
Configuring a persistence application involves specifying the bits of information, additional to the code, that the execution environment or persistence platform may require in order for the code to function as a runtime application. Packaging means putting all the pieces together in a way that makes sense and can be correctly interpreted and used by the infrastructure when the application is deployed into an application server or run in a stand-alone JVM. Deployment is the process of getting the application into an execution environment and running it.
One could view the mapping metadata as part of the overall configuration of an application, but we won’t cover that in this chapter because it has already been discussed in previous chapters. In this chapter, we will be discussing the primary runtime persistence configuration file, persistence.xml, which defines persistence units. We will go into detail about how to specify the different elements of this file, when they are required, and what the values should be.
Once the persistence unit has been configured, we will package a persistence unit with a few of the more common deployment units, such as EJB archives, web archives, and the application archives in a Java EE server. The resulting package will then be deployable into a compliant application server. We will also step through the packaging and deployment rules for Java SE applications.
Schema generation is the process of generating the schema tables to which the entities are mapped. We will list the properties that activate schema generation and describe the different forms it can take, such as creating tables in the database or generating DDL in script files. We will then outline all of the annotations that play a role in what gets generated.
Configuring Persistence Units
The persistence unit is the primary unit of runtime configuration. It defines the various pieces of information that the provider needs to know in order to manage the persistent classes during program execution and is configured within a persistence.xml file. There may be one or more persistence.xml files in an application, and each persistence.xml file may define multiple persistence units. There will most often be only one, though. Since there is one EntityManagerFactory for each persistence unit, you can think of the configuration of the persistence unit as the configuration of the factory for that persistence unit.
A common configuration file goes a long way to standardizing the runtime configuration, and the persistence.xml file offers exactly that. While some providers might still require an additional provider-specific configuration file, most will also support their properties being specified within the properties section (described in the “Adding Vendor Properties” section) of the persistence.xml file.
The persistence.xml file is the first step to configuring a persistence unit. All the information required for the persistence unit should be specified in the persistence.xml file. Once a packaging strategy has been chosen, the persistence.xml file should be placed in the META-INF directory of the chosen archive.
Each persistence unit is defined by a persistence-unit element in the persistence.xml file. All the information for that persistence unit is enclosed within that element. The following sections describe the metadata that a persistence unit may define when deploying to a Java EE server.
Persistence Unit Name
Every persistence unit must have a name that uniquely identifies it within the scope of its packaging. We will be discussing the different packaging options later, but in general, if a persistence unit is defined within a Java EE module, there must not be any other persistence unit of the same name in that module. For example, if a persistence unit named EmployeeService is defined in an EJB JAR named emp_ejb.jar, there should not be any other persistence units named EmployeeService in emp_ejb.jar. There may be persistence units named EmployeeService in a web module or even in another EJB module within the application, though.
Note
When dealing with JPA packaging, we recommend that persistence units be packaged in separate JAR files to make them more accessible and reusable.
We have seen in some of the examples in previous chapters that the name of the persistence unit is just an attribute of the persistence-unit element , as in the following:
This empty persistence-unit element is the minimal persistence unit definition. It may be all that is needed if the server defaults the remaining information, but not all servers will do this. Some may require other persistence unit metadata to be present, such as the data source to be accessed.
Transaction Type
The factory that is used to create entity managers for a given persistence unit will generate entity managers to be of a specific transactional type. We went into detail in Chapter 6 about the different types of entity managers, and one of the things we saw was that every entity manager must either use JTA or resource-local transactions. Normally, when running in a managed server environment, the JTA transaction mechanism is used. It is the default transaction type that a server will assume when none is specified for a persistence unit and is generally the only one that most applications will ever need, so in practice the transaction type will not need to be specified very often.
If the data source is required by the server, as it often will be, a JTA-enabled data source should be supplied (see the “Data Source” section). Specifying a data source that is not JTA-enabled might actually work in some cases, but the database operations will not be participating in the global JTA transaction or necessarily be atomic with respect to that transaction.
In situations such as those described in Chapter 6, when you want to use resource-local transactions instead of JTA, the transaction-type attribute of the persistence-unit element is used to explicitly declare the transaction type of RESOURCE_LOCAL or JTA, as in the following example:
Here we are overriding the default JTA transaction type to be resource-local, so all the entity managers created in the EmployeeService persistence unit must use the EntityTransaction interface to control transactions.
Persistence Provider
The Java Persistence API has a pluggable Service Provider Interface (SPI) that allows any compliant Java EE Server to communicate with any compliant JPA persistence provider implementation. Servers normally have a default provider, though, that is native to the server, meaning that it is implemented by the same vendor or is shipped with the server. In most cases, this default provider will be used by the server, and no special metadata will be necessary to explicitly specify it.
In order to switch to a different provider, the provider-supplied class that implements the javax.persistence.spi.PersistenceProvider interface must be listed in the provider element. Listing 14-1 shows a simple persistence unit that explicitly defines the EclipseLink provider class. The only requirement is that the provider JARs be on the server or application classpath and accessible to the running application at deployment time. The complete persistence header element is also included in Listing 14-1, but will not be included in subsequent XML examples.
Specifying a Persistence Provider
Data Source
A fundamental part of the persistence unit metadata is the description of where the provider should obtain database connections from in order to read and write entity data. The target database is specified in terms of the name of a JDBC data source that is in the server Java Naming and Directory Interface (JNDI) space . This data source must be globally accessible since the provider accesses it when the persistence application is deployed.
The typical case is that JTA transactions are used, so it is in the jta-data-source element that the name of the JTA data source should be specified. Similarly, if the transaction type of the persistence unit is resource-local, the non-jta-data-source element should be used.
Although JPA defines the standard elements in which to specify data source names, it does not dictate the format. In the past, a data source was made available in JNDI by being configured in a server-specific configuration file or management console. The name was not officially portable but in practice they were usually of the form jdbc/SomeDataSource. Listing 14-2 shows how a data source would be specified using an application-scoped JNDI name. This example assumes the provider is being defaulted.
Specifying JTA Data Source
Java EE Namespaces
Many applications use the old-style naming approach that assumes a component-scoped name (e.g., jdbc/SomeDataSource), but as of Java EE 6, three new namespaces exist to allow names to refer to global, application, or module scope. By using the corresponding standard namespace prefixes of java:global, java:app, or java:module, a resource can be made available to other components in a wider scope than just the component, and the name would be portable across container implementations.
We will use the application namespace in our examples because we think of the application scope as being the most useful and reasonable scope in which to make a data source available.
Note
The Java EE specification defines six default resources, which the product provides in its default configuration. We can configure a Java EE default resource provider by binding the JNDI name for the default resource to the JNDI name of the configured resource.
As of Java EE 7, containers provide a default data source (available at the JNDI name java:comp/DefaultDataSource), and if the provider is a native implementation for the server, it may use this default. In other cases, the data source will need to be specified.
Java EE Default Resources
Resource Class | Java EE JNDI Name |
|---|---|
javax.sql.DataSource | java:comp/DefaultDataSource |
javax.enterprise.concurrent.ContextService | java:comp/DefaultContextService |
javax.enterprise.concurrent.ManagedExecutorService | java:comp/DefaultManagedExecutorService |
javax.enterprise.concurrent.ManagedScheduledExecutorService | java:comp/DefaultManagedScheduledExecutorService |
javax.enterprise.concurrent.ManagedThreadFactory | java:comp/DefaultManagedThreadFactory |
javax.jms.ConnectionFactory | java:comp/DefaultJMSConnectionFactory |
The following link contains the XML Schema components for the Java EE 8 schema:
http://xmlns.jcp.org/xml/ns/javaee/ namespace.
Consider that many APIs that are required by the Java EE 8 platform are included in the Java Platform SE 8 and are thus available to Java EE applications.
In Java EE 8, the JNDI API provides naming and directory functionality. It will enable applications to access multiple naming and directory services, such as LDAP, DNS, and NIS.
The JNDI API provides applications with methods for performing standard directory operations, like for instance associating attributes with objects and searching for objects using their attributes.
A Java EE 8 component will also be able to locate its environment naming context by using JNDI interfaces.
Create a javax.naming.InitialContext object.
Look up the environment naming context in InitialContext under the name java:comp/env.
A component’s naming environment is stored directly in the environment naming context or in any of its direct or indirect subcontexts.
Some providers offer high-performance reading through database connections that are not associated with the current JTA transaction. The query results are then returned and made conformant with the contents of the persistence context. This improves the scalability of the application because the database connection does not get enlisted in the JTA transaction until later on when it absolutely needs to be, usually at commit time. To enable these types of scalable reads, the non-jta-data-source element value would be supplied in addition to the jta-data-source element. An example of specifying these two is in Listing 14-3.
Specifying JTA and Non-JTA Data Sources
Note that EmployeeDS is a regularly configured data source that accesses the employee database, but NonTxEmployeeDS is a separate data source configured to access the same employee database but not be enlisted in JTA transactions.
Mapping Files
In Chapter 13, we used XML mapping files to supply mapping metadata. Part or all of the mapping metadata for the persistence unit may be specified in mapping files. The union of all the mapping files (and the annotations in the absence of xml-mapping-metadata-complete) will be the metadata that is applied to the persistence unit.
You might wonder why multiple mapping files might be useful. There are actually numerous cases for using more than one mapping file in a single persistence unit, but it really comes down to preference and process. For example, you might want to define all the persistence-unit-level artifacts in one file and all the entity metadata in another file. In another case, it may make sense for you to group all the queries together in a separate file to isolate them from the rest of the physical database mappings.
Perhaps it suits the development process to even have a file for each entity, either to decouple them from each other or to reduce conflicts resulting from the version control and configuration management system. This can be a popular choice for a team that is working on different entities within the same persistence unit. Each may want to change the mappings for a particular entity without getting in the way of other team members who are modifying other entities. Of course, this must be negotiated carefully when there really are dependencies across the entities such as relationships or embedded objects.
It makes sense to group entity metadata together when the relationships between them are not static or when the object model may change. As a general rule, if there is strong coupling in the object model, the coupling should be considered in the mapping configuration model.
Some might just prefer to have a single mapping file with all the metadata contained within it. This is certainly a simpler deployment model and makes for easier packaging. There is built-in support available to those who are happy limiting their metadata to a single file and willing to name it orm.xml. If a mapping file named orm.xml exists in a META-INF directory on the classpath, for example beside the persistence.xml file, it does not need to be explicitly listed. The provider will automatically search for such a file and use it if one exists. Mapping files that are named differently or are in a different location must be listed in the mapping-file elements in the persistence.xml file.
Mapping files listed in the mapping-file elements are loaded as Java resources (using methods such as ClassLoader.getResource() , for example) from the classpath, so they should be specified in the same manner as any other Java resource that was intended to be loaded as such. The directory location component followed by the file name of the mapping file will cause it to be found, loaded, and processed at deployment time. For example, if we put all our persistence unit metadata in META-INF/orm.xml, all our queries in META-INF/employee_service_queries.xml, and all our entities in META-INF/employee_ service_entities.xml, we should end up with the persistence-unit-level definition shown in Listing 14-4. Remember, we don’t need to specify the META-INF/orm.xml file because it will be found and processed by default. The other mapping files could be in any directory, not necessarily just the META-INF directory. We put them in META-INF just to keep them together with the orm.xml file.
Specifying Mapping Files
Managed Classes
Managed classes are all the classes that must be processed and considered in a persistence unit, including entities, mapped superclasses, embeddables, and converter classes. Typical deployments will put all the entities and other managed classes in a single JAR, with the persistence.xml file in the META-INF directory and one or more mapping files also tossed in when XML mapping is used. The deployment process is optimized for these kinds of deployment scenarios to minimize the amount of metadata that a deployer has to specify.
Local classes: The annotated classes in the deployment unit in which its persistence.xml file was packaged.
Classes in mapping files: The classes that have mapping entries in an XML mapping file.
Explicitly listed classes: The classes that are listed as class elements in the persistence.xml file.
Additional JARs of managed classes: The annotated classes in a named JAR listed in a jar-file element in the persistence.xml file.
As a deployer you may choose to use any one or a combination of these mechanisms to cause your managed classes to be included in the persistence unit. We will discuss each in turn.
Local Classes
The first category of classes that gets included is the one that is the easiest and will likely be used the most often. We call these classes local classes because they are local to the deployment unit. When a JAR is deployed with a persistence.xml file in the META-INF directory, that JAR will be searched for all the classes that are annotated with @Entity, @MappedSuperclass, @Embeddable, or @Converter. This will hold true for various types of deployment units that we will describe in more detail later in the chapter.
This method is clearly the simplest way to cause a class to be included because all that has to be done is to put the annotated classes into a JAR and add the persistence.xml file in the META-INF directory of the JAR. The provider will take care of going through the classes and finding the entities. Other classes may also be placed in the JAR with the entities and will have no effect on the finding process, other than perhaps potentially slowing down the finding process if there are many such classes.
Classes in Mapping Files
Any class that has an entry in a mapping file will also be considered a managed class in the persistence unit. It need only be named in an entity, mapped-superclass, embeddable, or converter element in one of the mapping files. The set of all the classes from all the listed mapping files (including the implicitly processed orm.xml file) will be added to the set of managed classes in the persistence unit. Nothing special has to be done apart from ensuring that the classes named in a mapping file are on the classpath of the unit being deployed. If they are in the deployed component archive, they will likely already be on the classpath. If they aren’t, they must be explicitly included in the classpath just as the explicitly listed ones are (see the following “Explicitly Listed Classes” section).
Explicitly Listed Classes
When the persistence unit is small or when there is not a large number of entities, we may want to list classes explicitly in class elements in the persistence.xml file. This will cause the listed classes to be added to the persistence unit.
Since a class that is local to the deployment unit will already be included, we don’t need to list it in a class element. Explicitly listing the classes is really useful in three main cases.
The first is when there are additional classes that are not local to the deployment unit JAR. For example, there is an embedded object class in a different JAR that we want to use in an entity in our persistence unit. We would list the fully qualified class in the class element in the persistence.xml file. We also need to ensure that the JAR or directory that contains the class is on the classpath of the deployed component, for example, by adding it to the manifest classpath of the deployment JAR.
In the second case, we want to exclude one or more classes that may be annotated as an entity. Even though the class may be annotated with @Entity, we don’t want it to be treated as an entity in this particular deployed context. For example, it may be used as a transfer object and need to be part of the deployment unit. In this case, we need to use a special element called exclude-unlisted-classes in the persistence.xml file, which disables local classes from being added to the persistence unit. When exclude-unlisted-classes is used, none of the classes in the local classes category described earlier will be included.
Note
There was a bug in the JPA 1.0 persistence_1_0.xsd schema that the default value of the exclude-unlisted-classes element was false. This meant that a value of true needed to be explicitly included as content, such as <exclude-unlisted-classes>true<exclude-unlisted-classes/>, instead of being able to simply include the empty element to signify that only the classes listed in the <class> elements need to be considered as entities. Some vendors actually worked around this bug by not validating the persistence.xml against the schema, but to be portable in JPA 1.0, you should explicitly set it to true when you wanted to exclude the unlisted classes. The bug was fixed in the JPA 2.0 persistence_2_0.xsd schema. Notice that JPA 2.2 will of course utilize the file named persistence_2_2.xsd, which can be found in this web link: http://www.oracle.com/webfolder/technetwork/jsc/xml/ns/persistence/index.html#2.2 .
The third case is when we expect to be running the application in a Java SE environment and we list the classes explicitly because that is the only portable way to do so in Java SE. We will explain deployment to the Java SE non-server environment later in the chapter.
Additional JARs of Managed Classes
The last way to get managed classes included in the persistence unit is to add them to another JAR and specify the name of the JAR in a jar-file element in the persistence.xml. The jar-file element is used to indicate to the provider a JAR that may contain annotated classes. The provider will then treat the named JAR as if it were a deployment JAR, and it will look for any annotated classes and add them to the persistence unit. It will even search for an orm.xml file in the META-INF directory in the JAR and process it just as if it were an additionally listed mapping file.
Any JAR listed in a jar-file entry must be on the classpath of the deployment unit. We must do this manually, though, since the server will not automatically do it for us. Again, this may be done by either putting the JAR in the lib directory of the EAR (or WAR if we are deploying a WAR), adding the JAR to the manifest classpath of the deployment unit, or by some other vendor-specific means.
When listing a JAR in a jar-file element, it must be listed relative to the parent of the JAR file in which the META-INF/persistence.xml file is located. This matches what we would put in the classpath entry in the manifest. For example, assume the enterprise archive (EAR), which we will call emp.ear, is structured as shown in Listing 14-5.
Entities in an External JAR
The contents of the persistence.xml file should be as shown in Listing 14-6, with the jar-file element containing lib/emp-classes.jar to reference the emp-classes.jar in the lib directory in the EAR file. This would cause the provider to add the annotated classes it found in emp-classes.jar (Employee.class) to the persistence unit, and because the JAR is in the lib directory of the EAR, it would automatically be on the application classpath.
Contents of persistence.xml
Shared Cache Mode
At the end of Chapter 12, we went into some detail about caching and the cache that is shared by all the entity managers obtained from the same entity manager factory. In the “Static Configuration of the Cache” section of that chapter, we described the options for setting the shared cache mode, but we will summarize here how the shared-cache-mode element works in the persistence.xml file.
The shared-cache-mode Element’s Options
Value | Description |
|---|---|
UNSPECIFIED | The provider chooses whatever option is most appropriate for that provider. |
ALL | Cache all the entities in the persistence unit. |
NONE | Do not cache any of the entities in the persistence unit. |
DISABLE_SELECTED | Cache all entities except those annotated with @Cacheable(false). |
ENABLE_SELECTED | Cache no entities except those annotated with @Cacheable(true). |
It doesn’t make much sense to explicitly designate UNSPECIFIED as the option because it is exactly equivalent to not specifying the value at all and offers no real information. When not set, the element will be defaulted by the provider to whichever of the other four options makes the most sense for that provider.
The next two options, ALL and NONE , are “sweeping” options, meaning that they affect all the entities in the persistence unit, without exception. Any @Cacheable annotations will be ignored when either of these options is set.
The DISABLE_SELECTED and ENABLE_SELECTED options are “discretionary” options, and are used in conjunction with the @Cacheable annotation to determine the entities that are cached and those that are not. If the default for your provider is one of the discretionary options and you end up using the @Cacheable annotation to affect which entities get cached, you might want to explicitly set this element to the desired/expected mode instead of relying on the default provider behavior. This will avoid confusion that could result from switching providers and getting a different default that does not consider the @Cacheable annotations.
Validation Mode
The validation-mode element in the persistence.xml file determines whether validation is enabled or not (see the “Enabling Validation” section in Chapter 12). It may be set to AUTO, meaning that in the container environment, validation is enabled, but when not running in the container, validation will be enabled only if there is a validation provider available. Setting it to CALLBACK will enable validation and assume that a validation provider is on the classpath.
The default is AUTO, which enables validation, so if you do not intend to use validation, we recommend that you explicitly disable it by setting the validation-mode element to NONE. This will bypass the validation provider checks and prevent you from incurring any validation overhead if at some point later on a provider happens to show up on the classpath.
Adding Properties
The last section in the persistence.xml file is the properties section. The properties element gives a deployer the chance to supply standard and provider-specific settings for the persistence unit. To guarantee runtime compatibility, a provider must ignore properties it does not understand. While it is helpful to be able to use the same persistence.xml file across different providers, it also makes it easy to mistakenly type a property incorrectly and have it unintentionally and silently ignored. An example of adding some vendor properties is shown in Listing 14-7.
Using Provider Properties
Building and Deploying
One of the big wins that a standard persistence API brings is not only a portable runtime API but also a common way to compose, assemble, and configure an application that uses persistence. In this section, we describe some of the popular and practical choices that are used to deploy persistence-enabled applications.
Deployment Classpath
In some of the previous sections we say that a class or a JAR must be on the deployment classpath. When we say this we mean that the JAR must be accessible to the EJB JAR, the web archive (WAR) , or the enterprise application archive (EAR) . This can be achieved in several ways.
The first is by putting the JAR in the manifest classpath of the EJB JAR or WAR. This is done by adding a classpath entry to the META-INF/MANIFEST.MF file in the JAR or WAR. One or more directories or JARs may be specified, as long as they are separated by spaces. For example, the following manifest file classpath entry will add the employee/emp-classes.jar and the employee/classes directory to the classpath of the JAR that contains the manifest file:
A better way to get a JAR into the deployment unit classpath is to place the JAR in the library directory of the EAR. When a JAR is in the library directory, it will automatically be on the application classpath and accessible by all the modules deployed within the EAR. By default, the library directory is the lib directory in the EAR, although it may be configured to be any directory using the library-directory element in the application.xml deployment descriptor. The application.xml file would look something like the skeletal one shown in Listing 14-8.
Setting the Application Library Directory
When you are deploying a WAR and want to put an additional JAR of entities on the classpath, you can put the JAR in the WEB-INF/lib directory of the WAR. This causes the JAR to be on the classpath, and the classes in it are accessible to all the classes in the WAR.
Vendors usually provide their own vendor-specific way for deployers to add classes or JARs to the deployment classpath. This is usually offered at the application level and not at the level of a JAR or WAR; however, some may provide both.
Packaging Options
A primary focus of the Java Persistence API is its integration with the Java EE platform. Not only has it been integrated in fine-grained ways, such as allowing injection of entity managers into Java EE components, but it also has special status in Java EE application packaging. Java EE allows for persistence to be supported in a variety of packaging configurations that offer flexibility and choice. We will divide them into the different module types that the application might be deployed into: EJB modules, web modules, and persistence archives.
EJB JAR
Modularized business logic has traditionally ended up in session bean components, which is why session beans were designed with JPA to be the primary Java EE component clients of persistence. Session beans have traditionally been deployed in an EJB JAR, although since Java EE 6 they may also be deployed in a WAR with web components. For a discussion on deploying in a WAR, see the next section.
We assume that the reader is familiar with packaging and deploying EJB components in an EJB JAR, but if not, there are many books and resources available to learn about it.
As of EJB 3.0, we no longer need to have an ejb-jar.xml deployment descriptor, but if we choose to use one, it must be in the META-INF directory. When defining a persistence unit in an EJB JAR, the persistence.xml file is not optional. It must be created and placed in the META-INF directory of the JAR alongside the ejb-jar.xml deployment descriptor, if it exists. Although the existence of persistence.xml is required, the contents may be very sparse indeed, in some cases including only the name of the persistence unit.
The only real work in defining a persistence unit is to decide where we want our entities and managed classes to reside. We have a number of options available to us. The simplest approach is to simply dump our managed classes into the EJB JAR along with the EJB components. As we described in the “Local Classes” section earlier in the chapter, as long as the managed classes are correctly annotated, they will be automatically discovered by the provider at deployment time and added to the persistence unit. Listing 14-9 shows a sample enterprise application archive file that does this.
Packaging Entities in an EJB JAR
In this case, the orm.xml file contains any mapping information that we might have at the persistence-unit level, such as setting the schema for the persistence unit. In the persistence.xml file, we would need to specify only the name of the persistence unit and the data source. Listing 14-10 shows the corresponding persistence.xml file (without the namespace header).
Persistence.xml File for Entities Packaged in an EJB JAR
If we wanted to separate the entities from the EJB components, we could put them in a different JAR and reference that JAR in a jar-file entry in the persistence.xml file. We showed a simple example of doing this in the “Additional JARs of Managed Classes” section, but we show one again here with an additional orm.xml file and emp-mappings.xml mapping file. Listing 14-11 shows what the structure and contents of the EAR would look like.
Packaging Entities in a Separate JAR
The emp-classes.jar file containing the entities would be on the classpath since it is in the library directory of the EAR, as described in the “Deployment Classpath” section. In addition to processing the entities found in the emp-classes.jar file, the orm.xml file in the META-INF directory will also be detected and processed automatically. We need to explicitly list the additional emp_mappings.xml mapping file in a mapping-file element, though, in order for the provider to find it as a resource. The persistence unit portion of the persistence.xml file is shown in Listing 14-12.
Persistence.xml File for Entities Packaged in a Separate JAR
Web Archive
The web archive has become the most popular deployment vehicle for applications since almost everything a typical web application needs can be housed within it. Web artifacts and frameworks, business components like EJBs, CDI beans, and Spring beans, as well as persistent entities can all be deployed inside a web archive without the need for a separate deployment module. By using the WAR as the deployment vehicle for all three code tiers, the EJB JAR and EAR units become unnecessary, and the WAR becomes the new EAR equivalent.
The downside is that a WAR is a little more complex than the EJB JAR, and learning to package persistence units in web archives requires understanding the relevance of the persistence.xml file location. The location of the persistence.xml file determines the persistence unit root. The root of the persistence unit is defined as the JAR or directory that contains the META-INF directory, where the persistence.xml file is located. For example, in an EJB JAR, the persistence.xml file is located in the META-INF directory of the root of the JAR, so the root of the persistence unit is always the root of the EJB JAR file itself. In a WAR, the persistence unit root depends on where the persistence unit is located within the WAR. The obvious choice is to use the WEB-INF/classes directory as the root, which would lead us to place the persistence.xml file in the WEB-INF/classes/META-INF directory. Any annotated managed classes rooted in the WEB-INF/classes directory will be detected and added to the persistence unit. Similarly, if an orm.xml file is located in WEB-INF/classes/META-INF, it will be processed.
The web components and bean components are also placed in the classes directory. An example of packaging a persistence unit in the WEB-INF/classes directory, with the accompanying other application classes, is shown in Listing 14-13. We included the web.xml file, but it is no longer necessary if annotations on the servlet are used.
Packaging Entities in the WEB-INF/classes Directory
The persistence.xml file would be specified in exactly the same way as is shown in Listing 14-10. If we need to add another mapping file, we can put it anywhere on the deployment unit classpath. We just need to add a mapping-file element to the persistence.xml file. If, for example, we put emp-mapping.xml in the WEB-INF/classes/mapping directory, we would add the following element to the persistence.xml file:
Since the WEB-INF/classes directory is automatically on the classpath of the WAR, the mapping file is specified relative to that directory.
Persistence Archive
If we want to allow a persistence unit to be shared or accessible by multiple components, either in different Java EE modules or in a single WAR, we should use a persistence archive. It also promotes good design principles by keeping the persistence classes together. We saw a simple persistence archive back in Chapter 2 when we were first getting started and observed how it housed the persistence.xml file and the managed classes that were part of the persistence unit defined within it. By placing a persistence archive in the lib directory of an EAR, or in the WEB-INF/lib directory of a WAR, we can make it available to any enclosed component that needs to operate on the entities defined by its contained persistence unit.
The persistence archive is simple to create and easy to deploy. It is simply a JAR that contains a persistence.xml in its META-INF directory and the managed classes for the persistence unit defined by the persistence.xml file.
Listing 14-14 shows the contents of the WAR that we showed in Listing 14-13, but in this case it uses a simple persistence archive, emp-persistence.jar, to define the persistence unit that we have been using in the previous examples. This time, we need to only put the persistence archive in the WEB-INF/lib directory, and it will be both on the classpath and detected as a persistence unit.
Packaging Entities in a Persistence Archive
If the emp-persistence.jar JAR part of Listing 14-14 looks familiar, that’s because it is virtually the same as the EJB JAR structure that we showed in Listing 14-9 except that it is a persistence archive JAR instead of an EJB JAR. We just changed the name of the JAR and took out the session bean classes. The contents of the persistence.xml file can be exactly the same as what is shown in Listing 14-10. Just as with the other archive types, the orm.xml file in the META-INF directory will be automatically detected and processed, and other XML mapping files may be placed within the JAR and referenced by the persistence.xml file as a mapping-file entry.
Managed classes may also be stored in a separate JAR external to the persistence archive, just as they could be in other packaging archive configurations. The external JAR would be referenced by the persistence.xml file as a jar-file entry with the same rules for specification as described in the other cases. This is neither recommended nor useful, though, since the persistence archive itself is already separated from the other component classes. Seldom will there be a reason to create yet another JAR to store the managed classes, but there may be a case when the other JAR is pre-existing, and you need to reference it because you can’t or don’t want to put the persistence.xml file in the pre-existing JAR.
Persistence archives are actually a very tidy way of packaging a persistence unit. By keeping them self-contained (if they do not reference external JARs of classes using jar-file entries), they do not depend on any other components of the application but can sit as a layer underneath those components to be used by them.
Persistence Unit Scope
For simplicity, we have talked about a persistence unit in the singular. The truth is that any number of persistence units may be defined in the same persistence.xml file and used in the scope within which they were defined. You saw in the preceding sections, when we discussed how managed classes get included in the persistence unit, that local classes in the same archive will be processed by default. If multiple persistence units are defined in the same persistence.xml file, and exclude-unlisted-classes is not used on either one, the same classes will be added to all the defined persistence units. This may be a convenient way to import and transform data from one data source to another: simply by reading in entities through one persistence unit and performing the transformation on them before writing them out through another persistence unit.
The first rule is that persistence units are accessible only within the scope of their definition. We have already mentioned this in passing a couple of times, and we hinted at it again in the “Persistence Archive” section. We said that the persistence unit defined within a persistence archive at the EAR level was accessible to all the components in the EAR, and that a persistence unit defined in a persistence archive in a WAR is accessible only to the components defined within that WAR. In fact, in general a persistence unit defined from an EJB JAR is seen by EJB components defined by that EJB JAR, and a persistence unit defined in a WAR will be seen only by the components defined within that WAR. Persistence units defined in a persistence archive that lives in the EAR will be seen by all the components in the application.
The next part is that the names of persistence units must be unique within their scope. For example, there may be only one persistence unit of a given name within the same EJB JAR. Likewise, there may be only one persistence unit of a given name in the same WAR, as well as only one persistence unit of the same name in all the persistence archives at the EAR level. There may be a named persistence unit name in one EJB JAR and another that shares its name in another EJB JAR, or there may even be a persistence unit with the same name in an EJB JAR as there is in a persistence archive. It just means that whenever a persistence unit is referenced either within a @PersistenceContext, a @PersistenceUnit annotation, or a createEntityManagerFactory() method, the most locally scoped one will be used.
A final comment about naming is that just because it’s possible to have multiple persistence units with the same name in different component archive namespaces, doesn’t mean that it is a good idea. As a general rule, you should always give persistence units unique names within the application.
Outside the Server
There are some obvious differences between deploying in a Java EE server and deploying to a Java SE runtime environment. For example, some of the Java EE container services will not be present, and this spills out into the runtime configuration information for a persistence unit. In this section, we outline the differences to consider when packaging and deploying to a Java SE environment.
Configuring the Persistence Unit
As before, the place to start is the configuration of the persistence unit, which is chiefly in the creation of the persistence.xml file. We outline the differences between creating a persistence.xml file for a Java SE application and creating one for a Java EE application.
Transaction Type
When running in a server environment, the transaction-type attribute in the persistence unit defaults to being JTA. The JTA transaction layer was designed for use within the Java EE server and is intended to be fully integrated and coupled to the server components. Given this fact, JPA does not provide support for using JTA outside the server. Some providers may offer this support, but it cannot be portably relied on, and of course it relies on the JTA component being present.
The transaction type does not normally need to be specified when deploying to Java SE. It will just default to being RESOURCE_LOCAL, but may be specified explicitly to make the programming contract more clear.
Data Source
When we described configuration in the server, we illustrated how the jta-data-source element denotes the JNDI location of the data source that will be used to obtain connections. We also saw that some servers might even default the data source.
The non-jta-data-source element is used in the server to specify where resource-local connections can be obtained in JNDI. It may also be used by providers that do optimized reading through non-JTA connections.
When configuring for outside the server, not only can we not rely on JTA, as we described in the transaction type section, but we cannot rely on JNDI at all. We therefore cannot portably rely on either of the data source elements in Java SE configurations.
When using resource-local transactions outside the server, the provider obtains database connections directly vended out by the JDBC driver. In order for it to get these connections, it must obtain the driver-specific information, which typically includes the name of the driver class, the URL that the driver uses to connect to the database, and the user and password authentication that the driver also passes to the database. This metadata may be specified in whichever way the provider prefers it to be specified, but all vendors must support the standard JDBC properties in the properties section. Listing 14-15 shows an example of using the standard properties to connect to the Derby database through the Derby driver.
Specifying Resource-Level JDBC Properties
Providers
Many servers will have a default or native provider that they will use when the provider is not specified. It will automatically call into that provider to create an EntityManagerFactory at deployment time.
When not in a server, the factory is created programmatically using the Persistence class. When the createEntityManagerFactory() method is invoked, the Persistence class will begin a built-in pluggability protocol that goes out and finds the provider that is specified in the persistence unit configuration. If none was specified, the first one that it finds will be used. Providers export themselves through a service that exists in the provider JAR that must be on the classpath. The net result is that the provider element is not required.
In the majority of cases when only one provider will be on the classpath, the provider will be detected and used by the Persistence class to create an EntityManagerFactory for a given persistence unit. If you are ever in a situation in which you have two providers on the classpath and you want a particular one to be used, you should specify the provider class in the provider element. To prevent runtime and deployment errors, the provider element should be used if the application has a code dependency on a specific provider.
Listing the Managed Classes
One of the benefits of deploying inside the server is that it is a highly controlled and structured environment. Because of this, the server can support the deployment process in ways that cannot be achieved by a simple Java SE runtime. The server already has to process all the deployment units in an application and can do things like detect all the managed persistence classes in an EJB JAR or a persistence archive. This kind of class detection makes persistence archives a very convenient way to bundle a persistence unit.
The problem with this kind of detection outside the server is that the Java SE environment permits all kinds of different class resources to be added to the classpath, including network URLs or any other kind of resource that is acceptable to a classloader. There are no official deployment unit boundaries that the provider is aware of. This makes it difficult for JPA to require providers to support doing automatic detection of the managed classes inside a persistence archive. The official position of the API is that for an application to be portable across all vendors it must explicitly list all the managed classes in the persistence unit using class elements . When a persistence unit is large and includes a large number of classes, this task can become rather onerous.
In practice, however, some of the time the classes are sitting in a regular persistence archive JAR on the file system, and the provider runtime can do the detection that the server would do in Java EE if it can just determine the JAR to search in. For this reason, many of the major providers actually do support detecting the classes outside the server. This is really kind of an essential usability issue since the maintenance of a class list would be so cumbersome as to be a productivity bottleneck unless you had a tool manage the list for you.
A corollary to the official portability guideline to use class elements to enumerate the list of managed classes is that the exclude-unlisted-classes element is not guaranteed to have any impact in Java SE persistence units. Some providers may allow this element to be used outside the server, but it is not really very useful in the SE environment anyway, given the flexibility of the classpath and packaging allowances in that environment.
Specifying Properties at Runtime
One of the benefits of running outside the server is the ability to specify provider properties at runtime. This is available because of the overloaded createEntityManagerFactory() method that accepts a Map of properties in addition to the name of the persistence unit. The properties passed to this method are combined with those already specified, normally in the persistence.xml file. They may be additional properties or they may override the value of a property that was already specified. This may not seem very useful to some applications, since putting runtime configuration information in code is not normally viewed as being better than isolating it in an XML file. However, one can imagine this being a convenient way to set properties obtained from a program input, such as the command line, as an even more dynamic configuration mechanism.
In Listing 14-16 is an example of taking the user and password properties from the command line and passing them to the provider when creating the EntityManagerFactory.
Using Command-Line Persistence Properties
System Classpath
In some ways, configuring a persistence unit in a Java SE application is actually easier than configuring in the server because the classpath is simply the system classpath. Adding classes or JARs on the system classpath is a trivial exercise. In the server, we may have to manipulate the manifest classpath or add some vendor-specific application classpath configuration.
Schema Generation
Schema generation used to just refer to the process of taking the mappings in the persistence unit and inferring a possible schema of database tables to support those mappings. However, it now also includes more than simple table generation. Schema generation properties and scripts can now be used to create and/or drop the existing tables, and even cause data to be preloaded into them before running an application.
Note
Except where noted, the term “schema generation ” refers to the generation of tables for a pre-existing database schema, not necessarily issuing an actual CREATE SCHEMA database command.
One of the complaints around schema generation is that you can’t specify everything that you need to be able to finely tune the table schemas. This was not accidental. There are too many differences between databases and too many different settings to try to put in options for every database type. If every database-tuning option were exposed through JPA, we would end up duplicating the features of Data Definition Language (DDL) in an API that was not meant to be a database schema generation facility. As we mentioned earlier, the majority of applications find themselves in a meet-in-the-middle mapping scenario in any case, and when they do have control over the schema, the final schema will typically be tuned by a database administrator or someone with the appropriate level of database experience.
Tip
Although many of the schema generation annotation elements have been present since JPA 1.0, the specification did not require that providers support generation of tables until JPA 2.1. It was also in JPA 2.1 that the schema generation properties and API methods were introduced. Nothing was changed regarding schema generation in JPA 2.2.
The Generation Process
There are a number of different aspects of schema generation that can be specified independently or in combination with each other. Before we dive into them, we go over some of the concepts of schema generation and the basic process so that you can get a feel for what is happening. Then in subsequent sections, we describe the properties and annotations that can be used to produce a desired result.
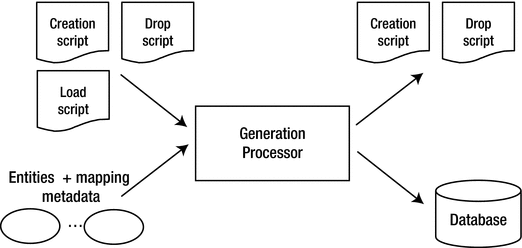
The generation processor
The schema generation process will typically happen either when the application is deployed (for example, when in a container), or when the entity manager factory gets created (on a Persistence.createEntityManagerFactory() invocation in Java SE).
There are three distinct operations supported by schema generation. You can create the schema objects, drop the schema (delete the schema objects), or preload data into a schema. Although the create and drop schema operations are specified within the same property, you can also mix and match which operations you want executed. The order in which they will be performed is going to be dictated by what is sensible, though. For example, if all three are specified, the old schema will first be dropped, the new one will be created, and then the data will be preloaded.
To control the inputs and outputs and what occurs during schema generation processing a number of standard properties can be specified either statically in the persistence.xml file or dynamically in a runtime call in Java SE to Persistence.createEntityManagerFactory() or Persistence.generateSchema(). Properties passed in at runtime will override properties defined in the persistence.xml file.
Deployment Properties
The standard properties that can be specified in property elements in the persistence.xml descriptor are listed in the sections that follow. Vendors may offer additional properties and options that overlap or subsume these, but the options listed here must be supported by all compliant vendors and should be used by applications wishing to remain portable. The properties all fall into one of two categories: generation output and generation input.
Tip
Some of the properties described in this section specify that a URL be supplied as a value either for a script source or a script target location. While the specification does not prescribe any other format, in many cases providers do support the use of a simple file path.
Generation Output
The very presence of one of the first two properties in this category determines that a schema generation operation occurs, either in the database or to scripts. The property value dictates which schema operations are to occur in the targeted location. The properties are not exclusive, meaning that more than one property can be included, causing the schema generation process to generate to multiple targets.
The second two properties (create-target and drop-target) are script output specifier properties and are used in combination with the script action property (javax.persistence.schema-generation.scripts.action).
javax.persistence.schema-generation.database.action
none (default): Do no schema generation in the database.
create: Generate the schema in the database.
drop: Drop the schema from the database.
drop-and-create: Drop the schema from the database and then generate a new schema in the database.
Example:
javax.persistence.schema-generation.scripts.action
none (default): Generate no scripts.
create: Generate a script to create the schema.
drop: Generate a script to drop the schema.
drop-and-create: Generate a script to drop the schema and a script to create the schema.
Note that there must be corresponding script targets for each value. If the create option is specified, then the javax.persistence.schema-generation.scripts.create-target property must also be supplied and have a value. If the drop option is specified, then the javax.persistence.schema-generation.scripts.drop-target property must be supplied and have a value. If drop-and-create is specified, then both properties must be supplied with values.
Example:
javax.persistence.schema-generation.scripts.create-target
This property is used to specify the location at which to generate the creation script and is used in conjunction with the javax.persistence.schema-generation.scripts.action. The value is a file URL and must specify an absolute path rather than a relative one. Use of this property in a container may be somewhat limited, depending on the degree of file system access the container allows.
Example:
javax.persistence.schema-generation.scripts.drop-target
This property is used to specify the location at which to generate the dropping script and is used in conjunction with the javax.persistence.schema-generation.scripts.action. Similar to the script create-target property, the value of this property is a file URL and must specify an absolute path rather than a relative one. Like the script create-target property, use of this property in a container may be somewhat limited.
Example:
Generation Input
The first two properties in this category specify whether the schema creation and dropping should be generated based on the mapping metadata, scripts, or both. They are really only useful for the special “both” case of mixing metadata with scripts, though1.
If the sources are combined, there is the additional option of ordering which happens first, the schema creation from the mapping metadata or the scripts. The option to use both sources is not likely to be a common requirement but can be useful to make specific customizations to a schema mostly generated from the metadata.
The second pair of properties, create-script-source and drop-script-source, can be used to specify the exact scripts to use as the inputs, and the last one, sql-load-script-source, can be used to preload data into the schema. The value of each of these three properties can be a file path relative to the root of the persistence unit or a file URL that is accessible by the persistence provider in whatever environment it is running in.
If an output property is specified, but no input property, the mapping metadata will be used as input.
javax.persistence.schema-generation.create-source
metadata: Generate schema from mapping metadata.
script: Generate schema from an existing script.
metadata-then-script: Generate schema from mapping metadata then from an existing script.
script-then-metadata: Generate schema from an existing script then from mapping metadata.
Example:
javax.persistence.schema-generation.drop-source
metadata: Generate DDL to drop schema from mapping metadata.
script: Use existing script to get DDL to drop schema script.
metadata-then-script: Generate DDL from mapping metadata, then use an existing script.
script-then-metadata: Use an existing script, then generate DDL from mapping metadata.
Example:
javax.persistence.schema-generation.create-script-source
This property specifies a script to use when creating a schema.
Example:
javax.persistence.schema-generation. drop-script-source
This property specifies a script to use when dropping a schema.
Example:
javax.persistence. sql-load-script-source
This property specifies a script to use when preloading a schema.
Example:
Runtime Properties
Runtime Schema Generation Property Differences
Property Name | Difference |
|---|---|
javax.persistence.schema-generation.create-script-source javax.persistence.schema-generation.drop-script-source javax.persistence.sql-load-script-source | java.io.Reader instead of String file path |
javax.persistence.schema-generation.scripts.create-target javax.persistence.schema-generation.scripts.drop-target | java.io.Writer instead of String file path |
Mapping Annotations Used by Schema Generation
When we mentioned schema generation in Chapter 4, we promised to go over the mapping annotation elements that are considered when schema generation occurs. In this section, we make good on that pledge and explain which elements get applied to the generated schema.
A couple of comments are in order before we start into them, though. First, the elements that contain the schema-dependent properties are, with a few exceptions, in the physical annotations. This is to try to keep them separate from the logical non-schema-related metadata. Second, these annotations are ignored, for the most part2, if the schema is not being generated. This is one reason why using them is a little out of place in the usual case, since schema information about the database is of little use once the schema has been created and is being used.
Unique Constraints
A unique constraint can be created on a generated column or join column by using the unique element in the @Column, @JoinColumn, @MapKeyColumn, or @MapKeyJoinColumn annotations. There are not actually very many cases where this will be necessary because most vendors will generate a unique constraint when it is appropriate, such as on the join column of one-to-one relationships. Otherwise, the value of the unique element defaults to false. Listing 14-17 shows an entity with a unique constraint defined for the STR column.
Including Unique Constraints
Note that the unique element is unnecessary on the identifier column because a primary key constraint will always be generated for the primary key.
A second way of adding a unique constraint is to embed one or more @UniqueConstraint annotations in a uniqueConstraints element in the @Table, @SecondaryTable, @JoinTable, @CollectionTable, or @TableGenerator annotations. Any number of unique constraints may be added to the table definition, including compound constraints. The value passed to the @UniqueConstraint annotation is an array of one or more strings listing the column names that make up the constraint. Listing 14-18 demonstrates how to define a unique constraint as part of a table.
Unique Constraints Specified in Table Definition
Null Constraints
Constraints on a column may also be in the form of null constraints. A null constraint just indicates that the column may or may not be null. It is defined when the column is declared as part of the table.
Null constraints are defined on a column by using the nullable element in the @Column, @JoinColumn, @MapKeyColumn, @MapKeyJoinColumn, or @OrderColumn annotations. A column allows null values by default, so this element really needs to be used only when a value for the field or property is required. Listing 14-19 demonstrates how to set the nullable element of basic and relationship mappings.
Null Constraints Specified in Column Definitions
Indexes
When a primary key is created during sequence generation it will automatically be indexed. However, additional indexes may be generated on a column or on a sequence of columns in a table by using the indexes element and specifying one or more @Index annotations, each of which specifies an index to add to the table. The indexes element can be specified on the @Table, @SecondaryTable, @JoinTable, @CollectionTable, and @TableGenerator annotations. Listing 14-20 shows an example of adding an index on the EMPNAME column during schema generation of the EMP table. We named the index, but the provider would name it for us if we did not specify a name. Note that multiple comma-separated column names can be specified in the columnNames string in the case of a multi-column index. An optional ASC or DESC can also be added to the column using the same syntax as in the @OrderBy annotation (see Chapter 5). By default they will be assumed to be in ascending order. We can even put an additional uniqueness constraint on the index using the unique element.
Adding an Index
Foreign Key Constraints
When an entity includes one or more join columns then during schema generation, persistence providers may choose to generate foreign key constraints based on those entity relationships. It is neither prescribed nor advised that they either generate them or not generate them, so different providers may do different things. You can control whether a foreign key constraint gets generated for a join column by using the foreignKey element in the @JoinColumn, @PrimaryKeyJoinColumn, or @MapKeyJoinColumn annotations. The @ForeignKey annotation is specified in the foreignKey element to explicitly set whether the constraint is to be generated, optionally give the constraint a name, and possibly even specify the exact constraint definition to be used. Listing 14-21 shows a join column with a foreign key constraint that includes both the constraint mode of CONSTRAINT and an explicit constraint definition. Note that the constraint is self-referential.
Foreign Key Constraint Definition on a Join Column
The foreignKey element may also be used in an annotation that includes a group of join columns. For example, the value element of @JoinColumns is an array of @JoinColumn, but if the foreignKey element is specified in @JoinColumns, it will apply to all of the join columns together. It would be unspecified to include both a foreignKey element in @JoinColumns as well as a foreignKey element in one or more of the embedded @JoinColumn annotations. Similar behavior would apply for the value elements of the @PrimaryKeyJoinColumns and @MapKeyJoinColumns annotations, for the joinColumns elements of @AssociationOverride, @CollectionTable, and @JoinTable, and the pkJoinColumns element of @SecondaryTable.
Listing 14-22 shows how to enforce that the provider not generate foreign key constraints for the secondary table primary key join columns (that in this case are using the default names).
Disabling Foreign Key Constraints Added on a Secondary Table
Note that the @JoinTable annotation has an additional inverseForeignKey element that applies a @ForeignKey annotation to the join columns in its inverseJoinColumns element.
String-Based Columns
When no length is specified for a column that is being generated to store string values, the length will be defaulted to 255. When a column is generated for a basic mapping of a field or property of type String, char[], or Character[], its length should be explicitly listed in the length element of the @Column annotation if 255 is not the desired maximum length. Listing 14-23 shows an entity with explicitly specified lengths for strings.
Specifying the Length of Character-Based Column Types
You can see from the previous example that there is no similar length element in the @JoinColumn annotation. When primary keys are string-based, the provider may set the join column length to the same length as the primary key column in the table that is being joined to. This is not required to be supported, however.
It is not defined for length to be used for large objects; some databases do not require or even allow the length of lobs (large objects) to be specified.
Floating Point Columns
Columns containing floating point types have a precision and scale associated with them. The precision is just the number of digits that are used to represent the value, and the scale is the number of digits after the decimal point. These two values may be specified as precision and scale elements in the @Column annotation when mapping a floating point type. Like other schema generation elements, they have no effect on the entity at runtime. Listing 14-24 demonstrates how to set these values.
Specifying the Precision and Scale of Floating Point Column Types
Tip
Precision may be defined differently for different databases. In some databases and for some floating point types, it is the number of binary digits, while for others it is the number of decimal digits.
Defining the Column
There may be a time when you are happy with all the generated columns except for one. The type of the column isn’t what you want it to be, and you don’t want to go through the trouble of manually generating the schema for the sake of one column. This is one instance when the columnDefinition element comes in handy. By hand-rolling the DDL for the column, we can include it as the column definition and let the provider use it to define the column.
The columnDefinition element is available in all the column-oriented annotation types, including @Column, @JoinColumn, @PrimaryKeyJoinColumn, @MapKeyColumn, @MapKeyJoinColumn, @OrderColumn, and @DiscriminatorColumn. Whenever a column is to be generated, the columnDefinition element may be used to indicate the DDL string that should be used to generate the type (not including the trailing comma). This gives the user complete control over what is generated in the table for the column being mapped. It also allows a database-specific type or format to be used that may supersede the generated type offered by the provider for the database being used3. Listing 14-25 shows some definitions specified for two columns and a join column.
Using a Column Definition to Control DDL Generation
In this example, we are using a Unicode character field for the primary key and then also for the join column that refers to the primary key. We also define the date to be assigned the default current date at the time the record was inserted (in case it was not specified).
Specifying the column definition is quite a powerful schema generation practice that allows overriding of the generated column to an application-defined custom column definition. But the power is accompanied by some risk as well. When a column definition is included, other accompanying column-specific generation metadata is ignored. Specifying the precision, scale, or length in the same annotation as a column definition would be both unnecessary and confusing.
Not only does using columnDefinition in your code bind you to a particular schema, but it also binds you to a particular database since the DDL tends to be database-specific. This is just a flexibility/portability trade-off, and you have to decide whether it is appropriate for your application.
Summary
It is a simple exercise to package and deploy persistence applications using the Java Persistence API. In most cases, it is just a matter of adding a very short persistence.xml file to the JAR containing the entity classes.
In this chapter, we described how to configure the persistence unit in the Java EE Server environment using the persistence.xml file and how in some cases the name may be the only setting required. We then explained when to apply and how to specify the transaction type, the persistence provider, and the data source. We showed how to use and specify the default orm.xml mapping file and then went on to use additional mapping files within the same persistence unit. We also discussed the various ways that classes may be included in the persistence unit and how to customize the persistence unit using standard and vendor-specific properties.
We looked at the ways that persistence units may be packaged and deployed to a Java EE application as part of an EJB archive, a web archive, or a persistence archive that is accessible to all the components in the application. We examined how persistence units may exist within different scopes of a deployed Java EE application and what the name-scoping rules were. We then compared the configuration and deployment practices of deploying an application to a Java SE environment.
Finally, we showed how a schema can be generated in the database to match the requirements of the persistence unit using either scripts or the domain model and the mapping metadata. We cautioned against using the generated schema for production systems, but showed how it can be used during development, prototyping, and testing to get up and running quickly and conveniently.
In the next chapter, we consider the accepted and best practices for testing applications that use persistence.