
The T&M Object Metamodel
2.1 THE OBJECT METAMODEL
Work on object-oriented development projects requires all developers to share a common understanding of the basic terms relating to object orientation. In this respect, the authors of this book have a different conception from those of method books.1 In addition, relying on an object-oriented programming language won’t help either since various languages implement the concepts more or less cleanly. For this reason, we begin this section with a definition of our so-called object metamodel.
A metamodel essentially provides the elements and relations that can be used to build models. In the context of our work it means that an object metamodel helps us to understand the concepts behind, for example, UML diagrams or the Java language constructs.
Our object metamodel reflects the principle of application orientation. We will show how the elements of technical object-oriented models correspond to the concepts and notions used for domain-specific analysis and modeling.
By the end of this chapter readers will know what the authors mean by, for example, inheritance. They will also understand the importance of relating the terms of an application domain to a hierarchy of classes.
When this chapter is used by a software team, it helps developers to arrive at a common understanding of object-oriented modeling and programming from the perspective of the T&M approach.
2.1.2 Definition: The Object Metamodel
Object orientation offers a set of concepts to describe domain-specific and technical models:2
Among the most important elements in our object metamodel are classes. A class has specific properties, for example, an interface with admissible operations and a hidden description of attributes and implementations of operations. An inheritance relationship is one of the most important relationships used to link classes. An inheritance relationship has certain properties. For example, a subclass inherits all attributes of its superclass. Inheritance as a pure software concept may be used in many different ways. One important formation rule of our object metamodel says that you should use inheritance mainly to model domain-specific generic terms and semantic members of these terms. Therefore, our Equipment Managment System (EMS) example, BusinessCard, is a specialization of the generic concept, Form.
The rules of composition are thus of great importance. They give us guidelines for utilizing various elements and relations in modeling. They thereby support a common understanding of models and a clean use of the elements from a software engineering viewpoint.
2.1.3 Context: What’s the Purpose of an Object Metamodel?
In the context of this book, we look at object-oriented application development from a software engineer’s perspective, that is as a way of designing models (see Chapter 6). In fact, the core of the T&M approach is to create a domain-specific and technical object-oriented model, based on the objects and terms of that application domain, and to derive an object-oriented program from it. To do this, we need an exact understanding of what all the basic terms of object-oriented modeling mean and how they should be used.
At this point, you may be asking yourselves why we have gone to all this trouble, since each known programming language in practice implements such an object metamodel. This is true. Each program written in one of these languages shows what the elements of the language mean. But the problem with object-oriented languages is similar to those with method books. In recent years, we have used different object-oriented (and conventional) programming languages in our projects based on the T&M approach. What we have found is that each language implements a more or less different object metamodel. This leads to situations that we do not find useful, neither from the software development nor from the user’s perspective. It has proven useful instead to turn a uniform object metamodel into the basis for conventions and program macros in our projects in order to achieve a common understanding of our modeling and programming efforts.
These issues led to the following requirements for our object metamodel: We have to define our object metamodel so that it can be used to describe the domain concepts of our future application. It has to be defined as closely as possible by the concepts of an object-oriented programming language so that we really can implement a domain model. And finally, our object metamodel should encourage software quality characteristics such as easy understanding and easy modification.
2.1.4 Context: A Classification of Programming Languages
When we talk about the basic elements of an object metamodel, we use the accepted classification of programming languages proposed by Peter Wegner. He defines a three-level model, where each level comprises the programming language characteristics that a language has on that level. The classification leads from object-based via class-based to the last level of object-oriented programming languages (see Figure 2.1).
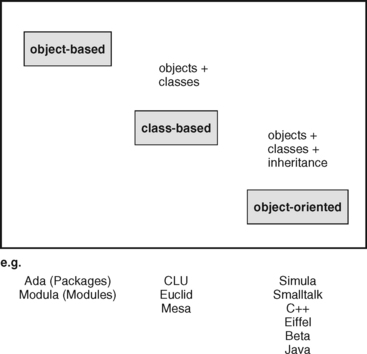
According to Wegner’s classification, a language is object-based if it creates and lets you manage objects as a primary language construct. In contrast, class-based languages have the class concept in addition to the object concept. This means that similar objects can be defined in appropriate classes, and that these classes are then responsible for creating objects as instances. Finally, an object-oriented language adds the inheritance concept to the features of a class-based language. This inheritance concept allows you to create a hierarchy of subclasses and superclasses. Such class hierarchies have to be supported by a polymorphic-type system to be able to call an object of a subclass indirectly in the context of a superclass, that is, through a typed identifier. In the course of this book, we will only deal with object-oriented languages. Based on this classification, we will describe the important elements of our object metamodel in detail.
2.1.5 The Object Metamodel and the Software Model
One of the fundamental ideas of the T&M approach is that the terms of the software model can be put in relation to the terms of the application domain. Figure 2.2 shows how the elements of the domain and the software models interrelate. The processes called generalization, specialization, use, and composition lead to a concept model based on domain-specific objects and concepts of the application domain. This concept model can be mapped onto a software model, formed by the elements and relationships specified by the object metamodel. Note that mapping the concept model onto the software model does not break the model, because the structure and meaning of the elements used in both models are similar.
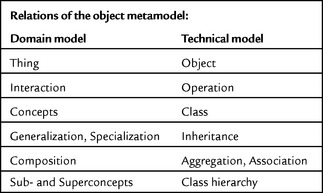
FIGURE 2.2 Interrelations between the domain and the software models defined in the object metamodel.
However, precisely this similarity represents a central rule of our object metamodel. For example, the model elements called term, generalization, specialization, composition, use, and hierarchy of terms correspond to the elements of the object metamodel called class, inheritance, aggregation, association, and class hierarchy. This means that terms are modeled by objects and that their behavior is modeled by operations, as shown in Figure 2.2.
This interrelation will become clear in this section as we continue interpreting the elements of the object metamodel from both the domain and the software perspectives. Note that we elaborated the software side of the object metamodel in more detail, because the main part of this book focuses on views relevant to the creation of the software model. Nevertheless, we will continue dealing with the domain modeling and the interrelation between the domain and the software models in later chapters (see particularly Chapters 6 and 9).
2.1.6 Definition: Objects
This section defines the term object from our two perspectives, that is, for the domain model and the software model.
Figure 2.3 shows how we describe a device within our EMS example, described in Chapter 1.
Both the structure and the behavior of similar objects are defined in the common class of these objects. This class also defines the visible and hidden properties of an object. From the software model, we need to ask ourselves to what extent the language we use supports encapsulation of an object’s properties. For example, with the appropriate declaration, we can access the internal structure of an object from the outside in both Java and C++; Smalltalk, on the other hand, does not let you protect operations from being called by clients at all.
Furthermore, a type is assigned to each object. In most statically typed object-oriented programming languages (e.g., C++), the type is defined by the class that an object belongs to.
Each object has to be created explicitly at runtime. To create an object at runtime, you call a creation operation of the relevant class. While they are created, objects are allocated in memory, and then perhaps initialized and bound to an identifier. Once created, this object is an instance of that class as long as it lives. Note that the type of an object also remains the same for an entire lifetime. On this basis it is important to understand the difference between static and dynamic types of object identifiers:
Objects are direct instances of their creating class. This means that, at runtime, these objects have the structure of attributes (also called fields) defined in the class. Such attributes can contain values (see Domain Values in Section 2.6.5) or references to other objects.
As mentioned above, each object has a state.
Each operation you declare for an object defines the name of this operation and its argument types and return type. All these elements together form the signature of an operation. The set of all signatures of the public operations of an object form its interface (see Figure 2.4), where public means that these operations are visible to the outside. In contrast, an internal interface can be accessed only by the object itself.
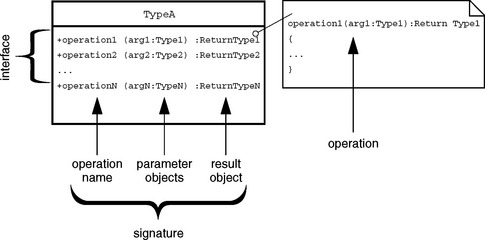
The interface of an object defines its services. We expect from an object to offer a set of domain services. The services an object offers at its interface are often realized so that services provided by other associated, that is, referenced, objects are used. In this connection, we often speak of a call-in or incoming interface, as opposed to a call-out or outgoing interface. For a programming language, the call-in interface is always explicit (because it is the public interface of an object), while the call-out interface can normally be determined only by analyzing the program code.
The idea of services supplies a basic interpretation of the use relationship between objects: one object offers services, acting as a provider, and another object, acting as a client, uses these services. An object can be both a provider and a client for other objects (see Figure 2.5).
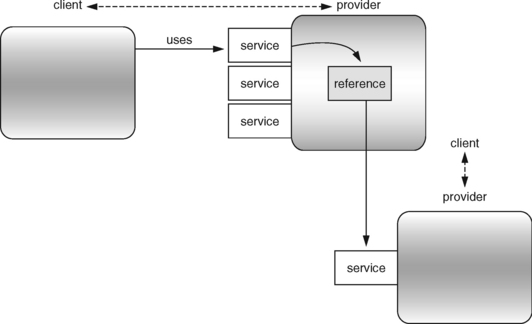
We have to distinguish the interface of an object and the call of services over this interface, both as terms and as concepts.
Conceptually, the interface’s elements are called operations, that is, executable steps or activities running on a computer system. In terms of programming languages, these operations are implemented by the constructs of each language and are then called procedures, methods, or routines.
When we call an operation, we often speak of sending a message to the called object. Such a message includes the identifier of the object (as the addressee), the name of the operation, and the call parameters. When polymorphism is used, then the respective operation in its specific implementation is executed at runtime. This is also called late or dynamic binding.
When handling objects, we often find that operations cannot always be called in any state of the object. The reason is that an object obeys a certain use or state model, which can be explicit (e.g., as a finite state automaton) or implicit. We speak of the protocol of an object:
Occasionally, the literature dealing with object orientation uses the terms protocol and interface synonymously. Our definition of protocol originates from the field of distributed systems, where the term describes the interplay beween two partner instances, which, in our sense, provide a bundle of services. However, popular object-oriented programming languages offer no way of representing a protocol at the interface, except for assertions in Eiffel.
Although the interface of an object defines the operations and perhaps attributes of the object that are visible from the outside, encapsulation means that you cannot access any property not explicity exported from the outside. This is normally called information hiding.
The encapsulation concept also means that, though the client knows the signature of an operation and can draw conclusions about that operation’s behavior from the contract model (see Section 2.3), the implementation is totally hidden. In this respect, any change to the implementation should be made in such a way that no change in the specified behavior is visible from the outside.
2.1.7 Discussion: Object Identity
It is important to understand that an object’s identity has nothing to do with it being addressable. The fact that an object is addressable means that you can access an object from within one or more contexts (which might then lead to the so-called dynamic alias problem; see Section 2.6.2). Addressability is an external object quality and depends on the context.
In contrast, the identity of an object allows you to uniquely identify this object, regardless of the path you have to use to reach this object. From a software-specific stance, identity means first and foremost that whether or not two identifiers point to the same object or to two objects in the same state can be determined on the level of programming language. This means that identity is an internal object quality, that is, it belongs to the object, regardless of its context and the way its structure and operations are defined.
In addition, we need a concept to obtain a domain-specific identity. This domain-specific identity has to be independent of the software-specific identity of an object. Two objects with a different software identity can have one single domain identity. For example, a bank customer can be a debtor in one context and a portfolio owner in another. The identity of that person must be unique, regardless of the behavior in the respective context. This means that the developers have to be able to express what they mean by identity and how this identity relates to equality: Do they mean equal values, equal behavior of objects, or equal domain identity of an object? Note that the domain identity can never be a global property of an object. It can be modeled in a meaningful way only in dependence from the application domain. We will propose a possible solution to this problem in Section 9.4.1.
2.1.8 T&M Design: Structuring an Interface
As mentioned earlier, objects have a state that can be probed or altered. Depending on this state, sometimes operations cannot be called for software and domain reasons. To better understand this relationship in the domain and software models, the domain description of how objects are handled and the description of their interfaces should be arranged similarly (see Figure 2.6).
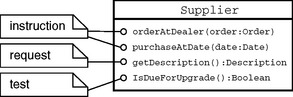
• From the domain-specific view, an object is organized as follows:
– Instructions (in the sense of commands, actions) change the state of an object, resulting in procedures.
– Requests supply information about the object in the form of domain-specific result objects, resulting in functions.
– Tests are a special form of requests that probe the domain-specific state of an object and return a Yes/No answer, resulting in predicates, which are used in assertions.
• From the software-specific view, the interface of an object is organized as follows:
– Procedures alter the (externally visible) state of an object. This change of state is not necessarily admissible at any given point in time. It normally depends on the actual internal state of an object.
– Functions return result objects, without changing the externally visible state of the object, that is, a function always returns the same result, while the state and arguments of the object remain the same. A function can be partial, if it returns a result only for specific arguments and object states.
– Predicates probe the state of an object and return a boolean result. They do not change the state and can be called at any given time.
We distinguish the concept of procedures, functions, and predicates rather than using a syntactic differentiation of a signature in input, input/output, and result parameters. Nevertheless, it is important to see how this differentiation is supported by a programming language to better understand our concepts. For example, in C++ each operation has the syntactic form of a function, and there is (currently) no primitive boolean type; in Smalltalk, on the other hand, each operation returns a result object.
2.1.9 Definition: Classes
In the domain model, classes model the concepts and terms behind the objects we use in our daily work. This means that a class is an abstraction of similar objects, based on the common behavior of different domain objects. The similarity of terms can be thought of as a generic term. Such generalizations or hierarchies of terms are part of the respective domain language, which forms the basis for cooperation and furthers a better understanding of the application domain. Hierarchies of terms are modeled by subclasses and superclasses.
In the software model, a class is a piece of program text describing the fundamental properties of the objects it can create. A class is defined by its name, its inheritance relationship to its superclasses, and a set of object properties (see Figure 2.7). These properties include the interface of objects and their internal implementation by algorithms and data structures. This means that a class defines the creation and behavior model of its instances. An object is always an instance of exactly one class.
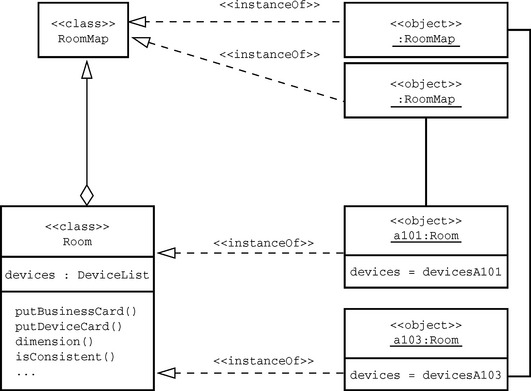
Thus, in addition to the behavior at runtime, a class also defines how its instances are created and initialized. Each object you create differs from all other instances of a class in that each one has its own memory location. In the example shown in Figure 2.7, this would be for each Room object the reference to the respective lists of devices.
Encapsulation is used to protect the internal representation of an object against inadvertent use. For example, the reference to the object with the devices identifier in Figure 2.7 is not visible in objects belonging to the RoomMap class; it belongs to the internal representation.
Classes define internal interfaces, in addition to the public interface. The internal interfaces of a class are first the so-called inheritance interface, which is used only for subclasses of a superclass and not by clients, and the private interface, which denotes the operations for use within one and only one class.
Many programming languages can protect, that is, hide, their internal interfaces by use of language constructs (e.g., protected and private in Java or C++).
You often find in the literature and programming environments that a reading and a writing operation are supplied for each attribute of a class. These are generic operations, not to be confused with “generic components” or “genericity”:
2.1.10 Discussion: Generic Operations
Generic operations are used in graphical interactive programming environments (e.g., VisualAge) to make application objects “accessible” for graphical interface elements. The same approach is often found in database application software.
These generic operations can violate the information-hiding principle at the public class interface, because they publish the internal structure of an object, at least in part. In addition, they can easily destroy the domain consistency of an object. In general, we recommend not using such generic operations.
Let’s look at a class, Account, where the generic operations could be setBalance and getBalance. When designing the class, the developer will have considerable troubles to implement the bank-specific handling of accounts using these operations. A better way would be to use deposit, withdraw, and calculateFees to define the conditions when a balance may be modified.
2.1.11 T&M Design: Generic Operations
Note that the T&M approach does use generic operations, provided that they are used at the internal interface.
It has proven to be a good idea from the software viewpoint to use generic operations to implement all probing and state-altering operations. Generic operations should thus be used in their defining class and all subclasses. More specifically, the generic operations are defined in the class that introduces the corresponding attribute. At this point, the attentive reader will probably ask whether these generic operations can be protected as internal interfaces by the mechanisms provided by the programming languages. The answer is that, C++ or a similar programming language have a special language construct (protected). But you can only implement this by appropriate categories and related programming conventions in Smalltalk.
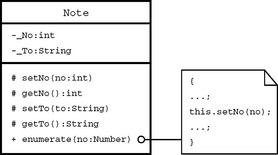
In the example shown in Figure 2.8, the class Note offers an operation, enumerate, with a parameter object of the class Number. Internally, this operation uses the protected generic operation, setNo, to set the encapsulated private attribute _No of type integer. This introduces a form of data abstraction to the internal relationship between classes. This approach can be used to implement abstract things. For example, generic operations can be abstracted to serve as template operations in superclasses, where their attributes are then added to subclasses.
2.1.12 Discussion: The Object Life Cycle
In the interplay between objects and classes, there are a few operations that limit the life cycle of an object; they are considered “critical situations” in software modeling and construction:
Conceptually, none of these operations can be assigned to the object itself, because an object cannot create, delete, or transform itself. These operations belong to the metalevel (see Section 2.7).
In programming languages where classes themselves are available as objects in the system, creating is normally implemented as a class operation, that is, for each class there is at least one operation (constructor) that can create instances of that class. In compiler languages, which do not represent classes as objects, the compiler generates code to create objects, and the actual instantiation is normally handled by the runtime system. The creating procedure is then normally defined as a specialized operation within the class text. In many cases, implementing another operation that puts the object in an initial state, in addition to the creating operation, has proven to be a good idea. This initialization operation can be called when creating an object and whenever needed during the object’s lifecycle.
Deleting technically specifies how an object is removed from the runtime memory. In object-oriented systems, this process comprises two steps:
• There is no more reference to the object in any location of the application system, and the object can no longer be reached in the application system.4
• An object is removed from the heap. This can be handled by the garbage collector, if available, when the object is no longer referenced. Otherwise, the delete operation has to be specifically written, and problems relating to lost objects, dangling pointers, and the correct deletion order of related objects have to be dealt with.
Transforming means transfering an object into another one. This is normally the case when an object is processed so that it changes its “character” due to a specific action, resulting in a “different” object.
Such a transformation of an object into another one is normally necessary for domain-specific reasons and rather difficult to reproduce in an object-oriented environment. From the technical stance, this often means that the object has to change its class and type membership, which is not supported in strongly typed object-oriented languages. Normally, if an objects needs to change class, you first create a new instance of the “target” class, then you transfer the required values from the old object to the new one, and finally, you delete the old object. Though this solution is simple, it can be problematic, because it can happen that both the software and the domain identities of the original objects are lost.
2.1.13 T&M Design: The Object Life Cycle
When we design the usage model (see Section 3.2.1) of an interactive system, we have to clarify how objects can be created. The users of our system have to clearly understand how and from where they can obtain new domain instances of their task-related objects. In practice, it has proven a good idea to use tools or domain containers (e.g., form files) to create new materials. In addition, the tools themselves can be created by use of toolboxes or tool managers.
The same rules apply to deleting objects. The question here is the domain view that a user has about the “deletion” of an object. We can easily see that there is a big difference between the software and domain views. To allow users to easily express that they no longer need an object, we recommend defining an explicit “location” for the domain-specific deletion of objects, for example, a tool or a domain container (e.g., a desktop bin).
Let’s look at these things in our EMS example. Assume that a developer changes offices. The device manager updates the room plan, using the Device Organizer tool, then puts the updated room plan into a device file and closes the device Organizer. The usage model assumes that both the room plan and the tool are still available for work. However, from the software view, once the room plan and the tool settings were saved, both objects could be deleted from the runtime system. If, however, the device manager moved an old work copy of the room plan to the bin and then empties the bin, this action tells us that he no longer has any use for this plan. Still, the actual software-specific deletion of the object could be postponed until the system is shut down.
We already said that transforming an object into another one is normally due to domain reasons. Let’s look at a bank example:
A customer consultant prepares for a meeting with a customer, filling in personal information in an application form for a small loan. Some information will be added in the course of his meeting with the customer. Next, the form is printed and signed by the customer, the customer consultant, and a second consultant. This means that the application form is now a contract for all participating parties. The customer consultant selects the “Contract signed” option in the form editor. From that point, no changes should be made to this contract object.
For the software implementation of this scenario, we could use different wrappers around an “object core” instead of changing the object’s class. We will introduce a more complex technique for role modeling in Section 9.4.1. For example, the roles of a core object could be “contract” and “form.”
2.1.14 Definition: Inheritance
An inheritance relationship is an essential feature that distinguishes object-oriented languages from conventional ones.
The inheritance unit is a class, and the inheritance relationship remains unchanged during runtime, at least in statically typed languages. Note that many object-oriented languages allow you to restrict the access to inherited properties (particularly for operations):
• First, you can generally restrict the interface for clients, that is, an inherited property that is visible in the superclass no longer belongs to the public interface in the subclass. Examples include the private inheritance in C++, where the subclass relation is lost, or the non-export in Eiffel, where type errors can occur due to the subclass relation.
• Second, you can restrict the interface, with the exception of specific classes, that is, only specific client classes can access the properties. For example, this can be implemented by selective export in Eiffel, or by breaking the data encapsulation between classes, for example, by using the friend construct in C++.
2.1.15 Discussion: Inheritance
You can think of inheritance as a mechanism that allows you to reuse specifications and code. In Simula 67, inheritance is called program concatenation. In addition, inheritance forms the basis for polymorphism in connection with the appropriate type system.
The way you use inheritance determines its meaning for the domain model and the software model. There has been vigorous discussion about single and multiple inheritance among language developers. Languages like Smalltalk or Beta support only single inheritance, while multiple inheritance is supported in Eiffel and C++. Java supports single inheritance on the class level, and the multiple inheritance concept can often be replaced by named interfaces.
Note that you should be careful when restricting access to inherited properties. This technique can be useful when building frameworks or implementing complex patterns. The downside, however, is that this often reduces the readability of your code or design. Major problems can occur with type or runtime errors, particularly with the non-inheritability of friend constructs in C++.
2.1.16 T&M Design: Inheritance
In our T&M design, we pragmatically assume consistent use of single inheritance when modeling concepts and terms in the domain model, because it ensures that our concept model is clear. After all, a concept model built in the form of a tree is easier to understand than a mesh of complex relationships, although our everyday language has many examples of meshed terms (like the relations of bird—flying animal—fast runner— ostrich). On the other hand, we do not simply map our everyday language to our application systems but reconstruct a domain language instead. This reconstruction should be easy to understand in our targeted application domain. And it should be as clear and minimal as possible.
In contrast, multiple inheritance is often useful in the software construction, provided that it is used in a disciplined way and supported by an appropriate low-cost language implementation. Section 8.3.1 shows an example that uses multiple inheritance.
Let’s look at these things in our EMS example. It is important for our device manager to be able to copy both the current business cards of all staff and a device identification card. For this reason, the class design for our EMS includes a copyable interface and the copy() operation. This interface implements two classes, BusinessCard and DeviceCard. However, the operation is implemented in a different way, because the data to be copied from business cards and device cards differ.
Concept modeling is the primary domain motivation for the use of inheritance. From the software view, we are additionally motivated by the separation of specification and implementation into a superclass and a number of subclasses (see Section 2.1.22).
Another software motivation is the use of inheritance for the incremental transfer and modification of properties from fixed class descriptions that cannot be changed in the source text. This is often the case in commercial class libraries. With a commercial library, if you want to change a property you often have no other way but subclassing to implement a change. In this way, you can implement changes even when the impact of such a change on client objects cannot be fully anticipated. In this case, you can encapsulate the change in a subclass, because dynamic binding lets you use both the instances of the new and the old class (polymorphic).
Finally, the last of the uses of inheritance we consider acceptable and useful serves to abstract common properties from existing classes. You should always carefully make sure that these common properties are motivated from the domain view, rather than reusing existing code and extracting attributes for the sole reason that you have a piece of code available. In fact, by our definition, inheritance is not about the reuse of existing code but about the abstraction of a common behavior. This view also justifies our critique of “extracting” common attributes into superclasses. These superclasses are oriented to the internal structure, having not much to do with behavior-specific abstractions. Structure-oriented inheritance hierarchies are often found in projects based on “traditional” data modeling.
In summary, our practical experience has shown that “artificial” superclasses oriented to code reuse and the internal structure tend to become hard to understand, thereby hindering further development of such a system.
2.1.17 Discussion: Role Relationships as an Alternative to Inheritance
As we have said, we use inheritance primarily for concept modeling. We interpret superclasses and subclasses in “Is-a” or “Seen-as” relationships. In this sense, a folder is a special form of a container. However, when developing large-scale application systems, we often incur a problem that cannot be elegantly solved in this way. In an organization with several departments or groups, each having a different view of the same work object in different contexts, you obviously have to deal with many different views that could be better modeled by different roles rather than by generalizing and specializing a term.
A generalization relationship connects objects solely through their common abstraction. A folder is a container, and a file is a container; that’s the only thing these two objects have in common. A folder is not a file only because both objects are containers. Things are different with changing roles. For example, a customer of our ficticious bank can be both a debtor and a portfolio owner, depending on the situation. We say that the customer plays different roles. Depending on the role, the customer has a different meaning for the bank. We could say that the customer has a different behavior. Nevertheless, when mapping that customer and his or her roles onto the application system, we have to ensure the customer’s domain identity in each of his or her roles. We have developed our own role pattern (see Section 9.4.1), because inheritance or use relationships won’t let us build these roles. This means that we add a role relationship to our application development process, in addition to specialization and generalization.
2.1.18 Definition: Use Relationships
A use relationship corresponds to the traditional call relationship or module import. In fact, it is the classic form of connecting two program components.
Let’s see what this looks like in our EMS example. Our device manager will occasionally want to copy the business card of an employee or a device identification card, for example, to use it as a template. He uses a photocopier for this purpose. To copy a business or identification card, we need a copy() operation. The photocopier is not interested in any other operation of the BusinessCard and DeviceCard classes. For this reason, we declared an identifier of the type copyable in the Copier class. At runtime, objects from both the type-confoming classes BusinessCard and DeviceCard are bound to this identifier.
2.1.19 Discussion: Use Relationships
A lot of practical experience and knowledge about the meaningful use of this form of component relationship has been collected in the modularization camp. This appeared to have been forgotten in the initial euphoric phase in the advent of object-oriented programming. For example, many modern method and construction textbooks still discuss the pros and cons of inheritance relationships, totally ignoring the use relationship. In our approach, the use relationship between classes ranks high, and its methodological use will be discussed in Section 2.3.
In the object-oriented model, the use relationship is generally based on pointers or references, and a static type is declared for an identifier. At runtime, this identifier can be bound to pointers or references to instances of classes of a conforming type. The idea behind this concept is reference semantics, which is covered in the classic Smalltalk literature, for example, by Adele Goldberg and David Robson. However, you will note quickly that this concept cannot be maintained for (arithmetic) calculations, where we need values in the mathematical sense. Section 2.7 discusses what all of this means for our object metamodel.
2.1.20 Definition: Polymorphism
On a class level, the use relationship means that the class text includes a static definition of the relationships that are basically allowed between the objects of that class and other classes. The actual relationship between objects is then determined by the principle of polymorphism at runtime.
Most statically typed languages use the inheritance relationship to control polymorphic binding. This means that objects of the declared class and all subclasses can be bound to an identifier. This polymorphism is typesafe, that is, all operations of the declared class can also be called in its subclasses as long as the relationship between the superclass and its subclasses is a type-subtype relationship.
Dynamically typed languages like Smalltalk allow unrestrained polymorphism. This means that whether or not an operation is supported by an object can be decided not at compile time but only when that operation is called. If that object doesn’t support the called operation, then the system reports a runtime error. This means that programming conventions should be used to control unrestrained polymorphism. The reason is mainly that, unless you can tell from the identifier names, the class text tells you nothing about the objects that are actually bound at runtime.
Dynamic binding is the prerequisite for polymorphism in connection with redefining operations in subclasses. Dynamic binding means that the runtime environment decides what implemented operation will be executed when you call it.
When you can bind different objects to one identifier at runtime, then these could have different implementations by the same operation names. It means that the static program text defines only the messages sent to an object.
In our EMS example, we defined an aspect class, copyable, for the photocopier. At runtime, instances of the BusinessCard and DeviceCard classes can be bound to identifiers of this type. The message copy() is bound to the operation implemented in either the BusinessCard or the DeviceCard class, depending on the specific case.
2.1.21 Definition: Abstract Classes
In object-oriented languages we often use their ability to separate classes by specification and implementation, for example:
• A superclass contains the specification, that is, it specifies behavior on an abstract level.
• The subclasses of this superclass contain implementations, that is, the behavior specified in the superclass is implemented on a concrete level.
From the software view, we implement specifications either by abstract classes or by named interfaces, as in Java.
• An abstract class is a class from which no instances can be created. They ususally contain at least one nonimplemented (i.e., abstract) operation.
• Abstract classes are used to specify a common interface and an abstract behavior for all subclasses that implement the concrete behavior.
• The abstract class itself can implement some operations, which will then be inherited.
We say that a class is abstract (or deferred) when at least one of its operations is abstract. Some object-oriented languages (e.g., Java and Eiffel) let you mark a class as an abstract class, even if it contains no abstract operations. In other languages, abstract classes have to be denoted as such by convention, or implicitly by a deferred method.
Abstract classes are often more than pure interface specifications. The operations declared in an abstract class can be used right there in the abstract class. Using these abstract operations you can implement several operations. They can be called to serve as template operations or standard implementations by client classes. This technique is important for building frameworks.
Figure 2.9 shows an abstract class whose interface includes the following operations: templateOperation, abstractOperation, and baseOperation. Both baseOperation and abstractOperation were used to implement templateOperation, while abstractOperation itself will be implemented later in the inheriting class.
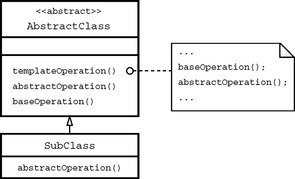
The subclasses of abstract superclasses are normally used on the basis of polymorphism. However, we often have to expand or specialize an interface in subclasses for domain or software reasons. If we want to use the instances of subclasses both polymorphic and by their dynamic type, we will soon find that we need a metaobject protocol (see Section 2.1.15).
2.1.22 Discussion: Specification and Implementation
An important way to use inheritance is to separate the specification from the implementation. A common superclass specifies the interface and the abstract behavior of all subclasses. The fact that no objects can be created from an abstract class tells us that we cannot use it directly. The subclasses are responsible for implementing the concrete behavior. On the other hand, it is normally sufficient for a client to know the abstract class with its abstract behavior. For example, you can hide an entire class tree “behind” the abstract superclass.
With their interface and behavior specifications, abstract classes define how their subclasses can be handled, thus defining in certain limits the entire system design.
Abstract classes with a hidden class tree form the basic idea for a fundamental design pattern, the so-called Family pattern of Erich Gamma,5 and expanded constructions like the Bridge pattern of Gamma et al. work similarly. The T&M design lets you implement aspects in this way (see Section 8.3.1) by use of aspect classes.
2.1.23 Definition: Loose Coupling
The use of abstract classes is one example of how you can develop systems with loosely coupled components.
As a result of loose coupling, you can replace both individual classes in the program code and objects at runtime by appropriate components with the same interface and similar behavior but a different implementation.
2.1.24 Discussion: Loose Coupling
Loose coupling was motivated by the discussion of modularization concepts (see Section 2.2). These concepts say that components should have little dependencies to the outside while having a strong contextual coherence inside. One technique to achieve loosely coupled components addresses only the type or interface of other components when using these components, without knowing the concrete classes and their implementation (Gamma et al.: “Program to an interface, not an implementation” p. 18). We take this concept a step further, reducing loose coupling to the section of the interface, which is the minimum required for use. Section 8.3 will discuss aspects for implementing loosely coupled tools and materials.
When using loose coupling between a client class and the abstract superclass it uses, we have to solve a construction problem: The concrete subclass has to be known at the location where we actually create an object. Initially, this seems to conflict with our decoupling idea. A number of mechanisms have been proposed to be able to create concrete objects without losing the decoupling concept. Gamma et al. describe these mechanisms in the form of creational patterns. Section 9.4.2 will introduce a creational pattern, the Product Trader, which is particularly useful for our T&M approach.
2.2 MODULARIZATION
Classes are traditional modularization units for object-oriented design. More recently, larger design and construction units, like design patterns or packages, have been proposed as modularization units. This section discusses the basic principles of modularization in view of using them in our object-oriented design.
2.2.2 Context: Modules and Object Orientation
In the software model, you can think of classes as a further development of the modular concept. As Bertrand Meyer says, “Classes provide the basic form of module”. This means that basically the same principles of maximum cohesion and minimum coupling apply to both modularization and the use relationship.
Unfortunately, these traditional modularization principles cannot simply be transposed to object orientation. First, classes or objects have a different granularity than common modules. Although it is customary to build an application system from far less than a hundred modules, the number of classes or objects can easily reach ten times that number in a moderately complex application. Each class includes a manageable number of operations.
If we think of objects and classes as the “atoms” of our object-oriented design, we obtain a totally different view. Obviously, we design and build our application in units or components, formed of more than one class or one object. Such a unit could be a container with a table of contents and markers or iterators (see Section 3.2.7). To implement such a container, we need mutual-use relationships. Note that some successful patterns, such as those described by Gamma et al., for example, Visitor, Observer, or Mediator, are also based on mutual use.
Recent discussion has led to the understanding that the conceptual design and construction units used in object orientation are often beyond a single class, and it has also led to the development of design patterns, clusters, subsystems, and frameworks. This means that the modularization principles in our object metamodel have to be reformulated in view of these design and construction units. We will attempt to reformulate them for the basic design units in Section 2.2.3 and for frameworks in Section 9.3.
2.2.3 Definition: Principles of Object-Oriented Modularization
Maximum cohesion and minimum coupling are the fundamental factors for traditional modular design.
Bertrand Meyer proposed a list of criteria and rules to facilitate the transfer of the modular concept to object orientation. We will briefly introduce some of these criteria and rules below.
One of the most important features of object orientation in this context is the open-close principle.
A design and construction unit should meet the following important criteria:
• Decomposability: A design problem should be decomposed in smaller and less complex partial problems, which are mapped to design and construction units. These units should form a simple and independent structure.
• Composability: Design and construction units should be composed by simply recombining them into new software systems in different application domains.
• Understandability: Each design and construction unit of a software system should be understood independently of the other units.
• Continuity: A change to the design problem resulting from the domain or software system context should lead to changes only in one or a few design and construction units.
To meet these criteria, we have to observe the following rules:
• Direct mapping: The structure of the software system should closely relate to the structures identified in the application domain.
• Few interfaces: Each design and construction unit should interact with as small a number of other units as possible.
• Small interfaces: When two design and construction units interact, then they should exchange as small an amount of information as possible.
• Explicit interfaces: When two design and construction units interact, then this exchange should be explicit.
• Information hiding: Clients should see and access only relevant properties of a design and construction unit.
• Open-closed principle: Design and construction units should be both open and closed.
2.3 THE CONTRACT MODEL
We want to use an object-oriented approach to develop not only expandable, reusable, and modifiable but also correct and robust classes. We try to achieve robustness by modeling behavioral objects, that is, modeling objects characterized by their behavior and not by their inner structure—their attributes. We use the contract model to sketch a concept allowing us to specify the behavior of operations in a “semiformal” way. This contract model represents an important contribution to better software quality and should form the basis of each development project. It provides what Bertrand Meyer calls “contracting for software reliability.”
2.3.2 Definition: Contract Model
We can define the essence of the contract model as follows:
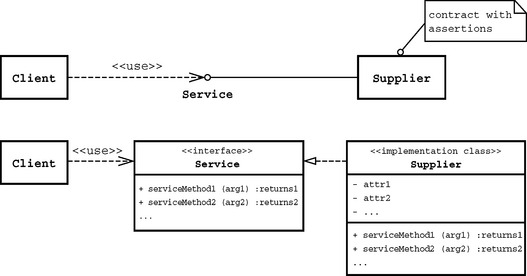
The use relationship between classes is interpreted as a service relationship between a client and a provider (see Figure 2.10). In this context, a class offers a service that another class, acting as the client, wants to use. These two classes enter a contract relationship, where the contract specifies all underlying assertions as well as the rights and obligations of both parties relating to that service.
The contract model is implemented by pre- and post-conditions for operations as well as for class invariants, having the form of boolean expressions and residing in the provider class.
Contracts established between classes always refer to operation calls, that is, requests for services. The pre-condition specified for a contract defines the rules that have to be observed to be able to call an operation. The client is responsible for observing this pre-condition. More specifically, the client has to ensure that the specified conditions are met. In order for the client to meet this obligation, the predicates used as test questions in the pre-condition have to be accessible at the provider’s interface. Before calling an operation, the client can then test for observation of the pre-condition and establish the required state, if that pre-condition is not yet met.
Once the pre-condition is in place, the requested operation is executed, and the provider declares that they guarantee the post-condition. This condition is also composed of boolean expressions and does not have to be tested by the client. The client can assume that the condition holds when the operation has terminated.
An invariant is formulated for a class as an overall property of that class, which preserves its consistency. This holds true for each service provided, that is, its observance is tested upon each call.
2.3.3 Discussion: The Contract Model
By stating assertions within the interplay between clients and service providers, we can make a significant step towards the correctness and reliability of our software system. In this context, correctness refers to the conformity between specification and implementation. We want to use invariants and pre- and post-conditions to describe parts of a behavior specification contained in the class text and make them checkable. This means that the contract model helps us to
2.3.4 Context: The Contract Model and Abstract Data Types
From the software view, classes should be implementations of abstract data types. Using known language features available in most object-oriented programming languages we can only define operations and attributes. However, if we want to use types to model “a set of programming language objects with similar behavior,” we need an adequate means of expression. The reason is that the specification of abstract data types involves axiomatic semantics, which is normally expressed by axioms and equations. Object-oriented programming languages do not normally support such axiomatic semantics. We can use the contract model, which Bertrand Meyer describes as “design by contract,” to overcome the gap between specification and implementation of abstract data types.
2.3.5 T&M Design: The Contract Model
The contract model is currently supported only by Eiffel among the object-oriented languages, where assertions can be formulated as an independent sublanguage (see Figure 2.11). However, it has proven useful in practical projects to try to transport the assertion concept to other programming languages. For example, our JWAM framework implements the assertion concept in Java.
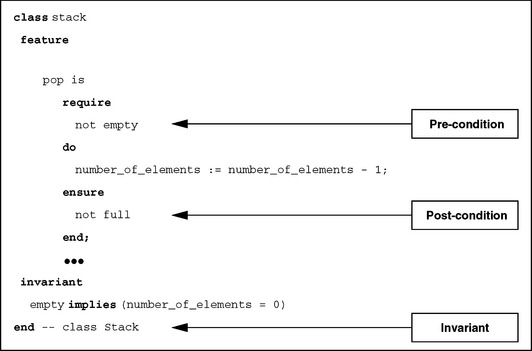
As in the case of a commercial contract, we have to check for the observance of a contract, and the violation of the contract has to have corresponding consequences. The contract model is more than a pure piece of documentation only if contract violations are sanctioned. For this reason, we should link assertions to an appropriate exception mechanism. An exception will then be thrown at the client’s end as soon as a pre-condition is violated, while a violation of post-conditions and invariants will lead to exceptions at the provider’s end.
2.4 TYPES
Current object-oriented programming languages use classes and types interchangeably. Though this is practical, it blurs the conceptual differences we want to observe to ensure a clean software system. This holds true particularly when we use a dynamically typed programming language like Smalltalk, or when we have additional type definition options for interfaces, as in Java.
2.4.2 Definition: Types
With this definition of type, we have determined at least the checkable interface used by instances of that type. This means that an identifier we declared to have that type can be bound only to objects that meet this interface. In other words: a type should be checked. For this reason, we like typed languages, because declared identifiers and parameters of our program can then be checked for typesafe use either statically (at compile time) or dynamically (at runtime).
In addition, we want to specify potential limits for the behavior of these instances. As we saw in Section 2.3 on the contract model, it is not easy to transfer the axiomatic semantics of abstract data types to an object-oriented construction. Nevertheless, we expect that instances of a specific type behave in a “semantically compliant” manner. Accordingly, assertions should also be included in the definition of a type.
A type in the sense of an abstract data type does not tell us anything about the concrete implementation of the interface and its behavior. This means that implementations and information about the internal structure are not part of the definition of a type.
2.4.3 Context: The Theoretical Concept of Types
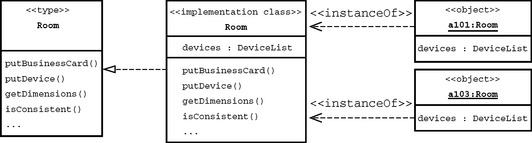
The concept of types is primarily motivated by software-specific factors. We use types to specify our construction units. Following the general definition developed by Luca Cardelli and Peter Wegner, a type is a set of objects with similar behavior. In their formulation, Cardelli and Wegner didn’t focus on the object-oriented elements, that is, classes and objects, but generally refer to programming language objects. When we try to transfer this to object orientation, we could say that, for example, the two rooms, a101 and a103, in Figure 2.12 have the same interface and a similar behavior, so that we can use the type Room to describe them.
Traditionally (e.g., by the definition of Hoare), an object of a programming language may have one and only one type. The object-oriented inheritance principle requires us to expand this concept of types. By this principle, an object is exactly the instance of a (creating) class, but it can have more than one type.
A type is characterized by the set of its properties. For example, an object x is of type T exactly when object x meets the properties characterized by type T. The following properties can be described by a type:
• the names of operations or the entire signatures of an object; and
• the behavior of operations (e.g., pre- and post-conditions and invariants).
Real-world type systems normally offer only a fraction of these properties.
Conceptual methods used to specify the behavior of subtypes are discussed in the seminal work of Barbara Liskov and Jeannette Wing. The problem relating to the covariant redefinition of parameter types and a proposed solution are discussed by Bertrand Meyer.
2.4.4 Discussion: Types
Building subtypes is primarily a specification concept that we can use to express that objects behave similarly. This concept reaches beyond the usual check for identical interface names. This means that it is not sufficient to simply be able to interpret the called operation by the object. The reason for this is that it only means that the call does not immediately cause a runtime error. What we normally need is a way to interpret all operations specified by a type interpret, which leads us to the concept of similar behavior. Similar behavior is a much “softer” formulation than the identical behavior recommended by many computer scientists. Unfortunately, it is difficult to check it formally. In contrast, when we implement an object or redefine its properties, we expect it to behave both “in the sense of” the specification and formally compliant with its type.
Types and behavior specifications become increasingly important in the use of components. When components are shipped merely as binary units, then all that remains to evaluate their functionality is basically the interfaces and thus the type information. In that case, it is important to know what other characteristics are assigned to types, in addition to the signatures, for example, assertions of a contract model.
2.5 CLASSES AND TYPES
In the advent of object-oriented programming, many developers used classes and types synonymously. The reason for this was that the construction of classes was the only way to introduce user-defined types. Over the course of time, object-oriented programming languages have been improved and expanded so that the typing concept is now more pronounced. For this reason, developers should understand the conceptual differences between classes and types.
2.5.2 Classes in Your Design
From the domain-specific perspective, classes are our elementary design and construction units. In the design, we model the common features of similar objects in classes. These common features apply to objects in their behavior and state. In this context, class hierarchies should correspond to the domain-specific concept model. This means that they model the basic concepts or abstractions of your application domain.
On the construction level, a class defines how its instances behave and how they are built. In this context, class hierarchies express the generalization or specialization of this behavior and construction. The compiler and the runtime system ensure that the correct instances are created based on a set of “complete” class descriptions.
2.5.3 Differences between Types and Classes
Compared to a class, a type is primarily a specification concept that defines an “external” view of declared identifiers and program objects. Note that the emphasis is more on the software implementation rather than on the domain modeling and construction side. A type defines the syntactic and (to a limited extent) the semantic characteristics that can be guaranteed for the structure of the program.
Let’s take a closer look at these differences.
• Besides the interface, a class also defines the behavior and structure of its instances, that is, their internal state and the implementation of their operations.
• The type of an object refers intially only to its interface, that is, a set of messages to which the object can respond. The type of an identifier specifies what objects can be basically bound to it.
• To be able to define the behavior of the instances of a type, in addition to the interface, we can implement types by classes. As long as the type hierarchy and the class hierarchy match, you can use assertions and controlled redefinitions to achieve a similar behavior of objects.
• Some languages (e.g., Java) can use named interfaces instead of classes to introduce user-defined types. Most object-oriented programming languages provide primitive data types (e.g., integer) that are not defined as classes.
• An object can have different types, and objects from different classes can have the same type.
• One part of the interface of an object can be characterized by a type, and other parts by other types.
• For two objects to be of the same type, it is sufficient that only part of their interfaces are equal.
2.5.4 Discussion: Classes versus Types
Classes and types can be totally separate concepts if the type refers strictly to the interface definition. If a type represents only a named interface definition, then it merely guarantees that instances of that type recognize a certain set of messages. Each type names operations that have to be defined in some place of your program. A class can then declare the types it meets in the sense of named interfaces. The actual class that defines these operations is irrelevant and independent of the class hierarchy.
Of course, if the programming language we use couples the class and type concepts, then there is a relation between class and type. In that case, the class defines a type. When we say that “an object is an instance of a class,” we imply that the object supports the interface defined by the class. A type-compliant call of a message requires the object to understand the message, in other words, that the object’s class implements the called operation.
We can go one step further in coupling classes and types when we use the type definition to specify the behavior of instances. In this case, it appears to be meaningful to use an appropriate class to define the behavior of the instances of a type. If the type hierarchy and the class hierarchy match, then we can define and limit the concrete or abstract behavior of objects of a type by the class hierarchy. Appropriate means for this approach would be the contract model and the mapping of our concept model onto domain-specific class hierarchies, which are designed by the principles of generalization and specialization.
2.5.5 Background: Programming Languages and Types
Popular object-oriented languages use different type and class concepts, for example:
• Java separates classes and types by introducing interfaces, as does Objective C with its protocols. In these languages, a class can declare, besides its superclass, which named interfaces it meets. Classes can be grouped by class hierarchies and by their interfaces. This means that classes can fall under a common named interface, even when there is no inheritance relationship between them.
• C++ and Eiffel use the class construct to define both the type of an object and its implementation. In addition, these languages let you write pure specification classes, from which no instances can be created. Similar to C, C++ also supports types that are not classes.
• In Smalltalk, there are no type declarations for identifiers and program units, that is, there is no type checking during compilation. Consequently, whether or not an object is called by the appropriate message through an identifier is not checked, so that a runtime error occurs if the object does not offer the called operation. The Smalltalk world works with message conformity rather than with type conformity, in other words, not a specific class or type relationship is in the foreground, but the question of whether or not an object understands a message.
2.5.6 T&M Design: Classes and Types
In our T&M design, we need a clear understanding of the possibilities offered by classes and types as constructs, and which concepts we want to use in our applications. Do we want to separate a named interface from the definition of its behavior? Should there be a hierarchy of named interfaces, in addition to the class hierarchy, and what does this mean in our design? What kind of reliability would we like to have when calling messages, and when (at compile time or runtime) do we want to check this reliability? The answers to these questions determine whether or not we can easily deal with the constructs of a language, how we use that language, and whether or not we should add our own mechanisms, such as runtime type checks in Smalltalk.
Some answers originate from practical experience with the T&M design. For example, type systems represent a major support for the save construction of software systems. Dynamically typed languages like Smalltalk offer more flexibility during the actual construction phase, compared to statically typed languages. However, it is often meaningful to design in Smalltalk as if that language were typed. To be on the safe side, we will add dynamic type checks at important points in our software system.
Inheritance hierarchies should correspond to domain hierarchies, thus defining a similar behavior. This means that we normally work towards class hierarchies in the form of type hierarchies.
In cases where we cannot or do not want to fall back on multiple inheritance to implement software architectures technically, named interfaces are a meaningful alternative. We then have to stick to design conventions to ensure similar use behavior.
2.6 VALUES AND OBJECTS
Values and objects are two fundamental concepts for the development of interactive software. This section explains that the differentiation of values and objects is not a terminological trick, but important for the design and construction of software systems. We use the term domain values to introduce an important concept of the T&M approach. Domain values can be used as the “atomic” design and construction units for application-oriented software development.
2.6.2 Characteristics of Values and Objects
To better understand the following discussion of the terms value and object, it appears meaningful to understand first where these two terms differ. The taxonomy in Figure 2.13 is schematic and in no particular order, but shows the essential characteristics of values and objects. It is based on the seminal article by Bruce J. MacLennan. We will explain the differences listed in Figure 2.13 in a moment.

• A value has no temporal or spatial dimensions. This means that concepts like time, duration, and location are not applicable. Values have no beginning and no end, and they exist in no particular place. No values are created in expressions, and they are not consumed. For example, it wouldn’t make sense to talk about time in the equation 40 + 2 = 42, or about the fact that the addition “creates” a new value. And it would be equally useless to talk about “the 42 on top of this page” when referring to the value and not to its concrete representation in digits.
• In contrast, objects exist in time and space, and they have a beginning and an end. Any two objects can differ from one another merely because they reside in different locations. For example, you can create a folder. Two otherwise identical folders can be in different locations. It would make sense to talk about “the folder I used yesterday.”
Another difference between values and objects is that a value is abstract and has no identity.
• A value is an abstraction from all concrete contexts. It is not bound to the existence of concrete things. And because it has no identity—only equality—it wouldn’t make sense to talk about several instances of a value (although it would make sense to talk about its different representations). For example, $50 is a value. Though there are many bank notes representing this value, there is not more than one instance of the value itself. Also, it would only make sense to talk about whether or not a bank note is worth $50.
• In contrast, objects are concrete instances of a generic concept (a class) that have an identity. There can be many equivalent but different instances of a class. For example, you can create several instances of an application form on your electronic desktop that differ in that they reside in different folders.
Yet another difference is that a value is immutable or invariable.
• Though you can calculate and relate values to other values, they won’t change. Values can be named. The value of a name or an identifier (of an “unknown quantity”) cannot yet be calculated or can be undefined. The same name can be bound to another value, depending on the context. For example, when looking at the equation 40 + x = 42; pi = 3.14, the idea that adding x would change the value of the number 40 to 42 is wrong. Also, x is not a variable, but has a calculable value. We can call the number 3.14 by the name pi and use the same name to bind it to the value 3.1415 in another context.
• In contrast, an object can change over time, that is, its state can change without losing its identity. And this identity does not have to be linked to a specific name. For example, you can edit an application form that you created yesterday and sign it tomorrow. You could change the form’s name from “New application” to “Edited application” without risking that it might lose its identity.
Yet another difference relates to how you can use values and objects.
• Considering that a value has no identify and no location, and that it is invariable, it would be hard to build communication and cooperation on the basis of values alone, because values cannot be exchanged or edited. In situations where you have to communicate and cooperate on the basis of values, you often use a specific value to “build” an identity. For example, an abstract value of $500 won’t be of much use in the banking business. It will become useful only if it is connected with an account, and if this account is seen in its temporal change. Only then can you use that value for cooperative work. For instance, to build an account in a value-based database, you can use the account number for unique identification of all other values related to this account.
• In contrast, objects can be used jointly, if you can access them by references. Then they can be known by different names in different locations, and you can use them as a common work object. Unfortunately, there is an alias problem to be solved: An object can be changed in one context without another context taking notice of that change. For example, a form can be accessed by identifiers on two different electronic desktops. This means that two employees can use it for cooperative work and coordinate their work through this form. Problems will arise when one employee does not see that the other employee changed the form without prior agreement to do so.
2.6.3 Using Values
When we think of using values, we probably first think of mathematics or engineering, where numerical analysis is of prime interest. For example, mathematical problems are solved by operations on numbers, a form of values. However, in our everyday lives, values and numbers have a much broader meaning. We use them to identify, characterize, count, or order things and eventually to represent them as measurable entities.
We basically always use values when we model abstract entities and do not want to be distracted by concrete and objective characteristics. In doing this, we also abstract from the context of the thing represented by a value. In this sense, the authors of a popular textbook, Richard Bird and Philip Wadler, discussed functional programming as follows: “Somewhere, in outer space perhaps, one can imagine a universe of abstract values, but on earth they can only be recognized and manipulated by their representations. There are many representations for one and the same value” (p. 5).
What does this mean? It probably means that we always need values and numbers when we have to calculate or order things. There is no doubt that we then need integers or real numbers, as well as currency values or periods of time. Even when we try to represent measurable parameters, ignoring the concrete circumstances of an object, values like bank codes or the current Dow Jones index are certainly useful values.
2.6.4 Context: Values and Objects in Programming Languages
Many object-oriented languages support both value and object concepts. The difference between these concepts is normally implicit and hardly discussed explicitly. The conceptual separation is least clear in a language like Smalltalk. When talking about values, it is important to understand that a truly smooth transfer of the abstract concept of values to programming languages was successful only in purely functional languages, such as Miranda or Hope. These languages let us write value-oriented program code; for example:
• They use expressions that are almost algebraic, consisting of functions. Functions have no side effects, so that they are similar to the concept of algebraic expressions.
• They use mathematical variables. A variable is a name for a known or yet unknown value (as in “an equation in two unknowns”), but this value cannot change.
The idea behind functional languages is referential transparency.
• Referential transparency means that an expression can be fully understood on the basis of its partial expressions.
• Each partial expression (subexpression) is independent of its context.
• A variable is a name for a (known or unknown) immutable value.
Object-oriented programming languages suggest a totally different programming model.
• They use objects that encapsulate an internal state, which can only be changed through permissible operations.
• They use an imperative variable concept. A variable is an identifier for a memory location or container, the state (or value) of which can be changed through assignment.
• Each expression depends on its context, that is, on the state of all participating objects. An object can be known by different names in different contexts, so that changing the parts of an expression will normally lead to side-effects.
A closer look at values in object-oriented programming languages shows that many languages use values as so-called primitive types, such as integers, floating point numbers, or booleans. These value types behave as we would expect from values or numbers (apart from precision errors caused by representing them on a finite computer).
Some “puristic” languages—like Java, Eiffel, or Smalltalk—embed these value types in the normal class concept. However, such embedding can be problematic, because certain properties of objects cannot simply be transferred onto “value objects.” For example, arithmetic expressions would lose their mathematical semantics if an operation would change object 3 to an internal value 4. This is why we find it confusing when textbooks, such as the Smalltalk handbook of Adele Goldberg and David Robson, use number arithmetics as one of their primary examples for objects and their operations. We want to have numbers that behave like values, and objects that have all object properties.
2.6.5 Definition: Domain Values
The primitive built-in value types of an object-oriented programming language are easy to use. A problem can normally occur when you try to introduce user-defined value types. We refer to these values as domain values, because they are motivated by the application domain of a system.
The motivation for domain values is obvious. Language developers have tried to supply such data types, specific to an application domain, since the development of early programming languages. The only difference is that it was not as obvious as it is today, because most early applications were oriented to number-crunching tasks.
2.6.6 T&M Design: Domain Values
Domain values are of prime importance in the T&M approach. When we say we want to use classes and objects to model the concepts and things of our application domain, then this also applies to the values that play a role in that application domain.
Let’s look at the idea of domain values versus conventional programming in our bank example. Assume that we have accounts with account numbers. In an object-oriented application system, a specific account is an instance of the class Account. The account number in this object should be a domain value of the type AccountNumber. The appropriate attribute would have an identifier, AccountNumber.
In conventional programming, we would also have an attribute called AccountNumber, but declare it as an attribute of the type integer. The fact that it represents an account number can be seen only in the identifier AccountNumber.
2.6.7 Implementing Domain Values
In object-oriented languages, we have to use the class construct to build user-defined domain values. This is because classes are the only way to add new types and instances of these types to the system. This appears to have several benefits:
In a user-defined class, you can specify the set of values that can be created as instances of a type. To do this, a class can take an external representation of the desired value and only create a domain value object when the representation can be transferred into a valid (well-formed) value.
In this connection, we could implement further concepts, such as adding a so-called “undefined” (bottom) value and other special values to the set of valid values. The benefit is that you can distinguish explicitly between defined and special values, as suggested by Ward Cunningham. For example, many developers would use a workaround like 999 for a yet-unknown account number they have to represent as an integer. This means that, by convention, they turned a defined value of type integer into a special undefined value. Problems occur in programs that do not observe this convention; the above method would cause serious domain errors that such a program would not catch. To avoid this problem, you must not handle domain values as a simple set of values.
We have known since the seminal work of Tony Hoare that typing should include not only the defined set of values, but also the operations permissible on values of that type. Although this had been hard to implement for user-defined types in classic imperative languages, we actually get this option “for free” in object-oriented languages.
For example, we can think of permissible operations on values of the type AccountNumber. This is not as trivial as it may sound, because our account numbers should allow addition as well as relational operations. The reason is that the sum of account numbers is normally transmitted as a checksum in batch money transfers between banks. In addition, some banks add additional information to an account number. For example, you can derive the customer number or the type of account from an account number. All of these are permissible operations of the type.
Together with the introduction of special values, you can also define appropriate semantics for handling these values. In our bank example, an attempt to add an undefined account number to a “normal” number could lead to an exception.
On the other hand, implementing domain value types as classes has some drawbacks. To avoid a serious trap we have to take care that values belonging to domain value classes are always handled by value semantics rather than by reference semantics. This means that a domain value object must not be accessible for modification over two identifiers. More specifically, a domain value object should not be modifiable at all. This is the only way to maintain the referential transparency of the values we require. Some of the proposed solutions will be discussed in Section 8.10. In summary, we have compiled the following different techniques for building domain values:
• Domain values are instances of “normal” classes. Domain value objects are always passed as copies. This is an insecure programming convention.
• Domain values are built from classes allowing one single value-setting operation, while otherwise offering only probing operations. This uses a lot of memory.
• Refined techniques to build value objects are known from the literature by the name of body/handle (see James Coplien).
• A pattern that implements value objects with minimum space requirements is the Flyweight pattern of Gamma et al.
2.7 METAOBJECT PROTOCOLS
When developing interactive programs, we often observe that it is not sufficient to write program code to implement domain concepts or objects. We additionally have to be able to handle the elements of our program, that is, we have to be able to query and modify properties of objects and classes in our program. How important this meta-information really is becomes clear when we work with components. We have to rely on components giving us information about their interfaces and other properties, because such program code is normally inaccessible. This section discusses such meta-information. It is aimed at the more advanced reader because using or even designing metaobject protocols is not an everyday task. But when dveloping programming tools or components, you should understand the concepts and means of this type of meta-programming.
2.7.2 Motivation for a Metaobject Protocol
Simply speaking, we have used objects in object-oriented application development to model the concepts and things of a real-world application domain. Now let’s have a look at software engineering as a potential application domain. We normally do this when building programming tools or other software development tools. If software engineering is our application domain, then there is nothing that would deter us from selecting an object-oriented program as our object of modeling. To work with this object, we need a metaobject protocol, which should sound familiar to Smalltalk programmers. The following section explains what a metaobject protocol is all about. Figure 2.14 shows a schematic view of modeling an application domain versus modeling a software program.
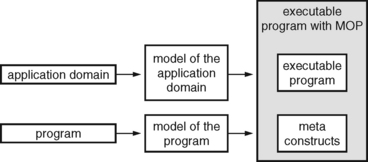
2.7.3 Definition: Metaobject Protocol (MOP)
Metaobjects can be classified in two categories:
1. Objects representing the (static) application model (e.g., which operations does an object offer).
2. Objects representing the runtime system (e.g., how an operation is executed; how an object accesses its attributes).
The organization of metaclasses and the behavior of metaobjects are described in a metalevel architecture. Metalevel architectures can be used for many different technical purposes. However, they are normally required only for large-scale application systems. The following section will, therefore, focus only on well-known applications.
2.7.4 Representing Your Application Model
We briefly mentioned in Section 2.1.20 that utilizing polymorphism in your development project means that the reference you obtain on an object may not be of the same type as the object itself but of a supertype of the object’s type.
In some situations, this supertype reference is not sufficient. What we need is a so-called downcast, or a conversion of a supertype reference into a subtype reference. Downcasting is useful in the following situations:
• In a specialized team of classes, one partner obtains the reference to another partner as a reference of the type of the abstract superclass, but it requires the full interface.
• A container with objects pertaining to different classes can only return a reference to the common superclass of the objects it contains. If you need to access an object taken from the container over its full interface, then you need a downcast.
• One example for a special case is building an object table for the entire system. This table includes references to all objects existing in the system and is continually updated. Such a table can be used to run queries on objects, similar to querying a database: for example, “Find all devices purchased more than three years ago.” For this purpose, we need to be able to query the class membership of each object as well as the references on objects having the same type, as the queried class has to be converted to the queried type.
To recover the original type information, each MOP lets you query the type of an object at runtime. You would normally represent the type of an object by its class object. Downcasting on an object level triggers a test for an inheritance relationship on the class object level (metalevel).
To make our programming lives easier and to hide the complexity of the metalevel, MOPs of typed languages (e.g., Java) offer a special operator to implement a downcast. This operator internally accesses the class metaobjects and checks for conformity of the downcast before it runs it. If there is no such protection mechanism, a downcast can cause critical errors in programs (e.g., as in C++), and it should be used only together with strictly controlled programming conventions.
Direct access to the state representations of objects, and avoiding their interface, is normally one of the most serious programming sins you can possibly think of. You should bear in mind that the class offers a set of domain-oriented operations, hiding access to the internal state representation. However, there are also technical tasks, for which a specific interface should allow direct access to the state representation. The following are examples for tasks that have to have access to the state representation of an object:
• Generic relational and copy operations; for example, copying business cards and identification cards to a clipboard and subsequently inserting the copy into the room plan by use of generic copy operations.
• Object input and output; for example saving objects to files, connecting to relational databases, or transporting objects within a distributed system.
If access to the representation of an object state is allowed, then we can specify an algorithm for these services for all classes. Otherwise, we would have to program the corresponding operations for each class. You can access the state of an object in either of the following two ways:
• The required information is implicitly available, because the required operations are generated automatically. For example, Eiffel uses relational copy and input and output operations for each class, without the developer’s intervention. This approach has several benefits. The developer does not have to program anything manually. The encapsulation of objects cannot be violated. And finally, the runtime behavior is improved, especially in compiler languages. On the other hand, a major drawback is poor flexibility: the developer cannot modify access operations or add new operations.
• To represent an object state, the developer can use a so-called attribute dictionary. This list maintains one attribute metaobject for each attribute, including the following information (which may differ, depending on the language):
– reference to the variable (for actual access); and
– other attributes (e.g., properties like “persistent” or “not persistent”).
• Based on the above information and information about the superclasses, the developer can write operations that iterate over the attribute metaobject list, running a specific action for each variable (e.g., copy, compare, save to database). Major drawbacks of this variant are loss in state encapsulation and poor runtime behavior.
It may be desirable in many cases to open up an application to the “outside,” that is, to allow other applications to call arbitrary public operations. For example, you can use an external interpreter to program frequently recurring processes in a script.
Take our device management system as an example. If, after upgrading all PCs of one type, you want to update the device data in the room plan you could write a script. This script could then iterate over all old devices in a room plan and update the device data automatically.
To allow this flexibility, a MOP should support an operations list, similar to the attribute list described above, to handle queries on existing operations and call such operations. Languages like Java support this technique by the so-called introspection. Such an operations list maintains a metaobject entry for each operation with the following information:
To then call an operation, you either use the operation’s metaobject or a special operation (metacall) of the public object. This operation will then call the actual operation with the name you passed and the passed parameters.
2.7.5 Representing Your Runtime System
Though software developers are normally happy when they don’t have to know the details behind the implementation of a language, there are situations where you have to deal with the implementation. For this purpose, an MOP can present a well-defined interface, allowing you to redirect the control flow within the runtime system. This is of interest, particularly in two places:
To disclose the storage algorithm of instance variables, you need two additional operations, that is, one to read an instance variable and another to set an instance variable.
For example, Smalltalk uses the method instVarAt: i to return the value of the ith instance variable. The method instVarAt: i put: value assigns value to the ith instance variable. These two methods are called every time an instance variable is accessed. By overloading these methods, the standard storage algorithm can be replaced by your own algorithm for all classes or part of the class tree. Overloading the standard storage algorithm may be useful for efficiency reasons, or to store objects externally.
For objects with many instance variables that are seldom used, it may prove more efficient, in terms of required storage space, to create entries for each of these instance variables in a hash table instead of storing them in a consecutive memory block.
When the state of an object is to be updated immediately to reflect each change to a database, you also need to manipulate the storage mechanism. You can use the mechanisms to represent your application model (see Section 2.7.4) only to implement explicit operation calls to save entire objects.
You can use a metaoperation, to which each operation call is directed, to access the operation call mechanism. This metaoperation can run arbitrary actions either before or after the actual execution. Redirecting operations is useful for the following application domains:
• Distributed applications: In this case, the above mechanism lets you redirect operation calls for an object to another computer. To redirect operation calls, you pack the name and arguments of the operation before it is called (also called marshalling) and send the package to the server, where the actual operation runs. The result is then returned to the client, where it is unpacked and forwarded to the caller. The static CORBA (common object request broker architecture) interface is normally implemented in this way.
• Persistent objects: In a manner similar to the mechanism used for distributed objects, when an operation is called for an object not residing in the main memory, the call is caught. Based on the object reference, the referenced object is then loaded from a database, before the actual operation call of the freshly instantiated object is executed. In CORBA, this would correspond to the “incarnation” of an object by an object adapter.
• Additional handling of operation calls: There is a large number of algorithms you may want to apply on an operation call before or after it is executed. Good examples are the logging or auditing of operation calls. Another more sophisticated algorithm is used to check the authenticity of the caller and to guarantee to a certain extent that the client really is authorized to call that operation. This is relevant for virtually all software systems.
There are different implementation techniques to catch an operation call and have it handled by a metaobject before or after it is executed on the actual target object. The most common technique hides the target object from the client by using an intermediate proxy object. The proxy object catches the operation call and redirects it to the metaobject in charge. In simple cases, it can assume the metahandling itself, as in the example relating to security proxies described in Erich Gamma et al. (Chapter 4) or Frank Buschmann et al. (Section 3.4).
Another implementation technique modifies the virtual machine of a language so that it can work with enhanced object references. The enhancement is the so-called pointer swizzling, where a call is forwarded to a corresponding metaobject. For example, the object-oriented database ObjectStore uses this technique; although it does not forward calls to a generically accessible metaobject. Instead, it merely uses a restore mechanism to wake up the called object in the database.
This chapter on the T&M object metamodel has been kept quite concise. For readers who want to delve deeper into the material, we have assembled an annotated list of references that contains both practical and theoretical work.
Bird R.J., Wadler P. Introduction to Functional Programming. New York: Prentice Hall; 1988. A seminal textbook on functional programming.
Buschmann F., Meunier R., Rohnert H., Sommerlad P., Stal M. Pattern-Oriented Software Architecture—A System of Patterns. Chichester, New York: Wiley & Sons Ltd; 1996. A well-received pattern collection book.
Cardelli L., Wegner P. On Understanding Types, Data Abstraction, and Polymorphism. Computing Surveys. Vol. 17(No. 4), 1985. Dec. Seminal work on type systems.
Coplien J. Advanced C++: Programming Styles and Idioms. Reading, Mass.: Addison-Wesley; 1992. Coplien introduces, among others, the body/handle pattern.
Cunningham W. The CHECKS Pattern Language of Information Integrity. In: Coplien J.O., Schmidt D.C., eds. Pattern Languages of Program Design. Reading, Mass.: Addison-Wesley; 1995:145–156. Chapter 3 This is an interesting work on (domain) values in object-oriented languages.
Gamma E., Helm R., Johnson R., Vlissides J. Design Patterns. Reading, Mass.: Addison-Wesley; 1995. The present chapter refers to patterns from this book.
Goldberg A., Robson D. Smalltalk-80: The Language. Reading, Mass.: Addison-Wesley; 1989. This is a classic among programming language textbooks.
Hoare C.A.R. Notes on Data Structuring. In: Dahl O.-J., Dijkstra E.W., Hoare C.A.R., eds. Structured Programming. London: Academic Press, 1972. This is a theoretical classic on the concept of type and data types.
Johnson R.E., Russo V.F. Reusing Object-Oriented Designs. Department of Computer Science, University of Illinois at Urbana-Champaign; 1991. This work offers more on abstract classes.
Kiczales G., des Riverieres J., Bobrow D.G. The Art of the Metaobject Protocol. Cambridge, Mass: MIT Press; 1992. This work offers more on metaobject protocols.
No. 5, MayLiskov B., Data Abstraction and Hierarchy. OOPSLA 1987 Addendum to the Proceedings, ACM SIGPLAN Notices. 1988;Vol. 23:17–34.
Liskov B., Wing J.W. Family Values: A Behavioral Notion of Subtyping. Technical Report, Carnegie Mellon University, CMU-CS-93-187. 1993. These fundamental theoretical works treat abstract data types and the concept of type.
Luckham D.C., Vera J., Meldal S. Three Concepts of System Architecture. Technical Report CSL-TR-95-674. Stanford, Calif.: Stanford University. 1995. This work offers more on interfaces.
MacLennan B.J. Values and Objects in Programming Languages. ACM SIGPLAN Notices. Vol. 17(No. 12), 1982. Dec. This classic article distinguishes values and objects in programming languages.
Maes P., Nardi B., eds. Meta-Level Architectures and Reflection. The Netherlands, Amsterdam: North-Holland Publishers, 1988. This book offers more on the metaobject protocol.
Meyer B. Object-Oriented Software Construction, Second Edition. New York, London: Prentice-Hall; 1997. This fundamental book covers the concepts and mechanisms of object-oriented programming and programming languages. The explanation of the contract model is particularly important.
Pamas D.L. On the Criteria to Be Used in Decomposing Systems into Modules. Communication of the ACM. 1972;Vol. 5(No. 12):1053–1058. December This classical software engineering paper introduces important principles of modularization and information hiding.
Reenskaug T., Wold P., Lehne O.A. Working with Objects. Greenwich: Manning; 1996. This book presents interesting aspects of object-oriented design, especially regarding role-modeling.
Sebesta R.W. Concepts of Programming Languages. Reading, Mass.: Addison-Wesley; 1998. This is a good practice-oriented textbook about the concepts and constructs of programming languages; it presents design alternatives as examples.
Wegner P. Concepts and Paradigms of Object-Oriented Programming. OOPS Messenger. 1990;Vol. 1(No. 1):8–87. August This conceptual article contains the fundamental definition of the term “object-oriented.”
Zimmermann C., ed. Advances in Object-Oriented Metalevel Architectures and Reflection. Boca Raton, Florida: CRC Press, 1996. Another interesting paper on metaobject protocols.
1The authors of various method books diverge considerably on the basic concepts that will be discussed here.
2When speaking of technical models in the course of this book, we always mean technical software models. When discussing the modeling of technical embedded systems, we will make that clear.
4We will not be discussing problems with objects stored in a database, where they can be accessed as a result of database queries, at this point.
5E. Gamma: Objektorientierte Software-Entwicklung am Beispiel von ET++. Berlin, Heidelberg: Springer-Verlag, 1992.