
In the last chapter, we looked at a linear history. This can be fine for trivial repositories, but if we are confident working with branches, it will introduce almost no overhead, so we can wield the power of branches, even for our simplest projects.
There are many benefits from working actively with branches in Git. We will cover collaboration with multiple developers in the next chapter, but even for a solo developer, there are wins from branches. They primarily derive from the fact that we can use branches to isolate our work. When we isolate our work, we can mitigate some of the cost of multitasking. By isolating our work on a branch, we can always create a new branch, should an urgent task need to be developed. We can safely run experiments on a branch and only integrate our experiment if it comes out in a favorable way. As mentioned before, branches are a great cause of confusion around how Git works. This is very unfortunate as they are the key to both gaining the full value of Git and understanding many concepts including working with remote repositories and all but the simplest collaboration schemes.
In this chapter, we will focus on getting a healthy mental model around multiple branches and get enough hands-on experience that you will be able to use and reason about branches.
Creating Branches
A branch is a file containing the sha of the commit it points to
We can use the command git branch to manipulate and list branches. There are subtleties when it comes to remote branches, but we will cover those in the next chapter. When we use the command without arguments, we list the (local) branches.
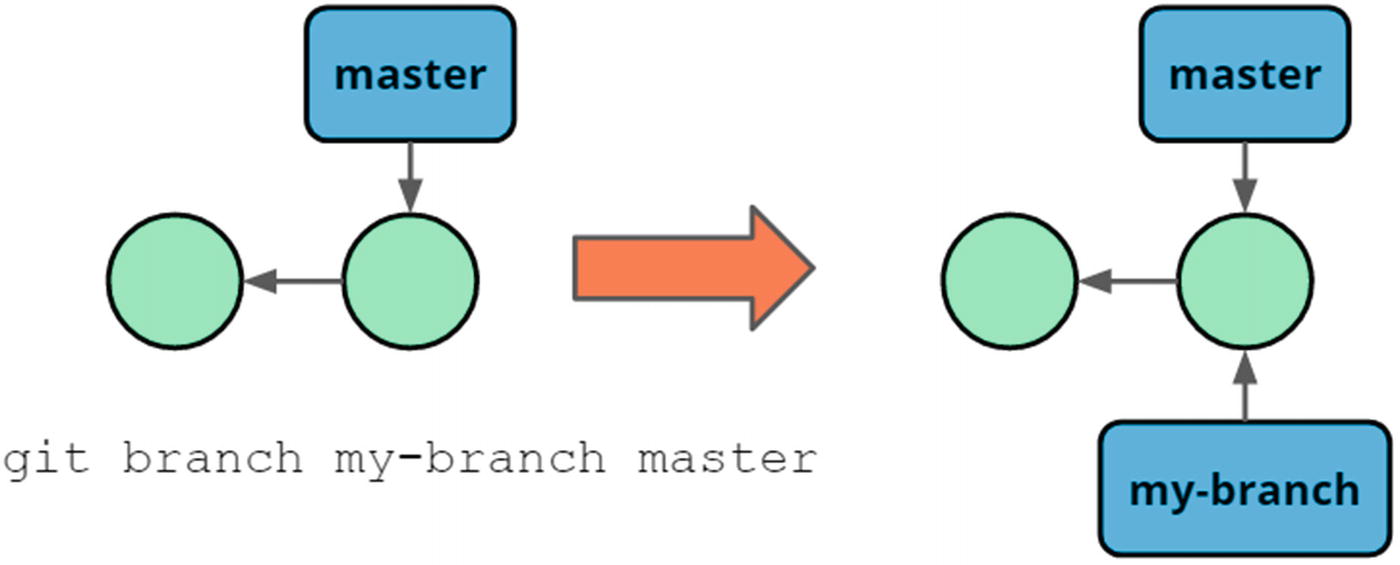
Creating a branch from a reference
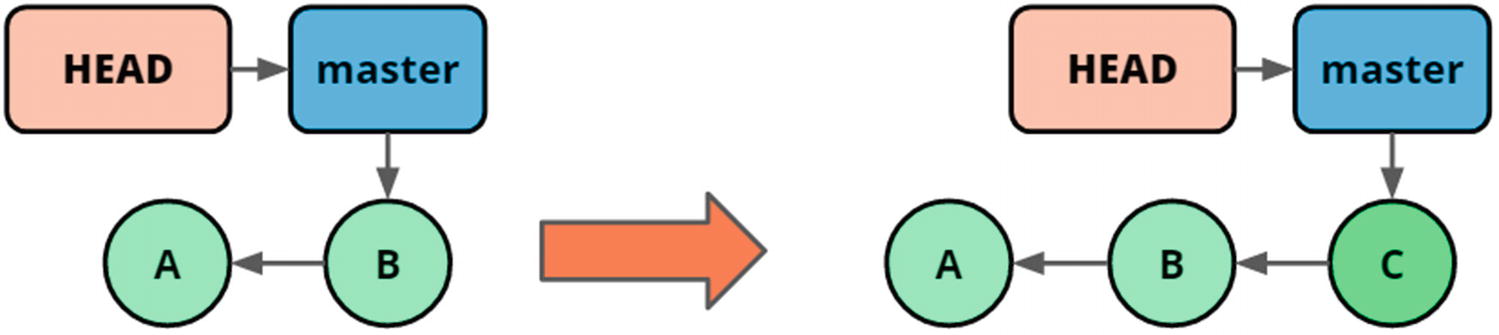
Creating commits on a branch will add the commit and update the branch pointer
Now that we have seen how it looks when we create commits on branches, we are ready for the next step in branching
Working with Multiple Branches
In Git, it really does not make any sense to work without any branches, and we are by default always working on one branch: the master branch. But the true power comes from juggling multiple branches. There are two primary tasks when working with multiple branches. One is keeping our work separate on different branches. We have covered that earlier. The other part is getting changes made on multiple branches into the same branch. This is commonly referred to as merging. There are multiple ways to do this. In this chapter, we are going to cover merging and rebasing.
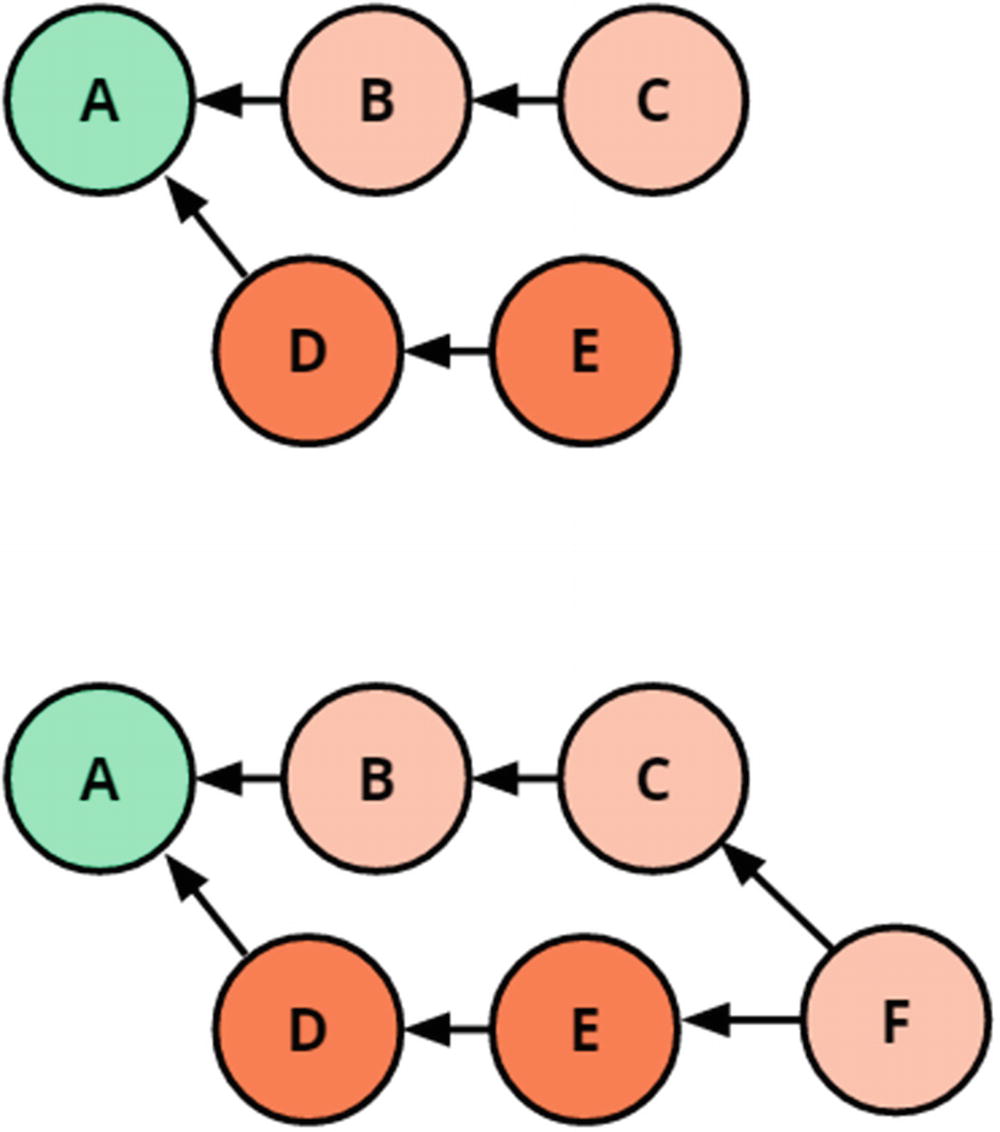
A common merge, merging the branches pointing to C and E, respectively
In the case that the changesets are compatible, Git will handle everything for us. If the changesets are not compatible, or Git fails to merge them, we will end up in a merge conflict. We will cover these later in this chapter. In most code bases I’ve been working with, merge conflicts have been uncommon.
Merge
Merging is another place where our language can come in the way of our understanding of Git. We both talk about the abstract merging of branches, disregarding how we intend to do this, and we talk about the command `git merge`.
The common way to use the merge command is with the form `git merge branch` which will merge the changeset from branch into the branch currently checked out, for example, git merge feature-123. There are other options, but I like this way of working as we then only change the branch that we are on, which is good as it leads to relatively few issues. This merge is how Figure 4-3 was created.
Fast-Forward Merges
Fast-forward merges are the simplest form of merges in Git. Unfortunately, there is also a bit of misunderstanding around how they work. This section will hopefully leave you in a state where you love fast-forward merges.

Doing a fast-forward merge does not result in any new commits, but is a simple operation
This also means that there is no possibility for any conflict doing a fast-forward merge. For this reason, fast-forward merges can be considered safe.
Some workflows use a Git feature where a new commit is created to mark the merge of a branch. This creates a merge commit, without a changeset, to mark that at this point the branches were merged. This is done with the command git merge --no-ff <branch>.
If we compare this out with the one from the log statement before the fast-forward merge, we can see the commit ID is identical. This means that no new commit has been created and the change has been purely a branch update.
As can be seen from the preceding exercise, fast-forward merges by default do not result in new commits. This means that this type of merges is a very quick operation as it is simply a two-step procedure: write updated sha to the branch file, and then check out the workspace at that revision.
Three-Way Merges
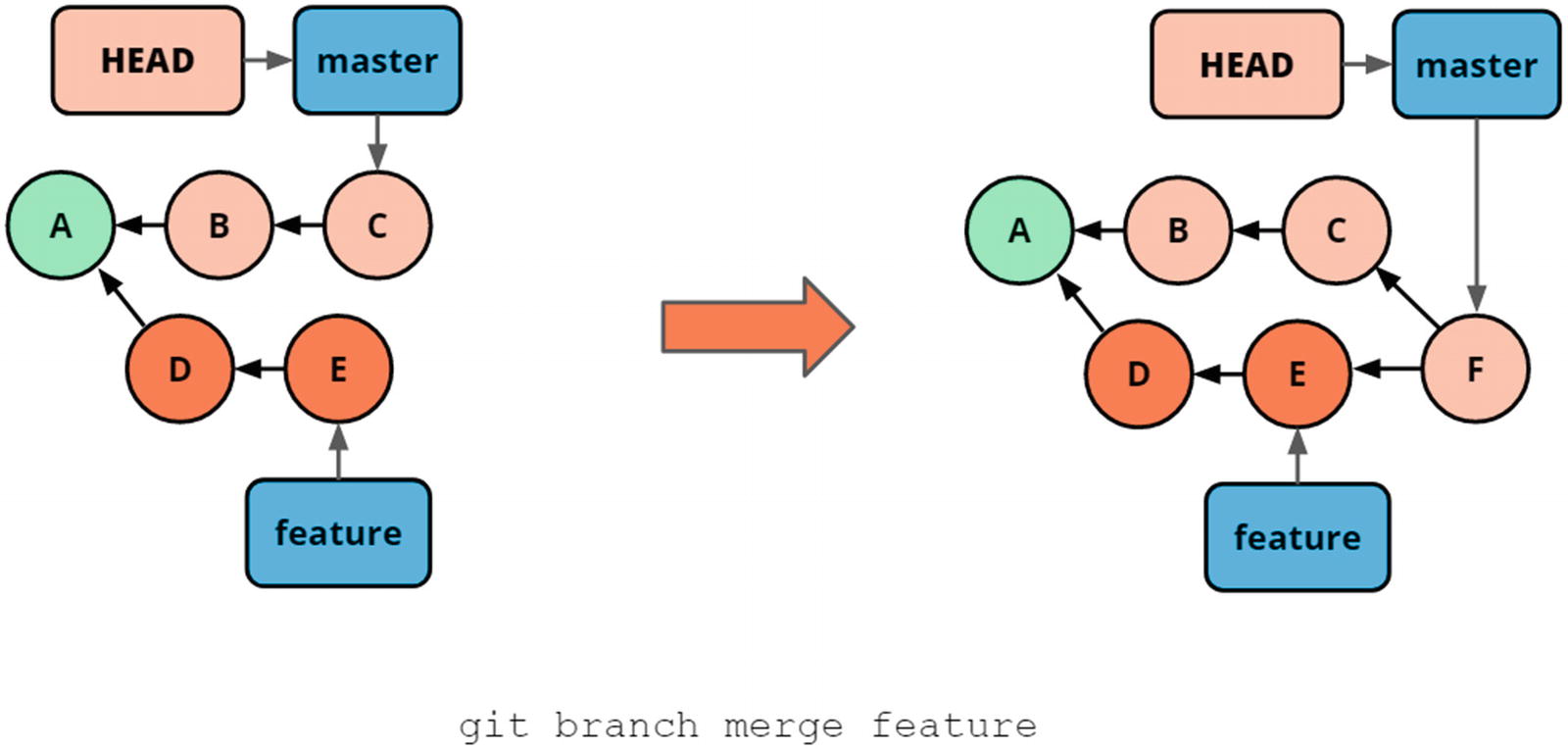
Merging two branches creates a new commit and updates a branch pointer

The different components of a three-way merge: source, target, and merge base
Git uses the merge base to determine the different changesets and calculate whether they overlap and thus cannot be automatically fused by Git. The result will be a commit and the receiving branch will be updated. When we have completed a three-way merge in one direction, if we do the merge in the other direction, it will always be a fast-forward merge.
In the preceding code, we walked through a three-way merge and noticed that repeating a three-way merge in the other direction caused a fast-forward merge.
The preceding exercise went through the happy path scenario. When our merges are simple, Git can easily resolve them automatically and we feel powerful. Unfortunately, it is not always the case that Git can resolve merges for us. We cover this in the next section.
Merge Conflicts
Git status shows that we are in a state of an unresolved merge conflict and instructs as to what our next steps are
Merge markers in a file show origin of different changes
If you encounter complex merge conflicts, often it helps to use an external merge tool such as meld or kdiff. Under normal circumstances must merge conflicts are simple to resolve and can simply be handled in your normal editor. Editors, such as Visual Studio Code, understand the markers that Git put in your files and this makes it easier to resolve the merge conflict.
There can be multiple merge conflicts in the same file. Git looks at smaller chunks, to figure out similarities between versions of files. This makes it easier to handle merge conflicts as you do not have to decide on an entire file in one go, but rather can decompose into smaller segments to compare.
Having resolved the merge conflict, we see we are in a similar situation as the happy path three-way merge. We just had to help Git a little bit along the way.
As can be seen in this exercise, it is not a daunting task to resolve a merge conflict. It can however be difficult in complex scenarios and when working with a code base that we are not comfortable with.
Rebase
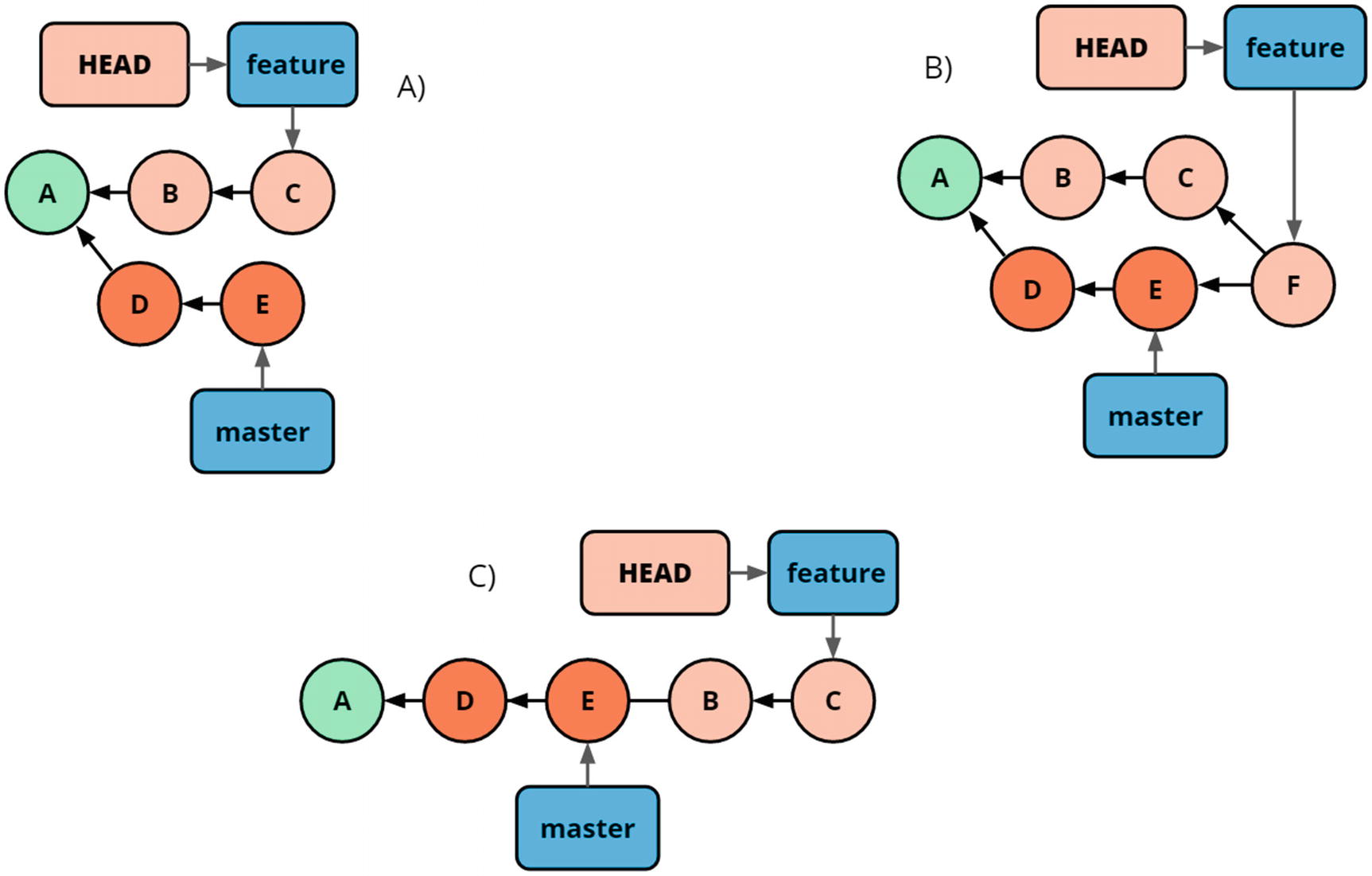
Rebase vs. merge. Starting from A, B is the result from merging master to feature, while C is the result of rebasing feature onto master
We use the git rebase <target> command to rebase HEAD on top of <target>. Assuming feature is checked out, we would write git rebase master to rebase the feature branch on top of master. This can be seen in Figure 4-7(c).
Here, we use show to see the commit that feature previously pointing to is still present, and thus we can recover safely from the rebase.
While our intuition around a rebase is that we move a branch, this is not the case. New commits are made on top of the merge base, and the old commits are left without any references to them. They can thus be recovered until garbage collection occurs.
There are many diverse opinions on the case of rebasing or merging. I have a few opinions on this. First, it is key that the entire team works in a way that results in a consistent history no matter who delivers a given changeset. This most likely means everyone rebases or everyone merges. There can also be implications coming from the workflow that the team is using to develop. If, however, the workflow dictates whether you can use merges or rebases from a technical perspective, it probably needs to be looked at, and you need to reevaluate whether it is a sane way of working.
Second, if you are not working on a shared branch, you should always rebase. This leaves your history clean and bundles your commits nicely together for a concise delivery. This also makes it easier for you to manipulate your local history before you deliver, as we will cover in a later chapter. As rebasing changes the commit shas, it is considered bad practice to rebase branches that are public. However, you might be working on a public branch that are your own. It could be published to get a build from a continuous integration system , or feedback from a peer. In these cases, you should not refrain from rebasing your own, but public branch.
Tags
So far in this chapter, we have covered branches and how they are lightweight and easy to move around. There are many uses for a named reference for a commit that is more static. In Git, we have tags to supply that functionality. A tag is a reference to a commit. Commonly, tags are used to mark released versions of our source code, so we have a named reference to the source code that produced any given version of our software.
There are two types of tags, lightweight and annotated. Lightweight tags are like branches except they are static. This means that they are simply a reference to a commit with no additional information. Annotated tags are full objects in the Git object database, takes a message, and provides additional information. Annotated commits are created by adding -a, -s, or -m to the tag command. The tag command looks like this: git tag <target> for lightweight tags. For example, git tag v1.6.2 a233b will create a lightweight tag pointing at the commit with the prefix a233b.
If we omit the target, the tag will be created at HEAD.
As we have seen in this exercise, tags can be used to mark places in our history that has some significance.
Detached HEAD
If you have had any Git experience at all before you started reading this book, it is likely that you have found yourself in a detached head situation, and it is likely that it scared you. I know because it at least took me some time before this situation did not make me feel like I did something that I should not have done.
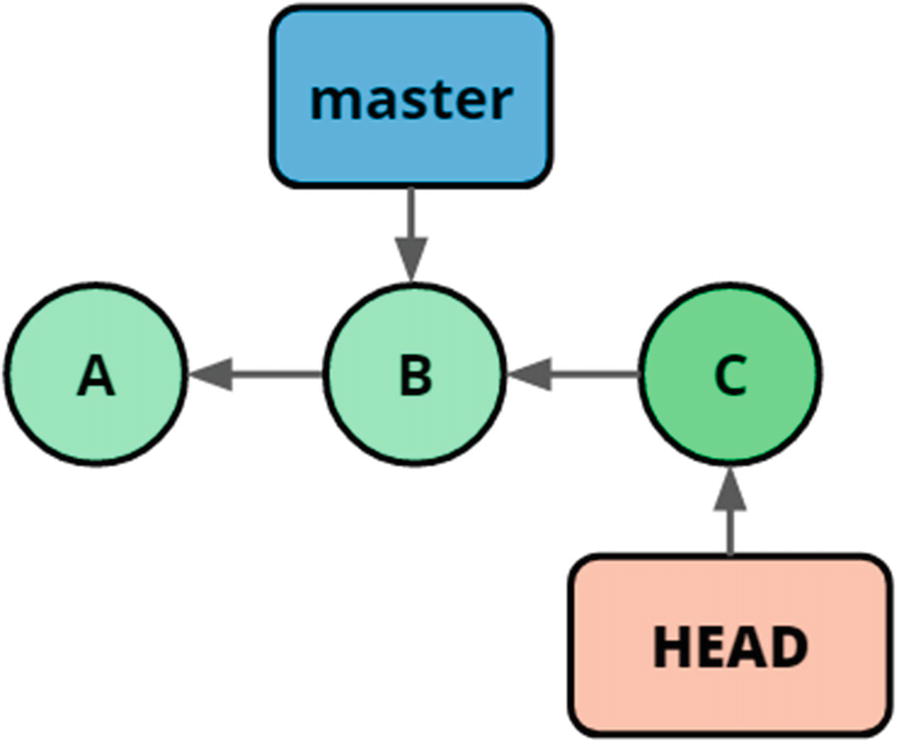
Detached head, with a dangling commit
If the purpose of ending up in a detached head situation is to simply look at code, to see what the state of the repository was at that point in time, there are no problems, and we can stay in the detached head state until we are ready to return to the branch we are working on. If we want to make changes, we are better off creating a branch; this can be most easily done at checkout time using the flag -b that will create a branch at the target we are checking out. This looks like git checkout -b <branch-name> <target>. If we want to create a branch called bugfix at the tag v1.2.7, we use the command git checkout -b bugfix v1.2.7.
As can be seen from the following exercise, there is no reason to be afraid of the detached head, and it is easy to recover from.
Git Katas
Basic-branching
Three-way-merge
Merge-conflict
Merge-mergesort
Rebase-branch
Git-tag
Detached-head
Summary
In this chapter, we came far about talking about branches in Git and how they work. We covered the different types of merges and contrasted merges to rebases. We walked through resolving merge conflicts. We closed off the chapter with a brief description of how we can use tags to mark interesting points in our code base. Finally, we deflated the detached head situation.
Now that we have the foundations for branches in order, we can move on to collaboration using Git.