
After numbers, strings are the most important data type in Python. Strings are ubiquitous: You print them to the screen, you read them from the user, and, as we will see in Chapter 8, files are often treated as big strings. The World Wide Web can be thought of as a collection of Web pages, most of which consist of text. Plus the XML markup language, which is entirely text based, has become a popular file format for packages such as Microsoft Office.
Strings are a good example of an aggregate data structure, and they provide our first look at indexing and slicing—techniques that are used to extract substrings from strings.
The chapter also contains a brief introduction to Python’s regular expression library, which is a supercharged mini-language designed for processing strings.
We’ve already introduced strings in Chapter 2, so you may want to go back to it if you need a refresher on string basics.
When working with strings, we often want to access their individual characters. For example, suppose you know that s is a string, and you want to access its constituent characters individually. String indexing is how you do it:
>>> s = 'apple' >>> s[0] 'a' >>> s[1] 'p' >>> s[2] 'p' >>> s[3] 'l' >>> s[4] 'e'
Python uses square brackets to index strings: The number inside indicates which character to get (Figure 6.1). Python’s index values always start at 0 and always end at one less than the length of the string.
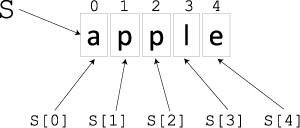
So if s labels a string of length n, s[0] is the first character, s[1] is the second character, s[2] is the third character, and so on up to s[n-1], which is the last character.
If you try to index past the right end of the string, you will get an “out of range” error:
>>> s[5]
Traceback (most recent call last):
File "<pyshell#6>", line 1, in <module>
s[5]
IndexError: string index out of rangeSuppose instead of the first character of s, you want to access the last character of s. The ungainly expression s[len(s) - 1] works, but it seems rather complicated for accessing the last character of a string.
Fortunately, Python has a more convenient way of accessing characters near the right end of a string: negative indexing. The idea is that the characters of a string are indexed with negative numbers going from right to left:
>>> s = 'apple' >>> s[-1] 'e' >>> s[-2] 'l' >>> s[-3] 'p' >>> s[-4] 'p' >>> s[-5] 'a'
Thus the last character of a string is simply s[-1]. Figure 6.2 shows how negative index values work.

If you need to access every character of a string in sequence, a for-loop can be helpful. For example, this program calculates the sum of the character codes for a given string:
# codesum.py
def codesum1(s):
""" Returns the sums of the character
codes of s.
"""
total = 0
for c in s:
total = total + ord(c)
return totalHere is a sample call:
>>> codesum1('Hi there!')
778When you use a for-loop like this, at the beginning of each iteration the loop variable c is set to be the next character in s. The indexing into s is handled automatically by the for-loop.
Compare codesum1 with this alternative implementation, which uses regular string indexing:
def codesum2(s):
""" Returns the sums of the character
codes of s.
"""
total = 0
for i in range(len(s)):
total = total + ord(s[i])
return totalThis gives the same results as codesum1, but the implementation here is a little more complex and harder to read.
Strings consist of characters, and characters themselves turn out to be a surprisingly complex issue. As mentioned in Chapter 2, all characters have a corresponding character code that you can find using the ord function:
>>> ord('a')
97
>>> ord('b')
98
>>> ord('c')
99Given a character code number, you can retrieve its corresponding character using the chr function:
>>> chr(97) 'a' >>> chr(98) 'b' >>> chr(99) 'c'
Character codes are assigned using the Unicode coding scheme, which is a large and complex standard for encoding all the symbols and characters that occur in all the world’s languages.
Not all characters have a standard visible symbol. For example, you can’t see a newline character, a return character, or a tab (although you can certainly see their effects). They are whitespace characters, characters that appear as blanks on the printed page.
To handle whitespace and other unprintable characters, Python uses a special notation called escape sequences, or escape characters. Table 6.1 shows the most commonly used escape characters.
The backslash, single-quote, and double-quote escape characters are often needed for putting those characters into a string. For instance:
>>> print('' and " are quotes')
' and " are quotes
>>> print('\ must be written \')
must be written \The standard way in Python for ending a line is to use the
character:
>>> print('one
two
three')
one
two
threeIt’s important to realize that each escape character is only a single character. The leading is needed to tell Python that this is a special character, but that does not count as an extra character when determining a string’s length. For example:
>>> len('')
1
>>> len('a
b
c')
5Slicing is how Python lets you extract a substring from a string. To slice a string, you indicate both the first character you want and one past the last character you want. For example:
>>> food = 'apple pie' >>> food[0:5] 'apple' >>> food[6:9] 'pie'
The indexing for slicing is the same as for accessing individual characters: The first index location is always 0, and the last is always one less than the length of the string. In general, s[begin:end] returns the substring starting at index begin and ending at index end - 1.
Note that if s is a string, then you can access the character at location i using either s[i] or s[i:i+1].
If you leave out the begin index of a slice, then Python assumes you mean 0; and if you leave off the end index, Python assumes you want everything to the end of the string. For instance:
>>> food = 'apple pie' >>> food[:5] 'apple' >>> food[6:] 'pie' >>> food[:] 'apple pie'
Here’s a useful example of slicing in practice. This function returns the extension of a filename.
# extension.py
def get_ext(fname):
""" Returns the extension of file
fname.
"""
dot = fname.rfind('.')
if dot == -1: # no . in fname
return ''
else:
return fname[dot + 1:]Here’s what get_ext does:
>>> get_ext('hello.text')
'text'
>>> get_ext('pizza.py')
'py'
>>> get_ext('pizza.old.py')
'py'
>>> get_ext('pizza')
''The get_ext function works by determining the index position of the rightmost '.' (hence the use of rfind to search for it from right to left). If there is no '.' in fname, the empty string is returned; otherwise, all the characters from the '.' onward are returned.
You can also use negative index values with slicing, although it’s a bit confusing the first time you use it. For example:
>>> food = 'apple pie' >>> food[-9:-4] 'apple' >>> food[:-4] 'apple' >>> food[-3:0] '' >>> food[-3:] 'pie'
When working with negative slicing, or negative indexes in general, it is often useful to write the string you are working with on a piece of paper, and then write the positive and negative index values over the corresponding characters (as in Figure 6.2). While this does take an extra minute or two, it’s a great way to prevent common indexing errors.
Python strings come prepackaged with a number of useful functions; use dir on any string (for example, dir('')) to see them all. While it’s not necessary to memorize precisely what all these functions do, it is a good idea to have a general idea of their abilities so that you can use them when you need them. Thus, in this section we present a list of all the functions that come with a string, grouped together by type.
This is not meant to be a complete reference: A few infrequently used parameters are left out, and not every detail of every function is explained. For more complete details, read a function’s doc string, or the online Python documentation (http://docs.python.org/dev/3.0/).
The first, and largest, group of functions is composed of ones that test if a string has a certain form. The testing functions in Table 6.2 all return either True or False. Testing functions are sometimes called Boolean functions, or predicates.
Table 6.2. String-Testing Functions
NAME | RETURNS TRUE JUST WHEN . . . |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
As shown in Table 6.3, there are several ways to find substrings within a string. The difference between index and find functions is what happens when they don’t find what they are looking for. For instance:
>>> s = 'cheese'
>>> s.index('eee')
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
s.index('eee')
ValueError: substring not found
>>> s.find('eee')
-1The find function raises a ValueError; this is an example of exception, which we will talk about in more detail in Chapter 9. The index function returns -1 if the string being searched for is not found.
Normally, string-searching functions search the string from left to right, beginning to end. However, functions beginning with an r search from right to left. For example:
>>> s = 'cheese'
>>> s.find('e')
2
>>> s.rfind('e')
5In general, find and index return the smallest index where the passed-in string starts, while rfind and rindex return the largest index where it starts.
Python gives you a variety of functions for changing the case of letters (Table 6.4). Keep in mind that Python never modifies a string: For all these functions, Python creates and returns a new string. We often talk as if the string were being modified, but this is only a convenient phrasing and does not mean the string is really being changed.
Table 6.4. String-Searching Functions
NAME | RETURNED STRING |
|---|---|
|
|
| All letters of |
| All letters of |
| Lowercase letters are made uppercase, and uppercase letters are made lowercase |
| Title-case version of |
The string-formatting functions listed in Table 6.5 help you to make strings look nicer for presenting to the user or printing to a file.
The string format function is especially powerful, and it includes its own mini-language for formatting strings. To use format, you supply it variables or values—for example:
>>> '{0} likes {1}'.format('Jack', 'ice cream')
'Jack likes ice cream'The {0} and {1} in the string refer to the arguments in format: They are replaced by the values of the corresponding strings or variables. You can also refer to the names of keyword parameters:
>>> '{who} {pet} has fleas'.format(pet = 'dog', who = 'my')
'my dog has fleas'These examples show the most basic use of format; there are many other options for spacing strings, converting numbers to strings, and so on. All the details are provided in Python’s online documentation (http://docs.python.org/dev/3.0/library/string.html#formatstrings).
The stripping functions shown in Table 6.6 are used for removing unwanted characters from the beginning or end of a string. By default, whitespace characters are stripped, and if a string argument is given, the characters in that string are stripped. For example:
>>> name = ' Gill Bates '
>>> name.lstrip()
'Gill Bates '
>>> name.rstrip()
' Gill Bates'
>>> name.strip()
'Gill Bates'
>>> title = '_-_- Happy Days!! _-_-'
>>> title.strip()
'_-_- Happy Days!! _-_-'
>>> title.strip('_-')
' Happy Days!! '
>>> title.strip('_ -')
'Happy Days!!'Table 6.6. String-Stripping Functions
NAME | RETURNED STRING |
|---|---|
| Removes all |
| Removes all |
| Removes all |
The splitting functions listed in Table 6.7 chop a string into substrings.
Table 6.7. String-Splitting Functions
NAME | RETURNED STRING |
|---|---|
| Chops |
| Same as |
| Returns a list of substrings of |
| Same as |
| Returns a list of lines in |
The partition and rpartition functions divide a string into three parts:
>>> url = 'www.google.com'
>>> url.partition('.')
('www', '.', 'google.com')
>>> url.rpartition('.')
('www.google', '.', 'com')These partitioning functions always return a value consisting of three strings in the form (head, sep, tail). This kind of return value is an example of a tuple, which we will learn about in more detail in Chapter 7.
The split function divides a string into substrings based on a given separator string. For example:
>>> url = 'www.google.com'
>>> url.split('.')
['www', 'google', 'com']
>>> story = 'A long time ago, a princess ate an apple.'
>>> story.split()
['A', 'long', 'time', 'ago,', 'a', 'princess', 'ate', 'an', 'apple.']The split function always returns a list of strings; a Python list always begins with a [ and ends with a ], and uses commas to separate elements. As we’ll see in Chapter 7, lists and tuples are very similar, the main difference being that lists can be modified, but tuples are constant.
Python strings come with two replacing functions, as shown in Table 6.8. Note that the replace function can easily be used to delete substrings within a string:
>>> s = 'up, up and away'
>>> s.replace('up', 'down')
'down, down and away'
>>> s.replace('up', '')
', and away'Finally, Table 6.9 lists the remaining string functions.
Table 6.9. Other String Functions
NAME | RETURNED VALUE |
|---|---|
| Number of times |
| Sets the encoding of |
| Concatenates the strings in |
| Creates a translation table used to change the characters in |
| Makes the replacements in |
| Adds enough 0s to the left of |
The translate and maketrans functions are useful when you need to convert one set of characters into another. For instance, here’s one way to convert strings to “leet-speak”:
>>> leet_table = ''.maketrans('EIOBT', '31087')
>>> 'BE COOL. SPEAK LEET!'.translate (leet_table)
'83 C00L. SP3AK L337!'The online documentation (http://docs.python.org/dev/3.0/library/stdtypes.html) also explains how to replace more than single characters.
The zfill function is used for formatting numeric strings:
>>> '23'.zfill(4) '0023' >>> '-85'.zfill(5) '-0085'
However, it’s not a very flexible function, so most programmers prefer using one of Python’s other string-formatting techniques.
The join function can be quite useful. It concatenates a sequence of strings, including a separator string. For example:
>>> ' '.join(['once', 'upon', 'a', 'time']) 'once upon a time' >>> '-'.join(['once', 'upon', 'a', 'time']) 'once-upon-a-time' >>> ''.join(['once', 'upon', 'a', 'time']) 'onceuponatime'
While Python strings provide many useful functions, real-world string processing often calls for more powerful tools.
Thus, programmers have developed a mini-language for advanced string processing known as regular expressions. Essentially, a regular expression is a way to compactly describe a set of strings. They can be used to efficiently perform common string-processing tasks such as matching, splitting, and replacing text. In this section, we’ll introduce the basic ideas of regular expressions, as well as a few commonly used operators (Table 6.10).
Consider the string 'cat'. It represents a single string consisting of the letters c, a, and t. Now consider the regular expression 'cats?'. Here, the ? does not mean an English question mark but instead represents a regular expression operator, meaning that the character to its immediate left is optional. Thus the regular expression 'cats?' describes a set of two strings: 'cat' and 'cats'.
Another regular expression operator is |, which means “or.” For example, the regular expression 'a|b|c' describes the set of three strings 'a', 'b', and 'c'.
The regular expression 'a*' describes an infinite set of strings: '', 'a', 'aa', 'aaa', 'aaaa', 'aaaaa', and so on. In other words, 'a*' describes the set of all strings consisting of a sequence of 0 or more 'a's. The regular expression 'a+' is the same as 'a*' but excludes the empty string ''.
Finally, within a regular expression you can use round brackets to indicate what substring an operator ought to apply to. For example, the regular expression '(ha)+!' describes these strings: 'ha!', 'haha!', 'hahaha!', and so on. In contrast, 'ha+!' describes a very different set: 'ha!', 'haa!', 'haaa!', and so on.
You can mix and match these (and many other) regular expression operators in any way you want. This turns out to be a very useful way to describe many commonly occurring types of strings, such as phone numbers and e-mail addresses.
A common application of regular expressions is string matching. For example, suppose you are writing a program where the user must enter a string such as done or quit to end the program. To help recognize these strings, you could write a function like this:
# allover.py
def is_done1(s):
return s == 'done' or s == 'quit'Using regular expressions, an identically behaving function might look like this:
# allover.py
import re # use regular expressions
def is_done2(s):
return re.match('done|quit', s) != NoneThe first line of this new version imports Python’s standard regular expression library. To match a regular expression, we use the re.match(regex, s) function, which returns None if regex does not match s, and a special regular expression match object otherwise. We don’t care about the details of the match object in this example, so we only check to see if the result is None or not.
In such a simple example, the regular expression version is not much shorter or better than the first version; indeed, is_done1 is probably preferable! However, regular expressions really start to shine as your programs become larger and more complex. For instance, suppose we decide to add a few more possible stopping strings. For the regular expression version, we just rewrite the regular expression string to be, say, 'done|quit|over|finished|end|stop'. In contrast, to make the same change to the first version, we’d need to include or s == for each string we added, which would make for a very long line of code that would be hard to read.
Here’s a more complex example. Suppose you want to recognize funny strings, which consist of one or more 'ha' strings followed immediately by one or more '!'s. For example, 'haha!', 'ha!!!!!', and 'hahaha!!' are all funny strings. It’s easy to match these using regular expressions:
# funny.py
import re
def is_funny(s):
return re.match('(ha)+!+', s) != NoneNotice that the only essential difference between this is_funny and is_done2 is that a different regular expression is used inside match. If you try writing this same function without using regular expressions, you will quickly see how much work '(ha)+!+' is doing for us.
We have barely scratched the surface of regular expressions: Python’s re library is large and has many regular expression functions that can perform string-processing tasks such as matching, splitting, and replacing. There are also tricks for speeding up the processing of commonly used regular expressions, and numerous shortcuts for matching commonly used characters. The Python Regular Expression HOWTO, written by Andrew Kuchling, is a good place to get more details and examples (www.amk.ca/python/howto/regex/).