
Nowadays, it’s quite common to jumpstart a development project by modifying an existing one. Starting out in this way gives you a head start and can speed up the development process.
In this chapter, we’ll create a sample application, Echoes Player (Lite), to be used throughout the book to demonstrate the various assets of Angular and ngrx tools. Echoes Player starts from a boilerplate made by the AngularClass team ( https://angularclass.com/ ) and is based on the official boilerplate of the Angular 2 Webpack starter ( https://github.com/AngularClass/angular2-webpack-starter ).
We’ll go into detail on the following subjects:
Structure overview
The world of Webpack tooling
The development and deployment workflow
Note
Webpack is a module bundler mainly used for web development. It creates a dependency graph from any files that have been loaded by a proper loader plugin so that those files can be imported into other files using any form of module loading. It is also used for bundling a production-ready version for deployment.
Before we begin, though, it’s important to understand the boilerplate’s underlying principles, along with the libraries and tools that are included with it and how they can assist us during development.
Boilerplate Overview
The structure of a project is organized into a well-defined set of directories and files. The dependencies of this boilerplate are indicated in the package.json file. However, aside from tracking the dependencies, package.json includes the scripts section—tasks that can be run with npm in the terminal.
This boilerplate’s package .json file includes quite a few ordered scripts that we can interact with; however, we will only use a few of these. Some scripts use other scripts with a switch, some are relevant for production or testing mode, while others are relevant for several development modes. We’ll interact with some of these scripts later in this book.
Looking at the directories structure (Figure 2-1), we can see that on the first level of the project there are only two directories: config and src. Let’s take a high-level look at them and their contents now.
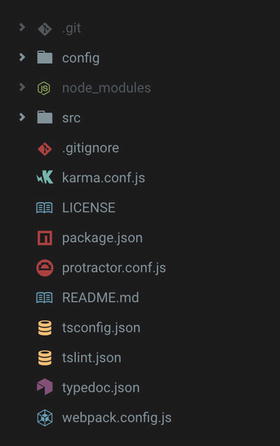
Figure 2-1. Directories structure for this book’s boilerplate
The “config” directory
The config directory includes the main build and deploy code as part of its tools. The config files for Webpack (the build tool that is being used) can be found here.
There are three main config files for Webpack. Each is destined for an environment that will be run and compiled by Webpack:
development config – webpack.dev.js
production config – webpack.prod.js
test config – webpack.test.js
There is also a webpack.common.js file, since there are common configuration settings that all of these environments consume.
Note
The gh-pages branch in Github serves as a static web server. For example, the Echoes Player ng2 project can be accessed through http://orizens.github.io/echoes-player . The source files are served from http://github.com/orizens/echoes-player/tree/gh-pages .
There are also other configuration files, including tests configuration files for unit tests run using Karma and an end-to-end configuration file for protractor. Since we will experiment with writing unit tests, let’s review Karma’s configuration file.
Karma
Karma is a node.js package that can be installed using npm:
npm install karma --save-devCustomizing Karma with Configuration
Karma’s plugins, adapters, and preprocessors are also node modules that can be installed via the npm registry.
Karma is configurable via the karma.conf.js file. There are a few settings that we can configure in this file in order to customize the testing environment.
Karma loads the files that have been included within the “files” array entry. Since this boilerplate is using Webpack and the module system, these files are loaded via a single script file: spec-bundle.js. This ensures that all the required dependencies of the project have been loaded successfully.
The “preprocessors” entry allows us to define a processing tool for each entry that has been defined in the “files” section. In our case, the files that have been loaded should be compiled using Webpack and its relevant Webpack test configuration file (the “webpack” entry is a custom entry key that is being read only by the karma-webpack plugin). In addition to that, multiple preprocessors can be run on each entry in our boilerplate. The “coverage” and “sourcemap” preprocessors are useful for creating a coverage summary for the test’s results and a source map dictionary file for the typescript files of the application’s code. The “coverage” preprocessors create a new directory with the results formatted as a mini HTML website (this is defined in the “coverageReporter” entry).
Karma-Supported Frameworks
Karma is agnostic for several values within the configuration file. It can run the tests on any browser that has had its launcher loaded as a plugin. Most browsers have a launcher. In addition to that, tests can be run on multiple browsers simultaneously. This is defined in the “browsers” entry.
Karma is also agnostic to the testing framework that is being used for writing and asserting tests. Each framework should be plugged into karma with a dedicated adapter. In our boilerplate, we are using Jasmine. It’s also the default testing framework being used by the Angular team and is documented on the documentation website of Angular (https://angular.io/docs/ts/latest/guide/).
Configuring Karma’s Output Results
In order to display the results of tests, karma uses the “reporters” entry to figure out who or what it should report the result to. A reporter is usually a script that sends the result to an output device. This output device can be the terminal, an HTML file, or a Continuous Integration (CI) server (i.e., Travis-ci, Jenkins). Karma includes the default reporters “dots” and “progress.” Our boilerplate is configured to use the default reporter “mocha,” which prints the description of each test (or, more precisely, a spec) in a green color with a success or error indicator (which will be then printed in a red color). In addition, the “coverage” reporter is used in conjunction with its preprocessor to output a coverage result for the whole application.
Karma’s Test Process Modes
Two entries that are important to notice are “singleRun” and “autoWatch.” The “singleRun” entry tells karma to run all the tests exactly once and then exit the process and terminate the test task. This is useful when the test process is integrated with a CI such as “Travis-CI” or “Jenkins”. If this entry is set to false, then the process of the test runs the tests once and then hangs and waits for another command; the task is terminated. This usually goes along with the “autoWatch” entry, which tells karma to watch for changes within the files that have been loaded. If set to true, karma will run the tests again as long as the process is alive. It is disregarded when “singleRun” is set to true.
There are more settings that have been defined within the karma.conf.js file; however, we overviewed the important ones for our needs in this book. There is very good documentation on karma’s website as well as other useful information. Table 2-1 summarizes the settings relevant to the karma.conf.js boilerplate that we’ll work with in this book.
Table 2-1. Summary of Karma Configuration File in This Book’s Boilerplate
Karma Entry | Plugins |
|---|---|
Testing Framework | Jasmine |
Preprocessors | Webpack, coverage, sourcemap |
Browsers | Chrome |
Single Run | true |
Reporters | mocha, coverage |
Webpack
Webpack is a module bundler tool, but it has lots more to offer. Webpack provides a very thorough toolset for bundling projects, running a development and testing environment, and much more.
As I stated before, there are four Webpack configuration files in our boilerplate. Each one includes the proper configuration settings for its purpose, be it development, production, testing, or Github deployment. However, there are common settings that all four share; these are configured in the webpack.common.js file.
Webpack Common Settings
Let’s review the common settings in the webpack.common.js file. You’ll notice first that there are a few required node modules that we’ll use later as plugins for post-processing.
There are constants there that are used for the following:
title – defines the title that will be rendered in the index.html title element
baseUrl – used for defining index.html, the “base” URL element for loading related URLs
isDevServer – used by the Webpack Dev Server package in order to include the webpack-dev-server.js file in index.html
/*
* Webpack Constants
*/
const HMR = helpers.hasProcessFlag('hot');
const METADATA = {
title: 'Echoes Player Lite - Open Source Media Player for Youtube',
baseUrl: '/',
isDevServer: helpers.isWebpackDevServer()
};Note
Webpack Dev Server is a complementary npm package separate from Webpack. It is a small web server based on nodejs and express.js, and is used to serve Webpack bundles during development only. For more info, go to https://webpack.github.io/docs/webpack-dev-server.html .
A Webpack configuration file eventually produces a json object. The boilerplate exports a function, which returns this configuration object. In the following sections, I will focus on some of these configuration options that represent the actual configuration that Webpack is using.
Entry
Via “Entry,” we can define bundles that Webpack will start from; it eventually produces bundled files. This is a simple key-value object in which the key represents the name of the output file and the value represents the starting point for bundling the file and its dependencies.
The following three files are produced in our boilerplate:
polyfills – required libraries for adding missing functionality to old browsers (like es6 features and others)
vendor – third-party library files, such as Angular’s packages, RxJS, ngrx’s files, and others
main – the actual code of the application that we write on our own
entry: {'polyfills': './src/polyfills.browser.ts','vendor': './src/vendor.browser.ts','main': './src/main.browser.ts'},
Resolve
“Resolve” is a group of settings that can be used to configure how files are resolved when required. Since we’re going to use Typescript to write code and then load files with a .ts extension, this can be useful.
resolve: {/** An array of extensions that should be used to resolve modules.** See: http://webpack.github.io/docs/configuration.html#resolve-extensions*/extensions: ['', '.ts', '.js', '.json'],// Make sure root is srcroot: helpers.root('src'),// remove other default valuesmodulesDirectories: ['node_modules'],},
Module: pre-loaders, loaders, and post-loaders
The “module” setting is one of the most useful settings and is an interesting option in Webpack. This setting is what makes Webpack a module loader that is agnostic to the extension of the module.
A loader, in Webpack’s world, is a kind of plugin that assists Webpack in importing a file to the application and parsing it as it should be. A loader is defined using a simple json object. For example, in order to be able to load HTML files as strings, we can use raw-loader and define it like so:
{
test: /.html$/,
loader: 'raw-loader',
exclude: [helpers.root('src/index.html')]
}This json object is added to the “loaders” array and provides the following instructions for Webpack:
test – a regular expression that applies this loader when one of the import or require statements points to a file with a .html extension
loader – Use one or more loaders to load this (html) type of file; in this case, use raw-loader only.
exclude (optional) – Ignore these paths/files before you try to load the file.
Now you can understand how Webpack can treat any kind of file as a module by using any type of loader.
Note
A loader is an npm package that can be installed with the npm command line. The convention for naming a loader is usually appending the word “loader” as a post-fix. There’s no need to import the loader—Webpack does that.
The “pre-loaders” array is a collection of loaders that process the loaded files before the primary loaders are applied. The “post-loader” array is a collection of loaders that process the loaded files after the pre-loaders and loaders are applied.
There are several methods by which to apply multiple loaders to the same type of file.
Array of strings – each loader is defined separately and is applied by the order of the array; i.e., loaders: ['to-string-loader', 'css-loader']
Separated by “!” – each loader is separated by “!” in one string. Webpack applies the loaders from right to left; i.e., loaders: 'to-string-loader!css-loader'
Plugins
“Plugins ” is a collection of processors that operates on the bundles after both the loading and its processors are complete. It’s like post-processing the output result of Webpack’s file bundling.
Webpack’s object, “webpack,” includes several built-in plugins. Usually, a plugin is the result of a newly created object, such as:
new webpack.optimize.CommonsChunkPlugin({
name: ['polyfills', 'vendor'].reverse()
})The order of the plugins in this array doesn’t matter (unless plugins apply to the same bundle or for a common goal).
Similar to loaders, a plugin is usually a function that is applied by Webpack’s compiler.
Node
The “Node” settings supply polyfills or mocks for various objects in the node environment.
Customized Settings
There are more settings with which to customize Webpack’s build. Some of the settings that we’re going to review in this section are configured with a different or additional value in each Webpack configuration file.
This is so we apply values that are proper for the intended goal. For instance, in a production bundle we would like to minify the bundle and perhaps use lite source maps, which should be loaded from an external source once needed. We might want to use special development settings, which can make the development workflow faster and may assist us in being more productive.
Note
The webpack.common.js configuration is merged with any of the other Webpack configuration files at runtime. The other files add their settings to the common file and don’t override it.
Output
The “Output” setting is the counterpart to “Entry.” Contrary to the entry setting, there should only be one output setting; this affects all entries. Let’s review some of the options in this setting. The output file’s extension is a JavaScript (*.js) extension file.
filename – We can set the name of the output file by using brackets. [name].bundle.js is an example of a technique used for template-like variables that should be applied to each entry (when multiple entries are configured).
path – This is the target directory where the file should be placed at the end of compilation.
sourceMapFilename – We can set the template name for the sourcemap file that is generated: [file].map.
For more options, navigate to https://webpack.github.io/docs/configuration.html#output .
devtool
This setting allows Webpack to create source maps to the generated files in various ways. A source map is a standard way to interpret transpiled code to its origin. This feature enables us to view the original source code as it is written (i.e., in Typescript) in the browser’s developer tool.
Webpack’s “devtool” setting enables few useful values. Each setting has its pros and cons in terms of build performance, rebuild performance, quality of the generated code, and production support. These configurations are shown in Table 2-2.
Table 2-2. Summary of Webpack’s Devtool Configuration Values (adapted from https://webpack.github.io/docs/configuration.html#devtool )
Devtool value | Build Speed | Rebuild Speed | Production |
|---|---|---|---|
eval | 3 | 3 | no |
cheap-eval-source-map | 1 | 2 | no |
cheap-source-map | 1 | 0 | yes |
cheap-module-eval-source-map | 0 | 2 | no |
cheap-module-source-map | 0 | - | yes |
eval-source-map | - | 1 | no |
source-map | - | - | yes |
This concludes our introduction to Webpack and its responsibilities in our boilerplate.
Third-Party Libraries
Next, I will focus on the correct files that allow us to add third-party libraries. I call these “correct” since there is a reason for adding third-party libraries using these files.
As discussed in the Webpack section, there are three bundles of files—main.browser.ts, vendor.browser.ts, and polyfill.browser.ts—each of which includes portions of the code and libraries that we use for our application. For performance reasons, it is a best practice to include as few as possible outgoing requests within our index.html file so our application loads faster.
Since main.browesr.ts includes the code that we add to the application—the code that we write—we will focus on the other two main bundle files right now: vendor.browser.ts and polyfills.browser.ts. Lets understand each file’s purpose and contents.
Vendor Libraries (vendor.browser.ts)
Located in the root of the src directory, vendor.browser.ts is the file that is compiled with Webpack’s “vendor” entry. Here’s an excerpt that shows the importing of Angular’s two packages:
import '@angular/platform-browser';
import '@angular/platform-browser-dynamic';
import '@angular/core';
import '@angular/common';
import '@angular/forms';
import '@angular/http';
import '@angular/router';In the following chapters, we will add third-party libraries like @ngrx/store, which will be included once and will be served from the output file vendor.js.
As of the time of writing this book, it is advised to include imports of specific RxJS operators and objects within this file in order to reduce the inclusion of redundant code in our applications.
You will notice that, thanks to Webpack’s DefinePlugin plugin, there’s a reference to a global “ENV” variable. DefinePlugin allows us to define global environment variables that we can use inside our application, treating it like a node.js environment. This is useful in case we would like to write code that should run only when our application is in production mode.
Polyfills (polyfills.browser.ts)
Polyfill in web development is a term coined by Remy Sharp ( https://remysharp.com ) back in 2010. A Polyfill is a code snippet (usually one file) that provides an implementation of a feature to compensate for the lack of this feature in browsers that don’t support it yet. Here’s an excerpt of the polyfills.browser.ts file importing some ES6 core implementations:
import 'core-js/es6/symbol';
import 'core-js/es6/object';
import 'core-js/es6/function';
import 'core-js/es6/parse-int';
import 'core-js/es6/parse-float';
import 'core-js/es6/number';
import 'core-js/es6/math';As of the time of writing this book, only some of ES6 features are supported in most browsers. In order to use ES6 features in all browsers, we add implementations of these features in this file. Other non-related ES6 features should be included in this file as well. For instance, zone.js is included in this file as it’s currently not part of any spec and has been proposed to the TC39 (Ecmascript Technical Committee).
The App Directory
The writing of components and logic is one of the most important takeaways of this book. Mostly, we’ll focus on the app directory’s contents in order to add new components, reducers, and services. Let’s look at this directory.
App Component
In the root of the app directory , the main application’s module is defined and its complementary files reside. I will review some of the most important files relevant to the project we are tackling in this book.
app.module.ts
This file is the main module. Eventually, Angular bootstraps it as the application in main.browser.ts. We will import other modules in this file and define them as needed. A good example of a module is the HttpModule.
app.component.ts
This is the main application component. Its template usually outlines the main structure of the application. It can include high-level components (container components) without any input properties. These high-level components can be feature modules.
In Echoes Player, the “app.component.ts” template includes some high-level components and one route outlet component to which a different component is rendered when the route changes.
Core Directory
The core directory includes a few core elements that are defined as the app’s base elements that every module might use. The app/core directory includes the following directories inside:
components
directives
services
interfaces
pipes
store (with its reducers)
effects (side effects with ngrx/effects)
In this book, we will focus on the core/store and core/effects directories when creating the core reactive elements that the app will use. Let’s do a quick review of these directories.
The contents of the core directory are wrapped in a CoreModule, which is defined in index.ts. This is a shared module that every module can import and use its exported features.
Store Directory
This module defines the core store module that the app can use. The store incorporates ngrx/store as the reactive state-management solution.
Eventually, this directory will include directories of reducers and actions. Each directory defines a reducer for handling its state updates or actions that will be used as “tokens” to dispatch a state update.
“*.reducer.ts” File
A reducer is a pure function that takes both a new state and an action object as arguments and returns a new state based on the action’s type and payload (optional relevant data that has been attached to this property).
A reducer is a portion of the store and represents a certain data structure in the store. It is a function that may transform the representation of a state and produce a new value to be saved within the store object. Usually, a reducer will be similar to the following structure:
// my-reducer.reducer.tsimport { ActionReducer, Action } from '@ngrx/store';import { MyReducerActions } from './my-reducer.actions';export interface SomeInterface {items: Item[],filter: string}let initialState: SomeInterface = {items: [],filter: ''}export functoin MyReducer (state: SomeInterface = initialState, action: Action): ActionReducer<SomeInterface> {switch (action.type) {case MyReducerActions.ADD_ITEMS:return Object.assign({}, state, { items: [...items, ...action.payload] });case MyReducerActions.UPDATE_FILTER:return Object.assign({}, state, { filter: action.payload });default:return state;}}
This is a common body structure for a reducer function. It includes a switch statement, which returns a new state object (or the same state) according to the action’s type.
It’s important to note that a reducer must return a new state object and not just mutate the state in any form. This is one of the characters of a pure function, and by returning a new state object, Angular can leverage the performance of state changes. It may boost performance of change detection by identifying which objects have changed, thus running the change cycle only when necessary and saving the browser from re-rendering components that don’t need an update.
We’ll dive into this in more detail in the following chapters.
Effects Directory
This directory includes various side effects that result from some of the actions that we’ll work with. A side effect in this context is usually a “chain” of actions—a flow where a certain action should always followed by another action.
An effect is defined with the decorator @Effect:
// some-effect.effect.ts
@Effect()
addItemsReady$ = this.actions$
.ofType(MyReducerActions.ADD_ITEMS)
.map(action => action.payload)
.switchMap(items => this.someServiceInfo.fetchMoreData(items)
.map(items => this.myReducerActions.queueItems(items))
.catch(() => Observable.of(this.myReducerActions.addItemsFailed(media)))
);This @Effect decorator reacts to the ADD_ITEMS action. Whenever this action is dispatched, there should be a side effect—a call to the fetchMoreData method, which results in new observable objects. This is why we use switchMap to “listen” to the new stream. When this stream is resolved, the second action object should be invoked by the myReducerActions action creator and handled by the MyReducer reducer. If something goes wrong, a good practice is to define a “catch” handler that dispatches an action object with addItemsFailed.
Note
An action creator is a function that takes one or more optional data arguments and returns an action object with both type and payload. This method encapsulates the attachment of the action type and provides a simple pure function with which to dispatch an action. This also makes code that uses an action creator easier to test and reason about.
Using a layer of effects is useful for several use cases. In this layer, we can initiate requests in order to update a backend service. It is also useful for updating or adding additional data to a state (think of paging lists of data). Beyond that, it promotes the perspective of designing services as “pure” stateless objects, allowing us to use it for fetching and updating data from/to a backend service while not keeping the state in these objects, but rather keeping it in our store.
We’ll go into more depth with effects later in this book so we can understand how they contribute to the structure and flow of logic in our application (or any other application).
Services Directory
This directory includes the core services of this application. Usually, feature modules should consume these services in order to interact with external data API (YouTube’s API, in this case).
Most of the code is already written for these services; however, we’ll update these as we go along with the book in order to experiment and understand reactive programming with services in Angular.
Other Directories (home)
In this level of directories, next to the app.*.ts files, we’ll create container components (smart components) for those components that have access to the application’s services and core features.
The HomeModule includes the home component, which is an example of such a container component. It stands on its own and connects to the store and services of the application.
We’ll create several smart components, each of which will eventually be activated via routes that we’ll create. Each smart component may define its own nested routes to which other components are attached.
To create modular and maintainable components, it is very useful to create smaller, nested components within the smart component directory (not necessarily attached to nested routes).
Running the Project
Let’s go ahead and run this chapter’s code. After you have downloaded this chapter’s project files from the chapter-02 directory, open a terminal (or a command line). There are a few preliminary steps to take to prepare our project to run.
run npm install (or npm i as a shortcut). This will install all the required dependencies of this project. This takes some time, but no more than two or three minutes (depending on your Internet connection).
run npm start. This will compile the project and run a local server.
Once you see these lines in the terminal (Figure 2-2), it means that the compile phase has been completed successfully and that you can navigate to the browser to see the project.

Figure 2-2. Lines indicating that the compiling phase has been completed
Now you can open the browser and navigate to http://localhost:3000. You should be able to see an empty application skeleton (Figure 2-3), which we’ll add components to in the next chapters.
Figure 2-3. Empty boilerplate awaiting use
Alternative Boilerplates
The AngularClass boilerplate is just one of a few boilerplates that you can start an Angular-based application with. There are many other boilerplates with additional features and concepts, such as the following:
Server-side rendering
Angular material
ES6-only boilerplate
Other UI libraries
The Official Angular CLI Tool
At the time of writing this book, the Angular team has released the first official version—1.0.0—of the angular-cli tool for creating Angular-based applications. It is an open source project available at https://github.com/angular/angular-cli .
This tool is a command-line interface for creating new Angular applications and generating code during development. With a few short, simple commands in the command line, you can create new components, services, and other common files.
The main command you would use to interact with this tool in the command line is ng. The angular-cli tool abstracts the use of Webpack and karma, as well as a lot of the configurations and tools that have been covered in this chapter. The store and effects files are not part of this tool yet. In addition, it includes several npm scripts for running various tasks for testing, building, and production.
Summary
In this chapter I introduced the boilerplate code that the Echoes Player (Lite) application will be based on. We reviewed the main build tool, which orchestrates all files in order to assist us with many useful operations, such as writing Typescript and compiling it to a one-bundle JavaScript file.
I also introduced the directories and file structure of this boilerplate, pointing to the important directories where we will add ngrx/store and ngrx/effects.
In the next chapter, we will dive into state management with the ngrx/store library and will connect it to a component.