
Data science is all about data, which inevitably also includes sensitive information about people, organizations, government agencies, and so on. Any confidential information must be handled with utmost care and kept secret from villains. Protecting privacy and squeezing out value from data are opposing forces, somewhat similar to securing a software system while also trying to optimize its performance. As you improve one you diminish the other. As data scientists, we must ensure both that data is properly protected and that our data science product is capable of fending off abuse as well as unintended usage (for example, prevent it from being used to manipulate people by recommending to them specific items or convincing them to act in some particular manner). All protective actions should nicely interplay with the usefulness of a data science product; otherwise, there is no point in developing the product.
Because data security is part of a very broad domain of security engineering, the goal of this chapter is simply to steer your attention to the myriad details you should be aware of. It contains lots of small examples to explain concepts in a pragmatic fashion. It starts with an overview of attack types and tools to combat them. Then, to give you a sense of the types of data privacy regulations that you need to be aware, this chapter elaborates on the European Union’s General Data Protection Regulation (GDPR), which affects solutions that process data about EU citizens. Finally, the chapter discusses securing machine learning models to respect privacy.
Checking for Compromise
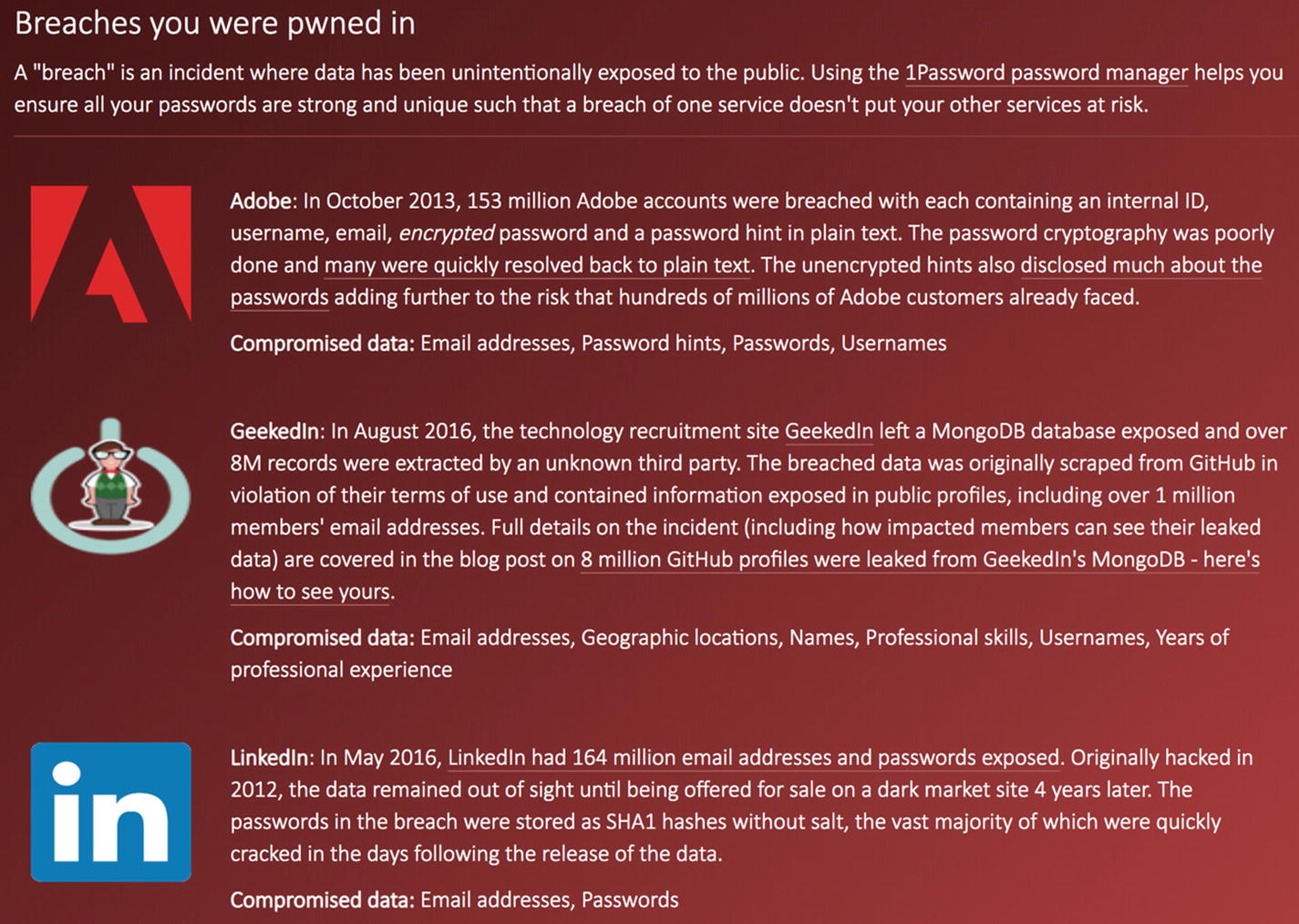
The report showing incidents regarding my e-mail
Your private details have possibly leaked out to malevolent persons due to inappropriate security measures.
Parties you have never contacted know something about you. In my case, I had never visited GeekedIn, although my e-mail was registered in their system; the data about people was collected by inappropriately scraping public GitHub profiles.
This example highlights important mutual responsibilities between entities who collect personal data and users who provide personal data. On one hand, the entities must make best efforts to comply with security standards, and on the other, users must be knowledgeable about dangers and follow general safety advice pertaining to the Internet. For example, users should know to never use the same user account/password combination on multiple web sites (read also reference [1]), never provide sensitive data over an unsecured connection, never click links in suspicious e-mails (how to recognize spam and fishing sites is a topic on its own), and so forth. Computing in the modern world requires adequate security awareness from all participants. This is like being a pedestrian in traffic; you still need to obey basic rules irrespective of whether you have a driver’s license or not. Of course, as you aspire to drive a motor vehicle, you must gain enough experience and attain a proper license. Some large vehicles can only be driven by professional drivers. The same applies in data science. As you accumulate more data, you need to ensure that your security skills are at an adequate level, as a potential data breach doesn’t only affect you. Many areas of data science are strictly regulated, and companies need to obtain certificates from authorities to handle sensitive data. Various government entities have a variety of different laws and regulations pertaining to data security (we will touch upon the GDPR in the next section as an example). Consult reference [2] to read about an interesting initiative encompassing the whole Web that aims to establish transparency and freedom on the Internet.
Most data science products are remotely accessible via APIs, which allows efficient data exchange scenarios and creation of mashups (introduced in Chapter 8). In all situations, data must be protected both in transit and at rest. Consequently, the external network is usually some secure overlay on the public Web (for example, a secure HTTPS channel, a dedicated virtual private network, etc.). The Internet is a hostile environment, and your product will eventually become a target, especially if it contains precious confidential data.
There are lots of organizations dedicated to sharing best security practices for various technologies, and you should check out at least a few of their web sites. For example, the Open Web Application Security Project (OWASP) is focused on improving the security of software (visit https://www.owasp.org ) by promoting proven practices and standards. SecTools.org ( https://sectools.org ) compiles many of the best network security tools in one place. (For a good overview of developing secure solutions, check out references [3], [4], and [5].) Other great resources are SecAppDev ( https://secappdev.org ), which is a specialized conference about developing secure products, and the ISO/IEC 27000 family of standards, which prescribes techniques for organizations to keep information assets secure (visit https://www.iso.org/isoiec-27001-information-security.html ).
Burp Suite ( https://portswigger.net ) helps in finding web security issues.
Snort ( https://www.snort.org ) is an intrusion prevention system that enables real-time monitoring of networks and taking actions based upon predefined rules.
Snyk ( https://snyk.io ) automates finding and fixing vulnerabilities in your dependencies. It supports many programming languages, including Python.
Clair ( https://github.com/coreos/clair ) performs static analysis of vulnerabilities in application containers (supports Docker).
Docker Bench for Security ( https://github.com/docker/docker-bench-security ) gives valuable advice on how to make your Docker packaged application secure.
Gitrob ( https://github.com/michenriksen/gitrob ) is a tool to help find potentially sensitive files pushed to public repositories on GitHub. This type of omission is very common, especially when a deployment process is disorganized.
Vault ( https://www.hashicorp.com/products/vault ) is a tool to solve problems that Gitrob is trying to detect (refer to the previous item).
OSS Supply Chain Attack
Open-source software (OSS) is a new attack vector where social engineering plays the central role (refer to [6]). A villain starts his journey by making valuable contributions to an open-source project until he gains the confidence of the project sponsors and other contributors. Once he’s in possession of proper credentials, he plants vulnerabilities directly into the supply of open-source components. For example, there was a known compromise of PyPI (SSH Decorator), and we are likely to see many more of these types of attack in the future. Due to the huge number of downloads of popular open-source frameworks, the rate at which bogus code spreads can be blistering. Don’t forget that if you incorporate open-source components into your own data science product, you are still legally responsible for the security of your product; you are the last link in the chain of responsibility. Therefore, always check the security profile of any open-source component that you consider using.
One way to combat this problem is to resist the temptation to eagerly seek out the latest versions of OSS. Upgrades to versions should be made in a controlled fashion, possibly supported by a centralized enterprise risk management (ERM) tool; a good choice is JFrog Artifactory (see https://jfrog.com/artifactory ), which has a free community edition. ERM introduces an important level of indirection and may also improve availability by caching artifacts. Developers should only retrieve components approved by the QA department.
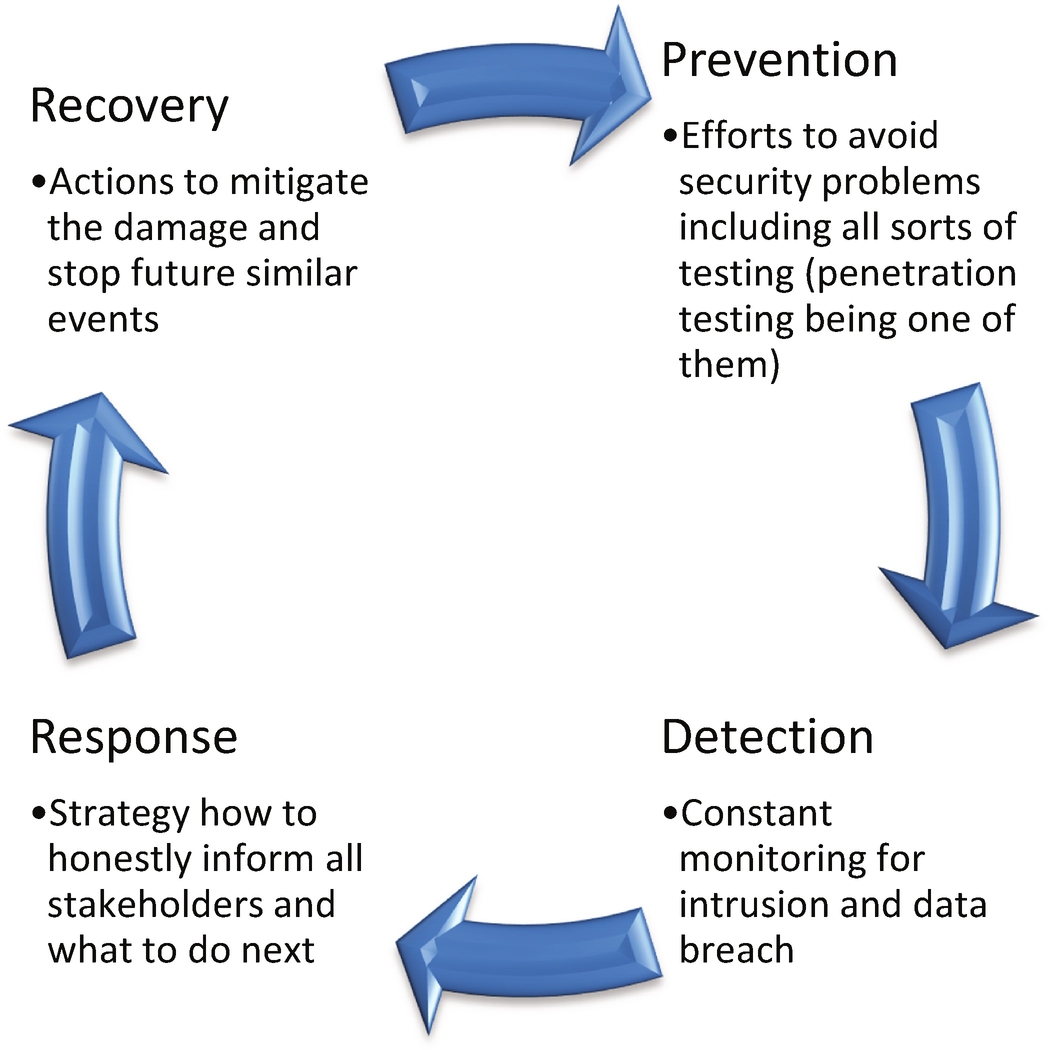
The main phases of handling security events
It is crucial to have these planned well in advance, when everything works fine. For example, you must verify a backup procedure before the first recovery attempt (assuming that you do have such a procedure established, which is a high priority). Your response to clients must be formulated during a calm period; never attempt to hide the issue! Actually, as you will see later, the GDPR even mandates proper notifications, as specified in Articles 33 and 34 (articles are statements in the GDPR that are treated as obligatory rules).
There are three main ways in which companies may acquire information about you: disclosure, collection, and inference (also watch section 10 of reference [7] and read the sidebar “What Is Privacy?”). Let’s use a recommender system as an example (introduced in Chapter 8). If you explicitly rate a movie, then you are voluntarily disclosing information. Disclosure is the most obvious form of data gathering, since users are fully aware and have control over this process. Collection is a bit more peculiar.1 Namely, as you click movie descriptions, the system records these events and alters your profile accordingly. Furthermore, not clicking a recommended movie is also a useful input, as is the length of time you spend on a page reading about a movie; watching a trailer is another strong indicator that you are attracted to that item. Finally, inference is quite enigmatic. It refers to the capability of machines to discover facts about you based on seemingly innocuous data. The biggest challenge is how to control such inferred information from further abuse. Put another way, if you are the owner of the basic facts, then you should retain ownership over derived values, too. A good proposal that aims to solve this conundrum is given in reference [8].
What is Privacy?
The term privacy has different meanings depending on the viewpoint (i.e., it is a subjective notion). A common attribute of privacy is the expectation regarding control. You might perceive unsolicited marketing messages (e-mails, text messages, notifications, etc.) as a privacy violation if you never agreed to receive such stuff and you are given no option to remove your name from the matching address books. From this perspective, the existence or lack of control defines whether you will classify those messages as spam.
There is a subtle tipping point between level of privacy and usefulness/capabilities of data science products. At one extreme, only nonexistent (deleted) data is absolutely private. Of course, in that case you can get nothing of value out of a data science service. For example, if you haven’t rated any movies or performed any other activity on a movie recommender site, then you shouldn’t be surprised that you get purely nonpersonalized content. The other extreme is public data, which obviously contains the highest level of informational content and totally lacks privacy. So, all stakeholders in a data science world must balance privacy and utility. If users can retain control and alter their decisions about the level of privacy, then the basics are properly set.
In her book Privacy in Context: Technology, Policy, and the Integrity of Social Life (Stanford University Press, 2009), Professor Helen Nissenbaum suggested that privacy is about contextual integrity. In certain contexts, you assume that whatever personal information you divulge in confidence will not be used in unexpected ways or shared without your authorization. For example, if you tell your doctor about your health issues, you assume that the doctor won’t share those details with your employer. Therefore, anything tightly associated with a particular behavioral norm is sort of a privacy.
Introduction to the GDPR
It is interesting to peek into this EU law impacting all organizations that handle personal data of EU citizens (including in their Big Data solutions) (also consider watching the video course at [9]). The law applies to both EU-based organizations (regardless of where data processing happens) and non-EU-based organizations handling data about EU citizens (in the rest of the text, by “EU” I mean both EU and European Economic Area [EEA] countries). The GDPR is an incremental evolution of previous data protection laws to accommodate recent technological advances (such as the Internet of Things, Big Data, e-commerce, etc.). Essentially, it is a law that attempts to codify behavioral patterns of organizations to ensure that they respect privacy of people. As a law, it is strictly monitored by local Data Protection Authorities, who enforce accountability for lapses in data security. The idea is to enable interoperable data science solutions with shared expectations about data privacy. Even if you do not work in an EU country, chances are that your organization may be processing data on behalf of an EU-based company. Moreover, it is beneficial to take a look at how privacy may be formulated as a law. The GDPR is not a security standard, so concrete techniques on how to implement it are beyond the scope of this book.
The GDPR is composed of two types of items: 99 articles and 173 recitals. The former may be approximated with business requirements, while the latter serve as principles that explain the reasons for the articles. I like how the GDPR is presented at https://gdpr-info.eu with an additional key issues element type (which depicts some common problems in applying the GDPR, with references to articles and recitals).2 I suggest that you keep Article 4 open while sifting through the GDPR, as it contains definitions of key terms (such as data subject, personal data, controller, processor, etc.).
The major contribution of the GDPR is the mapping of data to rights in regard to control and processing embodied in Recital 1? See https://gdpr-info.eu/recitals/no-1/ : “The protection of natural persons in relation to the processing of personal data is a fundamental right.” The idea is to balance people’s fundamental rights and freedoms with personal data processing, including rights of controllers (any organization that decides to do anything with your personal data). For example, if a company possesses extremely sensitive data about you, then a data breach may potentially endanger some of your basic rights, such as your right to preserve your private life and family life (consider the users affected by the 2015 hack of the Ashley Madison web site, a dating site for married people seeking affairs).
Article 5 sets forth the principles relating to processing of personal data. In some sense, this should be your entry point into the GDPR. Article 6 explains in detail what is meant by lawful processing (there are six legal reasons for processing personal data). Articles 5 and 6 cover the basic category of data. Article 9 also specifies special categories of personal data together with more stringent processing rules.
Caution
Make sure to always follow a well-documented process for any decision making in relation to personal data processing. Any controller must prove to regulators that proper governance is in place and that all measures to protect privacy are strictly obeyed. This is part of the accountability principle.
Tip
Adhering to the GDPR can help you to streamline your data processing pipeline. Item 1c of Article 5 states the following regarding the processing of personal data: “Personal data shall be adequate, relevant and limited to what is necessary in relation to the purposes for which they are processed (‘data minimisation’).” So, you are forced to rethink the volume of data at rest and in transit. Reducing the amount of data is definitely beneficial regardless of data security requirements.
Right of access by the data subject, which encompasses the right to receive a copy of all data as well as meta-data (for example, lineage information regarding where the data came from, or how it is handled).
Right to rectification, so that the data subject can fix errors in data.
Right to erasure, so that data may be removed even before the retention period ends. Of course, some erasures cannot be satisfied, for legal reasons.
Right to restrict processing until erroneous data is fixed or deleted.
Right to data portability that allows efficient data exchange between controllers (for example, if the data subject chooses to transfer data from one controller to another in an automated fashion) and guarantees the receipt of data from a controller in a standard machine-readable format.
Right to object to processing of data on the grounds of jeopardizing some of the fundamental personal rights and freedoms.
Right not to be “subject to” automated decision-making, including profiling.
A controller must respond to any request within one month, free of charge. Definitely, it pays off to automate many tasks, if possible. One particularly dangerous approach is to always let people remotely manage their personal data. The recommendation from Recital 63 related to this is, “Where possible, the controller should be able to provide remote access to a secure system which would provide the data subject with direct access to his or her personal data.” Any remote access over the Internet immediately entails a myriad of security issues, and a mistake can be devastating.
In order to maintain security and to prevent processing in infringement of this Regulation, the controller or processor should evaluate the risks inherent in the processing and implement measures to mitigate those risks, such as encryption. Those measures should ensure an appropriate level of security, including confidentiality, taking into account the state of the art and the costs of implementation in relation to the risks and the nature of the personal data to be protected. In assessing data security risk, consideration should be given to the risks that are presented by personal data processing, such as accidental or unlawful destruction, loss, alteration, unauthorised disclosure of, or access to, personal data transmitted, stored or otherwise processed which may in particular lead to physical, material or non-material damage.
—Recital 83, GDPR
The GDPR suggests a people-oriented, risk-based security system. This is very important to understand, as any absolutistic approach would definitely fail. Security standards like ISO 27001, NIST, and others may give guidance about appropriate techniques, but they should be applied in the context of the impact on fundamental rights and freedoms of data subjects, rather than organizations, in case of a security breach. Therefore, at the heart of GDPR Article 32 is risk management, which is a broad topic applicable in any software development project. The main difference here is that estimating the severity of risk must include the number of data subjects potentially impacted by an attack.3 Also, be warned that volume influences both the probability and impact of the risk, so it is imprecise to calculate risk as barely a multiple of probability, impact, and volume. In other words, risk = probability(volume) × impact(volume); both of these quantities are a function of volume and may have nonlinear relationships. For example, the chance that your system is going to be a target of an attack increases as it stores more records. Furthermore, any data breach will have a higher impact, as more data subjects will be hit. As it is hard to express these quantities as real numbers, you may use ordinal numbers instead (take inspiration from T-shirt sizing of agile user stories). For example, a risk with low probability and low impact would have low severity.
Caution
Don’t be blinded by numbers. If there is a threat that may jeopardize somebody’s life, then the highest risk level applies. I have already mentioned the data breach of the Ashley Madison dating site. At least two people whose data was exposed thereafter committed suicide, so any similar system should treat risks related to data theft as critical.
Is your capability to remove superfluous data operational? GDPR dictates that all data must be removed after the specified retention period or when requested by a data subject. As a controller you must take care to enforce and supervise data removal at any external processor, especially if it is outside of the EU.
Do you have areas that you judge are probably noncompliant with the GDPR? This is a special risk type and you should assess risks based upon article numbers. In other words, articles with lower identifiers are heavier than those enumerated later. This means that breaking core principles defined in Article 5 is more severe than not following Article 32.
Do you have adequate control over processors? Have you arranged what happens after termination of a contract with a processor? You must take care to get back the data or ensure that it is fully erased after completion of the contract.
Have you planned in enough capacity to promptly respond to requests from data subjects? In some sense, this is an extension of the usual customer support that most organizations already have.
Is your access control mechanism flexible enough to support all use cases related to processing of data? You may want to apply an attribute-based access control model that comes with a recommended architecture, as shown in Figure 9-3 (see also reference [10]).
Do you have a documented response plan? You must respond to a data breach not later than 72 hours after becoming aware of such an event. Of course, the event may have happened much earlier, but the 72-hour period doesn’t begin until you become aware of the event. Investigation of an issue should continue even after this initial period, to incorporate defensive mechanisms to prevent such occurrences in the future. The regulator will usually help in deciding if and how to contact data subjects.
Is monitoring of activities of employees in compliance with the GDPR? Employees are also data subjects internal to an organization, so overzealous data collection of their activities might cause privacy problems.
Is auditing of data processing activities defined and implemented, as described in Article 30?
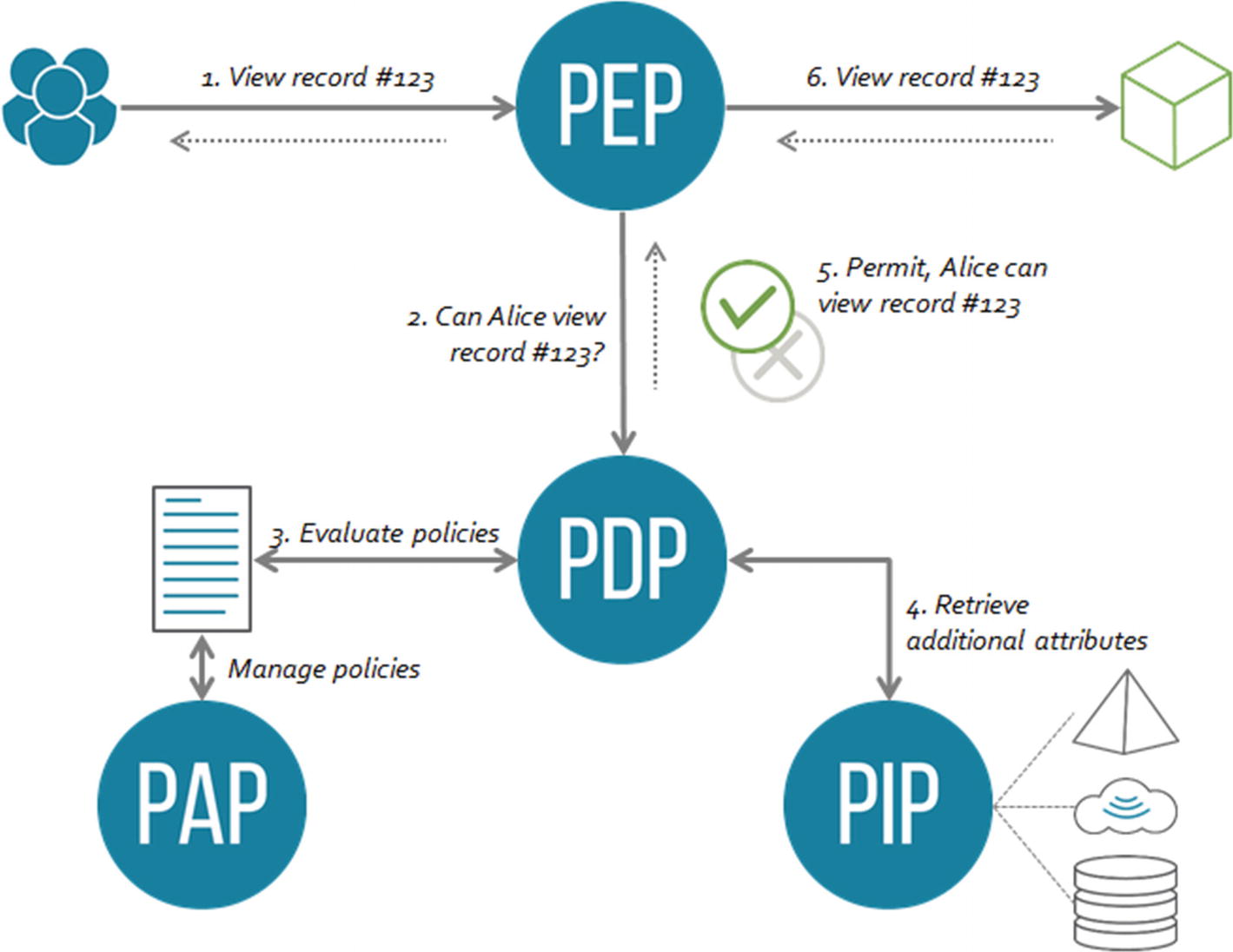
The main components of this architecture are Policy Enforcement Point (PEP), Policy Decision Point (PDP), and Policy Information Point (PIP), as documented by David Brossard at http://bit.ly/abac_architecture
Referring to Figure 9-2, the PEP can be part of the API gateway that intercepts requests and passes the corresponding authorization requests to the PDP. The PDP decides whether to approve or not each request based on predefined policies. These are edited by a separate component, the Policy Authoring Point (PAP). The PDP may gather extra attributes from the PIP, which is a hub that collects attributes from various external sources.
One viable heuristics is to research accepted industry standards and ensure that your practices are commensurate with those of similar enterprises. If you are going to embark into research related to health care, then you may find plenty of peer companies in that same domain. Just ensure to avoid staying behind them. Again, this depends on the context, so take care if you process a special category of data as described in the GDPR.
Article 32 also expands upon availability of your service in relation to its effect on data subjects. This is where domain-driven design and, especially, microservices can help a lot. Having a single database could pose a huge security concern, as it can be a single point of failure (in this case, a target of a data breach). Microservices may choose different technologies to process data, so an attack targeting a specific technology would have a limited scope. Microservices may improve availability as a distributed system, and thus realize the concept of segmentation. Finally, because each microservice is responsible for a dedicated business domain (i.e., has a well-defined bounded context), it is possible to select proper security measures on a case-by-case basis. For example, a health care system may have auxiliary segments that are apart from core services and do not require the same level of protection as patient records. For more information about crafting secure microservices-based systems, watch the video at reference [5].
Another benefit, or positive side effect, of relying on microservices to deliver secure data science products is the high focus on automation and the DevOps paradigm. Centralized logging, monitoring, and distributed tracing (all supported by tools), as well as active execution of robustness and security tests (even in production), aid in complying with Article 32, which has a section about operational awareness and effectiveness of security measures. These are by default part of the DevOps culture that enables having large-scale microservices-based systems in production.
Machine Learning and Security
Attacks on artificial intelligence (AI) systems are a reality. As described in reference [11], researchers have managed to alter just a tiny part of an image used by an AI system in health care to fool the system into believing that some health problem is present, or vice versa. In reference [12], researchers have illustrated how image recognition technology can be fooled in many ways. It is also possible to ferret out personal details from machine learning (ML) models. This imposes another security dimension to be aware of. The major difficulty in assessing an ML-based system’s security risk is related to our inability to grasp exactly what is contained inside a trained model. This is associated with interpretability of models, and most models (including those utilized by neural networks) are hard to understand. So, it is impossible to guarantee that a trained model is bullet-proof against some sort of reverse engineering. A similar reasoning applies to ML algorithms (i.e., they are also victims of different attacks).
For a more detailed introduction to the topic of ML security, you may want to read reference [13]. Another superb source of knowledge is the EvadeML project (visit https://evademl.org ), which aims to investigate how to make ML methods more robust in the presence of adversaries. In the next few subsections, I will present two types of attack and how they work: a decision-time attack (attack on models) and a training-time attack (attack on algorithms, commonly known as a poisoning attack). To make the text lighter and applicable to a broad audience, I will err on the side of accuracy to make matters more comprehensible.
Membership Inference Attack
Let’s look at a black-box attack (published in [14]) for figuring out whether some target model was trained using a supervised learning method with a given partial record. This case study is interesting because it leverages an adversarial use of machine learning to train another ML system capable of classifying predictions of the initial system. Apparently, machine learning is used against machine learning to squeeze out information from the target model. The vulnerability of an ML model to this type of attack applies broadly. Nowadays, big cloud providers such as Amazon, Google, Microsoft, and BigML are offering machine learning as a service (MLaaS) , and their set of offerings is also susceptible to this sort of attack (actually, they were the primary focus of the attack described in [14]). Thus, having unrealistic expectations regarding the security of ML may put your system at risk. Of course, many weaknesses can be mitigated, but only if you are aware of the issues.
The basic idea is to send a query to the target model and feed its prediction into the adversarial system.4 The final output would be a signal indicating whether or not data from the query is part of the training dataset. Sending queries and collecting predictions are the only allowable interactions with the target model. (White-box attacks rely on knowing the internal structural details of the target model, so it is an easier problem to solve than the black-box variant.) The premise is that the target model’s behavior when it receives input from a training dataset is noticeably different than its behavior when it receives data never seen before by the system. In some sense, this attack belongs to the family of side-channel attacks.5
Why should we bother with this? Well, suppose that we have acquired a person’s consent to participate in a data science project (consent is one of the legal bases in GDPR to process personal data). We show her our privacy notice stating that her data will be used only for model training purposes and will be kept secure permanently. Once she agrees to this, any potential data breach from a membership inference attack is automatically a privacy concern. If our data science project stores a special category of data, such as data about health, finance, or a similar sensitive domain, then we should be very vigilant about this potential problem. Be warned that you cannot eschew responsibility by claiming that such leakage wasn’t your fault because you are using a commercial cloud service. In the light of the GDPR, as a controller, you are fully liable and accountable for any data processing action carried out by your processor.
Where is the side channel here? In Chapter 7 we talked about the phenomenon of overfitting a model. This happens when we eagerly try to reduce the training prediction error. Consequently, the model picks up tiny details from the training set that are not relevant for generalization. An overfitted model would behave differently depending on whether you provide a record from the training dataset or provide something brand new. The membership inference attack relies on this behavioral difference to categorize the input as either part of or not part of the training dataset (overfitting is not the only possibility, but for the sake of simplicity, assume that it is). Obviously, avoiding overfitting can help prevent membership inference attacks, and regularization is one way to achieve that (see Chapter 7 for details). Hence, improving our ML system to better generalize turns out to be beneficial from the security aspect, too.
Shadow Training
Shadow training is a unique technique whose architecture is depicted in Figure 9-4. It resonates well with the fundamental theorem of software engineering coined by David Wheeler: “All problems in computer science can be solved by another level of indirection.” In shadow training, shadow models are trained using the same ML platform as was used for the target model. The target system is totally opaque to us, including its private training dataset. The shadow models are trained using synthetic training sets. One simple way to generate a shadow training set is to rely on statistical knowledge about the population from which the training set of the target model was drawn. More specifically, we need to know the marginal distributions of various features and then sample from these distributions. The end result is a statistically valid representative of the private training dataset of the target model. We produce multiple shadow models with different configurations to boost accuracy. The shadow test sets are generated in a similar fashion.
The i-th shadow training set is used to produce the i-th shadow model. This training dataset contains records and their true labels. The output of every shadow model given an input from the matching training dataset is added to the so-called attack training dataset (used to train the final attack model). The test sets are used to create records in the attack training dataset that denote responses of shadow models on unseen data.
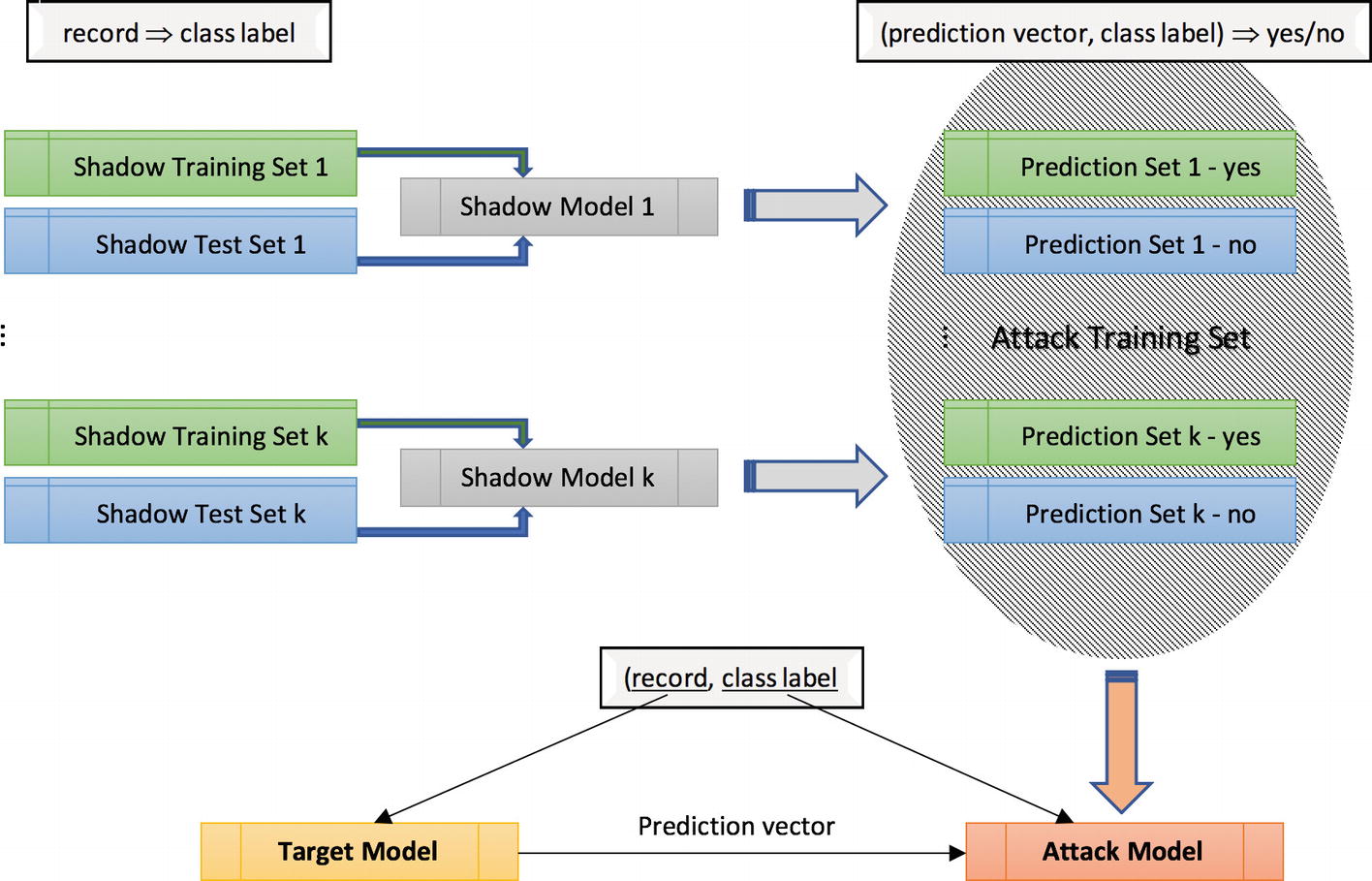
The overall structure of the shadow training process as well as its execution, as described in [14]
Poisoning Attack
Label modification attack: The attacker` tries to alter the labels in the dataset. Obviously, this applies only to supervised learning methods. In the case of binary classifiers, this type of action is known as label flipping.
Poison insertion attack: The attacker tries to contaminate some limited number of arbitrary feature vectors by adding bogus records.
Data modification attack: The attacker attempts to modify an arbitrary number of records (both features and labels).
Boiling frog attack: An attacker gradually delivers poisoned records in each training iteration. The idea is to keep incremental changes small enough to avoid being detected. Of course, over time the cumulative effect can be significant. The name of the attack comes from a fable whose lesson is that if you put a frog in lukewarm water and slowly increase the water’s temperature, then you may cook the frog without the danger that it will jump out of the pot, as it would if you dropped it in boiling water.
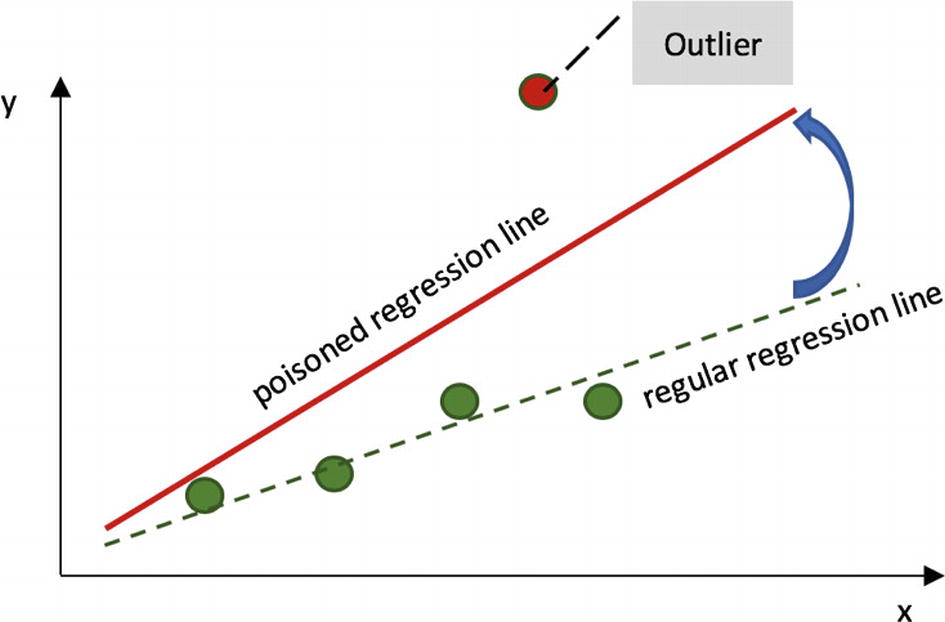
Even a single outlier can move the regression line far away from the planned one
Exercise 9-1. Study a Privacy Policy
Bitly (see http://bit.ly ) is a popular service to shorten long URLs. It also enables you to track pertinent usage metrics of your links. There is a free plan, so you may start experimenting with the site. Obviously, as it collects information about you (after all, your custom links already reveal a lot about your interests), privacy is a big concern.
Read Bitly’s privacy policy document at https://bitly.com/pages/privacy . It is written in an approachable style despite being legal text. Besides learning how Bitly handles your profile, you can also get ideas about how to structure a similar artifact for your own data science product.
Summary
Data protection is at the center of data science, since data points are proxies for people and organizations. Cyber-attacks are ubiquitous and will become an even more prevalent problem as smart devices take over bigger responsibilities. This chapter just touched the surface of data security, the goal simply being to steer your attention to this important area. There are plenty of free resources to further expand your knowledge and gain experience in security engineering. One light framework is the Common Sense Security Framework ( https://commonsenseframework.org ), which you could use as a starting point to implement a safe solution. You should also try out Foolbox, a Python toolbox to create adversarial examples for fooling neural networks. It comes with lots of code snippets for trying out various attacks (available at https://github.com/bethgelab/foolbox ).
You, as a data scientist, must know the limitations of technologies, especially their security aspects. Putting unjustified trust into machines whose decisions may impact humans is very dangerous. We are just at the dawn of the AI era and can expect similar attacks in the future and further revelations about the possibilities and weaknesses of these technologies. Keeping abreast of the latest AI research in academia is of utmost importance, as most new attacks are described in published research papers.
References
- 1.
Marrian Zhou, “Goodbye Passwords? WebAuthn Is Now an Official Web Standard,” CNET, http://bit.ly/web_authn , March 4, 2019.
- 2.
Ian Sample, “Tim Berners-Lee Launches Campaign to Save the Web from Abuse,” The Guardian, http://bit.ly/magna_carta_web , Nov. 5, 2018.
- 3.
Ross J. Anderson, Security Engineering: A Guide to Building Dependable Distributed Systems, Second Edition, John Wiley & Sons, 2008.
- 4.
Michael Howard, David LeBlanc, and John Viega, 24 Deadly Sins of Software Security: Programming Flaws and How to Fix Them, McGraw-Hill Professional, 2009.
- 5.
Sam Newman, “Securing Microservices: Protect Sensitive Data in Transit and at Rest,” O’Reilly Media, available at https://learning.oreilly.com/learning-paths/learning-path-building/9781492041481/ , April 2018.
- 6.
Brian Fox, “Open Source Software Is Under Attack; New Event-Stream Hack Is Latest Proof,” Sonatype Blog, http://bit.ly/oss_supply_chain_attack , Nov. 27, 2018.
- 7.
Ani Adharki, John DeNero, and David Wagner (instructors), “Foundations of Data Science: Prediction and Machine Learning,” UC Berkeley (BerkeleyX) edX Course, https://www.edx.org/course/foundations-of-data-science-prediction-and-machine-learning-0 , 2018.
- 8.
Rob Matheson, “Putting Data Privacy in the Hands of Users,” MIT News, http://bit.ly/data_control , Feb. 20, 2019.
- 9.
John Elliott, “GDPR: The Big Picture,” Pluralsight Course, https://www.pluralsight.com/courses/gdpr-big-picture , 2018.
- 10.
Vincent C. Hu, D. Richard Kuhn, and David F. Ferraiolo, “Access Control for Emerging Distributed Systems,” IEEE, Computer 51, no. 10 (October 2018): pp. 100–103.
- 11.
Cade Metz and Craig S. Smith, “Warnings of a Dark Side to A.I. in Health Care,” New York Times, http://bit.ly/adversarial_ai , March 21, 2019.
- 12.
Douglas Heaven, “The Best Image-Recognition AIs Are Fooled by Slightly Rotated Images,” NewScientist, http://bit.ly/2UVRXW8 , March 13, 2019.
- 13.
Yevgeniy Vorobeychik and Murat Kantarcioglu, Adversarial Machine Learning, Morgan & Claypool Publishers, 2018.
- 14.
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov, “Membership Inference Attacks Against Machine Learning Models,” 2017 IEEE Symposium on Security and Privacy (SP), IEEE, https://www.cs.cornell.edu/~shmat/shmat_oak17.pdf .