
In Clojure, sequences are a unified way to read, write, and modify any data structure that is logically a collection of items. They are built into Clojure at a very basic level, and are by far the most convenient and idiomatic way to handle collections. They fill the role occupied by lists in other Lisp dialects. More than just a collection API, they are the framework around which program flow and logic are often constructed, and are designed to be as easy-to-use as the basis for recursion and higher-order function application.
Fundamentally, sequences are an abstraction, a common programming interface that generalizes behavior common to all collections and exposes it via a library of sequence functions. Sequences are a result of the observation that the classic operations on linked lists, such as "first" and "rest" (or "car" and "cdr", for those with a lisp background) and work equally well on just about any data type. For example, the first function returns the first item in a sequence. Whether the sequence is actually a list, vector, set, or even a map doesn't matter.
user=> (def mylist '(1 2 3))
user=> (first mylist)
1
user=> (def myvec [1 2 3])
user=> (first myvec)
1
user=> (def myset #{1 2 3})
user=> (first myset)
1
user=> (def mymap {:a 1 :b 2 :c 3})
user=> (first mymap)
[:a 1]Similarly, the rest function operates on any sequence, returning a sequence of everything except the first item:
user=> (def mylist '(1 2 3)) user=> (rest mylist) (2 3)
Sequence functions are extremely useful. For example, with just first and rest (and another function, empty?, which returns true if a sequence is empty) it is possible to implement a very common Lisp idiom: a function that recurses over a list. However, because you're using sequences, it doesn't have to be a list—it can be any collection.
(defn printall [s]
(if (not (empty? s))
(do
(println (str "Item: " (first s)))
(recur (rest s)))))This function takes a sequence, and checks that it is not empty. If it is empty, it does nothing (implicitly returns nil). If it has items, it prints a string as a side effect, printing "Item:" concatenated with the first item in the sequence. It then recurses, passing the rest of the sequence to the next iteration. It works on lists:
user=> (printall '(1 2 3)) Item: 1 Item: 2 Item: 3 nil
And on vectors:
user=> (printall ["vector" "of" "strings"]) Item: vector Item: of Item: strings nil
And even on strings, which happen to be sequences of characters:
user=> (printall " Hello") Item: H Item: e Item: l Item: l Item: o nil
Because sequences are so generic, the same function works perfectly well for all these disparate collection types.
Warning
Technically, the various types of data structure are not sequences themselves, but rather can be turned into sequences with the seq function. seq takes a single argument and creates a sequence view of it. For example, a vector is not a sequence, but the result of (seq any-vector) is. Since almost all the sequence functions call seq on their arguments internally, there isn't much distinction in practice most of the time. Be aware of this, however, in case you run across a function that actually requires a sequence, not a collection that is sequence-able: there is a difference. You can just call seq on any collection to efficiently retrieve a sequence view of it.
Sequences can be created from nearly any backing collection type.
Clojure's persistent collections: Maps, sets, lists, and vectors all work nicely as sequences.
Java arrays: This can result in a mismatch, however, since Java arrays are mutable and sequences are not to avoid difficult bugs, avoid modifying arrays while you are using a sequence based on them.
Any Java collection which implements the java.lang.Iterable interface: Again, however, Java collections are mutable whereas sequences are not, so avoid modifying a collection while using a sequence view of it.
Natively: Sequences can also be constructed directly without being backed by another collection type.
It is important to understand the underlying logical structure of a sequence. Sequences that were created in different ways have widely differing implementations. A sequence representation of a vector, for example, is still a vector under the hood, with the same performance characteristics. But all sequences share the same conceptual model: a singly-linked list implemented in terms of first and rest. first and rest, incidentally, are identical to car and cdr in traditional Lisps. They were renamed to more accurately reflect their intent in terms familiar to modern programmers.
Every sequence, conceptually, consists of these two parts: the first item in the sequence, accessed by the first function, and another sequence representing all the rest of the items, accessed by the rest function. Each sequence of n items is actually comprised of n−1 component sequences. The sequence ends when rest returns empty. All other sequence functions can be defined in terms of first and rest, although sequences created from collection types implement them directly for better performance.
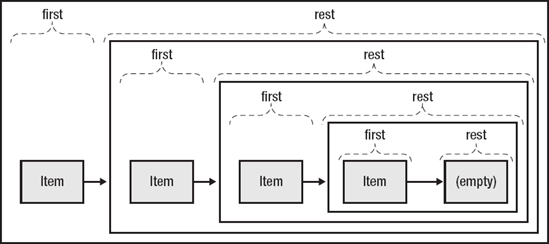
Using this model of sequences, it is easy to construct them directly using either the cons or conj functions. The cons function stands for "construct" and takes two arguments, an item and a sequence. It returns a new sequence created using the item as its first and the sequence as its rest. A sequence created by cons is known as a "cons cell"—a simple first/rest pair. Sequences of any length can be constructed by chaining together multiple cons cells.
user=> (cons 4 '(1 2 3)) (4 1 2 3)
The conj function is similar to cons and stands for "conjoin." The main difference from cons is that (if possible) it reuses the underlying implementation of the sequence instead of always creating a cons cell. This usually results in sequences that are more efficient. Whether the new item is appended to the beginning or end depends on the underlying representation of the sequence. Unlike cons, conj takes a sequence as its first parameter, and the item to append as the second:
user=> (conj '(1 2 3) 4) (4 1 2 3)
conj also supports adding any number of items at once: just use additional parameters. The parameters are appended to the front of the sequence in the order they are provided.
user=> (conj '(1 2 3) 4 5 6) (6 5 4 1 2 3)
Warning
A feature of conj you should take note of is that it doesn't call seq on its argument. It can work on data structures directly as well as sequences. In this case, it adds the new item wherever it's most efficient, not necessarily at the front (as it does with sequences). With vectors, for example, the most efficient place to add items is the end. So (conj [1 2] 3) yields [1 2 3], not [3 1 2]. If you know you want a sequence, and you want the added item at the front, call seq on the vector first: (conj (seq [1 2]) 3) yields (3 1 2) as expected. You could also just use cons instead. Use conj when you don't want to convert your collection to a sequence.
For both conj and cons, if you supply nil in place of the sequence, it constructs a sequence containing only one item, the one you specified.
user=> (cons 1 nil) (1)
This is used in another common Lisp idiom, constructing a list recursively using cons or conj. The following function demonstrates recursively constructing a sequence of all the integers from 1 to the provided parameter:
(defn make-int-seq [max]
(loop [acc nil n max]
(if (zero? n)
acc
(recur (cons n acc) (dec n)))))With each iteration, this function con ses the value of n (initially the maximum value) to an accumulator sequence argument (initially nil), and then recurses, passing the new accumulator and the new decremented value of n. When n reaches zero, the function simply returns the accumulator, which at that point contains all the integers from 1 to the maximum.
user=> (make-int-seq 5) (1 2 3 4 5)
The first/rest architecture of sequences is the basis for another extremely important aspect of Clojure sequences: laziness. Lazy sequences provide a conceptually simple and highly efficient way to operate on amounts of data too large to fit in system memory at once. They can be infinitely long, but still can be utilized efficiently by any standard sequence function. As a high-level abstraction, they allow the developer to focus on the computation being performed, rather than managing the ins and outs of loading or creating data.
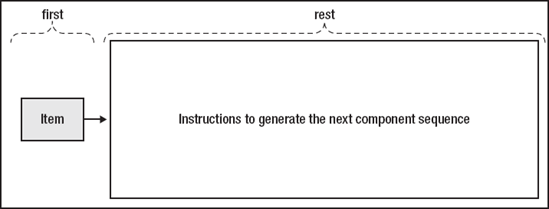
Laziness is made possible by the observation that logically, the rest of a sequence doesn't need to actually exist, provided it can be created when necessary. Rather than containing an actual, concrete series of values, the rest of a lazy sequence can be implemented as a function which returns a sequence. From the perspective of functions using the sequence, there is no difference; when they call the rest function, they get a sequence. The difference is that in the case of a normal sequence, it is returning a data structure that already existed in memory. In a lazy sequence, calling rest actually calculates and instantiates the new sequence, with a freshly calculated value for its first and updated instructions on how to generate still more values as its rest.
For efficiency, once a lazy sequence is realized, the value is cached as a normal, non-lazy sequence—subsequent accesses to the sequence are handled normally, rather than being lazily generated. This ensures that the calculation needed to generate it is only called once: using large, "heavyweight" calculations as generators in lazy sequences pose no problem, since they are guaranteed not to be executed more than once. The cached values are stored as long as there is code using them. When no references remain, the cached sequence is garbage collected like any other object.
To see a lazy sequence at work, consider the map function. The map function is an extremely important sequence manipulation tool in Clojure. It works by taking a sequence and a function as arguments, and returns a new sequence which is the result of applying the supplied function to each of the values in the original sequence. For example, if you run map with the sequence '(1 2 3 4 5 6 7) and a function which squares its parameter, (fn [x] (*x x)), the return value of map will be '(1 4 9 16 25 36 49). This is the sequence formed by squaring each of the values in the original sequence.
user => (map
(fn [x] (* x x))
'(1 2 3 4 5 6 7))
(1 4 9 16 25 36 49)What is not immediately apparent is that the return value of map is actually always a lazy sequence. Since the return value is immediately printed to the REPL anyway, the difference is transparent—the actual values are immediately realized.
To see the internal workings of the lazy sequence, let's add a side effect to your square function, so you can see when it's being executed (normally, side effects in functions provided to map are not a great design practice, but here they will provide insight into how lazy sequences work). In your new square function, you will now print out the value of each parameter as it is processed. To make things simpler, you'll use defn to define it rather than inlining it in the call to map:
(defn square [x]
(do(println (str "Processing: " x))
(* x x)))This function is exactly the same as the previous version, except that it uses do to run an explicit side effect, printing out the value of each parameter as it is processed. Running it returns this rather surprising and somewhat messy result:
user => (map square '(1 2 3 4 5) (Processing:1 Processing:2 1 Processing:3 4 Processing:4 9 Processing:5 16 25)
The reason why the code is so ugly is that the println calls are being called in the middle of printing out the results. The square function (containing println call) is not being called until it is absolutely required—until the system is actually ready to realize the lazy values. So your tracing statements from println and the actual output of the function, "(1 4 9 16 25)", are all mixed up.
To make this even clearer, let's bind the result of the map call to a symbol:
user =>(def map-result (map square '(1 2 3 4 5)) #'user/map-result
You now have a symbol map-result which is, supposedly, bound to a sequence of the squares. However, you didn't see the trace statement. square was never actually called! map-result is a lazy sequence. Logically, it does contain the squares you expected, but they haven't been realized yet. It's not a sequence of squares, but a promise of a sequence of squares. You can pass it all around the program, or store it, and the actual work of calculating the squares is deferred until it is required.
Now, let's retrieve some of its values using the nth function, which retrieves the value at a certain index of a sequence. Calling (nth map-result 2) should return 9, since 3 squared is 9, and 3 was the 2nd item in the original sequence (counting from 0 becauseall indexes in Clojure start at 0).
user => (nth map-result 2) Processing:1 Processing:2 Processing:3 9
You can see from the trace statements that the square function was called three times—just enough to calculate the third value in the sequence. Making the exact same call again, however, does not call the square function:
user => (nth map-result 2) 9
The values were already cached, so there was no need to call square to calculate them again. Now, printing the value of the whole sequence:
user => (println map-result) (1 4 Processing:4
9 Processing:5 16 25)
It only calls square twice, for the two remaining unrealized values in the lazy sequence. The cached values are not recalculated.
This example shows how the lazy sequence returned by map defers the actual calculation of its values until they are absolutely required.
Obtaining a lazy sequence is easy. Most of Clojure's built-in sequence functions such as map and filter return lazy sequences by default. If you want to generate your own lazy sequences, there are two ways to do so: constructing it directly or using a function that generates a lazy sequence for you.
To build a lazy sequence manually, use the built-in lazy-seq macro to wrap code that would otherwise return a normal sequence. lazy-seq builds a lazy sequence with any code it contains as a deferred value. Code wrapped in lazy-seq is not executed immediately, but "saved for later" within the context of a lazy sequence.
For example, the following function generates an infinite lazy sequence formed by taking a base, and then successively adding a number to it.
(defn lazy-counter [base increment]
(lazy-seq
(cons base (lazy-counter (+ base increment) increment))))Then, you can call the function, and use the take function to get the first several values of the lazy sequence. (take has two arguments, a number and a collection. It returns a sequence obtained by taking the number of elements from the collection.)
user=> (take 10 (lazy-counter 0 2)) (0 2 4 6 8 10 12 14 16 18)
The sequence, logically, is truly infinite. For example, to get the millionth number, counting by 3 starting from 2, just use nth:
user=> (nth (lazy-counter 2 3) 1000000) 3000002
Because it is infinite, you can use lazy-counter to get a sequence of any length—the only limitation will be how long it takes the computer to count up to a million, a billion, or whatever number you choose.
Compare this to a non-lazy version:
(defn counter [base increment]
(cons base (counter (+ base increment) increment)))This function doesn't even make it off the ground. It crashes with a StackOverflowError almost immediately. Because it doesn't defer any execution, it immediately recurses until it uses up all the stack space in the JVM. The lazy version doesn't have this problem. Although it is defined recursively, the contents of lazy-seq are only called when the internal code that processes lazy sequences is ready to unfold the next value. This is done in a way which does not consume stack space, and so lazy sequences are effective as well as logically infinite.
Warning
Be careful with infinite sequences. They are logically infinite, but care is required not to attempt to realize an infinite number of values. Trying to print an infinite lazy sequence in the REPL directly, for example, without using take or an equivalent can lock the program as it churns through the lazy sequence, on to infinity, without stopping. In this and other common scenarios, it is still possible to write code that will continue processing an infinite sequence forever, locking up the thread in which it is running. Infinite sequences can be very useful, but make sure code that utilizes them has proper exit conditions and doesn't depend on hitting the end of the sequence. Just because the sequence is infinite doesn't mean you want to take an infinite amount of time to process it, or try to load the whole thing into memory at once. Sadly, computers are finite machines.
For many common cases where a lazy sequence is required, it's often easier to use a sequence generator function than lazy-seq directly. In particular, iterate is useful. It generates an infinite sequence of items by calling a supplied function, passing the previous item as an argument. It takes two arguments: the function to call and an initial value for the first item in the sequence.
For example, to generate an infinite lazy sequence of all the integers use iterate with the built-in increment function, inc:
user=> (def integers (iterate inc 0)) #'user/integers user=> (take 10 integers) (0 1 2 3 4 5 6 7 8 9)
By providing a custom function, iterate can also be used to provide functionality identical to the lazy-counter function defined above:
(defn lazy-counter-iterate [base increment]
(iterate (fn [n] (+ n increment)) base))
user=> (nth (lazy-counter-iterate 2 3) 1000000)
3000002There are several other functions that generate sequences similarly to iterate: see the section "The Sequence API."
It is important to understand how lazy sequences consume memory. It is possible to use large, even infinite sequences in a memory-efficient way, but unfortunately it is also possible to inadvertently consume large amounts of memory, even resulting in a Java OutOfMemoryError if they exceed the available heap space in the JVM instance.
Use the following guidelines to reason about how lazy sequences consume memory:
Lazy sequences which have not yet been realized consume no appreciable memory (other than the few bytes used to contain their definition).
Once a lazy sequence is realized, it will consume memory for all the values it contains, provided there is a reference to the realized sequence, until the reference to the realized sequence is discarded and the sequence is garbage collected.
The final distinction is key. To illustrate the difference, consider the following two code snippets entered at the REPL.
user=> (def integers (iterate inc 0)) #'user/integers user=> (nth integers 1000000) 1000000
And:
user=> (nth (iterate inc 0) 1000000) 1000000
Although these two code snippets are identical in respect to what they do, profiling the JVM indicates that the former statement results in ~60 megabytes of heap space being utilized after the call to nth, while the latter results in no appreciable increase. Why?
In the first sample, the lazy sequence is referenced by a symbol. The sequence is initially unrealized, and takes up very little memory. However, in order to retrieve the selected value, nth must realize the sequence up to the value selected. All values from 0 to 1000000 are now cached in the sequence bound to the integers symbol, and it is this that utilizes the memory.
So why doesn't using nth in the second example use up memory as well? The answer is that nth itself does not maintain any references. As it goes through a sequence, it retrieves the rest from each entry, and drops any references to the sequence itself. The sequence created by (iterate inc 0) is supplied as an initial argument, but unlike the first example, no permanent reference to it is maintained, and nth "forgets" it almost immediately as it progresses. No cached values are ever saved, and so no memory is used.
All the built in-sequence functions, such as nth, are careful not to maintain any memory-consuming references, so ensuring proper memory usage is a responsibility of the developer. Keeping track of memory usage means, primarily, keeping track of references to lazy sequences.
It may sound complicated at first, but in time, once you're used to working with Clojure, eliminating extraneous references comes fairly easily. Clojure's own emphasis on pure functions itself greatly helps to discourage indiscriminate reference-making. The only area where it is easy to make a mistake is when writing your own sequence-consuming functions, and as long as you maintain a clear idea of which symbols reference potentially infinite sequences, it should provide no great difficulty. The important thing is to know what to look for when presented with an OutOfMemoryError.
Clojure provides a complete set of sequence manipulation functions. Being familiar with them and their capabilities will save a great deal of effort, as it is often possible to eliminate a surprising amount of code with a single call to one of these functions.
The functions in this section provide various means for creating sequences, either directly or from existing data structures.
The seq function takes a single argument, a collection, and returns a sequence representation of the collection. Most sequence manipulation functions automatically call seq on their arguments, so they can accept collections without requiring a manual call to seq.
user=> (seq [1 2 3 4 5])
(1 2 3 4 5)
user=> (seq {:a 1 :b 2 :c 3})
([:a 1] [:b 2] [:c 3])vals takes a single argument, a map, and returns a sequence of the values in the map.
user=> (vals {:key1 "value1" :key2 "value2" :key3 "value3"})
(" value1" "value2" "value3")keys takes a single argument, a map, and returns a sequence of the keys in the map.
user=> (keys {:key1 "value1" :key2 "value2" :key3 "value3"})
(:key1 :key2 :key3)rseq takes a single argument, which must be a vector or a sorted map. It returns a sequence of its values in reversed order; operation returns in constant time.
user=> (rseq [1 2 3 4]) (4 3 2 1)
lazy-seq is a macro which wraps a form that returns a sequence. It produces a lazy sequence, which is discussed in detail in the previous section "Constructing Lazy Sequences Directly."
repeatedly takes a single argument, a function with no arguments, and returns an infinite lazy sequence obtained by calling the function repeatedly. Note that if the function is a pure function, it will simply return the same value every time, since it has no arguments.
user=> (take 5 (repeatedly (fn []"hello")))
("hello" "hello" "hello" "hello" "hello")Usually, repeatedly is more useful with an impure function, such as one based on rand-int, which returns a random integer between 0 and its argument.
user=> (take 5 (repeatedly (fn [] (rand-int 5)))) (3 0 4 3 2)
iterate takes two arguments: a function with a single argument and a value. It returns an infinite lazy sequence obtained by starting with the supplied value, and then by calling the supplied function passing the previous item in the sequence as its argument.
user=> (take 10 (iterate inc 5)) (5 6 7 8 9 10 11 12 13 14)
This example uses the increment function inc to generate an infinite sequence of integers, starting at 5. For a more detailed discussion, see the previous section, "Constructing Lazy Sequences Using Sequence Generator Functions."
repeat takes one or two arguments. The single-argument version returns an infinite lazy sequence consisting of the argument value repeated endlessly.
user=> (take 5 (repeat "hi"))
("hi" "hi" "hi" "hi" "hi")The two-argument version takes a number as its first argument and a value as its second. It returns a lazy sequence the length of the first argument, consisting of repetitions of the second argument.
user=> (repeat 5 "hi")
("hi" "hi" "hi" "hi" "hi")range takes one, two, or three arguments. The one-argument version takes a number as its argument and returns a lazy sequence of numbers from 0 to the argument (exclusive).
user=> (range 5) (0 1 2 3 4)
The two-argument version takes two numbers as its arguments and returns a lazy sequence of numbers from the first argument (inclusive) to the second argument (exclusive).
user=> (range 5 10) (5 6 7 8 9)
The three-argument version takes three numbers as its arguments and returns a lazy sequence of numbers from the first argument (inclusive) to the second argument (exclusive) incremented by the third argument.
user=> (range 4 16 2) (4 6 8 10 12 14)
distinct takes a single argument, a sequence or collection. It returns a sequence obtained by removing all duplicates from the argument.
user=> (distinct [1 2 2 3 3 4 1]) (1 2 3 4)
filter takes two arguments: a predicate function which takes a single argument and returns a boolean value, and a sequence/collection. Returns a lazy sequence consisting only of items in the second argument for which the predicate function returns true.
user=> (filter (fn [s] (= a (first s))) ["ant" "bee" "ape" "cat" "dog"])
("ant" "ape")In this example, the predicate function tests whether the first letter of its argument is an "a" character.
remove is similar to filter, except that the resulting sequence contains only items for which the predicate function returns false.
user=> (remove (fn [s] (= a (first s))) ["ant" "bee" "ape" "cat" "dog"])
("bee" "cat" "dog")cons takes two arguments, a value and a sequence/collection. It returns a sequence formed by appending the value to the sequence.
user=> (cons 1 [ 2 3 4]) (1 2 3 4)
concat takes any number of arguments, all sequences/collections. It returns a lazy sequence formed by concatenating the provided sequences.
user=> (concat [1 2 3] '(4 5 6) [7 8 9]) (1 2 3 4 5 6 7 8 9)
lazy-cat is a macro that takes any number of forms as arguments, all sequences/collections. It resolves to a lazy sequence formed by concatenating the provided sequences. lazy-cat differs from concat in that the expressions provided are not even evaluated until they are required. lazy-cat is, as the name suggests, like concat, but lazier. Use lazy-cat when the result might not be entirely consumed, and so the cost of even evaluating the provided forms might be avoided.
user=> (lazy-cat [1 2 3] '(4 5 6) [7 8 9]) (1 2 3 4 5 6 7 8 9)
mapcat takes a function as its first argument and any number of sequences/collections as additional arguments. It applies the map function with the provided function to the sequence arguments, and then concatenates all the results. mapcat assumes that the supplied function returns a collection or sequence, as it applies concat to its results.
user=> (mapcat (fn [x] (repeat 3 x)) [1 2 3]) (1 1 1 2 2 2 3 3 3)
In this example, the supplied function returns a sequence of its argument repeated 3 times. mapcat concatenates the result of applying the function to each of the supplied sequences/collections.
cycle takes a single argument, a sequence/collection. It returns a lazy infinite sequence obtained by successively repeating the values in the supplied sequence/collection.
user=> (take 10 (cycle [:a :b :c])) (:a :b :c :a :b :c :a)
interleave takes any number of sequences/collections as arguments. It returns a lazy sequence obtained by taking the first value from each argument sequence, then the second, then the third, etc. It stops when one of the argument sequences runs out of values.
user=> (interleave [:a :b :c] [1 2 3]) (:a 1 :b 2 :c 3) user=> (interleave [:a :b :c] (iterate inc 1)] (:a 1 :b 2 :c 3) user=> (interleave [:a :b :c] [1 2 3] [A B C]) (:a 1 A :b 2 B :c 3 C)
interpose takes two arguments, a value and a sequence/collection. It returns a lazy sequence obtained by inserting the supplied value between the values in the sequence.
user=> (interpose :a [1 2 3 4]) (1 :a 2 :a 3 :a 4 :a 5)
rest takes a single sequence/collection as an argument. It returns a sequence of all items in the passed sequence except the first. If there are no more items, it returns an empty sequence.
user=> (rest [1 2 3 4]) (2 3 4) user=> (rest []) ()
next takes a single sequence/collection as an argument. It returns a sequence of all items in the passed sequence, except the first. If there are no more items, it returns nil.
user=> (next [1 2 3 4]) (2 3 4) user=> (next []) nil
drop takes two arguments, a number and a sequence/collection. It returns a sequence of all items after the provided number of items. If there are no more items, drop returns an empty sequence.
user=> (drop 2 [:a :b :c :d :e]) (:c :d :e)
drop-while takes two arguments, a predicate function taking a single argument and a sequence/collection. It returns a sequence of all items in the original sequence, starting from the first item for which the predicate function returns false.
user=> (drop-while pos? [2 1 5 −3 6 −2 −1]) (−3 6 −2 −1)
This example uses the pos? function as a predicate. pos? returns true for all numbers greater than zero, otherwise false.
take takes two arguments, a number and a sequence/collection. It returns a sequence consisting of the first items in the provided sequence. The returned sequence will be limited in length to the provided number.
user=> (take 2 [1 2 3 4 5]) (1 2)
take-nth takes two arguments, a number and a sequence/collection. It returns a sequence of items from the supplied sequence, taking the first item and every Nth item, where N is the supplied number.
user=> (take-nth 3 [1 2 3 4 5 6 7 8 9 10]) (1 4 7 10)
take-while takes two arguments, a predicate function taking a single argument and a sequence/collection. It returns a sequence of all items in the original sequence, up until the first item for which the predicate function returns false.
user=> (take-while pos? [2 1 5 −3 6 −2 −1]) (2 1 5)
drop-last takes one or two arguments. The one argument version takes a sequence/collection. It returns a sequence containing all but the last item in the provided sequence
user=> (drop-last [1 2 3 4 5]) (1 2 3 4)
The two-argument version takes a number and a sequence/collection. It returns a sequence containing all but the last N items in the provided sequence, where N is the provided number.
user=> (drop-last 2 [1 2 3 4 5]) (1 2 3)
reverse takes a single argument, a sequence/collection. It returns a sequence of the items in reverse order. reverse is not lazy.
user=> (reverse [1 2 3 4 5]) (5 4 3 2 1)
sort takes one or two arguments. The one-argument version takes a sequence/collection and returns a sequence of the items sorted according to their natural ordering.
user=> (sort [2 3 5 4 1]) (1 2 3 4 5)
The two-argument version takes an object implementing java.util.Comparator and a sequence collection. It returns a sequence of items sorted according to the comparator.
sort-by takes two or three arguments. The two-argument version takes a key function which takes a single argument, and a sequence/collection. It returns a sequence of the items sorted by the values returned by applying they key function to the item. The key function should then return a naturally sortable value, such as a string or a number.
user=> (sort-by (fn [n] (/ 1 n)) [2 3 5 4 1]) (5 4 3 2 1)
This example supplies a function that returns the reciprocal of its argument as a key function. The result sequence is ordered not by the values themselves, but by the result of applying the key function to them. That is, they are ordered by their reciprocals.
The two-argument version takes a key function, an object implementing java.util.Comparator and a sequence collection. It functions the same as the two argument version, except it uses the supplied comparator to sort the results of the key function.
split-at takes two arguments: a number and a sequence/collection. It returns a vector of two items. The first item in the result vector is a sequence obtained by taking the first N items from the supplied sequence, where N is the supplied number. The second item in the result vector is the rest of the items in the supplied sequence.
user=> (split-at 2 [:a :b :c :d :e :f]) [(:a :b) (:c :d :e :f)]
split-with takes two arguments: a predicate function taking a single argument and a sequence/collection. It returns a vector of two items. The first item in the result vector is a sequence obtained by taking items from the supplied sequence until the first item where applying the supplied predicate returns false. The second item in the result vector contains the rest of the items in the supplied sequence.
user=> (split-with pos? [2 1 5 −3 6 −2 −1]) [(2 1 5) (−3 6 −2 −1)]
partition takes two or three arguments. The two argument version takes a number and a sequence/collection and returns a lazy sequence of lazy sequences. Each child sequence is N items long and populated by every N items from the provided sequence, where N is the provided number.
user=> (partition 2 [:a :b :c :d :e :f]) ((:a :b) (:c :d) (:e :f))
The three-argument version takes two numbers, and a sequence/collection. It works the same way as the two argument version, with the exception that the child sequences are populated at offsets given by the second number provided. This allows overlap of items between the child sequences.
user=> (partition 2 1 [:a :b :c :d :e :f]) ((:a :b) (:b :c) (:c :d) (:d :e) (:e :f))
map takes a function as its first argument and any number of collections/sequences as additional arguments. The provided function should take the same number of arguments as there are additional sequences. It returns a lazy sequence obtained by applying the provided function to each item in the provided sequence(s).
user=> (map pos? [2 1 5 −3 6 −2 −1]) (true true true false true false false) user=> (map + [2 4 8] [1 3 5]) (3 7 13)
first
first takes a single sequence/collection as an argument. It returns the first item in the sequence, or nil if the sequence is empty.
user=> (first [1 2 3 4]) 1
second
second takes a single sequence/collection as an argument. It returns the second item in the sequence, or nil if the sequence is empty.
user=> (second [1 2 3 4]) 2
nth
nth takes two arguments: a sequence/collection and a number. It returns the Nth item of the provided sequence, where N is the provided number. Sequences are indexed from zero, so (nth sequence 0) is equivalent to (first sequence). It throws an error if the sequence has fewer than N items.
user=> (nth [:a :b :c :d] 2) :c
last
last takes a single sequence/collection as an argument. It returns the last item in the sequence. If the sequence is empty, returns nil.
user=> (last [1 2 3 4]) 4
reduce takes two or three arguments. In the two argument version, the first argument is a function which must take two arguments and the second argument is a sequence/collection. reduce applies the supplied function to the first two items in the supplied sequence, then calls the supplied function again with the result of the first call and the next item, and so on for each item in the sequence.
user=> (reduce + [1 2 3 4 5]) 15
In this example, reduce applies the addition function to a list of integers, resulting in their sum total.
The three argument version is similar, except that it takes a function, an initial value, and a sequence/collection. The function is applied to the initial value and the first item of the sequence, instead of the first two items of the collection. The following example illustrates this by building a map from a sequence, using each item as a key and its reciprocal as a value. An empty map is provided as the initial value:
user=> (reduce (fn [my-map value]
(assoc my-map value (/ 1 value)))
{}
[1 2 3 4 5])
{5 1/5, 4 1/4, 3 1/3, 2 1/2, 1 1}apply
apply takes two or more arguments. The first argument is a function and the last argument is a sequence/collection. Other arguments may be any values. It returns the result of calling the supplied function with the supplied values, and the values of the supplied sequence, as arguments. Calling (apply f a b [c d e]) is identical to calling (f a b c d e). The advantage of apply is that it is possible to build dynamic sequences of arguments.
user=> (apply + 1 [2 3]) 6
An example using apply on a dynamic list of arguments: calling + with the integers 0–5 as arguments. This call is equivalent to (+ 1 2 3 4 5), except the argument list is generated dynamically.
user=> (apply + (range 1 6)) 15
empty?
empty? takes a single sequence/collection as an argument. It returns true if the sequence has no items, otherwise false.
user=> (empty? [1 2 3 4]) false user=> (empty? []) true
some takes two arguments: a predicate function taking a single argument and a sequence/collection. It returns the value of the predicate function if there is at least one item in the provided sequence for which it does not return false or nil, else nil.
user=> (some (fn [n] (< n 5)) [6 9 7 3]) true user=> (some (fn [n] (< n 5)) [6 9 7 5]) nil
every?
every? takes two arguments: a predicate function taking a single argument and a sequence/collection. It returns true if the predicate function is true for every value in the sequence, otherwise false.
user=> (every? (fn [n] (< n 5)) [2 1 4 3]) true user=> (every? (fn [n] (< n 5)) [2 1 5 3]) false
dorun
dorun takes one or two arguments: a lazy sequence or optionally a number and a lazy sequence. It causes the lazy sequence to be realized, solely for side effects. dorun always returns nil and does not retain the head of the list, so it will not consume memory.
To demonstrate, the following example applies the map function to a lazy sequence, supplying the println function to map. Normally, println is not a good candidate for an argument to map, since it executes only for side effects and always returns nil.
user=> (def result (map println (range 1 5))) #'user/result user=> (dorun result) 1 2 3 4 nil
In this example, the result symbol is bound to a lazy sequence, the product of map. The actual values of this sequence are all nil, since they are the result of calling println. They are unused in this example. However, whenever the generator function (println) for the sequence is called, it results in a side effect. Since the sequence returned by map is lazy, the generator function is not called until the call to dorun, which forces the sequence to be sequentially evaluated.
If a numeric parameter is provided, dorun evaluates the sequence only as far as that index.
user=> (def result (map println (range 1 10))) #'user/result user=> (dorun 2 result) 1 2
3 nil
Be very careful to always use a numeric parameter to dorun when calling it with an infinite sequence or else the execution will never terminate.
doall
doall, rdentical to dorun, with the exception that as the sequence is evaluated, it is saved and returned by the function. In essence, doall returns a non-lazy version of a lazy sequence. As such, it will result in memory consumption proportional to the size of the sequence. Invoking on an infinite sequence without a numeric parameter will result in an OutOfMemoryError as the system attempts to cache a sequence of infinite length.
user=> (def result (map println (range 1 5))) #'user/result user=> (doall result) 1 2 3 4 (nil nil nil nil)
Note how the function, after executing the generator function for side effects, also returns the actual sequence of values resulting from the call to map. In this case, they are all nil, the return value of println.
The more you use sequences, the more you will come to appreciate them. Having a highly integrated, extremely powerful generic collection management library at your fingertips is hard to do without when you go back to a language without it.
When writing idiomatic Clojure, one cannot use sequences too much. Any point in code where there is more than one object is a candidate for using a sequence to manage the collection. Doing so provides for free all the sequence functions, both built-in and user generated. They will greatly aid in writing expressive, succinct programs.