
Handlers for user-facing requests spend most of their time calling App Engine services, such as the datastore or memcache. As such, making user-facing requests fast requires understanding how your application calls services, and applying techniques to optimize the heaviest uses of calls.
We’ve seen three optimization techniques already, but they’re worth reviewing:
Store heavily used results of datastore queries, URL fetches, and large computations in memcache. This exchanges expensive operations (even simple datastore gets) for fast calls to the memcache in the vast majority of cases, at the expense of a potentially stale view of the data in rare cases.
Defer work outside of the user-facing request by using task queues. When the work to prepare results for users occurs outside of the user-facing request, it’s easy to see how user-facing requests are dominated by requests to the datastore or memcache.
Use the datastore and memcache batch APIs when operating on many independent elements (when batch size limitations are not an issue). Every call to the service has remote procedure call overhead, so combining calls into batches saves overhead. It also reduces clock time spent on the call, because the services can perform the operations on the elements in parallel.
Another important optimization technique is to call services asynchronously. When you call a service asynchronously, the call returns immediately. Your request handler code can continue executing while the service does the requested work. When your code needs the result, it calls a method that waits for the service call to finish (if it hasn’t finished already), and then returns the result. With asynchronous calls, you can get services and your app code doing multiple things at the same time, so the user response is ready sooner.
App Engine supports asynchronous service APIs to the datastore, memcache, and URL Fetch services in both Python and Java. Support for asynchronous calls is also currently supported in a few other places, specifically the Python Blobstore API and the Java Images API (not described in this book).
All of these optimization techniques require understanding your application’s needs and recognizing where the benefits of the technique justify the added code complexity. App Engine includes a tool called AppStats to help you understand how your app calls services and where you may be able to optimize the call patterns. AppStats hooks into your application logic to collect timing data for service calls, and reports this data visually in a web-based interface.
In this chapter, we demonstrate how to call services using the asynchronous APIs. We also walk through the process of setting up and using AppStats, and see how it can help us understand our application’s performance.
Consider the following call to the URL Fetch service, shown here in Python:
from google.appengine.api import urlfetch
# ...
response = urlfetch.fetch('http://store.example.com/products/molasses')
process_data(response)When execution of the request handler reaches this line, a sequence of events takes place. The app issues a remote procedure call to the URL Fetch service. The service prepares the request, then opens a connection with the remote host and sends it. The remote host does whatever it needs to do to prepare a response, invoking handler logic, making local connections to database servers, performing queries, and formatting results. The response travels back over the network, and the URL Fetch service concludes its business and returns the response data to the app. Execution of the request handler continues with the next line.
From the point when it makes the service call to the point it receives the response data, the app is idle. If the app has multithreading enabled in its configuration, the handler’s instance can use the spare CPU to handle other requests. But no further progress is made on this request handler.
In the preceding case, that’s the best the request handler can do: it needs the response in order to proceed to the next line of execution. But consider this amended example:
ingred1 = urlfetch.fetch('http://store.example.com/products/molasses')
ingred2 = urlfetch.fetch('http://store.example.com/products/sugar')
ingred3 = urlfetch.fetch('http://store.example.com/products/flour')
combine(ingred1, ingred2, ingred3)Here, the request handler issues the first request, then waits for the first response before issuing the second request. It waits again for the second response before issuing the third. The total running time of just these three lines is equal to the sum of the execution times of each call, and during that time the request handler is doing nothing but waiting. Most importantly, the code does not need the data in the first response in order to issue the second or third request. In fact, it doesn’t need any of the responses until the fourth line.
These calls to the URL Fetch service are synchronous: each call waits for the requested action to be complete before proceeding. With synchronous calls, your code has complete results before it proceeds, which is sometimes necessary, but sometimes not. Our second example would benefit from service calls that are asynchronous, where the handler can do other things while the service prepares its results.
When your app makes an asynchronous service call, the call returns immediately. Its return value is not the result of the call (which is still in progress). Instead, the call returns a special kind of object called a future, which represents the call and provides access to the results when you need them later. A future is an I.O.U., a promise to return the result at a later time. Your app is free to perform additional work while the service does its job. When the app needs the promised result, it calls a method on the future. This call either returns the result if it’s ready, or waits for the result.
A synchronous call can be thought of as an asynchronous call that waits on the future immediately. In fact, this is precisely how the App Engine synchronous APIs are implemented.
Here is the asynchronous version of the second example. Note that the Python URL Fetch API:
ingred1_rpc = urlfetch.make_fetch_call(
urlfetch.create_rpc(), 'http://store.example.com/products/molasses')
ingred2_rpc = urlfetch.make_fetch_call(
urlfetch.create_rpc(), 'http://store.example.com/products/sugar')
ingred3_rpc = urlfetch.make_fetch_call(
urlfetch.create_rpc(), 'http://store.example.com/products/flour')
combine(
ingred1_rpc.get_result(),
ingred2_rpc.get_result(),
ingred3_rpc.get_result())The make_fetch_call() function calls each issue their
request to the service, then return immediately. The requests execute in
parallel. The total clock time of this code, including the
get_result() calls, is equal to the longest of the three
service calls, not the sum. This is a potentially dramatic speed increase
for our code.
Figure 17-1 illustrates the difference between a synchronous and an asynchronous call, using the Python URL Fetch API as an example.
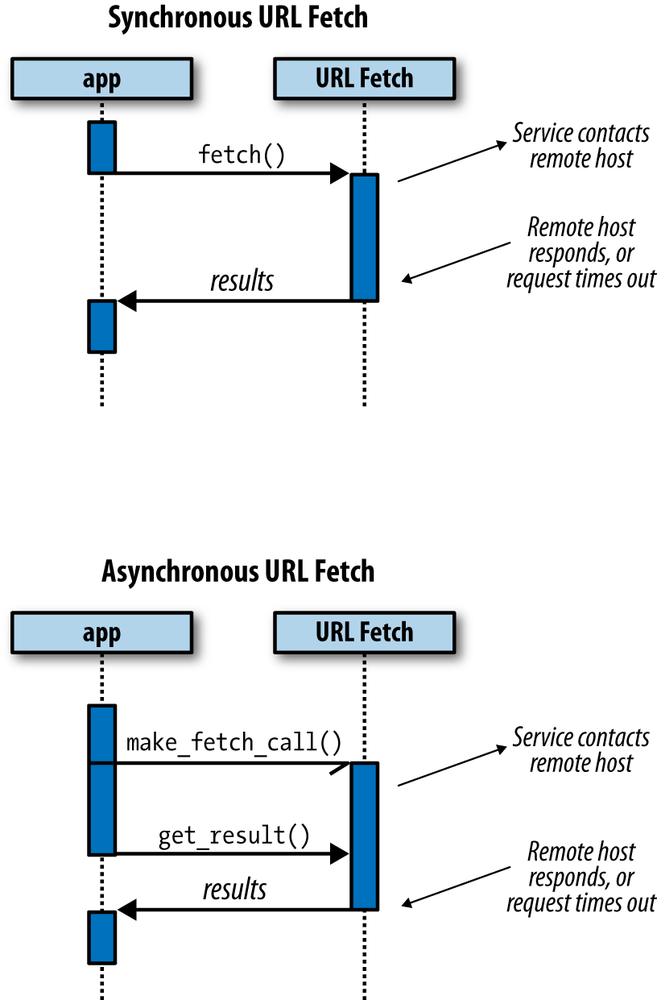
The example above was trivial: we could determine an obvious optimization just from looking at the code, and the change was not complicated. In a real app, reordering your code and data dependencies to best exploit asynchronous calls can add complexity. Like most optimization, it’s an investment to gain performance.
The Python and Java service APIs have their own particular ways of making asynchronous calls. Furthermore, not every service has an official asynchronous API in every runtime environment. Let’s take a look at what’s available, first for Python, then for Java.
The Python runtime environment has documented asynchronous calls for the datastore, memcache, Blobstore, and URL Fetch services. The calling syntax varies slightly between the URL Fetch service and the other services, but the general idea is the same.
All asynchronous calls in Python return an RPC (remote procedure call) object. You can call the
get_result() method of this object to wait for results (if
necessary), and either raise exceptions to report service errors, or
return the result.
More specifically, the RPC object advances through four states during its lifetime:
Created. The object has been created, but has not been associated with a call.
In progress. The service call has been initiated and associated with the object.
Ready. The call has completed, either with results or with an error.
Checked. The status of the call has been reported to the application, such as by having raised an exception to represent an error.
When you call a service’s asynchronous function, the service
returns an RPC object in the “in progress” state. Calling the RPC
object’s get_result() method advances it through the
“ready” state to the “checked” state. Calling get_result()
on an RPC object in the “checked” state will return the result (if any)
again, but will not reraise exceptions.
You can advance the RPC object through the last two states
manually by using methods. The wait() method waits for the
fetch to finish (“in progress” to “ready”). The
check_result() method verifies and reports the final status
(“ready” to “checked”). Calling any of these methods advances the object
to the appropriate state, performing the tasks along the way. If the
starting state for the method has already passed, such as calling
wait() when in the “ready” state, the method does
nothing.
Figure 17-2 illustrates the RPC object states and transitions.

The Python datastore API in the google.appengine.ext.db package has
asynchronous equivalents for the major functions. The arguments are
the same. Instead of returning a result, the asynchronous functions
return an RPC object, whose get_result() method returns
the expected result. Table 17-1 lists
each function and its asynchronous equivalent.
A brief example:
from google.appengine.ext import db
# ...
get_rpcs = {}
for k in keys:
get_rpcs[k] = db.get_async(k)
# ...
# ...
v1 = get_rpcs[k1].get_result()The asynchronous calls are only available as package functions.
The methods of the Model class, such as
obj.put(), do not have asynchronous versions. Of course,
you can pass any model instance to the package functions.
A transaction function can contain asynchronous function calls. When the transaction function exits, any asynchronous calls made within the function that are not in the “checked” state are resolved before the transaction commits.
Queries can be performed asynchronously. Normally, a Query object doesn’t make a service call
until results are fetched. If you use the object as an iterable, the
first few results are fetched immediately, and subsequent results are
prefetched asynchronously, as needed. You can start the asynchronous
prefetching process early by calling the run() method.
run() returns an iterable of results just like the
object. The only difference is the asynchronous prefetching process is
started before the first use of the iterable:
from google.appengine.ext import db
class Player(db.Expando):
pass
# ...
# Prepare the query. (No service calls.)
query = Player.all().order('-score')
# Call the service asynchronously to start prefetching results.
results = query.run()
# ...
for player in results:
# ...In contrast, the fetch() method initiates
synchronous service calls to perform the query and retrieve the
requested number of result entities.
The Python memcache API includes asynchronous versions
of a set of the Client methods. All of the memcache’s
functionality is available with asynchronous calls, although only a
subset of the calling syntax is supported. In particular, only methods
of the Client class have asynchronous versions,
not the package functions. For most methods, only the batch versions
have asynchronous equivalents, but of course you can always call a
batch method with a single element. Table 17-2 lists the methods.
Table 17-2. Python methods of api.memcache.Client and their asynchronous equivalents
from google.appengine.api import memcache
# ...
client = memcache.Client()
add_rpc = client.add_multi_async(mapping)
# ...
if add_rpc.get_result().get(k, None) is None:
# ...The Python Blobstore API has asynchronous versions of the major functions. Table 17-3 lists the functions.
The BlobInfo methods do no have asynchronous
equivalents. To delete a Blobstore value asynchronously, use the
blobstore function.
In this example, we call the Blobstore service asynchronously to create an upload URL, then pass the RPC object to the template engine rendering the page. This allows us to finish other work and fire up the template engine while the service call is in progress. The template itself blocks on the RPC object to get the result when it is needed at the last possible moment:
import jinja2
from google.appengine.ext import blobstore
template_env = jinja2.Environment(
loader=jinja2.FileSystemLoader(os.getcwd()))
# ...
template = template_env.get_template('form.html')
context = {
'upload_url_rpc': blobstore.create_upload_url_async('/formhandler'),
'orig_data': load_orig_data(),
}
self.response.out.write(template.render(context))The template calls the get_result() method of the
RPC object to get the value it needs:
<!-- ... -->
<form action="{{ upload_url_rpc.get_result() }}" method="post">
<!-- ... -->
</form>The Python URL Fetch asynchronous API uses a slightly
different syntax from the others. The asynchronous equivalent of
urlfetch.fetch(...) is
urlfetch.make_fetch_call(urlfetch.create_rpc(), ...).
Like the _async() methods, it returns an RPC object.
Unlike the others, you must create the RPC object first, and pass it
in as the first argument. The function updates the RPC object, then
returns it. The remaining arguments are equivalent to
urlfetch.fetch().
Tip
This style of passing an RPC object to a service call predates
the _async-style methods in the other APIs. It appears
inconsistently throughout the Python service APIs, so you might
notice some other modules have it. The ext.blobstore
module has a create_rpc() method, and many methods
accept an rpc keyword argument. The
api.memcache module also has a
create_rpc() method, although only the
_async methods of the Client class support
it.
Asynchronous calling of the URL Fetch service is only available
using the urlfetch API. The Python standard library
urllib2 always calls the service synchronously.
To make the most of the parallel execution of
asynchronous calls, a request handler should initiate the call as soon
as possible in the handler’s lifetime. This can be as straightforward
as calling asynchronous methods early in a routine, then calling the
get_results() method at the point in the routine where
the results are needed. If your handler uses multiple diverse
components to perform tasks, and each component may require the
results of asynchronous calls, you could have the main routine ask
each component to initiate its service calls, then allow the
components to get their own results as control reaches the appropriate
points in the code.
The Python RPC object offers another way to organize the code
that handles the results of fetches: callbacks. A callback is a
function associated with the RPC object that is called at some point
after the RPC is complete, when the app calls the wait(),
check_results(), or get_results() method.
Specifically, the callback is invoked when the object goes from the
“in progress” state to the “ready” state. Since the RPC never reverts
states, the callback is only called once, even if the app accesses
results multiple times.
You can set a callback by setting the callback
attribute of the RPC object. (Be sure to do this before calling
wait(), check_results(), or
get_results().)
rpc = db.get_async(k)
rpc.callback = some_func
# ...
# Wait for the call to finish, then calls some_func.
rpc.wait()Tip
In the URL Fetch API, and other APIs that let you create an
RPC object explicitly, you can also pass the callback function value
as the callback keyword argument to
create_rpc().
The callback function is called without arguments. This is odd, because a common use for a callback function is to process the results of the service call, so the function needs access to the RPC object. There are several ways to give the callback function access to the object.
One way is to use a bound method, a feature of Python that lets you refer to a method of an instance of a class as a callable object. Define a class with a method that processes the results of the call, using an RPC object stored as a member of the class. Create an instance of the class, then create the RPC object, assigning the bound method as the callback. Example 17-1 demonstrates this technique.
Example 17-1. Using an object method as a callback to access the RPC object
from google.appengine.api import urlfetch
# ...
class CatalogUpdater(object):
def prepare_urlfetch_rpc(self):
self.rpc = urlfetch.make_fetch_call(
urlfetch.create_rpc(),
'http://api.example.com/catalog_feed')
self.rpc.callback = self.process_results
return self.rpc
def process_results(self):
try:
results = self.rpc.get_result()
# Process results.content...
except urlfetch.Error, e:
# Handle urlfetch errors...
class MainHandler(webapp.RequestHandler):
def get(self):
rpcs = []
catalog_updater = CatalogUpdater(self.response)
rpcs.append(catalog_updater.prepare_urlfetch_rpc())
# ...
for rpc in rpcs:
rpc.wait()Another way to give the callback access to the RPC object is to use a nested function (sometimes called a closure). If the callback function is defined in the same scope as a variable whose value is the RPC object, the function can access the variable when it is called.
Example 17-2
demonstrates the use of a nested function as a callback. The create_callback() function creates a
function object, a lambda expression, that calls another
function with the RPC object as an argument. This function object is
assigned to the callback property of the RPC
object.
Example 17-2. Using a nested function as a callback to access the RPC object
from google.appengine.api import urlfetch
def process_results(rpc):
try:
results = self.rpc.get_result()
# Process results.content...
except urlfetch.Error, e:
# Handle urlfetch errors...
def create_callback(rpc):
# Use a function to define the scope for the lambda.
return lambda: process_results(rpc)
# ...
rpc = urlfetch.create_rpc()
rpc.callback = create_callback(rpc)
urlfetch.make_fetch_call(rpc, 'http://api.example.com/catalog_feed')
# ...
rpc.wait()If you’ve used other programming languages that support function
objects, the create_callback()
function may seem unnecessary. Why not create the function object
directly where it is used? In Python, the scope of an inner function
is the outer function, including its variables. If the outer function
redefines the variable containing the RPC object (rpc),
when the inner function is called it will use that value. By wrapping
the creation of the inner function in a dedicated outer function, the
value of rpc in the scope of the callback is always set
to the intended object.
Someone still needs to call the wait() method on
the RPC object so the callback can be called. But herein lies the
value of callbacks: the component that calls wait() does
not have to know anything about what needs to be done with the
results. The main routine can query its subcomponents to prepare and
return RPC objects, then later it can call wait() on each
of the objects. The callbacks assigned by the subcomponents are called
to process each result.
Note
If you have multiple asynchronous service calls in progress
simultaneously, the callback for an RPC is invoked if the service
call finishes during any call to wait()—even if the
wait() is for a different RPC. Of course, the
wait() doesn’t return until the fetch for its own RPC
object finishes and its callbacks are invoked. A callback is only
invoked once: if you call wait() for an RPC whose
callback has already been called, it does nothing and returns
immediately.
If your code makes multiple simultaneous asynchronous calls,
be sure not to rely on an RPC’s callback being called only during
its own wait().
The Java runtime environment includes asynchronous APIs for the
datastore, memcache, URL Fetch, and Images services. (The Images service
is not described here.) The location of these methods differs slightly
from service to service, but they all use the same standard mechanism
for representing results:
java.util.concurrent.Future<T>.
For each synchronous method that returns a value of a particular
type, the asynchronous equivalent for that method returns a
Future<T> wrapper of that type. The method invokes
the service call, then immediately returns the
Future<T> to the app. The app can proceed with other
work while the service call is in progress. When it needs the result,
the app calls the get() method of the
Future<T>, which waits for the call to complete (if
needed) and then returns the result of type T:
import java.util.concurrent.Future;
import com.google.appengine.api.urlfetch.URLFetchService;
import com.google.appengine.api.urlfetch.URLFetchServiceFactory;
import com.google.appengine.api.urlfetch.HTTPResponse;
// ...
URLFetchService urlfetch = URLFetchServiceFactory.getURLFetchService();
Future<HTTPResponse> responseFuture =
urlfetch.fetchAsync(new URL("http://store.example.com/products/molasses"));
// ...
HTTPResponse response = responseFuture.get();The get() method accepts optional parameters that set
a maximum amount of time for the app to wait for a pending result. This
amount is specified as two arguments: a long, and a
java.util.concurrent.TimeUnit (such as
TimeUnit.SECONDS). This timeout is separate from any
deadlines associated with the service itself; it’s just how long the app
will wait on the call.
The Future<T> has a cancel()
method, which cancels the service call. This method returns
true if the call was canceled successfully, or
false if the call had already completed or was previously
canceled. The isCancelled() method (note the spelling)
returns true if the call has been canceled in the past.
isDone() returns true if the call is not in
progress, including if it succeeded, failed, or was canceled.
Service calls that don’t return values normally have a
void return type in the API. The asynchronous versions of
these return a Future<java.lang.Void>, so you can
still wait for the completion of the call. To do so, simply call the
get() method in a void context.
To call the datastore asynchronously in Java, you use a
different service class: AsyncDatastoreService. You get an instance
of this class by calling
DatastoreServiceFactory.getAsyncDatastoreService(). Like
its synchronous counterpart, this factory method can take an optional
DatastoreServiceConfig value.
The methods of AsyncDatastoreService are identical
to those of DatastoreService, except that return values
are all wrapped in Future<T> objects.
There are no explicit asynchronous methods for fetching query
results. Instead, the PreparedQuery methods
asIterable(), asIterator(), and
asList() always return immediately and begin prefetching
results in the background. (This is true even when using the
DatastoreService API.)
Committing a datastore transaction will wait for all
previous asynchronous datastore calls since the most recent commit.
You can commit a transaction asynchronously using the
commitAsync() method of the Transaction.
Calling get() on its Future will block
similarly.
When using AsyncDatastoreService with transactions,
you must provide the Transaction instance explicitly with each
call. Setting the implicit transaction management policy to
AUTO (in DatastoreServiceConfig) will have
no effect. This is because the automatic policy sometimes has to
commit transactions, and this would block on all unresolved calls,
possibly unexpectedly. To avoid confusion,
AsyncDatastoreService does not support implicit
transactions.
To call the memcache asynchronously in Java, you use the
AsyncMemcacheService service class. You get
an instance of this class by calling
MemcacheServiceFactory.getAsyncMemcacheService(). The
methods of AsyncMemcacheService are identical to those of
MemcacheService, except that return values are all
wrapped in Future<T> objects.
AppStats is a tool to help you understand how your code calls services. After you install the tool in your application, AppStats records timing data for requests, including when each service call started and ended relative to the request running time. You use the AppStats Console to view this data as a timeline of the request activity.
Let’s take another look at our contrived URL Fetch example from earlier in this chapter:
ingred1 = urlfetch.fetch('http://store.example.com/products/molasses')
ingred2 = urlfetch.fetch('http://store.example.com/products/sugar')
ingred3 = urlfetch.fetch('http://store.example.com/products/flour')
combine(ingred1, ingred2, ingred3)Figure 17-3 is the AppStats timeline for this code. It’s clear from this graph how each individual call contributes to the total running time. In particular, notice that the “Grand Total” is as large as the “RPC Total.”

Here’s the same example using asynchronous calls to the URL Fetch service:
ingred1_rpc = urlfetch.make_fetch_call(
urlfetch.create_rpc(), 'http://store.example.com/products/molasses')
ingred2_rpc = urlfetch.make_fetch_call(
urlfetch.create_rpc(), 'http://store.example.com/products/sugar')
ingred3_rpc = urlfetch.make_fetch_call(
urlfetch.create_rpc(), 'http://store.example.com/products/flour')
combine(
ingred1_rpc.get_result(),
ingred2_rpc.get_result(),
ingred3_rpc.get_result())Figure 17-4 shows the new chart, and the difference is dramatic: the URL Fetch calls occur simultaneously, and the “Grand Total” is not much larger than the longest of the three fetches.

AppStats is available for both Python and Java apps. The tool has two parts: the event recorder and the AppStats Console. Both parts live within your app, and are included in the runtime environment.
Once installed, you can use AppStats in both the development server and your live app. Running in the development server can give you a good idea of the call patterns, although naturally the timings will not match the live service.
The event recorder hooks into the serving infrastructure for your app to start recording at the beginning of each request, and store the results at the end. It records the start and end times of the request handler, and the start and end times of each remote procedure call (RPC) to the services. It also stores stack traces (and, for Python, local variables) at each call site.
The recorder uses memcache for storage, and does not use the datastore. It stores two values: a short record, and a long record. The short record is used by the AppStats Console to render a browsing interface for the long records. Only the most recent 1,000 records are retained. Of course, memcache values may be evicted more aggressively if your app uses memcache heavily. But in general, AppStats is able to show a representative sample of recent requests.
The performance overhead of the recorder is minimal. For typical user-facing requests, you can leave the recorder turned on for live traffic in a popular app. If necessary, you can limit the impact of the recorder by configuring it to only record a subset of traffic, or traffic to a subset of URLs. AppStats records and reports its own overhead.
Tip
AppStats accrues its timing data in instance memory during the request, and then stores the result in memcache at the end of the request handler’s lifetime. This works well for user-facing requests, even those that last many seconds. For non-user-facing task handlers that last many minutes and make many RPC calls, App Engine may kill the task (and log a critical error) due to excess memory consumption. AppStats can be useful for optimizing batch jobs, but you may want to watch carefully for memory overruns, and disable it for large task handlers when you’re not testing them actively.
In the next few sections, we’ll walk through how to install the event recorder and the Console, for Python and Java. Then we’ll take a closer look at the AppStats Console.
AppStats for Python includes two versions of the event recorder, one specifically for the Django web application framework, and another general purpose WSGI recorder.
If you’re using Django, edit your app’s settings.py, and find
MIDDLEWARE_CLASSES. Add the AppStatsDjangoMiddleware class, with an entry
like this:
MIDDLEWARE_CLASSES = (
'google.appengine.ext.appstats.recording.AppStatsDjangoMiddleware',
# ...
)For all other Python applications, you install the WSGI middleware, using an appengine_config.py file. This file is used to configure parts of the App Engine libraries, including AppStats. If you don’t have this file already, create it in your application root directory, and add the following Python function:
def webapp_add_wsgi_middleware(app):
from google.appengine.ext.appstats import recording
app = recording.appstats_wsgi_middleware(app)
return appApp Engine uses this middleware function for all WSGI applications, including those running in the Python 2.7 runtime environment.
Regardless of which method you use to install the recorder, you can specify additional configuration in the appengine_config.py file.
Three settings control which handlers get recorded. The first is a
global variable named appstats_FILTER_LIST that specifies
patterns that match environment variables. For example, to disable
recording for request handlers on a particular URL path:
appstats_FILTER_LIST = [
{
'PATH_INFO': '/batchjobs/.*',
},
]appstats_FILTER_LIST is a list of clauses.
Each clause is a mapping of environment variable names to regular
expressions. If the environment variables for a given request match all
the regular expressions in a clause, then the request is recorded. Do a
Google search for “WSGI environment variables” for more information on
the variables you can match. Also note that the regular expression
matches from the beginning of the environment variable (a “match”-style
regular expression).
The appstats_RECORD_FRACTION configuration variable
sets a percentage of requests not already filtered by
appstats_FILTER_LIST that should be recorded. The default
is 1.0 (100%). To only record a random sampling of 20 percent of the
requests:
appstats_RECORD_FRACTION = 0.2
If you need more control over how requests are selected for
recording, you can provide a function named
appstats_should_record(). The function takes a mapping of
environment variables and returns True if the request
should be recorded. Note that defining this function overrides the
appstats_FILTER_LIST and
appstats_RECORD_FRACTION behaviors, so if you want to
retain these, you’ll need to copy the logic that uses them into your
function.
The appstats_normalize_path(path) configuration
function takes the request path and returns a normalized request path,
so you can group related paths together in the reports. It’s common for
a single handler to handle all requests whose URL paths match a pattern,
such as /profile/13579, where 13579 is a
record ID. With appstats_normalize_path(), you can tell
AppStats to treat all such URL paths as one, like so:
def appstats_normalize_path(path):
if path.startswith('/profile/'):
return '/profile/X'
return pathOther settings let you control how AppStats uses memcache space, such as the number of retained events or how much stack trace data to retain. For a complete list of AppStats Python configuration variables, see the sample_appengine_config.py file in the SDK, in the google/appengine/ext/appstats/ directory.
The last step is to install the AppStats Console. Edit
app.yaml, and enable the
appstats built-in:
builtins: - appstats: on
The AppStats Console lives on the path /_ah/stats/ in
your application. The Console works in the development server as well as
the live app, and is automatically restricted to administrative
accounts.
You can add a link from the Administration Console sidebar to the AppStats Console using the Custom Pages feature (see Administration Console Custom Pages), with an entry like this in your app.yaml:
admin_console:
pages:
- name: AppStats
url: /_ah/stats/The Java version of the AppStats event recorder is a servlet filter. You install the filter by editing your deployment descriptor (web.xml) and adding lines such as the following:
<filter>
<filter-name>appstats</filter-name>
<filter-class>com.google.appengine.tools.appstats.AppstatsFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>appstats</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>The url-pattern controls which requests get recorded,
based on the URL. As above, the /* pattern matches all
requests. Adjust this pattern if needed.
The AppStats Console is a web servlet, like any other. Add the
following lines to web.xml to
install the Console at the path /_ah/stats/, restricted to
app administrators:
<servlet>
<servlet-name>appstats</servlet-name>
<servlet-class>com.google.appengine.tools.appstats.AppstatsServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>appstats</servlet-name>
<url-pattern>/_ah/stats/*</url-pattern>
</servlet-mapping>
<security-constraint>
<web-resource-collection>
<url-pattern>/_ah/stats/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>You can add a link from the Administration Console sidebar to the AppStats Console using the Custom Pages feature (see Administration Console Custom Pages), with an entry like this in your appengine_web.xml file:
<admin-console>
<page name="AppStats" url="/_ah/stats" />
</admin-console>The AppStats Console is your window to your app’s service
call behavior. To open the Console, visit /_ah/stats/ in
your app, or if you configured it, use the link you added to the
Administration Console sidebar. AppStats works in your development
server as well as your live app.
Figure 17-5 shows an example of the AppStats Console. (A very small app is shown, to limit the size of the example.)
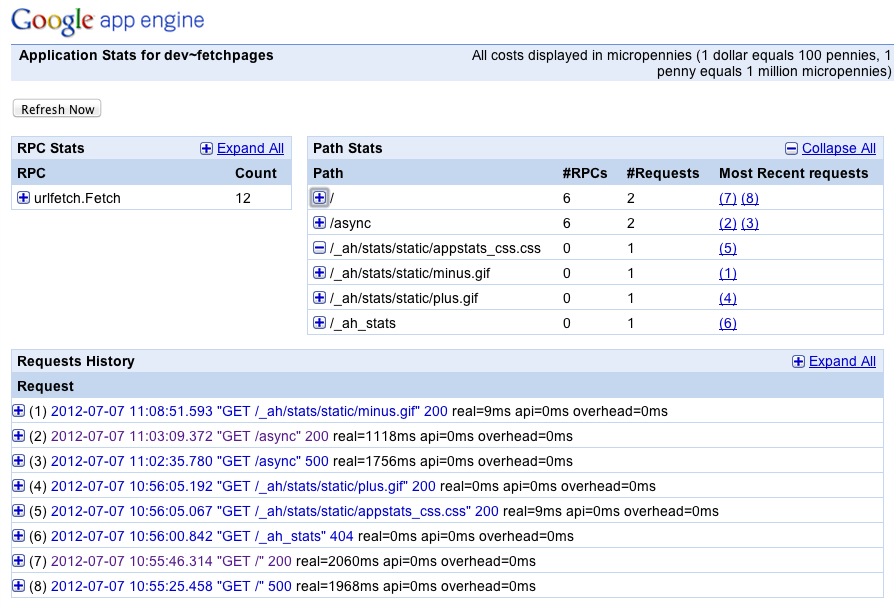
The front page of the Console shows a summary of recent service calls. RPC Stats is a summary of calls by service, with the most popular service at the top. Click to expand a service to see which recent request URLs called the service. Path Stats shows the same information organized by path, with the URL with the heaviest total number of calls at the top. Click to expand a path to see a summary of the path’s calls per service. The Most Recent Requests column references the Requests History table at the bottom of the screen.
The Requests History table at the bottom lists all recent requests
for which AppStats has data, up to 1,000 recent requests, with the most
recent request on top. Click the + to expand the tally of
service calls made during the request.
To view the complete data for the request, click the blue request date and path in the Requests History table. Figure 17-6 shows an expanded version of an example we saw earlier.
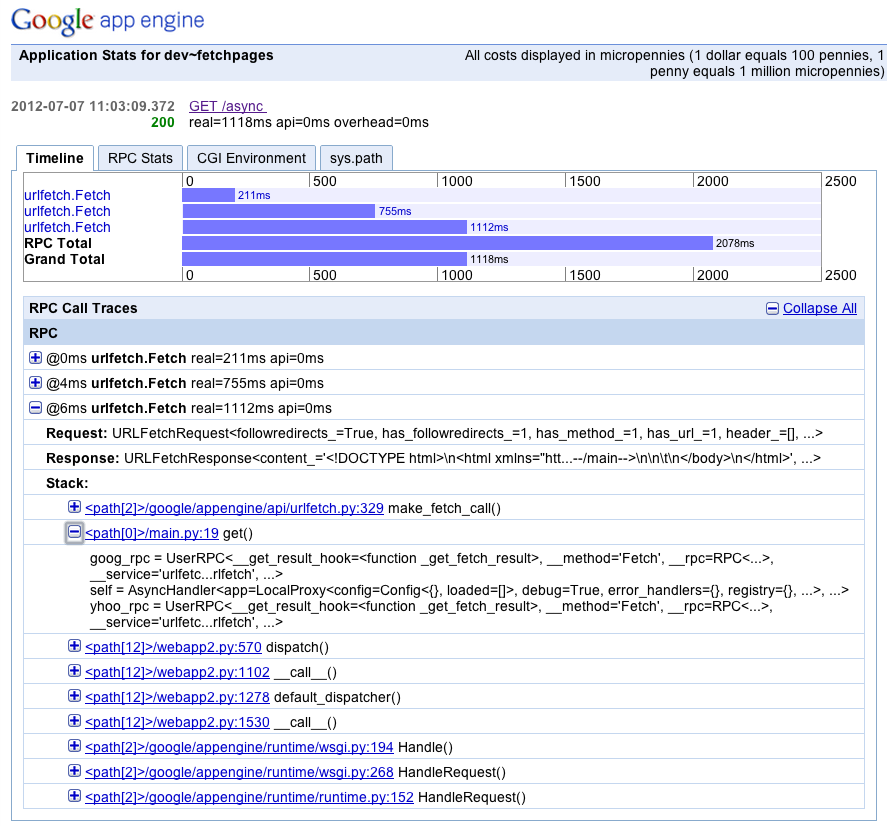
The centerpiece of the request details page is the timeline. The timeline shows the history of the entire request, with a separate line for each service call. From this you can see when each service call began and ended in the lifetime of the request, the total (aggregate) time of all service calls (the “RPC Total”), and the actual amount of time spent handling the request (“Grand Total”). As we saw earlier, the Grand Total can be less than the RPC Total if you use simultaneous asynchronous requests.
When running on App Engine (not the development server), the timeline also includes red bars on top of the blue ones. This represents an estimate of the monetary costs of the call, including API and bandwidth costs. (The unit, “API milliseconds,” is not always useful, except in comparison to other red bars in the graph.)
The RPC Call Traces table below the timeline lets you examine each RPC call to find out where in the code it occurred. In the Python version, each element in the stack trace also includes the local variables at the call site at the time of the call.
The Python and Java request details pages include another tab that shows the service call tallies (“RPC Stats”). The Python version also has tabs for the environment variables as they were set at the beginning of the request (“CGI Environment”), and the Python package load path as it is currently set in the AppStats Console (“sys.path”). (The “sys.path” is not the exact load path of the request being viewed; it is determined directly from the AppStats Console environment itself.)
Tip
Both the Python and Java interfaces to the datastore are libraries built on top of a more rudimentary service interface. The correspondence between library calls and datastore RPCs are fairly intuitive, but you’ll notice a few differences.
The most notable difference is how the datastore libraries fetch
query results. Some features of the query APIs, such as the != operator, use multiple datastore queries
behind the scenes. Also, when results are fetched using iterator-based
interfaces, the libraries use multiple datastore RPCs to fetch results
as needed. These will appear as RunQuery and
Next calls in AppStats.
Also, the local development server uses the RPC mechanism to
update index configuration, so it’ll sometimes show
CreateIndex and UpdateIndex calls that do
not occur when running on App Engine.
You can use stack traces to find where in the datastore library code each call is being made.