We now change our focus to a different kind of data structures, so-called recursive data structures. Those are data structures defined in terms of themselves, and in C, the only way that you can implement them is through pointers. If you pick up a random algorithm book, more than half of the data structures described there will likely be recursive, so we obviously can only scratch the surface of this topic, but in this chapter and the following two, we will see some examples.
A recursive data structure is one that contains members of its own type. In this chapter, we look at linked lists, where a list is defined as follows:
1.
A list is empty.
2.
Or a list contains an element and a list (the “tail” of the list).
We will modify it slightly in Chapter 4, so a list has a reference to two other lists. In Chapter 12, we have a search tree where
1.
A tree is empty.
2.
Or it contains a value and two subtrees.
In both cases, item 2 is the recursive part.
We could try to implement the list definition like this (notice that this is not valid C and will not compile):
struct list; // forward decl.
struct empty_list {};
struct nonempty_list {
int value;
struct list tail;
};
struct list {
enum { EMPTY, NON_EMPTY } tag;
union {
struct empty_list empty;
struct nonempty_list non_empty;
} list;
};
It is a direct translation of the definition. The “or” in the definition is naturally defined as a union, and we have two cases: empty and non-empty. Here, the element that the non-empty list contains is an integer. We need a tag, the enum to tell them apart, and we put that into a list struct. It is not directly recursive, because a struct list doesn’t contain a struct list, but it is indirectly recursive as a struct list contains a struct nonempty_list, which in turn contains a struct list.
The definition is overly complicated because we do not need an empty struct for an empty list, so we could also define the list like this, where it is obviously recursive:
struct list {
bool is_empty;
int value;
struct list tail;
};
There is a flag to indicate whether the list is empty and the values we need if it isn’t.
The definition won’t work, and it can’t work, because to allocate memory for a struct list, we must allocate memory for the embedded struct list, so we would need infinite memory. The recursion has a base case, the empty list, that for any given instance means that we use finite memory, but we have to allocate infinite memory if we define the list this way.
Pointers ride to the rescue. Instead of embedding the tail of the list into the struct, we can use a pointer to a list. The pointer takes up finite memory, regardless of how large the tail is.
Pointers are both necessary and sufficient to implement recursive data structures in C. With recursive data structures such as a list, we (usually) never have to worry about allocation overflow and such, so they are simpler to implement in that regard. Working with recursive data structures is mostly a question of moving pointers around to achieve what we want. That, of course, opens up new issues instead. We need to be careful with setting pointers correctly. Making sure that memory is correctly freed is often also more problematic if objects are connected in complicated ways. So it is a new set of challenges we will now encounter. The data structures we see, linked lists and search trees, are among the simplest, but they illustrate well the kind of programming you need to work with recursive data structures.
Singly Linked Lists
The definition “a list is empty or has an element and a tail” is a so-called singly linked list, since the non-empty, recursive, part refers to a single tail. We can implement them like this:
struct link {
int value;
struct link *next;
};
I have named the structure link rather than list. A list will be a pointer to a sequence, or chain, of such links. The pointer is NULL if the list is empty; otherwise, it will point to a link where we can find the first value in the list and a pointer to the next link in the chain. So, the list definition, updated to the pointer/link representation, is
1.
An empty list represented as NULL.
2.
Or a pointer to a struct link that has a value and a pointer, next, to a list.
We can allocate a link using
struct link *new_link(int val, struct link *next)
{
struct link *link = malloc(sizeof *link);
if (!link) return 0;
link->value = val;
link->next = next;
return link;
}
We get the size of the memory to allocate from sizeof *link (when link points to a struct link, it is the size of the struct). The sizeof operator cannot give us overflow—if you can represent a struct at all, then you can malloc() size for it. So, there is no need to worry about overflow, but of course we can still get an allocation error, so malloc() can return NULL, in which case we have to give up. We return a NULL pointer in return, so the user can handle the error. Otherwise, we set the value and next members.
Ignoring allocation errors, we can construct a list of the numbers 1, 2, and 3 with
struct link *list =
new_link(1, new_link(2, new_link(3, 0)));
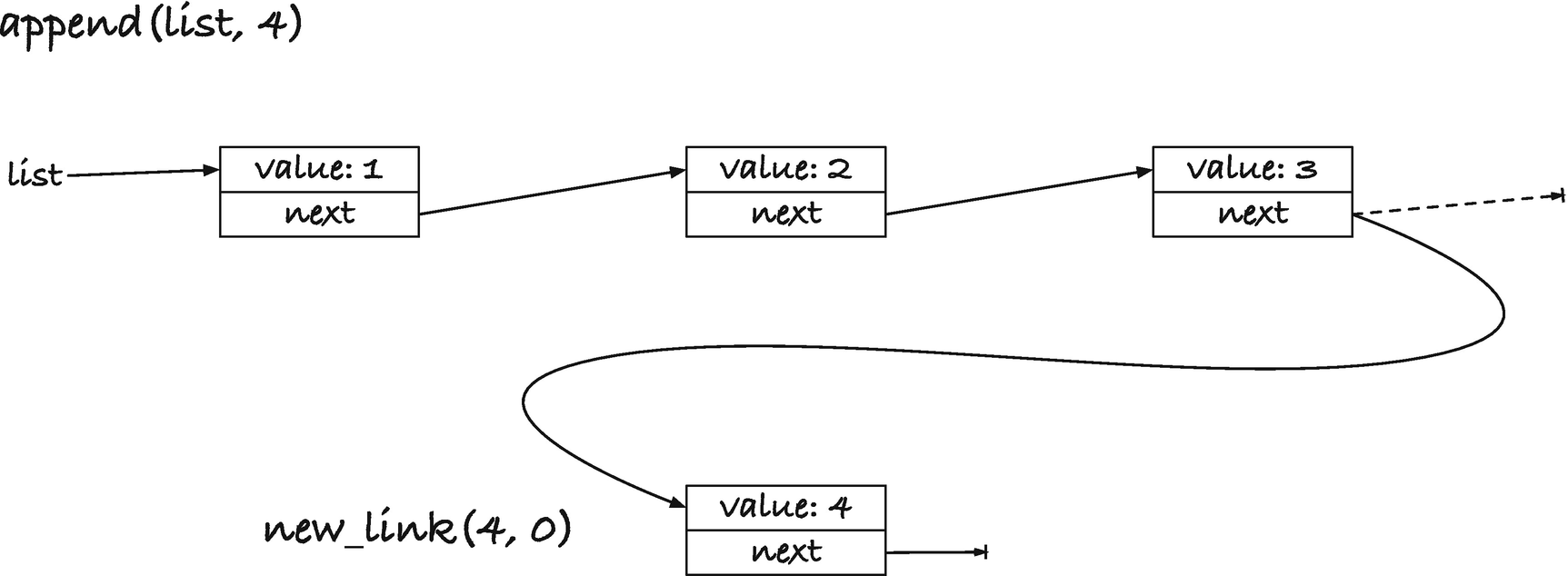
Since C evaluates the function arguments before it calls a function, we will first evaluate new_link(3, 0) which creates a link with value 3 and a NULL pointer for next; see the top-right corner of Figure 11-1. Here, I have drawn the NULL pointer as a pointer that ends in a short line. I will generally draw NULL pointers that way or, when figures would otherwise get too messy, leave them out entirely. When illustrating data structures, I will draw the individual structs as boxes and the pointers as arrows.
When we call new_link(2, - ), with "-" as the result of new_link(3, 0), we create a new link, the middle of Figure 11-1, where the value is 2, and the next pointer refers to the link from the first call. Then, when we call new_link(1, - ), bottom left of Figure 11-1, we create a link with value 1 where next points to the link from new_link(2, - ). You can think of new_link() as prepending a value to a list, but we can also make an explicit operation for that:
struct link *prepend(struct link *list, int val)
{
// new_link() returns 0 for allocation error,
// and we just propagate that.
return new_link(val, list);
}
With
struct link *list =
new_link(1, new_link(2, new_link(3, 0)));
we have a problem if any of the allocations fail. If the first allocation, new_link(3, 0), fails, we end up with a list of 1 and 2 instead of 1, 2, and 3. Not what we want, but not as bad as it could be. If one of the other new_link() calls fails, however, it is slightly worse. The failed call will look like an empty list, since the function returns NULL, but the input to the function call is an allocated link. If the function call fails, we lose access to that memory. Our program no longer has a pointer to it, and we have no way of getting one either, and so we cannot free() it. We should probably be more careful.
Figure 11-1
new_link(1, new_link(2, new_link(3, 0)));
We can write a function that frees an entire list. That means it must free all the links in the list’s chain, not just the first link (which we can easily free with free()). It could look like this:
void free_list(struct link *list)
{
while (list) {
// Remember next, we cannot get it
// after free(list)
struct link *next = list->next;
free(list);
list = next;
}
}
In the while-loop, list is a pointer that is either NULL (in which case we are done and leave the loop) or it points to a valid link. We need to free the link, but we also need to continue with its next pointer. If we free the link first, then we no longer have a valid pointer to the link, and thus we cannot safely get next, so we extract next first, then we free, and then we continue the loop.
Using a while (list) { ... } construction is typical for running through a list when implemented this way. We exploit that the NULL pointer evaluates to false, and we just need to remember to update list to list->next at the end of the loop body. For example, if you want to print the elements in an integer list, you can write
void print_list(struct link *list)
{
printf("[ ");
while (list) {
printf("%d ", list->value);
list = list->next;
}
printf("]
");
}
If you want to determine if a given integer is in a list, you can write
bool contains(struct link *list, int val)
{
while (list) {
if (list->value == val)
return true;
list = list->next;
}
return false;
}
It is the same pattern, and almost all loops through a list will follow this pattern.
Now that we can free a list, we can handle allocation errors when we attempt to construct one as well. If the construction fails, we can (for example) delete what we have so far and get an empty list instead of an incomplete one, without leaking memory. The following function constructs a list from an array, but if it gets an allocation error, it will clean up and return NULL:
struct link *make_list(int n, int array[n])
{
struct link *list = 0;
for (int i = n - 1; i >= 0; i--) {
struct link *link = new_link(array[i], list);
if (!link) { // Allocation error -- clean up
free_list(list);
return 0;
}
list = link;
}
return list;
}
It constructs the list from the array backward. Remember that new_link() prepends the new element to the list, so if we ran through the array from left to right, we would get a list with the elements in reverse. The variable list holds the head of the current list, and we update it to link at the end of the for-loop’s body, where we know that the allocation was successful.
Prepending to a list is a fast operation. We allocate a new struct link, and we set a value and a pointer, and that is all. But what about appending? That is both slower and turns out to be more complicated code:
struct link *append(struct link *list, int val)
{
if (!list) return new_link(val, 0);
struct link *last = list;
while (last->next) {
last = last->next;
}
last->next = new_link(val, 0);
// If we didn't set the last link, then we had
// an allocation error and should return 0.
// Otherwise we return the new list
if (!last->next) return 0;
else return list;
}
There is no avoiding having to find the last link in the chain if we want to append. With a singly linked list, we only have direct access to the first link in the chain (but we will fix that later in this chapter with doubly linked lists). So, we need to search through as many links as there are. We cannot use the while (list) pattern now, however, because then when we find the end of the list, list will be NULL, and we are one past the link we want. We must find the last link, which is the link where next is NULL. So, we must use while (list->next) to get that. In the code, I have named the variable last to indicate that it is the last link we are searching for. However, this won’t work if we start out with a NULL pointer. Then we would dereference a NULL pointer when we write last->next, and that is undefined behavior (and almost guaranteed to crash our program). We have to handle an empty list as a special case.
If we append to an empty list, we want a list with a single element, so if the input to append() is NULL, we return a new link (with 0 as its next pointer). Otherwise, we can search for the last link, and once we have it, we can allocate a new link and make the next pointer in the last link point to it; see Figure 11-2. In the figure, the original link is the one from Figure 11-1, with three links, 1, 2, and 3, and we append 4 to the list.
Figure 11-2
Appending to a singly linked list
That means that we create a new link for 4, with NULL for its next pointer, and then we change the old next pointer for link 3 (shown as a dashed pointer), so it is no longer NULL but points to the new link.
The allocation, however, can fail. We can still assign the result of the allocation to the last link’s next pointer—if the allocation fails, it then remains NULL—but we need to report the error. So if the allocation fails, we will return a NULL pointer. Otherwise, we return the original list. By returning the original list, we get the rule that append() either returns NULL, in case of an allocation failure, or returns the result of appending a value to a list—the list we get by appending the value to the input list. If the input is empty or contains values, we get the same result—the updated list.
It is not a pretty interface, I admit. There are several cases of what can happen. Errors give us NULL, which is fine. But with successful allocations, we modify the input if it isn’t NULL, and we return a completely new list if it is NULL. If we always wanted a new list, we could create one by copying the elements in the input. I won’t list the code here, but implementing it is a good exercise if you want to test yourself. That leads to a new headache if you don’t want to keep different copies of lists around because then you would have to remember to free the input when you do not want it any more. On the other hand, if you sometimes get a copy back, and sometimes not, what happens with code such as this:
struct link *list1 = make_list(n, array);
struct link *list2 = append(list1, val);
The make_list() function can return a NULL pointer, so list1 might be NULL. If it is, then list2 is a completely new list. If it isn’t, and append() didn’t fail, then list1 and list2 are pointers to the same list. So, should you free() both lists or just one of them? If they are the same, you can only free one. If they are different, you must free both. You can test if they are the same, of course. This isn’t the most difficult issue that will come up with memory management in this section—it gets worse, but we will alleviate it with a small change to the code in the next section. Still, it illustrates that we have to worry about assigning the result of an append to a new list.
The problem with freeing memory isn’t confined to append(). We have a similar problem with prepend(). Consider this code:
struct link *list1 = make_list(n, array);
struct link *list2 = prepend(list, -1);
// some code
free_list(list1);
free_list(list2);
If list1 is NULL, everything is fine. We prepend a link to it to get list2, and we can free both the NULL pointer in list1 and the link in list2. But if list1 has a chain of links, then list2 (if the prepend() succeeded) consists of one link and then a list that is shared with list1. When we free list1, we free all the links after the first in list2, so when we call free_list(list2), we can safely free the first link, but all the remaining are already gone. If we try to free() them, we get undefined behavior (and it won’t lead anywhere pleasant). Here, the problem isn’t that prepend() can sometimes give us a new list and sometimes an old list, but that it will provide us with a list where all but one link is shared with the old list. (Again, we will improve upon it in the next section.) I just want to show you the problems in a straightforward solution first, so you recognize that they exist, and will be careful in the future, and not conclude from a better solution that things are simple and that there is nothing to worry about. There most certainly is.
A more natural way to use prepend() (the wrapper we wrote around new_link()) and append() is like this:
list = append(list, 6);
list = prepend(list, 0);
We always update a list when we modify it, so we always assign the result back to the list. Unfortunately, this doesn’t work. The functions will give us NULL pointers if the allocation fails, and if we assign the result to the list, then we lose access to the allocated memory we already have. We leak. We always need to test the return values before we can update the existing pointer.
struct link *new_list = append(list, 6);
if (!list) {
perror("List error: ");
exit(1); // Just bail here
}
list = new_list;
new_list = prepend(list, 0);
if (!list) {
perror("List error: ");
exit(1); // Just bail here
}
list = new_list;
If you don’t mind losing the values you have already put into a list, for example, if you cannot handle allocation errors anyway and need to bail if you see them, you can simplify the user’s code by deleting the input of the operations:
struct link *prepend(struct link *list, int val)
{
struct link *new_list = new_link(val, list);
if (!new_list) free_list(list);
return new_list;
}
struct link *append(struct link *list, int val)
{
struct link *val_link = new_link(val, 0);
if (!val_link) {
free_list(list);
return 0;
}
if (!list) return val_link;
struct link *last = list;
while (last->next) {
last = last->next;
}
last->next = val_link;
return list;
}
In both functions, we allocate the new link early, and if it fails, we free the input and return NULL. Otherwise, we handle the operation without errors. With those operations, you can always assign a list operation back to the list itself and check if it is NULL to see if there were errors.
list = append(list, 6);
if (!list) goto error;
list = prepend(list, 0);
if (!list) goto error;
But let us leave allocation behind and look at a few operations where we do not add new elements to a list and thus can have no allocation failures. A simple operation is a concatenation. Given two lists, construct a new list that contains all the links from the two lists:
struct link *concatenate(struct link *x,
struct link *y)
{
if (!x) return y;
struct link *last = x;
while (last->next) {
last = last->next;
}
last->next = y;
return x;
}
We will need to find the last link in the first list to add the second list to it, so we have a special case if x is empty. If it is, we return y. The concatenation of an empty list with another is the links in the second list, so that will work. Otherwise, we find the last link, and by setting its next pointer to point to the first link in y, we have concatenated them.
Since we do not allocate new links, the function cannot fail. You still need to be careful with memory management, though. If you write
struct link *list3 = concatenate(list1, list2);
you now have three pointers to links, list1, list2, and list3. The list2 list is unchanged. It doesn’t matter if it was empty or not; we have not changed any of its links; we have just made the last link in list1 point to it. That is, we have made the last link in list1 point to it, iflist1wasn’t empty. If list1 was empty, then list3 is an alias for list2. If list1 was not empty, then list3 is an alias for (the modified) list1. This, of course, is an issue when we need to free the lists. If we free list2, then we have freed the tailing links in list2 (and list1 if it wasn’t empty). If we free list1, and it was empty to begin with, then we haven’t freed anything (because free(0) doesn’t do anything). But if list1 wasn’t empty, we have freed all three lists. We have freed list3 because it is an alias for the modified list1, and we have freed list2 because free_list() will free all the links in the list, and that includes those we got from list2. The only safe option is to free list3 and never list1 and list2 after appending them.
After appending two lists, you are best off by considering the input gone, and never look at it again. The first argument, unless empty, is modified, and the second argument is something you cannot safely free. If you do not want a concatenation operation that, in this way, destroys the input, you should program a version that makes a copy of the two lists instead. To test your understanding of linked lists, this is another good exercise that I recommend that you do.
If you have a concatenate() operation, then you can implement append() in terms of it:
struct link *append(struct link *list, int val)
{
return concatenate(list, new_link(val, 0));
}
It is a simple approach to implement the operation, but it is not a particularly good idea. The new_link() allocation can fail, and concatenate() won’t notice. So, we simply add allocation errors to the concatenate() function that is problematic enough as it is. It is not a bad idea to implement one operation using another in general, of course, but this particular choice is a poor one.
For a slightly more complex example, here is a function that reverses a list:
struct link *reverse(struct link *list)
{
if (!list) return 0;
struct link *next = list->next;
struct link *reversed = list;
reversed->next = 0;
while (next) {
struct link *next_next = next->next;
next->next = reversed;
reversed = next;
next = next_next;
}
return reversed;
}
Figure 11-3 shows the steps in the function, when run on a list with the values 1, 2, 3, and 4, in that order. The original list, with its four links, is shown in A). In B), we have the pointers we set up before the while-loop. We have a special case if the input list is empty, since we will need to be able to refer to the next link in the list, and there isn’t one if it is empty, so we handle that before we get to this point. If the list isn’t empty, we get a pointer, next, to the second link in the list, we make reversed point to the first link, and we set the first link’s next to NULL. The reversed pointer will hold the reversed list, and the reversed list must end with the first link in the input, which is what it does at this point. An invariant in the loop will be that reversed holds the reversed links of those we have processed so far. The first link’s next pointer is set to NULL because reversed should end after that link. The old pointer values are shown as dashed lines and the new and unchanged pointers as solid lines.
Now we start the while-loop in C), and in it we get hold of the next link’s next value. We need it to continue the loop later, where we have changed the link that next points to. We only need it for that, so we do not do anything with next_next yet. Now, we get hold of the link that next points at, however, and prepend it to reversed. Prepending it to reversed makes it the first element in the list of reversed links so far, which upholds the invariant. The way we prepend is through updating pointers. The next link’s next pointer should point to reversed (changing it here is the reason we needed next_next), and reversed should point to next so that the link is now the front of the reversed list.
Figure 11-3
Reversing a singly linked list
When we move to D), we first update next, so it points to the new next link. We do it at the end of the loop body, but in the figure I have listed it as the first statement in the code since it is a change we make between C) and D). We now do the same operation as we did to get to C). We prepend the current next link to reversed, remembering the next->next link in next_next. After that, reversed holds the values 3, 2, and 1 (if you follow the solid lines from what reversed points to, that should be clear). In E), we handle the last link. Here, next_next becomes NULL, so we terminate the while-loop when we are done, and reversed holds the reversed list.
Manipulating pointers like this is an integral part of working with recursive data structures. The example is the most complex we will see in this chapter, but it is not unusually so. If you need to manipulate a data structure in a nontrivial way, it helps to draw how you want to rearrange the pointers, like in the figure. It can get complicated, but drawings help immensely.
The last operation we will consider is deleting all links with a given value. The implementation can look like this:
struct link *delete_value(struct link *list,
int val)
{
if (!list) return 0;
if (list->value == val) {
struct link *next = list->next;
free(list);
return delete_value(next, val);
} else {
list->next = delete_value(list->next, val);
return list;
}
}
It is a recursive solution that says that deleting all occurrences of val in an empty list is the empty list (what else would it be?). If the first link’s value is val, then the result is what we get from deleting val from the rest of the list, and finally if the first value is not val, then the result is the current value followed by the result of deleting val from the rest of the list. Here, “followed by” is handled by assigning the result of the recursive call to the current link’s next pointer. In the case where we delete a link, we get its next pointer before we free(), since otherwise we would need to dereference to a deleted link, which is undefined behavior.
The function cannot fail; we do not attempt to allocate any new memory, but of course that doesn’t mean that we are entirely safe from memory management issues. If you write
delete_value(list, 42);
then is list now a valid pointer? That depends. If the first link in list had the value 42, we have deleted that link, but list still points to it. It points to a deallocated chunk of memory, so it is not valid. If list was empty, or didn’t have 42 in its first link, then list now holds the updated list where all occurrences of 42 are deleted.
With this function, however, the solution is easy. It is always safe to write this:
list = delete_value(list, 42);
because you get the updated list back. It might be the same address as the input, when we do not delete the first link, but if we do get a different address back, it is the list without 42, which is what we want.
To sum up, in this section, we have seen how we can implement a recursive data structure, a singly linked list, using a struct with a member that is a pointer to the same struct’s type. We have also seen how we can implement various operations on the type. Although the data structure is simple, we have learned that there are many potential pitfalls with memory management. We have to deal with allocation errors, but that is the least of our worries. The real problem is freeing memory correctly once allocated.
Correctly freeing memory is practically always a concern with recursive data structures. The problem is that they tend to create aliases for the same memory. Here, when we concatenate, for example, we end up with one reference to the tail part of another list. If we delete the list through the tail reference, then the chain of links from the front will eventually run into freed memory, and we cannot handle that. If we free from the front, then the original reference to the second list will point to freed memory.
While such aliasing is sometimes unavoidable, we can often alleviate it with a better interface to the operations, and we will do that in the next section. The interface we have implemented here is horrible when it comes to safe memory management, I admit. But I wanted to show you a lousy solution before I showed you a good one, so you would be aware of the problems and appreciate the solution.
The solution in the next chapter involves a (very) slight change to how we represent lists, and naturally given the topic of the book, it involves a pointer. Then practically all our problems go away. In Chapter 15, we will see another approach to dealing with aliasing between recursive data structures.
Adding a Level of Indirection
The leading cause of our troubles with memory management was that our operations returned new lists that potentially referred to links the input also referred to. We can change the implementation such that we modify the input instead of returning new lists. We won’t have to create new copies for each list that we return, but we will implement the operations such that we do not create more than one list with a pointer to the same link. When we prepend or append, we update the existing list; when we concatenate, we move the links from one list to another, so the second list no longer holds them. This isn’t possible with the representation we used so far for lists—a pointer to a link—for two reasons. We cannot modify the calling variables, so they no longer point to a function’s input, and we cannot modify an empty list, represented as a NULL pointer. The solution to both is one level of indirection: a list will no longer be a pointer to a link, but a pointer to a pointer to a link.
Adding a level of indirection in this way comes in handy in many applications. It is a case of calling functions by reference all over again. If we have to modify the variables the caller has, we need to get pointers to them, so we have to work with pointers to pointers to links. If we do that, then empty lists are no longer NULL pointers—that we cannot modify—but rather they point to a NULL pointer. We can modify such a list by changing the value it points to. We can use the same definition of links and the allocation function for them with the new lists:
struct link {
int value;
struct link *next;
};
struct link *new_link(int val, struct link *next)
{
struct link *link = malloc(sizeof *link);
if (!link) return 0;
link->value = val;
link->next = next;
return link;
}
I will rename the deallocation function to have one function for freeing link memory and another for lists. The function for freeing a chain of links is the same as before, but we call it free_links():
void free_links(struct link *list)
{
while (list) {
struct link *next = list->next;
free(list);
list = next;
}
}
Now we define a list to be a pointer to pointer to struct link and provide a macro to test if it represents an empty list—in which case it points to a pointer to NULL. For convenience, and to make the code more readable, we also provide a macro to get the links in a list:
typedef struct link ** list;
#define is_list_empty(x) (*(x) == 0)
#define list_links(x) *(x)
We can still heap-allocate lists. They have a different type, but we can heap-allocate any type we can get the size of (which we can, of course, with sizeof). If the allocation is successful, a good initial value for a list is the empty list, so the pointer it points to should be NULL:
list new_list(void)
{
list x = malloc(sizeof *x);
if (x) *x = 0;
return x;
}
When we free a list, we should free the links it points to and then the list itself:
void free_list(list x)
{
free_links(list_links(x));
free(x);
}
In many cases, the new representation doesn’t change anything. If we have a function that merely iterates through links, like print_list() or contains(), the only change is that we should get the links from the list using list_links():
void print_list(list x)
{
printf("[ ");
struct link *link = list_links(x);
while (link) {
printf("%d ", link->value);
link = link->next;
}
printf("]
");
}
bool contains(list x, int val)
{
struct link *links = list_links(x);
while (links) {
if (links->value == val)
return true;
links = links->next;
}
return false;
}
Where we see changes is when we create or modify lists, and in most cases, the code will still look the same; we just get some benefits practically for free. Take the make_list() function from earlier. It looks mostly like before, but by creating a list instead of a link pointer, we get some benefits.
list make_list(int n, int array[n])
{
list x = new_list();
if (!x) return 0;
for (int i = n - 1; i >= 0; i--) {
struct link *link =
new_link(array[i], list_links(x));
if (!link) { // Allocation error -- clean up
free_list(x);
return 0;
}
list_links(x) = link;
}
return x;
}
We allocate a list at the beginning, to get that over with. If the allocation fails, we will have to report an error, so we might as well do that up front. After that, we can use the list’s links as we used the link pointer in the previous version. It is initially the empty list, and as we update it, we add the links to the list. The code is exactly as before, except that we have to free the entire list if we get an allocation failure. We call free_list() to do that. We also called free_list() in the previous version, but that function only deleted links—we had no distinction between lists and links there—but you cannot use the free_links() function here.
If we successfully allocate all the links, we return the list, and here we have improved upon the interface of the previous function. With the make_list() from the last section, we could not distinguish between a failure and an empty list. We could, of course, check n before we called the function and that way determine if we expected to get an empty list back, but both empty lists and errors would give us NULL pointers. With our new representation, NULL is not an empty list and vice versa. An empty list is a pointer to a NULL pointer, and that is different from a NULL pointer. The new make_list() function gives us NULL if we have an error, and a list otherwise, and an empty list cannot be confused for NULL.
The prepend() function looks much like before as well. We create a link, and if that fails, we return an error. If not, the new link’s next pointer is the input list. Before, we returned the new link, and we could now have two aliases to the input string: a reference to it in the calling code and the next pointer in the new link. Now, we change the input list, so it points to the new link. Because of our new representation, we can modify the input list.
int prepend(list x, int val)
{
struct link *link =
new_link(val, list_links(x));
if (!link) return 0;
list_links(x) = link;
return 1;
}
For the append() and concatenate() functions, I will write a helper function that gives us the last link in a chain, when a list is not empty. It looks like the while-loops that did this in the previous section:
// Only call this with non-NULL links
struct link *last_link(struct link *x)
{
// When we start from x, there is always
// a link where we can get the next
struct link *prev = x;
while (prev->next) {
prev = prev->next;
}
return prev;
}
Now, to append, we have two cases. If the input list is empty, we do not have a last link, so we should put the new link we created as the (entire) link chain in the list. Otherwise, we need to get the last link in the link chain and put the new link as its next.
int append(list x, int val)
{
struct link *val_link = new_link(val, 0);
if (!val_link) return 0;
if (is_list_empty(x)) {
list_links(x) = val_link;
} else {
last_link(list_links(x))->next = val_link;
}
return 1;
}
Concatenate works similarly. We have two cases, one where x is empty, in which case we should set its link chain to the links in y, or it has links, in which case we should find the last and set the last link’s next to the links from y. In either case, we should remove the links from y so we do not have two lists containing the same links, so we do that before we return.
void concatenate(list x, list y)
{
if (is_list_empty(x)) {
list_links(x) = list_links(y);
} else {
last_link(list_links(x))->next =
list_links(y);
}
// remove alias to the old y links
*y = 0;
}
If you want a function that copies elements from one list to another, you can implement it using concatenate(). Free the existing links, then concatenate the links into the list (removing them from the second list in the process).
void copy_list(list x, list y)
{
free_links(list_links(x));
concatenate(x, y);
}
The two cases, empty and not, and the code that sets a link pointer, in append() and concatenate(), look very similar. If we take the append() case
if (is_list_empty(x)) {
list_links(x) = val_link;
} else {
last_link(list_links(x))->next = val_link;
we could imagine an operation last_next() that would give us
last_next(x) => *x
if x is empty, and
last_next(x) => last_link(*x)->next
otherwise. If we had such an operation, we could simplify the two cases into one:
last_next(x) = val_link;
Could we get such an operation? Not quite, but very close.
We need an address to write val_link into—either *x or the next value in the last link. If we write a function that gives us that:
struct link **last_next(struct link **x)
{
if (*x == 0) return x;
struct link *prev = *x;
while (prev->next) {
prev = prev->next;
}
return &prev->next;
}
we can write the two functions as
int append(list x, int val)
{
struct link *val_link = new_link(val, 0);
if (!val_link) return 0;
*last_next(x) = val_link;
return 1;
}
void concatenate(list x, list y)
{
*last_next(x) = list_links(y);
*y = 0;
}
Since last_next() gives us the address where we should write val_link or y’s links, we need to dereference before we assign, thus the *last_next(x) expression.
If you want to put lists on the stack, instead of allocating them on the heap with new_list() and then freeing them again with free_list(), you can do that as well. What you then need is memory to store the link pointer that a list contains. So, the easiest solution is to put a link pointer on the stack and work with its address. To make our code easier to read, we can give it a different name. We can define the type stack_list as a list we have allocated on the stack, like this:
typedef struct link * stack_list;
You cannot free such a list because you didn’t allocate it on the stack, but you should still free its links. A macro that frees the links, and set the pointer to NULL to make it an empty list after we free it, can look like this:
#define free_stack_list(x)
do { free_links(x); x = 0; } while(0)
To get a list from it, you take its address, but if you want a more informative operation, you can again use a macro:
#define stack_to_list(x) (&x)
You can use it as a list, for example, as the destination for a copy, with code like this:
x = make_list(n, array);
stack_list z = 0;
copy_list(stack_to_list(z), x);
free_list(x);
free_stack_list(z);
If you now want to test yourself, you can try to implement other operations. They work the same way as the first list implementations; you should just remember to update the input instead of returning new lists.
void delete_value(list x, int val)
{
// We can use the previous implementation, but update
// x...
}
void reverse(list x)
{
// We can use the previous implementation, but update
// x...
}
I will wait with implementing these two functions again until the next section, though. There, we try a slightly different representation, and I can cut off a line or two in the implementation because of that. It is a very minor change, however, so if you are up for it, you should give the functions a go now, before you read on.
Adding a Dummy Element
Adding a level of indirection solves many problems, but a related trick in my experience solves many more. If you have a data structure where you need to deal with special cases, such as empty lists represented by NULL pointers, more often than not, the special cases go away if you add one or more “dummy” elements to the structure. If you write code where you need to test that one or more pointers are NULL or not, quite often you can make the code simpler by assuring that they are not NULL. Add objects to the data structure that do not represent real data, but are there as dummies.
Singly linked lists are simple, so we won’t gain much from trying them here—we got most of the benefits in the previous section where we changed lists from pointers to links to pointers to pointers to links—we got rid of NULL as the representation of empty lists. So, the approach might underwhelm you in its usefulness. We gain a little more in the next chapter, but you will have to take my word for it when I say that for complex data structures, you can often gain a lot. We won’t have room for sufficiently interesting data structures in this book for me to show you. In any case, even if we only gain a little, you will see that with a simple dummy element at the beginning of each list, we gain all the benefits we got in the previous section, and in a few places, we write slightly simpler code.
Well, on with it. A list is once again a pointer to links, but we will never accept that a list is NULL, unless it is to return an error from a function. Instead, a list consists of one element that we do not consider part of the data it holds. It is a “head” or a “dummy” link. If you allocate a list, you allocate a link. If you put a list on the stack, you put a link on the stack (and then work with its address as the list). But the first link is not part of the real data.
So, a list is little more than a typedef, and we can define some macros to wrap calls to link allocation and deallocation:
typedef struct link * list;
#define new_list() new_link(0, 0)
#define free_list(x) free_links(x)
The make_list() function looks much like in the previous section. We allocate a list, and if that went well, we allocate the links. The only difference is that we write x->next instead of list_links(x) in the code.
list make_list(int n, int array[n])
{
list x = new_list();
if (!x) return 0;
for (int i = n - 1; i >= 0; i--) {
struct link *link = new_link(array[i], x->next);
if (!link) { // Allocation error -- clean up
free_list(x);
return 0;
}
x->next = link;
}
return x;
}
If you are not modifying the list, you also treat it as before, but when you iterate through the links, you start at x->next. The first link is not real data.
void print_list(list x)
{
printf("[ ");
struct link *link = x->next;
while (link) {
printf("%d ", link->value);
link = link->next;
}
printf("]
");
}
bool contains(list x, int val)
{
struct link *link = x->next;
while (link) {
if (link->value == val)
return true;
link = link->next;
}
return false;
}
There is nothing surprising in prepend() either:
int prepend(list x, int val)
{
struct link *link = new_link(val, x->next);
if (!link) return 0;
x->next = link;
return 1;
}
but with append() and concatenate(), we get slightly more readable code. At least, more readable if you found
*last_next(x) = val_link;
hard to read. Because a list always has at least one link, there is always a last link. We do not need the last_next() trick to get a link to append to. We can find the last link, it always exists, and then we can write to its next member.
struct link *last_link(list x)
{
struct link *prev = x;
while (prev->next) {
prev = prev->next;
}
return prev;
}
int append(list x, int val)
{
struct link *link = new_link(val, 0);
if (!link) return 0;
last_link(x)->next = link;
return 1;
}
void concatenate(list x, list y)
{
last_link(x)->next = y->next;
y->next = 0;
}
Here, we didn’t gain much over the second list representation, but I find this code more readable, and it is a step up compared to the first implementation we made. If we had gone directly to the dummy link solution, you would probably agree that we gained something going here.
With delete_value(), we gain a little as well. Because the input list always has a link, we can do this: imagine that we split the list in two, the links up to a link we will call front where all the elements we need to delete are gone and then the rest, from front->next, where we still need to delete. We can start by setting front to the list. The value in the dummy element doesn’t count, so everything up to and including front doesn’t have the value. Now we repeatedly look at front->next. If front->next has the value, we remove it (we set front->next to front->next->next and free()). Otherwise, we can move front to front->next because that link does not have the value, and then we can continue from that link. This idea can be implemented like this:
void delete_value(list x, int val)
{
struct link *front = x, *next = 0;
while (front) {
while ( (next = front->next) &&
next->value == val ) {
front->next = next->next;
free(next);
}
front = next;
}
}
We could also have used this algorithm without the dummy element (I left implementing delete_value() as an exercise in the previous section, and you can try implementing this solution). Without the dummy element, however, it is harder to set the first front pointer.
In reverse(), we avoid a special case when the list is empty. It is not a terrible burden to handle an empty list, of course, since the reverse of an empty list is just the empty list, but it goes away. We will always have a next pointer when we begin. We can use the list itself for the reversed pointer we needed earlier. Once we have a pointer to the list’s next link, we don’t need to remember it in the input any longer, which means that we can use the input’s next for reversed, and when we are done with reversing, we already have the reversed links stored there.
void reverse(list x)
{
struct link *next = x->next;
x->next = 0;
while (next) {
struct link *next_next = next->next;
next->next = x->next;
x->next = next;
next = next_next;
}
}
We started out with simple code for a linked list, but with various issues related to memory management. We resolved those issues by adding a level of indirection, so lists became more than pointers to links. That first step helped us remove aliases between links that could potentially be disastrous when freeing memory. If we are careful with how we write functions, we can avoid them, as long as we can modify our input lists. Adding a dummy element to the beginning of each list didn’t add much on top of that, yet still I will suggest that you always reach for a dummy element when you need a level of indirection. You get the indirection for free—you already have all the code needed to work with real elements, and you can reuse it for dummy elements—and you usually avoid a few special cases for free when you take that approach.
We got rid of memory management issues by removing the chance of aliases through different references, but this is, of course, only an option when we do not need different variables to share data. If you cannot avoid that multiple variables or structures refer to the same allocated data, you must have a strategy for how to delete it. The right strategy can be highly application dependent, but we will see some general approaches later in the book. For now, as long as our functions do not leak memory and leave the input and output in a consistent state that the user can rely on, we will be satisfied.
Doubly Linked Lists
With singly linked lists, we have immediate access to the first link in the chain, and we have to search through the list to access others. If we need to delete a link, we need to have a pointer to the link that goes before it and the link that goes after it, so we can connect those. We have access to the next link through the next pointer, but the previous one is something we must keep track of as we search through the list, or we must find it by searching from the beginning. Inserting a new link y after another, x, is easy. We simply need to point y->next = x->next and then x->next = y. But inserting ybeforex requires that we have access to the link before x (so we can insert after that link), which again requires that we have a pointer to it from whatever algorithm we are implementing, or that we search for it. With doubly linked lists, we keep track of both the link before and after any given link. We have two pointers, prev for the previous link and next for the next link.
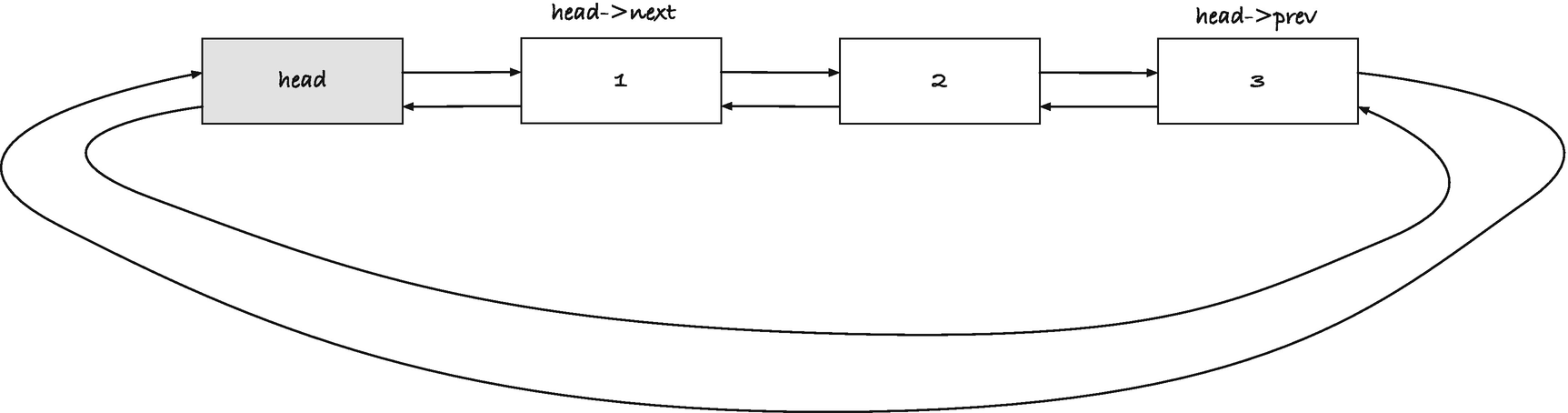
Figure 11-4
A doubly linked list with elements 1, 2, and 3 and dummy links at the beginning and end
struct link {
int value;
struct link *prev;
struct link *next;
};
struct link *new_link(int val,
struct link *prev,
struct link *next)
{
struct link *link = malloc(sizeof *link);
if (!link) return 0;
link->value = val;
link->prev = prev;
link->next = next;
return link;
}
With two pointers, we have more special cases to worry about. Either or both of the pointers can be NULL, so a straightforward implementation leaves a lot of case checking. However, as I hinted in the previous section, adding dummy elements can greatly reduce the need for special cases. If we add a dummy link at the beginning and end of each list (see Figure 11-4), all the real links always have non-NULL prev and next pointers, and that makes it very easy to manipulate lists.
As long as a link pointer isn’t NULL, its prev and next pointers aren’t NULL either. That means that we can access the data in neighboring links, and as long as those aren’t dummy links, their prev and next pointers aren’t NULL either.
Figure 11-5
A circular list with a dummy head
This isn’t perfect, though. We don’t have to check if a link’s prev and next are NULL, if it is a real and not a dummy link, but there are cases where we need a link’s neighbors to also have non-NULL prev and next links. That means that we have to check if the neighbors are dummies, which leaves almost as many special cases to check for. Our code will get simpler if we can ensure that even the dummy links have neighbors, but what should we make them point to?
A simple solution is the so-called circular list. We will use one dummy link per list, called head. Its next is the first real link in the list, and its prev is the last real link in the list. If the list is empty, the head’s two pointers point to the head itself; see Figure 11-5. With this representation, all links have neighbors.
A circular list doesn’t have to have a dummy element as its head, and some algorithms and data structures depend on circular lists where any link can function as the head (so we can move the head to adapt to data we process). For our purposes, however, having a dummy is easier, as it gives us a representation of empty lists that isn’t a NULL pointer.
To give ourselves informative names, we can typedef a list head to be a link.
typedef struct link list_head;
We can declare a head on the stack if we want to and use this macro to initialize it to an empty list:
#define init_list_head(x)
(list_head){ .prev = &(x), .next = &(x) }
You can use it as
list_head head = init_list_head(head);
to create a head for an empty list.
The operations we implement will take heads by reference, so we define a list to be a pointer to a head (which is the same as a pointer to a link, of course).
typedef list_head *list;
To heap-allocate a list, we must allocate a link (which we can do with the new_link() function from earlier). The head is a dummy, so it doesn’t matter what value we put in it. We cannot set the pointers in the call to new_link() because we do not have the address for the head before we allocate it, but we can use init_list_head():
list new_list(void)
{
struct link *head = new_link(0, 0, 0);
if (!head) return 0;
*head = init_list_head(*head);
return head;
}
To use a head as a list, get its address. To get the first or last “real” element in a list, we can use these macros:
#define front(x) (x)->next
#define last(x) (x)->prev
They will give you the head back if the list is empty, so you can test for an empty list with
#define is_empty(x) ((x) == front(x))
If you want to set a head to an empty list, you need to reinitialize it:
#define clear_head(head)
do { (head) = init_list_head(head); } while(0)
If you have a list, so a pointer to a head, you can do
#define clear_list(x) clear_head(*(x))
This doesn’t free the links it holds, however, so we need code to do that first, if we need it.
To free the links, we must iterate through them. In the last section, we would iterate as long as the current link isn’t NULL, but now links will never be NULL when we follow a chain of next pointers. Instead, we must iterate until we get back to the head. Other than that, there is nothing new. The free_links() function deletes all the (real) links in a list:
void free_links(list_head *head)
{
struct link *link = front(head);
while (link != head) {
struct link *next = link->next;
free(link);
link = next;
}
clear_list(head);
}
It also clears the head, that is, sets it to an empty list, so we don’t risk accessing deallocated links after we have freed them.
The free_list() frees a heap-allocated list as well.
#define free_list(x)
do { free_links(x); free(x); x = 0; } while(0)
This is a macro, so we can set the list pointer to NULL after we have freed it. That can make the code safer at times, but of course only if x is the only reference to the list. But it should be, if we free it, so greater problems are present if that isn’t the case.
Use free_links() if you have a stack-allocated head, but free_list() if you have allocated the list on the heap.
Link Operations
A simple operation on links is to connect them. If we have links x and y, and we want y to follow x, then we can connect them by setting x’s next to y and y’s prev to x.
static inline
void connect(struct link *x, struct link *y)
{
x->next = y;
y->prev = x;
}
Figure 11-6
Connecting two links
When we connect x and y, we move the next pointer in x to y, and we lose access to the links that followed x; see Figure 11-6. Likewise, we lose access to the links preceding y when we point y->prev to x. The link before y still points to y with its next, and the link after x still points to x with its prev, but unless we have access to those links from somewhere else, they are lost to us (which means we would leak memory if we didn’t handle this correctly). As the figure also illustrates, it is quite possible to put links in an inconsistent state, where for a link x, x->prev->next != x or x->next->prev != x. This is something we should avoid doing in our code, but intermediate states in an update often look like this.
I have written the operation as an inline function because it is short and best inlined. Since C99, the language has had the inline keyword, which works as a compiler hint to suggest that the function should be inlined if that gets us more efficient code.
inline
void connect(struct link *x, struct link *y)
{
x->next = y;
y->prev = x;
}
I would like to use inline, but it requires extra work. It is not enough to define an inline function; you must also provide a linker symbol for it, if the compiler decides not to inline. If you do not provide that, you will likely get a linker error. You can specify that you want to generate an external linkage function from the definition, of course.
extern inline
void connect(struct link *x, struct link *y)
{
x->next = y;
y->prev = x;
}
But now you get a copy of that in any compilation unit that includes the definition, including the linkage symbol, and that will certainly give you linker errors!
Instead, and this is the standard solution, you can declare an inline function static, as I have done. If so, if the function isn’t inlined, the compiler will generate a function, but it will only be visible from within the compilation unit, so you don’t get linker errors. However, you do get duplicated code for everything that the compiler doesn’t inline. It isn’t perfect, and you can set up your compilation environment to do better, but it suffices for us here.
If we have a link x and want to make sure that its prev and next links point back to itself, we can use this operation:
static inline
void connect_neighbours(struct link *x)
{
x->next->prev = x;
x->prev->next = (x);
}
It ensures that x at least is in a consistent state with respect to its neighbors.
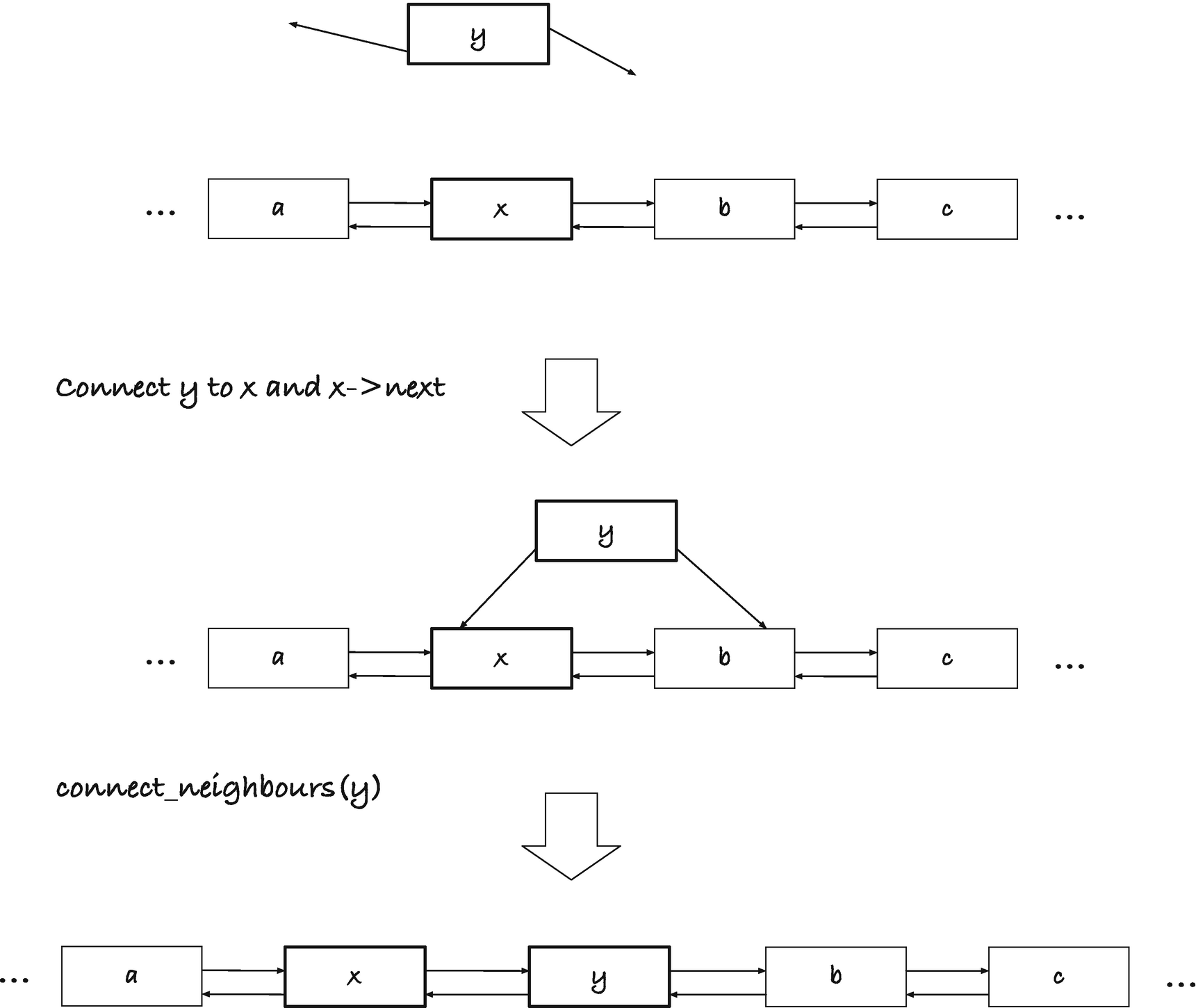
Now say we want to insert a link, y, after another, x; see Figure 11-7. We can do this by connecting y’s prev pointer to x and its next pointer to x->next, so it has the right neighbors, and then we connect the neighbors, so x->next will point to y and y->next will point back to y. In code, the operation can look like this:
static inline
void link_after(struct link *x, struct link *y)
{
y->prev = x;
y->next = x->next;
connect_neighbours(y);
}
This code exploits that x has a next link that we can update. If next or prev pointers could be NULL, we would have to handle special cases. Because we have a dummy head, this is not an issue.
If you want to insert a link before another instead of after, we can do this:
#define link_before(x, y)
link_after((x)->prev, y)
This assumes that x has a prev link, which is a valid link, but this is also guaranteed by the dummy link. Of course, both x and x->prev might be the dummy, but the code doesn’t look at the value we store in the links, so it doesn’t care. A link is a link, as far as this code is concerned.
Figure 11-7
Insert link y after link x
`
If we want to insert values, which we obviously do, we need to allocate links to hold them. There are cases where we would want to leave allocation to the caller; see, for example, Chapter 14. Then they can deal with allocation errors, and our code doesn’t have to worry about it. But for now, we can provide a function that inserts a value before a link:
int insert_val_after(struct link *after, int val)
{
struct link *link =
new_link(val, after, after->next);
if (!link) return 0;
connect_neighbours(link);
return 1;
}
The time we could gain from inlining is small compared to the overhead there is in allocating memory, so there would be little gain in inlining here.
Except for allocating a new link, there isn’t much new here. We use connect_neighbours() instead of insert_after() because we have already set the new link’s neighbors in the allocation, but we could just as easily have called insert_after().
If you want to insert a value before a link, we can use a macro:
#define insert_val_before(before, val)
insert_val_after((before)->prev, val)
This is just a wrapper around insert_val_after() where we get the prev link from before. There is no need for a function here.
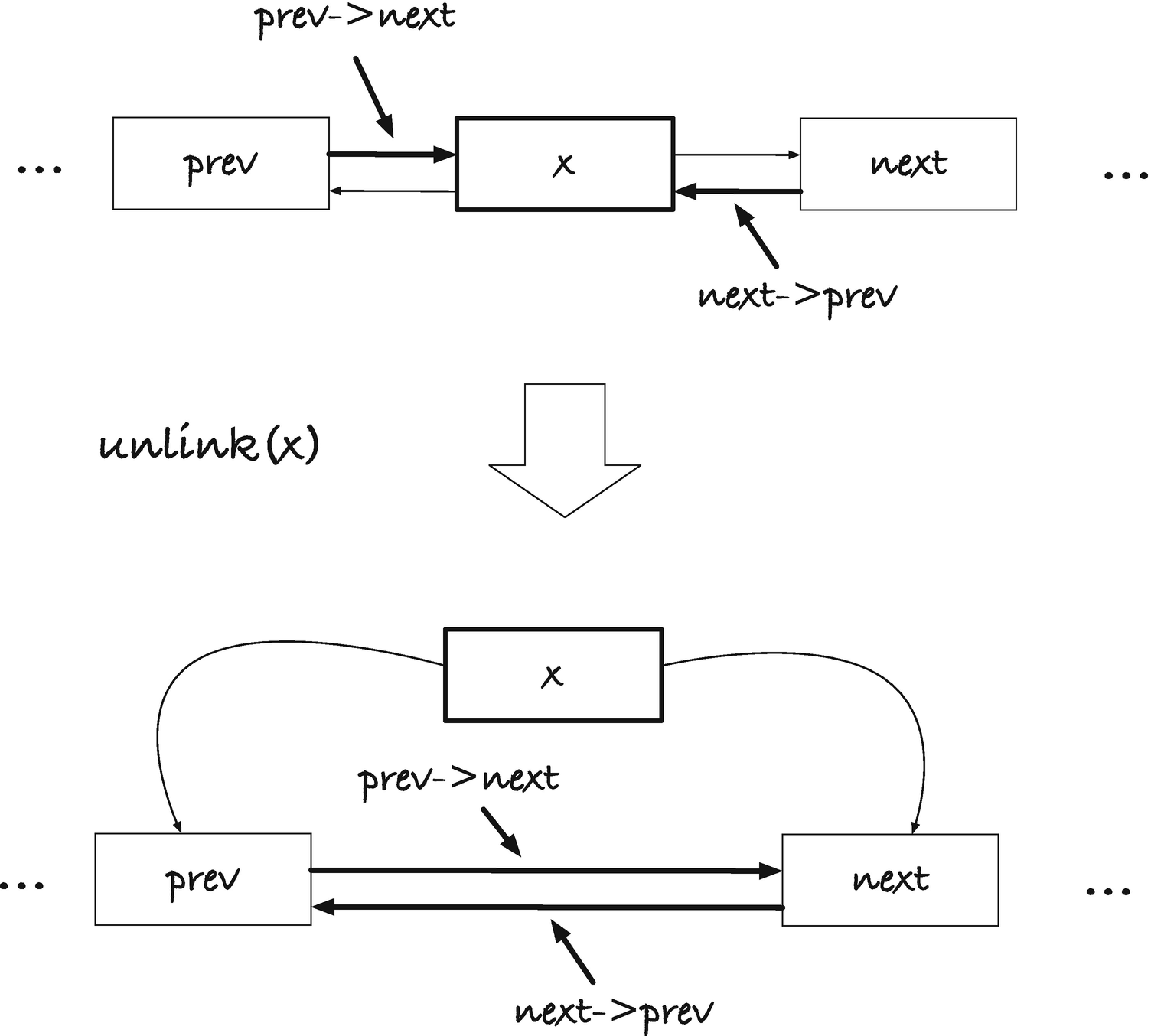
If we want to remove a link from a list, we should make its previous and next links point past it; the previous link’s next should point to the link’s next, and the next link’s prev should point to the link’s prev (see Figure 11-8).
The operation is fairly straightforward to implement:
static inline
void unlink(struct link *x)
{
x->next->prev = x->prev;
x->prev->next = x->next;
}
We will leave the link’s pointers alone, so they still point to the original previous and next link. After we have unlinked it, it might still be useful to have access to them, even though the link is no longer part of the list.
Figure 11-8
Unlinking x
If you want to delete a link, you should free it as well as unlink it. The following function does that:
static inline
void delete_link(struct link *x)
{
unlink(x); free(x);
}
List Operations
Given a list, we might want to prepend and append to it. We have two versions of both operations: the first where we already have a link we wish to prepend or append, in which case we can use the link_after() or link_before() operations, and the second where we have a value and need to allocate a link, where we can use the insert_val_after() and insert_val_before() operations. Turning the existing operations into prepend/append operations is only a question of giving them new names:
#define prepend_link link_after
#define append_link link_before
#define prepend insert_val_after
#define append insert_val_before
We didn’t have to define these macros, of course. We could equally well have used the existing. But giving them alternative names can make the intent of our code more explicit. A drawback is, of course, that compiler errors might get harder to read, as the compiler will have to explain the expansion of macros when it encounters an error. So it is a question of taste which you prefer.
The make_list() function looks much the same, but it is a little simpler than the singly linked list case. With a circular list, we have immediate access to the last element in the list, so append() is a fast operation. That means that we do not need to run through the array from the back to the front to prepend. We can run through the array from the beginning and forward and append.
list make_list(int n, int array[n])
{
list x = new_list();
if (!x) return 0;
for (int i = 0; i < n; i++) {
if (!append(x, array[i])) {
free_list(x);
return 0;
}
}
return x;
}
We allocate the head as the first operation (and report an error if we couldn’t). After that, we append the array elements one by one. If there is an allocation error in the append() operation, we free the list and return NULL. Otherwise, we have successfully created the list and can return it.
When we have to run through all the links in a list, things are a little different. We start with the head of the list, as we did when we introduced a dummy for the singly linked lists. That doesn’t change. We can get the first link we need to look at using the front() macro that gives us the next link in the head. But where we earlier continued iterating through next pointers until we hit NULL, we need a different termination condition. With a circular list, we never reach NULL. When we are done with all the links, we will have returned to the head of the list. That is what we must compare each link against.
The print_list() function looks like this:
void print_list(list x)
{
printf("[ ");
struct link *link = front(x);
while (link != x) {
printf("%d ", link->value);
link = link->next;
}
printf("]
");
}
We get the first link with front(x). If the list is empty, we will get the head back, so it is possible that link == x. When that happens, we never enter the loop, which is what we want. If there are no elements in the list, then we shouldn’t print any. If link is not x, we iterate. We print the current value and move link to the next link. Once link progresses all the way back to the head, the loop condition link != x is false, and we terminate.
The rule is this: you start with front(x), you iterate as long as link != x, and in each iteration you increment link = link->next. As a for-loop, where the three steps are made explicit, the function would look like this:
void print_list(list x)
{
printf("[ ");
for (struct link *link = front(x);
link != x;
link = link->next) {
printf("%d ", link->value);
}
printf("]
");
}
The contains() function, which also has to iterate through the list, follows the same pattern:
bool contains(list x, int val)
{
for (struct link *link = front(x);
link != x;
link = link->next) {
if (link->value == val)
return true;
}
return false;
}
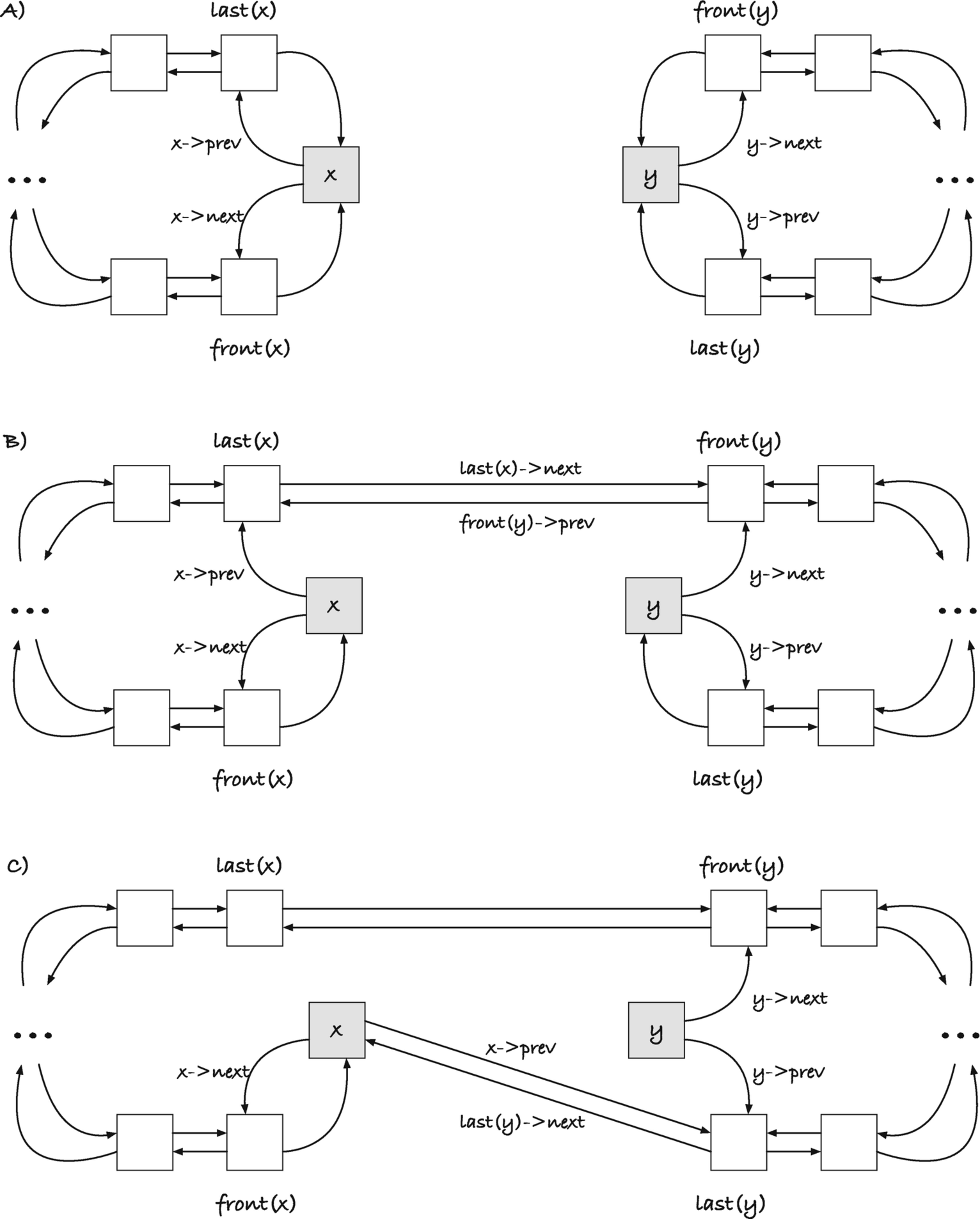
To concatenate two lists, x and y, putting the result in x, we must connect the last element in x, last(x), to the first in y, front(y), and then connect the last link in y, last(y), to x; see Figure 11-9. In A), we have the two lists before the operations. When we connect last(x) to front(y), we go to B). Both x and y are in inconsistent states because their last(x) and front(y) links do not point back to them, but that is fine. We don’t need consistency yet. We connect last(y) to x, C), and now x->prev points to last(y), and if we follow the links from x along the circle, we go through all the links from x and y and end up in x when we have seen them all.
This leaves x with all the links and y in an inconsistent state—it points to links that do not point back to it—so we should clear it when we are done to avoid future problems. In code, it looks like this:
void concatenate(list x, list y)
{
connect(last(x), front(y));
connect(last(y), x);
clear_list(y);
}
Getting the last elements is faster with circular lists than with the singly linked lists we had in the previous section. There, getting the last link in a list took time proportional to the number of links in the list, but here it takes constant time. Concatenate is thus a constant time operation with our current lists, whereas it was a linear time operation before.
Figure 11-9
Concatenating x and y, general case
We don’t delete y, but we empty it. The caller must free it if they no longer need it. We could free it here that just changes the API. It is a design choice.
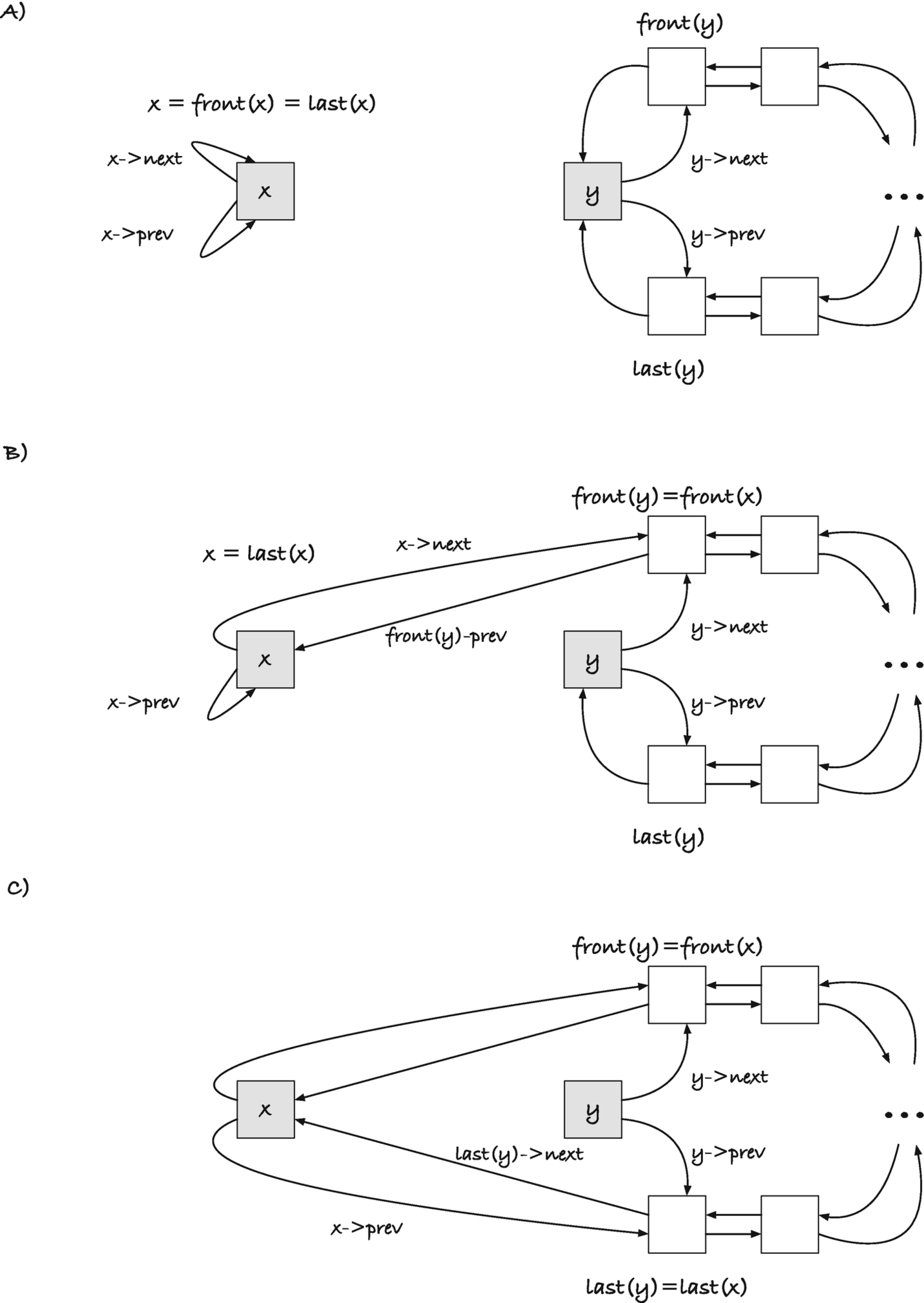
This process looks like something that would have special cases if x, y, or both are empty, since then there is overlap between the various front(), back(), and head links. By luck more than design, this isn’t the case. The same procedure works when one or both lists are empty. Consider the case where x is empty, and thus x = back(x); see Figure 11-10. When we connect back(x) with front(y), we move x->prev so it points at front(y), and front(y)->prev points to x. This doesn’t change back(y), and when we connect back(y) to x, x->prev becomes back(y), and once again we have a circle of all the links starting and ending in x (and an inconsistent y that we clear at the end).
If y is empty (see Figure 11-11), y = front(y) = last(y). We connect last(x) to front(y) = y and get the case in B), where last(x)->next points to y and y->prev points to last(x), which makes last(x)=last(y) (remember that last(y) is the link that y->prev points to). Then, when we connect last(y) to x in C), we point last(x) back to x (x->prev to last(y) which it was pointing to already). The y list is broken, which is always the case after concatenation, but x is back in its original state, which is what we want when we concatenate it with an empty list.
If both lists are empty, Figure 11-12 A), connecting last(x) to front(y) means pointing x->next to y and y->prev to x, B). That makes back(y) = x, so when we connect back(y) to x, we set x->next back to x, and we are back where we started with respect to x. We once again broke y, but who cares about y?
Cases where either list consists of one element do not need special treatment either. If front(x)=last(x) or front(y)=last(y), we only touch one of their pointers in the connect() operations, and the concatenation works as if they were different links.
Deleting all occurrences of a value is similar to the singly linked case, except that we do not need to keep track of the previous link, so we can remove one. Each link already has a pointer to the previous link, and unlinking and deleting individual links is easy. You still need to get the current link’s next pointer before you delete it, though, because once you have freed a link, you cannot get their content.
Figure 11-10
Concatenating x and y when x is empty
1
Figure 11-11
Concatenating x and y when y is empty
2
Figure 11-12
Concatenating x and y when both lists are empty
void delete_value(list x, int val)
{
struct link *link = front(x);
while (link != x) {
struct link *next = link->next;
if (link->value == val)
delete_link(link);
link = next;
}
}
Reversal is easier than for singly linked lists. You have direct access to both the beginning and end of circular doubly linked lists, so you can reverse them the way we did with arrays in Chapter 6. Start with pointers to both ends, swap the values, then move the pointers forward/backward, and stop when they meet.
#define swap_int(x,y)
do { int tmp = (x); (x) = (y); (y) = tmp; } while(0)
void reverse(list x)
{
struct link *left = front(x);
struct link *right = last(x);
while (left != right) {
swap_int(left->value, right->value);
left = left->next; right = right->prev;
}
}
This, of course, will only be fast if the values we store in links are small. Here, we have integers, and they are quick to swap, but nothing prevents us from implementing lists where each link holds massive amounts of data. For that matter, we might be writing generic code that doesn’t know what the links hold; see Chapter 14. Luckily, there is an even simpler way to reverse a doubly linked list that is just as fast. We can swap the pointers in each link.
#define swap_p(x,y)
do { struct link *tmp = (x); (x) = (y); (y) = tmp; } while(0)
void reverse(list x)
{
struct link *p = x;
do {
swap_p(p->prev, p->next);
p = p->prev;
} while (p != x);
}
When we swap the prev and next pointers in a link, we leave the list in an inconsistent state. The link’s neighbors do not point back at it. However, if we swap all the way around the list, we will have a consistent, reversed, list. Consider the example in Figure 11-13 where we reverse a list containing elements 1, 2, and 3. The next pointers are drawn as solid lines and the prev pointers as dashed lines. To read the links in order, you follow the solid arrows from front(x) and back to x. In A), before we reverse the list, you get 1, 2, and 3. Now, when reversing, we start by pointing p at x, A), and flip its prev/next to go to B). The flipped pointers are shown as thicker lines. To get to the next link, we cannot use p->next—it would take us to last(x) and not front(x)—but we can take p->prev to get to its previous next. It will take us to the link containing 1, and we are in the state in B). At this point, the list is not in a consistent state. From p, we can follow next pointers around the links we haven’t processed until we get to x, but the link x doesn’t match its neighbors. We will fix that as we process the links.
Figure 11-13
Reversing a list by swapping next/prev pointers
Once again, we switch p->next and p->prev, and we end up in C). We still have the unprocessed links in front of us—good because we need to process them—and the links x and 1 are correctly wired; 1 is last(x), which it should be in the reversed list, and 1’s next pointer connects it to x. The links between 1 and 2 are not wired correctly, but when we move on to D, they will be. Generally, from p->prev, we can follow next pointers back to x, and get the processed links, in reverse order from where we started. The links following p, i.e., the links we visit if we follow next pointers starting at p, gives us the unprocessed links in the original order. As we move on, and in the example that is the last step, we flip the pointers in link 3 to go to E), and now we have a consistent list. For all links q, q == q->prev->next and q == q->next->prev, and from x, we can run around the circle to get all the links. But since all the links were swapped, we run around the circle counterclockwise, and we get the links in reversed order.
If we start with an empty list, we still swap x’s prev and next pointers, since we use a do-while loop rather than the usual while loop. We use the do-while because we do not want to terminate at the first link, which will be x. This, however, is not a problem. If x is empty, then swapping prev and next gives us the original (empty) list back.
What if you wanted to make a copy of a list? You cannot simply point a list’s head at the links of another list because then we would not have a consistent list. If we want two lists with the same elements, they need to have separate links, which means we need to copy all the values from one list into new links for the copy. Luckily, this is fairly straightforward. We can iterate through the first list, get the values, and append them to the second.
list copy_list(list x)
{
list res = new_list();
if (!res) return 0;
for (struct link *p = front(x);
p != x; p = p->next) {
if (!append(res, p->value)) {
free_list(res);
return 0;
}
}
return res;
}
The only complication with copying is that we need to deal with allocation errors. That means that we need to check if the head is successfully allocated, and we need to check the status of each append(). If we see an error from append(), we must free the list we have already created before we return NULL, so we do not leak memory.
What about comparing two lists to determine if they are equal, that is, that they hold the same values and in the same order? Here, we need a loop that goes through the links in both lists. If we iterate through the links, pair by pair, we can determine that the lists are not equal if we see different values. If not, we will terminate when we reach the end of at least one of the lists. Should we reach the end of both lists at the same time, then the lists were equal, but if we only reached the end of one of the lists, they were clearly not—one is longer than the other, after all.
bool equal(list x, list y)
{
struct link *p = front(x);
struct link *q = front(y);
while ( (p != x) && (q != y) ) {
if (p->value != q->value)
return false;
p = p->next; q = q->next;
}
return (p == x) && (q == y);
}
The test (p == x) && (q == y) is true if we reached the end of both x and y, and false otherwise.
Sorting Doubly Linked Lists
There is nothing particularly special about sorting doubly linked lists, so this section is not here to teach you anything new about sorting. But sorting linked lists involves moving pointers around, and so it serves as an excellent excuse to learn more about that. With linked lists, we cannot access elements in constant time, as we can in an array, so we cannot use every algorithm for sorting, but many of the classical algorithms still work, and we will see some of those.
Incidentally, if you want to check if the elements in a list are sorted, you can do it like this:
bool is_sorted(list x)
{
struct link *p = front(x);
while (p->next != x) {
if (p->value > p->next->value)
return false;
p = p->next;
}
return true;
}
We iterate until p->next hits x. Usually, we stop when p reaches back to x, but in this case, we want to compare two consecutive links, and we do not want to compare a value with the dummy head, so we stop one link early. In the iteration, we check if the current value is larger than the next. If it is, those two links at least are out of order, and the list isn’t sorted. If all links are smaller or equal to the next, then the list is sorted.
Selection Sort
Selection sort works as follows: you scan through the list, collecting a sorted list behind you, and in each iteration, you identify a minimal value among the remaining links and append it to the sorted list. If you always take a minimal value, and your sorted list starts out empty, then you end up with a sorted list when you are done. If you implement selection sort on an array, you move the minimal element by swapping with the next unsorted element, but with linked lists, we can move links without swapping. We can unlink the minimal element from the unsorted list and append it to the end of the sorted list by setting the prev and next pointers correctly.
The main function looks like this, and I will explain the two helper functions, get_smallest() and move_links(), as follows:
void selection_sort(list x)
{
list_head sorted = init_list_head(sorted);
while (!is_empty(x)) {
struct link *next = get_smallest(x);
unlink(next);
append_link(&sorted, next);
}
move_links(x, &sorted);
}
We use a stack-allocated list head for the sorted list. There is no need to heap-allocate this list since we only use it while we sort. Then we iteratively identify a minimal element, unlink it from the existing list (making x one element shorter), and append it to sorted. Since we remove a link from x in each iteration, it will eventually be empty, at which point all the links are in sorted. At that point, the while-loop terminates. All that remains is to move the links back to x, so it now contains the sorted links.
Finding a minimal link involves searching through x’s remaining links.
struct link *get_smallest(list x)
{
assert(!is_empty(x));
struct link *p = front(x);
struct link *res = p;
while (p != x) {
if (p->value < res->value)
res = p;
p = p->next;
}
return res;
}
The function assumes that the input list is not empty (which it won’t be in selection_sort()), which means that we have a value in front(x). Of the links we have seen so far, the front must be the one with the smallest value, so we get a reference to it, res (for result). Now we iterate through the links, and if we see a link with a smaller value than the one we have, we update res so it points to the new link. When we are done with the loop, we have seen all the links in x, and res points to one with a minimal value.
When we are done sorting, the sorted list sits in sorted and x is empty. We need to move the links back to x, so the caller gets the sorted list; sorted is a local variable and will be lost as soon as the function returns. To get the links back, we need to connect them such that x->next points to the first link in sorted and x->prev points to the last. We should only do this if sorted is not empty because otherwise we would make x’s prev and next point to a variable that is soon to be deallocated. The function for moving the links back to x could look like this:
void move_links(list x, list y)
{
if (!is_empty(y)) {
connect(x, front(y));
connect(last(y), x);
}
}
If x wasn’t empty when we called the function, the links would be lost, except if y was empty, in which case x would be unchanged. For our selection_sort() function, this isn’t an issue. We will always have an empty x, so if y is also empty, we still get the right result. If you want a version that will always work, we can free x’s links first. This ensures that we will not leak memory when we change x’s links, and since free_links() sets the input to the empty list, we are guaranteed that x is empty after that. Such a version could look like this:
void move_links(list x, list y)
{
free_links(x);
if (!is_empty(y)) {
connect(x, front(y));
connect(last(y), x);
clear_list(y);
}
}
Here, we also clear y, to not leave it pointing to links that now belong to x. For selection_sort(), where sorted goes out of scope after we move the links, this isn’t an issue, but for a more general case, we should leave y in a state where it doesn’t refer to links that are no longer its.
An alternative implementation could look like this:
void move_links(list x, list y)
{
free_links(x);
if (!is_empty(y)) {
*x = *y;
connect_neighbours(x);
clear_list(y);
}
}
Here, we assign the full content of y into x, which includes the prev and next pointers. This is likely faster than two invocations of connect() and one of each of front() and last(). It sets x’s pointers correctly, but we still need to point the beginning and end links back to x, which is what connect_neighbours() does.
This version is faster than the previous if it is fast to copy the full content of a struct link from one address to another. When links consist of two points and an integer, that will be the case. If you pack more data into links, the trade-off might change. If you work with generic lists (Chapter 14), where links carry more data than captured by the struct link structure, you will only copy parts of the link (see Chapter 14 for details). When the links are the heads of lists, however, this will not be an issue.
Insertion Sort
The insertion sort algorithm works by scanning through the list, keeping a sorted list behind the current value, and in each iteration, taking the next value and inserting it at its correct, sorted, position behind the current index. If we sort arrays, we insert the next value by swapping elements toward the left, until we find the correct location, but with a linked list, we can simply unlink the next value and insert it into the sorted sequence.
void insertion_sort(list x)
{
list_head sorted = init_list_head(sorted);
struct link *p = front(x);
while (p != x) {
struct link *next = p->next;
unlink(p);
insert_sorted(&sorted, p);
p = next;
}
move_links(x, &sorted);
}
In this implementation, p runs through the list, and we unlink the values one by one to insert into the sorted list that we then move back into x when we are done. This is close to how we would implement it in an array, but since we are unlinking from x, we can simplify the code slightly. We can iteratively remove the head of the list, which is what p will be in any case when we keep unlinking it. Then the code looks like this:
void insertion_sort(list x)
{
list_head sorted = init_list_head(sorted);
while (!is_empty(x)) {
struct link *p = front(x);
unlink(p);
insert_sorted(&sorted, p);
}
move_links(x, &sorted);
}
Given a sorted list and a link, it is straightforward to insert the link at the correct position. Run through the list until we find the first link with a value larger than the one we are inserting, and then insert the new link before it.
void insert_sorted(list x, struct link *link)
{
struct link *p = front(x);
while (p != x && p->value < link->value)
p = p->next;
link_before(p, link);
}
There is the possibility that the new link has a value larger than all the links in the list (if nothing else, it will happen when we have an empty list). However, with our circular lists, we handle this situation the same as for other links if we test for termination before we test the current link’s value, p->value, in the loop condition. If we reach the end of the list before we see a link with a larger value, then the new link should go at the end of the list, but that means putting it before the list’s head, which is what we do.
This insert_sorted() function searches from the left and stops when it finds a larger value. It does what it is supposed to do, but it is from the opposite direction as the traditional array version of insertion sort. Links with the same value will be reversed if we sort with this insertion; in algorithmic terms, the implementation is “unstable.” If we want to preserve the order of links with the same value, we should put new links behind, not in front of, the existing links with that value. This is trivial to fix, though. Insert from the right instead of the left.
void insert_sorted(list x, struct link *link)
{
struct link *p = last(x);
while (p != x && p->value > link->value)
p = p->prev;
link_after(p, link);
}
Merge Sort
Merge sort is a divide and conquer algorithm, which means that we are looking at a recursive solution to sorting. The idea is this: split the list into two parts, sort them recursively, and then merge the result. The base case for the recursion is if the list is empty or has length 1, in which case it is already sorted.
void merge_sort(list x)
{
if (is_empty(x) || front(x)->next == x)
return; // length zero or one lists are sorted
list_head y = init_list_head(y);
split_list(x, &y);
merge_sort(x); merge_sort(&y);
merge(x, &y);
}
The list y goes on the stack, as there is no need to heap-allocate it.
In the array version of merge sort, splitting usually means that we take the first half of the elements and put in the first list and the second half of the elements and put them in the second list. This is easy in an array, where we identify sequences by indices, and getting the middle index is a simple matter of dividing the sequence length by two. With linked lists, however, we would have to run through all the links to count up the length and then back through the list to find the link where we should break the list in two. An easier solution is to run through the list and take every second link and move to the other list.
void split_list(list x, list y)
{
assert(is_empty(y));
struct link *p = front(x);
while (p != x) {
struct link *q = p->next;
unlink(p); append_link(y, p);
if (q == x) return;
p = q->next;
}
}
We run p through the list and point q to the link after p. We unlink p to move it into the other list, and then we update p, so we skip q, leaving that link in the list. If q is the head of the list, we shouldn’t skip past it—that would take us back to the beginning again—so we break the iteration and return from the function if/when that happens.
Merging two sorted lists means moving through them, in each iteration taking the smallest front of the two and putting it in the output list. We can implement it like this:
void merge(list x, list y)
{
list_head merged = init_list_head(merged);
struct link *p = front(x), *q = front(y);
while( (p != x) && (q != y) ) {
struct link *smallest;
if (p->value < q->value) {
unlink(p);
smallest = p; p = p->next;
} else {
unlink(q);
smallest = q; q = q->next;
}
append_link(&merged, smallest);
}
concatenate(&merged, x);
concatenate(&merged, y);
move_links(x, &merged);
}
We point p and q into the lists, starting at the front. Then we continue as long as we haven’t reached the end of either list, where we identify the smallest value of the two and unlink it (and move the corresponding pointer to the next link). We can still get p->next and q->next after we have unlinked them because we left a link’s pointers alone in the unlink operation. Of course, they will point somewhere else when we have appended the link, but we do that after we update the pointers. We append the smallest link to the output. When we have reached the end of either list, we are done in the loop. The other list will have elements left unless we started with two empty lists, but we know that these are larger than those we have in the result so far, so we can simply concatenate them into the result. We do not have to test which of the lists is empty, because if we concatenate both of them, one is empty and that operation will not break anything. We return the result through x, so the final step is moving the merged links there. It is a design choice to return through x, but by returning through one of the input lists, we avoid heap-allocating a result list. In any case, the input lists are destroyed in the process; we have moved all the links from them.
Since we remove the links from the lists when we merge them, we can simplify the code slightly. If we had copied results into the result, the original lists would be unchanged, and we would have to run variables p and q through them. So, if you want a merge() function that doesn’t destroy the input, it is a small change to the preceding function. Given that we do destroy the input, however, we might as well exploit it. Instead of using variables p and q, we can get the fronts of the lists directly and unlink the smallest in each iteration. Such an implementation could look like this:
void merge(list x, list y)
{
list_head merged = init_list_head(merged);
while( !is_empty(x) && !is_empty(y) ) {
struct link *smallest =
(front(x)->value < front(y)->value)
? front(x) : front(y);
unlink(smallest);
append_link(&merged, smallest);
}
concatenate(&merged, x);
concatenate(&merged, y);
move_links(x, &merged);
}
Here, we again loop as long as both lists have more links, but we pick the smallest link directly from the fronts. We unlink and append, and the unlink() operation will make smallest->next the new front of its lists, so we still have access to it. Otherwise, the function works as the previous version.
Quicksort
The quicksort algorithm gets its name from the low overhead of its operations. Its expected theoretical running time is not better than merge sort, but moving objects around involves fewer and simpler operations—on arrays, at least. If we quicksort a linked list, the operations are not that much simpler. Still, we can implement it to see how this algorithm can work on lists.
Quicksort is also a divide and conquer algorithm, with a recursion where the base case is the same as for merge sort—an empty list or a list with one element is already sorted. The recursive case splits the list into two parts as well, but with a different strategy. We pick a value, the pivot, from the list, and then we split the list into the elements smaller or equal to the pivot and then elements larger than the pivot. We sort the two parts. Now, because all the elements in one part are smaller than all the elements in the other, and because the parts are sorted, we get the sorted list from concatenating the two.
The dangerous part is doing exactly what I described because you could end up with one of the parts empty. If the pivot is the largest element in the list, for example, all the elements are less than or equal to it. Then we would recurse on the original data, entering an infinite recursion. To avoid this, we set the pivot aside in the recursion and put it back between the two sorted lists when we are done. It has to be larger than or equal to all the elements in the first list—because we constructed the list that way—so we will still get a sorted list.
The full algorithm, excluding the partition, looks like this:
void quick_sort(list x)
{
if (is_empty(x) || front(x)->next == x)
return; // length zero or one lists are sorted
// Remove the pivot, to make sure that we reduce
// the problem size each recursion
struct link *first = front(x); unlink(first);
int pivot = first->value;
list_head y = init_list_head(y);
partition(x, &y, pivot);
quick_sort(x); quick_sort(&y);
append_link(x, first); // Get first back into the list
concatenate(x, &y);
}
The partitioning looks like many of the functions we have seen before. Run through the links, and when you have a link with a value larger than the pivot, unlink it and put it in the second list:
void partition(list x, list y, int pivot)
{
assert(is_empty(y));
struct link *p = front(x);
while (p != x) {
struct link *next = p->next;
if (p->value > pivot) {
unlink(p); append_link(y, p);
}
p = next;
}
}
I think that by now you have gotten the hang of doubly linked circular lists. Most algorithms that work on them will look like something we have already seen by now, and all involve updating the prev and next pointers—because that is all that links really have—and typically, it involves simple linking and unlinking. Have fun with experimenting with lists; we will move on to the next topic.