
6
Processing Encrypted Multimedia Data Using Homomorphic Encryption
Sébastien CANARD1, Sergiu CARPOV2, Caroline FONTAINE3 and Renaud SIRDEY4
1Orange Labs, Applied Crypto Group, Caen, France
2Inpher, Lausanne, Switzerland
3LMF, ENS Paris-Saclay, University of Paris-Saclay, CNRS, Gif-sur-Yvette, France
4CEA, LIST, University of Paris-Saclay, Gif-sur-Yvette, France
In this chapter, we present the state of the art in homomorphic encryption techniques, which make it possible to process encrypted data. These techniques are very costly, but impressive progress has been made in recent years; experiments have already been carried out for industrial applications, including in the multimedia field. We shall present the results of some of these experiments, along with the theoretical background needed to understand their development.
6.1. Context
This chapter concerns encryption techniques in the cryptographic sense of the term, that is, techniques designed to ensure the confidentiality of data in general, regardless of its nature. We consider the data to be protected as bits, bit vectors or numbers. These data are first encoded in an alphabet or a suitable mathematical structure, depending on the chosen encryption technique.
Encryption techniques have been used since ancient times; their general development will not be discussed here. In this chapter, we shall focus on homomorphic techniques, in which operations performed on encrypted data are also performed, indirectly, on the underlying clear data. The result of the operation performed on the encrypted data remains encrypted, and is decryptable only by the holder of the private decryption key sk, who is thus the only person with access to the result of the computation in clear. For example, to move the computation of a function P(x1, x2), the client may encrypt sensitive data x1 and x2 locally using the public encryption key1 pk, and provide the server with the encrypted values HomEnc(x1) and HomEnc(x2). The server then evaluates a function fP (HomEnc(x1), HomEnc(x2)) such that, when the resulting encrypted value is transmitted to the client, it can be decrypted to obtain HomDec(fP (HomEnc(x1), HomEnc(x2))) = P(x1, x2). This capability opens up numerous perspectives for applications, as shown in Figure 6.1. For example, in the context of cloud computing, this approach reconciles the interests of both service providers and users (in the broadest sense: ordinary individuals, companies or even public authorities). Users can encrypt their data before transmitting it to service providers, meaning that the latter can process these data without ever accessing the clear text, eliminating any risk of data leaks.
This secure computation paradigm first appeared in the late 1970s, in a famous paper published by Rivest et al. (1978). In this paper, the authors defined and studied the applicative potential of a new notion of private homomorphism, conjecturing the existence of cryptosystems that would be malleable, but still offer a sufficient level of security2.
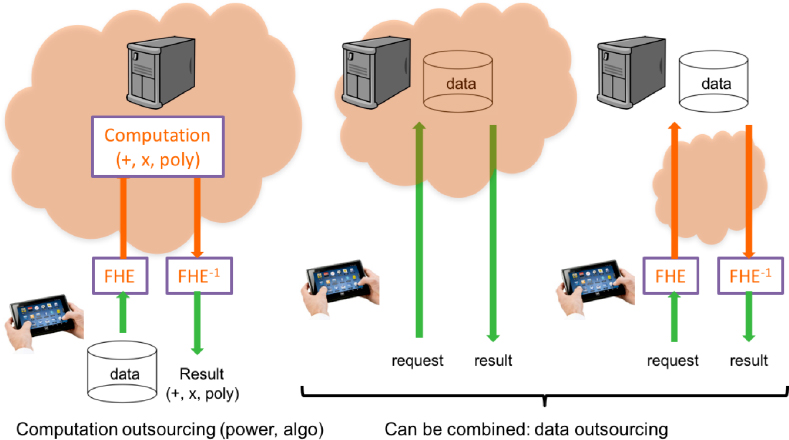
Figure 6.1. Typical usage scenarios for homomorphic encryption techniques. Data can be processed by the service provider without access to the clear information. The result is also encrypted, and it can only be decrypted by individuals with the appropriate key. Clear data are shown in green, with encrypted data in orange
In other words, the authors conjectured the existence of cryptosystems that would allow general computations to be performed directly on encrypted data without weakening them excessively from a security point of view. This idea remained purely theoretical for several years; the homomorphic properties (limited to one operation) of several famous cryptosystems, such as ElGamal or Goldwasser-Micali, were noted but tolerated, since the degree of malleability was considered acceptable in terms of security.
Important developments were made in this area in the late 1990s, driven by the wave of enthusiasm that followed the publication of Paillier’s cryptosystem (Paillier 1999). Besides offering high levels of performance, the Paillier cryptosystem stood out due to the fact that additions, and multiplications by a public integer, could be performed in the encrypted domain. It thus became possible to apply any linear (public) operator directly to encrypted data at reasonable computational cost. This possibility rapidly gave rise to new fields of applied research exploiting the properties of homomorphic encryption. An important step was reached in 2005 with the publication of the BGN scheme by Boneh et al. (2005), followed, in 2008–2010, by important publications by Aguilar-Melchor et al. (2008, 2010) and Gentry (2009). These authors demonstrated the possibility of performing both addition and multiplication with the same system, paving the way for applications involving polynomial computations on encrypted data. As we will see in this chapter, schemes of this type are costly to implement, but sufficient progress has been made in recent years so that applicative proofs of the concept are now available. Subsequent schemes are expensive, but the progress made since then is such that the first applicative proofs of concept have already emerged.
The aim of this chapter is to present the current state of the art of these techniques, which show great promise in terms of long-term applications. Research in this field is extremely dynamic, and each year sees the introduction of new techniques and significant improvements. This state of the art will continue to evolve. Nevertheless, we shall describe a number of component elements that will remain relevant and essential, even in new, as-yet unpublished systems. The practical use of homomorphic systems raises a number of questions. Our objective is threefold: (1) to present the current state of the art in a synthetic manner (section 6.2); (2) to provide points of reference relating to these questions and the choices that must be made with respect to their practical implementation (section 6.3), and finally (3) to present current experimental results demonstrating the real applicative potential of these systems (section 6.4).
6.2. Different classes of homomorphic encryption systems
As we saw briefly in section 6.1, there are several different classes of homomorphic encryption systems. In this section, we shall describe a selection of the most widespread examples, used in the experiments presented later. First, it is important to note that all of these schemes result in an increase in data size: encrypted data are larger than clear data. This is due to the fact that, for security reasons, these schemes are all probabilistic (the same clear data element can correspond to several encrypted elements, but evidently these encrypted elements are all decrypted in the same way). In other terms, these approaches introduce noise into encrypted messages. Further details concerning the security aspect are given in section 6.3.4.
6.2.1. Partial solutions in classic cryptography
The oldest homomorphic encryption techniques permit either addition or multiplication, but it is not possible to combine these operations. The best-known examples are Paillier’s scheme (Paillier 1999) for additions, and ElGamal’s scheme (ElGamal 1985) for multiplications3. For more details on versions of these classic, single-operation schemes, see Fontaine and Galand (2007).
The first scheme to allow a combination of an arbitrary number of additions and a single multiplication operation was BGN, published in Boneh et al. (2005), based on pairing techniques.
Catalano and Fiore (2015) proposed an iterative construction approach that can be applied to this kind of scheme to permit an additional level of multiplication. The Paillier cryptosystem, for example, can thus be extended to evaluate quadratic functions. It is important to note, however, that this construction induces a higher cost for additions of second-degree monomials than for additions of first-degree monomials.
Although the use of this technique is not without effects in terms of performance, it enables the calculation of classic distances, such as Hamming, Euclidean or Mahalanobis distances, in the context of clear versus encrypted vectors. Note that these distances can also be evaluated with an additive system, but this results in a quadratic increase of the communication cost. The expression to evaluate is linear in xxT (the tensor product of the encrypted vector with itself). These remarks are important in the sense that many applications of homomorphic encryption involve evaluating distances. Catalano and Fiore’s technique was also used in Herbert et al. (2019) to construct a scheme allowing an arbitrary number of additions and two levels of multiplications, thus permitting the evaluation of fourth-degree polynomials.
These schemes are sufficient for certain applications, and their security properties are clearly understood since they rely on well-known mathematical problems. However, they lack flexibility, insofar as an application cannot be adjusted after implementation to take the calculations of unexpected complexity into account. Moreover, they are potentially vulnerable to attacks using the computing capabilities of quantum computers.
We shall now provide a brief overview of Paillier’s cryptosystem (Paillier 1999), which will be used in some of the examples of applications presented in this chapter. Let p and q be two large prime numbers and n = pq. The clear domain of the Paillier cryptosystem is the ring of integers modulo ![]() and its encrypted domain is the ring of integers modulo
and its encrypted domain is the ring of integers modulo ![]() Values
Values ![]() must also be selected such that:
must also be selected such that:
The (public) encryption key is then given by n and g. The (private) decryption key is formed from p and q or the equivalent λ.
The encryption function corresponds to:
where m < n is the message and r is uniformly drawn from ![]()
Taking D = L(gλ mod n2) and D−1 as its multiplicative inverse in ![]() the decryption function requires us to evaluate:
the decryption function requires us to evaluate:
This cryptosystem has the following homomorphic properties:
- 1) HomDec(HomEnc(m1) · HomEnc(m2) mod n2) = m1 + m2 mod n (addition of two encrypted messages);
- 2) HomDec(HomEnc(m) · gk mod n2) = m + k mod n, for
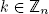 (addition of a clear integer to an encrypted message);
(addition of a clear integer to an encrypted message); - 3) HomDec(HomEnc(m)k mod n2) = km mod n, for
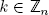 (multiplication of an encrypted message by a clear integer).
(multiplication of an encrypted message by a clear integer).
In terms of concrete dimensioning, using a 2048 bit modulus provides relatively good medium-term security (for example, the RGS ANSSI4 recommends this as the minimum modulus length for confidentiality requirements up to 2030).
6.2.2. Complete solutions in cryptography using Euclidean networks
Gentry (2009) proposed the first credible construction of a fully homomorphic encryption system in terms of security and (theoretical) efficiency. Gentry drew on previous work, notably Aguilar-Melchor et al. (2008, 2010) and Boneh et al. (2005); his main contribution lies in the development of a de-noising technique, bootstrapping, which essentially consists of performing a reencryption operation in a homomorphic way (i.e. the homomorphic equivalent of decryption followed by a re-encryption, without the data ever appearing in the clear during the operation). Encrypted elements contain a certain amount of noise due to the probabilistic aspect of encryption, and the application of operations to these elements increases the amount of noise in the resulting encrypted message. If measures are not taken to control the noise and it exceeds a certain threshold, then decryption will no longer operate correctly and it will be impossible to retrieve the original message. Gentry used bootstrapping to control this noise, thus extending the limits of homomorphic encryption much further than previously imagined. In theory, this technique means that polynomials of any degree can be evaluated; in practice, however, the computation and storage/transmission costs remain prohibitive.
Considerable developments have occurred in the intervening period. Current solutions permit the evaluation of general polynomials of higher degrees than in the early examples cited above, allowing for more complex applications. All of these solutions are based on the mathematical structure of Euclidean networks, and offer the advantage of post-quantum security, that is, resistance to known cryptanalysis attacks using quantum computers. This is a significant advantage, but, in the context of homomorphic encryption, comes at the cost of a large increase in encrypted file size, high computational cost and, for now, difficulties in the accurate derivation of security parameters. Nevertheless, the progress made in this field in recent years is impressive, and there is no doubt that future developments will enable more and more practical applications.
In this chapter, a distinction shall be made between two main families of schemes: somewhat homomorphic encryption (SHE) and fully homomorphic encryption (FHE). These will be presented from the simplest/fastest/cheapest/most limited to the most complex/slowest/most costly/most flexible.
6.2.2.1. Fixed or leveled SHE schemes
SHE schemes can only evaluate polynomials of a limited degree; this limit is fixed and cannot be parameterized. They are relatively cheap in terms of time and memory, but are not flexible. These solutions offer a broader range of potential applications than Paillier’s system, for example, but are more costly than the earlier system and present a similar level of rigidity.
Leveled SHE schemes are an alternative that may be used to evaluate a polynomial of limited degree; the upper bound of the degree can be chosen, but must be defined before the application is implemented.
These schemes are more flexible than fixed SHEs; applications may evolve following the initial implementation, as long as the degree of polynomials to evaluate remains below the predefined threshold.
Many examples of this type exist, and while the field was initially subject to much confusion, matters are now much clearer. There are three schemes which appear to be gaining in popularity: BFV (Fan and Vercauteren 2012), CKKS (Cheon et al. 2017, 2018) and TFHE (Chillotti et al. 2016, 2017, 2020). Only the first of these examples will be described in detail here, based on the fact that this approach is the simplest to explain.
BFV is a leveled, almost FHE scheme developed by Fan and Vercauteren (2012), drawing on Brakerski’s initial SHE scheme (Brakerski 2012). Further details can be found in the corresponding articles.
Let q and t be two security parameters (q for key size and t for message size) and let Δ = [q/t]. A distribution χ over the ring R of polynomials is required. The secret key s is an element in ![]() . The associated public key requires that we first select an element a from the polynomial ring with a value in
. The associated public key requires that we first select an element a from the polynomial ring with a value in ![]() and an element e selected according to the distribution χ, before calculating A = [–(as.e)]q. The couple (A, a) is used as the public key to encrypt a message m. More precisely, for a message in the ring of polynomials with values in
and an element e selected according to the distribution χ, before calculating A = [–(as.e)]q. The couple (A, a) is used as the public key to encrypt a message m. More precisely, for a message in the ring of polynomials with values in ![]() , this encryption process involves the following steps:
, this encryption process involves the following steps:
- – take u uniformly from the ring of polynomials with values in
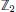 , and take e1, e2 according to the distribution χ;
, and take e1, e2 according to the distribution χ; - – calculate
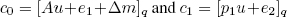 and generate the encrypted value c = (c0, c1).
and generate the encrypted value c = (c0, c1).
Decryption is then carried out by calculating:
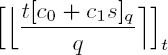
This scheme possesses the two necessary homomorphic properties:
- – addition: by simply adding two encrypted values
 with messages m and
with messages m and  respectively, component by component, we obtain a new encrypted value
respectively, component by component, we obtain a new encrypted value 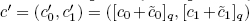 corresponding to the encrypted value of
corresponding to the encrypted value of 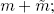
- – multiplication: this operation is more complicated. Given two encrypted values
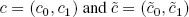 of messages m and
of messages m and 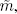 respectively, we can calculate:
respectively, we can calculate:
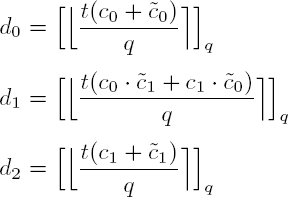
However, in this format, the output is not compatible with a new multiplication operation. A relinearization method must then be applied in order to obtain an encrypted value in the initial form, enabling further multiplications in the encrypted domain. This step involves the generation of a relinearization key (k0, k1) and the following formulas (where the values d2[i] correspond to the components of d2 in a base T associated with relinearization):
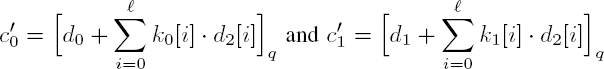
The encrypted message ![]() then corresponds to an encryption of
then corresponds to an encryption of ![]()
6.2.2.2. FHE schemes
FHE schemes have the capacity, in the strict sense, to evaluate polynomials of any degree (to an extent which is limited by computation time constraints and the factors of expansion accepted by the target application). A major advantage of these approaches is that the degree of polynomials does not need to be bounded prior to programming and implementation; however, this flexibility comes at a cost, in terms of both time and memory.
Many leveled approaches can be transformed into FHE approaches using the bootstrapping technique introduced by Gentry (2009), which we shall not describe in detail here. One notable example is the BFV approach presented above. This bootstrapping approach is costly, but a number of techniques have been developed to reduce its impact.
6.3. From theory to practice
Now, let us consider the practical implementation of these schemes. The first step is to consider the representation of the processing or calculation to apply to the data. From a programming perspective, this is coded at a more or less high level (such as C or C++); however, in this case, we shall consider representations in the form of Boolean or arithmetic circuits, depending on the required level of granularity. The case of a Boolean circuit is illustrated in Figure 6.2, but the same process may be transposed to an arithmetic circuit. Consider the normal circuit used to process plaintext data. This same circuit is then transformed by replacing the AND, XOR and NOT gates by their counterparts f× and f+ (the NOT gate is replaced by an addition of a plaintext value 1), so that the associated computations can be applied to the encrypted values. Using versions of the original data encrypted using the homomorphic scheme as input, the circuit then provides the results of the calculation in a form which is also encrypted by the homomorphic scheme.
There are several questions to address here, many of which are not easy to answer, particularly in light of constant developments in the state of the art and in practical implementations of these schemes. Some authors have proposed comparisons of the most promising schemes, but extracting generic rules which remain stable over time has proven difficult; in practice, method choice is generally guided by the constraints of the target applications. Nevertheless, in this section, we shall propose a number of elements that may guide developers in selecting appropriate solutions for use in applications drawing on this technology.
- – Choosing a scheme: this choice may be influenced by the available libraries, the degree of polynomials to evaluate, potential evolutions (flexibility: is the calculation likely to evolve over time?), the way in which the characteristics of the scheme correspond to the target application, and the desired security level (post-quantum or otherwise).
- – Choice of parameters: this question is tricky, as it has a significant bearing on both security and flexibility (dimensions of the circuit to evaluate), and has a major impact on cost in terms of space and time.
- – Encoding information: the choice of an encoding approach is linked to the chosen scheme, which imposes a specific algebraic structure. The choice of scheme may be guided by the chosen encoding approach, or vice-versa, depending on the constraints associated with the data. Furthermore, several data elements may be grouped into a single structure in order to process them in one go (parallel processing).
- – Limiting costs in terms of time and space: time and cost savings can be made by carefully choosing the circuit to evaluate, by hybridization with standard encryption approaches, selecting appropriate parameters and hardware and software acceleration (parallelization).
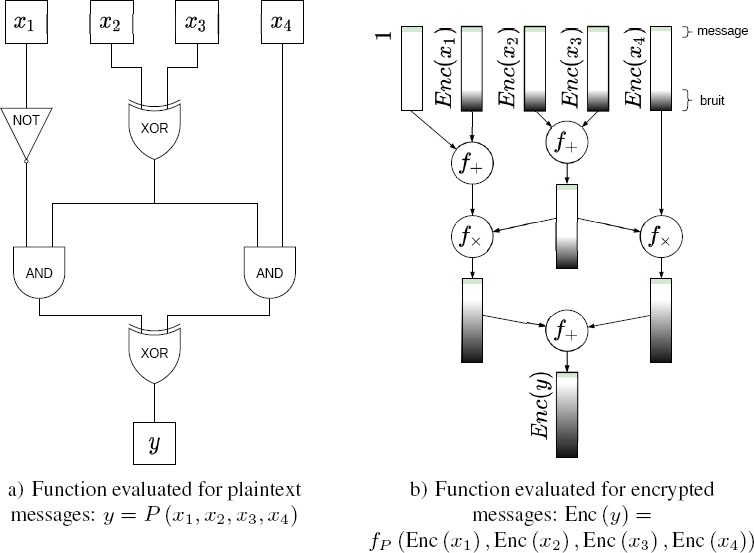
Figure 6.2. Computation expressed for plaintext data in the form of a circuit (Boolean)
COMMENT ON FIGURE 6.2.– The same circuit is used for calculations on encrypted data, replacing the AND and XOR gates with ad hoc operators as a function of the chosen encryption scheme. The result obtained in this way is encrypted, and can only be decrypted using the appropriate key. For simplicity’s sake, the notation Enc() is used here, replacing the more explicit HomEnc() used elsewhere in this chapter.
6.3.1. Algorithmics
In developing an application, the classic approach is to choose the algorithm with the lowest possible complexity to solve each problem. The average complexity value is usually considered. However, in our case, even if the application has branching conditions depending on certain data elements, the underlying circuit that will be evaluated in homomorphism will be evaluated in its entirety; in other words, all branches will be evaluated, whatever the data. This is essential for privacy reasons, and implies that the worst-case complexity measure always applies. Thus, algorithms must be chosen with a view to minimizing the worst case, rather than average, complexity.
6.3.2. Implementation and optimization
In this section, we shall describe several essential elements used to make homomorphic encryption systems more cost-effective. For reasons of space, we cannot provide all of the details here; readers may wish to consult the articles in the references. Further details can also be found in our case studies.
6.3.2.1. Data encoding
There are several ways of encoding plaintext data, depending on the chosen homomorphic scheme. SHE schemes of BFV type (described in section 6.2.2.1) and BGV type (Brakerski et al. 2012) define clear messages as polynomials of a degree less than n (size of the Euclidean lattice) with integer coefficients modulo p (a power of a prime number). Using only the zero-degree coefficient to encode data makes applications easier, as homomorphic operations then correspond to additions and multiplications on scalars modulo p. Boolean circuits can be executed in the case where p = 2. Nevertheless, a number of methods have been proposed in the literature for optimizing this polynomial space. Chen et al. (2018), for example, introduced a method for encoding a number modulo pn in a single encrypted element, while Yasuda et al. (2015) described a way of obtaining the scalar products of two vectors by encoding each vector as a single encrypted element.
The CKKS scheme features an additional operation, division by a constant, which cannot be found in the BFV and BGV schemes. With this operation, fixed-point real numbers can be encoded with a predefined precision. Many more practical applications use arithmetic on real numbers, rather than modulo p arithmetic. SHE schemes using polynomial rings can be used to encode vectors (of size n for BFV/BGV and size n/2 for CKKS) into a single encrypted element. Homomorphic operations become term-to-term operations in this case (the equivalent of the SIMD notion in processors). This technique is called batching and will be discussed briefly in section 6.3.3.
Fast bootstrapping FHE schemes, such as TFHE and FHEW (Ducas and Micciancio 2015; Bonnoron et al. 2018), on the other hand, are a special case in terms of encoding. Their message space is strictly Boolean (only one Boolean value is encoded per element, and there is no notion of batching). However, they natively support more homomorphic operations than SHE schemes. In TFHE and FHEW, more complex generic binary gates (such as thresholds) can be implemented directly. Thus, more complex operations can be performed at the individual gate level than in schemes, which rely on basic logic gates alone; this means that shallower circuits can be used.
The Chimera framework (Boura et al. 2018) introduces a hybrid solution that combines three homomorphic schemes (BFV, TFHE and CKKS) in a single application, in order to enjoy the advantages of each approach, according to the operations to be performed. The authors present a common algebraic structure for the clear message spaces and propose efficient algorithms for passing between these spaces. Chimera allows arithmetic and Boolean computations to be combined in the same homomorphic application, something which is difficult to achieve using a single homomorphic scheme. One example of an application is presented in Carpov et al. (2019). These authors used the TFHE scheme to train a logistic regression model, before using the CKKS scheme to find all of the features in a numerical database, which may be used to improve the quality of the initial model.
6.3.2.2. Circuit optimization
Multiplicative depth is the maximum number of consecutive multiplications in the arithmetic circuit that describes the homomorphic calculation. It is therefore related to the degree of the polynomial corresponding to the calculation to perform. Minimizing this depth is a key aim in improving the performance of fixed or leveled SHE schemes. The size of encrypted elements and the speed of execution of homomorphic operations are highly dependent on this depth, as multiplication has the greatest impact on cost in terms of both time and space. Multiplicative depth minimization can be performed manually when designing homomorphic applications. The design flow that we used to develop a homomorphic application with reduced multiplicative depth is presented in section 6.4.3. Several approaches have been presented in the literature, such as shallow circuits for sorting (Çetin et al. 2015) and Levenshtein distance for genomic similarity (Cheon et al. 2015).
In this context, automatic multiplicative depth optimization of Boolean circuits was first discussed in Carpov et al. (2017) and later in other studies (Aubry et al. 2020; Häner and Soeken 2020; Lee et al. 2020). These works are not limited to Boolean circuits, and the approaches presented can also be used to optimize arithmetic circuits. Several rules are proposed for the local rewriting of Boolean circuits. By applying these rules to critical parts of the circuit (notably the paths of maximum depth), the multiplicative depth can be reduced. The cited works differ in terms of the rewriting rules that they use, and the way in which these rules are applied. With respect to the performance of automatic methods, for example, the method published in Aubry et al. (2020) was able to transform a carry-propagating (128-bit) binary adder (depth 255) into an equivalent carry-forward binary adder with a multiplicative depth of 9.
Operations supported by fast bootstrapping FHE schemes, such as TFHE or FHEW, all have the same computational complexity. Computation time can be reduced by minimizing the number of logic gates to execute in the Boolean circuit. The body of literature on the subject of logical synthesis is vast, and many different optimization methods can be applied directly in order to reduce the size of Boolean circuits.
The optimization methods defined above change the Boolean circuit in order to minimize the complexity and/or number of homomorphic operations to perform. A further complementary approach concerns the optimal scheduling of relinearization (Chen 2017) and bootstrapping operations (Paindavoine and Vialla 2015; Benhamouda et al. 2017). In this case, the aim is to order homomorphic operations (relinearization in SHE schemes, bootstrapping in FHE) in such a way that the total execution time is minimized.
6.3.2.3. Software implementation
At first, implementations of SHE and FHE were not systematically published with each new scheme, but this practice became increasingly regular over time and is now universal. Only public, maintained examples will be cited here. Certain libraries focus on one or two schemes, while others are veritable experimental platforms including multiple schemes.
HElib5, launched by Halevi and Shoup in 2014 and maintained by IBM, offers an implementation of BGV (Brakerski et al. 2012) and CKKS (Cheon et al. 2017, 2018). It is intended to provide support for concept proofs rather than for production purposes.
The SEAL library6 was launched in 2015 by Laine et al. and is maintained by Microsoft. It currently implements BFV (Fan and Vercauteren 2012) and CKKS, and also targets at production applications.
Several implementations of BFV exist, such as FV-NFLlib7, which uses the NFLlib library8. Further implementations can be found in the PALISADE and CINGULATA libraries.
The TFHE library9 was created in 2016, and is run by a group of researchers who were involved in designing the eponymous scheme (Chillotti et al. 2016).
The HEAAN library10, launched in 2017, offers an implementation of the CKKS scheme, designed for fixed point number encryption.
The PALISADE project11 offers implementations of BGV, BFV, CKKS, FHEW (Ducas and Micciancio 2015) and a variant of TFHE.
The final platform for discussion, launched in 2012, differs from the others in the fact that it includes a compilation and circuit optimization engine, in addition to executing computations. This case is described in greater detail below.
6.3.2.4. Cingulata: a special case
Homomorphic encryption systems allow low-level arithmetic operations (such as addition and multiplication in binary space) to be performed directly on encrypted data. To facilitate the use of these libraries, compilation tools are needed to transform applications written in high-level programming languages into executables using a homomorphic encryption library. Cingulata, formerly known as Armadillo (Aguilar-Melchor et al. 2013; Carpov et al. 2015), is the first compilation and execution tool dedicated to homomorphic encryption. Cingulata combines a compiler chain with an execution environment, allowing developers to write the application and underlying algorithms in C++ without needing to take the inherent homomorphic encryption scheme or homomorphic operations into account. Applications are thus programmed in the same way as for non-encrypted data. Cingulata then couples the program with the chosen encryption scheme, and automatically recodes it to permit execution on encrypted input.
High-level abstractions and tools are provided to facilitate the implementation and execution of privacy-preserving applications. Cingulata is openly distributed as open source and is available from GitHub12.
Instrumented C++ types, such as the CiInt type for integers and CiBit type for Booleans, are used to denote encrypted (confidential) variables. The Cingulata environment tracks each bit of these variables independently. Operations on integers are performed using Boolean circuits. For example, a carry propagation adder is used to perform addition between two integers. The generation of Boolean circuits corresponding to integer operations is automatic, and two circuit generators are available, allowing users to minimize either the size or the multiplicative depth of the circuit. Users also have the option to implement their own circuit generators or combine existing generators.
Each bit, represented by a CiBit object, may be in a clear or encrypted state. Operations between clear and encrypted elements are optimized automatically. Operations between encrypted bits are executed by an object which implements the IBitExec interface. This object may either encapsulate a homomorphic library, track each bit in the BitTracker application, or carry out clear bit-to-bit execution for debugging purposes.
The use of the BitTracker object makes it possible to construct a representation of the application in the form of a Boolean circuit. The Cingulata chain can then minimize the size or multiplicative depth of the Boolean circuit using specialized optimization modules.
The ABC toolchain13, generally used for hardware synthesis, is used to minimize the size of the Boolean circuits, and Cingulata modules implement heuristics to minimize the multiplicative depth of the circuit (Carpov et al. 2017; Aubry et al. 2020).
The optimized Boolean circuit is then executed using the Cingulata parallel execution environment. The execution environment is generic, that is, it uses an object encapsulating a homomorphic library (TfheBitExec, BfvBitExec), to execute the Boolean gates of the circuit. The parallel scheduler is designed to take full advantage of multicore processors. A set of utility applications is provided for parameter generation (with a target security level), key generation, data encryption and decryption. These applications are also generic, in the same way as the runtime environment.
6.3.2.5. Hardware optimization
A first means of speeding up computation time is to deport part of the processing onto suitable hardware implementations. This is particularly critical for schemes using Euclidean networks, which are the most memory intensive and computationally intensive (handling polynomial multipliers of degree n ∈[4,096, 32,768] with coefficients of a size of log2 q ∈ [125,1,228] bits). One approach, which is relatively economical in terms of investment, is to use GPU cards. Nevertheless, the gains to be made in this case are highly dependent on the homomorphic scheme, since some are less suited to this treatment than others. Much better results can be obtained using specialized hardware components, such as FPGAs or ASICs. However, it is important to understand the expected benefits before implementing these hardware solutions. It is not reasonable to deport everything; a compromise must be found in order to maximize overall gains, offsetting accelerations in terms of calculation time against the time taken to transfer potentially voluminous data. Only the most time-consuming operations, notably multiplications, are deported to hardware.
Several approaches have already been explored. Most hardware implementations of multipliers rely on the use of the NTT (Number Theoretic Transform, a Fourier transform on finite fields). This can result in a very significant acceleration, but requires particular parameters, which can sometimes be over-dimensioned. Given that, in this case, n must be a power of 2, if the required value of n exceeds 2p then n = 2p+1, which is much larger, must be taken. This means that the body of data will be much larger, and calculations will be more costly. Moreover, the batching techniques that are usually used to reduce data size and parallelize computations are not natively compatible with this approach. Typical examples of NTT use include (Doröz et al. 2013; Pöppelmann et al. 2015; Sinha Roy et al. 2015).
Recent work has focused on designing accelerators for polynomial multiplication for SHEs, working on several RNS channels simultaneously in order to avoid explicit manipulation of large integers (Cathébras et al. 2018). These developments draw on work carried out by the signal processing community on the hardware implementation of the FFT, notably using the Spiral modulo tool for adaptations; in addition to finite field operations, and in contrast with the case of FFT, the coefficients of the transform change constantly. Thus, the development of a hardware module to generate these coefficients on-the-fly, coupled with the circuits produced by the Spiral tool, enables a potential acceleration with a factor of between 5 and 15 for multiplications of encrypted numbers (the main bottleneck in terms of SHE performance).
Another strategy may be used to avoid over-dimensioning parameters and facilitate the natural grouping of data via batching techniques: for example, the Karatsuba algorithm may be used for multiplication, as proposed in Migliore et al. (2017, 2018). Excellent results can be obtained in this case, notably by optimizing the co-design of the remaining software computation and the operations that are deported onto the hardware (Migliore et al. 2018).
Once again, there is a trade-off to be made, guided by the specificities of the target application. Is it better to use an algorithm such as NTT, which provides high acceleration but may use over-dimensioned parameters, or an algorithm such as Karatsuba, which offers lower acceleration for the same parameters but ensures that these parameters will be a better fit (leading to reduced computation cost and smaller encrypted elements)? There is no one-size-fits-all answer in this case, as the solution depends on application-specific constraints in terms of time/memory, parameter size and choice of encryption scheme.
6.3.3. Managing and reducing the size of encrypted elements
The size of the encrypted elements involved in computations performed with homomorphic encryption systems is a real problem, especially for schemes based on Euclidean networks, which result in significant inflations in message size. The scale of inflation ranges from a factor of 2 for Paillier to several (tens/hundreds of) thousands for the most greedy FHE. The first point to keep in mind is that this expansion factor strongly depends on the security parameters, as well as on the chosen system; as a general rule, the more flexible the scheme, the higher the inflation factor. However, there are certain techniques that can be applied to all schemes to generate significant space savings. Two complementary approaches are discussed below.
6.3.3.1. Encoding and batching
The first key point is to choose the right encoding approach for the data. Raw data must first be transformed into words in the clear message space of the chosen encryption scheme. In the case of the Paillier scheme, this space is the set of integers modulo n; for schemes based on Euclidean lattice structures, it is a polynomial of degree n (note that the value of n is very different in both cases, and the coefficients of the polynomials belong to large algebraic structures). This encoding can be done in a naive manner, but it is also possible to reduce data size at this stage by grouping several data elements into the same structure. This is only possible for certain algebraic structures, such as polynomials on rings; in this case, several data elements can be encoded in the coefficients of the polynomial, which will constitute the clear message. This technique, called batching, means that multiple data elements can be processed simultaneously. It thus constitutes a form of parallelization applied directly at the data encoding level: several data elements will be processed by processing a single clear message.
6.3.3.2. Transcryption
Another process which is extremely useful for reducing the data load on both client and server is illustrated in Figure 6.3. This process, known as transcryption, was presented in Naehrig et al. (2011). Data are initially encrypted using a classical symmetric encryption system, noted SymEnc, rather than with a homomorphic system, noted HomEnc; thus, the size of the data is not increased. The encrypted data SymEncSymKey(m) is sent to the server with no added cost, and will then be transcrypted by the server itself to produce a version as encrypted by the homomorphic system HomEnc(m). Without going into too much detail, note that this transcryption approach is possible for algebraic reasons (homomorphy), and that the key of the symmetric encryption system encrypted using the homomorphic system, that is, HomEnc(SymKey), needs to be sent alongside SymEncSymKey(m). Using these two data elements, the server can calculate the HomEnc(m) cipher without passing through m. The whole problem is thus deported onto the server. This comes at a cost, but offers a solution for a large number of otherwise impossible problems. Nevertheless, great care must be taken when choosing the symmetric encryption system, since the transcryption process requires the SymDec process to be evaluated in a homomorphic manner (in the encrypted domain of the homomorphic scheme). We must therefore choose a scheme for which SymDec gives rise to a circuit of which the homomorphic evaluation is as reasonable as possible, notably in terms of multiplicative depth.
Evidently, the first works focused on existing symmetric encryption schemes, initially on AES, which turned out to be much too costly (Gentry et al. 2012; Cheon et al. 2013; Doröz et al. 2016); the focus then shifted onto lighter encryption schemes such as Simon and Prince, designed for constrained environments, but these also proved to be too costly (Doröz et al. 2014; Lepoint and Naehrig 2014) (the relevant constraints here are not the same as those taken into account when designing these schemes). Given the unsuitable nature of existing schemes, several groups have worked on designing new schemes specific to this context. The first example is Low MC (Albrecht et al. 2015b); the initial version was attacked (Dinur et al. 2015), and then patched (Rechberger 2016). However, these schemes have a flaw linked to their block cipher structure. Canteaut et al. (2016, 2018) proposed a new approach based on stream cipher designs, and this appears to be much better suited to the context in terms of both performance and security. This approach notably allows part of the computation process to be carried out offline, facilitating the later online phase. Efficient solutions to this issue are now available. Two stream cipher schemes have been proposed: Kreyvium (Canteaut et al. 2016, 2018), based on the Trivium scheme, the security of which has been widely tested and recognized over the past decade; and FLIP (Méaux et al. 2016), the security of which is less certain (Duval et al. 2016). These solutions have been implemented and tested experimentally. Another more innovative solution was proposed in (Fouque et al. 2016), but this is less advanced from an experimental perspective.
It should be noted, however, that the transcryption process currently only applies to data transfers from the client to a homomorphic computer, and not to the transfer of computation results to the holder of the secret decryption keys, which are currently transferred in FHE encrypted form. Several solutions to this problem have been explored (Carpov and Sirdey 2016; Kuaté 2018), notably decomposing multislot homomorphic ciphertexts (before computation) and then recomposing them (after computation). However, these solutions are not fully satisfactory, either for performance reasons or because the homomorphic properties of the resulting ciphers are not preserved. Minimizing the bandwidth increase linked to the transfer of homomorphic computations to the client is an important question for current and future research.
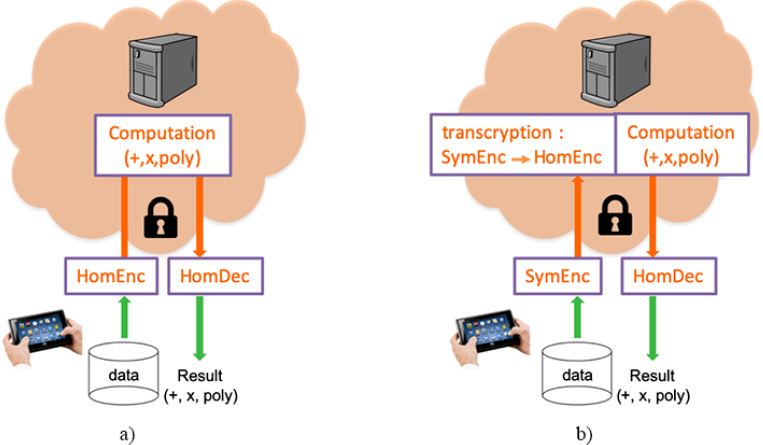
Figure 6.3. Use of a transcryption system to lighten the data load sent to the server: a) classic approach and b) transcryption architecture
6.3.4. Security
Evidently, since these schemes are designed to ensure data confidentiality, security is of paramount importance. As always, this question must be addressed both from a theoretical point of view (what security reductions can be proved between mathematical problems that are known to be difficult and the problems related to the security of the schemes to be evaluated) and from a practical standpoint (in concrete terms, what is the best known attack). We shall begin with some general remarks, valid for all homomorphic systems. The best security level reached by current homomorphic schemes is IND-CPA14, and we know that, inherently, no homomorphic scheme will be able to reach the IND-CCA2 security level due to the property of homomorphy itself. The question of whether a homomorphic scheme may reach IND-CCA1 remains open.
6.3.4.1. Schemes based on elliptic curves and pairings
Notable examples of schemes belonging to this category include Paillier (1999), ElGamal (1985) and BGN (Boneh et al. 2005; Herbert et al. 2019). Their theoretical security involves mathematical problems whose difficulty has been extensively studied (calculations of discrete logarithms in large groups, factorization of large integers, etc.). This means that we are on familiar ground, although further developments are possible. This familiarity is a significant advantage; nevertheless, these techniques will cease to be functional with the advent of quantum computers, which have the capacity to solve such problems in an efficient and effective manner. The best way of choosing appropriate parameters is to consult the article presenting the scheme in question in order to identify the mathematical problem, and then consult official documents such as those issued by the ANSSI15 or listed on the codecolorBlueKrypt16 website in order to select parameters in accordance with the desired security level.
6.3.4.2. Schemes based on Euclidean networks
The security of schemes based on Euclidean network structures involves different mathematical problems, such as the Bounded Distance Decoding Problem (BDD), the Shortest Vector Problem (SVP) or the resolution of linear systems of equations with errors (learning with errors (LWE)), in its original version or on rings (R-LWE). This family of mathematical problems differs from the previous group (factorization or discrete logarithm calculation) insofar as there are currently no known algorithms with the capacity to solve these problems in a much more efficient way on a quantum computer. For this reason, security schemes using these problems may be referred to as post-quantum: in the current state of the art, they are considered to be as resistant to quantum cryptanalysis as to classical cryptanalysis. This is a significant advantage in the long term, but comes at a high cost in terms of computation and data size, as we have seen.
The sticking point in this case is that these schemes are still relatively new, and the associated problems have received much less attention than their classic counterparts. This implies a less thorough understanding of their security. This consideration is particularly true for concrete security estimations, which go beyond reduction proofs and seek to find the best cryptanalysis strategies. From these cryptanalyses, relations between the parameters and the security level of the scheme can be deduced. This point is crucial, since the desired level of security and the duration of this security must be taken into account when deploying an application. The lack of stability in concrete security analysis also affects the choice of parameters; over-dimensioning is not an option, as the additional costs in terms of calculation and data size are not acceptable. This consideration does not preclude the use of these solutions, but is an important factor to bear in mind. Current research efforts are focused on analyzing the concrete deployment of these schemes, notably on the question of parameter choice and security. Increasing work is also being carried out in the field of cryptanalysis in order to develop understanding. Notable examples include some previous studies (Albrecht et al. 2015a, 2016; Peikert 2016; Bai et al. 2018; Albrecht et al. 2019; Bai et al. 2019; Espitau and Joux 2020) and the Martin Albrecht’s estimator17, which is updated as new developments occur, and is extremely useful for choosing parameters.
6.4. Proofs of concept and applications
Several applications have been explored in recent years, combining academic knowledge and industrial skill. We have worked on a number of cases, described below. Other works of interest include some previous studies (Pedrouzo-Ulloa et al. 2016; Bouslimi et al. 2016; Bourse et al. 2018). The cases considered here are presented in order of increasing multiplicative depth, and thus complexity.
6.4.1. Facial recognition
In this section, we present a proof of concept performed on a facial recognition application for biometric authentication. Details of this work can be found in Bouzerna et al. (2016). For further information on biometric techniques in general and facial recognition in particular, see Chapter 1.
6.4.1.1. Principle and system architecture
Consider a case in which an employer wishes to implement a facial recognition authentication system at a company site, alongside the existing badge authentication strategy. To do this, the biometric credentials of a number of employees must be stored (and processed) on a server. Our aim is to reinforce the confidentiality of these credentials using a three-party system architecture: the employer, the employee (using an off-site enrollment procedure) and a third party, responsible for key management. This architecture is interesting in that responsibility for the confidentiality of the credentials is shared between the employer (who holds the encrypted credentials but does not have access to the decryption key) and the third party (who possesses the encryption and decryption keys but does not have access to the encrypted credentials). Evidently, our model is not resistant to collusion between the employer and the third party; nevertheless, it remains relatively acceptable, particularly if the third party is an IS security agency or a provider offering turnkey authentication solutions to multiple companies.
A high-level view of the system architecture is shown in Figure 6.4, with Dilbert and Dogbert in the roles of employee and third party, respectively.
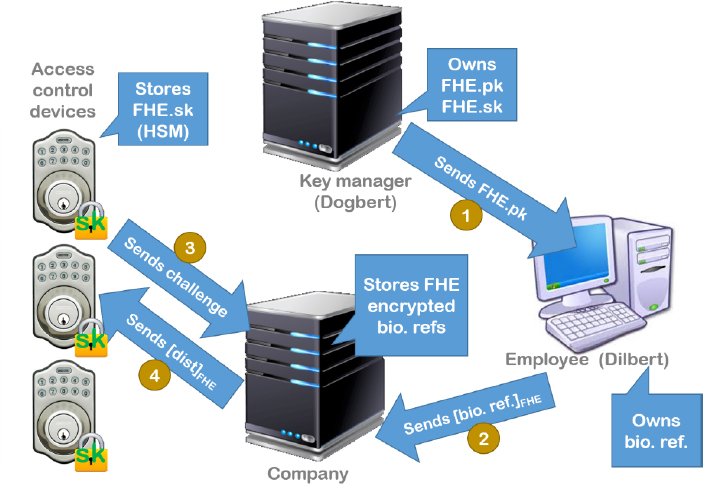
Figure 6.4. Facial recognition: synthetic view of the global system architecture
The principle here is to use homomorphic encryption so that the employer’s server can process biometric references directly in the encrypted domain. The architecture guarantees the following properties:
- – the third-party key manager (Dogbert) possesses both the public and secret keys, pk and sk, of the homomorphic encryption system; however, they do not have access to the reference data;
- – the access control devices (Device) know the sk and have access to computation results (a distance to compare to a threshold), but not to the reference data;
- – the employer does not have the sk, and thus cannot access the reference data or the (encrypted) results of computations;
- – the employee (Dilbert) must be confident that the third-party key manager (Dogbert) will not collude with the employer.
6.4.1.2. The face-matching algorithm
The face-matching algorithm used in this case is the OpenIMAJ18 implementation of the LTP (Local Ternary Patterns) algorithm (Tan and Triggs 2007). OpenIMAJ is one of the reference libraries for multimedia data processing, and the algorithm in question is known to give good results, particularly in suboptimal lighting conditions.
First, enrollment is carried out using one or more photographs of an individual’s face. This phase relies on advanced image processing techniques, and produces a reference made up of 118 distance maps, M(0), …, M(117), each corresponding to an 80 × 80 matrix of values in [0, 1]. The authentication process also requires one or more photographs of the individual, and generates 118 sets of coefficient coordinates S(0), …, S(117). A detailed description of the operation of the algorithm lies outside the scope of this work; instead, we shall focus on the passage into the encrypted domain. Further details can be found in Tan and Triggs (2007).
The matching part of the algorithm is most relevant for our purposes, in terms of execution in the encrypted domain. Matching relies on the following calculation:
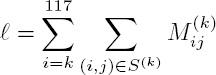
Given a threshold T, authentication will be successful if ![]() and fail otherwise. Typically, on an empirical base, a threshold value of T = 92 is appropriate.
and fail otherwise. Typically, on an empirical base, a threshold value of T = 92 is appropriate.
6.4.1.3. Converting the algorithm to the encrypted domain
With respect to the system architecture presented above, equation [6.2] must be evaluated in the encrypted domain. Helpfully, this can be carried out using an additive encryption system, with the hypothesis that the authentication request (coordinate subsets) is sent in unencrypted form19.
Table 6.1 presents a summary of the results obtained when the Paillier cryptosystem is used for homomorphic evaluation (using GMP for the modular arithmetic and OpenMP for parallelization). The evaluation step notably takes less than 2 seconds using an 8-core processor, and can easily be shortened to less than 1 second by using a more powerful machine. The online execution time is thus eminently reasonable. Note, too, that similar execution times can be obtained using an SHE such as BGV, optimized for additive function and using batching capacities. Performance is therefore a relatively unimportant factor in the choice of approach.
Table 6.1. Facial recognition: summary of performance
| Step | When? | Where? | Duration |
| Precomputation | Offline | Dogbert | ≈ 30 mins |
| Encryption | Enrollment | Dilbert | 21 secs |
| Evaluation | Authentication | Company | < 2 secs |
| Decryption | Authentication | Device | ε |
6.4.2. Classification
6.4.2.1. Elementary medical diagnostics
Healthcare data are inherently highly personal in nature. The confidentiality of this data is a priority for both storage and processing solutions. Its sensitive nature means that medical diagnosis is a prime domain for the application of computation techniques using encrypted data. In this section, which draws on the work of (Carpov et al. 2016), we describe a medical diagnosis application used to evaluate an individual’s risk of cardiovascular disease. In this context, homomorphic encryption is used to ensure that the patient’s health data remains confidential.
The implemented algorithm evaluates a set of rules which, when activated, correspond to cardiovascular risk factors. The set of 11 rules is shown in Figure 6.5. The result of the algorithm is an integer between 0 and 9; a higher value denotes a higher risk of cardiovascular disease. The algorithm was implemented in C++ and compiled using the Cingulata compilation chain (see section 6.3.2.4). The highlighted terms in Figure 6.5 were processed in encrypted form. Although the algorithm is relatively simple in terms of computation requirements, it represents a certain reality in the context of online medical diagnostics, as an example of a relatively simple algorithm handling intrinsically personal, sensitive data.
Figure 6.6 gives a schematic overview of this application in a cloud implementation. The patient fills out a form (using an Android tablet), providing their medical data, and the cardiovascular risk assessment application is executed in the cloud. Transcryption is used in order to limit the volume of transmitted data (see section 6.3.3.2), and Kreyvium symmetric stream cipher is used to encrypt medical data sent to the cloud. The Kreyvium encryption key, SymKey, is in the tablet.

Figure 6.5. Set of rules used in the cardiovascular risk evaluation algorithm
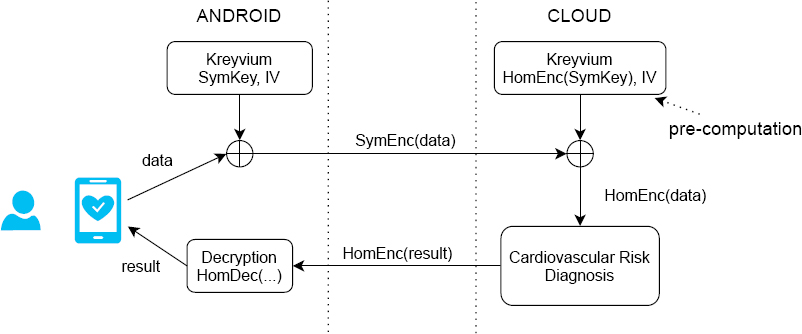
Figure 6.6. Homomorphic computation process for the cardiovascular risk evaluation
It is interesting to note that the transcryption key HomEnc(SymKey) is only sent to the cloud once, when the user registers. A public initialization vector IV, common to both parties, is used to synchronize the two streams in the transcryption process. The homomorphic execution of Kreyvium decryption, used to prepare the stream used for the transcryption operation, can be carried out offline by the cloud, in advance of the transaction itself, to minimize transaction length. This is one of the main advantages of this stream cipher-based transcryption solution.
Now, consider what happens online at the moment of transaction. Once the user’s data, encrypted using Kreyvium, is received by the cloud, the homomorphically encrypted Kreyvium stream (prepared in advance offline) is used for transcryption (a simple additive operation). In this way, the Cloud obtains the user’s medical data in a homomorphically encrypted form. The data then serve as input for the cardiovascular risk calculation algorithm, executed by the Cingulata environment in homomorphic form. The result of the calculation (the risk factor) is represented by four homomorphic numbers, one for each bit of the result. These ciphertexts are grouped into a single ciphertext using batching. The resulting ciphertext is sent back to the user’s tablet, which decrypts it using the secret key of the homomorphic scheme sk; the risk factor is then reconstructed from its binary form and displayed on the patient’s tablet.
6.4.2.1.1. Third-party recipients
In the case described above, the owner of the medical data is also the recipient of the result of the diagnostic algorithm. In other cases, however, the final recipient of the result may not be the owner of the input data, for example if a medical professional wishes to receive the results of the computation carried out using the patient’s data. Our architecture can easily be adapted to this case: only the initialization phase needs to be modified.
The patient, instead of sending their symmetric Kreyvium key encrypted homomorphically using their own public key pk-patient to the cloud, will send the symmetric Kreyvium key encrypted using the doctor’s homomorphic public key, pk-doctor. The decryption process then transforms the patient’s data into the doctor’s pre-authorized homomorphic domain. This process may be seen as the patient authorizing the doctor to access the result of the algorithm applied to their data. In the security model for this case of use, the cloud and the doctor must not collude, or patient data may be decrypted using the doctor’s homomorphic secret key.
6.4.2.1.2. Implementation and performance
The Android application on the patient side was developed in Java. Figure 6.7 shows a screenshot from the application, specifically the form into which the patient inserts their data. The BFV homomorphic encryption scheme (Fan and Vercauteren 2012), parameterized using 128 security bits, was used for homomorphic computations. The Kreyvium cryptosystem used in transcryption has a key length of 128 bits. Thus, in this configuration, the cloud diagnosis service offers end-to-end security of 128 bits. In terms of multiplicative depth, the Kreyvium algorithm has a depth of 12 and the risk calculation algorithm has a depth of 8. The leveled SHE library used here was then dimensioned to take a total multiplicative depth of 20 into account, in order to ensure error-free execution. Each homomorphic ciphertext has a size of around 250 kb.
Figure 6.7. Android application for calculating cardiovascular risk. Users fill in personal details and give information on their current health, diet and lifestyle following the guidelines given in Figure 6.5
During the first interaction between the patient and the cloud, the patient sends the transcryption key HomEnc(SymKey). This corresponds to 128 homomorphic ciphertexts (one per bit in the Kreyvium key). Hence, a total of ~32 Mb are sent to the cloud during this phase.
Since Kreyvium is used to send medical data to the cloud, the size of the encrypted payload transmitted over the network to the server is the same as that of the clear payload. The only additional element is the symmetric key encrypted using the homomorphic system: this is relatively small. Once the homomorphic calculation has been carried out, the patient or doctor receives a single ciphertext (~250 Kb) containing the encrypted result of the calculation. The total response time between the moment when the tablet sends the data and the moment the result of the calculation is received is less than 4 seconds, of which ~3.2 seconds are taken up by the homomorphic execution of the diagnostic algorithm.. The homomorphic execution of the Kreyvium decryption algorithm prior to transcryption takes around 8 minutes: this is why this step should be carried out in advance, offline.
6.4.2.2. Medical diagnostics using artificial neural networks
Cardiac arrhythmia corresponds to a set of conditions which causes an irregular heartbeat. While some of these conditions are relatively benign, others cause more or less problematic symptoms. For certain chronic patients, electrocardiogram (EKG) monitoring is crucial for identifying arrhythmia as soon as it occurs to prevent their state from worsening.
6.4.2.2.1. Context
Services now exist for collecting patient EKG data via specific portable devices, analyzing these data to detect arrhythmia and transmitting the results to a medical professional, who then produces a report. In this case, arrhythmia is detected via algorithms based on neural networks (NNs). Nevertheless, outsourcing the analysis of a patient’s EKG to a service that is not necessarily trusted clearly raises issues concerning the confidentiality of health data, which are particularly important since recent data protection regulations (such as the GDPR) impose strict analysis constraints for so-called special categories of data (Article 9). Thus, the option to perform this analysis on encrypted data, such that only the healthcare professional ultimately obtains the patients’ health information, is an important goal in this context.
6.4.2.2.2. Neural networks
The idea, developed in greater detail in Azraoui et al. (2019), is to create a simple NN compatible with the use of encrypted data. Learning is carried out using clear data taken from the PhysioBank database20.
A NN consists of a certain number of interconnected nodes, or neurones, with a layered structure. Each node carries out an operation according to the type of layer to which it belongs:
- – convolution layer (optional): generally used in image recognition, in order to obtain information about the similarity between the part of the original image covered by a filter and the filter itself. This layer is not used in our case;
- – activation layer: used to determine whether the filter pattern is truly present at a given position. The most well-known activation function types include the sigmoid (σ), hyperbolic tangent (tanh) and rectified linear unit (ReLU);
- – pooling operations consist of reducing the spatial size of the input in order to make it more manageable. This layer is not used in our case;
- – the fully connected layer correlates the output from the previous layer with the characteristics of each class.
Some of these layers require costly calculations, meaning that it may be difficult (if not impossible) to execute them directly on encrypted data. The idea is thus to approximate these functions in order to increase the efficiency of execution in the encrypted domain, without sacrificing the precision of the chosen model:
- – approximation of pooling functions: since the pooling function is nonlinear, it is often approximated by summing all values or calculating their mean;
- – approximation of the activation function: there are several ways of executing the activation function. The most effective (in terms of efficiency and prediction precision) consists of using the square function, which directly calculates x2 for any input x.
The NN in our study consists of two fully connected layers and an activation layer using x2 with an input vector of size 180, 40 hidden neurones and an output vector of size 16. A model of this type gives a precision of 96.34%.
6.4.2.2.3. Homomorphic encryption
In terms of homomorphic encryption, we have chosen to use the CKKS scheme implemented by Microsoft in SEAL 3.1. The CKKS scheme allows calculations to be carried out directly on floating point numbers. We set a precision of 15 bits after the point to ensure that the precision of the encrypted version is as good as if the same evaluation had been carried out on the unencrypted version. Network weights are not encrypted. Thus, operations are primarily carried out between clear and encrypted data elements, rather than between two encrypted elements; this results in a significant increase in performance. We selected m = 4 096 and q = 2 116 as parameters for the CKKS scheme, resulting in 128-bit security.
6.4.2.2.4. Experimental tests
Experimental tests were performed on a computer with six Intel Core i7-7800X processors at 4.0 GHz, 128 GB of RAM, and a 1 TB SSD. The results are summarized in Table 6.2. We performed two different tests for the NN models: one classifying a single heartbeat and the other classifying packets of 2,048 heartbeats.
6.4.3. RLE and image compression
Compression is a major, widely used step in the field of multimedia. Video compression processes typically aim to avoid transmitting redundant information (while coding the remaining information as efficiently as possible), in order to reduce bandwidth requirements. More precisely, the compression of a video sequence consists schematically of exploiting the spatial, temporal and spatio-temporal redundancies that naturally appear in a video stream destined for interpretation by the human visual system (HVS). The vast majority of modern video compression schemes encode the residual information in a non-conservative way, meaning that the output image of the decompressor is different from the input image of the compressor. This loss is rendered unnoticeable or minimal by exploiting the fact that the HVS is more sensitive to some types of information than others.
Table 6.2. Performance evaluation for EKG classification using homomorphic encryption
| Computational cost (ms) | Spatial cost (Mb) | |
| 1 heartbeat | 1 253 | 0.0018 |
| 2,048 heartbeats | 1 253 | 3.69 |
In this context, we will now focus on the RLE algorithm, which is probably the most basic compression algorithm currently available. This algorithm is used in several image formats, for example the BMP format, as well as in the coding of quantized DCT in H264. The idea is to see what can still be done when the image is encrypted. First, we shall study the complexity of implementation. Further details can be found in Canard et al. (2017).
6.4.3.1. Compression using a homomorphic machine
Our aim in this section is to understand the implications of the characteristics of homomorphic approaches in terms of the implementation of data compression algorithms. In concrete terms, the characteristics of the homomorphic machine impose, by construction, that the quantities of input and output data of a program are bounded (if not known) or, more generally, independent of the data of the encrypted domain. It is not, therefore, possible to directly implement a variable output rate algorithm; unfortunately, most of the usual compression algorithms fall into this category.
6.4.3.2. Study of the RLE algorithm
Given a sequence of input symbols e1, e2,…, the RLE algorithm consists simply of producing a sequence of {counter, symbol} pairs to compress repetitions. For example, the sequence of input symbols
gives the following sequence of {counter, symbol} pairs:

Figure 6.8. Pseudo-code of the classic version of the RLE algorithm
Despite its simplicity, this algorithm cannot be implemented directly in a homomorphic context: the reason for this, and possibilities for an implementation in principle, will be explained below. As a starting point, the pseudo-code of the algorithm in its usual form is shown in Figure 6.8. As we have just indicated, this algorithm does not conform to the constraints of the homomorphic machine: the loop in line 9 advances by variable increments depending on the number of iterations of the loop in line 11, and the stop loop criterion depends on the encrypted data (input). We will progressively regularize this algorithm below.
- – The first step is to eliminate the variable increment of the loop index i (line 9). This is done by internalizing the output of the symbol counter j (and the associated symbol) in an if of which the condition depends on the encrypted data (either the symbol changes, and in this case the counter and symbol are printed, or the symbol remains the same, and the counter is simply incremented). The assignment of the symbol counter j (line 11) can be regularized using a conditional assignment, as we have just seen.
- – The real difficulty lies in the test input[i + j] == input[i] in line 11. As we have seen, a condition may be regularized (schematically) by executing both branches then recombining their effects according to the numerical result of the condition evaluation. This notably implies that the passage to either clause of an if must be indistinguishable in terms of effect. The effect of the if in question is to print something when the condition is satisfied and do nothing otherwise (different effects). For the effect to be identical whatever branch of the if is executed, we must either systematically do nothing (which is unhelpful), or print a certain symbol which gives no indication as to whether or not there is something to print. This is known as indistinguishability.
The latter property is ensured by the semantic security of the underlying cryptosystem. For example, we could print a zero counter value (encrypted) followed by an arbitrary symbol (encrypted) and the decompressor would work. The problem is that in this case there would be no compression at all, since the output stream would systematically be twice as big as the input stream. For compression to be possible, the algorithm must be made to work at a constant compression rate. This implies relaxing the conservative compression characteristic of the algorithm. A constant compression rate can be achieved by working with a constant number of {counter, symbol} output pairs. Thus, the final algorithm (Figure 6.9) includes an additional parameter, n_pairs, which fixes the number of (encrypted) pairs, which will be systematically generated at output. Each of these pairs is initialized at 0 for the counter and an arbitrary symbol, in this case a, is used (lines 13–16 of the final algorithm). We then proceed to the compression phase (described below). The program then prints the set of n encrypted {counter, symbol} pairs. Whatever the input sequence, the algorithm always produces the same number of pairs as the output. From here, there are two possible cases:
- 1) the pre-defined number of pairs is sufficient to represent the input sequence, in which case the reconstruction produced by the decompressor will be correct; a certain number of pairs may remain unused (counter value of 0), meaning that compression is not optimal;
- 2) if the number of pairs is not sufficient, the decompressor will not be able to reconstruct the input sequence, and a form of padding will be needed to reconstruct a sequence of the correct length.
Compression will be applied when:
where α and β are the numbers of bits required to represent the symbols and counters, respectively.
The compression step (lines 17–29 of the final algorithm) then proceeds as follows. The integer k is initialized at 0 (or, more precisely, an encryption of 0): this counter designates the current pair in the pair buffer. The loop is executed on symbols in the input sequence, line 18. The for loop in line 19 corresponds to the assignment operation in a table with an encrypted index (this is a loop since its complexity is linear, as we saw earlier in this chapter). In functional terms, this loop is equivalent to output_ctr[k] = j and output[k] = input[i − 1], but with an encrypted k. Next, k (respectively, j) is incremented if the symbol changes (respectively, does not change) using a conditional assignment (lines 23 and 24). Finally, once the loop in line 18 is complete, the loop in line 26 corresponds to a new assignment of the pair buffer with encrypted k.
6.4.3.3. Implementation and experimental results
The HRLE algorithm (as shown in Figure 6.9) can be rewritten using Cingulata (section 6.3.2.4), which offers automatic multiplicative depth optimization. Using Cingulata, the subjacent circuit can be optimized simply and automatically, and the resulting efficiency level is close to that achieved through time-consuming manual optimizations.
Finally, a test run of HRLE was performed, with a compression ratio of 25% on a sequence of 64 values, representing a macroblock of size 8 × 8. We thus have an output budget of 16 bytes, corresponding to 8 {symbol, counter} pairs. The results of this execution are as follows. The initial circuit has an approximate depth of 70 with 12,000 AND gates; the output circuit has a depth of 23, but approximately 60,000 AND gates. The multiplicative depth has thus decreased, but at the cost of a fivefold increase in the number of AND gates. Overall, the result is still beneficial. Executing a circuit with a depth of 70 is not practically possible. The new circuit, with a depth of 23, executes in around 30 minutes (2,003 seconds) on a 48-core computer, taking into account the acceleration factor of 47.3 obtained by optimizing the circuit using Cingulata.
It is possible to go further. In Kuaté et al. (2018), the authors implemented H264 and HEVC pipelines, regularized for homomorphic execution, and were able to compress a 128 × 128 image in 244 seconds (H264) and 149 seconds (HEVC).
While these results are still limited, and the execution of a compression algorithm on homomorphically encrypted data still poses a number of significant problems, this approach clearly merits further investigation. If the transcryption of streams in the encrypted domain were to become affordable, this technique would pave the way for a wide range of helpful applications.

Figure 6.9. Pseudo-code of the homomorphic version of the RLE algorithm
6.5. Conclusion
As we have seen in this chapter, homomorphic encryption systems offer a range of attractive prospects in terms of functionality. While their use is still hampered by significant computational and storage costs, progress has been made to the extent that we may begin to consider deployment in certain realistic applications. Huge efforts are currently being made to ensure the usability of these solutions, first in applications such as those presented in this chapter, then in more demanding, currently unattainable contexts. Academic work is focused on reducing computation time and ciphertext size, and on understanding the security aspect of the schemes in question. Standardization is a further key aim, providing a solid point of reference for industrial use, and represents an important step toward the adoption and official acceptance of this technology.
A consortium of academic researchers, industrial players and government bodies21 has been working on standardization for homomorphic encryption since 2007, with the aim of further developing secure computation techniques. An ISO/IEC work group began to look at a draft version of a homomorphic encryption standard in early 2020. The aim of this standard is to standardize and simplify the APIs of homomorphic libraries, train developers in their use, and facilitate understanding of the security of homomorphic schemes.
6.6. Acknowledgments
We wish to thank all of our co-authors with whom we have worked on this topic, notably Carlos Aguilar-Melchor, Pascal Aubry, Monir Azraoui, Muhammad Barham, Bhaskar Biswas, Guillaume Bonnoron, Nabil Bouzerna, Beyza Bozdemir, Anne Canteaut, Joël Carthébras, Eleonora Ciceri, Paul Dubrulle, Orhan Ermis, Simon Fau, Fabien Galand, Nicolas Gama, Mariya Georgieva, Guy Gogniat, Vincent Herbert, Vianney Lapôtre, Ramy Masalha, Vincent Migliore, Marco Mosconi, María Naya-Plasencia, Thanh-Hai Nguyen, Donald Nokam Kuaté, Melek Onen, Pascal Paillier, Marie Paindavoine, Adeline Roux-Langlois, Boris Rozenberg, Cédric Seguin, Oana Stan, Arnaud Tisserand, Bastien Vialla, Sauro Vicini, and Philippe Wolf.
6.7. References
Aguilar-Melchor, C., Gaborit, P., Herranz, J. (2008). Additively homomorphic encryption with d-operand multiplications. Report, Cryptology ePrint Archive [Online]. Available at: http://eprint.iacr.org/2008/378.
Aguilar-Melchor, C., Gaborit, P., Herranz, J. (2010). Additively homomorphic encryption with d-operand multiplications. In CRYPTO 2010. IACR, Santa Barbara.
Aguilar-Melchor, C., Fau, S., Fontaine, C., Gogniat, G., Sirdey, R. (2013). Recent advances in homomorphic encryption: A possible future for signal processing in the encrypted domain. IEEE Signal Processing Magazine, 30(2), 108–117.
Albrecht, M.R., Player, R., Scott, S. (2015a). On the concrete hardness of learning with errors. Journal of Mathematical Cryptology, 9(3), 169–203.
Albrecht, M.R., Rechberger, C., Schneider, T., Tiessen, T., Zohner, M. (2015b). Ciphers for MPC and FHE. In EUROCRYPT 2015. IACR, Sofia.
Albrecht, M.R., Bai, S., Ducas, L. (2016). A subfield lattice attack on overstretched NTRU assumptions: Cryptanalysis of some of FHE and graded encoding schemes. Report, Cryptology ePrint Archive.
Albrecht, M.R., Ducas, L., Herold, G., Kirshanova, E., Postlethwaite, E.W., Stevens, M. (2019). The general sieve kernel and new records in lattice reduction. In EUROCRYPT 2019 – 38th Annual International Conference on the Theory and Applications of Cryptographic Techniques. IACR, Darmstadt.
Aubry, P., Carpov, S., Sirdey, R. (2020). Faster homomorphic encryption is not enough: Improved heuristic for multiplicative depth minimization of Boolean circuits. In Cryptographers’ Track at the RSA Conference. RSA, San Francisco.
Azraoui, M., Barham, M., Bozdemir, B., Canard, S., Ciceri, E., Ermis, O., Masalha, R., Mosconi, M., Önen, M., Paindavoine, M., Rozenberg, B., Vialla, B., Vicini, S. (2019). Sok: Cryptography for neural networks. In Privacy and Identity Management. Data for Better Living: AI and Privacy. IFIP, Windisch.
Bai, S., Stehlé, D., Wen, W. (2018). Measuring, simulating and exploiting the head concavity phenomenon in BKZ. In 24th International Conference on the Theory and Application of Cryptology and Information Security. ASIACRYPT, Brisbane.
Bai, S., Miller, S., Wen, W. (2019). A refined analysis of the cost for solving LWE via uSVP. In 11th International Conference on Cryptology in Africa. AFRICACRYPT, Rabat.
Benhamouda, F., Lepoint, T., Mathieu, C., Zhou, H. (2017). Optimization of bootstrapping in circuits. In 28th Annual ACM-SIAM Symposium on Discrete Algorithms. SIAM, Barcelona.
Boneh, D., Goh, E., Nissim, K. (2005). Evaluating 2-DNF formulas on Ciphertexts. In 2nd Annual Theory of Cryptography Conference. TCC, Cambridge.
Bonnoron, G., Ducas, L., Fillinger, M. (2018). Large FHE gates from tensored homomorphic accumulator. In 10th International Conference on Cryptology in Africa. AFRICACRYPT, Marrakech.
Boura, C., Gama, N., Georgieva, M., Jetchev, D. (2018). Chimera: Combining ring-LWE-based fully homomorphic encryption schemes. Report, Cryptology ePrint Archive [Online]. Available at: https://eprint.iacr.org/2018/758.
Bourse, F., Minelli, M., Minihold, M., Paillier, P. (2018). Fast homomorphic evaluation of deep discretized neural networks. In 38th Annual International Cryptology Conference. CRYPTO, Santa Barbara.
Bouslimi, D., Bellafqira, R., Coatrieux, G. (2016). Data hiding in homomorphically encrypted medical images for verifying their reliability in both encrypted and spatial domains. In 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. IEEE, Orlando.
Bouzerna, N., Sirdey, R., Stan, O., Nguyen, T.H., Wolf, P. (2016). An architecture for practical confidentiality-strengthened face authentication embedding homomorphic cryptography. In International Conference on Cloud Computing Technology and Science. IEEE, Luxembourg.
Brakerski, Z. (2012). Fully homomorphic encryption without modulus switching from classical GapSVP. In 32nd Annual Cryptology Conference. CRYPTO, Santa Barbara.
Brakerski, Z., Gentry, C., Vaikuntanathan, V. (2012). (Leveled) fully homomorphic encryption without bootstrapping. In 3rd Innovations in Theoretical Computer Science Conference. ACM, Cambridge.
Canard, S., Carpov, S., Kuaté, D.N., Sirdey, R. (2017). Running compression algorithms in the encrypted domain: A case-study on the homomorphic execution of RLE. In 15th Annual Conference on Privacy, Security and Trust. IEEE, Calgary.
Canteaut, A., Carpov, S., Fontaine, C., Lepoint, T., Naya-Plasencia, M., Paillier, P., Sirdey, R. (2016). Stream ciphers: A practical solution for efficient homomorphic-ciphertext compression. In Fast Software Encryption. IACR, Bochum.
Canteaut, A., Carpov, S., Fontaine, C., Lepoint, T., Naya-Plasencia, M., Paillier, P., Sirdey, R. (2018). Stream ciphers: A practical solution for efficient homomorphic-ciphertext compression. Journal of Cryptology, 31(3), 885–916.
Carpov, S. and Sirdey, R. (2016). Another compression method for homomorphic ciphertexts. In 4th ACM International Workshop on Security in Cloud Computing. ACM, Xi’an.
Carpov, S., Dubrulle, P., Sirdey, R. (2015). Armadillo: A compilation chain for privacy preserving applications. In 3rd International Workshop on Security in Cloud Computing. ACM, Singapore.
Carpov, S., Nguyen, T.H., Sirdey, R., Constantino, G., Martinelli, F. (2016). Practical privacy-preserving medical diagnosis using homomorphic encryption. In 9th International Conference on Cloud Computing (CLOUD). IEEE, San Francisco.
Carpov, S., Aubry, P., Sirdey, R. (2017). A multi-start heuristic for multiplicative depth minimization of Boolean circuits. In International Workshop on Combinatorial Algorithms. IWOCA, Newcastle.
Carpov, S., Gama, N., Georgieva, M., Troncoso-Pastoriza, J.R. (2019). Privacy-preserving semi-parallel logistic regression training with fully homomorphic encryption. IACR Cryptol. ePrint Arch., 101.
Catalano, D. and Fiore, D. (2015). Using linearly-homomorphic encryption to evaluate degree-2 functions on encrypted data. In 22nd ACM SIGSAC Conference on Computer and Communications Security. ACM, Denver.
Cathébras, J., Carbon, A., Milder, P., Sirdey, R., Ventroux, N. (2018). Data flow oriented hardware design of RNS-based polynomial multiplication for SHE acceleration. IACR Transactions on Cryptographic Hardware and Embedded Systems, 3, 69–88.
Çetin, G.S., Doröz, Y., Sunar, B., Savaş, E. (2015). Depth optimized efficient homomorphic sorting. In International Conference on Cryptology and Information Security in Latin America. LATINCRYPT, Guadalajara.
Chen, H. (2017). Optimizing relinearization in circuits for homomorphic encryption [Online]. Available at: https://arxiv.org/abs/1711.06319.
Chen, H., Laine, K., Player, R., Xia, Y. (2018). High-precision arithmetic in homomorphic encryption. In Cryptographers Track at the RSA Conference. RSA, San Francisco.
Cheon, J.H., Coron, J., Kim, J., Lee, M.S., Lepoint, T., Tibouchi, M., Yun, A. (2013). Batch fully homomorphic encryption over the integers. In EUROCRYPT. IACR, Athens.
Cheon, J.H., Kim, M., Lauter, K. (2015). Homomorphic computation of edit distance. In International Conference on Financial Cryptography and Data Security. FC, San Juan.
Cheon, J.H., Kim, A., Kim, M., Song, Y. (2017). Homomorphic encryption for arithmetic of approximate numbers. In ASIACRYPT. IACR, Hong Kong.
Cheon, J.H., Han, K., Kim, A., Kim, M., Song, Y. (2018). Bootstrapping for approximate homomorphic encryption. In Eurocrypt. IACR, Tel Aviv.
Chillotti, I., Gama, N., Georgieva, M., Izabachène, M. (2016). Faster fully homomorphic encryption: Bootstrapping in less than 0.1 seconds. In 22nd International Conference on the Theory and Application of Cryptology and Information Security. IACR, Hanoi.
Chillotti, I., Gama, N., Georgieva, M., Izabachène, M. (2017). Faster packed homomorphic operations and efficient circuit bootstrapping for TFHE. In 23rd International Conference on the Theory and Applications of Cryptology and Information Security. IACR, Hong Kong.
Chillotti, I., Gama, N., Georgieva, M., Izabachène, M. (2020). TFHE: Fast fully homomorphic encryption over the torus. Journal of Cryptology, 33(1), 34–91.
Dinur, I., Liu, Y., Meier, W., Wang, Q. (2015). Optimized interpolation attacks on LowMC. IACR, Cryptology ePrint Archive, 418 [Online]. Available at: https://eprint.iacr.org/2015/418.
Doröz, Y., Ozturk, E., Sunar, B. (2013). Evaluating the hardware performance of a million-bit multiplier. In Euromicro Conference on Digital System Design. IEEE, Los Alamitos.
Doröz, Y., Shahverdi, A., Eisenbarth, T., Sunar, B. (2014). Toward practical homomorphic evaluation of block ciphers using prince. In International Conference on Financial Cryptography and Data Security. WAHC, Christ Church.
Doröz, Y., Hu, Y., Sunar, B. (2016). Homomorphic AES evaluation using the modified LTV scheme. Designs, Codes and Cryptology, 80, 333–358 [Online]. Available at: https://doi.org/10.1007/s10623-015-0095-1.
Ducas, L. and Micciancio, D. (2015). FHEW: Bootstrapping homomorphic encryption in less than a second. In 34th Annual International Conference on the Theory and Applications of Cryptographic Techniques. IACR, Sofia.
Duval, S., Lallemand, V., Rotella, Y. (2016). Cryptanalysis of the FLIP family of stream ciphers. In 36th Annual International Cryptology Conference. IACR, Santa Barbara.
ElGamal, T. (1985). A public key cryptosystem and a signature scheme based on discrete logarithms. IEEE Transactions on Information Theory, 31(4), 469–472 [Online]. Available at: http://www.ams.org/mathscinet-getitem?mr=86j.
Espitau, T. and Joux, A. (2020). Certified lattice reduction. Advances in Mathematics of Communications, 14(1), 137–159.
Fan, J. and Vercauteren, F. (2012). Somewhat practical fully homomorphic encryption. Report, Cryptology ePrint Archive [Online]. Available at: http://eprint.iacr.org/2012/144.
Fontaine, C. and Galand, F. (2007). A survey of homomorphic encryption for nonspecialists 3. EURASIP Journal on Information Security, 1, 1–15.
Fouque, P.-A., Hadjibeyli, B., Kirchner, P. (2016). Homomorphic evaluation of lattice-based symmetric encryption schemes. In International Computing and Combinatorics Conference. COCOON, Ho Chi Minh City.
Gentry, C. (2009). A fully homomorphic encryption scheme. PhD Thesis, Stanford University, Stanford.
Gentry, C., Halevi, S., Smart, N.P. (2012). Homomorphic evaluation of the AES circuit. In 32nd International Cryptology Conference. IACR, Santa Barbara.
Häner, T. and Soeken, M. (2020). Lowering the t-depth of quantum circuits by reducing the multiplicative depth of logic networks [Online]. Available at: https://arxiv.org/abs/2006.03845.
Herbert, V., Biswas, B., Fontaine, C. (2019). Design and implementation of low-depth pairing-based homomorphic encryption scheme. Journal of Cryptographic Engineering, 9, 185–201.
Kuaté, D.N. (2018). Cryptographie homomorphe et transcodage d’image/video dans le domaine chiffré. (Homomorphic encryption and image/video transcoding in the encrypted domain). PhD Thesis, Université Paris Saclay, Paris.
Kuaté, D.N., Canard, S., Sirdey, R. (2018). Towards video compression in the encrypted domain: A case-study on the H264 and HEVC macroblock processing pipeline. In 17th International Conference in Cryptology and Network Security. CANS, Naples.
Lee, D., Lee, W., Oh, H., Yi, K. (2020). Optimizing homomorphic evaluation circuits by program synthesis and term rewriting. In 41st ACM SIGPLAN Conference on Programming Language Design and Implementation. ACM, London.
Lepoint, T. and Naehrig, M. (2014). A comparison of the homomorphic encryption schemes FV and YASHE. In AFRICACRYPT. IACR, Marrakech.
Méaux, P., Journault, A., Standaert, F.-X., Carlet, C. (2016). Towards stream ciphers for efficient FHE with low-noise ciphertexts. In Annual International Conference on the Theory and Applications of Cryptographic Techniques. IACR, Vienna.
Migliore, V., Seguin, C., Mendez Real, M., Lapotre, V., Tisserand, A., Fontaine, C., Gogniat, G., Tessier, R. (2017). A high-speed accelerator for homomorphic encryption using the Karatsuba algorithm. ACM Trans. Embedded Comput. Syst., 16(5), 138:1–138:17.
Migliore, V., Mendez Real, M., Lapotre, V., Tisserand, A., Fontaine, C., Gogniat, G. (2018). Hardware/software co-design of an accelerator for FV homomorphic encryption scheme using Karatsuba algorithm. IEEE Transactions on Computers, 67(3), 335–347.
Naehrig, M., Lauter, K.E., Vaikuntanathan, V. (2011). Can homomorphic encryption be practical? In Conference on Computer and Communications Security. ACM, Chicago, 113–124.
Paillier, P. (1999). Public-key cryptosystems based on composite degree residuosity classes. In International Conference on the Theory and Applications of Cryptographic Techniques. IACR, Prague.
Paindavoine, M. and Vialla, B. (2015). Minimizing the number of bootstrappings in fully homomorphic encryption. In International Conference on Selected Areas in Cryptography. SAC, New Brunswick.
Pedrouzo-Ulloa, A., Troncoso-Pastoriza, J.R., Pérez-González, F. (2016). Image denoising in the encrypted domain. In International Workshop on Information Forensics and Security (WIFS). IEEE, Abu Dhabi.
Peikert, C. (2016). How (not) to instantiate Ring-LWE. In International Conference on Security and Cryptography for Networks. SCN, Amalfi.
Pöppelmann, T., Naehrig, M., Putnam, A., Macias, A. (2015). Accelerating homomorphic evaluation on reconfigurable hardware. In Cryptographic Hardware and Embedded Systems. IACR, Saint-Malo.
Rechberger, C. (2016). The FHEMPCZK-cipher zoo. FSE Rump Session, 22 March.
Rivest, R.L., Adleman, L., Dertouzos, M.L. (1978). On data banks and privacy homomorphisms. In Foundations of Secure Computation, DeMillo, R.A. (ed.). Academia Press, New York.
Sinha Roy, S., Järvinen, K., Vercauteren, F., Dimitrov, V., Verbauwhede, I. (2015). Modular hardware architecture for somewhat homomorphic function evaluation. In Cryptographic Hardware and Embedded Systems. IACR, Saint-Malo.
Tan, X. and Triggs, B. (2007). Enhanced local texture feature sets for face recognition under difficult lighting conditions. In Analysis and Modeling of Faces and Gestures, Zhou, S.K., Zhao, W., Tang, X., Gong, S. (eds). Springer, Berlin/Heidelberg.
Yasuda, M., Shimoyama, T., Kogure, J., Yokoyama, K., Koshiba, T. (2015). New packing method in somewhat homomorphic encryption and its applications. Security and Communication Networks, 8(13), 2194–2213.
- 1 Symmetric homomorphic systems do exist, but are extremely rare. For this reason, in this chapter, homomorphic encryption systems are presumed to be asymmetric, with two distinct keys pk (public, to encrypt) and sk (private, to decrypt). However, our presentation can be transposed to symmetric systems if necessary by considering that the encryption key pk and the decryption key sk are both secret. Moreover, for reasons of simplicity, we shall not explicitly specify the keys used when this is obvious.
- 2 An encryption system is said to be malleable when the encrypted version of a message, HomEnc(m), can be used to calculate the encrypted version of another message of the form HomEnc(P(m)) for a certain function P, without ever needing to know the plaintext value of the message m. This property is seen, a priori, as a weakness in terms of security, but can be tolerated if the gain in terms of functionality is sufficient to compensate for the decrease in security.
- 3 The basic RSA scheme is homomorphic, but is not considered a good encryption scheme as such, because it is not semantically secure; the OAEP version, which is semantically secure, is no longer homomorphic.
- 4 Available at: https://www.ssi.gouv.fr/administration/guide/cryptographie-les-regles-du-rgs/.
- 5 Available at: https://github.com/homenc/HElib.
- 6 Available at: https://www.microsoft.com/en-us/research/project/microsoft-seal/ and https://github.com/Mi-crosoft/SEAL.
- 7 Available at: https://github.com/CryptoExperts/FV-NFLlib.
- 8 Available at: https://github.com/quarkslab/NFLlib.
- 9 Available at: https://github.com/tfhe/tfhe.
- 10 Available at: https://github.com/snucrypto/HEAAN.
- 11 Available at: https://palisade-crypto.org/.
- 12 Available at: https://github.com/CEA-LIST/Cingulata.
- 13 Available at: http://www.eecs.berkeley.edu/ãlanmi/abc/.
- 14 It is assumed that the reader is familiar with cryptographic security notions (semantic security, IND-CPA, IND-CCA, etc.). Further details and explanations may be found in Fontaine and Galand (2007).
- 15 Available at: www.ssi.gouv.fr/administration/guide/cryptographie-les-regles-du-rgs/.
- 16 Available at: www.keylength.com.
- 17 Available at: https://lwe-estimator.readthedocs.io/en/latest/.
- 18 Available at: www.openimaj.org.
- 19 If this is not the case, a homomorphic cryptosystem with the capacity to evaluate a single level of multiplication will suffice (Bouzerna et al. 2016).
- 20 Available at: https://www.physionet.org/physiobank/database/mitdb.
- 21 Microsoft Research, IBM, Intel, Alibaba, Inpher, CryptoExperts, CEA, NIST, EPFL and MIT, among others: a full list can be found at https://homomorphicencryption.org/participants.