
So far we have assumed that all of the components of an application are written in Java and collocated on the same high-speed network. However, that is not always the case.
For example, you might have a desktop application that needs to access a Coherence grid, and that application could be written in a language other than Java, such as C++ or any one of the number of languages supported by Microsoft's .NET platform. Some of these client applications might be physically located on the same network as the Coherence grid, but more likely than not, there will also be some that are in a remote location and connect to the Coherence grid over the WAN (Wide Area Network).
If your client application is written in Java you have an option of making it a full-blown, although possibly storage-disabled, member of the cluster. This is what you will likely do for a long-running, web-based application that is collocated with the data grid, and that is exactly what we have done so far. However, even though you can do the same for a desktop Java application, it is probably not a good idea.
Desktop applications, by their nature, will likely connect to and disconnect from the Coherence cluster several, or in some cases, many times a day. Even when they are storage-disabled it results in some overhead, as cluster membership information needs to be maintained. When you have a large number of client applications connecting to and disconnecting from the cluster, this overhead might be significant. The negative effect is further compounded if your clients access the cluster across an unreliable, high-latency WAN link, if they have long garbage collection cycles, or if, God forbid, you make your clients storage-enabled, as each membership change would then also trigger cluster repartitioning.
In general, you want to keep cluster membership as stable as possible, and the amount of network traffic caused by repartitioning to a minimum. In order to allow you to achieve this in situations where you have remote or unstable clients, Coherence provides a TCP-based messaging protocol called Coherence*Extend. Coherence*Extend is also your only option when you need to access data grid from non-Java applications, such as .NET or C++ clients.
In the remainder of this chapter, we will cover Coherence*Extend in detail and show you how to configure both Coherence cluster and Java clients to use it. However, before we do that we need to take a step back and discuss the networking protocols Coherence uses, in order to better understand how Coherence*Extend fits into the whole picture.
The Internet as a whole, as well as the vast majority of private networks in operation today, uses IP as a protocol of choice in the networking layer, so it is of no surprise that Coherence is an IP-based system as well.
IP is by design a best-effort delivery protocol and on its own does not provide any reliability guarantees. This means that transport layer protocols implemented on top of it must decide whether to support reliability or not, and to what extent.
The most popular transport layer protocol within the Internet Protocol Suite is the Transmission Control Protocol, or TCP. TCP is a reliable protocol—it guarantees that the messages sent from one computer to another will be transmitted and received successfully and in order. TCP is also a connection-based protocol, and requires connection between the two endpoints to be established before the message exchange begins.
The main benefit of TCP is its reliability—any lost messages are automatically retransmitted and duplicate messages are discarded by the protocol itself. This makes TCP very easy to use from the application developer's perspective, when a reliable point-to-point message delivery is required.
Another popular transport protocol is User Datagram Protocol, or UDP. Unlike TCP, UDP does not provide any reliability guarantees—messages can get lost on the way to the recipient and there is no built-in mechanism for retransmission. They can also be received out of order by the recipient, although this typically only happens under heavy traffic conditions. The main benefit of UDP is that it is very fast and does not require connection to be established in order to exchange the messages.
A Coherence cluster requires reliable message delivery between all members, so on the surface TCP seems like a better choice. Unfortunately, the fact that TCP requires connections to be established is a deal breaker. Coherence uses full-mesh peer-to-peer architecture, which means that whenever a new node joins the cluster, it would have to establish TCP connections with all other nodes. Imagine a cluster of a few hundred nodes and think about the implications of the last statement.
This would effectively prevent Coherence from scaling past a handful of nodes, which leaves us with UDP as an alternative. As far as scaling goes, UDP is great. It is a connectionless protocol, so there are no connections to establish when new members join the cluster. All that a new member needs to do is to send a single message to anyone who happens to be listening, effectively saying "I'm here to help out, let me know what you want me to do". It also doesn't require the sender to wait for the acknowledgment from the recipient, so it allows for a much higher throughput. Unfortunately, as we discussed earlier, UDP does not provide the reliability guarantees that Coherence requires.
In order to solve that problem, Coherence engineers created Tangosol Cluster Messaging Protocol (TCMP), an application layer protocol on top of UDP that ensures reliable, in-order delivery of UDP datagrams. TCMP is used for most of the communication between the cluster members, with TCP being used only for fast death detection of members and for Coherence*Extend support, as we'll discuss shortly.
TCMP makes certain assumptions about its environment that are typically true for a Coherence cluster within a data center, but would not necessarily be true in a general case. For one, it is optimized for the common scenario where all cluster members are on the same, reliable, low latency network, and the packet loss and the number of datagrams received out-of-order are minimal.
This is not necessarily true as soon as you move your clients to a different network switch, which will typically be the case with desktop applications, and is definitely not true if your clients connect to the Coherence cluster over WAN. In those cases, TCP-based Coherence*Extend is a much better choice.
Just like the TCMP, Coherence*Extend is a proprietary application layer protocol that can be used to communicate with the Coherence cluster. However, unlike TCMP, which is UDP-based, Coherence*Extend is a TCP-based protocol.
Note
Actually, Coherence*Extend is designed to be protocol independent, and there are two implementations provided out of the box: the TCP-based implementation and a JMS-based implementation.
However, Extend-JMS has been deprecated in Coherence 3.5, so in the remainder of this chapter, we will focus on the Extend-TCP implementation.
Coherence*Extend allows you to access remote Coherence caches using standard Coherence APIs you are already familiar with, which means that with some care you can make your applications protocol-agnostic and be able to switch between TCMP and Extend using configuration. It also allows you to submit entry processors and invocable agents for execution within the cluster, which is particularly useful when you need to overcome some of the inherent limitations of Coherence*Extend that we will discuss shortly.
In order to allow client applications to connect to the cluster via Coherence*Extend, you need to ensure that one or more proxy servers are running within the cluster. While you could easily turn all cluster members into proxy servers, this is probably not the best thing to do as proxy servers will be competing for CPU resources with cache services and other code executing on your storage nodes, such as filters, entry processors, and aggregators.
What you should do instead is configure Coherence*Extend proxy servers on a dedicated set of machines that serve no other purpose. This will allow you to scale your proxy servers independently from the storage-enabled members of the cluster. It is important to remember, however, that Coherence*Extend proxy servers are full-blown TCMP members, so they should have fast and reliable communication with the rest of the cluster. Ideally, they should be on the same network switch as the cache servers.
A typical Coherence*Extend deployment using the recommended architecture described previously will be similar to the following diagram:
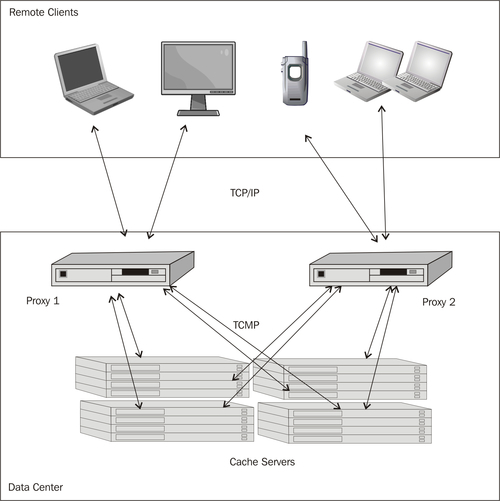
So much for the theory and background, let's get more practical and learn how to configure Coherence*Extend both within the cluster and on the client.
In order to configure a Coherence node to serve as a Coherence*Extend proxy server, you need to add a scheme similar to the following to your cache configuration file:
<cache-config> <caching-scheme-mapping> ... </caching-scheme-mapping> <caching-schemes> <proxy-scheme> <scheme-name>extend-tcp-proxy</scheme-name> <service-name>ExtendTcpProxyService</service-name> <thread-count>50</thread-count> <acceptor-config> <tcp-acceptor> <local-address> <address>localhost</address> <port>9099</port> </local-address> </tcp-acceptor> </acceptor-config> <autostart>true</autostart> </proxy-scheme> </caching-schemes> </cache-config>
Within the proxy-scheme element, you need to configure the number of threads the proxy server should use to process client requests, as well as the address and port number the server should listen on for client connections.
The proxy server threads are I/O-bound—they spend most of their lifetime waiting for the response from the cluster, so you can configure a high number of threads per CPU core. Ideally, you should have as many threads in the proxy server pool as there are client threads accessing proxy server. In the example above, the proxy server would be able to serve up to fifty single-threaded clients without any request blocking.
You can also configure a number of TCP-specific settings within the tcp-acceptor element, such as send and receive buffer size, the size of the backlog queue, whether to reuse the socket (it is not reused by default), as well as whether to use "keep-alives" (enabled by default) and TCP delay/Nagle algorithm (disabled by default). The detailed discussion of these topics is out of the scope of this book, so you should consult Coherence User's Guide and documentation within cache-config.dtd for details.
If you want to use POF for serialization, but don't have enabled POF globally for all the services, you also need to configure the serializer that the proxy server should use:
<acceptor-config> <tcp-acceptor> <local-address> <address>localhost</address> <port>9099</port> </local-address> </tcp-acceptor> <serializer> <class-name> com.tangosol.io.pof.ConfigurablePofContext </class-name> <init-params> <init-param> <param-type>string</param-type> <param-value> my-pof-config.xml </param-value> </init-param> </init-params> </serializer> </acceptor-config>
By default the proxy server will serve as a proxy for both the cache services and the invocation services running within the cluster, and will allow you to both read from and write into Coherence clustered caches. However, you can modify the defaults by adding a proxy-config element similar to the following within your proxy scheme definition:
<proxy-config> <cache-service-proxy> <enabled>true</enabled> <read-only>true</read-only> </cache-service-proxy> <invocation-service-proxy> <enabled>false</enabled> </invocation-service-proxy> </proxy-config>
Once you are satisfied with the configuration, you can test it by starting Coherence node as you normally would. If everything is configured correctly, you should see the ExtendTcpProxyService in the list of running services:
Services
(
TcpRing{...}
ClusterService{...}
InvocationService{...}
DistributedCache{...}
ReplicatedCache{...}
ProxyService{Name=ExtendTcpProxyService, State=(SERVICE_STARTED),
Id=5, Version=3.2, OldestMemberId=1}
)
Congratulations! You are ready to use Coherence*Extend to connect to the cluster.
Once you have one or more proxy servers up and running, you are ready to configure your client application to use Coherence*Extend. In order to do so, you need to configure a remote cache scheme on the client and map cache names to it. If you want to be able to send invocable agents for processing within the cluster, as we discussed in Chapter 6, Parallel and In-Place Processing, you will also need to configure a remote invocation scheme on the client.
In this section, you will learn how to do both. We will also discuss the closely related topic of address providers, which gives you full control over the selection of the proxy server that a client should connect to, but first things first.
In order to allow your client application to connect to a Coherence*Extend proxy server, you need to add a remote-cache-scheme definition to your client's cache configuration file:
<cache-config> <caching-scheme-mapping> ... </caching-scheme-mapping> <caching-schemes> <remote-cache-scheme> <scheme-name>extend-tcp</scheme-name> <service-name>ExtendTcpCacheService</service-name> <initiator-config> <tcp-initiator> <remote-addresses> <socket-address> <address>proxy1.mycompany.com</address> <port>9099</port> </socket-address> <socket-address> <address>proxy2.mycompany.com</address> <port>9099</port> </socket-address> ... </remote-addresses> </tcp-initiator> <outgoing-message-handler> <request-timeout>30s</request-timeout> </outgoing-message-handler> </initiator-config> </remote-cache-scheme> </caching-schemes> </cache-config>
As you can see, you need to specify the IP addresses of your proxy servers within the remote-addresses element. In the example above, we have specified a static list of remote addresses using socket-address elements, but this is just one of the ways to achieve the goal, as you'll see shortly.
In addition to proxy server addresses, the tcp-initiator element allows you to specify a number of TCP-specific configuration parameters, just as the tcp-acceptor element does on the server, as well as the client-specific connection timeout.
Finally, the outgoing-message-handler element allows you to configure the timeout for individual requests, as well as the heartbeat interval and timeout, which are used to detect network connection or proxy server failure, as we'll discuss soon.
The next thing you need to do in order to configure the client is to map cache names to the appropriate cache schemes by adding the necessary elements to the caching-scheme-mapping section of the cache configuration file, just like within the cluster. You can map cache names either directly to the remote cache scheme, or to a near cache scheme that uses the remote cache as a back cache.
The latter is especially interesting, as it allows you to bring frequently or recently used objects into the client's process, and can significantly improve read performance. For example, we can access the accounts cache through a near cache, while accessing all other caches directly:
<cache-config> <caching-scheme-mapping> <cache-mapping> <cache-name>accounts</cache-name> <scheme-name>accounts-scheme</scheme-name> </cache-mapping> <cache-mapping< <cache-name>*</cache-name> <scheme-name>extend-tcp</scheme-name> </cache-mapping> </caching-scheme-mapping> <caching-schemes> <near-scheme> <scheme-name>accounts-scheme</scheme-name> <front-scheme> <local-scheme> <eviction-policy>HYBRID</eviction-policy> <high-units>1000</high-units> </local-scheme> </front-scheme> <back-scheme> <remote-cache-scheme> <scheme-ref>extend-tcp</scheme-ref> </remote-cache-scheme> </back-scheme> <autostart>true</autostart> </near-scheme> <remote-cache-scheme> <scheme-name>extend-tcp</scheme-name> <!-- configuration details omitted for brevity --> </remote-cache-scheme> </caching-schemes> </cache-config>
If you want to be able to submit invocable agents from a client, you also need to configure a remote invocation service. This is very similar to the remote cache scheme we configured earlier—the only difference really is the name of the top-level configuration element:
<remote-invocation-scheme> <scheme-name>extend-tcp-invocation</scheme-name> <service-name>ExtendTcpInvocationService</service-name> <initiator-config> <tcp-initiator> <remote-addresses> <socket-address> <address>192.168.1.5</address> <port>9099</port> </socket-address> </remote-addresses> <connect-timeout>30s</connect-timeout> </tcp-initiator> <outgoing-message-handler> <heartbeat-interval>1s</heartbeat-interval> <heartbeat-timeout>10s</heartbeat-timeout> <request-timeout>30s</request-timeout> </outgoing-message-handler> </initiator-config> </remote-invocation-scheme>
The rest of the configuration should look fairly familiar by now, so let's move to the more interesting topic of address providers.
When specifying the list of proxy server addresses that a client can connect to, you can either specify a static list, as we did in the examples above, or you can implement and configure an address provider to use.
Address providers are a very interesting option, as they allow you to externalize the information about the available proxy servers. For example, you might find it easier from a maintenance perspective to keep a list of proxy server addresses in a text file on network share than to embed them into the cache configuration file, especially if the number of proxy servers is significant.
In order to create a custom address provider, you need to create a class that implements the com.tangosol.net.AddressProvider interface, either directly or by extending one of the base classes available in the sample code for this book. Once you implement it, configuring clients to use it is quite simple—all you need to do is replace the static address list with the address-provider element in the cache configuration file:
<tcp-initiator> <remote-addresses> <address-provider> <class-name> com.mycompany.MyAddressProvider </class-name> </address-provider> </remote-addresses> <connect-timeout>30s</connect-timeout> </tcp-initiator>
Before we conclude this section, we should also mention that an address provider is actually used even in the static configuration examples we've seen so far. One of the address providers that ships with Coherence is ConfigurableAddressProvider, which accepts configuration in the form of the socket-address XML elements we've seen earlier.
When a ConfigurableAddressProvider is instantiated on the client, it will randomize the list of available proxy server addresses during initialization. That way each client will attempt to connect to proxy servers in a slightly different order, which provides a somewhat crude, but in practice quite effective, load balancing algorithm for proxy servers.
If the connection to a proxy server fails at some point, whether because of the network or proxy server failure, the client will automatically attempt to reconnect to the next proxy server returned by the address provider. It is important to note that reconnection only occurs the next time client actively attempts to access the cluster, which is acceptable for most client applications.
However, some real-time client applications are completely passive—they simply register event listeners with a remote cache and react to event notifications, without ever issuing another active request to the cluster. In situations like these, reconnection will not occur automatically and has to be forced, either by running a low-priority background thread that periodically calls a lightweight method, such as size(), on each cache, or by listening for membership changes in the cluster and actively accessing the cache when the MemberEvent.MEMBER_LEFT event is received.
Now that we have both the cluster and the clients configured to use Coherence*Extend, we are ready to access remote Coherence caches from the client. For the most part, you already know how to do that, as the API is exactly the same whether you use TCMP or Coherence*Extend for communication: you use CacheFactory to obtain a reference to a NamedCache instance, and then use methods defined by the NamedCache interface to access or manipulate cached data, register listeners, execute queries, invoke entry processors, and so on.
However, even though the API is exactly the same, there are some major architectural differences between TCMP and Extend-based applications that have a significant impact on how certain things can be achieved.
Cluster-wide concurrency control using explicit locking is one such example. Explicit locking is disabled by default on a proxy server, which means that any attempt to lock a cache entry from a client will result in an exception. While you can enable it by setting the lock-enabled element of the cache-service-proxy to true, that is probably not a good idea.
Locks within the clustered cache are managed by the service the cache belongs to, and they are associated either with a thread or a member that requested a lock. The exact behavior is controlled using the lease-granularity option within cache scheme definition, and its value is thread by default.
The problem with that is that the proxy server uses a pool of threads to process client requests, and there are no guarantees that the same thread will be used to process subsequent requests from the same client. In other words, if the default, thread-scoped lease granularity is used, the chances are that an unlock request will fail because it will likely be executed by a different thread than the one that issued the original lock request, even though both requests originated from the same client.
This is exactly why Coherence User's Guide states that if you enable locking on the proxy server you must set lease granularity for the affected cache scheme to member as well. Unfortunately, this doesn't really help much either while setting lease granularity to member will prevent the problem described above, it creates another one, which is not so obvious. In my opinion, this makes the situation even worse.
Consider the following scenario, step by step:
Client A connected to a proxy server X requests a lock on a cache entry with a key '123' in the
accountscacheProxy server X forwards the lock request to the owner of the specified entry
The owner obtains the lock, registers member X (proxy server) as the lock owner because the lease granularity is set to
member, and returnstrueto the proxy server to let it know that the lock was acquired successfullyThe proxy server returns
trueto Client A, to notify it that the lock was acquired successfully
So far, so good—client A successfully obtained the lock and can go about modifying account '123' any way it wants, working under the assumption that it holds an exclusive lock on it and that any other client that wants to modify the same entry will have to wait until it releases the lock. However, things can get a bit dicey from here:
Client B connected to proxy server X requests a lock on the cache entry with a key '123' in the
accountscacheThe proxy server X forwards the lock request to the owner of the specified entry
The owner sees that member X already holds the lock and simply returns
true, as it should—multiple locks against the same entry by the same lock owner should always succeedThe proxy server returns
trueto Client B, to notify it that the lock was acquired successfully
Yup, I'm sure you can see the problem from miles away—both clients, A and B, believe that they hold an exclusive lock on the same piece of data and proceed accordingly. To make things worse, the first one to unlock the entry will succeed, while the second one will fail and the unlock method will return false. Unfortunately, that means that the client-side locking will work reliably only in the unlikely scenario that each client connects to its own, dedicated proxy server.
While you could try to handle the situation gracefully by checking the result of the unlock call and retrying the operation if necessary, this is very error-prone and will not work in all possible cases, so my advice is to leave locking disabled and use an alternative approach for mutating cache operations.
One option is to use an entry processor, as we discussed in Chapter 6. In addition to performance advantages we discussed earlier, entry processors eliminate the need for the explicit lock, as they execute on the entry owner and are guaranteed to execute atomically.
Another possibility is to let an invocable agent do the work. The agent will execute on the proxy server the client is connected to, which behaves like any other member of the cluster, and will be able to obtain and release locks successfully. You should be careful though and ensure that the lease granularity is set to the default, thread level, or you might run into the same issue you are trying to avoid.
For the most part, executing invocable agents from a Coherence*Extend client is no different than executing them from a normal cluster member. However, just as with the explicit concurrency controls, functionality is somewhat limited due to architectural differences.
For one, an agent submitted from an Extend client will always be executed on the proxy server the client is connected to. You cannot influence this by passing a set of members to execute the agent on to a query method, as you normally could, because Coherence*Extend client has no direct knowledge of the cluster and the members within it. Therefore, you should always pass a null member set to a query method.
Second, the remote invocation service only supports synchronous task execution, because of the limitations in the underlying Coherence*Extend protocol. That means that you can use query, but not the execute method of the InvocationService interface.
Even with these limitations, the remote invocation service is extremely useful, especially when the concurrency limitations described above are taken into account, so you should look for the opportunities to use it when building Coherence*Extend-based client applications.
Whether you use TCMP within the data center, or Coherence*Extend to allow access to your application from remote desktops, across the WAN, or even across the Internet, Coherence allows you to secure your application by limiting access based on the client's IP address.
While you typically don't need to do that when your whole application, including the Coherence cluster, is hidden behind a firewall, you might want to consider it when you open it up for access from remote Coherence*Extend clients.
In order to achieve that, you need to add an authorized-hosts section to the tcp-acceptor configuration element of your proxy server scheme:
<proxy-scheme> <scheme-name>extend-tcp-proxy</scheme-name> <service-name>ExtendTcpProxyService</service-name> <thread-count>5</thread-count> <acceptor-config> <tcp-acceptor> <local-address> <address>localhost</address> <port>9099</port> </local-address> <authorized-hosts> ... </authorized-hosts> </tcp-acceptor> </acceptor-config> <autostart>true</autostart> </proxy-scheme>
Within that section, you can specify:
One or more
host-addresselements, which allow you to specify individual names or addresses of the hosts that should be allowed accessOne or more
host-rangeelements, which allow you to grant access to all the hosts whose addresses fall into a specific range, with the typical example being access from a whole subnetOr finally, a
host-filterelement, which allows you to the evaluate client address using a built-in or custom implementation of a Coherence filter, as discussed in Chapter 5,
The last option is quite interesting as it allows you to dynamically determine if a particular host should be allowed to access the Coherence cluster or not. This can come in very handy if you are building a SaaS solution, for example, and need to be able to provision it for new customers as they sign up.
While you could just add a new customer's IP address using host-address or host-range elements, that would require you to restart all proxy servers in order for the change to take effect, which is not very convenient.
What you can do instead is implement a custom filter that simply checks if the address is present in the cache of allowed addresses. Once you have that in place, all you need to do when a new customer signs up is to add their IP address into that cache.
Keep in mind that any custom logic that you implement as part of your filter should execute as quickly as possible, so you will probably not want to perform database lookups or any other high-latency operations. Even with the caching approach described above, you might want to use either a replicated cache or a partitioned cache fronted by a CQC to store allowed IP addresses, in order to eliminate one network call and keep latency to a minimum.
For example, we could implement AuthorizedHostsFilter like this:
public class AuthorizedHostsFilter implements Filter {
private static final NamedCache hosts =
new ContinuousQueryCache(
CacheFactory.getCache("auth-hosts"),
AlwaysFilter.INSTANCE, false);
public boolean evaluate(Object o) {
InetAddress address = (InetAddress) o;
return hosts.containsKey(address.getHostAddress());
}
}
The important part is initialization of the static hosts field, which is set to an instance of a CQC that caches locally all the keys from the auth-hosts partitioned cache in order to improve access performance.
Now that we have that in place, the implementation of the evaluate method that will perform access checking is trivial—it simply casts the argument to java.net.InetAddress instance, which is what is always passed as an argument to a host filter, and checks if the auth-hosts cache contains the matching key.
The last thing we need to do is configure our proxy servers to use the host filter we just created:
<authorized-hosts> <host-filter> <class-name> ...security.AuthorizedHostsFilter </class-name> </host-filter> </authorized-hosts>
We have now secured the access to a Coherence cluster by ensuring that only hosts that are explicitly registered in the auth-hosts cache can access it.
However, that is only one part of the complete security solution—while it will not be possible for unauthorized hosts to connect to the cluster, they can still eavesdrop on the network traffic between the authorized clients and the proxy server and obtain the data they shouldn't be allowed to see. This would also allow them to impersonate one of the authorized hosts and gain direct cluster access.
In order to prevent them from doing that (or at least to make the task much more difficult and time consuming), we need to encrypt the traffic between the client and the proxy server. Fortunately, Coherence provides an easy way to do that, and the next section will show you how.
Network filters are another Coherence feature that can be used both with TCMP and Coherence*Extend, but which is much more applicable in a latter case. They are used to modify the contents of the messages exchanged between the client and the proxy server before they are transmitted over the wire.
Two common scenarios that are supported out of the box are encryption and compression. Encryption can be either password or private key-based, and is very useful when you want to address the security concerns described earlier and make network sniffing a non-issue. Unfortunately, as of Coherence 3.5, encryption is supported only by Java clients, and not by .NET and C++ Coherence*Extend clients.
This will hopefully be addressed in a future release, but in the meantime all is not lost if you need encryption support in .NET or C++—the necessary infrastructure for pluggable network filters is in place, so you can implement one yourself, as we'll do shortly.
In the remainder of this section we will first look at the built-in filters that ship with Coherence and how to configure them. Afterwards, we will implement a custom encryption filter for .NET client using an excellent open source encryption library, Bouncy Castle. You will also learn how to configure custom network filters both within the cluster and on the client.
All built-in network filters are configured within the cluster-config/filters section of the Coherence deployment descriptor, tangosol-coherence.xml. They are assigned unique names, which you need to reference when configuring Coherence*Extend clients and proxy servers to use them.
Each filter can also have one or more configuration parameters, which are defined within the init-params configuration section of each filter element. For example, the compression filter is configured like this:
<filter id="1"> <filter-name>gzip</filter-name> <filter-class> com.tangosol.net.CompressionFilter </filter-class> <init-params> <init-param id="1"> <param-name>strategy</param-name> <param-value>gzip</param-value> </init-param> <init-param id="2"> <param-name>level</param-name> <param-value>default</param-value> </init-param> </init-params> </filter>
When an instance of a network filter is created, Coherence will convert parameters defined for the filter into an XML element and pass it to the filter's setConfig method. In the case of the compression filter defined above, the following XML will be passed to its setConfig method:
<config> <strategy>gzip</strategy> <level>default</level> </config>
In some cases, you might want to override the default value specified in the configuration file for one or more parameters. You can do that in Java by allowing parameter override using system properties, just as the built-in symmetric encryption filter defined below does:
<filter id="2"> <filter-name>symmetric-encryption</filter-name> <filter-class> com.tangosol.net.security.PasswordBasedEncryptionFilter </filter-class> <init-params> <init-param id="1"> <param-name>password</param-name> <param-value system-property="tangosol.coherence.security.password"> </param-value> </init-param> </init-params> </filter>
In this case, the default value is an empty string, which is probably not what you want to use as a password, so you need to specify the password using the system property tangosol.coherence.security.password when starting a Coherence node.
Now that we have the filter configuration basics out of the way, let's look in more detail into the built-in filters Coherence provides.
The compression filter allows you to compress the network traffic between the nodes in the cluster, or in the case of Coherence*Extend, between the clients and the proxy servers.
Compression rarely makes sense within the cluster, as the network between the nodes will typically have plenty of bandwidth, so compression would only increase the CPU load without providing any real benefits. On the other hand, compression can greatly improve performance over low-bandwidth, high-latency WAN connections, so it might make sense to use it with the remote Coherence*Extend clients, or for cluster-to-cluster communication across the WAN.
In order to configure Coherence*Extend proxy server to use the compression filter, you need to add the use-filters configuration section to the acceptor-config element of the proxy scheme and specify the filter name within it:
<proxy-scheme> <scheme-name>extend-proxy</scheme-name> <service-name>ExtendTcpProxyService</service-name> <acceptor-config> <tcp-acceptor> ... </tcp-acceptor> <use-filters> <filter-name>gzip</filter-name> </use-filters> </acceptor-config> </proxy-scheme>
On the client, you need to do the same thing—the only difference is that you need to put the use-filters element within the initiator-config section of both the remote cache scheme and the remote invocation scheme.
The important thing to understand is that network filters are an all-or-nothing feature. If you decide to use them you need to ensure that all the clients and all proxy servers are configured identically, including the order of the filters within the use-filters section. Otherwise, communication between the clients and the proxy servers will not work.
Also, while the compression filter can be configured to use one of several compression strategies supported by Java, such as gzip, huffman-only, or filtered, if you need to use compression between .NET clients and proxy servers you should keep the default value of gzip, which is the only strategy supported in the current release of .NET Coherence client.
If you look at the filter definitions within the default Coherence deployment descriptor, tangosol-coherence.xml, you will notice that there are two encryption filter implementations: PasswordBasedEncryptionFilter, which uses a configurable password to perform symmetric encryption of network traffic, as well as the ClusterEncryptionFilter, which uses asymmetric encryption to protect the cluster join protocol, but afterwards generates a symmetric encryption key and switches over to a much faster symmetric encryption for data transfer.
The latter is significantly more difficult to configure as it requires that each node in the cluster has access to the public keys of all other nodes. It is also not supported by Coherence*Extend clients at the moment, so in the remainder of this section we will focus on the former: the password-based symmetric encryption filter.
You can configure Coherence*Extend clients and proxy servers to use encryption the same way we configured compression filter earlier—by referencing symmetric-encryption filter within the use-filters section of initiator-config on the client, and acceptor-config on the server:
<use-filters> <filter-name>symmetric-encryption</filter-name> </use-filters>
The Java implementation of encryption filter is based on the Java Cryptography Extensions (JCE), which means that you can use either a standard Cryptographic Service Provider that ships with the JDK, or plug in a third-party provider, such as Bouncy Castle (http://www.bouncycastle.org).
It also means that the encryption algorithm is configurable—algorithms that are available to you will be determined only by the provider you decide to use. This is the reason why Bouncy Castle is such an attractive alternative to a standard cryptography provider—it supports pretty much any cryptographic algorithm you can think of.
If you are not familiar with password-based encryption, it is important that you understand some basic concepts and terminology. The password that you specify is not used directly to encrypt the data. Instead, it is used only as a starting point for the creation of a secret key, which is then used to encrypt the data. This provides an additional layer of security—even if the attacker finds out the password itself, he or she will not be able to determine the secret key that should be used the decrypt the data unless he or she knows the remaining parameters used for secret key generation:
A salt, which is combined with the base password
An algorithm that is used to encrypt the combination of the password and salt
The number of iterations for which encryption should be performed
Basically, the secret key is generated by encrypting the combination of the password and salt for the specified number of iterations, using one of the available encryption algorithms.
Note
Oversimplification warning
The process is a bit more complex then described in the preceeding text, as the algorithm mentioned above is actually a combination of two algorithms: a hashing or pseudorandom function, such as MD5 or HMAC-SHA1, which is used to generate the secret key based on the password, salt, and iteration count, as well as the encryption algorithm, such as DES, TripleDES, or Rijndael/AES, which is used to encrypt messages using the generated secret key.
If you are interested in details, please check the RSA PKCS #5 standard or IETF RFC-2898, both of which can be easily found on the Internet.
Coherence provides sensible defaults for salt, algorithm, and the number of iterations, but you can override them by adding salt, algorithm, and iterations parameters to the filter definition and specifying values for them. Just make sure that you configure the filter exactly the same on both the client and the server or your secret keys will not match and the communication between the client and the server will fail.
Now that we understand how the built-in Java encryption filter works, let's see how we can implement one in .NET.
In order to create a custom network filter in Java, you need to create a class that implements the com.tangosol.io.WrapperStreamFactory interface:
public interface WrapperStreamFactory {
InputStream getInputStream(InputStream stream);
OutputStream getOutputStream(OutputStream stream);
}
Each method should return a new stream that wraps a specified input or output stream and adds necessary behavior. For example, you can implement compression by simply wrapping the original input and output stream with a java.util.zip.GZIPInputStream and java.util.zip.GZIPOutputStream respectively.
Custom filter implementation in .NET is very similar. The only difference is that your class needs to implement the Tangosol.IO.IWrapperStreamFactory interface:
public interface IWrapperStreamFactory
{
Stream GetInputStream(Stream stream);
Stream GetOutputStream(Stream stream);
}
Fortunately for us, the .NET implementation of Bouncy Castle encryption library provides a convenient Org.BouncCastle.Crypto.IO.CryptoStream class, so all we need to do is to create a wrapper around it that configures it properly:
public class PasswordBasedEncryptionFilter
: IWrapperStreamFactory, IXmlConfigurable
{
private char[] m_password;
private byte[] m_salt;
private int m_iterationCount;
private String m_algorithm;
public PasswordBasedEncryptionFilter()
{}
public Stream GetInputStream(Stream stream)
{
return new CipherInputStream(stream, GetCipher(false));
}
public Stream GetOutputStream(Stream stream){
return new CipherOutputStream(stream, GetCipher(true));
}
...
}
The CipherInputStream and CipherOutputStream classes used in this code are really just thin wrappers around the CryptoStream class provided by Bouncy Castle that simplify its configuration and handle few other minor details required by the IWrapperStreamFactory implementation, such as keeping track of the current position within the input stream.
The most important piece of code in the preceding example is probably the call to the GetCipher method, which is responsible for the creation of a block cipher that should be used for encryption or decryption. However, the details of this method are beyond the scope of this book. If you are interested in implementation details, feel free to review the full implementation of the PasswordBasedEncryptionFilter class in the sample code that accompanies the book.
This chapter addressed some very important topics when it comes to extending the reach of your Coherence-based applications outside of the data center and to platforms other than Java.
At the very beginning we discussed different network protocols Coherence uses and reasons for using Coherence*Extend instead of TCMP across WAN or from remote clients. It is important to choose the right option when architecting your application, as incorrect protocol choice for high-latency or unreliable clients can easily bring the whole cluster to its knees.
We then learned how to configure Coherence*Extend both within the cluster and on the client, and discussed topics such as remote caches, the remote invocation service, address providers, and network filters. We also learned how to secure Coherence*Extend deployments using both host-based access control and data encryption, and implemented a .NET version of a symmetric encryption filter that you can use in combination with a built-in Java encryption filter to encrypt network traffic between .NET clients and Coherence*Extend proxy servers.
However, before I show you how to do that, we need to take a step back and learn a bit more about the implementation of .NET Coherence*Extend clients, which is the subject of the next chapter.