
Chapter 3. Real Products

Our businesses are built on the idea of making money. We make money by delivering value to our customers.
How do we build better products? What is the magic formula or “secret sauce”?
The answer is continuous innovation, attention to detail, and feedback early and often from our customers. There is no such thing as a perfect plan, let alone a big, up-front perfect plan. Why do people think that they can build valuable products by trying to define everything up front?
With technology changing daily, customer needs change and, thus, our product designs must change as well. In this chapter, we will talk about what exactly is involved in effecting changes in the way we deliver products.
Do We Have the Insights We Need to Know What Customers Want Most/Next?
I know this is going to sound crazy but yes, you do. It’s called “talk to the customer.”
Human beings are extremely poor fortune tellers. Over the history of our species, we haven’t done so well at predicting the future or even guessing what might happen. In the rare cases that we have, the outcomes were already fairly obvious, or it came down to sheer dumb luck. (Or, in some cases, “predicting the future” has the effect of establishing a vision for future events and thus, is more of a self-fulfilling prophecy. Like if I envision a world where there are transporter beams and food synthesizers, someone will think “Hey, that’s a bitchin’ idea. I think I will devote my life to researching how to make that happen!”)
Instead, what we should be doing with respect to customers is talking to them, or, better yet, LISTENING to them. That’s one of the first signs of a great salesperson. They talk about 10 percent to 15 percent of the time, and most of that time is spent getting the customer to talk about what they want the other 85 percent to 90 percent. We need to listen to what the customers want and help them home in on key features that can be delivered within an iteration by helping them understand what is possible and then giving it to them.
This is part of why it is so critical to have a Product Owner who is dedicated to ensuring the success of the product. They do this by engaging with the customer(s) on a regular basis, sharing what has been created in the product, eliciting feedback, cultivating new ideas for features, and in general, just understanding what the customer wants most/next.
Organizations are surprised when they have a Product Owner looking after 2, 3, 5, or 10 different products. When I am coaching a client and I learn that a Product Owner has responsibility for five products, I reply: “Oh, so, what you are saying is that it’s ok for each of those products to be 20 percent successful, correct?” Granted, some products require less effort due to their maturity or size of market, etc. However, the idea is important here: don’t trivialize the need for CUSTOMER COLLABORATION.
As we create the product that the customer wants in an iterative and incremental fashion, we include them in the sharing of the results so that they can have those “A-ha!” moments more rapidly and earlier on. There are numerous (alleged) quotes by Steve Jobs that talk about this idea:
“You can’t just ask customers what they want and then give that to them. By the time you get it built, they’ll want something new.”
The key here is that you will NEVER have all the insights into what the customers want. In fact, they don’t know what the hell it is they want either. In the true spirit of perpetuating the myth of the omniscient/omnipotent/omnipresent leader of the corporate world, the customer will pretend that they know precisely what they want when in fact, they aren’t really sure. Also, as a customer, I may be absolutely 100 percent certain of what I want ... until I see a commercial or blog post or random cat picture on the Internet that changes my desires somehow.
Customers are human beings and as such, they respond to data and other stimuli. Knowing that customers are fickle and respond to change daily, how can we continue to build products in any other way than by accommodating those changes?
The days of having a detailed 1- to 5-year plan for products are over. Companies that still follow this model are already dead. They just don’t know it yet. The companies that follow a more empirical approach will be more capable of responding to change, delighting their customers, and well, more Agile ...
Breaking Down Requirements to Epics and User Stories
Unfortunately, Agile doesn’t have an easy way to break down requirements. In general, one important change with Agile is the paradigm shift from component-based, horizontal pieces to feature-based, vertical slices through the architecture from end to end.
Historically, teams have been aligned according to functional skillsets with user interface/user experience (UI/UX) people working on the front end of an application, services folks working on the middle tier and back end of the application, and database people working on the underlying database. Oftentimes, the UX/UI is completed rather quickly and independently of the services layer, and all of this is developed with little or no integration with the database.
The challenge with this approach is that ALL of the architecture, features, and supporting elements of the database are required before the application is usable. Also, if it is discovered along the way that particular features are no longer needed, there is considerable rework involved, as the underlying architecture pieces may have already been created.
Furthermore, because the teams are primarily focused on their respective components throughout development, at some point down the road the components must be integrated, and this is usually where the “fun” begins, that is, a good portion of the defects are found. Also, even if we have all of UX/UI or all of the services created, until the pieces are all integrated and synced up, the end user has nothing of value.
In Scrum, there are cross-functional teams that have UX/UI, DEV, QA, DB, and other skillsets all on the same team so that the features may be sliced into slivers of vertical functionality, which work from end to end. Each feature delivered has value because each feature works and can be used by the customer. Integration work between the components happens at the feature level, so the pieces are never out of sync.
If a customer decides that they do not want a feature, no problem. The architecture to support each feature is only built when the feature is built; thus, no more tightly coupled components to worry about.
If funding is cut or, better yet, whenever the customer sees the emerging product increment and feels that there is sufficient value, they can have it—no more waiting until all other component teams catch up in order to deploy. This essentially removes IT as a constraint and makes the decision to deploy or not purely a business decision. In addition to having incomplete components in various stages of development, IT has historically been a bottleneck to deployment by virtue of the fact that when they get “done” with a project, there is usually user acceptance to be done and entering the deployment pipeline and getting in line.
With Scrum, at the end of each Sprint, because every feature must meet the Definition of Done, deployment becomes a matter of “pushing the green button” (simply moving the code into the production environment)—an activity that might only take 15 minutes. This is incredibly powerful from a business perspective. They can literally release any time they want based on what makes sense strategically.
In terms of different WAYS to split features, Richard Lawrence has a great resource called the “Story Splitting Cheat Sheet,” which has various examples of stories and suggestions for how they might be split into smaller chunks for a Development Team to tackle. I typically use Richard’s poster as well, which is more of a mind map representation of the same information that can be posted in a team room or office area.
One of the most important things to remember about splitting requirements down into smaller pieces is that it takes practice and there absolutely WILL be mistakes. Nothing is easy, especially anything worthwhile. Over time, however, the Development Team will become very adept and skilled at splitting features into smaller chunks, and even the Product Owner will be able to produce Product Backlog Items, which are more appropriately sized during the first attempt.
Nordstrom’s Knows What I Want
I had searched my make/model of MacBook Pro (MBP) on Amazon for a replacement battery and after selecting a “brand new” battery at a low price, I ordered it.
When it came, it clearly wasn’t the right model. Disappointed.
I returned it because Amazon Prime is great about refunding your money with zero shipping charges either way. I wrote a negative review about the product listing itself because I was disappointed.
What would have made my experience better was if there were more pictures of the item, maybe with the back of the MBP pulled off to see where it goes and also—most importantly—part numbers.
The merchant has since included part numbers with all its listings.
They reached out to me to ask my permission to send me a FREE battery that matches my MBP model. I was surprised ... and very delighted. I said “Ok, sure. I really appreciate that.” I gave them the model number and my address.
I thought to myself: “If they do this, I will update my review or do a new review and say how they went the extra mile for me. Let’s see what happens.”
The next day, they emailed me back saying that they don’t carry that model ...
And, pointing out how their listings now have part numbers ...
And, asking me if there is anything else they can help me with ...
And, would I be willing to remove my review or update it based on this latest experience ...
I just shook my head in disbelief.
I sent them an e-mail back citing the infamous Nordstrom’s tire return story. Recounting this story from almost 30 years ago when I first heard it in college, I was inclined to look it up on Snopes. There is some debate about whether it is true or not and if so, to what degree.
Doesn’t matter.
The story represents what is in the mind of ALL customers. It is literally a textbook case of ultimate customer service—that is what people want. At a minimum, customers have a need they are trying to satisfy. If the need is met, there is maybe a 50/50 chance that they will return as a customer.
If the customer’s expectation is exceeded, then brand loyalty is strengthened and they will not only be a return customer, they will evangelize the product and brand to others.
If expectations are not met (or worse, negative expectations are met/exceeded in the negative direction) then no amount of additional cajoling will bring that person back to the realm of potential evangelist. In fact, if your customer is pissed off enough, they will become an evangelist AGAINST your product and company.
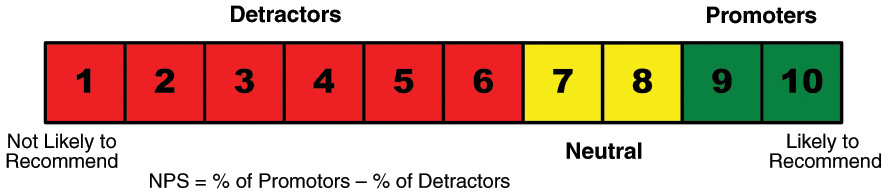
This is the idea of the Net Promoter Score. It is, in fact, the only metric that truly matters to me because it is a direct testament to how healthy a business or product is.
By asking one simple question—How likely is it that you would recommend [your company] to a friend or colleague?—you can track these groups and get a clear measure of your company’s performance through your customers’ eyes. Customers respond on a 0- to 10-point rating scale and are categorized as follows:
![]() Promoters (score 9–10) are loyal enthusiasts who will keep buying and refer others, fueling growth.
Promoters (score 9–10) are loyal enthusiasts who will keep buying and refer others, fueling growth.
![]() Passives (score 7–8) are satisfied but unenthusiastic customers who are vulnerable to competitive offerings.
Passives (score 7–8) are satisfied but unenthusiastic customers who are vulnerable to competitive offerings.
![]() Detractors (score 0–6) are unhappy customers who can damage your brand and impede growth through negative word of mouth.
Detractors (score 0–6) are unhappy customers who can damage your brand and impede growth through negative word of mouth.
To calculate your company’s NPS, take the percentage of customers who are Promoters and subtract the percentage who are Detractors (see Figure 3-1).
Getting back to my story, once the merchant promised to send me a “free, brand new battery that does match my model of MBP,” they should have gone to whatever length they needed to fulfill that promise: call Apple, go to another merchant, etc.
Instead, they simply reinforced the initial negative experience that I had with them and worse, they wasted my time, set a new negative expectation, did not deliver, inspired me to write this blog post, etc.
Now, I am done with that merchant ...
Well, almost. I might even update my post with this newly disappointing experience to reinforce my initial negative review.
If they came back and said, “Here’s a whole new MBP 17 fully loaded with software and upgrades, etc. We will give it to you to make you happy.” I would still be thinking “Yeah, sure, the check is in the mail ...”
Delight your customers, and they will become your most valuable allies. Make them mad, and you will be out of business.
Breaking Down the Product Backlog into Sprints
The product backlog is the wish list for ALL work that people want the team to conduct on the product. As such, if something is not on the product backlog, it doesn’t exist. I typically don’t get caught up in worrying about labeling or categorizing Product Backlog Items (PBIs) as “new feature,” “enhancement request,” “defect,” “technical debt,” “critical issue,” etc. It’s all just “work” to me. That is, the Product Owner needs to weigh the priority of ALL work that the Development Team is intended to do—it doesn’t matter what the nature of that work is.
Product Backlog
A list of features, defects, and other items related to the development and maintenance of a product. The list is ordered by value, with the first most valuable item at the top, then the second most valuable item, and so forth down the list. The items have Acceptance Criteria and estimates for at least those that could be pulled into a Sprint and ideally for all those targeted for the Release.
If there is a PBI in a Sprint that is not meeting the Definition of Done (DoD), then it’s simply not finished. It doesn’t make sense to log defects against the item. Just fix the problems or, better yet, don’t create any problems to begin with. Start with the end in mind by testing first and often. Then, you won’t have to worry about “defects” or “production emergencies” or other work that has to be done unexpectedly. Bake quality in.
Then, for code that is out there in production where your organization has compromised on quality and allowed crap code to be released (aka legacy code), your team can deal with those production defects either by creating new stories for them, if they aren’t critical issues, or they can break the Sprint each time there is something so severe it can’t wait. If there are enough of the uber-critical items, I might suggest using Kanban as a stop-gap so that your organization can enter “reactive mode” by allowing their work to be governed by interrupt-driven requests; that is, the most urgent, critical priority takes precedent over the rest and there is no notion of any REAL planning, not even down to weekly releases.
So now how do we actually break down the PBL into Sprints? First, we need to recognize that we will NEVER really understand what is in a Sprint until we actually get to the Sprint Planning meeting. So, we can more or less guess with a certain degree of certainty what is in the Sprint, which will be coming up next because we can look at the top of the product backlog and start working our way down. If we have a mature team that has a Velocity, we can roughly gauge by counting down the list the number of points or whatever unit they are using until we hit their Velocity number.
For instance, if the Development Team’s velocity is 40 items/Sprint, we can count down the product backlog until we hit 40 items and that would be ROUGHLY where the next Sprint Planning meeting would take us. If their velocity is 30 Story Points, then we can count down the product backlog until we hit 30 Story Points and THAT would be ROUGHLY where the Sprint Planning would take us.
However, anything beyond the next immediate Sprint is purely guesswork, or what I like to call PFM (pure frickin’ magic). If you want a VERY accurate understanding of what will be in the second Sprint coming up and the third, fourth, fifth, etc., then I would suggest you visit Madame Leota at Disneyland’s Haunted Mansion, and she can help you out as well as the guesswork that would go into predicting what stories will be in Sprint 2, Sprint 3, etc.
Realizing that there is uncertainty inherent in change and being able to respond to change rather than mindlessly following a comprehensive plan is the first step on the road to becoming more Agile in your thinking (and the road to recovery from believing that you can use big up-front plans to govern product development).
A better approach would be to continuously look for ways of splitting PBIs that are beyond the next immediate Sprint and are bigger than about a day’s worth of effort. This will give your team flexibility in sequencing and relieve them from doing any estimates at all.
When I worked on a project for the U.S. Treasury Department, we determined that no one really enjoyed estimating. In fact, they were really horrible at it, and the estimates weren’t really working for us in the process anyway. What they were really good at was recognizing that things needed to be split into smaller pieces. So, instead of going through the mental hopscotch of trying to create estimates for items, we simply decided to use a “1 Day or Less” policy. That is, every PBI had to be one day or less in effort or it would have to be split. This allowed for the team to avoid artificially fabricating estimates while still ensuring that the items were sized small.
The result was amazing.
The team loved working with PBIs, everyone had their metrics that they wanted (i.e., the Sprint Burndown Chart, based on items remaining each day). Everyone was happy.
If we think about an item that takes 10 days of effort using a two-week Sprint, if we are off by even a few hours, we are screwed because the item won’t be completed by the end of the Sprint. However, if we have 10 one-day items in the two-week Sprint and we complete 9/10, then we get an A- instead of an F. Perception is that the team mostly fulfills its commitments instead of mostly breaking its commitments.
So, long story short, I wouldn’t be TOO concerned about what PBIs are fitting into Sprints beyond the next most imminent Sprint and MAYBE the next one after that, just in case the team gets finished early (snicker, snort, guffaw). The team almost NEVER finishes early. More often than not, they OVERCOMMIT and have stuff that is incomplete. But we’ll talk about that issue later.
Why Does Every Increment Need to Be Shippable/Valuable to an End User?
Scrum is a lightweight framework that can be used by many different industries to develop products and services. As such, the notions of “shippable,” “valuable,” and “end user” can take on different meanings.
Mostly, we will look at these terms from a software product point of view where we are developing an application or system for use by someone or some group of people, that is, the end user(s). Those people are the ones who perceive what is valuable in the application.
First, let’s remember that an “increment” is a feature or set of features that represent part of an application. Increment can also refer to the cumulative sum of features that are being assembled for release. For instance, we go through Sprint 1 and at the end, we have six features created that represent a shippable product increment. At the end of Sprint 2, we have seven more features that represent a shippable product increment and the sum total of 13 integrated features from both Sprints represents a shippable product increment as well. The difference is that at the end of each Sprint, only the features created during that Sprint would be reviewed and demonstrated—not the entire increment that is being targeted for the Release.
Which is presumably the origin of this question: If we aren’t going to actually release each increment, then why does it have “to be shippable/valuable to an end user?”
We need to consider the product not only from the perspective of the end user but also the Business Sponsor. The Business Sponsor is making an investment using the organization’s money. They have many different options that they could pursue in terms of investing that money. They could buy stocks, acquire other companies, fund other projects or products, etc.
All investments in business are made with the expectation of some kind of return. In the case of product development, the return on the investment is functionality that can be used by the end user. In some cases, a company may not be developing a system or application that has a graphical user interface (GUI) so the end user might gain value from something that is not demonstrable by clicking buttons or scrolling the mouse, etc. Nonetheless, the value being delivered must be demonstrable in some way.
If I am a business sponsor and I see a Sprint go by with no tangible or deliverable customer value, then a yellow flag will be raised in my mind. It’s an alert and cause for concern. What’s going on? Maybe there is a reasonable explanation. However, I know that each iteration is supposed to be producing an increment of value. I am starting to get concerned that maybe I made a bad investment by funding this product.
If a second Sprint goes by with no tangible value, now a red flag is triggered in my mind and I am convinced that I have made a bad decision. I need some solid justification as to why I should continue to fund the development effort. If I don’t hear a plausible reason why I should continue with funding, that’s it. Further, three strikes and you are definitely out; if the next Sprint goes by with no tangible customer value being delivered, there won’t be discussion. I am cutting the funding, period.
Maybe everything is ok. Maybe not. If I were a mortgage company lending people money, I would not be ok with just receiving a balloon payment when the loan is due in 30 years. The Burndown for that would look like Figure 3-2.
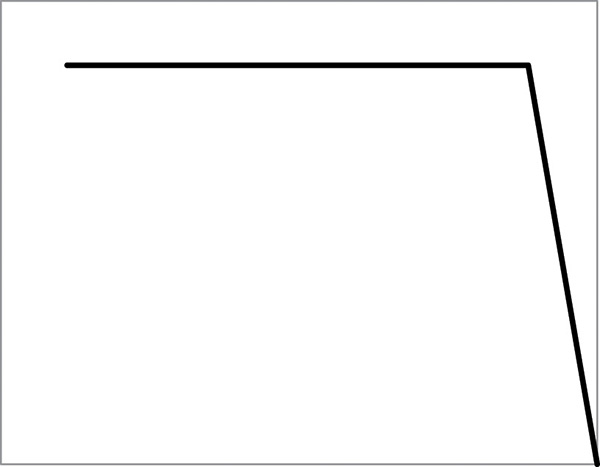
Are we going to make it? Not sure. Won’t know until the end.
Instead, I want to see gradual delivery of value all throughout the Sprint as represented by a nice consistent Burndown (see Figure 3-3).
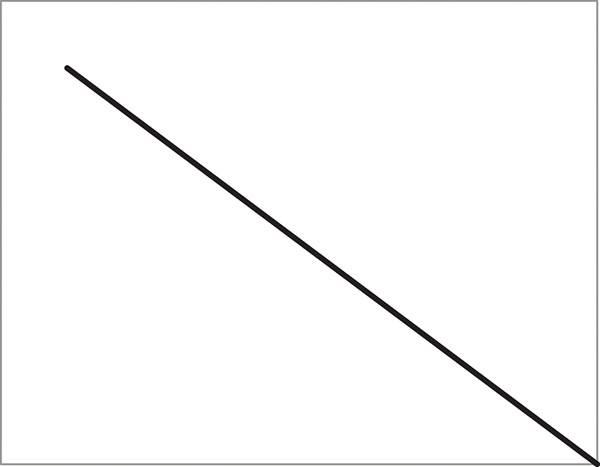
Furthermore, we want confirmation from the customer every single Sprint that we are on track to deliver the end product with regular, consistent delivery of value. Imagine if you were waiting to have a home built for you. Would you want to wait until the entire house was complete, only to discover that certain rooms were smaller than you had anticipated or that the traffic flow through the home was not comfortable for you? What about how the home sits on the lot?
Of course not. You would want to tour the site numerous times and at various stages during the construction to see firsthand how the home was taking shape. This is much the same case with applications. It makes much more sense to see the application emerge with all the functionality, and then if we see something we don’t like or that doesn’t make sense, we still have ample time to modify or change it.
What Is the Difference Between a Product Backlog and a Sprint Backlog?
The product backlog is basically one massive wish list for the product that never goes away until the product lifecycle is completely over; that is, until the company decides that they will no longer support or even acknowledge the product any longer, there will be a Product Backlog for it.
This product backlog is the place where any and ALL work will be captured: new features, enhancement requests, defects, support requests, ideas, technical debt items, action items for the Scrum Team that come from the Sprint Retrospective, and more. If it isn’t on the product backlog, it doesn’t exist.
The product backlog, then, is constantly changing, constantly evolving. Whenever some new discovery is made to the scope of the product, it is reflected in the product backlog. Items can be added, removed, split, reordered, combined, refined by adding Acceptance Criteria and estimates, and so on.
The person who is in charge of this product backlog is the Product Owner. They are ultimately responsible and accountable for ensuring that the product backlog is constantly maintained. The Product Owner ensures that the items on the product backlog are always in force-ranked order, with the most valuable item at the top, then the next most valuable item, and the next most valuable item, and so on ... all the way down the list.
The items toward the top of the product backlog are generally more granular, smaller, better understood, and more certain than the items further down the list. The items at the very top of the product backlog will have a high likelihood of being included in the next Sprint because when the Scrum Team meets to do Sprint Planning, they will begin at the top and work their way down from there.
The items included in the product backlog can be in any format necessary to ensure that there is understanding and confirmation across the whole Scrum Team for each feature. A commonly used format is called User Stories. This is a very specific template that is used by many organizations to capture the who, what, and why for each feature. Doing so helps us make the business case for each of the features.
Two other key elements for well-formed Product Backlog Items are Acceptance Criteria and Estimates. In fact, arguably, a PBI is not ready for Sprint Planning (and thus, is incomplete) without these two elements.
The items toward the top of the product backlog should represent maybe one to three days’ worth of effort each, whereas those items further down the list might be larger pieces, which require further discussion and breaking down or “splitting.” Oftentimes, when an organization is using User Stories, they refer to the larger stories as “epics,” which is simply an extension of the metaphor of a story as a requirement or feature. Epics are really BIG stories in the literary world. In fact, we could take many of the epics in literature and carve them up into individual, smaller stories, which would make sense and be more consumable.
Once the Scrum Team goes through the process of Sprint Planning, they will have a dedicated, committed subset of features that come from the product backlog, which we will call the Sprint backlog (see Figure 3-4). These are the PBIs that the Development Team has confirmed they are comfortable delivering for the upcoming Sprint.
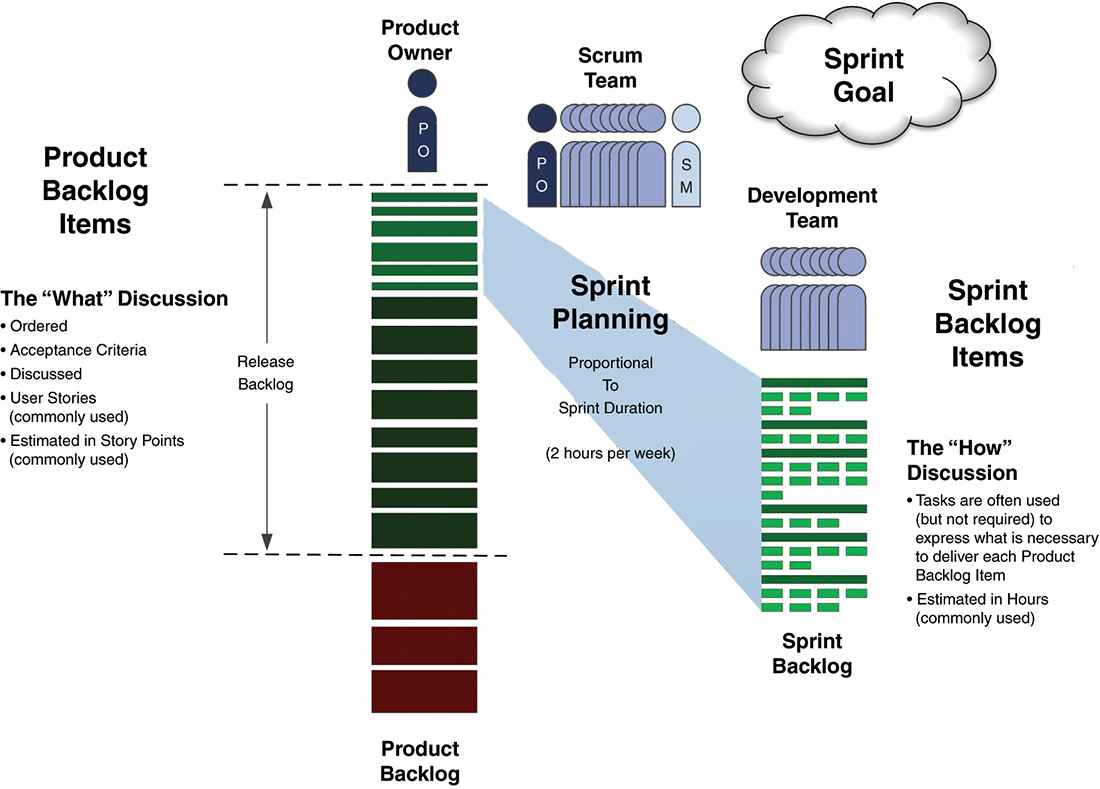
Over the years, various different Scrum proponents have had differing opinions on the use of “commitment” in relation to Sprint Planning, the Development Team, etc. At one point, there was an emphasis on the Development Team making a firm commitment during Sprint Planning. In recent years, the term has been replaced with “forecast” to signal that the team is really just estimating what they can do or is trying to guess.
In my experience, stakeholders and upper management are able to get to the point of being ok with uncertainty over the product lifecycle and even at the release level. However, what most people are NOT ok with is the Development Team’s lack of ownership and responsibility for their own delivery during a Sprint.
If we are trying to build trust, then we need to establish commitments and goals and deliver on those commitments. By doing so, trust is positively reinforced in the minds of the stakeholders. The understanding of the Sprint backlog as a commitment also comes with an understanding that if there is a critical impediment that blocks the Development Team and prevents them from progressing, then all bets are off for being committed to the original Sprint goal and Sprint backlog.
We can’t expect the Development Team to deliver on something that has external issues, which the Development Team is unable to resolve. The ScrumMaster will do his or her best to remove these, and if unable to, the issue will become quite visible until it affects the ability to deliver customer value. At that point, management and other stakeholders might need to use their influence to remove the impediment(s) on behalf of the team.
The Sprint backlog would have some indication of size, whether it is a total number of Story Points for all items on the Sprint backlog, or perhaps total hours for all tasks on the Sprint backlog, or even just a number of items on the Sprint backlog. By having a size for the Sprint backlog, we are able to produce a Sprint Burndown Chart, which is a visible measure of progress throughout the Sprint. Each day, the amount of remaining items, points, hours, etc., is totaled up and plotted on the Burndown Chart. We focus on work remaining because the amount of effort that was put forth doesn’t really give us an indication of the amount of effort remaining.
Imagine that you are driving from New York City to Washington, DC, because you have an important job interview. You estimate that the trip will take you 3.5 hours. You get in the car and start driving. After about 2 hours in the car, you stop and wonder if you are going to be on time for your interview. Is it correct to say, “I have been traveling for 2 hours so I must have 1.5 hours left. I will make it.”? Or does it make more sense to figure out where you are on the route and recalculate the time remaining based on new understanding of the route?
It doesn’t matter how long you have been traveling. What matters in determining whether you will make your interview or not is how much time is remaining.
Finally, we don’t estimate the ENTIRE product backlog because this would be a colossal waste of time. There might be items on that backlog that we won’t be implementing or that we won’t be implementing for a long time. Instead, we only focus on the portion of the product backlog that represents the targeted release. By only estimating the items we are trying to put into the Release, we can have an understanding of its size and then produce a release Burndown Chart, which helps us understand where we are along the line with implementing that feature.
What Goes into Sprint Planning?
The Sprint Planning meeting is the official Scrum ceremony or activity, which takes planned but uncommitted scope and identifies it as committed scope. The primary input to the Sprint Planning meeting then is the product backlog (PBL), which is where all of the planned but uncommitted scope is maintained. In order for Sprint Planning to progress smoothly, the PBL should already include at least enough value and functionality to fill one Sprint at a minimum.
Also, the items in the PBL must be understood well enough for them to be considered for a Sprint. Quite often, Scrum Teams use Bill Wake’s mnemonic INVEST as a reminder that the PBIs should be Independent, Negotiable, Valuable, Estimable, and Testable in order to ensure that they are ready for Sprint Planning consideration.
Prior to Sprint Planning, the Product Owner has presumably been refining the PBL by adding items, splitting them, removing items, reordering the items, identifying the Acceptance Criteria for each, and conferring with the Development Team for estimates of size and confirmation that the Acceptance Criteria are understood well enough to start work on the item. The PBL should ALWAYS be in force-ranked order from the most valuable item at the top, on down.
If any of these pieces are missing, then those activities would need to happen before the Scrum Team could proceed with Sprint Planning. It may be that there are a few PBIs that have not been discussed together as a team. Perhaps they have not reached consensus or agreement on the Acceptance Criteria or the Development Team has not had a chance to confer on estimates for some items. The Scrum Team would spend a brief amount of time working together to refine those items so that they could proceed with Sprint Planning.
Acceptance Criteria
Short statements of conditions that must be met in order for the Product Owner to consider the feature to be done. For instance: “I know this feature will be done when I can enter a vehicle price of $15,999.00 for Hawaii and I get a final price of $22,761 with all appropriate federal, state, and local taxes applied.” A feature is incomplete without Acceptance Criteria.
Once the PBL is in appropriate condition to proceed, the Product Owner would present the PBL to the Development Team, who should already be somewhat familiar with what is on the PBL and the order of things. Together they would then walk through each item, beginning with the top most valuable thing, and the Development Team would discuss whether they feel comfortable including that item in the upcoming Sprint. This process would continue until the Development Team feels that they have reached their capacity and no additional features could be responsibly included in the Sprint.
At that time, the Product Owner would have one last chance to review the Sprint Backlog, as proposed by the Development Team, and to make any last-minute substitutions or changes. For instance, if the Product Owner thought that the team would for certain get to item #7 on the PBL but stopped at item #6, they may think, “Well, now that I see where the boundary of the Sprint work will be, I am changing my mind and would rather have item #7 instead of item #6.”
At this point, the Scrum Team would decide upon a Sprint goal that represents the work that has been selected. What is a brief statement that could be used to describe what they are trying to accomplish in the upcoming Sprint? This statement would help to keep them focused and would serve as a brief summary to anyone who asks about the purpose of the upcoming Sprint.
For instance, when analyzing potential markets for specific features and classes of user, it is helpful to use personas, which define various aspects and characteristics of the users. We might have a persona named “Bob” who represents 45-year-old males with four children and who work as Agile product development consultants. We could further identify characteristics of the Bob user that are relevant and important to the features in our product. Then, a potential Sprint Goal might be “For users like Bob, provide the ability to [solve some problem with the product we are working on].” The Sprint goal would highlight at a high level the value that is being delivered for that Sprint.
It also serves as a concise way to determine if the Sprint delivered anything of value or not. The purpose of a Sprint is usually more complex than simply looking at whether a randomly selected collection of stories was completed or not. It’s useful, then, to ask “Did we meet our Sprint goal or not?” Perhaps a PBI or two was not completed, but the overall purpose and objective of the Sprint was still met. That would be important to know. Conversely, maybe ALL of the PBIs were delivered in the Sprint but the Sprint goal still was not accomplished. That would be important to know also.
Once the Scrum Team has decided WHAT will be included in the Sprint backlog, the Development Team would then use the second half of the Sprint Planning meeting discussing HOW they will deliver the functionality they just committed to. During this second half of the Sprint Planning meeting, the Product Owner would be somewhere close by so that they are available to answer questions that the Development Team might have. The Product Owner is not necessarily directly involved with the “HOW” discussion. In fact, it is important that they not be TOO involved, or they risk prescribing a solution instead of letting the Development Team come up with an innovative solution.
This is the point where the Development Team would have conversations about architecture design and integration and special needs in terms of objects, interfaces, databases, tables, etc., in order to deliver the functionality. The Development Team may also decide to break down the Sprint Backlog Items (SBI) further by creating tasks for each of the SBIs. Tasks might include creation of interfaces, objects, testing tasks, automation, or any other steps that the team feels are necessary to deliver the committed SBIs.
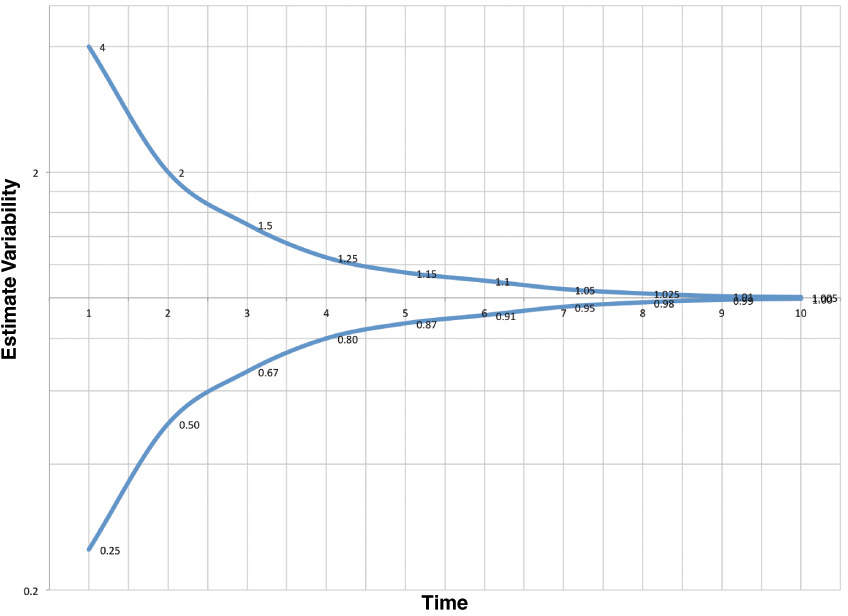
If tasks are used, it is often the case that the team will go through these tasks and provide estimates in terms of hours instead of Story Points. Although our abilities are very poor at providing precisely accurate estimates looking far out into the distance planning horizon, we don’t do TOO poorly when looking at shorter planning horizons. Thus, for a two-week Sprint, our estimates of time at the task level are usually not too bad. So, coming up with hour estimates for tasks is not such a bad practice. Trying to estimate PBIs or tasks that might not be in our SBL until five to six months from now would not really make much sense, and our estimates could be off by quite a large amount. Barry Boehm used a graph he called the “Funnel Curve,” which was a version of the “Cone of Uncertainty” that engineers had been using for years (see Figure 3-5).
Once the Development Team has finalized the discussion of HOW to deliver the items in the Sprint backlog, they can begin working on those items and should hold their daily Scrum immediately after to discuss what they will plan to accomplish for the next day. The cumulative size of the backlog, whether in total hours, total items, total points, etc., would be used as the basis for the Sprint Burndown Chart.
What Is the Typical Duration for Sprints?
There are several recommendations for Sprint durations among the various Scrum references. One source cites one to four weeks. Another mentions one month or less. This gives rise to many questions that focus too much on the minutiae and technicality and not enough on the spirit of what is being indicated.
The key concept is not really about how long or short the Sprints are or should be. The main point here is: How can we have as many opportunities to inspect and adapt as possible on our way to an actual release of the product?
If our customer changes their mind weekly but our Sprint duration is three weeks, then we are sort of screwed because we won’t be able to pick up the changes the customer indicated frequently enough to be responsive or to make adaptations to the plan. If our Sprints are one week long, then we have three times as many Sprint Planning meetings where we can bring items from the product backlog into the Sprint backlog and begin working on them. That’s three times as many opportunities to inspect and adapt on the plan as we would have with a four-week Sprint.
Longer Sprints might provide the Scrum Team more opportunity for cross-team collaboration in a multiteam environment. Also, when dealing with some products, like embedded software in a hardware device, the longer time box may be necessary from the hardware manufacturing perspective.
For software products, the most commonly used Sprint duration is two-week Sprints. Generally, most experienced coaches recommend starting with two-week Sprints, running for a while to see how it works out, and then making adjustments once the Scrum Team has some data points and experience to draw from in making changes to that duration.
The Scrum Team should make every effort possible to figure out how to work effectively in the time box they have chosen and not simply select another time box because the current one is challenging. Rise to the challenge. Make it work. Or, have a VERY compelling reason for selecting an alternative time box. It is important to understand that this will be your new Sprint duration from that point forward. So choose wisely. It is NOT ok to change the Sprint duration more frequently than maybe once per year at most, and I am more inclined to say that the team should never change it once they have selected the duration unless they are opting for shorter Sprints.
I often hear organizations and teams complain that they couldn’t possibly do shorter Sprints because there is no way for them to slice their PBIs into smaller chunks and have anything that is actually deliverable or even demonstrable. Challenge accepted. After a story writing workshop and some coaching time working with them, I am able to prove that it just takes discipline, some imagination, and looking at the art of the possible in order to create PBIs that will 1) provide end-to-end customer value and 2) fit into smaller Sprints and even just a couple of days.
I also hear organizations complain that with shorter Sprints comes more meetings and that they are already going to too many meetings. However, their logic is flawed in this regard. Although it is true that there are MORE meetings, it doesn’t really matter because the meetings are intended to be proportionally shorter. Thus, EXACTLY the same amount of time is spent, regardless of whether they have one-week, two-week, three-week, or four-week Sprints.
The guidelines are as follows:
![]() Sprint Planning meeting = 2 hours (or less)/week of Sprint duration
Sprint Planning meeting = 2 hours (or less)/week of Sprint duration
![]() Sprint Review meeting = 1 hour (or less)/week of Sprint duration
Sprint Review meeting = 1 hour (or less)/week of Sprint duration
![]() Sprint Retrospective meeting = 1 hour (or less)/week of Sprint duration
Sprint Retrospective meeting = 1 hour (or less)/week of Sprint duration
The daily Scrum is always 15 minutes or less and isn’t really dependent upon Sprint duration at all.
Backlog refinement is an ongoing activity, so it really doesn’t have a set time or definite duration.
Backlog Refinement
An ongoing activity in which the Product Owner adds, removes, moves, or splits items into smaller items. They also add Acceptance Criteria to the items so that the Development Team has a clear expectation of when the items will be considered done and so that they can provide an estimate of the effort and complexity of the item.
I really shudder to think of a retrospective meeting that lasted up to FOUR HOURS, regardless of whether it was for a four-week Sprint. That would be a LOT of reflecting on what was going on during the Sprint, and I would have to question whether the Scrum Team was addressing things along the way over the course of the four weeks.
The real issue that organizations have with shorter Sprints and “more” meetings is that they don’t do an effective job of truly time-boxing the meetings using these guidelines. There are also other telltale signs of dysfunction that are at play, which can be traced to the real root cause of not being able to have shorter Sprint duration.
At NAVTEQ, when I initially started working with them, their planning meetings for a two-week Sprint were lasting almost two days. Part of the problem was that the Product Owner wasn’t doing an effective job at backlog refinement and so a HUGE amount of time was spent rewriting their User Stories (the method they had selected for capturing PBIs), talking about the Acceptance Criteria in too fine of detail, and haggling too much over the estimates, that is, not trusting the Development Team’s estimates, or more senior-level people on the Development Team (and even former managers) anchoring and swaying others.
Another key factor to consider when selecting Sprint duration is the nature of the business model and maturity of the product under development. If the product is very new and at the “bleeding edge” of technology, then the Sprints will most likely need to be shorter to accommodate the myriad of changes due to discoveries in the technology. There also may be more rework as experiments are attempted and learning happens. If the product is much more mature and is in the phase where most of the work is enhancements to an existing system, it might be ok to have longer Sprints; though again, there is not much real advantage to having a four-week Sprint.
If your Scrum Team is just getting started, I would recommend trying two-week Sprints and also advise that the team should stick with that Sprint duration until there is a compelling reason to change. This will have the effect of surfacing many impediments and dysfunctions that are already there in the team and organization. After discovering these, the Scrum Team can work together on resolving those impediments and dysfunctions.
What Is the Measure of Progress on Product Delivery/Approximate Completion Date?
As I look at this question, I am fighting back the urge to provide very straightforward, matter-of-fact answers; like:
“Working software is the primary measure of progress.”
“It’s ‘done’ when it’s done ... or when the customer is delighted with it.”
“Scrum focuses on product delivery, NOT project management, so we will be ‘done’ when the product has been completely discontinued.”
“It’s ‘done’ when there is enough value to deliver to the customer.”
Etc.
Although there is truth in these statements, the root of the question begs a deeper, more descriptive explanation. Also, there are actually a couple of questions here, not just one, and these are in some ways related, but not completely.
First, let’s talk about measuring progress on product delivery. When I think about product delivery, I immediately think “value delivery.” The product is merely the packaged, branded form of the value that we are delivering to our customers. I also think about the analogy of buying a house using a mortgage.
Let’s assume we are buying a $500,000 house with a 30-year fixed mortgage at 3.35 percent APR. The total payments would be almost $800,000. Do you think that the mortgage company would be ok if you said, “Hey, don’t worry, we will write you a check 30 years from now for the full $800,000.” Hell, no. They want iterative, incremental delivery of value on their investment, confirmation that you are on the right track and aren’t going to default on the loan.
By the same idea, our customers are waiting patiently for us to deliver the value that they are anticipating in the software that they are paying for in some way. Telling the representative of the customer (“the business”) that you will deliver everything in 9 months or 12 months, etc., is just NOT ok.
They need iterative and incremental delivery of value to ensure that the release of the product is going to meet their expectations. In some cases, “the business” and/or customers don’t care about what’s delivered leading up to the final release, that is, after each iteration. However, they really should for the reason I have outlined: because they are receiving confirmation that the Development Team is on track with what they are delivering.
I often coach these individuals by saying, “Here’s why you SHOULD care about having something that is shippable every two weeks ...” When I explain it, my clients usually experience that “A-ha moment” and it sinks in at that point. I find that they are not only more cooperative, but also eager to see the shippable increment every Sprint.
Next, we have mention of “completion date.” Once again, in Scrum, we are more concerned with product delivery, not project execution. Our customers don’t care about project management. However, they DO care about delivery of value and thus, product delivery. The product is never 100 percent complete. There are always going to be enhancements and changes based on the feedback we get from the users.
Project Lifecycle
A project has a definite beginning and a definite end. It also has a definite scope and cost associated with it. For the purposes of Agile project management, projects can be used by the Product Owner as a means of securing finance for the product development effort. As such, there can be many formats for projects: monthly, quarterly, yearly, per Sprint, per release, etc.
Product Lifecycle
A product’s lifecycle is essentially indefinite. The hope of all who develop products is that their product will last 10, 15, 20, maybe even 30 years. Windows, for instance, has been around for about 25 years and has gone through many revisions, versions, etc. Someday, Microsoft might “sunset” Windows and replace it with another completely different product. During the product lifecycle, there can be many different projects.
I think what the person asking the question really meant to ask was, “When do we know that the release is done?” That again can vary widely. We might have releases that are based on Sprints. We release every Sprint or every X number of Sprints. That’s a no-brainer; the release is done when the timebox is up, whatever that timebox may be.
We could have timeboxed releases based on other increments of time also, such as monthly releases, quarterly releases, etc. Those would be done when the timebox has expired also, but are related to calendar time.
Then we have releases that are based on scope rather than on time. For instance, we may have a minimum viable product (MVP) represented by features that total up to 400 Story Points. Until ALL of those features are delivered, we basically cannot deliver. However, after that, the releases may be much smaller and varied based on the strategy of releasing the features. For example, Release 2 might be 100 Story Points’ worth of features. Release 3 might be 125 Story Points, Release 4 might be 75 Story Points, etc. These are feature/scope/value driven, not date driven.
In the case where the releases are driven by scope rather than a fixed date (timebox), we can try to come up with an ESTIMATED release date based on the Development Team’s velocity. Velocity is an average amount of value delivered per iteration. We typically use Story Points to measure velocity; however, the number of features/PBIs could be used also, especially if the PBIs are broken down into one-day chunks or less.
The release portion of the product backlog would be estimated in Story Points (or broken down) and then the total size for the release would be known. If the Development Team’s velocity is not known, we would need to take a guess or wait until they go through Sprint Planning and use the total of what they have selected for the Sprint as our very rough estimate of velocity.
Once the Development Team has a Sprint completed, we will have some actual data, albeit only one data point, which we can use as a “velocity.” As more Sprints are completed, the velocity will begin to reflect more closely what they can actually accomplish in a Sprint.
The velocity would then be divided into the total size for the release, and the estimated number of Sprints would be known at that point. We can then take the number of Sprints and multiply by the Sprint duration to find the number of weeks from the start date, and that will give us our estimated delivery date based on a fixed-scope release.
The reverse can be used with a fixed-date release to estimate the scope that will be delivered. We would start with the fixed date of the release and count backwards to get the number of weeks from our start date to the release date. We would then multiply that by the Development Team’s velocity to estimate the total number they could accomplish for that release. If we don’t know their velocity, we would need to guess initially and then update the estimates as their velocity becomes more consistent.
And so, it’s very clear when we are complete: either the fixed timebox is up or ALL of the fixed scope has been delivered.
What’s Done Is Done: User Stories

The “Definition of Done” is a fairly popular (and sometimes emotional) topic out in the Agileverse. It seems everyone has an opinion on the matter, ranging from “it depends” to “let the teams decide” to a meticulously designed set of business rules and criteria that account for every possible scenario. And as more organizations adopt Agile practices (and, specifically, Scrum), they seek to leverage guidance on this topic from those who have already blazed the trail.
Why is it such a complex topic?
One reason is that the word “done” is overused. We must distinguish between different contexts of done, which can be applied at the story level, epic level, release level, product level, and so on. In each case, the meaning of done has different criteria. For the purposes of this article, we are only going to look at the done criteria for a Product Backlog Item (aka PBI or User Story).
Another aspect of the problem with done is perspective. The word “done” is often used to mean “complete,” as in the Development Team saying: “We are done with this story.” It is also used to indicate “acceptance,” as in the Product Owner saying, “This story is done.” I typically teach and coach it this way: Don’t say “done.” Instead, use “complete” and “accepted” for more specific indications of status.
Thus, we can define two aspects of the Definition of Done: Completion Criteria and Acceptance Criteria (see Figure 3-6).

The Completion Criteria are summarized as follows:
![]() “Code complete”—as defined by the organization/teams
“Code complete”—as defined by the organization/teams
![]() “Unit tested”—as defined by the organization/teams
“Unit tested”—as defined by the organization/teams
![]() “Peer reviewed”—as defined by the organization/teams
“Peer reviewed”—as defined by the organization/teams
![]() “QA complete”—as defined by the organization/teams
“QA complete”—as defined by the organization/teams
![]() Documented—as needed; determined by the Scrum Team through tasking at the beginning of the Sprint
Documented—as needed; determined by the Scrum Team through tasking at the beginning of the Sprint
And various other criteria that the Product Owner may not think to ask for. Sometimes we call these “nonfunctional” requirements because they don’t really add user functionality or tangible value, yet if they were absent, the quality of the feature would suffer.
The Development Team determines when the Completion Criteria have been met, with coaching and guidance from the ScrumMaster if necessary. At that point, the story is considered “complete.”
The Acceptance Criteria can be summarized as follows:
![]() The list of expectations for a specific Product Backlog Item as defined by the Product Owner prior to the beginning of a Sprint
The list of expectations for a specific Product Backlog Item as defined by the Product Owner prior to the beginning of a Sprint
![]() The Product Owner may initially define these alone but eventually enlists the help of the Development Team and ScrumMaster
The Product Owner may initially define these alone but eventually enlists the help of the Development Team and ScrumMaster
![]() For cases where Acceptance Criteria are not clear, a spike User Story will be used to define the problem and Acceptance Criteria for a Product Backlog Item to be completed in a future Sprint
For cases where Acceptance Criteria are not clear, a spike User Story will be used to define the problem and Acceptance Criteria for a Product Backlog Item to be completed in a future Sprint
![]() The entire Scrum Team must agree to these Acceptance Criteria by the end of the Sprint Planning meeting
The entire Scrum Team must agree to these Acceptance Criteria by the end of the Sprint Planning meeting
![]() Minor changes to the Acceptance Criteria once the Sprint is under way as long as there is formal agreement between the Development Team, ScrumMaster, and Product Owner
Minor changes to the Acceptance Criteria once the Sprint is under way as long as there is formal agreement between the Development Team, ScrumMaster, and Product Owner
![]() When the DEVELOPMENT TEAM BELIEVES THESE ACCEPTANCE CRITERIA have been met, the Product Backlog Item is ready for a Product Owner review (demo), which occurs throughout the Sprint
When the DEVELOPMENT TEAM BELIEVES THESE ACCEPTANCE CRITERIA have been met, the Product Backlog Item is ready for a Product Owner review (demo), which occurs throughout the Sprint
![]() The review (demo) of each PBI should not be left until the very end of the Sprint
The review (demo) of each PBI should not be left until the very end of the Sprint
The Product Owner officially determines when these Acceptance Criteria have been met. At that point, the User Story is considered “accepted.”
This approach provides a framework that is modular and can be adaptable around the definitions of “code complete,” etc., but clearly delineates the roles and responsibilities associated with delivering and finalizing work on features.
If a particular organization is striving toward 100 percent automation of functional tests that become part of a holistic regression test suite, then “creating automated test scripts” would be expressed in the “QA complete” criteria.
Further, one group might agree on what “peer reviewed” means but not the “QA complete” criteria. Using this modular definition, each group can customize these definitions to suit their team’s specifications.
As part of this exercise of defining “done” I have also identified an example of the different stages at which events occur in terms of the Definition of Done (see Figure 3-7).
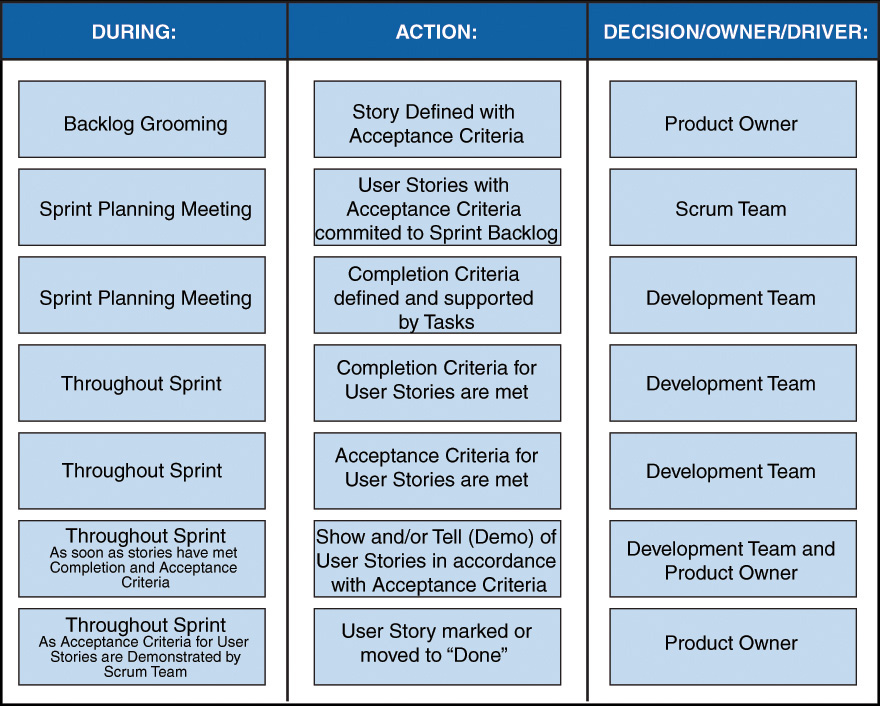
The first column defines the Scrum activity during which the action item in Column 2 takes place. Column 3 identifies which role(s) are chiefly responsible for the action item.
On many of the teams I have coached where there was a highly contentious relationship between the Product Owner and Development Team, this diagram has helped to sort through who was responsible for what and when. This, along with a well-defined definition of “done,” set expectations and the conflict was neutralized. The Scrum Team then revisits the “Definition of Done” at the end of each Sprint during the Sprint Retrospective.
Each organization (and team) must come to consensus on what the “Definition of Done” means for their particular projects/products at various levels (story, Sprint, release, etc.).
Story Points and the Burndown
Before we talk about estimation methods such as Story Points, we first need to take a look at estimation overall.
I don’t like the word estimate.
I would much rather use the terms guess, fortune telling, prediction, clairvoyance, prophesy, forecast, divination, assessment, opinion, and other apt terms.
The Merriam-Webster Dictionary lists the following definition of estimate:
2 a: to judge tentatively or approximately the value, worth, or significance of
b: to determine roughly the size, extent, or nature of
c: to produce a statement of the approximate cost of
Also included are synonyms: appraise, assess, evaluate, guess, and various others.
In fact, there is a huge movement right now called #NoEstimates introduced by Woody Zuill as a hashtag on Twitter. The surrounding documentation of arguments, both pro and con, is well known. I will summarize some of the points in this section and add my own opinion and color.
Ultimately, all references to “estimate” indicate that neither the verb nor the noun are intended to be permanent, fixed, definite, etc. And yet, estimates are usually taken to be commitments when dealing with projects and product development.
This is harmful.
Having an idea of size can be useful as long as our focus is not the accuracy of the estimate but rather the fitness of purpose, quality, and value of the thing being developed.
All this said, two methods of estimation are commonly used in Agile: absolute estimating and relative estimating.
Absolute estimation is what people generally think of when they hear the term “estimate.” It is the method that has been used for many years with traditional projects and product development. It is an attempt to guess the exact time, cost, size, etc., of something.
Primarily the way it works is someone considers various factors involved with the amount of time that it would take to complete a task or other work package. Then they decide upon their best guess of how long it will take and assert that as the estimate.
Absolute Estimation
When we attempt to guess at the cost or time for a particular task or feature, we are engaging in absolute estimating; that is, we are looking at individual items and assigning some value to them based upon an absolute scale. This is in contrast to relative estimating.
This estimate is then used in conjunction with a blended rate for the workers on the team who will be doing the work, or if known, the actual rate for the worker who will be doing the work, in order to derive the estimated cost of the work package. Then, all of the estimates for the work packages and tasks, etc., are rolled up in an effort to estimate the cost of the whole project—a practice that is always WRONG.
Let’s think about this ...
Assume we have three tasks: A, B, and C.
Now, let’s say that our margin of error for each is 25 percent. Joe Developer estimates that A will take 4 hours, B will take 6 hours, and C will take 10 hours. That really means that the tasks together will take 3 to 5 hours, 4.5 to 7.5 hours, and 7.5 to 12.5 hours, respectively. The total would be anywhere from 15 to 25 hours total.
Furthermore, Joe is on the same team as Susie Software. Joe only makes $75,000/year ($36/hour), but Susie makes $125,000/year ($60/hour). Traditionally, we would use a blended rate of $100K/year ($48/hour) for our estimates, which results in the following cost calculation: 20 hours × $48/hour = $960 total. We would use the initial estimates Joe gave us and the blended rate to calculate the cost of all tasks.
However, in reality, Tasks A, B, and C together could cost anywhere from $540 to $1,500 depending on who works on them: 15 hours would be the minimum time and $36/hour would be the minimum rate; 25 hours would be the maximum time and $60/hour would be the maximum rate.
So, in the end, the estimated costs for the sum of the tasks could actually be off by 44 percent to 56 percent, the difference of $540 from $960 and the difference of $1,500 from $960.
“What’s the big deal?” you may be asking.
Well, I think it’s a VERY big deal if you consider this a very simple case. Add a few 0s to it to represent the scale of ALL tasks and multiple Development Team people: $540,000 to $1,500,000 and yeah, that $960,000 gap would be quite a big deal to me as a business sponsor or CEO. The more tasks there are and the more team members we have, the more complexity we will have and consequently, even less accuracy around the estimates.
And yet, these are taken as commitments and gospel truth.
For this reason, absolute estimates have become an emotional topic among many and also what I like to call the “used car” game ...
I have a car for sale. I reason that I would really like to get $2,000 for it, and it is probably worth that much. However, I also know that if I ask $2,000, anyone who is interested is going to offer me less just because that’s how buyers are. So, I need to ask $3,000 with the intent of settling at $2,000.
Steve needs a car. He has $2,000 to spend that he has saved up. He goes hunting for a car and is interested in mine. He takes a look, test-drives it, and likes it well enough to make an offer. He is willing to pay $2,000 but he knows that I have jacked up the price and if he offers $2,000, we will settle somewhere around $2,500, which he can’t afford. He offers $1,500 and so the game of haggling begins ...
If both parties were straight with each other from the beginning, it would cut down on a lot of the ridiculous haggling and negotiation.
This same dance occurs with estimating. Development Teams and other individual contributors are sure that a task will take them less time but they inflate the estimates so that they have a buffer and because they know that management and PMs will inevitably ask them to do it in less time because that’s how they are. Management and PMs know that the workers are padding their estimates, so they ask them to do the work in a fraction of the estimate. If both sides were just transparent and honest with each other, it would build trust and cut down on this waste.
Which brings us to relative estimating ...
As human beings, we are really great at comparing things in terms of size. For instance, if I stand on the Brooklyn side of the East River and look at the Manhattan skyline, I can clearly see that one building is taller than another and another still is taller than those two, etc. However, if you were to ask me “How tall are those buildings EXACTLY?” I wouldn’t have any idea. I could guess or sit there and spend time counting the floors in each and then multiply by 10 or 12. But I wouldn’t be 100 percent accurate.
Relative Estimation
An estimating method that uses a scale to compare the complexity of items in relation to each other, rather than attempting to guess at an exact value from an absolute scale, as in absolute estimating. Oftentimes, a modified Fibonacci sequence or T-shirt sizes are used. Theoretically, there is no correlation between relative estimates and absolute estimates.
It turns out that we are just as great at comparing software features. If we have a list of 20 to 50 features, in an instant, I can draw upon my lifetime of experiences as a developer and QA engineer to say that one feature is slightly bigger than another and a third feature is much smaller than those two, etc.
In the end, my initial “gut feeling” estimates will be pretty close to actuals in terms of comparing the complexity, and that’s about as accurate as we need to be for the purpose of release planning. We want to have an idea of the size for the release so that we can track how we are progressing toward releasing.
In reality, there is no such thing as “gut feeling.” The same is true of so-called “intuition.” What is really happening when we have the sensation of knowing something without knowing how we know is that our brains are processing 30 to 45 years’ worth of experience and knowledge (in nanoseconds) without being conscious of doing so. In fact, when we begin to consciously think about things, we often consider unlikely scenarios that distort our ability to make logical decisions. This isn’t always the case, but the effect cannot be ignored.
A key feature of relative sizing is that it holds the complexity of the feature as a constant rather than the effort. If we consider building out a set of features such as those for a print dialog box, the complexity of that work will be consistent regardless of who works on it. A print dialog box might be middle of the road in terms of complexity. If a junior-level developer works on it, it might take two days. If a very senior-level person works on it, it may only take two hours. Likewise, there may be people on the team who are more methodical and thorough with their work and that causes them to take longer but produces higher-quality code in the end. As such, there can be a wide variance in the time it takes to produce the SAME functionality in the end. Thus, rather than guessing at time, agreeing on complexity as a constant factor is a more logical approach to estimation.
Oftentimes teams use T-shirt sizes to emphasize the fact that there is no correlation between the relative size assigned to a feature and the actual time it might take to deliver that feature. What we are interested in is understanding complexity, not time. With T-shirt sizes, however, adding an “M” to an “XL” or an “S” to an “L,” etc., just doesn’t make any sense. There is no way to come up with cumulative size for the release if letters are used because it is impossible to sum two letters. Usually, the teams that use T-shirt sizes end up assigning some point scale to the sizes that can then be summed to find a total size. (This also applies to “fruit salad” estimating, cat sizes, and all the other “cute” methods that people create.)
This is why teams have adopted point scales such as the modified Fibonacci sequence, powers of two, and others. With these point scales, the teams can assign values to the features based on relative complexity and avoid the anxiety of being held to an EXACT quote of size for a particular item.
The Fibonacci sequence or series is an infinite series that follows the pattern:
Fn = Fn – 1 + Fn – 2
and uses seed values:
F0 = 0, F1 = 1
This results in the following series:
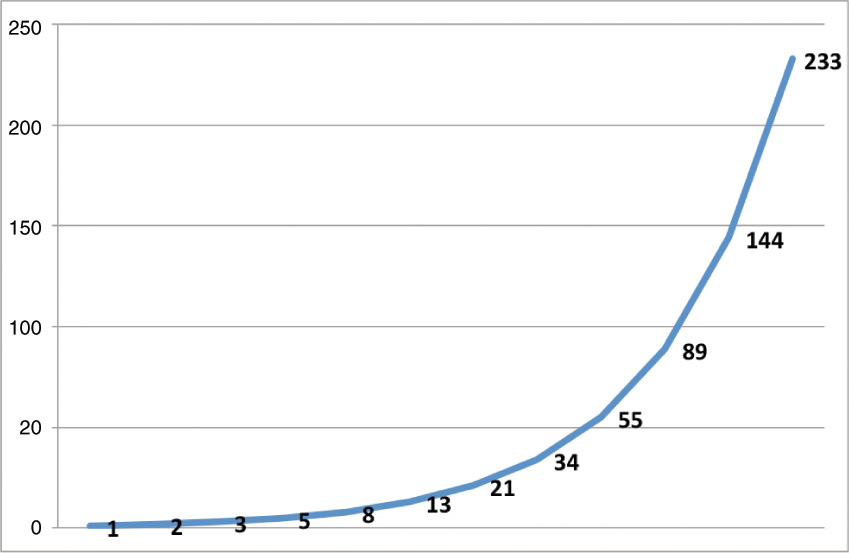
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, ...
It is an infinite series, which means that it continues on indefinitely. For estimating purposes, we don’t need a 0 or two values of 1. Also, many teams and organizations have decided to use more round numbers, such as 20 instead of 21, 40 instead of 34, and jump up to 100 as the next increment.
Why Fibonacci? As Mike Cohn points out in his book Agile Estimating and Planning:
These nonlinear sequences work well because they reflect the greater uncertainty associated with estimates for larger units of work.
Mike also mentioned that because the gaps between increments in Fibonacci are proportional as the numbers increase, it helps reiterate the relative size of the features being estimated. The difference between 8 and 9 is only 1, which is the same degree as the difference between 1 and 2. Using integers doesn’t give me the same effect as having a larger spread between values. If we plot Fibonacci, it looks like Figure 3-8.
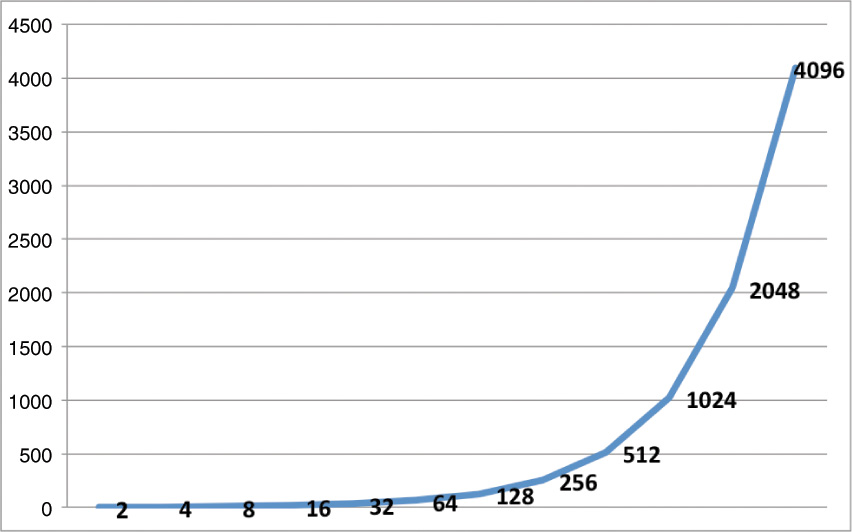
The same is true with powers of 2:
2, 4, 8, 16, 32, 64, 128, ...
The jump is also nonlinear in nature (see Figure 3-9).
I have had some teams who have preferred this scale to Fibonacci for various reasons, the most obvious being love of binary. (And the least obvious being their need to be different from what the rest of the world is doing ...)
When we set about estimating items on the product backlog, we want to focus on only those items that are being targeted for the release. If we spend time estimating items beyond that, the result might be wasted effort if/when those items are removed or found to be obsolete. Release planning is covered more extensively in its own section within this book. In short, we are either estimating the amount of scope we can produce by a fixed delivery date or we are estimating the delivery date based upon our fixed scope.
Now, by having a size for the release, we can track the progress for the release using a Burndown Chart, just as we would for Sprints using the Sprint Burndown. Scrum does not prescribe what units to use when generating a Burndown. It says that we should have some idea of how we are doing on a daily basis throughout the Sprint and an idea of how we are doing throughout the release after each Sprint.
Story Points are commonly used at the PBL level for release-level granularity. However, I have coached teams on several occasions that used number of items instead of Story Points. The most successful of these was a team who decided to break the PBIs into feature chunks of one day or less of effort. They hated “estimating” but didn’t mind splitting things. Arguably, that IS estimating, albeit informally.
For the Sprint backlog, we can use Story Points, PBIs, tasks, or hours to express the SBL size. The result would be a Sprint Burndown that reflects what is remaining each day in terms of those units chosen. The amount of work remaining lets me know if we are on track to meet our Sprint goal or not. The amount of work completed does not, however.
This problem is similar to the scenario of planning a road trip from NYC to San Diego. Let’s assume it takes four 10-hour days of driving to make the trip. Normally, after the first day, we would be in Nashville, the second day, we would reach Dallas, the third day El Paso, and the final day, San Diego. We get in the car and spend an entire 10-hour day. Does that mean we have three days remaining? No, not necessarily. We might only be in Washington, DC, or Roanoke, Virginia, due to extra-heavy traffic or an accident or roadwork and detours. From that point, we may still have 3.5 days remaining to get to San Diego, and that’s what we are really concerned with, not how long we have already spent.
Burndown patterns are discussed in this book with more detail under the Question:
“What are some trends of Burndown Charts and what do the patterns indicate?”

You don’t have to be afraid, just because I am Sicilian.
I am talking about product development here, not “garbage collection.”
I know it frustrates you that all this Agile stuff talks about uncertainty and fluffy stuff. I have a secret for you, however. It’s one of the most overlooked aspects of Agile. I will even let you in on this secret for absolutely FREE.
Here it goes ...
In Scrum, there are fixed time boxes or iterations we call Sprints. You probably knew that. However, what you probably didn’t realize is that if your Scrum Teams establish fanatical discipline and rigor around only releasing things that are in line with their strong and comprehensive Definition of Done every Sprint, you will have ...
FIXED DELIVERY DATES!!!
What will undermine this is if they compromise on the various criteria in the DoD, effectively cutting corners and introducing risk into the product. Also, if they extend the Sprints, change the duration repeatedly, or have nonsensical practices like magical mystery Sprints where hardening, innovation, and planning suddenly take place, then all bets are off in terms of having ...
FIXED DELIVERY DATES!!!
So, let the Scrum Teams be responsible and empowered to make the critical decisions that no one else can truly and effectively make. They will make the product sound in accordance with changing customer needs and technological advancements by baking quality in, integrating along the way, practicing emergent design, improving by coming up with new ideas, and doing smaller increments of ongoing planning, as Scrum intended. The result will be ...
FIXED DELIVERY DATES!!!
Now, we all know that a Development Team in Scrum is supposed to be five to nine (7 ± 2) people, right? If we use a blended rate of, say, $100K to represent the average salary for team members (including consultants), then we know for certain that a Development Team will cost $500 to 900K a year. Voila! We have ...
FIXED COSTS!!
Now, we can figure out what a Sprint costs by doing simple division. Let’s say a Sprint is two weeks. That gives us ~$19,000 to $35,000/Sprint depending on the Development Team size. Further, let’s assume our releases are every three Sprints (six weeks). Now we know that a release costs us ~$57,000 to $105,000. That’s a beautiful thing. That’s ...
FIXED COSTS!!!
You can’t ask for more!!
No, I mean literally, you CANNOT ask for more; like fixed scope, for instance. In order to get fixed costs and fixed delivery dates in Scrum, the trade-off here is that the scope is flexible. This is good, don’t freak out.
Having flexible scope ensures that we are able to roll with the punches and change as customer needs change, technology changes, and, most importantly, business priorities change. To help us with this, we want the Sprints to be as short as possible. If we have one-week Sprints, then we can formulate smaller increments in planning and ultimately have very granular refinements in our strategy rather than very drastic course corrections, which are costly.
We still have higher-level elements of planning that map to overall strategy: vision, roadmap, release-level planning, and insisting upon a Sprint goal for every Sprint. This helps keep us on target and focused with our longer-term strategy.
Not having fixed scope is a good thing. We could still have releases that are structured around fixed scope instead of fixed delivery dates. But it’s simply not realistic or REAL WORLD to expect to have more than one element fixed, one element firm, and one element flexible from among scope, cost, and time. Those who demand to have all three fixed (so-called “firm fixed price”) are best served in taking this up by seeking an audience with Oz in the Emerald City, since they are indeed in fantasyland ...
So, there it is:
FIXED DELIVERY DATES and FIXED COSTS
What Are Some Trends of Burndown Charts and What Do the Patterns Indicate?
Burndown charts are a way of tracking what work is REMAINING in a Sprint so that the Development Team can have a quick view as to how well they are tracking toward accomplishing the Sprint goal. With a glance, the Development Team can see if they are making sufficient progress or not.
To generate the Burndown chart, the team would first have some cumulative measure of size for the Sprint backlog coming out of the Sprint Planning meeting. For instance, the Scrum Team decides the features that can be completed in the Sprint, and since they have used Story Points to estimate the backlog items, they determine that their Sprint backlog is 40 Story Points in size.
Sprint Burndown
A chart that shows work remaining at various intervals throughout the Sprint lifecycle. The units can vary widely from hours, which are most often used with tasks, to simply the number of tasks, Story Points, and simply User Stories from the PBL.
Another example might be a team who breaks their PBIs down into tasks as part of the second half of Sprint Planning and then goes through the exercise of estimating those tasks in hours. When they are done, they would have a cumulative number of hours, which represents the Sprint backlog (tasks).
Yet another example would be the situation I previously mentioned with the U.S. Treasury Department where the Development Team simply broke PBIs into one-day chunks or less and then counted the number of PBIs and used that total as their Sprint backlog size after Sprint Planning.
Once the total size of the Sprint backlog is determined, updating the Burndown is nothing more than counting the units of work remaining each day (the items in “To Do” and “WIP”) and plotting a point on the chart. Thus, in the first example, the team might have 35 Story Points remaining on day two of the Sprint. Day three, they might have 30 remaining, etc.
This will provide a daily snapshot of where the team is along the way. Most frequently, the updating of the Burndown chart is done during the daily Scrum meeting, with all of the Development Team members present.
When teams use an electronic tool, the Burndown Chart is more ad hoc and “real time.” That is, as Development Team members complete PBIs or tasks and update these, the tool will automatically keep an updated record of the work remaining so that whenever someone runs the report or clicks a button to see the Burndown chart, they are seeing the most recent and up-to-date copy of the chart.
This brings us to an interpretation of the way the Burndown Chart looks. First off, I want to reiterate that the Burndown Charts are NOT for management or for measuring performance of the team or comparing one team to another. If an organization falls into that trap, I might suggest to a team that they don’t even bother with the Burndown chart. If they are collaborating regularly, having crucial conversations, inspecting and adapting, etc., along the way, then they will have a feel for how they are doing without the need of a Sprint Burndown Chart. If it helps the team, keep using it. If it is hurting the team, stop using it.
Uptick
There can be numerous different reasons for an uptick in the Burndown. Perhaps some task was added to the Sprint backlog that had been missed in Sprint Planning. Perhaps some of the work was grossly misestimated so that after someone started working on it, they discovered that they had a LOT more effort remaining. Perhaps the Product Owner or someone else has been adding items to the Sprint backlog without the Development Team’s permission or maybe they have been coercing the team into adding things and the ScrumMaster has not been properly protecting the team.
The major issue here is that stuff is being added to the scope at a greater rate than the Development Team is able to complete work. It is not unusual, especially in the first few Sprints a team works on in Scrum, to see an uptick in the Burndown chart (see Figure 3-10) as a result of new discoveries because they missed things going through Sprint Planning. If the team continuously has this issue, I would try to discover the pattern that was occurring by reflecting this back to the Development Team and asking them to provide some suggested root causes.
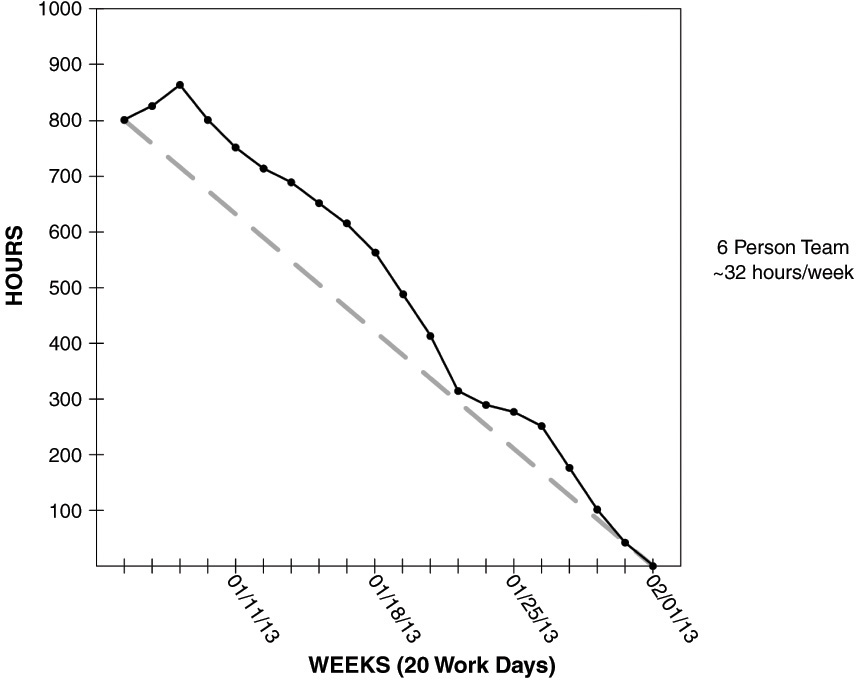
Flat Line
As with upticks, there can be multiple reasons for segments of the Burndown that are nearly or completely flat (see Figure 3-11). The Development Team may have encountered a major impediment that was blocking the entire team from accomplishing any work at all. That might result in the same work remaining after several days in a row. Once the impediment is removed, sometimes the team will make a choice to work extra to offset the impact of that impediment. However, this is usually not encouraged. It has the effect of sweeping the impact of that impediment under the rug instead of allowing the impact to remain visible and transparent.
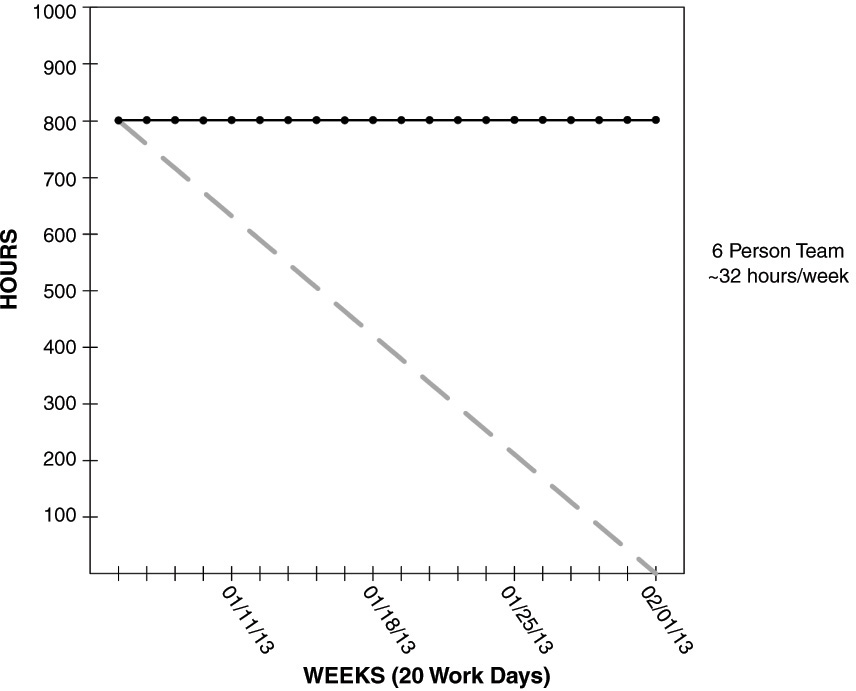
Another reason the Burndown might look flat is due to work being added to the Sprint backlog at the same rate that the team is accomplishing work, resulting in a net effort remaining of the same amount over several days. For instance, assume a team has 42 Story Points remaining. The next day, in spite of accomplishing 16 Story Points of work, they still have 42 remaining because somehow 16 Story Points were ADDED to the Sprint backlog.
Sharp Drop
This is a common occurrence with teams where they are using an electronic tool to generate the Burndown chart. Team members are so busy and focused on writing great software and moving forward that they forget to update things in the tool or they don’t want to “waste time” on the overhead of documentation. When the ScrumMaster or another team member points out that the Burndown chart is trending flat, the team may realize that it is because no one has been updating their own items in the tool. When they actually do go back and update things, there will be a sharp drop (see Figure 3-12) in the actual effort remaining from where it appeared to be.
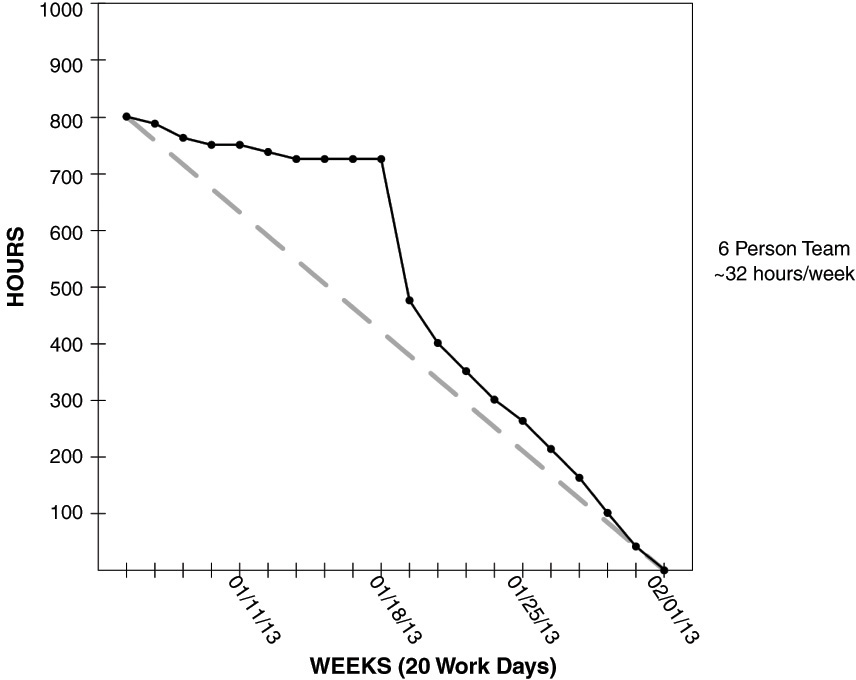
Another cause for a sharp drop in the Sprint Burndown Chart could result from the Product Owner discovering that a feature, which the team committed to, is no longer needed or valid. They would confer with the ScrumMaster and the Development Team and discuss how it no longer makes sense to move forward with that feature and ask the Development Team what the impact of that change is. If they have already started working on the feature, there may actually be extra work to back that feature out and leave the code clean and risk free. Also, the Development Team may have capacity to swap the discontinued PBI with a new one from the PBL. However, this is solely up to the discretion of the Development Team and would involve a negotiation with the Product Owner to discuss what is possible, reasonable, etc.
Perfect Line
When charts look exactly like the so-called “ideal line” (see Figure 3-13) we call that “BS” or a “LIE.” This is why I tend to advise against actually drawing the ideal line because it has the effect of anchoring the team in such a way that their Burndown chart closely follows this expectation rather than reflecting what the reality of their work remaining is. Most people can mentally envision how the line would look if everything went perfectly and they burned down exactly what they needed to each day to get to zero by the end of the Sprint. There’s no need to actually draw the line in, from my experience.
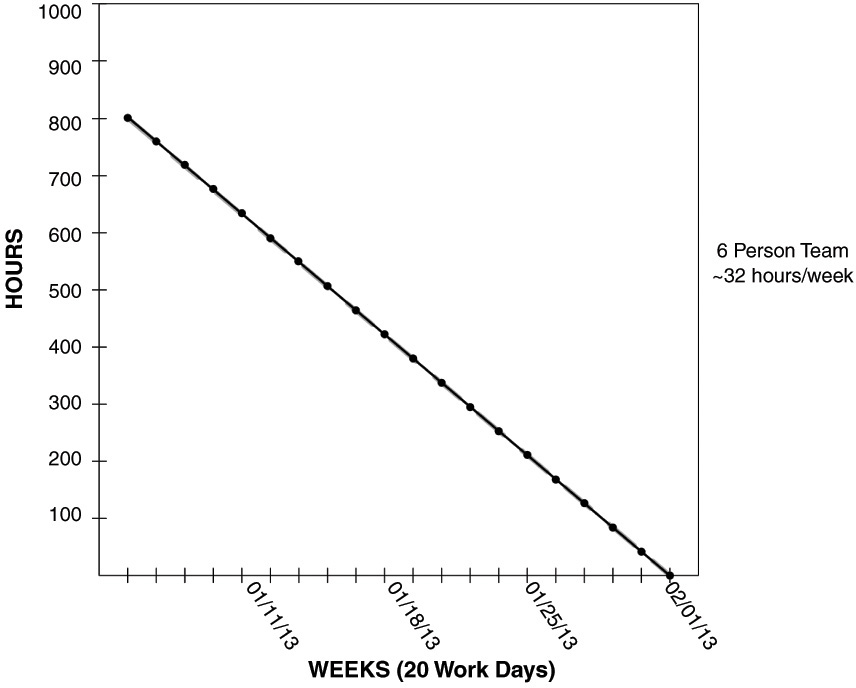
It’s possible that a Sprint may look exactly like the “ideal line.” However, if EVERY Sprint is following this pattern, then I would suspect there is something else going on in the Development Team.
In the end, there is not a single explanation for why a particular Burndown chart looks the way that it does. There needs to be a discussion within the Scrum Team to understand what the patterns REALLY represent, and the discussion needs to involve the full background information and history that the team is privy to. In the hands of someone who does not understand all of these factors, the Burndown chart can be a dangerous weapon, which demoralizes the team and strips away the trust and empowerment that have been built up along the way.
Should We Make a Big Change Between Sprints?
It’s not clear what “a big change” means. However, this question jumped out at me for several reasons. I will answer the question based on several different interpretations of what a big change means.
First, let’s talk about making a big change in terms of the way the team is operating and the practices they are following. I would certainly hope that the change would happen in between Sprints and not in the middle of a Sprint. It’s usually best if things are kept consistent while the Sprint is under way because then the assumptions upon which the Sprint goal and Sprint backlog were created would be different and thus, the Sprint goal and Sprint backlog would be invalid at that point.
Examples of a big change might be changing the delivery team size or composition, changing the Sprint duration, or any other fundamental change in basic Scrum elements. The Scrum Team should feel free to make changes to these things after careful introspection and with full understanding of what they are changing and exactly why.
Naturally, if something catastrophic is happening and the Scrum Team needs to take immediate, corrective action, then it might be necessary to make the change mid-Sprint. This should be such a rare occurrence that the team won’t even need to worry about it happening. They can deal with it as the need arises.
Another case where a big change might happen could be in the product itself—for example, the customer wants a significant portion of the product completely redone because the product no longer meets their expectations or delivers value to them. A more effective way of mitigating this risk to begin with would be to ensure that the Product Owner is checking in regularly with the customer and validating that the product is meeting their expectations in smaller, bite-sized chunks after each Sprint. There should not be sudden, critical changes in direction that happen unexpectedly.
Let’s assume that there was some kind of a disconnect between the customer and the product such that there is now a huge amount of change or rework required. That would certainly need to occur in between Sprints and not during the Sprint.
The Product Owner would be responsible for capturing the necessary changes in scope via the product backlog, and those new PBIs would be addressed in the appropriate time frame as Sprint Planning meetings happen. This would be respectful of the Development Team’s time, effort, focus, etc., by not expecting them to randomly change course mid-Sprint.
One last example of a big change might be some kind of catastrophic emergency situation, like a production defect or horribly wrong assumption, that will result in grave loss to the company or health/welfare if the Development Team were to continue on in their development effort. In this case, I would fully expect that the Product Owner would immediately cancel the Sprint, the Scrum Team would have their retrospective to discuss what’s going on, and then the Scrum Team would take the next appropriate course of action. This might be going through Sprint Planning in order to identify a new Sprint backlog with the updated scope.
In the end, major changes should only happen in between Sprints, but a main point of Scrum is to reduce the need for major changes along the way, with responsible, incremental, and iterative product development practices.
Closing
Without products, we have no business. In some cases, this means an actual product to sell in the marketplace. In others, it means having a work product that results in a service we develop to sell.
The product, regardless of what it is, solves some problem for our customers and in doing so, delivers value. Without demand created by customers, there is no market or need for our products. Thus, understanding the customer is vital to survival and even especially to success for organizations.
When the individuals creating the product work together closely with the customer and those who represent the customer, the products generate delight and the organization is successful.
In the next chapter, we discuss what it takes for teams to function well so that they may produce products that delight customers.