
The increasing diversity of networked applications makes the provision of an appropriate level of QoS a critical issue for the future of the Internet. The major portion of this book addresses how the end-system and DiffServ-offering network can cooperate in a positive way. The DiffServ concept is gaining in popularity as a simple and scalable service differentiation method because it does not require per-flow state management at the network nodes in the core network. The recent development of the Internet’s DiffServ model was an attempt to support service differentiation for aggregated traffic in a scalable manner. We can consider a variety of global Internet configurations in which multiple domains will exercise service differentiation and different configurations will lead to various types of global Internet traffic and QoS issues. However, one obvious possible contribution of the DiffServ framework employed by the core Internet is that it can shift the complexity of per-flow QoS provision from the core toward the edges of the network, where it may be feasible to maintain a certain amount of the per-flow state.
There are two main approaches to realizing the DiffServ concept: absolute and relative service differentiation. Absolute service differentiation (guaranteed service) [28], [29], [30], [31] seeks to provide guaranteed, end-to-end, absolute performance measures without the per-flow state in the network core by using admission control and sophisticated scheduling. Relative service differentiation (assured, or better-than-best-effort service) [32], [33] seeks to provide per-hop or per-class relative service gaps. In the latter approach, there are no absolute guarantees due to the lack of admission control or resource reservations. Consequently, a network cannot provide worst-case bounds for a service metric. However, the relative service differentiation approach can be more attractive because of its simplicity and flexibility with networked applications, which are becoming more network adaptive and tolerant of QoS requirements.
Other methods and architectures are available for achieving Internet QoS. This chapter briefly surveys Internet QoS for the purpose of providing a balanced perspective.
QoS can be parameterized in many different ways. Generally speaking, network QoS parameters include throughput, average end-to-end delay, delay bound, delay jitter, and loss rate. Different levels of QoS involve different trade offs between QoS assurance and resource utilization. To design a system that serves the dual purpose of QoS satisfaction and high resource utilization, it is important to determine the QoS requirements of applications and map application data to appropriate network service classes. Commonly used QoS performance parameters are detailed below:
Latency (delay and delay variation)—. Delay is the time elapsed while a data unit travels from one point (e.g., source premise/network ingress) to another (destination premise/network egress). Jitter is the variation in the delay. Some CM applications are delay-/jitter-sensitive because the transmitted information has to be replayed at the receiver in real or almost real time. QoS can be specified in a number of different ways, including average delay, variance of delay, and delay bound, among others.
Packet loss rate (reliability)—. Packets can be lost in a network because they may be dropped when a buffer in the network node overflows. Also, from a real-time application’s point of view, a packet that arrives at the destination after a certain deadline (delay bound) may be useless and may thus be counted as lost.
Most real-time applications have a certain level of tolerance for packet loss. It is difficult to set an absolute bound on the packet loss rate that cannot be exceeded under any circumstances. Thus, it is more common to set a specific packet loss rate dependent on the packet loss recovery/protection schemes employed by the application entities and the user’s subjective evaluation of the quality level. It is generally considered acceptable if the packet loss rate of a particular flow can be kept below a particular tolerance level most of the time. Note also that the packet loss effect is not strictly proportional to the service quality of a multimedia bit stream.
Throughput (bandwidth)—. Throughput directly reflects the amount of information a network is able to deliver during a certain time interval. Higher throughput results in better QoS in general. However, it is not appropriate to consider throughput as a direct QoS parameter for highly burst traffic such as encoded variable bit rate (VBR) video, for which throughput requirements change drastically over time. For application VBR traffic, the actual throughput quantity may not be interesting, as long as the information can be delivered reliably in a timely fashion, for playback in real time. Also, it is neither necessary nor affordable for VBR applications to reserve the peak rate bandwidth to present a desired throughput requirement to ensure QoS. The effective bandwidth [34] or minimum throughput rather than the peak rate is more commonly used.
Throughput, latency, loss rate, and offered traffic rate are all inter-related. In our research, we considered latency and packet loss rate as direct QoS parameters.
IntServ [16] has been discussed by the IETF as an architecture that can provide Internet QoS. IntServ is characterized by resource reservation and admission control, and it relies on a signaling protocol known as the Resource Reservation Protocol (RSVP) [21] for admission control and resource reservation. Routers are required to reserve resources to provide QoS for individual flows. When a host application needs to transmit real-time data requiring a specific QoS level (e.g., a guaranteed bandwidth), the host application sends a Reservation Request (RESV) message to the receiver to reserve resources (bandwidth, buffer space, etc.) along the nodes and links routing the message.
The IntServ approach has some similarity to establishing a virtual circuit with bandwidth and buffer reservation along a circuit, as exemplified by ATM networks. However, because IntServ is intended to be an extension of the Internet architecture and protocols, RSVP has one important difference from the virtual circuit signaling of ATM networks. In IntServ, routing decisions are made by the network’s routing protocol. In fact, the IntServ architecture is designed to withstand volatile topology and traffic load, so it is assumed that the routing protocol may change the routing of a flow to adapt to changes in topology and traffic load. RSVP is designed to deal with frequent routing changes and service outages during the life of a flow. Such robustness is achieved by the concept of “soft states.”
The state of a flow recorded in the intermediate routers along the path, which specifies the flow and its resource reservation, expires after a certain time duration. It is the responsibility of the end-users to maintain the reservations by periodically sending signaling messages to refresh the reservations. If the routing protocol changes the path of a flow, the signaling messages sent periodically by the source and destination (or destinations) start following the new path, and new reservations are made and maintained by the routers along the new path in response to those signaling messages. At the intermediate routers between the source and destination, the “packet filter” function recognizes the packets from the flow for which resources have been reserved. Through packet scheduling mechanisms, a router allocates reserved network resources to qualified packets and protects its resources from packets from other flows, following through with the reservation commitment.
Because resources are reserved on a per-flow basis, hard QoS guarantees of end-to-end service can be made for a flow. RSVP provides a set of QoS guaranteed services [35] to end-users. It can be effective in handling the QoS problem if the reservation protocol is well-tuned with all other IP procedures and underlying physical network technologies. In fact, the IETF’s Integrated Services over Specific Link Layers (ISSLL) working group is focusing on mapping IntServ’s universal specifications (i.e., technology-independent protocols) onto specific sub-network technologies. There are a number of interesting IETF requests for comments (RFCs) related to this mapping task. These include “A Framework for Integrated Services and RSVP Over ATM” (RFC 2382), “PPP in a Real Time-Oriented HDLC-Like Framing” (RFC 2687), “Integrated Services Mapping for Low-Speed Networks” (RFC 2688), and “Integrated Service Mapping on IEEE 802 Networks” (RFC 2815), among others.
However, the per-flow, stateful approach of IntServ has a major drawback: This architecture lacks scalability due to its maintenance of per-flow states. This means that the state of each traffic flow must be stored on every router along the delivery path. Considering the growth of Internet nodes and the number of flows, this lack of scalability is a significant issue. In addition, the reservation and signaling procedures needed to implement RSVP are complex. Periodic transmission of signaling messages for the “soft-state” architecture adds signaling traffic. Concerns have been voiced within the Internet community over the applicability and scalability of RSVP and the IntServ model [36], [37] in the global Internet infrastructure. Also, Internet service providers (ISPs) have expressed concern about the computational and memory overhead of RSVP, and many ISPs are reluctant to deploy the IntServ architecture. Since RSVP does not scale well with the number of sessions, we envision that IntServ will be deployed in only small, private networks or in access networks. IP version 6 (IPv6) [38] supports flows of packets and uses a hop-by-hop ad-hoc reservation protocol.
Multi-layer switching generally refers to an integration of Layer 2 switching with Layer 3 routing. Networks started to be constructed using an overlay model in which a logical IP router topology operates over and is independent of underlying layer 2 switching technology such as frame relay or ATM. There were, however, complexities in implementing and operating networks under this model. Although this approach captured the benefits of both Layer 2 and Layer 3 architectures, difficulties arose in the complexity of mapping between two separate topologies, address spaces, routing protocols, signaling protocols, and resource allocation systems. Further evolution of the peer model occurred, in which integrated switch/routers maintained a single IP addressing space and ran a single IP routing protocol just like a network of routers. Some work was required to map IP traffic to the Layer 2 switched path via IP switching control protocols. This work resulted in the evolution of multi-layer switching solutions. In particular, multi-protocol label switching (MPLS) [39] represents an important effort designed to decrease the complexity of combining Layer 2 switching and Layer 3 routing into an integrated system. The motivation for MPLS as a forwarding scheme is the desire to use a short, fixed-length label to decide packet handling. MPLS is the latest step in the evolution of multi-layer switching for IP-based networks.
In conventional IP forwarding, a router will typically consider datagrams to be in the same “forwarding equivalent (FE) class” if there is some address prefix X in that router’s routing tables that provides the longest match for each of the datagram’s destination addresses. IP performs a “hop-by-hop” routing, that is, each router in the passage of the datagram re-examines the datagram and assigns it to an FE Class as the datagram traverses the network. In contrast, in MPLS, the assignment of a particular packet to a particular FE class is typically done only once, as the packet enters the MPLS-providing network. The FE class to which the packet is assigned is encoded as a short, fixed-length value called a “label” in the MPLS protocol’s data unit’s header. A fixed-length-value “label” of an MPLS network can be viewed as being equivalent to a virtual channel number of a virtual-circuit network. A label, in its simplest form, identifies the path a packet should traverse. At each router supporting MPLS, called a label-switching router (LSR), each MPLS packet’s forwarding (e.g., choice outgoing port) is entirely determined by a single index lookup in a switching table using the packet’s MPLS label and incoming port as the key. The packet’s label is replaced with a new next-hop label retrieved from the switching table [40]. The switching tables of the LSRs along a path are configured when the connection of the path is established prior to the traffic flow. The signaling for establishing and terminating a virtual circuit is performed in accordance with the MPLS’ signaling protocol, called the Label Distribution Protocol (LDP).
When MPLS capability is added to the Internet, the MPLS header (including the label) is added to an IP datagram to form an MPLS protocol data unit. An MPLS label is carried or encapsulated in a Layer 2 header. We can view the MPLS function as an entity between the IP layer and underlying Layer 2. MPLS can operate on top of various link-level technologies, including packet-over-SONET, frame relay, ATM, Ethernet, and token ring. MPLS combines Layer 2 (link layer) switching technology with Layer 3 (network layer) services while reducing the complexity and operational costs. We further note that the MPLS signaling protocols can be used to configure routers to allocate certain network resources for DiffServ classes. Thus, MPLS can be used to facilitate DiffServ operation.
As a traffic engineering method to control traffic flows across networks, IETF QoS routing [41] allows a network to determine a path to support the QoS needs of one or more flows in the network. The path chosen may not be the “traditional shortest path,” which is typically computed by a distance vector and link state routing protocols based on current metrics such as hop counts. QoS routing dynamically determines routes based on constraints such as delay and bandwidth requirements. For example, QoS-enabled routers can support the ability of advanced applications to mark their packets for priority treatment. Marked packets are always sent first and are never dropped during congestion. A separate priority queue is maintained for marked packets and is never oversold.
The DiffServ architecture was conceived by the IETF community as a way to overcome the shortcomings of IntServ in providing scalable service discrimination on the Internet. This new framework achieves scalability and flexibility through prioritizing packets with simple packet marking and utilizing the corresponding packet forwarding.
The packet-forwarding mechanism includes differential treatment of individual packets at each network node as implemented by queue service disciplines and/or queue management disciplines. In addition, the forwarding path may require some monitoring, policing, and shaping of the network traffic designated for special treatment. It is a relatively simple task to forward packets on a per-packet basis as quickly as possible. Forwarding uses the packet header to find an entry in a forwarding table that determines the packet’s output interface.
Routing, however, is a more complex task, and it has continued to evolve over the past 20 years. Routing sets entries in the forwarding table and may have to react to a range of transit and other policies as well as keep track of route failures. Routing is maintained as a background process to the forwarding task.
In the forwarding path, DiffServ is realized by mapping a value contained in the DS byte (specifically, the DS codepoint, or simply DSCP) of the IP header to a particular forwarding treatment at each network node along the path. In DiffServ terminology, these treatments are called PHBs. For example, if the value that a packet carries translates to a low-delay PHB, a router would put that packet in a priority queue to service it promptly. Since routers only look at the DSCP to decide how to service a packet, no complicated treatment based on per-flow state is needed. This leads to increased scalability and flexibility.
Marking is performed by traffic conditioners at network boundaries, including the edges of a network (the first-hop router or source host) and administrative boundaries. Given the mode of operations described above, it is easy to see that if packets are marked irrespectively of the amount of underlying resources, the desired behavior cannot be obtained. Therefore, there is a need to control the amount of traffic injected into the network at every service level, and this is done in two ways. First, applications have to request specific amounts of resources, and they have to get authorization before they can start using them. Usage is policed at points close to the source, where the traffic load is light. Second, if data flows across domains, resources must also be allocated at boundaries between domains. To achieve scalability, resources are allocated to aggregate flows across domains rather than on a per-flow basis. Agreements between domains on the aggregate amount of traffic allowed to cross domain boundaries are called SLAs. SLAs are business agreements and are supposed to be long-lived.
The idea of using a simple bit pattern in the header to specify differentiated treatment was also used in Frame Relay networks as well as in ATM for the available bit rate (ABR) service. The difference is that DiffServ applies to aggregate flows, while these networks work on a per-connection basis.
Figure 2.1 shows the basic architecture of the DiffServ approach. As shown in the figure, traffic conditioners such as shapers, DS markers, and droppers are placed at the edges of the network. Given this functionality at the edge, interior routers use priority markings of packets to deliver differentiated services to various packets. This provides a very basic QoS architecture, in which most of the complexity is pushed to the edges of the network, where it is the most scalable. Because of the limited number of bits available for use in the DS field, the DiffServ working group has defined a small set of building blocks used by routers to deliver a number of services. These building blocks, called PHBs, are encoded in the DSCP part of the DS field. They specify the forwarding behavior for each packet received by individual routers on the Internet. It is envisioned that when these building blocks are employed on an end-to-end basis, they can be used to construct a variety of services to support a range of emerging applications.

Among initial PHBs being standardized are expedited forwarding (EF) [24] and assured forwarding (AF) [23]. The EF PHB group specifies a forwarding behavior in which packets see a very small amount of loss and a very low queueing delay. EF is for premium service [28] that provides users with a performance level of a “virtual leased line (VLL).” EF is based on the priority queuing idea, which gives the highest priority to packets in the EF class. To ensure that every packet marked with EF receives this service, EF requires every router to allocate enough forwarding resources so that the rate of incoming EF packets is always less than or equal to the rate at which the router can forward them. In order to preserve this property on an end-to-end basis, EF requires traffic to be shaped and reshaped in the network.
The AF PHB group specifies a forwarding behavior in which packets see a very small amount of loss. AF is for assured service [42] that offers an expected throughput better than the best-effort. The AF PHB group consists of four independently forwarded classes. Within each class, two or three drop preference levels are used to differentiate between flows in the class. The idea behind AF is to preferentially drop best-effort packets and packets that are outside of their contract when congestion occurs. By limiting the amount of AF traffic in a network and by managing best-effort traffic appropriately, routers can then ensure low-loss behavior to packets marked with an AF PHB. While it is relatively clear how to build predictable services with protocols and mechanisms provided by RSVP and IntServ, the ability to construct predictable services based on coarse-grained mechanisms provided by DiffServ is still an open issue. Since DiffServ specifies only the local forwarding behavior given to packets at individual routers, one of the biggest challenges is to be able to concatenate DiffServ mechanisms on an end-to-end basis to construct useful services for applications.
The IETF DiffServ working group takes a different view of using network resources from that of the IntServ working group. Their general model defines a class-based system in which packets are effectively marked with a well-known label. The label identifies the aggregate service level. A packet may receive different services, which is much like letters sent through the post office, which can be marked and delivered as registered, first-class, second-class, etc. This analogy is rough, yet it reflects a well-understood service model used in other commercial areas. One key, distinctive feature of the DiffServ model is that it is geared to a business model of operations based on a per-class basis. One DiffServ class may be used by many flows. Any packet within the same class must share resources with all other packets in that class. Packets are treated on a per-hop basis by traffic conditioners. The main issue with regard to QoS service provision is the handling of packets from aggregated flows through five basic network components of the DiffServ mechanism. They are as follows:
Classification—. The classifier separates submitted traffic into different classes.
Traffic conditioning—. A marker with metering and a policing component (e.g., the shaper and dropper) force the traffic to conform to a profile.
Queue management—. The queue manager controls the status of queues under congestion conditions.
Scheduling—. The scheduler determines when the packet will be forwarded.
Admission control—. This strict function is usually used in absolute service differentiation such as VLL for premium service.
For resource management in the network core nodes of a classified queue system, a simple forwarding mechanism is often used with two main QoS components: (1) queue management and (2) packet scheduling. Several schemes have been developed for each component. We provide a brief summary and evaluation of them below.
Network nodes must be able to identify the context of packets and perform the necessary actions to satisfy users’ requirements. Such actions may include the dropping of unauthorized packets, the redirection of packets to proxy servers, special queueing and scheduling, or routing decisions based on a criterion other than the destination address. We use the terms “packet filtering” and “packet classification” interchangeably to denote the mechanism that supports the above functions.
Specifically, the packet-filtering mechanism should parse a large portion of the packet header, including the information related to transport protocols, before a forwarding decision is made. Each incoming packet is classified using a set of rules defined by network management software or real-time reservation protocols such as RSVP. Packet filtering is required, for example, when a router is placed between an access (or customer) network and a core backbone network. The router must have the ability to block all unauthorized accesses that are initiated from the public network and destined to the access network. On the other hand, if accesses are initiated from a remote site of the access network, they can be forwarded into the intranet, which requires filtering capability. If this level of security is not enough, another policy requirement might be that authorized access attempts from the public network must be forwarded to an application-level proxy server that will authenticate the access.
Clearly, filtering mechanisms are very useful at the edges of an access network. In an edge network node, the router might need to identify the traffic that is initiated from specific customers and either police it or shape it to meet a predefined contract. Indeed, these actions are required by some of the DiffServ model proposals that are being considered for standardization by the IETF. Filtering policies that use the full packet header can be defined for distributing the available system or network resources.
The first task in a boundary node of a DiffServ domain is to identify packets belonging in streams or behavior aggregates. Packet classifiers select packets in a traffic stream based on the content of some portion of the packet header. Two types of classifiers have been defined: (1) the behavior aggregate (BA) classifier that classifies packets based only on the value of the DS field in the IP header; and (2) the multi-field (MF) classifier, which selects packets based on the value of a combination of one or more header fields such as source address, destination address, the DS field, protocol ID, source and destination port numbers, and other information such as incoming interfaces. Given that the classification problem becomes much harder as the number of fields that have to be matched increases, BA classifiers are preferable to MF classifiers. It is better to have BA classifiers at the domain’s core and position MF classifiers close to data sources, where the traffic load is lighter. Also, there are cases in which MF classifiers have to be installed at the edges of domains, such as when a customer’s domain has no DS capabilities but has contracted a service provider to provide DiffServ to some of its flows. Here, what the service provider can do is to install an MF classifier with filters for specified flows at the boundary of two networks. The classifier identifies packets belonging to specified flows so that they can be marked with the right DS value. For an MF classifier, a simple multi-stage classification algorithm was proposed in [43] to match multiple fields simultaneously to achieve both a high classification rate and a modest storage requirement in the worst case.
Traffic conditioning allows the enforcement of traffic profiles on incoming flows through the use of components such as meter, marker, shaper, and dropper, as illustrated in Figure 2.2. A traffic stream is selected by a classifier, which steers packets to a logical instance of a traffic conditioner. A meter is used to measure the traffic stream against a traffic profile. The state of the meter with respect to a particular packet (e.g., the stream is either in- or out-of-profile) may be used to determine a marking, dropping, or shaping action. When packets exit the traffic conditioner of a DiffServ boundary node, such as an edge router of a DiffServ network, each packet must be set to an appropriate value. The traffic profile is one part of the traffic conditioning agreement (TCA), which is an important subset of the SLA and specifies detailed service parameters for each service level [44]. A typical traffic profile uses a token bucket, which is specified by the token rate and burst size. An SLA is closely related to a pricing mechanism, which was not covered in our research. Our research primarily focused on absolute and relative service differentiation on the defined service level given by a TCA.
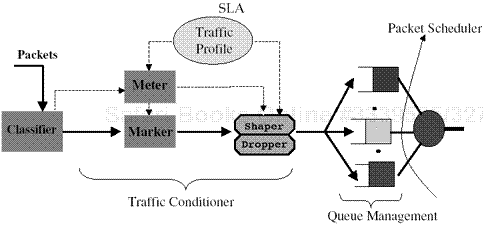
The IETF DiffServ working group distinguishes two different types of services, qualitative and quantitative services, which depend on the type of performance parameters offered [44]. Quantitative services provide concrete guarantees; for example, they may require a bound on the probability of a packet exceeding a delay threshold to be met. Qualitative services only offer a relative guarantee, such as requiring the loss probability of Class C to be low (or lower than that of Class D). To provide the quality negotiated in an SLA, an ISP must assure appropriate resources. A new SLA can be established only if enough resources are available.
This issue in a DiffServ environment corresponds to the traditional admission control problem extensively studied in the ATM world. However, two main differences should be pointed out. First, in DiffServ, an SLA applies only to aggregates of traffic rather than to microflows. Second, an SLA is usually defined in a static and permanent way. A dynamic SLA can be defined only if a network element (e.g., a bandwidth broker) is able to automatically renegotiate resources and is available in each network domain. To ensure system scalability, only a limited amount of dynamics is supported in [44].
One of the most simple yet efficient forms of queue management for TCP-based traffic is the random early detection (RED) scheme [45], which is recommended by the IETF [46] for active queue management to reduce delay and packet loss during congestion. There are many other variants of RED. Feng et al. [47] proposed to adjust RED parameters based on the past history of the queue size. Ott et al. [48] and Floyd and Fall [49] handled the fairness issue among microflows by identifying and punishing the misbehaving flow, monitoring the instantaneous queue size, and statistically estimating active flows. Other RED modifications with per-flow information include flow RED [50] and balanced RED (BRED) [51] for improved fairness.
In the context of service differentiation, Clark and Fang [52] proposed RED with an in/out bit (RIO), which serves as the basis for multiple or weighted RED. This multiple RED provides a different drop preference and discriminates against out-of-profile packets in times of network congestion. Drop preference in multiple RED is studied extensively for target throughput in the area of assured services. The result of previous work is summarized in Section 2.5.1.
The scheduling scheme controls the order in which individual packets get served. It is the most direct tool adopted by routers to serve every class queue. It was observed by Lefelhocz et al. [53] that queue management alone cannot provide flexible and robust control of bandwidth usage and that queue management algorithms need not be tuned precisely if scheduling is used effectively. Even though it is possible to provide bandwidth guarantees to some flows by using only a buffer acceptance algorithm [54], we agree with the viewpoint of Lefelhocz et al. that queue management alone is not sufficient to provide the required service quality without packet scheduling and end-to-end adjustments from feedback.
Due to the diverse traffic characteristics and different QoS requirements of sessions, the primary functions of packet scheduling are: (1) to control bandwidth sharing among service classes or among sessions in the same class; and (2) to provide isolation among these service classes to prevent one class from interfering with another class in realizing its QoS guarantee. In the past few years, several new scheduling policies have been proposed to support QoS guarantees. Zhang and Ferrari [55], [56] provided a good survey in comparing these scheduling policies. A brief overview of several of the most representative scheduling policies is given below.
Most scheduling policies can be classified into one of the following categories: frame-based, delay-based, or rate-based. Frame-based scheduling policies include the weighted round robin (WRR) and hierarchical round robin (HRR) [57]. Under such policies, time is divided into rounds or frames. HRR is a generalization of WRR and uses a multi-level framing strategy in which each session is assigned a slot in some level. The scheduler then serves these levels recursively. HRR can provide delay bounds that are tightly tied to frame size. Both HRR and WRR are non-work-conserving. They provide isolation and protection among sessions, but they do not allow bandwidth sharing among them. Deficit round robin (DRR) [58], however, is a work-conserving, frame-based scheduling policy.
The most typical delay-based scheduling is the earliest deadline first (EDF), or delay earliest due date (Delay-EDD) policy, in which packets are scheduled in the order of their deadlines. Generalized processor sharing (GPS) and its packetized version denoted by Packetized GPS (PGPS) [59] are examples of rate-based scheduling policies. GPS and PGPS are also known as the WFQ scheme [22].
In this research, we focused on WFQ scheduling because it is work-conserving and has many nice properties. For example, WFQ provides fair resource allocation measures that protect a well-behaved traffic source from uncontrolled sources, and it offers a means to create delay-bounded services without the need for resource reservation.
To ensure that commitments made for certain classes of packets can be met, it is necessary for resources to be explicitly requested so that a request can be refused if resources are not available. The decision about resource availability is called admission control. Hence, the role of admission control is to limit the number of flows admitted into the network in such a way that each individual flow obtains the desired QoS. Admission has been investigated widely as a means to provide service guarantees [60], [61], [62].
Traditional approaches to admission control require an a priori traffic specification in terms of the parameters of a deterministic or stochastic model. The admission decision is then based on the specifications of existing and new flows. However, it is usually difficult for the user to tightly characterize traffic in advance [61]. For many types of traffic, such as VBR compressed video, it is difficult to define adequate traffic descriptors that take into account the widely varying source characteristics occurring at a slow time scale (such as that resulting from a scene change). This is true even for stored media such as video-on-demand, since the user is expected to be able to exercise interactive control (such as pause, fast-forward, etc.). Traffic descriptors, such as the leaky bucket that has been proposed in standards bodies like the ATM Forum, are only adequate in describing the short time scale burstiness of variable-rate traffic. As a result, traffic specifications can be expected to be quite loose, thus causing conservative use of resources.
Stochastic models such as those based on effective bandwidth provide a solution in achieving a good statistical multiplexing gain. However, they suffer from two problems. First, it is difficult for users to come up with model parameters a priori. If requirements are over-estimated, resources are wasted and network utilization is reduced. If requirements are underestimated, then the network may allocate insufficient resources to a flow. The user has to either abort the flow or adapt to this situation by, for example, increasing the degree of compression of a video flow, thereby lowering its perceived quality. Second, it is difficult to police traffic according to a statistical model.
It is still not clear how to ensure that a traffic flow will conform to specified parameters, and admission control cannot be effective without such a mechanism. Measurement-based admission control [63], [64] avoids this problem by shifting the task of traffic specification from the user to the network. Instead of specifying traffic by users explicitly, the network attempts to learn the statistics of existing flows by making online measurements. This approach has several advantages. First, the user-specified traffic descriptor can be trivially simple (e.g., the peak rate). Second, an overly conservative specification does not result in a good over-allocation of resources in the entire duration of the session. Third, when traffic from different flows is multiplexed, experienced QoS often depends on their aggregate behavior, the statistics of which are easier to estimate than those of an individual flow. It is easier to predict the aggregate behavior rather than the behavior of an individual flow, which is a consequence of the law of large numbers.
There is a widespread consensus today that the Internet architecture must be extended with service differentiation mechanisms so that certain users and applications can get better service than others at a higher cost. One approach, referred to as absolute differentiated services, is based on sophisticated admission control and resource reservation mechanisms, which are used to provide guarantees for absolute performance measures such as minimum service rate or maximum end-to-end delay.
Another approach, which is simpler in terms of implementation, deployment, and network manageability, offers relative differentiated services among a few classes of service. These classes are ordered based on their packet forwarding quality, as measured by per-hop metrics for queueing delays and packet losses, giving the assurance that higher classes provide better performance quality than lower classes. Applications and users, in this context, can dynamically select the class that best meets their quality and pricing constraints, without a priori guarantees for the actual performance level of each class.
On going research efforts in service differentiation can be divided into absolute service differentiation [29], [30] and relative service differentiation [32], [33] concepts. These are briefly reviewed below.
Among various DiffServ approaches, absolute service differentiation is somewhat limited in the sense that it can only provide a coarse guaranteed QoS level without per-flow admission control. The absolute performance measures are minimum (or average) service rate, maximum end-to-end delay/jitter bound, and maximum packet loss rate. Absolute service differentiation demands more complexity because of the QoS provisioning overhead. It also trades off flexibility for more guarantees. If we can limit the absolute portion of DiffServ as much as possible, it will enhance the flexibility and scalability of the whole DiffServ architecture.
Following Clark’s [42] proposed RIO, quite a few papers have addressed the issue of bandwidth assurance and fairness among flows. The RIO mechanism provides for differentiated dropping of packets in the RED queue during congestion at the router. When user traffic flow exceeds the contracted target rate, packets are marked as OUT packets and are more susceptible to being dropped than IN packets, which are still within the service profile. Differentiated (or priority) dropping methods like RIO or multiple RED can differentiate the rate in a shared bandwidth by adjusting the queue occupancy with the proportion of each TCP flow’s desired rate.
Most existing methods [65], [66], [67], [68], [69] for AF PHB are mainly based on active queue management such as RIO. However, the bandwidth assurance performance of RIO is strongly affected by factors such as the round-trip time (RTT), the number of flows in AF and best-effort (BE) queues, the total subscription (or allocated bandwidth) level, the target rate, non-responsive flows, and RIO tuning parameters. Conclusions of these papers are summarized as follows:
TCP throughput is sensitive to a connection’s RTT because of the TCP window-based control mechanism. AF flows have less deviation from the achieved rate with respect to RTT than BE flows. At the under-subscription level, a change of RTT gives a larger deviation to both AF and BE flows because excess bandwidth is shared among out-of-profile and BE packets in inverse proportion to RTT. However, as a shared link is close to the over-subscription level, AF flows with longer RTTs get a little less than the target rate.
BE flows may have a negative impact on the performance of AF flows within one aggregated queue. BE flows are assigned as OUT packets and may compete with OUT packets of AF flows, which may prevent AF flows from obtaining their target rates.
The higher the subscription level of a queue, the less likely it is that the achieved rate of a flow will match its target rate. This situation is worse for AF flows with target rates that are higher than the average rate (the total shared link bandwidth divided by the number of flows). Because a flow with a higher target rate takes more time to increase its TCP window size up to the desired target rate after back-off.
When increasing the sending rate of a non-responsive flow (whether it is assigned to be traffic or not), all TCP flows get degraded, and TCP flows within AF flows cannot achieve their target rates in the over-subscription region. This effect is much worse if a non-responsive flow exists among AF flows. More strict enforcement mechanisms such as the per-flow queue (i.e., flow RED) are needed for fairness between flows within a queue.
The smaller the threshold value and the larger the drop probability for OUT packets in RIO parameters, the better the performance of AF flows with higher target rates. However, AF flows may still fail to achieve their target rates due to the reason stated in the item mentioned secondly. AF flows with higher target rates are affected by a larger drop probability for their OUT-marked packets.
The bandwidth assurance in assured service depends heavily on the above factors, so the target rate cannot be considered a hard contract. A subscriber may get more or less than the desired target rate.
The premium service in EF PHB [24] for DiffServ content provides a guaranteed QoS level similar to a VLL. Its implementation is based on strict priority queueing that either allows unlimited preemption of other traffic or offers over-provisioning, which provides a higher portion of the shared bandwidth, say more than the maximum arrival rate of aggregate EF flows. The main concern of EF PHB is delay/jitter minimization.
In addition to the DiffServ approach, other solutions can provide absolute, end-to-end delay bounds and relative per-hop delay differentiation. Rate- or delay-based schedulers provide absolute guarantees by using per-flow information and complex admission control mechanisms. Guaranteed statistical rates and delay bounds usually require a complex admission control policy [70] that operates through traffic aggregation and statistical multiplexing. A significant amount of processing overhead can provide guaranteed services without per-flow state management by using a technique called the dynamic packet state (DPS) [30], as discussed in Section 2.6.2. It is like a distributed implementation of the virtual clock algorithm. Bounds for rates and delay can be either coupled or decoupled.
In contrast to absolute service differentiation, relative service differentiation lies at the other end of the DiffServ spectrum. The former guarantees the worst-case bounds on a per-flow basis, while the latter provides service differentiation on a per-hop basis in the average case. Recently, a proportional service differentiation model as a special type of relative differentiated service was discussed by Dovrolis et al. [32], [33]. They promoted the concept of relative differentiation, which provides a proportional service gap, with their own proprietary scheduling. The proportional differentiation model aims at providing proportional quality spacing between classes, independent of class loads. This may not be achieved with other relative differentiation models, such as strict prioritization, capacity differentiation, or price differentiation [32]. Generally speaking, a higher priority class provides better (or at least not worse) queuing delay and packet loss behavior than a lower priority one. However, the proposed schedulers for proportional service differentiation in [32] are not ideal in the sense that the average delay experienced by different classes tends to deviate from the proportional model under light traffic loads in certain short time scales.
Even though the proportional service differentiation model provides service gaps between different DiffServ AF classes, it can only offer qualitative differentiation between adjacent classes. Applications, however, need a certain anticipated service like the bounded range of a service region, even if an absolute service guarantee is not possible. Christin et al. [71] proposed a quantitative AF service to provide proportional differentiation and service bounds of loss, packet delays, and service rates by adjusting the service rate allocation to traffic classes periodically and by dropping packets in a class selectively. These authors used a loss feedback loop to decide how much dropping would occur and in which class. The technique used in packet enqueueing and dequeueing procedures is a kind of combined queue management and rate allocation using rate-based scheduling.
End-to-end QoS can be obtained by cascading well-controlled network domains. This demands some form of bilateral agreement and a coordinated network configuration between two consenting service providers to support each other’s BA PHBs. This could be implemented using a centralized domain server (or an intelligent agent). Nichols et al. [28] suggested using a bandwidth broker (BB) for each network domain as the entity to be responsible for resource allocation and DiffServ QoS policy management. In this setup, each BB communicates policies to network nodes on its domain and handles traffic across the domain boundary with other BBs to provide customers with end-to-end QoS. The BB maintains the domain’s policy, which contains information regarding flows requesting an increased level of service. These flows either are local or represent aggregate requests from neighboring domains for transit traffic through the local domain. Based on the contents of the flow database, the BB instructs its own domain’s edge routers to set their policies and shaper parameters appropriately. In the literature thus far, this proposed BB architecture does not address QoS provisioning and admission control adequately. Another BB architecture for scalable support of guaranteed services was presented in [72] to decouple QoS control (e.g., admission and resource reservation) from data management (e.g., queue management and scheduling). In this scenario, the BB would perform QoS control functions such as admission control and QoS state management on a per-flow or aggregate basis, thus relieving core routers from QoS control.
The end-to-end per-flow QoS guarantee in the IntServ framework relies on a resource reservation architecture such as RSVP. Since it demands treatment of per-flow state information at intermediate routers, scalability of the solution is very limited. Some study has been done on the scalability of the reservation setup protocol. To give an example, the scalable resource reservation protocol (SRP) was proposed in [73] as a reservation protocol to achieve scaling for a large number of flows through aggregation over each network link. Here, clients do not signal connection parameters explicitly. Instead, servers mark packets not covered by an existing reservation as REQUEST flags. A router’s decision to accept a REQUEST packet is based on an estimate from measurements of already reserved traffic. A receiver marks packets as RESERVED at the appropriate rate (or, if a reservation fails, it may cease sending). Feedback consists of traffic specification parameters. To control resource abuse with the aggregation feature in SRP, a policing element may be placed at each router. The element provides any badly behaved user a higher probability of receiving a worse service than if it were well-behaved.
Stoica et al. [29], [30] proposed a stateless core architecture in absolute service differentiation for guaranteed service. This architecture uses a QoS parameter carried by the packet header to provide fair queueing [29] or guaranteed delay by using the DPS [30]. With the per-flow state only at boundary nodes, this kind of absolute differentiation seeks to provide end-to-end, per-flow, absolute performance without the complexity of per-flow QoS management in the network core. To be more precise, the DPS [30] was introduced through admission control based on an estimation of aggregate reservations and a novel scheduling mechanism, called the core jitter virtual clock (CJVC). This mechanism was developed to support end-to-end per-flow delay guarantees without requiring per-flow states in core routers.
DPS was proposed as an alternative approach to solving the resource allocation problem in the network core. The idea behind DPS is to carry resource allocation requests in each data packet travelling through the network rather than sending separate signaling messages. Routers then collect individual requests from each packet they forward and decide the level of allocated resources. In this model, each end-user flow performs admission control by sending a single message to test resource availability before any data packets are sent. This message also pins the path that subsequent packets will follow. However, the complexity increases with the number of flows in the network core.
Despite the fact that DPS requires only a constant state at interior routers, the overhead of this system can still be high because each data packet carries state information (i.e., request to allocate resources), which must be processed before the packet is forwarded down stream. This added processing requirement by DPS could be burdensome for today’s high-end routers, which are optimized to forward packets quickly by implementing forwarding path actions in hardware. Packets that carry DPS headers must be taken out of the fast path for further processing, thereby reducing the router’s throughput. This requirement makes the proposed approach less attractive when compared with the DiffServ architecture.
Short-term changes in the QoS goals for a DS domain are implemented by changing only the configuration of the edge behaviors without necessarily reconfiguring the behavior of interior network nodes. The next step is to formulate examples of how forwarding path components (PHBs, classifiers, and traffic conditioners) can be used to compose traffic aggregates, the packets of which experience specific forwarding characteristics as they travel within a DiffServ domain.
To provide QoS across a DiffServ domain, the term per-domain behavior (PDB) [74] has been introduced to describe the behavior experienced by a particular set of packets as they cross a DS domain. A PDB is a collection of packets that have the same DSCP, thus they receive the same PHB as they traverse from one edge of a single DiffServ network or domain to the other. A PDB specifies a forwarding path treatment for a traffic aggregate, and due to the role that the particular choices of edge and PHB configuration play in its resulting attributes, it is where the forwarding path and control plane interact. The measurable parameters of a PDB should be suitable for use in service-level specifications at the network edge. Associated with each PDB are measurable, quantifiable characteristics that can be used to describe what happens to packets of that PDB as they cross the network. This provides an external description of the edge-to-edge QoS that can be expected by packets of that PDB within that network. A PDB is formed at the edge of a network by selecting certain packets, by using classifiers, and by imposing rules on those packets via traffic conditioners.
There has been some effort to integrate IntServ and DiffServ networks into one system. That is, IntServ, based on RSVP signaling to offer per-flow QoS, could be applied at the boundaries of a large backbone network, while the scalable DiffServ solution, based on prioritization and operation on flow aggregates, could be implemented in the network core. The inter-operation between IntServ and DiffServ is currently being addressed in the ISSLL working group of the IETF. A model has been proposed in [75], in which RSVP signaling is used in association with DiffServ traffic handling to enable QoS in a scalable manner.
There may be two alternatives for achieving inter-operability between IntServ and DiffServ. The first option is to run IntServ and DiffServ independently of each other. In this option, some lows such as real-time flows might get an IntServ reservation, while others are supported by DiffServ mechanisms. This operation is simple, but it limits the use of RSVP to a small number of flows. Also in this mode, each node within the DiffServ network may be an RSVP-capable node. The second approach assumes a model in which peripheral access networks are both RSVP- and IntServ-aware. In this case, a mapping from an RSVP reservation to an appropriate DiffServ class has to be performed. These are interconnected by DiffServ networks that appear as a single network link to RSVP nodes. End-systems attached to peripheral IntServ networks signal to each other per-flow resource requests across DiffServ networks. Standard RSVP processing is applied within IntServ peripheral networks, and RSVP signaling messages are carried transparently through DiffServ networks. Nodes at boundaries between IntServ networks and DiffServ networks process RSVP messages and provide admission control based on the availability of appropriate resources within the DiffServ network.
IP multicasting offers scalable point-to-multipoint delivery necessary for using group communication applications on the Internet. The issue of heterogeneity in traditional IP multicasting has been addressed by a wide variety of research studies [76]. The DiffServ approach will bring benefits for multicast applications that need QoS support. But integration of multicasting support in the DiffServ domain faces several architectural conflicts that are mentioned in [77]. Under unicast, one packet in equals one packet out because of the packet replications in the multicast tree. Thus, although a source may inject only a single packet into the network, this packet may replicate several times over to produce a significantly greater amount of traffic than was originally injected into the network. This becomes especially evident in a highly dynamic group in which the addition of new members to the group introduces more traffic into the egress nodes [77], thus possibly adversely affecting other traffic in the network.
Traditional IP multicasting relies on a per-group state at routers along the multicast tree. Although this is scalable in terms of the number of receivers, it is not scalable in terms of per-group flows. If IP multicasting is extended to all nodes in a DiffServ domain, the per-group state would be extended onto core routers. This violates the fundamental principle of no per-flow state information. DiffServ provides sender-driven QoS based on how packets are marked at the boundaries of DiffServ domains, while QoS multicasting is inherently receiver-driven, especially for scalability. Sender-driven QoS will not suffice without other mechanisms to compensate for heterogeneity of the downstream receivers.
Although the integration of multicasting and DiffServ suffers from several architectural conflicts, multicasting support in the DiffServ domain is useful in several aspects [78]. First, DiffServ provides a mode for service differentiation on the Internet, and multicasting provides a method for conservation of network bandwidth. The integration of DiffServ and multicasting will provide a mode that can supply both service differentiation and conservation of network bandwidth at the same time. Second, it is likely that some form of the DiffServ model will be implemented in the next generation of the Internet. Therefore, multicasting support in a DiffServ domain will be useful from the standpoints of implementation and performance. Third, several evolving CM applications have a variety of QoS requirements and are predominantly group-oriented. In addition, these applications consume a large amount of network bandwidth. Thus, the support of multicasting in a DiffServ domain will facilitate meeting these goals for evolving classes of applications.
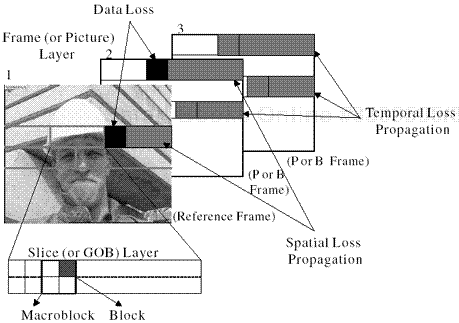
The coded video stream in a CM application is often packetized as a VBR flow due to the inter-frame dependency in the video encoder. Lakshman et al. [79] presented the framework of interaction between VBR video and ATM networks to provide a better QoS environment than the Internet. To get sustained video quality over a time-varying network, video applications should be aware of network conditions. For video streams, a lost packet may lead to the loss of its own content and the content of subsequent packets due to temporal and/or spatial loss propagation caused by inter-frame and inter-block correlation, as shown in Figure 2.3. If an application media stream is not prepared by taking possible packet loss into account, the effect can be more severe than expected. For example, a 3% packet loss in an MPEG-coded bit stream could translate into a 30% frame error rate [80]. Thus, Internet CM applications should be network-aware. That is, they should be adaptive in their transmission rate and in their selection of proper error-resilient features based on network conditions. On the other hand, it is also advisable that the network adapt to application’s request to a certain degree. Another comment on loss propagation is that error visibility may be dramatically reduced by means of error concealment techniques such as spatial/temporal interpolation and resynchronization.
Because of the variation in and unpredictability of bandwidth and other QoS parameters over IP networks, most media-streaming solutions are based on some type of layered (or scalable) CM coding scheme [81], [82], [83], [84], [85]. These solutions are typically complemented by packet loss recovery and/or error-resilient mechanisms.
An application source encodes its CM traffic into high- and low-level priorities (e.g., layered video) to minimize the effect of packet loss on delivered quality in a joint source/channel coding approach [14], [86]. The drop scheme performed at network nodes differentiates layered streams by using priority information. Nodes drop low-priority traffic before high-priority traffic when congestion occurs. A mechanism that dynamically adjusts the bandwidth of low- and high-priority levels at the source, based on feedback from the network, is also a popular idea. The goal of this approach is to maximize quality without involving any congestion control mechanism. It relies on the support of the priority drop by the network, which is not available in the best-effort Internet environment. Bajaj et al. [87] investigated the relative merit of priority dropping over uniform dropping for layered video, and they concluded that the performance benefit of priority dropping is less than expected.
The ability of some scalable compression techniques [82], [88] to produce more than two layers can support a wide range of bandwidth variation scenarios that characterize IP networks in general and the global Internet in particular. All types of scalable video in video compression standards such as MPEG-2, MPEG-4, and H.263 consist of a base layer (BL) and one or more enhancement layers (ELs). The BL part of a scalable video stream represents the minimum amount of data needed for decoding the underlying stream. The EL part of the stream carries the additional information required to enhance video quality when decoded by the receiver.
The network-layer QoS parameters include the average delay, delay jitter, packet loss ratio, and minimum throughput requirements. These parameters are presented explicitly to the network service provider by the owner of a flow. A translation must be done beforehand to map the application layer’s desired QoS onto network-layer QoS parameters. Such a mapping is necessary because the application-layer QoS may be different from the network-layer QoS. For example, the application-layer QoS of a video conference application may include the frame size (resolution), frame rate, PSNR, etc. To maximize decoded application quality as measured by either subjective or objective measures, multimedia content-aware packet classification is effective. Classification of video streams in terms of QoS parameters is necessary, the network is capable of providing different QoS levels, and QoS interaction is required between the application and QoS network.
Recently, there has been some effort to combine the characteristics of the end-to-end QoS guarantee of IntServ and the scalability of DiffServ [89], [90]. In this case, service mapping between IntServ and DiffServ is necessary. There are two instances in which mapping between IntServ and DiffServ is required. The first is when a domain’s BB gets an IntServ request from an end-host and has to translate it to a DiffServ request to the appropriate edge router so that availability of resources at the domain’s boundary can be checked. The second case occurs when a new flow has been admitted and the sending host (or first-hop router) has to translate the request for a specific level of IntServ to a value for the DS field in application packets.
In the first scheme (called default mapping), a standard mapping from the IntServ service type to an appropriate PHB is defined. This mapping is not necessarily one-to-one. For example, controlled-load, interactive voice traffic will most likely be mapped to a PHB having different latency characteristics than controlled-load, latency-tolerant traffic. For this reason, we may add a qualifier to the IntServ service type indicating its relative latency tolerance (high or low). The qualifier would be defined as a standard object in IntServ signaling messages.
In the second scheme (called configurable mapping), edge devices are allowed to modify the mapping. Under this approach, RESV messages originating at hosts carry the usual IntServ service type with a qualifier. When RESV messages arrive at an edge device (e.g., the first-hop router), the edge device determines the PHB (possibly by consulting with the BB) to obtain the corresponding DiffServ level. This value is appended to the RESV message by the edge device and carried to the sending host. When the RESV message arrives at the sending host, the sender (or intermediate IntServ routers) marks outgoing packets with indicated PHBs. The decision to modify well-known mapping at edge devices is determined by edge device configuration and/or policy. For example, when enough reservations have already been accommodated to reach the pre-negotiated capacity limit at some service level, a device may decide to use a PHB corresponding to a different service level with less assurance based on an established policy in response to a new reservation request that is of the same service level.