue #3 (data quality) would have been recognized as a data management issue at the time.
Issue #1: Who owned the risks?
Interestingly, at a project kick-off meeting, data quality was one of four project risks that were classified as high. Yet when asked why Company Y was unable to meet their own self-imposed deadline, their only response was that ‘Company X had bad data.’ If the potential quality of the data was identified early on as a high risk, who was obligated to develop the risk mitigation plan and monitor for risk occurrence? As Company Y had self-labeled themselves experts, the arbiters indicated a belief that the consultants owned this risk; this was backed up by demonstrating to the arbiters that the DMBOK shows that data quality was clearly a data management issue and therefore the risk belonged to Company Y.
Issue #2: Who was the project manager?
Believe it or not, the system integrator had the client’s chief information officer sign a contract stating that Company Y’s consultants were working under the CIO’s personal direction as the project manager! This document was shown to the arbitration panel; it turned out to be a rather poor move. The arbiters questioned the system integrator as to how, if Company X had hired “experts,” would they have been able to direct the work of Company Y’s expert consultants? Since the arbiters asked the question directly of the system integrator’s representative, proceedings began with the system integrator on a defensive footing--without us having to do any work.
How did data management play a role in this? First, we used the PMBOK, the Project Management Institute Body of Knowledge, a) to define what project managers do and b) to identify evidence of those behaviors on the parts of both defendant and plaintiff (see Figure 24). Second, we introduced time and attendance records for one expert consultant who billed more than two thousand hours to a task labeled “project management.” Both pieces of evidence were obtained by reverse-engineering the data we obtained as evidence from Company Y’s consultant shared drive, where all the project documentation was stored during the project. Needless to say, we won this point handily.
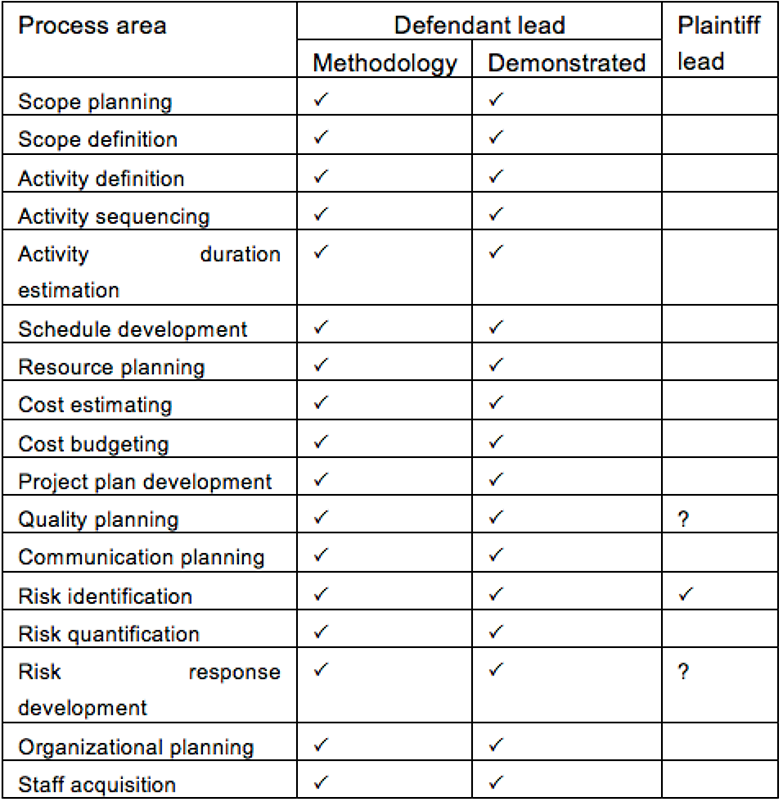
Figure 24 Establishing who the project manager was
Issue #3: Was the data of poor quality?
A fundamental mistake made when organizations hand over data conversion or migration tasks (“modification”) to consultants is the failure to conduct a baseline comparison of data quality before it is turned over. Organizations that forego this simple task are generally defenseless against allegations that a) the data is of poor quality and b) the poor quality inhibited successful modification. On the plus side, organizations performing such basic comparisons are better equipped to evaluate various proposals. In fact, organizations without this basic knowledge cannot make informed responses to such proposed plans or scenarios. Neither party can, in short, have an intelligent, useful conversation because a lack of project-specific information is a necessary albeit insufficient precondition to determining how long it will take and how much the conversion will cost.
The only defense when faced with this challenge is to investigate the possibility that modification activities introduced errors. We were able to offer defense in two instances, one micro and one macro.
Introducing micro errors into conversion data
We found a number of instances such as the one described below. When added together, it painted a picture of errors being introduced into the data by Company Y. Showing that Company Y’s conversion made the data worse—regardless of its condition before being handed over—was a pretty good refutation that the original data was of poor quality.
Example: When converting gender information, the system integrator introduced code that basically read as follows:
IF column 1 in source = “m” then set value of target data to “male”
ELSE set value of target data to “female”
This code is implemented in direct contradiction to IEEE programming standards, among others. Use of such modification programming code introduces errors into the target because values not equal to “m” in the source will be counted as “female” in the destination. This should not always be the case, as there are exceptions to every rule. For example, according to Canadian law at the time, the government mandated the tracking of nine gender codes:
- Male
- Female
- Formerly male now female
- Formerly female now male
- Uncertain
- Won’t tell
- Doesn’t know
- Male soon to be female
- Female soon to be male
All other values were counted as female after conversion by Company Y’s code. Demonstrably, the converted data was of poorer quality than the original, unconverted data as the number of females was incorrectly higher in the converted data.
Introducing macro errors by converting too much data
Our examination of converted data indicated that an order of magnitude more data existed in the target data set than was expected – the source dataset was one-tenth the size of the converted dataset. Our forensics discovered that, when the data didn’t “go in right,” Company Y’s consultant would rerun the conversion process. However, the ERP manufacturer had implemented code that prevented duplicate records from being created within the database. When the rerun also produced unsatisfactory results, the consultants located and disabled the code that prevented duplicate records from being introduced. They then ran the process multiple times (apparently 10), causing the data set to contain multiple duplicate records, resulting in significant dilution of existing data quality.
Once again, the conversion data was of demonstrably lower quality because it contained approximately 10 entries for each entry in the original, legacy data set. For example, a single legacy entry for “Jane Smith” in the original, unconverted data set typically resulted in 10 entries for “Jane Smith” in the migration data set. Each error in the original data was multiplied by 10 times by the conversion process, clearly indicating that Company Y’s conversion process had generated data of poorer quality than the unconverted data.
These macro and micro examples clearly demonstrated to the arbiters that the modification process had introduced errors into the data and, thus, the system integrator’s claim of poor quality data as the cause of failed data conversion became suspect.
Issue #4: Did the contractor (Company Y) exercise due diligence?
Our expert report introduced dozens of additional forensic artifacts used as project plans at one or more points during the project. Project planning is a basic approach to executing large complex tasks such as a system conversion. Project plans are used to keep everyone involved on the same page as to what is supposed to happen (and when) and what has happened so far during the project.
These project plans were not of the standard variety. Of particular note was the number of tasks constrained by predecessor tasks relative to the total number of tasks in each version of the project plans. In the most egregious example, a total of only 15 of 499 total tasks had predecessors. If this were truly the case, it would not matter when the remaining 484 tasks were begun (Figure 25).
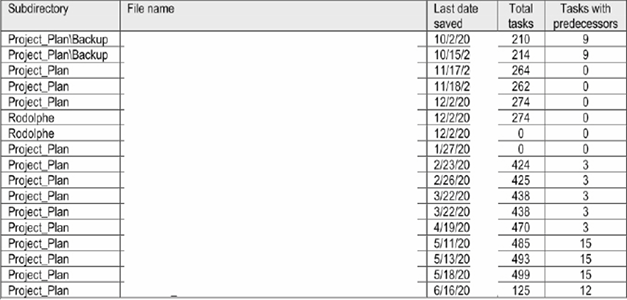
Figure 25 Alleged project management plans
The absurdity of these “plans” called into question the project management qualifications of Company Y. They clearly showed that Company Y’s consultants were not good at managing the project data. They hadn’t a clue how to manage the metadata, the data about the data, they were charged with managing.
The contrast between expected and actual behavior was highlighted using guidance from the previously mentioned PMBOK. It clearly showed that the consultants from Company Y were not competent to perform the duties to which they had been assigned. It further established in the mindset of arbiters an equivalency between PMBOK and the DMBOK.
Issue #5: Was Company Y’s approach adequate?
Data engineering, like most forms of engineering, establishes specific techniques and principles upon which its practitioners rely (see Figure 26). Most fundamental are the concepts of flexibility, adaptability and reusability. Data engineering methods permit discovery and modeling of the best “to-be” arrangement of the data—the data architecture required to best satisfy the organizational requirements.
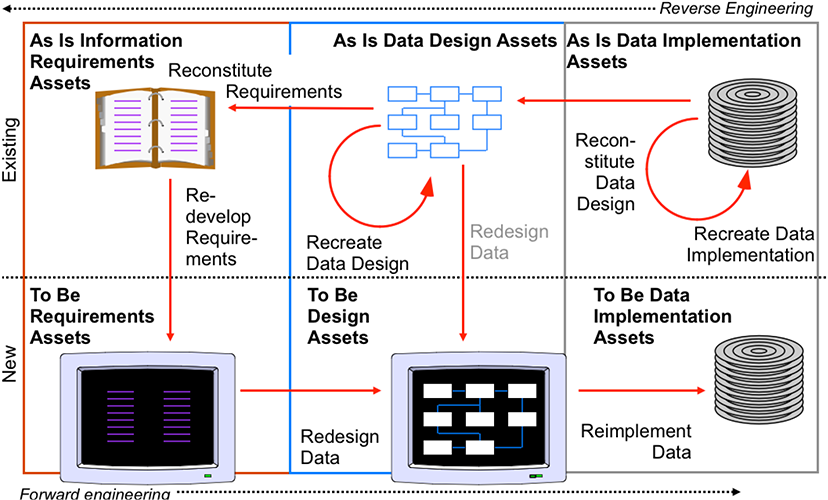
Figure 26 Lacking data reverse-engineering methods
A thorough examination of publicly available documentation of the system integrator’s methods revealed no instance even suggesting that such ideal data architecture would be defined. Moreover, upon questioning, none the consulting staff appeared to understand its fundamental importance. The arbiters were left sensing that the system integrator’s method was lacking in key areas—namely, defining an adequate “target” arrangement of the data that could satisfy Company X’s data needs.
Issue #6: Were required standards of care followed, and were work products of the required quality?
When deciding these various issues, the arbiters returned to the matter of the definition of standard of care that could be expected by the client of the contractors. After all, the consultants had promised in writing that the work would be done according to “industry standards.” During discovery, a few pointed questions were posed to Company Y’s consultants about these standards. The answers below were typical.
Question: What are the industry standards that you are referring to?
Answer: There is nothing written or codified, but it is the standards which are recognized by the consulting firms in our industry.
Question: I understand from what you told me just a moment ago that the industry standards that you are referring to here are not written down anywhere; is that correct?
Answer: That is my understanding.
Question: Have you made an effort to locate these industry standards and have simply not been able to do so?
Answer: I would not know where to begin to look.
At this point, we were able to convince the arbiters that, absent other sources, Google would not be an unreasonable place to begin. We demonstrated the ease of locating the IEEE standards and then used those standards to contrast with the performance and actions of the consultants. The arbiters were favorably impressed and, in the absence of the referenced best practices, allowed the application of the IEEE standards even though none of the consultants (or the client, for that matter) was a member of the IEEE.
The upshot was that the arbiters sided with our expert opinion and awarded millions to the client. Approaching the entire problem from a data management perspective afforded us unique insight to defend against the poor data quality charge, but it was our related forensics that revealed the various other items of evidence that led to a successful outcome for our client.