
Every application is different, and, while most have some elements of complexity in them, the difficult parts in one application will tend to be different than those in other types of applications. Chances are that whichever application you are working on at any given time will need to use at least one advanced feature of the API. This chapter introduces and explains some of these more advanced ORM features.
Many of the features in this chapter are targeted at applications that need to reconcile the differences between an existing data model and an object model. For example, when the data in an entity table would be better decomposed in the object model as an entity and a dependent object that is referenced by the entity, then the mapping infrastructure should be able to support that. Likewise, when the entity data is spread across multiple tables, the mapping layer should allow for this kind of configuration to be specified.
There has been no shortage of discussion in this book about how entities in JPA are just regular Java classes and not special objects that are required to extend a specific subclass or implement special methods. One of the benefits of entities being regular Java classes is that they can adhere to already established concepts and practices that exist in object-oriented systems. One of the traditional object-oriented innovations is the use of inheritance and creating objects in a hierarchy in order to inherit state and behavior.
This chapter discusses some of the more advanced mapping features and delves into the diverse possibilities offered by the API and the mapping layer. We also see how inheritance works within the framework of the Java Persistence API and how it affects the model.
Table and Column Names
In previous sections, we showed the names of tables and columns as uppercase identifiers. We did this, first, because it helps differentiate them from Java identifiers and, second, because the SQL standard defines that undelimited database identifiers do not respect case, and most tend to display them in uppercase.
Anywhere a table or column name is specified, or is defaulted, the identifier string is passed through to the JDBC driver exactly as it is specified, or defaulted. For example, when no table name is specified for the Employee entity, then the name of the table assumed and used by the provider will be Employee, which by SQL definition is no different from EMPLOYEE. The provider is neither required nor expected to do anything to try to adjust the identifiers before passing them to the database driver.
The following annotations should, therefore, be equivalent in that they refer to the same table in a SQL standard compliant database:
Some database names are intended to be case-specific and must be explicitly delimited. For example, a table might be called EmployeeSales, but without case distinction would become EMPLOYEESALES, clearly less readable and harder to ascertain its meaning. While it is by no means common, or good practice, a database in theory could have an EMPLOYEE table as well as an Employee table. These would need to be delimited in order to distinguish between the two. The method of delimiting is the use of a second set of double quotes, which must be escaped, around the identifier. The escaping mechanism is the backslash (the character), which would cause the following annotations to refer to different tables :
Notice that the outer set of double quotes is just the usual delimiter of strings in annotation elements, but the inner double quotes are preceded by the backslash to cause them to be escaped, indicating that they are part of the string, not string terminators.
When using an XML mapping file, the identifier is also delimited by including quotes in the identifier name. For example, the following two elements represent different columns:
The method of XML escaping is different than the one used in Java. Instead of using the backslash, XML escapes with an ampersand (&) character followed by a word describing the specific thing being escaped (in this case, "quot") and finally a trailing semicolon (;) character.
Tip
Some vendors support features to normalize the case of the identifiers that are stored and passed back and forth between the provider and the JDBC driver. This works around certain JDBC drivers that, for example, accept uppercase identifiers in the native SQL query SELECT statement, but pass them back mapped to lowercase identifiers.
Sometimes the database is set to use case-specific identifiers, and it would become rather tedious (and look exceedingly ugly) to have to put the extra quotes on every single table and column name. If you find yourself in that situation, there is a convenience setting in the XML mapping file that will be of value to you.
In general, an object-relational mapping XML file will contain the mapping information for the classes listed in it. The XML mapping files are discussed in Chapter 13.
By including the empty delimited-identifiers element in the XML mapping file, all identifiers in the persistence unit will be treated as delimited, and quotes will be added to them when they are passed to the driver. The only catch is that there is no way to override this setting. Once the delimited-identifiers flag is turned on, all identifiers must be specified exactly as they exist in the database. Furthermore, if you decide to turn on the delimited-identifiers option, make sure you remove any escaped quotes in your identifier names or you will find that they will be included in the name. Using escaping in addition to the delimited identifiers option will take the escaped quotes and wrap them with further quotes, making the escaped ones become part of the identifier.
Converting Entity State
Back in Chapter 4 we showed some of the ways that specific kinds of data, such as enumerated types, temporal types, and large objects, can be stored in the database. However, it would be impractical to define targeted support for each and every kind of data that is not a primitive, particularly because there will always be some application that wants to store the data in a new and different way, or is forced to do so because of a legacy database. Furthermore, an application might define its own set of types that the specification could clearly never predict. A more flexible and scalable solution, therefore, is to devise a way that enables the application to define its own conversion strategy for whatever type it deems necessary to convert. This is made possible through the use of converters.
Note
Converters were added to the JPA 2.1 specification. No changes were added to JPA version 2.2.
Creating a Converter
A converter is a application-specified class that implements the AttributeConverter<X,Y> interface. It can be declaratively applied to persistent attributes in any entity, mapped superclass, or embeddable class to control how the state of the attribute is stored in the database. It similarly defines how the state is converted from the database back into the object. These two conversion operations comprise the two methods of the AttributeConverter<X,Y> interface, shown in Listing 10-1.
AttributeConverter Interface
Note that the interface should be defined with two type parameters. The first type parameter represents the type of the entity attribute while the second represents the JDBC type to be used when storing the data in the database column. A sample converter implementation class is shown in Listing 10-2. It illustrates a simple converter needed to store a boolean entity attribute as an integer in the database .
Note
There is currently only support to convert an entity attribute to a single column in the database. The ability to store it across multiple columns may be standardized in a future release.
Boolean-to-Integer Converter
The converter class is annotated so that the container can detect and validate it. The conversion methods are trivial in this case because the conversion process is such a simple one, but the conversion logic could be more extensive if more was needed.
Converters can be used for explicit or automatic conversion of basic state, as the following sections describe.
Note
Converters are managed classes, hence when running in Java SE, each converter class should be included in a class element in the persistence.xml descriptor. The persistence.xml and orm.xml schemas were updated in JPA version 2.2.
Declarative Attribute Conversion
A converter can be used explicitly to convert an entity attribute by annotating the attribute with @Convert and setting the converter element to the converter class. For example, if we had a Boolean attribute named “bonded” in our Employee entity, it could be converted to an Integer in the mapped database column if we annotated the attribute with @Convert and specified the converter class declared in the previous section:
The attribute being converted should be of the correct type. Since the first parameterized type of the converter is Boolean, the attribute we are converting should be of type Boolean. However, wrapper and primitive types are autoboxed during conversion, so the attribute could also have been of type boolean.
Converting Embedded Attributes
If the attribute to be converted is part of an embeddable type and we are converting it from within a referencing entity, then we use the attributeName element to specify the attribute to convert. For example, if the bonded attribute was contained within a SecurityInfo embeddable object and the Employee entity had a securityInfo attribute, then we could convert it as shown in Listing 10-3.
Converting an Embedded Attribute
In the “Complex Embedded Objects ” section later in this chapter, we describe more advanced usages of embeddables; in particular, the dot notation is shown as a means to override nested embeddables. This same notation may also be used in the attributeName of the @Convert annotation to reference a nested embedded attribute.
Converting Collections
In Chapter 5, we showed that collections may be mapped as element collections if the values are a basic or embeddable type, or mapped as one-to-many or many-to-many relationships if the values are an entity type. Converters may be applied to element collections but since converters do not convert entity instances they may not, in general, be applied to relationship mappings1.
Element collections of basic types are simple to convert. They are annotated the same way as basic attributes that are not collections. Thus, if we had an attribute that was of type List<Boolean>, we would annotate it just as we did with our bonded attribute, and all of the boolean values in the collection would be converted:
If an element collection is a Map with values that are of a basic type, then the values of the Map will be converted. To perform conversion on the keys, the attributeName element should be used with a special value of “key” to indicate that the keys of the Map are to be converted instead of the values.
Recall from the “Overriding Embeddable Attributes” section in Chapter 5 that if we had an element collection that was a Map, and it contained embeddables, then we prefixed the name element of @AttributeOverride with “key.” or “value.”. This was to distinguish whether we were overriding the column for an embeddable key or value of the Map. Similarly, if we want to convert an embeddable attribute in a Map, then we would prefix the attributeName element with “key.” or “value.”, followed by the name of the embeddable attribute to be converted. As a special case, we can use the "key" or "key." prefix on either of the one-to-many or many-to-many collection relationships to map the keys if they are basic or embeddable types, respectively. Using the domain model in Listing 5-17, if we wanted to convert the employee last name to be stored as uppercase characters (assuming we have defined the corresponding converter class), we would annotate the attribute as shown in Listing 10-4.
Converting an Embeddable Attribute Key in a Relationship Map
Limitations
There are a few restrictions placed on converters, mostly to prevent users from doing things that would get them into trouble. For instance, converters cannot be used on identifier attributes, version attributes, or relationship attributes (unless you are converting the key part of a relationship Map, as in Listing 10-4). Hopefully this will not come as a surprise to you, since in most cases converting these types of attributes would arguably be a pretty bad idea. These attributes are heavily used by the provider as it manages the entities; changing their shape or even their value could cause inconsistencies or incorrect results.
Converters also cannot be used on attributes annotated with @Enumerated or @Temporal, but that doesn’t mean you can’t convert enumerated types or temporal types. It just means that if you use the standard @Enumerated or @Temporal annotations to map those types, then you also cannot use custom converters. If you are using a custom converter class, then you are taking over control of the value that gets stored and there is no need for you to use any of those annotations to get the JPA provider to do the conversion for you. Put simply, if you are doing custom conversion using converters on enumerated or temporal types, just leave the @ Enumerated or @Temporal annotations off.
Automatic Conversion
When we defined a converter to convert a boolean to an integer, we likely had in mind that it would be used in very specific places, on one or possibly a few attributes. You generally don’t want to convert every boolean attribute in your domain to an integer. However, if you frequently use a more semantically rich data type, such as the URL class, then you might want every attribute of that type to be converted. You can do this by setting the autoApply option on the @Converter annotation . In Listing 10-5, a URL converter is declared with the autoApply option enabled. This will cause every persistent attribute of type URL in the persistence unit to be converted to a string when the entity that contains it is written to the database.
Note
It is undefined if two converters are declared to be auto-applied to the same attribute type.
URL-to-String Converter
We can override the conversion on a per-attribute basis. If, instead of the auto-applied converter, we want to use a different converter for a given attribute, then we can annotate the attribute with the @Convert annotation and specify the converter class we want to use. Alternatively, if we want to disable the conversion altogether and let the provider revert to serialization of the URL , then we can use the disableConversion attribute:
Converters and Queries
Defining the converters and configuring which attributes to convert is pretty much all you need to do to get conversion to work. But there are a couple of additional points related to conversion that you should be aware of when querying.
The first is that the query processor will apply the converter to both the attributes targeted for conversion as well as the literals they are being compared against in a query. However, the operators are not modified. This means that only certain comparison operators will work once the query is converted. To illustrate this point, consider the following query:
This query will work fine if bonded is set to be converted from boolean to integer. The generated SQL will have converted both the bonded attribute and the literal true to the corresponding integer by invoking the convertToDatabaseColumn() method on it and the equals operator will work just as well on integers as it does on booleans.
However, we may want to query for all of the employees who are not bonded:
If we try to execute this query the parser will have no problem with it, but when it comes time to execute it the resulting SQL will contain a NOT and the value of e.bonded will have been converted to be an integer. This will generally cause a database exception since the NOT operation cannot be applied to an integer.
It is possible that you will bump into an issue or two if you do any significant querying across converted attributes. While you can usually rely on conversion of literals and input parameters used in comparison, if they are contained within a function, such as UPPER() or MOD(), they probably will not be converted. Even some of the more advanced comparison operations, such as LIKE, may not apply conversion to the literal operand. The moral is to try not to use converted attributes in queries, and if you do, play around and do some experimenting to make sure your queries work as expected.
Complex Embedded Objects
In Chapter 4, we looked at embedding objects within entities, and how an embedded object becomes part of, and dependent on, the entity that embeds it. We now explain how more can be done with embedded objects, and how they can contain more than just basic mappings.
Advanced Embedded Mappings
Embedded objects can embed other objects, have element collections of basic or embeddable types, and have relationships to entities. This is all possible under the assumption that objects embedded within other embedded objects are still dependent upon the embedding entity. Similarly, when bidirectional relationships exist within an embedded object, they are treated as though they exist in the owning entity, and the target entity points back to the owning entity, not to the embedded object.

Nested embeddables with relationships
The ContactInfo clas s contains an embedded object, as well as some relationships, and would be annotated as shown in Listing 10-6.
Embeddable ContactInfo Class
The Address class remains the same as in Listing 4-26 in Chapter 4, but we have added more depth to our contact information. Within the ContactInfo embeddable, we have the address as a nested embedded object, but we also have an additional unidirectional relationship to the phone number serving as the primary contact number. A bidirectional many-to-many relationship to the employee’s phone numbers would have a default join table named EMPLOYEE_PHONE, and on the Phone side the relationship attribute would refer to a list of Employee instances, with the mappedBy element being the qualified name of the embedded relationship attribute. By qualified, we mean that it must first contain the attribute within Employee that contains the embeddable, as well as a dot separator character (.) and the relationship attribute within the embeddable. Listing 10-7 shows the Phone class and its mapping back to the Employee entity.
Phone Class Referring to Embedded Attribute
A proviso about embeddable types is that if an embedded object is a part of an element collection, then the embedded object in the collection can only include mappings where the foreign key is stored in the source table. It can contain owned relationships, such as one-to-one and many-to-one, but it cannot contain one-to-many or many-to-many relationships where the foreign key is in either the target table or a join table. Similarly, it can't contain other collection table-based mappings like element collections.
Overriding Embedded Relationships
When we first introduced embeddables back in Chapter 4, we showed how embeddable types could be reused by being embedded within multiple entity classes. Even though the state is mapped within the embeddable, the embedding entity can override those mappings by using @AttributeOverride to redefine how the embedded state is mapped within that particular entity table. Now that we are using relationships within embeddables, @AttributeOverride does not suffice. To override how a relationship is mapped, we need to use @AssociationOverride, which provides us with the ability to override relationship join columns and join tables.
Before we look at an example of overriding an embeddable with a relationship in it, let’s first think about the reusability of such an object. If a relationship from entity A to entity B is defined within the embeddable of type E, then either the relationship is owned by A and the foreign key is in the table corresponding to A (or in a join table owned by A), or it is owned by B and the foreign key is going to be in B’s table (or a join table owned by B). If it is owned by B, then the foreign key will be to A’s table, and there would be no way to use E in any other entity because the foreign key would be to the wrong table. Similarly, if the relationship was bidirectional, then the attribute in B would be of type A (or a collection of A) and could not refer to an object of some other type. It can be understood, therefore, that only embeddables with relationships that are owned by the source entity, A, and that are unidirectional, can be reused in other entities.
Suppose the many-to-many relationship in ContactInfo was unidirectional and Phone didn’t have a reference back to the Employee that embedded the ContactInfo. We might want to embed instances of ContactInfo within a Customer entity as well. The CUSTOMER table, however, might have a PRI_CONTACT foreign key column instead of PRI_NUM, and of course we would not be able to share the same join table for both Employee and Customer relationships to the Phone. The resulting Customer class is shown in Listing 10-8.
Customer Class Embedding ContactInfo
We can override the zip attribute in the address that is embedded within contactInfo by using @AttributeOverride and navigating to the attribute in the nested embedded Address object.
Because we are overriding two associations we need to use the plural variant of @ AssociationOverrides . Note that if there had not been a join table explicitly specified for the phones attribute, then the default join table name would have been different depending upon which entity was embedding the ContactInfo. Since the default name is composed partly of the name of the owning entity, the table joining the Employee entity to the Phone entity would have defaulted to EMPLOYEE_PHONE, whereas in Customer the join table would have defaulted to CUSTOMER_PHONE.
Tip
There is currently no way to override the collection table for an element collection in an embeddable.
Compound Primary Keys
In some cases, an entity needs to have a primary key or identifier that is composed of multiple fields, or from the database perspective the primary key in its table is made up of multiple columns. This is more common for legacy databases and also occurs when a primary key is composed of a relationship, a topic that we discuss later in this chapter.
There are two options available for having compound primary keys in an entity, depending on how the entity class is structured. Both of them require the use of a separate class containing the primary key fields called a primary key class; the difference between the two options is determined by what the entity class contains.
Primary key classes must include method definitions for equals() and hashCode() in order to be able to be stored and keyed on by the persistence provider, and their fields or properties must be in the set of valid identifier types listed in the previous chapter. They must also be public, implement Serializable, and have a no-arg constructor.
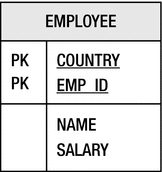
EMPLOYEE table with a compound primary key
ID Class
The first and most basic type of primary key class is an ID class. Each field of the entity that makes up the primary key is marked with the @Id annotation. The primary key class is defined separately and associated with the entity by using the @IdClass annotation on the entity class definition. Listing 10-9 demonstrates an entity with a compound primary key that uses an ID class. The accompanying ID class is shown in Listing 10-5.
Using an ID Class
The primary key class must contain fields or properties that match the primary key attributes in the entity in both name and type. Listing 10-10 shows the EmployeeId primary key class. It has two fields, one to represent the country and one to represent the employee number. We have also supplied equals() and hashCode() methods to allow the class to be used in sorting and hashing operations.
The EmployeeId ID Class
Note that there are no setter methods on the EmployeeId class. Once it has been constructed using the primary key values, it can’t be changed. We do this to enforce the notion that a primary key value cannot be changed, even when it is made up of multiple fields. Because the @Id annotation was placed on the fields of the entity, the provider will also use field access when it needs to work with the primary key class.
The ID class is useful as a structured object that encapsulates all of the primary key information. For example, when doing a query based upon the primary key, such as the find() method of the EntityManager interface, an instance of the ID class can be used as an argument instead of some unstructured and unordered collection of primary key data. Listing 10-11 shows a code snippet that searches for an Employee with a given country name and employee number. A new instance of the EmployeeId class is constructed using the method arguments and then used as the argument to the find() method.
Invoking a Primary Key Query on an Entity with an ID Class
Tip
Because the argument to find() is of type Object, vendors can support passing in simple arrays or collections of primary key information. Passing arguments that are not primary key classes is not portable.
Embedded ID Class
An entity that contains a single field of the same type as the primary key class is said to use an embedded ID class. The embedded ID class is just an embedded object that happens to be composed of the primary key components. We use an @EmbeddedId annotation to indicate that it is not just a regular embedded object but also a primary key class. When we use this approach, there are no @Id annotations on the class, nor is the @IdClass annotation used. You can think of @EmbeddedId as the logical equivalent to putting both @Id and @Embedded on the field.
Like other embedded objects, the embedded ID class must be annotated with @Embeddable, but the access type might differ from that of the entity that uses it. Listing 10-12 shows the EmployeeId class again, this time as an embeddable primary key class. The getter methods, equals() and hashCode() implementations, are the same as the previous version from Listing 10-10.
Embeddable Primary Key Class
Using the embedded primary key class is no different than using a regular embedded type, except that the annotation used on the attribute is @EmbeddedId instead of @Embedded. Listing 10-13 shows the Employee entity adjusted to use the embedded version of the EmployeeId class. Note that since the column mappings are present on the embedded type, we do not specify the mapping for EMP_ID as was done in the case of the ID class. If the embedded primary key class is used by more than one entity, then the @AttributeOverride annotation can be used to customize mappings just as you would for a regular embedded type. To return the country and id attributes of the primary key from getter methods, we must delegate to the embedded ID object to obtain the values.
Using an Embedded ID Class
We can create an instance of EmployeeId and pass it to the find() method just as we did for the ID class example, but, if we want to create the same query using JP QL and reference the primary key, we have to traverse the embedded ID class explicitly. Listing 10-14 shows this technique. Even though id is not a relationship, we still traverse it using the dot notation in order to access the members of the embedded class.
Referencing an Embedded ID Class in a Query
The decision to use a single embedded identifier attribute or a group of identifier attributes, each mapped separately in the entity class, mostly comes down to personal preference. Some people like to encapsulate the identifier components into a single entity attribute of the embedded identifier class type. The trade-off is that it makes dereferencing a part of the identifier a little bit longer in code or in JP QL, although having helper methods, like those in Listing 10-13, can help.
If you access or set parts of the identifier individually, then it might make more sense to create a separate entity attribute for each of the constituent identifier parts. This presents a more representative model and interface for the separate identifier components. However, if most of the time you reference and pass around the entire identifier as an object, then you might be better off with an embedded identifier that creates and stores a single instance of the composite identifier.
Derived Identifiers

Dependent and parent entity tables
The dependent object cannot exist without a primary key, and since that primary key consists of the foreign key to the parent entity it should be clear that a new dependent entity cannot be persisted without the relationship to the parent entity being established. It is undefined to modify the primary key of an existing entity, thus the one-to-one or many-to-one relationship that is part of a derived identifier is likewise immutable and must not be reassigned to a new entity once the dependent entity has been persisted or already exists.
We spent the last few sections discussing different kinds of identifiers, and you might think back to what you learned and realize that there are a number of different parameters that might affect how a derived identifier can be configured. For example, the identifier in either of the entities might be composed of one or a plurality of attributes. The relationship from the dependent entity to the parent entity might make up the entire derived identifier, or, as in Figure 10-3, there might be additional state in the dependent entity that contributes to it. One of the entities might have a simple or compound primary key, and in the compound case might have an ID class or an embedded ID class. All of these factors combine to produce a multitude of scenarios, each of which requires slightly different configurations. The basic rules for derived identifiers are outlined first, with some more detailed descriptions in the following sections.
Basic Rules for Derived Identifiers
A dependent entity might have multiple parent entities (i.e., a derived identifier might include multiple foreign keys).
A dependent entity must have all its relationships to parent entities set before it can be persisted.
If an entity class has multiple ID attributes, then not only must it use an ID class, but there must also be a corresponding attribute of the same name in the ID class as each of the ID attributes in the entity.
ID attributes in an entity might be of a simple type, or of an entity type that is the target of a many-to-one or one-to-one relationship.
If an ID attribute in an entity is of a simple type, then the type of the matching attribute in the ID class must be of the same simple type.
If an ID attribute in an entity is a relationship, then the type of the matching attribute in the ID class is of the same type as the primary key type of the target entity in the relationship (whether the primary key type is a simple type, an ID class, or an embedded ID class).
If the derived identifier of a dependent entity is in the form of an embedded ID class, then each attribute of that ID class that represents a relationship should be referred to by a @MapsId annotation on the corresponding relationship attribute.
The following sections describe how these rules may be applied.
Shared Primary Key
A simple, if somewhat less common case, is when the derived identifier is composed of a single attribute that is the relationship foreign key. As an example, suppose there was a bidirectional one-to-one relationship between Employee and EmployeeHistory entities. Because there is only ever one EmployeeHistory per Employee, we might decide to share the primary key. In Listing 10-15, if the EmployeeHistory is the dependent entity, then we indicate that the relationship foreign key is the identifier by annotating the relationship with @Id.
Derived Identifier with Single Attribute
The primary key type of EmployeeHistory is going to be of the same type as Employee, so if Employee has a simple integer identifier then the identifier of EmployeeHistory is also going to be an integer. If Employee has a compound primary key, either with an ID class or an embedded ID class, then EmployeeHistory is going to share the same ID class (and should also be annotated with the @IdClass annotation). The problem is that this trips over the ID class rule that there should be a matching attribute in the entity for each attribute in its ID class. This is the exception to the rule, because of the very fact that the ID class is shared between both parent and dependent entities.
Occasionally, somebody might want the entity to contain a primary key attribute as well as the relationship attribute, with both attributes mapped to the same foreign key column in the table. Even though the primary key attribute is unnecessary in the entity, some people might want to define it separately for easier access. Despite the fact that the two attributes map to the same foreign key column (which is also the primary key column), the mapping does not have to be duplicated in both places. The @Id annotation is placed on the identifier attribute and @MapsId annotates the relationship attribute to indicate that it is mapping the ID attribute as well. This is shown in Listing 10-16. Note that physical mapping annotations (e.g., @Column) should not be specified on the empId attribute since @MapsId is indicating that the relationship attribute is where the mapping occurs.
Derived Identifier with Shared Mappings
There are a couple of additional points worth mentioning about @MapsId, before we move on to derived identifiers with multiple mapped attributes.
The first point is really a logical follow-on to the fact that the relationship annotated with @MapsId defines the mapping for the identifier attribute as well. If there is no overriding @JoinColumn annotation on the relationship attribute, then the join column will be defaulted according to the usual defaulting rules. If this is the case, then the identifier attribute will also be mapped to that same default. For example, if the @JoinColumn annotation was removed from Listing 10-16 then both the employee and the empId attributes would be mapped to the default EMPLOYEE_ID foreign key column (assuming the primary key column in the EMPLOYEE table was ID).
Secondly, even though the identifier attribute shares the database mapping defined on the relationship attribute, from the perspective of the identifier attribute it is really a read-only mapping. Updates or inserts to the database foreign key column will only ever occur through the relationship attribute . This is one of the reasons why you must always remember to set the parent relationships before trying to persist a dependent entity.
Note
Do not attempt to set only the identifier attribute (and not the relationship attribute) as a means to shortcut persisting a dependent entity. Some providers may have special support for doing this, but it will not portably cause the foreign key to be written to the database.
The identifier attribute will get filled in automatically by the provider when an entity instance is read from the database, or flushed/committed. However, it cannot be assumed to be there when first calling persist() on an instance unless the user sets it explicitly.
Multiple Mapped Attributes
A more common case is probably the one in which the dependent entity has an identifier that includes not only a relationship, but also some state of its own. We use the example shown in Figure 10-3, where a Project has a compound identifier composed of a name and a foreign key to the department that manages it. With the unique identifier being the combination of its name and department, no department would be permitted to create more than one project with the same name. However, two different departments may choose the same name for their own projects. Listing 10-17 illustrates the trivial mapping of the Project identifier using @Id on both the name and dept attributes.
Project with Dependent Identifier
The compound identifier means that we must also specify the primary key class using the @IdClass annotation. Recall our rule that primary key classes must have a matching named attribute for each of the ID attributes on the entity, and usually the attributes must also be of the same type. However, this rule only applies when the attributes are of simple types, not entity types. If @Id is annotating a relationship, then that relationship attribute is going to be of some target entity type, and the rule extension is that the primary key class attribute must be of the same type as the primary key of the target entity. This means that the ProjectId class specified as the ID class for Project in Listing 10-17 must have an attribute named name, of type String, and another named dept that will be the same type as the primary key of Department. If Department has a simple integer primary key, then the dept attribute in ProjectId will be of type int, but if Department has a compound primary key with its own primary key class, say DeptId, then the dept attribute in ProjectId would be of type DeptId, as shown in Listing 10-18.
ProjectId and DeptId ID Classes
Using EmbeddedId
It is also possible to have a derived identifier when one or the other (or both) of the entities uses @EmbeddedId. When the ID class is embedded, the non-relationship identifier attributes are mapped within the embeddable ID class, as usual, but the attributes in the embedded ID class that correspond to relationships are mapped by the relationship attributes in the entity. Listing 10-19 shows how the derived identifier is mapped in the Project class when an embedded ID class is used. We annotate the relationship attribute with @MapsId("dept"), indicating that it is also specifying the mapping for the dept attribute of the embedded ID class. The dept attribute of ProjectId is of the same primary key type as Department in Listing 10-20.
Note that we have used multiple join columns on the department relationship because Department has a compound primary key. Mapping multipart identifiers is explained in more detail in the "Compound Join Columns" section later in the chapter.
Project and Embedded ProjectId Class
The Department entity has an embedded identifier, but it is not a derived identifier because the DeptId ID class does not have any attributes that correspond to relationship attributes in Department. The @Column annotations in the DeptId class map the identifier fields in the Department entity, but when DeptId is embedded in ProjectId, those column mappings do not apply. Once the dept attribute is mapped by the department relationship in Project, the @JoinColumn annotations on that relationship are used as the column mappings for the PROJECT table.
Department and Embedded DeptId Class
If the Department class had a simple primary key, for example a long instead of an ID class, then the dept attribute in ProjectId would just be the simple primary key type of Department (the long type), and there would only be one join column on the many-to-one department attribute in Project.
Alternative to Derived Identifiers
The @MapsId annotation and the ability to apply @Id to relationship attributes was introduced in JPA 2.0 to improve the situation that existed in JPA 1.0. At that time, only the one-to-one shared primary key scenario was specified using the @PrimaryKeyJoinColumn annotation (using the @Id annotation is the preferred and recommended method going forward).
Although there was no specified way to solve the general case of including a foreign key in an identifier, it was generally supported through the practice of adding one or more additional (redundant) fields to the dependent entity. Each added field would hold a foreign key to the related entity, and, because both the added field and the relationship would be mapped to the same join column(s), one or the other of the two would need to be marked as read-only (see "Read-Only Mappings" section), or not updatable or insertable. The following example shows how Listing 10-17 would be done using JPA 1.0. The ID class would be the same. Since the deptNumber and deptCountry attributes are identifier attributes, and can’t be changed in the database , there is no need to set their updatability to false.
Advanced Mapping Elements
Additional elements may be specified on the @Column and @JoinColumn annotations (and their @MapKeyColumn, @MapKeyJoinColumn, and @OrderColumn relatives), some of which apply to schema generation that is discussed in Chapter 14. Other parts we can describe separately as applying to columns and join columns in the following sections.
Read-Only Mappings
JPA does not really define any kind of read-only entity, although it will likely show up in a future release. The API does, however, define options to set individual mappings to be read-only using the insertable and updatable elements of the @Column and @JoinColumn annotations . These two settings default to true but can be set to false if we want to ensure that the provider will not insert or update information in the table in response to changes in the entity instance. If the data in the mapped table already exists and we want to ensure that it will not be modified at runtime, then the insertable and updatable elements can be set to false, effectively preventing the provider from doing anything other than reading the entity from the database. Listing 10-21 demonstrates the Employee entity with read-only mappings.
Making an Entity Read-Only
We don’t need to worry about the identifier mapping being modified, because it is illegal to modify identifiers. The other mappings, though, are marked as not being able to be inserted or updated, so we are assuming that there are already entities in the database to be read in and used. No new entities will be persisted, and existing entities will never be updated.
Note that this does not guarantee that the entity state will not change in memory. Employee instances could still get changed either inside or outside a transaction, but at transaction commit time or whenever the entities get flushed to the database, this state will not be saved and the provider will likely not throw an exception to indicate it. Be careful modifying read-only mappings in memory, however, as changing the entities can cause them to become inconsistent with the state in the database and could wreak havoc on a vendor-specific cache.
Even though all of these mappings are not updatable, the entity as a whole could still be deleted. A proper read-only feature will solve this problem once and for all in a future release, but in the meantime some vendors support the notion of read-only entities, and can optimize the treatment of them in their caches and persistence context implementations.
Optionality
As you’ll see in Chapter 14 when we talk about schema generation, there exists metadata that either permits the database columns to be null or requires them to have values. While this setting will affect the physical database schema, there are also settings on some of the logical mappings that allow a basic mapping or a single-valued association mapping to be left empty or required to be specified in the object model. The element that requires or permits such behavior is the optional element in the @Basic, @ManyToOne, and @OneToOne annotations.
When the optional element is specified as false, it indicates to the provider that the field or property mapping may not be null. The API does not actually define what the behavior is in the case when the value is null, but the provider may choose to throw an exception or simply do something else. For basic mappings, it is only a hint and can be completely ignored. The optional element may also be used by the provider when doing schema generation, because, if optional is set to true, then the column in the database must also be nullable.
Because the API does not go into any detail about ordinality of the object model, there is a certain amount of non-portability associated with using it. An example of setting the manager to be a required attribute is shown in Listing 10-22. The default value for optional is true, making it necessary to be specified only if a false value is needed.
Using Optional Mappings
Advanced Relationships
If you are in the opportune position of starting from a Java application and creating a database schema, then you have complete control over what the schema looks like and how you map the classes to the database. In this case, it is likely that you will not need to use very many of the advanced relationship features that are offered by the API. The flexibility of being able to define a data model usually makes for a less demanding mapping configuration. However, if you are in the unfortunate situation of mapping a Java model to an existing database, then in order to work around the data schema you might need access to more mappings than those we have discussed so far. The mappings described in the following sections are primarily for mapping to legacy databases, and will most often be used because they are the only option. A notable exception is the orphan removal feature, used to model a parent–child relationship.
Using Join Tables
We have already seen mappings such as the many-to-many and unidirectional one-to-many mappings that use join tables. Sometimes a database schema uses a join table to relate two entity types, even though the cardinality of the target entity in the relationship is one. A one-to-one or many-to-one relationship does not normally need a join table because the target will only ever be a single entity and the foreign key can be stored in the source entity table. But if the join table already exists for a many-to-one relationship, then of course we must map the relationship using that join table. To do so, we need only add the @JoinTable annotation to the relationship mapping.
Whether the relationship is unidirectional or bidirectional , the @JoinTable annotation is a physical annotation and must be defined on the owning side of the relationship, just as with all other mappings. However, because a join table is not the default configuration for mappings that are not many-to-many or unidirectional one-to-many, we do need to specify the annotation when we want a join table to be used. The elements of the @JoinTable annotation can still be used to override the various schema names.
In Listing 10-23, we see a join table being used for a many-to-one relationship from Employee to Department. The relationship may be unidirectional or it may be bidirectional, with a one-to-many relationship from Department back to Employee, but in either case the "many" side must always be the owner. The reason is because even if it were bidirectional, the @ManyToOne side could not be the owner because there would be no way for the @ManyToOne attribute to refer to the owning @OneToMany attribute side. There is no mappedBy element in the @ManyToOne annotation definition.
As with most other mappings, the non-owning side of a bidirectional relationship does not change based upon whether the relationship is mapped using a join table or not. It simply refers to the owning relationship and lets it map to the physical tables/columns accordingly.
Many-to-One Mapping Using a Join Table
Avoiding Join Tables
Up to this point, we have discussed a unidirectional one-to-many mapping in the context of using a join table, but it is also possible to map a unidirectional mapping without using a join table. It requires the foreign key to be in the target table, or "many" side of the relationship, even though the target object does not have any reference to the "one" side. This is called a unidirectional one-to-many target foreign key mapping, because the foreign key is in the target table instead of a join table.
To use this mapping, we first indicate that the one-to-many relationship is unidirectional by not specifying any mappedBy element in the annotation. Then we specify a @JoinColumn annotation on the one-to-many attribute to indicate the foreign key column. The catch is that the join column that we are specifying applies to the table of the target object, not to the source object in which the annotation appears.
Unidirectional One-to-Many Mapping Using a Target Foreign Key
The example in Listing 10-24 shows how simple it is to map a unidirectional one-to-many mapping using a target foreign key. The DEPT_ID column refers to the table mapped by Employee, and is a foreign key to the DEPARTMENT table, even though the Employee entity does not have any relationship attribute back to Department.
Before you use this mapping, you should understand the implications of doing so, as they can be quite negative, both from a modeling perspective and a performance perspective. Each row in the EMPLOYEE table corresponds to an Employee instance, with each column corresponding to some state or relationship in the instance. When there is a change in the row, there is the assumption that some kind of change occurred to the corresponding Employee, but in this case that does not necessarily follow. The Employee might have just been changed to a different Department, and because there was no reference to the Department from the Employee there was no change to the Employee.
From a performance standpoint, think of the case when both the state of an Employee is changed and the Department that it belongs to is changed. When writing out the Employee state, the foreign key to the Department is not known because the Employee entity does not have any reference to it. In this case, the Employee might have to be written out twice, once for the changed state of the Employee, and a second time when the Department entity changes are written out, and the foreign key from Employee to Department must be updated to point to the Department that is referring to it.
Compound Join Columns
Now that we have discussed how to create entities with compound primary keys, it is not a far stretch to figure out that, as soon as we have a relationship to an entity with a compound identifier , we will need some way to extend the way we currently reference it.
Up to this point, we have dealt with the physical relationship mapping only as a join column, but, if the primary key that we are referencing is composed of multiple fields, then we will need multiple join columns. This is why we have the plural @JoinColumns annotation that can hold as many join columns as we need to put into it.
There are no default values for join column names when we have multiple join columns. The simplest answer is to require the user to assign them, so, when multiple join columns are used, both the name element and the referencedColumnName element, which indicates the name of the primary key column in the target table, must be specified.

EMPLOYEE table with self-referencing compound foreign key
Listing 10-25 shows a version of the Employee entity that has a manager relationship, which is many-to-one from each of the managed employees to the manager, and a one-to-many directs relationship from the manager to its managed employees.
Self-Referencing Compound Relationships
Any number of join columns can be specified, although in practice very seldom are there more than two. The plural form of @JoinColumns may be used on many-to-one or one-to-one relationships or more generally whenever the single @JoinColumn annotation is valid.

Join table with a compound primary key
If we keep the Employee entity as the owner, where the join table is defined, then the mapping for this relationship will be as shown in Listing 10-26.
Join Table with Compound Join Columns
Orphan Removal
The orphanRemoval element provides a convenient way of modeling parent-child relationships, or more specifically privately owned relationships. We differentiate these two because privately owned is a particular variety of parent-child in which the child entity may only be a child of one parent entity, and may not ever belong to a different parent. While some parent-child relationships allow the child to migrate from one parent to another, in a privately owned mapping the owned entity was created to belong to the parent and cannot ever be migrated. Once it is removed from the parent, it is considered orphaned and is deleted by the provider.
Only relationships with single cardinality on the source side can enable orphan removal, which is why the orphanRemoval option is defined on the @OneToOne and @OneToMany relationship annotations, but on neither of the @ManyToOne or @ManyToMany annotations.
When specified, the orphanRemoval element causes the child entity to be removed when the relationship between the parent and the child is broken. This can be done either by setting to null the attribute that holds the related entity, or additionally in the one-to-many case by removing the child entity from the collection. The provider is then responsible, at flush or commit time (whichever comes first), for removing the orphaned child entity.
In a parent-child relationship, the child is dependent upon the existence of the parent. If the parent is removed, then by definition the child becomes an orphan and must also be removed. This second feature of orphan removal behavior is exactly equivalent to a feature that we covered in Chapter 6 called cascading, in which it is possible to cascade any subset of a defined set of operations across a relationship. Setting orphan removal on a relationship automatically causes the relationship to have the REMOVE operation option added to its cascade list, so it is not necessary to explicitly add it. Doing so is simply redundant. It is impossible to turn off cascading REMOVE from a relationship marked for orphan removal since its very definition requires such behavior to be present.
In Listing 10-27, the Employee class defines a one-to-many relationship to its list of annual evaluations. It doesn’t matter whether the relationship is unidirectional or bidirectional, the configuration and semantics are the same, so we need not show the other side of the relationship.
Employee Class with Orphan Removal of Evaluation Entities
Suppose an employee receives an unfair evaluation from a manager. The employee might go to the manager to correct the information and the evaluation might be modified, or the employee might have to appeal the evaluation, and if successful the evaluation might simply be removed from the employee record. This would cause it to be deleted from the database as well. If the employee decided to leave the company, then when the employee is removed from the system his evaluations will be automatically removed along with him.
If the collection in the relationship was a Map, keyed by a different entity type, then orphan removal would only apply to the entity values in the Map, not to the keys. This means that entity keys are never privately owned.
Finally, if the orphaned object is not currently managed in the persistence context, either because it has been created in memory and not yet persisted or because it is simply detached from the persistence context, orphan removal will not be applied. Similarly, if it has already been removed in the current persistence context orphan removal will not be applied.
Mapping Relationship State

Modeling state on a relationship using an association class

Join table with additional state
When we get to the object model, however, it becomes much more problematic. The issue is that Java has no inherent support for relationship state. Relationships are just object references or pointers, hence no state can ever exist on them. State exists on objects only, and relationships are not first-class objects.
The Java solution is to turn the relationship into an entity that contains the desired state and map the new entity to what was previously the join table. The new entity will have a many-to-one relationship to each of the existing entity types, and each of the entity types will have a one-to-many relationship back to the new entity representing the relationship. The primary key of the new entity will be the combination of the two relationships to the two entity types. Listing 10-28 shows all of the participants in the Employee and Project relationship.
Mapping Relationship State with an Intermediate Entity
Here we have the primary key entirely composed of relationships, with the two foreign key columns making up the primary key in the EMP_PROJECT join table. The date at which the assignment was made could be manually set when the assignment is created, or it could be associated with a trigger that causes it to be set when the assignment is created in the database. Note that, if a trigger were used, then the entity would need to be refreshed from the database in order to populate the assignment date field in the Java object.
Multiple Tables
The most common mapping scenarios are of the so-called meet-in-the-middle variety . This means that the data model and the object model already exist, or, if one does not exist, then it is created independently of the other model. This is relevant because there are a number of features in the Java Persistence API that attempt to address concerns that arise in this case.
Up to this point, we have assumed that an entity gets mapped to a single table and that a single row in that table represents an entity. In an existing or legacy data model, it was actually quite common to spread data, even data that was tightly coupled, across multiple tables. This was done for different administrative as well as performance reasons, one of which was to decrease table contention when specific subsets of the data were accessed or modified.
To account for this, entities may be mapped across multiple tables by using the @SecondaryTable annotation and its plural @SecondaryTables form. The default table or the table defined by the @Table annotation is called the primary table, and any additional ones are called secondary tables. We can then distribute the data in an entity across rows in both the primary table and the secondary tables simply by defining the secondary tables as annotations on the entity and then specifying when we map each field or property which table the column is in. We do this by specifying the name of the table in the table element in @Column or @JoinColumn. We did not need to use this element earlier, because the default value of table is the name of the primary table.
The only bit that is left is to specify how to join the secondary table or tables to the primary table. We saw in Chapter 4 how the primary key join column is a special case of a join column where the join column is just the primary key column (or columns in the case of composite primary keys). Support for joining secondary tables to the primary table is limited to primary key join columns and is specified as a @PrimaryKeyJoinColumn annotation as part of the @SecondaryTable annotation.

EMP and EMP_ADDRESS tables
To map this table structure to the Employee entity, we must declare EMP_ADDRESS as a secondary table and use the table element of the @Column annotation for every attribute stored in that table. Listing 10-29 shows the mapped entity. The primary key of the EMP_ADDRESS table is in the EMP_ID column. If it had been named ID, then we would not have needed to use the name element in the @PrimaryKeyJoinColumn annotation. It defaults to the name of the primary key column in the primary table.
Mapping an Entity Across Two Tables
In Chapter 4, we learned how to use the schema or catalog elements in @Table to qualify the primary table to be in a particular database schema or catalog. This is also valid in the @SecondaryTable annotation.
Previously, when discussing embedded objects, we mapped the address fields of the Employee entity into an Address embedded type. With the address data in a secondary table, it is still possible to do this by specifying the mapped table name as part of the column information in the @AttributeOverride annotation. Listing 10-30 demonstrates this approach. Note that we have to enumerate all of the fields in the embedded type even though the column names may match the correct default values.
Mapping an Embedded Type to a Secondary Table
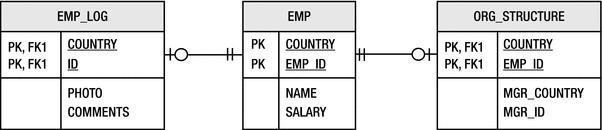
Secondary tables with compound primary key relationships
Listing 10-31 shows the Employee entity mapped to this table structure. The EmployeeId ID class from Listing 10-10 has been reused in this example.
Mapping an Entity with Multiple Secondary Tables
We have thrown a few curves into this example to make it more interesting. The first is that we have defined Employee to have a composite primary key. This requires additional information to be provided for the EMP_LOB table, because its primary key is not named the same as the primary table. The next difference is that we are storing a relationship in the ORG_STRUCTURE secondary table. The MGR_COUNTRY and MGR_ID columns combine to reference the ID of the manager for this employee. Since the employee has a composite primary key, the manager relationship must also specify a set of join columns instead of only one, and the referencedColumnName elements in those join columns refer to the primary key columns COUNTRY and EMP_ID in the entity’s own primary table EMPLOYEE.
Inheritance
One of the common mistakes made by novice object-oriented developers is that they get converted to the principle of reuse, but carry it too far. It is too easy to get caught up in the quest for reuse and create complex inheritance hierarchies all for the sake of sharing a few methods. These kinds of multi-level hierarchies will often lead to pain and hardship down the road as the application becomes difficult to debug and a challenge to maintain.
Most applications do enjoy the benefits of at least some inheritance in the object model. As with most things, though, moderation should be applied, especially when it comes to mapping the classes to relational databases. Large hierarchies can often lead to significant performance reduction, and it may be that the cost of code reuse is higher than you might want to pay.
In the following sections, we explain the support that exists in the API to map inheritance hierarchies and outline some of the repercussions.
Class Hierarchies
Because this is a book about the Java Persistence API, the first and most obvious place to start talking about inheritance is in the Java object model . Entities are objects, after all, and should be able to inherit state and behavior from other entities. This is not only expected but also essential for the development of object-oriented applications.
What does it mean when one entity inherits state from its entity superclass? It can imply different things in the data model, but in the Java model it simply means that when a subclass entity is instantiated, it has its own version or copy of both its locally defined state and its inherited state, all of which is persistent. While this basic premise is not at all surprising, it opens up the less obvious question of what happens when an entity inherits from something other than another entity. Which classes is an entity allowed to extend, and what happens when it does?
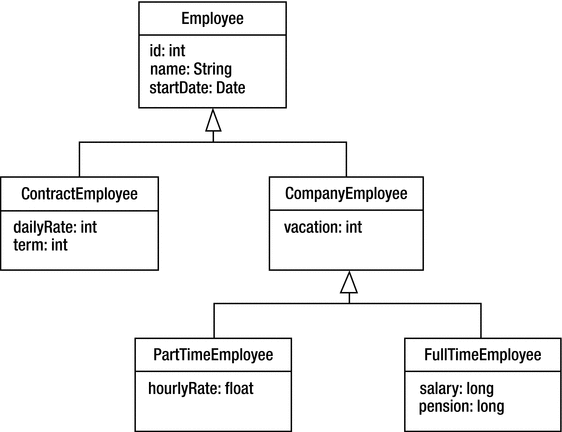
Inheritance class hierarchy
We differentiate between a general class hierarchy, which is a set of various types of Java classes that extend each other in a tree, and an entity hierarchy, which is a tree consisting of persistent entity classes interspersed with non-entity classes. An entity hierarchy is rooted at the first entity class in the hierarchy.
Mapped Superclasses
The Java Persistence API defines a special kind of class called a mapped superclass that is quite useful as a superclass for entities. A mapped superclass provides a convenient class in which to store shared state and behavior that entities can inherit from, but it is itself not a persistent class and cannot act in the capacity of an entity. It cannot be queried over and cannot be the target of a relationship. Annotations such as @Table are not permitted on mapped superclasses because the state defined in them applies only to its entity subclasses.
Mapped superclasses can be compared to entities in somewhat the same way that an abstract class is compared to a concrete class; they can contain state and behavior but just can’t be instantiated as persistent entities. An abstract class is of use only in relation to its concrete subclasses, and a mapped superclass is useful only as state and behavior that is inherited by the entity subclasses that extend it. They do not play a role in an entity inheritance hierarchy other than contributing that state and behavior to the entities that inherit from them.
Mapped superclasses may or may not be defined as abstract in their class definitions, but it is good practice to make them actual abstract Java classes. We don’t know of any good use cases for creating concrete Java instances of them without ever being able to persist them, and chances are that, if you happen to find one, you probably want the mapped superclass to be an entity.
All of the default mapping rules that apply to entities also apply to the basic and relationship state in mapped superclasses. The biggest advantage of using mapped superclasses is being able to define partial shared state that should not be accessed on its own without the additional state that its entity subclasses add to it. If you are not sure whether to make a class an entity or a mapped superclass, then you need only ask yourself if you will ever need to query across or access an instance that is only exposed as an instance of that mapped class. This also includes relationships, since a mapped superclass can’t be used as the target of a relationship. If you answer yes to any variant of that question, then you should probably make it a first-class entity.
Looking back at Figure 10-10, we could conceivably treat the CompanyEmployee class as a mapped superclass instead of an entity. It defines shared state, but perhaps we have no reason to query over it.
A class is indicated as being a mapped superclass by annotating it with the @MappedSuperclass annotation. The class fragments from Listing 10-32 show how the hierarchy would be mapped with CompanyEmployee as a mapped superclass.
Entities Inheriting from a Mapped Superclass
Transient Classes in the Hierarchy
Classes in an entity hierarchy, that are not entities or mapped superclasses, are called transient classes. Entities may extend transient classes either directly or indirectly through a mapped superclass. When an entity inherits from a transient class, the state defined in the transient class is still inherited in the entity, but it is not persistent. In other words, the entity will have space allocated for the inherited state, according to the usual Java rules, but that state will not be managed by the persistence provider. It will be effectively ignored during the lifecycle of the entity. The entity might manage that state manually through the use of lifecycle callback methods that we describe in Chapter 12, or other approaches, but the state will not be persisted as part of the provider-managed entity lifecycle.
One could conceive of having a hierarchy that is composed of an entity that has a transient subclass, which in turn has one or more entity subclasses. While this case is not really a common one, it is nonetheless possible and can be achieved in the rare circumstances when having shared transient state or common behavior is desired. It would normally be more convenient, though, to declare the transient state or behavior in the entity superclass than to create an intermediate transient class. Listing 10-33 shows an entity that inherits from a superclass that defines transient state that is the time an entity was created in memory.
Entity Inheriting from a Transient Superclass
In this example, we moved the transient state from the entity class into a transient superclass, but the end result is really quite the same. The previous example might have been a little neater without the extra class, but this example allows us to share the transient state and behavior across any number of entities that need only extend CachedEntity.
Abstract and Concrete Classes
We have mentioned the notion of abstract versus concrete classes in the context of mapped superclasses, but we didn’t go into any more detail about entity and transient classes. Most people, depending upon their philosophy, might expect that all non-leaf classes in an object hierarchy should be abstract, or at the very least that some of them would be. A restriction that entities must always be concrete classes would mess this up quite handily, and fortunately this is not the case. It is perfectly acceptable for entities, mapped superclasses, or transient classes to be either abstract or concrete at any level of the inheritance tree. As with mapped superclasses, making transient classes concrete in the hierarchy doesn’t really serve any purpose, and as a general rule should be avoided to prevent accidental development errors and misuse.
The case that we have not talked about is the one where an entity is an abstract class. The only difference between an entity that is an abstract class and one that is a concrete class is the Java rule that prohibits abstract classes from being instantiated. They can still define persistent state and behavior that will be inherited by the concrete entity subclasses below them. They can be queried, the result of which will be composed of concrete entity subclass instances. They can also bear the inheritance mapping metadata for the hierarchy.
Our hierarchy in Figure 10-10 had an Employee class that was a concrete class. We would not want users to accidentally instantiate this class and then try to persist a partially defined employee. We could protect against this by defining it to be abstract. We would then end up with all of our non-leaf classes being abstract and the leaf classes being persistent.
Inheritance Models
JPA provides support for three different data representations. The use of two of them is fairly widespread, while the third is less common and not required to be supported, though it is still fully defined with the intention that providers might be required to support it in the future.
When an entity hierarchy exists, it is always rooted at an entity class. Recall that mapped superclasses do not count as levels in the hierarchy because they contribute only to the entities beneath them. The root entity class must signify the inheritance hierarchy by being annotated with the @Inheritance annotation. This annotation indicates the strategy that should be used for mapping and must be one of the three strategies described in the following sections.
Every entity in the hierarchy must either define or inherit its identifier, which means that the identifier must be defined either in the root entity or in a mapped superclass above it. A mapped superclass may be higher up in the class hierarchy than where the identifier is defined.
Single-Table Strategy
The most common and performant way of storing the state of multiple classes is to define a single table to contain a superset of all the possible state in any of the entity classes. This approach is called, not surprisingly, a single-table strategy. It has the consequence that, for any given table row representing an instance of a concrete class, there may be columns that do not have values because they apply only to a sibling class in the hierarchy.
From Figure 10-10 we see that the id is located in the root Employee entity class and is shared by the rest of the persistence classes . All the persistent entities in an inheritance tree must use the same type of identifier. We don’t need to think about it very long before we see why this makes sense at both levels. In the object layer, it wouldn’t be possible to issue a polymorphic find() operation on a superclass if there were not a common identifier type that we could pass in. Similarly, at the table level, we would need multiple primary key columns but without being able to fill them all in on any given insertion of an instance that only made use of one of them.
The table must contain enough columns to store all the state in all the classes. An individual row stores the state of an entity instance of a concrete entity type, which would normally imply that there would be some columns left unfilled in every row. Of course, this leads to the conclusion that the columns mapped to concrete subclass state should be nullable, which is normally not a big issue but could be a problem for some database administrators.
In general, the single-table approach tends to be more wasteful of database tablespace, but it does offer peak performance for both polymorphic queries and write operations. The SQL that is needed to issue these operations is simple, optimized, and does not require joining.
To specify the single-table strategy for the inheritance hierarchy, the root entity class is annotated with the @Inheritance annotation with its strategy set to SINGLE_TABLE. In our previous model, this would mean annotating the Employee class as follows:
As it turns out, though, the single-table strategy is the default one, so we wouldn’t strictly even need to include the strategy element at all. An empty @Inheritance annotation would do the trick just as well.

A single-table inheritance data model
Discriminator Column
You may have noticed an extra column named EMP_TYPE in Figure 10-11 that was not mapped to any field in any of the classes in Figure 10-10. This field has a special purpose and is required when using a single table to model inheritance. It is called a discriminator column and is mapped using the @DiscriminatorColumn annotation in conjunction with the @Inheritance annotation we have already learned about. The name element of this annotation specifies the name of the column that should be used as the discriminator column, and if not specified will be defaulted to a column named DTYPE.
A discriminatorType element dictates the type of the discriminator column. Some applications prefer to use strings to discriminate between the entity types, while others like using integer values to indicate the class. The type of the discriminator column may be one of three predefined discriminator column types: INTEGER, STRING, or CHAR. If the discriminatorType element is not specified, then the default type of STRING will be assumed.
Discriminator Value
Every row in the table will have a value in the discriminator column called a discriminator value, or a class indicator, to indicate the type of entity that is stored in that row. Every concrete entity in the inheritance hierarchy, therefore, needs a discriminator value specific to that entity type so that the provider can process or assign the correct entity type when it loads and stores the row. The way this is done is to use a @DiscriminatorValue annotation on each concrete entity class. The string value in the annotation specifies the discriminator value that instances of the class will get assigned when they are inserted into the database. This will allow the provider to recognize instances of the class when it issues queries. This value should be of the same type as was specified or defaulted as the discriminatorType element in the @DiscriminatorColumn annotation.
If no @DiscriminatorValue annotation is specified, then the provider will use a provider-specific way of obtaining the value. If the discriminatorType was STRING, then the provider will just use the entity name as the class indicator string. If the discriminatorType is INTEGER, then we would either have to specify the discriminator values for every entity class or none of them. If we were to specify some but not others, then we could not guarantee that a provider-generated value would not overlap with one that we specified.
Listing 10-34 shows how our Employee hierarchy is mapped to a single-table strategy.
Entity Hierarchy Mapped Using a Single-Table Strategy
The Employee class is the root class, so it establishes the inheritance strategy and discriminator column. We have assumed the default strategy of SINGLE_TABLE and discriminator type of STRING.
Neither the Employee nor the CompanyEmployee classes have discriminator values, because discriminator values should not be specified for abstract entity classes, mapped superclasses, transient classes, or any abstract classes for that matter. Only concrete entity classes use discriminator values since they are the only ones that actually get stored and retrieved from the database.
The ContractEmployee entity does not use a @DiscriminatorValue annotation, because the default string "ContractEmployee", which is the default entity name that is given to the class, is just what we want. The FullTimeEmployee class explicitly lists its discriminator value to be "FTEmp", so that is what is stored in each row for instances of FullTimeEmployee. Meanwhile, the PartTimeEmployee class will get "PTEmp" as its discriminator value because it set its entity name to be "PTEmp", and the entity name gets used as the discriminator value when none is specified.

Sample of single-table inheritance data
Joined Strategy
From the perspective of a Java developer, a data model that maps each entity to its own table makes a lot of sense. Every entity, whether it is abstract or concrete, will have its state mapped to a different table. Consistent with our earlier description, mapped superclasses do not get mapped to their own tables but are mapped as part of their entity subclasses.
Mapping a table per entity provides the data reuse that a normalized 2 data schema offers and is the most efficient way to store data that is shared by multiple subclasses in a hierarchy. The problem is that, when it comes time to reassemble an instance of any of the subclasses, the tables of the subclasses must be joined together with the superclass tables. It makes it fairly obvious why this strategy is called the joined strategy. It is also somewhat more expensive to insert an entity instance, because a row must be inserted in each of its superclass tables along the way.
Recall from the single-table strategy that the identifier must be of the same type for every class in the hierarchy. In a joined approach, we will have the same type of primary key in each of the tables, and the primary key of a subclass table also acts as a foreign key that joins to its superclass table. This should ring a bell because of its similarity to the multiple-table case earlier in the chapter where we joined the tables together using the primary keys of the tables and used the @PrimaryKeyJoinColumn annotation to indicate it. We use this same annotation in the joined inheritance case since we have multiple tables that each contain the same primary key type and each potentially has a row that contributes to the final combined entity state.
While joined inheritance is both intuitive and efficient in terms of data storage, the joining that it requires makes it somewhat expensive to use when hierarchies are deep or wide. The deeper the hierarchy, the more joins it will take to assemble instances of the concrete entity at the bottom. The broader the hierarchy the more joins it will take to query across an entity superclass.

Joined inheritance data model
To map an entity hierarchy to a joined model, the @Inheritance annotation need only specify JOINED as the strategy. Like the single-table example, the subclasses will adopt the same strategy that is specified in the root entity superclass.
Even though there are multiple tables to model the hierarchy, the discriminator column is only defined on the root table, so the @DiscriminatorColumn annotation is placed on the same class as the @Inheritance annotation.
Tip
Some vendors offer implementations of joined inheritance without the use of a discriminator column. Discriminator columns should be used if provider portability is required.
Our Employee hierarchy example can be mapped using the joined approach shown in Listing 10-35. In this example, we used integer discriminator columns instead of the default string type.
Entity Hierarchy Mapped Using the Joined Strategy
Table-per-Concrete-Class Strategy
A third approach to mapping an entity hierarchy is to use a strategy where a table per concrete class is defined. This data architecture goes in the reverse direction of non-normalization of entity data and maps each concrete entity class and all its inherited state to a separate table. This has the effect of causing all shared state to be redefined in the tables of all the concrete entities that inherit it. This strategy is not required to be supported by providers but is included because it is anticipated that it will be required in a future release of the API. We describe it briefly for completeness.
The negative side of using this strategy is that it makes polymorphic querying across a class hierarchy more expensive than the other strategies. The problem is that it must either issue multiple separate queries across each of the subclass tables, or query across all of them using a UNION operation, which is generally regarded as being expensive when lots of data is involved. If there are non-leaf concrete classes, then each of them will have its own table. Subclasses of the concrete classes will have to store the inherited fields in their own tables, along with their own defined fields.
The bright side of table-per-concrete-class hierarchies when compared to joined hierarchies is seen in cases of querying over instances of a single concrete entity. In the joined case, every query requires a join, even when querying across a single concrete entity class. In the table-per-concrete-class case, it is akin to the single-table hierarchy because the query is confined to a single table . Another advantage is that the discriminator column goes away. Every concrete entity has its own separate table, and there is no mixing or sharing of schema, so no class indicator is ever needed.
Mapping our example to this type of hierarchy is a matter of specifying the strategy as TABLE_PER_CLASS and making sure there is a table for each of the concrete classes. If a legacy database is being used, then the inherited columns could be named differently in each of the concrete tables and the @AttributeOverride annotation would come in handy. In this case, the CONTRACT_EMP table didn’t have the NAME and S_DATE columns but instead had FULLNAME and SDATE for the name and startDate fields defined in Employee.
If the attribute that we wanted to override was an association instead of a simple state mapping, then we could still override the mapping, but we would need to use an @AssociationOverride annotation instead of @AttributeOverride. The @AssociationOverride annotation allows us to override the join columns used to reference the target entity of a many-to-one or one-to-one association defined in a mapped superclass. To show this, we need to add a manager attribute to the CompanyEmployee mapped superclass. The join column is mapped by default in the CompanyEmployee class to the MANAGER column in the two FT_EMP and PT_EMP subclass tables, but in PT_EMP the name of the join column is actually MGR. We override the join column by adding the @AssociationOverride annotation to the PartTimeEmployee entity class and specifying the name of the attribute we are overriding and the join column that we are overriding it to be. Listing 10-36 shows a complete example of the entity mappings, including the overrides.
Entity Hierarchy Mapped Using a Table-per-Concrete-Class Strategy

Table-per-concrete-class data model
Mixed Inheritance
We should begin this section by saying that the practice of mixing inheritance types within a single inheritance hierarchy is currently outside the specification. We are including it because it is both useful and interesting, but we are offering a warning that it might not be portable to rely on such behavior, even if your vendor supports it.
Furthermore, it really makes sense to mix only single-table and joined inheritance types. We show an example of mixing these two, bearing in mind that support for them is vendor-specific. The intent is that, in future releases of the specification, the more useful cases will be standardized and required to be supported by compliant implementations.
Mixed inheritance data model
In this example, the joined strategy is used for the Employee and ContractEmployee classes, while the CompanyEmployee, FullTimeEmployee, and PartTimeEmployee classes revert to a single-table model. To make this inheritance strategy switch at the level of the CompanyEmployee, we need to make a simple change to the hierarchy. We need to turn CompanyEmployee into an abstract entity instead of a mapped superclass so that it can bear the new inheritance metadata. Note that this is simply an annotation change, not making any change to the domain model.
The inheritance strategies can be mapped as shown in Listing 10-37. Notice that we do not need to have a discriminator column for the single-table subhierarchy since we already have one in the superclass EMP table.
Entity Hierarchy Mapped Using Mixed Strategies
Supporting the Java 8 Date and Time API
In Java EE 8, the Date and Time API was added as a new feature.
Because of that, many programmers asked for official support in the JPA 2.2 to be used as a simple AttributeConverter.
With JPA 2.2, we no longer need the converter; it added support for the mapping of the following java.time types:
Starting from the previous example, the Date and Time API example is shown in Listing 10-38.
Date and Time API
Note
You can find more information about the Java EE 8 Date and Time API at the following link:
http://www.oracle.com/technetwork/articles/java/jf14-date-time-2125367.html
Summary
Entity mapping requirements often go well beyond the simplistic mappings that map a field or a relationship to a named column. In this chapter, we addressed some of the more varied and diverse mapping practices that are supported by the Java Persistence API.
We discussed how to delimit database identifiers on a case-by-case basis, or for all the mappings in a persistence unit. We illustrated how delimiting identifiers allows the inclusion of special characters and provides case-sensitivity when the target database requires it.
A method of doing fine-grained conversion of basic attribute state was shown to be a powerful technique to adapt data. By creating converters we were also able to persist existing and newly defined data types in highly customizable ways. Conversion can be declaratively controlled on a flexible per-attribute or across-the-board basis.
We showed how embeddable objects can have state, element collections, further nested embeddables, and even relationships. We gave examples of reusing an embeddable object with relationships in it by overriding the relationship mappings within the embedding entity.
Identifiers may be composed of multiple columns. We revealed the two approaches for defining and using compound primary keys, and demonstrated when they could be used. We established how other entities can have foreign key references to entities with compound identifiers and explained how multiple join columns can be used in any context when a single join column applies. We also showed some examples of mapping identifiers, called derived identifiers, which included a relationship as part of their identities.
We explained some advanced relationship features, such as read-only mappings and optionality, and showed how they could be of benefit to some models. We then went on to describe some of the more advanced mapping scenarios that included using join tables or sometimes avoiding the use of join tables. The topic of orphan removal was also touched upon and clarified.
We went on to show how to distribute entity state across multiple tables and how to use the secondary tables with relationships. We even saw how an embedded object can map to a secondary table of an entity.
Finally, we went into detail about the three different inheritance strategies that can be used to map inheritance hierarchies to tables. We explained mapped superclasses and how they can be used to define shared state and behavior. We went over the data models that differentiate the various approaches and showed how to map an entity hierarchy to the tables in each case. We finished off by illustrating how to mix inheritance types within a single hierarchy.
In the next chapter, we continue our discussion of advanced topics but turn our attention to queries and the use of native SQL and stored procedures. We also exlain how to create entity graphs and use them to create query fetch plans.