
| 13 | Array-Based Lists |
KNOWLEDGE GOALS
![]() To understand the structure of a list ADT.
To understand the structure of a list ADT.
![]() To know the basic operations associated with a list ADT.
To know the basic operations associated with a list ADT.
![]() To recognize the difference between an array and a list.
To recognize the difference between an array and a list.
![]() To know how a linear search algorithm works.
To know how a linear search algorithm works.
![]() To understand the properties of a sorted list ADT.
To understand the properties of a sorted list ADT.
![]() To know how an insertion sort works.
To know how an insertion sort works.
![]() To understand the principle of “divide and conquer” as expressed in the binary search algorithm
To understand the principle of “divide and conquer” as expressed in the binary search algorithm
SKILL GOALS
To be able to:
![]() Represent a list ADT using a C++ class.
Represent a list ADT using a C++ class.
![]() Add an item into a list.
Add an item into a list.
![]() Remove an item from a list.
Remove an item from a list.
![]() Search for an item in a list.
Search for an item in a list.
![]() Sort the items in a list into ascending or descending order.
Sort the items in a list into ascending or descending order.
![]() Build a list in sorted order.
Build a list in sorted order.
![]() Search for an item in a sorted list using a linear search.
Search for an item in a sorted list using a linear search.
![]() Search for an item using a binary search.
Search for an item using a binary search.
Chapter 11 introduced the array, a data structure that is a collection of components of the same type given a single name. In general, a one-dimensional array is a structure used to hold a list of items. In this chapter, we examine algorithms that build and manipulate data stored as a list in a one-dimensional array. We all know intuitively what a “list” is; in our everyday lives we use lists all the time—grocery lists, lists of things to do, lists of addresses, lists of party guests. In computer applications, lists are very useful and popular ways to organize the data. In this chapter, we examine algorithms that build and manipulate a list implemented using a one-dimensional array to hold the items.
These algorithms are implemented as general-purpose functions that can be modified easily to work with many kinds of lists. We also consider the C string, a special kind of built-in one-dimensional array that is used for storing character strings. We conclude with a case study that uses an array as the main data structure.
13.1 What Is a List?
From a logical point of view, a list is a homogeneous collection of elements, with a linear relationship between elements. Here linear means that, at the logical level, every element in the list except the first one has a unique predecessor, and every element except the last one has a unique successor.1 The number of items in the list, which we call the length of the list, is a property of a list. That is, every list has a length.
Linear relationship A relationship in which every element except the first has a unique predecessor, and every element except the last has a unique successor.
Length The number of items in a list; it can vary over time.
Unsorted list A list in which data items are placed in no particular order with respect to their content; the only relationships between data elements consist of the list predecessor and successor relationships.
Sorted list A list whose predecessor and successor relationships are determined by the content of the keys of the items in the list; a semantic relationship exists among the keys of the items in the list.
Key A member of a class whose value is used to determine the logical and/or physical order of the items in a list.
Lists can be unsorted—their elements may be placed into the list in no particular order—or they can be sorted in a variety of ways. For instance, a list of numbers can be sorted by value, a list of strings can be sorted alphabetically, and a list of addresses could be sorted by ZIP code. When the elements in a sorted list are of composite types, one of the members of the structure, called the key member, determines their logical (and often physical) order. For example, a list of students on a class roll can be sorted alphabetically by name or numerically by student identification number. In the first case, the name is the key; in the second case, the identification number is the key. (See FIGURE 13.1.)
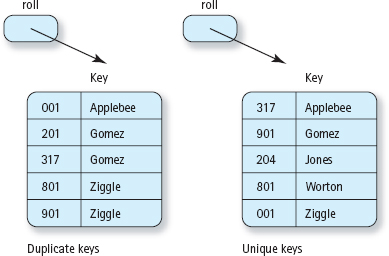
If a list cannot contain items with duplicate keys, we say that it has unique keys. (See FIGURE 13.2.) This chapter deals with both unsorted lists and lists of elements with unique keys, sorted from smallest to largest key value. The items on the list can be of any type, atomic or composite. In the following discussion, “item,” “element,” and “component” are synonyms; they refer to what is stored in the list.
13.2 The List as an Abstract Data Type
In this section, we will design an List ADT, which we implement as a general-purpose class in the next section. Let's think about this structure in terms of a to-do list. Before we begin to think about which operations we might need, however, we must ask an important question: For whom are we designing the ADT? We may be designing it for ourselves to keep in our library of classes. We may be designing it for others to use in a team project. In our discussion, we use the terms “client” and “user” interchangeably, as we sometimes think of them as referring to the people writing the software that uses the class, rather than the software itself.
Figure 13.1 List Sorted by Two Different Keys
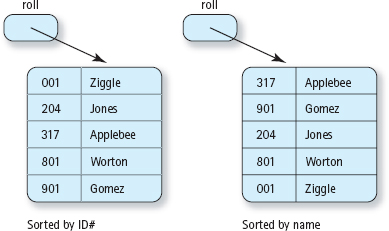
Figure 13.2 List with Duplicate Keys and List with Unique Keys
Let's think about which kinds of operations we might need in a to-do list. Ideally, we start with an empty list each morning and add things to it. Of course, there might also be items on the list left over from the previous day. As we accomplish a task on the list, we cross it off. We want to check whether an item is already on the list. We need to be able to check whether we can add one more item to the list. We also want to check whether the list is empty (we wish!). We ask how many things we have left to do. We go through the list one item at a time, looking for things to do.
Let's translate these observations into operations (responsibilities) for the list. Notice that constructors are obvious because they are prefaced by “create,” knowledge observers have a “get” shown, and Boolean observers are prefaced with “is.” Likewise, the choice of identifier for transformers gives their type away: “add” and “remove.” Note that this is our first experience with using an iterator, an operation that allows us to access the items in a structure one at a time.
Type
List
Domain
Each instance of type List is a collection of up to MAX_LENGTH components, each of type ItemType.
Operations
Create an initially empty list.
Is the list empty?
Is the list full?
Get the current length of the list.
Insert an item into the list.
Delete an item from the list.
Is an item in the list?
Iterate through the list, returning each item in turn.
This list of operations differs somewhat from the one listed for the IntList ADT that we defined in Chapter 12. First, we have thought about the operations we might need within the context of a specific example. Second, we have used the object-oriented form of the operations, in which the name gives an indication of exactly what the operation does. From this representation of our ADT, we can begin to form the specification for the class that will eventually implement the List ADT.
Refining Responsibilities
Let's go back through the responsibilities, refining them and converting them into function headings. Because we are designing a general-purpose class, we will ask simplified questions that exemplify how we believe the class may be employed. Because the class is intended for widespread use, we should pay special attention to the documentation right from the design stage.
The observers, the tests for full and empty lists, and returning the number of items need no further discussion. Here are their function headings with the appropriate documentation:
bool IsEmpty() const; // Post: Returns true if list is empty; false otherwise bool IsFull() const; // Post: Returns true if list if full; false otherwise int GetLength() const; // Post: Returns the length of the list
The observer that checks whether an item is in the list must take the item as a parameter. Calling this method isThere makes sense.
bool IsThere(ItemType item ) const;
// Post: Returns true if item is in the list and false otherwiseIn designing the transformers, we must make some decisions. For example, do we allow duplicates in our list? This choice has implications for removing items as well as adding items. If we allow duplicates, what do we mean by “deleting an item”? Do we delete just one copy or all of them? Because this chapter focuses on algorithms, for now we just make a decision and design our algorithms to fit that decision. We will examine the effects of other choices in the exercises.
Let's allow only one copy of an item in the list. This decision means that deleting an item removes just one copy. But do we assume that the item to be deleted is in the list? Is it an error if it is not? Or does the deletion operation mean “delete, if there”? Let's use the last meaning.
We now incorporate these decisions into the documentation for the method headings.
void Insert(ItemType item); // Pre: List is not full and item is not in the list // Post: item is in the list and length has been incremented void Delete(ItemType item); // Post: item is not in the list
The iterator allows the user to see each item in the list one at a time. Let's call the method that implements the “Get next item” responsibility GetNextItem. The list must keep track of the next item to return when the iterator is called. It does so with a data member that records the position of the next item to be returned. The constructor initializes this position to 0, and it is incremented in GetNextItem. The client could use the length of the list to control a loop. Another approach is to provide an observer HasNext that asks if the list contains another item that has not been seen. Let's use this second approach and explore the first approach in the exercises. Because invoking GetNextItem when HasNext is false causes an error, we must state the assumption in the documentation that there is an item to be accessed when GetNextItem is called.
What happens if a user adds or removes an item in the middle of an iteration? Nothing good, you can be sure! Depending on whether an insertion or deletion occurs before or after the iteration point, our iteration loop could end up skipping or repeating items.
We have several choices in how we handle this possibly dangerous situation. The list can handle this situation by resetting the current position when we are adding or deleting items, or it can disallow transformer operations while an iteration is taking place. We choose the latter option here by way of an assumption in the documentation. In case the user wants to restart an iteration, let's provide a ResetList method that reinitializes the current position.
void ResetList() // The current position is reset to access the first item in the list bool HasNext() // Returns true if there is another item to be returned; false // otherwise ItemType GetNextItem() // Assumptions: No transformers are called during the iteration. // There is an item to be returned; that is, hasNext is true when // this method is invoked // Pre: ResetList has been called if this is not the first iteration // Post: Returns item at the current position.
All we have left to write is the constructor.
List(); // Constructor // Post: Empty list has been created
Data Representation
As defined in Chapter 11, a one-dimensional array is a built-in data structure that consists of a fixed number of homogeneous components. One use for an array is to store a list of values. A list then is made up of an array of values and an integer variable length that says how many list elements are stored in the array. Let's call our array data. The class construct is used to encapsulate the length and the array of values. From our previous discussion of GetNextItem, we know that the list must contain a variable that indicates where in the list the next item is to be found in an iteration. Because we are working with arrays, we assume that this variable will be an integer index. Let's call it currentPos.
In FIGURE 13.3, you can see that the array goes from data[0] through data[MAX_LENGTH-1], but the list elements stored in the array go from data[0] through data[length-1]. The number of places in the array is fixed, but the number of values in the list that is stored there may vary.
We can use a C++ class named List to represent the List ADT in our programs. For the concrete data representation, we use three items: a one-dimensional array to hold the list items, an int variable that stores the current length of the list, and an int variable that is used for iteration. When we compile the List class, we need to supply definitions for MAX_LENGTH and ItemType, the type of the items in the list.

Here is the complete specification for the class List that implements the ADT List. For this implementation, we use a MAX_LENGTH of 100 and an ItemType of string.
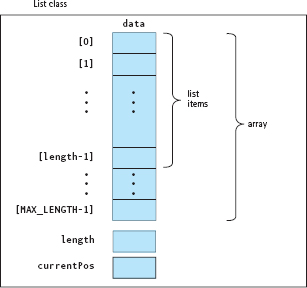
Figure 13.3 The Structure of the List Class

Figure13.4 myList: An Instance of Class List with Values
In Chapter 12, we classified ADT operations as constructors, transformers, observers, and iterators. IsEmpty, IsFull, GetLength, and IsThere are observers. Insert and Delete are transformers. GetNextItem is an iterator. ResetList is a transformer that initializes the list before the iterator GetNextItem is called. HasNext is an observer associated with an iteration. ResetList, HasNext, and GetNextItem work together to allow an iteration to occur. The class constructor is an ADT constructor operation.
To get a List object, we have to declare one:
List myList;
myList contains three variables (two int, one array), the data representation for a list. (See FIGURE 13.4.)
Example Program
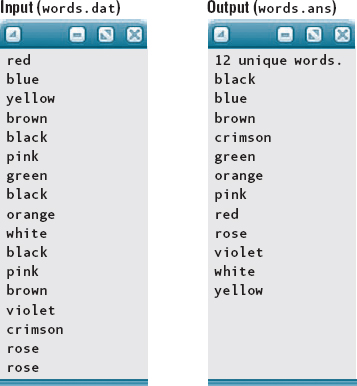
Let's look at an example of a client program. Suppose a data file contains a weather station's daily maximum temperature readings for one month, one integer value per day. Unfortunately, the temperature sensor is faulty and occasionally registers a temperature of 200 degrees. The following program uses the List class to store the temperature readings, delete any spurious readings of 200 degrees, and output the remaining readings in sorted order. Presumably, the data file contains no more than 31 integers for the month, so its length should be well within the List class's MAX_LENGTH of 100. However, just in case the file erroneously contains more than MAX_LENGTH values, the reading loop in the following program terminates not only if end-of-file is encountered but also if the list becomes full (IsFull). Another reason to use the IsFull operation in this loop can be found by looking at the function specifications in file list.h—namely, we must guarantee Insert's precondition that the list is not full.

Here is the input file:
temps.dat

Given an implementation of the List class, this is the expected output file:
temps.ans
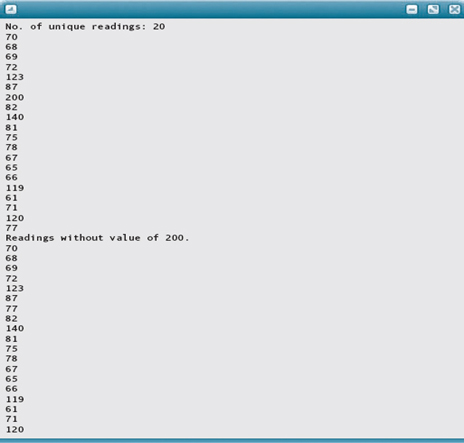
We now consider how to implement each of the ADT operations, given that the list items are stored in an array.
13.3 Implementation of List ADT
Basic Operations
As we discussed in Chapter 12, an ADT should be implemented in C++ by using a pair of files: the specification file (such as the preceding list.h file) and the implementation file, which contains the implementations of the class member functions. Here is how the implementation file list.cpp starts out:
#include “list.h” #include <iostream> using namespace std;
Let's look now at the implementations of the basic list operations.
Creating an Empty List
As we saw in FIGURE 13.4, the list exists in the array elements data[0] through data[length-1]. To create an empty list, it is sufficient to set the length member to 0. We do not need to store any special values into the data array to make the list empty, because only those values in data[0] through data[length-1] are processed by the list algorithms. We also need to set currentPos to 0 to initialize the list for an iteration. We will have more to say about this initialization choice when we look at the implementation of the GetNextItem function.
List::List()
{
length = 0;
currentPos = 0;
}The IsEmpty Operation
This operation returns true if the list is empty and false if the list is not empty. Using our convention that length equals 0 if the list is empty, the implementation of this operation is straightforward.
bool List::IsEmpty() const
{
return (length == 0);
}The IsFull Operation
The list is full if there is no more room in the array holding the list items—that is, if the list length equals MAX_LENGTH.
bool List::IsFull() const
{
return (length == MAX_LENGTH);
}The GetLength Operation
This operation simply returns to the client the current length of the list.
int List::GetLength() const
{
return length;
}Insertion and Deletion
To devise an algorithm for inserting a new item into the list, we first observe that we are working with an unsorted list. Nothing in the specification indicates that the values have to be maintained in any particular order. As a consequence, we can store a new value into the next available position in the array—data[length]—and then increment length. This algorithm brings up two questions: Do we need to check that the list has room for the new item? Do we need to be sure the item isn't in the list before we attempt to store it there? The answer to both questions is no. To see why, look back at the precondition on the Insert prototype in the specification:
void Insert(ItemType item); // Pre: List is not full and item is not in the list // Post: item is in the list and length has been incremented
The user is responsible for checking these two conditions; this code is written assuming the precondition is true.
void List::Insert(ItemType item)
{
data[length] = item;
length++;
}Deleting a component from a list consists of two steps: finding the component and removing it from the list. Before we can write the algorithm, we must know what to do if the component is not there. Delete can mean “Delete, if it's there” or “Delete, we know it is there” or “Delete one copy” or “Delete all copies.” In our discussion of the delete operation earlier, we chose to make this operation mean “Delete, if it's there.” This decision is reflected in the Delete prototype's documentation.
void Delete(ItemType item);
// Post: item is not in the listWe must start at the beginning of the list and search for the value to be deleted. If we find it, how do we remove it? We take the last value in the list (the one stored in data[length-1]), put it where the item to be deleted is located, and then decrement length. Moving the last item from its original position is appropriate only for an unsorted list because we don't need to preserve the order of the items in the list.
The definition “Delete, if it's there” requires a searching loop with a compound condition. We examine each component in turn and stop looking when we find the item to be deleted or when we have looked at all the items and know that it is not there.
void List::Delete(ItemType item)
{
int index = 0; while (index < length && item != data[index])
index++;
if (index < length) // item found
{
data[index] = data[length-1];
length--;
}
}To see how the While loop and the subsequent If statement work, let's look at the two possibilities: either item is in the list or it is not. If item is in the list, the loop terminates when the expression index < length is true and the expression item != data[index] is false. After the loop exit, the If statement finds the expression index < length to be true and removes the item. Conversely, if item is not in the list, the loop terminates when the expression index < length is false—that is, when index becomes equal to length. Subsequently, the If condition is false, and the function returns without changing anything.
Sequential Search
In the Delete function, the algorithm we used to search for the item to be deleted is known as a sequential or linear search in an unsorted list. We use the same algorithm to implement the IsThere function of the List class.
bool List::IsThere(ItemType item) const
{
int index = 0; // Index variable
while (index < length && item != data[index])
index++;
return (index < length);
}This algorithm is called a sequential search because it starts at the beginning of the list and looks at each item in sequence. We stop the search as soon as we find the item we are looking for (or when we reach the end of the list, at which point we conclude that the desired item is not present in the list).
We can use this algorithm in any program requiring a list search. In the form shown here, it searches a list of ItemType components, provided that ItemType is an integral type or the string class; that is, values of ItemType can be compared using the relational operators. However, using the relational operators between floating-point values may give unexpected results. Perhaps a note should be added to the specification file giving this warning.
This sequential search algorithm begins at the beginning of the list and searches forward. We could just as easily have begun searching from the last item backward. How would we modify the algorithm to begin at the end? We would initialize index to length-1 and decrement index each time through the loop, stopping when we found the item we wanted or when index became −1. These changes are highlighted in the following code:
bool List::IsThere(ItemType item) const
{
int index = length-1; // Index variable
while (index >= 0 && item != data[index])
index--;
return (index < length);
}Before we leave this search algorithm, let's introduce a variation that makes the program more efficient, albeit a little more complex. The While loop contains a compound condition: It stops when it either finds item or reaches the end of the list. We can insert a copy of item into data[length]—that is, into the array component beyond the end of the list—to act as a sentinel. By doing so, we are guaranteed to find item in the list. Then we can eliminate the condition that checks for the end of the list (index < length).
bool List::IsThere(ItemType item) const // Alternative version // Copy of item is stored at end of the list to ensure it is found { int index = 0; data[length] = item; // Store item at position beyond end while (item != data[index]) index++; return (index < length); }
Is this algorithm really better? Eliminating a condition saves the computer the time that would be required to test it. In this case, we save time during every iteration of the loop, so the savings add up quickly. Note, however, that we are gaining efficiency at the expense of space. We must declare the array size to be one larger than the user's limit to hold the sentinel value if the list becomes full. That is, we must change the documentation to read
const int MAX_LENGTH = 100; // Maximum number of components + 1or change the declaration of the array to be
ItemType data[MAX_LENGTH + 1];
The comment describes the processing of this loop. Recall that prototype (specification) documentation is intended for the user and contains no implementation details. If the code uses an unusual algorithm, this fact should be noted in the function's definition documentation, which is for the maintainer of the code.
Iterators
Iterators are used with composite types to allow the user to process an entire structure component by component. To give the user access to each item in sequence, we provide three operations: one to initialize the iteration (a process analogous to Open with a file), one to determine if there are more items, and one to return a copy of the “next component” each time it is called. The user can then set up a loop that processes each component. We call these operations ResetList, HasNext, and GetNextItem. Note that ResetList and HasNext are not iterators themselves, but rather are auxiliary functions that support the iteration. Yet another type of iterator takes an operation and applies it to every element in the list.
The ResetList function is analogous to the open operation for a file in which the file pointer is positioned at the beginning of the file so that the first input operation accesses the first component of the file. Where is the first item? At position 0; thus currentPos must be initialized to 0. Because the constructor sets up the list for the first iteration, ResetList is called only on subsequent iterations. However, if it is called for the first iteration, no harm is done: currentPos is just set twice.
The GetNextItem operation is analogous to an input operation; it accesses the next item (the one at currentPos), increments currentPos, and returns the item it accessed. What happens if the last item has been accessed? HasNext will return false. How can HasNext recognize when the last item has been accessed? By testing whether currentPos is equal to length.
void List::ResetList()
{
currentPos = 0;
}
bool List::HasNext() const
{
return (currentPos != length);
}
ItemType List::GetNextItem()
{
ItemType item;
item = data[currentPos];
currentPos++;
return item;
}Reset and GetNextItem are designed to be used in a loop in the client program that iterates through all of the items in the list. The precondition in the specifications for GetNextItem protects against trying to access an array element that is not in the list. Look back at the Temperature program. HasNext and GetNextItem were used once to print the original list; ResetList, HasNext, and GetNextItem were used once to print the corrected list.


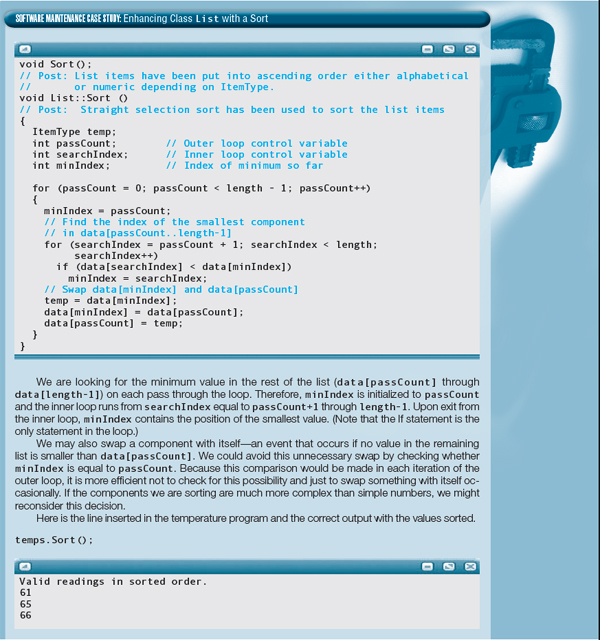

13.4 Sorted Lists
In the List class, both of the searching algorithms assume that the list to be searched is unsorted. A drawback to searching an unsorted list is that we must scan the entire list to discover that the search item is not there. Think what it would be like if your city telephone book contained people's names in random order rather than alphabetical order. To look up Mary Anthony's phone number, you would have to start with the first name in the phone book and scan sequentially, page after page, until you found it. In the worst case, you might have to examine tens of thousands of names, only to find out that Mary's name is not in the book.
Of course, telephone books are alphabetized, and the alphabetical ordering makes searching easier. If Mary Anthony's name is not in the book, you discover this fact quickly by starting with the A's and stopping the search as soon as you have passed the place where her name should be.
Let's define a sorted list ADT in which the components always remain in order by value, no matter which operations are applied. Following is the SortedList.h file that contains the declaration of a SortedList class.

How does the declaration of SortedList differ from the declaration of our original List class? Apart from a few changes in the documentation comments, there are only two differences:
1. The SortedList class does not supply a sorting operation to the client. Such an operation is not needed, because the list components are assumed to be kept in sorted order at all times.
2. The SortedList class has an additional class member in the private part: a BinarySearch function. This function is an auxiliary (“helper”) function that is used only by other class member functions and is inaccessible to clients. We discuss its purpose when we examine the class implementation.
Let's look at which changes, if any, are required in the algorithms for the ADT operations, given that we are now working with a sorted list instead of an unsorted list.
Basic Operations
The algorithms for the class constructor, IsEmpty, IsFull, GetLength, ResetList, HasNext, and GetNextItem are identical to those used for the List class. The constructor sets the private data member length to 0, IsEmpty reports whether length equals 0, IsFull reports whether length equals MAX_LENGTH, GetLength returns the value of length, and the three iteration-related functions set up subsequent iterations, determine whether there is an unseen item, and get the next item.
Insertion
To add a new value to an already sorted list, we could store the new value at data[length], increment length, and sort the array again. However, such a solution is not an efficient way of solving the problem. Inserting five new items results in five separate sorting operations.
If we were to insert a value by hand into a sorted list, we would write the new value out to the side and draw a line showing where it belongs. To find this position, we start at the top and scan the list until we find a value greater than the one we are inserting. The new value goes in the list just before that point.
We can use a similar process in our Insert function. We find the proper place in the list using the by-hand algorithm. Instead of writing the value to the side, we shift all the values larger than the new one down one place to make room for it. The main algorithm is expressed as follows, where item is the value being inserted.
WHILE place not found AND more places to look
IF item > current component in list
Increment current position
ELSE
Place found
Shift remainder of list down
Insert item
Increment lengthAssuming that index is the place where item is to be inserted, the algorithm for Shift List Down is
Set data[length] = data[length-1]
Set data[length-1] = data[length-2]
. .
. .
. .
Set data[index+1] = data[index]
This algorithm is illustrated in FIGURE 13.7. It is based on how we would accomplish the task by hand. Often, such an adaptation is the best way to solve a problem. However, in this case, further thought reveals a slightly better way. Notice that we search from the front of the list (people always do), and we shift down from the end of the list upward. We can combine the searching and shifting by beginning at the end of the list.
If item is the new item to be inserted, we can compare item to the value in data[length-1]. If item is less than this value, we put data[length-1] into data[length] and compare item to the value in data[length-2]. This process continues until we find the place where item is greater than or equal to the item in the list. We then store item directly below it. Here is the algorithm:
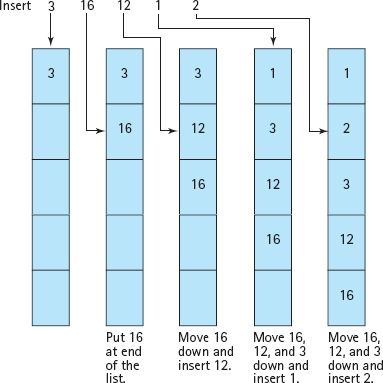
Figure 13.7 Inserting an Item into a Sorted List
Set index = length - 1 WHILE index >= 0 AND item < data[index] Set data[index + 1] = data[index] Decrement index Set data[index + 1] = item Increment length
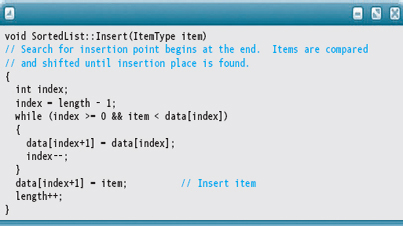
Notice that this algorithm works even if the list is empty. When the list is empty, length is 0 and the body of the While loop is not entered. Thus item is stored into data[0], and length is incremented to 1. Does the algorithm work if item is the smallest? The largest? Let's see: If item is the smallest, the loop body is executed length times, and index is −1. Thus item is stored into position 0, where it belongs. If item is the largest, the loop body is not entered. The value of index is still length-1, so item is stored into data[length], where it belongs.
Are you surprised that the general case also takes care of the special cases? This situation does not happen all the time, but it occurs often enough that it is good programming practice to start with the general case. If we begin with the special cases, we usually generate a correct solution, but we may not realize that we don't need to handle the special cases separately. So begin with the general case, then treat as special cases only those situations that the general case does not handle correctly.
This algorithm is the basis for another general-purpose sorting algorithm—an insertion sort, in which values are inserted one at a time into a list that was originally empty. The insertion sort is often used when input data must be sorted; each value is put into its proper place as it is read. We use this technique in the Problem-Solving Case Study at the end of this chapter.
Sequential Search
When we search for an item in an unsorted list, we won't discover that the item is missing until we reach the end of the list. If the list is already sorted, we know that an item is missing when we pass the place where it should be in the list. For example, suppose a list contains these values:
7
11
13
76
98
102
If we are looking for 12, we need only compare 12 with 7, 11, and 13 to know that 12 is not in the list.
If the search item is greater than the current list component, we move on to the next component. If the item is equal to the current component, we have found what we are looking for. If the item is less than the current component, then we know that it is not in the list. In either of the last two cases, we stop looking. We can restate this process algorithmically with the following code, in which found is set to true if the search item was found:
// Sequential search in a sorted list
index = 0;
while (index < length && item > data[index])
index++;
found = (index < length && item == data[index]);On average, searching a sorted list in this way takes the same number of iterations to find an item as searching an unsorted list. The advantage of this new algorithm is that we find out sooner if an item is missing. Thus it is slightly more efficient. There is an even better approach to searching in a sorted list, however.
Binary Search
A second search algorithm on a sorted list is considerably faster than a sequential search both for finding an item and for discovering that an item is missing. This algorithm is called a binary search. A binary search is based on the principle of successive approximation. The algorithm divides the list in half (divides by 2—that's why it's called binary search) and decides which half to look in next. Division of the selected portion of the list is repeated until the item is found or it is determined that the item is not in the list.
This method is analogous to the way in which we look up a word in a dictionary. We open the dictionary in the middle and compare the word with one on the page that we turned to. If the word we're looking for comes before this word, we continue our search in the left-hand section of the dictionary. Otherwise, we continue in the right-hand section of the dictionary. We repeat this process until we find the word. If it is not there, we realize that either we have misspelled the word or our dictionary isn't complete.
The algorithm for a binary search is given below. In this algorithm, the list of values is in the array data, and the value being looked for is item (see FIGURE 13.8).
1. Compare item to data[middle]. If item = data[middle], then we have found it. If item < data[middle], then we look in the first half of data. If item > data[middle], then we look in the second half of data.
2. Redefine data to be the half of data that we search next, and repeat Step 1.
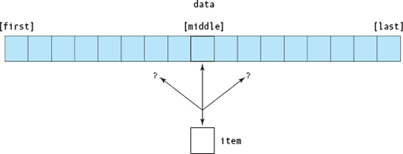
Figure 13.8 Binary Search
3. Stop when we have found item or know it is missing. We know it's missing when there is nowhere else to look and we still have not found it.
This algorithm should make sense. With each comparison, at best, we find the item for which we are searching; at worst, we eliminate half of the remaining list from consideration.
We need to keep track of the first possible place to look (first) and the last possible place to look (last). At any one time, we are looking only in data[first] through data[last]. When the function begins, first is set to 0 and last is set to length-1 to encompass the entire list.
Our three previous search algorithms have been Boolean observer operations. They just answer a simple question: Is this item in the list? Let's code the binary search as a void function that not only asks whether the item is in the list, but also asks which one it is (if the item is there). To do so, we need to add two parameters to the parameter list: a Boolean flag found (to tell us whether the item is in the list) and an integer variable position (to tell us which item it is). If found is false, position is undefined.
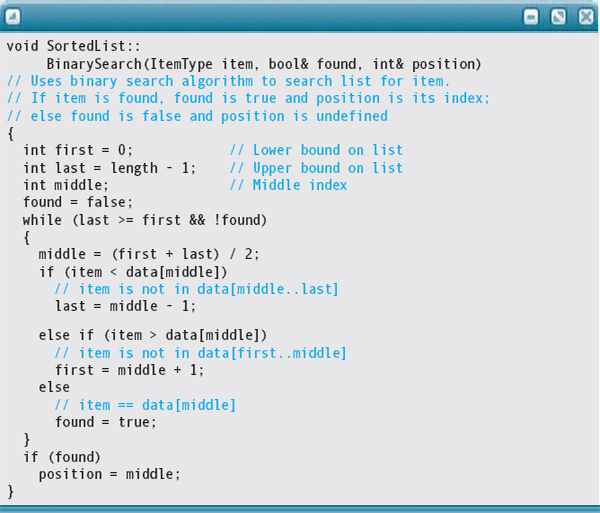
Should BinarySearch be a public member of the SortedList class? No. The function returns the index of the array element where the item was found. An array index is useless to a client of Sortedlist. The array containing the list items is encapsulated within the private part of the class and is inaccessible to clients. If you review the SortedList class declaration, you'll see that function BinarySearch is a private (not public), class member. We intend to use it as a helper function when we implement the public operations IsThere and Delete. The documentation reflects that it is a helper function: The function declaration has no documentation, and the function definition states what algorithm is used.
Let's do a code walk-through of the binary search algorithm. The value being searched for is 24. FIGURE 13.9A shows the values of first, last, and middle during the first iteration. In this iteration, 24 is compared with 103, the value in data[middle]. Because 24 is less than 103, last becomes middle-1 and first stays the same. FIGURE 13.9B shows the situation during the second iteration. This time, 24 is compared with 72, the value in data[middle]. Because 24 is less than 72, last becomes middle-1 and first again stays the same.
In the third iteration (FIGURE 13.9C), middle and first are both 0. The value 24 is compared with 12, the value in data[middle]. Because 24 is greater than 12, first becomes middle+1. In the fourth iteration (FIGURE 13.9D), first, last, and middle are all the same. Again, 24 is compared with the value in data[middle]. Because 24 is less than 64, last becomes middle-1. Now that last is less than first, the process stops; found is false.
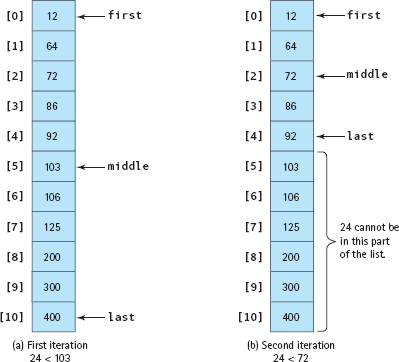
FIGURE 13.9A and B Code Walk-Through of BinarySearch Function (item is 13)
The binary search is the most complex algorithm that we have examined so far. The following table shows first, last, middle, and data[middle] for searches of the values 106, 400, and 406, using the same data as in the previous example. Examine the results in this table carefully.
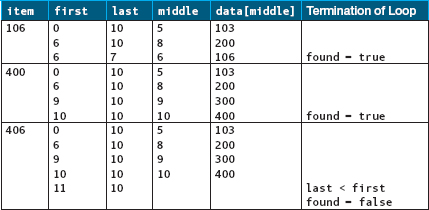
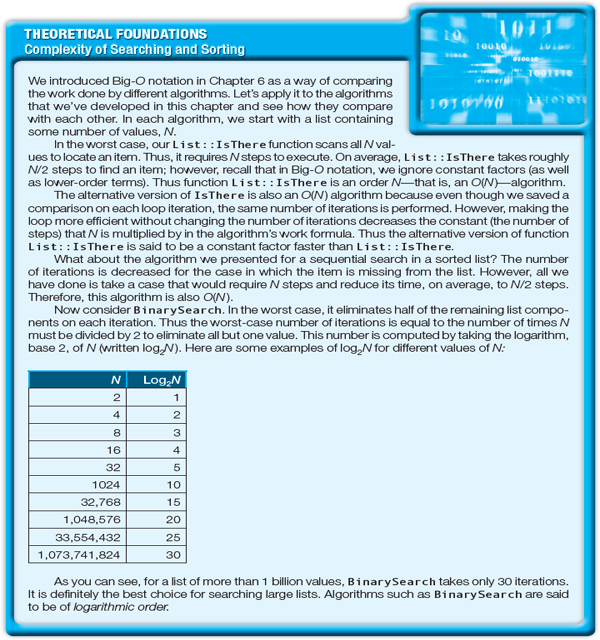
Notice in this table that whether we searched for 106, 400, or 406, the loop never executed more than four times. In fact, it never executes more than four times in a list of 11 components because the list is being cut in half each time through the loop. The following table compares a sequential search and a binary search in terms of the average number of iterations needed to find an item.
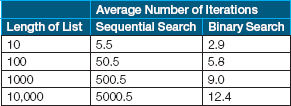
If the binary search is so much faster, why not use it all the time? It certainly is faster in terms of the number of times through the loop, but more computations are performed within the binary search loop than in the other search algorithms. Thus, if the number of components in the list is small (say, fewer than 20 items), a sequential search algorithm is faster because it performs less work at each iteration. As the number of components in the list increases, the binary search algorithm becomes relatively more efficient. Remember, however, that the binary search requires the list to be sorted, and sorting takes time. Keep three factors in mind when you are deciding which search algorithm to use:
1. The length of the list to be searched
2. Whether the list is already sorted
3. The number of times the list is to be searched
Given the BinarySearch function (a private member of the SortedList class), it's easy to implement the IsThere function (a public member of the class).
bool SortedList::IsThere (ItemType item) const // CALLS helper function BinarySearch to look for item { bool found; int position; // Not used but required for BinarySearch BinarySearch(item, found, position); return found; }
The body of IsThere calls BinarySearch, obtaining the result of the search in the variables found and position. Like the children's game of Pass It On, IsThere receives the value of found from BinarySearch and simply passes it on to the client (via the Return statement). The body of IsThere is not interested in where the item was found, so it ignores the value returned in the position argument. Why did we include this third argument when we designed BinarySearch? The answer is that the Delete operation, which we look at next, calls BinarySearch and does use the position argument.
Deletion
In the List class's Delete function, we deleted an item by moving up the last component in the list to fill the deleted item's position. Although this algorithm is fine for unsorted lists, it won't work for sorted lists. Moving the last component to an arbitrary position in the list is almost certain to disturb the sorted order of the components. Instead, we need a new algorithm for sorted lists.
Let's call BinarySearch to tell us the position of the item to be deleted. Then we can “squeeze out” the deleted item by shifting up all the remaining array elements by one position:
IF found Shift remainder of list up Decrement length
The algorithm for Shift List Up is
Set data[position] = data[position+1]
Set data[position+1] = data[position+2]
. .
. .
. .Here is the coded version of this algorithm:
void SortedList::Delete( ItemType item) // Calls helper function BinarySearch to find if the item is in the list // and the index position if there { bool found; // True if item is found int position; // Position of item, if found int index; // Index and loop control variable BinarySearch(item, found, position); if (found) { // Shift data[position..length-1] up one position for (index = position; index < length - 1; index++) data[index] = data[index+1]; length--; } }
Here is a similar client program that reads words, rather than numbers:

The only change necessary in the SortedList class was from
typedef int ItemType // Type of each component to using namespace std; typedef string ItemType; // Type of each component

13.5 Sorted List of Classes
In Chapter 12, we created an Entry class in preparation for an appointment calendar. Now let's create a sorted list of Entry objects. Sorted—by what? Name or time? Because we are looking ahead toward creating an appointment calendar, let's keep the list sorted by time.
Can we use our SortedList class as is or must we make some changes? If the items on the list can be compared using the relational operators, then the only change necessary is the type of ItemType. If the items on the list are of a type that cannot be compared by the relational operators, the class must provide a comparison operator. Our Entry class does not have a comparison function, but our TimeOfDay class does: ComparedTo. We must enhance class Entry with a ComparedTo function, which merely calls the TimeOfDay ComparedTo function.
Which SortedList functions need to be changed because they compare objects? Is-There, Insert, and Delete compare two objects. First we add function ComparedTo to class Entry.

Now we can examine the changes in the SortedList class.
IsThere
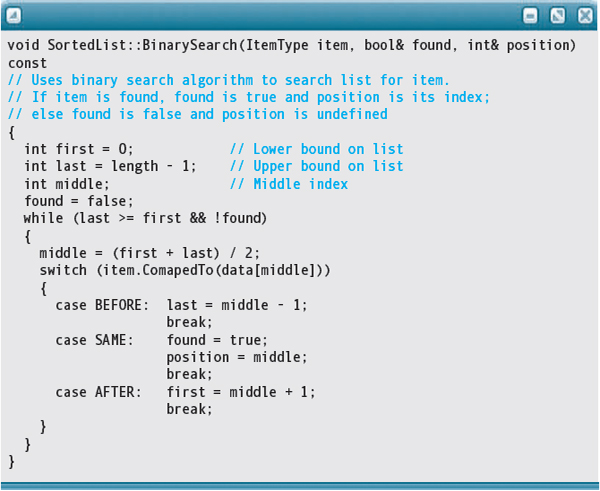
Because the list is sorted, we should first convert the BinarySearch algorithm. We need to replace the cascading If statements with a Switch statement using the result of ComparedTo. The initializations remain the same.
BinarySearch(In: item, Out: found, position)
WHILE last >= first and !found
Set middle to (first + last) / 2
SWITCH (item.ComparedTo(data[middle])
BEFORE: Set last to middle - 1
SAME: Set found to true
Set position to middle
AFTER: Set first to middle + 1IsThere(In: item) Return value: Boolean
BinarySearch(item, found, position) return found
Here is the revised code for function BinarySearch. IsThere doesn't change; it only calls BinarySearch.
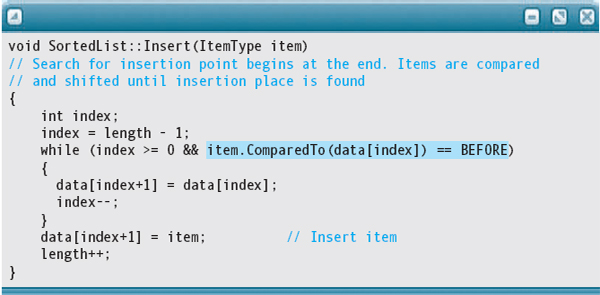
Insert and Delete
Function Delete calls BinarySearch to find the item to delete and makes no further comparison. Therefore, we don't need to make any changes in Delete. Insert repetitively compares item to a list value until one is found that is greater than item or there are no more values to check. Thus the code can be changed without having to rewrite the algorithm. The change is highlighted in the following code:
Here is a client program that inserts entries into a sorted list, demonstrates a test for a duplicate item, and then prints the list:
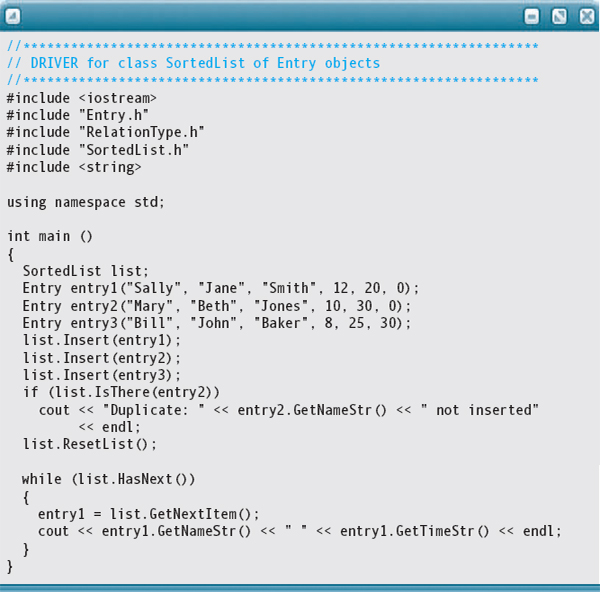
Output:

A word of caution is in order here: When you have classes that contain other classes that contain other classes, you should use the preprocessor commands
#ifndef SOMECLASS #define SOMECLASS … #endif
around the lower-level classes, to avoid duplicate definitions.
13.6 More on UML Diagrams
In Chapter 12, we introduced UML diagrams that show how classes relate to one another. It is clear that the sorted list of Entry objects is quite complex. Let's examine how the classes relate to one another.
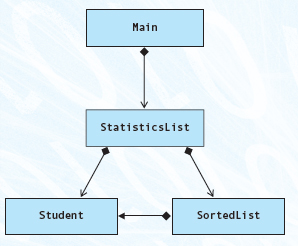
Class Entry contains (through composition) objects of classes Name and TimeOfDay.
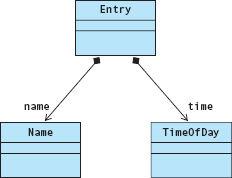
In turn, class SortedList contains an array of Entry objects.
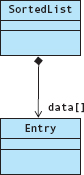
Now add the client program into the mix. What is its relationship to these classes? In our example, main declares three variables of type Entry and then inserts them into a variable of type SortedList. Through these our client program also contains objects of classes Name and TimeOfDay.
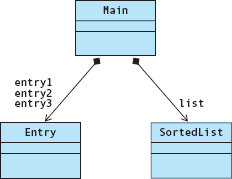
Technically, main is not a class, but rather a function. However, we give it a box in the UML diagram to show its relationship with the classes with which it interacts. In some other object-oriented programming languages, such as Java, main or its equivalent would be defined within a class because the class is the primary means of organizing code in those languages. Because C++ is more closely aligned with C, which is not object oriented, code in C++ can be organized into both classes and independent functions. Some programmers would argue that, to make a C++ application more purely object oriented, main should contain only a call to a method within a class; they would, therefore, omit main from the UML class diagram. Because we find it useful to have main do more than this, we diagram it as if it is in a separate class.
Problem-Solving Case Study
Calculating Exam Statistics Revisited
PROBLEM: You are the grader in your Government class. The teacher has asked you to prepare the following statistics. (No, this isn't a misprint! We are going to solve the same problem that we solved in Chapter 11, but in an entirely different way.) However, she has changed the input data and added some new output requirements. Each line in the input file contains a grade, which may be in either integer or real form, and a name. Three additional outputs must be provided: the name(s) of the students with the maximum grade, the names of the students above the average, and the names of the students below the average.
INPUT: A file, whose name is input from the keyboard, containing test grades.
OUTPUT: A file, whose name is input from the keyboard, showing the following statistics properly labeled:
Number of grades
Average grade
Lowest grade
Highest grade
Number of grades above the average
Number of grades below the average
Name of student(s) with the maximum grade
Names of students above the average
Names of students below the average
DISCUSSION: We have just designed and implemented several variations of a List class. Let's think about our current problem in terms of a list of grades. The first five tasks remain the same, but let's look at them in terms of list operations. We need to average the values in the list, find the maximum value in the list, find the minimum value in the list, count the number of values above the average, and count the number of values below the average. We know how to calculate an average: We sum the list of grades and divide by the number of grades. We found the minimum and maximum values in a file of numbers in the Studio Design program; the same algorithm can be used here. The third task involves looking at each grade, comparing it to the average, and incrementing one of two counters.
If all we had to do was find the average and the minimum and maximum grades, we could do the processing at the same time that we read the data values. However, the task of printing the number of grades above and below the average requires that each grade be examined twice: once to calculate the average, and again to compare each grade to the average. We can also find the minimum and maximum values as we initially read the grades.
The passive way of implementing this problem would be to pass the list of students/grades to functions that calculate the various statistics. The active (object-oriented) way of viewing the problem is to bind the list together with the operations into a class. But what would the structure look like? First we need a class that combines the student name and the grade. We have a Name class, but would a simple string do as well? You ask for a sample data file.
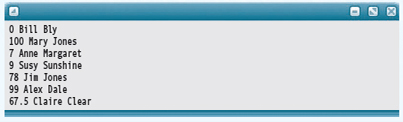
The grade comes first, followed by the first and last names. Thus the entire name could be read, stored, and printed as a single string. Should the grade be represented by an integer or a real number? Because both an integer and a real value can be read as a float, we can represent the grade as a real number. Which list class should we use to hold the grades? If we keep the list sorted by grade, we don't have to search for the minimum grade. Thus we need a ComparedTo function in the class that represents a student.
Here, then, is the specification for class Student:
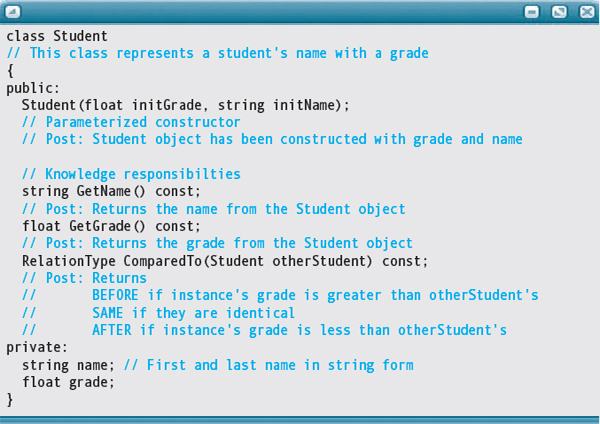
Which other data members do we need in addition to our list? At first glance, it looks like we need variables to hold the average, maximum grade, minimum grade, number below the average, and number above the average. On second thought, however, we realize that we can access the minimum grade directly, and we can calculate the number above the average from the number of grades and the number below the average. Here we are assuming that if a student has the average grade that he or she will be counted in the above-average group. Checking with the teacher, she confirms that our assumption is correct.
Now we can write the specification of our StatisticsList class:
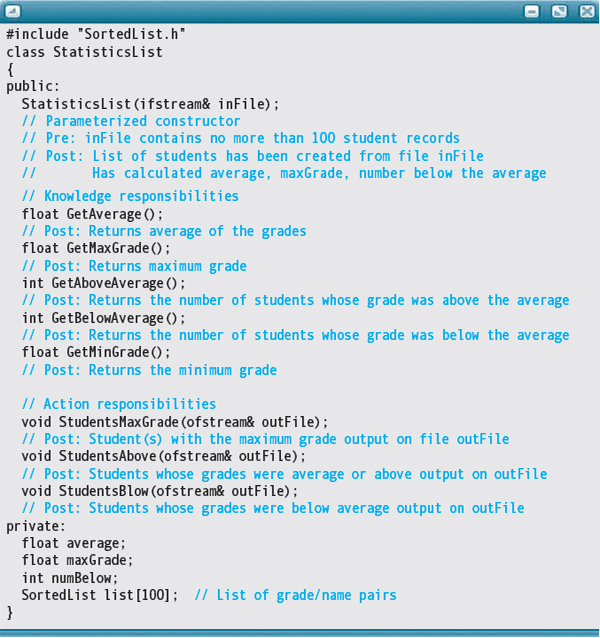
Where do all the calculations take place? In the constructor! The operations are bound within the class.
StatisticsList(In/out: inFile) (only constructor)
Get student
WHILE more students
Insert student into grade list
Set sum to sum plus student.GetGrade()
IF student.grade greater than maxSoFar
Set maxSoFar to student.GetGrade()
Get student
Set average to sum / list.GetLength()
WHILE (list.GetNextItem().GetGrade() < average)
Increment numBelowGet Student(In/out: inFile)
Return value: Student
inFile >> student.grade >> student.getline
GetStudent should be coded inline within the constructor.
The next five functions are just one line long and don't need further decomposition. The last three involve going through the list and writing the names of students who have the maximum grade, are above the average, or are below the average.
In getting the students with the maximum grade, there may be more than one such student. So first, we must look for the maximum grade and print the associated student. Then, we must cycle through the rest of the list printing associated names.
Students with Max Grade(In/out: outFile)
list.ResetList() Set student to GetNextItem() WHILE maxGrade > (student.GetGrade()) Set student to GetNextItem() Write on outFile student.GetName, “ had the maximum score.” WHILE list.HasNext() Write on outFile list.GetNextItem().GetName, “ had the maximum score.”
Students Above Average(In/out: outFile)
We know that there are numBelow people whose scores are below the average. Thus we must simply access and skip these students; then we write the rest of the list.
list.ResetList() FOR count going from 1 through numBelow Set item to list.GetNextItem() Write on outFile “Students who scored above the average:” FOR count going from numBelow+1 list.GetLength() Write on outFile list.GetNextItem.GetName()
Students Below(In/out: outFile)
We just need to access and print the first numBelow students, which are those students whose grades are below the average.
list.ResetList() Write on outFile “Students who scored below the average:” FOR count going from 1 through numBelow Write on outFile list.GetNextItem().GetName( )
We show only StatisticsList.cpp, the driver, and the input and output files here. We've seen the other files in this application earlier. Note that the SortedList class must be changed so that itemType is defined as Student.



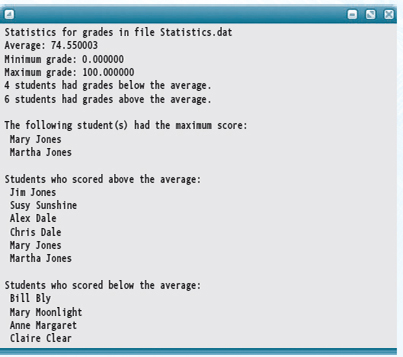
Here is a sample input file and the output file generated by a run of the application:
Statistics.dat:
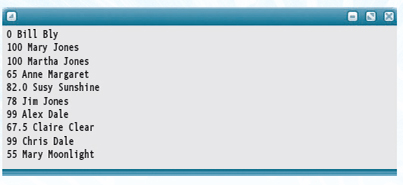
Statistics.out:
UML Diagrams: Here are the UML class diagrams for the classes in this problem.

Here is the UML diagram that shows how all of these classes are related.
TESTING: This implementation is based on a list of values. We must test for cases in which there are no grades, one grade, a few grades, and exactly the maximum number of grades. We already took care of the case where there were just a few grades. You are asked in the Case Study Follow-Up questions to design a full test plan for this Problem-Solving Case Study.
Which algorithm is more efficient: the array algorithm from Chapter 11 or the list algorithm? We can't answer that question because it depends on the range of possible grades and the sizes of the data sets. The amount of work done in the first solution is based on the range of grades; the loops go from 0 to 100 (or somewhere in between). The amount of work done in the second solution is based on the number of grades; the loops go from 0 to the number of grades. Thus the choice of algorithm depends on the context in which it will be used.
Testing and Debugging
In this chapter, we have discussed, designed, and coded algorithms to construct and manipulate items in a list. In addition to the basic list operations IsFull, IsEmpty, GetLength, ResetList, HasNext, and GetNextItem, the algorithms included three sequential searches, a binary search, insertion into sorted and unsorted lists, deletion from sorted and unsorted lists, and a selection sort. We have partially tested the List and SortedList classes, in which the items are numeric values or strings, and the SortedList class, in which the items are objects. We have tested our algorithms with lists of intermediate sizes. We should also test them with lists containing no components, one component, two components, MAX_LENGTH-1 components, and MAX_LENGTH components.
When we wrote the precondition stating that the list was not full for our list operations, we indicated that we could handle the problem another way—we could include an error flag in the function's parameter list. The function could call IsFull and set the error flag. With this approach, the insertion would not take place if the error flag were set to true. Both options are acceptable ways of handling the problem. The important point is that we clearly state whether the calling code or the called function is to check for the error condition. However, it is the calling code that must decide what to do when an error condition occurs. In other words, if errors are handled by means of preconditions, then the user must write the code to guarantee the preconditions. If errors are handled by flags, then the user must write the code to monitor the error flags.
Testing and Debugging Hints
1. Review the Testing and Debugging Hints for Chapter 12.
2. With string input, the >> operator stops at, but does not consume, the first trailing whitespace character. Likewise, if the get or getline function stops reading early because it encounters a newline character, the newline character is not consumed.
3. General-purpose functions (such as ADT operations) should be tested outside the context of a particular program, using a test driver.
4. Choose test data carefully so that you test all end conditions and some conditions in the middle. End conditions are those that reach the limits of the structure used to store them. For example, when testing a list, the test data should include cases in which the number of components is 0, 1, and MAX_LENGTH, as well as between 1 and MAX_LENGTH.
5. If a list ADT doesn't specify a precondition requiring the client to ensure that the number of items is less than a known maximum, be sure to include a test that verifies correct handling of an attempt to insert too many items.
6. Enclose lower-level classes in
#ifndef NAME #define NAME … #endif
![]() Summary
Summary
This chapter provided practice in working with lists stored in one-dimensional arrays. We examined algorithms that insert, delete, search, and sort data stored in a list, and we wrote functions to implement these algorithms. We can use these functions again and again in different contexts because they are members of general-purpose C++ classes (List and SortedList) that represent list ADTs.
We also saw algorithms for sequential and binary search, and for selection and insertion sorts. In developing our list classes, we explored the semantic distinctions between an unsorted list, an unsorted list with a sort operation, and a sorted list. Through all of this design effort, we gained greater experience in object-oriented design and the use of UML class diagrams.
![]() Quick Check
Quick Check
1. What are the three main properties of a list? (p. 642)
2. Where do we insert a new value into a list that isn't sorted? (p. 652)
3. If an item isn't in the list, when does a linear search discover that it is missing? (p. 653)
4. How does a sorted list ADT differ from a list ADT that includes a sort operation? (pp. 658–660)
5. When inserting into a sorted list, what happens to the components that precede the insertion point and the components that follow it? (pp. 660–662)
6. Where does the binary search algorithm get its name? (p. 663)
7. Which two members of a list class are used to represent the data in a list? (p. 646)
8. What are the major steps in deleting a value from a list? (p. 652)
9. Which operations in a sorted list are different from the operations in an unsorted list, and how do they differ? (pp. 660–664)
10. How many For loops are there in an implementation of a selection sort? (pp. 655- 658)
11. What condition ends a binary search? (p. 664)
![]() Answers
Answers
1. There are variable length, linear, and homogenous. 2. At the end of the list (assuming the list isn't already full). 3. When it has examined the last element in the list. 4. The components of a sorted list are always kept in order, but the components of a regular list are sorted only after the sort operation executes, and remain in order only until the next insertion or deletion. 5. The components that precede the insertion point remain where they are, and the ones following the insertion point shift over one place to make room. 6. The name comes from its pattern of dividing the area of the search by two on each iteration. 7. A data array containing the specified item type in each component, and a length represented by an int. 8. Search for the value, delete the value, shift any succeeding values up one place. 9. There is no sorting operation in the sorted list. The insert operation inserts a new value in its proper place rather than at the end of the list. The delete operation shifts the succeeding components up one place, rather than moving the last component into the vacated position. Searching in the sorted list can be done with a binary search rather than a linear search. 10. Two. 11. Either the value is found, or last is less than first and the value has not been found.
![]() Exam Preparation Exercises
Exam Preparation Exercises
1. Why do we say that a list is a “linear data structure”?
2. What do we mean when we say that a list is “homogeneous”?
3. If the Length operation associated with an unsorted list returns 43, and we then call the Delete operation for the list, passing it a value that matches the 21st item in the list:
a. What is the index of the component that is deleted?
b. What is the index of the component that takes its place?
c. What does the Length operation return after the deletion?
d. How many components in the list change their positions as a result of the deletion?
4. If ItemType is float, how do we need to change the following While loop condition, as written in the sequential search, and why do we need to change it?
while (index < length && item != data[index])
5. The following statements are supposed to swap two values in an array, but they are in the wrong order. Rearrange them into the proper order.
data[value2] = temp; data[value1] = data[value2]; temp = data[value1];
6. In a selection sort, what is accomplished by the inner loop each time it executes?
7. If the GetLength operation associated with a sorted list returns 43, and we then call the Delete operation for the list, passing it a value that matches the 21st item in the list:
a. What is the index of the component that is deleted?
b. What is the index of the component that takes its place?
c. What does the Length operation return after the deletion?
d. How many components in the list change their positions as a result of the deletion?
8. On average, a sequential search of a sorted list takes the same number of iterations as searching an unsorted list. True or false?
9. We should use a binary search for large sorted lists, but a sequential search is more efficient when a list has few components. True or false?
10. What is the log (base 2) of 32?
11. Why don't we need a separate sorting operation in a sorted list ADT?
12. A sorted list contains 16 elements, and the binary search operation is called with a value that matches the 12th value in the list. How many iterations does it take for the binary search to find this match?
13. Is the class Entry, as defined in this chapter, mutable?
14. Is our SortedList class mutable?
![]() Programming Warm-Up Exercises
Programming Warm-Up Exercises
1. Write a C++ Boolean function named Deleted that has three parameters: someItem (of type ItemType as used in this chapter), oldList, and newList (both of type List as defined in this chapter). The function returns true if someItem is found in oldList, but is not present in newlist.
2. The List type in this chapter allows us to store only one copy of an item in the list. Sometimes it is useful to have a list in which an item can appear any number of times. Change the implementation of the Insert function so that it adds an item to the list any time it is inserted.
3. What is wrong with the following code segment, and what must be changed in type List to make it work correctly?
List inVals;
for (int count = 1; count <= 100; count++)
{
cin >> inVal;
inVals.Insert(inVal);
}4. We would like to add a DeleteAll function to the List type from Exercise 2 that deletes all occurrences of an item from a list. Write the code that must be added to the specification file for the type to enable us to add this function.
5. Write the implementation of the DeleteAll function as described in Exercise 4.
6. We would like to add a Replace function to the List type in this chapter that takes two parameters, oldItem and newItem of ItemType. The function finds oldItem in the list, deletes it, and inserts newItem in its place. The list is unchanged if oldItem is not present in the list. Write the code that must be added to the specification file for the type to enable us to add this function.
7. Write the implementation of the Replace function as described in Exercise 6.
8. The SortedList type keeps items in ascending order. Which function(s) would need to be changed to make the list keep the items in descending order?
9. Change the implementation of the BinarySearch function so that it will work with a list that keeps items in descending order.
10. In Exercise 5, you wrote a DeleteAll function for the List type with duplicates. Implement a DeleteAll function for the SortedList type that allows duplicates, taking advantage of the fact that all occurrences of the item are stored in adjacent locations in the array. Note that the binary search does not necessarily return the position of the first occurrence of an item; it can return the position of any matching item. Thus, in this case, it may be more efficient to use a linear search to find the starting position for the matching items. Be sure that your function updates the length of the list as necessary.
11. In Exercise 6, you wrote a Replace function for the List type that deletes one value and replaces it with another. Reimplement the Replace function for the SortedList type. Note that in this case, the replacement value needs to be inserted in the proper position in the list to maintain the ordering of the items.
12. Write a code segment that fills a SortedList called inData with values that are input from a file called unsorted.
![]() Programming Problems
Programming Problems
1. Write a program using the List class from this chapter that implements a to-do list. The to-do items will be entered as strings. The user should be prompted to enter a command (add an item, mark an item as done or partially done, delete an item, and print the list) and data as necessary. Simply storing items in the list is easy, but the List class doesn't directly support the recording of the status of each task. You might want to go about this in several different ways. One approach would be to implement a struct or a class that represents an item and its status, and then modify the List class to work with this struct or class as its item type. Another way would be to keep three lists: Done, Partial, and Undone. When an item is created, it enters the Undone list. When its status is changed, it moves to one of the other lists as appropriate. Choose the approach that you prefer, and implement the application using proper style, effective prompts, and sufficient documentation.
2. Many instructors like to see the distribution of scores on an exam before they assign grades. You're working for an art history professor who has asked you to develop a program that will read all of the scores from an exam and print out a bar chart that shows their distribution. The range of the scores varies from exam to exam, and there are at most 250 students in the class. Use or modify the SortedList class from this chapter as necessary to help you do this task. The integer scores are entered into a file called exams.dat in random order. Your program's job is to read in the data, sort it, and output a bar chart with one * (star) for each exam that has a particular score. The first bar in the chart should be the highest score, and the last bar in the chart should be the lowest score. Each line of output should start with the score value, followed by the appropriate number of stars. When there is a score value that didn't appear on any exams, just output the value and no stars, then go to the next line.
3. Enhance the program in Problem 2 as follows: The data file now contains a score and a name. Modify the SortedList class so that it uses a struct consisting of the score and the name as its fields. The program should input the file data into the modified list. In addition to displaying the bar chart, the program should output the sorted list to a file called byscore.dat.
4. You've gathered lists of email addresses from a variety of sources, and now you want to send out a mass mailing to all of the addresses. However, you don't want to send out duplicate messages. All of the email addresses (represented as strings) have been combined on a single file called rawlist.dat. You need to write a program that reads all of the addresses and discards any that have been previously input. Use one of the list classes from this chapter, modifying it as necessary to work with string data, and to deal with as many as 1000 items. After all of the data have been read, output the new mailing list to a file called cleanlist.dat.
5. You're working for the state vehicle registry, and it just has been discovered that the people who make the license plates have been mistakenly producing occasional duplicates. You have a file (platesmade.dat) containing a list of plate numbers, which are recorded as the license plates are made. You need to write a program that reads this file and identifies any duplicates in the list so that notices can be sent out to recall them. The plate numbers, which consists of letters and numbers, should be stored as strings. Output the duplicates into a file called recallplates.dat. Use the SortedList class from this chapter to help you in writing this application, modifying it if necessary.
![]() Case Study Follow-Up
Case Study Follow-Up
1. Which of the two implementations of the statistics program (Chapter 11 or Chapter 13) do you think is clearer? Why?
2. For which function did StatisticsList not ensure the preconditions? Correct this error and rerun the driver, being sure to test whether the precondition is checked.
3. Write a test plan for the statistics program.
4. Is the StatisticsList class mutable? Explain your answer.
1. At the implementation level, a relationship also exists between the elements, but the physical relationship may not be the same as the logical one.