
In general, looking at kernel crashes requires at least a basic knowledge of what the kernel is supposed to do — since you’re looking for instances where it failed to do it! For those who have not had the opportunity to examine the internal structure of an operating system, this chapter attempts to provide a quick look at some of the basic functions, requirements, and structures you’ll need to know about.
An operating system kernel could be considered the “Master Control Program” for the machine, everything that is connected to it, and anything that runs on it. One of the basic functions of an OS is to control resources. Under this heading you will find memory, CPU time, disk space, and access to external devices like tapes or terminals. As a side benefit of this whole process, the kernel will also prevent users from stepping on one another’s code or data — corruption of resources is another area of vital concern.
The UNIX kernel is no different from any other kernel; the same basic requirements hold. It was designed with timesharing in mind, so there is an emphasis on switching rapidly between several processes that are ready to run, giving the illusion that all users have an equal shot at getting things done.
Let’s take a look at some of the major sections of the kernel code, broken up by function. Some of these are:
Process control. This function includes starting, suspending, and terminating processes, signal handling for responding to external events, and setting or changing priorities. The UNIX system calls fork and exec are handled by this section.
IPC (Interprocess communication). Allowing processes to communicate without interfering with the operation or data of the other process is done by IPC. This can be through a pipe or by using shared memory, semaphores, or messages (part of the System-V IPC suite).
Scheduling. Deciding who gets to run next, and for how long, is a vital part of any system. Choices made here will determine overall performance of the system.
I/O. Input and output requests include opening and closing, or reading and writing data on files or devices. Device setup and control (such as baud rate settings on a terminal or modem line) are also done here.
Networking. Communicating between machines requires various protocols to be established and followed. This is done with Streams modules in the Solaris 2 kernel.
File system management. There are lots of different ways to arrange data on disk. This arrangement is known as a file system, and there are various known types with specific properties. These include UFS (the UNIX File System, for local disks), NFS (the Network File System, for accessing files on other systems as if they were locally resident), HSFS (the High Sierra File System, also known as ISO-9660 format, for CD-ROM). In SunOS and Solaris 2, handling these types has been further subdivided into type-independent “virtual FS” code and file system-, format-specific code.
Memory management. This function covers both the memory that is available to a given process and how the kernel manages the hardware that keeps track of all this memory.
Accounting/monitoring/security. Accounting is generally desirable in one form or another. It allows you to monitor and analyze resource usage. If nothing else, you will want to be able to find out who has used up all your disk space! Security may be a separate major area of the code but is also usually involved in basic operations like accessing files: Users want the ability to keep other users from examining and modifying their data.
Let’s look at some of these sections in more detail, since these are the most common areas you will be examining when working with savecore files.
Once the machine is booted, there are only two ways in which the kernel code will be run: if a user makes a system call or if a device requests attention. These might be considered as the only two entrances into the kernel. A large portion of the kernel is devoted to handling user requests. This involves identifying the system call, validating the parameters, and heading off to the right area of the kernel to do the real work. The other entrance (from hardware signals) is via the device drivers, which handle the specific details about controlling various devices. One of these devices may in fact be the clock, which “ticks” every 100 milliseconds on Sun systems. This is also one way in which the scheduler gets invoked; if enough time has elapsed, the current user process may be suspended to allow another one to get some work done.
The following figure presents a fairly broad overview of the kernel and its component parts. The system call handling is one way — the only way — for user processes to get the kernel to do work for them. At the other end, devices can request attention through a device driver, which may involve other pieces of the kernel as well.
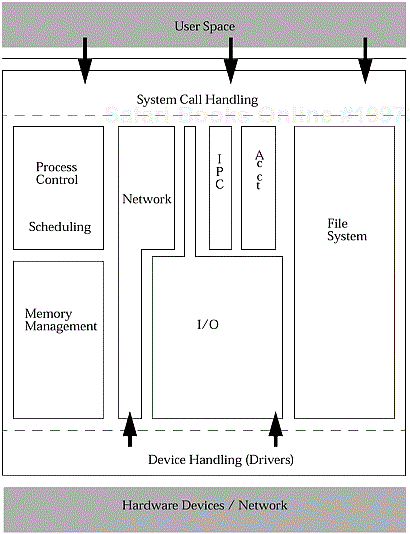
Let’s move back to system calls. From a system programmer’s standpoint, these requests look almost like a subroutine call to a kernel-level function. In actuality, the user program will issue a “software trap” instruction of some sort (dependent on the type of hardware) and will end up transferring control to the kernel temporarily in order to handle the system request. These system calls are the only way the user can access those facilities that are tightly controlled by the kernel. These normally include all the hardware (tapes, terminals, disks, etc.), memory, and any other user programs, plus software facilities such as IPC and pseudo-devices.
System calls exist to manipulate files (open, close, read, write), devices (ioctl), memory (mmap, sbrk), other processes (signals, IPC, fork, exec), and the process’s own environment (resource limits, priority, current directory). Every UNIX user program and utility does its work by using the appropriate system calls to find and manipulate the proper data.
Kernel system call handling generally goes through these basic steps:
Enter the system, identify the system call (verify that this is a legal request), and branch to the right system call handler.
Validate parameters (Is the file open? Is this process allowed to access this data? Is the buffer address legal and mapped in?)
Do the work, which may involve devices, network accesses, or other processes.
Return any error conditions to the user as a special numeric code.
Error return values are placed inside a special variable in the U-area (the user structure) or the thread structure, each of which contains per-process information needed by the kernel. Any error is returned as the result of the system call, along with an error flag to distinguish error codes from legitimate return values. The flag is the carry-bit in the processor status register (PSR) for SPARC systems. Error values are placed by the system call code in libc into the global variable errno, which is actually resident in libc itself.
The kernel scheduler is the section that decides what should be run next and starts it up. This usually involves a context switch; the complete set of state information for the currently executing code must be saved so it can be continued later, and state information for another process must be loaded to resume its execution. This context data includes the complete set of registers in the CPU, the stacks (user stack and kernel stack), and the pages that were in use and in memory for that process.
One of the major changes between the kernel in SunOS 4.x and in Solaris 2 was the modification to allow multiple threads of control within one user process. A thread of control could be viewed as a place where work is being done. For some programs, it’s possible to do some things in parallel: One section of the program can essentially be run independently of another. For “single-threaded” systems like the original UNIX kernel, actually doing this would require you to create a new process to run independently and do the work separately. Modern “multithreaded” kernels do allow several parts of a user program to be active at once, usually because they provide more than one CPU, which could be simultaneously running user code. There is no reason to restrict these processors to working with different user programs, so if the code allows it, more than one thread of control could be active and in execution at one time. This means that in SunOS 4.x, the process is the basic scheduling entity. In Solaris 2, one of the process’s threads is what gets scheduled. In either case, the system still needs to keep track of processes and process-specific information, as well as scheduling parameters, state information, and a kernel stack. This is done with several structures; we’ll look at each version of the OS separately, although there are many things in common.
The main pieces of information needed by the scheduler are contained within the process table.

The process table is a linked list of proc structures that describe processes and their various states. Those that are actually runnable are normally linked together on a separate list. Each process table entry contains enough information to schedule that process and to find the rest of it in case it’s been swapped out to disk. This set of structures is used and updated primarily by the scheduler, but other things may change a process into a “runnable” state. Often device driver interrupt routines will do this when I/O is completed or when data arrives to be read.
The information needed to actually run the process is contained in the U-area, or user structure. This area includes pointers to open files, the current working directory, the effective user ID, and the context (register contents, PC value, stack). This may be swapped out to disk if necessary; the kernel maintains a pool of U-areas for active processes and swaps idle structures out to make room. When analyzing a core dump, you may not see any information about what a process is doing if it has been idle for a long period: all the information about that process’s state, including the kernel stack, is not in the core file because it was not in memory.
Process structures are defined in /usr/include/sys/proc.h; the definition of a user structure can be found in /usr/include/sys/user.h.
In Solaris 2, the information needed to run an individual thread of control is contained in a kernel thread structure rather than in the process’s user structure. This makes the U-area significantly shorter (since a lot of information was pulled from it), so the remainder is now attached to the end of the process table structure, and a linked list of threads is attached to each process. Thus, each process table entry contains all the process-wide information, but each possible thread of control has its own structure containing the necessary state information. Along with the thread structure is an lwp structure, one per thread. The lwp structure contains the less commonly used data about a particular thread (accounting, for instance). Just as the U-area in SunOS 4.x contained process information that could be swapped out, the lwp contains thread information that can be swapped to disk if necessary.
These structures are defined in various /usr/include/sys header files. Look for thread.h, proc.h, usr.h, and klwp.h. (Note that lwp.h does not refer to kernel lwp structures!)

Here, you can see that the per-process information contained in the U-areas and proc structures includes a pointer to a list of structures containing information about each thread of control. Normally, processes contain only one thread. It takes special coding, libraries, and initial design work to build a multithreaded process. The kernel itself does have multiple internal threads that all link to the process table entry for sched, the scheduler. These “system” threads are scheduled and handled just like user program threads, although with a higher priority. They include NFS handlers, Streams management functions, interrupt service routines, and the page daemon.
The piece of the kernel that deals with file systems is the part that determines disk organization, for instance, what actual disk blocks on what device you need to access in order to perform a read, or directory lookup, or file creation. However, there are many different ways of organizing disks. In an attempt to make some of the facilities in the kernel share standard interfaces, there are some virtual layers, in file handling in particular, which insulate the basic kernel functions from the details about file system organization and file types.
In SunOS 4.x and Solaris 2, a VFS (Virtual File System) layer handles the basic details of mounting and unmounting file systems without worrying about their underlying structure. Device- or file-system-specific code is invoked indirectly to perform the needed operations for mounting, unmounting, getting statistics, or flushing data out to the device.
UNIX File Systems (UFS) are the most common systems, with NFS (Network File System) a close runner-up. A new entry in the list is HSFS, which handles a format compatible with DOS CD-ROM. Other new types include procfs to define and handle /proc, which in Solaris 2 is a pseudo-file system without any real files, just processes. All of these file system types have a common set of operations that must be performed, and specific code for each different type handles the details of how these operations are done. A Virtual File System structure contains a pointer to an array of functions that “do the job.” Nobody cares, at the VFS layer, what kind of file system is underneath as long as the appropriate functions have been provided.
Speaking in a generic sense, the “inode” or index node is the source of all knowledge about a file. There are actually different types of inodes, used for different types of files. In addition, a “virtual” layer was imposed in the middle to remove the necessity for identifying various file types. In the beginning, the inode was used to describe a UFS local file, and it held all the data defining where that file lived, its attributes, ownership, and other vital information. When other file system types were introduced, it became necessary to define a vnode (a virtual inode) that would point to the actual inode with the real file system and type-specific access information. Thus, we now may have a vnode that points to an inode (UFS), an rnode (a remote file system—NFS), an snode (indicating a special file, or a device), a tmpnode (used for tmpfs), or (new in Solaris 2.3) a cnode (for cachefs file systems). Most layers of the system deal with vnodes until they really need to access the file data pointed to by that vnode.
UFS directory entries on disk really contain just an inode number and a name, which allows multiple names to refer to the same file by using the same inode (index, or file) number. (The format of a directory entry for both SunOS 4.x and Solaris 2 is described in /usr/include/sys/dirent.h.) The filename is used only when opening a file; from then on a “handle” (file descriptor) is used by the program to refer to the file and read to the vnode.
Several tables in the kernel keep information about open files in one way or another. As usual, all these tables and structures are linked. The links are set up to make finding the vnode easy for the user process. Let’s assume the user wants to read data from a file. The following figure shows the various structures that are referenced and the pointers that are followed, in order for a program to open a file, get a file descriptor, and use that descriptor to retrieve some data from the file.

As you can see, the kernel must pass through the following structures before it can find the real location of the data that the user wants to read.
The U-area (user structure) keeps an array of pointers for file references. There is one pointer (one array element) per open file. The file descriptor that the user program gets from an open() system call is an index into this array. These array elements really just contain pointers to:
A file table entry, which contains the modes with which a file was opened (read-only, read-write) and the current “position” within that file where the next I/O operation will take place. Every separate open() request generates a new file table entry. There is only one file table in the system. Each file table entry contains a pointer to:
A vnode, which identifies some generic characteristics of the file and points to:
the real inode (for UFS files), snode (for special device files) or rnode (for remote networked files), which tells you, finally, how to get to the actual data.
At the bottom of the picture, directory entries (out on disk) also indicate the inode by means of an index or file number kept in the directory itself. These would be used during an open() request to translate the name of the file into an inode. You should note that no table in the kernel actually contains the filename once that file has been successfully opened.
There are pointers from user structures (U-areas) down to vnodes and inodes, but there are no pointers back up from vnodes to U-areas. You also find pointers (index numbers) from a directory entry to an inode, but not from the inode back out to the directory. Essentially, this is a many-to-one relationship at each stage — and there is no way to establish a single link back the other way. A commonly asked question is “How can I tell who has this file open?” Unfortunately, it’s not an easy question to answer. You can identify a vnode associated with the file, but then you need to search every file table entry to see if it points to that vnode. Once you have a list of file table entries that refer to that particular file, then you need to search every U-area in the system to find all the pointers to those file table entries. The fuser program in Solaris 2 will locate processes that are using certain files, but it does require super-user access to search the kernel tables. The same thing holds for finding filenames on disk. If you know the inode, you must search every directory entry to see if that name refers to the desired inode. A program called ncheck helps you do this for disk files on a single file system.
Managing memory has several levels of software as well. High-level functions keep track of memory associated with each process, but low-level hardware specific code must handle the mechanics of dealing with the memory management unit (MMU) and setting up the virtual addressing. These lower-level functions are known as the hat (Hardware Address Translation) layer.
Higher-level, more generic functions keep track of the ranges of memory addresses that are valid for a particular process address space and identify pages that are in use.
Each process has an address space (as) structure associated with it, defining the valid segments of the address space and what their attributes are. For user programs, each individual segment will eventually point to a vnode. This vnode is used to identify the file you will need to fetch data from when it can’t be found in memory or to store pages in when they have to be removed (paged out). The as structures also allow the system to identify a segmentation violation; a page fault results in a search down the list of valid segments to find the appropriate address range. If the address isn’t found, it’s a segmentation violation and a SEGV signal is sent to the process.
In addition, each page of physical memory that is not initially grabbed by the kernel at boot has a page structure associated with it, indicating how that page is being used. (Locked-down kernel pages will not have such a structure because they are dedicated to the kernel, and cannot be used for any other purpose). It’s not always possible to get from a page structure back to “who’s using it,” but sometimes you can get general information on the page state (“on the free list” versus “locked down” or in use). Each page structure does contain information about what file it belongs to and which page within that file the data came from.
These are some of the more commonly examined areas of the kernel. This is not because most errors occur here, but because these are often the starting points when looking for information on the state of the system and the processes (or threads) running on it.