
Spring Cloud Function plays a critical role in the hybrid cloud or on-premises/private cloud space. Building events/data pipelines that span across the local datacenter and the cloud increases complexity due to the firewall boundaries. Data pipelines play an important role when you want to acquire, move, or transform data as it comes (streaming) or when it’s offline (batch).
So, what are event data pipelines?
4.1 Data Event Pipelines

An illustration depicts the OnStar event-driven data pipeline implementation for vehicles. The vehicle sends data to nearby Cell tower, Cell tower relays data to OnStar datacenter. OnStar datacenter routes information to the call center. Through this emergency services such as police, medical response team and towing company are activated.
An example event-driven data pipeline implementation for vehicles using OnStar
All data regarding the incident is collated, processed, analyzed, and sent to various target systems, both internal and external to OnStar. This is an example of event data pipeline.
A data pipeline is a set of processes that takes raw data from disparate sources, and then filters, transforms, and moves the data to target stores, where it can be analyzed and presented in a visually compelling way.

An illustration depicts the data pipeline as a set of processes that ingests the structured or unstructured data and retrieves and transforms the data through data lakes or data warehouses which is further analyzed through A I or M L processes.
Data pipeline process
The data can also be unstructured or structured. Unstructured data can be from a multitude of resources, including Internet-based platforms such as Twitter, to an automotive device emanating data.
Structured data usually originates from within the company’s applications. This data needs to be combined at a landing zone of object stores. These object stores can be on-premises or in the cloud. Once the data is ingested into the object stores, it is then retrieved and transformed, usually through an ETL process in other datastores such as data lakes or data warehouses. This data is then further analyzed using BI tools such as Power BI and Tableau or further processed with the AI/ML processes.
This whole process—from data ingestion to consumption—is called the data pipeline.
Let’s dive a bit deeper into the various sub-processes outlined in the data pipeline process.
4.1.1 Acquire Data
Acquiring data is the first step in the data pipeline process. Here, business owners and data architects decide on what data to use to fulfil the requirements for a specific use case.
For example, in the case of a collision event detection for OnStar, the data needs to be acquired from sensors. This sensor data then needs to be combined with data from internal and external partners, like finance, towing partners, rental partners, and so on.
Data Identification
Data | Type of Data | Data Source |
|---|---|---|
Sensor | Unstructured (JSON, CSV) | Sensors |
Rental info | Relational (RDBMS) | External rental agency |
User info | Relational (RDBMS) | OnStar registration |
Vehicle info | Relational (RDBMS) | Vehicle data systems |
Towing info | Relational (RDBMS) | External towing company |
4.1.2 Store/Ingest Data
The data from various sources is acquired and stored as raw data into the store of choice. The method of ingestion can be stream-based or batch-based.
For example, in the case of OnStar, sensor data is streamed at regular intervals or is event-based. Other data, such as rental info, can either be batch based or on-demand query driven. The raw datastore can be an S3 object store hosted in the cloud or on-premises.
4.1.3 Transform Data
The data that is stored raw in the object store is then processed. The process may include converting or transforming unstructured data into structured data and storing it in an RDBMS database.
For example, in OnStar, partner data and internal data will be combined and transformed into a common data model. The sensor data will also be transformed into an RDBMS format.
4.1.4 Load Data
Once the data is transformed, it is then loaded into a single or multiple databases with a common schema. This schema is based on a predefined data model specific to the use case. The target datastore can be a data lake or another RDBMS store. Here again, it depends on the type of analysis that needs to be done.
For example, if this an OLTP type of analysis, the data needs to be processed and sent to requesting systems quickly. This would require an RDBMS store. Data that needs to be available for reporting and research can be stored in a data lake.
4.1.5 Analyze Data
During this sub-process, the data that is stored in a data lake or RDBMs will be analyzed using tools such as Tableau, Power BI, or a dedicated web page for reporting.
In the case of OnStar, data that is stored in the data lake will be analyzed using Tableau or Power BI, while the data that needs immediate attention will be analyzed by a custom dashboard or reporting interface on the web.
Spring Cloud Function plays an integral role in the whole process, especially when combined with tools such as Spring Cloud Data Flow, AWS Glue, Azure Data Factory, Google’s data flow, and so on. You will dive deep into these tools in this chapter.
4.2 Spring Cloud Function and Spring Cloud Data Flow and Spring Cloud Streams
Spring Cloud Data Flow (SCDF) is a Spring.io-based product that supports the creation and deployment of a data pipeline. It supports batch and event-driven data, which makes it versatile. SCDF pipelines can be built programmatically or wired up through a GUI. It is heavily based on the Spring Framework and Java, which makes it very popular among Spring developers.

A screenshot of a S C D F. It shows the stream vehicle data pipelines definition, status and applications.
A sample graphical representation of a data pipeline in SCDF
As you can see from the dashboard, you can build stream-based or batch-based (task) data pipelines and manage these through a single dashboard.
SCDF, unlike other the data pipeline tools available in the cloud, can be deployed in a Kubernetes, Docker, or Cloud Foundry environment, making it a portable tool for data pipeline development and deployment.
4.2.1 Spring Cloud Function and SCDF
Spring Cloud Function and SCDF are perfectly matched, as they are built out of the same framework, Spring. You can deploy Spring Cloud Function as a source, processor, sink, or as a trigger for the pipeline. Since the data pipelines are usually invoked sporadically for processing data, you can optimize utilization of resources and costs with a Spring Cloud Function.
Let’s look at a sample implementation of Spring Cloud Function with SCDF.
In this example, you will build a simple data pipeline using RabbitMQ as a source, do a simple transformation, and store the messages in a log. You will publish sample vehicle information into a RabbitMQ topic called VehicleInfo and do a simple transformation, then store it in a log file.
RabbitMQ ➤ Transform ➤ Log
SCDF deployed on Kubernetes or locally in Docker
Kubernetes or Docker
A RabbitMQ cluster/instance
A queue to publish messages
Code from GitHub at https://github.com/banup-kubeforce/SCDF-Rabbit-Function.git
Additional prerequisites for each environment can be found at https://dataflow.spring.io/docs/installation
Local machine: Docker Compose is an easy way to get an instance of Spring Cloud Data Flow up and running. The details of the installation are available at https://dataflow.spring.io/docs/installation/local/docker/
Kubernetes: Instructions for installing this on Kubernetes are available athttps://dataflow.spring.io/docs/installation/kubernetes/.

A screenshot depicts the helm command to install the S C D F. It consists of name, last deployed, namespace, status, test suite, notes, chart name, chart version and app version.
Successful execution of a helm chart for SCDF

A screenshot depicts the command to get external I P of the S C D F. The command used is dollar kubect 1 get pods-n s c d f-system.
Get the external IP of the SCDF

A screenshot depicts the command to get the status of the S C D F. The command used is dollar kubect 1 get s v c-n s c d f-system.
Get the status of SCDF
You can now access SCDF using the external IP. For example, http://20.241.228.184:8080/dashboard
The next step is to add applications. Spring provides a standard set of templates that you can use to build your pipeline.
Step 2: Add Applications to your SCDF Instance

A screenshot depicts the S C D F add application view to create a data pipeline.
Add application view in SCDF

A screenshot depicts the options to add applications and docker-based or rabbit M Q kafka-based.
Pick the starters of your choice. If SDCF is deployed in Kubernetes, pick Docker based starters
Figure 4-8 shows you the options to add applications that are custom built through the Registering One or More Applications option. You import the application coordinates from an HTTP URI or use a properties file. There is also an option to import some prebuilt starters from Spring. Furthermore, you can choose starters that are Maven- or Docker-based or RabbitMQ- or Kafka-based. RabbitMQ and Kafka are used as backbone messaging systems for internal SCDF components and not for external use. When deploying to a Kubernetes cluster, you have to choose a Docker-based starter. When deploying locally in a Docker environment, you can choose between Maven and Docker-based starters.

A screenshot depicts the S C D F running on a Kubernetes environment and prebuilt templates installed in S C D F.
Prebuilt templates are installed in SCDF
These prebuilt templates come in three categories—source, processor, and sink. They allow you to wire up a data pipeline without the need for coding. If you want a custom component, you can follow the examples in https://dataflow.spring.io/docs/stream-developer-guides/.
The next step is to create a stream using the starter templates you loaded.
Step 3: Create a Stream

A screenshot depicts the streams button to create a stream in the streams dashboard.
The Streams dashboard
- 1.
Pick the source.

A screenshot depicts the create stream and picking the available option from the source.
Create a source
- 2.
Pick a processor.

A screenshot depicts a selection and creation of a processor for the transform component.
Create a processor
- 3.
Pick a sink.

A screenshot depicts a selection and creation of a sink for the log component.
Create a sink
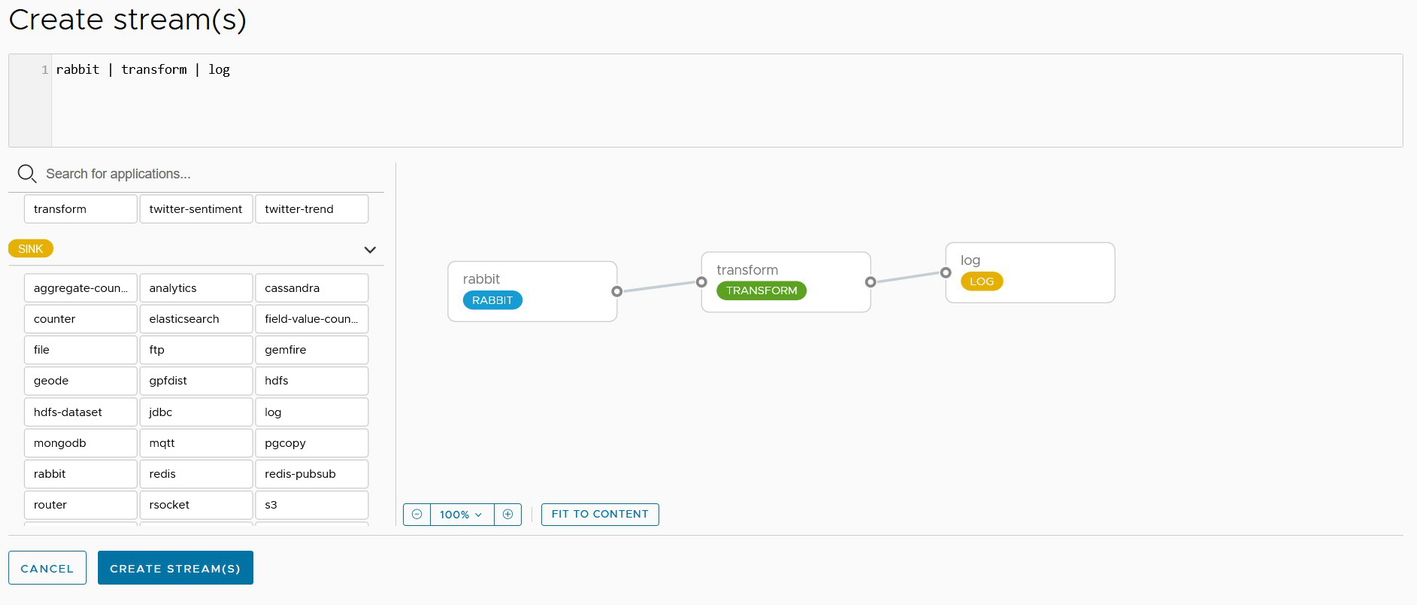
A screenshot depicts wiring the data pipeline by dragging the output of the first component to the input of the second component.
Wiring the data pipeline
- 4.
Configure RabbitMQ.

Two screenshot depicts the configured Rabbit M Q and the properties of the Rabbit. It consists of a username, password, port and host.
Set the properties for rabbit
- 5.
Configure the transform.

A screenshot depicts the properties for transform. It consists of general and spel. function and update and cancel buttons.
Set the transform properties
- 6.
Configure the sink.

A screenshot depicts setting properties for log. It represents general, log along with cancel and update buttons.
Setting properties for the log
- 7.
Wire up the data pipeline.

A screenshot depicts the wiring up of the data pipeline. It represents stream D S L expression on create stream dashboard.
Wire up the data pipeline
- 8.
Deploy the stream

A screenshot depicts the successful deployment of a data pipeline by an external Spring Cloud Function.
Successful deployment of a data pipeline
Step 4: Create a function to publish data to RabbitMQ
Here, you create a Spring Cloud Function to publish the data to start the data-pipeline process.
SenderConfig
QueueSender
SenderFunction
A POM with the necessary dependencies for RabbitMQ and Spring Cloud Functions, as shown in Listing 4-1.
pom.xml with RabbitMQ Dependencies
application.properties
1. Create the SenderConfig Component
application.properties
2. Create the QueueSender Component
QueueSender.java
3. Wrap the Sender in Spring Cloud Function framework
SenderFunction.java
Step 5: Test the function using Postman
Use the GET function on Postman and provide the URL to the senderFunction.

A screenshot depicts the G E T function on Postman with the U R L.
You should get the result shown in this image.
Check the RabbitMQ queue for any messages.

A screenshot depicts the Rabbit M Q Queue for any messages. It represents Exchange, Routing key, Redelivered, Properties, and Payload under the Queries tab with a message the server reported 0 messages remaining.
Now you have a function that can post messages to a RabbitMQ topic. The SCDF data pipeline will be listening to the queue and will start processing.

A screenshot depicts the details of the vehicle data pipeline. It shows the logs associated with each of the components to monitor.
Details of the VehicleDataPipeline stream
You have seen how to create a data pipeline in SCDF that monitors a topic in RabbitMQ. You created a Spring Cloud Function that posts messages into the RabbitMQ topic. Spring Cloud Function can also be deployed as a source in SCDF; more information on how to develop code for SCDF is available on the SCDF site.
4.3 Spring Cloud Function and AWS Glue
AWS Glue works very similarly to Spring Cloud Data Flow in that you can wire up a data pipeline that has a source, processor, and sink. More information can be found at https://us-east-2.console.aws.amazon.com/gluestudio/home?region=us-east-2#/.
Spring Cloud Function can participate in the data pipeline process as a trigger, or simply by integrating with one of the components in the data pipeline.
For example, if you have AWS Kinesis as a source and you need to get data from a vehicle, you can have Spring Cloud Function stream the data that it gets into AWS Kinesis.
In the example in this section, you will be publishing data into AWS Kinesis and then kick off an AWS Glue job manually.
The flow will be:
Spring Cloud Function ➤ Kinesis ➤ AWS Glue Job ➤ S3
Subscription to AWS, AWS Glue job, Kinesis, and S3
AWS Glue job with Kinesis as the source and S3 as the target
Code from GitHub at https://github.com/banup-kubeforce/Kinesis_trigger.git
It is assumed that you have some knowledge of AWS Glue, as we do not delve into the details of this product. The focus is on creating the Spring Cloud Function.
4.3.1 Step 1: Set Up Kinesis
You can get to Kinesis at https://us-east-1.console.aws.amazon.com/kinesis/home?region=us-east-1#/home.
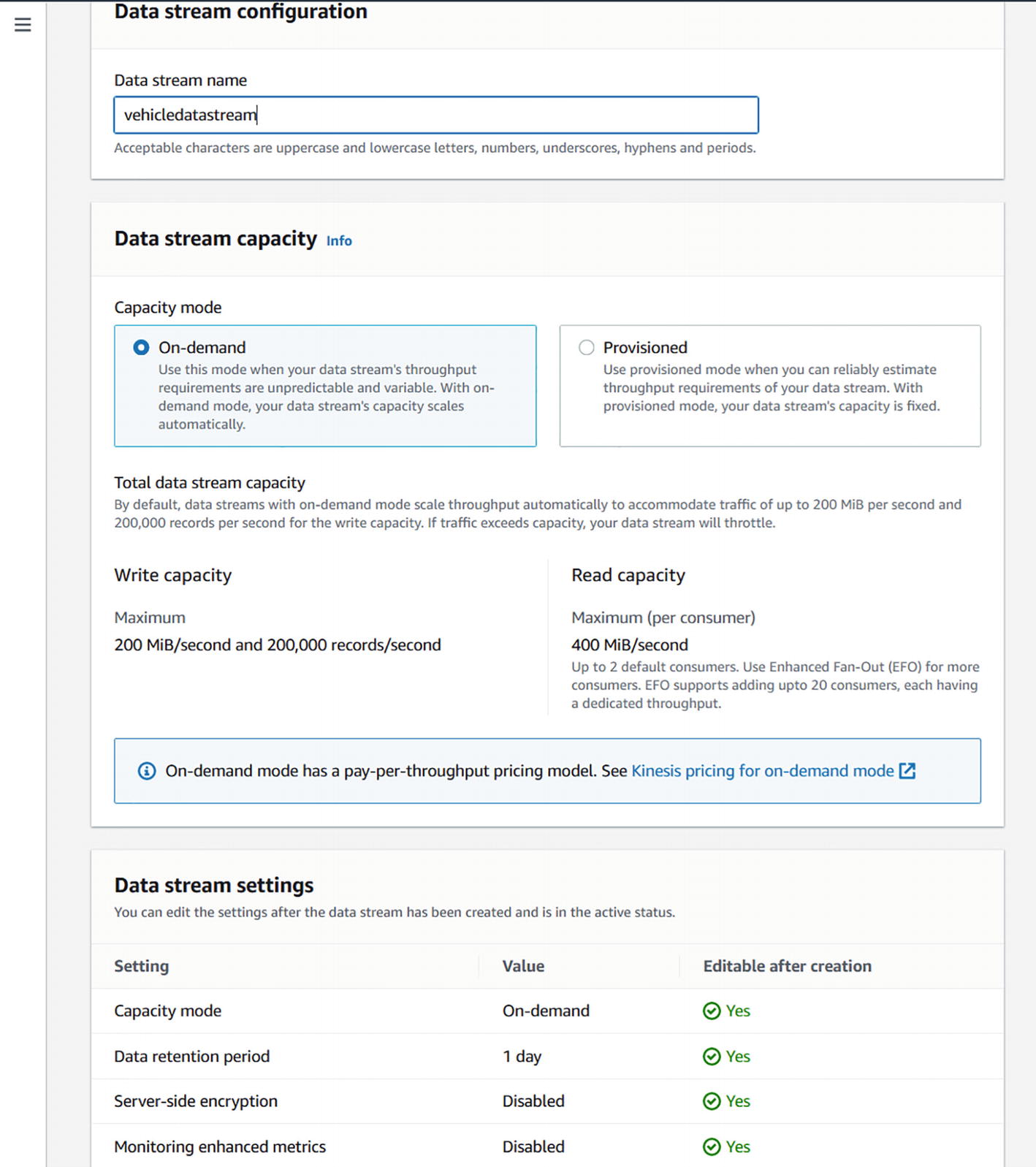
A screenshot depicts the setup for Kinesis to create a data stream for a vehicle. It shows the data stream configuration, data stream capacity and data stream settings.
Create a vehicledatastream in AWS Kinesis

A screenshot depicts the active vehicle data stream under the monitoring tab.
vehicledatastream is active
You can now connect and publish to the stream using your Spring Cloud Function.
4.3.2 Step 2: Set Up AWS Glue
You can access the AWS Glue Studio at https://us-east-1.console.aws.amazon.com/gluestudio/home?region=us-east-1#/.
Once you have the subscription, you can begin creating a glue job.

A screenshot depicts the creation of a job on A W S glue studio.
AWS Glue Studio, Create a Job
Create a job called vehicledatapipeline. Use Amazon Kinesis as the source and Amazon S3 as the target. Ensure that you set the proper configurations for each of these components.

A screenshot depicts the Configuration of amazon kinesis as the source and amazon S 3 integration for each component.
Configure Kinesis and S3 integration
Now you have a job in AWS Glue that you can trigger manually or via a function.
4.3.3 Step 3: Create a Function to Load Data into Kinesis
application.properties
pom.xml dependecies
TrackDetail.java
ProducerService.java
ProducerServiceImpl.java
ProducerFunction.java

A screenshot depicts the successful run of the function.
Successful run of the function
8: Test with Postman. Run a POST-based test against ProducerFunction to publish data into Kinesis.

A screenshot depicts the post-based test against the producer function. It includes the tabs params, authorization, headers, body, pre-request script, tests, and settings with a button to send.
Postman test
You will get a message that the data is saved.

A screenshot depicts the data metrics found on the kinesis dashboard.
Kinesis dashboard showing the data metrics
10: Run Glue manually. From the Glue Studio, start the process by clicking Run, as shown in Figure 4-24.

A screenshot depicts the glue job run from the glue studio.
The Glue job run
In this section, you learned how to create a Spring Cloud Function that can post data into AWS Kinesis that is part of the data pipeline. You learned that you can publish data into Kinesis and trigger the AWS Glue pipeline manually, but I also encourage you to explore other ways you can implement Spring Cloud Function for AWS Glue, such as creating and deploying triggers. More information on how to create AWS Glue triggers in Spring is available at https://docs.aws.amazon.com/sdk-for-java/latest/developer-guide/examples-glue.html.
4.4 Spring Cloud Function and Google Cloud Dataflow
Google Cloud Dataflow is very similar to Spring Cloud Data Flow, in that it allows you to wire up a data pipeline with a source, processor, and sink. The Dataflow product is easier to develop with. You can read about Dataflow and its capabilities at https://cloud.google.com/dataflow.
For the example in this section, you will create a dataflow that includes cloud pub/sub:
Spring Cloud Function ➤Dataflow {Cloud Pub/Sub ➤ Cloud Storage}
Subscription to Google Data Flow
A cloud pub/sub instance
A cloud storage bucket
Code from GitHub at https://github.com/banup-kubeforce/GooglePubSub
Step 1: Create and configure a cloud pub/sub instance.
Before coming to this step, ensure that you are subscribed to cloud pub/sub. Also ensure that you have proper subscriptions to the APIs.

A screenshot depicts the creation and configuration of cloud pub or sub-instance in google cloud.
Cloud Pub/Sub with a topic
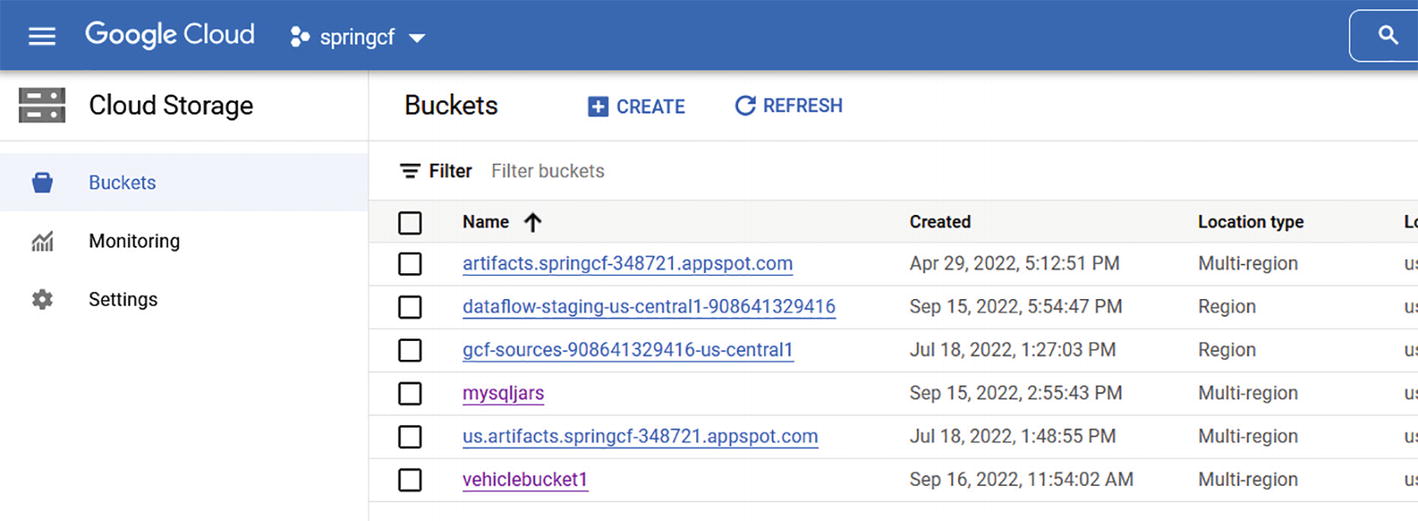
A screenshot depicts the google cloud storage with vehicle bucket 1. It includes the tabs create and refresh with a list of names under buckets.
Google Cloud Storage with vehiclebucket1
Now you are ready to build the Dataflow data pipeline.
Step 3: Create a data pipeline. Navigate to the Dataflow dashboard and create a pipeline. I created a pipeline using a prebuilt template.
1: Pick the template

A screenshot of a data flow option in google cloud. It shows the template used to create the data pipeline in the drop-down and the filter option shows many data flow template formats.
Create a data pipeline from the template
2: Set the parameters for pub/sub and cloud storage.

A screenshot depicts the data flow parameter setup. It shows the option to create a pipeline template, data flow template, regional endpoint, input pub per subtopic, output file name prefix and temporary file location.
Complete the parameters set up for Dataflow
3: Verify the creation of the data pipeline.

A screenshot depicts the successful creation of vehicle data pipeline and its pipeline summary.
Successful creation of vehicledatapipeline

A screenshot depicts the created job from the template in google cloud.
An associated job is created

A screenshot depicts the graphical representation of the job. It consists of read pub-sub event, a 5-meter window and write files.
Execution of the pipeline

A screenshot depicts the vehicle bucket details. It consists of vehicle bucket 1, location, storage class, public access and protection, under the objects tab, it shows the vehicle info.
The bucket shows the posted document
Step 4: Create the Spring Cloud Function.
MessageEntity class to formulate the message
TrackDetail class as the entity class
PubSubPublisher class that subscribes to the topic and publishes data
ProducerFunction class to implement the Spring Cloud Function
Maven dependencies
Maven Dependencies
application.properties
1: Create the MessageEntity class.
MessageEntity.java
2: Create the TrackDetail class.
TrackDetail.java
3: Create the PubSubPublisher.
PubSubPublisher.java
4: Create the Spring Cloud Function.
ProducerFunction.java
5: Run the application and test if a message is published to Cloud Pub/Sub.
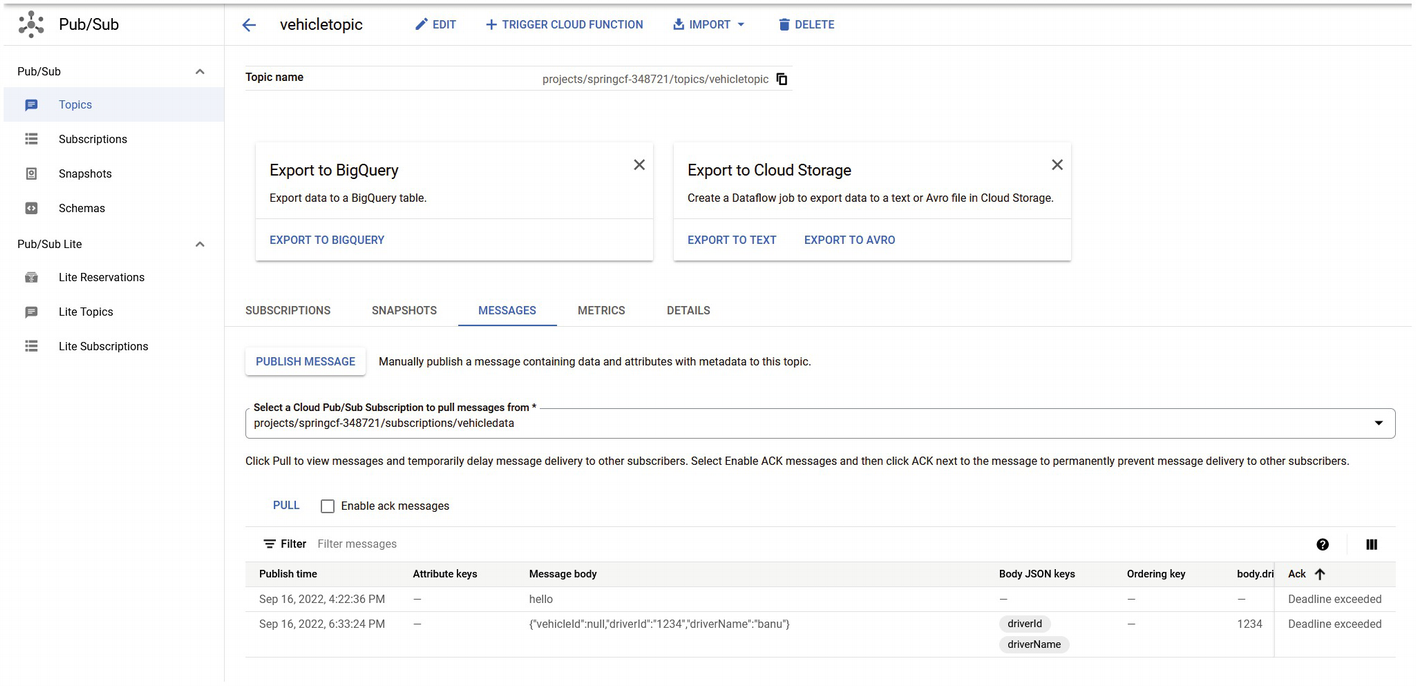
A screenshot depicts the message posted in the pub per sub console in google cloud.
The message has been posted in Cloud Pub/Sub
6: Verify is the message has been loaded into Cloud Storage.

A screenshot depicts the cloud storage console to verify that the message has been loaded into the storage. It shows the bucket details of vehicle bucket one.
The message is loaded into Cloud Storage
In this section, you learned how to use Spring Cloud Function to trigger a Google Cloud Dataflow-based data pipeline.
4.5 Summary
This chapter explained how to create dataflow and data pipelines, whether on-premises using SCDF or in the cloud. For the cloud, you can use SCDF or cloud-native tools.
Spring Cloud Function is versatile and can be used in the context of data pipelines as a trigger or as part of the flow.
With AWS Glue and Google Data Flow, you saw that you can use Spring Cloud Function as a trigger for the flows. This requires some additional coding by adding some relevant libraries and invoking the flow.
Upcoming chapters discuss other use cases of Spring Cloud Function.