
It may seem very counterintuitive that I put a full chapter into manipulating history. Version control is at its core about traceability, reproducibility, and immutability. But Git lets you manipulate the history. For any public history, published to colleagues or available on the Internet, we must tread very carefully and use with care and responsibility the powers this chapter bestows us. But for local history, before we'd publish it can bring tremendous value to sculpt the version history to fit the logical units.
In this chapter, we will first cover undo a change that is present in our history with revert. This allows us to safely undo previous work while maintaining full traceability and immutability.
Next, we are going to cover reset which is the big red button for undoing large chunks of our history, and not just removing changes from our workspace but also removing them from our history. It also does less impactful stuff and is my favorite tool for juggling branches locally.
Last, we cover the interactive rebase which allows us to combine, split, delete, and reorder commits in our history. This is an extremely powerful tool, but can feel a bit scary, and again should be kept a long distance from public history. In terms of delivering the best possible history to colleagues or your future self, no tool is better.
Reverting Commits
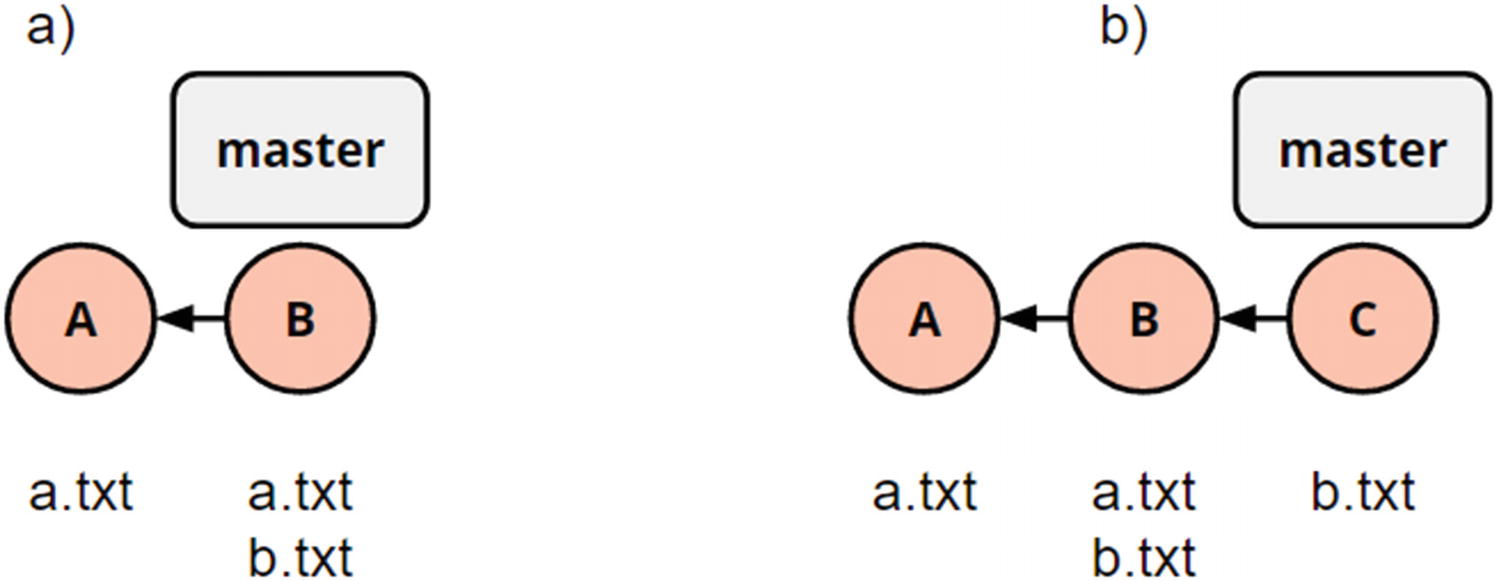
(a) Two commits adding a file each. (b) History after running the command git revert a
In this scenario, we are not actively manipulating history, we are rather using Git as a shortcut to revert a change. Without Git, we would be forced to manually try and figure out how to undo the given changes and then create that commit ourselves.
This also means that we are not doing anything that can compromise the traceability established through Git. As such, it is safe from an auditing perspective to use revert on public history. Whether you are breaking any functionality that you did not intend is beyond the scope of Git. Always run your tests!
We see a simple history and we want to undo the changes introduced in commit c8482 with the message “Add File A”.
As expected, we now only have b.txt in our workspace. As has been shown in this exercise, reverting commits can be a safe way to undo a change introduced at an arbitrary point in history.
Reverting commits can be done easily and safely if you as a developer take care of the semantics of the changes you are juggling. It will likely be safer than trying to revert changes manually, without tool assistance. Git tooling like revert and others are another good reason to make your commits atomic and self-contained.
Reset
Reset is one of my favorite Git commands, not only because of its powerful functionality but also because it is one of the commands that allow us to uncover the most knowledge on how Git works and how our intuition might be in conflict with this.
Git is overall very conservative with taking actions that might cause you to lose your work unexpectedly. Git reset, in its hard mode, is one of the ways that Git will throw away unsaved work without warning. It does require an active choice by the user, so this is not too bad in itself. Unfortunately, reset is also one of the commands that have a horrible user experience. I hope to guide you through the command and combined with the exercise and doing the katas that you will feel confident introducing the reset command in your everyday coding life.
Git reset has three modes: soft, mixed, and hard. We will go through them in turn and end up with an exercise covering all three.
Soft Reset
In the soft mode, git reset --soft <ref>, we are only manipulating HEAD. That is, the reference currently checked out will be changed to the target given as an argument. In other words, the soft reset can be used to move a branch pointer.
This can be useful if, for instance, you forgot to create your feature branch before you started your work and thus have created your commits on master. Then, you could make it look like you did the right thing all along by first creating your feature branch at master and then resetting --soft master to origin/master.
(b) Is the result from starting in (a) and running git reset --soft B
The soft reset can be used to squash a series of commits together into a single commit. It is done by resetting to the point from which your work started and then creating a commit. The squash works because all your work, represented by the newest commit, will then be in the stage that you can commit into a single commit. This is not a typical scenario and is usually better solved by the interactive rebase that we will cover later in this chapter.
Mixed Reset
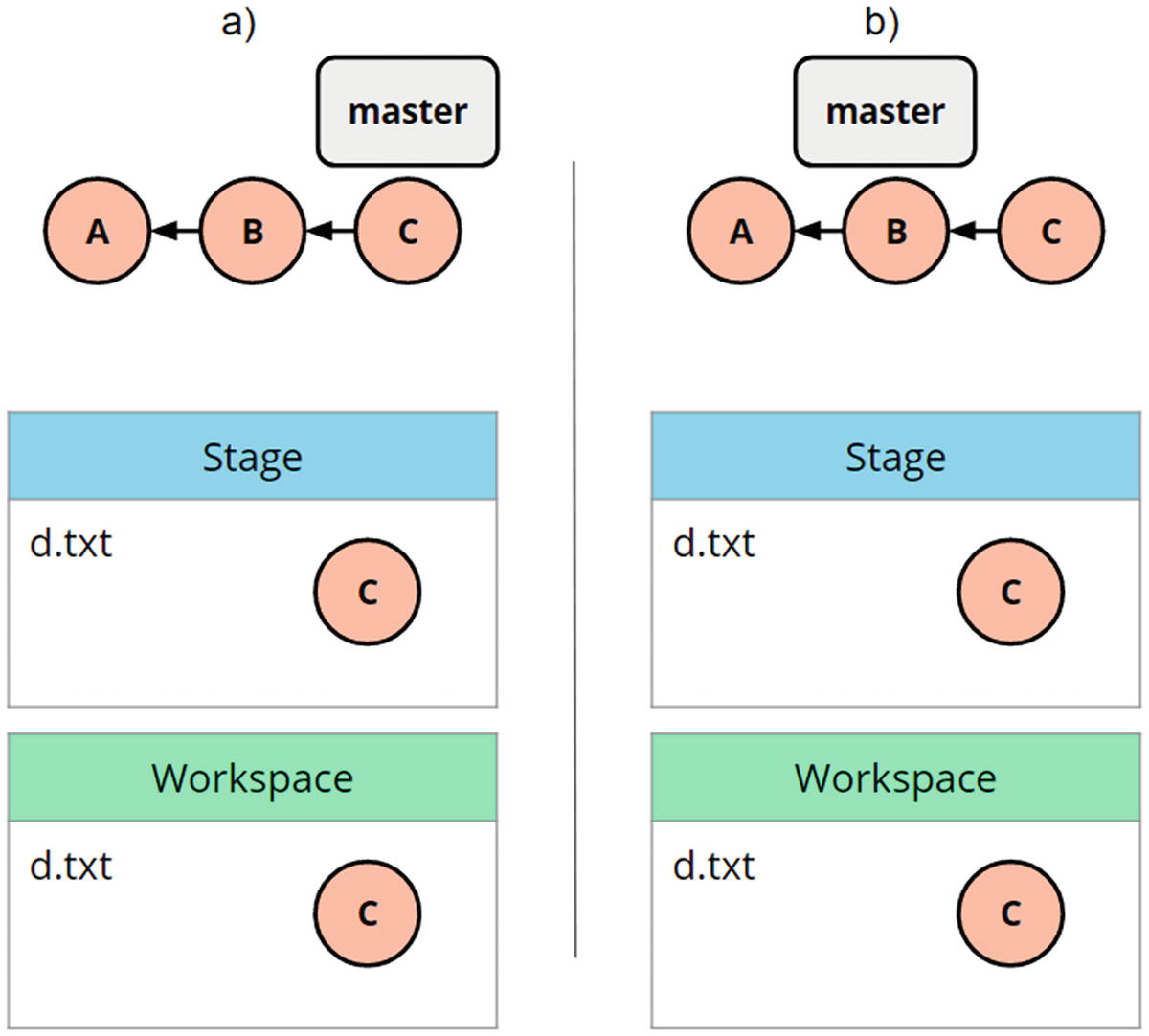
The mixed reset is the default behavior when you do not pass a mode to git reset. Mixed reset, besides updating HEAD as soft does, also updates the stage to the targeted place. When we do not pass any ref to reset, HEAD is the default behavior. This leads to the confusing situation that the most common use case for reset --mixed is unstaging files. That is if you have at some point used git add to stage a path, and you no longer want that path to be staged, you can use the command git reset <path>. The logic is that you overwrite the stage with what is in the commit pointed to by the ref, which is HEAD by default. It took me some time to wrap my head around the fact that to remove something from the stage, you have to put something else there.

Showing that git reset d.txt changes the stage, but not the workspace
Based on the earlier texts, a reasonable question would be, what would happen if we reset mixed to B, for instance? In this case, we would put B and only B into the stage and update HEAD.
Hard Reset

git reset --hard B updates HEAD, stage, and workspace to the content of B
While the hard reset is considered off limits by some, it is part of my day-to-day workflow. If we are disciplined around making commits often and take care in running git status before we do a hard reset, we have a powerful and simple tool at our disposal. I have many times seen developers accidentally messing up their local histories with pulls when they did not mean to, or by having contaminated their master branch. The way I do this personally is by avoiding pull in all but the simplest cases. Most often, I will use git fetch to update my local cache and then use git reset --hard origin/master to start from the most up-to-date scratch. When I have made certain to keep my work on isolated branches, this is a safe command to run.
We note that the master branch is now pointing to the commit 9 rather than 10.
So now we have seen the three different modes of the git reset command. It can be daunting and this kata is my favorite one because it encapsulates a lot of learning. This is why I really recommend you go through this kata a few times, until you have built your reset intuition and can wield git reset --hard like a ninja.
In this section, we have been using reset in all its modes for different purposes. One important thing to remember is that no matter what, if you put your data in a commit, you can restore it, even after a hard reset. I hope this section has shown you the power that this safety can give you.
Interactive Rebase
Some of the tricks we have been going through earlier can be used to manipulate history. But the real powerful and granular way to approach tweaking your local history is with the interactive rebase. Remember, if our history is local, we are free to tinker with it as we want. This capability gives us the opportunity and responsibility to consider the history we publish as a part of the delivery. The Git history that we deliver is also a form of communication, and it should be chopped up in the right commits in the right order, with good, clear commit messages. An interactive rebase is invoked by adding the flag --interactive to the git rebase command, for example, git rebase --interactive master.
The best way to go about preparing your Git history is the interactive rebase. Conceptually, you give Git a rebase target, which is what you want to rebase on top of. Then, Git provides you with a rebase plan that it intends to execute. You can change this plan, before Git executes it. This allows you to skip commits entirely, edit them, reorder them, or squash them together. The plan takes the form of Action Sha. And deleting a line will simply make the rebase skip that commit. If you do not edit the plan, it is the same as leaving out the --interactive flag on the rebase command.
Pick adds the commit at this point.
Squash melds this commit into the previous commit.
Edit stops to edit this commit.
Drop does not pick this commit.
The preceding actions and reordering are how interactive rebases are most commonly used.
The interactive rebase is perhaps the most powerful Git command, and almost any Git task can be solved using this command. I hope that becoming aware of this command will help you on your journey to always delivering a well-groomed history to your collaboration partners, and your future self.
Git Katas
Revert.
Reset.
Reorder the history.
Then, I suggest you do the reset kata again; it is always a healthy exercise to revisit 1F642.
Summary
Manipulating the history is often proclaimed to be a big no-no in version control because of traceability. But as long as we only rewrite history that is local or only has been published to temporary branches, we have the obligation to make the history the most usable it can be. Whether that is to squash multiple commits together or even split commits into different bundles, it is all about considering the history you deliver as part of your deliverable.
Remember, all the commands we have covered here are safe, and in the chapter on Git internals, we will cover how to recover from accidents.