
5
Crypto-Compression of Videos
Cyril BERGERON1, Wassim HAMIDOUCHE2 and Olivier DÉFORGES2
1Thales SIX GTS France, Gennevilliers, France
2IETR, INSA Rennes, Univ Rennes, France
Recent developments in digital communication systems and the widespread use of video content have raised new concerns about media security and privacy. This chapter addresses these emerging security issues by providing a state of the art of partial, perceptual and selective encryption approaches. We also present recent work in the field of video crypto-compression, with a particular focus on selective encryption adapted to video compression standards. In this context, methods are proposed for evaluating the visual privacy offered by these solutions.
5.1. Introduction
5.1.1. Background
The quest for confidentiality in communications has long been a subject of interest for scholars, dating back to ancient times (with examples including Caesar’s code, Al-Kindi’s cryptanalysis, Vigenère’s cipher, etc.). Over the centuries, what began as a form of art evolved into a fully fledged science in its own right under the name of cryptology (including cryptography and cryptanalysis). The notion of secrecy in communications was initially brought into focus by the need to protect crucial data in the military and diplomatic fields (Kerckhoffs 1883); it was later adopted in the civilian world in order to preserve the confidentiality of information and messages, notably in an industrial context, for the protection of commercial exchanges, exclusive knowledge and innovations. Finally, the digital revolution (with the rise of telecommunications, computers, the Internet and social networks) created a need for new methods of storing and transmitting digital data in order to prevent undesirable disclosure and fraudulent copying.
Claude Shannon, the founding father of information theory, actually developed his mathematical theory through his work in the field of cryptology at Bell Labs during World War II. His seminal work on the notion of secrecy, “Communications Theory of Secrecy Systems” (Shannon 1949), was written in 1945 (although it would only be declassified by the U.S. Department of Defense in 1949), predating the work that would lead to his two fundamental theorems on source and channel coding. Information security thus forms an integral part of the information theory “triptych” of source coding, cryptography and channel coding.
5.1.2. Video compression
The recent evolution of digital communication systems (xDSL, 3G, 4G and 5G) has led to an explosion of multimedia services and applications (IPTV, content sharing and social networking); the vast majority of data exchanged over networks now consists of video content1. Video compression is an integral part of many multimedia applications available today and is essential for meeting the needs of users (for applications such as digital TV, streaming and videoconferencing). Numerous video coding standards have been developed over recent decades, created by standardization committees such as ITU-T (the International Telecommunication Union-Telecommunication standardization sector), or ISO/IEC JTC1/SC29/WG11 by MPEG (the Moving Picture Experts Group). Codecs such as Advanced Video Coding (AVC) and High Efficiency Video Coding (HEVC) (ITU-T 2013) mean that video service providers are still able to maintain good quality content, despite demands for higher video resolutions, and to adapt to a variety of different transmission rates. For example, the latest HEVC video encoding standard, published in 2013, went well beyond the compression performance of existing video encoders, allowing up to 50% bitrate reduction over AVC for equivalent subjective video quality (Sullivan et al. 2012).
5.1.3. Video security
The increased use of video compression in various video-on-demand systems, video communication services, social networks and media sharing platforms has raised not only public knowledge and use of these services, but also raises crucial security challenges in terms of copyright protection, data protection and privacy. For example, the widespread use of social networks means that people may now be recorded anywhere, with or without their knowledge, and published on the Internet without their consent: this directly impacts their privacy rights.
Security and content protection in the field of video have thus become an important issue in the last decades and have attracted considerable scientific research (in the areas of steganography, watermarking, partial encryption, etc.). By analogy with channel coding, source coding and cryptography have long been studied separately. The idea of combining source coding and security aspects under the term crypto-compression has opened up promising new avenues alongside work on joint source-channel coding.
Selective encryption appears to be one of the most promising new tools combining compression and cryptography, and has received most attention in the scientific literature over the past few years.
In this chapter, we present different approaches to protection used and studied in the state of the art, including crypto-compression systems. We notably focus on the selective encryption scheme used in video compression standards: AVC, HEVC and its scalable extension SHVC. Finally, we shall present different methods used to objectively measure and subjectively evaluate selective encryption in order to quantify the level of visual security offered by various approaches.
Section 5.2 presents the state of the art in encryption systems, while section 5.3 is devoted to different aspects of selective encryption. Approaches to measuring image and video quality are presented in section 5.4. Section 5.5 concerns perspectives for further development in this area, and some conclusions are presented in section 5.6.
5.2. State of the art
Traditionally, encryption schemes are considered to be distinct and independent from information compression approaches. Standard symmetric encryption algorithms, such as AES and DES, are used to encrypt all bits in a video stream (Wu and Kuo 2005), in the same way as a text file, that is, without considering the specific structure of the video stream. Unfortunately, this general approach, based on successive compression and encryption phases, is not optimized for video content.
Several different video encryption systems have been presented in the literature over the past three decades (Liu and Koenig 2010; Jolly and Vikas 2011; Stutz and Uhl 2012).
As we see from Figure 5.1, video encryption methods can be grouped into three broad categories, operating at different stages in the transmission process:
- – visual encryption methods, where modifications are applied in the spatial (or pixel) domain before compression;
- – crypto-compression methods, in which encryption occurs as part of the compression process;
- – naive encryption methods, which are applied after compression at system/transport level.
The families and sub-families of methods presented in the following sections are also clearly illustrated in Figure 5.1.
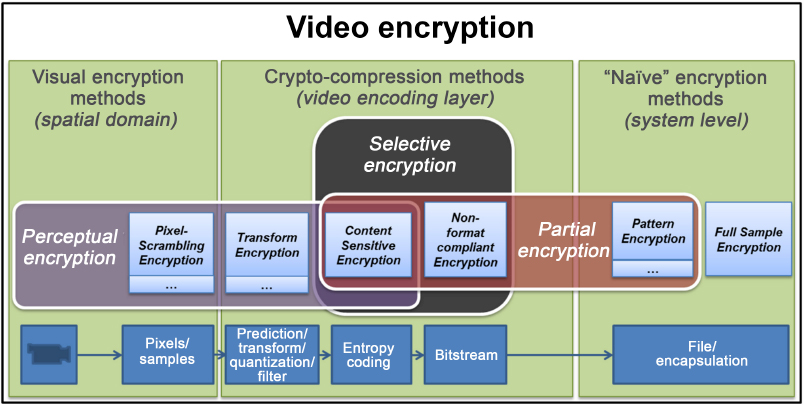
Figure 5.1. Video encryption methods
5.2.1. Naive encryption
The simplest and most common method used in secure video transmission is to encrypt the entire video stream. This approach is called full sample encryption, and was standardized by MPEG under the name of Common Encryption (CENC) for files (ISO/IEC 23001-7 2016) and MPEG-2 video transport streams (ISO/IEC 23001-9 2016). Using this technique, which is also known as full encryption, all compressed video streams are treated as opaque data; the attention to the structure and specificity of the compressed content is not taken into account, meaning that the video stream cannot be analyzed at the transport or low-level layers. The fact that the video data are encrypted in their entirety makes this method computationally complex and ill-suited to the transmission of a high bitrate video streams, with low latency and low complexity constraints (Tawalbeh et al. 2013; Asghar et al. 2014). Furthermore, the bitstreams encrypted using these standards can only be decoded following the application of the corresponding decryption process (as the encryption process breaks the syntax of the video bitstream).
These two challenges have been handled independently by two broad subsets of encryption methods proposed in the literature: partial encryption methods (section 5.2.2) and perceptual encryption methods (section 5.2.3), shown in Figure 5.1.
5.2.2. Partial encryption
Partial encryption involves protecting a portion of the bitstream (bytes or bits) while leaving the remainder clear (i.e. unchanged). Limiting the number of encrypted bits considerably reduces the complexity of cryptographic operations (XOR) and the use of the encryption algorithm itself, without compromising the security of the process. The MPEG CENC standard also defines subsample encryption and pattern encryption, where only the data relating to entropically compressed video streams is partially encrypted. Pattern encryption, as the name suggests, involves the encryption of only certain sequences of data bytes, leaving other sequences unencrypted, following a regular user-defined pattern (Figure 5.2). This method greatly reduces use of the encryption system (in this case AES), thus decreasing the latency induced at both the encoder and decoder ends of the process.
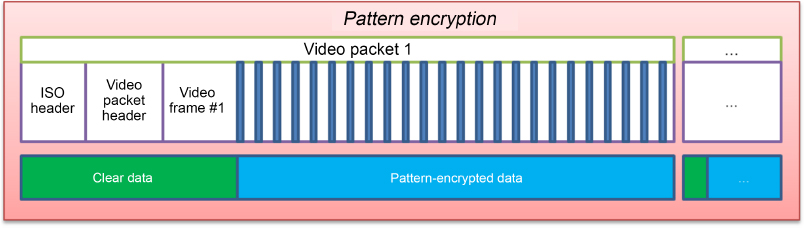
Figure 5.2. Principle of pattern encryption
Furthermore, leaving the headers of the video frames unencrypted means that certain information, such as the frame number, remains accessible, so that specific portions of the video can be decrypted without needing to process the entire video. Nevertheless, as in the case of full encryption, encrypted bitstreams cannot be decoded without the correct decryption mechanism: the encrypted video cannot be displayed.
5.2.3. Perceptual encryption
The second main subset includes all methods of encryption where video content is visually degraded, either completely or locally (i.e. in only one or more areas of the image). Unlike naive encryption, these methods generate a protected bitstream that can be decoded without requiring access to the encryption key. For this reason, some authors use the term format compliant encryption (or the more general term format-preserving encryption, which is wider than image/video encryption), since these approaches preserve the format and syntax of the resulting stream. Others have used the term “transparent encryption”, highlighting the fact that the protected video sequence cannot be detected as “encrypted” at any point in the transmission chain.
Note that these perceptual encryption methods also have the property of adjusting the level of visual degradation obtained after decoding. This adjustment means that a person who does not have access to the decryption key may be authorized to visualize a low-quality, but interpretable, version of the protected video. In the case of on-site video surveillance, for example, individual identification is not relevant for detecting suspicious events or crowd movements, except to law enforcement officers who may request authorization from the authorities to obtain a decryption key, notably in investigative contexts.
Methods in this subset often rely on pixel scrambling, an approach which degrades visual content prior to compression using a cryptographic mechanism (Podesser et al. 2002; Ye 2010; Liu et al. 2013). Unfortunately, this method also has certain drawbacks: modifying pixels in the spatial domain (i.e. the sample domain) alters the compression efficiency of the video codec. In the case of lossless compression, based on a modification of the statistics of the samples to be processed, operations such as entropy coding no longer effectively reduce the bitrate. Moreover, in the case of lossy compression, reversibility is not guaranteed as compression artifacts may prevent correct retrieval of the original protected content.
5.2.4. Crypto-compression methods
In response to these issues, several authors have proposed encryption methods that operate on the video coding layer by modifying the compression algorithm. Thus, information is compressed and protected in a single pass through cryptographic mechanisms within the different compression stages, as shown in Figure 5.3.
One example is the transform encryption approach, where the selected transform (DCT (Liu et al. 2006; Weng and Preneel 2007), DWT (Zeng and Lei 1999; Lian et al. 2004)) differs from the normalized version, although the syntax obtained in this way remains compatible with the chosen compression format. These methods, therefore, intrinsically modify the steps in the compression process and, in most cases, modify the compression performance of encoders, which may be problematic if the bitrate allocated to video transmission is limited. For example, randomly permuting the transformed coefficients (TC) has been shown to “distort” the probability distribution of these coefficients, making entropy coding less efficient and thus increasing the compressed video bitrate (Tang 1997; Shi et al. 1999).

Figure 5.3. Stages in the video compression process
5.2.5. Selective encryption methods
As we saw in section 5.2.1, C. Shannon carried out an in-depth study of the close relationship between data compression and encryption (Shannon 1949). Shannon demonstrated that removing redundancy in a source could strengthen the encryption process. In section 5.2.4, we saw that video encryption involves compressing data using a video encoder that eliminates most of the redundancy in the source before encrypting the entire bitstream, assuming that the resulting bits have the same importance and statistics. This theoretical approach thus implies the use of a perfect encoder that removes all statistical redundancy in the source prior to encryption. However, despite the ever-increasing efficiency of video codecs in terms of compression, their associated bitstreams have their own syntax and structure that can be considered as a bias for cryptanalysis attacks. It is worth noting that some joint source-channel coding solutions rely on this statistical bias and have proven to be effective in recovering errors in compressed bitstreams transmitted over noisy channels (Bergeron and Lamy-Bergot 2004; Sabeva et al. 2006). Selective encryption, on the other hand, takes the coding structure of the video bitstream into account and encrypts only the most sensitive information. Note that the term “selective” relates directly to the choice of information to protect.
Selective encryption methods evolved as an efficient alternative to existing encryption methods for different video and image codecs (Wen et al. 2002; Bergeron and Lamy-Bergot 2005; Dufaux and Ebrahimi 2008; Shahid et al. 2011; Stutz and Uhl 2012; Peng et al. 2013; Van Wallendael et al. 2013a, 2013b; Shahid and Puech 2014; Farajallah et al. 2015; Boyadjis et al. 2017).
As the selective encryption operation is carried out during the final stage of video compression, that is, entropy encoding, this encryption can also be carried out independently of the compression (or decompression) process by means of transcoding, as some authors have suggested (Boyadjis et al. 2014).
In this sense, selective encryption may be considered as a subset of partial encryption methods, since only part of the information is protected. However, it cannot be automatically considered as a subset of perceptual encryption methods, since some of the selective encryption methods described in the literature do not necessarily provide a format compliant bitstream: this is known as non-format compliant selective encryption (Lian et al. 2006).
Section 5.3 presents solutions where the encrypted bitstream remains standard-compliant, taking advantage of both the benefits of perceptual encryption methods (decodability, visual degradation adjustment and spatially or temporally localized encryption) and the partial encryption methods described earlier (low computational cost of encryption/decryption, lower latency, and information accessibility).
5.3. Format-compliant selective encryption
5.3.1. Properties
In this chapter, we have chosen to focus on format-compliant selective encryption methods, which combine the advantages of the partial encryption (section 5.2.2) and perceptual encryption (section 5.2.3) methods described above. This type of encryption approach respects certain key properties:
- – the syntax of the compression standard is preserved so that the compressed stream remains readable by any format-compliant decoder, and cannot be identified as such; this element of discretion is particularly valuable if communications are being monitored;
- – the approach is guaranteed to be efficient in terms of rate/distortion, avoiding non-controlled fluctuations in bitrate which may exceed or “clog” the available capacity;
- – the complexity and processing times involved in these approaches are moderate, and the number of encryption (and decryption) operations is limited;
- – encryption may be temporally and locally restricted within the video, and the level of encryption (with associated levels of visual degradation) can be adjusted by selecting the appropriate number of elements within the video content.
These selective encryption methods thus imply modifying the entropy encoder within the compression step by partially encrypting the symbols resulting from the compression algorithm. The challenge lies in determining which data should be selected for this encryption.
It is hard to understand the challenges inherent in modifying the entropy encoder without a clear understanding of the process. To illustrate these issues, let us consider the CAVLC (Context Adaptive Variable Length Coding) entropy encoder of the H.264/AVC standard. This encoder transforms each symbol resulting from the various compression steps (intra prediction, motion vector, TC, etc.) into a variable length codeword (VLC), where each associated length is directly related to the probability of the symbol occurring. To encode motion vectors (specifically, the difference with respect to the default motion vector), the standard uses a look-up table (see Table 5.1) to entropically encode the (x, y) coordinates of the vector.
Table 5.1. VLC codewords: differences in movement vectors (CAVLC H.264/AVC). For a color version of this table, see www.iste.co.uk/puech/multimedia2.zip
| Index | VLC codeword | Mvd_lX |
| 0 | 1 | 0 |
| 1 | 010 | 1 |
| 2 | 011 | -1 |
| 3 | 00100 | 2 |
| 4 | 00101 | -2 |
| 5 | 00110 | 3 |
| 6 | 00111 | -3 |
| 7 | 0001000 | 4 |
| 8 | 0001001 | -4 |
| … |
Note that when the coordinate values are of low amplitudes (compared to the default motion vector), they are coded using short code words; this is statistically consistent since motion vectors generally have values close to those of their collocated neighbors.
In the case of CABAC (Context-Adaptive Binary Arithmetic Coding), used in H.264/AVC and HEVC, the entropy encoder is based on an adaptive binary arithmetic coding technique using context models. The arithmetic coding step and context modeling mean that the bits in CABAC compressed streams are highly interdependent, as shown in Figure 5.4.
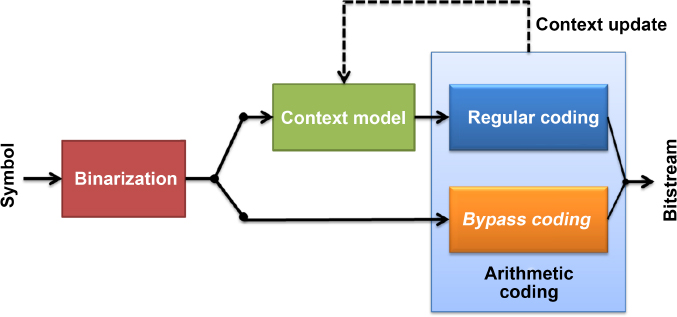
Figure 5.4. Diagram of the CABAC encoder
However, the arithmetic encoder only uses context models for regular coding; these models are not used in bypass encoding, and, in this case, the probability models are not updated during arithmetic encoding so that modifications to these values have no impact on the CABAC encoding.
There are two ways of applying selective encryption in this case:
- – encrypt the symbols directly and generate a new codeword from the look-up table or from the CABAC encoder. This method maintains standard compatibility but can modify the length of the generated codeword, meaning that the size of the post-compression stream may be different;
- – encrypt certain bits of the VLC (such as those shown in codecolorBlue in Table 5.1) or, in the case of CABAC, bits that have been encoded using Bypass Coding. This approach limits possibilities, but the bitsize of the video stream is preserved.
The majority of the algorithms used in the state of the art are of the first type, and therefore bitrate preservation is not guaranteed. Some authors (Van Wallendael et al. 2013a) have studied the impact of all the encryptable parameters in the HEVC syntax in terms of video quality and bitrate: the degradations obtained with constant bitrate selective encryption algorithms were essentially similar. Furthermore, changing the compression efficiency of a compression chain is not recommended and can also present a bias for statistical attacks based on the probability of occurrence of the compressed symbol.
5.3.2. Constant bitrate format compliant selective encryption
In this section, we shall consider methods that present no additional cost in terms of rate, ensuring that the transport layer will not be affected by the encryption process, while preserving the advantages of the solutions described above. The main challenge in this case concerns the selection of the sensitive data to encrypt from within the possibilities offered by the video format, without affecting compression efficiency.
In our case, the only way to ensure bitrate conservation is to select only “cipherable” bits, which will only produce valid codewords of identical size when modified by a classic cryptographic algorithm. This selection of cipherable bits also entails identifying parts of the data stream that do not influence the decoding process, that is, where modifications resulting from encryption do not result in desynchronization or create non-compatible bit streams. For example, if the number of non-zero coefficients (the values of which will be modified) is encrypted, then the expected number of coefficients would be different and the rest of the decoding would be desynchronized; a compatible decoder would thus be unable to interpret the rest of the stream, and an error message would result. The set of eligible cipherable bits is known as the encryption space (ES), and is different for each codec.
Certain authors have provided more or less complete encryption space solutions (specifying the set of symbols and associated cipherable bits) for different video compression formats. Bergeron and colleagues (Bergeron and Lamy-Bergot 2005; Bergeron 2007) proposed a selective encryption scheme for H.264/AVC (CAVLC) bitstreams based on a selection of certain bits in different codewords, such as the luma prediction modes Intra4 × 4 and Intra16 × 16, intra-chroma prediction modes, coefficient values suffixes and motion vectors. Shahid et al. proposed a selective encryption scheme for CABAC with AVC (Shahid et al. 2011) and for HEVC (Shahid et al. 2009). Hamidouche et al. (2015) introduced a more thorough selection approach for HEVC and its scalable extension SHVC, encrypting motion vectors, TC and intra-prediction modes.
As we see from Figure 5.5, all of these solutions maintain the conformity of the bitstream format without altering compression efficiency. Nevertheless, note that these solutions use different standard cryptographic schemes to generate pseudo-random numbers (PRNG) to modify the cipherable bits: AES-CTR (Bergeron and Lamy-Bergot 2005), AES-CFB (Shahid et al. 2009, 2011) and chaos coding (Hamidouche et al. 2015).
For each symbol considered, it is important to note that the bits designated as cipherable must retain this capability in any bitstream, and that cases where a given configuration would permit delayed resynchronization cannot be considered. Cipherable bits correspond to cases where several codewords of the same length are available and no a posteriori change in context will occur when switching from one to the other, and encryption consists of swapping from one value of a symbol to another. This presents a twofold advantage: first, compatibility with the requirements of the video standard in question is guaranteed; second, it makes it difficult to find an angle of attack to try to break the encryption key, as it aims to make all solutions possible, hence removing the possibility of ruling out some cases based on non-respect of standard syntax.

Figure 5.5. Constant bitrate format compatible selective encryption: key principle
5.3.3. Standardized selective encryption
In 2019, the MPEG standardization committee (ISO/IEC JTC1/SC29/WG11) began work on standardizing a selective encryption process compatible with the H.264/AVC and H.265/HEVC video compression formats (alongside a new image compression standard, HEIF (High Efficiency Image Format), a file format for images and image sequences recently standardized by MPEG (ISO/IEC 23008-12 2017), based on the ISOBMFF format (ISO/IEC 14496-12 2012) and using AVC and HEVC intra-mode encoders for still images), under the name MPEG A-VIMAF: Visual Identity Management Application Format (ISO/IEC 23000-21 2019). These selective solutions are compliant with their respective standards, and are thus compatible with the constant bitrate format; they have also been integrated into the CENC (Common Encryption Standard) for the ISOBMFF – ISO Base Media File Format – (ISO/IEC 23001-7 2016) under the name of content sensitive encryption (CSE).
For simplicity’s sake, we will not go into detail concerning all partially cipherable symbols and their associated restrictions here. In this section, we shall simply present lists of codewords containing cipherable bits in Tables 5.2 (AVC CAVLC mode), 5.3 (AVC CABAC mode) and 5.4 (HEVC mode).
Table 5.2. Cipherable codewords for AVC (CAVLC)
| Codewords | Cipherable bits | Constraints? |
| Slice QP Delta | Suffix bits | No |
| Macroblock QP Delta | Suffix bits | No |
| Macroblock type | Certain suffix bits | Yes |
| IPCM | All bits | No |
| Intra Luma Prediction | All bits | Yes |
| Intra Chroma Prediction | Final bit | Yes |
| Motion prediction reference | Suffix bits | Yes |
| Motion prediction vector | Suffix bits | No |
| Trailing ones | All bits | No |
| Level Suffix | All bits | No |
| Total zeros | Final bit | Yes |
| Run Before | Certain bits | Yes |
| Codewords | Cipherable bits | Constraints? |
| IPCM | All bits | No |
| Motion prediction vector | Suffix bits | Yes |
| Motion prediction vector sign | All bits | No |
| Sign of coefficient level | All bits | No |
| Absolute value of coef. level | Suffix bits | Yes |
For reasons of efficiency, the pseudo-random number generator (PRNG) used by MPEG for the CSE standard is the AES Counter Mode (CTR). Figure 5.6 shows how AES-CTR generates a pseudo-random sequence from a 128 bit block, an initialization vector (IV) which is incremented for each block and a chosen encryption key (of 128, 192 or 256 bits). AES-CTR mode offers a number of advantages:
- – its robustness to errors and loss has been widely validated (Isa et al. 2011; Boyadjis et al. 2015);
- – the algorithm is fast and parallel-friendly for software/hardware optimization (Gueron and Krasnov 2014);
- – its symmetry properties mean that autonomous encryption/decryption systems can be designed by transcoding (Boyadjis et al. 2014).
| Codewords | Cipherable bits | Constraints? |
| Motion vector difference | Suffix bits | Yes |
| Motion vector difference sign | All bits | No |
| Delta QP sign syntax element | All bits | Yes |
| Transform coefficient sign | All bits | Yes |
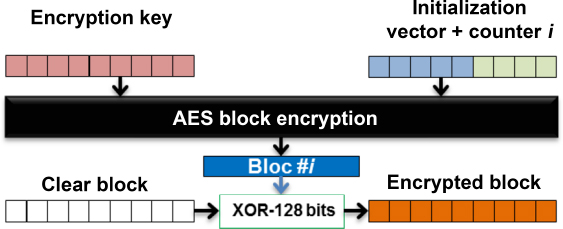
Figure 5.6. Standard AES-CTR operating mode
Obviously, the generated 16-byte (128-bit) block cipher cannot be applied directly to the compressed stream: as we saw previously, a video parser is used to locate cipherable bits. The encryption or decryption processes are performed using a simple XOR operation between the identified bits and the generated cipher blocks, as shown in Figure 5.7.

Figure 5.7. Content sensitive encryption process
5.3.4. Locally applied selective encryption
Many countries have rules and regulations issued by local authorities concerning video surveillance and the protection of personal data (for example, the GDPR in Europe). For example, in France, cameras can be installed in or adjacent to public spaces, but must be registered with the CNIL (Commission nationale de l’informatique et des libertés). Devices used to visualize either live or recorded images must only be accessible to authorized individuals, and can only be used by the police or legal authorities in the context of judicial requisition following an incident. Thus, it may be necessary to mask certain fixed areas in the camera’s field of vision (if part of this field is private and filming is not authorized), and individual anonymization by dynamic masking (blurring) of faces or any other identifying features may be required. In this context, the selective encryption method can also be used to protect regions of interest (ROI) in the video content (such as human faces or predefined areas) and leave the rest of the video (background) unencrypted, meaning that it is not subject to visual degradation (except as a result of compression). Since the process is reversible, authorized individuals in possession of the key have the ability to reconstruct the content of the video in its entirety, including masked areas, where necessary. The first stage in this approach is to divide the video into independent regions, in which non-confidential “clear” zones and confidential “protected” zones will be defined, as shown in Figure 5.8.
Since each codec has its own specificities, we have chosen to focus on the most widespread examples, AVC and HEVC. Nevertheless, this approach may be generalized to other codecs using different terminologies and constraints.
In the AVC and HEVC codecs, slice and tile concepts can be used to divide video frames into independent regions. This is possible due to the fact that dependencies between neighboring blocks and entropy coding dependencies are reset at slice (or tile) boundaries, preventing reconstruction issues in clear areas (see section 5.3.4.1). Furthermore, certain coding restrictions are taken into account in order to prevent the propagation of encryption errors outside the ROI in the inter-coding configuration (as in the case of predicted frames, such as P- and B-frames); these are presented in section 5.3.4.2.

Figure 5.8. Example of zone (selective) encryption
5.3.4.1. Controlling the propagation of selective encryption in intra-coding
In conventional compression approaches, the first frame of a video is intra-coded, that is, coded intrinsically without using previous frames, and successively compressed blocks may use pre-coded pixels in a process known as intra-prediction. This coding scheme is very efficient, since it avoids re-encoding some of the information that has already been encoded in the neighborhood of the block in question. However, in the case of selective encryption, if a block is encrypted, the resulting degradation may be propagated to adjacent blocks. The AVC and HEVC standards include tools to control error propagation, designed to prevent the emergence of unwanted effects as a result of noisy transmission: slices, slice groups (AVC only) and tiles (HEVC only). For region-selective encryption, these tools can be used to prevent uncontrolled degradation of adjacent zones (which should remain clear), as shown in Figure 5.9.
5.3.4.2. Controlling the propagation of selective encryption in inter-coding
Coding processes using predictions based on previously coded images are subject to reconstruction dependencies; in the context of region-selective encryption, certain tools must therefore be used to prevent drift error propagation.
To ensure perfect reconstruction over the video sequence in the clear (unencrypted) area, the motion prediction mechanism is constrained to the clear area, to point exclusively to previous frames inside another clear area, as shown in Figure 5.10.
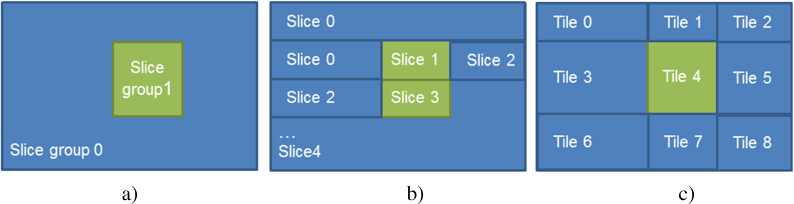
Figure 5.9. Image split into two zones, “protected” in green and “clear” in blue: a) by slice groups, b) by slices and c) by tiles

Figure 5.10. Management of the motion vector constraint with a protected zone and a clear zone
SEI (Supplemental Enhancement Information) messages can be used to indicate this constraint for motion vectors, known as the motion-constrained slice group set in AVC and motion-constrained tile-based adaptation in HEVC. In HEVC specifically, the merge mode derives motion vector information from a list of neighboring spatial and temporal candidates; both decoding operations may thus propagate errors from encrypted tiles to unencrypted areas if content is not properly decrypted (with no key or using the wrong decryption key). In merge mode, temporal candidates for clear zone tiles must be taken from within the clear zone of the reference frames. In order to prevent the propagation of encryption outside the ROI tile, additional encoding constraints must be applied:
- – motion vectors are restricted to referring only to the colocalized tile in the predicted block;
- – in-loop filters must be disabled on the boundaries of the tile or slice (as in the case of intra-coding, to prevent them from being used as a reference).
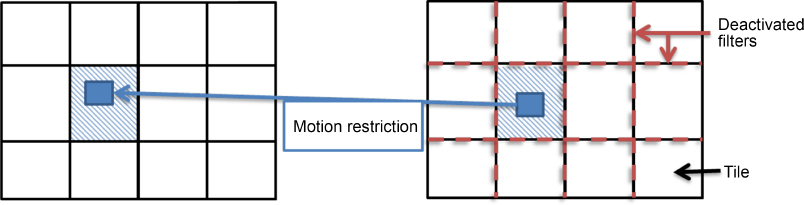
Figure 5.11. Restriction of motion vectors and in-loop filters on tile boundaries
Although selective encryption does not directly increase the bit rate of the video stream, the constraints imposed in the case of region-selective encryption tend to have a negative impact on compression performance, depending on the resolution and content of the video. However, they are necessary and permit “clean” reconstruction, even at tile boundaries, as shown in Figure 5.11. These restrictions ensure perfect reconstruction of clear areas, even if part of the reference frame is encrypted using a region-selective encryption method.
5.3.4.3. Differentiated access in selective encryption
Given the possibility of defining and encrypting multiple regions in a dynamic manner, for certain applications, different encryptions may be applied to different zones, enabling differentiated access, as shown in Figure 5.12.
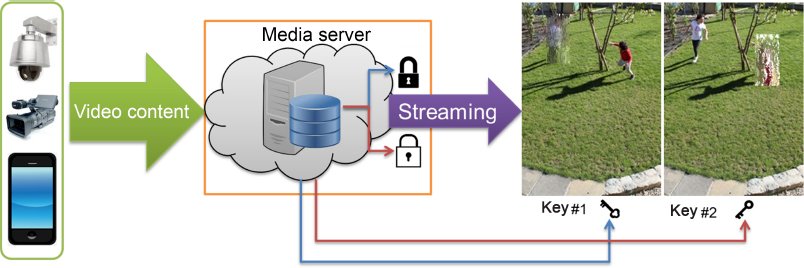
Figure 5.12. Multi-access to protected multimedia streaming content
For example, consider the case of a personal video shared on social networks. The individuals featuring in the video may be blurred by selective encryption. Based on the individuals present, different access rights may be assigned to different users with access to the media file, as shown in Figure 5.13.
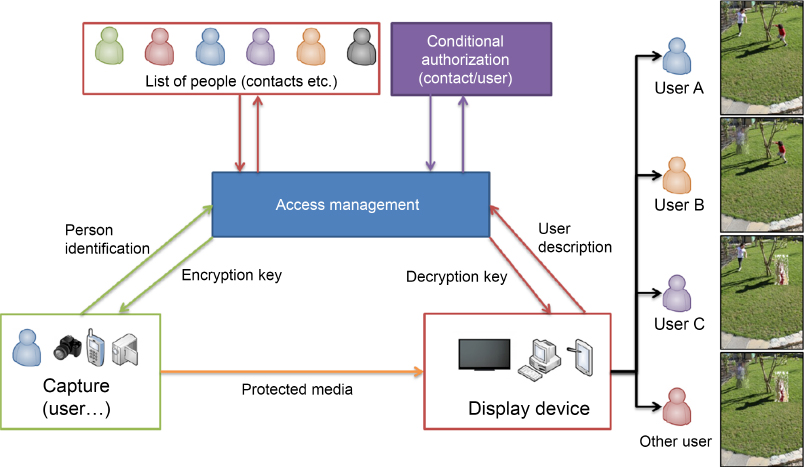
Figure 5.13. Example of selective encryption using type-conditional user access
In this figure, a user A records a video and identifies the people in the video; they may then “anonymize” each individual using a different key via selective encryption. When another user wishes to decode the video, they must retrieve the keys associated with each protected zone from a user, but the available keys will vary depending on their assigned access rights. In our case, user A is able to access all zones, but users B and C can only access certain, different parts of the video, as a function of the privacy restrictions imposed by the individuals featuring in the film. Finally, for any other unauthorized user, the two encrypted zones will remain anonymized. Other approaches based on image sharing will be presented in Chapter 8.
Recent work by the ISO/IEC on standardized protection, in the form of common encryption (CENC) (ISO/IEC 23001-7 2016) and MPEG A-VIMAF (ISO/IEC 23000-21 2019), has enabled the use of multiple decryption keys for the same mutimedia content (Bergeron et al. 2017). Each key is linked to an identifier and an encrypted zone, as shown in Figure 5.14.
ISOBMFF media files can now contain a combination of encrypted and unencrypted sets with multiple keys; note, however, that it is not possible to use multiple keys for the same zone in the context of common encryption.
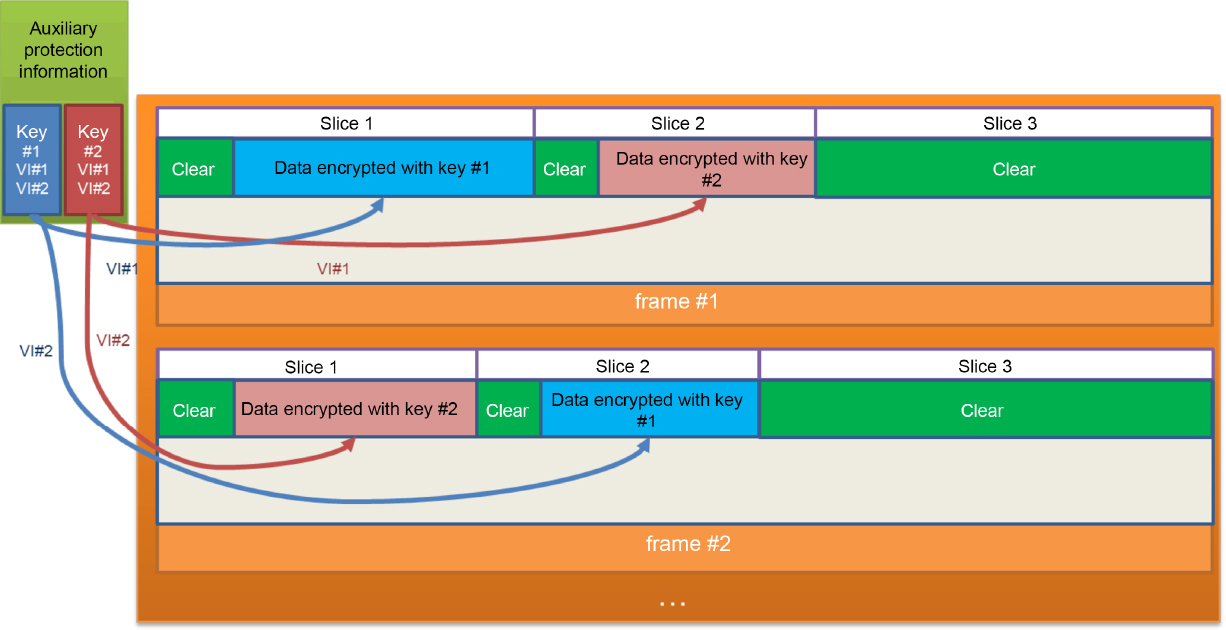
Figure 5.14. Example of an ISOBMFF file with two key identifiers, where selective encryption is applied to certain slices of different frames
5.3.5. Decrypting selective encryption
The subject of robustness to attacks has received relatively little attention in the context of research on selective encryption. As part of the CSE standardization process, MPEG launched a challenge to test the scheme (Bergeron et al. 2018). Three HEVC and three AVC bitstreams encrypted by CSE (Figure 5.15), along with the three open source software packages (Kvazaar (Tampere University of Technology 2015), GPAC (Telecom ParisTech 2008) and OpenHEVC (IETR-INSA Rennes 2015)) used to compress-encrypt and decompress-decrypt HEIF images and video sequences, were provided in order to evaluate the robustness of these solutions to different types of attacks.

Figure 5.15. Extract from an encrypted video sequence used in the “Break the Content Sensitive Encryption Challenge”
The challenge website2 supplies all the necessary information concerning the generation and decryption of HEVC bitstreams encrypted using CSE on various platforms. To date, there have been no successful attacks on this content.
In terms of security in selective encryption, although these solutions require relatively few encrypted bits (approximately 15–20% for AVC and HEVC) and the modifications made to compressed symbols do not affect the coherence of the syntax (while degrading visual reconstruction), it is hard to estimate and perfectly reconstruct the original bitstream: any attempt to identify the original message will be coherent and valid in terms of the syntax, and will thus be decodable.
Furthermore, it is important to note that video compression algorithms are not systematic and that each standard offers a variety of methods for compressing the same information. This means that it is not easy to find the original coded (and encrypted) bitstream, despite the fact that part of the information remains unencrypted.
The size of encrypted symbols is preserved during the process (the number of bits is unchanged), and also have the particularity of being intrinsically statistically similar since they are entropically designed by the standard (the size of a symbol depends on its probability of occurrence). These properties mean that formal statistical biases will not appear during a frequency attack.
5.4. Image and video quality
The relevance of encryption is an important question to consider. From a security perspective, the coded element must offer a high level of protection against cryptographic attacks. This level is generally estimated using statistical or correlation measurements. For images and videos, histogram analysis is also commonly used. In this case, perceptual quality is also an issue, and is even harder in cases of selective encryption where differences in the encryption level have a significant impact on image rendering.
The perceptual quality of images is based on image quality metrics, which may be split into two categories. The first group of subjective metrics rely on testing by human observers. These methods are time-consuming to implement, but are essential for calibration purposes. The second group of metrics are objective: in this case, distortion is estimated based on measurements in the image, with the goal of replicating subjective scores as closely as possible. There are two types of objective metrics: Full Reference (FR), as in the case of the MSE (Mean Squared Error), PSNR or SSIM (Structural Similarity Index) (Wang et al. 2004), where the distortion between the source and the coded image is estimated, or No Reference (NR), such as the NIQE (Natural Image Quality Evaluator) (Mittal et al. 2013), which operates blindly without knowledge of the reference. All of these metrics are widely known and used in quality optimization approaches.
The use of encryption, whether local or total, raises new questions to which responses are not always available in the present state of the art (Reza and Barbeau 2012):
- – Which are the best methods to use for subjective quality testing?
- – Which quality metrics are best-suited to the type of degradations resulting from encryption?
- – What is the appropriate visual degradation threshold for a given application?
For images, various studies have shown that the usual objective quality metrics are no longer effective when applied to encrypted data (Hofbauer and Uhl 2010, 2016).
This is due to the fact that the relationship between visual quality and security is not symmetrical. Furthermore, these metrics have been developed to estimate a level of quality but do not directly indicate the intelligibility of the content. While certain image-specific metrics have been proposed (Xiang et al. 2016), no solutions have yet been developed for encrypted videos, to the best of our knowledge. A further explanation relates to the lack of existing work on subjective evaluations of visually encrypted videos to use as a starting point. In terms of databases, there are only two available in this context and they only contain images. Both relate to selective encryption, the first for images encoded in JPEG2000 format (Autrusseau et al. 2010) and the second for JPEG (Le Philippe et al. 2017).
In sections 5.4.1 and 5.4.2, we present a thorough study of the objective and subjective quality of selectively encrypted videos. At the end of section 5.4.2, we also present a complete public database on encrypted HEVC videos (Fezza et al. 2019a, 2019b).
5.4.1. Experiments on encryption solutions
5.4.1.1. Content-sensitive encryption: a subjective approach
The robustness of an encryption scheme can be evaluated using different tools. The vast majority of studies make a strong link between the degree of perceptual encryption and video quality. Metrics of the video quality assessment (VQA) type have been widely used to assess the security of visual encryption. Yao et al. (2008), for example, used three objective quality metrics: image entropy, structural distortion and spatial correlation. A range of VQAs have been proposed to improve measurement accuracy: the correlation coefficient (CC) (Jagadeesh et al. 2013), the edge similarity score (ESS), the luminance similarity score (LSS) (Mao and Wu 2004), the similarity of local entropy (SLE) (Sun et al. 2011) and encryption quality (EQ) (Ahmed et al. 2007). Hu et al. introduced a metric known as semantic distortion measurement (SDM), which measures the degree of semantic distortion in a video.
The main shortcoming of these encryption-oriented metrics is that they focus on only one specific parameter of the video, neglecting the multimodal character of human perception. Moreover, there are no studies on subjective quality that assess the user-perceived quality of encrypted videos. The objective measures mentioned above process videos as a binary sequence without taking into account the properties of the human visual system (HVS). In the rest of this chapter, we shall present a comprehensive study of both objective and subjective evaluation methods for assessing the quality of encrypted images.
In this context, the selective encryption solution introduced in section 5.3 and standardized by MPEG is used. While maintaining compatibility, we encrypt a set of HEVC syntax elements including motion vector differences “MV”, the signs of these differences “MVs”, the coefficients of the transforms “TC” and their sign “TCs”. The configuration “All” corresponds to the encryption of all of these elements. This solution is implemented in Kvazaar (Viitanen et al. 2015), an open source free HEVC encoder, to create a new version (called secure Kvazaar) with the ability to compress and encrypt UHD HEVC video in real time. The subjective and objective studies conducted took account of different possible encryption scenarios and quantization parameters.
Three levels were considered for the basic CSE scheme:
- – encryption of TC alone: TC;
- – encryption of the signs of the transformed coefficients alone: TCs;
- – encryption of all syntax elements: All = {TC; TCs; MV; MVs}.
Similarly, for the extension of the scheme to the scalable SHVC coder, the objective study covers three scenarios:
- – base layer encryption only: {SE-SHVC-BL;
- – enhancement layer encryption only: SE-SHVC-EL;
- – encryption of both the base and enhancement layers: SE-SHVC-All = {SE-SHVC-BL; SE-SHVC-EL.
5.4.1.2. Test environment and apparatus
Subjective tests were carried out in the psychovisual laboratory at the IETR (INSA Rennes), which follows the recommendations of the ITU-R (ITU-R 2012). A 40-inch Full HD Samsung UE40F6640SS screen was used to view video sequences. Thirty-three observers – 24 men and 9 women, aged from 20 to 55 – participated in the experiment. All subjects were checked for color perception and visual acuity (10/10 in each eye, without correction).
As video content can have a significant impact on visual perception, we selected a set of sequences from the MPEG test base used by the JCT-VC expert group. Videos were primarily selected on the basis of their color, movement and texture characteristics. Five source sequences, each 10 s long but with different resolutions (classes), were selected for testing (see Table 5.5). The video sequences are compressed and encrypted in real time using the Kvazaar encoder with three levels of quantization for QP (22, 27 and 32) and for a low delay IPPP configuration. Syntax elements were encrypted in one of the three modes described above: TC, TCs and All. Finally, these different coding configurations give a set of 45 encrypted sequences: 5 sources × 3 QP × 3 encryption schemes.
Table 5.5. Set of video sequences used in the experiment
| Class | Resolution | Images per second | Video |
| B | 1,920 x 1,080 | 50 | BasketballDrive, Cactus |
| D | 1,280 x 720 | 60 | FourPeople |
| B | 1,920 x 1,080 | 24 | Kimono |
| E | 416 x 240 | 60 | BQSquare |
5.4.1.3. Evaluation procedure
The quality assessment used here is based on the Double Stimulus Continuous Quality Scale (DSCQS) (ITU-R 2012). Observers viewed each encrypted video twice, along with the original video. Participants were asked to quantify the degree of visibility of the content of encrypted videos, assigning a numerical score to each encrypted video according to a scale shown in Table 5.6, ranging from 1 (video content completely invisible) to 5 (video content clearly visible).
Table 5.6. Subjective scoring scale
| Degree of content visibility | Score |
| Clearly visible | 5 |
| Visible | 4 |
| Somewhat visible | 3 |
| Barely visible | 2 |
| Completely invisible | 1 |
At the end of each test, a graphical interface was displayed for 10 s for users to indicate their scores. Additional sequences were displayed prior to the experiment so that users were comfortable with the testing process. Finally, in order to prevent the occurrence of memorization phenomena, sequences were mixed so that two successive videos presented different characteristics.
5.4.2. Video quality: experimental results
5.4.2.1. Objective measures of selective encryption
The new encryption schemes presented above were implemented in the SHVC reference program, the Scalable Reference software Model (SHM), version 4.1 (Boyce et al. 2016). For this measure, we considered the classic test conditions used in SHVC, including two video sequences of size 2,560 × 1,600 (class A) and five sequences of size 1,920 × 1,080 (class B) (Seregin and He 2013). These videos were configured using a low delay P configuration (image I followed by P images), two layers (L = 2) and three scalability configurations: 2x, 1.5x and SNR. The PSNR was used to assess the quality of the decoded video.
Table 5.7 shows mean performances in terms of the PSNR and encryption space (ES, ratio of encrypted bits in the SHVC stream) of the three proposed encryption schemes, for videos in classes A and B and using different quantization values for QP. We see that the PSNR drops off sharply in the case of SE-SHVC-BL and SE-SHVC-All (PSNR of Y less than 10 dB); the first of these options encrypts the base layer (BL) alone, while the second applies encryption to all layers. Furthermore, we see that the SE-SHVC-BL scheme encrypts less than 7.5% of the SHVC video stream for all three scalability configurations.
Table 5.7. Video quality and ES analysis for QPEL = 22
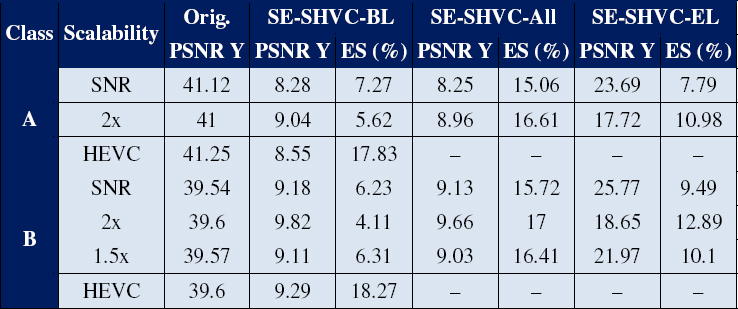
Figure 5.16 shows the visual quality of the ninth image from the BasketballDrive video, selectively encrypted using the SE-SHVC-BL and SE-SHVC-EL schemes.
Note, too, that the SE-SHVC-BL, in which only the BL is encrypted, also affects the quality of the enhancement layer EL. The reason for this is that inter-layer prediction, which is based on the decoded BL image and its motion vector, propagates errors to the EL layer. However, the SE-SHVC-EL scheme, in which only the EL is encrypted and the BL remains unchanged, has less of an impact on the quality of the EL image than the SE-SHVC-BL scheme. This is explained by the fact that most of the information is contained in the BL layer, while the EL layer only contains details.

Figure 5.16. Visual quality of image #9 from the BasketballDrive video sequences with SNR scalability configuration a) and b) SE-SHVC-BL, c) and d) SE-SHVC-EL
Table 5.8 shows the encryption quality EQ and the Hamming distance of the three coding schemes in different scalability configurations for the Traffic video sequence. The EQ is the average frequency difference between the bytes in the source and encrypted videos. The security level of the proposed schemes is assessed by calculating the HD between the original and coded images in the same sequence. The HD value between a source image P and an encrypted image C, which gives the probability of a bit change, should be close to 50% (Wang et al. 2014). In this case, a classic plain-text sensitivity attack becomes ineffective. The results shown in Table 5.8 demonstrate the robustness of the proposed selective encryption solution.
To evaluate the ROI-based secure coding solution introduced previously, seven other video sequences with different resolutions and temporal frequencies were considered, maintaining the same SHVC (Seregin and He 2013) test conditions. These videos were simultaneously compressed and encrypted using the Kvazaar encoder in an IPPP-type inter-coding configuration. The videos were coded using a uniform 4 × 4 tile distribution (i.e. four tiles wide, four tiles high), applying restrictions to the motion vector and preventing the use of in-loop filters across tile boundaries (as explained in section 5.3.4). The PSNR and SSIM values between the source and ROI-encrypted images are given in Table 5.9.
Table 5.8. Encryption quality for the Traffic sequence
| Schemes | EQ | HQ | ||
| 2x | SNR | 2x | SNR | |
| SE-SHVC-BL | 10,942 | 15,499 | 0.48 | 0.51 |
| SE-SHVC-All | 11,056 | 15,439 | 0.48 | 0.51 |
| SE-SHVC-EL | 2,880 | 1,561 | 0.37 | 0.32 |
Table 5.9. PSNR (dB) and SSIM between source and encrypted videos (QP = 22)
| Schemes | Unencrypted | ROI encryption | ||
| PSNR | SSIM | PSNR | SSIM | |
| PeopleOnStreet | 42.8 | 0.93 | 11.2 | 0.23 |
| Kimono | 42.2 | 0.96 | 9.9 | 0.22 |
| ParkScene | 43.3 | 0.91 | 10.7 | 0.20 |
| Cactus | 42.5 | 0.94 | 10.4 | 0.23 |
| BQTereeace | 41.8 | 0.90 | 10.8 | 0.24 |
| BasketballDrive | 41.5 | 0.96 | 10.1 | 0.23 |
| Vidyol | 45.2 | 0.92 | 11.3 | 0.21 |
We also note that, compared to a compressed but unencrypted image, the quality of the encrypted image is significantly lower. The average PSNR within the ROI remains below 11.4 dB for all of the encrypted sequences. Similarly, the mean SSIM values are under 0.24. These objective measurements show that the proposed schemes permit secure and adaptive ROI encryption.
Figure 5.17 shows videos that have been decoded and decrypted using the correct key, on the left, and without a key, on the right.

Figure 5.17. Image #9 from HEVC videos encrypted using the proposed scheme: a) correctly decrypted, b) encrypted
As we have seen, the proposed encryption method is format-compatible and does not increase encoding cost. However, in the specific case of ROI encoding, an average loss of 12% compression efficiency is observed. This is directly linked to the tiling operation, and to the restrictions preventing error propagation outside the ROI. The loss is therefore highly dependent on the tiling configuration.
5.4.2.2. Subjective verification of selective encryption
Subjective quality analyses are generally based on the Mean Opinion Score (MOS) for each video used in the test. This value is obtained using equation [5.1], where sijk is the score assigned by participant i for the degree of visibility j of sequence k and N is the number of observers:
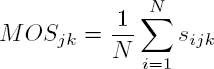
To obtain a better assessment of result compliance, a confidence interval, typically 95%, is associated with each MOS. This is given by equation [5.2]. Thus, scores must be contained in the interval [MOSjk − ICjk,MOSjk + ICjk] to respect the experimental conditions:
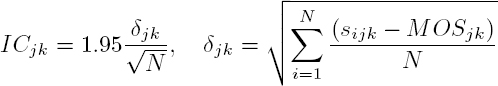
Before analyzing the data, we assessed the distribution of the scores given by each participant. The goal here is to eliminate observer scores that would be significantly inconsistent, and would therefore interfere with the results. We applied a filtering procedure based on the recommendations of the ITU-R (ITU-R 2012). Following this stage, two participants were rejected and 31 were retained.
The subjective scores assigned by participants, collected via a dedicated graphical interface, were then used to measure the perceptual quality of encrypted videos. Figure 5.18 shows the perceived degree of visibility (expressed by the MOS) of different selective encryption schemes and for different quantization levels with QP = 22, QP = 27 and QP = 32. It shows that the scores assigned by the subjects fall within a range from 3 (somewhat visible) down to 1 (completely invisible), depending on the chosen encryption scheme. This implies that visibility to a human observer is very significantly degraded when only the TC are encrypted. The score of 3 on the scale reflects a perceptual level of “somewhat visible”: the observer is able to recognize the overall context of the video (sports, movie, nature) without seeing its details. The same results were obtained by encrypting the sign bit of the transformed coefficients (TCs), with a slight variation in the MOS depending the video content and QP.
However, the results change completely for the final encryption scheme (All). In this case, observer scores varied from “barely visible” (2) to “completely invisible” (1). A score of 2 indicates that subjects are able to perceive some elements of the video, but without recognizing the context.
Figure 5.18 also shows that MOS values are highly dependent on video class (resolution). Thus, “BQSquare” (class E) is completely invisible with a MOS of ≃1 and very little variation as a function of QP. BasketballDrive, on the other hand, obtained high visibility scores for both TC and TCs, due to the strong motion component of this particular sequence. In this case, there is a very significant drop in perceptual level for the (All) configuration, notably when the motion vector is encrypted.

Figure 5.18. Subject visibility scores including a confidence interval of 95% for a) QP = 22, b) QP = 27 and c) QP = 32
5.4.2.3. A new encrypted video database
We recently developed a new public database of selectively encrypted HEVC videos alongside their subjective measures. The main characteristics are outlined below (Fezza et al. 2019a, 2019b).
5.4.2.3.1. Preparing the database
A total of seven original videos were selected: FourPeople, Pontoon, Crowd_run, Djoko, Voiles, Fallout4 and Pedestrian_area. These sequences provide a variety of content, including interior and exterior, with a wide range of color, texture and movement. Sequences are classified according to their spatial and temporal complexities, using spatial information (SI) and temporal information (TI) indicators (ITU-T 2008).
Each sequence has a 10 s duration, and different resolutions and temporal image rates were considered, as shown in Table 5.10. Two further sequences, BasketballDrive and GTAV, were used in the learning phase.
Table 5.10. Video sequences used in testing
| Name | Resolution | Images/second |
| Pontoon, Crowd_run, Djoko, Voiles | 1,920 x 1,080 | 50 |
| Fallout4 | 1,920 x 1,080 | 60 |
| FourPeople | 1,280 x 720 | 60 |
| Pedestrian_area | 1,920 x 1,080 | 25 |
The video sequences were encoded using the HEVC (HM) reference program. Four quantization levels were applied: ![]() We chose to use a Random Access (RA) coding configuration, given that neither low latency contexts nor ROI encryption will be considered in this case. A new syntax element encryption element, IPM, corresponding to intra-prediction mode, was used in addition to the four previous elements (TC, TCs, MV, MVs).
We chose to use a Random Access (RA) coding configuration, given that neither low latency contexts nor ROI encryption will be considered in this case. A new syntax element encryption element, IPM, corresponding to intra-prediction mode, was used in addition to the four previous elements (TC, TCs, MV, MVs).
Table 5.11 shows the different coding configurations as a function of encrypted syntax elements, with {·} indicating the set of elements taken into account.
The five encryption schemes were selected in order to cover a broad image quality spectrum, as shown in Figure 5.19. We thus have a total of 140 encrypted videos: 7 original sequences × 4 QP × 5 encryption schemes. We also have 28 compressed but non-encrypted video sequences (7 originals × 4 QP), included in the database as references, giving a grand total of 168 sequences.
5.4.2.3.2. Test environment and methodology
Tests were carried out in the psychovisual laboratory at the IETR, as before, in compliance with the ITU recommendations (ITU-R 2012; ITU-T 2008). A 75-inch 4K Sony Bravia X94C screen was used for display purposes.
Table 5.11. 5 encryption schemes with corresponding syntax elements
| Configurations | QP | Encrypted syntax elements |
| Config1 | 22, 27, 32, 37 | {IPM} |
| Config2 | 22, 27, 32, 37 | {TC} |
| Config3 | 22, 27, 32, 37 | {TC, TCs} |
| Config4 | 22, 27, 32, 37 | {IPM, MV, MVs} |
| Config5 (All) | 22, 27, 32, 37 | {IPM, TC, TCs, MV, MVs} |

Figure 5.19. Examples for the Pontoon video sequence with different levels of encryption
The scoring scale used here is that presented in section 5.4.1.3, ranging from 1, where the content is completely invisible, to 5, for perfectly visible. A single stimulus (SS) protocol, in which each sequence was presented individually without the reference, was used. Non-encrypted sequences were included in the test set for scoring alongside the other sequences. A total of 18 subjects (6 women, 12 men) participated in the test. Due to the number of sequences to view, each session was split into two parts so that each viewing period lasted no more than 20 min. MOS values were calculated for each sequence, after the definition of a confidence interval and elimination of incoherent results (of which there were no instances in this case).
5.4.3. CSE: a complete real-time solution
Alongside our work with MPEG on standardizing the specificities of ROI encryption, we worked with researchers at Tampere University of Technology, Finland, to develop a complete end-to-end standardized selective encryption solution (CSE, see section 5.3.3) based on tile configurations (Abu Taha et al. 2020).
The system relies entirely on open-source programs: as we see from Figure 5.20, HEVC compression was carried out using Kvazaar (Tampere University of Technology 2015), encapsulation using GPAC and decompression using OpenHEVC (IETR-INSA Rennes 2015). Encryption and selective decryption, which in this solution are based on the AES standard, were integrated into Kvazaar and OpenHEVC, respectively. The Siru SDR20 transceiver platform, which is scalable and at the heart of future developments in radio systems, was used for wireless transmission.

Figure 5.20. End-to-end encryption solution
Two examples of solutions developed for 4K TV content, in a secure production and transmission context with low latency and in a dense environment, will be presented below. In this case, there were two video streams to manage in parallel: A, for 4K video with wired transmission, and B, for encrypted HD video:
- – A: 4K video recorded by the 4K camera, encoded in real time by Kvazaar using a 22-core Xeon processor, sent over a wired IP connection, decoded and displayed by OpenHEVC on a portable computer.
- – B: HD video processed in the same way as for stream A, but with selective encryption performed at the encoding stage and with wireless transition over an SDR Siru connection. One portable computer was used for simultaneous decryption and decompression, displaying a high-quality video. A second computer was used for decompression without decryption, displaying correct content for non-protected zones alone (background).
Figure 5.21 shows a screenshot of decoded images at the end of the process. A 6 × 3 tile configuration was used in this case.

Figure 5.21. Encrypted and unencrypted HEVC tiles
5.5. Perspectives and directions for future research
Despite the high levels of effort dedicated to developing encryption and video encoding approaches in recent years, further work is still needed in many different areas. Some of these prospects will be explored below.
5.5.1. Versatile Video Coding
While the HEVC standard brought about significant improvements in terms of the development of new products and services, video is now being used in unprecedented ways, creating new needs. For example, applications are being developed to provide immersive, natural visualization experiences: these rely on very high resolutions (4K, 8K) to ensure a correct quality of service.
Furthermore, the use of video services is increasing exponentially with the proliferation of mobile components, leading to greater reliance on video in daily life, whether for social networking, video-on-demand, television, online gaming or e-learning.
In response to these new challenges, the Joint Video Expert Team (JVET) standardization group launched a new coding standard, applicable to both MPEG and ITU, in July 2020: this is Versatile Video Coding (VVC) (ITU-T 2020). VVC far exceeds HEVC in terms of performance, with an objective quality increase of around 35% (Schwarz et al. 2007; Alshina et al. 2016) and, more importantly, a subjective increase of 50% (Sidaty et al. 2017). This comes at the cost of a significant increase in complexity, with a ratio of around 10 at the coder level and of around 3 for the decoder.
The general principle of the codec remains a hybrid scheme: this new development is not a new or groundbreaking approach, and essentially consists of improving certain elements of the existing method. VVC is based on a reference program VTM, which integrates all of the basic building blocks of the codec.
New tools in the standard include (1) quadtree image coding, using a classic Quad-Tree Binary Tree or advanced Triple Tree approach (QTBT + TT); (2) advanced intra-prediction, with 67 modes; (3) improved inter prediction using affine motion estimation; (4) improved transforms, using Adaptive Multiple Transforms (AMT) and Non-Separable Secondary Transforms (NSST); (5) new filtering schemes in the form of Adaptive In-Loop Filters (ALF). Conversely, other functions have barely changed: for example, the entropy coding approach still relies on CABAC.
The adaptation of existing encryption schemes to a new standard such as VVC can, to a great extent, be based on existing concepts, although the specific characteristics of new elements must also be taken into account. We are in the final stages of adaptations to our own approach. Another interesting strategy could be to integrate selective encryption into the AV1 (Alliance for Open Media 2018) codec, developed by the Alliance for Open Media, which offers similar performance and presents similar characteristics to HEVC.
5.5.2. Immersive and omnidirectinal video
We are currently witnessing an upsurge in interest for immersive media technologies, such as virtual reality (VR), and omnidirectional video streaming. Omindirectional videos are spherical, panoramic videos, allowing spectators to view a scene from all directions (see Figure 5.22).
Full spherical coverage requires significantly higher resolutions than classic 2D content in order to meet consumer expectations.
The compression solutions used in these cases must facilitate both transmission and storage. One conventional method is to project 360◦ images onto a 2D support (typically with 8K resolution) before applying a classic codec. Unfortunately, the projection phase creates sampling problems and results in distortions. A more sophisticated approach is to take account of the intrinsic spherical nature of omnidirectional content within the definition of coding schemes. Several techniques have been proposed, aiming to improve compression efficiency by taking account of geometric representations (Li et al. 2016) or the spherical nature of visual content (Simone et al. 2016), or via the use of adaptive distribution methods (Hosseini and Swaminathan 2016).

Figure 5.22. Immersive application using a VR headset
Incorporating geometric representations within encryption schemes may offer the means of obtaining private, secure omnidirectional HEVC videos, with reduced complexity for the decryption phase.
5.6. Conclusion
In this chapter, we have presented different ways of protecting compressed videos, explaining the different terminologies used in the state of the art over the past two decades. We chose to focus on selective encryption methods, combining different advantages which are, in our view, essential: namely, selective encryption of parts of information to avoid excessive use of the cryptographic system and visual encryption, which we have shown to be relevant for a variety of video applications.
The video crypto-compression methods presented here respect compression rates (preserving the efficiency of compression models), maintain visual confidentiality (as demonstrated in this chapter) and offer robust resistance to cryptanalysis attacks. The methods that we have presented and proposed for visual privacy evaluation make it possible to design perceptual encryption systems with different levels of visual security, adapted to the specific needs of the user. The availability of multiple levels of degradation (and thus of confidentiality) opens up new and interesting perspectives for application, notably with respect to anonymization in the context of video surveillance.
Standardization within MPEG highlights the interest of this solution and shows promise in terms of use in the near future. Furthermore, the standard allows images in HEIF format to be protected in the same way: this format has come to replace JPEG in some contexts, notably for Apple devices. The advent of the new H.266/VVC codec (ISO/IEC MPEG I Part 3) also offers interesting perspectives for future investigation in the field of selective encryption: as we have shown in this chapter, the CSE methods presented here may be adapted and applied theoretically to any video or image codec.
5.7. References
Abu Taha, M., Hamidouche, W., Sidaty, N., Viitanen, M., Vanne, J., El Assad, S., Deforges, O. (2020). Privacy protection in real time HEVC standard using chaotic system. Cryptography, 4(2), 18.
Ahmed, H.E.H., Kalash, H.M., Allah, O.S.F. (2007). Encryption efficiency analysis and security evaluation of RC6 block cipher for digital images. In International Conference on Electrical Engineering. IEEE, Lahore.
Alliance for Open Media (2018). Press release – Videolan joins the alliance for open media. VideoLAN [Online]. Available at: https://www.videolan.org/press/aomedia.html.
Alshina, E., Alshin, A., Choi, K., Park, M. (2016). Performance of JEM 1 tools analysis. 2nd JVET Meeting. San Diego.
Asghar, M., Ghanbari, M., Fleury, M., Reed, M.J. (2014). Confidentiality of a selectively encrypted H.264 coded video bit-stream. Journal of Visual Communication and Image Representation, 25(2), 487–498.
Autrusseau, F., Stuetz, T., Pankajakshan, V. (2010). Subjective quality assessment of selective encryption techniques [Online]. Available at: http://www.irccyn.ecnantes.fr/ãutrusse/Databases.
Bergeron, C. (2007). Optimisation conjointe source/canal d’une transmission vidéo H.264/AVC sur un lien sans fil. PhD Thesis, Télécom ParisTech [Online]. Available at: https://pastel.archives-ouvertes.fr/pastel-00004234/file/these_final_bergeron.pdf.
Bergeron, C. and Lamy-Bergot, C. (2004). Soft-input decoding of variable-length codes applied to the H.264 standard. In 6th Workshop on Multimedia Signal Processing. IEEE, Siena.
Bergeron, C. and Lamy-Bergot, C. (2005). Compliant selective encryption for H.264/AVC video streams. In 7th Workshop on MMSP. IEEE, Shanghai.
Bergeron, C., Sidaty, N., Hamidouche, W., Boyadjis, B., Feuvre, J.L., Lim, Y. (2017). Real-time selective encryption solution based on ROI for MPEG – A visual identity management AF. In 2017 22nd International Conference on Digital Signal Processing. IEEE, London.
Bergeron, C., Hamidouche, W., Feuvre, J.L., Boyadjis, B. (2018). Content sensitive encryption: Decryption challenge [Online]. Available at: http://open-hevc.insa-rennes.fr/press-release/avc-and-hevc-selective-video-encryption-decryption-challenge/.
Boyadjis, B., Perrin, M.-E., Bergeron, C., Lecomte, S. (2014). A real-time ciphering transcoder for H.264 and HEVC streams. In International Conference on Image Processing (ICIP). IEEE, Paris.
Boyadjis, B., Bergeron, C., Lecomte, S. (2015). Auto-synchronized selective encryption of video contents for an improved transmission robustness over errorprone channels. In International Conference on Image Processing (ICIP). IEEE, Quebec.
Boyadjis, B., Bergeron, C., Pesquet-Popescu, B., Dufaux, F. (2017). Extended selective encryption of H.264/AVC (CABAC) and HEVC-encoded video streams. IEEE Transactions on Circuits and Systems for Video Technology, 27(4), 892–906.
Boyce, J.M., Ye, Y., Chen, J., Ramasubramonian, A.K. (2016). Overview of SHVC: Scalable extensions of the high efficiency video coding standard. IEEE Transactions on Circuits and Systems for Video Technology, 26(1), 20–34.
Cisco (2017). Cisco visual networking index: Forecast and methodology, 2016–2021. White paper, Cisco.
Dufaux, F. and Ebrahimi, T. (2008). Scrambling for privacy protection in video surveillance systems. IEEE Transactions on Circuits and Systems for Video Technology, 18(8), 1168–1174.
Farajallah, M., Hamidouche, W., Déforges, O., El Assad, S. (2015). ROI encryption for the HEVC coded video contents. In International Conference on Image Processing (ICIP). IEEE, Quebec.
Fezza, S.A., Hamidouche, W., Kamraoui, R.A., Déforges, O. (2019a). Encrypted HEVC videos database and MOS values [Online]. Available at: https://sites.google.com/view/ietr-selectvidencrypt-database.
Fezza, S.A., Hamidouche, W., Kamraoui, R.A., Déforges, O. (2019b). Visual security assessment of selective video encryption. In Eleventh International Conference on Quality of Multimedia Experience. QoMEX, Berlin.
Gueron, S. and Krasnov, V. (2014). Speeding up counter mode in software and hardware. In Eleventh International Conference on Information Technology: New Generations. ITNG, Las Vegas.
Hamidouche, W., Farajallah, M., Raulet, M., Déforges, O., El Assad, S. (2015). Selective video encryption using chaotic system in the SHVC extension. In International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, Brisbane.
Hofbauer, H. and Uhl, A. (2010). Visual quality indices and low quality images. In European Workshop on Visual Information Processing. EUVIP, Paris.
Hofbauer, H. and Uhl, A. (2016). Identifying deficits of visual security metrics for images. Signal Processing: Image Communication, 46(2), 60–75.
Hosseini, M. and Swaminathan, V. (2016). Adaptive 360 VR video streaming: Divide and conquer! In IEEE International Symposium on Multimedia (ISM). IEEE, San Jose.
Hu, Y., Zhou, W., Zhao, S., Chen, Z., Li, W. (2018). SDM: Semantic distortion measurement for video encryption. In International Conference on Automatic Face Gesture Recognition. IEEE, Xi’an.
IETR-INSA Rennes (2015). OpenHEVC decoder, LGPLv3 [Online]. Available at: https://github.com/OpenHEVC/openHEVC.
Isa, H., Bahari, I., Sufian, H., Z’aba, M.R. (2011). AES: Current security and efficiency analysis of its alternatives. In 7th International Conference on Information Assurance and Security (IAS). IEEE, Malacca.
ISO/IEC 14496-12 (2012). ISOBMFF ISO base media file format. ISO/IEC JTC1/SC29/WG11 (MPEG). Tokyo.
ISO/IEC 23000-21 (2019). VIMAF Visual Identity Management Application Format. ISO/IEC JTC1/SC29/WG11 (MPEG). Tokyo.
ISO/IEC 23001-7 (2016). Common encryption in ISO base media file format files. ISO/IEC JTC1/SC29/WG11 (MPEG). Tokyo.
ISO/IEC 23001-9 (2016). Common encryption of MPEG-2 transport streams. ISO/IEC JTC1/SC29/WG11 (MPEG). Tokyo.
ISO/IEC 23008-12 (2017). HEIF High Efficiency Image File Format. ISO/IEC JTC1/SC29/WG11 (MPEG), Tokyo.
ITU-R (2012). Methodology for the subjective assessment of the quality of television picture. Recommendation, ITU-R, Geneva.
ITU-T (2004). AVC Advanced Video Coding standard. Recommendation, ITU-T, Geneva.
ITU-T (2008). Subjective video quality assessment methods for multimedia applications. Recommendation, ITU-T, Geneva.
ITU-T (2013). HEVC High Efficiency Video Coding standard. Recommendation, ITU-T, Geneva.
ITU-T (2020). VVC Versatile Video Coding standard. Recommendation, ITU-T, Geneva.
Jagadeesh, P., Nagabhushan, P., Pradeep Kumar, R. (2013). A novel perceptual image encryption scheme using geometric objects based kernel. International Journal of Computer Science and Information Technology, 5, 165–173.
Jolly, S. and Vikas, S. (2011). Video encryption: A survey. International Journal of Computer Science, 8(2), 525–534.
Kerckhoffs, A. (1883). La cryptographie militaire. Journal des sciences militaires, IX, 5–38, 161–191.
Le Philippe, N., Itier, V., Puech, W. (2017). Visual saliency-based confidentiality metric for selective crypto-compressed JPEG images. In International Conference on Image Processing (ICIP). IEEE, Beijing.
Li, J., Wen, Z., Li, S., Zhao, Y., Guo, B., Wen, J. (2016). Novel tile segmentation scheme for omnidirectional video. In International Conference on Image Processing (ICIP). IEEE, Phoenix.
Lian, S., Sun, J., Wang, Z. (2004). Perceptual cryptography on SPIHT compressed images or videos. In International Conference on Multimedia and Expo. IEEE, Taipei.
Lian, S., Liu, Z., Ren, Z., Wang, H. (2006). Secure advanced video coding based on selective encryption algorithms. IEEE Transactions on Consumer Electronics, 52(2), 621–629.
Liu, F. and Koenig, H. (2010). A survey of video encryption algorithms. Computers & Security, 29(1), 3–15.
Liu, G., Ikenaga, T., Goto, S., Baba, T. (2006). A selective video encryption scheme for MPEG compression standard. IEICE Transactions on Fundamentals of Electronics, Communications and Computer, E89-A(1), 194–202.
Liu, Z., Li, S., Liu, W., Wang, Y., Liu, S. (2013). Image encryption algorithm by using fractional Fourier transform and pixel scrambling operation based on double random phase encoding. Optics and Lasers in Engineering, 51(1), 8–14.
Mao, Y. and Wu, M. (2004). Security evaluation for communication-friendly encryption of multimedia. In International Conference Image Processing. IEEE, Singapore.
Mittal, A., Soundararajan, R., Bovik, A.C. (2013). Making a completely blind image quality analyzer. IEEE Signal Process. Letters, 20(3), 209–212.
Peng, F., Zhu, X.-W., Long, M. (2013). An ROI privacy protection scheme for H.264 video based on FMO and chaos. IEEE Transactions on Information Forensics and Security, 8(10), 1688–1699.
Podesser, M., Schmidt, H.P., Uhl, A. (2002). Selective bitplane encryption for secure transmission of image data in mobile environments. In 5th Nordic Signal Processing Symposium on Mobile Environments. Hurtigruta, Tromsø-Trondheim.
Reza, T.A. and Barbeau, M. (2012). QoS aware adaptive security scheme for video streaming. In International Symposium on Foundations and Practice of Security. FPS, Montreal.
Sabeva, G., Jamaa, S.B., Kieffer, M., Duhamel, P. (2006). Robust decoding of H.264 encoded video transmitted over wireless channels. In Workshop on Multimedia Signal Processing. IEEE, Victoria.
Schwarz, H., Marpe, D., Wiegand, T. (2007). Overview of the scalable video coding extension of the H.264/AVC standard. IEEE Transactions on Circuits and Systems for Video Technology, 17, 1103–1120.
Seregin, V. and He, Y. (2013). Common SHM test conditions and software reference configurations. Document, JCTVC, Geneva.
Shahid, Z. and Puech, W. (2014). Visual protection of HEVC video by selective encryption of CABAC binstrings. IEEE Transactions on Multimedia, 16(1), 24–36.
Shahid, Z., Chaumont, M., Puech, W. (2009). Selective and scalable encryption of enhancement layers for dyadic scalable H.264/AVC by scrambling of scan patterns. In International Conference on Image Processing. IEEE, Cairo.
Shahid, Z., Chaumont, M., Puech, W. (2011). Fast protection of H.264/AVC by selective encryption of CAVLC and CABAC for I&P frames. IEEE Transactions on Circuits and Systems for Video Technology, 21(5), 565–576.
Shannon, C.E. (1949). Communication theory of secrecy systems. Bell System Technical Journal, 28(4), 656–715.
Shi, C., Wang, S.-Y., Bhargava, B. (1999). MPEG video encryption in real-time using secret key cryptography. In International Conference on Parallel and Distributed Processing Techniques and Applications. PDPTA, Las Vegas.
Sidaty, N., Hamidouche, W., Déforges, O., Philippe, P. (2017). Compression efficiency of the emerging video coding tools. In International Conference on Image Processing (ICIP). IEEE, Beijing.
Simone, F.D., Frossard, P., Wilkins, P., Birkbeck, N., Kokaram, A. (2016). Geometry-driven quantization for omnidirectional image coding. In Picture Coding Symposium (PCS). IEEE, Nuremberg.
Stutz, T. and Uhl, A. (2012). A survey of H.264 AVC/SVC encryption. IEEE Transactions on Circuits and Systems for Video Technology, 22(3), 325–339.
Sullivan, G.J., Ohm, J.-R., Han, W.-J., Wiegand, T. (2012). Overview of the High Efficiency Video Coding (HEVC) standard. IEEE Transactions on Circuits and Systems for Video Technology, 22(12), 1649–1668.
Sun, J., Xu, Z., Liu, J., Yao, Y. (2011). An objective visual security assessment for cipher-images based on local entropy. Multimedia Tools Appl., 53, 75–95.
Tampere University of Technology (2015). Kvazaar HEVC encoder, LGPLv2.1 [Online]. Available at: https://github.com/ultravideo/kvazaar.
Tang, L. (1997). Methods for encrypting and decrypting MPEG video data efficiently. In Fourth ACM International Conference on Multimedia. ACM, Boston.
Tawalbeh, L.A., Mowafi, M., Aljoby, W. (2013). Use of elliptic curve cryptography for multimedia encryption. IET Information Security, 7(2), 67–74.
Telecom ParisTech (2008). GPAC, GPAC Licensing [Online]. Available at: https://github.com/gpac/gpac.
Van Wallendael, G., Boho, A., De Cock, J., Munteanu, A., Van de Walle, R. (2013a). Encryption for high efficiency video coding with video adaptation capabilities. IEEE Transactions on Consumer Electronics, 59(3), 634–642.
Van Wallendael, G., De Cock, J., Van Leuven, S., Boho, A., Lambert, P., Preneel, B., Van de Walle, R. (2013b). Format-compliant encryption techniques for high efficiency video coding. In International Conference on Image Processing (ICIP). IEEE, Melbourne.
Viitanen, M., Koivula, A., Lemmetti, A., Vanne, J., Hamalainen, T.D. (2015). Kvazaar HEVC encoder for efficient intra coding. In International Symposium on Circuits and Systems (ISCAS). IEEE, Lisbon.
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P. (2004). Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4), 600–612.
Wang, X., Luan, D., Bao, X. (2014). Cryptanalysis of an image encryption algorithm using Chebyshev generator. Digital Signal Processing, 25, 244–247.
Wen, J., Severa, M., Zeng, W., Luttrell, M., Jin, W. (2002). A format-compliant configurable encryption framework for access control of video. IEEE Transactions on Circuits and Systems for Video Technology, 12, 545–557.
Weng, L. and Preneel, B. (2007). On encryption and authentication of the DC DCT coefficient. In International Conference on Signal Processing and Multimedia Applications. INSTICC, Barcelona.
Wu, C.-P. and Kuo, C.-C. (2005). Design of integrated multimedia compression and encryption system. IEEE Transactions on Multimedia, 7(5), 828–839.
Xiang, T., Guo, S., Li, X. (2016). Perceptual visual security index based on edge and texture similarities. IEEE Transactions on Information Forensics and Security, 11(5), 951–963.
Yao, Y., Xu, Z., Li, W. (2008). Visual security assessment for video encryption. In Third International Conference on Communications and Networking in China. Chinacom, Hangzhou.
Ye, G. (2010). Image scrambling encryption algorithm of pixel bit based on chaos map. Pattern Recognition Letters, 31(5), 347–354.
Zeng, W. and Lei, S. (1999). Efficient frequency domain video scrambling for content access control. In International Conference on Multimedia. ACM, Orlando.
- 1 According to the Cisco Visual Networking Index (VNI), video content is expected to account for 82% of all consumer Internet traffic in 2021 (Cisco 2017).
- 2 Available at: http://openhevc.insa-rennes.fr/press-release/avc-and-hevc-selective-video-encryption-decryption-challenge/.