
| 12 | Classes and Abstraction |
KNOWLEDGE GOALS
![]() To understand the difference between specification and implementation of an abstract data type.
To understand the difference between specification and implementation of an abstract data type.
![]() To understand the concepts of encapsulation and abstraction.
To understand the concepts of encapsulation and abstraction.
![]() To understand how control and data abstraction facilitate modifiability and reuse.
To understand how control and data abstraction facilitate modifiability and reuse.
![]() To understand the basic class design principles.
To understand the basic class design principles.
![]() To understand how encapsulation and information hiding are enforced by the C++ compiler.
To understand how encapsulation and information hiding are enforced by the C++ compiler.
SKILL GOALS
To be able to:
![]() Declare a C++ class type.
Declare a C++ class type.
![]() Declare class objects, given the declaration of a class type.
Declare class objects, given the declaration of a class type.
![]() Write client code that invokes class member functions.
Write client code that invokes class member functions.
![]() Implement class member functions.
Implement class member functions.
![]() Organize the code for a C++ class into two files: the specification (.h) file and the implementation file.
Organize the code for a C++ class into two files: the specification (.h) file and the implementation file.
![]() Write a C++ class constructor.
Write a C++ class constructor.
Chapter 9 introduced the concept of control abstraction, in which the outward operation of a function is separated from its internal implementation. In the last two chapters, we learned how to define and use new data types. In this chapter, we add the analogous concept of data abstraction, the separation of a data type's logical properties from its implementation. Data abstraction, when combined with control abstraction, is embodied by the concept of the abstract data type. We first revisit the idea of abstract data types, and then introduce the C++ language feature through which we can implement them: the class. Using classes, we bind data and actions together into self-contained entities called objects—which is the foundation of object-oriented programming.
12.1 Abstract Data Types
We live in a complex world. Throughout the course of each day, we are constantly bombarded with information, facts, and details. To cope with complexity, the human mind engages in abstraction—the act of separating the essential qualities of an idea or object from the details of how it works or is composed.
With abstraction, we focus on the what, not the how. For example, our understanding of automobiles is largely based on abstraction. Most of us know what the engine does (it propels the car), but fewer of us know—or want to know—precisely how the engine works internally. Abstraction allows us to discuss, think about, and use automobiles without having to know everything about how they work.
In the world of software design, it is now recognized that abstraction is an absolute necessity for managing immense, complex software projects. In introductory computer science courses, programs are usually small (perhaps 50 to 200 lines of code) and understandable in their entirety by one person. By comparison, large commercial software products composed of hundreds of thousands—even millions—of lines of code cannot be designed, understood, or tested thoroughly without using abstraction in various forms. To manage complexity, software developers regularly use two important abstraction techniques: control abstraction and data abstraction.
In Chapter 9, we defined control abstraction as the separation of the logical properties of an action from its implementation. We engage in control abstraction whenever we write a function that reduces a complicated algorithm to an abstract action performed by a function call. By invoking a library function, as in the expression
4.6 + sqrt(x)
we depend only on the function's specification, a written description of what it does. We can use the function without having to know its implementation (the algorithms that accomplish the result). By invoking the sqrt function, our program is less complex because all the details involved in computing square roots remain hidden.
Abstraction techniques also apply to data. Every data type consists of a set of values (the domain) along with a collection of allowable operations on those values. As we mentioned in the introduction to this chapter, data abstraction is the separation of a data type's logical properties from its implementation details. Data abstraction comes into play when we need a data type that is not built into the programming language. We then define the new type as an abstract data type (ADT), concentrating only on its logical properties and deferring the details of its implementation.
Abstract data type A data type whose properties (domain and operations) are specified independently of any particular implementation.
As with control abstraction, an abstract data type has both a specification (the what) and an implementation (the how). The specification of an ADT describes the characteristics of the data values as well as the behavior of each of the operations on those values. The user of the ADT needs to understand only the specification, not the implementation, to use it.
Here's a very informal specification of a list ADT that contains integer numbers:
TYPE
IntList
DOMAIN
Each IntList value is a collection of up to 100 separate integer numbers.
OPERATIONS
Create a list
Insert an item into the list.
Delete an item from the list.
Search the list for an item.
Return the current length of the list.
Sort the list into ascending order.
Print the list.
Notice the complete absence of implementation details. We have not mentioned how the data might actually be stored in a program (it could be in an array, or on a file, or in a struct) or how the operations might be implemented (for example, the length operation could keep the number of elements in a variable, or it could count the elements each time it is called). Concealing the implementation details reduces complexity for the user and also shields the user from changes in the implementation.
Following is the specification of another ADT, one that might be useful for representing TimeOfDay in a program.
TYPE
TimeOfDay
DOMAIN
Each TimeOfDay value is a time of day in the form of hours, minutes, and seconds.
OPERATIONS
Create a time object.
Print (or write) the time.
Return an object containing the time, incremented by one second.
Compare two times for equality.
Determine if one time is “less than” (comes before) another.
Although we refer to “time” in our informal list of operations, we are careful to call this ADT “TimeOfDay” to differentiate it from elapsed time, which also might be a useful ADT.
The specification of an ADT defines data values and operations in an abstract form that can be given as documentation to both the user and the programmer. Ultimately, of course, the ADT must be implemented in program code. To implement an ADT, the programmer must do two things:
1. Choose a concrete data representation of the abstract data, using data types that already exist.
Data representation The concrete form of data used to represent the abstract values of an abstract data type.
2. Implement each of the allowable operations in terms of program instructions.
To implement the IntList ADT, we could choose a concrete data representation consisting of a record with two items: a 100-element array in which to store the items and an int variable that keeps track of the number of items in the list. To implement the IntList operations, we must create algorithms based on the chosen data representation.
To implement the TimeOfDay ADT, we might use three int variables for the data representation— one for the hours, one for the minutes, and one for the seconds. Alternatively, we might use three strings as the data representation. Or we might keep the TimeOfDay as seconds and convert the TimeOfDay to hours, minutes, and seconds as needed. The specification of the ADT does not confine us to any particular data representation. As long as we satisfy the specification, we are free to choose among the various alternative data representations and their associated algorithms. Our choice may be based on time efficiency (the speed at which the algorithms execute), space efficiency (the economical use of memory space), or simplicity and readability of the algorithms. Over time, you will acquire knowledge and experience that will help you decide which implementation is best for a particular context.

12.2 C++ Classes
In previous chapters, we have treated data values as passive quantities to be acted upon by functions. That is, we have passed values to and from functions as arguments, and our functions performed some operation. We took the same approach even when we defined new data types. For example, in Chapter 10, we viewed a student record as passive data, and we implemented operations on the data type as functions to which we passed a record. Similarly, in Chapter 11, we treated an array as a passive quantity, passing it to functions to be processed. (See FIGURE 12.1.)
This separation of operations and data does not correspond very well with the notion of an abstract data type. After all, an ADT consists of both data values and operations on those values. It is preferable to view an ADT as defining an active data structure—one that contains both data and operations within a single, cohesive unit (see FIGURE 12.2). C++ supports this view through the structured type known as a class.
Class A data type in a programming language that is used to represent an abstract data type.

Figure 12.1 Data and Operations as Separate Entities
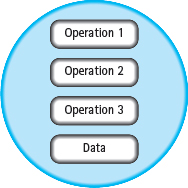
Figure 12.2 Data and Operations Bound into a Single Unit
In Figure 10.2, we listed the four structured types available in the C++ language: the array, the struct, the union, and the class. A class can be used to represent a record but is almost always designed so that its components (class members) include not only data but also functions that manipulate that data.1
Class member A component of a class. Class members may be either data or functions.
Here is the syntax template for the C++ class:
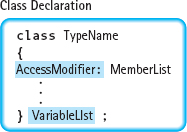
AccessModifier is defined as either of the two keywords, public or private:

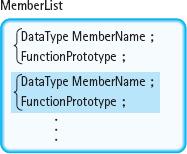
MemberList is one or more declarations of fields or functions:
Here is a C++ class declaration corresponding to the TimeOfDay ADT that we defined in the previous section:
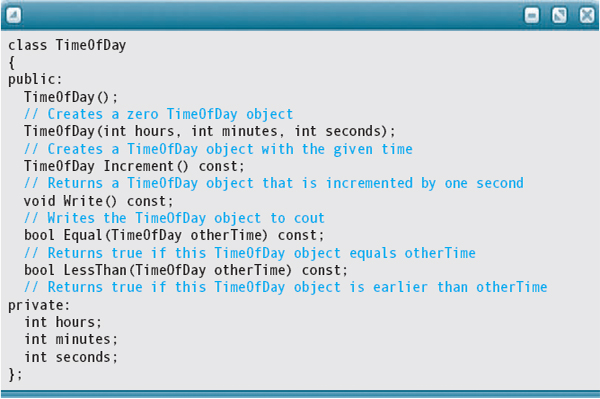
(For now, ignore the word const appearing in some of the function prototypes. We explain this use of const later in the chapter.)
The TimeOfDay class has nine members—four member functions (Increment, Write, Equal, LessThan), three member variables (hours, minutes, seconds), and two strangelooking constructs that look something like functions, but have no return value. The latter are examples of a special function called a class constructor. A constructor is a member function that is implicitly invoked whenever a class object is declared (created). A constructor function has an unusual name: the name of the class itself. It is not preceded by either a return type or the keyword void.
Our class declaration includes two constructors, differentiated by their parameter lists. The first constructor is parameterless and initializes a TimeOfDay object to some default value, such as 00:00:00, when it is declared. A parameterless constructor is known in C++ as a default constructor. The second has three int parameters, which are used to initialize the private data members when a class object is declared.
TimeOfDay startTime; // Create a 0 TimeOfDay object
TimeOfDay endTime(10, 24, 3); // Create a TimeOfDay object with 10
// hours, 24 minutes, and 3 seconds
As you might guess, the three data member variables (hours, minutes, and seconds) form the concrete data representation for the TimeOfDay ADT. The familiar-looking member functions correspond to the operations we listed for the TimeOfDay ADT: return a TimeOfDay object incremented by one second, print the time, compare two times for equality, and determine if one TimeOfDay object is less than another. Although the Equal function compares two TimeOfDay variables for equality, its parameter list has only one parameter—a TimeOfDay variable. Similarly, the LessThan function has only one parameter, even though it compares two times. We'll see why when we look at the implementation of the class.
Like a struct declaration, the declaration of the TimeOfDay class defines a data type but does not create variables of the type. Class variables (more often referred to as class objects or class instances) are created by using ordinary variable declarations, as shown earlier. Any software that declares and manipulates TimeOfDay objects is called a client of the class.
Class object (class instance) A variable of a class type.
Client Software that declares and manipulates objects of a particular class.
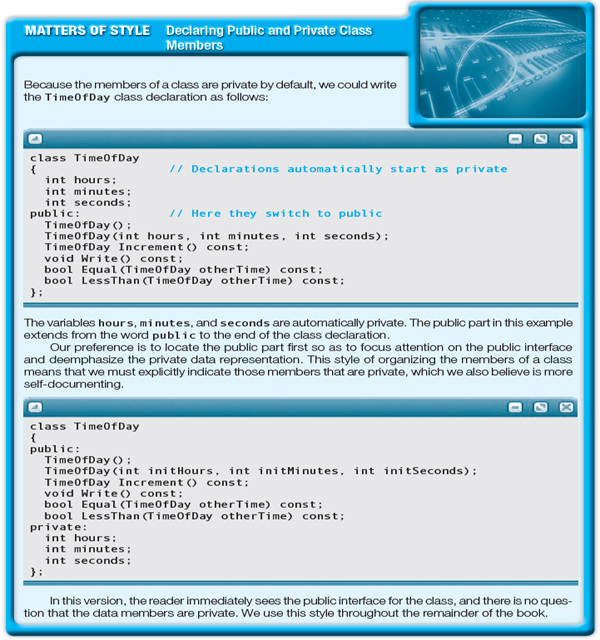
When you look at the preceding declaration of the TimeOfDay class, you will see the reserved words public and private, each followed by a colon. Data and/or functions declared following the word public and before the word private constitute the public interface; clients can access these class members directly. Class members declared after the word private are considered private information and are inaccessible to clients. If client code attempts to access a private item, the compiler will produce an error message.
Private class members can be accessed only by the class's member functions. In the TimeOfDay class, the private variables hours, minutes, and seconds can be accessed only within the member functions Increment, Write, Equal, and LessThan, not by client code. This separation of class members into private and public parts is a hallmark of ADT design. To preserve the properties of an ADT correctly, an instance of the ADT should be manipulated only through the operations that form the public interface. We will have more to say about this issue later in the chapter.
C++ does not require you to declare public and private class members in a fixed order. By default, class members are private; the word public is used to “open up” any members for public access. Once you have done so, if you wish to declare subsequent members as private, you must insert the private reserved word, as we did in the preceding example. A class can contain any number of public and private sections.
Regarding public versus private accessibility, we can now describe more fully the difference between C++ structs and classes. C++ defines a struct to be a class whose members are all, by default, public. In contrast, members of a class are, by default, private. Furthermore, it is common practice to use only data—not functions—as members of a struct. Note that you can declare struct members to be private and you can include member functions in a struct—but then you might as well use a class! Hence, most programmers use the struct in the manner that is traditional from C, as a way to represent a record structure, and implement ADTs only with classes.
Implementing the Member Functions
Let's take a look at how we implement the TimeOfDay class. There are many subtle details that we have yet to cover formally, and we'll point some of them out along the way. But don't worry: We'll come back to the C++ rules that govern all of these issues later. For now, we want to drill down into some concrete code, so that you can begin to get a sense of how a real class is implemented.
Constructors
The constructors for TimeOfDay are very straightforward. In the default constructor, 0 is stored in each data field.
TimeOfDay::TimeOfDay()
{
hours = 0;
minutes = 0;
seconds = 0;
}
In the parameterized constructor, the first parameter is stored in hours, the second is stored in minutes, and the third is stored in seconds.
TimeOfDay::TimeOfDay(int initHours, int initMinutes,
int initSeconds)
{
hours = initHours;
minutes = initMinutes;
seconds = initSeconds;
}
Note that the name of the class must precede the name of each function, with the :: scope resolution operator appearing in between. This format indicates to which class the function definition belongs.
Increment
In this function we are returning a new object that is the same as the current object, except that it has been incremented by one second. In C++, we also refer to the current object as the instance, meaning the object to which a member function is applied. Keep in mind that member functions are defined within a class; thus, when you invoke one of them, it is running within the context of the other declarations within its class. This is a different notion of executing a function than we're used to—the member function is not running separately at the level of main.
We'll soon take a closer look at the semantics of member function execution. For now, just note that we use different terminology (instance to which it is applied) as a way to remind ourselves that a function is executing in a different environment.
The first step in Increment is to declare a duplicate of the TimeOfDay object to which the function is applied. To do so, we need to call the parameterized constructor, passing it the data members of the current object.
TimeOfDay TimeOfDay::Increment() const
{
// Create a duplicate of instance
TimeOfDay result(hours, minutes, seconds); // Constructor call
Notice that we do not pass anything into the Increment function. Because it resides inside the current object (instance), it has access to all of the values it needs to create the new object.
Next the seconds data member (of the duplicate) is incremented. If this action makes the value greater than 59, seconds must be set to 0, and the minutes data member must be incremented. If it makes the value of minutes greater than 59, then it must be set to 0, and the hours data member must be incremented. If the hours data member becomes greater than 23, it must be set to 0.
result.seconds++; // Increment seconds
if (result.seconds > 59) // Adjust if seconds carry
{
result.seconds = 0;
result.minutes++;
if (result.minutes > 59) // Adjust if minutes carry
{
result.minutes = 0;
result.hours++;
if (result.hours > 23) // Adjust if hours carry
result.hours = 0;
}
}
return result;
}
Look closely at the difference between how we accessed the member fields of the instance in the constructor call and how we access the fields of the result object. We can refer directly to members of the instance (hours, minutes, seconds). When we want to access members of another object, however, we must use dot notation, just as we did for a struct (result.hours, result.minutes, result.seconds).
Wait—how can we access the data members of the result object? Aren't they private? Yes, but in C++, the private keyword only restricts access by client code. Within the implementation of a class, we are allowed to access the private members of any objects of the same class.
Write
To make the time uniform, we want to print two digits for each field, so we must check whether the value in each field is a single digit. If it is, we must print a 0 before we print the value. Again, notice that nothing is passed into Write—it automatically has access to the member fields of the instance.
void TimeOfDay::Write() const
{
if (hours < 10)
cout << '0';
cout << hours << ':';
if (minutes < 10)
cout << '0';
cout << minutes << ':';
if (seconds < 10)
cout << '0';
cout << seconds;
}
LessThan
This Boolean operation compares two objects of class TimeOfDay: The first is the instance, and the second is passed in through a parameter of the function. As we saw with Increment, the data members of the instance can be accessed directly, but the data members of the other object must be accessed with dot notation.
How do we compare times? First we check the hours. If they are the same, we then check the minutes. If they are the same, we check the seconds. Let's look at this process in algorithm form.
LessThan(In: otherTime) Return value: Boolean
IF (hours < otherTime.hours) Return True ELSE IF (hours > otherTime.hours) Return False ELSE IF (minutes < otherTime.minutes) Return True ELSE IF (minutes > otherTime.minutes) Return False ELSE IF (seconds < otherTime.seconds) Return True ELSE Return False
This algorithm can also be expressed using logical operators, as shown here:
hours < otherTime.hours || hours == otherTime.hours
&& minutes < otherTime.minutes || hours == otherTime.hours
&& minutes == otherTime.minutes
&& seconds < otherTime.seconds)
Which depiction is better? This is purely a matter of style. The first version is easier to read and, therefore, to debug. The second version is more elegant. In this case we opt for elegance.
bool TimeOfDay::LessThan(TimeOfDay otherTime) const
{
return (hours < otherTime.hours || hours == otherTime.hours
&& minutes < otherTime.minutes || hours == otherTime.hours
&& minutes == otherTime.minutes
&& seconds < otherTime.seconds);
}
Equal
As in the LessThan function, the two objects being compared by Equal are the instance to which the function is applied and the parameter. The function returns true if all three data fields are identical and false otherwise.
bool TimeOfDay::Equal(TimeOfDay otherTime) const
{
return (hours == otherTime.hours
&& minutes == otherTime.minutes
&& seconds == otherTime.seconds);
}
Classes, Objects, and Members
It is important to restate that a class is a type, not an object. Like any type, a class is a pattern from which you can create many concrete values of that type. With a class, these values are called objects. We say that we instantiate the class to make an object. An object is an instance (concrete example) of its class. Think of a class as a cookie cutter and objects of that class as the cookies.
The declarations
TimeOfDay time1; TimeOfDay time2(17, 58, 2);
create two objects that are instances of the TimeOfDay class: time1 and time2.
The pattern specified by the private data member declarations in the class is that each object of class TimeOfDay should have member variables called hours, minutes, and seconds. Thus time1 has its own variables called hours, minutes, and seconds, and time2 has a separate set of variables called hours, minutes, and seconds. time1's hours, minutes, and seconds contain the values 0, 0, and 0, whereas time2's variables contain the values 17, 58, and 2. FIGURE 12.3 provides a visual image of the objects time1 and time2.

Figure 12.3 Conceptual View of Two Objects
(In truth, the C++ compiler does not waste memory by placing duplicate copies of a member function—say, Increment—into both time1 and time2. Instead, the compiler generates just one physical copy of Increment, and it executes this one copy of the function whenever it is called from any class instance. Nevertheless, the diagram in FIGURE 12.3 is a good mental picture of two different class objects.)
Be sure you are clear about the difference between the terms object and member. FIGURE 12.3 depicts two objects of the TimeOfDay class, and each object has nine members.
Built-in Operations on Objects
In many ways, programmer-defined classes are like built-in types. For example, you can declare as many objects of a class as you like. You can pass objects as arguments to functions and return them as function values. Like any variable, an object can be automatic (that is, it is created each time control reaches its declaration and destroyed when control exits its surrounding block) or static (that is, it is created once when control reaches its declaration and destroyed when the program terminates).
In other ways, C++ treats structs and classes differently from built-in types. Most of the built-in operations do not apply to structs or classes. For example, you cannot use the + operator to add two TimeOfDay objects, nor can you use the == operator to compare two TimeOfDay objects for equality.
Two built-in operations that are valid for struct and class objects are member selection (.) and assignment (=). As with structs, you select an individual member of a class by using dot notation. That is, you write the name of the class object, then a dot, then the member name. The statement
TimeOfDay time3 = time1.Increment();
invokes the Increment function for the time1 object, presumably to create an object that is one second later than time1. The other built-in operation, assignment, performs aggregate assignment of one class object to another with the following semantics: If x and y are objects of the same class, then the assignment x = y copies the data members of y into x. Following is a fragment of client code that demonstrates member selection and assignment:
int inputHours; int inputMinutes; int inputSeconds; TimeOfDay time1(5, 20, 0); cout << “Enter hours, minutes, seconds: “; cin >> inputHours >> inputMinutes >> inputSeconds; TimeOfDay time2(inputHours, inputMinutes, inputSeconds); if (time1.LessThan(time2)) DoSomething(); time2 = time1; // Member-by-member assignment time2.Write(); // 05:20:00 has been output
From the very beginning, you have been working with C++ classes in a particular context: input and output. The standard header file iostream contains the declarations of two classes—istream and ostream—that manage a program's I/O. The C++ standard library declares cin and cout to be objects of these classes:
istream cin; ostream cout;
The istream class has many member functions, two of which—the get function and the ignore function—you have already seen in statements like these:
cin.get(someChar); cin.ignore(200, ' '),
As with any C++ class object, we use dot notation to select a particular member function to invoke.
You have also used C++ classes when performing file I/O. The header file fstream contains declarations for the ifstream and ofstream classes. The client code
ifstream dataFile; dataFile.open(“input.dat”);
declares an ifstream class object named dataFile, then invokes the class member function open to try to open the file input.dat for input.
We will not examine in detail the istream, ostream, ifstream, and ofstream classes and all of their member functions. To study these classes would be beyond the goals of this book. What is important to recognize is that classes and objects are fundamental to all I/O activity in a C++ program.
Class Scope
We said earlier that member names must be unique within a struct. Additionally, in Chapter 9 we mentioned four kinds of scope in C++: local scope, global scope, namespace scope, and class scope. Class scope applies to the member names within structs, unions, and classes. To say that a member name has class scope means that the name is bound to that class (or struct or union). If the same identifier happens to be declared outside the class, the two identifiers are unrelated.
Let's look at an example. The TimeOfDay class has a member function named Write. In the same program, another class (say, SomeClass) could also have a member function named Write. Furthermore, the program might have a global Write function that is completely unrelated to any classes. If the program has statements like
TimeOfDay checkInTime; SomeClass someObject; int n; . . . checkInTime.Write(); someObject.Write(); Write(n);
then the C++ compiler has no trouble distinguishing among the three Write functions. The first two are function applications, where the dot notation denotes member selection in the context of the specific class instance (object). The first statement invokes the Write function of the TimeOfDay class for the checkInTime object, and the second statement invokes the Write function of the SomeClass class for the someObject instance of that class. The final statement does not use dot notation, so the compiler knows that the global Write function is being called.
12.3 Information Hiding
Conceptually, an object has an invisible wall around it. This wall, called the abstraction barrier, protects private data and functions from being accessed by client code. The same barrier also prohibits the object from directly accessing data and functions outside the object. This barrier is a critical characteristic of classes and abstract data types.
Abstraction barrier The invisible wall around an object that encapsulates implementation details. The wall can be breached only through the public interface.
Black box A device whose inner workings remain hidden from view.
Information hiding The encapsulation and hiding of implementation details to keep the user of an abstraction from depending on or incorrectly manipulating these details.
For an object to share information with the outside world (that is, with clients), there must be a gap in the abstraction barrier. This gap is the public interface—the members declared to be public. If the only public members are functions and constants, and if we keep all of the member variables private, then the only way that a client can manipulate the internal values of the object is indirectly—through the operations in the public interface.
Electrical engineers work with a similar concept called a black box. A black box is a module or device whose inner workings remain hidden from view. The user of the black box depends only on the written specification of what it does, not on how it does it. The user connects wires to the interface and assumes that the module works correctly if it satisfies the specification (see FIGURE 12.4).
In software design, the black box concept is referred to as information hiding. Information hiding protects the user of a class from having to know all of the details of its implementation. Information hiding also assures the class's implementor that the user cannot directly access any private code or data to compromise the correctness of the implementation.
You have already been introduced to encapsulation and information hiding in this book. In Chapter 8, we discussed the possibility of hiding a function's implementation in a separate file. In this chapter, we will see how to hide the implementations of class member functions by placing them in files that are kept separate from the client code.
The creator of a C++ class is free to choose which members will be private and which will be public. However, making data members public (as in a struct) allows the client to inspect and modify the data directly. Because information hiding is so fundamental to data abstraction, most classes exhibit a typical pattern: The private part contains data, and the public part contains the functions that manipulate the data.

Figure 12.4 A Black Box
The TimeOfDay class exemplifies this organization. The data members hours, minutes, and seconds are private, so the compiler prohibits a client from accessing them directly. As a consequence, the following client statement results in a compile-time error:
TimeOfDay checkInTime; checkInTime.hours = 9; // Prohibited in client code
Because only the class's member functions can access the private data, the creator of the class can offer a reliable product, knowing that external access to the private data is impossible. If it is acceptable to let the client inspect (but not modify) private data members, then a class might provide observer functions. The TimeOfDay class has four such functions: Write, Increment, Equal, and LessThan. Because these observer functions are not intended to modify the private data, they are declared with the word const following the parameter list:
void Write() const; TimeOfDay Increment() const; bool Equal(TimeOfDay) const; bool LessThan(TimeOfDay) const;
C++ refers to these functions as const member functions. Within the body of a const member function, a compile-time error occurs if any statement tries to modify any of the private instance variables. Although not required by the language, it is good practice to declare as const those member functions that should not modify private data within the object.
User-Written Header Files
As you create your own user-defined data types, you will often find that a data type can be useful in more than one program. For example, suppose you are working on several programs that need an enumeration type consisting of the names of the 12 months of the year. Instead of typing the statement
enum Months
{
JANUARY, FEBRUARY, MARCH, APRIL, MAY, JUNE,
JULY, AUGUST, SEPTEMBER, OCTOBER, NOVEMBER, DECEMBER
};
at the beginning of every program that uses the Months type, you can put this statement into a separate file named, say, months.h. You can then use months.h just as you use systemsupplied header files such as iostream and cmath. By using an #include directive, you ask the C++ preprocessor to physically insert the contents of the file into your program. (Although many C++ systems use the filename extension .h [or no extension at all] to denote header files, other systems use extensions such as .hpp or .hxx.)
When you enclose the name of a header file in angle brackets, as in
#include <iostream>
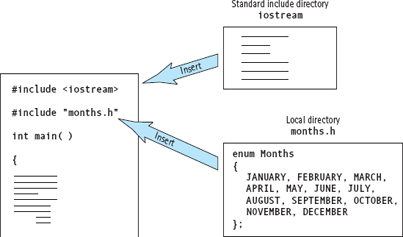
Figure 12.5 Including Header Files
the preprocessor looks for the file in the standard include directory, which contains all the header files supplied by the C++ system. If you enclose the name of a header file in double quotes,
#include “months.h”
then the preprocessor will look for the file in the programmer's current directory. This mechanism allows us to write our own header files that contain type declarations and constant declarations. We can use a simple #include directive instead of retyping the declarations in every program that needs them (see FIGURE 12.5).
Header files also play an important role in preserving information hiding when we implement a class, as we see next.
Specification and Implementation Files
An abstract data type consists of two parts: a specification and an implementation. The specification describes the behavior of the data type without reference to its implementation. The implementation creates an abstraction barrier by hiding both the concrete data representation and the code for the operations.
The TimeOfDay class declaration serves as the specification of TimeOfDay. This declaration presents the public interface to the user in the form of function prototypes. To implement the TimeOfDay class, we provided function definitions for all the member functions.
In C++, it is customary (but not required) to package the class declaration and the class implementation into separate files. One file—the specification file—is a header (.h) file containing only the class declaration. The second file—the implementation file—contains the function definitions for the class member functions. Let's look first at the specification file.
The Specification File
Following is the specification file for the TimeOfDay class. This class declaration is the same as the one we presented earlier with one exception: We include function preconditions and postconditions to specify the semantics of the member functions as unambiguously as possible for the user of the class.

In principle, a specification file should not reveal any implementation details to the user of the class. The file should specify what each member function does without disclosing how it does it. However, as you can see in the preceding class declaration, one implementation detail is visible to the user: The concrete data representation of our ADT is listed in the private part. Nonetheless, the data representation is still considered hidden information in the sense that the compiler prohibits client code from accessing the data directly.
Here is a client program that manipulates two objects of class TimeOfDay. This program is written without knowing how the class is implemented.
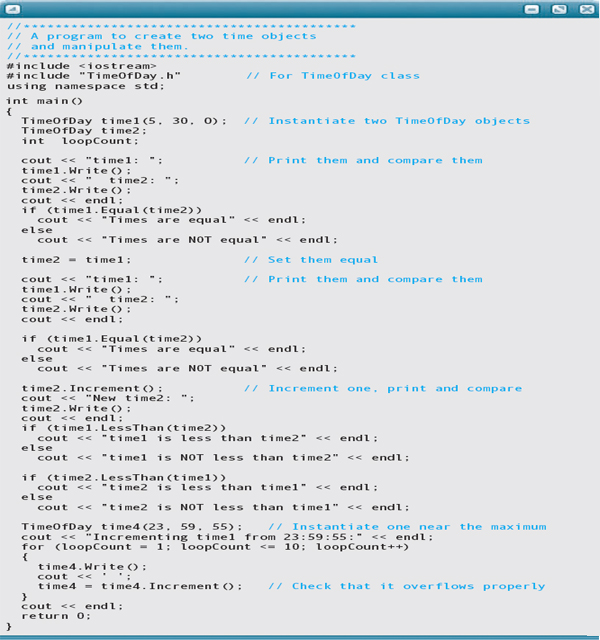
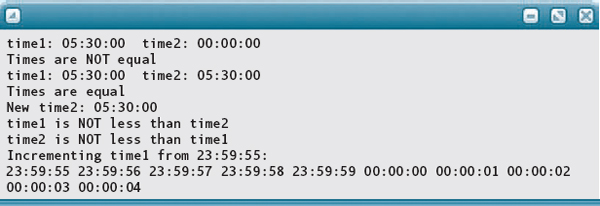
Output:
The Implementation File
The specification (.h) file for the TimeOfDay class contains only the class declaration. The implementation file must provide the function definitions for all the class member functions. In the opening comments of the implementation file below, we document the file name as TimeOfDay.cpp. Your system may use a different file name suffix for source code files— perhaps .c, .C, or .cxx.
Here is the code shown previously. We do not repeat the documentation from the function prototypes in the specification file. We do add documentation for the programmers who must maintain the code in case clarification is necessary. Immediately following the program code, we explain the new features.
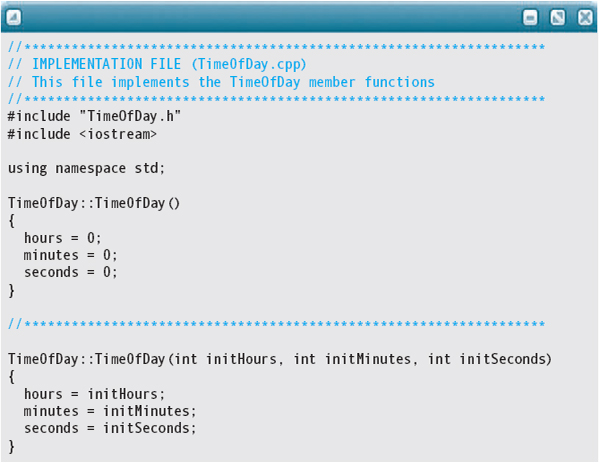

This implementation file demonstrates several important points.
1. The file begins with the preprocessor directive
#include “TimeOfDay.h”
Both the implementation file and the client code must #include the specification file. FIGURE 12.6 illustrates this shared access to the specification file, which guarantees that all declarations related to an abstraction are consistent. That is, both client.cpp and TimeOfDay.cpp must reference the same declaration of the TimeOfDay class located in TimeOfDay.h.
2. In the heading of each function definition, the name of the member function is prefixed by the class name (TimeOfDay) and the C++ scope resolution operator (::). As discussed earlier, several different classes might potentially have member functions with the same name—say, Write. In addition, there may be a global Write function that is not a member of any class. The scope resolution operator eliminates any uncertainty about which particular function is being defined.
3. Although clients of a class must use the dot operator to refer to class members (for example, startTime.Write()), members of a class refer to one another directly without using dot notation. Looking at the body of the Increment function, you can see that the statements refer directly to the member variables hours, minutes, and seconds without using the dot operator.
An exception to this rule occurs when a member function manipulates two or more class objects. Consider the Equal function. Suppose that the client code has two class objects, startTime and endTime, and uses the statement
if (startTime.Equal(endTime))
.
.
.

Figure 12.6 Shared Access to a Specification File
At execution time, the startTime object is the object to which the Equal function is applied. In the body of the Equal function, the relational expression
hours == otherTime.hours
refers to members of two different objects. The unadorned identifier hours refers to the hours member of the object (instance) for which the function is invoked (that is, startTime). The expression otherTime.hours refers to the hours member of the object that is passed to the parameter, otherTime, as a function argument: endTime.
4. Increment, Write, Equal, and LessThan are observer functions; they do not modify the private data. Because we have declared them to be const member functions, the compiler prevents these functions from assigning new values to the private data. The use of const is both an aid to the user of the class (a visual signal that this function does not modify any private data) and an aid to the class implementor (a way of preventing accidental modification of the data). Note that the word const must appear in both the function prototype (in the class declaration) and the heading of the function definition.
Compiling and Linking a Multifile Program
Now that we have created a specification file and an implementation file for our TimeOf-Day class, how do we (or any other programmer) make use of these files in our programs? Let's begin our exploration of this issue by looking at the notion of separate compilation of source code files.
In earlier chapters, we have referred to the concept of a multifile program—a program divided up into several files containing source code. In C++, each of these files may be compiled separately and at different times. In this process, the compiler translates each source code file into an object code file. FIGURE 12.7 shows a multifile program consisting of the source code files myprog.cpp, file2.cpp, and file3.cpp. We can compile each of these files independently, yielding the object code files myprog.obj, file2.obj, and file3.obj. Although each .obj file contains machine language code, it is not yet in executable form. The system's linker program brings the object code together to form an executable program file. (In FIGURE 12.7, we use the file name suffixes .cpp, .obj, and .exe. Your C++ system may use different file name conventions.)

Figure 12.7 Separate Compilation and Linking
Files such as file2.cpp and file3.cpp typically contain function definitions for functions that are called by the code in myprog.cpp. An important benefit of separate compilation is that modifying the code in just one file requires recompiling only that file. The new .obj file is then relinked with the other existing .obj files. Of course, if a modification to one file affects the code in another file—for example, if it changes a function's interface by altering the data types of the function parameters—then the affected files must also be modified and recompiled.
Returning to our TimeOfDay class, let's assume we have created the TimeOfDay.h and TimeOfDay.cpp files. Now we can compile TimeOfDay.cpp into object code. You are probably using a C++ system that provides an integrated environment—a program that bundles the editor, the compiler, and the linker into one package. Integrated environments put you back into the editor when a compile-time or link-time error occurs, pinpointing the location of the error. Some integrated environments also manage project files. Project files contain information about all the constituent files of a multifile program. With project files, the system automatically recompiles or relinks any files that have become out of date because of changes to other files of the program.
If you are using a command line system, you will write one-line commands to the operating system telling it to compile or link certain files. Whichever environment you use— integrated environment or the command line—the overall effect is the same: The source code files are compiled into object code files, which are linked into an executable program, which is then executed.
Before leaving the topic of multifile programs, we must stress an important point. In the example in Figure 12.7, the files TimeOfDay.h and TimeOfDay.obj must be available to users of the TimeOfDay class. The user needs to examine TimeOfDay.h to see what TimeOfDay objects do and how to use them. The user must also be able to link his or her program with TimeOfDay.obj to produce an executable program. However, the user does not need to see TimeOfDay.cpp. To use the terminology introduced earlier, the implementation of TimeOfDay should be treated as a black box.
The main purpose of abstraction is to simplify the programmer's job by reducing complexity. Users of an abstraction should not have to look at its implementation to learn how to use it, nor should they have to write programs that depend on implementation details. In the latter case, any changes in the implementation could “break” the user's programs. In Chapter 8, the Software Engineering Tip box entitled “Conceptual Versus Physical Hiding of a Function Implementation” discussed the hazards of writing code that relies on implementation details.
12.4 What Is an Object?
We started this chapter by talking about abstraction and abstract data types. We then examined the class construct, which is the C++ mechanism for implementing an ADT. We have discussed how information hiding can be accomplished through the design of the public interface and by having specification and implementation files. Now let's step back and take broader view of objects and their use.
In object-oriented programming (OOP), the term object has a very specific meaning: It is a self-contained entity encapsulating data and operations on the data. In other words, an object represents an instance of an ADT. More specifically, an object has an internal state (the current values of its data, called attributes), and it has a set of methods (operations, which are implemented by functions in C++). If a class has been properly designed, the methods should be the only means by which an object's state can be modified by another object. To inspect the state of the object, methods are also employed; in addition, some objects provide public constants that can be inspected. For example, the string class makes the npos constant public, so that we can determine the maximum size of a string.
Attributes The data represented by an object; its internal state.
An object-oriented program consists of a collection of objects, which communicate with one another by message passing. If object A wants object B to perform some task, object A sends a message containing the name of the object (B, in this case) and the name of the particular method to execute. Object B responds by executing this method in its own way, possibly changing its state and sending messages to other objects as well.
As you can tell, an object is conceptually quite different from a traditional data structure. A C struct is a passive data structure that contains only data and is acted upon by a program. In contrast, an object is an active data structure; the data and the code that manipulates the data are bound together within the object. In OOP jargon, an object knows how to manipulate its own state.
The vocabulary of the Smalltalk programming language, which pioneered many ideas related to object-oriented programming, has influenced the vocabulary of OOP. The literature of OOP is full of phrases such as “methods,” “attributes,” and “sending a message to.” Here are some OOP terms and their C++ equivalents:
OOP |
C++ |
Object |
Object or class instance |
Attribute |
Data member |
Method |
Member function |
Message passing |
Function application (of a public member function) |
Let's review the TimeOfDay class, albeit changed slightly to reflect objectoriented terminology and principles. There are six public methods (called responsibilities in object-oriented terminology): Increment, Write, Equal, LessThan, and the two constructors. One constructor takes the hours, minutes, and seconds as parameters, and the other sets the TimeOfDay to zero.
Responsibilities The public operations provided by a class for outside use.
In object-oriented terminology, two types of responsibilities (operations) exist: action responsibilities and knowledge responsibilities. All of TimeOfDay's public methods are either constructors or knowledge responsibilities. None of them takes action (changes the state of the object). As you can see, it is important for an object to be able to report on its own status; that is, each object should have methods that report the internal state of its private data in a manner that is appropriate to the information hiding goals of its public interface. Given such methods, we do not need a Write method. If the client code can inspect the internal state (not change it), then the code can print a TimeOfDay object in a form that is relevant to the problem using the ADT.
Here is the revised specification for the TimeOfDay class, in which the Write function has been removed. We omit the documentation that hasn't changed.
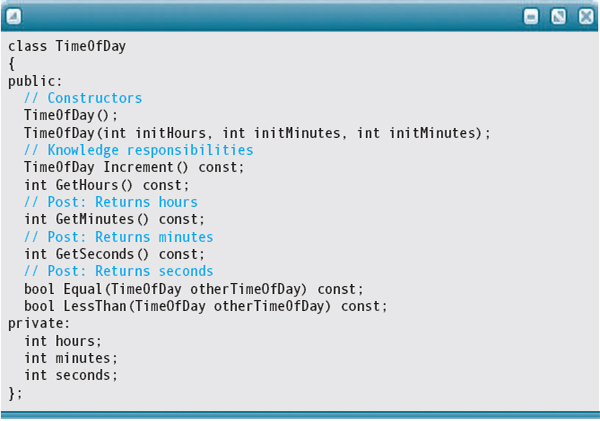
Here is the part of the implementation file for class TimeOfDay that implements the new functions:
#include TimeOfDay.h
using namespace std;
…
int TimeOfDay::GetHours() const
{
return hours;
}
int TimeOfDay::GetMinutes() const
{
return minutes;
}
int TimeOfDay::GetSeconds() const
{
return seconds;
}

12.5 Class Design Principles
Because classes are a fundamental building block of object-oriented programming, we now consider the principles that result in a well-designed class that can be used in the context of larger problems.
Encapsulation
A primary principle for class design is encapsulation. The dictionary tells us that a capsule is a sealed container that protects its contents from outside contaminants or harsh conditions to keep them intact. To encapsulate something is to place it into a capsule. In object-oriented programming, the capsule is a class, and its attributes are the contents we want to protect. By itself, the class construct doesn't protect its attributes. Instead, we must consciously provide that protection by defining a formal interface that limits access from other classes.
Encapsulation Designing a class so that its attributes are isolated from the actions of external code except through the formal interface.
Formal interface The components of a class that are externally accessible, which consist of the class's nonprivate attributes and responsibilities.
Reliable The property of a unit of software that it can be counted on to always operate consistently, according to the specification of its interface.
What is a formal interface? In terms of class design, it is a written description of all the ways that the class may interact with other classes. The collection of responsibilities and nonprivate attributes defines the formal interface. In C++, we implement responsibilities with functions, and attributes are data fields within a class.
If the contents of an object can be changed only through a well-designed interface, then we don't have to worry about bugs in the rest of the application affecting it in unintended ways. As long as we design the class so that its objects can handle any data that are consistent with the interface, we know that it is a reliable unit of software.
Here's an analogy that illustrates the difference between a class that is encapsulated and one that is not. Suppose you are a builder, building a house in a new development. Other builders are working in the same development. If each builder keeps all of his or her equipment and materials within the property lines of the house that he or she is building, and enters and leaves the site only via its driveway, then construction proceeds smoothly. The property lines encapsulate the individual construction sites, and the driveway is the only interface by which people, equipment, and materials can enter or leave a site.
Now imagine the chaos that would occur if builders started putting their materials and equipment in other sites without telling one another. And what would happen if they began driving through other sites with heavy equipment to get to their own? The materials would get used in the wrong houses, tools would be lost or run over by stray vehicles, and the whole process would break down. FIGURE 12.8 illustrates this situation.
Let's make this analogy concrete in C++ by looking at two interface designs for the same Date class—one encapsulated, and the other not encapsulated.

Figure 12.8 Encapsulation Draws Clear Boundaries Around Classes; Failing to Encapsulate Classes Can Lead to Chaos.
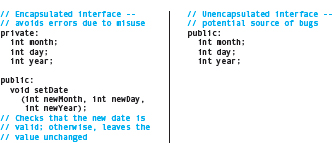
The interface on the right allows client code to directly change the fields of a Date object. Thus, if the client code assigns the values 14, 206, and 83629 to these fields, you end up with a nonsense date of the 206th day of the 14th month of the year 83629. The encapsulated implementation on the left makes these fields private. It then provides a public method that takes date values as arguments, and checks that the date is valid before changing the fields within the object.
This example shows that there is no special C++ syntax for encapsulation. Rather, we achieve encapsulation by carefully designing the class interface to ensure that its objects have complete control over what information enters and leaves them.
Encapsulation greatly simplifies the work of a programming team, because each class can be developed by a different team member, without worrying about how other classes are being implemented. In a large project, encapsulation permits each programmer to work independently on a different part. As long as each class meets its design specification, then the separate classes can interact safely.
Design specification The written description of the behavior of a class with respect to its interface.
What do we mean by design specification? Given a formal interface to a class, the design specification is additional written documentation that describes how a class will behave for each possible interaction through the interface. We should be very clear here that we are referring to the problem-solving phase. The design specification is part of stating the problem. It is distinct from the specification file in the implementation phase, which defines the interface to a class. Depending on the context, we may refer to the design specification simply as the specification.
The formal interface is where we define how we will call a method, and the design specification is where we describe what the method will do. You can think of the formal interface as the syntax of a class, and the specification as its semantics. By definition, the specification includes the formal interface. We have seen how this information can be written as preconditions and postconditions.
Abstraction
Encapsulation is the basis for abstraction in programming. We've seen that there are two types of abstraction: data abstraction and control abstraction. As an example of data abstraction, consider that the external representation of a date might be integer values for the day and year, and a string that specifies the name of the month. But we might implement the date within the class using a standard value that calendar makers call the Julian day, which is the number of days since January 1, 4713 b.c.
Abstraction The separation of the logical properties (interface and specification) of an object from its implementation (internal data representation and algorithms)
The advantage of using the Julian day is that it simplifies arithmetic on dates, such as computing the number of days between dates. All of the complexity of dealing with leap years and the different number of days in the months is captured in formulas that convert between the conventional representation of a date and the Julian day. From the user's perspective, however, the methods of a Date object receive and return a date as two integers and a string. FIGURE 12.9 shows the two implementations, having the same external abstraction.
In many cases, the external and internal representations are identical. We don't tell the user that, however, because we may want to change the implementation in the future. For example, we might initially develop a Date class using variables for the month, day, and year. Later, if we decide that a Julian day representation is more efficient, we can rewrite the implementation of the class. Because encapsulation has provided data abstraction, the change doesn't affect the client code.
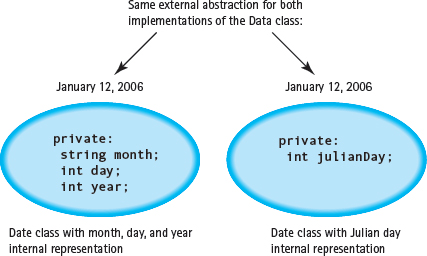
Figure 12.9 Data Abstraction Permits Different Internal Representations for the Same External Abstraction
This example also illustrates control abstraction. Suppose that the specification for the Date class says that it takes into account all of the special leap-year rules. In the Julian day implementation, only the Julian day conversion formulas handle those rules; the other responsibilities merely perform integer arithmetic on the Julian day number.
A user may assume that every Date responsibility separately deals with leap years. Control abstraction lets us program a more efficient implementation and then hide those details from the user.
Designing for Modifiability and Reuse
Applying the principle of abstraction has two additional benefits: modifiability and reuse.
Modifiability The property of an encapsulated class definition that allows the implementation to be changed without having an effect on code that uses it (except in terms of speed or memory space).
Reuse The ability to include a class in client code, without additional modification to either the class or the client code.
Encapsulation enables us to modify the implementation of a class after its initial development. Perhaps we are rushing to meet a deadline, so we create a simple but inefficient implementation. In the maintenance phase, we then replace the implementation with a more efficient version. The modification is undetectable with the exception that applications run faster and require less memory.
An encapsulated class is self-contained, which means we can import and use it in other applications. Whether we want to do so depends on whether the class provides a useful abstraction. For example, a Date class that assumes all years are in the range of 1900 to 1999 is not very useful today, even though that was a common approach used by twentieth-century programmers.
Reuse also means that a class can be extended to form new related classes. For example, a utility company has software to manage its fleet of vehicles. As shown in FIGURE 12.10, a class that describes a Vehicle can be used in multiple applications. Each application can add extensions to the Vehicle class to suit its particular requirements. Reuse is a way to save programming effort. It also ensures that objects have the same behavior every place that they are used—and consistent behavior helps us to avoid programming errors.
Of course, preparing a class that is suitable for wider reuse requires us to think beyond the immediate situation. Such a class should provide certain basic services that enable it to be used more generally. For example, it should have observers that enable client code to retrieve any information from an object that we envision as potentially useful.

Figure 12.10 Reuse
Not every class needs to be designed for general reuse. In some cases, we merely need a class that has specific properties for the problem at hand, and that won't be used elsewhere. If you are designing a class that may be used in other situations, however, then it is a good idea to make it more general.
Keep in mind that even though C++'s class construct provides a mechanism to support encapsulation, it is up to the programmer to use this capability in a way that results in actual encapsulation. There is no keyword or construct that distinguishes a class as encapsulated. Instead, the programmer must draw the boundaries around the class in a manner that keeps other code out.
There are two types of boundaries that we can draw: physical and visual. We can physically keep a user from accessing members in a class by declaring them to be private, and we can make the class implementation invisible to a user by the appropriate use of the header and implementation files.
Mutability
An immutable object cannot be changed after it is instantiated; a mutable object has at least one function (method) that allows the client to change the value of a data member in the object. Although many objects can be immutable, others require the client's ability to change the internal contents of an object after instantiation. Mutability is a key distinguishing characteristic of the interface of an object. While immutable objects are naturally encapsulated, because they are immune to change, we must take special care to ensure that mutable objects remain encapsulated.
Mutability The ability of a client to change the value(s) of an object's state (data members) after it is created.
Our TimeOfDay class is immutable because we did not define a function that allowed the client to change any of its values. Had the Increment function actually changed the instance to which it was applied, the class would have been mutable instead.
Let's look at an example of a mutable object. Suppose we are creating a database of birth records for a hospital. A birth record is an object that contains the following information:
Birth Record
Date of birth
Time of day of birth
Mother's name
Father's name
Baby's name
Baby's weight
Baby's length
Baby's gender
A nurse enters all of this information into the database shortly after the baby is born. In some cases, the parents may not have chosen a name for the baby yet. Rather than keep the nurse waiting for the parents to make up their minds, the database allows all of the other information to be entered and creates a Birth Record object with an empty string for the name of the baby. Later, when the name is chosen, the nurse changes the name in the database.
There are two ways to change this database record. One would be to call a method that directly changes the value in the baby's name field. For example, we could write the function as follows:
void SetBabyName (Name newName)
{
babysName = newName;
}
Given an instance of the BirthRecord class called newBaby, we can call this method with the following statement:
newBaby.SetBabyName(someName); // Changes the baby name field
Such a method is called a transformer or a mutator. A transformer is an example of an action responsibility. Having a transformer makes BirthRecord a mutable class. Note that there is no special C++ syntax to denote that SetBabyName is a transformer. Instead, a method is a transformer simply by virtue of what it does: It changes the information stored in an existing object. We can ensure that a method is not a transformer only by using const in its heading.
Wouldn't it be easier to just make the babysName field public and to assign a new value to it without calling a method? Yes, but that would destroy the encapsulation of the BirthRecord class. Making the change through a transformer preserves encapsulation because it permits us to employ data and control abstraction. For example, we could later enhance this transformer to check that the new name contains only alphabetic characters.
The second way to change the name assumes that BirthRecord is an immutable class. We create a new record, copy into it all of the information except the name from the old record, and insert the new name at that point. For example, the following is a constructor that takes another BirthRecord object as an argument, and automatically does the copying:
BirthRecord (BirthRecord oldRecord, // Constructor
Name newName)
{
dateOfBirth = oldRecord.dateOfBirth;
timeOfBirth = oldRecord.timeOfBirth;
mothersName = oldRecord.mothersName;
fathersName = oldRecord.fathersName;
babysName = newName; // Change name to new name
babysWeight = oldRecord.babysWeight;
babysLength = oldRecord.babysLength;
babysGender = oldRecord.babysGender;
}
We would then update the birth record as follows:
BirthRecord updatedBaby(newBaby, someName);
Note that this statement doesn't change the old object, but rather it creates a new object containing the required information from the old object, together with the new name.
As you can see, using the transformer is simpler. It is also much faster for the computer to call a method that assigns a new value to a field than to create a whole new object.



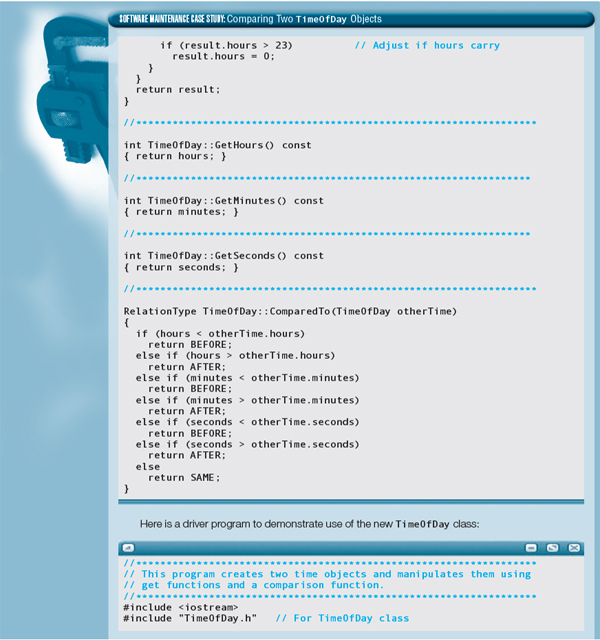

12.6 The Name ADT
We have presented the ADT TimeOfDay and implemented it as a C++ class. It sits in a file ready to be used in any program that needs a TimeOfDay object. Now let's look at another ADT that will be useful in the future: the Name ADT.
In Chapter 4, we displayed a name in different formats. In Chapter 9, the Health Profile program used a name. Adding a name to the BMI and the Mortgage programs would make sense. Names are often necessary pieces of information. Let's stop this duplication of effort and do the job once and for all—let's write the code to support a name as an abstract data type.
We need to make the domain and operations general enough that they can be used in any program that keeps track of a name. The informal specification of the ADT is given here:
TYPE
Name
DOMAIN
Each Name is a name in the form of first name, middle name, and last name.
OPERATIONS
Construct a Name instance
Inspect the first name
Inspect the middle name
Inspect the last name
Inspect the middle initial
Compare two names for “before,” “same,” and “after”
Note that there is no operation to output the name in any particular format. Because we are allowing the user to inspect the parts of the name, the user can combine the parts to suit his or her purpose.
We create the Name ADT in two stages: specification, followed by implementation. The result of the first stage is a C++ specification (.h) file containing the declaration of a Name class. This file must also describe for the user the precise semantics of each ADT operation.
The second stage—implementation—requires us to (1) choose a concrete data representation for a name, and (2) implement each of the operations as a C++ function definition. The result is a C++ implementation file.
Specification of the ADT
The domain of our ADT is the set of all names made up of a first, middle, and last name. To represent the Name ADT as program code, we use a C++ class named Name. The ADT operations become public member functions of the class. Let's now specify the operations more carefully.
Construct a Name Instance
We use a C++ default constructor to create an instance of a Name ADT. The default constructor for TimeOfDay sets the hours, seconds, and minutes to zero. Blanks would be the logical equivalent for class Name.
The parameterized constructor must supply three arguments for this operation: the first name, the middle name, and the last name. Although we haven't yet determined a concrete data representation for a name, we must decide which data types the client should use for these arguments. The logical choice is for each value to be represented by a string. But what if we want to change a name after it has already been constructed? Let's not allow the user to do this; that is, let's make Name an immutable class.
Inspect the Name's First, Middle, and Last Names
All three of these operations are observer operations. They give the client access—albeit indirectly—to the private data. In the Name class, we represent these operations as valuereturning member functions with the following prototypes:
string GetFirstName(); string GetMiddleName(); string GetLastName();
Inspect the Middle Initial
This operation requires that the first letter of the middle name be extracted and returned. In Chapter 4, we accessed the middle initial as a one-character string. Should we return it as a string here or as a char variable? It really doesn't matter as long as we are consistent in our code and in our documentation. Let's make this function a char function, just for the sake of variety.
Compare Two Names
This operation compares two names and determines whether the first name comes before the second, the names are the same, or the first name comes after the second. To indicate the result of the comparison, we use the enumeration type we used for the TimeOfDay class:
enum RelationType {BEFORE, SAME, AFTER};
Then we can code the comparison operation as a class member function that returns a value of type RelationType. Here is the function prototype:
RelationType ComparedTo(Name otherName) const;
Because this is a class member function, the name being compared to otherName is the object (instance) for which the member function is invoked. For example, the following client code tests whether name1 comes before name2:
Name name1(string, string, string);
Name name2(string, string, string);
.
.
.
switch (name1.ComparedTo(name2))
{
case BEFORE :…
case SAME :…
case AFTER :…
}
We are now almost ready to write the C++ specification file for our Name class. However, the class declaration requires us to include the private part—the private variables that are the concrete data representation of the ADT. Choosing a concrete data representation properly belongs in the ADT implementation phase, not the specification phase. To satisfy the C++ class declaration requirement, however, we now choose a data representation. The simplest representation for a name is three string values—one each for the first, middle, and last. Here, then, is the specification file containing the Name class declaration.
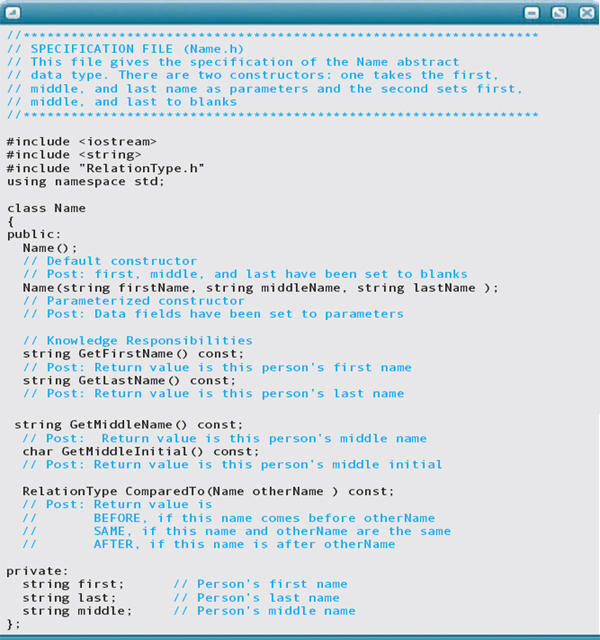

Notice that we use the word “Get” in the name of our observer functions. We did the same in the TimeOfDay class. Using “Get” as a prefix to the field name is an object-oriented convention used by many programmers. The corresponding name for transformers that change the value of a field would be “Set” preceding the field. In fact, many programmers refer to these kinds of operations generically as getters and setters.
Implementation File
We have already chosen a concrete data representation for a name, shown in the specification file as the string variables first, middle, and last. Now we must implement each class member function, placing the function definitions into a C++ implementation file named Name.cpp. The implementations of all but the ComparedTo function are so straightforward that no discussion is needed.
If we were to compare two names in our heads, we would look first at the last name. If the last names were different, we would immediately know which name came first. If the last names were the same, we would look at the first names. If the first names were the same, we would have to look at the middle name. As so often happens, we can use this algorithm directly in our function.

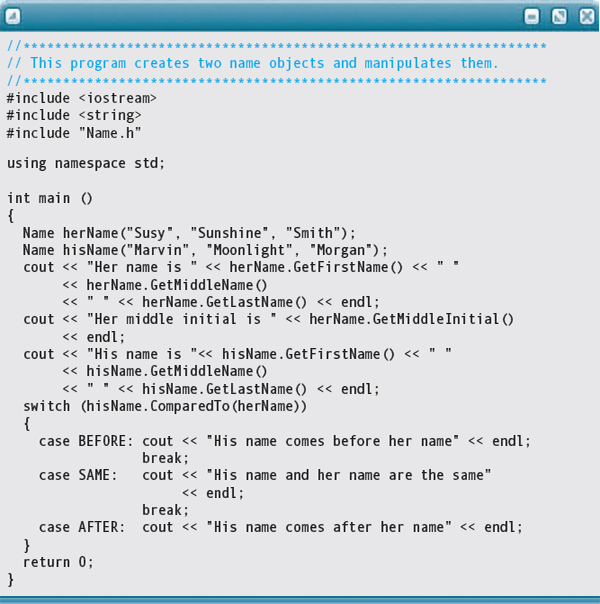
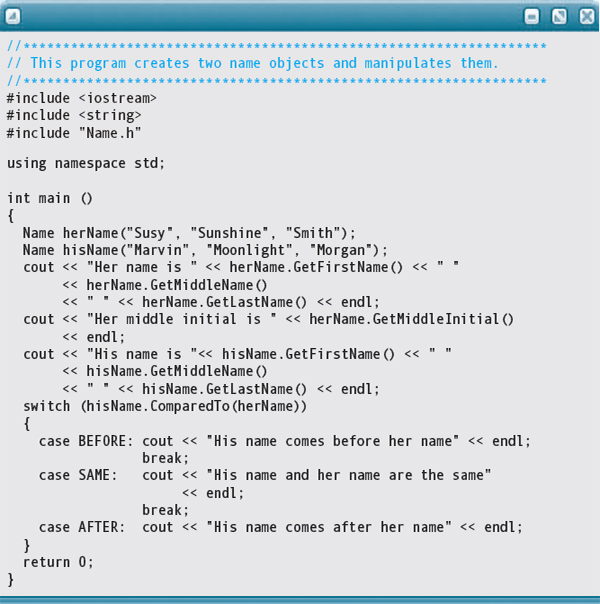
Here is a driver program that creates two Name objects and manipulates them:

Finally, here, is the output:
12.7 Composition
Two classes typically exhibit one of three relationships: They are independent of each other, they are related by inheritance, or they are related by composition. Here we cover composition: the relationship in which the internal data of one class includes an object of another class as a data member. Stated another way, an object is contained within another object.
Composition The relationship between classes in which one class contains an instance of another class as one of its attributes.
C++ does not have (or need) any special language notation for composition. You simply declare an object of one class to be one of the data members of another class. Let's look at an example.
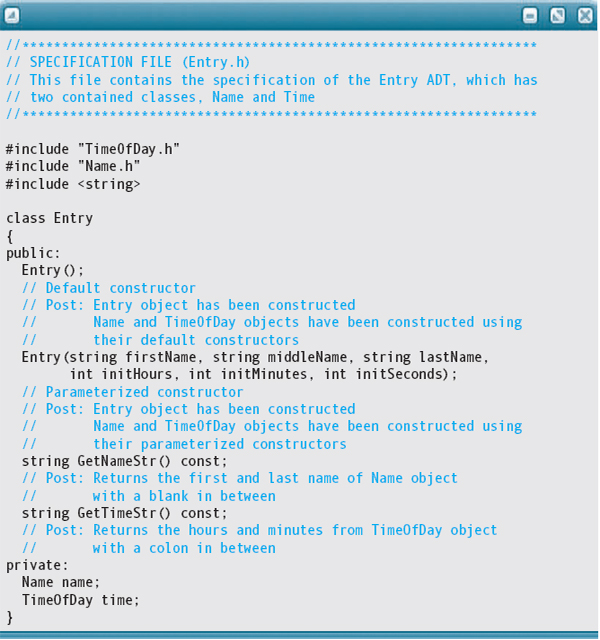
Design of an Entry Class
You are developing a program to represent an appointment book. Each Day object will be a sorted list of Appointment objects. In preparation, you decide to build an Entry ADT with two fields, an object of a Name ADT and an object of a TimeOfDay ADT. You may need to add more information for an Appointment object later, but this gives you a start. Constructing this object should be easy because you already have a TimeOfDay class and a Name class. For the purpose of an appointment calendar, you decide to ignore the person's middle name or initial and the seconds in the time. You can always add the middle name later if you decide that you need it. Of course, you do need operations that return the name and TimeOfDay to the client program.
Let's call the operations GetNameStr, which returns a name composed of the first and last names, and GetTimeStr, which returns the hours and minutes with a colon between the two values. Of course, we need constructors. How many? Well, you know that the Name class has two constructors: one that takes the parts of the name as parameters and one that sets the fields to blanks. The same is true of the TimeOfDay class. Thus we should have a default constructor for the Entry class, which calls the default constructors for Name and TimeOfDay, and a parameterized constructor, which passes its parameters to Name's and Time's parameterized constructors.
We now know enough to write the specification file.
Implementing the default class constructors involves invoking the default constructors for the Name object and the TimeOfDay object. The default Entry constructor has nothing else to do. In C++, default constructors are called automatically (although we've shown them explicitly in prior examples, as a matter of good documentation). Therefore, we can also leave the body of the default constructor for Entry empty, which we do here so that you can see an example of this coding style.
The parameterized constructor must pass its parameters to the Name and Time constructors. To do so, we use a constructor initializer. This C++ construct allows you to pass the information needed to construct an object that is declared in another class. The syntax is the heading of the containing class's constructor followed by a colon (:) and the name of a member object followed by a parameter list corresponding to the parameterized constructor for the class of the member object. If multiple constructor initializers are present, they are separated by commas.

The body for this function will be empty. The system takes care of constructing the Name and TimeOfDay objects. Here is the implementation file for class Entry:

Here is a simple driver that creates and prints a couple of Entry objects:
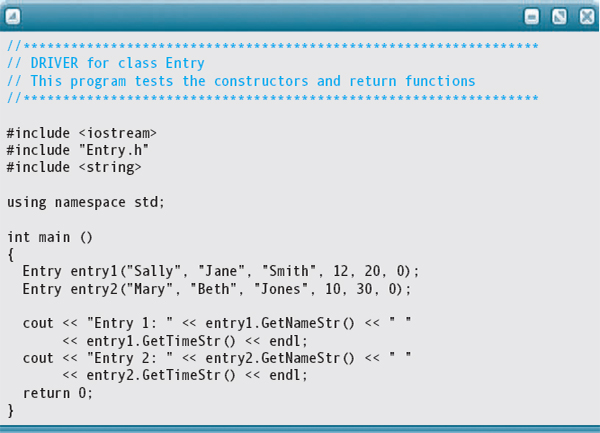
When we try to run this simple program, we get the following error:
error: multiple definition of 'enum RelationType'
How can that be? There is only one copy of file RelationType.h, but it is included in both TimeOfDay and Name. As a consequence, the preprocessor thinks RelationType is defined more than once. This happens often, so we have to tell the preprocessor to include file RelationType.h only if it hasn't been included before. The widely used solution to this problem is to write RelationType.h this way:
#ifndef RELATION
#define RELATION
enum RelationType {BEFORE, SAME, AFTER};
#endif
The lines beginning with # are directives to the preprocessor. RELATION (or any identifier you wish to use) is a preprocessor identifier, not a C++ program identifier. In effect, these directives say:
If the preprocessor identifier RELATION has not already been defined, then
1. Define RELATION as an identifier known to the preprocessor, and
2. Let the declaration of the enum RelationType pass through to the compiler.
If a subsequent #include “RelationType.h” is encountered, the test #ifndef RELATION will fail. The declaration will not pass through to the compiler a second time.
The multiple definition error has now been resolved, but there is another error:
Error : illegal operand EntryEr.cpp line 33 return “” + time.GetHours() + “:” + time.GetMinutes();
What could be wrong with this statement? We just created a string out of a string, an integer value, a colon, and another integer value. We have used concatenation to build strings since Chapter 2. Numbers are converted to strings for output. What's different about this statement? The C++ system automatically converts integers to strings for output, but there is no type cast from integers to strings anywhere except for output.
To create a string including integers, we could write it out to a file and then read it back in as a string. This approach would work, but it would be extremely time-consuming (disk access is more than a million times slower than memory access). Fortunately, the designers of the C++ language realized that there might be times when a conversion from integer to string would be useful. Thus they created a class called stringstream, which allows us to write values to a string as if we were writing them to a file. Because the data is not actually sent to a file but rather is kept in memory, the conversion is completed quickly.
We declare an object of class ostringstream, and use the insertion operator (<<) to send the integers to the object. To get them back as a string, we use the str member function of class ostringstream. Here is the corrected version of GetTimeStr, using an object of class ostringstream, followed by the output from the driver:
#include <sstream> // ostringstream
string Entry::TimeStr() const
// This function makes use of class sstream to create and return
// a string containing numeric values
{
string outStr;
ostringstream tempOut; // Declare an ostringstream
if (time.GetHours() < 10)
tempOut << '0';
tempOut << time.GetHours() << “:”;
if (time.GetMinutes() < 10)
tempOut << '0';
tempOut << time.GetMinutes() << “:”;
if (time.GetSeconds() < 10)
tempOut << '0';
tempOut << time.GetSeconds();
outStr = tempOut.str();
return outStr;
}
Once this function is inserted, the driver produces this output:

12.8 UML Diagrams
It can be difficult to understand the operation of an application just by looking at the written documentation. When many classes are interacting, keeping track of their relationships involves building a mental picture. Before long, we start drawing diagrams just to keep everything straight. Perhaps we use boxes to represent classes, and lines between them to represent collaborations (classes calling methods in other classes). Inside the boxes, we make notes about the classes. Then we start using solid and dashed lines to indicate different kinds of collaboration. Eventually, we have a diagram that captures all of the important structural information about the application. The trouble is, no one else knows what our diagram means! If programmers used a common set of symbols, then they could read one another's diagrams.
The Unified Modeling Language (UML) is just such a collection of symbols. It was developed specifically for diagramming object-oriented applications. Even though it has the word language in its name, UML is not a programming language; it is just a collection of graphical symbols. It is unified in the sense that it is made up from a combination of three different sets of symbols that were in use prior to its development. Each of those earlier conventions had its own strengths and weaknesses, so UML was created to provide a single set of symbols incorporating all of their best features.
The UML symbols are divided into subsets that are used for different purposes. There are UML diagrams for documenting just about every aspect of programming, from analyzing the problem to deploying the code on customer's computers. You could take an entire course in drawing UML diagrams!
We begin by looking at the simplest form of diagrams: the Class diagram.
Diagramming a Class
A class is represented in UML by a box that's divided into three sections. The top section holds the name of the class, the middle section lists its attributes (the data members of the class), and the bottom section lists responsibilities (methods). Here's a UML diagram of the TimeOfDay class:
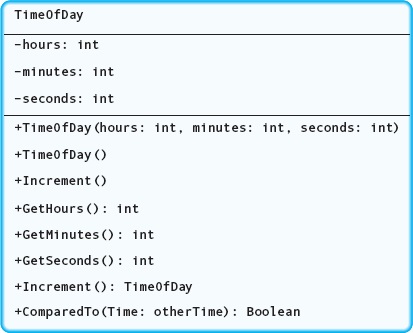
As you can see, the diagram lists the attributes and their types in the middle section. The minus sign in front of each attribute is shorthand for private. UML uses + to mean public. You can see that all of TimeOfDay's responsibilities are listed in the bottom section, showing parameters and return types for value-returning methods. As you can also see by the plus signs, TimeOfDay's functions are all public.
Diagramming Composition of Classes
When a class contains an instance of another class, such as the Name class field contained in the Entry class, we draw a solid diamond at the end of the line next to the containing class. (We just show the constructor as an example responsibility—in a proper UML diagram, all of the responsibilities would be listed.)

This is how UML documents composition. The class with the solid diamond is composed of (among other things) an instance of the class at the other end of the arrow. Notice that the name of the instance (name) is indicated beside the arrow.
Problem-Solving Case Study
Create an Array of Name Objects
PROBLEM: As a first pass of an appointment book, you decide to create a 24-hour listing of names organized by their associated hour. You have a file of entry data that needs to be converted to this form and then printed.
INPUT: The file of values that can be used to make Entry objects.
OUTPUT: The hour of the day and the associated name, ordered by hour.
DISCUSSION: We can read the data for an entry object, get the hour associated with the object, and use it as an index into the array. FIGURE 12.11 describes this structure.

Figure 12.11 Names Array Indexed by Hours
What happens if there is more than one person with the same hour? Well, let's store the name the first time we see an hour. If a subsequent entry has the same hour, we can write an error message. Here is the main algorithm:
| Main | Level 0 |
Open files IF files not ok Write error message Return 1 Get entry WHILE more entries Process entry Get entry Write time and name Close files
We have been opening and checking files for many chapters now. We can consider this a concrete step.
| GetEntry(In/out: inFile) Return value: Entry | Level 1 |
Read Name Read Time Create newEntry Return newEntry
| ProcessEntry(In/out: array Names, In: entry) |
Get Hours Set Names[hours] to entry.GetNameStr
Get Hours…How are we going to do that? We can get a string with the hours embedded and try to access the hours. However, if we have a TimeOfDay object rather than an Entry object, we can access the hours directly. We don't need an Entry object: We need a Name object and a TimeOfDay object. We let the fact that the file contains data corresponding to Entry objects mislead us. This design needs to be redone, but first we need to see an example of the file format.
Sample File
Mary Jane Smith 12 30 0 Susy Olive Oliver 11 45 5 Jane Birdsong Wren 8 15 30 William Jennings Brian 0 35 35 …
This information makes the processing even easier. We read the first, middle, and last names and create a Name object. The next value on the line is the hours. We don't need the minutes and seconds, but we will have to read past them. In fact, we don't need a TimeOfDay object at all; we can just use the hours directly.
| Main (Revised) | Level 0 |
Open files IF files not ok Write error message Return 1 Get name WHILE more data Get hours Set names[hours] to name Get name Write time and name Close files
| GetName(In/out: inFile) Return value: Name |
Get first, middle, last from inFile name = Name(first, middle, last) Return name
| WriteTimeName(In/out: outFile, In: names) |
FOR hour going from 0 to 23
Write “Hour: “, hour, “Name”, names[hour].GetFirstName(),
“”, names[hour].GetMiddleName(), “ “ on outFile
OpenFiles, GetName, and WriteTimeName should be coded as functions. Have we forgotten anything? Yes: We haven't taken care of duplicate hours. We must set every cell in the array to a default Name object. Before we store a Name object into the array, we must check whether an object there has a first name that is a blank. Again, we update the main module.
| Main (Second revision) | Level 0 |
Open files
IF files not ok
Write error message
Return 1
Set array names to all default Name objects
Get name
WHILE more data
Get hours
IF names[hours].GetFirstName() is a blank
Set names[hours] to name
ELSE
Write hours, “ is already taken” on outFile
Get name
Write time and name
Close files
| WriteTimeName(In/out: outFile, In: names) (Revised) |
FOR hour going from 0 to 23 IF names[hour].GetFirstName() != “ “ Write “Hour: “, hour, “Name”, names[hour].GetFirstName(), “ “, names[hour].GetMiddleName(), “ “, names[hour].GetLastName(), endl on outFile ELSE Write “Hour: “, “None one scheduled.”, endl on outFile
Here is a program listing, the input, and the output:


Input File

Output File

Testing and Debugging
Testing and debugging a C++ class amounts to testing and debugging each member function of the class. All of the techniques you have learned about so far—algorithm walk-throughs, code walk-throughs, hand traces, test drivers, verification of preconditions and postconditions, the system debugger, the assert function, and debug outputs—may be brought into play.
Consider how we might test this chapter's TimeOfDay class. Here is the class declaration, abbreviated by leaving out the function preconditions and postconditions:
class TimeOfDay
{
public:
TimeOfDay(int initHours, int initMinutes, int initSeconds);
TimeOfDay();
// Action responsibilities
TimeOfDay Increment() const;
RelationType ComparedTo(TimeOfDay otherDay);
// Knowledge responsibilities int GetHours() const;
int GetMinutes() const;
int GetSeconds() const;
private:
int hours;
int minutes;
int seconds;
};
To test this class fully, we must test each of the member functions. Let's step through the process of testing just one of them: the Increment function.
Before we implemented the Increment function, we started with a pseudocode algorithm, performed an algorithm walk-through, and translated the pseudocode into the following C++ function:
TimeOfDay TimeOfDay::Increment() const
{
// Create a duplicate of instance and increment duplicate
TimeOfDay result(hours, minutes, seconds);
result.seconds = result.seconds++; // Increment seconds
if (result.seconds > 59) // Adjust if seconds carry
{
result.seconds = 0;
result.minutes = result.minutes++;
if (result.minutes > 59) // Adjust if minutes carry
{
result.minutes = 0;
result.hours = result.hours++;
if (result.hours > 23) // Adjust if hours carry
result.hours = 0;
}
}
return result;
}
Now we perform a code walk-through, verifying that the C++ code faithfully matches the pseudocode algorithm. At this point (or earlier, during the algorithm walk-through), we do a hand trace to confirm that the logic is correct.
For the hand trace, we should pick values of hours, minutes, and seconds that ensure code coverage. To execute every path through the control flow, we need cases in which the following conditions occur:
1. The first If condition is false.
2. The first If condition is true and the second is false.
3. The first If condition is true, the second is true, and the third is false.
4. The first If condition is true, the second is true, and the third is true.
Below is a table displaying values of hours, minutes, and seconds that correspond to these four cases. For each case we also write down what we hope will be the values of the variables after executing the algorithm.
Using the initial values for each case, a hand trace of the code confirms that the algorithm produces the desired results.
Finally, we write a test driver for the Increment function, just to be sure that our understanding of the algorithm logic is the same as the computer's! Here is a possible test driver:

For input data, we supply at least the four test cases discussed earlier. The program's output should match the desired results—and it does. Notice that, because we are interested in checking the actual values from the observer methods, we do not have our driver apply output formatting to ensure that minutes and seconds have two digits when their values are less than ten.
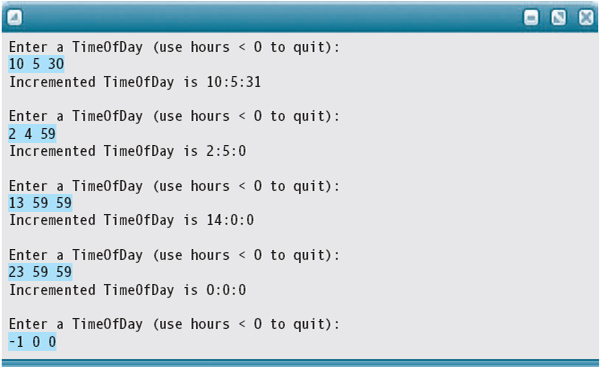
Now that we have tested the Increment function, we can apply the same steps to the remaining class member functions. We can create a separate test driver for each function, or we can write just one driver that tests all of the functions. The disadvantage of writing just one driver is that devising different combinations of input values to test several functions at once can quickly become complicated.
Before leaving the topic of testing a class, we must emphasize an important point: Even though a class has been tested thoroughly, it is still possible for errors to arise. Let's look at two examples using the TimeOfDay class. The first example is the client statement
TimeOfDay time1(24, 0, 0);
The precondition on the parameterized constructor requires the first argument to have a value from 0 through 23. We don't prevent an erroneous time from being constructed when the client ignores the precondition. The second example is the comparison
if (time1.ComparedTo(time2))
.
.
.
where the programmer intends time1 to be 11:00:00 on a Wednesday and time2 to be 1:20:00 on a Thursday. (The result of the test is AFTER, not BEFORE as the programmer expects.) The implicit precondition of ComparedTo requires the two times to be on the same day, not on two different days. This implicit precondition should be made explicit.
Do you see the common problem? In each example, the client has violated the function precondition. If a class has been well tested but errors occur when the client code uses the class, always check the member function preconditions. You can waste many hours trying to debug a class member function when, in fact, the function is correct but the error lies in the client code.
Testing and Debugging Hints
- The declaration of a class within the specification header file must end with a semicolon.
- Be sure to specify the full member selector when referencing a component of a class object.
- Regarding semicolons, the declarations and definitions of class member functions are treated the same as any C++ function. The member function prototype, which is located in the class declaration, ends with a semicolon. The function heading—the part of the function definition preceding the body—does not end with a semicolon.
- When implementing a class member function, don't forget to prefix the function name with the name of the class and the scope resolution operator (::).
TimeOfDay TimeOfDay::Increment() const { . . . } - For now, the only built-in operations that we apply to class objects are member selection (.) and assignment (=). To perform other operations, such as comparing two class objects, you must write class member functions.
- If a class member function inspects but does not modify the private data, it is a good idea to make it a const member function.
- A class member function does not use dot notation to access private members of the class object for which the function is invoked. In contrast, a member function must use dot notation to access the private members of a class object that is passed to it as an argument.
- A class constructor is declared without a return value type and cannot return a function value.
- If a client of a class has errors that seem to be related to the class, start by checking the preconditions of the class member functions. The errors may reside in the client, not the class.
- If a class has a member that is an object of another class and this member object's constructor requires arguments, you must pass these arguments using a constructor initializer:
SomeClass::SomeClass(…) : memberObject(arg1, arg2)
{
.
.
.
}
If there is no constructor initializer, the member object's default constructor is invoked.
![]() Summary
Summary
Abstraction is a powerful technique for reducing the complexity and increasing the reliability of programs. Separating the properties of a data type from the details of its implementation frees the user of the type from having to write code that depends on a particular implementation of the type. This separation also assures the implementor of the type that client code cannot accidentally compromise a correct implementation.
An abstract data type (ADT) is a type whose specification is separate from its implementation. The specification announces the abstract properties of the type. The implementation consists of (1) a concrete data representation and (2) the implementations of the ADT operations. In C++, an ADT can be realized by using the class mechanism. Class members can be designated as public or private. Most commonly, the private members are the concrete data representation of the ADT, and the public members are the functions corresponding to the ADT operations.
In object-oriented terminology, instances of ADTs are objects. That is, a class defines a pattern for instantiating an object. Among the public member functions of a class, the programmer often includes one or more class constructors—functions that are invoked automatically whenever a class object is created. When designing a class, the principles of abstraction, encapsulation, modifiability, and reuse must be considered. An immutable class provides no public function that changes a data value in the object; a mutable class does provide such a function.
Separate compilation of program units is central to the separation of specification from implementation. The declaration of a C++ class is typically placed in a specification (.h) file, and the implementations of the class member functions reside in the implementation file. The client code is compiled separately from the class implementation file, and the two resulting object code files are linked together to form an executable file. Through separate compilation, the user of an ADT can treat the ADT as an off-the-shelf component without ever seeing how it is implemented.
![]() Quick Check
Quick Check
- How do we create an implementation from a specification for an abstract data type? (pp. 583–586)
- Which C++ construct is designed to implement ADTs? (pp. 583–586)
- How does the use of a specification file help to provide encapsulation and information hiding for a class? (pp. 596–597)
- Write the declaration of a class object, called today, of class Date. (pp. 591–592)
- How would you call member function GetDay (which takes no parameters) of an object called today of class Date? (pp. 592–593)
- Where does the :: scope resolution operator appear in a member function definition within an implementation file? (p. 588)
- Which file, specification or implementation, omits member function bodies? (pp. 596- 602)
- What distinguishes a class constructor from other member functions? (p. 585)
- How can you determine if a class is immutable? (pp. 611–612)
![]() Answers
Answers
1![]() By choosing a data representation, and then writing out the operations for the ADT. 2. The class 3. It enables client code to see the formal interface to the class, but none of the implementation details that the creator of the class wishes to hide. 4. Date today; 5. today.GetDay(); 6. In the heading, between the name of the class and the name of the function. 7. The specification file. 8. Its name is identical to the name of the class; it is not void, nor does it have a return value type. 9. A class is immutable if there are no transformer (mutator) member functions.
By choosing a data representation, and then writing out the operations for the ADT. 2. The class 3. It enables client code to see the formal interface to the class, but none of the implementation details that the creator of the class wishes to hide. 4. Date today; 5. today.GetDay(); 6. In the heading, between the name of the class and the name of the function. 7. The specification file. 8. Its name is identical to the name of the class; it is not void, nor does it have a return value type. 9. A class is immutable if there are no transformer (mutator) member functions.
Exam Preparation Exercises
1. Dot notation is used only by class clients to refer to members. Other class members do not need to use dot notation. True or false?
2. Given the following declarations:
class Name
{
public:
string first;
string middle;
string last;
};
Name yourName;
Name myName;
What are the contents of the two Name variables after each of the following statements, assuming they are executed in the order listed?
a. yourName.first = “George”;
b. yourName.last = “Smith”;
c. myName = yourName;
d. myName.middle = “Nathaniel”;
e. yourName.middle = myName.middle.at(0) + “.”
3. What are the two major properties of an abstract data type that are defined in its specification?
4. How does the data representation differ from the domain of an abstract data type?
5. By default, are class members public or private?
6. Suppose you are given an object called current, of class Time: How would you write the call to its void member function, called plus, that adds an integer number of minutes to the current time? The number of minutes to add is found in variable period.
7. Which kind of operation—constructor, observer, transformer, or iterator—is implemented by a function that is declared as const?
8. A class may have multiple constructors, all with the same name. How does the compiler decide which one to call?
9. A class called Calendar has a default constructor and a constructor that accepts an integer value specifying the year. How would you invoke each of these constructors for an object called primary? Use the current year as the argument to the second constructor.
10. Which C++ language mechanism implements composition?
11. List three design principles for good class design.
12. What is a constructor initializer?
13. If a header file is used by more than one class, how do you keep the preprocessor from including the definition twice?
14. Distinguish between action responsibilities and knowledge responsibilities.
![]() Programming Warm-Up Exercises
Programming Warm-Up Exercises
1. Write a specification of a Date ADT.
a. What would be a good class representation?
b. Name possible action responsibilities.
c. Name possible knowledge responsibilities.
2. Write the specification file for class Date that implements the Date ADT as declared in Exercise 1.
3. Write the implementation for class Date from Exercise 2.
4. Write the specification for a Song ADT that represents a song entry in an MP3 library. It should have fields for title, album, artist, playing time in minutes and seconds, and music category. The music category is represented by an enumeration type called Category.
a. What operations should Song ADT have?
b. What observers should Song ADT have?
5. Write the specification file for class Song that implements the Song ADT from Exercise 4.
6. Write the implementation file for the class Song from Exercise 5.
7. Programming Problems 3 and 4 in Chapter 10 asked you to develop educational programs for teaching the periods of geologic time. Now that you know how to write classes, you can turn the Period ADT into a class. Write a specification file for class Period, which has a private field that's an enumeration type, representing the names of the periods. Class Period should have functions that return the period as a string, that return the period as an int, that return the starting date of the period, and that increment the period to the next most recent period (if the period is already NEOGENE, the increment operation should do nothing). It should have a default constructor that sets the period to PRECAMBRIAN, and a constructor with a parameter of the enumeration type to allow the user to create a Period object containing any period. For ease of reference, the table of the time periods is repeated here from Chapter 10. Be sure to use appropriate documenting comments.
| Period Name | Starting Date (millions of years) |
| Neogene | 23 |
| Paleogene | 65 |
| Cretaceous | 136 |
| Jurassic | 192 |
| Triassic | 225 |
| Permian | 280 |
| Carboniferous | 345 |
| Devonian | 395 |
| Silurian | 435 |
| Ordovician | 500 |
| Cambrian | 570 |
| Precambrian | 4500 |
8. Using the Period class as specified in Exercise 7, write a For statement that iterates through the periods of geologic times from earliest to most recent, writing out the name of the period and its starting date.
9. Write the function definitions of the two constructors for the Period class as specified in Exercise 7.
10. Write the function definition for the ToInt observer of the Period class specified in Exercise 7.
11. What would the file name be for the file containing the specification of the Period class in Exercise 7?
12. Write the include directive that would appear near the beginning of the Period class implementation file to include the specification file for the Period class as described in Exercise 7.
13. Because of floating-point representational errors, monetary amounts that need to be exact should not be stored in floating-point types. Code the specification for a class that represents an amount of money as dollars and cents. This class should have a default constructor that creates an object with zero dollars and zero cents, an observer for dollars, an observer for cents, and an observer that returns the amount as a float. It also should have transformers that add and subtract other values of class Money. Be sure to use appropriate documenting comments.
14. Write the function definitions of the two constructors for the Money class as specified in Exercise 13.
15. What would be the file name for the file containing the specification of the Money class in Exercise 13?
16. Write the include directive that would appear near the beginning of the Money class implementation file to include the specification file for the Money class as described in Exercise 13.
17. Write the function definitions for the observer in the Money class of Exercise 13 that returns the values as a float.
![]() Programming Problems
Programming Problems
1. Programming Problem 3 in Chapter 10 asked you to develop an educational program to teach users about geologic time. Rewrite that program using a class to implement an ADT representing a period of geologic time. If you did Programming Warm-Up Exercises 7 through 12, this will be a relatively easy task. The program should let the user enter a range of prehistoric dates (in millions of years), and then output the periods that are included in that range. Each time this is done, the user is asked if he or she wants to continue. The goal of the exercise is for the student to try to figure out when each period began, so that he or she can make a chart of geologic time. See Programming Warm-Up Exercise 7 for a list of the geologic time periods and their starting dates.
2. Programming Problem 4 in Chapter 10 asked you to write a second educational program for learning about geologic time. Rewrite that program using a class to implement an ADT representing a period of geologic time. If you did Programming Warm-Up Exercises 7 through 12, then you've already done some of this work. The ADT in those exercises needs to be enhanced with a constructor that takes a string as an argument and converts the string to the corresponding Period value (the constructor should work with any style of capitalization of the period names). In this program, the computer picks a date in geologic time and presents it to the student. The student guesses which period corresponds to the date. The student is allowed to continue guessing until he or she gets the right answer. The program then asks the user whether he or she wants to try again, and repeats the process if the answer is “yes.” You also may want to write a function that returns the period for a given date; however, this function does not need to be part of the class.
3. Several chapters since Chapter 5 have included Programming Problems that ask you to develop or rewrite a program that outputs the user's weight on different planets. The goal has been for you to see how the same program can be implemented in different ways. Here we would like you to rewrite the program using a class to represent the planet and its gravity. The class should include a constructor that allows a planet to be specified with a string, using any capitalization (if the string is not a planet name, then Earth should be assumed). The default constructor for the class will create an object representing Earth. The class has an observer operator that takes a weight on Earth as an argument and returns the weight on the planet. It should have a second observer that returns the name of the planet as a string with proper capitalization.
For ease of reference, the information for the original problem is repeated here. The following table gives the factor by which the weight must be multiplied for each planet. The program should output an error message if the user doesn't type a correct planet name. The prompt and the error message should make it clear to the user how a planet name must be entered. Be sure to use proper formatting and include appropriate comments in your code. The output should be labeled clearly and formatted neatly.
| Mercury | 0.4155 |
| Venus | 0.8975 |
| Earth | 1.0 |
| Moon | 0.166 |
| Mars | 0.3507 |
| Jupiter | 2.5374 |
| Saturn | 1.0677 |
| Uranus | 0.8947 |
| Neptune | 1.1794 |
| Pluto | 0.0899 |
4. Design, implement, and test a class that represents an amount of time in minutes and seconds. The class should provide a constructor that sets the time to a specified number of minutes and seconds. The default constructor should create an object for a time of zero minutes and zero seconds. The class should provide observers that return the minutes and the seconds separately, and an observer that returns the total time in seconds (minutes × 60 + seconds). Boolean comparison observers should be provided that test whether two times are equal, one time is greater than the other, or one time is less than the other. (You may use RelationType and function ComparedTo if you choose.) A function should be provided that adds one time to another, and another function that subtracts one time from another. The class should not allow negative times (subtraction of more time than is currently stored should result in a time of 0:00). This class should be immutable.
5. Design, implement, and test a class that represents a song on a CD or in an MP3 library. If you did Programming Warm-Up Exercises 4 through 6, you already have a good start. It should have members for title, album, artist, playing time in minutes and seconds, and music category. The music category is represented by an enumeration type called Category; make up an enumeration of your favorite categories. The class should have a constructor that allows all of the data members to be set, and a default constructor that sets all of the data members to appropriate empty values. It should have an observer operation for each data member, and an observer that returns all of the data for the song as a string. An observer that compares two songs for equality should be developed as well.
6. Design, implement, and test a class that represents a phone number. The number should be represented by a country code, an area code, a number, and a type. The first three values can be integers. The type member is an enumeration of HOME, OFFICE, FAX, CELL, and PAGER. The class should provide a default constructor that sets all of the integer values to zero and the type to HOME. A constructor that enables all of the values to be set should be provided as well. You also should provide a constructor that takes just the number and type as arguments, and sets the country and area codes to those of your location. The class will have observers that enable each data member to be retrieved, and transformers that allow each data member to be changed. An additional observer should be provided that compares two phone numbers for equality.
![]() Case Study Follow-Up
Case Study Follow-Up
1. Any duplicate time messages are written just before the listing of the events. Change the program so that duplicate time messages are written to cout instead, along with appropriate labels.
2. Add the name that goes with the duplicate time on the output.
3. Write a test plan for the case study program.
4. Implement the test plan written in Exercise 3.
5. The comparison function in class Name does not change the fields to all uppercase or all lowercase before comparing them. That would result, for example, in a comparison of the names MacTavish and Macauley indicating that MacTavish comes first alphabetically. Rewrite function ComparedTo in class Name so that all the strings are changed to all uppercase before the comparison is made.
6. Rerun the case study using the Name class as altered in Exercise 5.
1In C++, a struct is almost identical to a class. But because of its heritage from the C struct construct, most programmers use class to implement an ADT, and limit their use of struct to applications where a record is needed that has no associated operations.