
In this chapter, we evaluate the performance of the synergy effect through inter-corporation between the application level (e.g., layered FEC) and network-level (e.g., RSVP/IntServ and DiffServ). Our approach focuses on how to optimally combine the source and network, in a cost sense, to obtain reliable or predictable (i.e., provide minimum quality), and best (i.e., most cost-effective), end-to-end quality in multimedia applications, especially real-time video streaming over QoS-controlled networks such as IntServ and DiffServ. To meet this goal, the application source and network cooperate.
Many previous studies in this area have been limited to a particular layer, such as error-resilient techniques of application or transport layers in MPEG-4 and H-263 videos [102], [130]. For example, [130] proposed a method to improve the packet loss resiliency of video-compressed streams and the efficient usage of available network resources through coding mode selection and a TCP-friendly rate control mechanism. Wang et al. [102] provided a good review of error-control and concealment techniques in the video coding layer. [91] proposed a high-priority protection method to use FEC, and [131] proposed algorithms for the transport layer to improve video quality through loss control. Other work on the transport layer can be found in [132], [133], [134].
In this chapter, we will investigate an optimal source/network combination of a layered video source, selectively used FEC to secure a source layer, and a QoS-controlled network under a cost-based SLA. We evaluate approaches in each layer mentioned above and propose a cost-effective and efficient combined approach on QoS-controlled networks for a prioritized transportation of source layers (e.g., layered video streams). This framework belongs to the JSN adaptation, or more specifically, the unequal loss protection (ULP) technique. In this technique, a video stream is encoded in multiple layers as a BL and two ELs, and the packets within the ELs are classified based on their loss impacts so that they can be tailored to network conditions. The QoS of the BL should be guaranteed for minimum end-to-end video quality. The QoS of each video layer is unequally controlled by various tools in the video-coding, transport, and network layers. The video-coding layer also has several error-resilient tools, while in the transport layer, real-time transport control protocol (RTCP)-based QoS measurement, different levels of FEC, and/or re-transmission are used as tools. We propose efficient methods for combining these tools with QoS-controlled networks, especially DiffServ, with a simple price mechanism. End-to-end video quality is evaluated in our suggested metric to indicate a perceptual quality that the user feels in addition to generally used objective metrics (i.e., PSNR).
The remainder of this chapter is organized as follows. Section 7.2 reviews related work and the background of our approach. Sections 7.3 and 7.4 describe and analyze our JSN approach to integrating video layers, selective FEC, and network QoS levels under a total cost constraint condition. In Section 7.5, simulation results demonstrate the effectiveness of our JSN approach over QoS-controlled networks. Section 7.6 concludes the chapter and offers suggestions for future research.
In this section, related works and information for JSN adaptation are reviewed and related to our framework.
Scalable and error-resilient coding in MPEG-4 and H.263 are useful in real-world networks that are error-prone and heterogeneous, but both types of coding increase bit rate and end-to-end delay. Packet-switching channels suffer from packet losses, while circuit-switching channels suffer from bit errors. The impact of packet losses can be minimized by using MPEG-4 error-resilient tools such as a resynchronization marker (RM), header expansion code (HEC), and DP. RVLC does not help packet loss, but it is helpful for reducing bit errors. The error propagation of variable-length coding is restricted to the short range by the encoding of a VOP (an image frame) into two or more video packets, which are independently encoded and delimited by the RM. The number of video packets in a VOP is determined with respect to a channel’s condition. The HEC protects a VOP header by duplicating the header in all the video packets. DP is used to protect important data from any error propagation that began in data of less importance. The more important data can then be transported through a safer channel. DP is a useful tool in a packet-switching channel if the amount of important data for each VOP is large enough to be sent separately in an real-time transport protocol (RTP) packet.
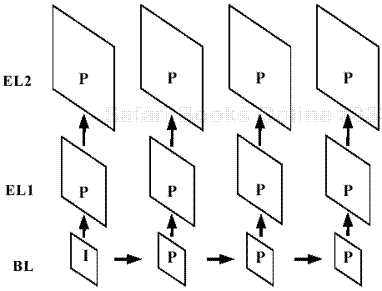
Scalable coding generates more than one bit stream from one image sequence. Each bit stream represents a temporal resolution (temporal scalability), spatial resolution (spatial scalability), or quantization resolution (SNR scalability). A bit stream of the coarsest resolution is called a BL. In addition to BL data, an EL, a bit stream of the next finer resolution, can create a video of higher quality and resolution. An EL cannot be decoded without its underlying layers. In a heterogeneous network condition, multiple layers of video bit streams can be selectively and/or simultaneously multicast to clients depending on the allocated bandwidth and capability of each terminal. Scalable coding is also useful in an error-prone network. When using scalability coding for error robustness, it is helpful to have a bit rate of the BL that is quite low in comparison with the total bit rate. At the same time, the amount of additional computation should be reasonably low. The number of macro-blocks in which DCT and motion estimation are performed is a major factor in the amount of computation. In that sense, encoding with temporal scalability or SNR scalability increases computation only a negligible amount, while encoding with normal spatial scalability increases the amount of computation by about 25% because image frames one-fourth the size of the original must also be encoded. Additional computation, however, can be dramatically reduced if, when encoding the EL, one uses the motion information obtained during the encoding of the BL. In this chapter, encoding with spatial scalability is used, mainly because the bit rate of the BL is low enough for our purposes. Because the image size of the BL is one-fourth the size of the original, the bit rate of the BL is, at most (and sometimes much less than), one-fourth that of the EL. Figure 7.1 shows the scalable encoding used in this chapter. The BL is encoded in the normal encoding fashion for a single-layer video in which most image frames are encoded in predictive (P) mode and intra (I) frames occur periodically. All frames of EL1 and EL2 are encoded in P mode. A concurrent image frame of the lower layer is used as a reference for prediction.
Loss or error control using FEC is used at the source side in this work. An effective end-to-end loss control will allow the recovery of lost data packets with as few redundant packets and as little delay as possible. FEC and re-transmission (e.g., ARQ) are possible choices. The degree of FEC and re-transmission is determined by the loss rate and delay constraints. Re-transmission can be considered as selective redundancy. Once or twice, re-transmission can be used, as in the findings of Zink et al. and Loguinov et al., when the RTT is much less than that required by delay constraints [135], [136]. For simplicity, however, re-transmission is not considered in this chapter.
The most popular FEC scheme on the Internet is the Reed-Solomon (RS) code, which uses maximum distance separable (MDS) coding in algebraic coding theory [91]. RS [n, k] takes k data packets and produces m = n – k parity packets. Lost data packets numbering less than or equal to m are recoverable if one knows which packets are lost. The sequence numbers in the RTP header are used to identify the lost packets. The residual packet loss ratio (PLR), that is, the PLR after FEC decoding, is dependent not only on the PLR of a channel, but also on the distribution of loss. The higher the PLR, the more parity packets will be used. If packet loss follows a Poisson process, the residual PLR becomes

where p is PLR without FEC. Poisson distribution is a very conservative assumption. Residual PLR can be reduced to zero if ![]() and if the loss distribution is forced to be uniform due to interleaving packets and the traffic shaping of edge routers to reduce instantaneous traffic bursts. In this chapter, we assume that residual PLR is near zero by virtue of the methods mentioned above.
and if the loss distribution is forced to be uniform due to interleaving packets and the traffic shaping of edge routers to reduce instantaneous traffic bursts. In this chapter, we assume that residual PLR is near zero by virtue of the methods mentioned above.
IntServ can provide a QoS guarantee to each flow, but it causes a scalability problem when there is an increased number of flows. It also requires the overhead of maintaining per-flow information and has a high connection setup cost. So, we focus on an approach to minimizing reserved network resources. DiffServ provides different QoS levels in an aggregate sense to avoid the limitations of IntServ, but it does not provide the per-flow guarantee. Under DiffServ’s architecture, incoming packets are policed and treated differently based on the SLA and DSCP in the IP header are considered as BAs. Those BAs are priority ordered so that higher priority BAs receive better QoS services (i.e., decreased queuing delays and lower loss rates) in relative service differentiation. We propose the proportional DiffServ model [32] as a relative DiffServ deployment to provide a service gap between classes so that ![]() (i, j = 1, . . . , N), where δi represents quality differentiation parameters (δ1 < δ2 < ... < δN) and qi represents the performance metrics of class i (queuing delay or loss rate). We assume that the DiffServ program provides proportional service differentiation among BAs classified by DSCPs and that it bounds the metrics within certain values even under the worst conditions by using intelligent traffic conditioning and admission control at the edge nodes. The SLA in our work specifies that the unit cost to use each BA is inversely proportional to the service quality provided.
(i, j = 1, . . . , N), where δi represents quality differentiation parameters (δ1 < δ2 < ... < δN) and qi represents the performance metrics of class i (queuing delay or loss rate). We assume that the DiffServ program provides proportional service differentiation among BAs classified by DSCPs and that it bounds the metrics within certain values even under the worst conditions by using intelligent traffic conditioning and admission control at the edge nodes. The SLA in our work specifies that the unit cost to use each BA is inversely proportional to the service quality provided.
In this section, we investigate a cost-effective and practically optimal combination in layered video as a JSN approach over QoS-controlled networks such as IntServ and DiffServ. Assumptions in our proposed approach are as follows:
Total cost constraints with a given unit cost curve are defined in the SLA as a contract between user networks and a service provider. Network QoS is closely related to the pricing mechanism. The unit cost for reservation in IntServ can be calculated as the unit cost in the DS level providing a corresponding loss rate (e.g., less than 1%).
An image frame of each layer is encoded into video packets that can be independently decoded. The loss priorities of the packets can be determined while they are being encoded. That is, encoded source data can be split into data-splitting units with different loss priorities.
Within the DiffServ domain, the loss rate for each DiffServ class (or DS level)[1] is bounded even in the worst situation.
Proportional DiffServ is assumed to be able to identify the DiffServ class of each packet, and the unit cost is inversely proportional to the loss rate.
Since the loss distribution must necessarily be uniform, the residual PLR can be kept to a negligible level by using an FEC code that satisfies
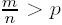 , where p is the PLR without FEC.
, where p is the PLR without FEC.
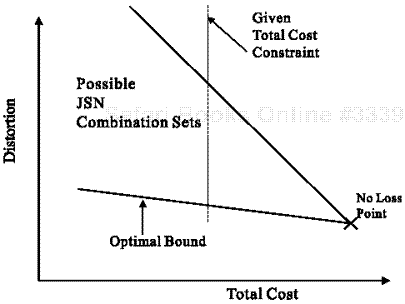
A cost-distortion (C-D) curve should be considered over QoS networks rather than the R-D curve shown in Figure 7.1(a) on the video-coding side because the source rates for the video layers have different unit costs. Assumed layered video is typically characterized as in Figure 7.2(b). The curves in Figure 7.2(b) represent different JSN combinations. Note that curves (1) and (2) have an almost linear R-D relationship because the BL is fully protected and the error propagation effect is minor in those cases. But, curves (1) and (2) are more expensive than the curve (3) case. We can propose a novel, cost-effective JSN adaptation based on C-D rather than on R-D relations. Then, the goal of our approach is to find a practically optimal combination set, {source-data splitting, selective FEC, or network QoS levels}, close to an optimal bound in case there is a given total cost constraint as shown in Figure 7.2. We can expect a cost-effective and best JSN combination at this set in terms of end-to-end video quality. We thus expand C-D arguments over QoS-controlled networks (Figure 7.3).

Figure 7.2. (a) A typical operational R-D characteristic is composed of all possible operating points. (b) A typical R-D curve in the case of layered video with different protection policies. Case (1): both BL and EL1 are fully protected; Case (2): only BL is protected; and Case (3): no protected layers in three-layer video.
In this section, IntServ/RSVP is considered as a QoS-controlled network and is used for network reservation. This JSN case can produce several duple sets as service grades (e.g., {source adaptation, network-reservation degree}), as shown in Table 7.1. When we consider an N-layered video as a scalable source, it can reflect the user’s communication link conditions or user budgets and can be divided into N source data split units. The network reservation degree depends on how many source layers are reserved. For example, “Gold” reserves all video layers, “Silver” reserves only the BL as the minimum required quality, and “Bronze” does not guarantee at all, as in a best-effort network. Video quality improves as more layers are transported, while network cost is determined by how many layers are protected through IntServ/RSVP. An IntServ/RSVP channel will be an expensive channel for reservation, while a best-effort channel will be free or very cheap. The cost of IntServ/RSVP can be determined relative to that of DiffServ by setting the IntServ unit cost equal to that of the DS level providing similar QoS (i.e., the bounded level of packet loss rate).
Table 7.1. Proposed Service Grades Combined with Layered Streams and Network Resource Reservation (i.e., Intserv/RSVP)
Video Network | Gold | Silver | Bronze |
|---|---|---|---|
Note: The QoS of bold-marked layers is reserved and guaranteed by IntServ/RSVP, while the other layers are transported in best-effort mode. The horizontal division is for the different rates of video streams, and the vertical one is for the different network services provided. | |||
Gold | BL+EL1+EL2 | BL+EL1 | BL |
Silver | BL+EL1+EL2 | BL+EL1 | BL |
Bronze | BL+EL1+EL2 | BL+EL1 | BL |
Total cost as a constraint can be calculated from one of the assumptions in the first part of Section 7.3. An example is described in Section 7.5.1.
In this section, DiffServ plays the role of a QoS-controlled network providing proportional service differentiation. This is simpler, much more flexible, and more suitable in loss-tolerant and network-adaptive applications than expensive guaranteed service in IntServ. But, DiffServ itself cannot provide requested QoS at the per-flow level. If the BL within layered video streams of a video streaming application is not protected, DiffServ cannot guarantee better service in end-to-end video quality than the current best-effort Internet because some losses of the BL affect video quality severely due to their loss effect propagation. Therefore, we protect the BL with selective FEC rather than expensive network reservation in this case. This process can avoid the demerit of IntServ/RSVP, but causes a redundant rate. We want to find a cost-effective JSN adaptation to get the best video quality in the DiffServ architecture. Our goal is to increase the guaranteed (or assured) level in DiffServ using an FEC technique and source priority-aware packet processing with a total cost constraint. The RS code in FEC is used selectively to protect only the essential source layer, such as the BL, in layered video streams to provide minimum guaranteed end-to-end quality. Added FEC increases the rate and thus causes an increase in total cost. Thus, we need some source data re-allocation (or splitting) to satisfy the total cost constraint.
Our problem can be formulated as the following generalized C-D equations per flow f with p data splitting, assuming a secure BL with FEC to guarantee minimum quality:

subject to

where wk is the weighting factor of each splitting unit k of the source data contributing to the quality distortion, with the effect divided into error/loss propagation (i.e., reference frame is lost) and no propagation (i.e., loss only in the EL of our layered video); lq(k) is the loss rate in the q DS level to which source k is assigned; rk is the bit rate of k; pq(k) is the unit cost of using the q level; and Cf is the total cost constraint of flow f (Figure 7.4). Source data splitting k is ordered in accordance with priorities from 0 to p - 1 (i.e., p splittings), and k ∊ {0,..., p – 1}, where k = 0 is the BL corresponding to minimum guaranteed quality. lq(k) can be given as shown in Figure 7.1, as an example. In this chapter, it is assumed that only the BL is fully protected by using the appropriate RS code. Our approach is to obtain a practical solution of mapping k to q in terms of several data-splitting methods, while our previous work [125] provided a formal solution in the optimally formulated problem of Eq. (7.1). Our approaches for splitting source data and mapping them into DS levels are divided into the methods described in the next section.

Figure 7.4. A typical example of the lines of loss rate and unit cost in terms of DS level. L and C are constants that indicate the corresponding loss rate and unit cost of the Q0 DS level. m is a given proportional ratio between adjacent DS levels that allows the realization of the assumed proportional DiffServ.
In this section, we analyze an optimally cost-effective combination of video prioritized data splitting, selective FEC, and network QoS levels, especially for DiffServ networks. For IntServ/RSVP, the JSN adaptation is simple because the control factor consists of simply adjusting the reservation amount from the highest priority source data to a lower priority, up to the permitted user budget. A finer granular priority source is more preferable, but for the DiffServ case, we have to consider more factors because of the possibility of using FEC to protect minimum source data such as the BL.
In this case, we can involve more than three DS levels to give applications more flexibility to meet the total cost constraint.
For the example of three-layer video streams such as the r0 bit rate in the BL, r1 in EL1, and r2 in EL2, the reference mapping case for comparison is set as r0 to q = Q0–1, r1 to Q0, and r2 to Q0+1 DS levels, respectively. Then, we enhance end-to-end quality and obtain a predictable quality by protecting the BL using FEC. However, this increases the total cost by adding an additional rate, and it necessitates a re-assignment of lower priority streams into lower DS classes- such as ![]() to Q0 – 1, r1 to Q0 + α, and r2 to Q0 + 1 + α, where α is a positive integer—as well as an adjustment to meet the total cost constraint. The advantage of this case is that one is not troubled by the problem of splitting data of the same layer in source data splitting, as described in the next section. This makes this option attractive because it eliminates a complexity on the application side. The negative aspect is that there are more DS levels to control.
to Q0 – 1, r1 to Q0 + α, and r2 to Q0 + 1 + α, where α is a positive integer—as well as an adjustment to meet the total cost constraint. The advantage of this case is that one is not troubled by the problem of splitting data of the same layer in source data splitting, as described in the next section. This makes this option attractive because it eliminates a complexity on the application side. The negative aspect is that there are more DS levels to control.
In this section, we assume that DS classes are respectively compliant to AF services [23] and that the same DS levels as in the reference case are used. If we can split a layer into two streams and assign them into different DS levels, we may be able to adapt to time-varying network conditions more smoothly. This data splitting technique can be used to compensate additions of ![]() to the BL. There are several options for splitting layered source data:
to the BL. There are several options for splitting layered source data:
Data splitting in a frame unit—. This method splits the middle layer in a frame unit, such as the I frame or P or B frame. This temporal scalability helps network adaptation, but it is difficult to get optimal/flexible splitting because the unit is quite big and the number of I frames is small relative to the number of P or B frames.
Data splitting in a group of MBs (e.g., slice or video packet (VP))[137]—. uses the smallest meaningful unit in MPEG data and enables finer network adaptation. This provides the advantage of optimal splitting, but there is a trade off between packetization efficiency and finer splitting. For practicality, we propose to packetize data in VP units with RM to create a fairly uniform packet size, thus making FEC more adaptable and providing reasonably optimal splitting, to get better end-to-end video quality. This method enables the re-assembly and decoding of the splitting units at a receiver from a meaningful and easily splittable structure.
In this section, we provide an analysis of QoS mapping[2] between the three layers of a video stream and DS levels in order to get the best end-to-end quality under a total cost constraint and given a cost loss curve such as that shown in Figure 7.2. As for the performance comparison, “silver IntServ” (i.e., the BL is guaranteed by a reservation through RSVP, and the ELs are assigned into best-effort service) and “simple DiffServ” (i.e., r0 to q(k = 0) = Q0 – 1, r1 (k = 1) to Q0, and r2 (k = 2) to Q0 + 1 DS levels, respectively) serve as comparison references. q(k) means the q DS level to which the k portion in data splitting is assigned. For the curves of loss rate and unit cost in terms of DS levels, q ∊ {1,..., Q0,..., Q} are assumed, and the proportional quality ratio, m in Figure 7.2, is arbitrarily set to 2 as an example, which means that the quality gap between adjacent DS levels is differentiated as two (or one-half) times. Also, the corresponding unit cost is assumed to be the same as the ratio of the quality gap. That is,

Then, the reference total cost Cf of the “simple DiffServ” case is

The result distortion Df is

Then, we want to guarantee the BL with the RS code to recover the loss effect and provide minimum end-to-end quality. This causes an increase in the data bit rate due to the redundant bit rate. Therefore, new QoS mapping is required to prevent a violation of the cost constraint.
First, in the case of “changing DS levels,” the total cost is

Adjust integer α so that TC1 ≤ Cf. That is,
The related distortion is

![]() is less than the reference value Df for the secured BL, which severely affects the video quality (the experimental results will be shown in the next section). So, we can choose a value to satisfy the total cost constraint in Eq. (7.8). The corresponding distortion difference is
is less than the reference value Df for the secured BL, which severely affects the video quality (the experimental results will be shown in the next section). So, we can choose a value to satisfy the total cost constraint in Eq. (7.8). The corresponding distortion difference is
Because w0 has a much greater impact on quality than w1, w2, ![]() , which can be verified from the PSNR comparison presented in Section 7.5.
, which can be verified from the PSNR comparison presented in Section 7.5.
Second, in the case of “data splitting in a frame unit,” the EL1 layer among the three layers needs to be split in two, r1 = r10 + r11, the value of which are mapped into different DS levels. That is, r10 to Q0 + 1 and r11 to Q0 + 2 DS levels for the total cost not to exceed the total cost of the reference case Cf. Then, the resulting total cost TC2 and distortion ![]() are:
are:

To satisfy the condition TC2 ≤ Cf with a performance comparison between our proposed case and the reference case, we can obtain the splitting guideline so that ![]() . Also, the corresponding difference in distortion is:
. Also, the corresponding difference in distortion is:
Eq. (7.12) is usually a negative value because w0 affects video quality much more powerfully than w1 for the loss/error propagation in reference frames.
The third case is “Data splitting in a VP unit,” which is similar to the second case, but provides a much easier way of splitting by using a smaller splitting unit rather than a frame unit. In a VP unit, we can obtain a lower level of distortion under the same cost constraint as the second case. The analysis is similar to the second case except that the data unit being split is much finer.
Each layer in a video stream is mapped into different network QoS levels with layered FEC and is under a total cost constraint to get predictable and efficient quality in a cost-effective manner. Packets in different network levels experience different but controlled QoS (e.g., packet loss rate). The burstiness of loss patterns is controlled by the Gilbert model, otherwise known as the two-state Markov model, with related parameters (e.g., transient probabilities between good states (G: PLR < 2%) and bad states (B: PLR > 8%); 0.1 for “Good” → “Bad,” 0.1 for “Bad” → “Good,” if average PLR in a DS level is 5%). These probabilities are applied to simulate the given average, bounded, or worst-case loss rates for each DS level. A “Children 640 × 448 pixel size for full resolution, GOP = 10” test sequence (while the BL + EL1 results in 320 * 224, and the BL only results in 160 * 112) is commonly used for performance comparison. The average bit rates of the BL only, BL + EL1, and BL + EL1 + EL2 are 49 kbps, 464 kbps, and 1634 kbps respectively.
Since the concurrent image frame of the lower layer is used as a reference for prediction in the EL, an error in the ELs will not propagate to the following frames, but an error in the BL will propagate to the following frames before the next I frame. To identify the impact of a lost packet, we define two kinds of damaged frames:
Frozen frame (FF)—. A frame with loss in the BL and the following frame(s) before the next refreshed I frame. Video is frozen during FFs.
Corrupted frame (CF)—. A frame with loss only in the EL. Video quality deteriorates for a moment, but temporal continuity is maintained.
The impact of loss in scalable encoding can be measured by these proposed metrics: the frozen frame ratio (FFR) and corrupted frame ratio (CFR), which are ratios of FF and CF, respectively. In total, the damaged frame ratio, or DFR, is defined as DFR = FFR + CFR. The FFR quantifies the degree of continuity in moving pictures. We noted that most viewers felt uncomfortable during a frozen scene. By transporting the BL safely, we can guarantee continuity, thus denoting a low FFR. We argue that in terms of human perception, FFR quantifies the quality of “flow” in videos, while the conventional PSNR quantifies the quality of individual images.
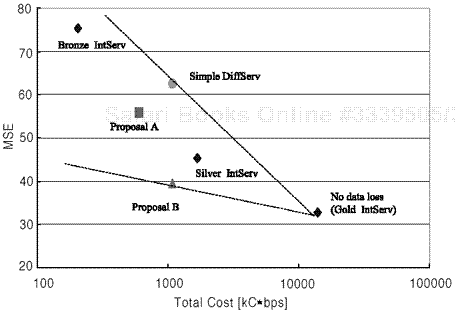
In this section, we show the experimental results of the proposed service mapping of IntServ, discussed in Section 7.3.1. Three-layer video streams (BL, EL1, and EL2) are used and mapped into different network services in IntServ: “Gold,” which is fully reserved for all layers (BL + EL1 + EL2), “Silver,” which protects only the BL, and “Bronze,” in which there is no reservation, there is only best-effort service, and we assume a 20% packet loss rate. The total cost of using IntServ can be calculated from the assumption that the unit cost per bps corresponds to that of a DS level providing a less than 1% loss rate when considering a “guaranteed level.” That is, the unit cost for reservation is calculated as 8C (which comes from the loss rate of L · 2-2 = 1.25%, L · 2-3 = 0.625% as possible choices) from Eq. (7.5) when L = 5% loss rate in the Q0 DS level. Then, the total cost is “peak rate × 8C,” as shown in Table 7.2. It is typical and practical to quantify the cost and recommend guidance for IntServ when considering cost.
Our proposed combination in Table 7.1 can act as a guide for recommending a reasonable choice for network conditions and communication links. The reservation cost is usually quite high, as was described Section 3.1, where we showed a simple cost calculation of IntServ corresponding to DiffServ. In this cost calculation, the cost differences among IntServ types are relatively large (i.e., TCSilver = 0.12 × TCGold, TCBronze = 0.014 × TCGold). In the Gold and Silver IntServ cases, FFR is zero because no BL packets are lost. Consequently, the BL can be decoded so that viewers do not experience any frozen (or jerked) scenes or abrupt mosaic patterns. The PSNR of Bronze (best-effort) in Figure 7.5 becomes very low from time to time, and the scene is frozen during 28% of the total duration, while in Gold and Silver, the scene is not frozen at all and the PSNR level is flat.
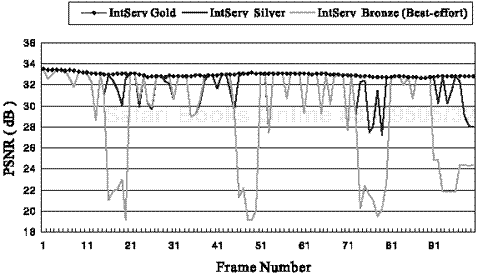
Table 7.2. Detailed Comparison of All Intserv Cases
Guarantee [bps] | Total Cost | FFR/DFR (%) | PSNR (dB) Avg./Dev. | |
|---|---|---|---|---|
Note: * means peak rate of “Children” sequence to be reserved. (The peak rate of the BL is 184 kbps, BL + EL1 + EL2 is 1.74 Mbps.) | ||||
Gold | 1.74Mbps* | 14 MC·bps | 00/00 | 33.0/0.19 |
Silver | 184Kbps* | 1.67MC·bps | 00/71 | 31.6/1.88 |
Bronze | 0 | 205kC·bps | 28/75 | 29.4/4.84 |
The quality of a DiffServ network can be enhanced through an efficient combination of video coding, a transport layer using FEC, and a network layer using DiffServ under the same total cost constraint as in IntServ. FEC is used to protect the BL and to guarantee the quality of the baseline. We propose QoS mapping suitable to the DiffServ domain to meet the cost constraint. Two proposed methods,—“changing DS levels” and “data splitting in VP,”—are compared to the reference, “simple DiffServ.” The reference case includes no guaranteed service, but the PLR is bounded within 2.5%, 5%, and 10% for the respective DS levels of Q0 – 1, Q0, and Q0 + 1.
To meet the total cost constraints of “simple DiffServ,” packets in the ELs are transported at cheaper DS levels than in “simple DiffServ,” and FEC is used to protect the BL, as described in Section 7.2.1. Therefore, (BL + rFEC) is assigned to Q0 – 1, EL1 to Q0 + 1, and EL2 to Q0 + 2 (BE, PLR = 20%). As shown in Figure 7.6, PSNR frequently drops sharply in “simple DiffServ” because of losses in the BL, while PSNR is much more stable in “changing DS levels” (i.e., Proposal A). Table 7.3 shows that the average PSNR of Proposal A differs very little from that of “simple DiffServ.” This means that the conventional PSNR average does not reveal the impact of abrupt changes and does not reflect the discomfort of viewers, which can be quantified by FFR. Even though more frames are damaged, FFR in Proposal A is kept at zero. It shows that Proposal A maintains a better perceptual video quality than “simple DiffServ,” while keeping the total cost at only 60% of that of “simple DiffServ.” In Proposal A, more EL frames are damaged, meaning that the DFR is larger than the DFR of “simple DiffServ.” This is because the ELs are assigned to worse DS levels to compensate for the bit rate increase in the BL, which is due to adding FEC under the total cost constraint. But, FFR is zero, which means that the BL is protected perfectly at the cost of more damaged EL packets and that there is a higher average and smaller standard deviation in PSNR. A comparison of the PSNR of the two programs reflects a small, objective difference in quality; but when this is subjectively evaluated, an audience is able to detect a big difference in quality. This difference in quality perception can be explained by the considerable difference in FFR. The zero FFR in Proposal A indicates superiority in perceptual quality, while a little increase in DFR indicates an adverse but perceptually unnoticeable effect. Although proposal A achieves higher video quality than “simple DiffServ,” it lacks flexibility because each layer is assigned to a particular DS level. It is recommended that a channel condition be adapted because the Internet condition varies with time.
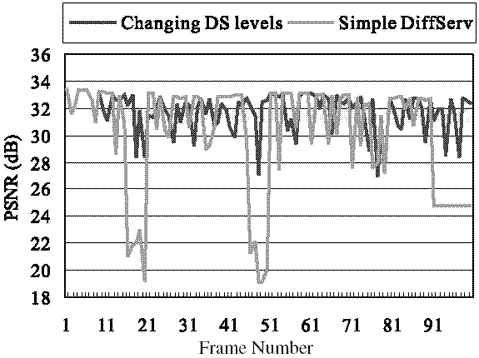
Table 7.3. Comparison Details Among Proposed Combinations
PSNR (dB) Avg./Dev. | Total Cost | FFR/DFR (%) | Mapping | |
|---|---|---|---|---|
Note: * represents the combination of data splitting in VP, FEC protection for the BL, and three DS levels. | ||||
Simple DiffServ | 30.2/4.11 | 1.08 MC·bps | 18/62 | BL → Q0 – 1, EL1 → Q0, EL2 → Q0 + 1 |
Proposal A (changing DS levels) | 30.7/1.98 | 599kC·bps | 00/75 | BL + rFEC → Q0 – 1, EL1 → Q0 + 1, EL2 → Q0 + 2 |
Proposal B* (using VP) | 32.2/1.41 | 1.08MC·bps | 00/68 | BL + rFEC → Q0 – 1, EL10 → Q0, EL11 + EL2 → Q0 + 1 |
IntServ ’Silver’ | 31.6/1.88 | 1.67MC·bps | 00/71 | BL → reserved EL1, EL2 → BE |
The basic method of Proposal B in Table 7.3 is the same as that of Proposal A except that a middle-priority source layer (i.e., EL1) needs to be split into two parts in the VP unit. The two parts are assigned to two different DS levels. The data ratios of the two parts are determined by a given network condition under a total cost constraint. Then, we split the data with the special help of a video coding layer. We mentioned this in Section 7.2.2 as a more flexible and cost-effective option. The experimental results of the data splitting in the VP (Proposal B) case are presented in Table 7.3 and Figure 7.7.
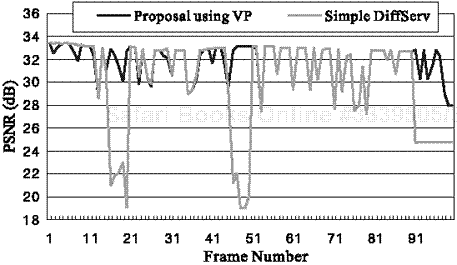
Proposal B employs the combined approach of using video coding, transport (i.e., FEC), and a QoS-controlled network (i.e., DiffServ) to provide better end-to-end video quality than using only DiffServ support (i.e., “simple DiffServ”).
We also compare our proposed DiffServ Proposal B with the “Silver” IntServ case, as shown in Figure 7.8 and Table 7.3. The proposed DiffServ cases indicate an equal or slightly better performance than Silver IntServ. However, our proposed DiffServ cases, as scalable solutions, have several strong qualities that IntServ lacks. They do not require any expensive resource reservation, or the overhead of maintaining per-flow state information, or the connection setup costs for network resource reservation. Also, they can guarantee a particular service quality that “simple DiffServ” cannot. “Silver” IntServ service can guarantee minimum video quality, but cannot provide the high quality of the proposed DiffServ case in a cost-effective manner. Figure 7.8 shows that Proposal B has better performance than IntServ “Silver” in terms of both PSNR and FFR/DFR, while costing less. Our proposed cases have zero FFR, which indicates that the BL is well-protected, and thus there is no loss from error propagation. This maximizes user satisfaction by preventing jerky, frozen, or abnormal frames. As shown in Table 7.3, the DFR values (especially the CFRs) of our proposed method exceed those of “simple DiffServ” because the BL is protected by FEC, which means that the FFRs are zero and the excess cost of FEC transportation is compensated by re-assigning the EL streams under a cost constraint. But the effect of CFR is quite small compared with that of FFR because the effect of CFR is mostly limited to lost packets while FFR has severe spatial and temporal effects through loss propagation.

Figure 7.8. Video-quality comparison between proposed DiffServ (data splitting in VP) and IntServ “Silver.”
In summary, we propose using scalable video coding to satisfy the requests of heterogeneous users and communication links. This method generates layered video streams (i.e., the BL, EL1, and EL2 MPEG-4 encoded stream with PPP mode that is only predictive frames except initial I frame) with loss priorities that are well-matched to different classes in the IntServ/RSVP-based services in Table 7.1. To overcome the flaws of IntServ/RSVP, our second proposal is based on DiffServ and uses FEC to protect the BL. While this proposal cannot provide a guaranteed service like IntServ, it is a cost-effective method. We introduce “simple DiffServ” as a reference, which we compare to our proposals, which use FEC to transport the layers and the error-resilient tools of MPEG-4 video.
We evaluate the performance comparison with the assumption that DS levels provide either bounded loss rates or the worst possible loss rates. Examples are DS levels of Q0 – 1 (worst PLR = 2.5%), Q0 (5%), Q0 + 1 (10%), and Q0 + 2 (BE, 20%), respectively. The unit cost of IntServ is assumed to be the same as the unit cost of DiffServ, the loss bound of which is 1%. In our two proposals for DiffServ, we assume that the loss rate can be bounded to a committed level and that losses are so well-distributed as to be recoverable by FEC. Because the BL is protected, FFR becomes zero. This is enabled at the expense of an increased CFR to meet a total cost constraint, but it minimizes quality degradation, especially in human perception. Subsequently, our proposal for DiffServ provides the benefits of a guaranteed service like IntServ/RSVP in a scalable manner by using a DiffServ concept. Also, it should be noted that the transmission of video layers with effective QoS mapping between source data with different priorities and DS levels is required. QoS mapping with different data splitting methods is performed and evaluated under total cost constraints in QoS-controlled networks. Data splitting in the VP case, with FEC in DiffServ, provides the best video quality, as revealed in Table 7.3. This case has shown itself to be the most practical and optimal method of combining video coding tools, FEC in the transport layer, and a QoS-controlled network layer under total cost constraints.
We practically address the JSN adaptation problem of a layered video stream as a scalable source over QoS-controlled networks with selective FEC to protect the basic, essential source data for maintaining minimum service quality under a C-D framework. The typical operational points are shown in Figure 7.9. We claim that our Proposal B is a practically sub-optimal point under total cost constraint.
In this chapter, we proposed and analyzed a JSN adaptation approach to provide efficient and cost-effective quality enhancement for streaming video services through the combination of error-resilient video packetization using VP splitting, adaptively used FEC, and QoS-controlled networks such as IntServ and DiffServ in an optimal manner in terms of a simple network price mechanism, that is, under a given total cost constraint. Our proposed JSN approach in DiffServ can guarantee minimum service quality by protecting the BL through selectively used FEC in a scalable manner without introducing resource reservation. End-to-end video quality was evaluated in terms of our proposed performance metrics, such as FFR and DFR, that indicate, in addition to PSNR, a perceptual quality that the user feels. The experimental results in the proposed DiffServ case, with VP partition of our JSN adaptation approach, clearly showed better quality than the case of supporting network QoS only as a cost-effective and practically optimal way.
We claim that the performance of the proposed method is not measured well enough by conventional objective measurements such as PSNR, which represent the quality of individual images. We propose the use of FFR/DFR to measure the continuity of scenes, which is the sequence of individual images. Even though our proposals do not show much enhancement in the average PSNR, they do show improvement in the FFR scale, which better reflects the user’s perceptions and judgments with regard to quality. Our study introduces ways to combine across network layers and sources and shows how effective our process can be in transmitting video. Performance can be improved by making progress in each layer and then using the combining technique.
A FGS video encoding standard is currently being finalized by the MPEG Forum, and it will enable finer data splitting. If packets with bit errors are not discarded, some packet parts can be used, which means that partial information can be recovered, thus enhancing quality. If the round-trip delay is low, re-transmission can be a powerful tool in combating losses. In the network layer, the application of ideas in this chapter to MPLS or 3G and 4G wireless networks will be very interesting topics to explore.