
The general goal of this book, Practical Concurrent Haskell: With Big Data Applications, is to give professionals, academics, and students comprehensive tips, hands-on examples, and case studies on the Haskell programming language, which is used to develop professional software solutions for business environments, such as cloud computing and big data. This book is not an introduction to programming in general. You should be familiar with your operating system and have a text editor.
To fully understand Haskell and its applications in modern technologies, such as cloud computing and big data, it's important to know where Haskell came from.
When we are discussing Haskell for the cloud, we have to look at it from an Erlang-style point of view. Concurrent and distributed programming in Haskell could be a challenging task, but once it has been accomplished and well integrated with a cloud environment, you will have a strong, reliable, efficient, secure, and portable platform for software applications.
Programming for the cloud with Haskell requires a generic network transportation API, importing and using libraries for sending static closure to remote nodes, and the power of API for distributed programming.
Generic network transport back-ends are developed for TCP (Transmission Control Protocol - represents one of the most used Internet communication protocols) and message of type in-memory, and several other implementations that are available for Windows Azure.
What Is Haskell?
Haskell is a lazy, purely functional programming language. The reason that it is called “lazy” is because only the expressions to determine the right answer to a specific problem are used. We can observe by specifying that the opposite of lazy is strict, which means that the evaluation strategy and mechanisms describe very common programming languages, such as C, C++, and Java.
In general, an evaluation strategy is used for argument(s) evaluation for a call or the invocation of a function with any kind of values that pass to the function. Let's take, for example, a call by a value using the reference that specifies the function that evaluates the argument before it proceeds to the evaluation of the function's body and content. Two capabilities are passed to the function: first, the ability to look up the current value of the argument, and, second, the ability to modify it through the assignment statement. A second type of strategy, called reduction strategy, is specific for lambda calculus; it is similar to an evaluation strategy.
The goal of a reduction strategy is to show how a complex expression is reduced to a simple expression using successive reduction steps. In practice, a reduction strategy is a function that maps a lambda calculus term with expressions that will be reduced to one particular reducible expression. For decades, mathematical logicians have studied the properties of this system. The shallow similarities between the description of evaluation strategies has led programming language researchers to speculate that the two strategies are identical—a belief that can be observed in popular books from the early 1980s; but as we have stated, they are different concepts. Lambda calculus is not the objective of this book, but lambda calculus represents a formal system in mathematical logic used to express computation based on function abstractions and applications that use variable binding and substitution.
In practice, most programming languages use the call-by-value and call-by-reference evaluation strategy for function strategies (C# and Java). The C++ programming language , as a lower-level language, combines different notions of parameter passing. Haskell, a pure functional language, and non-purely functional languages such as R, use call when needed.
To illustrate how the evaluation strategy is working, we have two examples: one in C++ and one in Haskell.
Here is the first simple example in C++ that simulates the call by reference, provided by wikipedia ( https://en.wikipedia.org/wiki/Evaluation_strategy ).
void modify(int p, int* q, int* r) {p = 27; // passed by value: only the local parameter is modified*q = 27; // passed by value or reference, check call site to determine which*r = 27; // passed by value or reference, check call site to determine which}int main() {int a = 1;int b = 1;int x = 1;int* c = &x;modify(a, &b, c); // a is passed by value, b is passed by reference by creating a pointer (call by value),// c is a pointer passed by value// b and x are changedreturn 0;}
The second example uses Haskell. You can see the evaluation strategy by using call by need, which represents a memorized version of call by name, where, if the argument that sends to the function is evaluated, that value is stored for different subsequent uses.
cond p x y = if p then x else yloop n = loop nz = cond True 42 (loop 0)
Haskell is known as a pure functional language because it does not allow side effects; by working with different examples, we can observe that Haskell is using a set as a system of monads to isolate all the impure computations from the rest of the program. For more information about monads, please see Chapter 2.
Side effects in Haskell are hidden, such that a generic over any type of monad may or may not incur side effects at runtime, depending on the monad that is used. In short, “side effects” mean that after every IO operation, the status of the system could be changed. Since a function can change the state—for example, change the contents of a variable, we can say that the function has side effects.
Haskell is a functional language because the evaluation process of a program is equal to the evaluation of a function in the purest and natural mathematical way. This is different from standard languages, such as C and Java, in which the evaluation process is taking place as a sequence with statements, one after other— known as an imperative language/paradigm. In the last few years, impure and functional languages like F# or Swift, have been adopted more and more.
When creating applications for cloud computing, it is very important to understand the structure of the Haskell program and to follow some basic steps , which are described in Chapter 2. Let’s overview these steps.
At the topmost level, Haskell software is a set of modules. The modules allow the possibility to control all the code included and to reuse software in large and distributed software in the cloud.
The top level of a model is compounded from a collection of declarations. Declarations are used to define things such as ordinary values, data types, type classes, and some fixed information.
At a lower level are expressions. The way that expressions are defined in a software application written in Haskell is very important. Expressions denote values that have a static type. Expressions represent the heart of Haskell programming.
At the last level , there is lexical structure, which captures the concrete representation of a software in text files.
A Little Bit of Haskell History
To discuss the full history of Haskell would be a laborious task. The following is from The Haskell 98 Report ( https://www.haskell.org/onlinereport/ ).
In September of 1987, a meeting was held at the conference on Functional Programming Languages and Computer Architecture (FPCA '87) in Portland, Oregon, to discuss an unfortunate situation in the functional programming community: there had come into being more than a dozen non-strict, purely functional programming languages, all similar in expressive power and semantic underpinnings. There was a strong consensus at this meeting that more widespread use of this class of functional languages was being hampered by the lack of a common language. It was decided that a committee should be formed to design such a language, providing faster communication of new ideas, a stable foundation for real applications development, and a vehicle through which others would be encouraged to use functional languages. This document describes the result of that committee's efforts: a purely functional programming language called Haskell, named after the logician Haskell B. Curry whose work provides the logical basis for much of ours.
Because of the huge impact that cloud computing and big data has on developing technologies, Haskell continues to evolve every day. The focus is on the following.
Syntactic elements: patterns guards, recursive do notation, lexically scoped type variables, metaprogramming facilities
Innovations on type systems: multiparameter type classes, functional dependencies, existential types, local universal polymorphism, and arbitrary rank-types
Extensions for control: monadic state, exceptions, and concurrency
As we mentioned, this book is not an introduction to Haskell. We remind you that there are two standards: 98 and 2010. The main complier, GHC, extends these languages in different ways. You are encouraged to read The Haskell 98 Report and the Haskell 2010 Language Report ( https://www.haskell.org/onlinereport/haskell2010/ ); both are freely available on the Internet .
The Cloud and Haskell
This section discusses the problem of designing distributed processes and implementation processes for cloud environments. Compared with other initial implementations, the aim isn’t to change the API. The API, such as the efforts to combine Erlang-style concurrent and distributed programming in Haskell to provide generic network transport API, libraries intended to send static closures to remote nodes, or a very rich API for distributed programming API, are and represents couple of examples of what we can use in the process of developing applications in Haskell for cloud environments. The real aim is to gain more flexibility in the network layer and transport layer, such as shared memory, IP and HPC interconnects, and configuration (i.e., neighbor discovery startup and tuning network parameters). When designing and implementing software applications with Haskell for the cloud, it’s better to consider both schemes, as shown in Figure 1-1 and Figure 1-2.
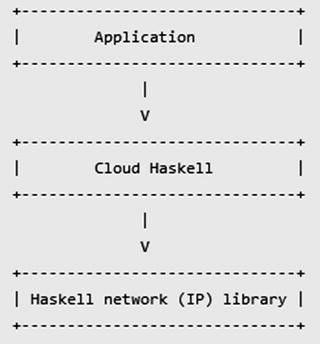
Figure 1-1. Haskell for cloud module dependencies (figure from http://haskell-distributed.github.io/wiki/newdesign.html )
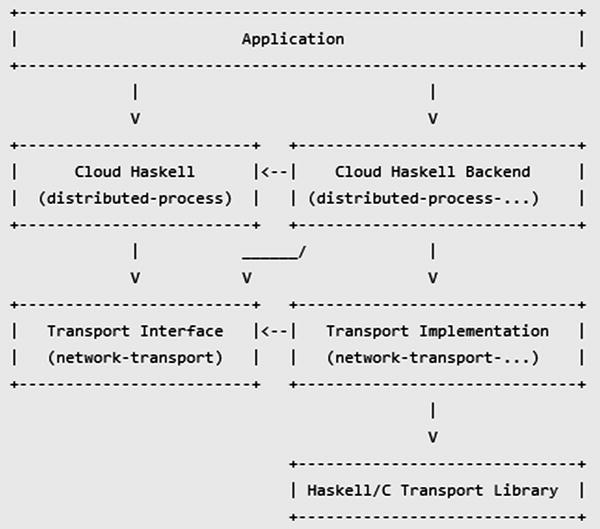
Figure 1-2. Designing the modules (figure from http://haskell-distributed.github.io/wiki/newdesign.html )
Figure 1-1 points outsome dependencies between different modules for the initial startup implementation in Cloud Haskell . The arrows indicate the direction of the dependencies.
Figure 1-1 indicates the initial implementation uses a single specific transport, based on TCP/IP (Haskell network (IP) Library).
Figure 1-2 shows the various modules that are provided in the new design. We divided a generic system into two layers: the Cloud Haskell layer and the Network Transport layer. Each layer has a back-end package that can be used with different transports .
According to the official documentation ( http://haskell-distributed.github.io/wiki/newdesign.html ), applications designed and developed with Haskell are encouraged to use the Cloud Haskell Layer.
Complete applications will necessarily depend on a specific Cloud Haskell backend and would require (hopefully minor) code changes to switch backend. However, libraries of reusable distributed algorithms could be written that depend only on the Cloud Haskell package.
The following code example, CountingSomeWords, illustrates how necessary imports are used in a distributed programming environment and how to make them to work with MapReduce.
module CountingSomeWords( Document, countingWordsLocally, countingWordsDistributed, __remoteTable) whereimport Control.Distributed.Processimport Control.Distributed.Process.Closureimport MapReduceimport MonoDistrMapReduce hiding (__remoteTable)import Prelude hiding (Word)type DocumentsWithWords = Stringtype SomeWord = Stringtype HowOften = Inttype countWords = IntcountingSomeWords :: MapReduce FilePath DocumentsWithWords SomeWord HowOften HowOftencountingSomeWords = MapReduce {aMap = const (map (, 1) . words), aReduce = const sum}countingWordsLocally :: Map FilePath DocumentsWithWords -> Map SomeWord HowOftencountingWordsLocally = localMapReduce countWordscountingSomeWords_ :: () -> MapReduce FilePath DocumentsWithWords SomeWord HowOften HowOftencountingSomeWords_ () = countingSomeWordsremotable ['countWords_]countingWordsDistributed :: [NodeId] -> Map FilePath DocumentsWithWords -> Process (Map SomeWord HowOften)countingWordsDistributed = distrMapReduce ($(mkClosure 'countWords_) ())
The next example will show how to use one of the most important characteristic of cloud computing within Haskell.
module MapReduce( -- * Map-reduce skeleton and implementationMapReduce(..), localMapReduce-- * Map-reduce algorithmic components, reducePerKey, groupByKey-- * Re-exports from Data.Map, Map) whereimport Data.Typeable (Typeable)import Data.Map (Map)import qualified Data.Map as Map (mapWithKey, fromListWith, toList)import Control.Arrow (second)-- | MapReduce skeletondata MapReduce k1 v1 k2 v2 v3 = MapReduce {mrMap :: k1 -> v1 -> [(k2, v2)], mrReduce :: k2 -> [v2] -> v3} deriving (Typeable)-- | Local (non-distributed) implementation of the map-reduce algorithm---- This can be regarded as the specification of map-reduce; see-- /Google's MapReduce Programming Model---Revisited/ by Ralf Laemmel-- (<http://userpages.uni-koblenz.de/∼laemmel/MapReduce/>).localMapReduce :: forall k1 k2 v1 v2 v3. Ord k2 =>MapReduce k1 v1 k2 v2 v3-> Map k1 v1-> Map k2 v3localMapReduce mr = reducePerKey mr . groupByKey . mapPerKey mrreducePerKey :: MapReduce k1 v1 k2 v2 v3 -> Map k2 [v2] -> Map k2 v3reducePerKey mr = Map.mapWithKey (mrReduce mr)groupByKey :: Ord k2 => [(k2, v2)] -> Map k2 [v2]groupByKey = Map.fromListWith (++) . map (second return)mapPerKey :: MapReduce k1 v1 k2 v2 v3 -> Map k1 v1 -> [(k2, v2)]mapPerKey mr = concatMap (uncurry (mrMap mr)) . Map.toList
Book Structure
This book has two parts.
Part I is covers eight chapters on the basics of Haskell, including what you need know to develop and move applications in cloud computing and big data environments.
Chapter 1 outlines the most important goals of this book and it guides you through the entire structure of the book.
Chapter 2 presents medium-advanced examples of source code that help you understand the difference between creating a software application for local use and a software application used for a cloud-computing environment.
Chapter 3 brings all the elements for developing software applications using parallelism concurrent techniques. Threads, distributed programming, and EVAL monad for parallelism represent the most important topics.
Chapter 4 goes through the different strategies used in the evaluation process during code execution. The strategies described in this section provide the most important steps needed to integrate within applications.
Chapter 5 focuses on the importance of using exceptions thrown by different situations of using a monad in order to integrate I/O operations within a purely functional context.
Chapter 6 covers the importance of cancellation conditions as a major component for developing an application using parallelism.
Chapter 7 discusses some powerful tools for resolving important issues that could appear in the process of developing distributed applications. These problems include race conditions due to forgotten locks, deadlocks, corruption, and lost wakeups.
Chapter 8 covers debugging, which plays an important role in the process of developing and updating software applications. Sometimes the debugging process is problematic because Haskell does not have a good debugger for advanced software applications. Some modern techniques that could be used in debugging process are discussed.
Part 2 is focused on developing advanced software applications using big data and cloud computing environments.
Chapter 9 covers the most important methods for processes and messages, and techniques used for matching messages. The section will present a domain-specific language for developing programs for a distributed computing environment.
Chapter 10 covers the most comprehensive techniques and methods for calling and using big data in Haskell by providing case studies and examples of different tasks.
Chapter 11 goes through concurrency design patterns with the goal to understand how to use them for applications based on big data.
Chapter 12 presents the steps necessary for designing large-scale programs in such a manner that there are no issues when ported in a big data or cloud environment.
Chapter 13 looks at Hadoop algorithms and finds the most suitable environment for running different data sets of varying sizes. The experiments in this chapter are executed on a multicore shared memory machine.
Chapter 14 covers the necessary tools and methods for obtaining an interactive debugger.
Chapter 15 presents MapReduce for cloud computing and big data, together with all the elements that can be used for developing professional applications based on data sets and for creating an efficient portability environment.
Chapter 16 offers original ideas for serving applications on data mining, web ranking, analysis of different graphs, and so on. Elements for improving efficiency by creating and developing caching mechanisms are provided.
Chapter 17 presents case studies that demonstrate the running process on large clusters. Parallelization of programs are provided and executed on large clusters.
Summary
This chapter introduced the main ideas behind cloud for Haskell, such as
the main concepts behind developing Haskell applications for cloud computing environments.
dependencies and how they are used to gain the greatest performance.
designing modules and setting the new layers necessary for every application developed with Haskell for the cloud.
It also covered the book’s structure and provided an overview.