
Appendix B
GPU Compute Capabilities
B.1 GPU Compute Capability Tables
As we discussed in Chapters 6-10, maximizing the kernel performance on a particular GPU requires knowledge of the resource limitations in the GPU hardware. Therefore, the main hardware resource provisions in each GPU are typically exposed to applications in a standardized system called compute capability. The general specifications and features of a compute device depend on its compute capability. For CUDA, the compute capability starts at Compute 1.0, and at the time of this writing the latest version is Compute 3.5. Each higher level of compute capability indicates a newer generation of GPU devices with a higher number of features. Table B.1 highlights the key features support differences between each of the compute capabilities. Features not listed can be considered supported by all compute capability variations; differences in memory coalescing are discussed in Section B.2. In general, a higher-level compute capability defines a superset of features of those of a lower level.
Table B.1 Key Functional Support Variations Between CUDA Compute Capabilities
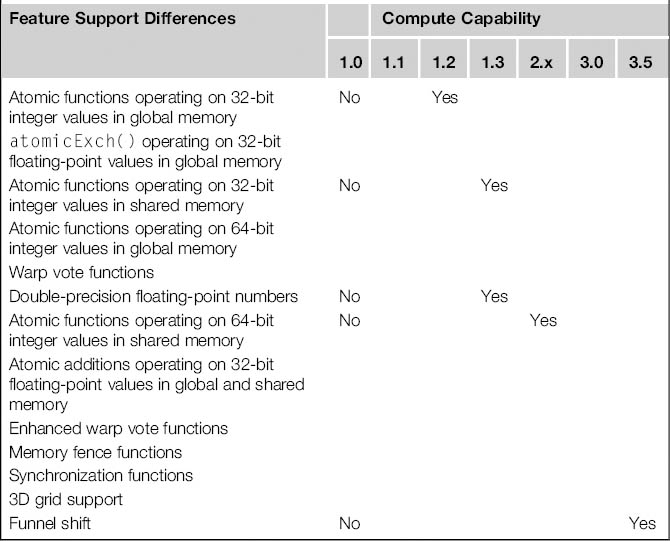
Table B.2 shows the main dimensions of compute capability specifications and gives the numerical value of each dimension for Compute 3.5. Each higher level of compute capability enhances one more of these dimensions.
Table B.2 Main Dimensions of Compute Capability and the Attributes of Compute 3.5
| Features | Compute 3.5 |
| Number of stream processors per multiprocessor (MP) | 192 |
| Max. number of threads per block | 1,024 |
| Max. grid dimensions X, Y, Z | 231 − 1,65535,65535 |
| Max. block dimensions X, Y, Z | 1,024, 1,024, 64 |
| Threads in a warp | 32 |
| Registers per MP | 65,536 (64 K) |
| Shared memory per MP | 49,152 (48 K) |
| Banks in shared memory | 32 |
| Total constant memory | 65,536 (64 K) |
| Cache working set for constants per MP | 8,192 (8 K) |
| Local memory per thread | 524,288 (512 K) |
| Cache working set for texture per MP | 6–8 KB |
| Max. number of active blocks per MP | 16 |
| Max. number of active warps per MP | 64 |
| Max. number of active threads per MP | 2,048 |
| 1D texture bound to CUDA array—max. width | 65,536 |
| 1D texture bound to linear memory—max. width | 227 |
| 2D texture bound to linear memory or CUDA array; max. dimensions X, Y | 65,000 and 65,536, respectively |
| 3D texture bound to a CUDA array max. dimensions X, Y, Z | 4 K×4 K×4 K |
| Max. width, height, and layers for a cube map–layered texture reference | 16,384×16,384×2,046 |
| Max. number of textures that can be bound to a kernel | 256 |
| 1D surface reference bound to a CUDA array—max. width | 65,536 |
| 1D layered surface reference—max. width and layers | 65,536×2,048 |
| 2D layered surface reference—max. width, height, and layers | 65,536×32,768×2,048 |
| 3D layered surface reference—max. width, height, and depth bound to a CUDA array | 65,536×32,768×2,048 |
| Max. width, height, and layers for a cube map–layered surface reference | 32,768×32,768×2,046 |
| Max. number of surfaces | |
| Max. number of instructions per kernel | 512 million microcode instructions |
Depending on the time of its introduction, each CUDA-enabled device supports up to a particular generation of compute capability. Many CUDA-enabled devices are introduced each year. Readers should refer to http://developer.nvidia.com/cuda-gpus for an updated list.
Many device-specific features and sizes can be determined calling runtime CUDA function cudaGetDeviceProperties(). See the CUDA Programmer Guide for more details.
B.2 Memory Coalescing Variations
Each level of compute capability also specifies a different level of hardware memory coalescing capability. Knowing the compute capability, one can determine the number of global memory transactions that a load instruction in a warp will incur. Later compute capabilities such as 2.x and higher substantially reduce the number of memory transactions and occurrence of noncoalesced accesses. In Compute 1.0 and Compute 1.1, memory transactions are done for either memory 64 B or 128 B segments. Coalescing of accesses in a warp requires that the kth thread in a warp access the kth word in a 64 B segment when accessing 32-bit words (or the kth word in two contiguous 128 B segments when accessing 128-bit words). Not all threads need to participate for coalescing to work. In the top of Figure B.1, one of the threads in a warp did not participate and the accesses are still coalesced into one transaction.
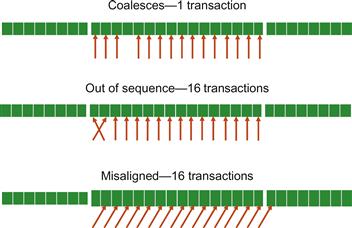
Figure B.1 Memory coalescing in compute 1.0 and Compute 1.1.
In particular, all accesses must be in sequence. If one or more of the accesses are out of sequence, the accesses will no longer be coalesced. In the middle of Figure B.1, two of the accesses are out of sequence. The accesses are therefore not coalesced; 16 transactions to the global memory are done for the access.
In Compute 1.2 and higher, the global memory transactions are issued in 32 B, 64 B, or 128 B segments. Having a smaller segment size allows the hardware to reduce waste of global memory bandwidth for some less coherent warp access patterns.
Figure B.2 illustrates improvements in memory coalescing in Compute 1.2. The top part shows that warp accesses within a segment can be out of sequence and still be fully coalesced into one transaction.
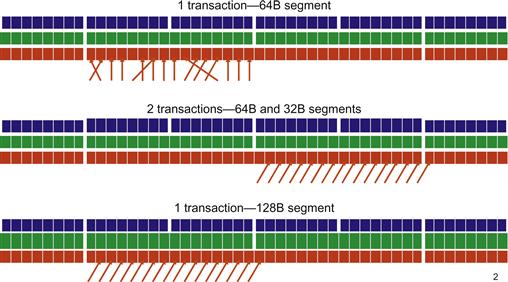
Figure B.2 Memory coalescing in compute 1.2 and higher.
The middle part shows that the access can be nonaligned across a 128 B boundary. One extra 32 B segment transaction will be issued and the accesses are still coalesced. The bottom part shows if warp accesses are nonaligned but stay within a 128 B boundary, a single 128 B segment transaction will be used to access all the words involved. In these two cases, the global memory bandwidth consumption is much less than that in Compute 1.0 or Compute 1.1 where 16 transactions of 64 B segments would be used.
Figure B.3 illustrates the improvements introduced in Compute 2.0 resulting in all aligned memory accesses to be considered coalesced and eliminating additional memory transactions.
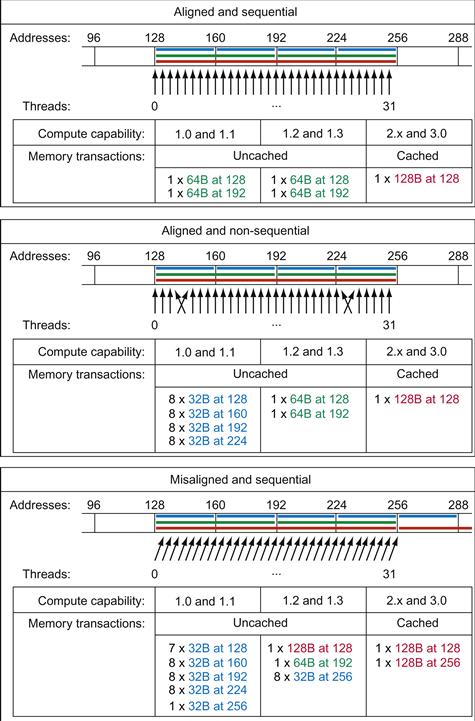
Figure B.3 Examples of global memory access and resulting memory transactions for each compute capability.