
3
The Sphere of Discourse and Text
3.1. Discourse analysis and pragmatics
3.1.1. Fundamental concepts
As noted by [VAN 85], the practice of analyzing speech, literature or simply language goes back more than 2000 years. The first works had a marked normative dimension and were located in the domain of rhetoric. They were intended to formulate rules for planning, organizing and delivering spoken communications in a legal or political context.
In the context of modern works in linguistics, notably since Zellig Harris [HAR 52], it is generally accepted that the sentence cannot be the maximal unit of linguistics studies. Consequently, many linguistic works consider that linguistic productions are made up of a set of interconnected utterances whose interpretation depends on the situation of communication. Some use the term discourse to designate such a set. Unfortunately, this term is one of the most polysemic terms that exists. The most precise definitions that have been proposed for it are those that have been formulated negatively in opposition to other linguistic entities.
One of the reasons behind this divergence is the multitude of movements and disciplines that have an interest in extra-sentential phenomena: functional linguistics, cognitive linguistics, sociolinguistics, textual linguistics, discourse analysis, etc. The common point between all of these approaches is the rejection of the Chomskyan idea expressed in his Standard Theory [CHO 57] according to which the sentence is the maximal linguistic unit.
Before addressing the key concepts in the domain of discourse analysis, it is pertinent to review the terminology.
3.1.1.1. Discourse versus speech
Like the French linguist Gustave Guillaume, some consider that discourse, being the language implemented or the language used by the speaking subject, can be considered to be a synonym of speech (see [DUB 71]). Linguists in this current prefer the opposition language/discourse to the Saussurian dichotomy language/speech because the term speech refers exclusively to spoken language.
3.1.1.2. Discourse versus sentence
Between the sentence and discourse, the boundaries seem relatively clear because it is generally accepted that discourse is a supra-sentential entity. However, as noted in [BEN 66], the nature of relationships between sentences is completely different from relationships between sub-sentential units like phonemes, morphemes or syntactic units. This makes works about discourse a specific domain within linguistics.
3.1.1.3. Discourse versus narrative text
According to the French linguist Emile Benveniste, the situation of utterance production is the difference between discourse and narrative text. Normally constituted discourse refers to the space-time of the utterance production and the here and the now refer to the place and time of the utterance production, respectively (see [LAC 97] for a detailed discussion). The narrative text, generally a set of written utterances, is characterized by its detachment from the situation of utterance production with a total absence of the personal pronoun I. Thus, in a narrative text, the third person is most common and the past tenses are used, such as the simple past and past anterior.
3.1.1.4. Discourse versus text
The most delicate distinction concerns the differentiation between discourse and text. Indeed, several currents differ on this subject. In order to give an idea of these divergences, Table 3.1 summarizes the main perspectives.
All of these points of view have advantages and disadvantages. From an automatic processing perspective, it seems that the point of view presented in [GAR 03] is particularly pertinent. Like Kamp and Reyle [KAM 93], he considers that discourse is a sequence of connected sentences and that this sequence has its own semantic representation. Therefore, the interpretation of discourse is considered to be an incremental process, where the semantic representation of a sentence must be connected to that of preceding sentences. A text, considered as a sequence of discourses, is defined according to the nature of the connections that exist between the discourses that compose it. This led Joaquín Garrido [GAR 03] to consider that the nature of these connections is what determines the genre of the text.
Table 3.1. Some perspectives on the difference between text and discourse
| Text | Discourse | |
| 1 | The text is composed of sentences that have the property of being grammatically cohesive. Text analysis focuses on the cohesion. | The discourse is made of utterances, sentences used in a specific context with a given communicative goal, which have the property of being coherent. Discourse analysis focuses on coherence. |
| 2 | The text is a physical object without meaning. | The discourse is a process whose meaning emerges from the interaction between the reader and the text. |
| 3 | Texts are written. | Discourse is from the domain of oral communication. |
| 4 | Text analysis is part of discourse analysis. | Discourse analysis pertains to all extra-sentential phenomena including those observed in texts. |
Some, like Richard Party [PAT 93], believe that discourse can be defined as an entity that has its own characteristics like uniqueness, continuity, intentionality and topicality. Uniqueness allows discourse to be perceived as an independent whole. Continuity, guaranteed by the presence of particular elements like discursive connectors, emerges from extra-sentential semantic phenomena. Intentionality focuses on the fact that discourse is above all an act of communication through which the locutor interacts with one or several interlocutors. Topicality pertains to the fact that a discourse must concern a specific subject that is identifiable by the locutor.
Generally, the actualization of discourse involves several levels of structuring at the same time. Such complexity gives rise to individual variations that are not always possible to predict, hence the difficulty of formally modeling discourse. Similarly, this multi-level nature opens the door to fairly varied interdisciplinary works with the objective of clarifying its different facets: psychological, social, ethnological, etc.
3.1.2. Utterance production
Benveniste considers utterance production to be a language mobilization process for the locutor. In other words, he considers it as an individual act of using language in a communication context whose final product is an utterance; the utterance being a linguistic entity directly related to the sentence. The sentence is a non-actualized language entity and therefore completely independent of all utterance production situations and their interpretive implications. The utterance, well-anchored in the situation of utterance production, finds its possible interpretations restricted and sometimes reduced to a single possible interpretation. In a certain way, the utterance can be considered to be a sentence anchored in a situation of utterance production.
3.1.2.1. Deictics (shifters)
The anchoring of utterances in a discourse is ensured by a particular category of words: deictics or shifters. This is a class of words that do not have a proper reference in language and only receive a meaning when they are included in a message. Linguists like Benveniste and Jakobson studied how facts of language relate to the context of utterance production. Deictics include a relatively large set of grammatical categories such as demonstratives, adverbs of time and space, personal pronouns and articles.
Deictics can refer to several aspects of the elocution context like:
- – The speaking subject or the modalization. For example, I told it to him. Other categories of words like adjectives and possessive pronouns like my, mine or Papa can also be associated with this category.
- – The time of the utterance production through words like now, today, tomorrow, in a week at the moment of the utterance. For example: The weather is nice today. Jakobson considered that because of their capacity to signal an anterior or posterior event at the time of the utterance production of the message, verbal tenses should also be included in this category.
- – The space in which the utterance is produced through words like here, beside and over there. For example, you can set that here.
3.1.2.2. Participants in a communicative event
In the classic models of communication, such as those presented by [DE 16, SHA 48], two participants are involved in the communication. One is charged with encoding or producing and the other is charged with decoding or understanding. In the context of utterance production, things are not so simple. Such analyses have identified four roles that can be filled by one or more people according to the case.
- – The locutor is the one that physiologically emits the (oral) message, or the writer or author of written messages. It is worth mentioning that the subject of the utterance (grammatical subject) does not necessarily correspond to the subject of the utterance production (locutor). For example, in the sentence Paul eats an apple, Paul is the subject of the utterance whereas the subject of the utterance production or the locutor is the person who pronounced this utterance.
- – The utterer is at the center of the communicative act because this is the participant who assumes the responsibility for the content of the message. The locutor and the utterer can be the same person or a different person.
- – The allocutor is the participant to whom the message is materially intended. This is sometimes also called the receiver or the recipient.
- – The addressee is the participant for whom the message is formulated. Note that, unlike the utterer, which is always singular because even in the case of we there is always an I behind it, the addressee can be plural, because a theoretically unlimited number of people can be addressed at the same time.
An extreme case of a communicative act is a monologue, when a person of sound mind talks to himself. In this situation, all of the participants are the same person. This observation is only valid in true monologues that can be observed in real life. In false monologues, which are relatively frequent in artistic works like operas, novels and plays, the monologue is used to reveal the feelings or thoughts of a character to the audience. In that case, things are quite different. First, the locutor and the utterer are no longer the same person: the locutor is the actor and the utterer is the character being played by the actor, and sometimes the author of the text performed. Second, even if the person is talking to himself, the true addressee of the message is the audience.
Another case that should be mentioned is quotes or indirect or reported speech. In this case, the locutor borrows the comment of another person, be this in a literal way or not. For example, in the case of [3.1], the utterance is pronounced by the professor, who is in fact the locutor, but the content is visibly not assumed by the professor. Rather, it is attributed to Michael, who is considered the utterer.
The history professor said to his students, “Your classmate Michael wrote, ‘World War I took place in the 19th century.’” [3.1]
Note that the distinction between the utterer and the locutor is not always clear. Indeed, between a total assumption and a complete detachment from the message’s content, there are nuances that can be configured by the locutor, notably through the use of the conditional or modal adverbs like most likely, maybe and probably.
There are also many cases where the allocutor and the addressee do not correspond to the same participant. This case is especially common in journalistic interviews on television or in the written press. The interviewee, in responding to questions, speaks to the journalist, the interviewer, who is the allocutor, but the real addressee of the message is the audience who watches or reads the interview.
When a message involves several participants (voices) during its production and/ or is intended for different audiences during its reception, this is called polyphony. Initially observed by Charles Bally and Mikhail Bakhtin, this phenomenon was taken up and developed by [DUC 87]. Note that Gérard Genette, the eminent French literary theorist, was also interested in similar cases in literature where it is possible to distinguish between the author, character and locutor. These literary studies were conducted under the label of narratology [GEN 07].
Finally, it is important to mention that the distinction presented here is not unanimously accepted by the community. For more details about the differences surrounding this issue, consult [RAB 10].
3.1.2.3. Time and space adverbials
In a discourse, a chronology makes it possible to situate events in relation to the moment of utterance production. It can be marked through a multitude of grammatical means such as articulators like first of all, in the first place, then, having said that and finally; conjunctions like when, once and after; time adverbs like today, yesterday and tomorrow; and nouns indicating time like Monday, night and evening. The use of verbal tenses like the present, future and past is the simplest way to express the chronological order of events.
The spatial situation of events is generally indicated by space adverbials like here, there, elsewhere and around. The adverbial here can be analyzed as the place where the I commits the act of utterance production.
3.1.3. Context, cotext and intertextuality
The factors examined above are, without a doubt, elements that are essential to what can be called context. However, the concept of context can extend far beyond these factors. As stated in [GOR 09], the concept of context is the main reason for the divergences between the different approaches to discourse analysis.
For example, in the analysis approach to verbal interactions presented in [KER 96], the concept of context includes the following elements: a spatiotemporal framework, a goal and participants.
The spatiotemporal framework, or the place where the interaction occurs, directly affects the nature of the interaction in various ways. On the one hand, the physical nature of the place (public place, open, office, etc.) can restrict the subjects and the way in which they can be addressed. For example, people tend not to discuss intimate topics like family problems in public places. On the other hand, the social, religious or institutional role of a place implies particular subjects and even a certain level of language. For example, people tend to be more formal and avoid using vulgar words in places of worship or a courthouse.
As for the goal, there is a distinction between transactional interactions that have a specific goal, like purchasing a plane ticket or requesting information about a given subject, and relational interactions whose only aim is to maintain a social relation, like chatting with friends.
Several factors intervene when it comes to determining the role of the participants:
- – The number: people do not speak in the same way as in a one-on-one conversation when they are in front of a large audience like at a conference or in a televised interview.
- – The individual properties: factors like age, gender and social status considerably affect the linguistic register to adopt.
- – Familiarity: sometimes called horizontal distance, this factor is related to the change in linguistic behavior depending on the degree of familiarity between the interlocutors. For example, people tend to be more formal with strangers than with people they know well or are close with like friends, work colleagues or family members.
- – The cultural context: cultural factors can play a very important role in the choice of the form of discourse. The status of elderly people and women is not the same in all societies. Similarly, some societies are very hierarchized, especially Eastern societies like India and Japan, where very polished language is used when addressing someone of a social rank that is considered superior.
The concept of cotext concerns textual context or the constraints that one part of a discourse exercises on the subsequent parts. Thus, aside from the initial part of a discourse, the interpretation of any part of a discourse must take the previous parts into consideration. To a certain extent, the cotext is a sub-type of the context. Consider passage [3.2], where the interpretation of the pronoun we as equal to (I + Samir + his friend Steven) cannot occur without using information conveyed by the previous part of the text.
I spent a nice day in Normandy with my friend Samir and his friend Steven. To return to Paris, we took the train at 8 p.m. [3.2]
The concept of intertextuality or transtextuality1 is used in situations where another conversation, discourse or text is referenced. This concept has been the topic of several studies, especially in literature where they focus on the relationships that exist between a text and pre-existing texts to which they refer in order to oppose or support them. The intertext of a given text is the set of writings to which the text is related, explicitly or not.
3.1.4. Information structure in discourse
3.1.4.1. Topic and comment
The topic is what the text/discourse is talking about. It is part of the information that is generally accepted or known by the interlocutors, either because it is provided by the text/discourse prior or because it is shared by the interlocutors. This information can concern generalities about the world like the sky is blue, gold is expensive and the moon rotates around the Earth, or individual information shared by the members of a given group such as members of the same family, work colleagues or members of a sports team.
The topic depends on the order of the sentence. Thus, two sentences that are considered semantically equivalent can have different topics if their elements are ordered differently. For example, in sentences [3.3], the topic in (a) is the agent the cat which in (b) becomes the patient the mouse:
| a) The cat chased the mouse. | Topic: the cat. |
| b) The mouse was chased by the cat. | Topic: the mouse. [3.3] |
In the case of sentences with an indefinite subject, the semantically empty subject has only a purely formal role in the sentence and consequently does not have a topical role (see sentences [3.4]):
| – It is raining. | Topic: the whole proposition. |
| – There is bread. | Topic: bread. [3.4] |
The comment or rheme concerns what the text says about the topic. It consists of new information that the text provides about the topic (see [3.5]).
| – Saturday morning, a car hit a small cat. | Comment: a small cat |
| – It was Adeline who did all the work. | Comment: Adeline. [3.5] |
3.1.4.2. Topical progression
Because a coherent text does not necessarily concern only one subject or topic, it is essential to study the mechanisms of topical progression. Topical progression pertains to the relationship between the topic of a sentence with the topic and comment of previous sentences. Four forms of topical progression are often cited in the literature: constant topic progression, linear topic progression, derived topic progression and inserted topic progression.
In the case of constant topic progression, the topic is shared by several successive sentences. This type of progression is particularly useful when describing an object or a character by mentioning its different properties and actions. This form of succession is commonly observed in narrative texts. Very often, the grammatical topic is confused with the grammatical subject. The use of anaphora is the natural method for this kind of repetition. Schematically, this kind of progression can be presented as shown in Figure 3.1.
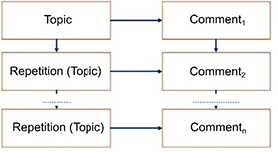
Figure 3.1. Diagram of constant topic progression
To make this type of progression clearer, examine text [3.6] where the topic Fabrice is repeated in the sentences either by the personal subject pronoun he or by the possessive adjective his:
Fabrice is a graduate of the Faculty of Pharmacy in Boston.
Two years ago, he went to do a six-month internship in
Copenhagen at a famous Danish company. There, he learned
many things about the pharmaceutical industry. Upon his
return to the US, he managed to get a good job in New York. [3.6]
In linear topic progression, each sentence activates another one. This occurs through a comment/topic exchange: the comment of one sentence becomes the topic of the following one and so on. A diagram of this kind of progression is provided in Figure 3.2.
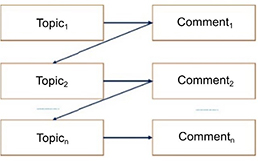
Figure 3.2. Diagram of linear topic progression
Ashley listened attentively to the words of Marilyn, her best friend. These words conjured up the bitter memory of her breakup with her ex-fiancé Mark. It was this break-up that pushed her to attempt suicide and then to shun everything to do with men. [3.7]
With derived topic progression, there is a main topic presented first and then derived (less central) topics follow. Often, the relationship between the main topic and the derived topics is meronymic (whole/part) or hyponymic (type/sub-type). See Figure 3.3 for the diagram of this progression.
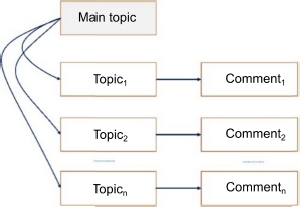
Figure 3.3. Diagram of derived topic progression
In passage [3.8], the relationship between the topic of the first utterance, Venice, and the topics of the subsequent utterances is meronymic. Canals, castles and gondolas are all components of the city of Venice:
Venice is by far the most beautiful city I have ever visited. Its canals made me forget about the stress of everyday life. Its marble castles made me think of the adventures in One Thousand and One Nights. The gondolas reminded me of the romantic period of my engagement. [3.8]
Finally, with inserted topic progression, it is sometimes possible to insert a local topic related to the main topic of the text within a constant topic progression. This results in the diagram provided in Figure 3.4.
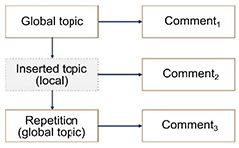
Figure 3.4. Diagram of inserted topic progression
Consider example [3.9] to illustrate this kind of progression. In this text, the discursive topic is Frank’s car. A new local topic is added in the following sentence, which is Frank repeated by the anaphor this man. This does not prevent new comments on the discursive topic from being added to the third utterance:
Frank’s car is really superb. This man, who is passionate about mechanics and everything related to the automobile industry, takes great care with what he owns. Even though it was manufactured in the 1960s, the car is in excellent shape. [3.9]
It should be noted that, naturally, authors do not hesitate to combine the types of topical progression to avoid monotony in their texts even if a particular form of progression generally prevails depending on the genre of the text. This wealth of types of topical progression makes the automatic detection of topics addressed by a text particularly delicate work.
3.1.4.3. The implicit, the presupposed and the assumed
The interpretation of an utterance does not only occur through the elements that are explicitly present. Often, it requires inferences about new elements (not given in the sentence) from the given elements. This information is called the implicit. The study and formalization of these interpretive mechanisms of this kind of utterance attracted the interest of several researchers (see, for example, [KEE 71, KEM 75, DUC 69]).
For example, from an utterance as simple as Close the door, we can infer the following information about this utterance:
- a) The locutor has a certain authority over the allocutor, as indicated by the use of the imperative.
- b) There is a door in a space nearby and it is open or at least that is what the locutor thinks.
- c) The locutor thinks that the allocutor is capable of closing the door.
- d) The locutor has a specific goal behind this request: he is cold, he wants to have a private conversation with someone in the room, he wants to start his break, etc.
In this example, the inferences a, c and d were made based on the utterance context whereas b can be inferred in all possible contexts because it depends on the verb to close. Some researchers prefer to talk about the implicit of the utterance production (the information in a, c and d) and the implicit of the utterance (the information in b). A classification on similar criteria consists of distinguishing two sub-types of the implicit: presupposition and the assumed.
A presupposition is information deduced from a lexical unit in the utterance. Such a unit could be an adverb like again, already or always that suggests an event prior to the moment of utterance production. It can also consist of an adjective, a verb, a superlative, etc. Consider the examples in Table 3.2.
Table 3.2. Examples of sentences with their presuppositions
| Sentence | Presupposition(s) |
| Paul still smokes. | Paul used to smoke before. |
| Michael does not smoke in the house anymore. | Michael used to smoke in the house before. |
| Mary was not feeling well last night. | She was feeling well before that time. |
| “Star Wars” is Jeff’s favorite film. | Jeff likes other films. |
| Cycling is Joe’s favorite sport. | Joe likes other sports. |
| William is smart but Arnold is strong. | William is not strong. |
The main difference between the assertion and the presupposition is that only the assertion is the focus, which is why it alone is affected by negation. For example, in The volcano in Paris is erupting, there are two distinct items: 1) there is a volcano in Paris (presupposition) and 2) this volcano is erupting (assertion). In the negative form the volcano in Paris is not erupting, it is the assertion that is refuted, the fact that the volcano is erupting. The presupposition remains valid, although this does not necessarily mean that it is true.
On the other hand, the assumed is information that the locutor implies without giving it and without the presence of a linguistic cue in the utterance that would make it possible to deduce it. Consider utterance [3.10] that can receive one or more of these interpretations: let’s go to another location, close the window, turn down the volume on the television, I cannot hear you clearly.
It is very noisy here. [3.10]
Thus, the addressee of the message with an implicit is obliged to infer the information because, taken literally, it does not have any significance for him or at least it seems marginal. In other words, in this case, the allocutor is entirely responsible for the interpretation constructed. Consequently, it can be said that, unlike the presupposition, the locutor has the possibility of negating the assumed. In practice, because it does not directly engage the locutor, the implicit is a very good way to make an observation to someone or to make a potentially embarrassing request.
3.1.4.4. Given versus new
The dichotomy given/new concerns what is known in opposition to what is unknown. Traditionally, two types are distinguished by the use of syntactic criteria: indefinite articles are used to mark nominal groups that correspond to unknown entities and after their introduction into the discourse, these entities are referred to by definite articles or anaphora ([HAR 51] cited in [BRO 88]).
Today, there are several diverging points of view regarding the specification of given or unknown information [CHA 76, CHA 87, HAL 70]. This presentation will adopt that of [PRI 81] who considers the different aspects of the problem. Starting from the observation of the simple dichotomy of new/old to consider the complexity of the organization of the information in the discourse, Prince proposes a taxonomy that includes three classes: new, inferrable and evoked. She proposes a tree diagram of this taxonomy, which is shown in Figure 3.5.
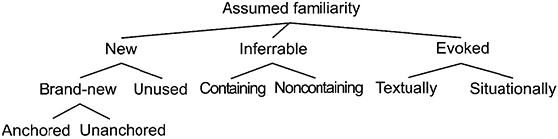
Figure 3.5. Prince’s taxonomy [PRI 81]
The term new concerns new information introduced to the discourse. There are two sub-types: new information for the interlocutor and new information for the discourse. In the first case, a completely new entity is introduced for the interlocutor for which he must entirely create the mental representation. In the second case, where an entity that is already known to the locutor is introduced into the discourse, the interlocutor must update his representation of the discourse to include this new entity. Consider the utterances in [3.11]. Assuming that these utterances are found at the start of a discourse, the entities the sea and Paul Broca, newly introduced in the discourse, are assumed to be known by the interlocutor. On the other hand, the entities a person and a store are new to both the interlocutor and the discourse. It should also be noted that Prince distinguishes between two types of these entities: anchored entities and unanchored entities. Anchored entities including the ones such as a person are considered as such because they are syntactically related to a nominal group that is not new, I:
- a) The sea is very rough today. [3.11]
- b) Paul Broca was born in Gironde.
- c) A person with whom I traveled told me she read your book.
- d) I entered a store where the manager was very angry.
Evoked entities are both known by both interlocutors (shared or supposedly known knowledge between the two interlocutors) and already introduced into the discourse. Prince distinguishes two sub-types of evoked entities: textually evoked entities and situationally evoked entities. Textually evoked entities are entities that have already been mentioned in the text, often by means of third person pronouns or a nominal group with a definite article. Situationally evoked entities are entities that have been indicated by a person, time or space deictic and whose interpretation is anchored by the situation.
Contrary to evoked entities, inferred entities do not have an explicit antecedent. Their presence can be guessed using an element that serves as an indirect antecedent. As emphasized in [CHA 76], these entities, which are not exactly new, are not entirely given either, because they cannot be replaced by an anaphor. Thus, inferred entities can be considered to be an intermediary category between given and new. For example, in [3.12], the use of a definite article before cotton wool indicates that even if this entity is being introduced for the first time in the discourse, its presence in the first aid kit can be inferred logically. This means that first aid kit can be considered to be an indirect antecedent of cotton wool:
We checked the first aid kit. Everything was there but the cotton wool was missing. [3.12]
3.1.5. Coherence
Coherence is a property of the content of a text that assembles words and sentences in one or more connected discourses. It is this property that allows a text to be perceived as a unit equipped with a meaning that conforms to a certain vision of the world. From the point of view of its content, a text can be considered to be a set of concepts and relations [DE 81]. These concepts, viewed as cognitive content, can be activated or, inversely, inhibited depending on their relevance to the context and their relations to the other concepts. Consider the texts [3.13] and [3.14]:
- – The sonata, from the Italian sonare that means to perform with an instrument, is a musical composition intended for one or more instruments. In France, some particular forms of the sonata like the cyclic form and theme form have been used by composers like Hector Berlioz and Gabriel Fauré. [3.13]
- – The bicycle is an excellent mode of transportation in both urban and rural environments. It is also one of the most commonly practiced sporting activities in winter, especially in countries like Canada and Iceland. The increase in train accidents in the south-west of the country is causing panic among travelers. [3.14]
The utterances in [3.13] seem logically related, unlike the utterances in [3.13]. Therefore, it can be said that [3.14] is a coherent text whereas [3.14] is not.
The concept of coherence is closely related to the quantity of information shared between the locutor and the addressee. Depending on the contextual information shared between the locutor and the addressee, a discourse can be determined to be coherent or not. Consider the mini dialogue in [3.15]. This mini dialogue can only be perceived as coherent if the addressee of utterance B (A) knows that John plays a main role in the transportation process. For example, as the driver of the truck transporting the merchandise:
- – A Did you transport the merchandise to the store?
- – B John went to see his father at the hospital. [3.15]
Among the most commonly observed relationships between the utterances of a coherent discourse are relations of causality and relations that express a chronological order.
The relation of causality concerns the way in which a situation or an event affects the conditions of realization of another situation or event. Consider utterance [3.16] where there is a logical cause and effect relation between (cause: driving with concentration) and (effect: Ralph’s victory):
Ralph drove with such concentration that he won the race. [3.16]
When the information is conveyed by several sentences, these kinds of relations can be marked explicitly by the use of discursive connectives that indicate deductions such as therefore, then, because of this, that is why and consequently (see example [3.17]):
Ralph drove with a great deal of concentration. That is why he won the race. [3.17]
Note that the semantic nature of the relation between the two propositions of cause and effect can vary considerably. For example, this relation can take the form of:
- – Logical consequence: if John was on a trip the day of the crime then we can say that it was not him that killed Mary.
- – The ultimate objective of an action: Paul is working hard at school to become an engineer.
- – The end and the means: by calling on his colleague, the technician was able to repair the machine.
Relations of chronological order concern the order of events. Sometimes, this order is hidden behind a causality relation [3.18a] but often it consists of a series of actions or events [3.18b]:
- a) The soldier was shot in his left leg and then he fell to the ground. (chronology and causality). [3.18]
- b) He called the director and then he went to dine in the restaurant on the corner. (simple succession).
3.1.6. Cohesion
Traditionally associated with the works of [HAL 64, HAS 68], the term cohesion can be defined as the set of means necessary for the construction of relations that transcend the level of grammar within a discourse [HAL 94] (see [MAR 01] for a detailed representation). Unlike coherence, cohesion is a property that concerns the structure of a text, notably its linguistic form, not its content. It is an objectively observable dimension because it is based on concrete elements. Cohesion can be seen as a necessary but not sufficient condition for coherence. In other words, on its own, cohesion is insufficient to interpret a discourse. Its role is limited to improving comprehension.
3.1.6.1. Lexical cohesion
To repeat a word from a previous sentence in a new sentence, anaphora seems the most natural means. However, two other important processes can be cited: repetition and the use of a lexical chain.
The simple repetition of a lexical unit several times is shown in [3.19]. This kind of repetition is often used in literature in order to emphasize something or to provide a sense of monotony or weight.
Sam is looking at the flowers. Sam is walking in the garden. Sam is going to school. [3.19]
A lexical chain consists of one word with lexical substitutes that are distributed throughout a given text. The relationship between the lexical units in a chain can be synonymy, antonymy or belonging to the same lexical field. Consider fragments [3.20]:
The dog is an incredible animal. Man’s best friend does not hesitate to risk its life to save its master. (Synonym)
The dog is an incredible animal. Sometimes, this canine/mammal/carnivore does not hesitate to take risks to save its master.
(Hyponym/Hyperonym) [3.20]The dog is an incredible animal. Like the cat, it is a top choice for a pet for many people. (Semantic field: domestic animals)
3.1.6.2. Anaphora
Anaphora is a very important way to ensure a link between different discursive units in speech and in writing. However, its role is more central in speech than in writing due to the dialogic structure that implies an exchange between two interlocutors and therefore requires referencing previously mentioned fragments of discourse.
The definition of anaphora that is generally given is that anaphora is a mechanism that relates two linguistic units. The first unit is often pronominal (a personal or demonstrative pronoun) and is called the anaphor. The second unit is an anterior segment, typically a nominal group (see [DUB 71] for example). Consider utterance [3.21a]. In this utterance, the nominal group Peter is repeated by the anaphor him. Note that sometimes the order can change, which means that the anaphor can come before or after the nominal group [3.21b]. This is called cataphora:
- a) Peter, I see him often.
- b) I often see him, Peter. [3.21]
A more specific definition of anaphora was proposed in [KRA 00]. It is based on several criteria to interpret anaphora like contextual dependency, the type of antecedent, the type of relation between the anaphor and the antecedent, and the interval of interpretations authorized by the anaphora. In a dialogue, two types of antecedents can be distinguished. The immediate antecedent concerns cases where the anaphor and the antecedent occur in the same conversational turn, as in utterance [3.21a]. In the case of a distant antecedent, the anaphor and the antecedent occur in two conversational turns that are potentially spoken by two different locutors. As an example, consider the segment in [3.22] extracted from a dialogue in a hotel reservation corpus collected at the CLIPS-IMAG laboratory [HOL 97]. In this extract, the anaphor it and its antecedent occur in two conversational turns of two different locutors, the customer C and the hotel receptionist H, respectively. Note the formal ambiguity of the attachment of the anaphor because in the utterance H, there are several nominal groups that could be candidates: a room, a person, a shower:
H = So, I have a room for one person with a shower and WC on the fourth floor looking out on the garden for 380 dollars, breakfast included. [3.22]
C = Very good, I’ll take it.
There are even more complex cases where the anaphor returns throughout several segments of the discourse. In these cases, the anaphora is very difficult to detect automatically because it requires a very large contextual window that often contains several ambiguities to be considered.
Several linguistic factors make it possible to find the referent of an anaphor. Some are decisive and therefore impossible to violate while others are facultative but they allow the search field to be limited.
- – The number, person and gender: obligatory, these distinctive features can direct the search (see examples [3.23]):
| John visited his friend and his cousins. He gave him a gift. | The feature singular of the anaphor him makes it possible to decide that his friend is the referent of the anaphor. [3.23] |
| We went to Dallas with my brother last year. He really appreciated your presence. | Here, we is equal to me and you plus him eventually, the anaphor he refers to my brother and your refers to the second person mentioned in we. |
| Paul and Mary graduated this year. She had the best grades at her school. | The feature feminine makes it possible to attribute the reference Mary to the anaphor she because the other candidate, Paul, has the feature masculine. |
- – Novelty: from a cognitive point of view, in case of a multitude of possibilities for the resolution, the most recent element, being the most prominent in the memory, has the advantage. Consider example [3.24]:
| Randy was playing table tennis with Will. They met Barry in the room. He was very happy that day. | Naturally, he refers to Barry, the most recent candidate, and not Will or Randy. [3.24] |
- – The topical role: an agent in a sentence has more chance of remaining in a second sentence. Examine examples [3.25]:
| Kati saw Amanda with her newspaper in the garden. She said hello to her. | Kati, the agent of the first sentence, is logically the antecedent of the anaphor she. |
| Kara was seen in the garden by Nicole. She said hello to her. | Here, logically she refers to Nicole, the agent of the first sentence, even if Kara was the focus. [3.25] |
- – Repetition: the repetition of an anaphor throughout a text makes it possible to identify the referent in all occurrences of this anaphor. Examine text fragment [3.26] where the anaphor she is repeated several times, making it possible to identify that the referent is Cynthia and making it unlikely that Martha is the referent of the utterance: she went...
Cynthia is a nurse. She likes her job a lot because she loves helping people. She works with her friend Martha in the same hospital. During the holidays last year, she went to Morocco with her husband. [3.26]
- – Reciprocity or parallelism: sometimes the agent of a sentence becomes the patient or the recipient in another sentence and its patient or recipient becomes the agent in the other sentence. This logical reciprocity allows the referent of the anaphor to be deduced. For example, in passage [3.27], the agent in the first utterance, John, becomes the recipient in the second utterance, while the recipient of the first utterance becomes the agent in the second utterance:
John gave a bouquet of flowers to Mary, Maurice’s sister. Mary gave him a pen (him = John). [3.27]
- – The semantics of the verb: sometimes the semantic relations between the arguments of certain verbs imply relations between the actants of the verbs, as in [3.28] where the agent of the verb to send is the recipient of the verb to receive and vice versa. This helps deduce that the referent of the anaphor he, the agent of the verb to receive, is Max:
Fred sent a postcard to his work colleague Max. He was very happy when he received it. (He = Max) [3.28]
3.1.7. Ellipses
Ellipses consist of omitting a certain number of elements from an utterance without affecting its intelligibility. The omission creates a puzzle effect that allows the auditor to find the omitted elements and complete the information. Like anaphora, ellipses are a linguistic phenomenon common in both spoken and written languages, but they play a more important role in spoken language, especially in responses to certain questions. In general, an ellipsis is an important way to avoid redundancies and consequently make the conversation simpler and more spontaneous. There are two types of ellipses: situational ellipses and grammatical ellipses.
Situational ellipses include a set of ellipses whose interpretation depends directly on the situation of elocution. As shown in the previous paragraphs, this situation can be the history of a dialogue, the physical context in which the conversation occurs, general knowledge about the world, etc. Consider the mini dialogue [3.29] where there is a situational ellipsis. In this example, note the double ellipsis in the response: the removal of the request formula I would like and the word room.
H: Would you like a single room or a double room?
C: A single, please. [3.29]
Grammatical ellipses consist of omitting words that syntactic knowledge of the language can make it possible to infer. The most commonly studied form of grammatical ellipsis is the verbal ellipsis [HAR 97]. In this kind of ellipsis, the verbal group is removed in contexts where it is considered inferrable, as in utterance [3.30]. In this utterance, the verb in the second proposition is removed, which suggests that it is the same verb as the one in the first proposition: eats.
Peter eats cherries and Paul strawberries. [3.30]
Mixed ellipses are possible in some contexts. To illustrate these ellipses, consider the example in [3.31]. In this exchange, we removed the segment I am which is easy to infer from the syntactic rule: subject + verb to be + qualifier, ‘in agreement’. Note that syntax alone is sufficient to infer the verb to be. Syntax also played a direct role in inferring the subject, however the form of the subject (noun, pronoun) as well as the person (1st person singular, 2nd person plural, etc.) requires discursive context. Thus, the final analysis of this ellipsis mobilizes both syntactic and contextual knowledge.
A: What do you think? [3.31]
B: Completely in agreement.
Some forms of ellipsis can be seen as particular cases of anaphora [KRA 00]. Ellipses are based on a strong connection to a previous part of the discourse, like anaphora. However, contrary to anaphora where a linguistic device is needed to refer to the previous part of the discourse, ellipses are characterized by the removal of elements shared with what has been said.
3.1.8. Textual sequences
Intuitively, when a reader reads a text, he/she is often able to label it as a text category: narration, description, etc. However, establishing such a categorization on linguistic bases is far from obvious. Several linguists have attempted to produce textual typologies like [WER 75, ADA 92, ADA 01].
Adam’s classification is based on the notion of sequence, which he considers to be the constituent unit of the text. A sequence is composed of micro-propositions that are in turn composed of n (micro) propositions. Adam proposes five main types:
- – Narrative sequences recount events that occur in a temporal or causal (chronological) link. Particularly common in novels, stories and narrative texts, they are also commonly used in journalism and sports reporting, some ads and accident statements. From a grammatical point of view, these sequences are marked by tenses like the imperfect, simple past and historical present, as well as adverbs and indications of time (now, tomorrow, two days later).
- – Descriptive sequences essentially pertain to the description of the spatial arrangement of propositions. This concerns texts that indicate the moral and/or physical qualities of a person, thing, landscape, location, etc. These sequences are characterized grammatically by the use of the present or the imperfect, as well as adverbs and place names.
- – Dialogical sequences, common in plays and some ancient philosophical texts, are also very frequently found in the different ways of interacting available today on the Internet like discussion forums and chat sites/software. The content of these sequences is distinguished by the management of speech acts as varied as promises, affirmations, threats, acknowledgements, etc.
- – Argumentative sequences are centered on the defense of a position or particular point of view. These sequences follow a logical reasoning framework: linking one or more premises and a conclusion. They are common in different types of university projects like theses and dissertations, essays and some political discourses characterized by the adoption of a position in relation to a given project, person or idea. Linguistically, these sequences are associated with dialogue acts like convince, persuade and cause to believe.
- – Explanatory sequences, like argumentative sequences, are frequently observed in university projects as well as handbooks and other forms of scientific books. They are intended to explain the how and why of a given phenomenon.
Note that Adam borrows the prototypical view of lexical semantics proposed in [KLE 90]. In other words, a text is no longer considered as belonging or not to a given category (discrete view) but rather as more or less typical or atypical, depending on its distance from the notional reference prototype of the category or discursive genre under consideration.
3.1.9. Speech acts
The theory of speech acts was developed by John Austin at the University of Oxford in the context of work on the philosophy of language that originated in the current of analytical philosophy [AUS 55]. Later, this theory was substantially developed by the works of John Searle at the University of California at Berkeley [SEA 69]. This theory is based on the distinction between two types of utterances: utterances that describe the world, called constatives, and utterances that modify it, called performatives (see examples [3.32]). The main property of constative acts is to receive a truth value. For example, in utterance [3.32a], the bush can be planted in the garden or not. On the other hand, truth values do not make sense in utterance [3.32b]. These cases include things like the sincerity of the person uttering the sentence, its capacity to realize its engagement, the failure or success of the act, etc. This concerns the condition of felicity rather than the condition of truth:
- a) John plants a rose bush in the garden at his house. (Constative)
- b) I promise to repay all my son’s debts. (Performative) [3.32]
Note that the boundary between the two types of acts is not completely clear-cut. For example, in [3.33], even though the utterer does not use a verb that explicitly indicates that he promises to buy the chocolate cookie, it is implicitly understood that this is a promise:
I will buy you a chocolate cookie tomorrow. [3.33]
The act committed by uttering a sentence with a performative value is called a speech act. There are three groups of speech acts: locutionary acts, illocutionary acts and perlocutionary acts.
3.1.9.1. Locutionary acts
These are acts that are accomplished as soon as a meaningful utterance is uttered orally or in writing, independent of the communicative role of this utterance. Consider utterance [3.33] whose phonetic, morphosyntactic and semantic formulation is a locutionary act.
3.1.9.2. Illocutionary acts
An illocutionary act is carried out on the world by producing the utterance. For example, a judge saying I declare that court is in session will effectively open the session. Austin describes five major types of illocutionary acts:
- – Verdictive: acts pronounced in a judicial and legal context. For example, the following verbs express a verdictive act: to declare guilty/innocent, to condemn, to decree, to acquit.
- – Exercitive: acts related to the exercise of authority generally in contexts as varied as military, administrative or familial contexts. The verbs to command, to order, to rule, to dictate, to prescribe, to pardon are examples of these acts.
- – Permissive: acts that commit the locutor to carry out actions in the future. For example, verbs like: to promise, to commit, to bet, to gamble, to guarantee.
- – Behabitive: acts related to behavior expressed by verbs like: to thank, to bless, to praise, to criticize.
- – Expositive: acts concerning the relationship between the locutor and the information that he transmits. For example, to affirm, to certify, to assure, to deny, to note, to notice, to observe, to discover.
It should be noted that John Searle conducted a critical study of Austin’s taxonomy and concluded by proposing his own. Like Austin’s taxonomy, it has five groups: assertives (assertion, affirmation), directives (order, command, demand), permissives (promise, offer, invitation), expressives (thanks, praise) and declaratives (declaration of marriage, nomination for a prize).
3.1.9.3. Perlocutionary acts
These are acts that either have a voluntary effect or not on the allocutor. They are the consequences of an illocutionary act:
- a) I will take you to the park next week. [3.34]
- b) I declare that court is in session.
Beyond the locutory act related to the formulation of the utterances in [3.34] (both a and b) and the illocutionary act related to the commitment, utterance [3.34a] has a possible perlocutionary effect, which is to persuade the allocutor of the kindness of the locutor. If we assume that utterance [3.34b] was produced by a judge in a court, it has the perlocutionary effect of attracting the attention of the listeners to the judge, putting an end to the lateral conversations of the people present, etc.
Finally, it is useful to mention that the theory of speech acts saw important developments in the 1990s, notably in the works of Sperber and Wilson on Relevance Theory in the cognitive pragmatics movement [SPE 89] and the works of Albert Assaraf on Link Theory [ASS 93].
3.2. Computational approaches to discourse
The computational approaches to processing discourse are very divergent. They differ with regard to the applicative objective. Some works have a mostly theoretical focus, long-term works, while others have clearly applicative ends. Discourse being a particularly rich domain, there is no single approach that considers all of its aspects, to my knowledge. Therefore, the works are limited to certain aspects and ignore others, like processing anaphora, recognizing topics or analyzing discourse structure. Given this diversity, this text will present a few representative domains without claiming to be exhaustive, as that would go beyond the objectives of this book.
Finally, it should be noted that the automatic processing of discourse is particularly useful in domains like automatic translation, automatic text summarization, information extraction, etc. (see [WEB 12] for a summary of its applications).
3.2.1. Linear segmentation of discourse
Linear segmentation is a simple form of discourse analysis. It consists of dividing the text into parts that are deemed independent, each of which plays a precise role in the text (see Figure 3.6).
Figure 3.6 shows that the segmentation assumes the existence of clear boundaries between the parts of the text concerned. Very generally, segmentation concerns relatively large parts of the text and does not attempt to process the finer points that can only be grasped by considering the dependency relations between parts of the text.
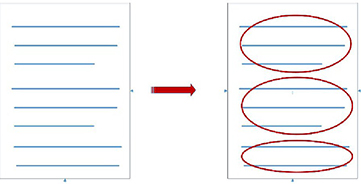
Figure 3.6. Linear segmentation of a text
The following sections will show in more detail how the segments can be determined based on a variety of dimensions including topics, emotions, opinions, etc.
A discourse is normally composed of a series of topics that revolve around various frameworks. Identifying these topics and their articulation within the discourse makes it possible to classify the text according to its content and its form. It is therefore normal that information retrieval is the privileged application domain of this issue (see, for example, [HEA 97, CAP 06]). In the context of spoken dialogue systems, topic recognition has been used to guide the syntactic analysis module and reduce the search space, consequently accelerating the analysis and improving the system’s performance [GAV 00a]. Topic recognition has also been used to segment classes or meetings [GAL 03, MAL 06].
A coherent discourse is characterized by a logical sequencing of the topics addressed therein. Modeling this sequencing can be used to make predictions about topics that will be addressed by considering a given history or simply to identify the topics in a sequence. It should be noted that there is no standard for topics and some researchers include many different practices under the label of topic recognition. For example, some include functional segmentation based on the roles filled by the identified units or consider the intentional structure of the discourse [MOO 93, LOC 98] or the speech acts [COL 97]. Others, inspired by works on scripts [SCH 77] or Story Grammar [KIN 78, MAN 84], focus on events in the discourse and their relations [CHA 08, FIN 09].
The general principle of topic segmentation consists of dividing the discourse and using lexical indicators to predict or recognize topics. Naturally, different forms of statistical models have been adopted to model the topic triggers. Simple models based on ngrams [CAV 94], HMM [BOU 02] and Bayesian networks [SAH 98, EIS 08] have been used for similar tasks. Other techniques like Latent Semantic Analysis and neural networks have also been used [FOL 96, WIE 95]. Given the considerable similarity between topic recognition and information retrieval, the technical details will be presented in section 4.3 dedicated to information retrieval in the sphere of applications.
3.2.2. Rhetorical structure theory and automatic discourse analysis
Adopting a theoretical framework seems beneficial for automatic discourse analysis. Among the existing frameworks, the Rhetorical Structure Theory (RST) has been adopted in many works. Although it was initially developed with the goal of improving automatic generation systems, this theory has acquired an independent theoretical status. Intended for describing the structure of texts rather than explaining the processes that underlie their creation and interpretation, RST considers the text as a set of blocks interconnected by hierarchical relations, like coherence or discourse. From this perspective, every block fills a particular role in relation to the other blocks. An example of a text analyzed with RST is shown in Figure 3.7.
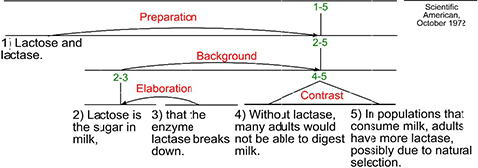
Figure 3.7. Example of a text analyzed according to RST [MAN 12]. For a color version of this figure, see www.iste.co.uk/kurdi/language2.zip
RST distinguishes between two types of relations: nucleus-satellite mononuclear relations and multinuclear relations. Mononuclear relations are marked by the dependency of an element called a satellite on a nucleus, whereas multinuclear relations are distinguished by the rhetorical equivalence of the elements involved. In the analysis diagrams, the root represents the set of units 1-5 of the text and the arrows, which each represent a mononuclear relation, point toward the dominant unit or block (e.g. presentation, elaboration). Multinuclear relations, in turn, are marked by two non-oriented arcs with the same root. Note that in the initial version of RST presented in [MAN 88], parallel relations can establish a relation between a discursive unit and a complex unit. More recent versions of RST explicitly require that a unique relation be present between each pair of units [STE 04, CAR 03]. Table 3.3 provides a list of mononuclear relations.
Table 3.3. Inventory of mononuclear relations established in [MAN 88]
| Name of the relation | Nucleus | Satellite |
| Anti-condition | Absence of the conditioning situation causes the occurrence of the resulting situation | The conditioning situation |
| Antithesis | Ideas approved by the author | Ideas rejected by the author |
| Background | Text whose comprehension is facilitated | Text serving to facilitate comprehension |
| Goal | A target situation | The intention underlying a situation |
| Intentional cause | A situation | Another situation that intentionally caused the first |
| Unintentional cause | A situation | Another situation that unintentionally caused the first |
| Circumstance | A text expressing the events or ideas located in the interpretive framework | A temporal or situational interpretive framework |
| Concession | A situation defended by the author | A situation that is apparently incompatible, but is still defended by the author |
| Condition | An action or situation whose occurrence results from the occurrence of the conditioning situation | The conditioning situation |
| Demonstration | An affirmation | Information intended to increase the reader’s belief in the affirmation |
| Elaboration | Source information | Supplementary information |
| Evaluation | A situation | An evaluation of the situation |
| Facilitation | An action | Information intended to help the reader accomplish this action |
| Interpretation | A situation | An interpretation of the situation |
| Justification | A text | Information justifying the production of the text by the author |
| Motivation | An action | Information intended to encourage the reader to accomplish an action |
| Reformulation | A situation | A reformulation of the situation |
| Intentional result | A situation | Another situation, intentionally caused by this one |
| Unintentional result | A situation | Another situation accidentally provoked by the first |
| Summary | A text | A brief summary of this text |
| Solution | A situation or a process that satisfies a need | A need, problem or question |
For more clarity, examine the passages in [3.35] for examples of mononuclear relations.
| [S Although he adores chemistry], [N he registered in the applied mathematics program]. | concession [3.35] |
| [N The inspector was succinct;] [S he mentioned causes related to the confidentiality of the inspection] | elaboration |
| [S Brass is an alloy that is mainly composed of copper and zinc.] [N Add five grams of brass.] | background |
Multinuclear relations are less numerous and less semantically restrictive, except in the case of contrast, which requires an opposition between the items involved (see Table 3.4).
Table 3.4. Inventory of multinuclear relations established in [MAN 88]
| Name of the relation | A segment | Other segment |
| Contrast | a possibility | the opposite possibility |
| Junction | (non-constraint) | (non-constraint) |
| List | an item | next item |
| Sequence | an item | next item |
For example, in an enumeration, all sorts of objects that do not have inherent links can be listed (see examples [3.36]):
| [Mary would like to spend the summer in Florida] whereas [John would like to go to Spain.] | Contrast [3.36] |
| [John is a chef in a French restaurant in New York]; [Michelle is a gymnastics teacher in Atlanta]. | List (no comparison or contrast) |
Aside from the relations between nucleus and satellite, [MAN 88] formulated constraints on the beliefs and objectives of the two actors involved, the writer (W) and their effects on the reader (R). For example, the constraints on the relation evidence are defined in Table 3.5 where N corresponds to Nucleus and S to Satellite.
Table 3.5. The constraints on the relation
| Constraint on N | R may not believe N to a satisfactory degree for W |
| Constraints on S | R believes S or he will find it credible |
| Constraints on S+N | The reading of S by R increases his belief in N |
| Effect | The belief of N has increased |
Like for syntactic analysis, discursive analysis is intended to create a complete representation of the object of analysis, which in this case is the discourse. To obtain such a representation, three actions similar to the syntactic analysis process must be conducted: segmentation, attachment, and disambiguation.
In the framework of discourse analysis systems, the text is first segmented in elementary discourse units (EDU). To avoid circularity (the choice of units based on analysis and the analysis based on units), this operation is carried out before the analysis. Note that the community does not unanimously agree about the form of EDU (see [POL 01, BAL 07] for a discussion). Behind this disagreement is a need for units that cover the entirety of the discourse. In other words, after having segmented the discourse, there should not be any segments that are not units. The problematic issues include the admission or not of discontinuities within EDU. These discontinuities are caused by dislocations or inserted sentences. To avoid the issue of segmentation, some researchers assume that segmentation has already been done by a module external to the discourse parser.
In [POL 04b], the segmentation occurs after a syntactic analysis step with lexical functional grammar (LFG). The identification of EDU is done first by segmenting the sentences into simpler units based on lexical, syntactic and semantic criteria. These units are then combined in a small tree structure equipped with a functional role that corresponds to the EDU. These units include elements such as greetings, connectives and discursive markers.
To construct a segmentation module, a syntactic analysis model is typically required first to provide the base on which the discourse segmentation will occur. The segmentation module is created by following these steps:
- a) Collect or find an appropriate corpus. In this case, this is a collection of texts.
- b) Annotate the corpus according to a discursive framework like RST.
- c) Manually annotate the linguistic elements that can be used as boundary markers between sentences. Lexical-syntactic factors are mainly used. Another factor is prosody, which plays an important role in defining sentence boundaries [HIR 96, LEV 04] in spoken discourse.
- d) Implement the linguistic rules identified in the previous sentence.
- e) Evaluate the segmentation module.
After the segmentation comes the attachment phase, where the parser must decide where it will connect the current segment in the tree under construction. Here as well, there are several strategies. For example, in the parser in [POL 04b] the attachment occurs on the basis of a set of rules related to a variety of information sources:
- – Syntactic information: a multitude of syntactic information is considered. For example, if the lexeme to be attached plays the role of subject or object, then the relation is one of subordination, as in the antecedent of relative propositions that can be a subject, object, or adverbial. In the case of a parallelism, it is a relation of coordination, because the coordinated elements have the same weight.
- – Lexical information: the repetition of the same lexeme or the occurrences of words linked by a relation of antonymy, synonymy or hyperonymy, as well as discursive connectives, adverbs and temporal indicators (aspect, tense and mode of the verb) all contribute to the attachment. For example, connectives like in that case, therefore and thus make it possible to predict a change in the discursive content and consequently the boundary of a discourse segment (for a detailed discussion, see [POL 04a]).
- – Structural information: this concerns the point of attachment of the current unit in the tree under construction.
- – Presence of incomplete construction constituents: this includes questions, opening greetings, internal units like sections and sub-sections, etc.
The weight attributed to these different knowledge sources varies depending on needs. For example, lexical knowledge has more importance for the point of attachment while semantic and syntactic knowledge is more relevant for choosing the relation type.
To move from the syntactic structure provided by the syntactic parser to a discursive structure, [POL 04b] uses a set of symbolic rules. Some examples are shown in Figure 3.8.

Figure 3.8. Example of rules used to construct the discursive structure starting from the syntactic structure [POL 04b]
The first rule describes the case of prepositional and adverbial groups that are often temporal modifiers that precede the main clause that they modify. These groups can either elaborate on the content of the main clause or modify the context of its interpretation. Lexical information is used to distinguish between several types of modifiers. The second rule describes the case of the subordination of an adjunct clause. They show that syntactic rules allow for a recursive search in the functional structures. Finally, the third rule expresses the disjunctive constraints that construct a relation at the level of discourse.
A simpler form of discourse analysis called chunking or partial analysis was also proposed in simulation to the partial syntactic analysis proposed by Abney (see for example [MID 03, SPO 05]). The main difference from the complete analysis just presented resides in the fact that the chunking process seeks to recognize segments or islands in the discourse, without attempting to analyze everything. Thus, a chunker will focus on identifying morphemes, terms and constructions that will help to indicate the discursive relations in a given context. For each of the identified items, the chunker attempts to find its arguments and to determine the type of semantic relation that connects them.
In terms of applications, the structural analysis of discourse has proven to be particularly promising in several applicative domains at the forefront of which is automatic text summarization [ONO 94]. More recently [MAR 00, THI 04] proposed an approach based on a varied weight attribution process for different components of a discursive tree.
3.2.3. Discourse interpretation: DRT3
The previous section discussed the construction of a tree structure for discourse. This level of analysis can easily be considered the syntax of the discourse. Naturally, every syntactic structure needs a semantic framework for its interpretation and that is where Discourse Representation Theory (DRT) comes in.
In modern semantics, a new movement emerged. The focus of this movement is discourse, which it considers to be the unit that must have a truth value, rather than the sentence. This movement was initiated by DRT, developed by Hans Kamp [KAM 81], with the goal of accounting for discursive phenomena like anaphora and tense, whose representation goes beyond the framework of predicate logic. A similar work was realized by Irene Heim called File Change Semantics (FCS) [HEI 82]. The works of Gilles Fauconnier on mental spaces are also considered in the same tradition as DRT [FAU 84]. Consider sentence [3.37] and the corresponding logical representation. A human being is naturally capable of guessing that the anaphor he refers to Max. For a computer program, a post-processing algorithm is required. Such an algorithm is intended to replace the free variable X with the appropriate antecedent and provide the correct representation:
Max is a cat. He likes Felina. [3.37]
cat(max) ⋀ likes(X, Felina) → [X is a free variable]
cat(max) ⋀ likes(max, felina)
To obtain representations of this type, DRT uses representations called discourse representation structures (DRS), which go beyond Montague semantics, which is limited to the sentence level. The discourse representations are incrementally enriched, similar to what a human being would do in receiving (listening or reading) a sequence of sentences. Illustrated representations in the forms of boxes are used for these structures following the example of the tradition that is popular in the domain of the psychology of language. Each box is composed of two parts: an upper part that contains the referents and a lower part that contains the conditions. The referents are the set of entities that were introduced in the context, while the conditions are the predicates that connect these entities.
To construct a representation of [3.37], it is first necessary to introduce the two basic elements in the discourse, which are: x, y, max, likes(y, Felina) in two different boxes, which correspond to the two sentences in the discourse. Then, the final representation is obtained with a juncture of the referents and the conditions of the two sentences (see Figure 3.9). Note that the equality of the symbols x and y is the way to express the fact that the two symbols refer to the same entity, thus identifying the referent of the anaphor. The DRT creates a temporary representation of the discursive units that it updates each time that new entities are introduced into the discourse. In other words, each sentence is interpreted in a given context. The result of the interpretation of this sentence contributes to updating the context and interpreting the other sentences and so on.
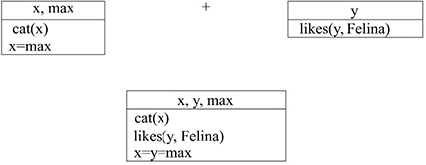
Figure 3.9. DRT representation of [3.35]
Consider utterance [3.38] with quantifiers as well as its logical representation:
Every farmer who owns a donkey feeds it. [3.38]
Contrary to Russel’s understanding, the indefinite article of the group a donkey must be replaced by a universal quantifier. Two boxes are used by the DRT to represent the two propositions in this sentence (see Figure 3.10).
In the context of natural language processing, it is possible to construct discursive representations according to DRT using algorithms. To show this, we will use the top-down approach presented in [BLA 05]. Consider example [3.39] to illustrate this algorithm:
A man yells. He dies. [3.39]
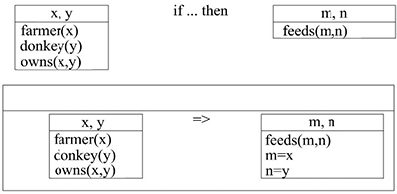
Figure 3.10. DRT representation of [3.35]
The first step of the algorithm is to construct the skeleton of the representation from the root of the tree corresponding to the first sentence of the micro-discourse (see Figure 3.11).

Figure 3.11. First step of the algorithm
To begin to populate the representation, proceed with a top-down exploration from left to right. This means visiting the symbols: S → NP → DET. Because there is an indefinite nominal group, a new object x is added in the upper part of the box (see Figure 3.12).
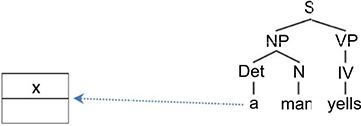
Figure 3.12. Second step of the algorithm
Continuing to explore the nominal group, we discover that it consists of a man. This fact is expressed in the form of a condition in the lower part of the box: man(x) (see Figure 3.13).

Figure 3.13. Third step of the algorithm
After having finished exploring the entirety of the nominal group, move on to the verbal group that includes an intransitive verb. This leads us to add a new constraint on x: yell(x) (see Figure 3.14).

Figure 3.14. Fourth step of the algorithm
The representation of the first sentence being complete, move on to the second sentence. By following the same approach described previously, start with the root of the tree (Figure 3.15).

Figure 3.15. Fifth step of the algorithm
To reach a unique representation of the discourse, first add the representation of the indefinite nominal group that is a new variable, y. The anaphora resolution occurs by admitting the equality of the two referents x and y. This equality is decided on the basis of the person (third), the number (singular) and the gender (masculine) (Figure 3.16).
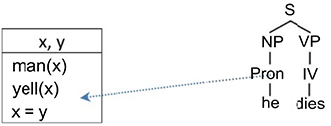
Figure 3.16. Sixth step of the algorithm
Finally, the representation of the verbal group, the intransitive verb dies, occurs with the condition dies(y). The semantics of the verbs yell and die create a logical sequence which, although a bit simplified in this example, confirms the equality decision between the two referents (Figure 3.17).
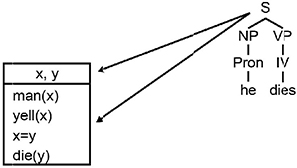
Figure 3.17. Seventh step of the algorithm
In summary, DRT makes it possible to reach several objectives. Thanks to the mechanism that updates temporary representations, it allows for the elegant processing of indefinite determinants and cases of presupposition. The identification of the unique denotation of a determinant makes it possible to process new entities introduced in the discourse as well as quantified variables. It is also an elegant way to account for anaphors, especially those that refer to quantified variables.
Similarly, according to the approach initiated in works on dynamic semantics (DS) [GRO 91], fragments of text or discourse are considered to be instructions to update the existing context. Contrary to DRT, this does not consist of updating the representation of the semantic content, but rather of updating the content itself [DEK 12].
It should be noted that DRT has been the object of large-scale applications, notably in the context of the Verbmobil project for the translation of spontaneous spoken dialogues [WAH 95, BOS 96].
3.2.4. Processing anaphora
Since the beginning of applications in the domain of Natural Language Processing, researchers have recognized the interest in processing phenomena like anaphora. Thus, applicative systems like STUDENT, an Intelligent tutoring system [BOB 64] and SHRDLU, a natural language command interface [WIN 72] have integrated anaphora resolution functionalities. Similarly, algorithms specifically dedicated for this task were created, such as those of [HOB 76, HOB 78].
The question of processing anaphora consists of resolving the challenging problem of finding their referents. Indeed, without identifying the referent, it is not possible to find an adequate semantic representation for certain sentences. Two criteria can be used to distinguish the different algorithms and approaches for processing anaphora: information resources and processing method. Most anaphora resolution algorithms count on linguistic information sources like agreement in gender and number, syntactic dependency, etc. There are two competing currents with regard to the processing method. On the one hand, there are knowledge-based approaches where system designers must provide a detailed and exhaustive description of phenomena to be covered. On the other hand, there are learning-based approaches which are generally based on real data that is manually annotated (see [DEO 04, MIT 98, WIS 16] for a general overview of these algorithms).
3.2.4.1. The naive syntactic approach of Hobbs
Syntactic approaches are used to filter a pronoun’s antecedent candidates. As noted, syntactic factors are important but not sufficient to determine an antecedent. The basic idea of Hobbs’ algorithm [HOB 76, HOB 78] is to move through the syntactic parsing tree of a sentence searching for a nominal group that satisfies predefined constraints like number and gender. More specifically, the search is carried out according to the following steps [HOB 78]:
- 1) Start with the node of the Nominal Group NP that immediately dominates the pronoun.
- 2) Move higher in the tree until the first node NP is encountered or until the node of the sentence S. Call this node X and the route taken to find it R.
- 3) Go through all of the branches above X and to the left of the route R, following a breadth-first left-to-right manner. Propose as an antecedent any node NP encountered that has a node NP or S between it and X.
- 4) If X is the highest node S in the parsing tree, then go through the parsing trees of preceding sentences in chronological order, with the most recent sentence first, always from left to right and breadth first. When a node NP is encountered, propose it as antecedent. If X is not the highest node S in the sentence, then move on to phase 5.
- 5) Go from X until the first node NP or S is encountered. Call this new node X and the route to it R.
- 6) If X is an NP and if R does not cross the node N’ directly dominated by X then propose X as the antecedent.
- 7) Go through the branches above X to the left of the route R following a breadth-first left-to-right manner. Propose any NP encountered as an antecedent.
- 8) If X is a node S, then go through all the branches of X to the right of R following a breadth-first, right-to-left manner, but without going above any NP or S encountered. Propose any node NP encountered as an antecedent.
- 9) Go to step 4.
Although this algorithm is rather basic, a comparison with systems such as those described in [BAL 97, MIT 97, TET 99] show that it is not entirely obsolete. In addition, as noted by Hobbs, its low cost computationally and its simplicity of implementation make it appealing even today, especially in the context of applications that require processing in real time. This explains the adaptation of this algorithm to other languages (see for example [DUT 08]).
3.2.4.2. The discursive approach: centering theory (CT)
The theory of Grosz and Sidner distinguishes between three main components of discourse [GRO 86]: the linguistic structure, the intentional structure, and an attentional state. Regarding the linguistic aspects, discourse is seen as a set of segments and relations relating the pairs of segments. The intentional structure in turn includes the communicative intentions and relations between them. The attentional states concern the focus of the attention of the participants in the discourse at a given moment. Two types of attentional states are distinguished here: local and global. The first concerns relations between utterances in a discourse segment that contribute to the creation of a local coherence (intrasegment). The second concerns the relations between the segments within the discourse (intersegment). Changes in the attentional state depend on both the intentional structure and the linguistic structure.
The foundational ideas of CT were discussed in the works of [GRO 77, SID 79, ARA 81] and concern the semantic links between an utterance and the preceding and subsequent utterances in the context of a discourse segment for local relations. Among others, these ideas pertained to the levels of focus in a discourse, the possible centers of focus in a discourse and using them to choose the referent of an anaphora, and finally the relations between the change of focus and the complexity of inferences necessary for the integration of the current utterance with the rest of the discourse. The working hypothesis is that at any moment, there is a single unit (among the units evoked in the discourse) that takes center stage. This is the centered unit. To clarify this principle, consider passages [3.40] and [3.41]:
- a) John helped the truck driver Michael to find the street where the factory was. [3.40]
- b) He looked at a map of the area while Michael drove.
- c) He finally managed to find the location.
- a) John helped the truck driver Michael to find the street where the factory was.
- b) He looked at a map of the area while Michael drove. [3.41]
- c) Suddenly, he braked when he saw a small cat crossing the street.
In passage [3.40], the pronoun he in utterance c refers to John because it is logical to infer that the person looking at the map will manage to find the location. Similarly, the action of driving the truck normally excludes looking at a map. The anaphor he in passage [3.41] logically corresponds to Michael because the realization of the action of the verb to brake presupposes the action of driving.
According to Hobbs’ syntactic approach, passages [3.40] and [3.41] are perfectly equivalent in terms of coherence. On the other hand, according to CT, passage [3.40] is more coherent than passage [3.41]. Indeed, as Michael is the center of the utterances a and b, the change of the center in passage [3.41] makes inferring the referent of the anaphora more challenging and consequently decreases the coherence of the discourse.
More formally, according to the model proposed by CT, discourse is composed of a set of segments, each of which represents a part of the discourse model. The centers are semantically prominent entities that are part of the discursive model of each utterance Ei in a discourse segment (DS) that consists of a series of utterances: E1, E2, …. Em. Each utterance is associated with two centers: forward-looking centers and backward-looking centers.
Forward-looking centers Cv (Ei, DS) represent the set of entities evoked by the utterance Ei in a DS. These entities can be repeated by subsequent entities in the DS and are ordered according to their prominence. In other words, the more highly ranked an entity is, the more chance it has of being repeated. The order of elements is determined by a number of factors such as the grammatical role of the entity, the order of the entity and the informational novelty that it conveys according to Prince’s criteria [PRI 81]. For example, in passage [3.40]: Cv(Ea)={John, Michael, street, factory}. The highest ranked entity is called the Preferred Center Cp. Thus, the preferred center is John: Cp(Ea) =John. The Cp serves to predict the backward-looking center Cr of the next utterance.
The backward-looking center Cr(Ei,DS) represents the most highly ranked discourse segment for Ui, among those evoked by the previous utterances in the DS. It has the role of connecting an utterance to a previous utterance, which is in turn connected to a previous one and so on. Based on the results of several psycholinguistic studies, CT stipulates that a given utterance Ui cannot have several Cr at one time [HUD 88, GOR 93]. For example, in passage [3.40], the backward-looking center of the utterance a is undefined: Cr(Ea)=[?]4, because this utterance is the first in the DS. However, the backward-looking center for utterance b is John: Cr(Eb)= John (the highest ranked entity in utterance a cp(Ea)=John or Cv(Ea)).
Aside from the centers just presented, CT includes the following two rules concerning the center realization and movement: the pronominal rule and the transition specification rule.
The pronominal rule stipulates that pronominalization is a possible way to mark the prominence of an element and that the Cr are often removed or pronominalized. Consequently, if there are a multitude of pronouns in an utterance and if they correspond to several entities in the previous utterance, then the Cr must be one of these pronouns. Naturally, if there is only one pronoun in an utterance, this pronoun must correspond to the Cr. More formally, this rule asserts that if an entity among the ones listed in Cv(Ei-1, SD) is realized in the form of a pronoun in Ei, then Cr(Ei, SD) must also be a pronoun.
The transition specification rule concerns relations between adjacent utterances. It stipulates that the different types of transition require variable quantities of inferences, thus causing variations in levels of coherence. The transitions that require fewer inferences correspond to a more coherent discourse, where there is minimal change to the center. Four types of transitions are described in [BRE 87]. The order of preference of the transitions is: continuation > retention > smooth shift > rough shift (see Table 3.6 for a summary).
Table 3.6. The four types of transition possible in a discourse segment

Continuation occurs when a locutor indicates that he intends to discuss a particular topic. This implies that the center of an utterance has a good chance of spreading not only to the next utterance but also to the rest of the utterances in the discourse segment. In other words, in the case of a continuation: Cr(En+1)=Cr(En) or Cr(En)=[?] for En at the start of a discourse and Cr(En+1) = Cp(En+1). It is also very likely that Cr(En+2)=Cr(En).
In the case of retention, the locutor repeats the center of an utterance from one utterance to another but seems to want to change the center in the ensuing utterances. This translates into the fact that the current backward-looking center and the next utterances are the same, but the center is not the most highly ranked entity among the ones listed. More formally, this gives: Cr(En+1) = Cr(En) or Cr(En) = [?] for En at the start of the discourse and Cr(En) != Cp(En+1). This means that it is very likely that Cr(En+2) != Cr(En).
With a smooth shift, the locutor turns his attention toward a new entity about which he intends to continue speaking. In this case, Cr(En+1) != Cr(En) and Cr(En+1) = Cp(En+1).
In the case of a rough shift, like a smooth shift, the locutor turns his attention toward a new entity. However, it is very likely that this new entity will not be the focus of the utterances that follow. Therefore, Cr(En+1) != Cr(En) and Cr(En+1) != Cp(En+1).
To illustrate these transitions, examine passage [3.42]:
E1 The genie has lived in the magic lamp for thousands of years. [3.42]
E2 He currently serves Aladdin.
E3 He promised him he would find the lost treasure.
E4 He does not believe him.
An analysis of passage [3.42] utterance by utterance according to CT gives the steps presented in Figure 3.18.

Figure 3.18. Algorithm for processing pronominal references [BRE 87]
The algorithm in [BRE 87] proposes processing pronominal references according to the principles just described (see Figure 3.19).
Figure 3.19. Transition of centers in example [3.39]
A generalization of CT called Veins Theory (VT) was proposed by [CRI 98]. The basic idea of this theory consists of identifying the veins in discursive trees. The role of these veins is to define the domains of the referential accessibility of each unit in the discourse. It should be noted that CT has been applied in the context of automatic scoring systems for written texts based on the distinction between the types of transitions, like in the e-rater system [MIL 00].
From a psycholinguistic point of view, several works have confirmed the cognitive relevance of CT principles. The studies in [CLA 79] found that the reading time for passages where the referent is found in the preceding utterance are shorter than in passages where the referent is found two or three utterances back. Similarly, [CRA 90] found that subjects managed to identify the referent more quickly when it was a grammatical subject than when it was an object.
3.2.4.3. Learning-based approaches
Learning-based approaches use a different philosophy to solve the problem. Rather than manually coding linguistic rules that describe syntactic, semantic and discursive patterns, they annotate representative corpora. The linguistic knowledge is therefore reduced to a minimum and the parameters of the final model are automatically induced. Typically, anaphora and/or their possible referents are annotated with features such as gender, number, grammatical role (like subject or object) or linguistic form (like proper noun or definite or indefinite nominal group). In order to coordinate efforts in the domain of the annotation of corpora intended to train algorithms to process anaphora and coreferences, several standards were created, including MATE5 [POE 04, POE 99].
Bayesian classifiers and recurring neuronal networks have been used with the same objective [HUA 13, FRA 08, WIS 16], but the basic classifiers of Decision Trees (DTs) were the most commonly used framework for these tasks [MCC 95, KWA 08, SOO 01, PAU 99] until the recent return to neuronal network-based methods. Simplicity and performance are the reasons cited to justify the use of Decision Trees for classification. The fact that these trees generate rules makes them more appealing for linguistic applications. Historically, several versions of DT algorithms were proposed, like ID3, C4.5 and C5.1.3 [QUI 79, QUI 93, KOH 99]. In the DTs employed for anaphora resolution, the leaves represent the classes and the branches correspond to the conjunction of features that lead to the leaves and therefore the classes. [MCC 95] described a comparison of DTs with a handwritten rule-based system. The work was realized on the English Joint-Venture (EJV) corpus. This is a corpus that is rich in conferences from projects realized by several entities: government, private companies, individuals, etc. The list of features used in the corpus annotation includes (see Figure 3.20 for an overview):
- – NAME i: does the reference i contain a name? The possible values are Yes and No.
- – JV-CHILD i: does the reference i refer to a Joint Venture child? For example, a company or a project resulting from a partnership between two entities. The possible values are Yes, No and Unknown.
- – ALIAS: does one reference contain an alias for another? In other words, is the name of a reference a substring of the name of another? The possible values are Yes and No.
- – BOTH-JV-CHILD: do both references refer to a JV child? Three values are possible: Yes, No, Unknown.
- – COMMON-NP: do the two references share a common Noun Phrase (NP)? These are generally references to a complex nominal group, as in the case of relative propositions and appositions. This feature compares the simple constituent NPs to each reference. The possible values are Yes and No.
- – SAME-Sentence: do the references appear in the same sentence? Yes and No are the possible values for this feature.
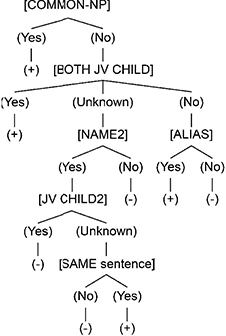
Figure 3.20. Decision tree C4.5 for coreference resolution [MCC 95]
The features in the example can have three possible values at maximum: Yes, No, Unknown, while only two classes are possible in this tree: coreference (+) and absence of coreference (-). Note that the interest of decision trees obtained by automatic processing, compared to rules written by linguists, resides in the fact that these rules are automatically induced according to criteria related to the gain of information and are therefore more optimal compared to the content of a corpus used for learning. Moreover, these trees have a much lower production cost. To understand these differences, examine the tree construction algorithm presented in Figure 3.21.

Figure 3.21. Basic algorithm for creating decision trees [QUI 79]
The skeleton of the decision tree to be constructed will have the form given in Figure 3.22.
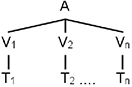
Figure 3.22. Skeleton of a decision tree
The choice of the most informative attribute is the most interesting aspect in the DT construction algorithm. To do this, criteria based on information theory are used, starting with the concept of entropy that indicates the degree of impurity or the disorder of the data in the database in the case formalized by the equation [3.43] [SHA 48]. In this equation, we assume that an attribute A takes n values while p(i) is the probability that s belongs to the category i. The attributes will make it possible to share the data in the corpus in subsets according to the values of A:
In this algorithm, what we are looking for is not exactly entropy, but the attribute that reduces this entropy. To do this, we use another measure that depends directly on the entropy, the information gain, whose formula is given in [3.44].
In equation [3.42], v corresponds to the values of A, p(v) is the probability of the value v in the set S and p(v, c) is the probability that an object will be in class C and that it will have the value v. The probabilities p(v) and p(v, c) are statistically calculated according to the occurrences in the corpus.6
The comparison of the F-measures (see section 4.1.9.2 for an introduction) by McCarthy between the handwritten system and the computer system shows that the system that uses DTs gives better results than rule-based systems, at 86.5% and 78.9% respectively. Despite their advantages in terms of results, the major inconvenience of learning-based systems is the necessity of having good-quality corpora with appropriate annotation. Unfortunately, such corpora are not always available, especially for languages with few linguistic resources.