
![]()
Zero Downtime Linux
One of the key factors that made me take Unix-type systems so seriously, when compared to Microsoft servers, was the lack of reboots that were required for production systems.
In my experience, after their initial build you can generally expect Unix derivatives to run continuously for a year without even a hint of them needing your attention. Some sysadmins even claim to have inherited boxes that haven’t been rebooted for a decade and, in the right environment, I can believe it. That’s not to encourage such a practice, of course, because that means there hasn’t been any kernel security patching taking place over that decade.
As some of you know, a few years ago that last statement became obsolete. That’s because for a relatively short period of time, sysadmins have been able to patch their Linux kernels live and without any disruption to services or reboots. In this chapter, I discuss how the year 2015 advanced live kernel patching on Linux one important step further. The chapter also explores some of the immediately available options to those wanting to take advantage of this illuminating technology. Those sysadmins who do are certain to benefit from a significant increase in uptime and security on their production servers.
Incidentally, when it comes to monitoring, you can keep a much closer eye on your reboots (accidental or otherwise) and overall uptime by using a clever little tool called tuptime, which can be found at https://github.com/rfrail3/tuptime.
The Promise of Continuous Availability
I should say that I’ve long been a proponent that critical services should not aim for high availability (HA) but instead continuous availability (CA). I remember reading that the massive online video streaming giant, Netflix (http://www.netflix.com), conceded that even they had to accept their service would fail at certain points despite the unquestionable might of the cloud technologies that they employed. It’s quite a remarkable statement if you think about it; assuming that Netflix has some of the best architects and engineers on the planet working for it and reportedly now uses the dominant cloud provider, Amazon Web Services, almost exclusively.
Over the last few years, I’ve been following with interest the attempts by developers to provide solutions to the live patching of kernels. As mentioned, such a solution removes the need to reboot a Linux server after applying a kernel patch; these patches might fix security headaches or apply well-needed bug fixes.
As a result of my interest in this area, when the first fully-matured commercial service came to market, I became one of the earlier customers of Ksplice’s “Uptrack” service (http://www.ksplice.com). This was at the start of 2010. Even at that stage I found the service to be very slick and used it around-the-clock for years on key production servers, predominantly running Debbie and Ian’s favorite distribution of Linux. I’ll cover Uptrack in a little more depth later on.
The main aim of Uptrack (for my purposes at least) was to defer reboots and keep the number of maintenance windows, which had to start at midnight, to an absolute minimum. These were mostly only required following the application of kernel security patches. Such a patching run might be required from three times a year to once a month, depending on what you were using your machines for and the versions or bugs involved.
Ksplice’s Uptrack (then just referred to as “Ksplice” from what I can gather) was mainly authored by an unquestionably clever man called Jeff Arnold at the Massachusetts Institute of Technology. Even during its testing phase, where 50 kernel vulnerabilities from May 2005 to December 2007 were studied, Ksplice was able to successfully patch an impressive 84% of those presented.
It’s safe to say that Ksplice was the first notable commercial enterprise that attracted attention in the marketplace. Nowadays, there are also other conspicuous competitors such as KernelCare (http://www.kernelcare.com), which, at the time of writing, has around 2,500 providers using its software service according to its web site.
As with all exciting new technologies, a degree of landscape change is inevitable. Oracle acquired Ksplice in July, 2011 and as a result the service is now only offered to Oracle Linux Premier Support customers. Legacy customers (I’m very pleased to say) are still able to use their accounts.
Two quotes that caught my attention a while ago were made by the venerable Linus Torvalds when kernel version 4 went live on April 12, 2015. There was much ado in the press about the jump to version 4 of the kernel, mainly because of the sizeable jump in version numbers I suspect (see Figure 4-1). Good, old Torvalds, who at times can be a master of the understatement, said that the new kernel “doesn’t have all that much special” and that “much have been made of the new kernel patching infrastructure”. He cited the main reason of the version bump being because lots of housekeeping was done.
Figure 4-1. There was a big jump in kernel version numbers this year
I suspect that quote about the kernel patching was a case of everyone talking about something “new” to such an extent that in his mind it quickly became “old” news. Far be it from me to argue with anyone like Torvalds and his deity-like status; I’m sure that he wouldn’t mind me saying that the newer kernels do include the most important change to live kernel patching for some time.
Live Patching the Kernel
The fact that live kernel patching code now sits inside the mainstream kernel, known as livepatch, was a contentious topic for a while, albeit only the foundations of the code that will ultimately be required.
The story goes that long-standing Linux stalwart, SUSE (https://www.suse.com/products/live-patching/), harking back to 1992, was developing “kGraft” in order to provide zero downtime functionality for their enterprise customers running SUSE Enterprise Linux. Meanwhile, Red Hat was developing kPatch (http://rhelblog.redhat.com/2014/02/26/kpatch/), which is now included in Red Hat Enterprise Linux (RHEL) version 7.0 as a “technology preview”.
It seems that the sometimes vociferous Torvalds had something to say about two solutions that essentially solve the same problem being present in the Linux kernel: “It pretty quickly became obvious to the interested parties that it’s absolutely impractical in this case to have several isolated solutions for one task to coexist in the kernel.”
When debates were taking place about whether the kernel would include kGraft or kPatch, it appeared that Red Hat did have a slight advantage. This was thanks to the fact that there was no advanced preparation required for the kernel in order to allow a system to use live kernel updates and that errors were caught better.
After lots of humming and harring, an agreement was reached. The long and short of such a discussion (http://linuxplumbersconf.org/2014/wp-content/uploads/2014/10/LPC2014_LivePatching.txt) can be summed up as follows: “Question: Can we run both kPatch and kGraft in same kernel? Answer: Yes!”
There was then apparently a new kernel patch written by Red Hat called livepatch that enabled both kGraft and kPatch to operate in perfect harmony. Having had it reviewed in November 2014, the code was accepted as being able to cut the mustard and dutifully merged into the kernel by Torvalds et al. in February 2015.
It’s been said that neither Red Hat nor SUSE were (officially at least) aware of each other’s project to provide live kernel patching. What matters is that a fair compromise was reached and both parties have been left feeling satisfied, publically at least.
According to the code commit that Torvalds submitted to the kernel, Red Hat’s kPatch works by sending the kernel a stop_machine() when it is satisfied that it is safe to do so. At that point, it injects the new code into the live kernel. Don’t get me wrong, we’re not forcing a “halt” or anything that lasts more than a fraction of a second, so it’s effectively an instantaneous action that your server doesn’t even notice.
Apparently kGraft, on the other hand, works on a per-task basis by keeping track of checkpoints, achieving its goals by patching as it goes. There’s a sample of the ruminations that were involved in a post by someone who knows their stuff from SUSE at https://lkml.org/lkml/2014/11/7/354.
As a result of compromises, relatively minor rewrites and a healthy dose of cooperation, you now have the basic infrastructure required for live kernel patching present in Linux. This includes an application programming interface (API) and an application binary interface (ABI), which allow userspace to enable, disable, and display a list of which patches were applied. It’s certainly a good start.
Apparently, the live kernel patching software makes great use of the kernel’s ftrace (“function tracer”) functionality. The code is entirely self-contained, which means that it doesn’t even speak to other components of the kernel or more accurately cause them any undue disruption. At the time of release, only x86 hardware was able to take advantage of the technology. PowerPC, S/390, and ARM are already being looked at for its inclusion in their kernels.
Torvalds notes that “once this common infrastructure gets merged, both Red Hat and SUSE have agreed to immediately start porting their current solutions on top of this, abandoning their out-of-tree code.” To get to this stage, both parties took their respective development paths relatively seriously, which in turn is promising for ongoing development. One example is that, in 2014, Red Hat started a Special Interest Group (SIG) for its existing customers using their RHEL 7 servers. As multiple common vulnerabilities and exposures (CVEs) were announced a few CVEs were handpicked and offered to users to see how easy it was to live patch against security issues and bug fixes.
Ksplice’s Uptrack
Figure 4-2 shows the modus operandi behind live kernel patching, as demonstrated by Oracle’s Ksplice service called “Uptrack”. The uname -r command lets you display the --kernel-release in use by the system.
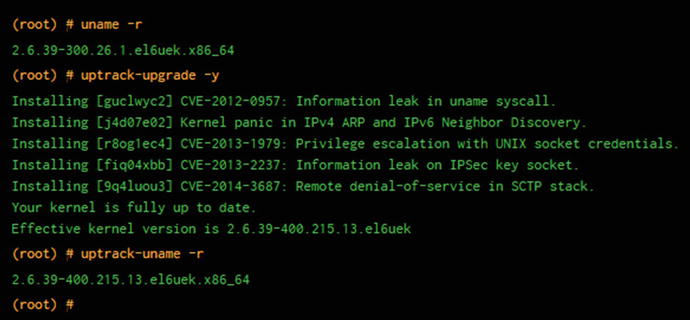
Figure 4-2. Oracle Ksplice’s magical Upstart in a nutshell, displayed at http://ksplice.oracle.com
Running the uptrack-upgrade command with the -y option (“yes”) installs all of the available patches being offered at that time by Uptrack.
Finally, when running uptrack-uname -r, you are able check the effective kernel release in use by the system (note -400 versus -300). It all happens in an instant. Isn’t that clever? You can certainly see why Red Hat and SUSE got in on the act after Uptrack hit the market.
Next, to check which patches have been applied by Uptrack, you can run the following command:
# uptrack-show
If you manually installed a few patches but have missed some, or if you want to see which have yet to be applied, you can try this command:
# uptrack-show --available
You can also set up fully automatic patching by changing the relevant line in the config file /etc/uptrack/uptrack.conf. I’d recommend avoiding this for production boxes and suggest that you only use this feature on less critical systems until you’ve tested the patches for obvious reasons. You could use something like Puppet to trigger the upgrade command around your server estate. Once you’ve tested the patches on a box, with the same kernel version and distribution, the rest of the estate would then patch themselves automatically.
Also within that config file, you can set install_on_reboot so that following a (potentially unexpected) reboot the patches will be bumped up to the same level as before without needing to hurriedly apply your kernel updates through your package manager. If there are other updates that could have also have been applied, then you probably want to set the option upgrade_on_reboot to “yes” to incorporate those too.
If you ever need to remove patches, then simply use this command in order to remove them all:
# uptrack-remove -y
Alternatively, rather than -y you can choose specifically which patch to remove by using a Ksplice ID (which you can glean from the uptrack-show command). You might need to use this if there’s ever a patch misbehaving with, for example, a driver for some of your system hardware.
First Impressions
I can say with all honesty that during the years I used Uptrack on mission-critical Linux routers, I didn’t suffer any unwelcome downtime and found the service from Ksplice to be excellent. Note though that the key word is “service”.
The premise of live kernel patching (for all intents and purposes) is taking a diff to compare what was and what is “different” in the current kernel. Programmers then meticulously pick through the bones of the patch to be applied and create a specific type of patch that can be deployed in their patching infrastructure. This is then replicated (sometimes using different specialist kernel programmers) across the different architectures and distributions that they supported.
Back in the day, prior to the acquisition by Oracle, which understandably locked it down somewhat for use by its premium customers, there were many more distributions supported by Ksplice. That said, RHEL, CentOS, Debian, Ubuntu, Virtuozzo, and OpenVZ patches are still available to previous customers—for now at least. If my memory serves, I used Ksplice in production without any headaches on early container technology (which is still excellent incidentally), namely OpenVZ.
If you’re interested in trying out the magic yourself, however, Ubuntu and Fedora users can install a free desktop edition. I’d highly recommend it; the desktop page can be found at http://www.ksplice.com/try/desktop.
The only issues that I encountered (and Ksplice staff at the time responded quickly) occurred on two separate occasions. This was when seemingly harmless error messages were generated following the application of some kernel patches. Needless to say, if I’m logged into a production system and I see nasty-looking errors that certainly shouldn’t be there, I’m on the case immediately. The support team was clearly very able and prompt to respond despite, being in a different timezone (and despite the fact that I was only a few-dollars-a-month customer). Otherwise, the most important factor, that of course being the reliability of my very precious production systems, was flawless. This meant that I managed to sleep for many hours more when I would have otherwise been awake squinting at screens during a number of different maintenance windows.
KernelCare—Worth the Cost
I would be remiss not to mention KernelCare’s offering in a little more detail. Now that Ksplice is essentially an exclusive club, there’s little stopping you going to KernelCare. It is a service run by a company called CloudLinux, which has been around since 2009 and aims to make sysadmins’ lives as easy to possible. The fact that Ksplice began offering CloudLinux as one of its supported distros in August 2010 (https://www.cloudlinux.com/company/news/index.php?ELEMENT_ID=495), prior to the Oracle acquisition, has not escaped me.
If you’re using KernelCare’s service for two machines and more, it’s less than three dollars each month per machine. Believe me when I say that when your key engineers walk into work looking well-rested for several months in a row, those few dollars are well worth it. I haven’t tried the KernelCare service myself, but it’s safe to say that trying it out for a few months on less critical systems is a good way of dipping your toe in the water.
The nice thing about the live kernel patching business model is that, because of the number of supported distributions and architectures being so relatively few, if the service provider’s programmers mess up porting a patch to their service then all hell breaks loose. Hundreds if not thousands of customers will be affected, which generally means a pretty swift fix if a failure occurs and lots of decent testing beforehand.
KernelCare certainly appears to have ambitions to pick up where Ksplice left off. A quote from the web site follows and bear in mind that there’s a very low entry point, allowing just one server a month to use its service for a few dollars: “KernelCare supports CentOS/RHEL 5, 6 and 7, CloudLinux 5 and 6, OpenVZ, Virtuozzo, PCS, Debian 6 and 7 and Ubuntu 14.04. Other kernels will follow.” There’s also a mailing list to keep abreast of developments: http://kernelcare.com/mailing-lists.php.
One thing I remember that might be worth pointing out is that, using Uptrack at least, even if you are automatically applying your kernel patches, you should bear in mind that you’re not also, by default, applying updates to your operating system’s Uptrack package. In short, join the mailing list to make sure you know when important changes are made to the software; this applies to the patches too.
Try kPatch
Rather than trying out a commercial service, thanks to the new mainstream kernel code from Red Hat and SUSE, you can actually get your hands dirty immediately if you want. Be aware that it’s still in the early days, however. One example is by visiting this kPatch page on the excellent GitHub: https://github.com/dynup/kpatch.
It’s pretty difficult to miss the caveat in rather large letters near the top of that page, and I’d take this advice if I were you:
“WARNING: Use with caution! Kernel crashes, spontaneous reboots, and data loss may occur!”
There’s also a useful and brief explanation of this kPatch method and livepatch:
“Starting with Linux 4.0, the Linux kernel has livepatch, which is a new converged live kernel patching framework. Livepatch is similar in functionality to the kpatch core module, though it doesn’t yet have all the features that kpatch does.”
Fedora 21, RHEL 7, CentOS 7, Oracle Linux 7, Ubuntu 14.04, Debian 8, and Debian 7.x are mentioned as prerequisites at the time of writing. The next caveat however mentions that “the kpatch-build command has only been tested and confirmed to work on Fedora 20, RHEL 7, Oracle Linux 7, CentOS 7, and Ubuntu 14.04” even though modern kernels should support it fine.
There’s also a nicely written “How It Works” section, the mechanism’s limitations, and a relatively comprehensive FAQ with some decent technical detail for those interested. I’ll be keeping a close eye on that page over the coming months to see how things progress.
Not the End of Reboots
Live kernel patching technology certainly does not mean the end of reboots as we know it.
I tried to do some reading up on this subject a few years ago, having become intrigued with the lsof command’s functionality present in the Debian command checkrestart (which is buried inside the debian-goodies package if you’re interested). The invaluable checkrestart essentially looks for old files that are still in use after a new file has replaced it on the filesystem.
It checks for files being kept open by processes and then compares the list with those files still actually visible on your filesystem. After that, it dutifully warns if non-existent “old” files are still loaded in memory (they could pose a security risk for example).
It’s certainly not uncommon for these culprits to be shared libraries. Once it has identified which services need “refreshed” then the clever checkrestart offers a few suggestions on how to do just that with init script formats, such as service postfix restart or /etc/init.d/postfix restart.
The latest version of the Debian distro, code-named “Jessie,” has a new systemd-friendly incarnation called needrestart. I like the fact that needrestart is presented in a package of its own, as it will probably get more coverage and be developed further if it’s popular. It’s no longer buried deep inside a goody bag.
Some of the features of needrestart—the newer version of checkrestart that’s bundled with “Jessie”—include (per https://packages.debian.org/jessie/admin/needrestart):
- Support for systemd (but does not require it)
- Binary blacklisting (i.e. display managers)
- Detection of pending kernel upgrades
- Detection of required restarts of interpreter-based daemons
- Support for Perl, Python, and Ruby
- Full integration into the apt/dpkg using hooks
If you run these tools (or the lsof command on its own) then some services such as glibc and dbus will likely show lots of results after certain upgrades. You soon realize (I think that it’s a great learning experience) that after some package upgrades, it’s almost impossible not to knock the server over when clearing down the multitudinous shared libraries manually.
As a result, until there’s a consensus to absolutely ensure that every package and service can “live restart” without bringing a server down, then unfortunately production server reboots taking place in the middle of the night will still exist. I may have missed something of course and there may be other ways that I’ve not yet come across to assist with such package upgrades. It’s easy to see that this area of computing evolves at a rate of knots. I, for one, will be casting my beady eye over any developments in the live kernel patching arena frequently.
Summary
The main rule of thumb is to install as few packages on your servers as possible (less is “less” in this case). I can’t emphasize that point enough. Also, know what every one of your servers does. By that I mean isolate your services. For example, make sure a web server is only responsible for HTTP and keep your mail servers running on entirely separate boxes. This way, the number of sleepless nights that you’ll work through will definitely be reduced. The knock-on effect is that your uptime stats will shine brightly and become a target that most other sysadmins can only aspire to.