
![]()
A Simple Parser
The Interpreter pattern discussed in Chapter 11 does not cover parsing. An interpreter without a parser is pretty incomplete, unless you persuade your users to write PHP code to invoke the interpreter! Third-party parsers are available that could be deployed to work with the Interpreter pattern, and that would probably be the best choice in a real-world project. This appendix, however, presents a simple object-oriented parser designed to work with the MarkLogic interpreter built in Chapter 11. Be aware that these examples are no more than a proof of concept. They are not designed for use in real-world situations.
![]() Note The interface and broad structure of this parser code are based on Steven Metsker’s Building Parsers with Java (Addison-Wesley, 2001). The brutally simplified implementation is my fault, however, and any mistakes should be laid at my door. Steven has given kind permission for the use of his original concept.
Note The interface and broad structure of this parser code are based on Steven Metsker’s Building Parsers with Java (Addison-Wesley, 2001). The brutally simplified implementation is my fault, however, and any mistakes should be laid at my door. Steven has given kind permission for the use of his original concept.
The Scanner
In order to parse a statement, you must first break it down into a set of words and characters (known as tokens). The following class uses a number of regular expressions to define tokens. It also provides a convenient result stack that I will be using later in this section. Here is the Scanner class:
namespace giparse;
class Scanner {
// token types
const WORD = 1;
const QUOTE = 2;
const APOS = 3;
const WHITESPACE = 6;
const EOL = 8;
const CHAR = 9;
const EOF = 0;
const SOF = -1;
protected $line_no = 1;
protected $char_no = 0;
protected $token = null;
protected $token_type = -1;
// Reader provides access to the raw character data. Context stores
// result data
function __construct( Reader $r, Context $context ) {
$this->r = $r;
$this->context = $context;
}
function getContext() {
return $this->context;
}
// read through all whitespace characters
function eatWhiteSpace( ) {
$ret = 0;
if ( $this->token_type != self::WHITESPACE &&
$this->token_type != self::EOL ) {
return $ret;
}
while ( $this->nextToken() == self::WHITESPACE ||
$this->token_type == self::EOL ) {
$ret++;
}
return $ret;
}
// get a string representation of a token
// either the current token, or that represented
// by the $int arg
function getTypeString( $int=-1 ) {
if ( $int<0 ) { $int=$this->tokenType(); }
if ( $int<0 ) { return null; }
$resolve = array(
self::WORD => 'WORD',
self::QUOTE => 'QUOTE',
self::APOS => 'APOS',
self::WHITESPACE => 'WHITESPACE',
self::EOL => 'EOL',
self::CHAR => 'CHAR',
self::EOF => 'EOF' );
return $resolve[$int];
}
// the current token type (represented by an integer)
function tokenType() {
return $this->token_type;
}
// get the contents of the current token
function token() {
return $this->token;
}
// return true if the current token is a word
function isWord( ) {
return ( $this->token_type == self::WORD );
}
// return true if the current token is a quote character
function isQuote( ) {
return ( $this->token_type == self::APOS ||
$this->token_type == self::QUOTE );
}
// current line number in source
function line_no() {
return $this->line_no;
}
// current character number in source
function char_no() {
return $this->char_no;
}
// clone this object
function __clone() {
$this->r = clone($this->r);
}
// move on to the next token in the source. Set the current
// token and track the line and character numbers
function nextToken() {
$this->token = null;
$type;
while ( ! is_bool($char=$this->getChar()) ) {
if ( $this->isEolChar( $char ) ) {
$this->token = $this->manageEolChars( $char );
$this->line_no++;
$this->char_no = 0;
$type = self::EOL;
return ( $this->token_type = self::EOL );
} else if ( $this->isWordChar( $char ) ) {
$this->token = $this->eatWordChars( $char );
$type = self::WORD;
} else if ( $this->isSpaceChar( $char ) ) {
$this->token = $char;
$type = self::WHITESPACE;
} else if ( $char == "'" ) {
$this->token = $char;
$type = self::APOS;
} else if ( $char == '"' ) {
$this->token = $char;
$type = self::QUOTE;
} else {
$type = self::CHAR;
$this->token = $char;
}
$this->char_no += strlen( $this->token() );
return ( $this->token_type = $type );
}
return ( $this->token_type = self::EOF );
}
// return an array of token type and token content for the NEXT token
function peekToken() {
$state = $this->getState();
$type = $this->nextToken();
$token = $this->token();
$this->setState( $state );
return array( $type, $token );
}
// get a ScannerState object that stores the parser's current
// position in the source, and data about the current token
function getState() {
$state = new ScannerState();
$state->line_no = $this->line_no;
$state->char_no = $this->char_no;
$state->token = $this->token;
$state->token_type = $this->token_type;
$state->r = clone($this->r);
$state->context = clone($this->context);
return $state;
}
// use a ScannerState object to restore the scanner's
// state
function setState( ScannerState $state ) {
$this->line_no = $state->line_no;
$this->char_no = $state->char_no;
$this->token = $state->token;
$this->token_type = $state->token_type;
$this->r = $state->r;
$this->context = $state->context;
}
// get the next character from source
private function getChar() {
return $this->r->getChar();
}
// get all characters until they stop being
// word characters
private function eatWordChars( $char ) {
$val = $char;
while ( $this->isWordChar( $char=$this->getChar() )) {
$val .= $char;
}
if ( $char ) {
$this->pushBackChar( );
}
return $val;
}
// get all characters until they stop being space
// characters
private function eatSpaceChars( $char ) {
$val = $char;
while ( $this->isSpaceChar( $char=$this->getChar() )) {
$val .= $char;
}
$this->pushBackChar( );
return $val;
}
// move back one character in source
private function pushBackChar( ) {
$this->r->pushBackChar();
}
// argument is a word character
private function isWordChar( $char ) {
return preg_match( "/[A-Za-z0-9_-]/", $char );
}
// argument is a space character
private function isSpaceChar( $char ) {
return preg_match( "/ | /", $char );
}
// argument is an end of line character
private function isEolChar( $char ) {
return preg_match( "/ | /", $char );
}
// swallow either , or
private function manageEolChars( $char ) {
if ( $char == " " ) {
$next_char=$this->getChar();
if ( $next_char == " " ) {
return "{$char}{$next_char}";
} else {
$this->pushBackChar();
}
}
return $char;
}
function getPos() {
return $this->r->getPos();
}
}
class ScannerState {
public $line_no;
public $char_no;
public $token;
public $token_type;
public $r;
}
First, I set up constants for the tokens that interest me. I am going to match characters, words, whitespace, and quote characters. I test for these types in methods dedicated to each token: isWordChar(), isSpaceChar(), and so on. The heart of the class is the nextToken() method. This attempts to match the next token in a given string. The Scanner stores a Context object. Parser objects use this to share results as they work through the target text.
Note also a second class: ScannerState. The Scanner is designed so that Parser objects can save state, try stuff out, and restore if they’ve gone down a blind alley. The getState() method populates and returns a ScannerState object. setState() uses a ScannerState object to revert state if required.
namespace giparse;
//...
class Context {
public $resultstack = array();
function pushResult( $mixed ) {
array_push( $this->resultstack, $mixed );
}
function popResult( ) {
return array_pop( $this->resultstack );
}
function resultCount() {
return count( $this->resultstack );
}
function peekResult( ) {
if ( empty( $this->resultstack ) ) {
throw new Exception( "empty resultstack" );
}
return $this->resultstack[count( $this->resultstack ) -1 ];
}
}
As you can see, this is just a simple stack, a convenient noticeboard for parsers to work with. It performs a similar job to that of the context class used in the Interpreter pattern, but it is not the same class.
Notice that the Scanner does not itself work with a file or string. Instead, it requires a Reader object. This would allow me to easily to swap in different sources of data. Here is the Reader interface and an implementation: StringReader:
namespace giparse;
interface Reader {
function getChar();
function getPos();
function pushBackChar();
}
class StringReader implements Reader {
private $in;
private $pos;
function __construct( $in ) {
$this->in = $in;
$this->pos = 0;
}
function getChar() {
if ( $this->pos >= strlen( $this->in ) ) {
return false;
}
$char = substr( $this->in, $this->pos, 1 );
$this->pos++;
return $char;
}
function getPos() {
return $this->pos;
}
function pushBackChar() {
$this->pos--;
}
function string() {
return $this->in;
}
}
This simply reads from a string one character at a time. I could easily provide a file-based version, of course.
Perhaps the best way to see how the Scanner might be used is to use it. Here is some code to break up the example statement into tokens:
$context = new giparseContext();
$user_in = "$input equals '4' or $input equals 'four'";
$reader = new giparseStringReader( $user_in );
$scanner = new giparseScanner( $reader, $context );
while ( $scanner->nextToken() != giparseScanner::EOF ) {
print $scanner->token();
print " {$scanner->char_no()}";
print " {$scanner->getTypeString()} ";
}
I initialize a Scanner object and then loop through the tokens in the given string by repeatedly calling nextToken(). The token() method returns the current portion of the input matched. char_no() tells me where I am in the string, and getTypeString() returns a string version of the constant flag representing the current token. This is what the output should look like:
$ 1 CHAR
input 6 WORD
7 WHITESPACE
equals 13 WORD
14 WHITESPACE
' 15 APOS
4 16 WORD
' 17 APOS
18 WHITESPACE
or 20 WORD
21 WHITESPACE
$ 22 CHAR
input 27 WORD
28 WHITESPACE
equals 34 WORD
35 WHITESPACE
' 36 APOS
four 40 WORD
' 41 APOS
I could, of course, match finer-grained tokens than this, but this is good enough for my purposes. Breaking up the string is the easy part. How do I build up a grammar in code?
The Parser
One approach is to build a tree of Parser objects. Here is the abstract Parser class that I will be using:
namespace giparse;
abstract class Parser {
const GIP_RESPECTSPACE = 1;
protected $respectSpace = false;
protected static $debug = false;
protected $discard = false;
protected $name;
private static $count=0;
function __construct( $name=null, $options=null ) {
if ( is_null( $name ) ) {
self::$count++;
$this->name = get_class( $this )." (".self::$count.")";
} else {
$this->name = $name;
}
if ( is_array( $options ) ) {
if ( isset( $options[self::GIP_RESPECTSPACE] ) ) {
$this->respectSpace=true;
}
}
}
protected function next( Scanner $scanner ) {
$scanner->nextToken();
if ( ! $this->respectSpace ) {
$scanner->eatWhiteSpace();
}
}
function spaceSignificant( $bool ) {
$this->respectSpace = $bool;
}
static function setDebug( $bool ) {
self::$debug = $bool;
}
function setHandler( Handler $handler ) {
$this->handler = $handler;
}
final function scan( Scanner $scanner ) {
if ( $scanner->tokenType() == Scanner::SOF ) {
$scanner->nextToken();
}
$ret = $this->doScan( $scanner );
if ( $ret && ! $this->discard && $this->term() ) {
$this->push( $scanner );
}
if ( $ret ) {
$this->invokeHandler( $scanner );
}
if ( $this->term() && $ret ) {
$this->next( $scanner );
}
$this->report("::scan returning $ret");
return $ret;
}
function discard() {
$this->discard = true;
}
abstract function trigger( Scanner $scanner );
function term() {
return true;
}
// private/protected
protected function invokeHandler(
Scanner $scanner ) {
if ( ! empty( $this->handler ) ) {
$this->report( "calling handler: ".get_class( $this->handler ) );
$this->handler->handleMatch( $this, $scanner );
}
}
protected function report( $msg ) {
if ( self::$debug ) {
print "<{$this->name}> ".get_class( $this ).": $msg ";
}
}
protected function push( Scanner $scanner ) {
$context = $scanner->getContext();
$context->pushResult( $scanner->token() );
}
abstract protected function doScan( Scanner $scan );
}
The place to start with this class is the scan() method. It is here that most of the logic resides. scan() is given a Scanner object to work with. The first thing that the Parser does is defer to a concrete child class, calling the abstract doScan() method. doScan() returns true or false; you will see a concrete example later in this section.
If doScan() reports success, and a couple of other conditions are fulfilled, then the results of the parse are pushed to the Context object’s result stack. The Scanner object holds the Context that is used by Parser objects to communicate results. The actual pushing of the successful parse takes place in the Parser::push() method:
protected function push( Scanner $scanner ) {
$context = $scanner->getContext();
$context->pushResult( $scanner->token() );
}
In addition to a parse failure, there are two conditions that might prevent the result from being pushed to the scanner’s stack. First, client code can ask a parser to discard a successful match by calling the discard() method. This toggles a property called $discard to true. Second, only terminal parsers (that is, parsers that are not composed of other parsers) should push their result to the stack. Composite parsers (instances of CollectionParser, often referred to in the following text as collection parsers) will instead let their successful children push their results. I test whether or not a parser is terminal using the term() method, which is overridden to return false by collection parsers.
If the concrete parser has been successful in its matching then I call another method: invokeHandler(). This is passed the Scanner object. If a Handler (that is, an object that implements the Handler interface) has been attached to Parser (using the setHandler() method), then its handleMatch() method is invoked here. I use handlers to make a successful grammar actually do something, as you will see shortly.
Back in the scan() method, I call on the Scanner object (via the next() method) to advance its position by calling its nextToken() and eatWhiteSpace() methods. Finally, I return the value that was provided by doScan().
In addition to doScan(), notice the abstract trigger() method. This is used to determine whether a parser should bother to attempt a match. If trigger() returns false then the conditions are not right for parsing. Let’s take a look at a concrete terminal Parser. CharacterParse is designed to match a particular character:
namespace giparse;
class CharacterParse extends Parser {
private $char;
function __construct( $char, $name=null, $options=null ) {
parent::__construct( $name, $options );
$this->char = $char;
}
function trigger( Scanner $scanner ) {
return ( $scanner->token() == $this->char );
}
protected function doScan( Scanner $scanner ) {
return ( $this->trigger( $scanner ) );
}
}
The constructor accepts a character to match and an optional parser name for debugging purposes. The trigger() method simply checks whether the scanner is pointing to a character token that matches the sought character. Because no further scanning than this is required, the doScan() method simply invokes trigger().
Terminal matching is a reasonably simple affair, as you can see. Let’s look now at a collection parser. First I’ll define a common superclass, and then go on to create a concrete example:
namespace gi/parse;
// This abstract class holds subparsers
abstract class CollectionParse extends Parser {
protected $parsers = array();
function add( Parser $p ) {
if ( is_null( $p ) ) {
throw new Exception( "argument is null" );
}
$this->parsers[]= $p;
return $p;
}
function term() {
return false;
}
}
class SequenceParse extends CollectionParse {
function trigger( Scanner $scanner ) {
if ( empty( $this->parsers ) ) {
return false;
}
return $this->parsers[0]->trigger( $scanner );
}
protected function doScan( Scanner $scanner ) {
$start_state = $scanner->getState();
foreach( $this->parsers as $parser ) {
if ( ! ( $parser->trigger( $scanner ) &&
$scan=$parser->scan( $scanner )) ) {
$scanner->setState( $start_state );
return false;
}
}
return true;
}
}
The abstract CollectionParse class simply implements an add() method that aggregates Parsers and overrides term() to return false.
The SequenceParse::trigger() method tests only the first child Parser it contains, invoking its trigger() method. The calling Parser will first call CollectionParse::trigger() to see if it is worth calling CollectionParse::scan(). If CollectionParse::scan() is called, then doScan() is invoked and the trigger() and scan() methods of all Parser children are called in turn. A single failure results in CollectionParse::doScan() reporting failure.
One of the problems with parsing is the need to try stuff out. A SequenceParse object may contain an entire tree of parsers within each of its aggregated parsers. These will push the Scanner on by a token or more and cause results to be registered with the Context object. If the final child in the Parser list returns false, what should SequenceParse do about the results lodged in Context by the child’s more successful siblings? A sequence is all or nothing, so I have no choice but to roll back both the Context object and the Scanner. I do this by saving state at the start of doScan() and calling setState() just before returning false on failure. Of course, if I return true then there’s no need to roll back.
For the sake of completeness, here are all the remaining Parser classes:
namespace giparse;
// This matches if one or more subparsers match
class RepetitionParse extends CollectionParse {
private $min;
private $max;
function __construct( $min=0, $max=0, $name=null, $options=null ) {
parent::__construct( $name, $options );
if ( $max < $min && $max > 0 ) {
throw new Exception(
"maximum ( $max ) larger than minimum ( $min )");
}
$this->min = $min;
$this->max = $max;
}
function trigger( Scanner $scanner ) {
return true;
}
protected function doScan( Scanner $scanner ) {
$start_state = $scanner->getState();
if ( empty( $this->parsers ) ) {
return true;
}
$parser = $this->parsers[0];
$count = 0;
while ( true ) {
if ( $this->max > 0 && $count >= $this->max ) {
return true;
}
if ( ! $parser->trigger( $scanner ) ) {
if ( $this->min == 0 || $count >= $this->min ) {
return true;
} else {
$scanner->setState( $start_state );
return false;
}
}
if ( ! $parser->scan( $scanner ) ) {
if ( $this->min == 0 || $count >= $this->min ) {
return true;
} else {
$scanner->setState( $start_state );
return false;
}
}
$count++;
}
return true;
}
}
// This matches if one or other of two subparsers match
class AlternationParse extends CollectionParse {
function trigger( Scanner $scanner ) {
foreach ( $this->parsers as $parser ) {
if ( $parser->trigger( $scanner ) ) {
return true;
}
}
return false;
}
protected function doScan( Scanner $scanner ) {
$type = $scanner->tokenType();
foreach ( $this->parsers as $parser ) {
$start_state = $scanner->getState();
if ( $type == $parser->trigger( $scanner ) &&
$parser->scan( $scanner ) ) {
return true;
}
}
$scanner->setState( $start_state );
return false;
}
}
// this terminal parser matches a string literal
class StringLiteralParse extends Parser {
function trigger( Scanner $scanner ) {
return ( $scanner->tokenType() == Scanner::APOS ||
$scanner->tokenType() == Scanner::QUOTE );
}
protected function push( Scanner $scanner ) {
return;
}
protected function doScan( Scanner $scanner ) {
$quotechar = $scanner->tokenType();
$ret = false;
$string = "";
while ( $token = $scanner->nextToken() ) {
if ( $token == $quotechar ) {
$ret = true;
break;
}
$string .= $scanner->token();
}
if ( $string && ! $this->discard ) {
$scanner->getContext()->pushResult( $string );
}
return $ret;
}
}
// this terminal parser matches a word token
class WordParse extends Parser {
function __construct( $word=null, $name=null, $options=null ) {
parent::__construct( $name, $options );
$this->word = $word;
}
function trigger( Scanner $scanner ) {
if ( $scanner->tokenType() != Scanner::WORD ) {
return false;
}
if ( is_null( $this->word ) ) {
return true;
}
return ( $this->word == $scanner->token() );
}
protected function doScan( Scanner $scanner ) {
$ret = ( $this->trigger( $scanner ) );
return $ret;
}
}
By combining terminal and nonterminal Parser objects, I can build a reasonably sophisticated parser. You can see all the Parser classes I use for this example in Figure B-1.
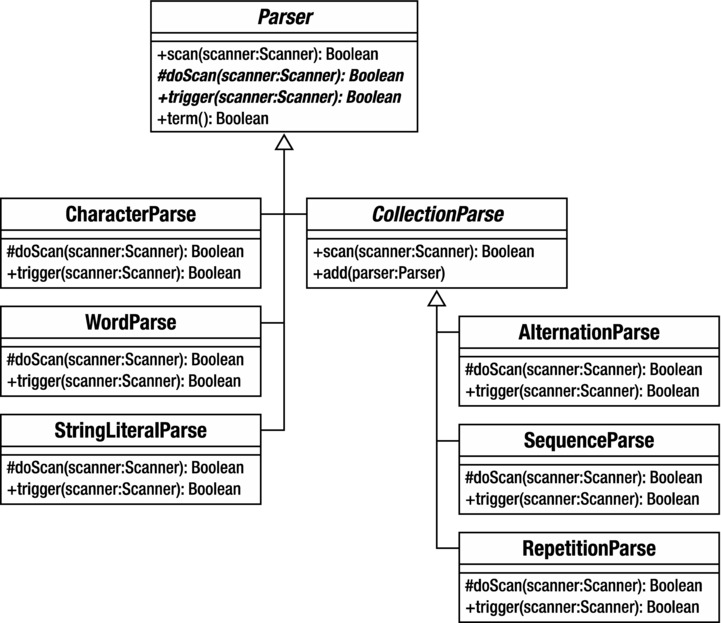
Figure B-1. The Parser classes
The idea behind this use of the Composite pattern is that a client can build up a grammar in code that closely matches EBNF notation. Table B-1 shows the parallels between these classes and EBNF fragments.
Table B-1. Composite Parsers and EBNF
Class |
EBNF Example |
Description |
|---|---|---|
| AlternationParse | orExpr | andExpr | Either one or another |
| SequenceParse | 'and' operand | A list (all required in order) |
| RepetitionParse | ( eqExpr )* | Zero or more required |
Now to build some client code to implement the mini-language. As a reminder, here is the EBNF fragment I presented in Chapter 11:
expr ::= operand (orExpr | andExpr )*
operand ::= ( '(' expr ')' | <stringLiteral> | variable ) ( eqExpr )*
orExpr ::= 'or' operand
andExpr ::= 'and' operand
eqExpr ::= 'equals' operand
variable ::= '$' <word>
This simple class builds up a grammar based on this fragment and runs it:
class MarkParse {
private $expression;
private $operand;
private $interpreter;
private $context;
function __construct( $statement ) {
$this->compile( $statement );
}
function evaluate( $input ) {
$icontext = new InterpreterContext();
$prefab = new VariableExpression('input', $input );
// add the input variable to Context
$prefab–>interpret( $icontext );
$this->interpreter->interpret( $icontext );
$result = $icontext->lookup( $this->interpreter );
return $result;
}
function compile( $statement_str ) {
// build parse tree
$context = new giparseContext();
$scanner = new giparseScanner(
new giparseStringReader($statement_str), $context );
$statement = $this->expression();
$scanresult = $statement->scan( $scanner );
if ( ! $scanresult || $scanner->tokenType() != giparseScanner::EOF ) {
$msg = "";
$msg .= " line: {$scanner->line_no()} ";
$msg .= " char: {$scanner->char_no()}";
$msg .= " token: {$scanner->token()} ";
throw new Exception( $msg );
}
$this->interpreter = $scanner->getContext()->popResult();
}
function expression() {
if ( ! isset( $this->expression ) ) {
$this->expression = new giparseSequenceParse();
$this->expression->add( $this->operand() );
$bools = new giparseRepetitionParse( );
$whichbool = new giparseAlternationParse();
$whichbool->add( $this->orExpr() );
$whichbool->add( $this->andExpr() );
$bools->add( $whichbool );
$this->expression->add( $bools );
}
return $this->expression;
}
function orExpr() {
$or = new giparseSequenceParse( );
$or->add( new giparseWordParse('or') )->discard();
$or->add( $this->operand() );
$or->setHandler( new BooleanOrHandler() );
return $or;
}
function andExpr() {
$and = new giparseSequenceParse();
$and->add( new giparseWordParse('and') )->discard();
$and->add( $this->operand() );
$and->setHandler( new BooleanAndHandler() );
return $and;
}
function operand() {
if ( ! isset( $this->operand ) ) {
$this->operand = new giparseSequenceParse( );
$comp = new giparseAlternationParse( );
$exp = new giparseSequenceParse( );
$exp->add( new giparseCharacterParse( '(' ))->discard();
$exp->add( $this->expression() );
$exp->add( new giparseCharacterParse( ')' ))->discard();
$comp->add( $exp );
$comp->add( new giparseStringLiteralParse() )
->setHandler( new StringLiteralHandler() );
$comp->add( $this->variable() );
$this->operand->add( $comp );
$this->operand->add( new giparseRepetitionParse( ) )
->add($this->eqExpr());
}
return $this->operand;
}
function eqExpr() {
$equals = new giparseSequenceParse();
$equals->add( new giparseWordParse('equals') )->discard();
$equals->add( $this->operand() );
$equals->setHandler( new EqualsHandler() );
return $equals;
}
function variable() {
$variable = new giparseSequenceParse();
$variable->add( new giparseCharacterParse( '$' ))->discard();
$variable->add( new giparseWordParse());
$variable->setHandler( new VariableHandler() );
return $variable;
}
}
This may seem like a complicated class, but all it is doing is building up the grammar I have already defined. Most of the methods are analogous to production names (that is, the names that begin each production line in EBNF, such as eqExpr and andExpr). If you look at the expression() method, you should see that I am building up the same rule as I defined in EBNF earlier:
// expr ::= operand (orExpr | andExpr )*
function expression() {
if ( ! isset( $this->expression ) ) {
$this->expression = new giparseSequenceParse();
$this->expression->add( $this->operand() );
$bools = new giparseRepetitionParse( );
$whichbool = new giparseAlternationParse();
$whichbool->add( $this->orExpr() );
$whichbool->add( $this->andExpr() );
$bools->add( $whichbool );
$this->expression->add( $bools );
}
return $this->expression;
}
In both the code and the EBNF notation, I define a sequence that consists of a reference to an operand, followed by zero or more instances of an alternation between orExpr and andExpr. Notice that I am storing the Parser returned by this method in a property variable. This is to prevent infinite loops, as methods invoked from expression() themselves reference expression().
The only methods that are doing more than just building the grammar are compile() and evaluate(). compile() can be called directly or automatically via the constructor, which accepts a statement string and uses it to create a Scanner object. It calls the expression() method, which returns a tree of Parser objects that make up the grammar. It then calls Parser::scan(), passing it the Scanner object. If the raw code does not parse, the compile() method throws an exception. Otherwise, it retrieves the result of compilation as left on the Scanner object’s Context. As you will see shortly, this should be an Expression object. This result is stored in a property called $interpreter.
The evaluate() method makes a value available to the Expression tree. It does this by predefining a VariableExpression object named input and registering it with the Context object that is then passed to the main Expression object. As with variables such as $_REQUEST in PHP, this $input variable is always available to MarkLogic coders.
![]() Note See Chapter 11 for more about the VariableExpression class that is part of the Interpreter pattern example.
Note See Chapter 11 for more about the VariableExpression class that is part of the Interpreter pattern example.
The evaluate() method calls the Expression::interpret() method to generate a final result. Remember, you need to retrieve interpreter results from the Context object.
So far, you have seen how to parse text and how to build a grammar. You also saw in Chapter 11 how to use the Interpreter pattern to combine Expression objects and process a query. You have not yet seen, however, how to relate the two processes. How do you get from a parse tree to the interpreter? The answer lies in the Handler objects that can be associated with Parser objects using Parser::setHandler(). Let’s take a look at the way to manage variables. I associate a VariableHandler with the Parser in the variable() method:
$variable->setHandler( new VariableHandler() );
Here is the Handler interface:
namespace giparse;
interface Handler {
function handleMatch( Parser $parser,
Scanner $scanner );
}
class VariableHandler implements giparseHandler {
function handleMatch( giparseParser $parser, giparseScanner $scanner ) {
$varname = $scanner->getContext()->popResult();
$scanner->getContext()->pushResult( new VariableExpression( $varname ) );
}
}
If the Parser with which VariableHandler is associated matches on a scan operation, then handleMatch() is called. By definition, the last item on the stack will be the name of the variable. I remove this and replace it with a new VariableExpression object with the correct name. Similar principles are used to create EqualsExpression objects, LiteralExpression objects, and so on.
Here are the remaining handlers:
class StringLiteralHandler implements giparseHandler {
function handleMatch( giparseParser $parser, giparseScanner $scanner ) {
$value = $scanner->getContext()->popResult();
$scanner->getContext()->pushResult( new LiteralExpression( $value ) );
}
}
class EqualsHandler implements giparseHandler {
function handleMatch( giparseParser $parser, giparseScanner $scanner ) {
$comp1 = $scanner->getContext()->popResult();
$comp2 = $scanner->getContext()->popResult();
$scanner->getContext()->pushResult(
new EqualsExpression( $comp1, $comp2 ) );
}
}
class BooleanOrHandler implements giparseHandler {
function handleMatch( giparseParser $parser, giparseScanner $scanner ) {
$comp1 = $scanner->getContext()->popResult();
$comp2 = $scanner->getContext()->popResult();
$scanner->getContext()->pushResult(
new BooleanOrExpression( $comp1, $comp2 ) );
}
}
class BooleanAndHandler implements giparseHandler {
function handleMatch( giparseParser $parser, giparseScanner $scanner ) {
$comp1 = $scanner->getContext()->popResult();
$comp2 = $scanner->getContext()->popResult();
$scanner->getContext()->pushResult(
new BooleanAndExpression( $comp1, $comp2 ) );
}
}
Bearing in mind that you also need the Interpreter example from Chapter 11 at hand, you can work with the MarkParse class like this:
$input = 'five';
$statement = "( $input equals 'five')";
$engine = new MarkParse( $statement );
$result = $engine->evaluate( $input );
print "input: $input evaluating: $statement ";
if ( $result ) {
print "true! ";
} else {
print "false! ";
}
This should produce the following results:
input: five evaluating: ( $input equals 'five')
true!