
B. Objective-C Language Summary
This appendix summarizes the Objective-C language in a format suitable for quick reference. It is not intended that this be a complete definition of the language, but rather a more informal description of its features. You should thoroughly read the material in this appendix after you have completed the text. Doing so will not only reinforce the material you have learned, but also provide you with a better global understanding of Objective-C.
This summary is based on the ANSI C99 (ISO/IEC 9899:1999) standard with Objective-C language extensions, which are not standardized. As of this writing, the latest version of the GNU gcc compiler is version 3.3, which does not fully conform to the ANSI C99 standard1
Extensions to the C language in the gcc compiler that are not part of the ANSI standard are not summarized here.2
Digraphs and Identifiers
Digraph Characters
The following special two-character sequences (digraphs) are equivalent to the listed single-character punctuators:

Identifiers
An identifier in Objective-C consists of a sequence of letters (upper- or lowercase), universal character names (1.2.1), digits, or underscore characters. The first character of an identifier must be a letter, an underscore, or a universal character name. The first 31 characters of an identifier are guaranteed to be significant in an external name, and the first 63 characters are guaranteed to be significant for an internal identifier or macro name.
Universal Character Names
A universal character name is formed by the characters u followed by four hexadecimal numbers or the characters U followed by eight hexadecimal numbers. If the first character of an identifier is specified by a universal character, its value cannot be that of a digit character. Universal characters, when used in identifier names, can also not specify a character whose value is less than A016 (other than 2416, 4016, or 6016) or a character in the range D80016 through DFFF16, inclusive.
Universal character names can be used in identifier names, character constants, and character strings.
Keywords
The identifiers listed here are keywords that have special meanings to the Objective-C compiler.

Directives
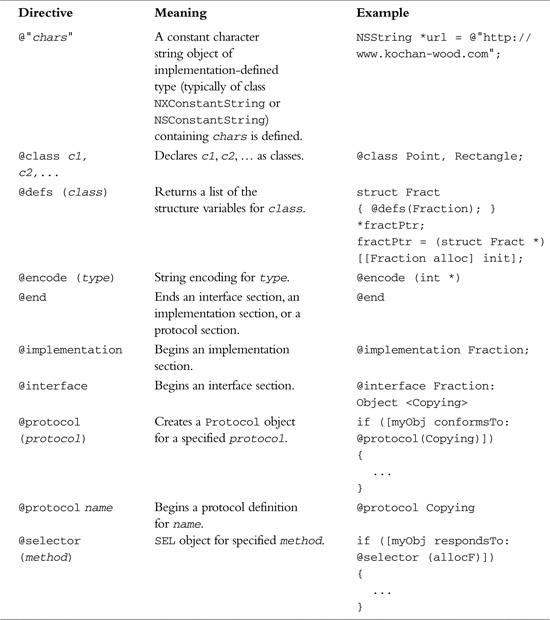
Compiler directives begin with an @ sign and are used specifically for working with classes and objects. These are summarized in Table B.1.
Table B.1. Compiler Directives
Predefined Identifiers
Table B.2 lists identifiers that have special meanings in Objective-C programs. Some are typedefs and macros defined in the header file <objc/objc.h>.
Table B.2. Special Predefined Identifiers

Comments
There are two ways to insert comments into program. A comment can begin with the two characters //, in which case any characters that follow on the line are ignored by the compiler.
A comment can also begin with the two characters /* and end when the characters */ are encountered. Any characters can be included inside the comment, which can extend over multiple lines of the program. A comment can be used anywhere in the program where a blank space is allowed. Comments, however, cannot be nested, which means that the first */ characters encountered end the comment, no matter how many /* characters you use.
Constants
Integer Constants
An integer constant is a sequence of digits, optionally preceded by a plus or minus sign. If the first digit is 0, the integer is taken as an octal constant, in which case all digits that follow must be 0–7. If the first digit is 0 and is immediately followed by the letter x (or X), the integer is taken as a hexadecimal constant and the digits that follow can be in the range 0–9 or a–f (or A–F).
The suffix letter l or L can be added to the end of a decimal integer constant to make it a long int constant. If the value can't fit into a long int, it's treated as a long long int. If the suffix letter l or L is added to the end of an octal or a hexadecimal constant, it is taken as a long int if it can fit; if it can't fit there, it is taken as a long long int. Finally, if it can't fit in a long long int, it is taken as an unsigned long long int constant.
The suffix letters ll or LL can be added to the end of a decimal integer constant to make it a long long int. When added to the end of an octal or a hexadecimal constant, it is taken as a long long int first, and if it can't fit there, it is taken as an unsigned long long int constant.
The suffix u or U can be added to the end of an integer constant to make it unsigned. If the constant is too large to fit inside an unsigned int, it's taken as an unsigned long int. If it's too large for an unsigned long int, it's taken as an unsigned long long int.
Both an unsigned and long suffix can be added to an integer constant to make it an unsigned long int. If the constant is too large to fit in an unsigned long int, it's taken as an unsigned long long int.
Both an unsigned and a long-long suffix can be added to an integer constant to make it an unsigned long long int.
If an unsuffixed decimal integer constant is too large to fit into a signed int, it is treated a long int. If it's too large to fit into a long int, it's treated as a long long int.
If an unsuffixed octal or hexadecimal integer constant is too large to fit into a signed int, it is treated as an unsigned int. If it's too large to fit into an unsigned int, it's treated as a long int, and if it's too large to fit into a long int, it's treated as an unsigned long int. If it's too large for an unsigned long int, it's taken as a long long int. Finally, if it's too large to fit into a long long int, the constant is treated as an unsigned long long int.
Floating-point Constants
A floating-point constant consists of a sequence of decimal digits, a decimal point, and another sequence of decimal digits. A minus sign can precede the value to denote a negative value. In addition, either the sequence of digits before the decimal point or after the decimal point can be omitted, but not both.
If the floating-point constant is immediately followed by the letter e (or E) and an optionally signed integer, the constant is expressed in scientific notation. This integer (the exponent) represents the power of 10 by which the value preceding the letter e (the mantissa) is multiplied (for example, 1.5e-2 represents 1.5 × 10-2 or .015).
A hexadecimal floating constant consists of a leading 0x or 0X, followed by one or more decimal or hexadecimal digits, followed by a p or P, followed by an optionally signed binary exponent. For example, 0x3p10 represents the value 3 × 210.
Floating-point constants are treated as double precision values by the compiler. The suffix letter f or F can be added to specify a float constant instead of a double one, and the suffix letter l or L can be added to specify a long double constant.
Character Constants
A character enclosed within single quotation marks is a character constant. How the inclusion of more than one character inside the single quotation marks is handled is implementation-defined. A universal character can be used in a character constant to specify a character not included in the standard character set.
Escape Sequences
Special escape sequences are recognized and are introduced by the backslash character. These escape sequences are listed here:

In the octal character case, from one to three octal digits can be specified. In the last three cases, hexadecimal digits are used.
Wide Character Constants
A wide character constant is written as L'x'. The type of such a constant is wchar_t, as defined in the standard header file <stddef.h>. Wide character constants provide a way to express a character from a character set that cannot be fully represented with the normal char type.
Character String Constants
A sequence of zero or more characters enclosed within double quotation marks represents a character string constant. Any valid character can be included in the string, including any of the escape characters listed previously. The compiler automatically inserts a null character ('�') at the end of the string.
Normally, the compiler produces a pointer to the first character in the string and the type is “pointer to char.” However, when the string constant is used with the sizeof operator to initialize a character array, or with the & operator, the type of the string constant is “array of char.”
Character string constants cannot be modified by the program.
Character String Concatenation
The preprocessor automatically concatenates adjacent character string constants together. The strings can be separated by zero or more whitespace characters. So, the three strings
"a" " character "
"string"
are equivalent to the single string
"a character string"
after concatenation.
Multibyte Characters
Implementation-defined sequences of characters can be used to shift between different states in a character string so that multibyte characters can be included.
Wide Character String Constants
Character string constants from an extended character set are expressed using the format L"...". The type of such a constant is “pointer to wchar_t,” where wchar_t is defined in <stddef.h>.
Constant Character String Objects
A constant character string object can be created by placing an @ character in front of a constant character string. The type of the object is implementation-defined and is typically NXConstantString or NSConstantString. Using such string objects in a program usually requires the use of a header file (such as <NSString.h>) that defines the particular constant string object class.
Enumeration Constants
An identifier that has been declared as a value for an enumerated type is taken as a constant of that particular type and is otherwise treated as type int by the compiler.
Data Types and Declarations
This section summarizes the basic data types, derived data types, enumerated data types, and typedef. Also summarized in this section is the format for declaring variables.
Declarations
When defining a particular structure, union, enumerated data type, or typedef, the compiler does not automatically reserve any storage. The definition merely tells the compiler about the particular data type and (optionally) associates a name with it. Such a definition can be made either inside or outside a function or method. In the former case, only the function or method knows of its existence; in the latter case, it is known throughout the remainder of the file.
After the definition has been made, variables can be declared to be of that particular data type. A variable that is declared to be of any data type will have storage reserved for it, unless it is an extern declaration, in which case it might or might not have storage allocated (see the section “Storage Classes and Scope”).
The language also enables storage to be allocated at the same time that a particular structure, union, or enumerated data type is defined. This is done by simply listing the variables before the terminating semicolon of the definition.
Basic Data Types
The basic Objective-C data types are summarized in Table B.3. A variable can be declared to be of a particular basic data type using the following format:
type name = initial_value;
The assignment of an initial value to the variable is optional and is subject to the rules summarized in the section “Variables.” More than one variable can be declared simultaneously using the following general format:
type name = initial_value, name = initial_value, .. ;
Before the type declaration, an optional storage class can also be specified, as summarized in the section “Variables.” If a storage class is specified and the type of the variable is int, then int can be omitted. For example
static counter;
declares counter to be a static int variable.
Table B.3. Summary of Basic Data Types
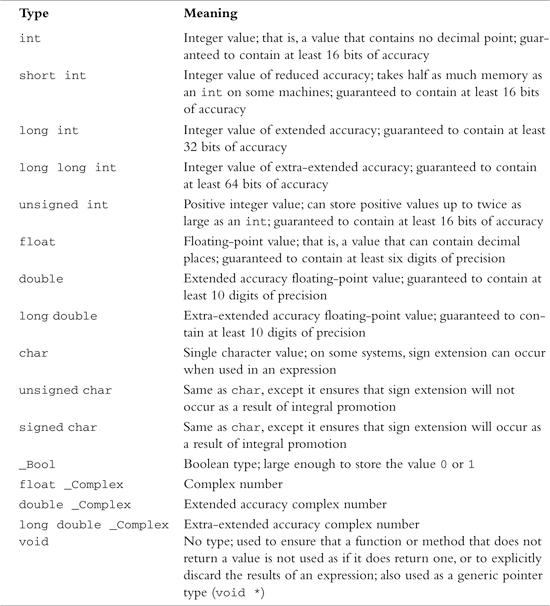
Note that the signed modifier can also be placed in front of the short int, int, long int, and long long int types. Because these types are signed by default anyway, this has no effect.
_Complex and _Imaginary data types enable complex and imaginary numbers to be declared and manipulated, with functions in the library for supporting arithmetic on these types. Normally, you should include the file <complex.h> in your program, which defines macros and declares functions for working with complex and imaginary numbers. For example, a double_Complex variable c1 can be declared and initialized to the value 5 + 10.5i with a statement such as follows:
double _Complex c1 = 5 + 10.5 * I;
Library routines such as creal and cimag can then be used to extract the real and imaginary parts of c1, respectively.
An implementation is not required to support types _Complex and _Imaginary, and it can optionally support one but not the other.
Derived Data Types
A derived data type is one that is built up from one or more of the basic data types. Derived data types are arrays, structures, unions, and pointers (which include objects). A function or method that returns a value of a specified type is also considered a derived data type. Each of these, with the exception of functions and methods, is summarized in the following paragraphs. Functions and methods are separately covered in the sections “Functions” and “Classes,” respectively.
Arrays
Single-Dimensional Arrays
Arrays can be defined to contain any basic data type or any derived data type. Arrays of functions are not permitted (although arrays of function pointers are).
The declaration of an array has the following basic format:
type name[n] = { initExpression, initExpression, .. };
The expression n determines the number of elements in the array name and can be omitted, provided a list of initial values is specified. In such a case, the size of the array is determined based on the number of initial values listed or on the largest index element referenced if designated initializers are used.
Each initial value must be a constant expression if a global array is defined. Fewer values can exist in the initialization list than there are elements in the array, but more cannot exist. If fewer values are specified, only that many elements of the array are initialized—the remaining elements are set to 0.
A special case of array initialization occurs in the case of character arrays, which can be initialized by a constant character string. For example
char today[] = "Monday";
declares today as an array of characters. This array is initialized to the characters 'M', 'o', 'n', 'd', 'a', 'y', and '�', respectively.
If you explicitly dimension the character array and don't leave room for the terminating null, the compiler doesn't place a null at the end of the array:
char today[6] = "Monday";
This declares today as an array of six characters and sets its elements to the characters 'M', 'o', &'n', 'd', 'a', and 'y', respectively.
By enclosing an element number in a pair of brackets, specific array elements can be initialized in any order. For example
int x = 1233;
int a[] = { [9] = x + 1, [2] = 3, [1] = 2, [0] = 1 };
defines a 10-element array called a (based on the highest index into the array) and initializes the last element to the value of x + 1 (1234) and the first three elements to 1, 2, and 3, respectively.
Variable-Length Arrays
Inside a function, method, or block you can dimension an array using an expression containing variables. In that case, the size is calculated at runtime. For example, the function
int makeVals (int n)
{
int valArray[n];
...
}
defines an automatic array called valArray with a size of n elements, where n is evaluated at runtime and can vary between function calls. Variable-length arrays cannot be initialized.
Multidimensional Arrays
The general format for declaring a multidimensional array follows:
type name[d1][d2]...[dn] = initializationList;
The array name is defined to contain d1 x d2 x…x dn elements of the specified type. For example
int three_d [5][2][20];
defines a three-dimensional array, three_d, containing 200 integers.
A particular element is referenced from a multidimensional array by enclosing the desired subscript for each dimension in its own set of brackets. For example, the statement
three_d [4][0][15] = 100;
stores 100 into the indicated element of the array three_d.
Multidimensional arrays can be initialized in the same manner as one-dimensional arrays. Nested pairs of braces can be used to control the assignment of values to the elements in the array.
The following declares matrix to be a two-dimensional array containing four rows and three columns:
int matrix[4][3] =
{ { 1, 2, 3 },
{ 4, 5, 6 },
{ 7, 8, 9 } };
Elements in the first row of matrix are set to the values 1, 2, and 3, respectively; in the second row they are set to 4, 5, and 6, respectively; and in the third row they are set to 7, 8, and 9, respectively. The elements in the fourth row are set to 0 because no values are specified for that row. The declaration
int matrix[4][3] =
{ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
initializes matrix to the same values because the elements of a multidimensional array are initialized in dimension order—that is, from leftmost to rightmost dimension.
The declaration
int matrix[4][3] =
{ { 1 },
{ 4 },
{ 7 } };
sets the first element of the first row of matrix to 1, the first element of the second row to 4, and the first element of the third row to 7. All remaining elements are set to 0 by default.
Finally, the declaration
int matrix[4][3] = { [0][0] = 1, [1][1] = 5, [2][2] = 9 };
initializes the indicated elements of the matrix to the specified values.
Structures
General Format:
struct name
{
memberDeclaration
memberDeclaration
...
} variableList;
The structure name is defined to contain the members as specified by each memberDeclaration. Each such declaration consists of a type specification followed by a list of one or more member names.
Variables can be declared at the time that the structure is defined simply by listing them before the terminating semicolon, or they can subsequently be declared using the following format:
struct name variableList;
This format cannot be used if name is omitted when the structure is defined. In that case, all variables of that structure type must be declared with the definition.
The format for initializing a structure variable is similar to that for arrays. Its members can be initialized by enclosing the list of initial values in a pair of curly braces. Each value in the list must be a constant expression if a global structure is initialized.
The declaration
struct point
{
float x;
float y;
} start = {100.0, 200.0};
defines a structure called point and a struct point variable called start with initial values as specified. Specific members can be designated for initialization in any order with the notation
.member = value
in the initialization list, as in
struct point end = { .y = 500, .x = 200 };
The declaration
struct entry
{
char *word;
char *def;
} dictionary[1000] = {
{ "a", "first letter of the alphabet" },
{ "aardvark", "a burrowing African mammal" },
{ "aback", "to startle" }
};
declares dictionary to contain 1,000 entry structures, with the first 3 elements initialized to the specified character string pointers. Using designated initializers, you could have also written it like this:
struct entry
{
char *word;
char *def;
} dictionary[1000] = {
[0].word = "a", [0].def = "first letter of the alphabet",
[1].word = "aardvark", [1].def = "a burrowing African mammal",
[2].word = "aback", [2].def = "to startle"
};
or equivalently like this:
struct entry
{
char *word;
char *def;
} dictionary[1000] = {
{ {.word = "a", .def = "first letter of the alphabet" },
{.word = "aardvark", .def = "a burrowing African mammal"} ,
{.word = "aback", .def = "to startle"}
};
An automatic structure variable can be initialized to another structure of the same type like this:
struct date tomorrow = today;
This declares the date structure variable tomorrow and assigns to it the contents of the (previously declared) date structure variable today.
A memberDeclaration that has the format
type fieldName : n
defines a field that is n bits wide inside the structure, where n is an integer value. Fields can be packed from left to right on some machines and right to left on others. If fieldName is omitted, the specified number of bits is reserved but cannot be referenced. If fieldName is omitted and n is 0, the field that follows is aligned on the next storage unit boundary, where a unit is implementation-defined. The type of a field can be int, signed int, or unsigned int. It is implementation-defined whether an int field is treated as signed or unsigned. The address operator (&) cannot be applied to a field, and arrays of fields cannot be defined.
Unions
General Format:
union name
{
memberDeclaration
memberDeclaration
...
} variableList;
This defines a union called name with members as specified by each memberDeclaration. Each member of the union shares overlapping storage space, and the compiler ensures that enough space is reserved to contain the largest member of the union.
Variables can be declared at the time that the union is defined, or they can be subsequently declared using the notation
union name variableList;
provided the union was given a name when it was defined.
It is the programmer's responsibility to ensure that the value retrieved from a union is consistent with the last value stored inside the union. The first member of a union can be initialized by enclosing the initial value, which, in the case of a global union variable, must be a constant expression, inside a pair of curly braces:
union shared
{
long long int l;
long int w[2];
} swap = { 0xffffffff };
A different member can be initialized instead by specifying the member name, as in
union shared swap2 = {.w[0] = 0x0, .w[1] = 0xffffffff};
This declares the union variable swap and sets the l member to hexadecimal ffffffff.
An automatic union variable can also be initialized to a union of the same type, as in
union shared swap2 = swap;
Pointers
The basic format for declaring a pointer variable is as follows:
type *name;
The identifier name is declared to be of type “pointer to type,” which can be a basic data type or a derived data type. For example
int *ip;
declares ip to be a pointer to an int, and the declaration
struct entry *ep;
declares ep to be a pointer to an entry structure. If Fraction is defined as a class, the declaration
Fraction *myFract;
declares myFract to be an object of type Fraction—or more explicitly, myFract is used to hold a pointer to the object's data structure after an instance of the object is created as assigned to the variable.
Pointers that point to elements in an array are declared to point to the type of element contained in the array. For example, the previous declaration of ip would also be used to declare a pointer into an array of integers.
More advanced forms of pointer declarations are also permitted. For example, the declaration
char *tp[100];
declares tp to be an array of 100 character pointers, and the declaration
struct entry (*fnPtr) (int);
declares fnPtr to be a pointer to a function that returns an entry structure and takes a single int argument.
A pointer can be tested to see whether it's null by comparing it against a constant expression whose value is 0. The implementation can choose to internally represent a null pointer with a value other than 0. However, a comparison between such an internally represented null pointer and a constant value of 0 must prove equal.
The manner in which pointers are converted to integers and integers are converted to pointers is machine dependent, as is the size of the integer required to hold a pointer.
The type “pointer to void” is the generic pointer type. The language guarantees that a pointer of any type can be assigned to a void pointer and back again without changing its value.
The type id is a generic object pointer. Any object from any class can be assigned to an id variable, and vice versa.
Other than these two special cases, assignment of different pointer types is not permitted and typically results in a warning message from the compiler if attempted.
Enumerated Data Types
General Format:
enum name { enum_1, enum_2, .. } variableList;
The enumerated type name is defined with enumeration values enum_1, enum_2,…, each of which is an identifier or an identifier followed by an equals sign and a constant expression. variableList is an optional list of variables (with optional initial values) declared to be of type enum name.
The compiler assigns sequential integers to the enumeration identifiers starting at 0. If an identifier is followed by = and a constant expression, the value of that expression is assigned to the identifier. Subsequent identifiers are assigned values beginning with that constant expression plus one. Enumeration identifiers are treated as constant integer values by the compiler.
If you want to declare variables to be of a previously defined (and named) enumeration type, you can use the following construct:
enum name variableList;
A variable declared to be of a particular enumerated type can be assigned only a value of the same data type, although the compiler might not flag this as an error.
typedef
The typedef statement is used to assign a new name to a basic or derived data type. The typedef does not define a new type but simply a new name for an existing type. Therefore, variables declared to be of the newly named type are treated by the compiler exactly as if they were declared to be of the type associated with the new name.
In forming a typedef definition, proceed as though a normal variable declaration were being made. Then, place the new type name where the variable name would normally appear. Finally, in front of everything, place the keyword typedef.
As an example,
typedef struct
{
float x;
float y;
} POINT;
associates the name POINT with a structure containing two floating-point members called x and y. Variables can subsequently be declared to be of type POINT, like so:
POINT origin = { 0.0, 0.0 };
Type Modifiers: const, volatile, and restrict
The keyword const can be placed before a type declaration to tell the compiler the value cannot be modified. So, the declaration
const int x5 = 100;
declares x5 to be a constant integer (that is, it won't be set to anything else during the program's execution). The compiler is not required to flag attempts to change the value of a const variable.
The volatile modifier explicitly tells the compiler that the value changes (usually dynamically). When a volatile variable is used in an expression, its value is accessed each place it appears.
To declare port17 to be of type “volatile pointer to char,” you would write this line:
char *volatile port17.
The restrict keyword can be used with pointers. It is a hint to the compiler for optimization (similar to the register keyword for variables). The restrict keyword specifies to the compiler that the pointer will be the only reference to a particular object—that is, it will not be referenced by any other pointer within the same scope. The lines
int * restrict intPtrA;
int * restrict intPtrB;
tell the compiler that, for the duration of the scope in which intPtrA and intPtrB are defined, they will never access the same value. Their use for pointing to integers (in an array, for example) is mutually exclusive.
Expressions
Variable names, function names, message expressions, array names, constants, function calls, array references, and structure and union references are all considered expressions. Applying a unary operator (where appropriate) to one of these expressions is also an expression, as is combining two or more of these expressions with a binary or ternary operator. Finally, an expression enclosed within parentheses is also an expression.
An expression of any type other than void that identifies a data object is called an lvalue. If it can be assigned a value, it is known as a modifiable lvalue.
Modifiable lvalue expressions are required in certain places. The expression on the left side of an assignment operator must be a modifiable lvalue. The unary address operator can be applied only to a modifiable lvalue or a function name. Finally, the increment and decrement operators can be applied only to modifiable lvalues.
Summary of Objective-C Operators
Table B.4 summarizes the various operators in the Objective-C language. These operators are listed in order of decreasing precedence, and operators grouped together have the same precedence.
As an example of how to use Table B.4, consider the following expression:
b | c & d * e
The multiplication operator has higher precedence than both the bitwise OR and bitwise AND operators because it appears above both of these in Table B.4. Similarly, the bitwise AND operator has higher precedence than the bitwise OR operator because the former appears above the latter in the table. Therefore, this expression would be evaluated as
b | ( c & ( d * e ) )
Now, consider the following expression:
b % c * d
Table B.4. Summary of Objective-C Operators
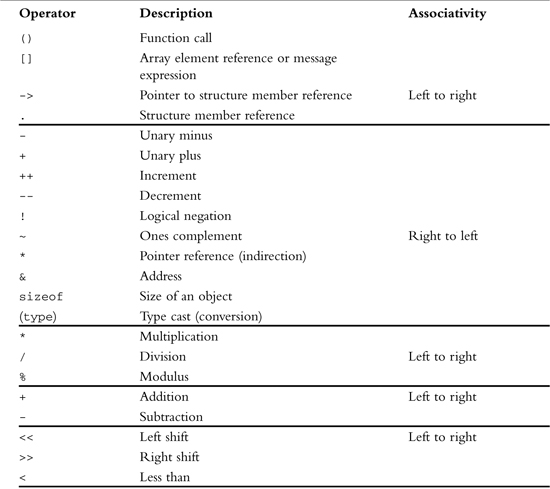
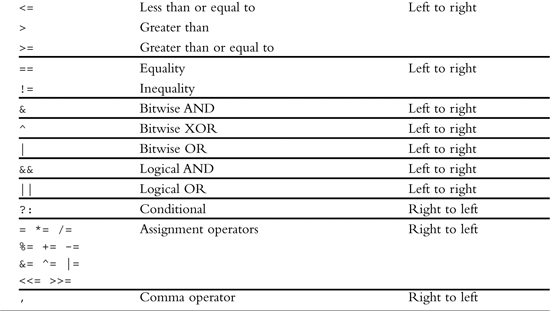
Because the modulus and multiplication operators appear in the same grouping in Table B.4, they have the same precedence. The associativity listed for these operators is left to right, indicating that the expression would be evaluated as follows:
( b % c ) * d
As another example, the expression
++a->b
would be evaluated as
++(a->b)
because the -> operator has higher precedence than the ++ operator.
Finally, because the assignment operators group from right to left, the statement
a = b = 0;
would be evaluated as
a = (b = 0);
which would have the net result of setting the values of a and b to 0. In the case of the expression
x[i] + ++i
it is not defined whether the compiler will evaluate the left side of the plus operator or the right side first. Here, the way that it's done affects the result because the value of i might be incremented before x[i] is evaluated.
Another case in which the order of evaluation is not defined is in the expression shown here:
x[i] = ++i
In this situation, it is not defined whether the value of i will be incremented before or after its value is used to index into x.
The order of evaluation of function and method arguments is also undefined. Therefore, in the function call
f (i, ++i);
or in the message expression
[myFract setTo: i over: ++i];
i might be incremented first, thereby causing the same value to be sent as the two arguments to the function or method.
The Objective-C language guarantees that the && and || operators will be evaluated from left to right. Furthermore, in the case of &&, it is guaranteed that the second operand will not be evaluated if the first is 0; in the case of ||, it is guaranteed that the second operand will not be evaluated if the first is nonzero. This fact is worth bearing in mind when forming expressions such as
if ( dataFlag || [myData checkData] )
...
because, in this case, checkData is invoked only if the value of dataFlag is 0. As another example, if the array object a is defined to contain n elements, the statement that begins
if (index >= 0 && index < n && ([a objectAtIndex: index] == 0))
...
references the element contained in the array only if index is a valid subscript into the array.
Constant Expressions
A constant expression is an expression in which each of the terms is a constant value. Constant expressions are required in the following situations:
- As the value after a case in a
switchstatement - For specifying the size of an array
- For assigning a value to an enumeration identifier
- For specifying the bit field size in a structure definition
- For assigning initial values to external or static variables
- For specifying initial values to global variables
- As the expression following the
#ifin a#ifpreprocessor statement
In the first four cases, the constant expression must consist of integer constants, character constants, enumeration constants, and sizeof expressions. The only operators that can be used are the arithmetic operators, bitwise operators, relational operators, conditional expression operator, and type cast operator.
In the fifth and sixth cases, in addition to the rules cited earlier, the address operator can be implicitly or explicitly used. However, it can be applied only to external or static variables or functions. So, for example, the expression
&x + 10
would be a valid constant expression, provided that x is an external or static variable. Furthermore, the expression
&a[10] - 5
is a valid constant expression if a is an external or static array. Finally, because &a[0] is equivalent to the expression a
a + sizeof (char) * 100
is also a valid constant expression.
For the last situation that requires a constant expression (after the #if), the rules are the same as for the first four cases, except the sizeof operator, enumeration constants, and the type cast operator cannot be used. However, the special defined operator is permitted (see the section “The #if Directive”).
Arithmetic Operators
Given that
![]()
the expression

In each expression, the usual arithmetic conversions are performed on the operands (see the section “Conversion of Basic Data Types”). If a is unsigned, -a is calculated by first applying integral promotion to it, subtracting it from the largest value of the promoted type, and adding 1 to the result.
If two integral values are divided, the result is truncated. If either operand is negative, the direction of the truncation is not defined (that is, –3 / 2 can produce –1 on some machines and –2 on others); otherwise, truncation is always toward 0 (3 / 2 always produces 1). See the section “Basic Operations with Pointers” for a summary of arithmetic operations with pointers.
Logical Operators
![]()
the expression
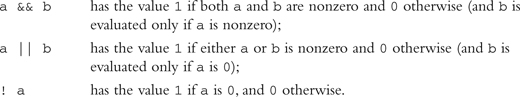
The usual arithmetic conversions are applied to a and b (see the section “Conversion of Basic Data Types”). The type of the result in all cases is int.
Relational Operators
Given that
![]()
the expression
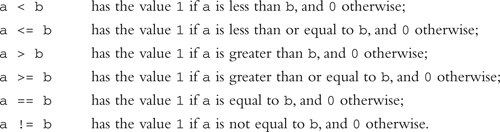
The usual arithmetic conversions are performed on a and b (see the section “Conversion of Basic Data Types”). The first four relational tests are meaningful for pointers only if they both point into the same array or to members of the same structure or union. The type of the result in each case is int.
Bitwise Operators
Given that
![]()
the expression

The usual arithmetic conversions are performed on the operands, except with << and >>, in which case just integral promotion is performed on each operand (see the section “Conversion of Basic Data Types”). If the shift count is negative or is greater than or equal to the number of bits contained in the object being shifted, the result of the shift is undefined. On some machines, a right shift is arithmetic (sign fill) and on others logical (zero fill). The type of the result of a shift operation is that of the promoted left operand.
Increment and Decrement Operators
Given that
![]()
the expression

The section “Basic Operations with Pointers” describes these operations on pointers.
Assignment Operators
Given that

the expression
![]()
In the first expression, if a is one of the basic data types (except void), it is converted to match the type of l. If l is a pointer, a must be a pointer to the same type as l, a void pointer, or the null pointer.
If l is a void pointer, a can be of any pointer type. The second expression is treated as if it were written l = l op (a), except l is evaluated only once (consider x[i++] += 10).
Conditional Operator
Given that
![]()
the expression
![]()
Expressions b and c must be of the same data type. If they are not, but are both arithmetic data types, the usual arithmetic conversions are applied to make their types the same. If one is a pointer and the other is 0, the latter is taken as a null pointer of the same type as the former. If one is a pointer to void and the other is a pointer to another type, the latter is converted to be a pointer to void and is the resulting type.
Type Cast Operator
Given that

the expression
![]()
Note that the use of a parenthesized type in a method declaration or definition is not an example of the use of the type cast operator.
sizeof Operator
Given that
![]()
the expression
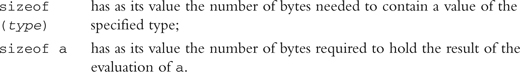
If type is char, the result is defined to be 1. If a is the name of an array that has been dimensioned (either explicitly or implicitly through initialization) and is not a formal parameter or undimensioned extern array, sizeof a gives the number of bytes required to store the elements in a.
If a is the name of a class, sizeof (a) gives the size of the data structure needed to hold an instance of a.
The type of the integer produced by the sizeof operator is size_t, which is defined in the standard header file <stddef.h>.
If a is a variable length array, then the expression is evaluated at runtime; otherwise, it is evaluated at compile time and can be used in constant expressions (refer to the section “Constant Expressions”).
Comma Operator
![]()
the expression
![]()
Basic Operations with Arrays
Given that
the expression

In each case, the type of the result is the type of the elements contained in a. See the section “Basic Operations with Pointers” for a summary of operations with pointers and arrays.
Basic Operations with Structures3
Given that

the expression


Basic Operations with Pointers
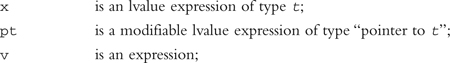
the expression

Pointers to Arrays
Given that

the expression

The actual type of the integer produced by subtracting two pointers is specified by ptrdiff_t, which is defined in the standard header file <stddef.h>.
Pointers to Structures
Given that

the expression

Compound Literals
A compound literal is a type name enclosed in parentheses followed by an initialization list. It creates an unnamed value of the specified type, which has scope limited to the block in which it is created, or global scope if defined outside of any block. In the latter case, the initializers must all be constant expressions.
As an example,
(struct point) {.x = 0, .y = 0}
is an expression that produces a structure of type struct point with the specified initial values. This can be assigned to another struct point structure, like so:
origin = (struct point) {.x = 0, .y = 0};
Or, it can be passed to a function or method expecting an argument of struct point, like so:
moveToPoint ((struct point) {.x = 0, .y = 0});
Types other than structures can be defined as well—for example, if intPtr is of type int *, the statement
intPtr = (int [100]) {[0] = 1, [50] = 50, [99] = 99 };
(which can appear anywhere in the program) sets intptr pointing to an array of 100 integers, whose 3 elements are initialized as specified.
If the size of the array is not specified, it is determined by the initializer list.
Conversion of Basic Data Types
The Objective-C language converts operands in arithmetic expressions in a predefined order, known as the usual arithmetic conversions:
- If either operand is of type
long double, the other is converted tolong doubleand that is the type of the result. - If either operand is of type
double, the other is converted todoubleand that is the type of the result. - If either operand is of type
float, the other is converted tofloatand that is the type of the result. - If either operand is of type
_Bool,char,short int,intbit field, or an enumerated data type, it is converted toint, if anintcan fully represent its range of values; otherwise, it is converted tounsigned int. If both operands are of the same type, that is the type of the result. - If both operands are signed or both are unsigned, the smaller integer type is converted to the larger integer type and that is the type of the result.
- If the unsigned operand is equal in size or larger than the signed operand, the signed operand is converted to the type of the unsigned operand and that is the type of the result.
- If the signed operand can represent all the values in the unsigned operand, the latter is converted to the type of the former if it can fully represent its range of values, and that is the type of the result.
- If this step is reached, both operands are converted to the unsigned type corresponding to the type of the signed type.
Step 4 is known more formally as integral promotion.
Conversion of operands is well behaved in most situations, although the following points should be noted:
- Conversion of a
charto anintcan involve sign extension on some machines, unless thecharis declared asunsigned. - Conversion of a signed integer to a longer integer results in extension of the sign to the left; conversion of an unsigned integer to a longer integer results in zero fill to the left.
- Conversion of any value to a
_Boolresults in0if the value is zero and1otherwise. - Conversion of a longer integer to a shorter one results in truncation of the integer on the left.
- Conversion of a floating-point value to an integer results in truncation of the decimal portion of the value. If the integer is not large enough to contain the converted floating-point value, the result is not defined, as is the result of converting a negative floating-point value to an unsigned integer.
- Conversion of a longer floating-point value to a shorter one might or might not result in rounding before the truncation occurs.
Storage Classes and Scope
The term storage class refers to the manner in which memory is allocated by the compiler in the case of variables and to the scope of a particular function or method definition. Storage classes are auto, static, extern, and register. A storage class can be omitted in a declarartion and a default storage class will be assigned, as discussed next.
The term scope refers to the extent of the meaning of a particular identifier within a program. An identifier defined outside any function, method, or statement block (herein referred to as a BLOCK) can be referenced anywhere subsequent in the file. Identifiers defined within a BLOCK are local to that BLOCK and can locally redefine an identifier defined outside it. Label names are known throughout the BLOCK, as are formal parameter names. Labels, instance variables, structure and structure member names, union and union member names, and enumerated type names do not have to be distinct from each other or from variable, function, or method names. However, enumeration identifiers do have to be distinct from variable names and from other enumeration identifiers defined within the same scope. Class names have global scope and so must be distinct from other variables and type names with the same scope.
Functions
If a storage class is specified when a function is defined, it must be either static or extern. Functions that are declared static can be referenced only from within the same file that contains the function. Functions specified as extern (or that have no class specified) can be called by functions or methods from other files.
Variables
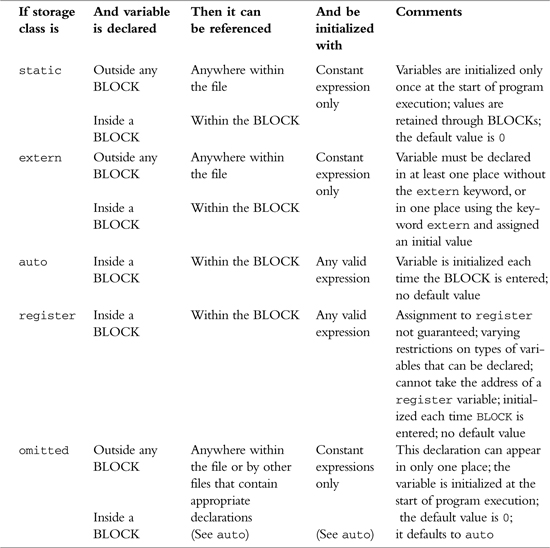
Table B.5 summarizes the various storage classes that can be used in declaring variables as well as their scopes and methods of initialization.
Table B.5. Variables: Summary of Storage Classes, Scope, and Initialization.
Instance Variables
Instance variables can be accessed by any instance method defined for the class, either in the interface section that explicitly defines the variable or in categories created for the class. Inherited instance variables can also be accessed directly without any special declarations. Class methods do not have access to instance variables.
The special directives @private, @protected, and @public can be used to control the scope of an instance variable. After these directives appear, they remain in effect until the closing curly brace ending the declaration of the instance variables is encountered or until another of the three listed directives is used. For example
@interface Point: Object
{
@private
int internalID;
@protected
float x;
float y;
@public
BOOL valid;
}
begins an interface declaration for a class called Point containing four instance variables. The internalID variable is private, the x and y variables are protected (the default), and the valid variable is public.
These directives are summarized in Table B.6.
Table B.6. Scope of Instance Variables

Functions
This section summarizes the syntax and operation of functions.
Function Definition
General Format:
returnType name ( type1 param1, type2 param2, .. )
{
variableDeclarations
programStatement
programStatement
...
return expression;
}
The function called name is defined, which returns a value of type returnType and has formal parameters param1, param2, …. param1 is declared to be of type type1, param2 of type type2, and so on.
Local variables are typically declared at the beginning of the function, but that's not required. They can be declared anywhere, in which case their access is limited to statements appearing after their declaration in the function.
If the function does not return a value, returnType is specified as void.
If just void is specified inside the parentheses, the function takes no arguments. If .. is used as the last (or only) parameter in the list, the function takes a variable number of arguments, as in the following:
int printf (char *format, ...)
{
...
}
Declarations for single-dimensional array arguments do not have to specify the number of elements in the array. For multidimensional arrays, the size of each dimension except the first must be specified.
See the section “The return Statement” for a discussion of the return statement.
An older way of defining functions is still supported. The general format is
returnType name (param1, param2, .. )
param_declarations
{
variableDeclarations
programStatement
programStatement
...
return expression;
}
Here, just the parameter names are listed inside the parentheses. If no arguments are expected, nothing appears between the left and right parentheses. The type of each parameter is declared outside the parentheses and before the opening curly brace of the function definition. For example
unsigned int rotate (value, n)
unsigned int value;
int n;
{
...
}
defines a function called rotate that takes two arguments called value and n. The first argument is an unsigned int, and the second is an int.
The keyword inline can be placed in front of a function definition as a hint to the compiler. Some compilers replace the function call with the actual code for the function itself, thus providing for faster execution. An example is shown here:
inline int min (int a, int b)
{
return ( a < b ? a : b);
}
Function Call
General Format:
name ( arg1, arg2, .. )
The function called name is called and the values arg1, arg2, … are passed as arguments to the function. If the function takes no arguments, just the open and closed parentheses are specified (as in initialize ()).
If you are calling a function that is defined after the call, or in another file, you should include a prototype declaration for the function, which has the following general format:
returnType name (type1 param1, type2 param2, .. );
This tells the compiler the function's return type, the number of arguments it takes, and the type of each argument. As an example, the line
long double power (double x, int n);
declares power to be a function that returns a long double and that takes two arguments—the first of which is a double and the second of which is an int. The argument names inside the parentheses are actually dummy names and can be omitted if desired, so
long double power (double, int);
works just as well.
If the compiler has previously encountered the function definition or a prototype declaration for the function, the type of each argument is automatically converted (where possible) to match the type expected by the function when the function is called.
If neither the function's definition nor a prototype declaration has been encountered, the compiler assumes the function returns a value of type int and automatically converts all float arguments to type double and performs integral promotion on any integer arguments as outlined in 5.17. Other function arguments are passed without conversion.
Functions that take a variable number of arguments must be declared as such. Otherwise, the compiler is at liberty to assume the function takes a fixed number of arguments based on the number actually used in the call.
If the function was defined with the old-style format (refer to the section “Function Definition”), a declaration for the function takes the following format:
returnType name ();
Arguments to such functions are converted, as described in the previous paragraph.
A function whose return type is declared as void causes the compiler to flag any calls to that function that try to make use of a returned value.
All arguments to a function are passed by value; therefore, their values cannot be changed by the function. If, however, a pointer is passed to a function, the function can change values referenced by the pointer, but it still cannot change the value of the pointer variable itself.
Function Pointers
A function name, without a following set of parentheses, produces a pointer to that function. The address operator can also be applied to a function name to produce a pointer to it.
If fp is a pointer to a function, the corresponding function can be called either by writing
fp ()
or
(*fp) ()
If the function takes arguments, they can be listed inside the parentheses.
Classes
This section summarizes the syntax and semantics associated with classes.
Class Definition
A class definition consists of declaring the instance variables and methods in an interface section and defining the code for each method in an implementation section.
Interface Section
@interface className : parentClass <protocol, ...>
{
instanceVariableDeclarations
}
methodDeclaration
methodDeclaration
...
@end
The class className is declared with the parent class parentClass. If className also adopts one or more formal protocols, the protocol names are listed inside a pair of angular brackets after parentClass. In that case, the corresponding implementation section must contain definitions for all such methods in the listed protocol(s).
If the colon and parentClass are omitted, a new root class is declared.
Instance Variable Declarations
The optional instanceVariableDeclarations section lists the type and name of each instance variable for the class. Each instance of className gets its own set of these variables, plus any variables inherited from parentClass. All such variables can be referenced directly by name either by instance methods defined in className or by any subclasses of className. If access has been restricted with a @private directive, subclasses cannot access the variables declared as such (refer to the section “Instance Variables”).
Class methods do not have access to instance variables.
Method Declaration
General Format:
mType (returnType) name1 : (type1) param1 name2 : (type2) param2, ...;
The method name1:name2:.. is declared, which returns a value of type returnType and has formal parameters param1, param2, …. param1 is declared to be of type type1, param2 is declared to be of type type2, and so on.
Any of the names after name1 (meaning name2, …) can be omitted, in which case a colon is still used as a placeholder and becomes part of the method name (see the following example).
If mType is +, a class method is declared, but if mType is –, an instance method is declared.
If the declared method is inherited from a parent class, the parent's definition is overridden by the new definition. In such a case, the method from the parent class can still be accessed by sending a message to super.
Class methods are invoked when a corresponding message is sent to a class object, whereas instance methods are invoked when a corresponding message is sent to an instance of the class. Class methods and instance methods can have the same name.
The same method name can also be used by different classes. The capability of objects from different classes to respond to the same named method is known as polymorphism.
If the method does not return a value, returnType is void. If the function returns an id value, returnType can be omitted, although specifying id as the return type is better programming practice.
If , ... is used as the last (or only) parameter in the list, the method takes a variable number of arguments, as in
-(void) print: (NSSTRING *) format, ...
{
...
}
As an example of a class declaration, the interface declaration section
@interface Fraction: Object
{
int numerator, denominator;
}
+(Fraction *) newFract;
-(void) setTo: (int) n : (int) d;
-(void) setNumerator: (int) n andDenominator: (int) d;
-(int) numerator;
-(int) denominator;
@end
declares a class called Fraction whose parent is Object. The Fraction class has two integer instance variables called numerator and denominator. It also has one class method called newFract, which returns a Fraction object. It has two instance methods called setTo:: and setNumerator:andDenominator:, each of which takes two arguments and does not return a value. It also has two instance methods called numerator and denominator that take no arguments and return an int.
Implementation Section
General Format:
@implementation className;
methodDefinition
methodDefinition
...
@end
The class called className is defined. The parent class and instance variables are not typically redeclared in the implementation section (although they can be) because they have been previously declared in the interface section.
Unless the methods for a category are being implemented (see the section “Category Definition”), all the methods declared in the interface section must be defined in the implementation section. If one or more protocols were listed in the interface section, all the protocols' methods must be defined—either implicitly through inheritance or explicitly by definition in the implementation section.
Each methodDefinition contains the code that will be executed when the method is invoked.
Method Definition
General Format:
mType (returnType) name1 : (type1) param1 : name2 (type2) param2, ...
{
variableDeclarations
programStatement
programStatement
...
return expression;
}
The method name1:name2:... is defined, which returns a value of type returnType and has formal parameters param1, param2, …. param1 is declared to be of type type1, param2 is declared to be of type type2, and so on. If mType is +, a class method is defined; if mType is –, an instance method is defined. This method declaration must be consistent with the corresponding method declaration from the interface section or from a previously defined protocol definition.
An instance method can reference the class's instance variables and any variables it has inherited directly by name. If a class method is being defined, it cannot reference any instance variables.
The identifier self can be used inside a method to reference the object on which the method was invoked—that is, the receiver of the message.
The identifier super can be used inside a method to reference the parent class of the object on which the method was invoked.
If returnType is not void, one or more return statements with expressions of type returnType must appear in the method definition. If returnType is void, use of a return statement is optional, and if used, it cannot contain a value to return.
As an example of a method definition
-(void) setNumerator: (int) n andDenominator: (int) d
{
numerator = n;
denominator = d;
}
defines a setNumerator:andDenominator: method in accordance with its declaration (refer to the section “Method Declaration”). The method sets its two instance variables to the supplied arguments and does not execute a return (although it could) because the method is declared to return no value.
Declarations for single-dimensional array arguments do not have to specify the number of elements in the array. For multidimensional arrays, the size of each dimension except the first must be specified.
Local variables can be declared inside a method and are typically declared at the start of the method definition. Automatic local variables are allocated when the method is invoked and deallocated when the method is exited.
See the section “The return Statement” for a discussion of the return statement.
Category Definition
General Format:
@interface className (categoryName) <protocol,...>
methodDeclaration
methodDeclaration
...
@end
This defines the category categoryName for the class specified by className with the associated listed methods. If one or more protocols are listed, the category adopts the listed protocol(s).
The compiler must know about className through a previous @interface section declaration for the class.
You can define as many categories as you want in as many different source files as you want. The listed methods become part of the class and are inherited by subclasses.
Categories are uniquely defined by className/categoryName pairs. For example, in a given program there can be only one NSArray (Private) category. However, individual category names can be reused. So, a given program can include an NSArray (Private) category and an NSString (Private) category, and both categories will be distinct from each other.
You do not need to implement the methods defined in a category that you do not intend to use.
A category can only extend the definition of a class with additional methods, or it can override existing methods in the class. It cannot define any new instance variables for the class.
If more than one category declares a method with the same name for the same class, it is not defined which method will be executed when invoked.
As an example
#import "Complex.h"
@interface Complex (ComplexOps)
-(Complex *) abs;
-(Complex *) exp;
-(Complex *) log;
-(Complex *) sqrt;
@end
defines a category for the Complex class called ComplexOps, with four instance methods. Presumably, a corresponding implementation section appears somewhere that implements one or more of these methods:
#import "ComplexOps.h"
@implementation Complex (ComplexOps)
-(Complex *) abs
{
...
}
-(Complex *) exp
{
...
}
-(Complex *) log
{
...
}
-(Complex *) sqrt
{
...
}
@end
A category that defines methods meant for other subclasses to implement is known as an informal protocol or abstract category. Unlike formal protocols, the compiler does not perform any checks for conformance to an informal protocol. At runtime, an object might or might not test for conformance to an informal protocol on an individual method basis. For example, one method might be required at runtime, whereas another method in the same protocol might not.
Protocol Definition
General Format:
@protocol protocolName <protocol, ...>
methodDeclaration
methodDeclaration
...
@end
The protocol called protocolName is defined with associated methods. If other protocols are listed, protocolName also adopts the listed protocols.
This definition is known as a formal protocol definition.
A class conforms to the protocolName protocol if it defines or inherits all the methods declared in the protocol plus all the methods of any other protocols that are listed. The compiler checks for conformance and generates a warning if a class does not conform to a declared formal protocol. Objects might or might not be tested for conformance to a formal protocol at runtime.
Protocols are often not associated with any particular class but provide a way to define a common interface that is shared among classes.
Special Type Modifiers
The method parameters and return type declared in protocols can use the type qualifiers listed in Table B.7. These qualifiers are used for distributed object applications.
Table B.7. Special Protocol Type Modifiers

Object Declaration
General Format:
className *var1, *var2, ...;
This defines var1, var2, … to be objects from the class className. Note that this declares pointer variables and does not reserve space for the actual data contained in each object. The declaration
Fraction *myFract;
defines myFract as a Fraction object or, technically, as a pointer to one. To allocate the actual space for the data structure of a Fraction, the alloc or new method is typically invoked on the class, like so:
myFract = [Fraction alloc];
This causes enough space to be reserved for a Fraction object and a pointer to it to be returned and assigned to myFract. The variable myFract is often referred to as an object or as an instance of the Fraction class. As the alloc method in the root object is defined, a newly allocated object has all its instance variables set to 0. However, that does not mean the object has been properly initialized and an initialization method (like init) should be invoked on the object before it is used.
Because the myFract variable has been explicitly declared as an object from the Fraction class, the variable is said to be statically typed. The compiler can check the use of statically typed variables for consistency by consulting the class definition for proper use of methods and their arguments and return types.
id Object Declaration
General Format:
id <protocol,...> var1, var2, ...;
This declares var1, var2, … to be objects from an indeterminate class that conform to the protocol(s) listed in the angular brackets. The protocol list is optional.
Objects from any class can be assigned to id variables, and vice versa. If one or more protocols is listed, the compiler checks that methods used from the listed protocols on any of the declared variables are used in a consistent manner—that is, consistent with respect to argument and return types for the methods declared in the formal protocol.
For example, in the statements
id <MathOps> number;
...
result = [number add: number2];
the compiler checks whether the MathOps protocol defines an add: method. If it does, it then checks for consistency with respect to the argument and return types for that method. So, if the add: method takes an integer argument and you are passing it a Fraction object above, the compiler complains.
The system keeps track of the class to which each object belongs; therefore, at runtime it can determine the class of an object and then select the correct method to invoke. These two processes are known as dynamic typing and dynamic binding, respectively.
Message Expressions
Format 1:
[receiver name1: arg1 name2: arg2, name3: arg3 .. ]
The method name1:name2:name3 … from the class specified by receiver is invoked and the values arg1, arg2, … are passed as arguments. This is called a message expression. The value of the expression is the value returned by the method, or void if the method is declared as such and returns no value. The type of the expression is that of the type declared for the method invoked.
Format 2:
[receiver name];
If a method takes no arguments, this format is used to invoked the method name from the class specified by receiver.
If receiver is an id type, the compiler looks among the declared classes for a definition or inherited definition of the specified method. If no such definition is found, the compiler issues a warning that the receiver might not respond to the specified message. It further assumes the method returns a value of type id and converts any float arguments to type double and performs integral promotion on any integer arguments as outlined earlier in the section “Conversion of Basic Data Types.” Other method arguments are passed without conversion.
If receiver is a class object (which can be created by simply specifying the class name), the specified class method is invoked. Otherwise, receiver is an instance of a class and the corresponding instance method is invoked.
If receiver is a statically typed variable or expression, the compiler looks in the class definition for the method (or for any inherited methods) and converts any arguments (where possible) to match the expected arguments for the method. So, a method expecting a floating value that is passed an integer has that argument automatically converted when the method is invoked.
If receiver is a null object pointer—that is, nil—it can be sent messages. If the method associated with the message returns an object, the value of the message expression is nil. If the method does not return an object, the value of the expression is not defined.
If the same method is defined in more than one class (either by explicit definition or from inheritance), the compiler checks for consistency for argument and return types among the classes.
All arguments to a method are passed by value; therefore, their values cannot be changed by the method. If a pointer is passed to a method, the method can change values referenced by the pointer, but it still cannot change the value of the pointer itself.
Statements
A program statement is any valid expression (usually an assignment or a function call) that is immediately followed by a semicolon, or it is one of the special statements described in the following. A label can optionally precede any statement and consists of an identifier followed immediately by a colon (see the goto statement).
Compound Statements
Program statements contained within a pair of braces are known collectively as a compound statement or block and can appear anywhere in the program that a single statement is permitted. A block can have its own set of variable declarations, which override any similarly named variables defined outside the block. The scope of such local variables is the block in which they are defined.
The break Statement
break;
Execution of a break statement from within a for, while, do, or switch statement causes execution of that statement to be immediately terminated. Execution continues with the statement that immediately follows the loop or switch.
The continue Statement
General Format:
continue;
Execution of the continue statement from within a loop causes any statements that follow the continue in the loop to be skipped. Execution of the loop otherwise continues as normal.
The do Statement
General Format:
do
programStatement
while ( expression );
programStatement is executed as long as expression evaluates to nonzero. Note that, because expression is evaluated each time after the execution of programStatement, it is guaranteed that programStatement will be executed at least once.
The for Statement
General Format:
for ( expression_1; expression_2; expression_3 )
programStatement
expression_1 is evaluated once when execution of the loop begins. Next, expression_2 is evaluated. If its value is nonzero, programStatement is executed and then expression_3 is evaluated. Execution of programStatement and the subsequent evaluation of expression_3 continue as long as the value of expression_2 is nonzero. Because expression_2 is evaluated each time before programStatement is executed, programStatement might never be executed if the value of expression_2 is 0 when the loop is first entered.
Variables local to the for loop can be declared in expression_1. The scope of such variables is the scope of the for loop. For example
for ( int i = 0; i < 100; ++i)
...
declares the integer variable i and sets its initial value to 0 when the loop begins. The variable can be accessed by any statements inside the loop, but it is not accessible after the loop is terminated.
The goto Statement
General Format:
goto identifier;
Execution of the goto causes control to be sent directly to the statement labeled identifier. The labeled statement must be located in the same function or method as the goto.
The if Statement
Format 1:
if ( expression )
programStatement
If the result of evaluating expression is nonzero, programStatement is executed; otherwise, it is skipped.
Format 2:
if ( expression )
programStatement_1
else
programStatement_2
If the value of expression is nonzero, programStatement_1 is executed; otherwise, programStatement_2 is executed. If programStatement_2 is another if statement, an if-else if chain is affected, like so:
if ( expression_1 )
programStatement_1
else if ( expression_2 )
programStatement_2
...
else
programStatement_n
An else clause is always associated with the last if statement that does not contain an else. Braces can be used to change this association if necessary.
The null Statement
;
Execution of a null statement has no effect and is used primarily to satisfy the requirement of a program statement in a for, do, or while loop. The following statement copies a character string pointed to by from to one pointed to by to:
while ( *to++ = *from++ )
;
In this statement, the null statement is used to satisfy the requirement that a program statement appear after the looping expression of the while.
The return Statement
Format 1:
return;
Execution of the return statement causes program execution to be immediately returned to the calling function or method. This format can be used only to return from a function or method that does not return a value.
If execution proceeds to the end of a function or method and a return statement is not encountered, it returns as if a return statement of this form had been executed. Therefore, in such a case, no value is returned.
Format 2:
return expression;
The value of expression is returned to the calling function or method. If the type of expression does not agree with the return type declared in the function or method declaration, its value is automatically converted to the declared type before it is returned.
The switch Statement
General Format:
switch ( expression )
{
case constant_1:
programStatement
programStatement
...
break;
case constant_2:
programStatement
programStatement
...
break;
...
case constant_n:
programStatement
programStatement
...
break;
default:
programStatement
programStatement
...
break;
}
expression is evaluated and compared against the constant expression values constant_1, constant_2, …, constant_n. If the value of expression matches one of these case values, the program statements that immediately follow are executed. If no case value matches the value of expression, the default case, if included, is executed. If the default case is not included, no statements contained in the switch are executed.
The result of the evaluation of expression must be of integral type and no two cases can have the same value. Omitting the break statement from a particular case causes execution to continue into the next case.
The while Statement
General Format:
while ( expression )
programStatement
programStatement is executed as long as the value of expression is nonzero. Because expression is evaluated each time before the execution of programStatement, programStatement might never be executed.
The Preprocessor
The preprocessor analyzes the source file before the compiler proper sees the code. Here is what the preprocessor does:
- It replaces trigraph sequences by their equivalents (refer to the section “Compound Statements”).
- It joins any lines that end with a backslash character (
) together into a single line. - It divides the program into a stream of tokens.
- It removes comments, replacing them by a single space.
- It processes preprocessor directives (see the section “Preprocessor Directives”) and expands macros.
Trigraph Sequences
To handle non-ASCII character sets, the following three-character sequences (called trigraphs) are recognized and treated specially wherever they occur inside a program (as well as inside character strings):

Preprocessor Directives
All preprocessor directives begin with the character #, which must be the first nonwhitespace character on the line. The # can be optionally followed by one or more space or tab characters.
The #define Directive
Format 1:
#define name text
This defines the identifier name to the preprocessor and associates with it whatever text appears after the first blank space after name to the end of the line. Subsequent use of name in the program causes text to be substituted directly into the program at that point.
Format 2:
#define name(param_1, param_2, ..., param_n) text
The macro name is defined to take arguments as specified by param_1, param_2, …, param_n, each of which is an identifier. Subsequent use of name in the program with an argument list causes text to be substituted directly into the program at that point, with the arguments of the macro call replacing all occurrences of the corresponding parameters inside text.
If the macro takes a variable number of arguments, three dots are used at the end of the argument list. The remaining arguments in the list are collectively referenced in the macro definition by the special identifier __VA_ARGS__. As an example, the following defines a macro called myPrintf to take a variable number of arguments:
#define myPrintf(...) printf ("DEBUG: " __VA_ARGS__);
Legitimate macro uses would include
myPrintf ("Hello world! ");
as well as
myPrintf ("i = %i, j = %i ", i, j);
If a definition requires more than one line, each line to be continued must be ended with a backslash character. After a name has been defined, it can be used anywhere in the file.
The # operator is permitted in #define directives that take arguments and is followed by the name of an argument to the macro. The preprocessor puts double quotation marks around the actual value passed to the macro when it's invoked. That is, it turns it into a character string. For example, the definition
#define printint(x) printf (# x " = %d ", x)
with the call
printint (count);
is expanded by the preprocessor into
printf ("count" " = %i ", count);
or, equivalently
printf ("count = %i ", count);
The preprocessor puts a character in front of any " or characters when performing this stringizing operation. So, with the definition
#define str(x) # x
the call
str (The string " " contains a tab)
expands to the following:
"The string "\t" contains a tab"
The ## operator is also allowed in #define directives that take arguments. It is preceded (or followed) by the name of an argument to the macro. The preprocessor takes the value passed when the macro is invoked and creates a single token from the argument to the macro and the token that follows (or precedes) it. For example, the macro definition
#define printx(n) printf ("%i ", x ## n );
with the call
printx (5)
printf ("%i ", x5);
The definition
#define printx(n) printf ("x" # n " = %i ", x ## n );
with the call
printx(10)
produces
printf ("x10 = %i ", x10);
after substitution and concatenation of the character strings.
Spaces are not required around the # and ## operators.
The #error Directive
General Format:
#error text
...
The specified text is written as an error message by the preprocessor.
The #if Directive
Format 1:
#if constant_expression
...
#endif
The value of constant_expression is evaluated. If the result is nonzero, all program lines up until the #endif directive are processed; otherwise, they are automatically skipped and are not processed by the preprocessor or the compiler.
Format 2:
#if constant_expression_1
...
#elif constant_expression_2
...
#elif constant_expression_n
...
#else
...
#endif
If constant_expression_1 is nonzero, all program lines up until the #elif are processed and the remaining lines up to the #endif are skipped. Otherwise, if constant_expression_2 is nonzero, all program lines up until the next #elif are processed and the remaining lines up to the #endif are skipped. If none of the constant expressions evaluates to nonzero, the lines after the #else (if included) are processed.
The special operator defined can be used as part of the constant expression, so
#if defined (DEBUG)
...
#endif
causes the code between the #if and #endif to be processed if the identifier DEBUG has been previously defined (see also #ifdef in the next section). The parentheses are not necessary around the identifier, so
#if defined DEBUG
works just as well.
The #ifdef Directive
General Format:
#ifdef identifier
...
#endif
If the value of identifier has been previously defined (either through a #define or with the -D command-line option when the program was compiled), all program lines up until the #endif are processed; otherwise, they are skipped. As with the #if directive, #elif and #else directives can be used with a #ifdef directive.
The #ifndef Directive
General Format:
#ifndef identifier
...
#endif
If the value of identifier has not been previously defined, all program lines up until the #endif are processed; otherwise, they are skipped. As with the #if directive, #elif and #else directives can be used with a #ifndef directive.
The #import Directive4
Format 1:
#import "fileName"
If the file specified by fileName has been previously included in the program, this statement is skipped. Otherwise, the preprocessor searches an implementation-defined directory or directories first for the file fileName. Typically, the same directory that contains the source file is searched first, and if the file is not found there, a sequence of implementation-defined standard places is searched. After it's found, the contents of the file are included in the program at the precise point that the #import directive appears. Preprocessor directives contained within the included file are analyzed; therefore, an included file can itself contain other #import or #include directives.
Format 2:
#import <fileName>
If the file has not been previously included, the preprocessor searches for the specified file only in the standard places. Specifically, the current source directory is omitted from the search. The action taken after the file is found is otherwise identical to that described previously.
In either format, a previously defined name can be supplied and expansion will occur. So, the following sequence works:
#define ROOTOBJECT <objc/Object.h>
...
#import ROOTOBJECT
The #include Directive
This behaves the same way as #import except no check is made for previous inclusion of the specified header file.
The #line Directive
General Format:
#line constant "fileName"
This directive causes the compiler to treat subsequent lines in the program as if the name of the source file were fileName and as if the line number of all subsequent lines began at constant. If fileName is not specified, the filename specified by the last #line directive, or the name of the source file (if no filename was previously specified), is used.
The #line directive is primarily used to control the filename and line number that are displayed whenever an error message is issued by the compiler.
The #pragma Directive
#pragma text
This causes the preprocessor to perform some implementation-defined action. For example, under the pragma
#pragma loop_opt(on)
causes special loop optimization to be performed on a particular compiler. If this pragma is encountered by a compiler that doesn't recognize the loop_opt pragma, it is ignored.
The special keyword STDC is used after the #pragma for special meaning. Current supported switches that can follow a #pragma STDC are FP_CONTRACT, FENV_ACCESS, and CX_LIMITED_RANGE.
The #undef Directive
General Format:
#undef identifier
The specified identifier becomes undefined to the preprocessor. Subsequent #ifdef or #ifndef directives behave as if the identifier were never defined.
The # Directive
This is a null directive and is ignored by the preprocessor.
Predefined Identifiers
The following identifiers are defined by the preprocessor:

Root Object Methods and Categories
Table B.8 summarizes the instance and class methods defined for the root object Object.
Table B.8. Root Object Methods


Table B.9 lists the informal protocols that are defined for the root object Object.
Table B.9. Informal Object Protocols
