
“First make it work, then make it right, and, finally, make it fast.”
—Stephen C. Johnson and Brian W. Kernighan in“The C Language and Models for Systems Programming,” Byte magazine (August 1983)
When we learn to program in a new language, we write very small programs at first. In Python, small programs are tiny; tasks like searching a text file, shrinking a digital image, or creating a diagram can be completed with ten lines of code or less. At the beginning of a programmer’s learning path, each of these lines is hard work: learning simple things such as appending a value to a list or cutting a string in two seems to take forever. Each line contains at least one bug. Consequently, we make progress in microscopic steps. But after some time our knowledge of the language becomes more firm. What seemed unachievable a few hours, days, or weeks ago, suddenly is easy. So we start writing more ambitious programs. We start writing code that does not fit on a single screen page any more. Quickly, our programs grow beyond 100 lines. This is an interesting size for a program, and we have reached it with the MazeRun game. We started developing the MazeRun game from scratch in the first part of the book. We incrementally added new features one by one. In this chapter, we will add one more feature. How does our programming style need to adapt to a growing program? Can we continue to add small features one by one forever? Or do we have to take care of aspects we did not consider before?
Organized and Unorganized Code
As an example, we will load tile data from a text file. In Chapter 2, we implemented the tiles as a list of tuples. Placing this information in a file would make it easier to extend the in-game graphics and to test our program. We can easily store the tiles and their indices in a text file tiles.txt:
REMARK x and y positions of tiles in the .xpm file# 0 00 1o 1 0x 1 1. 2 0* 3 0g 5 0
To use this information, we need to read the text file, parse its contents, and collect the bounding rectangles of all tiles as a dictionary containing Pygame.Rect objects. We also need to ignore the line starting with REMARK. Both reading and parsing can be done with a small Python program. The first working version of the code written by a less experienced Python programmer might look like this:
tilefile = open('tiles.txt')TILE_POSITIONS = {}for text_str in tilefile.readlines():print([text_str])x = text_str[2]# print(data)# if 'REMARK' in data == True: # didn't workdata = text_strif text_str.find('REMARK') == 0:text_str = text_str.strip()#print(line[7:]) # doesnt need to be printedcontinueelse:import pygamey = int(text_str[4])r = pygame.rect.Rect(int(x)*32, int(y)*32, int(32), int(32))key = data.split()[0]TILE_POSITIONS[key] = r# print(TILE_POSITIONS[-1])continueprint(TILE_POSITIONS)
This program works correctly, but it looks very messy. The code is hard to understand, mostly because we have to read and understand all the lines to figure out what the program does. For sure, the program contains unnecessary lines, although we may not easily see which. For skilled Python programmers, on the other hand, parsing a text file won’t be a real challenge. They might give in to the temptation to solve the task with as few lines as possible:
from pygame import Rectmkrect = lambda x: (x[0], Rect(int(x[1])*32, int(x[2])*32, 32, 32))tile_positions = dict(map(mkrect, [l.split(' ') for l in open('tiles.txt')if l[0]!='R']))print(tile_positions)
This program works correctly as well. Although shorter, it not easy to comprehend either. We could argue which of the two programs is the uglier one: one might prefer the second for brevity or the first because it uses less complicated language features, making it (theoretically) more accessible for a novice programmer. I will leave that decision up to you, because there is a lot to improve in both programs! In this chapter, we will clean up these programs for reading tile coordinates from a text file.
Software Entropy : Causes of Unorganized Code
When a program grows, it becomes unorganized more easily. Keeping our programs clean becomes more important. But why do programs become unorganized in the first place? Why do we need to organize more and do more cleanup work when a program grows? As we saw in the preceding section, there are multiple possibilities to solve the same programming problem. Obviously, the number of possible implementations grows with increasing size. Suppose we divide a four-line program into functions. For simplicity, let us assume we can move the boundaries between functions freely. We could create four functions with one line each, or we could have one four-line function, two two-line functions, and three other combinations (see Figure 14-1). Now consider dividing an eight-line program into functions. With the code being twice as long, we could create eight one-line functions. We could create one eight-line function. We could create between one and four two-line functions. We could create any combination of sizes in between. The number of possibilities grows much faster than the number of lines. If we take into account not only functions but all kinds of program constructs (lists vs. dictionaries, for loops vs. list comprehensions, classes, modules, etc.), the number of possible implementations for the same problem becomes practically infinite.
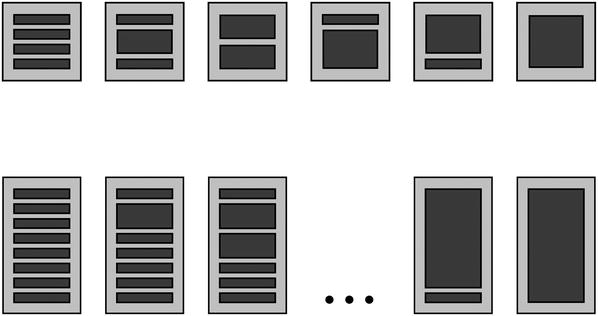
Figure 14-1. Possibilities to structure a program into functions. Top row: a four-line program; all six possibilities are shown (four one-line functions, two two-line functions, etc.). Bottom row: an eight-line program; only five out of many possibilities are shown. With more rows, the number of possible structures grows exponentially.
Which of these possible implementations is the best? That depends on what our program does, the kind of input used, what libraries we are using, and the expectations of the users. We will call this briefly the context of your program. Now there is a nasty fact: When a program grows, the context will change. When we add new functionality, new types of input, new libraries, the context shifts gradually. When the context changes, code that seemed the best solution before becomes an inferior one. Changing context is one main reason why finding the ideal implementation is hard.
A second cause of unorganized code is that programs are written by humans. For instance, it is easier to write code that works than code that works and is neatly written. Programs are usually written in multiple sessions. It occurs that we start adding something to the program one day, but forget to finish it the next. Last but not least, time pressure causes code to be written quickly instead of cleanly. Keeping code clean requires high self-discipline by the programmer and is a constant battle against laziness, forgetfulness, haste, and other manifestations of human imperfection.
For both reasons, changing context and human imperfection, it is an intrinsic property of all programs that they become unorganized over time. This phenomenon of code unorganizing itself has been termed Software Entropy, borrowing the concept from the Second Law of Thermodynamics. In less glamorous terms the law says: Disorder grows by itself. Whatever the reasons are, it is us who have to clean up. We need to know how to recognize, clean up, or prevent unorganized code.
How to Recognize Unorganized Code?
There are many ways in which code can be unorganized. Some of them have been given fancy names like code smells or unpythonic code. These terms are good to start a conversation about coding practices with other Python programmers. However, when we are looking for clear rules these keywords are of little use. There is no definition what pythonic code is and what not. Here, we will instead examine four aspects of code that needs cleanup: readability, structural weaknesses, redundancy, and design weaknesses.
Readability
In a bigger program, we spend more time reading than writing code. Therefore it is crucial that the code is understandable. We can ask ourselves a very simple question: Do we understand the code when we read it? Code written by both beginners and advanced programmers can be more or less readable. Clearly, littering code with print statements and commented lines like in the first example makes it less readable. In the second example, playing code golf (solving the problem with as few keystrokes as possible) doesn’t help either. Readability starts with small things. Compare the line
if text_str.find('REMARK') == 0:with the semantically identical line
if line.startswith('REMARK'):The second expression is closer to English, more explicit, and thus more readable. Readability manifests itself in many aspects of the code: choosing descriptive variable names , code formatting, reasonable choice of data structures (imagine writing a program using only tuples), code modularization, and use of comments. Of course, experience matters when reading code. Knowing advanced language features and some libraries is part of the game. But many times it is necessary to look at a section of code and quickly figure out what it does and why it exists instead of manually tracing the code line by line. If you find it difficult to answer these questions without executing the code in your mind, readability needs to be improved.
Structural Weaknesses
There are two very common kinds of structural weaknesses: The first is lack of structure. A typical sign that structure is lacking are big blobs of code not containing any structure: functions with 100 lines and more, programs without any functions, and so on. In Python, it is ok to write programs without any functions. For instance, I frequently write short data analysis scripts without even thinking about functions. But above 100 lines, they become throwaway code very quickly. Above 100 lines, structuring is necessary, and the bigger the program, the more important it becomes.
The second structural weakness are pseudostructures, code that looks structured but in fact is another form of monolithic blob. A straightforward example are multiple for loops, if conditions, and other code blocks like in the following example:
for line in tilefile:if not line.startswith('REMARK'):try:columns = line.split(' ')if len(columns) == 3:x = int(columns[1])y = int(columns[2])if 0 < x 100:if 0 < y < 100:r = Rect(...)...
As a rule of thumb, when you reach the fourth level of indentation in any Python program (everything before column 16 being whitespace), something is weird. Usually the code can be improved by restructuring it. Especially, if there are multiple nested for loops, performance may quickly suffer.
A less obvious example of pseudostructures is code split into multiple functions, but with responsibilities that are not clearly defined. Consider the following example:
def get_number():a = input("enter first number")return adef calculate(a):b = input("enter second number")result = float(a) + (b)print("the result of the addition is:", end="")return resultdef output(r):print("{}".format(r))num = get_number()result = calculate(num)output(result)
In this example, input and output are partially performed by the calculate function. The boundaries between functions are hard to understand, and the code becomes harder to manage. This kind of structural weakness becomes very common when the code becomes longer. There are many other kinds of structural weaknesses.
Redundancy
Redundancy violates the Don’t Repeat Yourself principle (DRY) of programming. Commonly, redundancy emerges from copy-pasting code fragments. The most obvious form of redundancy are duplicate lines. For instance, in the first code example of this chapter, the continue statement occurs twice:
...if text_str.find('REMARK') == 0:...continue...continue
In this case, the first continue is redundant, because the second one will be executed. The second continue is redundant as well, because the loop terminates anyway. Redundant lines like these increase the size of the program and compromise readability . In this case, we can simply remove them. Another kind of redundancy is when blocks of code repeat with small variations. Sometimes, repetitive blocks emerge, because the programmer uses Ctrl-C + Ctrl-V as a programming tool; sometimes they evolve by themselves. In both cases, duplicate code blocks can be removed by moving the redundant lines into a separate function or class. Such reorganizations, called refactoring, can become complex operations in a bigger program. A more subtle form of redundancy is redundancy in data structures. Given that redundancy occurs on many levels and is sometimes hard to see, it is not surprising that redundancy is among the top reasons for defects in larger programs.
Design Weakness es
Program design is a more difficult aspect. Good program design leads to robust programs that are tolerant toward unusual inputs and have a well-defined range of accepted values and clear error messages when the input is wrong. In general, robust design prevents defects from creeping in. In the MazeRun game, there is at least one design weakness: the random maze generator sometimes creates inaccessible spots in the maze. This is not a problem at the moment, but it might become one in the future.
A second aspect of good design is extensibility: How easy or hard is it to add something new to the program without breaking existing functionality. The fewer places need to be changed in order to implement a simple feature, the more extensible the design is. Good design anticipates what kind of changes will occur in the future. When you would like to evaluate a design, ask yourself: How comfortable would you feel about changing the code? If there are regions you would prefer not to touch, the design might need improvement.
Taken together, code that is hard to read, unstructured, redundant or contains design flaw s may be considered unorganized (see Figure 14-2 ). Often, several of these symptoms occur together. You can find all four symptoms in the two code fragments for loading the tile coordinates. Now imagine similar symptoms in a 1000-line program that stretches over many screen pages—again, the problem grows with increasing size. But it does not help us to complain about badly organized code; we need to think about how to improve it. Therefore, we will look at a few Best Practices of cleaning up Python programs next.

Figure 14-2. “I don’t get it. The kitchen got dirty all by itself.” Software becomes messy over time.
Cleaning Up Python Instructions
I hope that the preceding examples have convinced you that cleaning up code is a necessity. The principle of Software Entropy tells us that code becomes unorganized by itself, but it does not clean up itself (also see Figure 14-2). Cleaning up code is an everyday programming task. Cleaning up code involves a number of very simple tasks. Most of them require little knowledge of Python, so that we can start right away to improve our initial implementation. To clean up code, it helps to have a working version of the code to start with. Ideally, there are automated tests that tell us if we broke anything. Let’s brush, wipe, and polish until our code shines!
Place import Statements Together
To understand a program, it is necessary to know which other modules it requires to work (its dependencies). In Python, dependencies are mainly reflected by import statements. The first functional unit of a Python program should therefore be a separate block with all import statements. We simply collect all import statements from our program and move them to the beginning of the file. This way, it is easy to see which components the code requires at one glance. It is worth importing only the Python objects that are really used. In our case, there is a single import statement, and we only use pygame.Rect. Our import block becomes:
from pygame import RectWe separate the imports from any code that follows by an empty line.
Place Constants Together
After the import section is a good place for all constants. A constant is a variable whose value does not change during program execution. Typical constants are input and output file names, path variables, column labels, or scaling factors used in calculations. We will simply collect all these constants in a separate section after the import block. In Python, there are no technical means to make a variable constant; their values can always be overwritten. To make it easier to distinguish constants from variables that change their value, Python constants are by convention written in UPPER_CASE letters. We have two constants in the tile coordinate loader. First, there is the size of tiles in pixels we need for calculating rectangles. We will place it in a constant SIZE. Second, there is the file name "tiles.txt". This file name assumes the file is in the current directory. To make the program usable from different locations, we need to provide the full path. We could write
TILE_POSITION_FILE = '/home/krother/projects/maze_run/tiles.txt'However, this will only work on my own computer, which makes the code very inflexible. A better alternative for file names is to use the expression os.path.dirname(__file__) to determine the location of the current Python module. We can then add our filename to the path with os.path.join. The complete import and constant sections of the program are now:
import osfrom pygame import Rect
CONFIG_PATH = os.path.split(__file__)[0]TILE_POSITION_FILE = os.path.join(CONFIG_PATH, 'tiles.txt')SIZE = 32
Again, we separate the constants from other code blocks by one or two empty lines. In the initial messy code, the variable TILE_POSITIONS looks like a constant but is modified by the program. We change it to lower case for later use:
tile_positions = {}As a program evolves, many constants will change. In a program below 1000 lines, such changes are often easy to accommodate by editing the code. But if the values of constants change every second time you run the program, it is time to move them to an input file, to create a command-line option using the argparse module or read a configuration file using the configparser module.
Remove Unnecessary Lines
In programming, lines we think are important at first, later may turn out to be not important at all. A frequent intuitive reaction is to think “maybe I will need them later” and leave the unnecessary code in. However, a program is not a warehouse! Unnecessary code needs to be culled rigorously. If you have illustrative code examples that you don’t want to lose, copy them to a separate file and create a separate git commit for it. In our example, we have many examples of unnecessary lines: print statements, commented lines, and the redundant continue statements mentioned previously. We can simply delete them (seven lines in total). The program becomes much more readable immediately! Now it becomes easier to notice that there is an redundant variable assignment:
data = text_strThe variables data and text_str are identical. We can get rid of the extra assignment. We might also recognize that the following if condition is a blind alley:
if text_str.find('REMARK') == 0:text_str = text_str.strip()
The modified variable text_str is not used afterward. We can therefore get rid of this code block and replace the following else by the opposite of the if statement. As a result, our procedure becomes a lot clearer than it was before:
tile_positions = {}for text_str in open(TILE_POSITION_FILE).readlines():x = text_str[2]if text_str.find('REMARK') != 0:y = int(text_str[4])r = Rect(int(x)*32, int(y)*32, int(32), int(32))key = text_str.split()[0]tile_positions[key] = rprint(tile_positions)
After removing lines, it is a very good moment to verify that the program is still working. We have already cleaned up many issues in our code, but we are not done yet.
Choose Meaningful Variable Names
Well-chosen variable names have a huge impact on readability. As a general rule, names containing English words are better than acronyms. English words that describe meaning are better than words describing a variable type. Very short variable names are often fine if the variables themselves are short-lived (e.g., x and y in our example). We can improve the readability by replacing r with rect, key with name, and text_str with row. Table 14-1 contains a few examples of good and bad variable names.
Table 14-1. Examples of Bad and Good Variable Names
Bad | Good | Explanation |
|---|---|---|
xs | xsize | xs is too short |
str_list | column_labels | str_list describes a type |
dat | book | dat is not meaningful |
xy | position | xy is not meaningful |
plrpos | player position | explicit words |
line_from_text_file | line | too much reference |
l | ? | The worst variable name of all time! Depending on the font, it could be easily mistaken for a 1. |
It is worth rechecking variable names from time to time. Their meaning changes while you develop the code—an incomprehensible variable name is bad, but a misleading one is even worse. With cleaned-up variable names, defects usually become easier to find.
Idiomatic Python Code
There are a few minor improvements to be made. We can use Python idioms, short, precise expressions that are applicable in many situations. Here, I would like to give just two short examples. First, we can make the conditional expression more readable, as mentioned previously:
if not row.startswith('REMARK'):Second, we can use the csv module to pick the columns of the file apart. This is less error-prone than parsing the file yourself. Also, using the with statement is a generally recommended way to open files (because they are closed automatically afterward):
with open(filename) as f:for row in csv.reader(f, delimiter=' '):
Finding the right idioms is difficult, and opinions on which idiom is the best differ. It requires a combination of knowledge and experience. There is neither a complete catalog of Python idioms nor a set if clear rules when to use them. The closest thing is the book Fluent Python by Luciano Ramalho (O’Reilly, 2015).
Refactoring
Until now, our cleanup was mostly focused on individual lines. In the next section, we will examine the structure of the program as a whole. Improving the program structure is referred to as refactoring. Refactoring is an important Best Practice to maintain larger programs. Entire books are devoted to refactoring techniques, and we can only get a glimpse of the topic here. If you would like to get an idea what kind of refactorings exist, the website https://sourcemaking.com/refactoring is a good starting point.
Hint
When refactoring code on a larger scale, having a good Test Suite is essential. The goal of refactoring is always to have the program do the same thing as before. It is quite easy (and tempting) to take a program apart, reassemble it, and miss a detail that causes the program to work differently afterward.
After the basic cleanup, we will focus on improving the structure of our code further. Generally, structuring means creating clearly separated functions, classes, modules, and other units of code.
Extract Functions
Probably the most important refactoring is to divide code into well-chosen functions. There are different reasons to write functions in Python. Here we do it mainly to divide a longer piece of code into smaller chunks. To extract a function from existing code, we need to write a function definition and define input parameters and a return statement for the output. We indent the code in between and add a call to the function, and a docstring. For instance, we can extract a function for creating Rect objects from our code:
def get_rectangle(row):"""Returns a pygame.Rect for a given tile"""x = int(row[1])y = int(row[2])return Rect(x*SIZE, y*SIZE, SIZE, SIZE)
Creating a separate function for just three lines might seem overkill at first. You may object that the code inside get_rectangle is too simple. But this is exactly the point! We want simple code. First, simple code stays clean for a longer time when Software Entropy sets in; for instance, if our function needs to cover one or two special cases (and grows), the code still will be readable. Second, simple code is understandable by other people (colleagues, interns, supervisors, or our successor). Third, simple code is more reliable under pressure: when programmers are plagued by deadlines, nervous managers, and after-dark debugging sessions, simple code is their best friend. We call the get_rectangle function from a second function load_tile_positions that contains most of the remaining code:
def load_tile_positions(filename):"""Returns a dictionary of positions {name: (x, y), ..} parsed from the file"""tile_positions = {}with open(filename) as f:for row in csv.reader(f, delimiter=' '):name = row[0]if not name.startswith('REMARK'):rect = get_rectangle(row)tile_positions[name] = rectreturn tile_positions
When you want to split your own program into functions, you first need to identify a coherent piece of code and then move it into a function. There are some typical functions that frequently occur in Python programs:
reading input like data files or web pages
parsing data (i.e., preparing data for an analysis)
generating output such as writing a data file, printing results, or visualizing data
calculations of any kind
helper functions, code extracted from a bigger function to make it smaller
A reasonable function size when restructuring a program is 5–20 lines. If the function will be called from multiple places, it may even be shorter. Like modules, functions deserve a triple-quoted docstring right after the function definition. The documentation string should describe what the function is doing in human language (avoid Python terminology if possible).
Create a Simple Command-Line Interface
After dividing our code into functions, it is time to create a top-level interface for the program. This interface avoids code being executed accidentally (e.g., by an import). To create the interface, we group all remaining function calls at the end of the program and wrap them in a separate code block. By convention, it starts with a weird if statement:
if __name__ == '__main__':tile_positions = load_tile_positions(TILE_POSITION_FILE)print(tile_positions)
The if expression is a Python idiom that appears strange at first (especially if you have seen other programming languages). Expressed in human language it means: “Execute the following block of code if this file is started as the main Python program. If this file is imported as a module, do nothing.” The __main__ block helps us to avoid accidental execution of the code. We now can import the module from somewhere else:
from load_tiles import load_tile_positionstiles = load_tile_positions(my_filename)
In this case nothing is printed because the __main__ block is not executed when importing. The second use of the __main__ block is that we can run load_tiles.py as a Python program:
python3 load_tiles.pyNow we see the output produced by the print statement and can check whether it matches our expectations. Having a __main__ block in our program serves as a general entry point. If our module is not meant to be executed directly, we can use the __main__ block for simple test code (the code for the first part of this book contains a few examples). If we are writing a program that is to be used as a command-line tool, using the argparse module instead of sys.argv is a Best Practice. In a Python project, the bin/ directory is a good place for the command-line front end.
Structuring Programs into Modules
We have created separate modules throughout the first chapters already. In this chapter, we have worked on a single module. Therefore, we will simply list a few Best Practices to keep in mind when developing your own modules:
Modules shouldn’t become too big. Modules of 100-400 lines are of a good size; modules up to 1000 lines are tolerable, but I recommend splitting them up as soon as possible.
Each module should have a clearly defined purpose. For instance, loading data, writing data, and doing a calculation are all separate purposes that justify having their own modules. Also, if your constant section becomes large, it may be worth placing it in a separate module.
Creating a module is as simple as moving a piece of code to a new file and adding import statements in the original file.
Avoid circular imports at all costs. Whenever you come across a relation like A needs B, but B needs A, it is worth thinking about a better structure. It is always possible to avoid circular imports. You can avoid the problem by keeping A and B together, but probably this will cause problems later.
When importing your own modules, write explicit imports (avoid import *).
Add a triple-quoted docstring on top of each module.
Decomposing a program into separate modules is one of the easiest ways to structure programs.
The Cleaned Code
When we are done with these cleanup steps, it is time to verify that the program still works. The completely cleaned and refactored program to read tiles is
"""Load tile coordinates from a text file"""import csvimport osfrom pygame import RectCONFIG_PATH = os.path.dirname(__file__)TILE_POSITION_FILE = os.path.join(CONFIG_PATH, 'tiles.txt')SIZE = 32def get_rectangle(row):"""Returns a pygame.Rect for a given tile"""x = int(row[1])y = int(row[2])rect = Rect(x*SIZE, y*SIZE, SIZE, SIZE)return rectdef load_tile_positions(filename):"""Returns a dictionary of positions {name: (x, y), } from a text file"""tile_positions = {}with open(filename) as f:for row in csv.reader(f, delimiter=' '):name = row[0]if not name.startswith('REMARK'):rect = get_rectangle(row)tile_positions[name] = rectreturn tile_positionsif __name__ == ' __main__':tile_positions = load_tile_positions(TILE_POSITION_FILE)print(tile_positions)
We realize that the program has not become shorter than our very first implementation. It even is a bit longer. But our implementation has several advantages worth pointing out:
It is easy to see what the program does.
Many parts of the code are easier to read than before.
The module can be imported and put to customized use (e.g., loading a different file or multiple ones).
We can use both functions independently. This is very valuable for writing automated tests (in Part 3 of this book).
When debugging the program, it is sufficient to read a maximum of 10 lines at a time.
The program has a built-in self-test in form of the __main__ block.
Taken together, the program is a lot cleaner and more readable. Defects will have a much harder time hiding in this program. Also, this code will be considered well-written or pythonic by most experienced programmers.
PEP8 and pylint
Python has a standard coding style guide, known as PEP8 ( https://www.python.org/dev/peps/pep-0008 ). The PEP8 standards give clear guidelines on variable names , imports, docstrings , length of functions, indentation , and so on. Adhering to PEP8 is a Best Practice, because it makes our code readable for others. It also helps us to write in a consistent style. Fortunately, we don’t need to learn the complete PEP8 guideline by heart. The pylinttool helps us to check whether our code conforms to the PEP8 standard. As an example, we will examine our code before and after our cleanup session with pylint. First, we need to install the tool with
pip install pylintWe can then analyze any Python file with
pylint load_tiles.pyThe program produces several pages of console output. For us, two sections are interesting: warning messages and the code score.
Warning Messages
At the top of the pylintoutput, we find a section with warning messages that refer to PEP8 violations. Each warning contains the line number the warning refers to. For the code attributed to an inexperienced Python developer, we get
C: 1, 0: Missing module docstring (missing-docstring)C: 7, 0: Invalid constant name "tilefile" (invalid-name)
whereas the cleaned-up code results in
C: 18, 4: Invalid variable name "x" (invalid-name)C: 19, 4: Invalid variable name "y" (invalid-name)W: 25, 4: Redefining name 'tile_positions' from outer scope (line 36) (redefined-outer-name)C: 26,27: Invalid variable name "f" (invalid-name)C: 36, 4: Invalid constant name "tile_positions" (invalid-name)
All of these warnings point us to things that could be improved. Variable name s with one character are discouraged, as is using a variable with the same name inside and outside a function. We could start renaming our variables (make them longer) and constants (to uppercase characters). However we will restrain ourselves for a moment and scroll to the bottom of the output.
Code Score
At the end the pylint output we find a score for our code of up to 10 points:
Global evaluation-----------------Your code has been rated at 7.73/10
Working with pylint is sometimes very rewarding. When we start fixing PEP8 issues, we can rerun pylint and see our score improve. This makes the PEP8 standard a bit treacherous. You may have noticed that after cleaning up our code, we have more PEP8 warnings than in the previous, messy code. This tells us that the warnings and the score pylint produces do not represent bigger changes in the code well. Focusing too much on style conformity distracts from more important issue. A Best Practice is to use pylint to conform with the PEP8 style guidelines, but don’t try to push every Python file to a pylint score of 10.0. Usually a score around 7.0 is already good enough. It is OK to ignore warning messages you do not agree with. Use your reason. According to Python core developer Raymond Hettinger, “PEP8 is a guideline, not a lawbook.” Think of PEP8 as a layer of paint on our building (see Figure 14-3). It improves how our code looks, but it does not support the roof.
Figure 14-3. Adhering to the PEP8 coding standard is like a good layer of paint: it looks beautiful and protects your code from bad weather.
Make It Work, Make It Right, Make It Fast
When writing small programs that fit on one screen page, it was not much of a problem how exactly the code was written. We cared mostly about getting the program to run. But with growing size, the lack of readability will fall on our feet. We need to organize our code, or make it right. During our cleanup, we followed a guideline formulated by Stephen C. Johnson and Brian W. Kernighan : “First make it work, then make it right, and, finally, make it fast.” This guideline has been attributed to different people, including Kent Beck (also see http://c2.com/cgi/wiki?MakeItWorkMakeItRightMakeItFast ). It certainly applies to Python programs above 100 lines. Let’s take a closer look at the three parts of the guideline.
Make It Work
Here, work means that the program finishes without Exceptions and that there are no semantic errors that we know of. In Part 1, we have already learned many debugging techniques to make a program work. In Part 2, we used automated testing to detect defects more thoroughly.
Make It Right
Making it right generally means organizing your code. In this chapter, we have already seen cleanup steps to make a program more readable and well-structured and to make the logic of execution transparent. However, these cleanup strategies are only the beginning. Keeping code well-organized becomes more important, as our programs grow further. Besides organizing functions and modules, designing classes and their interplay, building Python packages, and developing an architectureincluding all components of a system are topics where you can expect to find a lot of refactoring. These topics go beyond the scope of this book, though.
Make It Fast
When your program works correctly and is well-structured and readable, it is worth looking at its performance. Often at this stage, a program turns out to be fast enough already. If it is not, well-organized code is at least easier to tune for higher performance. There are many options to accelerate Python programs, ranging from adding computing power and compiling Python to faster programming languages and eliminating bottlenecks from the Python code itself. Performance optimization is not a topic of this book, but in Chapter 11 you find an example for writing performance tests.
Examples of Well-Organized Code
The transition from less than 100 to above 100 lines of Python code is interesting. When a program grows beyond 100 lines, there are very many possibilities to write the same program. Which is the right one? To give you some tentative answers, we look at the structures of programs written by some of the best Python programmers on the planet. In Table 14-2, the structures of seven Python projects by well-known programmers are summarized. Instead of their (mostly huge) main projects, I selected smaller everyday or pet projects for the comparison. The projects are
shirts by Joel Grus, author of the book Data Science from Scratch (O’Reilly, 2015 ). The program compares images of T-shirts using machine learning. ( https://github.com/joelgrus/shirts )
pipsi by Armin Ronacher, author of the web framework Flask. pipsi is a tool to make package installation into virtual environments easier. ( https://github.com/mitsuhiko/pipsi )
crawler by Guido van Rossum, the inventor of Python himself, is a fast web crawler to follow links in web pages in under 500 lines. ( https://github.com/gvanrossum/500lines/tree/master/crawler )
move-out by Ola Sitarska, one of two developers who ignited the Djangogirlsmovement, is a Django web application to share stuff when moving out. ( https://github.com/olasitarska/move-out )
python-progressbar by Nilton Volpatois a module to display progress bars on the command line. ( https://github.com/niltonvolpato/progressbar )
gizeh by Zulko, a serial author of graphics libraries for Python, is a package to create vector graphics in Python. ( https://github.com/Zulko/gizeh )
Table 14-2. Metrics for Seven Python Projects of Between 100–1000 Lines. The packages, modules, functions, and classes were counted with Unix command-line tools. The comments, blank, and code lines were counted with the cloc tool.
Project | Packages | Modules | Funcs | Classes | Blank Lines | Comments | Code Lines |
|---|---|---|---|---|---|---|---|
shirts | 0 | 2 | 6 | 0 | 59 | 55 | 227 |
pipsi | 0 | 5 | 40 | 2 | 123 | 22 | 486 |
crawler | 0 | 3 | 30 | 5 | 91 | 90 | 531 |
move-out | 3 | 23 | 35 | 25 | 170 | 34 | 599 |
python-progressbar | 1 | 6 | 61 | 17 | 223 | 231 | 567 |
gizeh | 1 | 14 | 57 | 5 | 230 | 242 | 614 |
When comparing the projects in Table 14-2, we see that all projects contain 10%–25% empty lines and up to 25% lines with comments. We also see that there are big differences in the structures of the code. The shirts project is essentially a cleaned and commented linear script for data analysis, while pipsi and python-progressbar are decomposed into 40+ smaller code units usable for different purposes. Classes are used by most but not all of the authors (e.g., gizeh places a stronger emphasis on functions, while move-out uses classes derived from the Django framework). We conclude that even among prominent programmers, there is apparently more than one way to do it right.
Best Practices
There are infinite possibilities to implement the same functionality.
Software Entropy is the phenomenon that code becomes unorganized over time.
Unorganized code is less readable, less structured, or redundant or contains other design weaknesses.
Cleaning up code is an everyday programming task.
Place import statements at the beginning of a Python module.
Place constants together, their names written in UPPER_CASE.
Unnecessary lines need to be removed rigorously.
Variables should have meaningful names.
Refactoringa program into small, simple functions makes it easier to understand.
Large programs should be split into modules of up to 400 lines.
A __main__ block is not executed upon imports.
pylint is a tool that checks adherence to the PEP8 coding standard.
Obey the central Dogma of Programming: Make it work, make it nice, make it fast.