
What is Clojure and why would someone want to learn it? At first glance, some may vote Clojure the least likely to succeed among modern programming languages, because it is new and complicated. Worst of all, it is just flat-out strange, a bewildering soup of parentheses and brackets to anyone not already familiar with the Lisp family of languages.
And yet, it is gaining popularity and momentum faster than any other new language on the market. First released to the public in fall 2007, and reaching its first stable release in May 2009, it already fosters an active, passionate community, a thriving ecosystem of libraries and tools, and is used in an increasing number of serious professional applications.
One way or another, Clojure seems to push all the right buttons. But, what are they and what makes Clojure a good choice for your project?
Every year, brilliant computer scientists in academic institutions around the world publish hundreds, even thousands of papers filled with new and interesting ideas. These new concepts undergo natural selection and slowly, eventually, the best and most useful of them matriculate into real-world use.
Clojure includes many of the latest and greatest of these ideas that have not yet found good (or any) implementations in other languages. The most obvious are those relating to parallel processing: Software Transactional Memory and agent-based processing are baked into the language at a fundamental level. Others (for example, persistent immutability) are more subtle design philosophies that are a synthesis of modern academic research and decades of real-world lessons.
Despite its academic credentials, Clojure's primary design goal is to remain useful and above all usable. Its advanced features are carefully selected to actually deliver to developers robust, clean code that is easy to reason and fast to write. Clojure is not an ivory tower language, but one written by a developer intended to be used in the field, every day.
Depending on your programming background, the following statement could cause either enthusiasm or mild revulsion: Clojure is a full-fledged, bona fide dialect of the venerable Lisp programming language.
Lisp has a reputation for being exceedingly powerful and expressive, and Clojure is no exception. Its functional and metaprogramming facilities make it an extremely tractable medium, malleable clay to C's stone or Java's wood. You can replace thousands of lines of code in a static language with hundreds or even dozens of lines of Clojure, with corresponding improvements in bug count and development time. Boilerplate code is all but eliminated. Domain Specific Languages (DSLs) become not only easy, but the norm—Lisp programs are often written "from the ground up," evolving constructs and syntax that are most suited to the problem domain[1]. You can modify programs on the fly without recompilation or restarting.
Historically, however, Lisp also has its detractors, and many of the complaints are more than justified[2]. Lisp has suffered greatly from incomplete specifications, idiosyncratic implementations, archaic limitations, and cruft accumulated over its five decades of existence. And to many, its syntax is just too, too strange.
Clojure fixes most of these problems. It maintains Lisp's ideals and philosophy while making a clean break with the limitations of the past. It is fast, clean, and prioritizes power and elegance. Without altering Lisp's code-as-data philosophy, it provides intuitive and visually distinctive syntax that makes it much more pleasant to read than historical Lisps. After the initial learning phase, it is remarkably easy to read and write, parentheses notwithstanding.
Those who already know Lisp will immediately find themselves extremely comfortable with Clojure. To those who don't, there is no reason to be intimidated. Clojure is a clean, painless way to learn what makes people so passionate about Lisp, without having to suffer through the bad stuff. Stick with it, and it's highly probable you'll find yourself loving it, even the parenthesis, after just a few weeks of playing with the code.
Whether or not you like Java as a language, the Java Virtual Machine is a superb piece of software that deserves respect. It is mature, stable, and fast. As an industry standard, there are thousands of well-tested libraries for just about any purpose. Many companies already have heavy investments in the Java platform.
By running on the JVM, Clojure immediately gains access to all of this. It is not just a port of another language to the JVM: Clojure is designed from the ground up to run within the Java environment and to easily integrate with Java. For application development, it functions equally well as a complete, stand-alone language or as an embeddable scripting tool within a larger Java program. It can be used anywhere Java can, and in most cases is much easier to write.
A key characteristic of Clojure is that it is a functional language, which means that functions are the fundamental building-block for programs rather than instructions, as is the case in most other programming languages (known as imperative languages). Functional programming provides some substantial advantages over imperative programming, which will be discussed in this section. Functional style is inherent to Clojure and central to its philosophy.
Note
Nearly all programming languages have some construct called a function. In most programming languages, the best way to think of a function is as a subroutine, a series of instructions that are grouped together for convenience. In Clojure and other functional languages, functions are best thought of as more like their counterparts in mathematics—a function is simply an operation that takes a number of parameters (also called arguments) and returns a value.
Imperative languages perform complex tasks by executing large numbers of instructions, which sequentially modify a program state until a desired result is achieved. Functional languages achieve the same goal through nested function composition—passing the result of one function as a parameter to the next. By composing and chaining function calls, along with recursion (a function calling itself), a functional program can express any possible task that a computer is capable of performing. An entire program can itself be viewed as a single function, defined in terms of smaller functions. The nesting structure determines the computational flow, and all the data is handled through function parameters and return values (see Figures 1-1 and 1-2).
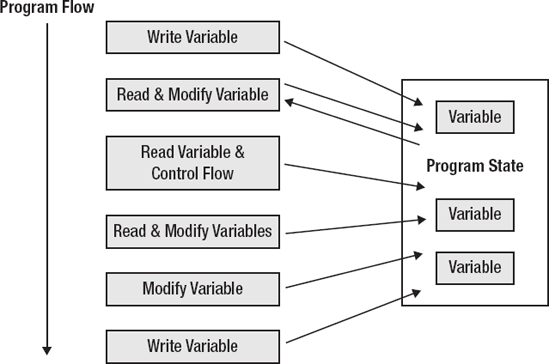
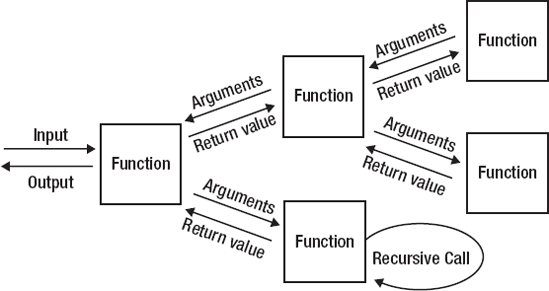
Incidentally, this is the reason that Clojure code can look so strange to those unfamiliar with functional programming. It is optimized to make it easy to express function composition rather than blocks of instructions. As your experience and understanding of functional programming grows, the more natural Clojure's syntax will feel.
Pure functions are an important concept in functional programming, as shown in Figure 1-3. Stated simply, a pure function is one that depends upon nothing but its parameters, and does nothing but return a value. If a function reads from anywhere except its parameters, it is not pure. If it changes anything in the program state (known as a side effect), it is not pure either.
Functional programming is largely concerned with the careful management (or elimination) of state and side effects. Both are necessary for programs to do anything useful, but are regarded as necessary evils, and functional programmers do their best to use them as little as possible.
State is any data the program stores that can possibly be changed by more than one piece of code. It is dangerous because if the code's behavior is dependent on a piece of state, it is impossible to analyze what it might do without taking into account all the possible values of that state, as well as every other part of the program that might modify that state. This problem is exponentially magnified in parallel programs, where it is not always easy to tell even what order code will execute in. It becomes nearly impossible to predict what a given state might be.
Side effects are anything a function does when it is executed, besides just returning a value. If it changes program state, writes to a hard disk, or performs any kind of IO, it has executed a side effect. Of course, side effects are necessary for a program to interact with anything, including the user. But they also make a function much more difficult to understand and to reuse in different contexts.
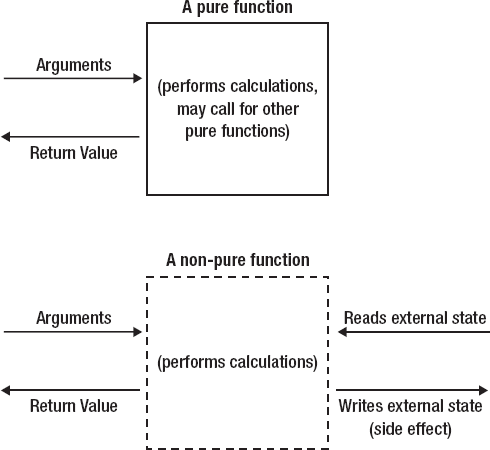
Purely functions have a number of advantages:
They are remarkably easy to parallelize. Since each function is a distinct, encapsulated unit, it does not matter if functions are run in the same process or even on the same machine.
Pure functions lead to a high degree of code encapsulation and reusability. Each function is effectively a black box. Therefore, understand the inputs and the outputs, and you understand the function. There's no need to know or care about the implementation. Object-oriented languages try to achieve this with objects, but actually it is impossible to guarantee, because objects have their own state. An object's type and method signatures can never tell the whole story; programmers also have to account for how it manages its state and how its methods impact that state. In a complex system, this quickly grows in complexity and often the advantages of class encapsulation quickly disappear. A pure function, however, is guaranteed to be entirely described by its interface—no extra knowledge required.
They are easier to reason about. In a purely functional program, the execution tree is very straightforward. By tracing the function call structure, you can tell exactly and entirely what the program is doing. In order to understand an imperative, stateful program you need not only to understand the code, but all of the possible permutations of state that may exist at any point in time. Purely functional code is much more transparent. In some cases, it is even possible to write tools that do automated analysis and transformations of source code, something that is next to impossible in an imperative language.
Pure functions are very easy to write unit tests for. One of the most difficult aspects of unit testing is anticipating and accounting for all the possible combinations of state and execution paths. Pure functions have well-defined, stateless behavior that is extremely simple to test.
Of course, most programs can't be programmed entirely in pure functions. Side effects are inevitable. Displaying something to the screen, reading from a file on a hard disk, or sending a message over a network are all examples of side effects that cannot be dispensed with. Similarly, programs can't do entirely without state. The real world is stateful, and real-world programs need to store and manipulate data that can change over time.
In effect, Clojure does not enforce functional purity. A few languages do, such as Haskell, but they are (rightly or wrongly) considered to be academic, difficult to learn, and difficult to apply to problems found in the real world. Clojure's goal is not to prevent programmers from using state or side effects, but to make it safe and straightforward.
Clojure has two ways of maintaining functional purity as much as possible while still allowing a developer to easily do everything they need.
Side effects are explicit, and the exception rather than the rule. They are simple to add, when necessary, but they stand out from the natural flow of the language. This ensures that developers are precisely aware of when and why they occur and what their precise effects are.
All program state is contained in thread-safe structures, backed by Clojure's thoughtfully planned inventory of concurrency-mangement features. This ensures that with an absolute minimum of effort, program state is always safe and consistent. Updates to state are explicit and atomic and clearly identifiable.
Most of Clojure's unique style is emergent from these two characteristics. Very naturally, Clojure code tends to segregate itself into purely-functional and effect-producing areas, with a single function that contains side effects of manipulating state relying on other, pure functions for most of the actual processing and program logic.
This not only preserves the benefits of purely functional programming throughout most of a Clojure application, but also encourages good style. Of course, as with any other language, it is possible to write messy, obfuscated code. But more than most other languages, Clojure by its nature encourages users to write code that is easy to read and debug. Explicit state and side effects mean that it is extremely easy to read over a program and see what it is doing, without even needing to always understand how.
Warning
There is a major exception to Clojure's rules about state management and side effects: Java objects. Clojure allows you to work with Java object as well as native Clojure structures, but Java objects are still Java objects and full of umanaged state. It cannot be helped. A good Clojure program will use Java objects only for interfacing with Java libraries, and therefore restrict the use of mutable state.
One of the most important ways in which Clojure encourages purely functional style where possible is to provide a capable, high-performance set of immutable data structures.
Immutable data structures are, as their name suggests, data structures that cannot change. They are created with a specific value or contents, which remain constant over the entire life cycle of the object. This ensures that the object can be freely used in multiple places, from multiple threads, without any fear of race conditions or other conflicts. If an object is read-only, it can always be safely and immediately read from any point in the program.
This begs the obvious question: What if the program logic requires that the value of a data structure change? The answer is simple—rather than modifying the existing data structure (causing all kinds of potentially bad effects for other parts of the program that use it), the structure is copied with the changes in place (see Figures 1-4 and 1-5). The old object remains exactly as it was, and other threads or portions of code currently operating on it will continue to function without problems, unaware that there is a new version. Meanwhile, the code that "changed" the object uses the new object, identical to the old one except for the modifications.
This sounds as if it might be extremely inefficient, but it isn't. Because the base object is immutable, the "modified" object can share its structure except for the actual point of change. The system only needs to store the differential, not an entire copy. This property is called persistence—a data structure shares memory with the previous version of itself. There is a small computational time overhead when making a change, but the memory usage can often actually be lower. In many scenarios, objects can share large parts of their structure, increasing efficiency. Old versions of objects are maintained as long as they are used as part of a newer version (or referenced from elsewhere), and are silently garbage collected when they are no longer useful.
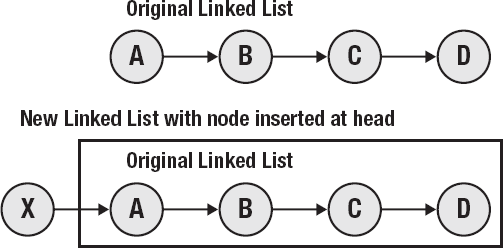
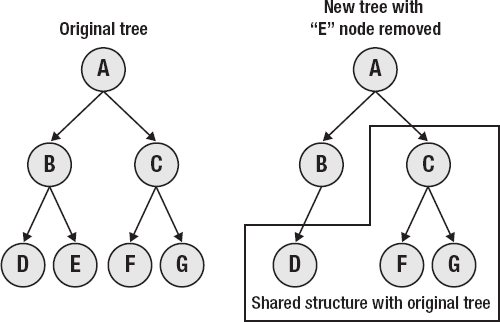
Another interesting effect of immutable, persistent data objects is that it is easy to maintain previous versions and roll back through them as necessary. This makes it extremely easy and efficient to implement things like undo histories or backtracking algorithms.
Clojure provides the following common immutable data structures:
Linked lists: These are simple, singly-linked lists that support fast traversal and insertion.
Vectors: Similar to an array, vectors are indexed by integer values and support extremely fast lookup by index.
Hash maps: Hash maps use hash trie datastructures to provide unordered storage for key/value pairs and support extremely fast lookups.
Sorted maps: Sorted maps also provide key/value lookups, using a balanced binary tree as the underlying implementation. They are also, unsurprisingly, sorted, and provide operations for range-based access at the cost of being slightly slower than hash maps.
Hash and sorted sets: Sets are groups of distinct items, similar to the mathematical concept. They support operations such as finding the union, difference, and intersection. They can be implemented as hash tries or using a binary tree with similar performance tradeoffs as the map implementations.
These objects all provide a number of other interesting features, besides immutability:
They support fast value-based equality semantics—two data structures are equal if and only if they contain the same items.
They implement the non-optional, read-only portion of the
java.util.* collection interfaces(namely Collection, List and, Map) andjava.lang.IterableAPIs. This means that they can be used as drop-in replacements for most of Java's collections, making it much easier to interface with Java libraries.They fully implement the sequence abstraction, as discussed in Chapter 5.
Clojure makes it extremely easy to work with all these data structures, and together with primitive types they provide everything a program needs for internal data storage.
Very clearly, Clojure is not object-oriented. Given how the programming world is dominated by OO paradigms and languages, many programmers will no doubt be at a loss about how to program in any other way. However, Clojure's rejection of the object-oriented philosophy is not a weakness, but rather can be a great strength, and can be leveraged to provide complex functionality while keeping code extremely simple.
For the last decade, at least, the object-oriented style has dominated computer programming through its promises of data abstraction, code reuse, encapsulation, and modularity. It has delivered on these with varying levels of success, and is no doubt an improvement over the sequential or procedural styles that preceded it. But a number of problems have also become apparent:
An object's mutable state is unmanageable and dangerous in a highly concurrent environment.
It doesn't really solve the problems of code abstraction and modularization. It is just as easy to write over-dependent "spaghetti" code in an object-oriented language as any other. It still takes skill and special effort to write code that can truly be used without problems in a variety of environments.
Inheritance is fragile and can be dangerous. Increasingly, even experts in object-oriented languages are discouraging its use.
It encourages a high degree of ceremony and code bloat. Simple functionality in Java can require several interdependent classes. Efforts to reduce close coupling through techniques like dependency injection involve even more unnecessary interfaces, configuration files, and code generation. Most of the bulk of a program is not actual program code, but defining elaborate structures to support it.
Clojure is the next evolutionary step in programming languages. It builds upon the good parts of object-oriented design, while eliminating the constraints and misfeatures that cause problems.
The notion of object orientation is not itself well defined. While usually considered a single paradigm, the object-oriented style uses a single concept—classes—to conflate a variety of actual, distinct features. Clojure isolates each of these desirable functionalities and provides separate, simpler, more powerful features to provide them separately, allowing developers to use only the features that make sense in a particular context.
Modularity: Classes and packages provide a way to group code that naturally goes together and is interdependent. Clojure accomplishes this with its namespacing mechanism.
Polymorphism: Inheritance and interface implementation allows common code to process objects differently depending on their type, without knowing the type or even all possible types ahead of time. Clojure multimethods provide this functionality and more—it is possible to dispatch different code based not only on type, but also on arbitrary properties.
Encapsulation: Classes can be used to hide implementation details behind a common interface. As discussed, this concept is alive and well in Clojure—functions are best thought of not by what they do, but what parameters they take and what they return.
Reusablity: Classes can, theoretically, be reused in different environments, put together like bricks to build up larger programs. While this usually isn't possible, it is still a worthwhile goal. Clojure also pursues this goal of modular reusability, only by composing functions instead of classes. But unlike classes, pure functions are guaranteed not to have side effects which hamper reuse.
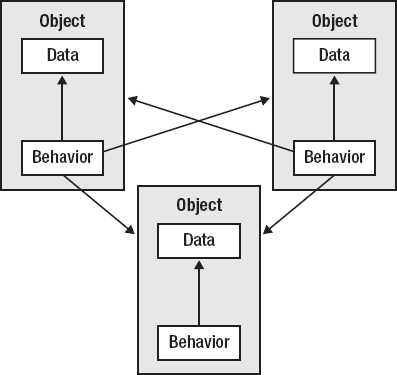
Another major philosophical difference between Clojure and object-oriented languages is that OO languages try to unify data and behavior within classes, in some cases blurring the line between what is data and what is code structure. Properties and methods are littered throughout the code together, and completely interdependent and inseparable.
Clojure strives for a separation between data and behavior. The Clojure web site quotes Alan Perlis who says, "It is better to have 100 functions operate on one data structure than to have 10 functions operate on 10 data structures." Clojure tries to avoid interdependence of data on code, but instead provides a large library of functions that operate on the simple, basic data types. The important, emphasized part of a Clojure program is not the data classes and structures, but the functional code which operates upon them.
An object-oriented program consists of a set of class definitions, each of which probably contains some state, some code, and references to other classes. Programs look something like Figure 1-6.
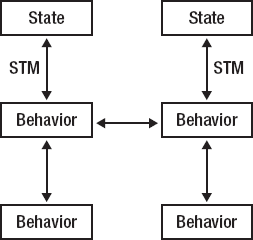
Clojure programs, on the other hand, are best thought of as a collection of functions (as befits a functional language). They are understood not by grasping the relationships between data or objects, but by understanding the flow from function to function, and the limited points where the code touches the program state. They look more like Figure 1-7.
It is worth noting that there are some problem domains, such as simulations, where an object-oriented approach is extremely natural. Clojure understands that, which is why as a language, it places more emphasis on flexibility and extensibility than any particular philosophy.
Thus, it should come as no surprise that Clojure is flexible and powerful enough to build up a custom object-oriented solution that fits the problem. It is entirely possible to use Clojure's macros and metaprogramming facilities to build an object system, completely within Clojure, and use it where appropriate. Common Lisp has something similar: CLOS, the Common Lisp Object System, built on top of Lisp macros from within Lisp. There is no reason a Clojure user could not do the same; indeed, there are several fledgling projects within the Clojure community designed to provide exactly these features.
The important fact is that Clojure frees you to use whatever style and structure makes sense for your project. Object-oriented systems are powerful, but they are only one tool, and the only mechanism most languages provide for abstraction and reuse. Clojure gives many different tools for abstraction and reuse to use where they make sense, along with the ability to build your own tools.
Nearly every program needs to maintain a working state of some kind. There will always be a need for a program to store facts and data, and update or manipulate them, from time to time.
Traditionally, programming languages deal with this problem by allowing programs direct access to memory at various levels of abstraction. Whether manipulating bytes of RAM directly in low-level languages like C or assembly or allocating objects to a garbage-collected heap as in Java or Microsoft's .NET, most programming languages are built around the concept of directly using sequential instructions to modify a shared memory space.
In this paradigm, it is entirely the responsibility of the programmer to ensure that state manipulation and access is done in a reasonable way that does not cause problems. It was never easy. Even in the simplest case, extensive use of mutable state makes programs difficult to reason about—any part of the program can change state, and it's not easy to tell where it's happening. Rich Hickey, Clojure's inventor, calls mutable, stateful objects "the new spaghetti code."
Unfortunately, with the advent of multithreaded programs, the difficult of managing state increases exponentially. Not only must a programmer understand possible program states, but they must go to great lengths to ensure that state is protected and modified in an orderly way to prevent corrupted data and race conditions. This, in turn, requires complicated locking policies—policies which there is no way of enforcing. Failure to comply with these policies does not cause obvious problems, but rather insidious bugs that often do not surface until the application is under load in a production setting, and can be nearly impossible to track down.
In general, enabling concurrency in a traditional language requires thoughtful planning, an extremely thorough grasp of execution paths and program structure, and extreme care in implementation.
Clojure provides an alternative: a fast, easy way for programmers to use as much state as they need without any extra effort to manage it, even in a highly concurrent setting. It accomplishes this through its particular philosophy of state and identity, its immutable objects, and software transactional memory (STM).
In order to understand Clojure's treatment of state, it is useful to step back and consider from an extremely high-level philosophical standpoint, what, exactly, the terms "state" and "change" even mean in the context of a running software program.
Traditionally, most programmers would say that "change" means that, given an object or data structure O, its value at a given time—call it T1—is different from that at a later time, T2. O is still O, whether we are looking at it, T1, or T2. However, some of its properties or values may be different, depending on when asked. Traditional concurrent programming is concerned with using locks and semaphores to ensure that inquires or updates regarding O's properties or values from different threads occur in an orderly way that won't cause problems.
Clojure provides a different point of view. In Clojure's world, O at T1 and O at T2 are not even conceptually the same object O, but two different ones: O1 and O2. They may have similarities in their values or properties or they may not, but the key point is that they are different system objects. What's more, they are immutable, in the strict sense of functional programming. If an additional "change" is made to O2, for example, it doesn't result a change to the properties or values of O2 but the creation of an entirely new object, O3. An object itself never changes.
To help get a grasp on this, consider the following example. In all programming languages (as well as common sense) the number 3 is the number 3, and never any other number. If I increment 3, I get a new number, 4. I have not changed the value of 3, only the value of whatever variable or storage register was containing it. The notion of changing the value of "the number 3" to something other than 3 is absurd—it is hard to even imagine what it might mean, let alone the havoc it might wreak on the rest of the program which relies on the value of 3 being 3.
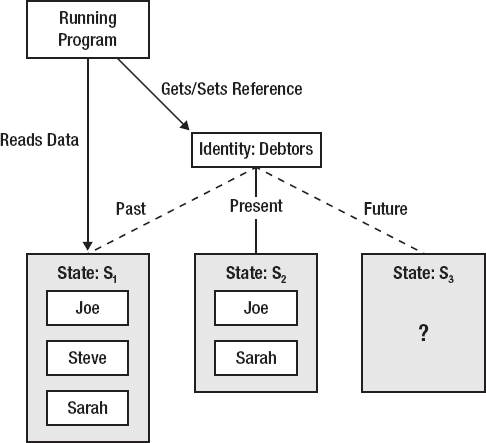
Clojure merely takes this intuitive notion regarding value, and extends it to larger composite values. Take, for example, a set, say "people who owe me money." Initially, the set might consist of S1 = {Joe, Steve, Sarah}. But then I get a letter from Steve, and it has a check. He's finally paid up. People who owe me money is now S2 = {Joe, Sarah}. These two sets are not the same by the definition of set equality: One contains Steve, one doesn't. S1 is not equal to S2 any more than 3 = 4.
Most programming languages would handle the preceding scenario by mutating the value of the set, S. In a concurrent scenario, this could cause all sorts of problems. If one thread is iterating through S while Steve is removed, it will inevitably throw an error, probably some variation of "Index out of bounds." To compensate, the programmer must manually add a system of locks to ensure that the iteration and the update occur sequentially, not at the same time, even if the code is running in different threads.
Clojure has a different philosophy. The solution is not to restrict access to S to sequential operations: that is merely a Band-Aid that does not address the real issue. The real conceptual problem is that, for a moment in time as it iterates through the set, the program assumes that {Joe, Sarah} = {Joe, Steve, Sarah}. This is obviously not true, and it is this disconnect that causes the problem. Normally, it is a reasonable expectation that an object equals itself, but not in a concurrent system that allows mutation.
By using only immutable objects, Clojure restores the guarantee that objects always equal themselves. In Clojure's system, S1 and S2 are different to the program, just as they are semantically and conceptually. An operation taking place on S1 remains unaffected by the creation of S2 and will finish without errors.
Obviously there is some relationship between S1 and S2. From a human perspective, they both represent the same concept, "the set of people who owe me money." Clojure tracks this by introducing the concept of identity, as distinct from value. Identity, in Clojure, is a named reference that points to an object. In the above example, there would be one identity, for example, debtors. At one point in time, debtors refers to S1, and, at another time, is updated to refer to S2. But this update is atomic, and therefore avoids concurrency effects like race conditions. There is no point at which the value of debtors is in an ambiguous state—it always refers to either S1 or S2, never something halfway. It is always safe to retrieve the current value of debtors, and it is always safe to swap its value for a new one. This is shown in Figure 1-8.
A proper view of state and identity isn't the whole answer, however. Often, in a program changes to one identity depend on the state of another or a new value of an identity needs to be calculated based on the existing value without worrying that another thread will update the identity in the middle of the operation. That wouldn't cause an error, as discussed, but it might result in the results of the other calculation being inappropriately overwritten.
To accommodate these scenarios, Clojure provides software transactional memory (STM). STM works by providing an extra management layer between the program and the computer's memory. Whenever a program needs to coordinate changes to one or more identities, it wraps the exchange in a transaction, similar in concept to those used to ensure integrity in database systems. Within a transaction, the programmer can perform multiple calculations based on identities, assign them new values and then commit the changes. From the perspective of the rest of the program, transactions happen instantaneously and atomically: First the identities have one value, and then another, with no need to worry about intermediate states or inconsistent data. If two transactions conflict, one is forced to retry, starting over with new values of the identities involved. This happens automatically; the programmer just writes the code, the transaction logic is handled automatically by the STM engine.
Clojure makes the following guarantees. Transactions are always:
Atomic. Either all the changes made in a transaction are committed to an identity or none are. The program will never commit some changes and not others. This provides guaranteed protection from corrupting data or creating any kind of inconsistent state.
Consistent. Transactions can be validated before they are committed. Clojure provides an easy mechanism for adding run-time checks to make sure that the new value is always what it ought to be, and that there are no problems with the new value before it is assigned to an identity.
Isolated. No transaction "sees" the effects of any other transaction while it is running. At the beginning of the transaction, the program takes a "snapshot" of all identities involved, which it uses for all its operations. This ensures code within transactions can be written freely, without any worry that the identities might have changed and, so to speak, swept the rug out from under the executing code.
This system ensures that there is never any blocking, and therefore, never any deadlocks. Read operations always execute immediately, returning the current value of an identity. Because the objects stored in the STM system are immutable, read operations never block a writing operation. If the read takes place and the program state changes just afterward, the object returned from the read operation does not (cannot) change, so any code using it can continue without errors. The next time the identity is read in another transaction or outside of any transaction, however, it will of course return the new value.
If one writing transaction completes while another is still underway, the STM system manages the conflict. If the two updates are on separate identities, both are committed immediately without any trouble or waiting. However, if two updating transactions conflict, they will be prioritized by the STM system, and one may be required to restart and retry. All of this occurs automatically, and without any need for special treatment by the developer.
Clojure also provides a commute operation—a writing operation which specifies that it may be performed in any order relative to other transactions. Commutative operations never block or cause retries.
The result is that the only scenario where the program cannot proceed immediately is when two write operations conflict. In all scenarios, however, data integrity is guaranteed—one of the transactions is restarted, from the beginning. Even in high-contention environments, the STM system is able to prioritize and ensure that a given transaction will almost always complete in a timely manner.
This chapter contains a lot of dense material, and the rest of the book will be spent in unpacking it as well as showing how to actually use it in a real-world program. But the features previously outlined are truly the heart and soul of Clojure.
Understanding that Clojure is a highly dynamic, metaprogrammable dialect of Lisp will allow you to play off of Clojure's strengths, using powerful abstractions to avoid redundancy and drudgery in code.
Knowing that Clojure is a functional language that encourages functional purity when possible will help you structure your program flow in simple, elegant ways. Keeping this in mind will help you break down your tasks into discrete, small units of code, and orchestrate the flow of data between functions. You will soon come to love its immutable data structures, and the liberating experience they provide, knowing that they always safe to use.
Most of all, realizing Clojure's special relationship with persistent data structures will allow you to write robust, scalable applications with high levels of concurrency. Updating and managing data structures will become simple, allowing you to focus on the code that really matters and is fun to write, the code that gets stuff done.
[1] For an excellent book on the unique power of Lisp in general, read Paul Graham's On Lisp, http://www.paulgraham.com/onlisp.html, (New Jersey: Prentice Hall, 2003).
[2] See Steve Yegge's "Lisp is Not an Acceptable Lisp," http://steve-yegge.blogspot.com/2006/04/lisp-is-not-acceptable-lisp.html, 2003.