
This chapter looks at how Spring Cloud Function can be leveraged in AI/ML. You learn about the AI/ML process and learn where Spring Cloud Function fits in the process. You also learn about some of the offerings from the cloud providers, such as AWS, Google, and Azure.
Before delving into the details of Spring Cloud Function implementation, you need to understand the AI/ML process. This will set the stage for implementing Spring Cloud Function.
5.1 AI/ML in a Nutshell

A process of the M L lifecycle. The 4 processing steps are, gathering requirements, setting A I slash M L pipeline, performing A I slash M L, and monitoring.
ML lifecycle
- 1)Gathering requirements
Model requirements
This is an important step in the AI/ML process. This determines the ultimate success or failure of the AI/ML model activity. The requirements for models must match the business objectives.
What is the return on investment (ROI) expected from this activity?
What are the objectives? Examples may include reduce manufacturing costs, reduce equipment failures, or improve operator productivity.
What are the features that need to be included in the model?
In character recognition, it can be histograms counting the number of black pixels along horizontal and vertical directions, the number of internal holes, and so on.
In speech recognition, it can be recognizing phonemes.
In computer vision, it can be a lot of features such as objects, edges, shape size, depth, and so on.
- 2)Setting up the data pipeline
- Data collection
- i.
What datasets to integrate
- ii.
What are the sources
- iii.
Are the datasets available
Data cleaning: This activity involves removing inaccurate or noisy records from the dataset. This may include fixing spelling and syntax errors, standardizing datasets, removing empty fields, and removing duplicate data. 45 percent of a data scientist’s time is spent on cleaning data (https://analyticsindiamag.com/data-scientists-spend-45-of-their-time-in-data-wrangling/).
Data labeling: Tagging or labeling raw data such as images, videos, text, audio, and so on, is an important part of the AI/ML activity. This makes the data meaningful and allows the machine learning model to identify a particular class of objects. This helps a lot in the supervised learning activities such as image classification, image segmentation, and so on.
- 3)Performing the AI/ML tasks
Feature engineering: This refers to all activities that are performed to extract and select features for machine learning models. This includes the use of domain knowledge to select and transform the most relevant variables from raw data to create predictive models. The goal of feature engineering is to improve the performance of machine learning algorithms. The success or failure of the predictive model is determined by feature engineering and ensure that the model will be comprehensible to humans.
Train model: In this step the machine learning algorithm is fed with sufficient training data to learn from. The training model dataset consists of sample output data and the corresponding sets of input data that influence the output. This is a iterative process that takes the input data through the algorithm and correlates it against the sample output. The result is then used to modify the model. This iterative process is called “model fitting” until the model precision meets the goals.
Model evaluation: This process involves using metrics to understand the model’s performance, including its strengths and weaknesses. For example, doing a classification prediction, the metrics can include true positives, true negatives, false positives, and false negatives. Other derived metrics can be accuracy, precision, and recall. Model evaluation allows you to determine how well the model is doing, the usefulness of the model, how additional model training will improve performance, and whether you should include more features.
Deploy model: This process involves deploying a model to a live environment. These models can then be exposed to other processes through the method of model serving. The deployment of models can involve a process of storing the models in a store such as Google Cloud Storage.
- 4)
Monitoring the AI/ML models
In this process, you want to make sure that the model is working properly and that the model predictions are effective. The reason you need to monitor model is that models may degrade over time due to these factors:
Variance in deployed data
Variance refers to the sensitivity of the learning algorithms to the training dataset. Every time you try to fit a model, the output parameters may vary ever so slightly, which will alter the predictions. In a production environment where the model has been deployed, these variances may have a significant impact if they’re not corrected in time.
Changes in data integrity
Machine learning data is dynamic and requires tweaking to ensure the right data is supplied to the model. There are three types of data integrity problems—missing values, range violations, and type mismatches. Constant monitoring and management of these types of issues is important for a good operational ML.
Data drift
Data drift occurs when the training dataset does not match the data output in production.
Concept drift
Concept drift is the change in relationships between input and output data over time. For example, when you are trying to predict consumer purchasing behavior, the behavior may be influenced by factors other than what you specified in the model. factors that are not explicitly used in the model prediction are called hidden contexts.
Let’s evaluate these activities from a compute perspective. This will allow us to determine what kind of compute elements we can assign to these process
Some of the activities in this process are short lived and some are long running process. For example, deploying models and accessing the deployed models is a short lived process. While Training models and model evaluation require both a manual and programmatic intervention and will take a lot of processing time.
Where to Use Spring Cloud Function in the AI/ML Process
AI/ML Process | Human | Compute | |
|---|---|---|---|
Spring Cloud Function (Short Run) | Batch (Long Run) | ||
Model requirements | Human/manual process | ||
Collect data | Integration triggers, data pipeline sources or sinks | Data pipeline process-Transformation | |
Data cleaning | Integration triggers | Transformation process | |
Data labeling | Tagging discrete elements-updates, deletes | Bulk tagging | |
Feature engineering | Manual | ||
Train model | Trigger for training | Training process | |
Model evaluation | Manual | Triggers for evaluation | Bulk evaluation |
Deploy models | Model serving, model | Bulk storage | |
Monitoring models | alerts |
AI/ML processes require varying compute and storage requirements. Depending on the model size, the time taken to train, the complexity of the model, and so on, the process may require different compute and storage at different times. So, the environment should be scalable. In earlier days, AI/ML activities were conducted with a fixed infrastructure, through over-allocated VMs, dedicated bare metal servers, or parallel or concurrent processing units. This made the whole process costly and it was left to companies with deep pockets to be able to conduct proper AI/ML activities.
Today, with all the cloud providers providing some level of AI/ML activities through an API or SaaS approach, and with the ability to pay per use or pay as you go, companies small and big have begun to utilize AI/ML in their compute activities.
Codeless inference makes getting started easy
Scalable infrastructure
No management of infrastructure required
Separate storage for the model, which is very convenient for tracking versions of the model and for comparing their performance
Cost structure allows you to pay per use
Ability to use different frameworks
5.1.1 Deciding Between Java and Python or Other Languages for AI/ML
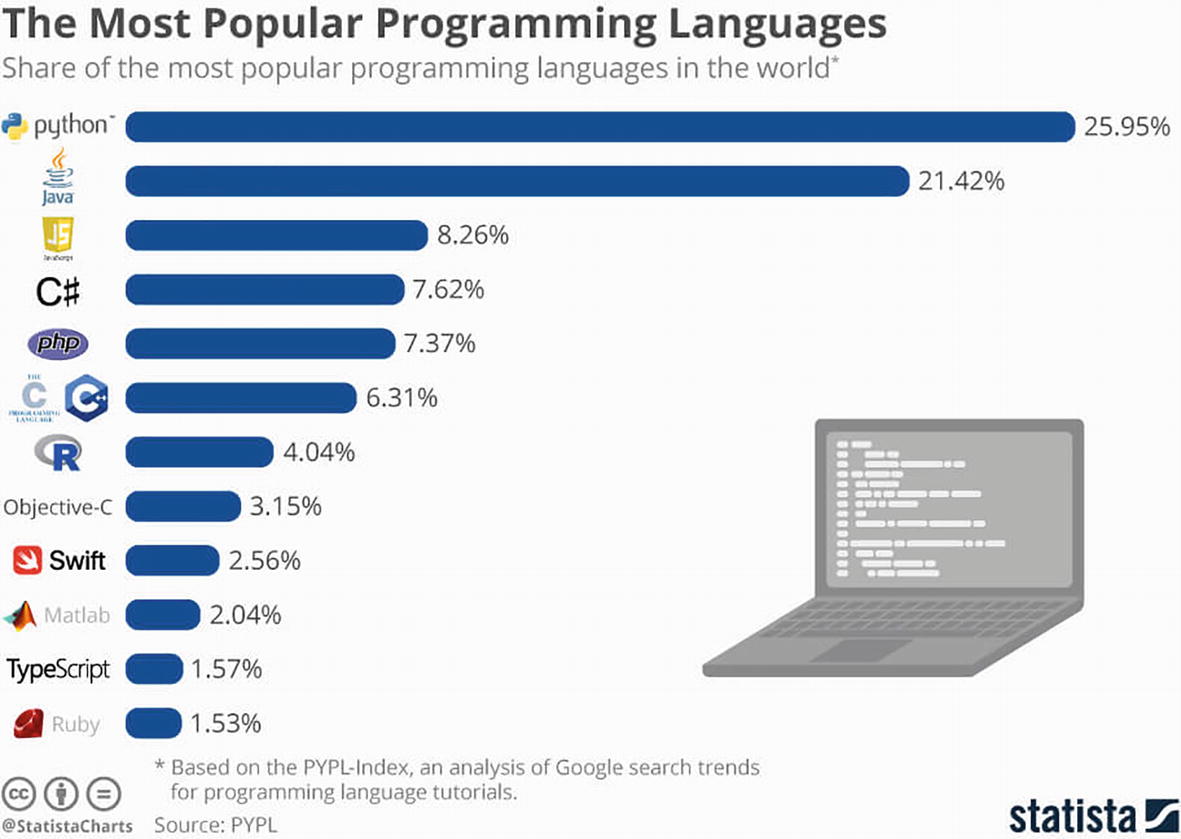
A pictorial horizontal bar graph of the most popular programming languages. It mentions the logo of worldwide languages with percentages and a laptop image. Python has the highest at 25.95 and Ruby, has the lowest at 1.53.
AI/ML language popularity
It is very important to understand that the popularity of a language does not equate to it being a good, robust, secure language for use in AI/ML.
Enterprises have standardized on Java, so they prefer to have their AI/ML platform written in Java to ease the integration into existing systems.
Apache.org , the open source community for Java, is very robust and has many libraries and tools that have been tuned toward speed of compute, data processing, and so on. Tools such as Hadoop, Hive, and Spark are integral to the AI/ML process. Developers can easily use these tools and libraries in their java code.
Java can be used at all touchpoints in the AI/ML process, including data collection, cleansing, labeling, model training, and so on. This way you can standardize on one language for AI/ML needs.
JVMs allow for applications to be portable across different machine types.
Due to Java’s object-oriented mechanisms and JVMs, it is easier to scale.
Java-based computation for AI/ML can be made to perform faster with some tuning at the algorithm and JVM level. Therefore, it is a preferred language for sites like Twitter, Facebook, and so on.
Java is a strong typing programming language, meaning developers must be explicit and specific about variables and types of data.
Finally, production codebases are often written in Java. If you want to build an enterprise-grade application, Java is the preferred language.
Since Java is a preferred enterprise language for AI/ML, we can safely say that Spring Cloud Function is a better framework to use when developing enterprise-grade functions for AI/ML.
This chapter explores the different offerings from the different cloud providers and explains how you can use Spring Cloud Function with these offerings.
5.2 Spring Framework and AI/ML
A lot of frameworks have been developed in Java that can be leveraged using the Spring Framework. The latest of these frameworks was developed by AWS and is called DJL (Deep Java Library). This library can integrate with PyTorch, TensorFlow, Apache MXNet, ONNX, Python, and TFLite based models.
One of the important capabilities that you need is model serving, where you can leverage Spring Cloud Function to serve trained models, and DJL provides this capability out of the box. It’s called djl-serving.

An illustrated model of the on-prem data center. The flow of data includes trained model data, the model serving, an enterprise application, a firewall, and an external application.
On-premises and Spring Cloud Function deployment for model serving
5.3 Model Serving with Spring Cloud Function with DJL
Before you explore the cloud provider’s option, it’s a good idea try this out locally. To do that, you need a framework installed and access to a good tensor model and an image. The framework that you use in this example is called djl-serving.
5.3.1 What Is DJL?
Deep Java Library (DJL) https://docs.djl.ai/ is a high-level, engine-agnostic Java framework for deep learning. It allows you to connect to any framework like TensorFlow or PyTorch and conduct AI/ML activities from Java.

A model of layers of the deep java library. It includes a java framework with a logo of spring boot, and spring cloud function. An M L framework of m x net, Tensor flow, PyTorch. Deep Lava Library is mentioned between the frameworks.
Deep Java Library (DJL) layers
There are many components in DJL that are useful to look at, but the DJL serving is interesting.
djl-serving Run with a Tensorflow Model
On subsequent runs, the model server will be available at port 8080 at http://localhost:8080.

A photograph of a kitten with closed eyes and legs laid out.
Image of a kitten for the model to predict
Next, run the following and you will see the output with probabilities.

A screenshot of the window. It has the class name and probability input and outputs. It represents the D J L results.
DJL results for the image

An X-ray image. It diagnosis the lungs using a saved model.
Xray image provided to the saved_model
Next, you see how you can use DJL to create a Spring Cloud Function to serve models.
5.3.2 Spring Cloud Function with DJL
For this example, we borrow an example from DJL called pneumonia detection. This sample is available at https://github.com/deepjavalibrary/djl-demo/tree/master/pneumonia-detection.
This example uses an Xray image from https://djlai.s3.amazonaws.com/resources/images/chest_xray.jpg.
{kind=link}
It predicts using a model from https://djl-ai.s3.amazonaws.com/resources/demo/pneumonia-detection-model/saved_model.zip.
The Spring Cloud Function you create will take an image, load the model, and provide a prediction, as in the cat example.
DJL libraries
A model: https://djl-ai.s3.amazonaws.com/resources/demo/pneumonia-detection-model/saved_model.zip
The URL of the image to analyze: https://djl-ai.s3.amazonaws.com/resources/images/chest_xray.jpg
{kind=link}
Step 1: Create the Spring Cloud Function with DJL framework. Add dependencies to the Hadoop file.
Dependencies for DJL
Step 2: Create the Spring Cloud Function.
XRAYFunction.java
Step 3: Test locally. Run the Spring Cloud Function and invoke the endpoint http://localhost:8080/xrayFunction
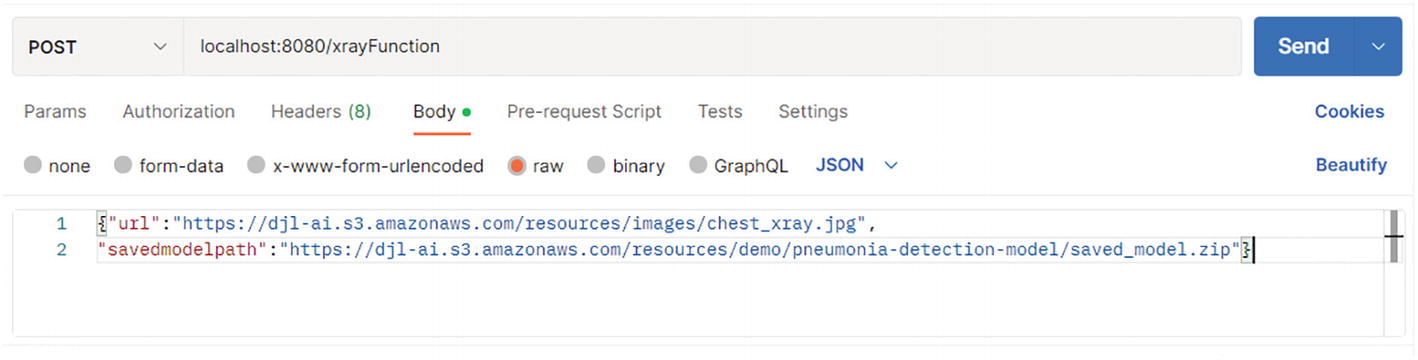
A screenshot of the postman testing. It highlights the local host, body, and row options with a testing program.
Testing with a POST in Postman

A screenshot of programming functions with number, date, and time. It represents the results from image evaluation.
Prediction results from the image evaluation

A flow diagram of the saved model. It classifies as training and deployment. It represents the tensor flow components. The output from the training is sent to the saved model and further to the deployment.
TensorFlow components1
This section successfully demonstrated that Spring Cloud Function can act as a model server in AI/ML. This is a critical function, as you can move the loading and serving of models from traditional servers to a function-based, “pay-per-use” model.
You also learned how to use deep learning Java libraries in your functions. You can deploy this Spring Cloud Function to any cloud, as shown in Chapter 2.
5.4 Model Serving with Spring Cloud Function with Google Cloud Functions and TensorFlow
This section explores the model serving on Google. It uses TensorFlow, which is a Google product from AI/ML and explains how to build and save an AI model with datasets such as MNIST (https://en.wikipedia.org/wiki/MNIST_database).
5.4.1 TensorFlow
TensorFlow was developed by Google and is an open source platform for machine learning. It is an interface for expressing and executing machine learning algorithms. The beauty of TensorFlow is that a model expressed in TensorFlow can be executed with minimal changes on mobile devices, laptops, or large-scale systems with multiple GPUs and CPUs. TensorFlow is flexible and can express a lot of algorithms, including training and inference algorithms for deep neural networks, speech recognition, robotics, drug discovery, and so on.
In Figure 5-9, you can see that TensorFlow can be deployed to multiple platforms and has many language interfaces. Unfortunately, TensorFlow is written in Python, so most of the models are written and deployed in Python. This poses a unique challenge for enterprises who have standardized on Java.
Even though TensorFlow is written in Python, there are lots of frameworks written in Java that work on a saved model.
Let’s look at how you can work with TensorFlow on the Google Cloud platform.
Google and AI/ML Environment2
 A table with 4 columns and 6 rows. The column headers are the features, compute engine, A L platform prediction, and cloud functions. It categorizes features and descriptions. A table with 4 columns and 6 rows. The column headers are the features, compute engine, A L platform prediction, and cloud functions. It categorizes features and descriptions. |
As you can see from Table 5-2, cloud functions are recommended for experimentation. Google recommends Compute Engine with TF Serving, or its SaaS platform (AI Platform) for predictions for production deployments.
The issue with this approach is that a function-based approach is more than just an experimentation environment. Functions are a way of saving on cost while exposing the serving capabilities for predictions through APIs. It is a serverless approach, so enterprises do not have to worry about scaling.
5.4.2 Example Model Training and Serving
In this section you see how to train an AI model locally and upload it to Google Cloud Storage. You will then download the model and test an image through a Cloud Function API. You will use a model that is based on MNIST. More about MNIST can be found at https://en.wikipedia.org/wiki/MNIST_database.
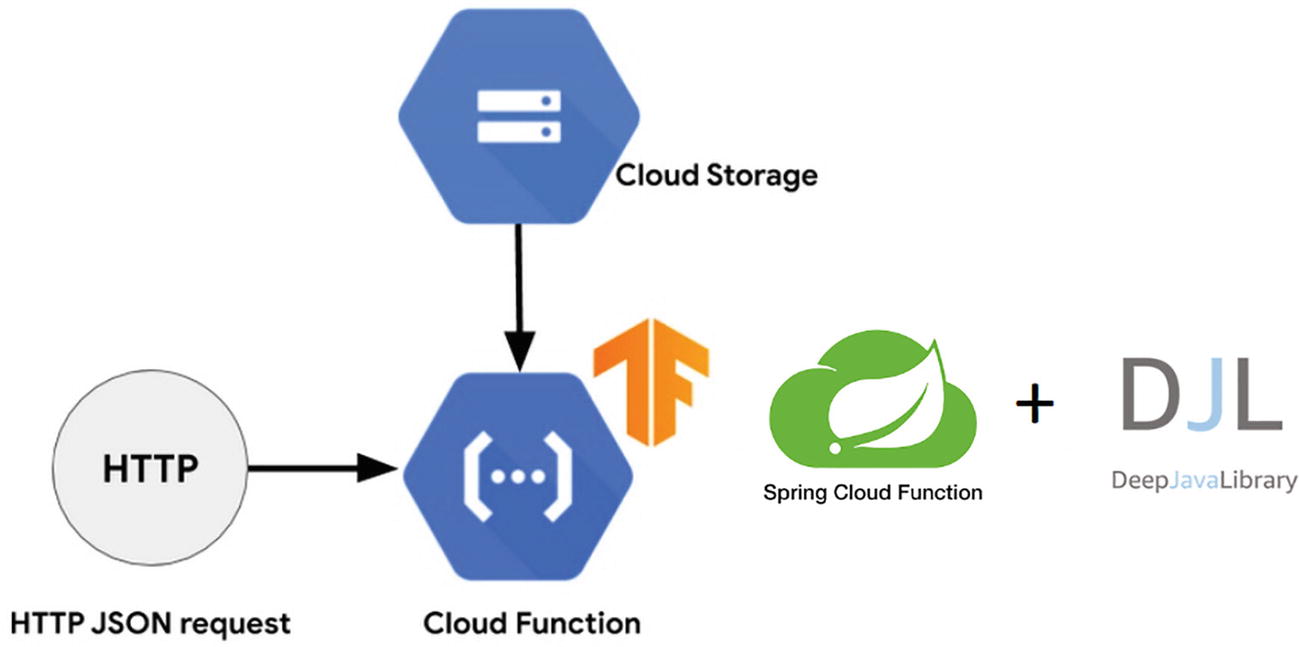
A model of spring cloud function. It indicates the tensor flow of H T T P J SON request, cloud storage, and cloud function with two logos of spring cloud function, and deep java library.
Spring Cloud Function with DJL and TensorFlow
You use the same example outlined at https://cloud.google.com/blog/products/ai-machine-learning/how-to-serve-deep-learning-models-using-tensorflow-2-0-with-cloud-functions. This will allow you to concentrate more on the Spring Cloud Function code that you will be creating rather than the actual implementation in Python.
You will then serve the model using Spring Cloud Function.
Step 2: Create a project. Create a project called MNIST and then create a main.py file with the code in Listing 5-4. I used PyCharm to run this code.
main.py
The key is tf.saved_model.save(model, export_dir="c://Users//banua//Downloads/MNIST/models").
This will save the model so that any model server can use it.
Step 3: Run the project.

A screenshot of the window. It represents the successful run of M N I S T. The pop-up text reads as generated model files located in the root of the project.
Successful run of MNIST and model building
Zip the assets, variables, and the saved_model.pb. file as Savedmodel3.zip and upload it to the Google Cloud Storage.
Step 4: Upload the models into Cloud Storage. Navigate to your Google Cloud Console and subscribe to Cloud Storage. It is available at cloud.google.com.
Create a storage bucket in Google Cloud Storage and upload the two files into the storage bucket. Use the defaults for this example. If you are using free credits from Google, this storage should be covered.

A screenshot of the Google cloud storage bucket. It includes the name of the bucket, choosing store data, choosing default storage, choosing control access, and protecting access with highlighted lines.
Google Cloud Storage Bucket creation steps
Name your bucket mnist-soc and leave the others set to the defaults; then click Create.

A screenshot of a mnist soc application. It highlights the object option and mentions the model's name, size, and type. It represents the models located in cloud storage.
Models deployed into Cloud Storage

A screenshot represents the U R L for a model. It indicates a mnist soc application with a live object option. It highlights the public and authentication U R L with a link.
URL for the savedmodel3.zip
The URL you use for testing this example is https://storage.googleapis.com/mnist-soc/savedmodel3.zip.
The test image you use for this example is https://storage.googleapis.com/mnist-soc/test.png.
{kind=link}
Note that the function that you created in Section 5.2 will be deployed in Step 5. If you use savedmodel3.zip and test.png, it will fail. But you will know that the function is working because you will get an error message that the model could not be loaded. This is an acceptable outcome for the model you created.
Step 5: Deploy the Spring Cloud Function to Google Functions. In this step, you take the function you created in Section 5.2 and deploy it into the Google Cloud Functions environment. The prerequisites and steps are the same as discussed in Chapter 2.
Google account
Subscription to Google Cloud Functions
Google CLI (This is critical, as it is a more efficient way than going through the Google Portal)
Code from GitHub at https://github.com/banup-kubeforce/DJLXRay-GCP.git
Dependencies for GCP Added
Deploy the Spring Cloud Function to Google Cloud Functions. Make sure that you build and package before you run the following command. A JAR file must be present in the target/deploy directory in the root of your project.

A screenshot of multiple programming functions. It denotes the deployed function, memory, and time.
Successfully deployed function with the specifed memory and timeout

A screenshot includes functions and cloud functions in the console. It highlights the create function and refresh. It indicates a filter option with details of the first gen.
Function shows up in the console

A screenshot highlights the cloud function, D J L X ray -G C P. The testing option with Test the function is highlighted. The test was successfully executed.
Successful execution of the test

A screenshot of the window denotes the multiple output logs. It highlights one log code no-16392, code- 200 with box .It displays the execution time.
Logs show the execution times
This section explored the capabilities of TensorFlow and explained how you can use DJL and Spring Cloud Function together to access a saved TensorFlow model. DJL makes it easy for Java programmers to access any of the saved models generated using Python frameworks, such as PyTorch (pytorch.org) and TensorFlow.
You also found that you have to set the memory and timeout based on the saved model size and store the model closer to the function, such as in Google’s storage offerings.
5.5 Model Serving with Spring Cloud Function with AWS Lambda and TensorFlow
This section emulates what you did in Chapter 2 for Lambda. It is best to finish that exercise before trying this one.
AWS account
AWS Lambda function subscription
AWS CLI (optional)
Code from GitHub at https://github.com/banup-kubeforce/DJLXRay-AWS.git
Step 1: Prep your Lambda environment. Ensure that you have access and a subscription to the AWS Lambda environment.
DJL Dependencies
Step 3: Deploy the Spring Cloud Function to Lambda. You should follow the process outlined in Chapter 2 to build and package the Spring Cloud Function and deploy it to Lambda.

A screenshot of the window of the successful execution. It highlights the body and pretty options and mentions the class name with probability.
Successful execution
5.6 Spring Cloud Function with AWS SageMaker or AI/ML
This section explores the offering from AWS called SageMaker and shows how you can use Spring Cloud Function with it.

A model of the A W S sage maker. The process includes labeling data, building, training, tuning, deploying, and discovering. Each step has a logo associated with it.
AWS SageMaker flow
SageMaker allows you to build and deploy models with Python as the language of choice, but when it comes to endpoints, there are Java SDKs much like AWS Glue that create prediction APIs or serve models for further processing. You can leverage Lambda functions for these APIs.
So, as you saw in TensorFlow, you have to work in Python and Java to model and expose models for general-purpose use.
Let’s run through a typical example and see if you can then switch to exposing APIs in Spring Cloud Function.
This example uses the same sample to build, train, and deploy as in this hands-on tutorial in AWS.
https://aws.amazon.com/getting-started/hands-on/build-train-deploy-machine-learning-model-sagemaker/

A screenshot of the create notebook instance. It includes Notebook instance settings, Permissions, and encryption. It asks for the notebook instance name, type, elastic inference, platform identifier, and I A M role.
Notebook instance in SageMaker with properties set

A screenshot of the deployment of the notebook. It highlights the amazon sage maker and search notebook instance. It asks for name, instance, creation time, status, and actions.
Successful deployment of the notebook

A screenshot of the jupyter notebook. It highlights the option for new notebooks. It has the title files, running, cluster, sage maker example, and conda.
Pick a framework in the Jupyter notebook
As you can see from the list, most frameworks use Python. This example uses conda_python3, as suggested in the AWS tutorial.

A screenshot of the window of the Jupyter notebook code. It creates a sage maker for instance. In this program, the log mentions import libraries, defines I A M role, X G boost container.
Code to create a SageMaker instance

A screenshot of the window for the creation of a bucket. This program includes the bucket name, steps, and process. The bucket was created successfully.
Create a bucket

A screenshot of the window for downloading the data to a data frame. The program includes the process of trying, except, and printing data.
Download the data into a dataframe

A screenshot of the window for the work on the dataset. The program includes splitting the dataset to train data, test data, split data, and print.
Work on the dataset

A screenshot of the window for inputs and outputs. It indicates the training of the model with 3 steps.
Train the model
A screenshot of the window with the input and outputs. It indicates the S 3 training completion. It mentions that the training job was completed.
Training is complete

A screenshot of the window for the deployment of the model. It indicates the programming function.
Deploy the model

A screenshot of the window of Amazon sage maker. It has endpoints that include the name, A R N, creation time, status, and last update.
Endpoint of the deployment

A screenshot of the window indicates the endpoint settings. It includes the name, type, A R N, creation time, status, last updated, U R L.
Details of the endpoint
AWS SDK Dependencies

A screenshot of the window with the programming function input and output components. It represents the sage maker supplier in Java.
SageMakerSupplier.java
Deploy the function in Lambda, as shown in Chapter 2.
This section explained how to create and deploy a model in AWS SageMaker. You then called the SageMaker endpoint using the SageMaker JDK client in the Spring Cloud Function, which was deployed in AWS Lambda.
The Java-based Lambda function can be tuned to be more responsive and have a shorter cold startup time by using mechanisms such GraalVMs.
5.7 Summary
As you learned in this chapter, you can serve models using Spring Cloud Function. But you also learned that serving models using Spring Cloud Function and Java is a stretch because the AI/ML models are written in Python. While Python may be popular, it is also important to note that in an enterprise, Java is king. Finding ways to leverage Java in AI/ML is the key to having an integrated environment within your enterprise. Cold starts of Python-based functions take a long time. This is where using Java and frameworks such as GraalVM speeds up the startup times.
The next chapter explores some real-world use cases of IoT and Conversation AI and explains how Spring Cloud Function can be used.